# Objective
It's sometimes desirable to get a `Res<T>` rather than `&T` from
`World::get_resource`.
Alternative to #9940, partly adresses #9926
## Solution
added additional methods to `World` and `UnsafeWorldCell` to retrieve a
resource wrapped in a `Res`.
- `UnsafeWorldCell::get_resource_ref`
- `World::get_resource_ref`
- `World::resource_ref`
I can change it so `World::resource_mut` returns `ResMut` instead of
`Mut` as well if that's desired, but that could also be added later in a
seperate pr.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Mike <mike.hsu@gmail.com>
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
# Objective
- Address junk leftover by TypeUuid removal
## Solution
- Get rid of unused deps and imports
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Resolves#11377
## Solution
- Add marker component `IsDefaultUiCamera` that will be choosen first as
the default camera.
If you want the IsDefaultUiCamera default camera to be in another
window, thats now possible.
- `IsDefaultUiCamera` is expected to be within a single Camera, if that
assertion fails, one PrimaryWindow Camera will be choosen.
---
## Changelog
### Added
- Added `IsDefaultUiCamera` marker component.
---------
Co-authored-by: Mateusz Wachowiak <mateusz_wachowiak@outlook.com>
# Objective
Allow TextureAtlasBuilder in AssetLoader.
Fixes#2987
## Solution
- TextureAtlasBuilder no longer hold just AssetIds that are used to
retrieve the actual image data in `finish`, but &Image instead.
- TextureAtlasBuilder now required AssetId only optionally (and it is
only used to retrieve the index from the AssetId in TextureAtlasLayout),
## Issues
- The issue mentioned here
https://github.com/bevyengine/bevy/pull/11474#issuecomment-1904676937
now also extends to the actual atlas texture. In short: Calling
add_texture multiple times for the same texture will lead to duplicate
image data in the atlas texture and additional indices.
If you provide an AssetId we can probably do something to de-duplicate
the entries while keeping insertion order (suggestions welcome on how
exactly). But if you don't then we are out of luck (unless we can and
want to hash the image, which I do not think we want).
---
## Changelog
### Changed
- TextureAtlasBuilder `add_texture` can be called without providing an
AssetId
- TextureAtlasBuilder `finish` no longer takes Assets<Image> and no
longer returns a Handle<Image>
## Migration Guide
- For `add_texture` you need to wrap your AssetId in Some
- `finish` now returns the atlas texture image directly instead of a
handle. Provide the atlas texture to `add` on Assets<Texture> to get a
Handle<Image>
# Objective
allow automatic fixing of bad joint weights.
fix#10447
## Solution
- remove automatic normalization of vertexes with all zero joint
weights.
- add `Mesh::normalize_joint_weights` which fixes zero joint weights,
and also ensures that all weights sum to 1. this is a manual call as it
may be slow to apply to large skinned meshes, and is unnecessary if you
have control over the source assets.
note: this became a more significant problem with 0.12, as weights that
are close to, but not exactly 1 now seem to use `Vec3::ZERO` for the
unspecified weight, where previously they used the entity translation.
# Objective
DXC+DX12 debug builds with an environment map have been broken since
https://github.com/bevyengine/bevy/pull/11366 merged due to an internal
compiler error in DXC. I tracked it down to a single `break` statement
and reported it upstream
(https://github.com/microsoft/DirectXShaderCompiler/issues/6183)
## Solution
Workaround the ICE by setting the for loop index variable to the max
value of the loop to avoid the `break` that's causing the ICE.
This works because it's the last thing in the for loop.
The `reflection_probes` and `pbr` examples both appear to still work
correctly.
# Objective
After #10520, I was experiencing seriously degraded performance that
ended up being due to never-drained `AssetEvent` events causing havoc
inside `extract_render_asset::<A>`. The same events being read over and
over again meant the same assets were being prepared every frame for
eternity. For what it's worth, I was noticing this on a static scene
about every 3rd or so time running my project.
* References #10520
* Fixes#11240
Why these events aren't sometimes drained between frames is beyond me
and perhaps worthy of another investigation, but the approach in this PR
effectively restores the original cached `EventReader` behavior (which
fixes it).
## Solution
I followed the [`CachedSystemState`
example](3a666cab23/crates/bevy_ecs/src/system/function_system.rs (L155))
to make sure that the `EventReader` state is cached between frames like
it used to be when it was an argument of `extract_render_asset::<A>`.
# Objective
Plugins are an incredible tool for encapsulating functionality. They are
low-key one of Bevy's best features. Combined with rust's module and
privacy system, it's a match made in heaven.
The one downside is that they can be a little too verbose to define. 90%
of all plugin definitions look something like this:
```rust
pub struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.init_resource::<CameraAssets>()
.add_event::<SetCamera>()
.add_systems(Update, (collect_set_camera_events, drive_camera).chain());
}
}
```
Every so often it gets a little spicier:
```rust
pub struct MyGenericPlugin<T>(PhantomData<T>);
impl<T> Default for MyGenericPlugin<T> {
fn default() -> Self { ... }
}
impl<T> Plugin for MyGenericPlugin<T> { ... }
```
This is an annoying amount of boilerplate. Ideally, plugins should be
focused and small in scope, which means any app is going to have a *lot*
of them. Writing a plugin should be as easy as possible, and the *only*
part of this process that carries any meaning is the body of `fn build`.
## Solution
Implement `Plugin` for functions that take `&mut App` as a parameter.
The two examples above now look like this:
```rust
pub fn my_plugin(app: &mut App) {
app.init_resource::<CameraAssets>()
.add_event::<SetCamera>()
.add_systems(Update, (collect_set_camera_events, drive_camera).chain());
}
pub fn my_generic_plugin<T>(app: &mut App) {
// No need for PhantomData, it just works.
}
```
Almost all plugins can be written this way, which I believe will make
bevy code much more attractive. Less boilerplate and less meaningless
indentation. More plugins with smaller scopes.
---
## Changelog
The `Plugin` trait is now implemented for all functions that take `&mut
App` as their only parameter. This is an abbreviated way of defining
plugins with less boilerplate than manually implementing the trait.
---------
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
# Objective
Fixes#11533
When `AssetPath`s are created from a string type, they are parsed into
an `AssetSource`, a `Path`, and a `Label`.
The current method of parsing has some unnecessary quirks:
- The presence of a `:` character is assumed to be the start of an asset
source indicator.
- This is not necessarily true. There are valid uses of a `:` character
in an asset path, for example an http source's port such as
`localhost:80`.
- If there are multiple instances of `://`, the last one is assumed to
be the asset source deliminator.
- This has some unexpected behavior. Even in a fully formed path, such
as `http://localhost:80`, the `:` between `localhost` and `80` is
assumed to be the start of an asset source, causing an error since it
does not form the full sequence `://`.
## Solution
Changes the `AssetPath`'s `parse_internal` method to be more permissive.
- Only the exact sequence `://` is taken to be the asset source
deliminator, and only the first one if there are multiple.
- As a consequence, it is no longer possible to detect a malformed asset
source deliminator, and so the corresponding error was removed.
# Objective
https://github.com/bevyengine/bevy/pull/5103 caused a bug where
`Sprite::rect` was ignored by the engine. (Did nothing)
## Solution
My solution changes the way how Bevy calculates the rect, based on this
table:
| `atlas_rect` | `Sprite::rect` | Result |
|--------------|----------------|------------------------------------------------------|
| `None` | `None` | `None` |
| `None` | `Some` | `Sprite::rect` |
| `Some` | `None` | `atlas_rect` |
| `Some` | `Some` | `Sprite::rect` is used, relative to `atlas_rect.min`
|
# Objective
One of a few Bevy Asset improvements I would like to make: #11216.
Currently asset processing and asset saving are handled by the same
trait, `AssetSaver`. This makes it difficult to reuse saving
implementations and impossible to have a single "universal" saver for a
given asset type.
## Solution
This PR splits off the processing portion of `AssetSaver` into
`AssetTransformer`, which is responsible for transforming assets. This
change involves adding the `LoadTransformAndSave` processor, which
utilizes the new API. The `LoadAndSave` still exists since it remains
useful in situations where no "transformation" of the asset is done,
such as when compressing assets.
## Notes:
As an aside, Bikeshedding is welcome on the names. I'm not entirely
convinced by `AssetTransformer`, which was chosen mostly because
`AssetProcessor` is taken. Additionally, `LoadTransformSave` may be
sufficient instead of `LoadTransformAndSave`.
---
## Changelog
### Added
- `AssetTransformer` which is responsible for transforming Assets.
- `LoadTransformAndSave`, a `Process` implementation.
### Changed
- Changed `AssetSaver`'s responsibilities from processing and saving to
just saving.
- Updated `asset_processing` example to use new API.
- Old asset .meta files regenerated with new processor.
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Make APIs more consistent and ergonomic by adding a `new` constructor
for `Circle` and `Sphere`.
This could be seen as a redundant "trivial constructor", but in
practise, it seems valuable to me. I have lots of cases where formatting
becomes ugly because of the lack of a constructor, like this:
```rust
Circle {
radius: self.radius(),
}
.contains_local_point(centered_pt)
```
With `new`, it'd be formatted much nicer:
```rust
Circle::new(self.radius()).contains_local_point(centered_pt)
```
Of course, this is just one example, but my circle/sphere definitions
very frequently span three or more lines when they could fit on one.
Adding `new` also increases consistency. `Ellipse` has `new` already,
and so does the mesh version of `Circle`.
## Solution
Add a `new` constructor for `Circle` and `Sphere`.
# Objective
- Fix documentation for `AssetReader::is_directory` (it is currently
exactly the same as docs for `read_directory`)
---------
Co-authored-by: Kanabenki <lucien.menassol@gmail.com>
# Objective
- Some passes recreate a sampler when creating a bind group to be
cached, even if the sampler is always the same.
## Solution
- Store the sampler in the corresponding pipeline resource.
# Objective
While working on #11527 I spotted that the internal field for the label
of a `Schedule` is called `name`. Using `label` seems more in line with
the other naming across Bevy.
## Solution
Renaming the field was straightforward since it's not exposed outside of
the module. This also means a changelog or migration guide isn't
necessary.
# Objective
Fixes#11411
## Solution
- Added a simple example how to create and configure custom schedules
that are run by the `Main` schedule.
- Spot checked some of the API docs used, fixed `App::add_schedule` docs
that referred to a function argument that was removed by #9600.
## Open Questions
- While spot checking the docs, I noticed that the `Schedule` label is
stored in a field called `name` instead of `label`. This seems
unintuitive since the term label is used everywhere else. Should we
change that field name? It was introduced in #9600. If so, I do think
this change would be out of scope for this PR that mainly adds the
example.
# Objective
Rust analyzer kept complaining about a cyclic dependency due to
`bevy_input` having a dev-dependency on `bevy`.
`bevy_input` was also missing `bevy_reflect`'s "smol_str" feature which
it needs to compile on its own.
Fixes#10256
## Solution
Remove the dev-dependency on `bevy` from `bevy_input` since it was only
used to reduce imports for 1 test and 3 doc examples by 1 line each, as
`bevy_input` already has dependencies on everything needed for those
tests and doctests to work.
Add `bevy_reflect`'s "smol_str" feature to `bevy_input`'s dependency
list as it needs it to actually compile.
# Objective
Fixes#10414.
That issue and its comments do a great job of laying out the case for
this.
## Solution
Added an optional `spatial_scale` field to `PlaybackSettings`, which
overrides the default value set on `AudioPlugin`.
## Changelog
- `AudioPlugin::spatial_scale` has been renamed to
`default_spatial_scale`.
- `SpatialScale` is no longer a resource and is wrapped by
`DefaultSpatialScale`.
- Added an optional `spatial_scale` to `PlaybackSettings`.
## Migration Guide
`AudioPlugin::spatial_scale` has been renamed to `default_spatial_scale`
and the default spatial scale can now be overridden on individual audio
sources with `PlaybackSettings::spatial_scale`.
If you were modifying or reading `SpatialScale` at run time, use
`DefaultSpatialScale` instead.
```rust
// before
app.add_plugins(DefaultPlugins.set(AudioPlugin {
spatial_scale: SpatialScale::new(AUDIO_SCALE),
..default()
}));
// after
app.add_plugins(DefaultPlugins.set(AudioPlugin {
default_spatial_scale: SpatialScale::new(AUDIO_SCALE),
..default()
}));
```
# Objective
TypeUuid is deprecated, remove it.
## Migration Guide
Convert any uses of `#[derive(TypeUuid)]` with `#[derive(TypePath]` for
more complex uses see the relevant
[documentation](https://docs.rs/bevy/latest/bevy/prelude/trait.TypePath.html)
for more information.
---------
Co-authored-by: ebola <dev@axiomatic>
# Objective
- Fixes a hurdle encountered when debugging a panic caused by the file
watcher loading a `.gitignore` file, which was hard to debug because
there was no file name in the report, only `asset paths must have
extensions`
## Solution
- Panic with a formatted message that includes the asset path, e.g.
`missing expected extension for asset path .gitignore`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Doonv <58695417+doonv@users.noreply.github.com>
Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>Even better no_std</h2>
<p>Switching from thiserror to derive_more allows for no_std builds on
stable rust</p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/blob/master/Changelog.md">ruzstd's
changelog</a>.</em></p>
<blockquote>
<h1>After 0.5.0</h1>
<ul>
<li>Make the hashing checksum optional (thanks to <a
href="https://github.com/tamird"><code>@tamird</code></a>)
<ul>
<li>breaking change as the public API changes based on features</li>
</ul>
</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="e620d2a856"><code>e620d2a</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/50">#50</a>
from KillingSpark/remove_thiserror</li>
<li><a
href="9e9d204c63"><code>9e9d204</code></a>
make clippy happy</li>
<li><a
href="f4a6fc0cc1"><code>f4a6fc0</code></a>
bump the version, this is an incompatible change</li>
<li><a
href="64d65b5c4f"><code>64d65b5</code></a>
fix test compile...</li>
<li><a
href="07bbda98c8"><code>07bbda9</code></a>
remove the error_in_core feature and switch the io_nostd to use the
Display t...</li>
<li><a
href="e15eb1e568"><code>e15eb1e</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/49">#49</a>
from tamird/clippy</li>
<li><a
href="92a3f2e6b2"><code>92a3f2e</code></a>
Avoid unnecessary cast</li>
<li><a
href="f588d5c362"><code>f588d5c</code></a>
Avoid slow zero-filling initialization</li>
<li><a
href="e79f09876f"><code>e79f098</code></a>
Avoid single-match expression</li>
<li><a
href="c75cc2fbb9"><code>c75cc2f</code></a>
Remove useless assertion</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.4.0...v0.5.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- `AssetPath` implements reflection, but is not registered as a type in
the plugin.
- Fixes#11481.
## Solution
- Register the `AssetPath` type when `AssetPlugin::build` is called.
---
## Changelog
- Registered `AssetPath` type for use in reflection.
# Objective
- `World::get_resource`'s comment on it's `unsafe` usage meant to say
"mutably" but instead said "immutably."
- Fixes#11430.
## Solution
- Replace "immutably" with "mutably."
# Objective
#10946 added bounding volume types and an `IntersectsVolume` trait, but
didn't actually implement intersections between bounding volumes.
This PR implements AABB-AABB, circle-circle / sphere-sphere, and
AABB-circle / AABB-sphere intersections.
## Solution
Implement `IntersectsVolume` for bounding volume pairs. I also added
`closest_point` methods to return the closest point on the surface /
inside of bounding volumes. This is used for AABB-circle / AABB-sphere
intersections.
---------
Co-authored-by: IQuick 143 <IQuick143cz@gmail.com>
# Objective
TextureAtlases are commonly used to drive animations described as a
consecutive range of indices. The current TextureAtlasBuilder uses the
AssetId of the image to determine the index of the texture in the
TextureAtlas. The AssetId of an Image Asset can change between runs.
The TextureAtlas exposes
[`get_texture_index`](https://docs.rs/bevy/latest/bevy/sprite/struct.TextureAtlas.html#method.get_texture_index)
to get the index from a given AssetId, but this needlessly complicates
the process of creating a simple TextureAtlas animation.
Fixes#2459
## Solution
- Use the (ordered) image_ids of the 'texture to place' vector to
retrieve the packed locations and compose the textures of the
TextureAtlas.
# Objective
It would be convenient to be able to call functions with `Commands` as a
parameter without having to move your own instance of `Commands`. Since
this struct is composed entirely of references, we can easily get an
owned instance of `Commands` by shortening the lifetime.
## Solution
Add `Commands::reborrow`, `EntiyCommands::reborrow`, and
`Deferred::reborrow`, which returns an owned version of themselves with
a shorter lifetime.
Remove unnecessary lifetimes from `EntityCommands`. The `'w` and `'s`
lifetimes only have to be separate for `Commands` because it's used as a
`SystemParam` -- this is not the case for `EntityCommands`.
---
## Changelog
Added `Commands::reborrow`. This is useful if you have `&mut Commands`
but need `Commands`. Also added `EntityCommands::reborrow` and
`Deferred:reborrow` which serve the same purpose.
## Migration Guide
The lifetimes for `EntityCommands` have been simplified.
```rust
// Before (Bevy 0.12)
struct MyStruct<'w, 's, 'a> {
commands: EntityCommands<'w, 's, 'a>,
}
// After (Bevy 0.13)
struct MyStruct<'a> {
commands: EntityCommands<'a>,
}
```
The method `EntityCommands::commands` now returns `Commands` rather than
`&mut Commands`.
```rust
// Before (Bevy 0.12)
let commands = entity_commands.commands();
commands.spawn(...);
// After (Bevy 0.13)
let mut commands = entity_commands.commands();
commands.spawn(...);
```
# Objective
Document a few common cases of which lifetime is required when using
SystemParam Derive
## Solution
Added a table in the doc comment
---------
Co-authored-by: laund <me@laund.moe>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Prep for https://github.com/bevyengine/bevy/pull/10164
- Make deferred_lighting_pass_id a ColorAttachment
- Correctly extract shadow view frusta so that the view uniforms get
populated
- Make some needed things public
- Misc formatting
# Objective
- Extend reflection to the standard library's `Wrapping` and
`Saturating` generic types.
This wasn't my use-case but someone in the discord was surprised that
this wasn't already done. I decided to make a PR because the other
`std::num` items were reflected and if there's a reason to exclude
`Wrapping` and `Saturating`, I am unaware of it.
## Solution
Trivial fix
---
## Changelog
Implemented `Reflect` for `Wrapping<T>` and `Saturating<T>` from
`std::num`.
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- Add the ability to describe storage texture bindings when deriving
`AsBindGroup`.
- This is especially valuable for the compute story of bevy which
deserves some extra love imo.
## Solution
- This add the ability to annotate struct fields with a
`#[storage_texture(0)]` annotation.
- Instead of adding specific option parsing for all the image formats
and access modes, I simply accept a token stream and defer checking to
see if the option is valid to the compiler. This still results in useful
and friendly errors and is free to maintain and always compatible with
wgpu changes.
---
## Changelog
- The `#[storage_texture(..)]` annotation is now accepted for fields of
`Handle<Image>` in structs that derive `AsBindGroup`.
- The game_of_life compute shader example has been updated to use
`AsBindGroup` together with `[storage_texture(..)]` to obtain the
`BindGroupLayout`.
## Migration Guide
# Objective
#8219 changed the target type of a `transmute` without changing the one
transmuting from ([see the relevant
diff](55e9ab7c92 (diff-11413fb2eeba97978379d325353d32aa76eefd0af0c8e9b50b7f394ddfda7a26R351-R355))),
making them incompatible. This PR fixes this by changing the initial
type to match the target one (modulo lifetimes).
## Solution
Change the type to be transmuted from to match the one transmuting into
(modulo lifetimes)
# Objective
- This PR makes it so that `ReflectSerialize` and `ReflectDeserialize`
traits are properly derived on `Name`. This avoids having the internal
hash “leak” into the serialization when using reflection.
## Solution
- Added a conditional derive for `ReflectDeserialize` and
`ReflectSerialize` via `#[cfg_attr()]`
---
## Changelog
- `Name` now implements `ReflectDeserialize` and `ReflectSerialize`
whenever the `serialize` feature is enabled.
# Objective
Fix weird visuals when drawing a gizmo with a non-normed normal.
Fixes#11401
## Solution
Just normalize right before we draw. Could do it when constructing the
builder but that seems less consistent.
## Changelog
- gizmos.circle normal is now a Direction3d instead of a Vec3.
## Migration Guide
- Pass a Direction3d for gizmos.circle normal, eg.
`Direction3d::new(vec).unwrap_or(default)` or potentially
`Direction3d::new_unchecked(vec)` if you know your vec is definitely
normalized.
# Objective
- Since #11218, example `asset_processing` fails:
```
thread 'main' panicked at crates/bevy_asset/src/io/source.rs:489:18:
Failed to create file watcher: Error { kind: PathNotFound, paths: ["examples/asset/processing/imported_assets/Default"] }
```
start from a fresh git clone or delete the folder before running to
reproduce, it is in gitignore and should not be present on a fresh run
a657478675/.gitignore (L18)
## Solution
- Auto create the `imported_assets` folder if it is configured
---------
Co-authored-by: Kyle <37520732+nvdaz@users.noreply.github.com>
# Objective
`Direction2d::from_normalized` & `Direction3d::from_normalized` don't
emphasize that importance of the vector being normalized enough.
## Solution
Rename `from_normalized` to `new_unchecked` and add more documentation.
---
`Direction2d` and `Direction3d` were added somewhat recently in
https://github.com/bevyengine/bevy/pull/10466 (after 0.12), so I don't
think documenting the changelog and migration guide is necessary (Since
there is no major previous version to migrate from).
But here it is anyway in case it's needed:
## Changelog
- Renamed `Direction2d::from_normalized` and
`Direction3d::from_normalized` to `new_unchecked`.
## Migration Guide
- Renamed `Direction2d::from_normalized` and
`Direction3d::from_normalized` to `new_unchecked`.
---------
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
# Objective
Currently, the `primitives` module is inside of the prelude for
`bevy_math`, but the actual primitives are not. This requires either
importing the shapes everywhere that uses them, or adding the
`primitives::` prefix:
```rust
let rectangle = meshes.add(primitives::Rectangle::new(5.0, 2.5));
```
(Note: meshing isn't actually implemented yet, but it's in #11431)
The primitives are meant to be used for a variety of tasks across
several crates, like for meshing, bounding volumes, gizmos, colliders,
and so on, so I think having them in the prelude is justified. It would
make several common tasks a lot more ergonomic.
```rust
let rectangle = meshes.add(Rectangle::new(5.0, 2.5));
```
## Solution
Add `primitives::*` to `bevy_math::prelude`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Currently, the only way to create an AABB is to specify its `min` and
`max` coordinates. However, it's often more useful to use the center and
half-size instead.
## Solution
Add `new` constructors for `Aabb2d` and `Aabb3d`.
This:
```rust
let aabb = Aabb3d {
min: center - half_size,
max: center + half_size,
}
```
becomes this:
```rust
let aabb = Aabb3d::new(center, half_size);
```
I also made the usage of "half-extents" vs. "half-size" a bit more
consistent.
# Objective
Currently, the `Ellipse` primitive is represented by a `half_width` and
`half_height`. To improve consistency (similarly to #11434), it might
make more sense to use a `Vec2` `half_size` instead.
Alternatively, to make the elliptical nature clearer, the properties
could also be called `radius_x` and `radius_y`.
Secondly, `Ellipse::new` currently takes a *full* width and height
instead of two radii. I would expect it to take the half-width and
half-height because ellipses and circles are almost always defined using
radii. I wouldn't expect `Circle::new` to take a diameter (if we had
that method).
## Solution
Change `Ellipse` to store a `half_size` and `new` to take the half-width
and half-height.
I also added a `from_size` method similar to `Rectangle::from_size`, and
added the `semi_minor` and `semi_major` helpers to get the
semi-minor/major radius.
# Objective
The `Rectangle` and `Cuboid` primitives currently use different
representations:
```rust
pub struct Rectangle {
/// The half width of the rectangle
pub half_width: f32,
/// The half height of the rectangle
pub half_height: f32,
}
pub struct Cuboid {
/// Half of the width, height and depth of the cuboid
pub half_extents: Vec3,
}
```
The property names and helpers are also inconsistent. `Cuboid` has
`half_extents`, but it also has a method called `from_size`. Most
existing code also uses "size" instead of "extents".
## Solution
Represent both `Rectangle` and `Cuboid` with `half_size` properties.
# Objective
Implements #9216
## Solution
- Replace `DiagnosticId` by `DiagnosticPath`. It's pre-hashed using
`const-fnv1a-hash` crate, so it's possible to create path in const
contexts.
---
## Changelog
- Replaced `DiagnosticId` by `DiagnosticPath`
- Set default history length to 120 measurements (2 seconds on 60 fps).
I've noticed hardcoded constant 20 everywhere and decided to change it
to `DEFAULT_MAX_HISTORY_LENGTH` , which is set to new diagnostics by
default. To override it, use `with_max_history_length`.
## Migration Guide
```diff
- const UNIQUE_DIAG_ID: DiagnosticId = DiagnosticId::from_u128(42);
+ const UNIQUE_DIAG_PATH: DiagnosticPath = DiagnosticPath::const_new("foo/bar");
- Diagnostic::new(UNIQUE_DIAG_ID, "example", 10)
+ Diagnostic::new(UNIQUE_DIAG_PATH).with_max_history_length(10)
- diagnostics.add_measurement(UNIQUE_DIAG_ID, || 42);
+ diagnostics.add_measurement(&UNIQUE_DIAG_ID, || 42);
```
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
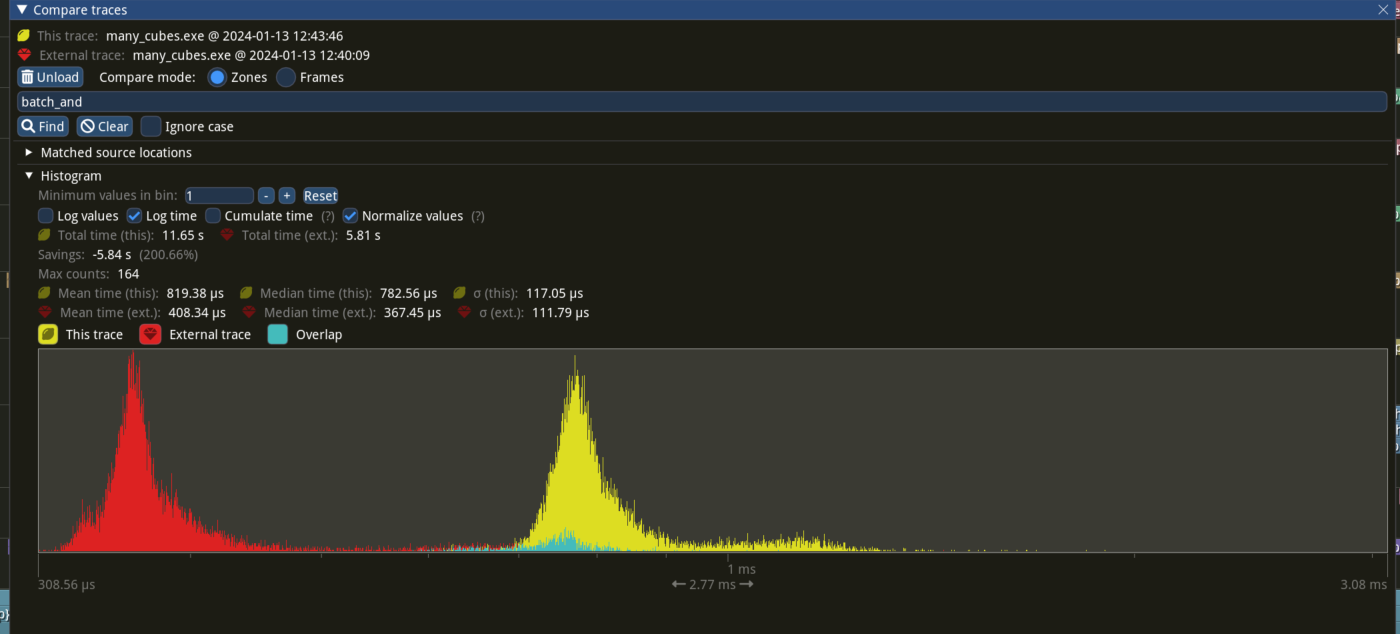
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
# Objective
Adjust bevy internals to utilize `Option<Res<State<S>>>` instead of
`Res<State<S>>`, to allow for adding/removing states at runtime and
avoid unexpected panics.
As requested here:
https://github.com/bevyengine/bevy/pull/10088#issuecomment-1869185413
---
## Changelog
- Changed the use of `world.resource`/`world.resource_mut` to
`world.get_resource`/`world.get_resource_mut` in the
`run_enter_schedule` and `apply_state_transition` systems and handled
the `None` option.
- `in_state` now returns a ` FnMut(Option<Res<State<S>>>) -> bool +
Clone`, returning `false` if the resource doesn't exist.
- `state_exists_and_equals` was marked as deprecated, and now just runs
and returns `in_state`, since their bevhaviour is now identical
- `state_changed` now takes an `Option<Res<State<S>>>` and returns
`false` if it does not exist.
I would like to remove `state_exists_and_equals` fully, but wanted to
ensure that is acceptable before doing so.
---------
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
- `FromType<T>` for `ReflectComponent` and `ReflectBundle` currently
require `T: FromWorld` for two reasons:
- they include a `from_world` method;
- they create dummy `T`s using `FromWorld` and then `apply` a `&dyn
Reflect` to it to simulate `FromReflect`.
- However `FromWorld`/`Default` may be difficult/weird/impractical to
implement, while `FromReflect` is easier and also more natural for the
job.
- See also
https://discord.com/channels/691052431525675048/1146022009554337792
## Solution
- Split `from_world` from `ReflectComponent` and `ReflectBundle` into
its own `ReflectFromWorld` struct.
- Replace the requirement on `FromWorld` in `ReflectComponent` and
`ReflectBundle` with `FromReflect`
---
## Changelog
- `ReflectComponent` and `ReflectBundle` no longer offer a `from_world`
method.
- `ReflectComponent` and `ReflectBundle`'s `FromType<T>` implementation
no longer requires `T: FromWorld`, but now requires `FromReflect`.
- `ReflectComponent::insert`, `ReflectComponent::apply_or_insert` and
`ReflectComponent::copy` now take an extra `&TypeRegistry` parameter.
- There is now a new `ReflectFromWorld` struct.
## Migration Guide
- Existing uses of `ReflectComponent::from_world` and
`ReflectBundle::from_world` will have to be changed to
`ReflectFromWorld::from_world`.
- Users of `#[reflect(Component)]` and `#[reflect(Bundle)]` will need to
also implement/derive `FromReflect`.
- Users of `#[reflect(Component)]` and `#[reflect(Bundle)]` may now want
to also add `FromWorld` to the list of reflected traits in case their
`FromReflect` implementation may fail.
- Users of `ReflectComponent` will now need to pass a `&TypeRegistry` to
its `insert`, `apply_or_insert` and `copy` methods.
This pull request re-submits #10057, which was backed out for breaking
macOS, iOS, and Android. I've tested this version on macOS and Android
and on the iOS simulator.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
When working within `bevy_ecs`, we can't use the `log_once` macros due
to their placement in `bevy_log` - which depends on `bevy_ecs`. All this
create does is migrate those macros to the `bevy_utils` crate, while
still re-exporting them in `bevy_log`.
created to resolve this:
https://github.com/bevyengine/bevy/pull/11417#discussion_r1458100211
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
After the Gizmos changes, `App::init_gizmos_group` turned into a
important function that for sure mustn't panic. The problem is: the
actual implementation causes a panic if somehow the code is runned
before `GizmoPlugin` was added to the App
- The error occurs here for example:
```rust
fn main() {
App::new()
.init_gizmo_group::<MyGizmoConfig>()
.add_plugins(DefaultPlugins)
.run();
}
#[derive(Default, Reflect, GizmoConfigGroup)]
struct MyGizmoConfig;
```

## Solution
- Instead of panicking when getting `GizmoConfigStore`, insert the store
in `App::init_gizmos_group` if needed
---
## Changelog
### Changed
- Changed App::init_gizmos_group to insert the resource if it don't
exist
### Removed
- Removed explicit init of `GizmoConfigStore`
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Some users want to change the default texture usage of the main camera
but they are currently hardcoded
## Solution
- Add a component that is used to configure the main texture usage field
---
## Changelog
Added `CameraMainTextureUsage`
Added `CameraMainTextureUsage` to `Camera3dBundle` and `Camera2dBundle`
## Migration Guide
Add `main_texture_usages: Default::default()` to your camera bundle.
# Notes
Inspired by: #6815
# Objective
- Tests are manually checking whether derived types implement certain
traits. (Specifically in `bevy_reflect.)
- #11182 introduces
[`static_assertions`](https://docs.rs/static_assertions/) to
automatically check this.
- Simplifies `Reflect` test in #11195.
- Closes#11196.
## Solution
- Add `static_assertions` and replace current tests.
---
I wasn't sure whether to remove the existing test or not. What do you
think?
# Objective
- Add methods to get Change Ticks for a given resource by type or
ComponentId
- Fixes#11390
The `is_resource_id_changed` requested in the Issue already exists, this
adds their request for `get_resource_change_ticks`
## Solution
- Added two methods to get change ticks by Type or ComponentId
# Objective
Closes#10570.
#10946 added bounding volume types and traits, but didn't use them for
anything yet. This PR implements `Bounded2d` and `Bounded3d` for Bevy's
primitive shapes.
## Solution
Implement `Bounded2d` and `Bounded3d` for primitive shapes. This allows
computing AABBs and bounding circles/spheres for them.
For most shapes, there are several ways of implementing bounding
volumes. I took inspiration from [Parry's bounding
volumes](https://github.com/dimforge/parry/tree/master/src/bounding_volume),
[Inigo Quilez](http://iquilezles.org/articles/diskbbox/), and figured
out the rest myself using geometry. I tried to comment all slightly
non-trivial or unclear math to make it understandable.
Parry uses support mapping (finding the farthest point in some direction
for convex shapes) for some AABBs like cones, cylinders, and line
segments. This involves several quat operations and normalizations, so I
opted for the simpler and more efficient geometric approaches shown in
[Quilez's article](http://iquilezles.org/articles/diskbbox/).
Below you can see some of the bounding volumes working in 2D and 3D.
Note that I can't conveniently add these examples yet because they use
primitive shape meshing, which is still WIP.
https://github.com/bevyengine/bevy/assets/57632562/4465cbc6-285b-4c71-b62d-a2b3ee16f8b4https://github.com/bevyengine/bevy/assets/57632562/94b4ac84-a092-46d7-b438-ce2e971496a4
---
## Changelog
- Implemented `Bounded2d`/`Bounded3d` for primitive shapes
- Added `from_point_cloud` method for bounding volumes (used by many
bounding implementations)
- Added `point_cloud_2d/3d_center` and `rotate_vec2` utility functions
- Added `RegularPolygon::vertices` method (used in regular polygon AABB
construction)
- Added `Triangle::circumcenter` method (used in triangle bounding
circle construction)
- Added bounding circle/sphere creation from AABBs and vice versa
## Extra
Do we want to implement `Bounded2d` for some "3D-ish" shapes too? For
example, capsules are sort of dimension-agnostic and useful for 2D, so I
think that would be good to implement. But a cylinder in 2D is just a
rectangle, and a cone is a triangle, so they wouldn't make as much sense
to me. A conical frustum would be an isosceles trapezoid, which could be
useful, but I'm not sure if computing the 2D AABB of a 3D frustum makes
semantic sense.
# Objective
This PR aims to implement multiple configs for gizmos as discussed in
#9187.
## Solution
Configs for the new `GizmoConfigGroup`s are stored in a
`GizmoConfigStore` resource and can be accesses using a type based key
or iterated over. This type based key doubles as a standardized location
where plugin authors can put their own configuration not covered by the
standard `GizmoConfig` struct. For example the `AabbGizmoGroup` has a
default color and toggle to show all AABBs. New configs can be
registered using `app.init_gizmo_group::<T>()` during startup.
When requesting the `Gizmos<T>` system parameter the generic type
determines which config is used. The config structs are available
through the `Gizmos` system parameter allowing for easy access while
drawing your gizmos.
Internally, resources and systems used for rendering (up to an including
the extract system) are generic over the type based key and inserted on
registering a new config.
## Alternatives
The configs could be stored as components on entities with markers which
would make better use of the ECS. I also implemented this approach
([here](https://github.com/jeliag/bevy/tree/gizmo-multiconf-comp)) and
believe that the ergonomic benefits of a central config store outweigh
the decreased use of the ECS.
## Unsafe Code
Implementing system parameter by hand is unsafe but seems to be required
to access the config store once and not on every gizmo draw function
call. This is critical for performance. ~Is there a better way to do
this?~
## Future Work
New gizmos (such as #10038, and ideas from #9400) will require custom
configuration structs. Should there be a new custom config for every
gizmo type, or should we group them together in a common configuration?
(for example `EditorGizmoConfig`, or something more fine-grained)
## Changelog
- Added `GizmoConfigStore` resource and `GizmoConfigGroup` trait
- Added `init_gizmo_group` to `App`
- Added early returns to gizmo drawing increasing performance when
gizmos are disabled
- Changed `GizmoConfig` and aabb gizmos to use new `GizmoConfigStore`
- Changed `Gizmos` system parameter to use type based key to retrieve
config
- Changed resources and systems used for gizmo rendering to be generic
over type based key
- Changed examples (3d_gizmos, 2d_gizmos) to showcase new API
## Migration Guide
- `GizmoConfig` is no longer a resource and has to be accessed through
`GizmoConfigStore` resource. The default config group is
`DefaultGizmoGroup`, but consider using your own custom config group if
applicable.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
This adds events for assets that fail to load along with minor utility
methods to make them useful. This paves the way for users writing their
own error handling and retry systems, plus Bevy including robust retry
handling: #11349.
* Addresses #11288
* Needed for #11349
# Solution
```rust
/// An event emitted when a specific [`Asset`] fails to load.
#[derive(Event, Clone, Debug)]
pub struct AssetLoadFailedEvent<A: Asset> {
pub id: AssetId<A>,
/// The original handle returned when the asset load was requested.
pub handle: Option<Handle<A>>,
/// The asset path that was attempted.
pub path: AssetPath<'static>,
/// Why the asset failed to load.
pub error: AssetLoadError,
}
```
I started implementing `AssetEvent::Failed` like suggested in #11288,
but decided it was better as its own type because:
* I think it makes sense for `AssetEvent` to only refer to assets that
actually exist.
* In order to return `AssetLoadError` in the event (which is useful
information for error handlers that might attempt a retry) we would have
to remove `Copy` from `AssetEvent`.
* There are numerous places in the render app that match against
`AssetEvent`, and I don't think it's worth introducing extra noise about
assets that don't exist.
I also introduced `UntypedAssetLoadErrorEvent`, which is very useful in
places that need to support type flexibility, like an Asset-agnostic
retry plugin.
# Changelog
* **Added:** `AssetLoadFailedEvent<A>`
* **Added**: `UntypedAssetLoadFailedEvent`
* **Added:** `AssetReaderError::Http` for status code information on
HTTP errors. Before this, status codes were only available by parsing
the error message of generic `Io` errors.
* **Added:** `asset_server.get_path_id(path)`. This method simply gets
the asset id for the path. Without this, one was left using
`get_path_handle(path)`, which has the overhead of returning a strong
handle.
* **Fixed**: Made `AssetServer` loads return the same handle for assets
that already exist in a failed state. Now, when you attempt a `load`
that's in a `LoadState::Failed` state, it'll re-use the original asset
id. The advantage of this is that any dependent assets created using the
original handle will "unbreak" if a retry succeeds.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
fix an occasional crash when moving ui root nodes between cameras.
occasionally, updating the TargetCamera of a ui element and then
removing the element causes a crash.
i believe that is because when we assign a child in taffy, the old
parent doesn't remove that child from it's children, so we have:
```
user: create root node N1, camera A
-> layout::set_camera_children(A) :
- create implicit node A1
- assign 1 as child -> taffy.children[A1] = [N1], taffy.parents[1] = A1
user: move root node N1 to camera B
-> layout::set_camera_children(B) :
- create implicit node B1
- assign 1 as child -> taffy.children[A1] = [N1], taffy.children[B1] = [N1], taffy.parents[1] = B1
-> layout::set_camera_children(A) :
- remove implicit node A1 (which still has N1 as a child) ->
-> taffy sets parent[N1] = None ***
-> taffy.children[B1] = [N1], taffy.parents[1] = None
user: remove N1
-> layout::remove_entities(N1)
- since parent[N1] is None, it's not removed from B1 -> taffy.children[B1] = [N1], taffy.parents[1] is removed
-> layout::set_camera_children(B)
- remove implicit node B1
- taffy crash accessing taffy.parents[N1]
```
## Solution
we can work around this by making sure to remove the child from the old
parent if one exists (this pr).
i think a better fix may be for taffy to check in `Taffy::remove` and
only set the child's parent to None if it is currently equal to the node
being removed but i'm not sure if there's an explicit assumption we're
violating here (@nicoburns).
# Objective
- `DynamicUniformBuffer::push` takes an owned `T` but only uses a shared
reference to it
- This in turn requires users of `DynamicUniformBuffer::push` to
potentially unecessarily clone data
## Solution
- Have `DynamicUniformBuffer::push` take a shared reference to `T`
---
## Changelog
- `DynamicUniformBuffer::push` now takes a `&T` instead of `T`
## Migration Guide
- Users of `DynamicUniformBuffer::push` now need to pass references to
`DynamicUniformBuffer::push` (e.g. existing `uniforms.push(value)` will
now become `uniforms.push(&value)`)
# Objective
Expand the existing `Query` API to support more dynamic use cases i.e.
scripting.
## Prior Art
- #6390
- #8308
- #10037
## Solution
- Create a `QueryBuilder` with runtime methods to define the set of
component accesses for a built query.
- Create new `WorldQueryData` implementations `FilteredEntityMut` and
`FilteredEntityRef` as variants of `EntityMut` and `EntityRef` that
provide run time checked access to the components included in a given
query.
- Add new methods to `Query` to create "query lens" with a subset of the
access of the initial query.
### Query Builder
The `QueryBuilder` API allows you to define a query at runtime. At it's
most basic use it will simply create a query with the corresponding type
signature:
```rust
let query = QueryBuilder::<Entity, With<A>>::new(&mut world).build();
// is equivalent to
let query = QueryState::<Entity, With<A>>::new(&mut world);
```
Before calling `.build()` you also have the opportunity to add
additional accesses and filters. Here is a simple example where we add
additional filter terms:
```rust
let entity_a = world.spawn((A(0), B(0))).id();
let entity_b = world.spawn((A(0), C(0))).id();
let mut query_a = QueryBuilder::<Entity>::new(&mut world)
.with::<A>()
.without::<C>()
.build();
assert_eq!(entity_a, query_a.single(&world));
```
This alone is useful in that allows you to decide which archetypes your
query will match at runtime. However it is also very limited, consider a
case like the following:
```rust
let query_a = QueryBuilder::<&A>::new(&mut world)
// Add an additional access
.data::<&B>()
.build();
```
This will grant the query an additional read access to component B
however we have no way of accessing the data while iterating as the type
signature still only includes &A. For an even more concrete example of
this consider dynamic components:
```rust
let query_a = QueryBuilder::<Entity>::new(&mut world)
// Adding a filter is easy since it doesn't need be read later
.with_id(component_id_a)
// How do I access the data of this component?
.ref_id(component_id_b)
.build();
```
With this in mind the `QueryBuilder` API seems somewhat incomplete by
itself, we need some way method of accessing the components dynamically.
So here's one:
### Query Transmutation
If the problem is not having the component in the type signature why not
just add it? This PR also adds transmute methods to `QueryBuilder` and
`QueryState`. Here's a simple example:
```rust
world.spawn(A(0));
world.spawn((A(1), B(0)));
let mut query = QueryBuilder::<()>::new(&mut world)
.with::<B>()
.transmute::<&A>()
.build();
query.iter(&world).for_each(|a| assert_eq!(a.0, 1));
```
The `QueryState` and `QueryBuilder` transmute methods look quite similar
but are different in one respect. Transmuting a builder will always
succeed as it will just add the additional accesses needed for the new
terms if they weren't already included. Transmuting a `QueryState` will
panic in the case that the new type signature would give it access it
didn't already have, for example:
```rust
let query = QueryState::<&A, Option<&B>>::new(&mut world);
/// This is fine, the access for Option<&A> is less restrictive than &A
query.transmute::<Option<&A>>(&world);
/// Oh no, this would allow access to &B on entities that might not have it, so it panics
query.transmute::<&B>(&world);
/// This is right out
query.transmute::<&C>(&world);
```
This is quite an appealing API to also have available on `Query` however
it does pose one additional wrinkle: In order to to change the iterator
we need to create a new `QueryState` to back it. `Query` doesn't own
it's own state though, it just borrows it, so we need a place to borrow
it from. This is why `QueryLens` exists, it is a place to store the new
state so it can be borrowed when you call `.query()` leaving you with an
API like this:
```rust
fn function_that_takes_a_query(query: &Query<&A>) {
// ...
}
fn system(query: Query<(&A, &B)>) {
let lens = query.transmute_lens::<&A>();
let q = lens.query();
function_that_takes_a_query(&q);
}
```
Now you may be thinking: Hey, wait a second, you introduced the problem
with dynamic components and then described a solution that only works
for static components! Ok, you got me, I guess we need a bit more:
### Filtered Entity References
Currently the only way you can access dynamic components on entities
through a query is with either `EntityMut` or `EntityRef`, however these
can access all components and so conflict with all other accesses. This
PR introduces `FilteredEntityMut` and `FilteredEntityRef` as
alternatives that have additional runtime checking to prevent accessing
components that you shouldn't. This way you can build a query with a
`QueryBuilder` and actually access the components you asked for:
```rust
let mut query = QueryBuilder::<FilteredEntityRef>::new(&mut world)
.ref_id(component_id_a)
.with(component_id_b)
.build();
let entity_ref = query.single(&world);
// Returns Some(Ptr) as we have that component and are allowed to read it
let a = entity_ref.get_by_id(component_id_a);
// Will return None even though the entity does have the component, as we are not allowed to read it
let b = entity_ref.get_by_id(component_id_b);
```
For the most part these new structs have the exact same methods as their
non-filtered equivalents.
Putting all of this together we can do some truly dynamic ECS queries,
check out the `dynamic` example to see it in action:
```
Commands:
comp, c Create new components
spawn, s Spawn entities
query, q Query for entities
Enter a command with no parameters for usage.
> c A, B, C, Data 4
Component A created with id: 0
Component B created with id: 1
Component C created with id: 2
Component Data created with id: 3
> s A, B, Data 1
Entity spawned with id: 0v0
> s A, C, Data 0
Entity spawned with id: 1v0
> q &Data
0v0: Data: [1, 0, 0, 0]
1v0: Data: [0, 0, 0, 0]
> q B, &mut Data
0v0: Data: [2, 1, 1, 1]
> q B || C, &Data
0v0: Data: [2, 1, 1, 1]
1v0: Data: [0, 0, 0, 0]
```
## Changelog
- Add new `transmute_lens` methods to `Query`.
- Add new types `QueryBuilder`, `FilteredEntityMut`, `FilteredEntityRef`
and `QueryLens`
- `update_archetype_component_access` has been removed, archetype
component accesses are now determined by the accesses set in
`update_component_access`
- Added method `set_access` to `WorldQuery`, this is called before
`update_component_access` for queries that have a restricted set of
accesses, such as those built by `QueryBuilder` or `QueryLens`. This is
primarily used by the `FilteredEntity*` variants and has an empty trait
implementation.
- Added method `get_state` to `WorldQuery` as a fallible version of
`init_state` when you don't have `&mut World` access.
## Future Work
Improve performance of `FilteredEntityMut` and `FilteredEntityRef`,
currently they have to determine the accesses a query has in a given
archetype during iteration which is far from ideal, especially since we
already did the work when matching the archetype in the first place. To
avoid making more internal API changes I have left it out of this PR.
---------
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
Tried using "embedded_watcher" feature and `embedded_asset!()` from
another crate. The assets embedded fine but were not "watched." The
problem appears to be that checking for the feature was done inside the
macro, so rather than checking if "embedded_watcher" was enabled for
bevy, it would check if it was enabled for the current crate.
## Solution
I extracted the checks for the "embedded_watcher" feature into its own
function called `watched_path()`. No external changes.
### Alternative Solution
An alternative fix would be to not do any feature checking in
`embedded_asset!()` or an extracted function and always send the
full_path to `insert_asset()` where it's promptly dropped when the
feature isn't turned on. That would be simpler.
```
($app: ident, $source_path: expr, $path: expr) => {{
let mut embedded = $app
.world
.resource_mut::<$crate::io::embedded::EmbeddedAssetRegistry>();
let path = $crate::embedded_path!($source_path, $path);
//#[cfg(feature = "embedded_watcher")]
let full_path = std::path::Path::new(file!()).parent().unwrap().join($path);
//#[cfg(not(feature = "embedded_watcher"))]
//let full_path = std::path::PathBuf::new();
embedded.insert_asset(full_path, &path, include_bytes!($path));
}};
```
## Changelog
> Fix embedded_watcher feature to work with external crates
Rebased and finished version of
https://github.com/bevyengine/bevy/pull/8407. Huge thanks to @GitGhillie
for adjusting all the examples, and the many other people who helped
write this PR (@superdump , @coreh , among others) :)
Fixes https://github.com/bevyengine/bevy/issues/8369
---
## Changelog
- Added a `brightness` control to `Skybox`.
- Added an `intensity` control to `EnvironmentMapLight`.
- Added `ExposureSettings` and `PhysicalCameraParameters` for
controlling exposure of 3D cameras.
- Removed the baked-in `DirectionalLight` exposure Bevy previously
hardcoded internally.
## Migration Guide
- If using a `Skybox` or `EnvironmentMapLight`, use the new `brightness`
and `intensity` controls to adjust their strength.
- All 3D scene will now have different apparent brightnesses due to Bevy
implementing proper exposure controls. You will have to adjust the
intensity of your lights and/or your camera exposure via the new
`ExposureSettings` component to compensate.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
Co-authored-by: Marco Buono <thecoreh@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
gltf-rs does its own computations when accessing `transform.matrix()`
which does not use glam types, rendering #11238 useless if people were
to load gltf models and expecting the results to be deterministic across
platforms.
## Solution
Move the computation to bevy side which uses glam types, it was already
used in one place, so I created one common function to handle the two
cases.
The added benefit this has, is that some gltf files can have
translation, rotation and scale directly instead of matrix which skips
the transform computation completely, win-win.
# Objective
> Old MR: #5072
> ~~Associated UI MR: #5070~~
> Adresses #1618
Unify sprite management
## Solution
- Remove the `Handle<Image>` field in `TextureAtlas` which is the main
cause for all the boilerplate
- Remove the redundant `TextureAtlasSprite` component
- Renamed `TextureAtlas` asset to `TextureAtlasLayout`
([suggestion](https://github.com/bevyengine/bevy/pull/5103#discussion_r917281844))
- Add a `TextureAtlas` component, containing the atlas layout handle and
the section index
The difference between this solution and #5072 is that instead of the
`enum` approach is that we can more easily manipulate texture sheets
without any breaking changes for classic `SpriteBundle`s (@mockersf
[comment](https://github.com/bevyengine/bevy/pull/5072#issuecomment-1165836139))
Also, this approach is more *data oriented* extracting the
`Handle<Image>` and avoiding complex texture atlas manipulations to
retrieve the texture in both applicative and engine code.
With this method, the only difference between a `SpriteBundle` and a
`SpriteSheetBundle` is an **additional** component storing the atlas
handle and the index.
~~This solution can be applied to `bevy_ui` as well (see #5070).~~
EDIT: I also applied this solution to Bevy UI
## Changelog
- (**BREAKING**) Removed `TextureAtlasSprite`
- (**BREAKING**) Renamed `TextureAtlas` to `TextureAtlasLayout`
- (**BREAKING**) `SpriteSheetBundle`:
- Uses a `Sprite` instead of a `TextureAtlasSprite` component
- Has a `texture` field containing a `Handle<Image>` like the
`SpriteBundle`
- Has a new `TextureAtlas` component instead of a
`Handle<TextureAtlasLayout>`
- (**BREAKING**) `DynamicTextureAtlasBuilder::add_texture` takes an
additional `&Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasLayout::from_grid` no longer takes a
`Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasBuilder::finish` now returns a
`Result<(TextureAtlasLayout, Handle<Image>), _>`
- `bevy_text`:
- `GlyphAtlasInfo` stores the texture `Handle<Image>`
- `FontAtlas` stores the texture `Handle<Image>`
- `bevy_ui`:
- (**BREAKING**) Removed `UiAtlasImage` , the atlas bundle is now
identical to the `ImageBundle` with an additional `TextureAtlas`
## Migration Guide
* Sprites
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(SpriteSheetBundle {
- sprite: TextureAtlasSprite::new(0),
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ texture: texture_handle,
..Default::default()
});
}
```
* UI
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(AtlasImageBundle {
- texture_atlas_image: UiTextureAtlasImage {
- index: 0,
- flip_x: false,
- flip_y: false,
- },
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ image: UiImage {
+ texture: texture_handle,
+ flip_x: false,
+ flip_y: false,
+ },
..Default::default()
});
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- The
[`build-templated-pages`](4778fbeb65/tools/build-templated-pages)
tool is used to render the Markdown templates in the
[docs-template](4778fbeb65/docs-template)
folder.
- It depends on out outdated version of `toml_edit`.
## Solution
- Bump `toml_edit` to 0.21, disabling all features except `parse`.
# Objective
Add support for presenting each UI tree on a specific window and
viewport, while making as few breaking changes as possible.
This PR is meant to resolve the following issues at once, since they're
all related.
- Fixes#5622
- Fixes#5570
- Fixes#5621
Adopted #5892 , but started over since the current codebase diverged
significantly from the original PR branch. Also, I made a decision to
propagate component to children instead of recursively iterating over
nodes in search for the root.
## Solution
Add a new optional component that can be inserted to UI root nodes and
propagate to children to specify which camera it should render onto.
This is then used to get the render target and the viewport for that UI
tree. Since this component is optional, the default behavior should be
to render onto the single camera (if only one exist) and warn of
ambiguity if multiple cameras exist. This reduces the complexity for
users with just one camera, while giving control in contexts where it
matters.
## Changelog
- Adds `TargetCamera(Entity)` component to specify which camera should a
node tree be rendered into. If only one camera exists, this component is
optional.
- Adds an example of rendering UI to a texture and using it as a
material in a 3D world.
- Fixes recalculation of physical viewport size when target scale factor
changes. This can happen when the window is moved between displays with
different DPI.
- Changes examples to demonstrate assigning UI to different viewports
and windows and make interactions in an offset viewport testable.
- Removes `UiCameraConfig`. UI visibility now can be controlled via
combination of explicit `TargetCamera` and `Visibility` on the root
nodes.
---------
Co-authored-by: davier <bricedavier@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
- Update async channel to v2.
## Solution
- async channel doesn't support `send_blocking` on wasm anymore. So
don't compile the pipelined rendering plugin on wasm anymore.
- Replaces https://github.com/bevyengine/bevy/pull/10405
## Migration Guide
- The `PipelinedRendering` plugin is no longer exported on wasm. If you
are including it in your wasm builds you should remove it.
```rust
#[cfg(all(not(target_arch = "wasm32"))]
app.add_plugins(bevy_render::pipelined_rendering::PipelinedRenderingPlugin);
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Partial fix for #11235
- Fixes#11274
- Fixes#11320
- Fixes#11273
## Solution
- check update mode to trigger redraw request, instead of once a redraw
request has been triggered
- don't ignore device event in case of `Reactive` update mode
- make sure that at least 5 updates are triggered on application start
to ensure everything is correctly initialized
- trigger manual updates instead of relying on redraw requests when
there are no window or they are not visible
> Replaces #5213
# Objective
Implement sprite tiling and [9 slice
scaling](https://en.wikipedia.org/wiki/9-slice_scaling) for
`bevy_sprite`.
Allowing slice scaling and texture tiling.
Basic scaling vs 9 slice scaling:

Slicing example:
<img width="481" alt="Screenshot 2022-07-05 at 15 05 49"
src="https://user-images.githubusercontent.com/26703856/177336112-9e961af0-c0af-4197-aec9-430c1170a79d.png">
Tiling example:
<img width="1329" alt="Screenshot 2023-11-16 at 13 53 32"
src="https://github.com/bevyengine/bevy/assets/26703856/14db39b7-d9e0-4bc3-ba0e-b1f2db39ae8f">
# Solution
- `SpriteBundlue` now has a `scale_mode` component storing a
`SpriteScaleMode` enum with three variants:
- `Stretched` (default)
- `Tiled` to have sprites tile horizontally and/or vertically
- `Sliced` allowing 9 slicing the texture and optionally tile some
sections with a `Textureslicer`.
- `bevy_sprite` has two extra systems to compute a
`ComputedTextureSlices` if necessary,:
- One system react to changes on `Sprite`, `Handle<Image>` or
`SpriteScaleMode`
- The other listens to `AssetEvent<Image>` to compute slices on sprites
when the texture is ready or changed
- I updated the `bevy_sprite` extraction stage to extract potentially
multiple textures instead of one, depending on the presence of
`ComputedTextureSlices`
- I added two examples showcasing the slicing and tiling feature.
The addition of `ComputedTextureSlices` as a cache is to avoid querying
the image data, to retrieve its dimensions, every frame in a extract or
prepare stage. Also it reacts to changes so we can have stuff like this
(tiling example):
https://github.com/bevyengine/bevy/assets/26703856/a349a9f3-33c3-471f-8ef4-a0e5dfce3b01
# Related
- [ ] Once #5103 or #10099 is merged I can enable tiling and slicing for
texture sheets as ui
# To discuss
There is an other option, to consider slice/tiling as part of the asset,
using the new asset preprocessing but I have no clue on how to do it.
Also, instead of retrieving the Image dimensions, we could use the same
system as the sprite sheet and have the user give the image dimensions
directly (grid). But I think it's less user friendly
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
Adds support for accessing raw extension data of loaded GLTF assets
## Solution
Via the GLTF loader settings, you can specify whether or not to include
the GLTF source. While not the ideal way of solving this problem,
modeling all of GLTF within Bevy just for extensions adds a lot of
complexity to the way Bevy handles GLTF currently. See the example GLTF
meta file and code
```
(
meta_format_version: "1.0",
asset: Load(
loader: "bevy_gltf::loader::GltfLoader",
settings: (
load_meshes: true,
load_cameras: true,
load_lights: true,
include_source: true,
),
),
)
```
```rs
pub fn load_gltf(mut commands: Commands, assets: Res<AssetServer>) {
let my_gltf = assets.load("test_platform.gltf");
commands.insert_resource(MyAssetPack {
spawned: false,
handle: my_gltf,
});
}
#[derive(Resource)]
pub struct MyAssetPack {
pub spawned: bool,
pub handle: Handle<Gltf>,
}
pub fn spawn_gltf_objects(
mut commands: Commands,
mut my: ResMut<MyAssetPack>,
assets_gltf: Res<Assets<Gltf>>,
) {
// This flag is used to because this system has to be run until the asset is loaded.
// If there's a better way of going about this I am unaware of it.
if my.spawned {
return;
}
if let Some(gltf) = assets_gltf.get(&my.handle) {
info!("spawn");
my.spawned = true;
// spawn the first scene in the file
commands.spawn(SceneBundle {
scene: gltf.scenes[0].clone(),
..Default::default()
});
let source = gltf.source.as_ref().unwrap();
info!("materials count {}", &source.materials().size_hint().0);
info!(
"materials ext is some {}",
&source.materials().next().unwrap().extensions().is_some()
);
}
}
```
---
## Changelog
Added support for GLTF extensions through including raw GLTF source via
loader flag `GltfLoaderSettings::include_source == true`, stored in
`Gltf::source: Option<gltf::Gltf>`
## Migration Guide
This will have issues with "asset migrations", as there is currently no
way for .meta files to be migrated. Attempting to migrate .meta files
without the new flag will yield the following error:
```
bevy_asset::server: Failed to deserialize meta for asset test_platform.gltf: Failed to deserialize asset meta: SpannedError { code: MissingStructField { field: "include_source", outer: Some("GltfLoaderSettings") }, position: Position { line: 9, col: 9 } }
```
This means users who want to migrate their .meta files will have to add
the `include_source: true,` setting to their meta files by hand.
# Objective
The ability to ignore the global volume doesn't seem desirable and
complicates the API.
#7706 added global volume and the ability to ignore it, but there was no
further discussion about whether that's useful. Feel free to discuss
here :)
## Solution
Replace the `Volume` type's functionality with the `VolumeLevel`. Remove
`VolumeLevel`.
I also removed `DerefMut` derive that effectively made the volume `pub`
and actually ensured that the volume isn't set below `0` even in release
builds.
## Migration Guide
The option to ignore the global volume using `Volume::Absolute` has been
removed and `Volume` now stores the volume level directly, removing the
need for the `VolumeLevel` struct.
# Objective
This PR is heavily inspired by
https://github.com/bevyengine/bevy/pull/7682
It aims to solve the same problem: allowing the user to extend the
tracing subscriber with extra layers.
(in my case, I'd like to use `use
metrics_tracing_context::{MetricsLayer, TracingContextLayer};`)
## Solution
I'm proposing a different api where the user has the opportunity to take
the existing `subscriber` and apply any transformations on it.
---
## Changelog
- Added a `update_subscriber` option on the `LogPlugin` that lets the
user modify the `subscriber` (for example to extend it with more tracing
`Layers`
## Migration Guide
> This section is optional. If there are no breaking changes, you can
delete this section.
- Added a new field `update_subscriber` in the `LogPlugin`
---------
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>
# Objective
The table [here](https://github.com/nagisa/rust_tracy_client) shows
which versions of [Tracy](https://github.com/wolfpld/tracy) should be
used combined with which Rust deps.
Reading `bevy_log`'s `Cargo.toml` can be slightly confusing since the
exact versions are not picked from the same row.
Reading the produced `Cargo.lock` when building a Bevy example shows
that it's the most recent row that is resolved, but this should be more
clearly understood without needing to check the lock file.
## Solution
- Specify versions from the compatibility table including patch version
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- `bevy_gizmos` cannot work if both `bevy_sprite` and `bevy_pbr` are
disabled.
- It silently fails to render, making it difficult to debug.
- Fixes#10984
## Solution
- Log an error message when `GizmoPlugin` is registered.
## Alternatives
I chose to log an error message, since it seemed the least intrusive of
potential solutions. Some alternatives include:
- Choosing one dependency as the default, neglecting the other. (#11035)
- Raising a compile error when neither dependency is enabled. ([See my
original
comment](https://github.com/bevyengine/bevy/issues/10984#issuecomment-1873420426))
- Raising a compile warning using a macro hack. ([Pre-RFC - Add
compile_warning!
macro](https://internals.rust-lang.org/t/pre-rfc-add-compile-warning-macro/9370/7?u=bd103))
- Logging a warning instead of an error.
- _This might be the better option. Let me know if I should change it._
---
## Changelog
- `bevy_gizmos` will now log an error if neither `bevy_pbr` nor
`bevy_sprite` are enabled.
# Objective
- Implementing `Default` for
[`CubicCurve`](https://docs.rs/bevy/latest/bevy/math/cubic_splines/struct.CubicCurve.html)
does not make sense because it cannot be mutated after creation.
- Closes#11209.
- Alternative to #11211.
## Solution
- Remove `Default` from `CubicCurve`'s derive statement.
Based off of @mockersf comment
(https://github.com/bevyengine/bevy/pull/11211#issuecomment-1880088036):
> CubicCurve can't be updated once created... I would prefer to remove
the Default impl as it doesn't make sense
---
## Changelog
- Removed the `Default` implementation for `CubicCurve`.
## Migration Guide
- Remove `CubicCurve` from any structs that implement `Default`.
- Wrap `CubicCurve` in a new type and provide your own default.
```rust
#[derive(Deref)]
struct MyCubicCurve<P: Point>(pub CubicCurve<P>);
impl Default for MyCubicCurve<Vec2> {
fn default() -> Self {
let points = [[
vec2(-1.0, -20.0),
vec2(3.0, 2.0),
vec2(5.0, 3.0),
vec2(9.0, 8.0),
]];
Self(CubicBezier::new(points).to_curve())
}
}
```
Based on discussion after #11268 was merged:
Instead of panicking should the impl of `TypeId::hash` change
significantly, have a fallback and detect this in a test.
# Objective
In #11330 I found out that `Parent::get` didn't get inlined, **even with
LTO on**!
This means that just to access a field, we have an instruction cache
invalidation, we will move some registers to the stack, will jump to new
instructions, move the field into a register, then do the same dance in
the other direction to go back to the call site.
## Solution
Mark trivial functions as `#[inline]`.
`inline(always)` may increase compilation time proportional to how many
time the function is called **and the size of the function marked with
`inline`**. Since we mark as `inline` functions that consists in a
single instruction, the cost is absolutely negligible.
I also took the opportunity to `inline` other functions. I'm not as
confident that marking functions calling other functions as `inline`
works similarly to very simple functions, so I used `inline` over
`inline(always)`, which doesn't have the same downsides as
`inline(always)`.
More information on inlining in rust:
https://nnethercote.github.io/perf-book/inlining.html
Not always, but skip it if the new length is smaller.
For context, `path_cache` is a `Vec<Vec<Option<Entity>>>`.
# Objective
Previously, when setting a new length to the `path_cache`, we would:
1. Deallocate all existing `Vec<Option<Entity>>`
2. Deallocate the `path_cache`
3. Allocate a new `Vec<Vec<Option<Entity>>>`, where each item is an
empty `Vec`, and would have to be allocated when pushed to.
This is a lot of allocations!
## Solution
Use
[`Vec::resize_with`](https://doc.rust-lang.org/stable/std/vec/struct.Vec.html#method.resize_with).
With this change, what occurs is:
1. We `clear` each `Vec<Option<Entity>>`, keeping the allocation, but
making the memory of each `Vec` re-usable
2. We only append new `Vec` to `path_cache` when it is too small.
* Fixes#11328
### Note on performance
I didn't benchmark it, I just ran a diff on the generated assembly (ran
with `--profile stress-test` and `--native`). I found this PR has 20
less instructions in `apply_animation` (out of 2504).
Though on a purely abstract level, I can deduce this leads to less
allocation.
More information on profiling allocations in rust:
https://nnethercote.github.io/perf-book/heap-allocations.html
## Future work
I think a [jagged vec](https://en.wikipedia.org/wiki/Jagged_array) would
be much more pertinent. Because it allocates everything in a single
contiguous buffer.
This would avoid dancing around allocations, and reduces the overhead of
one `*mut T` and two `usize` per row, also removes indirection,
improving cache efficiency. I think it would both improve code quality
and performance.
# Objective
`TypeId` contains a high-quality hash. Whenever a lookup based on a
`TypeId` is performed (e.g. to insert/remove components), the hash is
run through a second hash function. This is unnecessary.
## Solution
Skip re-hashing `TypeId`s.
In my
[testing](https://gist.github.com/SpecificProtagonist/4b49ad74c6b82b0aedd3b4ea35121be8),
this improves lookup performance consistently by 10%-15% (of course, the
lookup is only a small part of e.g. a bundle insertion).
# Objective
While working on #10832, I found this code very dense and hard to
understand.
I was not confident in my fix (or the correctness of the existing code).
## Solution
Clean up, test and document the code used in the `apply_animation`
system.
I also added a pair of length-related utility methods to `Keyframes` for
easier testing. They seemed generically useful, so I made them pub.
## Changelog
- Added `VariableCurve::find_current_keyframe` method.
- Added `Keyframes::len` and `is_empty` methods.
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
The purpose of this PR is to begin putting together a unified identifier
structure that can be used by entities and later components (as
entities) as well as relationship pairs for relations, to enable all of
these to be able to use the same storages. For the moment, to keep
things small and focused, only `Entity` is being changed to make use of
the new `Identifier` type, keeping `Entity`'s API and
serialization/deserialization the same. Further changes are for
follow-up PRs.
## Solution
`Identifier` is a wrapper around `u64` split into two `u32` segments
with the idea of being generalised to not impose restrictions on
variants. That is for `Entity` to do. Instead, it is a general API for
taking bits to then merge and map into a `u64` integer. It exposes
low/high methods to return the two value portions as `u32` integers,
with then the MSB masked for usage as a type flag, enabling entity kind
discrimination and future activation/deactivation semantics.
The layout in this PR for `Identifier` is described as below, going from
MSB -> LSB.
```
|F| High value | Low value |
|_|_______________________________|________________________________|
|1| 31 | 32 |
F = Bit Flags
```
The high component in this implementation has only 31 bits, but that
still leaves 2^31 or 2,147,483,648 values that can be stored still, more
than enough for any generation/relation kinds/etc usage. The low part is
a full 32-bit index. The flags allow for 1 bit to be used for
entity/pair discrimination, as these have different usages for the
low/high portions of the `Identifier`. More bits can be reserved for
more variants or activation/deactivation purposes, but this currently
has no use in bevy.
More bits could be reserved for future features at the cost of bits for
the high component, so how much to reserve is up for discussion. Also,
naming of the struct and methods are also subject to further
bikeshedding and feedback.
Also, because IDs can have different variants, I wonder if
`Entity::from_bits` needs to return a `Result` instead of potentially
panicking on receiving an invalid ID.
PR is provided as an early WIP to obtain feedback and notes on whether
this approach is viable.
---
## Changelog
### Added
New `Identifier` struct for unifying IDs.
### Changed
`Entity` changed to use new `Identifier`/`IdentifierMask` as the
underlying ID logic.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
# Objective
- It is common to run a system only when the clock is paused or not
paused, but this run condition doesn't exist.
## Solution
- Add the "paused" run condition.
---
## Changelog
- Systems can now be scheduled to run only if the clock is paused or not
using `.run_if(paused())` or `.run_if(not(paused()))`.
---------
Co-authored-by: radiish <cb.setho@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/11222
## Solution
SSAO's sample_mip_level was always giving negative values because it was
in UV space (0..1) when it needed to be in pixel units (0..resolution).
Fixing it so it properly samples lower mip levels when appropriate is a
pretty large speedup (~3.2ms -> ~1ms at 4k, ~507us-> 256us at 1080p on a
6800xt), and I didn't notice any obvious visual quality differences.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Implement bounding volume trait and the 4 types from
https://github.com/bevyengine/bevy/issues/10570. I will add intersection
tests in a future PR.
## Solution
Implement mostly everything as written in the issue, except:
- Intersection is no longer a method on the bounding volumes, but a
separate trait.
- I implemented a `visible_area` since it's the most common usecase to
care about the surface that could collide with cast rays.
- Maybe we want both?
---
## Changelog
- Added bounding volume types to bevy_math
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
In the past `winit:🪟:Window` was not Send + Sync on web.
https://github.com/rust-windowing/winit/pull/2834 made
`winit:🪟:Window` Sync + Send so Bevy's `unsafe impl` is no longer
necessary.
## Solution
Remove the unsafe impls.
# Objective
This dependency is seemingly no longer used directly after #7267.
Unfortunately, this doesn't fix us having versions of `event-listener`
in our tree.
Closes#10654
## Solution
Remove it, see if anything breaks.
# Objective
- Since #11227, Bevy doesn't work on mobile anymore. Windows are not
created.
## Solution
- Create initial window on mobile after the initial `Resume` event.
macOS is included because it's excluded from the other initial window
creation and I didn't want it to feel alone. Also, it makes sense. this
is needed for Android
cfcb6885e3/crates/bevy_winit/src/lib.rs (L152)
- request redraw during plugin initialisation (needed for WebGPU)
- request redraw when receiving `AboutToWait` instead of at the end of
the event handler. request to redraw during a `RedrawRequested` event
are ignored on iOS
# Objective
Issue #10243: rendering multiple triangles in the same place results in
flickering.
## Solution
Considered these alternatives:
- `depth_bias` may not work, because of high number of entities, so
creating a material per entity is practically not possible
- rendering at slightly different positions does not work, because when
camera is far, float rounding causes the same issues (edit: assuming we
have to use the same `depth_bias`)
- considered implementing deterministic operation like
`query.par_iter().flat_map(...).collect()` to be used in
`check_visibility` system (which would solve the issue since query is
deterministic), and could not figure out how to make it as cheap as
current approach with thread-local collectors (#11249)
So adding an option to sort entities after `check_visibility` system
run.
Should not be too bad, because after visibility check, only a handful
entities remain.
This is probably not the only source of non-determinism in Bevy, but
this is one I could find so far. At least it fixes the repro example.
## Changelog
- `DeterministicRenderingConfig` option to enable deterministic
rendering
## Test
<img width="1392" alt="image"
src="https://github.com/bevyengine/bevy/assets/28969/c735bce1-3a71-44cd-8677-c19f6c0ee6bd">
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
I want to run a system once after a given delay.
- First, I tried using the `on_timer` run condition, but it uses a
repeating timer, causing the system to run multiple times.
- Next, I tried combining the `on_timer` with the `run_once` run
condition. However, this causes the timer to *tick* only once, so the
system is never executed.
## Solution
- ~~Replace `on_timer` by `on_time_interval` and `on_real_timer` by
`on_real_time_interval` to clarify the meaning (the old ones are
deprecated to avoid a breaking change).~~ (Reverted according to
feedback)
- Add `once_after_delay` and `once_after_real_delay` to run the system
exactly once after the delay, using `TimerMode::Once`.
- Add `repeating_after_delay` and `repeating_after_real_delay` to run
the system indefinitely after the delay, using `Timer::finished` instead
of `Timer::just_finished`.
---
## Changelog
### Added
- `once_after_delay` and `once_after_real_delay` run conditions to run
the system exactly once after the delay, using `TimerMode::Once`.
- `repeating_after_delay` and `repeating_after_real_delay` run
conditions to run the system indefinitely after the delay, using
`Timer::finished` instead of `Timer::just_finished`.
# Objective
- Implements change described in
https://github.com/bevyengine/bevy/issues/3022
- Goal is to allow Entity to benefit from niche optimization, especially
in the case of Option<Entity> to reduce memory overhead with structures
with empty slots
## Discussion
- First PR attempt: https://github.com/bevyengine/bevy/pull/3029
- Discord:
https://discord.com/channels/691052431525675048/1154573759752183808/1154573764240093224
## Solution
- Change `Entity::generation` from u32 to NonZeroU32 to allow for niche
optimization.
- The reason for changing generation rather than index is so that the
costs are only encountered on Entity free, instead of on Entity alloc
- There was some concern with generations being used, due to there being
some desire to introduce flags. This was more to do with the original
retirement approach, however, in reality even if generations were
reduced to 24-bits, we would still have 16 million generations available
before wrapping and current ideas indicate that we would be using closer
to 4-bits for flags.
- Additionally, another concern was the representation of relationships
where NonZeroU32 prevents us using the full address space, talking with
Joy it seems unlikely to be an issue. The majority of the time these
entity references will be low-index entries (ie. `ChildOf`, `Owes`),
these will be able to be fast lookups, and the remainder of the range
can use slower lookups to map to the address space.
- It has the additional benefit of being less visible to most users,
since generation is only ever really set through `from_bits` type
methods.
- `EntityMeta` was changed to match
- On free, generation now explicitly wraps:
- Originally, generation would panic in debug mode and wrap in release
mode due to using regular ops.
- The first attempt at this PR changed the behavior to "retire" slots
and remove them from use when generations overflowed. This change was
controversial, and likely needs a proper RFC/discussion.
- Wrapping matches current release behaviour, and should therefore be
less controversial.
- Wrapping also more easily migrates to the retirement approach, as
users likely to exhaust the exorbitant supply of generations will code
defensively against aliasing and that defensive code is less likely to
break than code assuming that generations don't wrap.
- We use some unsafe code here when wrapping generations, to avoid
branch on NonZeroU32 construction. It's guaranteed safe due to how we
perform wrapping and it results in significantly smaller ASM code.
- https://godbolt.org/z/6b6hj8PrM
## Migration
- Previous `bevy_scene` serializations have a high likelihood of being
broken, as they contain 0th generation entities.
## Current Issues
- `Entities::reserve_generations` and `EntityMapper` wrap now, even in
debug - although they technically did in release mode already so this
probably isn't a huge issue. It just depends if we need to change
anything here?
---------
Co-authored-by: Natalie Baker <natalie.baker@advancednavigation.com>
Update to `glam` 0.25, `encase` 0.7 and `hexasphere` to 10.0
## Changelog
Added the `FloatExt` trait to the `bevy_math` prelude which adds `lerp`,
`inverse_lerp` and `remap` methods to the `f32` and `f64` types.
# Objective
When you have no idea what to put after `#` when loading an asset, error
message may help.
## Solution
Add all labels to the error message.
## Test plan
Modified `anti_alias` example to put incorrect label, the error is:
```
2024-01-08T07:41:25.462287Z ERROR bevy_asset::server: The file at 'models/FlightHelmet/FlightHelmet.gltf' does not contain the labeled asset 'Rrrr'; it contains the following 25 assets: 'Material0', 'Material1', 'Material2', 'Material3', 'Material4', 'Material5', 'Mesh0', 'Mesh0/Primitive0', 'Mesh1', 'Mesh1/Primitive0', 'Mesh2', 'Mesh2/Primitive0', 'Mesh3', 'Mesh3/Primitive0', 'Mesh4', 'Mesh4/Primitive0', 'Mesh5', 'Mesh5/Primitive0', 'Node0', 'Node1', 'Node2', 'Node3', 'Node4', 'Node5', 'Scene0'
```
# Objective
`Column` unconditionally requires three separate allocations: one for
the data, and two for the tick Vecs. The tick Vecs aren't really needed
for Resources, so we're allocating a bunch of one-element Vecs, and it
costs two extra dereferences when fetching/inserting/removing resources.
## Solution
Drop one level lower in `ResourceData` and directly store a `BlobVec`
and two `UnsafeCell<Tick>`s. This should significantly shrink
`ResourceData` (exchanging 6 usizes for 2 u32s), removes the need to
dereference two separate ticks when inserting/removing/fetching
resources, and can significantly decrease the number of small
allocations the ECS makes by default.
This tentatively might have a non-insignificant impact on the CPU cost
for rendering since we're constantly fetching resources in draw
functions, depending on how aggressively inlined the functions are.
This requires reimplementing some of the unsafe functions that `Column`
wraps, but it also allows us to delete a few Column APIs that were only
used for Resources, so the total amount of unsafe we're maintaining
shouldn't change significantly.
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
When creating a normalized direction from a vector, it can be useful to
get both the direction *and* the original length of the vector.
This came up when I was recreating some Parry APIs using bevy_math, and
doing it manually is quite painful. Nalgebra calls this method
[`Unit::try_new_and_get`](https://docs.rs/nalgebra/latest/nalgebra/base/struct.Unit.html#method.try_new_and_get).
## Solution
Add a `new_and_length` method to `Direction2d` and `Direction3d`.
Usage:
```rust
if let Ok((direction, length)) = Direction2d::new_and_length(Vec2::X * 10.0) {
assert_eq!(direction, Vec2::X);
assert_eq!(length, 10.0);
}
```
I'm open to different names, couldn't come up with a perfectly clear one
that isn't too long. My reasoning with the current name is that it's
like using `new` and calling `length` on the original vector.
# Objective
In #9604 we removed the ability to define an `EntityCommand` as
`fn(Entity, &mut World)`. However I have since realized that `fn(Entity,
&mut World)` is an incredibly expressive and powerful way to define a
command for an entity that may or may not exist (`fn(EntityWorldMut)`
only works on entities that are alive).
## Solution
Support `EntityCommand`s in the style of `fn(Entity, &mut World)`, as
well as `fn(EntityWorldMut)`. Use a marker generic on the
`EntityCommand` trait to allow multiple impls.
The second commit in this PR replaces all of the internal command
definitions with ones using `fn` definitions. This is mostly just to
show off how expressive this style of command is -- we can revert this
commit if we'd rather avoid breaking changes.
---
## Changelog
Re-added support for expressively defining an `EntityCommand` as a
function that takes `Entity, &mut World`.
## Migration Guide
All `Command` types in `bevy_ecs`, such as `Spawn`, `SpawnBatch`,
`Insert`, etc., have been made private. Use the equivalent methods on
`Commands` or `EntityCommands` instead.
# Objective
- Make it possible to react to arbitrary state changes
- this will be useful regardless of the other changes to states
currently being discussed
## Solution
- added `StateTransitionEvent<S>` struct
- previously, this would have been impossible:
```rs
#[derive(States, Eq, PartialEq, Hash, Copy, Clone, Default)]
enum MyState {
#[default]
Foo,
Bar(MySubState),
}
enum MySubState {
Spam,
Eggs,
}
app.add_system(Update, on_enter_bar);
fn on_enter_bar(trans: EventReader<StateTransition<MyState>>){
for (befoare, after) in trans.read() {
match before, after {
MyState::Foo, MyState::Bar(_) => info!("detected transition foo => bar");
_, _ => ();
}
}
}
```
---
## Changelog
- Added
- `StateTransitionEvent<S>` - Fired on state changes of `S`
## Migration Guide
N/A no breaking changes
---------
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
# Motivation
When spawning entities into a scene, it is very common to create assets
like meshes and materials and to add them via asset handles. A common
setup might look like this:
```rust
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
) {
commands.spawn(PbrBundle {
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
..default()
});
}
```
Let's take a closer look at the part that adds the assets using `add`.
```rust
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
```
Here, "mesh" and "material" are both repeated three times. It's very
explicit, but I find it to be a bit verbose. In addition to being more
code to read and write, the extra characters can sometimes also lead to
the code being formatted to span multiple lines even though the core
task, adding e.g. a primitive mesh, is extremely simple.
A way to address this is by using `.into()`:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }.into()),
material: materials.add(Color::RED.into()),
```
This is fine, but from the names and the type of `meshes`, we already
know what the type should be. It's very clear that `Cube` should be
turned into a `Mesh` because of the context it's used in. `.into()` is
just seven characters, but it's so common that it quickly adds up and
gets annoying.
It would be nice if you could skip all of the conversion and let Bevy
handle it for you:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
```
# Objective
Make adding assets more ergonomic by making `Assets::add` take an `impl
Into<A>` instead of `A`.
## Solution
`Assets::add` now takes an `impl Into<A>` instead of `A`, so e.g. this
works:
```rust
commands.spawn(PbrBundle {
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
..default()
});
```
I also changed all examples to use this API, which increases consistency
as well because `Mesh::from` and `into` were being used arbitrarily even
in the same file. This also gets rid of some lines of code because
formatting is nicer.
---
## Changelog
- `Assets::add` now takes an `impl Into<A>` instead of `A`
- Examples don't use `T::from(K)` or `K.into()` when adding assets
## Migration Guide
Some `into` calls that worked previously might now be broken because of
the new trait bounds. You need to either remove `into` or perform the
conversion explicitly with `from`:
```rust
// Doesn't compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }.into()),
// These compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }),
let mesh_handle = meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
```
## Concerns
I believe the primary concerns might be:
1. Is this too implicit?
2. Does this increase codegen bloat?
Previously, the two APIs were using `into` or `from`, and now it's
"nothing" or `from`. You could argue that `into` is slightly more
explicit than "nothing" in cases like the earlier examples where a
`Color` gets converted to e.g. a `StandardMaterial`, but I personally
don't think `into` adds much value even in this case, and you could
still see the actual type from the asset type.
As for codegen bloat, I doubt it adds that much, but I'm not very
familiar with the details of codegen. I personally value the user-facing
code reduction and ergonomics improvements that these changes would
provide, but it might be worth checking the other effects in more
detail.
Another slight concern is migration pain; apps might have a ton of
`into` calls that would need to be removed, and it did take me a while
to do so for Bevy itself (maybe around 20-40 minutes). However, I think
the fact that there *are* so many `into` calls just highlights that the
API could be made nicer, and I'd gladly migrate my own projects for it.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
`SceneSpawner::spawn_dynamic_sync` currently returns `()` on success,
which is inconsistent with the other `SceneSpawner::spawn_` methods that
all return an `InstanceId`. We need this ID to do useful work with the
newly-created data.
## Solution
Updated `SceneSpawner::spawn_dynamic_sync` to return `Result<InstanceId,
SceneSpawnError>` instead of `Result<(), SceneSpawnError>`
# Objective
Different platforms use their own implementations of several
mathematical functions (especially transcendental functions like sin,
cos, tan, atan, and so on) to provide hardware-level optimization using
intrinsics. This is good for performance, but bad when you expect
consistent outputs across machines.
[`libm`](https://github.com/rust-lang/libm) is a widely used crate that
provides mathematical functions that don't use intrinsics like `std`
functions. This allows bit-for-bit deterministic math across hardware,
which is crucial for things like cross-platform deterministic physics
simulation.
Glam has the `libm` feature for using [`libm` for the
math](d2871a151b/src/f32/math.rs (L35))
in its own types. This would be nice to expose as a feature in
`bevy_math`.
## Solution
Add `libm` feature to `bevy_math`. We could name it something like
`enhanced-determinism`, but this wouldn't be accurate for the rest of
Bevy, so I think just `libm` is more fitting and explicit.
# Objective
- Since #10702, the way bevy updates the window leads to major slowdowns
as seen in
- #11122
- #11220
- Slow is bad, furthermore, _very_ slow is _very_ bad. We should fix
this issue.
## Solution
- Move the app update code into the `Event::WindowEvent { event:
WindowEvent::RedrawRequested }` branch of the event loop.
- Run `window.request_redraw()` When `runner_state.redraw_requested`
- Instead of swapping `ControlFlow` between `Poll` and `Wait`, we always
keep it at `Wait`, and use `window.request_redraw()` to schedule an
immediate call to the event loop.
- `runner_state.redraw_requested` is set to `true` when
`UpdateMode::Continuous` and when a `RequestRedraw` event is received.
- Extract the redraw code into a separate function, because otherwise
I'd go crazy with the indentation level.
- Fix#11122.
## Testing
I tested the WASM builds as follow:
```sh
cargo run -p build-wasm-example -- --api webgl2 bevymark
python -m http.server --directory examples/wasm/ 8080
# Open browser at http://localhost:8080
```
On main, even spawning a couple sprites is super choppy. Even if it says
"300 FPS". While on this branch, it is smooth as butter.
I also found that it fixes all choppiness on window resize (tested on
Linux/X11). This was another issue from #10702 IIRC.
So here is what I tested:
- On `wasm`: `many_foxes` and `bevymark`, with `argh::from_env()`
commented out, otherwise we get a cryptic error.
- Both with `PresentMode::AutoVsync` and `PresentMode::AutoNoVsync`
- On main, it is consistently choppy.
- With this PR, the visible frame rate is consistent with the diagnostic
numbers
- On native (linux/x11) I ran similar tests, making sure that
`AutoVsync` limits to monitor framerate, and `AutoNoVsync` doesn't.
## Future work
Code could be improved, I wanted a quick solution easy to review, but we
really need to make the code more accessible.
- #9768
- ~~**`WinitSettings::desktop_app()` is completely borked.**~~ actually
broken on main as well
### Review guide
Consider enable the non-whitespace diff to see the _real_ change set.
# Objective
When `BlobVec::reserve` is called with an argument causing capacity
overflow, in release build capacity overflow is ignored, and capacity is
decreased.
I'm not sure it is possible to exploit this issue using public API of
`bevy_ecs`, but better fix it anyway.
## Solution
Check for capacity overflow.
# Objective
- Since #10520, assets are unloaded from RAM by default. This breaks a
number of scenario:
- using `load_folder`
- loading a gltf, then going through its mesh to transform them /
compute a collider / ...
- any assets/subassets scenario should be `Keep` as you can't know what
the user will do with the assets
- android suspension, where GPU memory is unloaded
- Alternative to #11202
## Solution
- Keep assets on CPU memory by default
# Objective
- Resolves#10913.
- Extend `Touches` with methods that are implemented on `ButtonInput`.
## Solution
- Add function `clear_just_pressed` that clears the `just_pressed` state
of the touch input.
- Add function `clear_just_released` that clears the `just_released`
state of the touch input.
- Add function `clear_just_canceled` that clears the `just_canceled`
state of the touch input.
- Add function `release` that changes state of the touch input from
`pressed` to `just_released`.
- Add function `release_all` that changes state of every touch input
from `pressed` to `just_released`
- Add function `clear` that clears `just_pressed`, `just_released` and
`just_canceled` data for every input.
- Add function `reset_all` that clears `pressed`, `just_pressed`,
`just_released` and `just_canceled` data for every input.
- Add tests for functions above.
# Objective
- Fix#11117 by implementing `Reflect` for `EntityHashMap`
## Solution
- By implementing `TypePath` for `EntityHash`, Bevy will automatically
implement `Reflect` for `EntityHashMap`
---
## Changelog
- `TypePath` is implemented for `EntityHash`
- A test called `entity_hashmap_should_impl_reflect` was created to
verify that #11117 was solved.
# Objective
In my code I use a lot of images as render targets.
I'd like some convenience methods for working with this type.
## Solution
- Allow `.into()` to construct a `RenderTarget`
- Add `.as_image()`
---
## Changelog
### Added
- `RenderTarget` can be constructed via `.into()` on a `Handle<Image>`
- `RenderTarget` new method: `as_image`
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- Fixes#11187
## Solution
- Rename the `AddChild` struct to `PushChild`
- Rename the `AddChildInPlace` struct to `PushChildInPlace`
## Migration Guide
The struct `AddChild` has been renamed to `PushChild`, and the struct
`AddChildInPlace` has been renamed to `PushChildInPlace`.
# Objective
- Since #10911, example `button` crashes when clicking the button
```
thread 'main' panicked at .cargo/registry/src/index.crates.io-6f17d22bba15001f/accesskit_consumer-0.16.1/src/tree.rs:139:9:
assertion `left == right` failed
left: 1
right: 0
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Encountered a panic in system `bevy_winit::accessibility::update_accessibility_nodes`!
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
```
## Solution
- Re-add lost negation
# Objective
- Fixes#11119
## Solution
- Creation of the serialize feature to ui
---
## Changelog
### Changed
- Changed all the structs that implement Serialize and Deserialize to
only implement when feature is on
## Migration Guide
- If you want to use serialize and deserialize with types from bevy_ui,
you need to use the feature serialize in your TOML
```toml
[dependencies.bevy]
features = ["serialize"]
```
# Objective
Fixes Gizmos crash due to the persistence policy being set to `Unload`
## Solution
Change it to `Keep`
Co-authored-by: rqg <ranqingguo318@gmail.com>
# Objective
- No point in keeping Meshes/Images in RAM once they're going to be sent
to the GPU, and kept in VRAM. This saves a _significant_ amount of
memory (several GBs) on scenes like bistro.
- References
- https://github.com/bevyengine/bevy/pull/1782
- https://github.com/bevyengine/bevy/pull/8624
## Solution
- Augment RenderAsset with the capability to unload the underlying asset
after extracting to the render world.
- Mesh/Image now have a cpu_persistent_access field. If this field is
RenderAssetPersistencePolicy::Unload, the asset will be unloaded from
Assets<T>.
- A new AssetEvent is sent upon dropping the last strong handle for the
asset, which signals to the RenderAsset to remove the GPU version of the
asset.
---
## Changelog
- Added `AssetEvent::NoLongerUsed` and
`AssetEvent::is_no_longer_used()`. This event is sent when the last
strong handle of an asset is dropped.
- Rewrote the API for `RenderAsset` to allow for unloading the asset
data from the CPU.
- Added `RenderAssetPersistencePolicy`.
- Added `Mesh::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `Image::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `ImageLoaderSettings::cpu_persistent_access`.
- Added `ExrTextureLoaderSettings`.
- Added `HdrTextureLoaderSettings`.
## Migration Guide
- Asset loaders (GLTF, etc) now load meshes and textures without
`cpu_persistent_access`. These assets will be removed from
`Assets<Mesh>` and `Assets<Image>` once `RenderAssets<Mesh>` and
`RenderAssets<Image>` contain the GPU versions of these assets, in order
to reduce memory usage. If you require access to the asset data from the
CPU in future frames after the GLTF asset has been loaded, modify all
dependent `Mesh` and `Image` assets and set `cpu_persistent_access` to
`RenderAssetPersistencePolicy::Keep`.
- `Mesh` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `Image` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `MorphTargetImage::new()` now requires a new `cpu_persistent_access`
parameter. Set it to `RenderAssetPersistencePolicy::Keep` to mimic the
previous behavior.
- `DynamicTextureAtlasBuilder::add_texture()` now requires that the
`TextureAtlas` you pass has an `Image` with `cpu_persistent_access:
RenderAssetPersistencePolicy::Keep`. Ensure you construct the image
properly for the texture atlas.
- The `RenderAsset` trait has significantly changed, and requires
adapting your existing implementations.
- The trait now requires `Clone`.
- The `ExtractedAsset` associated type has been removed (the type itself
is now extracted).
- The signature of `prepare_asset()` is slightly different
- A new `persistence_policy()` method is now required (return
RenderAssetPersistencePolicy::Unload to match the previous behavior).
- Match on the new `NoLongerUsed` variant for exhaustive matches of
`AssetEvent`.
# Objective
- We want to use `static_assertions` to perform precise compile time
checks at testing time. In this PR, we add those checks to make sure
that `EntityHashMap` and `PreHashMap` are `Clone` (and we replace the
more clumsy previous tests)
- Fixes#11181
(will need to be rebased once
https://github.com/bevyengine/bevy/pull/11178 is merged)
---------
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>

# Objective
Lightmaps, textures that store baked global illumination, have been a
mainstay of real-time graphics for decades. Bevy currently has no
support for them, so this pull request implements them.
## Solution
The new `Lightmap` component can be attached to any entity that contains
a `Handle<Mesh>` and a `StandardMaterial`. When present, it will be
applied in the PBR shader. Because multiple lightmaps are frequently
packed into atlases, each lightmap may have its own UV boundaries within
its texture. An `exposure` field is also provided, to control the
brightness of the lightmap.
Note that this PR doesn't provide any way to bake the lightmaps. That
can be done with [The Lightmapper] or another solution, such as Unity's
Bakery.
---
## Changelog
### Added
* A new component, `Lightmap`, is available, for baked global
illumination. If your mesh has a second UV channel (UV1), and you attach
this component to the entity with that mesh, Bevy will apply the texture
referenced in the lightmap.
[The Lightmapper]: https://github.com/Naxela/The_Lightmapper
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR is part of a project aimed at improving the API documentation of
`bevy_hierarchy`. Other PRs will be based on this.
This PR in particular is also an experiment in providing a high level
overview of the tools provided by a Bevy plugin/crate. It also provides
general information about universal invariants, so statement repetition
in crate items can be dramatically reduced.
## Other changes
The other PRs of this project that expand on this one:
- #10952
- #10953
- #10954
- #10955
- #10956
- #10957
---------
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
# Objective
- `EntityHashMap`, `EntityHashSet` and `PreHashMap` are currently not
Cloneable because of a missing trivial `Clone` bound for `EntityHash`
and `PreHash`. This PR makes them Cloneable.
(the parent struct `hashbrown::HashMap` requires the `HashBuilder` to be
`Clone` for the `HashMap` to be `Clone`, see:
https://github.com/rust-lang/hashbrown/blob/master/src/map.rs#L195)
## Solution
- Add a `Clone` bound to `PreHash` and `EntityHash`
---------
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>
# Objective
`bevy_math` re-exports Glam, but doesn't have a feature for enabling
`approx` for it. Many projects (including some of Bevy's own crates)
need `approx`, and it'd be nice if you didn't have to manually add Glam
to specify the feature for it.
## Solution
Add an `approx` feature to `bevy_math`.
# Objective
I often need a direction along one of the cartesian XYZ axes, and it
currently requires e.g. `Direction2d::from_normalized(Vec2::X)`, which
isn't ideal.
## Solution
Add direction constants that are the same as the ones on Glam types. I
also copied the doc comment format "A unit vector pointing along the ...
axis", but I can change it if there's a better wording for directions.
# Objective
I frequently encounter cases where I need to get the opposite direction.
This currently requires something like
`Direction2d::from_normalized(-*direction)`, which is very inconvenient.
## Solution
Implement `Neg` for `Direction2d` and `Direction3d`.
# Objective
If you have multiple windows, there is no way to determine which window
a `TouchInput` event applies to. This fixes that.
## Solution
- Add the window entity directly to `TouchInput`, just like the other
input events.
- Fixes#6011.
## Migration Guide
+ Add a `window` field when constructing or destructuring a `TouchInput`
struct.
This expands upon https://github.com/bevyengine/bevy/pull/11134.
I found myself needing `tonemapping_pipeline_key` for some custom 2d
draw functions. #11134 exported the 3d version of
`tonemapping_pipeline_key` and this PR exports the 2d version. I also
made `alpha_mode_pipeline_key` public for good measure.
# Objective
When panic handler prints to stdout instead of stderr, I've observed two
outcomes with this PR test #11169:
- Sometimes output is mixed up, so it is not clear where one record ends
and another stards
- Sometimes output is lost
## Solution
Print to stderr.
## Changelog
- Panic handler in `LogPlugin` writes to stderr instead of stdin.
# Objective
`SystemName` might be useful in systems which accept `&mut World`.
## Solution
- `impl ExclusiveSystemParam for SystemName`
- move `SystemName` into a separate file, because it no longer belongs
to a file which defines `SystemParam`
- add a test for new impl, and for existing impl
## Changelog
- `impl ExclusiveSystemParam for SystemName`
Turns out whenever a normal prepass was active (which includes whenever
you use SSAO) we were attempting to read the normals from the prepass
for the specular transmissive material. Since transmissive materials
don't participate in the prepass (unlike opaque materials) we were
reading the normals from “behind” the mesh, producing really weird
visual results.
# Objective
- Fixes#11112.
## Solution
- We introduce a new `READS_VIEW_TRANSMISSION_TEXTURE` mesh pipeline
key;
- We set it whenever the material properties has the
`reads_view_transmission_texture` flag set; (i.e. the material is
transmissive)
- If this key is set we prevent the reading of normals from the prepass,
by not setting the `LOAD_PREPASS_NORMALS` shader def.
---
## Changelog
### Fixed
- Specular transmissive materials no longer attempt to erroneously load
prepass normals, and now work correctly even with the normal prepass
active (e.g. when using SSAO)
# Objective
- Refactor collide code and add tests.
## Solution
- Rebase the changes made in #4485.
Co-authored-by: Eduardo Canellas de Oliveira <eduardo.canellas@bemobi.com>
# Objective
There are a lot of doctests that are `ignore`d for no documented reason.
And that should be fixed.
## Solution
I searched the bevy repo with the regex ` ```[a-z,]*ignore ` in order to
find all `ignore`d doctests. For each one of the `ignore`d doctests, I
did the following steps:
1. Attempt to remove the `ignored` attribute while still passing the
test. I did this by adding hidden dummy structs and imports.
2. If step 1 doesn't work, attempt to replace the `ignored` attribute
with the `no_run` attribute while still passing the test.
3. If step 2 doesn't work, keep the `ignored` attribute but add
documentation for why the `ignored` attribute was added.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#11050
Rename ArchetypeEntity::entity to ArchetypeEntity::id to be consistent
with `EntityWorldMut`, `EntityMut` and `EntityRef`.
## Migration Guide
The method `ArchetypeEntity::entity` has been renamed to
`ArchetypeEntity::id`
# Objective
- There is an warning about non snake case on system_param.rs generated
by a macro
## Solution
- Allow non snake case on the function at fault
# Objective
Implement `ExclusiveSystemParam` for `PhantomData`.
For the same reason `SystemParam` impl exists: to simplify writing
generic code.
786abbf3f5/crates/bevy_ecs/src/system/system_param.rs (L1557)
Also for consistency.
## Solution
`impl ExclusiveSystemParam for PhantomData`.
## Changelog
Added: PhantomData<T> now implements ExclusiveSystemParam.
# Objective
Mostly for consistency.
## Solution
```rust
impl ExclusiveSystemParam for WorldId
```
- Also add a test for `SystemParam for WorldId`
## Changelog
Added: Worldd now implements ExclusiveSystemParam.
# Objective
- Custom render passes, or future passes in the engine (such as
https://github.com/bevyengine/bevy/pull/10164) need a better way to know
and indicate to the core passes whether the view color/depth/prepass
attachments have been cleared or not yet this frame, to know if they
should clear it themselves or load it.
## Solution
- For all render targets (depth textures, shadow textures, prepass
textures, main textures) use an atomic bool to track whether or not each
texture has been cleared this frame. Abstracted away in the new
ColorAttachment and DepthAttachment wrappers.
---
## Changelog
- Changed `ViewTarget::get_color_attachment()`, removed arguments.
- Changed `ViewTarget::get_unsampled_color_attachment()`, removed
arguments.
- Removed `Camera3d::clear_color`.
- Removed `Camera2d::clear_color`.
- Added `Camera::clear_color`.
- Added `ExtractedCamera::clear_color`.
- Added `ColorAttachment` and `DepthAttachment` wrappers.
- Moved `ClearColor` and `ClearColorConfig` from
`bevy::core_pipeline::clear_color` to `bevy::render::camera`.
- Core render passes now track when a texture is first bound as an
attachment in order to decide whether to clear or load it.
## Migration Guide
- Remove arguments to `ViewTarget::get_color_attachment()` and
`ViewTarget::get_unsampled_color_attachment()`.
- Configure clear color on `Camera` instead of on `Camera3d` and
`Camera2d`.
- Moved `ClearColor` and `ClearColorConfig` from
`bevy::core_pipeline::clear_color` to `bevy::render::camera`.
- `ViewDepthTexture` must now be created via the `new()` method
---------
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fix ci hang, so we can merge pr's again.
## Solution
- switch ppa action to use mesa stable versions
https://launchpad.net/~kisak/+archive/ubuntu/turtle
- use commit from #11123
---------
Co-authored-by: Stepan Koltsov <stepan.koltsov@gmail.com>
# Objective
- Provides an alternate solution to the one implemented in #10791
without breaking changes.
## Solution
- Changes the bounds of macro-generated `TypePath` implementations to
universally ignore the types of fields, rather than use the same bounds
as other implementations. I think this is a more holistic solution than
#10791 because it totally erases the finicky bounds we currently
generate, helping to untangle the reflection trait system.
# Objective
- Make the implementation order consistent between all sources to fit
the order in the trait.
## Solution
- Change the implementation order.
Matches versioning & features from other Cargo.toml files in the
project.
# Objective
Resolves#10932
## Solution
Added smallvec to the bevy_utils cargo.toml and added a line to
re-export the crate. Target version and features set to match what's
used in the other bevy crates.
# Objective
Register and Serialize `Camera3dDepthTextureUsage` and
`ScreenSpaceTransmissionQuality`.
Fixes: #11036
## Solution
Added the relevant derives for reflection and serialization and type
registrations.
# Objective
Outlines are drawn for UI nodes with `Display::None` set and their
descendants. They should not be visible.
## Solution
Make all Nodes with `Display::None` inherit an empty clipping rect,
ensuring that the outlines are not visible.
Fixes#10940
---
## Changelog
* In `update_clipping_system` if a node has `Display::None` set, clip
the entire node and all its descendants by replacing the inherited clip
with a default rect (which is empty)
# Objective
The documentation for the `States` trait contains an error! There is a
single colon missing from `OnExit<T:Variant>`.
## Solution
Replace `OnExit<T:Variant>` with `OnExit<T::Variant>`. (Notice the added
colon.)
---
## Changelog
### Added
- Added missing colon in `States` documentation.
---
Bevy community, you may now rest easy.
The error conditions were not documented, this requires the user to
inspect the source code to know when to expect a `None`.
Error conditions should always be documented, so we document them.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Improves #11052
# Changelog
- Remove `Window::fit_canvas_to_parent`, as its resizing on wasm now
respects its CSS configuration.
## Migration Guide
- Remove uses of `Window::fit_canvas_to_parent` in favor of CSS
properties, for example:
```css
canvas {
width: 100%;
height: 100%;
}
```
# Objective
- After #10336, some gltf files fail to load (examples
custom_gltf_vertex_attribute, gltf_skinned_mesh, ...)
- Fix them
## Solution
- Allow padding in base 64 decoder
# Objective
Fix#10731.
## Solution
Rename `App::add_state<T>(&mut self)` to `init_state`, and add
`App::insert_state<T>(&mut self, state: T)`. I decided on these names
because they are more similar to `init_resource` and `insert_resource`.
I also removed the `States` trait's requirement for `Default`. Instead,
`init_state` requires `FromWorld`.
---
## Changelog
- Renamed `App::add_state` to `init_state`.
- Added `App::insert_state`.
- Removed the `States` trait's requirement for `Default`.
## Migration Guide
- Renamed `App::add_state` to `init_state`.
# Objective
- Update winit dependency to 0.29
## Changelog
### KeyCode changes
- Removed `ScanCode`, as it was [replaced by
KeyCode](https://github.com/rust-windowing/winit/blob/master/CHANGELOG.md#0292).
- `ReceivedCharacter.char` is now a `SmolStr`, [relevant
doc](https://docs.rs/winit/latest/winit/event/struct.KeyEvent.html#structfield.text).
- Changed most `KeyCode` values, and added more.
KeyCode has changed meaning. With this PR, it refers to physical
position on keyboard rather than the printed letter on keyboard keys.
In practice this means:
- On QWERTY keyboard layouts, nothing changes
- On any other keyboard layout, `KeyCode` no longer reflects the label
on key.
- This is "good". In bevy 0.12, when you used WASD for movement, users
with non-QWERTY keyboards couldn't play your game! This was especially
bad for non-latin keyboards. Now, WASD represents the physical keys. A
French player will press the ZQSD keys, which are near each other,
Kyrgyz players will use "Цфыв".
- This is "bad" as well. You can't know in advance what the label of the
key for input is. Your UI says "press WASD to move", even if in reality,
they should be pressing "ZQSD" or "Цфыв". You also no longer can use
`KeyCode` for text inputs. In any case, it was a pretty bad API for text
input. You should use `ReceivedCharacter` now instead.
### Other changes
- Use `web-time` rather than `instant` crate.
(https://github.com/rust-windowing/winit/pull/2836)
- winit did split `run_return` in `run_onDemand` and `pump_events`, I
did the same change in bevy_winit and used `pump_events`.
- Removed `return_from_run` from `WinitSettings` as `winit::run` now
returns on supported platforms.
- I left the example "return_after_run" as I think it's still useful.
- This winit change is done partly to allow to create a new window after
quitting all windows: https://github.com/emilk/egui/issues/1918 ; this
PR doesn't address.
- added `width` and `height` properties in the `canvas` from wasm
example
(https://github.com/bevyengine/bevy/pull/10702#discussion_r1420567168)
## Known regressions (important follow ups?)
- Provide an API for reacting when a specific key from current layout
was released.
- possible solutions: use winit::Key from winit::KeyEvent ; mapping
between KeyCode and Key ; or .
- We don't receive characters through alt+numpad (e.g. alt + 151 = "ù")
anymore ; reproduced on winit example "ime". maybe related to
https://github.com/rust-windowing/winit/issues/2945
- (windows) Window content doesn't refresh at all when resizing. By
reading https://github.com/rust-windowing/winit/issues/2900 ; I suspect
we should just fire a `window.request_redraw();` from `AboutToWait`, and
handle actual redrawing within `RedrawRequested`. I'm not sure how to
move all that code so I'd appreciate it to be a follow up.
- (windows) unreleased winit fix for using set_control_flow in
AboutToWait https://github.com/rust-windowing/winit/issues/3215 ; ⚠️ I'm
not sure what the implications are, but that feels bad 🤔
## Follow up
I'd like to avoid bloating this PR, here are a few follow up tasks
worthy of a separate PR, or new issue to track them once this PR is
closed, as they would either complicate reviews, or at risk of being
controversial:
- remove CanvasParentResizePlugin
(https://github.com/bevyengine/bevy/pull/10702#discussion_r1417068856)
- avoid mentionning explicitly winit in docs from bevy_window ?
- NamedKey integration on bevy_input:
https://github.com/rust-windowing/winit/pull/3143 introduced a new
NamedKey variant. I implemented it only on the converters but we'd
benefit making the same changes to bevy_input.
- Add more info in KeyboardInput
https://github.com/bevyengine/bevy/pull/10702#pullrequestreview-1748336313
- https://github.com/bevyengine/bevy/pull/9905 added a workaround on a
bug allegedly fixed by winit 0.29. We should check if it's still
necessary.
- update to raw_window_handle 0.6
- blocked by wgpu
- Rename `KeyCode` to `PhysicalKeyCode`
https://github.com/bevyengine/bevy/pull/10702#discussion_r1404595015
- remove `instant` dependency, [replaced
by](https://github.com/rust-windowing/winit/pull/2836) `web_time`), we'd
need to update to :
- fastrand >= 2.0
- [`async-executor`](https://github.com/smol-rs/async-executor) >= 1.7
- [`futures-lite`](https://github.com/smol-rs/futures-lite) >= 2.0
- Verify license, see
[discussion](https://github.com/bevyengine/bevy/pull/8745#discussion_r1402439800)
- we might be missing a short notice or description of changes made
- Consider using https://github.com/rust-windowing/cursor-icon directly
rather than vendoring it in bevy.
- investigate [this
unwrap](https://github.com/bevyengine/bevy/pull/8745#discussion_r1387044986)
(`winit_window.canvas().unwrap();`)
- Use more good things about winit's update
- https://github.com/bevyengine/bevy/pull/10689#issuecomment-1823560428
## Migration Guide
This PR should have one.
# Objective
- Update base64 requirement from 0.13.0 to 0.21.5.
- Closes#10317.
## Solution
- Bumped `base64` requirement and manually migrated code to fix a
breaking change after updating.
# Objective
`Has<T>` in some niche cases may behave in an unexpected way.
Specifically, when using `Query::get` on a `Has<T>` with a despawned
entity.
## Solution
Add precision about cases wehre `Query::get` could return an `Err`.
Use `'w` for world lifetime consistently.
When implementing system params, useful to look at how other params are
implemented. `'w` makes it clear it is world, not state.
# Objective
- Fixes#10587, where the `Aabb` component of entities with `Sprite` and
`Handle<Image>` components was not automatically updated when
`Sprite::custom_size` changed.
## Solution
- In the query for entities with `Sprite` components in
`calculate_bounds_2d`, use the `Changed` filter to detect for `Sprites`
that changed as well as sprites that do not have `Aabb` components. As
noted in the issue, this will cause the `Aabb` to be recalculated when
other fields of the `Sprite` component change, but calculating the
`Aabb` for sprites is trivial.
---
## Changelog
- Modified query for entities with `Sprite` components in
`calculate_bounds_2d`, so that entities with `Sprite` components that
changed will also have their AABB recalculated.
# Objective
- Provide way to check whether multiple inputs are pressed.
## Solution
- Add `all_pressed` method that checks if all inputs are currently being
pressed.
# Objective
- Allow checking if a resource has changed by its ComponentId
---
## Changelog
- Added `World::is_resource_changed_by_id()` and
`World::is_resource_added_by_id()`.
# Objective
Being able to do:
```rust
ev_scene_ready.read().next().unwrap();
```
Which currently isn't possible because `SceneInstanceReady` doesn't
implement `Debug`.
## Solution
Implement `Debug` for `SceneInstanceReady`.
---
## Changelog
### Added
- Implement Std traits for `SceneInstanceReady`.
# Objective
- Fix an inconsistency in the calculation of aspect ratio's.
- Fixes#10288
## Solution
- Created an intermediate `AspectRatio` struct, as suggested in the
issue. This is currently just used in any places where aspect ratio
calculations happen, to prevent doing it wrong. In my and @mamekoro 's
opinion, it would be better if this was used instead of a normal `f32`
in various places, but I didn't want to make too many changes to begin
with.
## Migration Guide
- Anywhere where you are currently expecting a f32 when getting aspect
ratios, you will now receive a `AspectRatio` struct. this still holds
the same value.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The definition of several `QueryState` methods use unnecessary explicit
lifetimes, which adds to visual noise.
## Solution
Elide the lifetimes.
# Objective
- bevy_sprite crate is missing docs for important types. `Sprite` being
undocumented was especially confusing for me even though it is one of
the first types I need to learn.
## Solution
- Improves the situation a little by adding some documentations.
I'm unsure about my understanding of functionality and writing. I'm
happy to be pointed out any mistakes.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
# Objective
`Instant` and `Duration` from the `instant` crate are exposed in
`bevy_utils` to have a single abstraction for native/wasm.
It would be useful to have the same thing for
[`SystemTime`](https://doc.rust-lang.org/std/time/struct.SystemTime.html).
---
## Changelog
### Added
- `bevy_utils` now re-exposes the `instant::SystemTime` struct
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>
# Objective
- Users are often confused when their command effects are not visible in
the next system. This PR auto inserts sync points if there are deferred
buffers on a system and there are dependents on that system (systems
with after relationships).
- Manual sync points can lead to users adding more than needed and it's
hard for the user to have a global understanding of their system graph
to know which sync points can be merged. However we can easily calculate
which sync points can be merged automatically.
## Solution
1. Add new edge types to allow opting out of new behavior
2. Insert an sync point for each edge whose initial node has deferred
system params.
3. Reuse nodes if they're at the number of sync points away.
* add opt outs for specific edges with `after_ignore_deferred`,
`before_ignore_deferred` and `chain_ignore_deferred`. The
`auto_insert_apply_deferred` boolean on `ScheduleBuildSettings` can be
set to false to opt out for the whole schedule.
## Perf
This has a small negative effect on schedule build times.
```text
group auto-sync main-for-auto-sync
----- ----------- ------------------
build_schedule/1000_schedule 1.06 2.8±0.15s ? ?/sec 1.00 2.7±0.06s ? ?/sec
build_schedule/1000_schedule_noconstraints 1.01 26.2±0.88ms ? ?/sec 1.00 25.8±0.36ms ? ?/sec
build_schedule/100_schedule 1.02 13.1±0.33ms ? ?/sec 1.00 12.9±0.28ms ? ?/sec
build_schedule/100_schedule_noconstraints 1.08 505.3±29.30µs ? ?/sec 1.00 469.4±12.48µs ? ?/sec
build_schedule/500_schedule 1.00 485.5±6.29ms ? ?/sec 1.00 485.5±9.80ms ? ?/sec
build_schedule/500_schedule_noconstraints 1.00 6.8±0.10ms ? ?/sec 1.02 6.9±0.16ms ? ?/sec
```
---
## Changelog
- Auto insert sync points and added `after_ignore_deferred`,
`before_ignore_deferred`, `chain_no_deferred` and
`auto_insert_apply_deferred` APIs to opt out of this behavior
## Migration Guide
- `apply_deferred` points are added automatically when there is ordering
relationship with a system that has deferred parameters like `Commands`.
If you want to opt out of this you can switch from `after`, `before`,
and `chain` to the corresponding `ignore_deferred` API,
`after_ignore_deferred`, `before_ignore_deferred` or
`chain_ignore_deferred` for your system/set ordering.
- You can also set `ScheduleBuildSettings::auto_insert_sync_points` to
`false` if you want to do it for the whole schedule. Note that in this
mode you can still add `apply_deferred` points manually.
- For most manual insertions of `apply_deferred` you should remove them
as they cannot be merged with the automatically inserted points and
might reduce parallelizability of the system graph.
## TODO
- [x] remove any apply_deferred used in the engine
- [x] ~~decide if we should deprecate manually using apply_deferred.~~
We'll still allow inserting manual sync points for now for whatever edge
cases users might have.
- [x] Update migration guide
- [x] rerun schedule build benchmarks
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Finish the work done in #8942 .
## Solution
- Rebase the changes made in #8942 and fix the issues stopping it from
being merged earlier
---------
Co-authored-by: Thomas <1234328+thmsgntz@users.noreply.github.com>
# Objective
Make direction construction a bit more ergonomic.
## Solution
Add `Direction2d::from_xy` and `Direction3d::from_xyz`, similar to
`Transform::from_xyz`:
```rust
let dir2 = Direction2d::from_xy(0.5, 0.5).unwrap();
let dir3 = Direction3d::from_xyz(0.5, 0.5, 0.5).unwrap();
```
This can be a bit cleaner than using `new`:
```rust
let dir2 = Direction2d::new(Vec2::new(0.5, 0.5)).unwrap();
let dir3 = Direction3d::new(Vec3::new(0.5, 0.5, 0.5)).unwrap();
```
Fixes https://github.com/bevyengine/bevy/issues/10974
# Objective
Duplicate the ordering logic of the `Main` schedule into the `FixedMain`
schedule.
---
## Changelog
- `FixedUpdate` is no longer the main schedule ran in
`RunFixedUpdateLoop`, `FixedMain` has replaced this and has a similar
structure to `Main`.
## Migration Guide
- Usage of `RunFixedUpdateLoop` should be renamed to `RunFixedMainLoop`.
# Objective
Fixes#10968
## Solution
Pull startup schedules from a list of `ScheduleLabel`s in the same way
the update schedules are handled.
---
## Changelog
- Added `MainScheduleOrder::startup_labels` to allow the editing of the
startup schedule order.
## Migration Guide
- Added a new field to `MainScheduleOrder`, `startup_labels`, for
editing the startup schedule order.
# Objective
Keep up to date with wgpu.
## Solution
Update the wgpu version.
Currently blocked on naga_oil updating to naga 0.14 and releasing a new
version.
3d scenes (or maybe any scene with lighting?) currently don't render
anything due to
```
error: naga_oil bug, please file a report: composer failed to build a valid header: Type [2] '' is invalid
= Capability Capabilities(CUBE_ARRAY_TEXTURES) is required
```
I'm not sure what should be passed in for `wgpu::InstanceFlags`, or if we want to make the gles3minorversion configurable (might be useful for debugging?)
Currently blocked on https://github.com/bevyengine/naga_oil/pull/63, and https://github.com/gfx-rs/wgpu/issues/4569 to be fixed upstream in wgpu first.
## Known issues
Amd+windows+vulkan has issues with texture_binding_arrays (see the image [here](https://github.com/bevyengine/bevy/pull/10266#issuecomment-1819946278)), but that'll be fixed in the next wgpu/naga version, and you can just use dx12 as a workaround for now (Amd+linux mesa+vulkan texture_binding_arrays are fixed though).
---
## Changelog
Updated wgpu to 0.18, naga to 0.14.2, and naga_oil to 0.11.
- Windows desktop GL should now be less painful as it no longer requires Angle.
- You can now toggle shader validation and debug information for debug and release builds using `WgpuSettings.instance_flags` and [InstanceFlags](https://docs.rs/wgpu/0.18.0/wgpu/struct.InstanceFlags.html)
## Migration Guide
- `RenderPassDescriptor` `color_attachments` (as well as `RenderPassColorAttachment`, and `RenderPassDepthStencilAttachment`) now use `StoreOp::Store` or `StoreOp::Discard` instead of a `boolean` to declare whether or not they should be stored.
- `RenderPassDescriptor` now have `timestamp_writes` and `occlusion_query_set` fields. These can safely be set to `None`.
- `ComputePassDescriptor` now have a `timestamp_writes` field. This can be set to `None` for now.
- See the [wgpu changelog](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v0180-2023-10-25) for additional details
# Objective
- Make the implementation order consistent between all sources to fit
the order in the trait.
## Solution
- Change the implementation order.
# Objective
A workaround for a webgl issue was introduced in #9383 but one function
for mesh2d was missed.
## Solution
Applied the migration guide from #9383 in
`mesh2d_normal_local_to_world()
Note: I'm not using normals so I have not tested the bug & fix
# Objective
The documentation for `AnimationPlayer::play` mentions a non-existent
`transition_duration` argument from an old iteration of the API. It's
confusing.
## Solution
Remove the offending sentence.
# Objective
Since #10776 split `WorldQuery` to `WorldQueryData` and
`WorldQueryFilter`, it should be clear that the query is actually
composed of two parts. It is not factually correct to call "query" only
the data part. Therefore I suggest to rename the `Q` parameter to `D` in
`Query` and related items.
As far as I know, there shouldn't be breaking changes from renaming
generic type parameters.
## Solution
I used a combination of rust-analyzer go to reference and `Ctrl-F`ing
various patterns to catch as many cases as possible. Hopefully I got
them all. Feel free to check if you're concerned of me having missed
some.
## Notes
This and #10779 have many lines in common, so merging one will cause a
lot of merge conflicts to the other.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- The example in the docs is unsound.
Demo:
```rust
#[derive(Resource)]
struct MyRes(u32);
fn main() {
let mut w = World::new();
w.insert_resource(MyRes(0));
let (mut res, comp) = split_world_access(&mut w);
let mut r1 = res.get_resource_mut::<MyRes>().unwrap();
let mut r2 = res.get_resource_mut::<MyRes>().unwrap();
*r1 = MyRes(1);
*r2 = MyRes(2);
}
```
The API in the example allows aliasing mutable references to the same
resource. Miri also complains when running this.
## Solution
- Change the example API to make the returned `Mut` borrow from the
`OnlyResourceAccessWorld` instead of borrowing from the world via `'w`.
This prevents obtaining more than one `Mut` at the same time from it.
I didn't notice minus where vertices are generated, so could not
understand the order there.
Adding a comment to help the next person who is going to understand Bevy
by reading its code.
# Objective
- Reduce nesting in `process_handle_drop_internal()`.
- Related to #10896.
## Solution
- Use early returns when possible.
- Reduced from 9 levels of indents to 4.
# Objective
add `RenderLayers` awareness to lights. lights default to
`RenderLayers::layer(0)`, and must intersect the camera entity's
`RenderLayers` in order to affect the camera's output.
note that lights already use renderlayers to filter meshes for shadow
casting. this adds filtering lights per view based on intersection of
camera layers and light layers.
fixes#3462
## Solution
PointLights and SpotLights are assigned to individual views in
`assign_lights_to_clusters`, so we simply cull the lights which don't
match the view layers in that function.
DirectionalLights are global, so we
- add the light layers to the `DirectionalLight` struct
- add the view layers to the `ViewUniform` struct
- check for intersection before processing the light in
`apply_pbr_lighting`
potential issue: when mesh/light layers are smaller than the view layers
weird results can occur. e.g:
camera = layers 1+2
light = layers 1
mesh = layers 2
the mesh does not cast shadows wrt the light as (1 & 2) == 0.
the light affects the view as (1+2 & 1) != 0.
the view renders the mesh as (1+2 & 2) != 0.
so the mesh is rendered and lit, but does not cast a shadow.
this could be fixed (so that the light would not affect the mesh in that
view) by adding the light layers to the point and spot light structs,
but i think the setup is pretty unusual, and space is at a premium in
those structs (adding 4 bytes more would reduce the webgl point+spot
light max count to 240 from 256).
I think typical usage is for cameras to have a single layer, and
meshes/lights to maybe have multiple layers to render to e.g. minimaps
as well as primary views.
if there is a good use case for the above setup and we should support
it, please let me know.
---
## Migration Guide
Lights no longer affect all `RenderLayers` by default, now like cameras
and meshes they default to `RenderLayers::layer(0)`. To recover the
previous behaviour and have all lights affect all views, add a
`RenderLayers::all()` component to the light entity.
# Objective
Printing `DynamicStruct` with a debug format does not show the contained
type anymore. For instance, in `examples/reflection/reflection.rs`,
adding `dbg!(&reflect_value);` to line 96 will print:
```rust
[examples/reflection/reflection.rs:96] &reflect_value = DynamicStruct(bevy_reflect::DynamicStruct {
a: 4,
nested: DynamicStruct(bevy_reflect::DynamicStruct {
b: 8,
}),
})
```
## Solution
Show the represented type instead (`reflection::Foo` and
`reflection::Bar` in this case):
```rust
[examples/reflection/reflection.rs:96] &reflect_value = DynamicStruct(reflection::Foo {
a: 4,
nested: DynamicStruct(reflection::Bar {
b: 8,
}),
})
```
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
The `Despawn` command breaks the hierarchy whenever you use it if the
despawned entity has a parent or any children. This is a serious footgun
because the `Despawn` command has the shortest name, the behavior is
unexpected and not likely to be what you want, and the crash that it
causes can be very difficult to track down.
## Solution
Until this can be fixed by relations, add a note mentioning the footgun
in the documentation.
## Solution
`Commands.remove` and `.retain` (because I copied `remove`s doc)
referenced `EntityWorldMut.remove` and `retain` for more detail but the
`Commands` docs are much more detailed (which makes sense because it is
the most common api), so I have instead inverted this so that
`EntityWorldMut` docs link to `Commands`.
I also made `EntityWorldMut.despawn` reference `World.despawn` for more
details, like `Commands.despawn` does.
# Objective
Fixes#5891.
For mikktspace normal maps, normals must be renormalized in vertex
shaders to match the way mikktspace bakes vertex tangents and normal
maps so that the exact inverse process is applied when shading.
However, for invalid normals like `vec3<f32>(0.0, 0.0, 0.0)`, this
normalization causes NaN values, and because it's in the vertex shader,
it affects the entire triangle and causes it to be shaded as black:

*A cone with a tip that has a vertex normal of [0, 0, 0], causing the
mesh to be shaded as black.*
In some cases, normals of zero are actually *useful*. For example, a
smoothly shaded cone without creases requires the apex vertex normal to
be zero, because there is no singular normal that works correctly, so
the apex shouldn't contribute to the overall shading. Duplicate vertices
for the apex fix some shading issues, but it causes visible creases and
is more expensive. See #5891 and #10298 for more details.
For correctly shaded cones and other similar low-density shapes with
sharp tips, vertex normals of zero can not be normalized in the vertex
shader.
## Solution
Only normalize the vertex normals and tangents in the vertex shader if
the normal isn't [0, 0, 0]. This way, mikktspace normal maps should
still work for everything except the zero normals, and the zero normals
will only be normalized in the fragment shader.
This allows us to render cones correctly:

Notice how there is still a weird shadow banding effect in one area. I
noticed that it can be fixed by normalizing
[here](d2614f2d80/crates/bevy_pbr/src/render/pbr_functions.wgsl (L51)),
which produces a perfectly smooth cone without duplicate vertices:

I didn't add this change yet, because it seems a bit arbitrary. I can
add it here if that'd be useful or make another PR though.
# Objective
`update_accessibility_nodes` is one of the most nested functions in the
entire Bevy repository, with a maximum of 9 levels of indentations. This
PR refactors it down to 3 levels of indentations, while improving
readability on other fronts. The result is a function that is actually
understandable at a first glance.
- This is a proof of concept to demonstrate that it is possible to
gradually lower the nesting limit proposed by #10896.
PS: I read AccessKit's documentation, but I don't have experience with
it. Therefore, naming of variables and subroutines may be a bit off.
PS2: I don't know if the test suite covers the functionality of this
system, but since I've spent quite some time on it and the changes were
simple, I'm pretty confident the refactor is functionally equivalent to
the original.
## Solution
I documented each change with a commit, but as a summary I did the
following to reduce nesting:
- I moved from `if-let` blocks to `let-else` statements where
appropriate to reduce rightward shift
- I extracted the closure body to a new function `update_adapter`
- I factored out parts of `update_adapter` into new functions
`queue_node_for_update` and `add_children_nodes`
**Note for reviewers:** GitHub's diff viewer is not the greatest in
showing horizontal code shifts, therefore you may want to use a
different tool like VSCode to review some commits, especially the second
one (anyway, that commit is very straightforward, despite changing many
lines).
# Objective
A nodes outline should be clipped using its own clipping rect, not its
parents.
fixes#10921
## Solution
Clip outlines by the node's own clipping rect, not the parent's.
If you compare the `overflow` ui example in main with this PR, you'll
see that the outlines that appear when you hover above the images are
now clipped along with the images.
---
## Changelog
* Outlines are now clipped using the node's own clipping rect, not the
parent's.
# Objective
- Improve readability.
- Somewhat relates to #10896.
## Solution
- Use early returns to minimize nesting.
- Change `emitter_translation` to use `if let` instead of `map`.
# Objective
The `update_emitter_positions`, and `update_listener_positions` systems
are added for every call to `add_audio_source`.
Instead, add them once in the `AudioPlugin` directly.
Also merged the calls to `add_systems`.
Caught while working on my schedule visualizer c:
# Objective
Test more complex function signatures for exclusive systems, and test
that `StaticSystemParam` is indeed a `SystemParam`.
I mean, it currently works, but might as well add a test for it.
# Objective
- Resolves#10853
## Solution
- ~~Changed the name of `Input` struct to `PressableInput`.~~
- Changed the name of `Input` struct to `ButtonInput`.
## Migration Guide
- Breaking Change: Users need to rename `Input` to `ButtonInput` in
their projects.
# Objective
A better alternative version of #10843.
Currently, Bevy has a single `Ray` struct for 3D. To allow better
interoperability with Bevy's primitive shapes (#10572) and some third
party crates (that handle e.g. spatial queries), it would be very useful
to have separate versions for 2D and 3D respectively.
## Solution
Separate `Ray` into `Ray2d` and `Ray3d`. These new structs also take
advantage of the new primitives by using `Direction2d`/`Direction3d` for
the direction:
```rust
pub struct Ray2d {
pub origin: Vec2,
pub direction: Direction2d,
}
pub struct Ray3d {
pub origin: Vec3,
pub direction: Direction3d,
}
```
and by using `Plane2d`/`Plane3d` in `intersect_plane`:
```rust
impl Ray2d {
// ...
pub fn intersect_plane(&self, plane_origin: Vec2, plane: Plane2d) -> Option<f32> {
// ...
}
}
```
---
## Changelog
### Added
- `Ray2d` and `Ray3d`
- `Ray2d::new` and `Ray3d::new` constructors
- `Plane2d::new` and `Plane3d::new` constructors
### Removed
- Removed `Ray` in favor of `Ray3d`
### Changed
- `direction` is now a `Direction2d`/`Direction3d` instead of a vector,
which provides guaranteed normalization
- `intersect_plane` now takes a `Plane2d`/`Plane3d` instead of just a
vector for the plane normal
- `Direction2d` and `Direction3d` now derive `Serialize` and
`Deserialize` to preserve ray (de)serialization
## Migration Guide
`Ray` has been renamed to `Ray3d`.
### Ray creation
Before:
```rust
Ray {
origin: Vec3::ZERO,
direction: Vec3::new(0.5, 0.6, 0.2).normalize(),
}
```
After:
```rust
// Option 1:
Ray3d {
origin: Vec3::ZERO,
direction: Direction3d::new(Vec3::new(0.5, 0.6, 0.2)).unwrap(),
}
// Option 2:
Ray3d::new(Vec3::ZERO, Vec3::new(0.5, 0.6, 0.2))
```
### Plane intersections
Before:
```rust
let result = ray.intersect_plane(Vec2::X, Vec2::Y);
```
After:
```rust
let result = ray.intersect_plane(Vec2::X, Plane2d::new(Vec2::Y));
```
# Objective
Implement `TryFrom<Vec2>`/`TryFrom<Vec3>` for direction primitives as
considered in #10857.
## Solution
Implement `TryFrom` for the direction primitives.
These are all equivalent:
```rust
let dir2d = Direction2d::try_from(Vec2::new(0.5, 0.5)).unwrap();
let dir2d = Vec2::new(0.5, 0.5).try_into().unwrap(); // (assumes that the type is inferred)
let dir2d = Direction2d::new(Vec2::new(0.5, 0.5)).unwrap();
```
For error cases, an `Err(InvalidDirectionError)` is returned. It
contains the type of failure:
```rust
/// An error indicating that a direction is invalid.
#[derive(Debug, PartialEq)]
pub enum InvalidDirectionError {
/// The length of the direction vector is zero or very close to zero.
Zero,
/// The length of the direction vector is `std::f32::INFINITY`.
Infinite,
/// The length of the direction vector is `NaN`.
NaN,
}
```
# Objective
- Resolves#10784
## Solution
- As @ickshonpe mentioned in #10784, this is intended behavior but could
benefit from mentioning it in docs.
- I'm also thinking about adding a helper function to disable os scaling
such as `disable_os_scaling()`, but not sure if it's needed.
---
## Changelog
> Add a comment about scaling behavior that happens, and point user to
how he can avoid that behavior.
# Objective
Adds `EntityCommands.retain` and `EntityWorldMut.retain` to remove all
components except the given bundle from the entity.
Fixes#10865.
## Solution
I added a private unsafe function in `EntityWorldMut` called
`remove_bundle_info` which performs the shared behaviour of `remove` and
`retain`, namely taking a `BundleInfo` of components to remove, and
removing them from the given entity. Then `retain` simply gets all the
components on the entity and filters them by whether they are in the
bundle it was passed, before passing this `BundleInfo` into
`remove_bundle_info`.
`EntityCommands.retain` just creates a new type `Retain` which runs
`EntityWorldMut.retain` when run.
---
## Changelog
Added `EntityCommands.retain` and `EntityWorldMut.retain`, which remove
all components except the given bundle from the entity, they can also be
used to remove all components by passing `()` as the bundle.
# Objective
The name `TextAlignment` is really deceptive and almost every new user
gets confused about the differences between aligning text with
`TextAlignment`, aligning text with `Style` and aligning text with
anchor (when using `Text2d`).
## Solution
* Rename `TextAlignment` to `JustifyText`. The associated helper methods
are also renamed.
* Improve the doc comments for text explaining explicitly how the
`JustifyText` component affects the arrangement of text.
* Add some extra cases to the `text_debug` example that demonstate the
differences between alignment using `JustifyText` and alignment using
`Style`.
<img width="757" alt="text_debug_2"
src="https://github.com/bevyengine/bevy/assets/27962798/9d53e647-93f9-4bc7-8a20-0d9f783304d2">
---
## Changelog
* `TextAlignment` has been renamed to `JustifyText`
* `TextBundle::with_text_alignment` has been renamed to
`TextBundle::with_text_justify`
* `Text::with_alignment` has been renamed to `Text::with_justify`
* The `text_alignment` field of `TextMeasureInfo` has been renamed to
`justification`
## Migration Guide
* `TextAlignment` has been renamed to `JustifyText`
* `TextBundle::with_text_alignment` has been renamed to
`TextBundle::with_text_justify`
* `Text::with_alignment` has been renamed to `Text::with_justify`
* The `text_alignment` field of `TextMeasureInfo` has been renamed to
`justification`
# Objective
- Fixes#10806
## Solution
Replaced `new` and `index` methods for both `TableRow` and `TableId`
with `from_*` and `as_*` methods. These remove the need to perform
casting at call sites, reducing the total number of casts in the Bevy
codebase. Within these methods, an appropriate `debug_assertion` ensures
the cast will behave in an expected manner (no wrapping, etc.). I am
using a `debug_assertion` instead of an `assert` to reduce any possible
runtime overhead, however minimal. This choice is something I am open to
changing (or leaving up to another PR) if anyone has any strong
arguments for it.
---
## Changelog
- `ComponentSparseSet::sparse` stores a `TableRow` instead of a `u32`
(private change)
- Replaced `TableRow::new` and `TableRow::index` methods with
`TableRow::from_*` and `TableRow::as_*`, with `debug_assertions`
protecting any internal casting.
- Replaced `TableId::new` and `TableId::index` methods with
`TableId::from_*` and `TableId::as_*`, with `debug_assertions`
protecting any internal casting.
- All `TableId` methods are now `const`
## Migration Guide
- `TableRow::new` -> `TableRow::from_usize`
- `TableRow::index` -> `TableRow::as_usize`
- `TableId::new` -> `TableId::from_usize`
- `TableId::index` -> `TableId::as_usize`
---
## Notes
I have chosen to remove the `index` and `new` methods for the following
chain of reasoning:
- Across the codebase, `new` was called with a mixture of `u32` and
`usize` values. Likewise for `index`.
- Choosing `new` to either be `usize` or `u32` would break half of these
call-sites, requiring `as` casting at the site.
- Adding a second method `new_u32` or `new_usize` avoids the above, bu
looks visually inconsistent.
- Therefore, they should be replaced with `from_*` and `as_*` methods
instead.
Worth noting is that by updating `ComponentSparseSet`, there are now
zero instances of interacting with the inner value of `TableRow` as a
`u32`, it is exclusively used as a `usize` value (due to interactions
with methods like `len` and slice indexing). I have left the `as_u32`
and `from_u32` methods as the "proper" constructors/getters.
This removes the `From<Vec2/3>` implementations for the direction types.
It doesn't seem right to have when it only works if the vector is
nonzero and finite and produces NaN otherwise.
Added `Direction2d/3d::new` which uses `Vec2/3::try_normalize` to
guarantee it returns either a valid direction or `None`.
This should make it impossible to create an invalid direction, which I
think was the intention with these types.
# Objective
Fixes#10291
This adds a way to easily log messages once within system which are
called every frame.
## Solution
Opted for a macro-based approach. The fact that the 'once' call is
tracked per call site makes the `log_once!()` macro very versatile and
easy-to-use. I suspect it will be very handy for all of us, but
especially beginners, to get some initial feedback from systems without
spamming up the place!
I've made the macro's return its internal `has_fired` state, for
situations in which that might be useful to know (trigger something else
alongside the log, for example).
Please let me know if I placed the macro's in the right location, and if
you would like me to do something more clever with the macro's
themselves, since its looking quite copy-pastey at the moment. I've
tried ways to replace 5 with 1 macro's, but no success yet.
One downside of this approach is: Say you wish to warn the user if a
resource is invalid. In this situation, the
`resource.is_valid()` check would still be performed every frame:
```rust
fn my_system(my_res: Res<MyResource>) {
if !my_res.is_valid() {
warn_once!("resource is invalid!");
}
}
```
If you want to prevent that, you would still need to introduce a local
boolean. I don't think this is a very big deal, as expensive checks
shouldn't be called every frame in any case.
## Changelog
Added: `trace_once!()`, `debug_once!()`, `info_once!()`, `warn_once!()`,
and `error_once!()` log macros which fire only once per call site.
# Objective
Resolves Issue #10772.
## Solution
Added the deprecated warning for QueryState::for_each_unchecked, as
noted in the comments of PR #6773.
Followed the wording in the deprecation messages for `for_each` and
`for_each_mut`
# Objective
After #6547, `Query::for_each` has been capable of automatic
vectorization on certain queries, which is seeing a notable (>50% CPU
time improvements) for iteration. However, `Query::for_each` isn't
idiomatic Rust, and lacks the flexibility of iterator combinators.
Ideally, `Query::iter` and friends should be able to achieve the same
results. However, this does seem to blocked upstream
(rust-lang/rust#104914) by Rust's loop optimizations.
## Solution
This is an intermediate solution and refactor. This moves the
`Query::for_each` implementation onto the `Iterator::fold`
implementation for `QueryIter` instead. This should result in the same
automatic vectorization optimization on all `Iterator` functions that
internally use fold, including `Iterator::for_each`, `Iterator::count`,
etc.
With this, it should close the gap between the two completely.
Internally, this PR changes `Query::for_each` to use
`query.iter().for_each(..)` instead of the duplicated implementation.
Separately, the duplicate implementations of internal iteration (i.e.
`Query::par_for_each`) now use portions of the current `Query::for_each`
implementation factored out into their own functions.
This also massively cleans up our internal fragmentation of internal
iteration options, deduplicating the iteration code used in `for_each`
and `par_iter().for_each()`.
---
## Changelog
Changed: `Query::for_each`, `Query::for_each_mut`, `Query::for_each`,
and `Query::for_each_mut` have been moved to `QueryIter`'s
`Iterator::for_each` implementation, and still retains their performance
improvements over normal iteration. These APIs are deprecated in 0.13
and will be removed in 0.14.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
when loading gltfs we may want to filter the results. in particular, i
need to be able to exclude cameras.
i can do this already by modifying the gltf after load and before
spawning, but it seems like a useful general option.
## Solution
add `GltfLoaderSettings` struct with bool members:
- `load_cameras` : checked before processing camera nodes.
- `load_lights` : checked before processing light nodes
- `load_meshes` : checked before loading meshes, materials and morph
weights
Existing code will work as before. Now you also have the option to
restrict what parts of the gltf are loaded. For example, to load a gltf
but exclude the cameras, replace a call to
`asset_server.load("my.gltf")` with:
```rust
asset_server.load_with_settings(
"my.gltf",
|s: &mut GltfLoaderSettings| {
s.load_cameras = false;
}
);
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fixes#10444
Currently manually removing an asset prevents it from being reloaded
while there are still active handles. Doing so will result in a panic,
because the storage entry has been marked as "empty / None" but the ID
is still assumed to be active by the asset server.
Patterns like `images.remove() -> asset_server.reload()` and
`images.remove() -> images.insert()` would fail if the handle was still
alive.
## Solution
Most of the groundwork for this was already laid in Bevy Asset V2. This
is largely just a matter of splitting out `remove` into two separate
operations:
* `remove_dropped`: remove the stored asset, invalidate the internal
Assets entry (preventing future insertions with the old id), and recycle
the id
* `remove_still_alive`: remove the stored asset, but leave the entry
otherwise untouched (and dont recycle the id).
`remove_still_alive` and `insert` can be called any number of times (in
any order) for an id until `remove_dropped` has been called, which will
invalidate the id.
From a user-facing perspective, there are no API changes and this is non
breaking. The public `Assets::remove` will internally call
`remove_still_alive`. `remove_dropped` can only be called by the
internal "handle management" system.
---
## Changelog
- Fix a bug preventing `Assets::remove` from blocking future inserts for
a specific `AssetIndex`.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/10786
## Solution
The bind_group_layout entries for the prepass were wrong when not all 4
prepass textures were used, as it just zipped [17, 18, 19, 20] with the
smallvec of prepass `bind_group_layout` entries that potentially didn't
contain 4 entries. (eg. if you had a depth and motion vector prepass but
no normal prepass, then depth would be correct but the entry for the
motion vector prepass would be 18 (normal prepass' spot) instead of 19).
Change the prepass `get_bind_group_layout_entries` function to return an
array of `[Option<BindGroupLayoutEntryBuilder>; 4]` and only add the
layout entry if it exists.
# Objective
avoid panics from `calculate_bounds` systems if entities are despawned
in PostUpdate.
there's a running general discussion (#10166) about command panicking.
in the meantime we may as well fix up some cases where it's clear a
failure to insert is safe.
## Solution
change `.insert(aabb)` to `.try_insert(aabb)`
# Objective
> Issue raised on
[Discord](https://discord.com/channels/691052431525675048/1002362493634629796/1179182488787103776)
Currently the following code fails due to a missing `TypePath` bound:
```rust
#[derive(Reflect)] struct Foo<T>(T);
#[derive(Reflect)] struct Bar<T>(Foo<T>);
#[derive(Reflect)] struct Baz<T>(Bar<Foo<T>>);
```
## Solution
Add `TypePath` to the per-field bounds instead of _just_ the generic
type parameter bounds.
### Related Work
It should be noted that #9046 would help make these kinds of issues
easier to work around and/or avoid entirely.
---
## Changelog
- Fixes missing `TypePath` requirement when deriving `Reflect` on nested
generics
# Objective
Fixes#10401
## Solution
* Allow sources to register specific processed/unprocessed watch
warnings.
* Specify per-platform watch warnings. This removes the need to cover
all platform cases in one warning message.
* Only register watch warnings for the _processed_ embedded source, as
warning about watching unprocessed embedded isn't helpful.
---
## Changelog
- Asset sources can now register specific watch warnings.
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
These type are unavailable to editors and scripting interfaces making
use of reflection.
## Solution
`#[derive(Reflect)]` and call `.register_type` during plugin
initialization.
---
## Changelog
### Added
- Implement `Reflect` for audio-related types, and register them.
# Objective
- Materials should be a more frequent rebind then meshes (due to being
able to use a single vertex buffer, such as in #10164) and therefore
should be in a higher bind group.
---
## Changelog
- For 2d and 3d mesh/material setups (but not UI materials, or other
rendering setups such as gizmos, sprites, or text), mesh data is now in
bind group 1, and material data is now in bind group 2, which is swapped
from how they were before.
## Migration Guide
- Custom 2d and 3d mesh/material shaders should now use bind group 2
`@group(2) @binding(x)` for their bound resources, instead of bind group
1.
- Many internal pieces of rendering code have changed so that mesh data
is now in bind group 1, and material data is now in bind group 2.
Semi-custom rendering setups (that don't use the Material or Material2d
APIs) should adapt to these changes.
# Objective
Keep essentially the same structure of `EntityHasher` from #9903, but
rephrase the multiplication slightly to save an instruction.
cc @superdump
Discord thread:
https://discord.com/channels/691052431525675048/1172033156845674507/1174969772522356756
## Solution
Today, the hash is
```rust
self.hash = i | (i.wrapping_mul(FRAC_U64MAX_PI) << 32);
```
with `i` being `(generation << 32) | index`.
Expanding things out, we get
```rust
i | ( (i * CONST) << 32 )
= (generation << 32) | index | ((((generation << 32) | index) * CONST) << 32)
= (generation << 32) | index | ((index * CONST) << 32) // because the generation overflowed
= (index * CONST | generation) << 32 | index
```
What if we do the same thing, but with `+` instead of `|`? That's almost
the same thing, except that it has carries, which are actually often
better in a hash function anyway, since it doesn't saturate. (`|` can be
dangerous, since once something becomes `-1` it'll stay that, and
there's no mixing available.)
```rust
(index * CONST + generation) << 32 + index
= (CONST << 32 + 1) * index + generation << 32
= (CONST << 32 + 1) * index + (WHATEVER << 32 + generation) << 32 // because the extra overflows and thus can be anything
= (CONST << 32 + 1) * index + ((CONST * generation) << 32 + generation) << 32 // pick "whatever" to be something convenient
= (CONST << 32 + 1) * index + ((CONST << 32 + 1) * generation) << 32
= (CONST << 32 + 1) * index +((CONST << 32 + 1) * (generation << 32)
= (CONST << 32 + 1) * (index + generation << 32)
= (CONST << 32 + 1) * (generation << 32 | index)
= (CONST << 32 + 1) * i
```
So we can do essentially the same thing using a single multiplication
instead of doing multiply-shift-or.
LLVM was already smart enough to merge the shifting into a
multiplication, but this saves the extra `or`:

<https://rust.godbolt.org/z/MEvbz4eo4>
It's a very small change, and often will disappear in load latency
anyway, but it's a couple percent faster in lookups:

(There was more of an improvement here before #10558, but with `to_bits`
being a single `qword` load now, keeping things mostly as it is turned
out to be better than the bigger changes I'd tried in #10605.)
---
## Changelog
(Probably skip it)
## Migration Guide
(none needed)
# Objective
the pbr prepass vertex shader currently only sets
`VertexOutput::world_position` when deferred or motion prepasses are
enabled.
the field is always in the vertex output so is otherwise undetermined,
and the calculation is very cheap.
## Solution
always set the world position in the pbr prepass vert shader.
# Objective
`GlobalsUniform` provides the current time to shaders, which is useful
for animations. `UiMaterial` is an abstraction that makes it easier to
write custom shaders for UI elements.
This PR makes it possible to use the `GlobalsUniform` in `UiMaterial`
shaders.
## Solution
The `GlobalsUniform` is bound to `@group(0) @binding(1)`. It is
accessible in shaders with:
```wgsl
#import bevy_render::globals::Globals
@group(0) @binding(1)
var<uniform> globals: Globals;
```
---
## Changelog
Added `GlobalsUniform` in `UiMaterial` shaders
## Discussion
Should I modify the existing ui_material example to showcase this?
# Objective
Related to #10612.
Enable the
[`clippy::manual_let_else`](https://rust-lang.github.io/rust-clippy/master/#manual_let_else)
lint as a warning. The `let else` form seems more idiomatic to me than a
`match`/`if else` that either match a pattern or diverge, and from the
clippy doc, the lint doesn't seem to have any possible false positive.
## Solution
Add the lint as warning in `Cargo.toml`, refactor places where the lint
triggers.
# Objective
- Follow up to #9694
## Solution
- Same api as #9694 but adapted for `BindGroupLayoutEntry`
- Use the same `ShaderStages` visibilty for all entries by default
- Add `BindingType` helper function that mirror the wgsl equivalent and
that make writing layouts much simpler.
Before:
```rust
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2,
multisampled: false,
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: bevy::render::render_resource::BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(PostProcessSettings::min_size()),
},
count: None,
},
],
});
```
After:
```rust
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout"),
&BindGroupLayoutEntries::sequential(
ShaderStages::FRAGMENT,
(
texture_2d_f32(),
sampler(SamplerBindingType::Filtering),
uniform_buffer(false, Some(PostProcessSettings::min_size())),
),
),
);
```
Here's a more extreme example in bevy_solari:
86dab7f5da
---
## Changelog
- Added `BindGroupLayoutEntries` and all `BindingType` helper functions.
## Migration Guide
`RenderDevice::create_bind_group_layout()` doesn't take a
`BindGroupLayoutDescriptor` anymore. You need to provide the parameters
separately
```rust
// 0.12
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
// ...
},
],
});
// 0.13
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout",
&[
BindGroupLayoutEntry {
// ...
},
],
);
```
## TODO
- [x] implement a `Dynamic` variant
- [x] update the `RenderDevice::create_bind_group_layout()` api to match
the one from `RenderDevice::creat_bind_group()`
- [x] docs
# Objective
- Fixes#7680
- This is an updated for https://github.com/bevyengine/bevy/pull/8899
which had the same objective but fell a long way behind the latest
changes
## Solution
The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter :
WorldQuery` have been added and some of the types and functions from
`WorldQuery` has been moved into them.
`ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`.
`WorldQueryFilter` is safe (as long as `WorldQuery` is implemented
safely).
`WorldQueryData` is unsafe - safely implementing it requires that
`Self::ReadOnly` is a readonly version of `Self` (this used to be a
safety requirement of `WorldQuery`)
The type parameters `Q` and `F` of `Query` must now implement
`WorldQueryData` and `WorldQueryFilter` respectively.
This makes it impossible to accidentally use a filter in the data
position or vice versa which was something that could lead to bugs.
~~Compile failure tests have been added to check this.~~
It was previously sometimes useful to use `Option<With<T>>` in the data
position. Use `Has<T>` instead in these cases.
The `WorldQuery` derive macro has been split into separate derive macros
for `WorldQueryData` and `WorldQueryFilter`.
Previously it was possible to derive both `WorldQuery` for a struct that
had a mixture of data and filter items. This would not work correctly in
some cases but could be a useful pattern in others. *This is no longer
possible.*
---
## Notes
- The changes outside of `bevy_ecs` are all changing type parameters to
the new types, updating the macro use, or replacing `Option<With<T>>`
with `Has<T>`.
- All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL`
so I moved it to `WorldQueryFilter` and
replaced all calls to it with `true`. That should be the only logic
change outside of the macro generation code.
- `Changed<T>` and `Added<T>` were being generated by a macro that I
have expanded. Happy to revert that if desired.
- The two derive macros share some functions for implementing
`WorldQuery` but the tidiest way I could find to implement them was to
give them a ton of arguments and ask clippy to ignore that.
## Changelog
### Changed
- Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which
now have separate derive macros. It is not possible to derive both for
the same type.
- `Query` now requires that the first type argument implements
`WorldQueryData` and the second implements `WorldQueryFilter`
## Migration Guide
- Update derives
```rust
// old
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA
}
#[derive(WorldQuery)]
struct QueryFilter {
_c: With<ComponentC>
}
// new
#[derive(WorldQueryData)]
#[world_query_data(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA,
}
#[derive(WorldQueryFilter)]
struct QueryFilter {
_c: With<ComponentC>
}
```
- Replace `Option<With<T>>` with `Has<T>`
```rust
/// old
fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>)
{
for (entity, has_a_option) in query.iter(){
let has_a:bool = has_a_option.is_some();
//todo!()
}
}
/// new
fn my_system(query: Query<(Entity, Has<ComponentA>)>)
{
for (entity, has_a) in query.iter(){
//todo!()
}
}
```
- Fix queries which had filters in the data position or vice versa.
```rust
// old
fn my_system(query: Query<(Entity, With<ComponentA>)>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Entity, With<ComponentA>>)
{
for entity in query.iter(){
//todo!()
}
}
// old
fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>)
{
for entity in query.iter(){
//todo!()
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Kind of helps #10509
## Solution
Add a line to `prepass.wgsl` that ensure the `instance_index` push
constant is always used on WebGL 2. This is not a full fix, as the
_second_ a custom shader is used that doesn't use the push constant, the
breakage will resurface. We have satisfying medium term and long term
solutions. This is just a short term hack for 0.12.1 that will make more
cases work. See #10509 for more details.
# Objective
- `insert_reflect` relies on `reflect_type_path`, which doesn't gives
the actual type path for object created by `clone_value`, leading to an
unexpected panic. This is a workaround for it.
- Fix#10590
## Solution
- Tries to get type path from `get_represented_type_info` if get failed
from `reflect_type_path`.
---
## Defect remaining
- `get_represented_type_info` implies a shortage on performance than
using `TypeRegistry`.
# Objective
Fixes#10688
There were a number of issues at play:
1. The GLTF loader was not registering Scene dependencies properly. They
were being registered at the root instead of on the scene assets. This
made `LoadedWithDependencies` fire immediately on load.
2. Recursive labeled assets _inside_ of labeled assets were not being
loaded. This only became relevant for scenes after fixing (1) because we
now add labeled assets to the nested scene `LoadContext` instead of the
root load context. I'm surprised nobody has hit this yet. I'm glad I
caught it before somebody hit it.
3. Accessing "loaded with dependencies" state on the Asset Server is
boilerplatey + error prone (because you need to manually query two
states).
## Solution
1. In GltfLoader, use a nested LoadContext for scenes and load
dependencies through that context.
2. In the `AssetServer`, load labeled assets recursively.
3. Added a simple `asset_server.is_loaded_with_dependencies(id)`
I also added some docs to `LoadContext` to help prevent this problem in
the future.
---
## Changelog
- Added `AssetServer::is_loaded_with_dependencies`
- Fixed GLTF Scene dependencies
- Fixed nested labeled assets not being loaded
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#10676, preventing a possible memory leak for commands which
owned resources.
## Solution
Implemented `Drop` for `CommandQueue`. This has been done entirely in
the private API of `CommandQueue`, ensuring no breaking changes. Also
added a unit test, `test_command_queue_inner_drop_early`, based on the
reproduction steps as outlined in #10676.
## Notes
I believe this can be applied to `0.12.1` as well, but I am uncertain of
the process to make that kind of change. Please let me know if there's
anything I can do to help with the back-porting of this change.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#10157
## Solution
Add `AssetMetaCheck` resource which can configure when/if asset meta
files will be read:
```rust
app
// Never attempts to look up meta files. The default meta configuration will be used for each asset.
.insert_resource(AssetMetaCheck::Never)
.add_plugins(DefaultPlugins)
```
This serves as a band-aid fix for the issue with wasm's
`HttpWasmAssetReader` creating a bunch of requests for non-existent
meta, which can slow down asset loading (by waiting for the 404
response) and creates a bunch of noise in the logs. This also provides a
band-aid fix for the more serious issue of itch.io deployments returning
403 responses, which results in full failure of asset loads.
If users don't want to include meta files for all deployed assets for
web builds, and they aren't using meta files at all, they should set
this to `AssetMetaCheck::Never`.
If users do want to include meta files for specific assets, they can use
`AssetMetaCheck::Paths`, which will only look up meta for those paths.
Currently, this defaults to `AssetMetaCheck::Always`, which makes this
fully non-breaking for the `0.12.1` release. _**However it _is_ worth
discussing making this `AssetMetaCheck::Never` by default**_, given that
I doubt most people are using meta files without the Asset Processor
enabled. This would be a breaking change, but it would make WASM / Itch
deployments work by default, which is a pretty big win imo. The downside
is that people using meta files _without_ processing would need to
manually enable `AssetMetaCheck::Always`, which is also suboptimal.
When in `AssetMetaCheck::Processed`, the meta check resource is ignored,
as processing requires asset meta files to function.
In general, I don't love adding this knob as things should ideally "just
work" in all cases. But this is the reality of the current situation.
---
## Changelog
- Added `AssetMetaCheck` resource, which can configure when/if asset
meta files will be read
# Objective
Resolves#10743.
## Solution
Copied over the documentation written by @stepancheng from PR #10718.
I left out the lines from the doctest where `<()>` is removed, as that
seemed to be the part people couldn't decide on whether to keep or not.
## Objective
Currently, events are dropped after two frames. This cadence wasn't
*chosen* for a specific reason, double buffering just lets events
persist for at least two frames. Events only need to be dropped at a
predictable point so that the event queues don't grow forever (i.e.
events should never cause a memory leak).
Events (and especially input events) need to be observable by systems in
`FixedUpdate`, but as-is events are dropped before those systems even
get a chance to see them.
## Solution
Instead of unconditionally dropping events in `First`, require
`FixedUpdate` to first queue the buffer swap (if the `TimePlugin` has
been installed). This way, events are only dropped after a frame that
runs `FixedUpdate`.
## Future Work
In the same way we have independent copies of `Time` for tracking time
in `Main` and `FixedUpdate`, we will need independent copies of `Input`
for tracking press/release status correctly in `Main` and `FixedUpdate`.
--
Every run of `FixedUpdate` covers a specific timespan. For example, if
the fixed timestep `Δt` is 10ms, the first three `FixedUpdate` runs
cover `[0ms, 10ms)`, `[10ms, 20ms)`, and `[20ms, 30ms)`.
`FixedUpdate` can run many times in one frame. For truly
framerate-independent behavior, each `FixedUpdate` should only see the
events that occurred in its covered timespan, but what happens right now
is the first step in the frame reads all pending events.
Fixing that will require timestamped events.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
forward for bevy user to consume
# Objective
- since winit 0.27 an event WindowOccluded will be produced:
https://docs.rs/winit/latest/winit/event/enum.WindowEvent.html#variant.Occluded
- on ios this is currently the only way to know if an app comes back
from the background which is an important time to to things (like
resetting the badge)
## Solution
- pick up the winit event and forward it to a new `EventWriter`
---
## Changelog
### Added
- new Event `WindowOccluded` added allowing to hook into
`WindowEvent::Occluded` of winit
# Objective
I tried setting `ClearColorConfig` in my app via `Color::FOO.into()`
expecting it to work, but the impl was missing.
## Solution
- Add `impl From<Color> for ClearColorConfig`
- Change examples to use this impl
## Changelog
### Added
- `ClearColorConfig` can be constructed via `.into()` on a `Color`
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
`wgpu` has a helper method `texture.as_image_copy()` for a common
pattern when making a default-like `ImageCopyTexture` from a texture.
This is used in various places in Bevy for texture copy operations, but
it was not used where `write_texture` is called.
## Solution
- Replace struct `ImageCopyTexture` initialization with
`texture.as_image_copy()` where appropriate
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- Window size, scale and position are not correct on the first execution
of the systems
- Fixes#10407, fixes#10642
## Solution
- Don't run `update` before we get a chance to create the window in
winit
- Finish reverting #9826 after #10389
# Objective
The `generate_composite_uuid` utility function hidden in
`bevy_reflect::__macro_exports` could be generally useful to users.
For example, I previously relied on `Hash` to generate a `u64` to create
a deterministic `HandleId`. In v0.12, `HandleId` has been replaced by
`AssetId` which now requires a `Uuid`, which I could generate with this
function.
## Solution
Relocate `generate_composite_uuid` from `bevy_reflect::__macro_exports`
to `bevy_utils::uuid`.
It is still re-exported under `bevy_reflect::__macro_exports` so there
should not be any breaking changes (although, users should generally not
rely on pseudo-private/hidden modules like `__macro_exports`).
I chose to keep it in `bevy_reflect::__macro_exports` so as to not
clutter up our public API and to reduce the number of changes in this
PR. We could have also marked the export as `#[doc(hidden)]`, but
personally I like that we have a dedicated module for this (makes it
clear what is public and what isn't when just looking at the macro
code).
---
## Changelog
- Moved `generate_composite_uuid` to `bevy_utils::uuid` and made it
public
- Note: it was technically already public, just hidden
# Objective
It is currently impossible to control the relative ordering of two 2D
materials at the same depth. This is required to implement wireframes
for 2D meshes correctly
(https://github.com/bevyengine/bevy/issues/5881).
## Solution
Add a `Material2d::depth_bias` function that mirrors the existing 3D
`Material::depth_bias` function.
(this is pulled out of https://github.com/bevyengine/bevy/pull/10489)
---
## Changelog
### Added
- Added `Material2d::depth_bias`
## Migration Guide
`PreparedMaterial2d` has a new `depth_bias` field. A value of 0.0 can be
used to get the previous behavior.
# Objective
Resolves #10727.
`outline.width` was being assigned to `node.outline_offset` instead of
`outline.offset`.
## Solution
Changed `.width` to `.offset` in line 413.
# Objective
Bevy_hierarchy is very useful for ECS only usages of bevy_ecs, but it
currently pulls in bevy_reflect, bevy_app and bevy_core with no way to
opt out.
## Solution
This PR provides features `bevy_app` and `reflect` that are enabled by
default. If disabled, they should remove these dependencies from
bevy_hierarchy.
---
## Changelog
Added features `bevy_app` and `reflect` to bevy_hierarchy.
# Objective
Updates [`futures-lite`](https://github.com/smol-rs/futures-lite) in
bevy_tasks to the next major version (1 -> 2).
Also removes the duplication of `futures-lite`, as `async-fs` requires v
2, so there are currently 2 copies of futures-lite in the dependency
tree.
Futures-lite has received [a number of
updates](https://github.com/smol-rs/futures-lite/blob/master/CHANGELOG.md)
since bevy's current version `1.4`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
- Fix#10499
## Solution
- Use `.get_represented_type_info()` module path and type ident instead
of `.reflect_*` module path and type ident when serializing the `Option`
enum
---
## Changelog
- Fix serialization bug
- Add simple test
- Add `serde_json` dev dependency
- Add `serde` with `derive` feature dev dependency (wouldn't compile for
me without it)
---------
Co-authored-by: hank <hank@hank.co.in>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Explain https://github.com/bevyengine/bevy/issues/10625.
This might be obvious to those familiar with Bevy internals, but it
surprised me.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
I incorrectly assumed that moving a system from `Update` to
`FixedUpdate` would simplify logic without hurting performance.
But this is not the case: if there's single-threaded long computation in
the `FixedUpdate`, the machine won't do anything else in parallel with
it. Which might be not what users expect.
So this PR adds a note. But maybe it is obvious, I don't know.
# Objective
fix webgpu+chrome(119) textureSample in non-uniform control flow error
## Solution
modify view transmission texture sampling to use textureSampleLevel.
there are no mips for the view transmission texture, so this doesn't
change the result, but it removes the need for the samples to be in
uniform control flow.
note: in future we may add a mipchain to the transmission texture to
improve the blur effect. if uniformity analysis hasn't improved, this
would require switching to manual derivative calculations (which is
something we plan to do anyway).
## Objective
- Split different types of gizmos into their own files
## Solution
- Move `arc_2d` and `Arc2dBuilder` into `arcs.rs`
- turns out there's no 3d arc function! I'll add one Soon(TM) in another
MR
## Changelog
- Changed
- moved `gizmos::Arc2dBuilder` to `gizmos::arcs::Arc2dBuilder`
## Migration Guide
- `gizmos::Arc2dBuilder` -> `gizmos::arcs::Arc2dBuilder`
# Objective
Problems:
* The clipped, non-visible regions of UI nodes are interactive.
* `RelativeCursorPostion` is set relative to the visible part of the
node. It should be relative to the whole node.
* The `RelativeCursorPostion::mouse_over` method returns `true` when the
mouse is over a clipped part of a node.
fixes#10470
## Solution
Intersect a node's bounding rect with its clipping rect before checking
if it contains the cursor.
Added the field `normalized_visible_node_rect` to
`RelativeCursorPosition`. This is set to the bounds of the unclipped
area of the node rect by `ui_focus_system` expressed in normalized
coordinates relative to the entire node.
Instead of checking if the normalized cursor position lies within a unit
square, it instead checks if it is contained by
`normalized_visible_node_rect`.
Added outlines to the `overflow` example that appear when the cursor is
over the visible part of the images, but not the clipped area.
---
## Changelog
* `ui_focus_system` intersects a node's bounding rect with its clipping
rect before checking if mouse over.
* Added the field `normalized_visible_node_rect` to
`RelativeCursorPosition`. This is set to the bounds of the unclipped
area of the node rect by `ui_focus_system` expressed in normalized
coordinates relative to the entire node.
* `RelativeCursorPostion` is calculated relative to the whole node's
position and size, not only the visible part.
* `RelativeCursorPosition::mouse_over` only returns true when the mouse
is over an unclipped region of the UI node.
* Removed the `Deref` and `DerefMut` derives from
`RelativeCursorPosition` as it is no longer a single field struct.
* Added some outlines to the `overflow` example that respond to
`Interaction` changes.
## Migration Guide
The clipped areas of UI nodes are no longer interactive.
`RelativeCursorPostion` is now calculated relative to the whole node's
position and size, not only the visible part. Its `mouse_over` method
only returns true when the cursor is over an unclipped part of the node.
`RelativeCursorPosition` no longer implements `Deref` and `DerefMut`.
# Objective
- Fixes#10695
## Solution
Fixed obvious blunder in `PartialEq` implementation for
`UntypedAssetId`'s where the `TypeId` was not included in the
comparison. This was not picked up in the unit tests I added because
they only tested over a single asset type.
# Objective
- I've been experimenting with different patterns to try and make async
tasks more convenient. One of the better ones I've found is to return a
command queue to allow for deferred &mut World access. It can be
convenient to check for task completion in a normal system, but it is
hard to do something with the command queue after getting it back. This
pr adds a `append` to Commands. This allows appending the returned
command queue onto the system's commands.
## Solution
- I edited the async compute example to use the new `append`, but not
sure if I should keep the example changed as this might be too
opinionated.
## Future Work
- It would be very easy to pull the pattern used in the example out into
a plugin or a external crate, so users wouldn't have to add the checking
system.
---
## Changelog
- add `append` to `Commands` and `CommandQueue`
# Objective
Enables warning on `clippy::undocumented_unsafe_blocks` across the
workspace rather than only in `bevy_ecs`, `bevy_transform` and
`bevy_utils`. This adds a little awkwardness in a few areas of code that
have trivial safety or explain safety for multiple unsafe blocks with
one comment however automatically prevents these comments from being
missed.
## Solution
This adds `undocumented_unsafe_blocks = "warn"` to the workspace
`Cargo.toml` and fixes / adds a few missed safety comments. I also added
`#[allow(clippy::undocumented_unsafe_blocks)]` where the safety is
explained somewhere above.
There are a couple of safety comments I added I'm not 100% sure about in
`bevy_animation` and `bevy_render/src/view` and I'm not sure about the
use of `#[allow(clippy::undocumented_unsafe_blocks)]` compared to adding
comments like `// SAFETY: See above`.
# Objective
First, some terminology:
- **Minor radius**: The radius of the tube of a torus, i.e. the
"half-thickness"
- **Major radius**: The distance from the center of the tube to the
center of the torus
- **Inner radius**: The radius of the hole (if it exists), `major_radius
- minor_radius`
- **Outer radius**: The radius of the overall shape, `major_radius +
minor_radius`
- **Ring torus**: The familiar donut shape with a hole in the center,
`major_radius > minor_radius`
- **Horn torus**: A torus that doesn't have a hole but also isn't
self-intersecting, `major_radius == minor_radius`
- **Spindle torus**: A self-intersecting torus, `major_radius <
minor_radius`
Different tori from [Wikipedia](https://en.wikipedia.org/wiki/Torus),
where *R* is the major radius and *r* is the minor radius:

Currently, Bevy's torus is represented by a `radius` and `ring_radius`.
I believe these correspond to the outer radius and minor radius, but
they are rather confusing and inconsistent names, and they make the
assumption that the torus always has a ring.
I also couldn't find any other big engines using this representation;
[Godot](https://docs.godotengine.org/en/stable/classes/class_torusmesh.html)
and [Unity
ProBuilder](https://docs.unity3d.com/Packages/com.unity.probuilder@4.0/manual/Torus.html)
use the inner and outer radii, while
[Unreal](https://docs.unrealengine.com/5.3/en-US/BlueprintAPI/GeometryScript/Primitives/AppendTorus/)
uses the minor and major radii.
[Blender](https://docs.blender.org/manual/en/latest/modeling/meshes/primitives.html#torus)
supports both, but defaults to minor/major.
Bevy's `Torus` primitive should have an efficient, consistent, clear and
flexible representation, and the current `radius` and `ring_radius`
properties are not ideal for that.
## Solution
Change `Torus` to be represented by a `minor_radius` and `major_radius`.
- Mathematically correct and consistent
- Flexible, not restricted to ring tori
- Computations and conversions are efficient
- `inner_radius = major_radius - minor_radius`
- `outer_radius = major_radius + minor_radius`
- Mathematical formulae for things like area and volume rely on the
minor and major radii, no conversion needed
Perhaps the primary issue with this representation is that "minor
radius" and "major radius" are rather mathematical, and an inner/outer
radius can be more intuitive in some cases. However, this can be
mitigated with constructors and helpers.
# Objective
Make the impl block for RemovedSystem generic so that the methods can be
called for systems that have inputs or outputs.
## Solution
Simply adding generics to the impl block.
# Objective
Adds `.entry` to `EntityWorldMut` with `Entry`, `OccupiedEntry` and
`VacantEntry` for easier in-situ modification, based on `HashMap.entry`.
Fixes#10635
## Solution
This adds the `entry` method to `EntityWorldMut` which returns an
`Entry`. This is an enum of `OccupiedEntry` and `VacantEntry` and has
the methods `and_modify`, `insert_entry`, `or_insert`, `or_insert_with`
and `or_default`. The only difference between `OccupiedEntry` and
`VacantEntry` is the type, they are both a mutable reference to the
`EntityWorldMut` and a marker for the component type, `HashMap` also
stores things to make it quicker to access the data in `OccupiedEntry`
but I wasn't sure if we had anything it would be logical to store to
make accessing/modifying the component faster? As such, the differences
are that `OccupiedEntry` assumes the entity has the component (because
nothing else can have an `EntityWorldMut` so it can't be changed outside
the entry api) and has different methods.
All the methods are based very closely off `hashbrown::HashMap` (because
its easier to read the source of) with a couple of quirks like
`OccupiedEntry.insert` doesn't return the old value because we don't
appear to have an api for mem::replacing components.
---
## Changelog
- Added a new function `EntityWorldMut.entry` which returns an `Entry`,
allowing easier in-situ modification of a component.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
- Fixes#10629
- `UntypedAssetId` and `AssetId` (along with `UntypedHandle` and
`Handle`) do not hash to the same values when pointing to the same
`Asset`. Additionally, comparison and conversion between these types
does not follow idiomatic Rust standards.
## Solution
- Added new unit tests to validate/document expected behaviour
- Added trait implementations to make working with Un/Typed values more
ergonomic
- Ensured hashing and comparison between Un/Typed values is consistent
- Removed `From` trait implementations that panic, and replaced them
with `TryFrom`
---
## Changelog
- Ensured `Handle::<A>::hash` and `UntypedHandle::hash` will produce the
same value for the same `Asset`
- Added non-panicing `Handle::<A>::try_typed`
- Added `PartialOrd` to `UntypedHandle` to match `Handle<A>` (this will
return `None` for `UntypedHandles` for differing `Asset` types)
- Added `TryFrom<UntypedHandle>` for `Handle<A>`
- Added `From<Handle<A>>` for `UntypedHandle`
- Removed panicing `From<Untyped...>` implementations. These are
currently unused within the Bevy codebase, and shouldn't be used
externally, hence removal.
- Added cross-implementations of `PartialEq` and `PartialOrd` for
`UntypedHandle` and `Handle<A>` allowing direct comparison when
`TypeId`'s match.
- Near-identical changes to `AssetId` and `UntypedAssetId`
## Migration Guide
If you relied on any of the panicing `From<Untyped...>` implementations,
simply call the existing `typed` methods instead. Alternatively, use the
new `TryFrom` implementation instead to directly expose possible
mistakes.
## Notes
I've made these changes since `Handle` is such a fundamental type to the
entire `Asset` ecosystem within Bevy, and yet it had pretty unclear
behaviour with no direct testing. The fact that hashing untyped vs typed
versions of the same handle would produce different values is something
I expect to cause a very subtle bug for someone else one day.
I haven't included it in this PR to avoid any controversy, but I also
believe the `typed_unchecked` methods should be removed from these
types, or marked as `unsafe`. The `texture_atlas` example currently uses
it, and I believe it is a bad choice. The performance gained by not
type-checking before conversion would be entirely dwarfed by the act of
actually loading an asset and creating its handle anyway. If an end user
is in a tight loop repeatedly calling `typed_unchecked` on an
`UntypedHandle` for the entire runtime of their application, I think the
small performance drop caused by that safety check is ~~a form of cosmic
justice~~ reasonable.
# Objective
- Standardize fmt for toml files
## Solution
- Add [taplo](https://taplo.tamasfe.dev/) to CI (check for fmt and diff
for toml files), for context taplo is used by the most popular extension
in VScode [Even Better
TOML](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml
- Add contribution section to explain toml fmt with taplo.
Now to pass CI you need to run `taplo fmt --option indent_string=" "` or
if you use vscode have the `Even Better TOML` extension with 4 spaces
for indent
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
- Give all the intuitive groups of gizmos their own file
- don't be a breaking change
- don't change Gizmos interface
- eventually do arcs too
- future types of gizmos should be in their own files
- see also https://github.com/bevyengine/bevy/issues/9400
## Solution
- Moved `gizmos.circle`, `gizmos.2d_circle`, and assorted helpers into
`circles.rs`
- Can also do arcs in this MR if y'all want; just figured I should do
one thing at a time.
## Changelog
- Changed
- `gizmos::CircleBuilder` moved to `gizmos::circles::Circle2dBuilder`
- `gizmos::Circle2dBuilder` moved to `gizmos::circles::Circle2dBuilder`
## Migration Guide
- change `gizmos::CircleBuilder` to `gizmos::circles::Circle2dBuilder`
- change `gizmos::Circle2dBuilder` to `gizmos::circles::Circle2dBuilder`
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
This PR adds some helpers for `Triangle2d` to work with its winding
order. This could also be extended to polygons (and `Triangle3d` once
it's added).
## Solution
- Add `WindingOrder` enum with `Clockwise`, `Counterclockwise` and
`Invalid` variants
- `Invalid` is for cases where the winding order can not be reliably
computed, i.e. the points lie on a single line and the area is zero
- Add `Triangle2d::winding_order` method that uses a signed surface area
to determine the winding order
- Add `Triangle2d::reverse` method that reverses the winding order by
swapping the second and third vertices
The API looks like this:
```rust
let mut triangle = Triangle2d::new(
Vec2::new(0.0, 2.0),
Vec2::new(-0.5, -1.2),
Vec2::new(-1.0, -1.0),
);
assert_eq!(triangle.winding_order(), WindingOrder::Clockwise);
// Reverse winding order
triangle.reverse();
assert_eq!(triangle.winding_order(), WindingOrder::Counterclockwise);
```
I also added tests to make sure the methods work correctly. For now,
they live in the same file as the primitives.
## Open questions
- Should it be `Counterclockwise` or `CounterClockwise`? The first one
is more correct but perhaps a bit less readable. Counter-clockwise is
also a valid spelling, but it seems to be a lot less common than
counterclockwise.
- Is `WindingOrder::Invalid` a good name? Parry uses
`TriangleOrientation::Degenerate`, but I'm not a huge fan, at least as a
non-native English speaker. Any better suggestions?
- Is `WindingOrder` fine in `bevy_math::primitives`? It's not specific
to a dimension, so I put it there for now.
# Objective
Fix the `bevy_asset/file_watcher` feature in practice depending on
multithreading, while not informing the user of it.
**As I understand it** (I didn't check it), the file watcher feature
depends on spawning a concurrent thread to receive file update events
from the `notify-debouncer-full` crate. But if multithreading is
disabled, that thread will never have time to read the events and
consume them.
- Fixes#10573
## Solution
Add a `compile_error!` causing compilation failure if `file_watcher` is
enabled while `multi-threaded` is disabled.
This is considered better than adding a dependency on `multi-threaded`
on the `file_watcher`, as (according to @mockersf) toggling on/off
`multi-threaded` has a non-zero chance of changing behavior. And we
shouldn't implicitly change behavior. A compilation failure prevents
compilation of code that is invalid, while informing the user of the
steps needed to fix it.
# Objective
- Sometimes it's very useful to know if a `Transform` contains any `NaN`
or infinite values. It's a bit boiler-plate heavy to check translation,
rotation and scale individually.
## Solution
- Add a new method `is_finite` that returns true if, and only if
translation, rotation and scale all are finite.
- It's a natural extension of `Quat::is_finite`, and `Vec3::is_finite`,
which return true if, and only if all their components' `is_finite()`
returns true.
---
## Changelog
- Added `Transform::is_finite`
# Objective
The `map_async` method involves a type `BufferAsyncError`:
https://docs.rs/bevy/latest/bevy/render/render_resource/struct.BufferSlice.html#method.map_async
This type is not re-exported in Bevy, so if a user wants to store a
struct involving this type they have to add wgpu manually to their
manifest.
## Solution
- Re-export wgpu::BufferAsyncError
---
## Changelog
### Added
- Re-export wgpu::BufferAsyncError
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- Fix adding `#![allow(clippy::type_complexity)]` everywhere. like #9796
## Solution
- Use the new [lints] table that will land in 1.74
(https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#lints)
- inherit lint to the workspace, crates and examples.
```
[lints]
workspace = true
```
## Changelog
- Bump rust version to 1.74
- Enable lints table for the workspace
```toml
[workspace.lints.clippy]
type_complexity = "allow"
```
- Allow type complexity for all crates and examples
```toml
[lints]
workspace = true
```
---------
Co-authored-by: Martín Maita <47983254+mnmaita@users.noreply.github.com>
# Objective
- Follow up on https://github.com/bevyengine/bevy/pull/10519, diving
deeper into optimising `Entity` due to the `derive`d `PartialOrd`
`partial_cmp` not being optimal with codegen:
https://github.com/rust-lang/rust/issues/106107
- Fixes#2346.
## Solution
Given the previous PR's solution and the other existing LLVM codegen
bug, there seemed to be a potential further optimisation possible with
`Entity`. In exploring providing manual `PartialOrd` impl, it turned out
initially that the resulting codegen was not immediately better than the
derived version. However, once `Entity` was given `#[repr(align(8)]`,
the codegen improved remarkably, even more once the fields in `Entity`
were rearranged to correspond to a `u64` layout (Rust doesn't
automatically reorder fields correctly it seems). The field order and
`align(8)` additions also improved `to_bits` codegen to be a single
`mov` op. In turn, this led me to replace the previous
"non-shortcircuiting" impl of `PartialEq::eq` to use direct `to_bits`
comparison.
The result was remarkably better codegen across the board, even for
hastable lookups.
The current baseline codegen is as follows:
https://godbolt.org/z/zTW1h8PnY
Assuming the following example struct that mirrors with the existing
`Entity` definition:
```rust
#[derive(Clone, Copy, Eq, PartialEq, PartialOrd, Ord)]
pub struct FakeU64 {
high: u32,
low: u32,
}
```
the output for `to_bits` is as follows:
```
example::FakeU64::to_bits:
shl rdi, 32
mov eax, esi
or rax, rdi
ret
```
Changing the struct to:
```rust
#[derive(Clone, Copy, Eq)]
#[repr(align(8))]
pub struct FakeU64 {
low: u32,
high: u32,
}
```
and providing manual implementations for `PartialEq`/`PartialOrd`/`Ord`,
`to_bits` now optimises to:
```
example::FakeU64::to_bits:
mov rax, rdi
ret
```
The full codegen example for this PR is here for reference:
https://godbolt.org/z/n4Mjx165a
To highlight, `gt` comparison goes from
```
example::greater_than:
cmp edi, edx
jae .LBB3_2
xor eax, eax
ret
.LBB3_2:
setne dl
cmp esi, ecx
seta al
or al, dl
ret
```
to
```
example::greater_than:
cmp rdi, rsi
seta al
ret
```
As explained on Discord by @scottmcm :
>The root issue here, as far as I understand it, is that LLVM's
middle-end is inexplicably unwilling to merge loads if that would make
them under-aligned. It leaves that entirely up to its target-specific
back-end, and thus a bunch of the things that you'd expect it to do that
would fix this just don't happen.
## Benchmarks
Before discussing benchmarks, everything was tested on the following
specs:
AMD Ryzen 7950X 16C/32T CPU
64GB 5200 RAM
AMD RX7900XT 20GB Gfx card
Manjaro KDE on Wayland
I made use of the new entity hashing benchmarks to see how this PR would
improve things there. With the changes in place, I first did an
implementation keeping the existing "non shortcircuit" `PartialEq`
implementation in place, but with the alignment and field ordering
changes, which in the benchmark is the `ord_shortcircuit` column. The
`to_bits` `PartialEq` implementation is the `ord_to_bits` column. The
main_ord column is the current existing baseline from `main` branch.

My machine is not super set-up for benchmarking, so some results are
within noise, but there's not just a clear improvement between the
non-shortcircuiting implementation, but even further optimisation taking
place with the `to_bits` implementation.
On my machine, a fair number of the stress tests were not showing any
difference (indicating other bottlenecks), but I was able to get a clear
difference with `many_foxes` with a fox count of 10,000:
Test with `cargo run --example many_foxes --features
bevy/trace_tracy,wayland --release -- --count 10000`:

On avg, a framerate of about 28-29FPS was improved to 30-32FPS. "This
trace" represents the current PR's perf, while "External trace"
represents the `main` branch baseline.
## Changelog
Changed: micro-optimized Entity align and field ordering as well as
providing manual `PartialOrd`/`Ord` impls to help LLVM optimise further.
## Migration Guide
Any `unsafe` code relying on field ordering of `Entity` or sufficiently
cursed shenanigans should change to reflect the different internal
representation and alignment requirements of `Entity`.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: NathanW <nathansward@comcast.net>
Bevy introduced unintentional breaking behaviour along with the v0.12.0
release regarding the `App::set_runner` API. See: #10385, #10389 for
details. We weren't able to catch this before release because this API
is only used internally in one or two places (the very places which
motivated the break).
This commit adds a regression test to help guarantee some expected
behaviour for custom runners, namely that `app::update` won't be called
before the runner has a chance to initialise state.
# Objective
There is no easy way to discard some amount for `Time<Fixed>`'s
overstep. This can be useful for online games when the client receives
information about a tick (which happens when you get a FPS drop or the
ping changes for example) it has not yet processed, it can discard
overstep equal to the number of ticks it can jump ahead.
Currently the workaround would be to create a new `Time<Fixed>` copy the
old timestep, advance it by the overstep amount that would remain after
subtracting the discarded amount, and using `.context_mut()` to
overwrite the old context with the new one. If you overwrite the whole
`Time<Fixed>` or forget to copy over the timestep you can introduce
undesirable side effects.
## Solution
Introduce a `discard_overstep` method, which discards the provided
amount of overstep. It uses satuarting_sub to avoid errors (negative
`Duration`s do not exist).
---
## Changelog
- Added `discard_overstep` function to `Time<Fixed>`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Allow bevy applications that does not have any assets folder to start
from a read-only directory. (typically installed to a systems folder)
Fixes#10613
## Solution
- warn instead of panic when assets folder creation fails.
# Objective
- Currently, in 0.12 there is an issue that it is not possible to build
bevy for Wasm with feature "file_watcher" enabled. It still would not
compile, but now with proper explanation.
- Fixes https://github.com/bevyengine/bevy/issues/10507
## Solution
- Remove `notify-debouncer-full` dependency on WASM platform entirely.
- Compile with "file_watcher" feature now on platform `wasm32` gives
meaningful compile error.
---
## Changelog
### Fixed
- Compile with "file_watcher" feature now on platform `wasm32` gives
meaningful compile error.
# Add and implement constructors for Primitives
- Adds more Primitive types and adds a constructor for almost all of
them
- Works towards finishing #10572
## Solution
- Created new primitives
- Torus
- Conical Frustum
- Cone
- Ellipse
- Implemented constructors (`Primitive::new`) for almost every single
other primitive.
---------
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Handy to have a constant instead of `VolumeLevel::new(0.0)`
- `VolumeLevel::new` is not `const`
## Solution
- Adds a `VolumeLevel::ZERO` constant, which we have for most of our
other types where it makes sense.
---
## Changelog
- Add `VolumeLevel::ZERO`
# Objective
The way `bevy_app` works was changed unnecessarily in #9826 whose
changes should have been specific to `bevy_winit`.
I'm somewhat disappointed that happened and we can see in
https://github.com/bevyengine/bevy/pull/10195 that it made things more
complicated.
Even worse, in #10385 it's clear that this breaks the clean abstraction
over another engine someone built with Bevy!
Fixes#10385.
## Solution
- Move the changes made to `bevy_app` in #9826 to `bevy_winit`
- Revert the changes to `ScheduleRunnerPlugin` and the `run_once` runner
in #10195 as they're no longer necessary.
While this code is breaking relative to `0.12.0`, it reverts the
behavior of `bevy_app` back to how it was in `0.11`.
Due to the nature of the breakage relative to `0.11` I hope this will be
considered for `0.12.1`.
# Objective
- Fix the panic on using Images in UiMaterials due to assets not being
loaded.
- Fixes#10513
## Solution
- add `let else` statement that `return`s or `continue`s instead of
unwrapping, causing a panic.
# Objective
- Fixes#10518
## Solution
I've added a method to `LoadContext`, `load_direct_with_reader`, which
mirrors the behaviour of `load_direct` with a single key difference: it
is provided with the `Reader` by the caller, rather than getting it from
the contained `AssetServer`. This allows for an `AssetLoader` to process
its `Reader` stream, and then directly hand the results off to the
`LoadContext` to handle further loading. The outer `AssetLoader` can
control how the `Reader` is interpreted by providing a relevant
`AssetPath`.
For example, a Gzip decompression loader could process the asset
`images/my_image.png.gz` by decompressing the bytes, then handing the
decompressed result to the `LoadContext` with the new path
`images/my_image.png.gz/my_image.png`. This intuitively reflects the
nature of contained assets, whilst avoiding unintended behaviour, since
the generated path cannot be a real file path (a file and folder of the
same name cannot coexist in most file-systems).
```rust
#[derive(Asset, TypePath)]
pub struct GzAsset {
pub uncompressed: ErasedLoadedAsset,
}
#[derive(Default)]
pub struct GzAssetLoader;
impl AssetLoader for GzAssetLoader {
type Asset = GzAsset;
type Settings = ();
type Error = GzAssetLoaderError;
fn load<'a>(
&'a self,
reader: &'a mut Reader,
_settings: &'a (),
load_context: &'a mut LoadContext,
) -> BoxedFuture<'a, Result<Self::Asset, Self::Error>> {
Box::pin(async move {
let compressed_path = load_context.path();
let file_name = compressed_path
.file_name()
.ok_or(GzAssetLoaderError::IndeterminateFilePath)?
.to_string_lossy();
let uncompressed_file_name = file_name
.strip_suffix(".gz")
.ok_or(GzAssetLoaderError::IndeterminateFilePath)?;
let contained_path = compressed_path.join(uncompressed_file_name);
let mut bytes_compressed = Vec::new();
reader.read_to_end(&mut bytes_compressed).await?;
let mut decoder = GzDecoder::new(bytes_compressed.as_slice());
let mut bytes_uncompressed = Vec::new();
decoder.read_to_end(&mut bytes_uncompressed)?;
// Now that we have decompressed the asset, let's pass it back to the
// context to continue loading
let mut reader = VecReader::new(bytes_uncompressed);
let uncompressed = load_context
.load_direct_with_reader(&mut reader, contained_path)
.await?;
Ok(GzAsset { uncompressed })
})
}
fn extensions(&self) -> &[&str] {
&["gz"]
}
}
```
Because this example is so prudent, I've included an
`asset_decompression` example which implements this exact behaviour:
```rust
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.init_asset::<GzAsset>()
.init_asset_loader::<GzAssetLoader>()
.add_systems(Startup, setup)
.add_systems(Update, decompress::<Image>)
.run();
}
fn setup(mut commands: Commands, asset_server: Res<AssetServer>) {
commands.spawn(Camera2dBundle::default());
commands.spawn((
Compressed::<Image> {
compressed: asset_server.load("data/compressed_image.png.gz"),
..default()
},
Sprite::default(),
TransformBundle::default(),
VisibilityBundle::default(),
));
}
fn decompress<A: Asset>(
mut commands: Commands,
asset_server: Res<AssetServer>,
mut compressed_assets: ResMut<Assets<GzAsset>>,
query: Query<(Entity, &Compressed<A>)>,
) {
for (entity, Compressed { compressed, .. }) in query.iter() {
let Some(GzAsset { uncompressed }) = compressed_assets.remove(compressed) else {
continue;
};
let uncompressed = uncompressed.take::<A>().unwrap();
commands
.entity(entity)
.remove::<Compressed<A>>()
.insert(asset_server.add(uncompressed));
}
}
```
A key limitation to this design is how to type the internally loaded
asset, since the example `GzAssetLoader` is unaware of the internal
asset type `A`. As such, in this example I store the contained asset as
an `ErasedLoadedAsset`, and leave it up to the consumer of the `GzAsset`
to handle typing the final result, which is the purpose of the
`decompress` system. This limitation can be worked around by providing
type information to the `GzAssetLoader`, such as `GzAssetLoader<Image,
ImageAssetLoader>`, but this would require registering the asset loader
for every possible decompression target.
Aside from this limitation, nested asset containerisation works as an
end user would expect; if the user registers a `TarAssetLoader`, and a
`GzAssetLoader`, then they can load assets with compound
containerisation, such as `images.tar.gz`.
---
## Changelog
- Added `LoadContext::load_direct_with_reader`
- Added `asset_decompression` example
## Notes
- While I believe my implementation of a Gzip asset loader is
reasonable, I haven't included it as a public feature of `bevy_asset` to
keep the scope of this PR as focussed as possible.
- I have included `flate2` as a `dev-dependency` for the example; it is
not included in the main dependency graph.
# Objective
Addresses #[10438](https://github.com/bevyengine/bevy/issues/10438)
The objective was to include the failing path in the error for the user
to see.
## Solution
Add a `path` field to the `ReadAssetBytesError::Io` variant to expose
the failing path in the error message.
## Migration Guide
- The `ReadAssetBytesError::Io` variant now contains two named fields
instead of converting from `std::io::Error`.
1. `path`: The requested (failing) path (`PathBuf`)
2. `source`: The source `std::io::Error`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#10532
## Solution
I've updated the various `Event` send methods to return the sent
`EventId`(s). Since these methods previously returned nothing, and this
information is cheap to copy, there should be minimal negative
consequences to providing this additional information. In the case of
`send_batch`, an iterator is returned built from `Range` and `Map`,
which only consumes 16 bytes on the stack with no heap allocations for
all batch sizes. As such, the cost of this information is negligible.
These changes are reflected for `EventWriter` and `World`. For `World`,
the return types are optional to account for the possible lack of an
`Events` resource. Again, these methods previously returned no
information, so its inclusion should only be a benefit.
## Usage
Now when sending events, the IDs of those events is available for
immediate use:
```rust
// Example of a request-response system where the requester can track handled requests.
/// A system which can make and track requests
fn requester(
mut requests: EventWriter<Request>,
mut handled: EventReader<Handled>,
mut pending: Local<HashSet<EventId<Request>>>,
) {
// Check status of previous requests
for Handled(id) in handled.read() {
pending.remove(&id);
}
if !pending.is_empty() {
error!("Not all my requests were handled on the previous frame!");
pending.clear();
}
// Send a new request and remember its ID for later
let request_id = requests.send(Request::MyRequest { /* ... */ });
pending.insert(request_id);
}
/// A system which handles requests
fn responder(
mut requests: EventReader<Request>,
mut handled: EventWriter<Handled>,
) {
for (request, id) in requests.read_with_id() {
if handle(request).is_ok() {
handled.send(Handled(id));
}
}
}
```
In the above example, a `requester` system can send request events, and
keep track of which ones are currently pending by `EventId`. Then, a
`responder` system can act on that event, providing the ID as a
reference that the `requester` can use. Before this PR, it was not
trivial for a system sending events to keep track of events by ID. This
is unfortunate, since for a system reading events, it is trivial to
access the ID of a event.
---
## Changelog
- Updated `Events`:
- Added `send_batch`
- Modified `send` to return the sent `EventId`
- Modified `send_default` to return the sent `EventId`
- Updated `EventWriter`
- Modified `send_batch` to return all sent `EventId`s
- Modified `send` to return the sent `EventId`
- Modified `send_default` to return the sent `EventId`
- Updated `World`
- Modified `send_event` to return the sent `EventId` if sent, otherwise
`None`.
- Modified `send_event_default` to return the sent `EventId` if sent,
otherwise `None`.
- Modified `send_event_batch` to return all sent `EventId`s if sent,
otherwise `None`.
- Added unit test `test_send_events_ids` to ensure returned `EventId`s
match the sent `Event`s
- Updated uses of modified methods.
## Migration Guide
### `send` / `send_default` / `send_batch`
For the following methods:
- `Events::send`
- `Events::send_default`
- `Events::send_batch`
- `EventWriter::send`
- `EventWriter::send_default`
- `EventWriter::send_batch`
- `World::send_event`
- `World::send_event_default`
- `World::send_event_batch`
Ensure calls to these methods either handle the returned value, or
suppress the result with `;`.
```rust
// Now fails to compile due to mismatched return type
fn send_my_event(mut events: EventWriter<MyEvent>) {
events.send_default()
}
// Fix
fn send_my_event(mut events: EventWriter<MyEvent>) {
events.send_default();
}
```
This will most likely be noticed within `match` statements:
```rust
// Before
match is_pressed {
true => events.send(PlayerAction::Fire),
// ^--^ No longer returns ()
false => {}
}
// After
match is_pressed {
true => {
events.send(PlayerAction::Fire);
},
false => {}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Give us the ability to load untyped assets in AssetLoaders.
## Solution
Basically just copied the code from `load`, but used
`asset_server.load_untyped` instead internally.
## Changelog
Added `load_untyped` method to `LoadContext`
# Objective
- Implement a subset of
https://github.com/bevyengine/rfcs/blob/main/rfcs/12-primitive-shapes.md#feature-name-primitive-shapes
## Solution
- Define a very basic set of primitives in bevy_math
- Assume a 0,0,0 origin for most shapes
- Use radius and half extents to avoid unnecessary computational
overhead wherever they get used
- Provide both Boxed and const generics variants for shapes with
variable sizes
- Boxed is useful if a 3rd party crate wants to use something like
enum-dispatch for all supported primitives
- Const generics is useful when just working on a single primitive, as
it causes no allocs
#### Some discrepancies from the RFC:
- Box was changed to Cuboid, because Box is already used for an alloc
type
- Skipped Cone because it's unclear where the origin should be for
different uses
- Skipped Wedge because it's too niche for an initial PR (we also don't
implement Torus, Pyramid or a Death Star (there's an SDF for that!))
- Skipped Frustum because while it would be a useful math type, it's not
really a common primitive
- Skipped Triangle3d and Quad3d because those are just rotated 2D shapes
## Future steps
- Add more primitives
- Add helper methods to make primitives easier to construct (especially
when half extents are involved)
- Add methods to calculate AABBs for primitives (useful for physics, BVH
construction, for the mesh AABBs, etc)
- Add wrappers for common and cheap operations, like extruding 2D shapes
and translating them
- Use the primitives to generate meshes
- Provide signed distance functions and gradients for primitives (maybe)
---
## Changelog
- Added a collection of primitives to the bevy_math crate
---------
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
# Objective
Closes#10319
## Changelog
* Added a new `Color::rgba_from_array([f32; 4]) -> Color` method.
* Added a new `Color::rgb_from_array([f32; 3]) -> Color` method.
* Added a new `Color::rgba_linear_from_array([f32; 4]) -> Color` method.
* Added a new `Color::rgb_linear_from_array([f32; 3]) -> Color` method.
* Added a new `Color::hsla_from_array([f32; 4]) -> Color` method.
* Added a new `Color::hsl_from_array([f32; 3]) -> Color` method.
* Added a new `Color::lcha_from_array([f32; 4]) -> Color` method.
* Added a new `Color::lch_from_array([f32; 3]) -> Color` method.
* Added a new `Color::rgba_to_vec4(&self) -> Vec4` method.
* Added a new `Color::rgba_to_array(&self) -> [f32; 4]` method.
* Added a new `Color::rgb_to_vec3(&self) -> Vec3` method.
* Added a new `Color::rgb_to_array(&self) -> [f32; 3]` method.
* Added a new `Color::rgba_linear_to_vec4(&self) -> Vec4` method.
* Added a new `Color::rgba_linear_to_array(&self) -> [f32; 4]` method.
* Added a new `Color::rgb_linear_to_vec3(&self) -> Vec3` method.
* Added a new `Color::rgb_linear_to_array(&self) -> [f32; 3]` method.
* Added a new `Color::hsla_to_vec4(&self) -> Vec4` method.
* Added a new `Color::hsla_to_array(&self) -> [f32; 4]` method.
* Added a new `Color::hsl_to_vec3(&self) -> Vec3` method.
* Added a new `Color::hsl_to_array(&self) -> [f32; 3]` method.
* Added a new `Color::lcha_to_vec4(&self) -> Vec4` method.
* Added a new `Color::lcha_to_array(&self) -> [f32; 4]` method.
* Added a new `Color::lch_to_vec3(&self) -> Vec3` method.
* Added a new `Color::lch_to_array(&self) -> [f32; 3]` method.
## Migration Guide
`Color::from(Vec4)` is now `Color::rgba_from_array(impl Into<[f32; 4]>)`
`Vec4::from(Color)` is now `Color::rgba_to_vec4(&self)`
Before:
```rust
let color_vec4 = Vec4::new(0.5, 0.5, 0.5);
let color_from_vec4 = Color::from(color_vec4);
let color_array = [0.5, 0.5, 0.5];
let color_from_array = Color::from(color_array);
```
After:
```rust
let color_vec4 = Vec4::new(0.5, 0.5, 0.5);
let color_from_vec4 = Color::rgba_from_array(color_vec4);
let color_array = [0.5, 0.5, 0.5];
let color_from_array = Color::rgba_from_array(color_array);
```
# Objective
Close#10504. Improve the development experience for working with scenes
by not requiring the user to specify a matching version of `ron` in
their `Cargo.toml`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- When compiling bevy for both singlethreaded and multithreaded contexts
and using `Task` directly, you can run into errors where you expect a
`Task` to be returned but `FakeTask` is instead. Due to `FakeTask` being
private the only solution is to ignore the return at all however because
it *is* returned that isn't totally clear. The error is confusing and
doesn't provide a solution or help figuring it out.
## Solution
- Made `FakeTask` public and added brief documentation providing a use
(none) that helps guide usage (no usage) of FakeTask.
In gamepad.rs, `ButtonSettings` `is_pressed` and `is_released` are both
private, but their implementations use publicly available values.
Keeping them private forces consumers to unnecessarily re-implement this
logic, so just make them public.
## Objective
- Add an arrow gizmo as suggested by #9400
## Solution
(excuse my Protomen music)
https://github.com/bevyengine/bevy/assets/14184826/192adf24-079f-4a4b-a17b-091e892974ec
Wasn't horribly hard when i remembered i can change coordinate systems
whenever I want. Gave them four tips (as suggested by @alice-i-cecile in
discord) instead of trying to decide what direction the tips should
point.
Made the tip length default to 1/10 of the arrow's length, which looked
good enough to me. Hard-coded the angle from the body to the tips to 45
degrees.
## Still TODO
- [x] actual doc comments
- [x] doctests
- [x] `ArrowBuilder.with_tip_length()`
---
## Changelog
- Added `gizmos.arrow()` and `gizmos.arrow_2d()`
- Added arrows to `2d_gizmos` and `3d_gizmos` examples
## Migration Guide
N/A
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Allows chained systems taking an `In<_>` input parameter to be run as
one-shot systems. This API was mentioned in #8963.
In addition, `run_system(_with_input)` returns the system output, for
any `'static` output type.
## Solution
A new function, `World::run_system_with_input` allows a `SystemId<I, O>`
to be run by providing an `I` value as input and producing `O` as an
output.
`SystemId<I, O>` is now generic over the input type `I` and output type
`O`, along with the related functions and types `RegisteredSystem`,
`RemovedSystem`, `register_system`, `remove_system`, and
`RegisteredSystemError`. These default to `()`, preserving the existing
API, for all of the public types.
---
## Changelog
- Added `World::run_system_with_input` function to allow one-shot
systems that take `In<_>` input parameters
- Changed `World::run_system` and `World::register_system` to support
systems with return types beyond `()`
- Added `Commands::run_system_with_input` command that schedules a
one-shot system with an `In<_>` input parameter
# Objective
- Ensure ExtendedMaterial can be referenced in bevy_egui_inspector
correctly
## Solution
Add a more manual `TypePath` implementation to work around bugs in the
derive macro.
# Objective
Make sure a camera which has had its render target changed recomputes
its info.
On main, the following is possible:
- System A has an inactive camera with render target set to the default
`Image` (i.e. white 1x1 rgba texture)
Later:
- System B sets the same camera active and sets the `camera.target` to a
newly created `Image`
**Bug**: Since `camera_system` only checks `Modified` and not `Added`
events, the size of the render target is not recomputed, which means the
camera will render with 1x1 size even though the new target is an
entirely different size.
## Solution
- Ensure `camera_system` checks `Added` image assets events
## Changelog
### Fixed
- Cameras which have their render targets changed to a newly created
target with a different size than the previous target will now render
properly
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Afonso Lage <lage.afonso@gmail.com>
Fix a precision issue with in the manual near-clipping function.
This only affected lines that span large distances (starting at 100_000~
units) in my testing.
Fixes#10403
# Objective
- Reduce work from inactive cameras
Tracing was done on the `3d_shapes` example on PR
https://github.com/bevyengine/bevy/pull/10543 .
Doing tracing on a "real" application showed more instances of
unnecessary work.
## Solution
- Skip work on inactive cameras
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
The quality of Bevy's text rendering can vary wildly depending on the
font, font size, pixel alignment and scale factor.
But this situation can be improved dramatically with some small
adjustments.
## Solution
* Text node positions are rounded to the nearest physical pixel before
rendering.
* Each glyph texture has a 1-pixel wide transparent border added along
its edges.
This means font atlases will use more memory because of the extra pixel
of padding for each glyph but it's more than worth it I think (although
glyph size is increased by 2 pixels on both axes, the net increase is 1
pixel as the font texture atlas's padding has been removed).
## Results
Screenshots are from the 'ui' example with a scale factor of 1.5.
Things can get much uglier with the right font and worst scale
factor<sup>tm</sup>.
### before
<img width="300" alt="list-bad-text"
src="https://github.com/bevyengine/bevy/assets/27962798/482b384d-8743-4bae-9a65-468ff1b4c301">
### after
<img width="300" alt="good_list_text"
src="https://github.com/bevyengine/bevy/assets/27962798/34323b0a-f714-47ba-9728-a59804987bc8">
---
## Changelog
* Font texture atlases are no longer padded.
* Each glyph texture has a 1-pixel wide padding added along its edges.
* Text node positions are rounded to the nearest physical pixel before
rendering.
# Objective
Fixes#10436
Alternative to #10465
## Solution
`load_untyped_async` / `load_internal` currently has a bug. In
`load_untyped_async`, we pass None into `load_internal` for the
`UntypedHandle` of the labeled asset path. This results in a call to
`get_or_create_path_handle_untyped` with `loader.asset_type_id()`
This is a new code path that wasn't hit prior to the newly added
`load_untyped` because `load_untyped_async` was a private method only
used in the context of the `load_folder` impl (which doesn't have
labels)
The fix required some refactoring to catch that case and defer handle
retrieval. I have also made `load_untyped_async` public as it is now
"ready for public use" and unlocks new scenarios.
# Objective
Currently, if a large amount of inactive cameras are spawned, they will
immensely slow down performance.
This can be reproduced by adding
```rust
let default_image = images.add(default());
for _ in 0..10000 {
commands.spawn(Camera3dBundle {
camera: Camera {
is_active: false,
target: RenderTarget::Image(default_image.clone()),
..default()
},
..default()
});
}
```
to for example `3d_shapes`.
Using `tracy`, it's clear that preparing view bind groups for all
cameras is still happening.
Also, visibility checks on the extracted views from inactive cameras
also take place.
## Performance gains
The following `tracy` comparisons show the effect of skipping this
unneeded work.
Yellow is Bevy main, red is with the fix.
### Visibility checks

### Bind group preparation

## Solution
- Check if the cameras are inactive in the appropriate places, and if so
skip them
## Changelog
### Changed
- Do not extract views from inactive cameras or check visiblity from
their extracted views
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
(This is my first PR here, so I've probably missed some things. Please
let me know what else I should do to help you as a reviewer!)
# Objective
Due to https://github.com/rust-lang/rust/issues/117800, the `derive`'d
`PartialEq::eq` on `Entity` isn't as good as it could be. Since that's
used in hashtable lookup, let's improve it.
## Solution
The derived `PartialEq::eq` short-circuits if the generation doesn't
match. However, having a branch there is sub-optimal, especially on
64-bit systems like x64 that could just load the whole `Entity` in one
load anyway.
Due to complications around `poison` in LLVM and the exact details of
what unsafe code is allowed to do with reference in Rust
(https://github.com/rust-lang/unsafe-code-guidelines/issues/346), LLVM
isn't allowed to completely remove the short-circuiting. `&Entity` is
marked `dereferencable(8)` so LLVM knows it's allowed to *load* all 8
bytes -- and does so -- but it has to assume that the `index` might be
undef/poison if the `generation` doesn't match, and thus while it finds
a way to do it without needing a branch, it has to do something slightly
more complicated than optimal to combine the results. (LLVM is allowed
to change non-short-circuiting code to use branches, but not the other
way around.)
Here's a link showing the codegen today:
<https://rust.godbolt.org/z/9WzjxrY7c>
```rust
#[no_mangle]
pub fn demo_eq_ref(a: &Entity, b: &Entity) -> bool {
a == b
}
```
ends up generating the following assembly:
```asm
demo_eq_ref:
movq xmm0, qword ptr [rdi]
movq xmm1, qword ptr [rsi]
pcmpeqd xmm1, xmm0
pshufd xmm0, xmm1, 80
movmskpd eax, xmm0
cmp eax, 3
sete al
ret
```
(It's usually not this bad in real uses after inlining and LTO, but it
makes a strong demo.)
This PR manually implements `PartialEq::eq` *without* short-circuiting,
and because that tells LLVM that neither the generations nor the index
can be poison, it doesn't need to be so careful and can generate the
"just compare the two 64-bit values" code you'd have probably already
expected:
```asm
demo_eq_ref:
mov rax, qword ptr [rsi]
cmp qword ptr [rdi], rax
sete al
ret
```
Since this doesn't change the representation of `Entity`, if it's
instead passed by *value*, then each `Entity` is two `u32` registers,
and the old and the new code do exactly the same thing. (Other
approaches, like changing `Entity` to be `[u32; 2]` or `u64`, affect
this case.)
This should hopefully merge easily with changes like
https://github.com/bevyengine/bevy/pull/9907 that also want to change
`Entity`.
## Benchmarks
I'm not super-confident that I got my machine fully consistent for
benchmarking, but whether I run the old or the new one first I get
reasonably consistent results.
Here's a fairly typical example of the benchmarks I added in this PR:

Building the sets seems to be basically the same. It's usually reported
as noise, but sometimes I see a few percent slower or faster.
But lookup hits in particular -- since a hit checks that the key is
equal -- consistently shows around 10% improvement.
`cargo run --example many_cubes --features bevy/trace_tracy --release --
--benchmark` showed as slightly faster with this change, though if I had
to bet I'd probably say it's more noise than meaningful (but at least
it's not worse either):

This is my first PR here -- and my first time running Tracy -- so please
let me know what else I should run, or run things on your own more
reliable machines to double-check.
---
## Changelog
(probably not worth including)
Changed: micro-optimized `Entity::eq` to help LLVM slightly.
## Migration Guide
(I really hope nobody was using this on uninitialized entities where
sufficiently tortured `unsafe` could could technically notice that this
has changed.)
# Objective
After #9002, it seems that "single shot" animations were broken. When
completing, they would reset to their initial value. Which is generally
not what you want.
- Fixes#10480
## Solution
Avoid `%`-ing the animation after the number of completions exceeds the
specified one. Instead, we early-return. This is also true when the
player is playing in reverse.
---
## Changelog
- Avoid resetting animations after `Repeat::Never` animation completion.
# Objective
Fixes an issue where Bevy will look for `.meta` files in the root of the
server instead of `imported_assets/Default` on the web.
## Solution
`self.root_path.join` was seemingly forgotten in the `read_meta`
function on `HttpWasmAssetReader`, though it was included in the `read`
function. This PR simply adds the missing function call.
# Objective
* In Bevy 0.11 asset loaders used `anyhow::Error` for returning errors.
In Bevy 0.12 `AssetLoader` (and `AssetSaver`) have associated `Error`
type. Unfortunately it's type bounds does not allow `anyhow::Error` to
be used despite migration guide claiming otherwise. This makes migration
to 0.12 more challenging. Solve this by changing type bounds for
associated `Error` type.
* Fix#10350
## Solution
Change associated `Error` type bounds to require `Into<Box<dyn
std::error::Error + Send + Sync + 'static>>` to be implemented instead
of `std::error::Error + Send + Sync + 'static`. Both `anyhow::Error` and
errors generated by `thiserror` seems to be fine with such type bound.
---
## Changelog
### Fixed
* Fixed compatibility with `anyhow::Error` in `AssetLoader` and
`AssetSaver` associated `Error` type
# Objective
Fixes#10439
`Timer::percent()` and `Timer::percent_left()` return values in the
range of 0.0 to 1.0, even though their names contain "percent".
These functions should be renamed for clarity.
## Solution
- Rename `Timer::percent()` to `Timer::fraction()`
- Rename `Timer::percent_left()` to `Timer::fraction_remaining()`
---
## Changelog
### Changed
- Renamed `Timer::percent()` to `Timer::fraction()`
- Renamed `Timer::percent_left()` to `Timer::fraction_remaining()`
## Migration Guide
- `Timer::percent()` has been renamed to `Timer::fraction()`
- `Timer::percent_left()` has been renamed to
`Timer::fraction_remaining()`
# Objective
This is similar to #10439.
`Time::<Fixed>::overstep_percentage()` and
`Time::<Fixed>::overstep_percentage_f64()` returns values from 0.0 to
1.0, but their names use the word "percentage". These function names
make it easy to misunderstand that they return values from 0.0 to 100.0.
To avoid confusion, these functions should be renamed to
"`overstep_fraction(_f64)`".
## Solution
Rename them.
---
## Changelog
### Changed
- Renamed `Time::<Fixed>::overstep_percentage()` to
`Time::<Fixed>::overstep_fraction()`
- Renamed `Time::<Fixed>::overstep_percentage_f64()` to
`Time::<Fixed>::overstep_fraction_f64()`
## Migration Guide
- `Time::<Fixed>::overstep_percentage()` has been renamed to
`Time::<Fixed>::overstep_fraction()`
- `Time::<Fixed>::overstep_percentage_f64()` has been renamed to
`Time::<Fixed>::overstep_fraction_f64()`
# Objective
Hot reloading shader imports on windows is currently broken due to
inconsistent `/` and `\` usage ('/` is used in the user facing APIs and
`\` is produced by notify-rs (and likely other OS apis).
Fixes#10500
## Solution
Standardize import paths when loading a `Shader`. The correct long term
fix is to standardize AssetPath on `/`-only, but this is the right scope
of fix for a patch release.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- `CommandQueue::apply` calculates the address of the end of the
internal buffer as a `usize` rather than as a pointer, requiring two
casts of `cursor` to `usize`. Casting pointers to integers is generally
discouraged and may also prevent optimizations. It's also unnecessary
here.
## Solution
- Calculate the end address as a pointer rather than a `usize`.
Small note:
A trivial translation of the old code to use pointers would have
computed `end_addr` as `cursor.add(self.bytes.len())`, which is not
wrong but is an additional `unsafe` operation that also needs to be
properly documented and proven correct. However this operation is
already implemented in the form of the safe `as_mut_ptr_range`, so I
just used that.
# Objective
- The docs on `AssetPath::try_parse` say that it will return an error
when the string is malformed, but it actually just `.unwrap()`s the
result.
## Solution
- Use `?` instead of unwrapping the result.
# Objective
Calling `RenderDevice::poll` requires an instance of `wgpu::Maintain`,
but the type was not reexported by bevy. Working around it requires
adding a dependency on `wgpu`, since bevy does not reexport the `wgpu`
crate as a whole anywhere.
## Solution
Reexport `wgpu::Maintain` in `render_resource`, where the other wgpu
types are reexported.
# Objective
There is an if statement checking if a node is present in a graph
moments after it explicitly being added.
Unless the edge function has super weird side effects and the tests
don't pass, this is unnecessary.
## Solution
Removed it
# Objective
- Allow registration of one-shot systems when those systems have already
been `Box`ed.
- Needed for `bevy_eventlisteners` which allows adding event listeners
with callbacks in normal systems. The current one shot system
implementation requires systems be registered from an exclusive system,
and that those systems be passed in as types that implement
`IntoSystem`. However, the eventlistener callback crate allows users to
define their callbacks in normal systems, by boxing the system and
deferring initialization to an exclusive system.
## Solution
- Separate the registration of the system from the boxing of the system.
This is non-breaking, and adds a new method.
---
## Changelog
- Added `World::register_boxed_system` to allow registration of
already-boxed one shot systems.
# Objective
Had an issue where I had `VisibilityBundle` inside a bundle that
implements `Clone`, but since `VisibilityBundle` doesn't implement
`Clone` that wasn't possible. This PR fixes that.
## Solution
Implement `Clone` for `VisibilityBundle` by deriving it. And also
`SpatialBundle` too because why not.
---
## Changelog
- Added implementation for `Clone` on `VisibilityBundle` and
`SpatialBundle`.
# Objective
Fix a shader error that happens when using pbr morph targets.
## Solution
Fix the function name in the `prepass.wgsl` shader, which is incorrectly
prefixed with `morph::` (added in
61bad4eb57 (diff-97e4500f0a36bc6206d7b1490c8dd1a69459ee39dc6822eb9b2f7b160865f49fR42)).
This section of the shader is only enabled when using morph targets, so
it seems like there are no tests / examples using it?
# Objective
- Entities with both a `BackgroundColor` and a
`Handle<CustomUiMaterial>` are extracted by both pipelines and results
in entities being overwritten in the render world
- Fixes#10431
## Solution
- Ignore entities with `BackgroundColor` when extracting ui material
entities, and document that limit
# Objective
- There is a specialized hasher for entities:
[`EntityHashMap`](https://docs.rs/bevy/latest/bevy/utils/type.EntityHashMap.html)
- [`EntityMapper`] currently uses a normal `HashMap<Entity, Entity>`
- Fixes#10391
## Solution
- Replace the normal `HashMap` with the more performant `EntityHashMap`
## Questions
- This does change public API. Should a system be implemented to help
migrate code?
- Perhaps an `impl From<HashMap<K, V, S>> for EntityHashMap<K, V>`
- I updated to docs for each function that I changed, but I may have
missed something
---
## Changelog
- Changed `EntityMapper` to use `EntityHashMap` instead of normal
`HashMap`
## Migration Guide
If you are using the following types, update their listed methods to use
the new `EntityHashMap`. `EntityHashMap` has the same methods as the
normal `HashMap`, so you just need to replace the name.
### `EntityMapper`
- `get_map`
- `get_mut_map`
- `new`
- `world_scope`
### `ReflectMapEntities`
- `map_all_entities`
- `map_entities`
- `write_to_world`
### `InstanceInfo`
- `entity_map`
- This is a property, not a method.
---
This is my first time contributing in a while, and I'm not familiar with
the usage of `EntityMapper`. I changed the type definition and fixed all
errors, but there may have been things I've missed. Please keep an eye
out for me!
Preparing next release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fixes#10209
- Assets should work in single threaded
## Solution
- In single threaded mode, don't use `async_fs` but fallback on
`std::fs` with a thin layer to mimic the async API
- file `file_asset.rs` is the async imps from `mod.rs`
- file `sync_file_asset.rs` is the same with `async_fs` APIs replaced by
`std::fs`
- which module is used depends on the `multi-threaded` feature
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes a small typo in `bevy_window/src/window.rs`
## Solution
Change `Should be used instead 'scale_factor' when set.` to `Should be
used instead of 'scale_factor' when set.`
# Objective
- Adopt #10239 to get it in time for the release
- Fix accessibility on macOS and linux
## Solution
- call `on_event` from AcccessKit adapter on winit events
---------
Co-authored-by: Nolan Darilek <nolan@thewordnerd.info>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Changes the default clear color to match the code block color on
Bevy's website.
## Solution
- Changed the clear color, updated text in examples to ensure adequate
contrast. Inconsistent usage of white text color set to use the default
color instead, which is already white.
- Additionally, updated the `3d_scene` example to make it look a bit
better, and use bevy's branding colors.

# Objective
Fixes https://github.com/bevyengine/bevy/issues/9077 (see this issue for
motivations)
## Solution
Implement 1 and 2 of the "How to fix it" section of
https://github.com/bevyengine/bevy/issues/9077
`update_directional_light_cascades` is split into
`clear_directional_light_cascades` and a generic
`build_directional_light_cascades`, to clear once and potentially insert
many times.
---
## Changelog
`DirectionalLight`'s computation is now generic over `CameraProjection`
and can work with custom camera projections.
## Migration Guide
If you have a component `MyCustomProjection` that implements
`CameraProjection`:
- You need to implement a new required associated method,
`get_frustum_corners`, returning an array of the corners of a subset of
the frustum with given `z_near` and `z_far`, in local camera space.
- You can now add the
`build_directional_light_cascades::<MyCustomProjection>` system in
`SimulationLightSystems::UpdateDirectionalLightCascades` after
`clear_directional_light_cascades` for your projection to work with
directional lights.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy's default bias values for directional and spot lights currently
cause significant artifacts. We should fix that so shadows look good by
default!
This is a less controversial/invasive alternative to #10188, which might
enable us to keep the default bias value low, but also has its own sets
of concerns and caveats that make it a risky choice for Bevy 0.12.
## Solution
Bump the default normal bias from `0.6` to `1.8`. There is precedent for
values in this general area as Godot has a default normal bias of `2.0`.
### Before

### After

## Migration Guide
The default `shadow_normal_bias` value for `DirectionalLight` and
`SpotLight` has changed to accommodate artifacts introduced with the new
shadow PCF changes. It is unlikely (especially given the new PCF shadow
behaviors with these values), but you might need to manually tweak this
value if your scene requires a lower bias and it relied on the previous
default value.
# Objective
Reimplement #8793 on top of the recent rendering changes.
## Solution
The batch creation logic is quite convoluted, but I tested it on enough
examples to convince myself that it works.
The initial value of `batch_image_handle` is changed from
`HandleId::Id(Uuid::nil(), u64::MAX)` to `DEFAULT_IMAGE_HANDLE.id()`,
which allowed me to make the if-block simpler I think.
The default image from `DEFAULT_IMAGE_HANDLE` is always inserted into
`UiImageBindGroups` even if it's not used. I tried to add a check so
that it would be only inserted when there is only one batch using the
default image but this crashed.
---
## Changelog
`prepare_uinodes`
* Changed the initial value of `batch_image_handle` to
`DEFAULT_IMAGE_HANDLE.id()`.
* The default image is added to the UI image bind groups before
assembling the batches.
* A new `UiBatch` isn't created when the next `ExtractedUiNode`s image
is set to `DEFAULT_IMAGE_HANDLE` (unless it is the first item in the UI
phase items list).
# Objective
fix crash / misbehaviour when `DeferredPrepass` is used without
`DepthPrepass`.
- Deferred lighting requires the depth prepass texture to be present, so
that the depth texture is available for binding. without it the deferred
lighting pass will use 0 for depth of all meshes.
- When `DeferredPrepass` is used without other prepass markers, and with
any materials that use `OpaqueRenderMode::Forward`, those entities will
try to queue to the `Opaque3dPrepass` render phase, which doesn't exist,
causing a crash.
## Solution
- check if the prepass phases exist before queueing
- generate prepass textures if `Opaque3dDeferred` is present
- add a note to the DeferredPrepass marker to note that DepthPrepass is
also required by the default deferred lighting pass
- also changed some `With<T>.is_some()`s to `Has<T>`s
# Objective
I was working with forward rendering prepass fragment shaders and ran
into an issue of not being able to access vertex colors in the prepass.
I was able to access vertex colors in regular fragment shaders as well
as in deferred shaders.
## Solution
It seems like this `if` was nested unintentionally as moving it outside
of the `deferred` block works.
---
## Changelog
Enable vertex colors in forward rendering prepass fragment shaders
# Objective
Alternative to #7310
## Solution
Implemented the suggestion from
https://github.com/bevyengine/bevy/pull/7310#discussion_r1083356655
I am guessing that these were originally split as an optimization, but I
am not sure since I believe the original author of the code is the one
speculating about combining them up there.
## Benchmarks
I ran three benchmarks to compare main, this PR, and the approach from
#7310
([updated](https://github.com/rparrett/bevy/commits/rebased-parallel-check-visibility)
to the same commit on main).
This seems to perform slightly better than main in scenarios where most
entities have AABBs, and a bit worse when they don't (`many_lights`).
That seems to make sense to me.
Either way, the difference is ~-20 microseconds in the more common
scenarios or ~+100 microseconds in the less common scenario. I would
speculate that this might perform **very slightly** worse in
single-threaded scenarios.
Benches were run in release mode for 2000 frames while capturing a trace
with tracy.
| bench | commit | check_visibility_system mean μs |
| -- | -- | -- |
| many_cubes | main | 929.5 |
| many_cubes | this | 914.0 |
| many_cubes | 7310 | 1003.5 |
| | |
| many_foxes | main | 191.6 |
| many_foxes | this | 173.2 |
| many_foxes | 7310 | 167.9 |
| | |
| many_lights | main | 619.3 |
| many_lights | this | 703.7 |
| many_lights | 7310 | 842.5 |
## Notes
Technically this behaves slightly differently -- prior to this PR, view
visibility was determined even for entities without `GlobalTransform`. I
don't think this has any practical impact though.
IMO, I don't think we need to do this. But I opened a PR because it
seemed like the handiest way to share the code / benchmarks.
## TODO
I have done some rudimentary testing with the examples above, but I can
do some screenshot diffing if it seems like we want to do this.
# Objective
- Revert #10296
## Solution
- Avoid implementing `Display` without a justification
- `Display` implementation is a guarantee without a direct use, takes
additional time to compile and require work to maintain
- `Debug`, `Reflect` or `Serialize` should cover all needs
# Objective
The `BuildWorldChildren` API was missing several methods that exist in
`BuildChildren`.
## Solution
Added the methods (and tests) for consistency.
# Objective
If we add the stack index to `Node` then we don't need to walk the
`UiStack` repeatedly during extraction.
## Solution
Add a field `stack_index` to `Node`.
Update it in `ui_stack_system`.
Iterate queries directly in the UI's extraction systems.
### Benchmarks
```
cargo run --profile stress-test --features trace_tracy --example many_buttons -- --no-text --no-borders
```
frames (yellow this PR, red main):
<img width="447" alt="frames-per-second"
src="https://github.com/bevyengine/bevy/assets/27962798/385c0ccf-c257-42a2-b736-117542d56eff">
`ui_stack_system`:
<img width="585" alt="ui-stack-system"
src="https://github.com/bevyengine/bevy/assets/27962798/2916cc44-2887-4c3b-a144-13250d84f7d5">
extract schedule:
<img width="469" alt="extract-schedule"
src="https://github.com/bevyengine/bevy/assets/27962798/858d4ab4-d99f-48e8-b153-1c92f51e0743">
---
## Changelog
* Added the field `stack_index` to `Node`.
* `ui_stack_system` updates `Node::stack_index` after a new `UiStack` is
generated.
* The UI's extraction functions iterate a query directly rather than
walking the `UiStack` and doing lookups.
# Objective
<img width="1920" alt="Screenshot 2023-04-26 at 01 07 34"
src="https://user-images.githubusercontent.com/418473/234467578-0f34187b-5863-4ea1-88e9-7a6bb8ce8da3.png">
This PR adds both diffuse and specular light transmission capabilities
to the `StandardMaterial`, with support for screen space refractions.
This enables realistically representing a wide range of real-world
materials, such as:
- Glass; (Including frosted glass)
- Transparent and translucent plastics;
- Various liquids and gels;
- Gemstones;
- Marble;
- Wax;
- Paper;
- Leaves;
- Porcelain.
Unlike existing support for transparency, light transmission does not
rely on fixed function alpha blending, and therefore works with both
`AlphaMode::Opaque` and `AlphaMode::Mask` materials.
## Solution
- Introduces a number of transmission related fields in the
`StandardMaterial`;
- For specular transmission:
- Adds logic to take a view main texture snapshot after the opaque
phase; (in order to perform screen space refractions)
- Introduces a new `Transmissive3d` phase to the renderer, to which all
meshes with `transmission > 0.0` materials are sent.
- Calculates a light exit point (of the approximate mesh volume) using
`ior` and `thickness` properties
- Samples the snapshot texture with an adaptive number of taps across a
`roughness`-controlled radius enabling “blurry” refractions
- For diffuse transmission:
- Approximates transmitted diffuse light by using a second, flipped +
displaced, diffuse-only Lambertian lobe for each light source.
## To Do
- [x] Figure out where `fresnel_mix()` is taking place, if at all, and
where `dielectric_specular` is being calculated, if at all, and update
them to use the `ior` value (Not a blocker, just a nice-to-have for more
correct BSDF)
- To the _best of my knowledge, this is now taking place, after
964340cdd. The fresnel mix is actually "split" into two parts in our
implementation, one `(1 - fresnel(...))` in the transmission, and
`fresnel()` in the light implementations. A surface with more
reflectance now will produce slightly dimmer transmission towards the
grazing angle, as more of the light gets reflected.
- [x] Add `transmission_texture`
- [x] Add `diffuse_transmission_texture`
- [x] Add `thickness_texture`
- [x] Add `attenuation_distance` and `attenuation_color`
- [x] Connect values to glTF loader
- [x] `transmission` and `transmission_texture`
- [x] `thickness` and `thickness_texture`
- [x] `ior`
- [ ] `diffuse_transmission` and `diffuse_transmission_texture` (needs
upstream support in `gltf` crate, not a blocker)
- [x] Add support for multiple screen space refraction “steps”
- [x] Conditionally create no transmission snapshot texture at all if
`steps == 0`
- [x] Conditionally enable/disable screen space refraction transmission
snapshots
- [x] Read from depth pre-pass to prevent refracting pixels in front of
the light exit point
- [x] Use `interleaved_gradient_noise()` function for sampling blur in a
way that benefits from TAA
- [x] Drill down a TAA `#define`, tweak some aspects of the effect
conditionally based on it
- [x] Remove const array that's crashing under HLSL (unless a new `naga`
release with https://github.com/gfx-rs/naga/pull/2496 comes out before
we merge this)
- [ ] Look into alternatives to the `switch` hack for dynamically
indexing the const array (might not be needed, compilers seem to be
decent at expanding it)
- [ ] Add pipeline keys for gating transmission (do we really want/need
this?)
- [x] Tweak some material field/function names?
## A Note on Texture Packing
_This was originally added as a comment to the
`specular_transmission_texture`, `thickness_texture` and
`diffuse_transmission_texture` documentation, I removed it since it was
more confusing than helpful, and will likely be made redundant/will need
to be updated once we have a better infrastructure for preprocessing
assets_
Due to how channels are mapped, you can more efficiently use a single
shared texture image
for configuring the following:
- R - `specular_transmission_texture`
- G - `thickness_texture`
- B - _unused_
- A - `diffuse_transmission_texture`
The `KHR_materials_diffuse_transmission` glTF extension also defines a
`diffuseTransmissionColorTexture`,
that _we don't currently support_. One might choose to pack the
intensity and color textures together,
using RGB for the color and A for the intensity, in which case this
packing advice doesn't really apply.
---
## Changelog
- Added a new `Transmissive3d` render phase for rendering specular
transmissive materials with screen space refractions
- Added rendering support for transmitted environment map light on the
`StandardMaterial` as a fallback for screen space refractions
- Added `diffuse_transmission`, `specular_transmission`, `thickness`,
`ior`, `attenuation_distance` and `attenuation_color` to the
`StandardMaterial`
- Added `diffuse_transmission_texture`, `specular_transmission_texture`,
`thickness_texture` to the `StandardMaterial`, gated behind a new
`pbr_transmission_textures` cargo feature (off by default, for maximum
hardware compatibility)
- Added `Camera3d::screen_space_specular_transmission_steps` for
controlling the number of “layers of transparency” rendered for
transmissive objects
- Added a `TransmittedShadowReceiver` component for enabling shadows in
(diffusely) transmitted light. (disabled by default, as it requires
carefully setting up the `thickness` to avoid self-shadow artifacts)
- Added support for the `KHR_materials_transmission`,
`KHR_materials_ior` and `KHR_materials_volume` glTF extensions
- Renamed items related to temporal jitter for greater consistency
## Migration Guide
- `SsaoPipelineKey::temporal_noise` has been renamed to
`SsaoPipelineKey::temporal_jitter`
- The `TAA` shader def (controlled by the presence of the
`TemporalAntiAliasSettings` component in the camera) has been replaced
with the `TEMPORAL_JITTER` shader def (controlled by the presence of the
`TemporalJitter` component in the camera)
- `MeshPipelineKey::TAA` has been replaced by
`MeshPipelineKey::TEMPORAL_JITTER`
- The `TEMPORAL_NOISE` shader def has been consolidated with
`TEMPORAL_JITTER`
# Objective
- We need to check multiple times if a color is fully transparent, e.g.
for performance optimizations.
- Make code more readable.
- Reduce code duplication, to simplify making changes if needed (e.g. if
we need to take floating point weirdness into account later on).
## Solution
- Introduce a new `Color::is_fully_transparent` helper function to
determine if the alpha of a color is 0.
- Use the helper function in our UI rendering code.
---
## Changelog
- Added `Color::is_fully_transparent` helper function.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Right now, we flip the `world_normal` in response to `double_sided &&
!is_front`, however when calculating `N` from tangents and the normal
map, we don't flip the normal read from the normal map, which produces
extremely weird results.
## Solution
- Pass `double_sided` and `is_front` flags to the
`apply_normal_mapping()` function and use them to conditionally flip
`Nt`
## Comparison
Note: These are from a custom scene running with the `transmission`
branch, (#8015) I noticed lighting got pretty weird for the back side of
translucent `double_sided` materials whenever I added a normal map.
### Before
<img width="1392" alt="Screenshot 2023-10-31 at 01 26 06"
src="https://github.com/bevyengine/bevy/assets/418473/d5f8c9c3-aca1-4c2f-854d-f0d0fd2fb19a">
### After
<img width="1392" alt="Screenshot 2023-10-31 at 01 25 42"
src="https://github.com/bevyengine/bevy/assets/418473/fa0e1aa2-19ad-4c27-bb08-37299d97971c">
---
## Changelog
- Fixed a bug where `StandardMaterial::double_sided` would interact
incorrectly with normal maps, producing broken results.
# Objective
- Work towards GPU-driven culling
(https://github.com/bevyengine/bevy/pull/10164)
## Solution
- Pass the view frustum to the shader view uniform
---
## Changelog
- View Frustums are now extracted to the render world and made available
to shaders
# Objective
- Address inconsistent term usage in the docs for the alignment
properties for UI nodes. Fixes#10218
- `JustifyContent::Stretch` is missing despite being supported by Taffy,
being as the default value for Grids, so it should be added to Bevy as
well
## Solution
- Consistently provide links to the mdn site for the css equivalent
- Match (mostly) the documentation given on the pub struct and the
underlying enums
- Use the term `items` consistently to refer each child in the container
- Add `JustifyContent::Stretch` and map it to Taffy
## Migration Guide
- The `JustifyContents` enum has been expanded to include
`JustifyContents::Stretch`.
# Objective
Align all error-like types to implement `Error`.
Fixes #10176
## Solution
- Derive `Error` on more types
- Refactor instances of manual implementations that could be derived
This adds thiserror as a dependency to bevy_transform, which might
increase compilation time -- but I don't know of any situation where you
might only use that but not any other crate that pulls in bevy_utils.
The `contributors` example has a `LoadContributorsError` type, but as
it's an example I have not updated it. Doing that would mean either
having a `use bevy_internal::utils::thiserror::Error;` in an example
file, or adding `thiserror` as a dev-dependency to the main `bevy`
crate.
---
## Changelog
- All `…Error` types now implement the `Error` trait
Existing truncation code limits the number of attribute buffers to be
less than or equal to the number of vertices.
Instead the number of elements from each attribute buffer should be
limited to the length of the shortest buffer as mentioned in the earlier
warning.
# Objective
- Fixes#10267
## Solution
- Moves the `.take()` from the outer loop of attribute buffers, to the
inner loop of attribute values.
---
# Objective
`normalize` method that expresses a rectangle relative to a normalized
[0..1] x [0..1] space defined by another rectangle.
Useful for UI and texture atlas calculations etc.
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
- When finding the `CursorIcon` doc, it should be easier to find out
where to use it.
- When saying it is partially copied from the browser, be more clear
about the provenance and link to the spec document.
## Solution
- Link to the example code.
- Link to the CSS3 UI spec document.
Extracted the easy stuff from #8974 .
# Problem
1. Commands from `update_previous_view_projections` would crash when
matching entities were despawned.
2. `TaaPipelineId` and `draw_3d_graph` module were not public.
3. When the motion vectors pointed to pixels that are now off screen, a
smearing artifact could occur.
# Solution
1. Use `try_insert` command instead.
2. Make them public, renaming to `TemporalAntiAliasPipelineId`.
3. Check for this case, and ignore history for pixels that are
off-screen.
# Objective
- Remove special cases where `clippy::doc_markdown` lint is disabled.
## Solution
- Add default values back into `clippy.toml` by adding `".."` to the
list of `doc-valid-idents`.
- Add `"VSync"` and `"WebGL2"` to the list of `doc-valid-idents`.
- Remove all instances where `clippy::doc_markdown` is allowed.
- Fix `max_mip` formatting so that there isn't a warning.
# Objective
- Have more docs for `bevy_text` to avoid reading the source code for
some things.
## Solution
- Add some additional docs.
## Changelog
- `TextSettings.max_font_atlases` in `bevy_text` has been renamed to `
TextSettings.soft_max_font_atlases`.
## Migration Guide
- Usages of `TextSettings.max_font_atlases` from `bevy_text` must be
changed to `TextSettings.soft_max_font_atlases`.
# Situation
- In case of parent without visibility components, the visibility
inheritance of children creates a panic.
## Solution
- Apply same fallback visibility as parent not found instead of panic.
# Objective
Make it obvious why stuff renders pink when rendering stuff with bevy
with `default_features = false` and bevy's default tonemapper
(TonyMcMapFace, it requires a LUT which requires the `tonemapping_luts`,
`ktx2`, and `zstd` features).
Not sure if this should be considered as fixing these issues, but in my
previous PR (https://github.com/bevyengine/bevy/pull/9073, and old
discussions on discord that I only somewhat remember) it seemed like we
didn't want to make ktx2 and zstd required features for
bevy_core_pipeline.
Related https://github.com/bevyengine/bevy/issues/9179
Related https://github.com/bevyengine/bevy/issues/9098
## Solution
This logs an error when a LUT based tonemapper is used without the
`tonemapping_luts` feature enabled, and cleans up the default features a
bit (`tonemapping_luts` now includes the `ktx2` and `zstd` features,
since it panics without them).
Another solution would be to fall back to a non-lut based tonemapper,
but I don't like this solution as then it's not explicitly clear to
users why eg. a library example renders differently than a normal bevy
app (if the library forgot the `tonemapping_luts` feature).
I did remove the `ktx2` and `zstd` features from the list of default
features in Cargo.toml, as I don't believe anything else currently in
bevy relies on them (or at least searching through every hit for `ktx2`
and `zstd` didn't show anything except loading an environment map in
some examples), and they still show up in the `cargo_features` doc as
default features.
---
## Changelog
- The `tonemapping_luts` feature now includes both the `ktx2` and `zstd`
features to avoid a panic when the `tonemapping_luts` feature was enable
without both the `ktx2` and `zstd` feature enabled.
# Objective
- `deferred_rendering` and `load_gltf` fail in WebGPU builds due to
textureSample() being called on the diffuse environment map texture
after non-uniform control flow
## Solution
- The diffuse environment map texture only has one mip, so use
`textureSampleLevel(..., 0.0)` to sample that mip and not require UV
gradient calculation.
# Objective
- Build on the changes in https://github.com/bevyengine/bevy/pull/9982
- Use `ImageSamplerDescriptor` as the "public image sampler descriptor"
interface in all places (for consistency)
- Make it possible to configure textures to use the "default" sampler
(as configured in the `DefaultImageSampler` resource)
- Fix a bug introduced in #9982 that prevents configured samplers from
being used in Basis, KTX2, and DDS textures
---
## Migration Guide
- When using the `Image` API, use `ImageSamplerDescriptor` instead of
`wgpu::SamplerDescriptor`
- If writing custom wgpu renderer features that work with `Image`, call
`&image_sampler.as_wgpu()` to convert to a wgpu descriptor.
# Objective
- Folder handles are not shared. Loading the same folder multiple times
will result in different handles.
- Once folder handles are shared, they can no longer be manually
reloaded, so we should add support for hot-reloading them
## Solution
- Reuse folder handles based on their path
- Trigger a reload of a folder if a file contained in it (or a sub
folder) is added or removed
- This also covers adding/removing/moving sub folders containing files
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Assets v2 does not currently offer a public API to load untyped assets
## Solution
- Wrap the untyped handle in a `LoadedUntypedAsset` asset to offer a
non-blocking load for untyped assets. The user does not need to know the
actual asset type.
- Handles to `LoadedUntypedAsset` have the same path as the wrapped
asset, but their handles are shared using a label.
The user side of `load_untyped` looks like this:
```rust
use bevy::prelude::*;
use bevy_internal::asset::LoadedUntypedAsset;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.add_systems(Update, check)
.run();
}
#[derive(Resource)]
struct UntypedAsset {
handle: Handle<LoadedUntypedAsset>,
}
fn setup(
mut commands: Commands,
asset_server: Res<AssetServer>,
) {
let handle = asset_server.load_untyped("branding/banner.png");
commands.insert_resource(UntypedAsset { handle });
commands.spawn(Camera2dBundle::default());
}
fn check(
mut commands: Commands,
res: Option<Res<UntypedAsset>>,
assets: Res<Assets<LoadedUntypedAsset>>,
) {
if let Some(untyped_asset) = res {
if let Some(asset) = assets.get(&untyped_asset.handle) {
commands.spawn(SpriteBundle {
texture: asset.handle.clone().typed(),
..default()
});
commands.remove_resource::<UntypedAsset>();
}
}
}
```
---
## Changelog
- `load_untyped` on the asset server now returns a handle to a
`LoadedUntypedAsset` instead of an untyped handle to the asset at the
given path. The untyped handle for the given path can be retrieved from
the `LoadedUntypedAsset` once it is done loading.
## Migration Guide
Whenever possible use the typed API in order to directly get a handle to
your asset. If you do not know the type or need to use `load_untyped`
for a different reason, Bevy 0.12 introduces an additional layer of
indirection. The asset server will return a handle to a
`LoadedUntypedAsset`, which will load in the background. Once it is
loaded, the untyped handle to the asset file can be retrieved from the
`LoadedUntypedAsset`s field `handle`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#9395
Alternative to #9415 (See discussion here)
## Solution
Do clamping like
[`fit-content`](https://www.w3.org/TR/css-sizing-3/#column-sizing).
## Notes
I am not sure if this is a valid approach. It doesn't seem to cause any
obvious issues with our existing examples.
# Objective
- Hot reloading doesn't work the first time it is used
## Solution
- Currently, Bevy processor:
1. Create the `imported_assets` folder
2. Setup a watcher on it
3. Clear empty folders, so the `imported_assets` folder is deleted
4. Recreate the `imported_assets` folder and add all the imported assets
- On a first run without an existing `imported_assets` with some
content, hot reloading won't work as step 3 breaks the file watcher
- This PR stops the empty root folder from being deleted
- Also don't setup the processor internal asset server for file
watching, freeing up a thread
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#9473
## Solution
Added `resolve()` method to AssetPath. This method accepts a relative
asset path string and returns a "full" path that has been resolved
relative to the current (self) path.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
First of all, this PR took heavy inspiration from #7760 and #5715. It
intends to also fix#5569, but with a slightly different approach.
This also fixes#9335 by reexporting `DynEq`.
## Solution
The advantage of this API is that we can intern a value without
allocating for zero-sized-types and for enum variants that have no
fields. This PR does this automatically in the `SystemSet` and
`ScheduleLabel` derive macros for unit structs and fieldless enum
variants. So this should cover many internal and external use cases of
`SystemSet` and `ScheduleLabel`. In these optimal use cases, no memory
will be allocated.
- The interning returns a `Interned<dyn SystemSet>`, which is just a
wrapper around a `&'static dyn SystemSet`.
- `Hash` and `Eq` are implemented in terms of the pointer value of the
reference, similar to my first approach of anonymous system sets in
#7676.
- Therefore, `Interned<T>` does not implement `Borrow<T>`, only `Deref`.
- The debug output of `Interned<T>` is the same as the interned value.
Edit:
- `AppLabel` is now also interned and the old
`derive_label`/`define_label` macros were replaced with the new
interning implementation.
- Anonymous set ids are reused for different `Schedule`s, reducing the
amount of leaked memory.
### Pros
- `InternedSystemSet` and `InternedScheduleLabel` behave very similar to
the current `BoxedSystemSet` and `BoxedScheduleLabel`, but can be copied
without an allocation.
- Many use cases don't allocate at all.
- Very fast lookups and comparisons when using `InternedSystemSet` and
`InternedScheduleLabel`.
- The `intern` module might be usable in other areas.
- `Interned{ScheduleLabel, SystemSet, AppLabel}` does implement
`{ScheduleLabel, SystemSet, AppLabel}`, increasing ergonomics.
### Cons
- Implementors of `SystemSet` and `ScheduleLabel` still need to
implement `Hash` and `Eq` (and `Clone`) for it to work.
## Changelog
### Added
- Added `intern` module to `bevy_utils`.
- Added reexports of `DynEq` to `bevy_ecs` and `bevy_app`.
### Changed
- Replaced `BoxedSystemSet` and `BoxedScheduleLabel` with
`InternedSystemSet` and `InternedScheduleLabel`.
- Replaced `impl AsRef<dyn ScheduleLabel>` with `impl ScheduleLabel`.
- Replaced `AppLabelId` with `InternedAppLabel`.
- Changed `AppLabel` to use `Debug` for error messages.
- Changed `AppLabel` to use interning.
- Changed `define_label`/`derive_label` to use interning.
- Replaced `define_boxed_label`/`derive_boxed_label` with
`define_label`/`derive_label`.
- Changed anonymous set ids to be only unique inside a schedule, not
globally.
- Made interned label types implement their label trait.
### Removed
- Removed `define_boxed_label` and `derive_boxed_label`.
## Migration guide
- Replace `BoxedScheduleLabel` and `Box<dyn ScheduleLabel>` with
`InternedScheduleLabel` or `Interned<dyn ScheduleLabel>`.
- Replace `BoxedSystemSet` and `Box<dyn SystemSet>` with
`InternedSystemSet` or `Interned<dyn SystemSet>`.
- Replace `AppLabelId` with `InternedAppLabel` or `Interned<dyn
AppLabel>`.
- Types manually implementing `ScheduleLabel`, `AppLabel` or `SystemSet`
need to implement:
- `dyn_hash` directly instead of implementing `DynHash`
- `as_dyn_eq`
- Pass labels to `World::try_schedule_scope`, `World::schedule_scope`,
`World::try_run_schedule`. `World::run_schedule`, `Schedules::remove`,
`Schedules::remove_entry`, `Schedules::contains`, `Schedules::get` and
`Schedules::get_mut` by value instead of by reference.
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
When a mesh vertex attribute has a vertex count mismatch, a warning
message is printed with the index of the attribute which did not match.
Change to name the attribute, or fall back to the old behaviour if it
was not a known attribute.
Before:
```
MeshVertexAttributeId(2) has a different vertex count (32) than other attributes (64) in this mesh, all attributes will be truncated to match the smallest.
```
After:
```
Vertex_Uv has a different vertex count (32) than other attributes (64) in this mesh, all attributes will be truncated to match the smallest.
```
## Solution
Name the mesh attribute which had a count mismatch.
## Changelog
- If a mesh vertex attribute has a different count than other vertex
attributes, name the offending attribute using a human readable name
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- the style of import used by bevy guarantees merge conflicts when any
file change
- This is especially true when import lists are large, such as in
`bevy_pbr`
- Merge conflicts are tricky to resolve. This bogs down rendering PRs
and makes contributing to bevy's rendering system more difficult than it
needs to
## Solution
- Use wildcard imports to replace multiline import list in `bevy_pbr`
I suspect this is controversial, but I'd like to hear alternatives.
Because this is one of many papercuts that makes developing render
features near impossible.
Closes#9946
# Objective
Add a new type mirroring `wgpu::SamplerDescriptor` for
`ImageLoaderSettings` to control how a loaded image should be sampled.
Fix issues with texture sampler descriptors not being set when loading
gltf texture from URI.
## Solution
Add a new `ImageSamplerDescriptor` and its affiliated types that mirrors
`wgpu::SamplerDescriptor`, use it in the image loader settings.
---
## Changelog
### Added
- Added new types `ImageSamplerDescriptor`, `ImageAddressMode`,
`ImageFilterMode`, `ImageCompareFunction` and `ImageSamplerBorderColor`
that mirrors the corresponding wgpu types.
- `ImageLoaderSettings` now carries an `ImageSamplerDescriptor` field
that will be used to determine how the loaded image is sampled, and will
be serialized as part of the image assets `.meta` files.
### Changed
- `Image::from_buffer` now takes the sampler descriptor to use as an
additional parameter.
### Fixed
- Sampler descriptors are set for gltf textures loaded from URI.
# Objective
- Fixes#10250
```
[Log] ERROR crates/bevy_render/src/render_resource/pipeline_cache.rs:823 failed to process shader: (wasm_example.js, line 376)
error: no definition in scope for identifier: 'bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_'
┌─ crates/bevy_pbr/src/deferred/deferred_lighting.wgsl:44:20
│
44 │ frag_coord.z = bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_(deferred_data.b).w;
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ unknown identifier
│
= no definition in scope for identifier: 'bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_'
```
## Solution
- Fix the import path
The "gray" issue is since #9258 on macOS
... at least they're not white anymore
<img width="1294" alt="Screenshot 2023-10-25 at 00 14 11"
src="https://github.com/bevyengine/bevy/assets/8672791/df1a1138-c26c-4417-9b49-a00fbb8561d7">
Updates the requirements on
[async-io](https://github.com/smol-rs/async-io) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/smol-rs/async-io/releases">async-io's
releases</a>.</em></p>
<blockquote>
<h2>v2.0.0</h2>
<ul>
<li><strong>Breaking:</strong> <code>Async::new()</code> now takes types
that implement <code>AsFd</code>/<code>AsSocket</code> instead of
<code>AsRawFd</code>/<code>AsRawSocket</code>, in order to implement I/O
safety. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/142">#142</a>)</li>
<li><strong>Breaking:</strong> <code>Async::get_mut()</code>,
<code>Async::read_with_mut()</code> and
<code>Async::write_with_mut()</code> are now <code>unsafe</code>. The
underlying source is technically "borrowed" by the polling
instance, so moving it out would be unsound. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/142">#142</a>)</li>
<li>Expose miscellaneous <code>kqueue</code> filters in the
<code>os::kqueue</code> module. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/112">#112</a>)</li>
<li>Expose a way to get the underlying <code>Poller</code>'s file
descriptor on Unix. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/125">#125</a>)</li>
<li>Add a new <code>Async::new_nonblocking</code> method to allow users
to avoid duplicating an already nonblocking socket. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/159">#159</a>)</li>
<li>Remove the unused <code>fastrand</code> and <code>memchr</code>
dependencies. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/131">#131</a>)</li>
<li>Use <code>tracing</code> instead of <code>log</code>. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/140">#140</a>)</li>
<li>Support ESP-IDF. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/144">#144</a>)</li>
<li>Optimize the <code>block_on</code> function to reduce allocation,
leading to a slight performance improvement. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/149">#149</a>)</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/smol-rs/async-io/blob/master/CHANGELOG.md">async-io's
changelog</a>.</em></p>
<blockquote>
<h1>Version 2.0.0</h1>
<ul>
<li><strong>Breaking:</strong> <code>Async::new()</code> now takes types
that implement <code>AsFd</code>/<code>AsSocket</code> instead of
<code>AsRawFd</code>/<code>AsRawSocket</code>, in order to implement I/O
safety. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/142">#142</a>)</li>
<li><strong>Breaking:</strong> <code>Async::get_mut()</code>,
<code>Async::read_with_mut()</code> and
<code>Async::write_with_mut()</code> are now <code>unsafe</code>. The
underlying source is technically "borrowed" by the polling
instance, so moving it out would be unsound. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/142">#142</a>)</li>
<li>Expose miscellaneous <code>kqueue</code> filters in the
<code>os::kqueue</code> module. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/112">#112</a>)</li>
<li>Expose a way to get the underlying <code>Poller</code>'s file
descriptor on Unix. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/125">#125</a>)</li>
<li>Add a new <code>Async::new_nonblocking</code> method to allow users
to avoid duplicating an already nonblocking socket. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/159">#159</a>)</li>
<li>Remove the unused <code>fastrand</code> and <code>memchr</code>
dependencies. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/131">#131</a>)</li>
<li>Use <code>tracing</code> instead of <code>log</code>. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/140">#140</a>)</li>
<li>Support ESP-IDF. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/144">#144</a>)</li>
<li>Optimize the <code>block_on</code> function to reduce allocation,
leading to a slight performance improvement. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/149">#149</a>)</li>
</ul>
<h1>Version 1.13.0</h1>
<ul>
<li>Use <a
href="https://crates.io/crates/rustix/"><code>rustix</code></a> instead
of <a href="https://crates.io/crates/libc/"><code>libc</code></a>/<a
href="https://crates.io/crates/windows-sys/"><code>windows-sys</code></a>
for system calls (<a
href="https://redirect.github.com/smol-rs/async-io/issues/76">#76</a>)</li>
<li>Add a <code>will_fire</code> method to <code>Timer</code> to test if
it will ever fire (<a
href="https://redirect.github.com/smol-rs/async-io/issues/106">#106</a>)</li>
<li>Reduce syscalls in <code>Async::new</code> (<a
href="https://redirect.github.com/smol-rs/async-io/issues/107">#107</a>)</li>
<li>Improve the drop ergonomics of <code>Readable</code> and
<code>Writable</code> (<a
href="https://redirect.github.com/smol-rs/async-io/issues/109">#109</a>)</li>
<li>Change the "<code>wepoll</code>" in documentation to
"<code>IOCP</code>" (<a
href="https://redirect.github.com/smol-rs/async-io/issues/116">#116</a>)</li>
</ul>
<h1>Version 1.12.0</h1>
<ul>
<li>Switch from <code>winapi</code> to <code>windows-sys</code> (<a
href="https://redirect.github.com/smol-rs/async-io/issues/102">#102</a>)</li>
</ul>
<h1>Version 1.11.0</h1>
<ul>
<li>Update <code>concurrent-queue</code> to v2. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/99">#99</a>)</li>
</ul>
<h1>Version 1.10.0</h1>
<ul>
<li>Remove the dependency on the <code>once_cell</code> crate to restore
the MSRV. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/95">#95</a>)</li>
</ul>
<h1>Version 1.9.0</h1>
<ul>
<li>Fix panic on very large durations. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/87">#87</a>)</li>
<li>Add <code>Timer::never</code> (<a
href="https://redirect.github.com/smol-rs/async-io/issues/87">#87</a>)</li>
</ul>
<h1>Version 1.8.0</h1>
<ul>
<li>Implement I/O safety traits on Rust 1.63+ (<a
href="https://redirect.github.com/smol-rs/async-io/issues/84">#84</a>)</li>
</ul>
<h1>Version 1.7.0</h1>
<ul>
<li>Process timers set for exactly <code>now</code>. (<a
href="https://redirect.github.com/smol-rs/async-io/issues/73">#73</a>)</li>
</ul>
<h1>Version 1.6.0</h1>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="7e89eec4d1"><code>7e89eec</code></a>
v2.0.0</li>
<li><a
href="356431754c"><code>3564317</code></a>
tests: Add test for <a
href="https://redirect.github.com/smol-rs/async-io/issues/154">#154</a></li>
<li><a
href="a5da16f072"><code>a5da16f</code></a>
Expose Async::new_nonblocking</li>
<li><a
href="0f2af634d8"><code>0f2af63</code></a>
Avoid needless set_nonblocking calls</li>
<li><a
href="62e3454f38"><code>62e3454</code></a>
Migrate to Rust 2021 (<a
href="https://redirect.github.com/smol-rs/async-io/issues/160">#160</a>)</li>
<li><a
href="59ee2ea27c"><code>59ee2ea</code></a>
Use set_nonblocking in Async::new on Windows (<a
href="https://redirect.github.com/smol-rs/async-io/issues/157">#157</a>)</li>
<li><a
href="d5bc619021"><code>d5bc619</code></a>
Remove needless as_fd/as_socket calls (<a
href="https://redirect.github.com/smol-rs/async-io/issues/158">#158</a>)</li>
<li><a
href="0b5016e567"><code>0b5016e</code></a>
m: Replace socket2 calls with rustix</li>
<li><a
href="8c3c3bd80b"><code>8c3c3bd</code></a>
m: Optimize block_on by caching Parker and Waker</li>
<li><a
href="1b1466a6c1"><code>1b1466a</code></a>
Update this crate to use the new polling breaking changes (<a
href="https://redirect.github.com/smol-rs/async-io/issues/142">#142</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/smol-rs/async-io/compare/v1.13.0...v2.0.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
A follow-up PR for https://github.com/bevyengine/bevy/pull/10221
## Changelog
Replaced usages of texture_descriptor.size with the helper methods of
`Image` through the entire engine codebase
# Objective
Reduce code duplication and improve APIs of Bevy's [global
taskpools](https://github.com/bevyengine/bevy/blob/main/crates/bevy_tasks/src/usages.rs).
## Solution
- As all three of the global taskpools have identical implementations
and only differ in their identifiers, this PR moves the implementation
into a macro to reduce code duplication.
- The `init` method is renamed to `get_or_init` to more accurately
reflect what it really does.
- Add a new `try_get` method that just returns `None` when the pool is
uninitialized, to complement the other getter methods.
- Minor documentation improvements to accompany the above changes.
---
## Changelog
- Added a new `try_get` method to the global TaskPools
- The global TaskPools' `init` method has been renamed to `get_or_init`
for clarity
- Documentation improvements
## Migration Guide
- Uses of `ComputeTaskPool::init`, `AsyncComputeTaskPool::init` and
`IoTaskPool::init` should be changed to `::get_or_init`.
# Objective
- Handle pausing audio when Android app is suspended
## Solution
- This is the start of application lifetime events. They are mostly
useful on mobile
- Next version of winit should add a few more
- When application is suspended, send an event to notify the
application, and run the schedule one last time before actually
suspending the app
- Audio is now suspended too 🎉https://github.com/bevyengine/bevy/assets/8672791/d74e2e09-ee29-4f40-adf2-36a0c064f94e
---------
Co-authored-by: Marco Buono <418473+coreh@users.noreply.github.com>
# Objective
Fog color was passed to shaders without conversion from sRGB to linear
color space. Because shaders expect colors in linear space this resulted
in wrong color being used. This is most noticeable in open scenes with
dark fog color and clear color set to the same color. In such case
background/clear color (which is properly processed) is going to be
darker than very far objects.
Example:

[bevy-fog-color-bug.zip](https://github.com/bevyengine/bevy/files/13063718/bevy-fog-color-bug.zip)
## Solution
Add missing conversion of fog color to linear color space.
---
## Changelog
* Fixed conversion of fog color
## Migration Guide
- Colors in `FogSettings` struct (`color` and `directional_light_color`)
are now sent to the GPU in linear space. If you were using
`Color::rgb()`/`Color::rgba()` and would like to retain the previous
colors, you can quickly fix it by switching to
`Color::rgb_linear()`/`Color::rgba_linear()`.
# Objective
- After #9826, there are issues on "run once runners"
- example `without_winit` crashes:
```
2023-10-19T22:06:01.810019Z INFO bevy_render::renderer: AdapterInfo { name: "llvmpipe (LLVM 15.0.7, 256 bits)", vendor: 65541, device: 0, device_type: Cpu, driver: "llvmpipe", driver_info: "Mesa 23.2.1 - kisak-mesa PPA (LLVM 15.0.7)", backend: Vulkan }
2023-10-19T22:06:02.860331Z WARN bevy_audio::audio_output: No audio device found.
2023-10-19T22:06:03.215154Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Linux 22.04 Ubuntu", kernel: "6.2.0-1014-azure", cpu: "Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz", core_count: "2", memory: "6.8 GiB" }
thread 'main' panicked at crates/bevy_render/src/pipelined_rendering.rs:91:14:
Unable to get RenderApp. Another plugin may have removed the RenderApp before PipelinedRenderingPlugin
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
- example `headless` runs the app twice with the `run_once` schedule
## Solution
- Expose a more complex state of an app than just "ready"
- Also block adding plugins to an app after it has finished or cleaned
up its plugins as that wouldn't work anyway
## Migration Guide
* `app.ready()` has been replaced by `app.plugins_state()` which will
return more details on the current state of plugins in the app
# Objective
- Replace md5 by another hasher, as suggested in
https://github.com/bevyengine/bevy/pull/8624#discussion_r1359291028
- md5 is not secure, and is slow. use something more secure and faster
## Solution
- Replace md5 by blake3
Putting this PR in the 0.12 as once it's released, changing the hash
algorithm will be a painful breaking change
# Objective
Even at `reflectance == 0.0`, our ambient and environment map light
implementations still produce fresnel/specular highlights.
Such a low `reflectance` value lies outside of the physically possible
range and is already used by our directional, point and spot light
implementations (via the `fresnel()` function) to enable artistic
control, effectively disabling the fresnel "look" for non-physically
realistic materials. Since ambient and environment lights use a
different formulation, they were not honoring this same principle.
This PR aims to bring consistency to all light types, offering the same
fresnel extinguishing control to ambient and environment lights.
Thanks to `@nathanf` for [pointing
out](https://discord.com/channels/691052431525675048/743663924229963868/1164083373514440744)
the [Filament docs section about
this](https://google.github.io/filament/Filament.md.html#lighting/occlusion/specularocclusion).
## Solution
- We use [the same
formulation](ffc572728f/crates/bevy_pbr/src/render/pbr_lighting.wgsl (L99))
already used by the `fresnel()` function in `bevy_pbr::lighting` to
modulate the F90, to modulate the specular component of Ambient and
Environment Map lights.
## Comparison
⚠️ **Modified version of the PBR example for demo purposes, that shows
reflectance (_NOT_ part of this PR)** ⚠️
Also, keep in mind this is a very subtle difference (look for the
fresnel highlights on the lower left spheres, you might need to zoom in.
### Before
<img width="1392" alt="Screenshot 2023-10-18 at 23 02 25"
src="https://github.com/bevyengine/bevy/assets/418473/ec0efb58-9a98-4377-87bc-726a1b0a3ff3">
### After
<img width="1392" alt="Screenshot 2023-10-18 at 23 01 43"
src="https://github.com/bevyengine/bevy/assets/418473/a2809325-5728-405e-af02-9b5779767843">
---
## Changelog
- Ambient and Environment Map lights will now honor values of
`reflectance` that are below the physically possible range (⪅ 0.35) by
extinguishing their fresnel highlights. (Just like point, directional
and spot lights already did.) This allows for more consistent artistic
control and for non-physically realistic looks with all light types.
## Migration Guide
- If Fresnel highlights from Ambient and Environment Map lights are no
longer visible in your materials, make sure you're using a higher,
physically plausible value of `reflectance` (⪆ 0.35).
# Objective
- I want to use the `debug_glam_assert` feature with bevy.
## Solution
- Re-export the feature flag
---
## Changelog
- Re-export `debug_glam_assert` feature flag from glam.
# Objective
Fixes#5101
Alternative to #6511
## Solution
Corrected the behavior for ignored fields in `FromReflect`, which was
previously using the incorrect field indexes.
Similarly, fields marked with `#[reflect(skip_serializing)]` no longer
break when using `FromReflect` after deserialization. This was done by
modifying `SerializationData` to store a function pointer that can later
be used to generate a default instance of the skipped field during
deserialization.
The function pointer points to a function generated by the derive macro
using the behavior designated by `#[reflect(default)]` (or just
`Default` if none provided). The entire output of the macro is now
wrapped in an [unnamed
constant](https://doc.rust-lang.org/stable/reference/items/constant-items.html#unnamed-constant)
which keeps this behavior hygienic.
#### Rationale
The biggest downside to this approach is that it requires fields marked
`#[reflect(skip_serializing)]` to provide the ability to create a
default instance— either via a `Default` impl or by specifying a custom
one. While this isn't great, I think it might be justified by the fact
that we really need to create this value when using `FromReflect` on a
deserialized object. And we need to do this _during_ deserialization
because after that (at least for tuples and tuple structs) we lose
information about which field is which: _"is the value at index 1 in
this `DynamicTupleStruct` the actual value for index 1 or is it really
the value for index 2 since index 1 is skippable...?"_
#### Alternatives
An alternative would be to store `Option<Box<dyn Reflect>>` within
`DynamicTuple` and `DynamicTupleStruct` instead of just `Box<dyn
Reflect>`. This would allow us to insert "empty"/"missing" fields during
deserialization, thus saving the positional information of the skipped
fields. However, this may require changing the API of `Tuple` and
`TupleStruct` such that they can account for their dynamic counterparts
returning `None` for a skipped field. In practice this would probably
mean exposing the `Option`-ness of the dynamics onto implementors via
methods like `Tuple::drain` or `TupleStruct::field`.
Personally, I think requiring `Default` would be better than muddying up
the API to account for these special cases. But I'm open to trying out
this other approach if the community feels that it's better.
---
## Changelog
### Public Changes
#### Fixed
- The behaviors of `#[reflect(ignore)]` and
`#[reflect(skip_serializing)]` are no longer dependent on field order
#### Changed
- Fields marked with `#[reflect(skip_serializing)]` now need to either
implement `Default` or specify a custom default function using
`#[reflect(default = "path::to::some_func")]`
- Deserializing a type with fields marked `#[reflect(skip_serializing)]`
will now include that field initialized to its specified default value
- `SerializationData::new` now takes the new `SkippedField` struct along
with the skipped field index
- Renamed `SerializationData::is_ignored_field` to
`SerializationData::is_field_skipped`
#### Added
- Added `SkippedField` struct
- Added methods `SerializationData::generate_default` and
`SerializationData::iter_skipped`
### Internal Changes
#### Changed
- Replaced `members_to_serialization_denylist` and `BitSet<u32>` with
`SerializationDataDef`
- The `Reflect` derive is more hygienic as it now outputs within an
[unnamed
constant](https://doc.rust-lang.org/stable/reference/items/constant-items.html#unnamed-constant)
- `StructField::index` has been split up into
`StructField::declaration_index` and `StructField::reflection_index`
#### Removed
- Removed `bitset` dependency
## Migration Guide
* Fields marked `#[reflect(skip_serializing)]` now must implement
`Default` or specify a custom default function with `#[reflect(default =
"path::to::some_func")]`
```rust
#[derive(Reflect)]
struct MyStruct {
#[reflect(skip_serializing)]
#[reflect(default = "get_foo_default")]
foo: Foo, // <- `Foo` does not impl `Default` so requires a custom
function
#[reflect(skip_serializing)]
bar: Bar, // <- `Bar` impls `Default`
}
#[derive(Reflect)]
struct Foo(i32);
#[derive(Reflect, Default)]
struct Bar(i32);
fn get_foo_default() -> Foo {
Foo(123)
}
```
* `SerializationData::new` has been changed to expect an iterator of
`(usize, SkippedField)` rather than one of just `usize`
```rust
// BEFORE
SerializationData::new([0, 3].into_iter());
// AFTER
SerializationData::new([
(0, SkippedField::new(field_0_default_fn)),
(3, SkippedField::new(field_3_default_fn)),
].into_iter());
```
* `Serialization::is_ignored_field` has been renamed to
`Serialization::is_field_skipped`
* Fields marked `#[reflect(skip_serializing)]` are now included in
deserialization output. This may affect logic that expected those fields
to be absent.
# Objective
To get the width or height of an image you do:
```rust
self.texture_descriptor.size.{width, height}
```
that is quite verbose.
This PR adds some convenient methods for Image to reduce verbosity.
## Changelog
* Add a `width()` method for getting the width of an image.
* Add a `height()` method for getting the height of an image.
* Rename the `size()` method to `size_f32()`.
* Add a `size()` method for getting the size of an image as u32.
* Renamed the `aspect_2d()` method to `aspect_ratio()`.
## Migration Guide
Replace calls to the `Image::size()` method with `size_f32()`.
Replace calls to the `Image::aspect_2d()` method with `aspect_ratio()`.
# Objective
- Fix#10165
- On iOS simulator on apple silicon Macs, shader validation is going
through the host, but device limits are reported for the device. They
sometimes differ, and cause the validation to crash on something that
should work
```
-[MTLDebugRenderCommandEncoder validateCommonDrawErrors:]:5775: failed assertion `Draw Errors Validation
Fragment Function(fragment_): the offset into the buffer _naga_oil_mod_MJSXM6K7OBRHEOR2NVSXG2C7OZUWK527MJUW4ZDJNZTXG_memberfog that is bound at buffer index 6 must be a multiple of 256 but was set to 448.
```
## Solution
- Add a custom flag when building for the simulator and override the
buffer alignment
# Objective
- Closes#10049.
- Detect DDS texture containing a cubemap or a cubemap array.
## Solution
- When loading a dds texture, the header capabilities are checked for
the cubemap flag. An error is returned if not all faces are provided.
---
## Changelog
### Added
- Added a new texture error `TextureError::IncompleteCubemap`, used for
dds cubemap textures containing less than 6 faces, as that is not
supported on modern graphics APIs.
### Fixed
- DDS cubemaps are now loaded as cubemaps instead of 2D textures.
## Migration Guide
If you are matching on a `TextureError`, you will need to add a new
branch to handle `TextureError::IncompleteCubemap`.
# Objective
While reviewing #10187 I noticed some other mistakes in the UI node
docs.
## Solution
I did a quick proofreading pass and fixed a few things. And of course,
the typo from that other PR.
## Notes
I occasionally insert a period to make a section of doc self-consistent
but didn't go one way or the other on all periods in the file.
---------
Co-authored-by: Noah <noahshomette@gmail.com>
# Objective
Simplify bind group creation code. alternative to (and based on) #9476
## Solution
- Add a `BindGroupEntries` struct that can transparently be used where
`&[BindGroupEntry<'b>]` is required in BindGroupDescriptors.
Allows constructing the descriptor's entries as:
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::with_indexes((
(2, &my_sampler),
(3, my_uniform),
)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 2,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 3,
resource: my_uniform,
},
],
);
```
or
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::sequential((&my_sampler, my_uniform)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 0,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 1,
resource: my_uniform,
},
],
);
```
the structs has no user facing macros, is tuple-type-based so stack
allocated, and has no noticeable impact on compile time.
- Also adds a `DynamicBindGroupEntries` struct with a similar api that
uses a `Vec` under the hood and allows extending the entries.
- Modifies `RenderDevice::create_bind_group` to take separate arguments
`label`, `layout` and `entries` instead of a `BindGroupDescriptor`
struct. The struct can't be stored due to the internal references, and
with only 3 members arguably does not add enough context to justify
itself.
- Modify the codebase to use the new api and the `BindGroupEntries` /
`DynamicBindGroupEntries` structs where appropriate (whenever the
entries slice contains more than 1 member).
## Migration Guide
- Calls to `RenderDevice::create_bind_group({BindGroupDescriptor {
label, layout, entries })` must be amended to
`RenderDevice::create_bind_group(label, layout, entries)`.
- If `label`s have been specified as `"bind_group_name".into()`, they
need to change to just `"bind_group_name"`. `Some("bind_group_name")`
and `None` will still work, but `Some("bind_group_name")` can optionally
be simplified to just `"bind_group_name"`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- bump naga_oil to 0.10
- update shader imports to use rusty syntax
## Migration Guide
naga_oil 0.10 reworks the import mechanism to support more syntax to
make it more rusty, and test for item use before importing to determine
which imports are modules and which are items, which allows:
- use rust-style imports
```
#import bevy_pbr::{
pbr_functions::{alpha_discard as discard, apply_pbr_lighting},
mesh_bindings,
}
```
- import partial paths:
```
#import part::of::path
...
path::remainder::function();
```
which will call to `part::of::path::remainder::function`
- use fully qualified paths without importing:
```
// #import bevy_pbr::pbr_functions
bevy_pbr::pbr_functions::pbr()
```
- use imported items without qualifying
```
#import bevy_pbr::pbr_functions::pbr
// for backwards compatibility the old style is still supported:
// #import bevy_pbr::pbr_functions pbr
...
pbr()
```
- allows most imported items to end with `_` and numbers (naga_oil#30).
still doesn't allow struct members to end with `_` or numbers but it's
progress.
- the vast majority of existing shader code will work without changes,
but will emit "deprecated" warnings for old-style imports. these can be
suppressed with the `allow-deprecated` feature.
- partly breaks overrides (as far as i'm aware nobody uses these yet) -
now overrides will only be applied if the overriding module is added as
an additional import in the arguments to `Composer::make_naga_module` or
`Composer::add_composable_module`. this is necessary to support
determining whether imports are modules or items.
# Objective
This PR aims to make it so that we don't accidentally go over
`MAX_TEXTURE_IMAGE_UNITS` (in WebGL) or
`maxSampledTexturesPerShaderStage` (in WebGPU), giving us some extra
leeway to add more view bind group textures.
(This PR is extracted from—and unblocks—#8015)
## Solution
- We replace the existing `view_layout` and `view_layout_multisampled`
pair with an array of 32 bind group layouts, generated ahead of time;
- For now, these layouts cover all the possible combinations of:
`multisampled`, `depth_prepass`, `normal_prepass`,
`motion_vector_prepass` and `deferred_prepass`:
- In the future, as @JMS55 pointed out, we can likely take out
`motion_vector_prepass` and `deferred_prepass`, as these are not really
needed for the mesh pipeline and can use separate pipelines. This would
bring the possible combinations down to 8;
- We can also add more "optional" textures as they become needed,
allowing the engine to scale to a wider variety of use cases in lower
end/web environments (e.g. some apps might just want normal and depth
prepasses, others might only want light probes), while still keeping a
high ceiling for high end native environments where more textures are
supported.
- While preallocating bind group layouts is relatively cheap, the number
of combinations grows exponentially, so we should likely limit ourselves
to something like at most 256–1024 total layouts until we find a better
solution (like generating them lazily)
- To make this mechanism a little bit more explicit/discoverable, so
that compatibility with WebGPU/WebGL is not broken by accident, we add a
`MESH_PIPELINE_VIEW_LAYOUT_SAFE_MAX_TEXTURES` const and warn whenever
the number of textures in the layout crosses it.
- The warning is gated by `#[cfg(debug_assertions)]` and not issued in
release builds;
- We're counting the actual textures in the bind group layout instead of
using some roundabout metric so it should be accurate;
- Right now `MESH_PIPELINE_VIEW_LAYOUT_SAFE_MAX_TEXTURES` is set to 10
in order to leave 6 textures free for other groups;
- Currently there's no combination that would cause us to go over the
limit, but that will change once #8015 lands.
---
## Changelog
- `MeshPipeline` view bind group layouts now vary based on the current
multisampling and prepass states, saving a couple of texture binding
entries when prepasses are not in use.
## Migration Guide
- `MeshPipeline::view_layout` and
`MeshPipeline::view_layout_multisampled` have been replaced with a
private array to accomodate for variable view bind group layouts. To
obtain a view bind group layout for the current pipeline state, use the
new `MeshPipeline::get_view_layout()` or
`MeshPipeline::get_view_layout_from_key()` methods.
# Objective
Users shouldn't need to change their source code between "development
workflows" and "releasing". Currently, Bevy Asset V2 has two "processed"
asset modes `Processed` (assumes assets are already processed) and
`ProcessedDev` (starts an asset processor and processes assets). This
means that the mode must be changed _in code_ when switching from "app
dev" to "release". Very suboptimal.
We have already removed "runtime opt-in" for hot-reloading. Enabling the
`file_watcher` feature _automatically_ enables file watching in code.
This means deploying a game (without hot reloading enabled) just means
calling `cargo build --release` instead of `cargo run --features
bevy/file_watcher`.
We should adopt this pattern for asset processing.
## Solution
This adds the `asset_processor` feature, which will start the
`AssetProcessor` when an `AssetPlugin` runs in `AssetMode::Processed`.
The "asset processing workflow" is now:
1. Enable `AssetMode::Processed` on `AssetPlugin`
2. When developing, run with the `asset_processor` and `file_watcher`
features
3. When releasing, build without these features.
The `AssetMode::ProcessedDev` mode has been removed.
# Objective
I encountered a problem where I had a plugin `FooPlugin` which did
```rust
impl Plugin for FooPlugin {
fn build(&self, app: &mut App) {
app
.register_asset_source(...); // more stuff after
}
}
```
And when I tried using it, e.g.
```rust
asset_server.load("foo://data/asset.custom");
```
I got an error that `foo` was not recognized as a source.
I found that this is because asset sources must be registered _before_
`AssetPlugin` is added, and I had `FooPlugin` _after_.
## Solution
Add clarifying note about having to register sources before
`AssetPlugin` is added.
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- Provides actionable feedback when users encounter the error in
https://github.com/bevyengine/bevy/issues/10162
- Complements https://github.com/bevyengine/bevy/pull/10186
## Solution
- Log an error when registering an AssetSource after the AssetPlugin has
been built (via DefaultPlugins). This will let users know that their
registration order needs changing
The outputted error message will look like this:
```rust
ERROR bevy_asset::server: 'AssetSourceId::Name(test)' must be registered before `AssetPlugin` (typically added as part of `DefaultPlugins`)
```
---------
Co-authored-by: 66OJ66 <hi0obxud@anonaddy.me>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fixes#10177 .
## Solution
Added a new run condition and tweaked the docs for `on_timer`.
## Changelog
### Added
- `on_real_time_timer` run condition
# Objective
This PR addresses the issue where Bevy displays one or several black
frames before the scene is first rendered. This is particularly
noticeable on iOS, where the black frames disrupt the transition from
the launch screen to the game UI. I have written about my search to
solve this issue on the Bevy discord:
https://discord.com/channels/691052431525675048/1151047604520632352
While I can attest this PR works on both iOS and Linux/Wayland (and even
seems to resolve a slight flicker during startup with the latter as
well), I'm not familiar enough with Bevy to judge the full implications
of these changes. I hope a reviewer or tester can help me confirm
whether this is the right approach, or what might be a cleaner solution
to resolve this issue.
## Solution
I have moved the "startup phase" as well as the plugin finalization into
the `app.run()` function so those things finish synchronously before the
"main schedule" starts. I even move one frame forward as well, using
`app.update()`, to make sure the rendering has caught up with the state
of the finalized plugins as well.
I admit that part of this was achieved through trial-and-error, since
not doing the "startup phase" *before* `app.finish()` resulted in
panics, while not calling an extra `app.update()` didn't fully resolve
the issue.
What I *can* say, is that the iOS launch screen animation works in such
a way that the OS initiates the transition once the framework's
[`didFinishLaunching()`](https://developer.apple.com/documentation/uikit/uiapplicationdelegate/1622921-application)
returns, meaning app developers **must** finish setting up their UI
before that function returns. This is what basically led me on the path
to try to "finish stuff earlier" :)
## Changelog
### Changed
- The startup phase and the first frame are rendered synchronously when
calling `app.run()`, before the "main schedule" is started. This fixes
black frames during the iOS launch transition and possible flickering on
other platforms, but may affect initialization order in your
application.
## Migration Guide
Because of this change, the timing of the first few frames might have
changed, and I think it could be that some things one may expect to be
initialized in a system may no longer be. To be honest, I feel out of my
depth to judge the exact impact here.
# Objective
Add a way to easily compute the up-to-date `GlobalTransform` of an
entity.
## Solution
Add the `TransformHelper`(Name pending) system parameter with the
`compute_global_transform` method that takes an `Entity` and returns a
`GlobalTransform` if successful.
## Changelog
- Added the `TransformHelper` system parameter for computing the
up-to-date `GlobalTransform` of an entity.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Noah <noahshomette@gmail.com>
# Objective
allow extending `Material`s (including the built in `StandardMaterial`)
with custom vertex/fragment shaders and additional data, to easily get
pbr lighting with custom modifications, or otherwise extend a base
material.
# Solution
- added `ExtendedMaterial<B: Material, E: MaterialExtension>` which
contains a base material and a user-defined extension.
- added example `extended_material` showing how to use it
- modified AsBindGroup to have "unprepared" functions that return raw
resources / layout entries so that the extended material can combine
them
note: doesn't currently work with array resources, as i can't figure out
how to make the OwnedBindingResource::get_binding() work, as wgpu
requires a `&'a[&'a TextureView]` and i have a `Vec<TextureView>`.
# Migration Guide
manual implementations of `AsBindGroup` will need to be adjusted, the
changes are pretty straightforward and can be seen in the diff for e.g.
the `texture_binding_array` example.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
deferred doesn't currently run unless one of `DepthPrepass`,
`ForwardPrepass` or `MotionVectorPrepass` is also present on the camera.
## Solution
modify the `queue_prepass_material_meshes` view query to check for any
relevant phase, instead of requiring `Opaque3dPrepass` and
`AlphaMask3dPrepass` to be present
# Objective
- Correct the description of an error type for the scene loader
## Solution
- Correct the description of an error type for the scene loader
# Objective
- This PR aims to make the various `*_PREPASS` shader defs we have
(`NORMAL_PREPASS`, `DEPTH_PREPASS`, `MOTION_VECTORS_PREPASS` AND
`DEFERRED_PREPASS`) easier to use and understand:
- So that their meaning is now consistent across all contexts; (“prepass
X is enabled for the current view”)
- So that they're also consistently set across all contexts.
- It also aims to enable us to (with a follow up PR) to conditionally
gate the `BindGroupEntry` and `BindGroupLayoutEntry` items associated
with these prepasses, saving us up to 4 texture slots in WebGL
(currently globally limited to 16 per shader, regardless of bind groups)
## Solution
- We now consistently set these from `PrepassPipeline`, the
`MeshPipeline` and the `DeferredLightingPipeline`, we also set their
`MeshPipelineKey`s;
- We introduce `PREPASS_PIPELINE`, `MESH_PIPELINE` and
`DEFERRED_LIGHTING_PIPELINE` that can be used to detect where the code
is running, without overloading the meanings of the prepass shader defs;
- We also gate the WGSL functions in `bevy_pbr::prepass_utils` with
`#ifdef`s for their respective shader defs, so that shader code can
provide a fallback whenever they're not available.
- This allows us to conditionally include the bindings for these prepass
textures (My next PR, which will hopefully unblock #8015)
- @robtfm mentioned [these were being used to prevent accessing the same
binding as read/write in the
prepass](https://discord.com/channels/691052431525675048/743663924229963868/1163270458393759814),
however even after reversing the `#ifndef`s I had no issues running the
code, so perhaps the compiler is already smart enough even without tree
shaking to know they're not being used, thanks to `#ifdef
PREPASS_PIPELINE`?
## Comparison
### Before
| Shader Def | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | No | No |
| `DEPTH_PREPASS` | Yes | No | No |
| `MOTION_VECTORS_PREPASS` | Yes | No | No |
| `DEFERRED_PREPASS` | Yes | No | No |
| View Key | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | No |
| `DEPTH_PREPASS` | Yes | No | No |
| `MOTION_VECTORS_PREPASS` | Yes | No | No |
| `DEFERRED_PREPASS` | Yes | Yes\* | No |
\* Accidentally was being set twice, once with only
`deferred_prepass.is_some()` as a condition,
and once with `deferred_p repass.is_some() && !forward` as a condition.
### After
| Shader Def | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ---------------------------- | ----------------- | --------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | Yes |
| `DEPTH_PREPASS` | Yes | Yes | Yes |
| `MOTION_VECTORS_PREPASS` | Yes | Yes | Yes |
| `DEFERRED_PREPASS` | Yes | Yes | Unconditionally |
| `PREPASS_PIPELINE` | Unconditionally | No | No |
| `MESH_PIPELINE` | No | Unconditionally | No |
| `DEFERRED_LIGHTING_PIPELINE` | No | No | Unconditionally |
| View Key | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | Yes |
| `DEPTH_PREPASS` | Yes | Yes | Yes |
| `MOTION_VECTORS_PREPASS` | Yes | Yes | Yes |
| `DEFERRED_PREPASS` | Yes | Yes | Unconditionally |
---
## Changelog
- Cleaned up WGSL `*_PREPASS` shader defs so they're now consistently
used everywhere;
- Introduced `PREPASS_PIPELINE`, `MESH_PIPELINE` and
`DEFERRED_LIGHTING_PIPELINE` WGSL shader defs for conditionally
compiling logic based the current pipeline;
- WGSL functions from `bevy_pbr::prepass_utils` are now guarded with
`#ifdef` based on the currently enabled prepasses;
## Migration Guide
- When using functions from `bevy_pbr::prepass_utils`
(`prepass_depth()`, `prepass_normal()`, `prepass_motion_vector()`) in
contexts where these prepasses might be disabled, you should now wrap
your calls with the appropriate `#ifdef` guards, (`#ifdef
DEPTH_PREPASS`, `#ifdef NORMAL_PREPASS`, `#ifdef MOTION_VECTOR_PREPASS`)
providing fallback logic where applicable.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
Fixes#10086
## Solution
Instead of serializing via `DynamicTypePath::reflect_type_path`, now
uses the `TypePath` found on the `TypeInfo` returned by
`Reflect::get_represented_type_info`.
This issue was happening because the dynamic types implement `TypePath`
themselves and do not (and cannot) forward their proxy's `TypePath`
data. The solution was to access the proxy's type information in order
to get the correct `TypePath` data.
## Changed
- The `Debug` impl for `TypePathTable` now includes output for all
fields.
# Objective
Time clamping happens consistently for apps that load non-trivial
things. While this _is_ an indicator that we should probably try to move
this work to a thread that doesn't block the Update, this is common
enough (and unactionable enough) that I think we should demote it for
now.
```
2023-10-16T18:46:14.918781Z WARN bevy_time::virt: delta time larger than maximum delta, clamping delta to 250ms and skipping 63.649253ms
2023-10-16T18:46:15.178048Z WARN bevy_time::virt: delta time larger than maximum delta, clamping delta to 250ms and skipping 1.71611ms
```
## Solution
Change `warn` to `debug` for this message
# Objective
Closes#10107
The visibility of `bevy::core::update_frame_count` should be `pub` so it
can be used in third-party code like this:
```rust
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.add_systems(Last, use_frame_count.before(bevy::core::update_frame_count));
}
}
```
## Solution
Make `bevy::core::update_frame_count` public.
---
## Changelog
### Added
- Documentation for `bevy::core::update_frame_count`
### Changed
- Visibility of `bevy::core::update_frame_count` is now `pub`
# Objective
- Added support for newer AMD Radeon cards in the mod.rs file located at
``crates/bevy_render/src/view/window/mod.rs``
## Solution
- All I needed to add was ``name.starts_with("Radeon") ||`` to the
existing code on line 347 of
``crates/bevy_render/src/view/window/mod.rs``
---
## Changelog
- Changed ``crates/bevy_render/src/view/window/mod.rs``
# Objective
Current `FixedTime` and `Time` have several problems. This pull aims to
fix many of them at once.
- If there is a longer pause between app updates, time will jump forward
a lot at once and fixed time will iterate on `FixedUpdate` for a large
number of steps. If the pause is merely seconds, then this will just
mean jerkiness and possible unexpected behaviour in gameplay. If the
pause is hours/days as with OS suspend, the game will appear to freeze
until it has caught up with real time.
- If calculating a fixed step takes longer than specified fixed step
period, the game will enter a death spiral where rendering each frame
takes longer and longer due to more and more fixed step updates being
run per frame and the game appears to freeze.
- There is no way to see current fixed step elapsed time inside fixed
steps. In order to track this, the game designer needs to add a custom
system inside `FixedUpdate` that calculates elapsed or step count in a
resource.
- Access to delta time inside fixed step is `FixedStep::period` rather
than `Time::delta`. This, coupled with the issue that `Time::elapsed`
isn't available at all for fixed steps, makes it that time requiring
systems are either implemented to be run in `FixedUpdate` or `Update`,
but rarely work in both.
- Fixes#8800
- Fixes#8543
- Fixes#7439
- Fixes#5692
## Solution
- Create a generic `Time<T>` clock that has no processing logic but
which can be instantiated for multiple usages. This is also exposed for
users to add custom clocks.
- Create three standard clocks, `Time<Real>`, `Time<Virtual>` and
`Time<Fixed>`, all of which contain their individual logic.
- Create one "default" clock, which is just `Time` (or `Time<()>`),
which will be overwritten from `Time<Virtual>` on each update, and
`Time<Fixed>` inside `FixedUpdate` schedule. This way systems that do
not care specifically which time they track can work both in `Update`
and `FixedUpdate` without changes and the behaviour is intuitive.
- Add `max_delta` to virtual time update, which limits how much can be
added to virtual time by a single update. This fixes both the behaviour
after a long freeze, and also the death spiral by limiting how many
fixed timestep iterations there can be per update. Possible future work
could be adding `max_accumulator` to add a sort of "leaky bucket" time
processing to possibly smooth out jumps in time while keeping frame rate
stable.
- Many minor tweaks and clarifications to the time functions and their
documentation.
## Changelog
- `Time::raw_delta()`, `Time::raw_elapsed()` and related methods are
moved to `Time<Real>::delta()` and `Time<Real>::elapsed()` and now match
`Time` API
- `FixedTime` is now `Time<Fixed>` and matches `Time` API.
- `Time<Fixed>` default timestep is now 64 Hz, or 15625 microseconds.
- `Time` inside `FixedUpdate` now reflects fixed timestep time, making
systems portable between `Update ` and `FixedUpdate`.
- `Time::pause()`, `Time::set_relative_speed()` and related methods must
now be called as `Time<Virtual>::pause()` etc.
- There is a new `max_delta` setting in `Time<Virtual>` that limits how
much the clock can jump by a single update. The default value is 0.25
seconds.
- Removed `on_fixed_timer()` condition as `on_timer()` does the right
thing inside `FixedUpdate` now.
## Migration Guide
- Change all `Res<Time>` instances that access `raw_delta()`,
`raw_elapsed()` and related methods to `Res<Time<Real>>` and `delta()`,
`elapsed()`, etc.
- Change access to `period` from `Res<FixedTime>` to `Res<Time<Fixed>>`
and use `delta()`.
- The default timestep has been changed from 60 Hz to 64 Hz. If you wish
to restore the old behaviour, use
`app.insert_resource(Time::<Fixed>::from_hz(60.0))`.
- Change `app.insert_resource(FixedTime::new(duration))` to
`app.insert_resource(Time::<Fixed>::from_duration(duration))`
- Change `app.insert_resource(FixedTime::new_from_secs(secs))` to
`app.insert_resource(Time::<Fixed>::from_seconds(secs))`
- Change `system.on_fixed_timer(duration)` to
`system.on_timer(duration)`. Timers in systems placed in `FixedUpdate`
schedule automatically use the fixed time clock.
- Change `ResMut<Time>` calls to `pause()`, `is_paused()`,
`set_relative_speed()` and related methods to `ResMut<Time<Virtual>>`
calls. The API is the same, with the exception that `relative_speed()`
will return the actual last ste relative speed, while
`effective_relative_speed()` returns 0.0 if the time is paused and
corresponds to the speed that was set when the update for the current
frame started.
## Todo
- [x] Update pull name and description
- [x] Top level documentation on usage
- [x] Fix examples
- [x] Decide on default `max_delta` value
- [x] Decide naming of the three clocks: is `Real`, `Virtual`, `Fixed`
good?
- [x] Decide if the three clock inner structures should be in prelude
- [x] Decide on best way to configure values at startup: is manually
inserting a new clock instance okay, or should there be config struct
separately?
- [x] Fix links in docs
- [x] Decide what should be public and what not
- [x] Decide how `wrap_period` should be handled when it is changed
- [x] ~~Add toggles to disable setting the clock as default?~~ No,
separate pull if needed.
- [x] Add tests
- [x] Reformat, ensure adheres to conventions etc.
- [x] Build documentation and see that it looks correct
## Contributors
Huge thanks to @alice-i-cecile and @maniwani while building this pull.
It was a shared effort!
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Cameron <51241057+maniwani@users.noreply.github.com>
Co-authored-by: Jerome Humbert <djeedai@gmail.com>
# Objective
Calling `asset_server.load("scene.gltf#SomeLabel")` will silently fail
if `SomeLabel` does not exist.
Referenced in #9714
## Solution
We now detect this case and return an error. I also slightly refactored
`load_internal` to make the logic / dataflow much clearer.
---------
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
As called out in #9714, Bevy Asset V2 fails to hot-reload labeled assets
whose source asset has changed (in cases where the root asset is not
alive).
## Solution
Track alive labeled assets for a given source asset and allow hot
reloads in cases where a labeled asset is still alive.
# Objective
- Since #9885, running on an iOS device crashes trying to create the
processed folder
- This only happens on real device, not on the simulator
## Solution
- Setup processed assets only if needed
# Objective
On nightly there is a warning on a missing lifetime:
```bash
warning: `&` without an explicit lifetime name cannot be used here
```
The details are in https://github.com/rust-lang/rust/issues/115010, but
the bottom line is that in associated constants elided lifetimes are no
longer allowed to be implicitly defined.
This fixes the only place where it is missing.
## Solution
- Add explicit `'static` lifetime
# Objective
Currently, the asset loader outputs
```
2023-10-14T15:11:09.328850Z WARN bevy_asset::asset_server: no `AssetLoader` found
```
when user forgets to add an extension to a file. This is very confusing
behaviour, it sounds like there aren't any asset loaders existing.
## Solution
Add an extra message on the end when there are no file extensions.
# Objective
#10105 changed the ssao input color from the material base color to
white. i can't actually see a difference in the example but there should
be one in some cases.
## Solution
change it back.
# Objective
From my understanding, although resources are not meant to be created
and removed at every frame, they are still meant to be created
dynamically during the lifetime of the App.
But because the extract_resource API does not allow optional resources
from the main world, it's impossible to use resources in the render
phase that were not created before the render sub-app itself.
## Solution
Because the ECS engine already allows for system parameters to be
`Option<Res>`, it just had to be added.
---
## Changelog
- Changed
- `extract_resource` now takes an optional main world resource
- Fixed
- `ExtractResourcePlugin` doesn't cause panics anymore if the resource
is not already inserted
This adds support for **Multiple Asset Sources**. You can now register a
named `AssetSource`, which you can load assets from like you normally
would:
```rust
let shader: Handle<Shader> = asset_server.load("custom_source://path/to/shader.wgsl");
```
Notice that `AssetPath` now supports `some_source://` syntax. This can
now be accessed through the `asset_path.source()` accessor.
Asset source names _are not required_. If one is not specified, the
default asset source will be used:
```rust
let shader: Handle<Shader> = asset_server.load("path/to/shader.wgsl");
```
The behavior of the default asset source has not changed. Ex: the
`assets` folder is still the default.
As referenced in #9714
## Why?
**Multiple Asset Sources** enables a number of often-asked-for
scenarios:
* **Loading some assets from other locations on disk**: you could create
a `config` asset source that reads from the OS-default config folder
(not implemented in this PR)
* **Loading some assets from a remote server**: you could register a new
`remote` asset source that reads some assets from a remote http server
(not implemented in this PR)
* **Improved "Binary Embedded" Assets**: we can use this system for
"embedded-in-binary assets", which allows us to replace the old
`load_internal_asset!` approach, which couldn't support asset
processing, didn't support hot-reloading _well_, and didn't make
embedded assets accessible to the `AssetServer` (implemented in this pr)
## Adding New Asset Sources
An `AssetSource` is "just" a collection of `AssetReader`, `AssetWriter`,
and `AssetWatcher` entries. You can configure new asset sources like
this:
```rust
app.register_asset_source(
"other",
AssetSource::build()
.with_reader(|| Box::new(FileAssetReader::new("other")))
)
)
```
Note that `AssetSource` construction _must_ be repeatable, which is why
a closure is accepted.
`AssetSourceBuilder` supports `with_reader`, `with_writer`,
`with_watcher`, `with_processed_reader`, `with_processed_writer`, and
`with_processed_watcher`.
Note that the "asset source" system replaces the old "asset providers"
system.
## Processing Multiple Sources
The `AssetProcessor` now supports multiple asset sources! Processed
assets can refer to assets in other sources and everything "just works".
Each `AssetSource` defines an unprocessed and processed `AssetReader` /
`AssetWriter`.
Currently this is all or nothing for a given `AssetSource`. A given
source is either processed or it is not. Later we might want to add
support for "lazy asset processing", where an `AssetSource` (such as a
remote server) can be configured to only process assets that are
directly referenced by local assets (in order to save local disk space
and avoid doing extra work).
## A new `AssetSource`: `embedded`
One of the big features motivating **Multiple Asset Sources** was
improving our "embedded-in-binary" asset loading. To prove out the
**Multiple Asset Sources** implementation, I chose to build a new
`embedded` `AssetSource`, which replaces the old `load_interal_asset!`
system.
The old `load_internal_asset!` approach had a number of issues:
* The `AssetServer` was not aware of (or capable of loading) internal
assets.
* Because internal assets weren't visible to the `AssetServer`, they
could not be processed (or used by assets that are processed). This
would prevent things "preprocessing shaders that depend on built in Bevy
shaders", which is something we desperately need to start doing.
* Each "internal asset" needed a UUID to be defined in-code to reference
it. This was very manual and toilsome.
The new `embedded` `AssetSource` enables the following pattern:
```rust
// Called in `crates/bevy_pbr/src/render/mesh.rs`
embedded_asset!(app, "mesh.wgsl");
// later in the app
let shader: Handle<Shader> = asset_server.load("embedded://bevy_pbr/render/mesh.wgsl");
```
Notice that this always treats the crate name as the "root path", and it
trims out the `src` path for brevity. This is generally predictable, but
if you need to debug you can use the new `embedded_path!` macro to get a
`PathBuf` that matches the one used by `embedded_asset`.
You can also reference embedded assets in arbitrary assets, such as WGSL
shaders:
```rust
#import "embedded://bevy_pbr/render/mesh.wgsl"
```
This also makes `embedded` assets go through the "normal" asset
lifecycle. They are only loaded when they are actually used!
We are also discussing implicitly converting asset paths to/from shader
modules, so in the future (not in this PR) you might be able to load it
like this:
```rust
#import bevy_pbr::render::mesh::Vertex
```
Compare that to the old system!
```rust
pub const MESH_SHADER_HANDLE: Handle<Shader> = Handle::weak_from_u128(3252377289100772450);
load_internal_asset!(app, MESH_SHADER_HANDLE, "mesh.wgsl", Shader::from_wgsl);
// The mesh asset is the _only_ accessible via MESH_SHADER_HANDLE and _cannot_ be loaded via the AssetServer.
```
## Hot Reloading `embedded`
You can enable `embedded` hot reloading by enabling the
`embedded_watcher` cargo feature:
```
cargo run --features=embedded_watcher
```
## Improved Hot Reloading Workflow
First: the `filesystem_watcher` cargo feature has been renamed to
`file_watcher` for brevity (and to match the `FileAssetReader` naming
convention).
More importantly, hot asset reloading is no longer configured in-code by
default. If you enable any asset watcher feature (such as `file_watcher`
or `rust_source_watcher`), asset watching will be automatically enabled.
This removes the need to _also_ enable hot reloading in your app code.
That means you can replace this:
```rust
app.add_plugins(DefaultPlugins.set(AssetPlugin::default().watch_for_changes()))
```
with this:
```rust
app.add_plugins(DefaultPlugins)
```
If you want to hot reload assets in your app during development, just
run your app like this:
```
cargo run --features=file_watcher
```
This means you can use the same code for development and deployment! To
deploy an app, just don't include the watcher feature
```
cargo build --release
```
My intent is to move to this approach for pretty much all dev workflows.
In a future PR I would like to replace `AssetMode::ProcessedDev` with a
`runtime-processor` cargo feature. We could then group all common "dev"
cargo features under a single `dev` feature:
```sh
# this would enable file_watcher, embedded_watcher, runtime-processor, and more
cargo run --features=dev
```
## AssetMode
`AssetPlugin::Unprocessed`, `AssetPlugin::Processed`, and
`AssetPlugin::ProcessedDev` have been replaced with an `AssetMode` field
on `AssetPlugin`.
```rust
// before
app.add_plugins(DefaultPlugins.set(AssetPlugin::Processed { /* fields here */ })
// after
app.add_plugins(DefaultPlugins.set(AssetPlugin { mode: AssetMode::Processed, ..default() })
```
This aligns `AssetPlugin` with our other struct-like plugins. The old
"source" and "destination" `AssetProvider` fields in the enum variants
have been replaced by the "asset source" system. You no longer need to
configure the AssetPlugin to "point" to custom asset providers.
## AssetServerMode
To improve the implementation of **Multiple Asset Sources**,
`AssetServer` was made aware of whether or not it is using "processed"
or "unprocessed" assets. You can check that like this:
```rust
if asset_server.mode() == AssetServerMode::Processed {
/* do something */
}
```
Note that this refactor should also prepare the way for building "one to
many processed output files", as it makes the server aware of whether it
is loading from processed or unprocessed sources. Meaning we can store
and read processed and unprocessed assets differently!
## AssetPath can now refer to folders
The "file only" restriction has been removed from `AssetPath`. The
`AssetServer::load_folder` API now accepts an `AssetPath` instead of a
`Path`, meaning you can load folders from other asset sources!
## Improved AssetPath Parsing
AssetPath parsing was reworked to support sources, improve error
messages, and to enable parsing with a single pass over the string.
`AssetPath::new` was replaced by `AssetPath::parse` and
`AssetPath::try_parse`.
## AssetWatcher broken out from AssetReader
`AssetReader` is no longer responsible for constructing `AssetWatcher`.
This has been moved to `AssetSourceBuilder`.
## Duplicate Event Debouncing
Asset V2 already debounced duplicate filesystem events, but this was
_input_ events. Multiple input event types can produce the same _output_
`AssetSourceEvent`. Now that we have `embedded_watcher`, which does
expensive file io on events, it made sense to debounce output events
too, so I added that! This will also benefit the AssetProcessor by
preventing integrity checks for duplicate events (and helps keep the
noise down in trace logs).
## Next Steps
* **Port Built-in Shaders**: Currently the primary (and essentially
only) user of `load_interal_asset` in Bevy's source code is "built-in
shaders". I chose not to do that in this PR for a few reasons:
1. We need to add the ability to pass shader defs in to shaders via meta
files. Some shaders (such as MESH_VIEW_TYPES) need to pass shader def
values in that are defined in code.
2. We need to revisit the current shader module naming system. I think
we _probably_ want to imply modules from source structure (at least by
default). Ideally in a way that can losslessly convert asset paths
to/from shader modules (to enable the asset system to resolve modules
using the asset server).
3. I want to keep this change set minimal / get this merged first.
* **Deprecate `load_internal_asset`**: we can't do that until we do (1)
and (2)
* **Relative Asset Paths**: This PR significantly increases the need for
relative asset paths (which was already pretty high). Currently when
loading dependencies, it is assumed to be an absolute path, which means
if in an `AssetLoader` you call `context.load("some/path/image.png")` it
will assume that is the "default" asset source, _even if the current
asset is in a different asset source_. This will cause breakage for
AssetLoaders that are not designed to add the current source to whatever
paths are being used. AssetLoaders should generally not need to be aware
of the name of their current asset source, or need to think about the
"current asset source" generally. We should build apis that support
relative asset paths and then encourage using relative paths as much as
possible (both via api design and docs). Relative paths are also
important because they will allow developers to move folders around
(even across providers) without reprocessing, provided there is no path
breakage.
# Objective
- According to the GLTF spec, it should not be possible to have a non
skinned mesh on a skinned node
> When the node contains skin, all mesh.primitives MUST contain JOINTS_0
and WEIGHTS_0 attributes
>
https://registry.khronos.org/glTF/specs/2.0/glTF-2.0.html#reference-node
- However, the reverse (a skinned mesh on a non skinned node) is just a
warning, see `NODE_SKINNED_MESH_WITHOUT_SKIN` in
https://github.com/KhronosGroup/glTF-Validator/blob/main/ISSUES.md#linkerror
- This causes a crash in Bevy because the bind group layout is made from
the mesh which is skinned, but filled from the entity which is not
```
thread '<unnamed>' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 5, Metal)>`
In a set_bind_group command
note: bind group = `<BindGroup-(27, 1, Metal)>`
Bind group 2 expects 2 dynamic offsets. However 1 dynamic offset were provided.
```
- Blender can export GLTF files with this kind of issues
## Solution
- When a skinned mesh is only used on non skinned nodes, ignore skinned
information from the mesh and warn the user (this is what three.js is
doing)
- When a skinned mesh is used on both skinned and non skinned nodes, log
an error
# Objective
Fixes#9676
Possible alternative to #9708
`Text2dBundles` are not currently drawn because the render-world-only
entities for glyphs that are created in `extract_text2d_sprite` are not
tracked by the per-view `VisibleEntities`.
## Solution
Add an `Option<Entity>` to `ExtractedSprite` that keeps track of the
original entity that caused a "glyph entity" to be created.
Use that in `queue_sprites` if it exists when checking view visibility.
## Benchmarks
Quick benchmarks. Average FPS over 1500 frames.
| bench | before fps | after fps | diff |
|-|-|-|-|
|many_sprites|884.93|879.00|🟡 -0.7%|
|bevymark -- --benchmark --waves 100 --per-wave 1000 --mode
sprite|75.99|75.93|🟡 -0.1%|
|bevymark -- --benchmark --waves 50 --per-wave 1000 --mode
mesh2d|32.85|32.58|🟡 -0.8%|
# Objective
cleanup some pbr shader code. improve shader stage io consistency and
make pbr.wgsl (probably many people's first foray into bevy shader code)
a little more human-readable. also fix a couple of small issues with
deferred rendering.
## Solution
mesh_vertex_output:
- rename to forward_io (to align with prepass_io)
- rename `MeshVertexOutput` to `VertexOutput` (to align with prepass_io)
- move `Vertex` from mesh.wgsl into here (to align with prepass_io)
prepass_io:
- remove `FragmentInput`, use `VertexOutput` directly (to align with
forward_io)
- rename `VertexOutput::clip_position` to `position` (to align with
forward_io)
pbr.wgsl:
- restructure so we don't need `#ifdefs` on the actual entrypoint, use
VertexOutput and FragmentOutput in all cases and use #ifdefs to import
the right struct definitions.
- rearrange to make the flow clearer
- move alpha_discard up from `pbr_functions::pbr` to avoid needing to
call it on some branches and not others
- add a bunch of comments
deferred_lighting:
- move ssao into the `!unlit` block to reflect forward behaviour
correctly
- fix compile error with deferred + premultiply_alpha
## Migration Guide
in custom material shaders:
- `pbr_functions::pbr` no longer calls to
`pbr_functions::alpha_discard`. if you were using the `pbr` function in
a custom shader with alpha mask mode you now also need to call
alpha_discard manually
- rename imports of `bevy_pbr::mesh_vertex_output` to
`bevy_pbr::forward_io`
- rename instances of `MeshVertexOutput` to `VertexOutput`
in custom material prepass shaders:
- rename instances of `VertexOutput::clip_position` to
`VertexOutput::position`
# Objective
Fixes#10069
## Solution
Extracted UI nodes were previously stored in a `SparseSet` and had a
predictable iteration order. UI borders and outlines relied on this. Now
they are stored in a HashMap and that is no longer true.
This adds `entity.index()` to the sort key for `TransparentUi` so that
the iteration order is predictable and the "border entities" that get
spawned during extraction are guaranteed to get drawn after their
respective container nodes again.
I **think** that everything still works for overlapping ui nodes etc,
because the z value / primary sort is still controlled by the "ui
stack."
Text above is just my current understanding. A rendering expert should
check this out.
I will do some more testing when I can.
# Objective
Fixes [#10061]
## Solution
Renamed `RenderInstance` to `ExtractInstance`, `RenderInstances` to
`ExtractedInstances` and `RenderInstancePlugin` to
`ExtractInstancesPlugin`
# Objective
- Add a [Deferred
Renderer](https://en.wikipedia.org/wiki/Deferred_shading) to Bevy.
- This allows subsequent passes to access per pixel material information
before/during shading.
- Accessing this per pixel material information is needed for some
features, like GI. It also makes other features (ex. Decals) simpler to
implement and/or improves their capability. There are multiple
approaches to accomplishing this. The deferred shading approach works
well given the limitations of WebGPU and WebGL2.
Motivation: [I'm working on a GI solution for
Bevy](https://youtu.be/eH1AkL-mwhI)
# Solution
- The deferred renderer is implemented with a prepass and a deferred
lighting pass.
- The prepass renders opaque objects into the Gbuffer attachment
(`Rgba32Uint`). The PBR shader generates a `PbrInput` in mostly the same
way as the forward implementation and then [packs it into the
Gbuffer](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L168)).
- The deferred lighting pass unpacks the `PbrInput` and [feeds it into
the pbr()
function](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L65)),
then outputs the shaded color data.
- There is now a resource
[DefaultOpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L599))
that can be used to set the default render method for opaque materials.
If materials return `None` from
[opaque_render_method()](ec1465559f/crates/bevy_pbr/src/material.rs (L131))
the `DefaultOpaqueRendererMethod` will be used. Otherwise, custom
materials can also explicitly choose to only support Deferred or Forward
by returning the respective
[OpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L603))
- Deferred materials can be used seamlessly along with both opaque and
transparent forward rendered materials in the same scene. The [deferred
rendering
example](https://github.com/DGriffin91/bevy/blob/deferred/examples/3d/deferred_rendering.rs)
does this.
- The deferred renderer does not support MSAA. If any deferred materials
are used, MSAA must be disabled. Both TAA and FXAA are supported.
- Deferred rendering supports WebGL2/WebGPU.
## Custom deferred materials
- Custom materials can support both deferred and forward at the same
time. The
[StandardMaterial](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L166))
does this. So does [this
example](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56).
- Custom deferred materials that require PBR lighting can create a
`PbrInput`, write it to the deferred GBuffer and let it be rendered by
the `PBRDeferredLightingPlugin`.
- Custom deferred materials that require custom lighting have two
options:
1. Use the base_color channel of the `PbrInput` combined with the
`STANDARD_MATERIAL_FLAGS_UNLIT_BIT` flag.
[Example.](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56)
(If the unlit bit is set, the base_color is stored as RGB9E5 for extra
precision)
2. A Custom Deferred Lighting pass can be created, either overriding the
default, or running in addition. The a depth buffer is used to limit
rendering to only the required fragments for each deferred lighting
pass. Materials can set their respective depth id via the
[deferred_lighting_pass_id](b79182d2a3/crates/bevy_pbr/src/prepass/prepass_io.wgsl (L95))
attachment. The custom deferred lighting pass plugin can then set [its
corresponding
depth](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L37)).
Then with the lighting pass using
[CompareFunction::Equal](ec1465559f/crates/bevy_pbr/src/deferred/mod.rs (L335)),
only the fragments with a depth that equal the corresponding depth
written in the material will be rendered.
Custom deferred lighting plugins can also be created to render the
StandardMaterial. The default deferred lighting plugin can be bypassed
with `DefaultPlugins.set(PBRDeferredLightingPlugin { bypass: true })`
---------
Co-authored-by: nickrart <nickolas.g.russell@gmail.com>
# Objective
While using joysticks for player aiming, I noticed that there was as
`0.05` value snap on the axis. After searching through Bevy's code, I
saw it was the default livezone being at `0.95`. This causes any value
higher to snap to `1.0`. I think `1.0` and `-1.0` would be a better
default, as it gives all values to the joystick arc.
This default livezone stumped me for a bit as I thought either something
was broken or I was doing something wrong.
## Solution
Change the livezone defaults to ` livezone_upperbound: 1.0` and
`livezone_lowerbound: -1.0`.
---
## Migration Guide
If the default 0.05 was relied on, the default or gamepad `AxisSettings`
on the resource `GamepadSettings` will have to be changed.
# Objective
- Fixes#8303
## Solution
- Replaced 1 instance of `OnceBox<T>` with `OnceLock<T>` in
`NonGenericTypeCell`
## Notes
All changes are in the private side of Bevy, and appear to have no
observable change in performance or compilation time. This is purely to
reduce the quantity of direct dependencies in Bevy.
# Objective
- The filter type on the `apply_global_wireframe_material` system had
duplicate filter code and the `clippy::type_complexity` attribute.
## Solution
- Extract the common part of the filter into a type alias
# Objective
- Use the `Material` abstraction for the Wireframes
- Right now this doesn't have many benefits other than simplifying some
of the rendering code
- We can reuse the default vertex shader and avoid rendering
inconsistencies
- The goal is to have a material with a color on each mesh so this
approach will make it easier to implement
- Originally done in https://github.com/bevyengine/bevy/pull/5303 but I
decided to split the Material part to it's own PR and then adding
per-entity colors and globally configurable colors will be a much
simpler diff.
## Solution
- Use the new `Material` abstraction for the Wireframes
## Notes
It's possible this isn't ideal since this adds a
`Handle<WireframeMaterial>` to all the meshes compared to the original
approach that didn't need anything. I didn't notice any performance
impact on my machine.
This might be a surprising usage of `Material` at first, because
intuitively you only have one material per mesh, but the way it's
implemented you can have as many different types of materials as you
want on a mesh.
## Migration Guide
`WireframePipeline` was removed. If you were using it directly, please
create an issue explaining your use case.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Add serde Deserialize and Serialize for structs that doesn't implement
it, even if they could benefit from it
## Solution
- Derive these traits for the structs Style, BackgroundColor,
BorderColor and Outline.
---
Adopted from #8954, co-authored by @pyrotechnick
# Objective
The Bevy ecosystem currently reflects `Quat` via "value" rather than the
more appropriate "struct" strategy. This behaviour is inconsistent to
that of similar types, i.e. `Vec3`. Additionally, employing the "value"
strategy causes instances of `Quat` to be serialised as a sequence `[x,
y, z, w]` rather than structures of shape `{ x, y, z, w }`.
The [comments surrounding the applicable
code](bec299fa6e/crates/bevy_reflect/src/impls/glam.rs (L254))
give context and historical reasons for this discrepancy:
```
// Quat fields are read-only (as of now), and reflection is currently missing
// mechanisms for read-only fields. I doubt those mechanisms would be added,
// so for now quaternions will remain as values. They are represented identically
// to Vec4 and DVec4, so you may use those instead and convert between.
```
This limitation has [since been lifted by the upstream
crate](374625163e),
glam.
## Solution
Migrating the reflect strategy of Quat from "value" to "struct" via
replacing `impl_reflect_value` with `impl_reflect_struct` resolves the
issue.
## Changelog
Migrated `Quat` reflection strategy to "struct" from "value"
Migration Guide
Changed Quat serialization/deserialization from sequences `[x, y, z, w]`
to structures `{ x, y, z, w }`.
---------
Co-authored-by: pyrotechnick <13998+pyrotechnick@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
~~Currently blocked on an upstream bug that causes crashes when
minimizing/resizing on dx12 https://github.com/gfx-rs/wgpu/issues/3967~~
wgpu 0.17.1 is out which fixes it
# Objective
Keep wgpu up to date.
## Solution
Update wgpu and naga_oil.
Currently this depends on an unreleased (and unmerged) branch of
naga_oil, and hasn't been properly tested yet.
The wgpu side of this seems to have been an extremely trivial upgrade
(all the upgrade work seems to be in naga_oil). This also lets us remove
the workarounds for pack/unpack4x8unorm in the SSAO shaders.
Lets us close the dx12 part of
https://github.com/bevyengine/bevy/issues/8888
related: https://github.com/bevyengine/bevy/issues/9304
---
## Changelog
Update to wgpu 0.17 and naga_oil 0.9
# Objective
- This PR aims to make creating meshes a little bit more ergonomic,
specifically by removing the need for intermediate mutable variables.
## Solution
- We add methods that consume the `Mesh` and return a mesh with the
specified changes, so that meshes can be entirely constructed via
builder-style calls, without intermediate variables;
- Methods are flagged with `#[must_use]` to ensure proper use;
- Examples are updated to use the new methods where applicable. Some
examples are kept with the mutating methods so that users can still
easily discover them, and also where the new methods wouldn't really be
an improvement.
## Examples
Before:
```rust
let mut mesh = Mesh::new(PrimitiveTopology::TriangleList);
mesh.insert_attribute(Mesh::ATTRIBUTE_POSITION, vs);
mesh.insert_attribute(Mesh::ATTRIBUTE_NORMAL, vns);
mesh.insert_attribute(Mesh::ATTRIBUTE_UV_0, vts);
mesh.set_indices(Some(Indices::U32(tris)));
mesh
```
After:
```rust
Mesh::new(PrimitiveTopology::TriangleList)
.with_inserted_attribute(Mesh::ATTRIBUTE_POSITION, vs)
.with_inserted_attribute(Mesh::ATTRIBUTE_NORMAL, vns)
.with_inserted_attribute(Mesh::ATTRIBUTE_UV_0, vts)
.with_indices(Some(Indices::U32(tris)))
```
Before:
```rust
let mut cube = Mesh::from(shape::Cube { size: 1.0 });
cube.generate_tangents().unwrap();
PbrBundle {
mesh: meshes.add(cube),
..default()
}
```
After:
```rust
PbrBundle {
mesh: meshes.add(
Mesh::from(shape::Cube { size: 1.0 })
.with_generated_tangents()
.unwrap(),
),
..default()
}
```
---
## Changelog
- Added consuming builder methods for more ergonomic `Mesh` creation:
`with_inserted_attribute()`, `with_removed_attribute()`,
`with_indices()`, `with_duplicated_vertices()`,
`with_computed_flat_normals()`, `with_generated_tangents()`,
`with_morph_targets()`, `with_morph_target_names()`.
# Objective
Closes#9955.
Use the same interface for all "pure" builder types: taking and
returning `Self` (and not `&mut Self`).
## Solution
Changed `DynamicSceneBuilder`, `SceneFilter` and `TableBuilder` to take
and return `Self`.
## Changelog
### Changed
- `DynamicSceneBuilder` and `SceneBuilder` methods in `bevy_ecs` now
take and return `Self`.
## Migration guide
When using `bevy_ecs::DynamicSceneBuilder` and `bevy_ecs::SceneBuilder`,
instead of binding the builder to a variable, directly use it. Methods
on those types now consume `Self`, so you will need to re-bind the
builder if you don't `build` it immediately.
Before:
```rust
let mut scene_builder = DynamicSceneBuilder::from_world(&world);
let scene = scene_builder.extract_entity(a).extract_entity(b).build();
```
After:
```rust
let scene = DynamicSceneBuilder::from_world(&world)
.extract_entity(a)
.extract_entity(b)
.build();
```
# Objective
Spatial audio was heroically thrown together at the last minute for Bevy
0.10, but right now it's a bit of a pain to use -- users need to
manually update audio sinks with the position of the listener / emitter.
Hopefully the migration guide entry speaks for itself.
## Solution
Add a new `SpatialListener` component and automatically update sinks
with the position of the listener and and emitter.
## Changelog
`SpatialAudioSink`s are now automatically updated with positions of
emitters and listeners.
## Migration Guide
Spatial audio now automatically uses the transform of the `AudioBundle`
and of an entity with a `SpatialListener` component.
If you were manually scaling emitter/listener positions, you can use the
`spatial_scale` field of `AudioPlugin` instead.
```rust
// Old
commands.spawn(
SpatialAudioBundle {
source: asset_server.load("sounds/Windless Slopes.ogg"),
settings: PlaybackSettings::LOOP,
spatial: SpatialSettings::new(listener_position, gap, emitter_position),
},
);
fn update(
emitter_query: Query<(&Transform, &SpatialAudioSink)>,
listener_query: Query<&Transform, With<Listener>>,
) {
let listener = listener_query.single();
for (transform, sink) in &emitter_query {
sink.set_emitter_position(transform.translation);
sink.set_listener_position(*listener, gap);
}
}
// New
commands.spawn((
SpatialBundle::from_transform(Transform::from_translation(emitter_position)),
AudioBundle {
source: asset_server.load("sounds/Windless Slopes.ogg"),
settings: PlaybackSettings::LOOP.with_spatial(true),
},
));
commands.spawn((
SpatialBundle::from_transform(Transform::from_translation(listener_position)),
SpatialListener::new(gap),
));
```
## Discussion
I removed `SpatialAudioBundle` because the `SpatialSettings` component
was made mostly redundant, and without that it was identical to
`AudioBundle`.
`SpatialListener` is a bare component and not a bundle which is feeling
like a maybe a strange choice. That happened from a natural aversion
both to nested bundles and to duplicating `Transform` etc in bundles and
from figuring that it is likely to just be tacked on to some other
bundle (player, head, camera) most of the time.
Let me know what you think about these things / everything else.
---------
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
- Followup to #7184.
- ~Deprecate `TypeUuid` and remove its internal references.~ No longer
part of this PR.
- Use `TypePath` for the type registry, and (de)serialisation instead of
`std::any::type_name`.
- Allow accessing type path information behind proxies.
## Solution
- Introduce methods on `TypeInfo` and friends for dynamically querying
type path. These methods supersede the old `type_name` methods.
- Remove `Reflect::type_name` in favor of `DynamicTypePath::type_path`
and `TypeInfo::type_path_table`.
- Switch all uses of `std::any::type_name` in reflection, non-debugging
contexts to use `TypePath`.
---
## Changelog
- Added `TypePathTable` for dynamically accessing methods on `TypePath`
through `TypeInfo` and the type registry.
- Removed `type_name` from all `TypeInfo`-like structs.
- Added `type_path` and `type_path_table` methods to all `TypeInfo`-like
structs.
- Removed `Reflect::type_name` in favor of
`DynamicTypePath::reflect_type_path` and `TypeInfo::type_path`.
- Changed the signature of all `DynamicTypePath` methods to return
strings with a static lifetime.
## Migration Guide
- Rely on `TypePath` instead of `std::any::type_name` for all stability
guarantees and for use in all reflection contexts, this is used through
with one of the following APIs:
- `TypePath::type_path` if you have a concrete type and not a value.
- `DynamicTypePath::reflect_type_path` if you have an `dyn Reflect`
value without a concrete type.
- `TypeInfo::type_path` for use through the registry or if you want to
work with the represented type of a `DynamicFoo`.
- Remove `type_name` from manual `Reflect` implementations.
- Use `type_path` and `type_path_table` in place of `type_name` on
`TypeInfo`-like structs.
- Use `get_with_type_path(_mut)` over `get_with_type_name(_mut)`.
## Note to reviewers
I think if anything we were a little overzealous in merging #7184 and we
should take that extra care here.
In my mind, this is the "point of no return" for `TypePath` and while I
think we all agree on the design, we should carefully consider if the
finer details and current implementations are actually how we want them
moving forward.
For example [this incorrect `TypePath` implementation for
`String`](3fea3c6c0b/crates/bevy_reflect/src/impls/std.rs (L90))
(note that `String` is in the default Rust prelude) snuck in completely
under the radar.
Updates the requirements on [toml_edit](https://github.com/toml-rs/toml)
to permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="ed597ebad1"><code>ed597eb</code></a>
chore: Release</li>
<li><a
href="257a0fdc59"><code>257a0fd</code></a>
docs: Update changelog</li>
<li><a
href="4b44f53a31"><code>4b44f53</code></a>
Merge pull request <a
href="https://redirect.github.com/toml-rs/toml/issues/617">#617</a> from
epage/update</li>
<li><a
href="7eaf286110"><code>7eaf286</code></a>
fix(parser): Failed on mixed inline tables</li>
<li><a
href="e1f20378a2"><code>e1f2037</code></a>
test: Verify with latest data</li>
<li><a
href="2f9253c9eb"><code>2f9253c</code></a>
chore: Update toml-test</li>
<li><a
href="c9b481cab5"><code>c9b481c</code></a>
test(toml): Ensure tables are used for validation</li>
<li><a
href="43d7f29cfd"><code>43d7f29</code></a>
Merge pull request <a
href="https://redirect.github.com/toml-rs/toml/issues/615">#615</a> from
toml-rs/renovate/actions-checkout-4.x</li>
<li><a
href="ef9b8372c8"><code>ef9b837</code></a>
chore(deps): update actions/checkout action to v4</li>
<li><a
href="d308188db7"><code>d308188</code></a>
chore: Release</li>
<li>Additional commits viewable in <a
href="https://github.com/toml-rs/toml/compare/v0.19.0...v0.20.2">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
fix#9605
spotlight culling uses an incorrect cluster aabb for orthographic
projections: it does not take into account the near and far cluster
bounds at all.
## Solution
use z_near and z_far to determine cluster aabb in orthographic mode.
i'm not 100% sure this is the only change that's needed, but i am sure
this change is needed, and the example seems to work well now
(CLUSTERED_FORWARD_DEBUG_CLUSTER_LIGHT_COMPLEXITY shows good bounds
around the cone for a variety of orthographic setups).
# Objective
Webgl2 broke when pcf was merged.
Fixes#10048
## Solution
Change the `textureSampleCompareLevel` in shadow_sampling.wgsl to
`textureSampleCompare` to make it work again.
# Objective
Currently, the only way for custom components that participate in
rendering to opt into the higher-performance extraction method in #9903
is to implement the `RenderInstances` data structure and the extraction
logic manually. This is inconvenient compared to the `ExtractComponent`
API.
## Solution
This commit creates a new `RenderInstance` trait that mirrors the
existing `ExtractComponent` method but uses the higher-performance
approach that #9903 uses. Additionally, `RenderInstance` is more
flexible than `ExtractComponent`, because it can extract multiple
components at once. This makes high-performance rendering components
essentially as easy to write as the existing ones based on component
extraction.
---
## Changelog
### Added
A new `RenderInstance` trait is available mirroring `ExtractComponent`,
but using a higher-performance method to extract one or more components
to the render world. If you have custom components that rendering takes
into account, you may consider migration from `ExtractComponent` to
`RenderInstance` for higher performance.
# Objective
- Improve antialiasing for non-point light shadow edges.
- Very partially addresses
https://github.com/bevyengine/bevy/issues/3628.
## Solution
- Implements "The Witness"'s shadow map sampling technique.
- Ported from @superdump's old branch, all credit to them :)
- Implements "Call of Duty: Advanced Warfare"'s stochastic shadow map
sampling technique when the velocity prepass is enabled, for use with
TAA.
- Uses interleaved gradient noise to generate a random angle, and then
averages 8 samples in a spiral pattern, rotated by the random angle.
- I also tried spatiotemporal blue noise, but it was far too noisy to be
filtered by TAA alone. In the future, we should try spatiotemporal blue
noise + a specialized shadow denoiser such as
https://gpuopen.com/fidelityfx-denoiser/#shadow. This approach would
also be useful for hybrid rasterized applications with raytraced
shadows.
- The COD presentation has an interesting temporal dithering of the
noise for use with temporal supersampling that we should revisit when we
get DLSS/FSR/other TSR.
---
## Changelog
* Added `ShadowFilteringMethod`. Improved directional light and
spotlight shadow edges to be less aliased.
## Migration Guide
* Shadows cast by directional lights or spotlights now have smoother
edges. To revert to the old behavior, add
`ShadowFilteringMethod::Hardware2x2` to your cameras.
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- After https://github.com/bevyengine/bevy/pull/9903, example
`mesh2d_manual` doesn't render anything
## Solution
- Fix the example using the new `RenderMesh2dInstances`
# Objective
- Fix TextureAtlasBuilder padding issue
TextureAtlasBuilder padding is reserved during add_texture() but can
still be changed afterwards. This means that changing padding after the
textures will be wrongly applied, either distorting the textures or
panicking if new padding is higher than texture+old padding.
## Solution
- Delay applying padding until finish()
# Objective
Allow Bevy apps to run without requiring to start from the main thread.
This allows other projects and applications to do things like spawning a
normal or scoped
thread and run Bevy applications there.
The current behaviour if you try this is a panic.
## Solution
Allow this by default on platforms winit supports this behaviour on
(x11, Wayland, Windows).
---
## Changelog
### Added
- Added the ability to start Bevy apps outside of the main thread on
x11, Wayland, Windows
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@nordicsemi.no>
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#8140
## Solution
- Added Explicit Error Typing for `AssetLoader` and `AssetSaver`, which
were the last instances of `anyhow` in use across Bevy.
---
## Changelog
- Added an associated type `Error` to `AssetLoader` and `AssetSaver` for
use with the `load` and `save` methods respectively.
- Changed `ErasedAssetLoader` and `ErasedAssetSaver` `load` and `save`
methods to use `Box<dyn Error + Send + Sync + 'static>` to allow for
arbitrary `Error` types from the non-erased trait variants. Note the
strict requirements match the pre-existing requirements around
`anyhow::Error`.
## Migration Guide
- `anyhow` is no longer exported by `bevy_asset`; Add it to your own
project (if required).
- `AssetLoader` and `AssetSaver` have an associated type `Error`; Define
an appropriate error type (e.g., using `thiserror`), or use a pre-made
error type (e.g., `anyhow::Error`). Note that using `anyhow::Error` is a
drop-in replacement.
- `AssetLoaderError` has been removed; Define a new error type, or use
an alternative (e.g., `anyhow::Error`)
- All the first-party `AssetLoader`'s and `AssetSaver`'s now return
relevant (and narrow) error types instead of a single ambiguous type;
Match over the specific error type, or encapsulate (`Box<dyn>`,
`thiserror`, `anyhow`, etc.)
## Notes
A simpler PR to resolve this issue would simply define a Bevy `Error`
type defined as `Box<dyn std::error::Error + Send + Sync + 'static>`,
but I think this type of error handling should be discouraged when
possible. Since only 2 traits required the use of `anyhow`, it isn't a
substantive body of work to solidify these error types, and remove
`anyhow` entirely. End users are still encouraged to use `anyhow` if
that is their preferred error handling style. Arguably, adding the
`Error` associated type gives more freedom to end-users to decide
whether they want more or less explicit error handling (`anyhow` vs
`thiserror`).
As an aside, I didn't perform any testing on Android or WASM. CI passed
locally, but there may be mistakes for those platforms I missed.
# Objective
assets v2 broke custom shader imports. fix them
## Solution
store handles of any file dependencies in the `Shader` to avoid them
being immediately dropped.
also added a use into the `shader_material` example so that it'll be
harder to break support in future.
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
https://github.com/bevyengine/bevy/pull/7328 introduced an API to
override the global wireframe config. I believe it is flawed for a few
reasons.
This PR uses a non-breaking API. Instead of making the `Wireframe` an
enum I introduced the `NeverRenderWireframe` component. Here's the
reason why I think this is better:
- Easier to migrate since it doesn't change the old behaviour.
Essentially nothing to migrate. Right now this PR is a breaking change
but I don't think it has to be.
- It's similar to other "per mesh" rendering features like
NotShadowCaster/NotShadowReceiver
- It doesn't force new users to also think about global vs not global if
all they want is to render a wireframe
- This would also let you filter at the query definition level instead
of filtering when running the query
## Solution
- Introduce a `NeverRenderWireframe` component that ignores the global
config
---
## Changelog
- Added a `NeverRenderWireframe` component that ignores the global
`WireframeConfig`
# Objective
Add support for drawing outlines outside the borders of UI nodes.
## Solution
Add a new `Outline` component with `width`, `offset` and `color` fields.
Added `outline_width` and `outline_offset` fields to `Node`. This is set
after layout recomputation by the `resolve_outlines_system`.
Properties of outlines:
* Unlike borders, outlines have to be the same width on each edge.
* Outlines do not occupy any space in the layout.
* The `Outline` component won't be added to any of the UI node bundles,
it needs to be inserted separately.
* Outlines are drawn outside the node's border, so they are clipped
using the clipping rect of their entity's parent UI node (if it exists).
* `Val::Percent` outline widths are resolved based on the width of the
outlined UI node.
* The offset of the `Outline` adds space between an outline and the edge
of its node.
I was leaning towards adding an `outline` field to `Style` but a
separate component seems more efficient for queries and change
detection. The `Outline` component isn't added to bundles for the same
reason.
---
## Examples
* This image is from the `borders` example from the Bevy UI examples but
modified to include outlines. The UI nodes are the dark red rectangles,
the bright red rectangles are borders and the white lines offset from
each node are the outlines. The yellow rectangles are separate nodes
contained with the dark red nodes:
<img width="406" alt="outlines"
src="https://github.com/bevyengine/bevy/assets/27962798/4e6f315a-019f-42a4-94ee-cca8e684d64a">
* This is from the same example but using a branch that implements
border-radius. Here the the outlines are in orange and there is no
offset applied. I broke the borders implementation somehow during the
merge, which is why some of the borders from the first screenshot are
missing 😅. The outlines work nicely though (as long as you
can forgive the lack of anti-aliasing):

---
## Notes
As I explained above, I don't think the `Outline` component should be
added to UI node bundles. We can have helper functions though, perhaps
something as simple as:
```rust
impl NodeBundle {
pub fn with_outline(self, outline: Outline) -> (Self, Outline) {
(self, outline)
}
}
```
I didn't include anything like this as I wanted to keep the PR's scope
as narrow as possible. Maybe `with_outline` should be in a trait that we
implement for each UI node bundle.
---
## Changelog
Added support for outlines to Bevy UI.
* The `Outline` component adds an outline to a UI node.
* The `outline_width` field added to `Node` holds the resolved width of
the outline, which is set by the `resolve_outlines_system` after layout
recomputation.
* Outlines are drawn by the system `extract_uinode_outlines`.
# Objective
- When I've tested alternative async executors with bevy a common
problem is that they deadlock when we try to run nested scopes. i.e.
running a multithreaded schedule from inside another multithreaded
schedule. This adds a test to bevy_tasks for that so the issue can be
spotted earlier while developing.
## Changelog
- add a test for nested scopes.
# Objective
Fix warnings:
- #[warn(clippy::needless_pass_by_ref_mut)]
- #[warn(elided_lifetimes_in_associated_constant)]
## Solution
- Remove mut
- add &'static
## Errors
```rust
warning: this argument is a mutable reference, but not used mutably
--> crates/bevy_hierarchy/src/child_builder.rs:672:31
|
672 | fn assert_children(world: &mut World, parent: Entity, children: Option<&[Entity]>) {
| ^^^^^^^^^^ help: consider changing to: `&World`
|
= note: this is cfg-gated and may require further changes
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#needless_pass_by_ref_mut
= note: `#[warn(clippy::needless_pass_by_ref_mut)]` on by default
```
```rust
warning: `&` without an explicit lifetime name cannot be used here
--> examples/shader/post_processing.rs:120:21
|
120 | pub const NAME: &str = "post_process";
| ^
|
= warning: this was previously accepted by the compiler but is being phased out; it will become a hard error in a future release!
= note: for more information, see issue #115010 <https://github.com/rust-lang/rust/issues/115010>
= note: `#[warn(elided_lifetimes_in_associated_constant)]` on by default
help: use the `'static` lifetime
|
120 | pub const NAME: &'static str = "post_process";
| +++++++
```
# Objective
Allow the user to choose between "Add wireframes to these specific
entities" or "Add wireframes to everything _except_ these specific
entities".
Fixes#7309
# Solution
Make the `Wireframe` component act like an override to the global
configuration.
Having `global` set to `false`, and adding a `Wireframe` with `enable:
true` acts exactly as before.
But now the opposite is also possible: Set `global` to `true` and add a
`Wireframe` with `enable: false` will draw wireframes for everything
_except_ that entity.
Updated the example to show how overriding the global config works.
# Objective
- Fixes#9884
- Add API for ignoring ambiguities on certain resource or components.
## Solution
- Add a `IgnoreSchedulingAmbiguitiy` resource to the world which holds
the `ComponentIds` to be ignored
- Filter out ambiguities with those component id's.
## Changelog
- add `allow_ambiguous_component` and `allow_ambiguous_resource` apis
for ignoring ambiguities
---------
Co-authored-by: Ryan Johnson <ryanj00a@gmail.com>
# Objective
- Finish documenting `bevy_gltf`.
## Solution
- Document the remaining items, add links to the glTF spec where
relevant. Add the `warn(missing_doc)` attribute.
# Objective
- See fewer warnings when running `cargo clippy` locally.
## Solution
- allow `clippy::type_complexity` in more places, which also signals to
users they should do the same.
# Objective
`bevy_a11y` was impossible to integrate into some third-party projects
in part because it insisted on managing the accessibility tree on its
own.
## Solution
The changes in this PR were necessary to get `bevy_egui` working with
Bevy's AccessKit integration. They were tested on a fork of 0.11,
developed against `bevy_egui`, then ported to main and tested against
the `ui` example.
## Changelog
### Changed
* Add `bevy_a11y::ManageAccessibilityUpdates` to indicate whether the
ECS should manage accessibility tree updates.
* Add getter/setter to `bevy_a11y::AccessibilityRequested`.
* Add `bevy_a11y::AccessibilitySystem` `SystemSet` for ordering relative
to accessibility tree updates.
* Upgrade `accesskit` to v0.12.0.
### Fixed
* Correctly set initial accessibility focus to new windows on creation.
## Migration Guide
### Change direct accesses of `AccessibilityRequested` to use
`AccessibilityRequested.::get()`/`AccessibilityRequested::set()`
#### Before
```
use std::sync::atomic::Ordering;
// To access
accessibility_requested.load(Ordering::SeqCst)
// To update
accessibility_requested.store(true, Ordering::SeqCst);
```
#### After
```
// To access
accessibility_requested.get()
// To update
accessibility_requested.set(true);
```
---------
Co-authored-by: StaffEngineer <111751109+StaffEngineer@users.noreply.github.com>
Conventionally, the second UV map (`TEXCOORD1`, `UV1`) is used for
lightmap UVs. This commit allows Bevy to import them, so that a custom
shader that applies lightmaps can use those UVs if desired.
Note that this doesn't actually apply lightmaps to Bevy meshes; that
will be a followup. It does, however, open the door to future Bevy
plugins that implement baked global illumination.
## Changelog
### Added
The Bevy glTF loader now imports a second UV channel (`TEXCOORD1`,
`UV1`) from meshes if present. This can be used by custom shaders to
implement lightmapping.
# Objective
- Handle suspend / resume events on Android without exiting
## Solution
- On suspend: despawn the window, and set the control flow to wait for
events from the OS
- On resume: spawn a new window, and set the control flow to poll
In this video, you can see the Android example being suspended, stopping
receiving events, and working again after being resumed
https://github.com/bevyengine/bevy/assets/8672791/aaaf4b09-ee6a-4a0d-87ad-41f05def7945
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
- Fixes#4610
## Solution
- Replaced all instances of `parking_lot` locks with equivalents from
`std::sync`. Acquiring locks within `std::sync` can fail, so
`.expect("Lock Poisoned")` statements were added where required.
## Comments
In [this
comment](https://github.com/bevyengine/bevy/issues/4610#issuecomment-1592407881),
the lack of deadlock detection was mentioned as a potential reason to
not make this change. From what I can gather, Bevy doesn't appear to be
using this functionality within the engine. Unless it was expected that
a Bevy consumer was expected to enable and use this functionality, it
appears to be a feature lost without consequence.
Unfortunately, `cpal` and `wgpu` both still rely on `parking_lot`,
leaving it in the dependency graph even after this change.
From my basic experimentation, this change doesn't appear to have any
performance impacts, positive or negative. I tested this using
`bevymark` with 50,000 entities and observed 20ms of frame-time before
and after the change. More extensive testing with larger/real projects
should probably be done.
# Objective
`Has<T>` was added to bevy_ecs, but we're still using the
`Option<With<T>>` pattern in multiple locations.
## Solution
Replace them with `Has<T>`.
# Objective
Add a new method so you can do `set_if_neq` with dereferencing
components: `as_deref_mut()`!
## Solution
Added an as_deref_mut method so that we can use `set_if_neq()` without
having to wrap up types for derefencable components
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Fixes#9363
## Solution
Moved `fq_std` from `bevy_reflect_derive` to `bevy_macro_utils`. This
does make the `FQ*` types public where they were previously private,
which is a change to the public-facing API, but I don't believe a
breaking one. Additionally, I've done a basic QA pass over the
`bevy_macro_utils` crate, adding `deny(unsafe)`, `warn(missing_docs)`,
and documentation where required.
# Objective
Avert a panic when removing resources from Scenes.
### Reproduction Steps
```rust
let mut scene = Scene::new(World::default());
scene.world.init_resource::<Time>();
scene.world.remove_resource::<Time>();
scene.clone_with(&app.resource::<AppTypeRegistry>());
```
### Panic Message
```
thread 'Compute Task Pool (10)' panicked at 'Requested resource bevy_time::time::Time does not exist in the `World`.
Did you forget to add it using `app.insert_resource` / `app.init_resource`?
Resources are also implicitly added via `app.add_event`,
and can be added by plugins.', .../bevy/crates/bevy_ecs/src/reflect/resource.rs:203:52
```
## Solution
Check that the resource actually still exists before copying.
---
## Changelog
- resolved a panic caused by removing resources from scenes
# Objective
Finish documenting `bevy_scene`.
## Solution
Document the remaining items and add a crate-level `warn(missing_doc)`
attribute as for the other crates with completed documentation.
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
# Objective
- sometimes when bevy shuts down on certain machines the render thread
tries to send the time after the main world has been dropped.
- fixes an error mentioned in a reply in
https://github.com/bevyengine/bevy/issues/9543
---
## Changelog
- ignore disconnected errors from the time channel.
# Objective
The `States::variants` method was once used to construct `OnExit` and
`OnEnter` schedules for every possible value of a given `States` type.
[Since the switch to lazily initialized
schedules](https://github.com/bevyengine/bevy/pull/8028/files#diff-b2fba3a0c86e496085ce7f0e3f1de5960cb754c7d215ed0f087aa556e529f97f),
we no longer need to track every possible value.
This also opens the door to `States` types that aren't enums.
## Solution
- Remove the unused `States::variants` method and its associated type.
- Remove the enum-only restriction on derived States types.
---
## Changelog
- Removed `States::variants` and its associated type.
- Derived `States` can now be datatypes other than enums.
## Migration Guide
- `States::variants` no longer exists. If you relied on this function,
consider using a library that provides enum iterators.
# Objective
I was wondering whether to use `Timer::finished` or
`Timer::just_finished` for my repeating timer. This PR clarifies their
difference (or rather, lack thereof).
## Solution
More docs & examples.
# Objective
- There were a few typos in the project.
- This PR fixes these typos.
## Solution
- Fixing the typos.
Signed-off-by: SADIK KUZU <sadikkuzu@hotmail.com>
# Objective
In order to derive `Asset`s (v2), `TypePath` must also be implemented.
`TypePath` is not currently in the prelude, but given it is *required*
when deriving something that *is* in the prelude, I think it deserves to
be added.
## Solution
Add `TypePath` to `bevy_reflect::prelude`.
# Objective
Text bounds are computed by the layout algorithm using the text's
measurefunc so that text will only wrap after it's used the maximum
amount of available horizontal space.
When the layout size is returned the layout coordinates are rounded and
this sometimes results in the final size of the Node not matching the
size computed with the measurefunc. This means that the text may no
longer fit the horizontal available space and instead wrap onto a new
line. However, no glyphs will be generated for this new line because no
vertical space for the extra line was allocated.
fixes#9874
## Solution
Store both the rounded and unrounded node sizes in `Node`.
Rounding is used to eliminate pixel-wide gaps between nodes that should
be touching edge to edge, but this isn't necessary for text nodes as
they don't have solid edges.
## Changelog
* Added the `rounded_size: Vec2` field to `Node`.
* `text_system` uses the unrounded node size when computing a text
layout.
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Improve compatibility with macOS Sonoma and Xcode 15.0.
## Solution
- Adds the workaround by @ptxmac to ignore the invalid window sizes
provided by `winit` on macOS 14.0
- This still provides a slightly wrong content size when resizing (it
fails to account for the window title bar, so some content gets clipped
at the bottom) but it's _much better_ than crashing.
- Adds docs on how to work around the `bindgen` bug on Xcode 15.0.
## Related Issues:
- https://github.com/RustAudio/coreaudio-sys/issues/85
- https://github.com/rust-windowing/winit/issues/2876
---
## Changelog
- Added a workaround for a `winit`-related crash under macOS Sonoma
(14.0)
---------
Co-authored-by: Peter Kristensen <peter@ptx.dk>
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Complete the documentation for `bevy_window`.
## Solution
The `warn(missing_doc)` attribute was only applying to the `cursor`
module as it was declared as an inner attribute. I switched it to an
outer attribute and documented the remaining items.
# Objective
Fixes: #9898
## Solution
Make morph behave like other keyframes, lerping first between start and
end, and then between the current state and the result.
## Changelog
Fixed jerky morph targets
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
Co-authored-by: CGMossa <cgmossa@gmail.com>
# Objective
The scetion for guides about flexbox has a link to grid and the section
for grid has a link to a guide about flexbox.
## Solution
Swapped links for flexbox and grid.
---
This is a duplicate of #9632, it was created since I forgot to make a
new branch when I first made this PR, so I was having trouble resolving
merge conflicts, meaning I had to rebuild my PR.
# Objective
- Allow other plugins to create the renderer resources. An example of
where this would be required is my [OpenXR
plugin](https://github.com/awtterpip/bevy_openxr)
## Solution
- Changed the bevy RenderPlugin to optionally take precreated render
resources instead of a configuration.
## Migration Guide
The `RenderPlugin` now takes a `RenderCreation` enum instead of
`WgpuSettings`. `RenderSettings::default()` returns
`RenderSettings::Automatic(WgpuSettings::default())`. `RenderSettings`
also implements `From<WgpuSettings>`.
```rust
// before
RenderPlugin {
wgpu_settings: WgpuSettings {
...
},
}
// now
RenderPlugin {
render_creation: RenderCreation::Automatic(WgpuSettings {
...
}),
}
// or
RenderPlugin {
render_creation: WgpuSettings {
...
}.into(),
}
```
---------
Co-authored-by: Malek <pocmalek@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Some beginners spend time trying to manually set the position of a
`TextBundle`, without realizing that `Text2dBundle` exists.
## Solution
Mention `Text2dBundle` in the documentation of `TextBundle`.
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Fixes#9625
## Solution
Adds `async-io` as an optional dependency of `bevy_tasks`. When enabled,
this causes calls to `futures_lite::future::block_on` to be replaced
with calls to `async_io::block_on`.
---
## Changelog
- Added a new `async-io` feature to `bevy_tasks`. When enabled, this
causes `bevy_tasks` to use `async-io`'s implemention of `block_on`
instead of `futures-lite`'s implementation. You should enable this if
you use `async-io` in your application.
# Objective
This is a minimally disruptive version of #8340. I attempted to update
it, but failed due to the scope of the changes added in #8204.
Fixes#8307. Partially addresses #4642. As seen in
https://github.com/bevyengine/bevy/issues/8284, we're actually copying
data twice in Prepare stage systems. Once into a CPU-side intermediate
scratch buffer, and once again into a mapped buffer. This is inefficient
and effectively doubles the time spent and memory allocated to run these
systems.
## Solution
Skip the scratch buffer entirely and use
`wgpu::Queue::write_buffer_with` to directly write data into mapped
buffers.
Separately, this also directly uses
`wgpu::Limits::min_uniform_buffer_offset_alignment` to set up the
alignment when writing to the buffers. Partially addressing the issue
raised in #4642.
Storage buffers and the abstractions built on top of
`DynamicUniformBuffer` will need to come in followup PRs.
This may not have a noticeable performance difference in this PR, as the
only first-party systems affected by this are view related, and likely
are not going to be particularly heavy.
---
## Changelog
Added: `DynamicUniformBuffer::get_writer`.
Added: `DynamicUniformBufferWriter`.
derive `Reflect` to `GlyphAtlasInfo`,`PositionedGlyph` and
`TextLayoutInfo`.
# Objective
- I need reflection gets all components of the `TextBundle` and
`clone_value` it
## Solution
- registry it
# Objective
mesh.rs is infamously large. We could split off unrelated code.
## Solution
Morph targets are very similar to skinning and have their own module. We
move skinned meshes to an independent module like morph targets and give
the systems similar names.
### Open questions
Should the skinning systems and structs stay public?
---
## Migration Guide
Renamed skinning systems, resources and components:
- extract_skinned_meshes -> extract_skins
- prepare_skinned_meshes -> prepare_skins
- SkinnedMeshUniform -> SkinUniform
- SkinnedMeshJoints -> SkinIndex
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
# Objective
Scheduling low cost systems has significant overhead due to task pool
contention and the extra machinery to schedule and run them. Event
update systems are the prime example of a low cost system, requiring a
guaranteed O(1) operation, and there are a *lot* of them.
## Solution
Add a run condition to every event system so they only run when there is
an event in either of it's two internal Vecs.
---
## Changelog
Changed: Event update systems will not run if there are no events to
process.
## Migration Guide
`Events<T>::update_system` has been split off from the the type and can
be found at `bevy_ecs::event::event_update_system`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Fixes#9707
## Solution
- At large translations (a few thousand units), the precision of
calculating the ray direction from the fragment world position and
camera world position seems to break down. Sampling the cubemap only
needs the ray direction. As such we can use the view space fragment
position, normalise it, rotate it to world space, and use that.
---
## Changelog
- Fixed: Jittery skybox at large translations.
# Objective
- https://github.com/bevyengine/bevy/pull/7609 broke Android support
```
8721 8770 I event crates/bevy_winit/src/system.rs:55: Creating new window "App" (0v0)
8721 8769 I RustStdoutStderr: thread '<unnamed>' panicked at 'Cannot get the native window, it's null and will always be null before Event::Resumed and after Event::Suspended. Make sure you only call this function between those events.', winit-0.28.6/src/platform_impl/android/mod.rs:1058:13
```
## Solution
- Don't create windows on `StartCause::Init` as it's too early
# Objective
- Make it possible to write APIs that require a type or homogenous
storage for both `Children` & `Parent` that is agnostic to edge
direction.
## Solution
- Add a way to get the `Entity` from `Parent` as a slice.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Implement the foundations of automatic batching/instancing of draw
commands as the next step from #89
- NOTE: More performance improvements will come when more data is
managed and bound in ways that do not require rebinding such as mesh,
material, and texture data.
## Solution
- The core idea for batching of draw commands is to check whether any of
the information that has to be passed when encoding a draw command
changes between two things that are being drawn according to the sorted
render phase order. These should be things like the pipeline, bind
groups and their dynamic offsets, index/vertex buffers, and so on.
- The following assumptions have been made:
- Only entities with prepared assets (pipelines, materials, meshes) are
queued to phases
- View bindings are constant across a phase for a given draw function as
phases are per-view
- `batch_and_prepare_render_phase` is the only system that performs this
batching and has sole responsibility for preparing the per-object data.
As such the mesh binding and dynamic offsets are assumed to only vary as
a result of the `batch_and_prepare_render_phase` system, e.g. due to
having to split data across separate uniform bindings within the same
buffer due to the maximum uniform buffer binding size.
- Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform
in arrays in GPU buffers rather than each one being at a dynamic offset
in a uniform buffer. This is the same optimisation that was made for 3D
not long ago.
- Change batch size for a range in `PhaseItem`, adding API for getting
or mutating the range. This is more flexible than a size as the length
of the range can be used in place of the size, but the start and end can
be otherwise whatever is needed.
- Add an optional mesh bind group dynamic offset to `PhaseItem`. This
avoids having to do a massive table move just to insert
`GpuArrayBufferIndex` components.
## Benchmarks
All tests have been run on an M1 Max on AC power. `bevymark` and
`many_cubes` were modified to use 1920x1080 with a scale factor of 1. I
run a script that runs a separate Tracy capture process, and then runs
the bevy example with `--features bevy_ci_testing,trace_tracy` and
`CI_TESTING_CONFIG=../benchmark.ron` with the contents of
`../benchmark.ron`:
```rust
(
exit_after: Some(1500)
)
```
...in order to run each test for 1500 frames.
The recent changes to `many_cubes` and `bevymark` added reproducible
random number generation so that with the same settings, the same rng
will occur. They also added benchmark modes that use a fixed delta time
for animations. Combined this means that the same frames should be
rendered both on main and on the branch.
The graphs compare main (yellow) to this PR (red).
### 3D Mesh `many_cubes --benchmark`
<img width="1411" alt="Screenshot 2023-09-03 at 23 42 10"
src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4">
The mesh and material are the same for all instances. This is basically
the best case for the initial batching implementation as it results in 1
draw for the ~11.7k visible meshes. It gives a ~30% reduction in median
frame time.
The 1000th frame is identical using the flip tool:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4615 seconds
```
### 3D Mesh `many_cubes --benchmark --material-texture-count 10`
<img width="1404" alt="Screenshot 2023-09-03 at 23 45 18"
src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf">
This run uses 10 different materials by varying their textures. The
materials are randomly selected, and there is no sorting by material
bind group for opaque 3D so any batching is 'random'. The PR produces a
~5% reduction in median frame time. If we were to sort the opaque phase
by the material bind group, then this should be a lot faster. This
produces about 10.5k draws for the 11.7k visible entities. This makes
sense as randomly selecting from 10 materials gives a chance that two
adjacent entities randomly select the same material and can be batched.
The 1000th frame is identical in flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4537 seconds
```
### 3D Mesh `many_cubes --benchmark --vary-per-instance`
<img width="1394" alt="Screenshot 2023-09-03 at 23 48 44"
src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f">
This run varies the material data per instance by randomly-generating
its colour. This is the worst case for batching and that it performs
about the same as `main` is a good thing as it demonstrates that the
batching has minimal overhead when dealing with ~11k visible mesh
entities.
The 1000th frame is identical according to flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4568 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d`
<img width="1412" alt="Screenshot 2023-09-03 at 23 59 56"
src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4">
This spawns 160 waves of 1000 quad meshes that are shaded with
ColorMaterial. Each wave has a different material so 160 waves currently
should result in 160 batches. This results in a 50% reduction in median
frame time.
Capturing a screenshot of the 1000th frame main vs PR gives:

```
Mean: 0.001222
Weighted median: 0.750432
1st weighted quartile: 0.453494
3rd weighted quartile: 0.969758
Min: 0.000000
Max: 0.990296
Evaluation time: 0.4255 seconds
```
So they seem to produce the same results. I also double-checked the
number of draws. `main` does 160000 draws, and the PR does 160, as
expected.
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --material-texture-count 10`
<img width="1392" alt="Screenshot 2023-09-04 at 00 09 22"
src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c">
This generates 10 textures and generates materials for each of those and
then selects one material per wave. The median frame time is reduced by
50%. Similar to the plain run above, this produces 160 draws on the PR
and 160000 on `main` and the 1000th frame is identical (ignoring the fps
counter text overlay).

```
Mean: 0.002877
Weighted median: 0.964980
1st weighted quartile: 0.668871
3rd weighted quartile: 0.982749
Min: 0.000000
Max: 0.992377
Evaluation time: 0.4301 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --vary-per-instance`
<img width="1396" alt="Screenshot 2023-09-04 at 00 13 53"
src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb">
This creates unique materials per instance by randomly-generating the
material's colour. This is the worst case for 2D batching. Somehow, this
PR manages a 7% reduction in median frame time. Both main and this PR
issue 160000 draws.
The 1000th frame is the same:

```
Mean: 0.001214
Weighted median: 0.937499
1st weighted quartile: 0.635467
3rd weighted quartile: 0.979085
Min: 0.000000
Max: 0.988971
Evaluation time: 0.4462 seconds
```
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite`
<img width="1396" alt="Screenshot 2023-09-04 at 12 21 12"
src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43">
This just spawns 160 waves of 1000 sprites. There should be and is no
notable difference between main and the PR.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --material-texture-count 10`
<img width="1389" alt="Screenshot 2023-09-04 at 12 36 08"
src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413">
This spawns the sprites selecting a texture at random per instance from
the 10 generated textures. This has no significant change vs main and
shouldn't.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --vary-per-instance`
<img width="1401" alt="Screenshot 2023-09-04 at 12 29 52"
src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6">
This sets the sprite colour as being unique per instance. This can still
all be drawn using one batch. There should be no difference but the PR
produces median frame times that are 4% higher. Investigation showed no
clear sources of cost, rather a mix of give and take that should not
happen. It seems like noise in the results.
### Summary
| Benchmark | % change in median frame time |
| ------------- | ------------- |
| many_cubes | 🟩 -30% |
| many_cubes 10 materials | 🟩 -5% |
| many_cubes unique materials | 🟩 ~0% |
| bevymark mesh2d | 🟩 -50% |
| bevymark mesh2d 10 materials | 🟩 -50% |
| bevymark mesh2d unique materials | 🟩 -7% |
| bevymark sprite | 🟥 2% |
| bevymark sprite 10 materials | 🟥 0.6% |
| bevymark sprite unique materials | 🟥 4.1% |
---
## Changelog
- Added: 2D and 3D mesh entities that share the same mesh and material
(same textures, same data) are now batched into the same draw command
for better performance.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective
Improve code-gen for `QueryState::validate_world` and
`SystemState::validate_world`.
## Solution
* Move panics into separate, non-inlined functions, to reduce the code
size of the outer methods.
* Mark the panicking functions with `#[cold]` to help the compiler
optimize for the happy path.
* Mark the functions with `#[track_caller]` to make debugging easier.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fix a performance regression in the "[bevy vs
pixi](https://github.com/SUPERCILEX/bevy-vs-pixi)" benchmark.
This benchmark seems to have a slightly pathological distribution of `z`
values -- Sprites are spawned with a random `z` value with a child
sprite at `f32::EPSILON` relative to the parent.
See discussion here:
https://github.com/bevyengine/bevy/issues/8100#issuecomment-1726978633
## Solution
Use `radsort` for sorting `Transparent2d` `PhaseItem`s.
Use random `z` values in bevymark to stress the phase sort. Add an
`--ordered-z` option to `bevymark` that uses the old behavior.
## Benchmarks
mac m1 max
| benchmark | fps before | fps after | diff |
| - | - | - | - |
| bevymark --waves 120 --per-wave 1000 --random-z | 42.16 | 47.06 | 🟩
+11.6% |
| bevymark --waves 120 --per-wave 1000 | 52.50 | 52.29 | 🟥 -0.4% |
| bevymark --waves 120 --per-wave 1000 --mode mesh2d --random-z | 9.64 |
10.24 | 🟩 +6.2% |
| bevymark --waves 120 --per-wave 1000 --mode mesh2d | 15.83 | 15.59 | 🟥
-1.5% |
| bevy-vs-pixi | 39.71 | 59.88 | 🟩 +50.1% |
## Discussion
It's possible that `TransparentUi` should also change. We could probably
use `slice::sort_unstable_by_key` with the current sort key though, as
its items are always sorted and unique. I'd prefer to follow up later to
look into that.
Here's a survey of sorts used by other `PhaseItem`s
#### slice::sort_by_key
`Transparent2d`, `TransparentUi`
#### radsort
`Opaque3d`, `AlphaMask3d`, `Transparent3d`, `Opaque3dPrepass`,
`AlphaMask3dPrepass`, `Shadow`
I also tried `slice::sort_unstable_by_key` with a compound sort key
including `Entity`, but it didn't seem as promising and I didn't test it
as thoroughly.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Some rendering system did heavy use of `if let`, and could be improved
by using `let else`.
## Solution
- Reduce rightward drift by using let-else over if-let
- Extract value-to-key mappings to their own functions so that the
system is less bloated, easier to understand
- Use a `let` binding instead of untupling in closure argument to reduce
indentation
## Note to reviewers
Enable the "no white space diff" for easier viewing.
In the "Files changed" view, click on the little cog right of the "Jump
to" text, on the row where the "Review changes" button is. then enable
the "Hide whitespace" checkbox and click reload.
# Objective
Rename the `num_font_atlases` method of `FontAtlasSet` to `len`.
All the function does is return the number of entries in its hashmap and
the unnatural naming only makes it harder to discover.
---
## Changelog
* Renamed the `num_font_atlases` method of `FontAtlasSet` to `len`.
## Migration Guide
The `num_font_atlases` method of `FontAtlasSet` has been renamed to
`len`.
# Objective
Occasionally, it is useful to pull `ComponentInfo` or
`ComponentDescriptor` out of the `Components` collection so that they
can be inspected without borrowing the whole `World`.
## Solution
Make `ComponentInfo` and `ComponentDescriptor` `Clone`, so that
reflection-heavy code can store them in a side table.
---
## Changelog
- Implement `Clone` for `ComponentInfo` and `ComponentDescriptor`
# Objective
- I spoke with some users in the ECS channel of bevy discord today and
they suggested that I implement a fallible form of .insert for
components.
- In my opinion, it would be nice to have a fallible .insert like
.try_insert (or to just make insert be fallible!) because it was causing
a lot of panics in my game. In my game, I am spawning terrain chunks and
despawning them in the Update loop. However, this was causing bevy_xpbd
to panic because it was trying to .insert some physics components on my
chunks and a race condition meant that its check to see if the entity
exists would pass but then the next execution step it would not exist
and would do an .insert and then panic. This means that there is no way
to avoid a panic with conditionals.
Luckily, bevy_xpbd does not care about inserting these components if the
entity is being deleted and so if there were a .try_insert, like this PR
provides it could use that instead in order to NOT panic.
( My interim solution for my own game has been to run the entity despawn
events in the Last schedule but really this is just a hack and I should
not be expected to manage the scheduling of despawns like this - it
should just be easy and simple. IF it just so happened that bevy_xpbd
ran .inserts in the Last schedule also, this would be an untenable soln
overall )
## Solution
- Describe the solution used to achieve the objective above.
Add a new command named TryInsert (entitycommands.try_insert) which
functions exactly like .insert except if the entity does not exist it
will not panic. Instead, it will log to info. This way, crates that are
attaching components in ways which they do not mind that the entity no
longer exists can just use try_insert instead of insert.
---
## Changelog
## Additional Thoughts
In my opinion, NOT panicing should really be the default and having an
.insert that does panic should be the odd edgecase but removing the
panic! from .insert seems a bit above my paygrade -- although i would
love to see it. My other thought is it would be good for .insert to
return an Option AND not panic but it seems it uses an event bus right
now so that seems to be impossible w the current architecture.
# Objective
- Fixes#9876
## Solution
- Reverted commit `5012a0fd57748ab6f146776368b4cf988bba1eaa` to restore
the previous default values for `OrthographicProjection`.
---
## Migration Guide
- Migration guide steps from #9537 should be removed for next release.
# Objective
Fix a typo introduced by #9497. While drafting the PR, the type was
originally called `VisibleInHierarchy` before I renamed it to
`InheritedVisibility`, but this field got left behind due to a typo.
# Objective
- When adding/removing bindings in large binding lists, git would
generate very difficult-to-read diffs
## Solution
- Move the `@group(X) @binding(Y)` into the same line as the binding
type declaration
# Objective
- `check_visibility` system in `bevy_render` had an
`Option<&NoFrustumCulling>` that could be replaced by `Has`, which is
theoretically faster and semantically more correct.
- It also had some awkward indenting due to very large closure argument
lists.
- Some of the tests could be written more concisely
## Solution
Use `Has`, move the tuple destructuring in a `let` binding, create a
function for the tests.
## Note to reviewers
Enable the "no white space diff" in the diff viewer to have a more
meaningful diff in the `check_visibility` system.
In the "Files changed" view, click on the little cog right of the "Jump
to" text, on the row where the "Review changes" button is. then enable
the "Hide whitespace" checkbox and click reload.
---
## Migration Guide
- The `check_visibility` system's `Option<&NoFrustumCulling>` parameter
has been replaced by `Has<NoFrustumCulling>`, if you were calling it
manually, you should change the type to match it
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Currently, in bevy, it's valid to do `Query<&mut Foo, Changed<Foo>>`.
This assumes that `filter_fetch` and `fetch` are mutually exclusive,
because of the mutable reference to the tick that `Mut<Foo>` implies and
the reference that `Changed<Foo>` implies. However nothing guarantees
that.
## Solution
Documenting this assumption as a safety invariant is the least thing.
# Objective
`single_threaded_task_pool` emitted a warning:
```
warning: use of `default` to create a unit struct
--> crates/bevy_tasks/src/single_threaded_task_pool.rs:22:25
|
22 | Self(PhantomData::default())
| ^^^^^^^^^^^ help: remove this call to `default`
|
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#default_constructed_unit_structs
= note: `#[warn(clippy::default_constructed_unit_structs)]` on by default
```
## Solution
fix the lint
I'm adopting this ~~child~~ PR.
# Objective
- Working with exclusive world access is not always easy: in many cases,
a standard system or three is more ergonomic to write, and more
modularly maintainable.
- For small, one-off tasks (commonly handled with scripting), running an
event-reader system incurs a small but flat overhead cost and muddies
the schedule.
- Certain forms of logic (e.g. turn-based games) want very fine-grained
linear and/or branching control over logic.
- SystemState is not automatically cached, and so performance can suffer
and change detection breaks.
- Fixes https://github.com/bevyengine/bevy/issues/2192.
- Partial workaround for https://github.com/bevyengine/bevy/issues/279.
## Solution
- Adds a SystemRegistry resource to the World, which stores initialized
systems keyed by their SystemSet.
- Allows users to call world.run_system(my_system) and
commands.run_system(my_system), without re-initializing or losing state
(essential for change detection).
- Add a Callback type to enable convenient use of dynamic one shot
systems and reduce the mental overhead of working with Box<dyn
SystemSet>.
- Allow users to run systems based on their SystemSet, enabling more
complex user-made abstractions.
## Future work
- Parameterized one-shot systems would improve reusability and bring
them closer to events and commands. The API could be something like
run_system_with_input(my_system, my_input) and use the In SystemParam.
- We should evaluate the unification of commands and one-shot systems
since they are two different ways to run logic on demand over a World.
### Prior attempts
- https://github.com/bevyengine/bevy/pull/2234
- https://github.com/bevyengine/bevy/pull/2417
- https://github.com/bevyengine/bevy/pull/4090
- https://github.com/bevyengine/bevy/pull/7999
This PR continues the work done in
https://github.com/bevyengine/bevy/pull/7999.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Alejandro Pascual Pozo <alejandro.pascual.pozo@gmail.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Dmytro Banin <banind@cs.washington.edu>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Make `bevy_ui` "root" nodes more intuitive to use/style by:
- Removing the implicit flexbox styling (such as stretch alignment) that
is applied to them, and replacing it with more intuitive CSS Grid
styling (notably with stretch alignment disabled in both axes).
- Making root nodes layout independently of each other. Instead of there
being a single implicit "viewport" node that all root nodes are children
of, there is now an implicit "viewport" node *per root node*. And layout
of each tree is computed separately.
## Solution
- Remove the global implicit viewport node, and instead create an
implicit viewport node for each user-specified root node.
- Keep track of both the user-specified root nodes and the implicit
viewport nodes in a separate `Vec`.
- Use the window's size as the `available_space` parameter to
`Taffy.compute_layout` rather than setting it on the implicit viewport
node (and set the viewport to `height: 100%; width: 100%` to make this
"just work").
---
## Changelog
- Bevy UI now lays out root nodes independently of each other in
separate layout contexts.
- The implicit viewport node (which contains each user-specified root
node) is now `Display::Grid` with `align_items` and `justify_items` both
set to `Start`.
## Migration Guide
- Bevy UI now lays out root nodes independently of each other in
separate layout contexts. If you were relying on your root nodes being
able to affect each other's layouts, then you may need to wrap them in a
single root node.
- The implicit viewport node (which contains each user-specified root
node) is now `Display::Grid` with `align_items` and `justify_items` both
set to `Start`. You may need to add `height: Val::Percent(100.)` to your
root nodes if you were previously relying on being implicitly set.
# Objective
- When initializing the renderer, Bevy currently create a detached task
- This is needed on wasm but not on native
## Solution
- Don't create a detached task on native but block on the future
# Objective
Replace instances of
```rust
for x in collection.iter{_mut}() {
```
with
```rust
for x in &{mut} collection {
```
This also changes CI to no longer suppress this lint. Note that since
this lint only shows up when using clippy in pedantic mode, it was
probably unnecessary to suppress this lint in the first place.
# Objective
- When reading API docs and seeing a reference to `ComponentId`, it
isn't immediately clear how to get one from your `Component`. It could
be made to be more clear.
## Solution
- Improve cross-linking of docs about `ComponentId`
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
# Objective
according to
[khronos](https://github.com/KhronosGroup/glTF/issues/1697), gltf nodes
with inverted scales should invert the winding order of the mesh data.
this is to allow negative scale to be used for mirrored geometry.
## Solution
in the gltf loader, create a separate material with `cull_mode` set to
`Face::Front` when the node scale is negative.
note/alternatives:
this applies for nodes where the scale is negative at gltf import time.
that seems like enough for the mentioned use case of mirrored geometry.
it doesn't help when scales dynamically go negative at runtime, but you
can always set double sided in that case.
i don't think there's any practical difference between using front-face
culling and setting a clockwise winding order explicitly, but winding
order is supported by wgpu so we could add the field to
StandardMaterial/StandardMaterialKey and set it directly on the pipeline
descriptor if there's a reason to. it wouldn't help with dynamic scale
adjustments anyway, and would still require a separate material.
fixes#4738, probably fixes#7901.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
The reasoning is similar to #8687.
I'm building a dynamic query. Currently, I store the ReflectFromPtr in
my dynamic `Fetch` type.
[See relevant
code](97ba68ae1e/src/fetches.rs (L14-L17))
However, `ReflectFromPtr` is:
- 16 bytes for TypeId
- 8 bytes for the non-mutable function pointer
- 8 bytes for the mutable function pointer
It's a lot, it adds 32 bytes to my base `Fetch` which is only
`ComponendId` (8 bytes) for a total of 40 bytes.
I only need one function per fetch, reducing the total dynamic fetch
size to 16 bytes.
Since I'm querying the components by the ComponendId associated with the
function pointer I'm using, I don't need the TypeId, it's a redundant
check.
In fact, I've difficulties coming up with situations where checking the
TypeId beforehand is relevant. So to me, if ReflectFromPtr makes sense
as a public API, exposing the function pointers also makes sense.
## Solution
- Make the fields public through methods.
---
## Changelog
- Add `from_ptr` and `from_ptr_mut` methods to `ReflectFromPtr` to
access the underlying function pointers
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
## Migration guide
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
# Objective
If you remove a `ContentSize` component from a Bevy UI entity and then
replace it `ui_layout_system` will remove the measure func from the
internal Taffy layout tree but no new measure func will be generated to
replace it since it's the widget systems that are responsible for
creating their respective measure funcs not `ui_layout_system`. The
widget systems only perform a measure func update on changes to a widget
entity's content. This means that until its content is changed in some
way, no content will be displayed by the node.
### Example
This example spawns a text node which disappears after a few moments
once its `ContentSize` component is replaced.
```rust
use bevy::prelude::*;
use bevy::ui::ContentSize;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.add_systems(Update, delayed_replacement)
.run();
}
fn setup(mut commands: Commands) {
commands.spawn(Camera2dBundle::default());
commands.spawn(
TextBundle::from_section(
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.",
TextStyle::default(),
)
);
}
// Waits a few frames to make sure the font is loaded and the text's glyph layout has been generated.
fn delayed_replacement(mut commands: Commands, mut count: Local<usize>, query: Query<Entity, With<Style>>) {
*count += 1;
if *count == 10 {
for item in query.iter() {
commands
.entity(item)
.remove::<ContentSize>()
.insert(ContentSize::default());
}
}
}
```
## Solution
Perform `ui_layout_system`'s `ContentSize` removal detection and
resolution first, before the measure func updates.
Then in the widget systems, generate a new `Measure` when a
`ContentSize` component is added to a widget entity.
## Changelog
* `measure_text_system`, `update_image_content_size_system` and
`update_atlas_content_size_system` generate a new `Measure` when a
`ContentSize` component is added.
# Objective
mikktspace tangent generation requires mesh indices, and currently fails
when they are not present. we can just generate them instead.
## Solution
generate the indices.
# Objective
`Val`'s natural place is in the `geometry` module with `UiRect`, not in
`ui_node` with the components.
## Solution
Move `Val` into `geometry`.
# Objective
Rename RemovedComponents::iter/iter_with_id to read/read_with_id to make
it clear that it consume the data
Fixes#9755.
(It's my first pull request, if i've made any mistake, please let me
know)
## Solution
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
## Changelog
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
Deprecate RemovedComponents::iter/iter_with_id
Remove IntoIterator implementation
Update removal_detection example accordingly
---
## Migration Guide
Rename calls of RemovedComponents::iter/iter_with_id to
read/read_with_id
Replace IntoIterator iteration (&mut <RemovedComponents>) with .read()
---------
Co-authored-by: denshi_ika <mojang2824@gmail.com>
# Objective
Fixes#9787
## Solution
~~"serialize" feature enables "bevy_asset" now~~
"serialize" feature no longer enables the optional "bevy_scene" feature
if it's not enabled from elsewhere (thanks to @mockersf)
# Objective
The rename is confusing. Each time I import `TypeRegistry` I have to
think at least 10 seconds about how to import it. And I've been working
a lot with bevy reflect, which multiplies the papercut.
In my crates, you can find lots of:
```rust
use bevy::reflect::{TypeRegistryInternal as TypeRegistry};
```
When I "go to definition" on `TypeRegistry` I get to `TypeRegistryArc`.
And when I mean `TypeRegistry` in my function signature, 100% of the
time I mean `TypeRegistry`, not the arc wrapper.
Rust has borrowing, and most use-cases of the TypeRegistry accepts
borrow of the registry, with no need to mutate it.
`TypeRegistryInternal` is also confusing. In bevy crates, it doesn't
exist. The bevy crate documentation often refers to `TypeRegistry` and
link to `TypeRegistryInternal`. It only exists in the bevy re-exports.
It makes it hard to understand which names qualifies which types.
## Solution
Remove the rename, keep the type names as they are in `bevy_reflect`
---
## Changelog
- Remove `TypeRegistry` and `TypeRegistryArc` renames from bevy
`bevy_reflect` re-exports.
## Migration Guide
- `TypeRegistry` as re-exported by the wrapper `bevy` crate is now
`TypeRegistryArc`
- `TypeRegistryInternal` as re-exported by the wrapper `bevy` crate is
now `TypeRegistry`
# Objective
When using `set_if_neq`, sometimes you'd like to know if the new value
was different from the old value so that you can perform some additional
branching.
## Solution
Return a bool from this function, which indicates whether or not the
value was overwritten.
---
## Changelog
* `DetectChangesMut::set_if_neq` now returns a boolean indicating
whether or not the value was changed.
## Migration Guide
The trait method `DetectChangesMut::set_if_neq` now returns a boolean
value indicating whether or not the value was changed. If you were
implementing this function manually, you must now return `true` if the
value was overwritten and `false` if the value was not.
# Objective
Fix#9747
## Solution
Linkers don't like what we're doing with CowArc (I'm guessing it has
something to do with `?Sized`). Weirdly the `Reflect` derive on
`AssetPath` doesn't fail, despite `CowArc` not implementing `Reflect`.
To resolve this, we manually implement "reflect value" for
`AssetPath<'static>`. It sadly cannot use `impl_reflect_value` because
that macro doesn't support static lifetimes.
---------
Co-authored-by: Martin Dickopp <martin@zero-based.org>
# Objective
Add tests for `ui_layout_system` and `UiSurface` to the
`bevy_ui::Layout` module.
## Solution
Spawn a dummy window entity with `Window` and `PrimaryWindow` components
so that `ui_layout_system` can run in a test without a window present.
---
## Changelog
Added tests to the `bevy_ui::layout` module.
# Objective
- I want to associate `TypeData` with `Mesh`, to make it
editable/inspectable in my reflection-based editor. `Mesh` has to
implement `Reflect` for that. The precise reflection behavior does not
matter.
## Solution
- `#[derive(Reflect)]`, ignore fields whose types aren't reflectable.
- Call `App::register_asset_reflect` in the `MeshPlugin`.
---
## Changelog
- `Mesh` now implements `Reflect`.
# Objective
- The tick access methods mention "ticks" (as in: plural). Yet, most of
them only access a single tick.
## Solution
- Rename those methods and fix docs to reflect the singular aspect of
the return values
---
## Migration Guide
The following method names were renamed, from `foo_ticks_bar` to
`foo_tick_bar` (`ticks` is now singular, `tick`):
- `ComponentSparseSet::get_added_ticks` → `get_added_tick`
- `ComponentSparseSet::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks` → `get_added_tick`
- `Column::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks_unchecked` → `get_added_tick_unchecked`
- `Column::get_changed_ticks_unchecked` → `get_changed_tick_unchecked`
# Objective
- Make it possible to snapshot/save states
- Useful for re-using parts of the state system for rollback safe states
- Or to save states with scenes/savegames
## Solution
- Conditionally add the derive if the `bevy_reflect` is enabled
---
## Changelog
- `NextState<S>` and `State<S>` now implement `Reflect` as long as `S`
does.
# Objective
- Fixes#6662
- Wireframe crash for skinned meshes:
```
wgpu error: Validation Error
Caused by:
In Device::create_render_pipeline
note: label = `opaque_mesh_pipeline`
Error matching ShaderStages(VERTEX) shader requirements against the pipeline
Location[4] Uint32x4 interpolated as Some(Flat) with sampling None is not provided by the previous stage outputs
Input is not provided by the earlier stage in the pipeline
```
- Wireframe crash for morphed meshes:
```
wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 14, Metal)>`
In a draw command, indexed:true indirect:false
note: render pipeline = `opaque_mesh_pipeline`
The pipeline layout, associated with the current render pipeline, contains a bind group layout at index 1 which is incompatible with the bind group layout associated with the bind group at 1
```
## Solution
- Fix the locations for skinned meshes in the wireframe shader
- Add the morph key to the wireframe specialisation key
- Morph the vertex in the wireframe shader
https://github.com/bevyengine/bevy/assets/8672791/ce0a9584-bd28-4d74-9c3f-256602e6fac5
# Objective
In `extract_text2d_sprite` the scaling by the scale factor should be
only be applied to the x and y axes but it's also applied to the z axis.
# Solution
Remove the scaling in the z axis
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
Implement `From<String>` and `From<&str>` for `TextSection`
Example from something I was working on earlier:
```rust
parent.spawn(TextBundle::from_sections([
TextSection::new("press ".to_string(), TextStyle::default()),
TextSection::new("space".to_string(), TextStyle { color: Color::YELLOW, ..default() }),
TextSection::new(" to advance frames".to_string(), TextStyle::default()),
]));
```
After an `impl From<&str> for TextSection` :
```rust
parent.spawn(TextBundle::from_sections([
"press ".into(),
TextSection::new("space".to_string(), TextStyle { color: Color::YELLOW, ..default() }),
" to advance frames".into(),
]));
```
* Potentially unhelpful without a default font, so behind the
`default_font` feature.
Co-authored-by: [hate](https://github.com/hate)
---------
Co-authored-by: hate <15314665+hate@users.noreply.github.com>
# Objective
`TextLayoutInfo::size` isn't the drawn size of the text, but a scaled
value. This is fragile, counter-intuitive and makes it awkward to
retrieve the correct value.
## Solution
Multiply `TextLayoutInfo::size` by the reciprocal of the window's scale
factor after generating the text layout in `update_text2d_layout` and
`bevy_ui::widget::text_system`.
---
fixes: #7787
## Changelog
* Multiply `TextLayoutInfo::size` by the reciprocal of the scale factor
after text computation to reflect the actual size of the text as drawn.
* Reorder the operations in `extract_text2d_sprite` to apply the
alignment offset before the scale factor scaling.
## Migration Guide
The `size` value of `TextLayoutInfo` is stored in logical pixels and has
been renamed to `logical_size`. There is no longer any need to divide by
the window's scale factor to get the logical size.
This needs to be much higher to avoid failures in CI. I don't love the
"loop until" test methodology generally, but this is testing internal
state and making this event driven would change the nature of the test.
# Objective
The `AssetServer` and `AssetProcessor` do a lot of `AssetPath` cloning
(across many threads). To store the path on the handle, to store paths
in dependency lists, to pass an owned path to the offloaded thread, to
pass a path to the LoadContext, etc , etc. Cloning multiple string
allocations multiple times like this will add up. It is worth optimizing
this.
Referenced in #9714
## Solution
Added a new `CowArc<T>` type to `bevy_util`, which behaves a lot like
`Cow<T>`, but the Owned variant is an `Arc<T>`. Use this in place of
`Cow<str>` and `Cow<Path>` on `AssetPath`.
---
## Changelog
- `AssetPath` now internally uses `CowArc`, making clone operations much
cheaper
- `AssetPath` now serializes as `AssetPath("some_path.extension#Label")`
instead of as `AssetPath { path: "some_path.extension", label:
Some("Label) }`
## Migration Guide
```rust
// Old
AssetPath::new("logo.png", None);
// New
AssetPath::new("logo.png");
// Old
AssetPath::new("scene.gltf", Some("Mesh0");
// New
AssetPath::new("scene.gltf").with_label("Mesh0");
```
`AssetPath` now serializes as `AssetPath("some_path.extension#Label")`
instead of as `AssetPath { path: "some_path.extension", label:
Some("Label) }`
---------
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
- Fix these warnings
```rust
warning: unused doc comment
--> /bevy/crates/bevy_pbr/src/light.rs:62:13
|
62 | /// Luminous power in lumens
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
63 | intensity: 800.0, // Roughly a 60W non-halogen incandescent bulb
| ---------------- rustdoc does not generate documentation for expression fields
|
= help: use `//` for a plain comment
= note: `#[warn(unused_doc_comments)]` on by default
```
```rust
warning: `&` without an explicit lifetime name cannot be used here
--> /bevy/crates/bevy_asset/src/lib.rs:89:32
|
89 | const DEFAULT_FILE_SOURCE: &str = "assets";
| ^
|
= warning: this was previously accepted by the compiler but is being phased out; it will become a hard error in a future release!
= note: for more information, see issue #115010 <https://github.com/rust-lang/rust/issues/115010>
= note: `#[warn(elided_lifetimes_in_associated_constant)]` on by default
help: use the `'static` lifetime
|
89 | const DEFAULT_FILE_SOURCE: &'static str = "assets";
|
```
# Objective
`TextureAtlas` supports pregenerated texture atlases with padding, but
`TextureAtlasBuilder` can't add padding when it creates a new atlas.
fixes#8150
## Solution
Add a method `padding` to `TextureAtlasBuilder` that sets the amount of
padding to add around each texture.
When queueing the textures to be copied, add the padding value to the
size of each source texture. Then when copying the source textures to
the output atlas texture subtract the same padding value from the sizes
of the target rects.
unpadded:
<img width="961" alt="texture_atlas_example"
src="https://github.com/bevyengine/bevy/assets/27962798/8cf02442-dc3e-4429-90f1-543bc9270d8b">
padded:
<img width="961" alt="texture_atlas_example_with_padding"
src="https://github.com/bevyengine/bevy/assets/27962798/da347bcc-b083-4650-ba0c-86883853764f">
---
## Changelog
`TextureAtlasBuilder`
* Added support for building texture atlases with padding.
* Adds a `padding` method to `TextureAtlasBuilder` that can be used to
set an amount of padding to add between the sprites of the generated
texture atlas.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Related to #9715
- Example `asset_processing` logs the following error:
```
thread 'IO Task Pool (1)' panicked at 'Failed to initialize asset processor log. This cannot be recovered. Try restarting. If that doesn't work, try deleting processed asset folder. No such file or directory (os error 2)', crates/bevy_asset/src/processor/mod.rs:867:25
```
## Solution
- Create the log directory if needed
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Bevy Asset V2 Proposal
## Why Does Bevy Need A New Asset System?
Asset pipelines are a central part of the gamedev process. Bevy's
current asset system is missing a number of features that make it
non-viable for many classes of gamedev. After plenty of discussions and
[a long community feedback
period](https://github.com/bevyengine/bevy/discussions/3972), we've
identified a number missing features:
* **Asset Preprocessing**: it should be possible to "preprocess" /
"compile" / "crunch" assets at "development time" rather than when the
game starts up. This enables offloading expensive work from deployed
apps, faster asset loading, less runtime memory usage, etc.
* **Per-Asset Loader Settings**: Individual assets cannot define their
own loaders that override the defaults. Additionally, they cannot
provide per-asset settings to their loaders. This is a huge limitation,
as many asset types don't provide all information necessary for Bevy
_inside_ the asset. For example, a raw PNG image says nothing about how
it should be sampled (ex: linear vs nearest).
* **Asset `.meta` files**: assets should have configuration files stored
adjacent to the asset in question, which allows the user to configure
asset-type-specific settings. These settings should be accessible during
the pre-processing phase. Modifying a `.meta` file should trigger a
re-processing / re-load of the asset. It should be possible to configure
asset loaders from the meta file.
* **Processed Asset Hot Reloading**: Changes to processed assets (or
their dependencies) should result in re-processing them and re-loading
the results in live Bevy Apps.
* **Asset Dependency Tracking**: The current bevy_asset has no good way
to wait for asset dependencies to load. It punts this as an exercise for
consumers of the loader apis, which is unreasonable and error prone.
There should be easy, ergonomic ways to wait for assets to load and
block some logic on an asset's entire dependency tree loading.
* **Runtime Asset Loading**: it should be (optionally) possible to load
arbitrary assets dynamically at runtime. This necessitates being able to
deploy and run the asset server alongside Bevy Apps on _all platforms_.
For example, we should be able to invoke the shader compiler at runtime,
stream scenes from sources like the internet, etc. To keep deployed
binaries (and startup times) small, the runtime asset server
configuration should be configurable with different settings compared to
the "pre processor asset server".
* **Multiple Backends**: It should be possible to load assets from
arbitrary sources (filesystems, the internet, remote asset serves, etc).
* **Asset Packing**: It should be possible to deploy assets in
compressed "packs", which makes it easier and more efficient to
distribute assets with Bevy Apps.
* **Asset Handoff**: It should be possible to hold a "live" asset
handle, which correlates to runtime data, without actually holding the
asset in memory. Ex: it must be possible to hold a reference to a GPU
mesh generated from a "mesh asset" without keeping the mesh data in CPU
memory
* **Per-Platform Processed Assets**: Different platforms and app
distributions have different capabilities and requirements. Some
platforms need lower asset resolutions or different asset formats to
operate within the hardware constraints of the platform. It should be
possible to define per-platform asset processing profiles. And it should
be possible to deploy only the assets required for a given platform.
These features have architectural implications that are significant
enough to require a full rewrite. The current Bevy Asset implementation
got us this far, but it can take us no farther. This PR defines a brand
new asset system that implements most of these features, while laying
the foundations for the remaining features to be built.
## Bevy Asset V2
Here is a quick overview of the features introduced in this PR.
* **Asset Preprocessing**: Preprocess assets at development time into
more efficient (and configurable) representations
* **Dependency Aware**: Dependencies required to process an asset are
tracked. If an asset's processed dependency changes, it will be
reprocessed
* **Hot Reprocessing/Reloading**: detect changes to asset source files,
reprocess them if they have changed, and then hot-reload them in Bevy
Apps.
* **Only Process Changes**: Assets are only re-processed when their
source file (or meta file) has changed. This uses hashing and timestamps
to avoid processing assets that haven't changed.
* **Transactional and Reliable**: Uses write-ahead logging (a technique
commonly used by databases) to recover from crashes / forced-exits.
Whenever possible it avoids full-reprocessing / only uncompleted
transactions will be reprocessed. When the processor is running in
parallel with a Bevy App, processor asset writes block Bevy App asset
reads. Reading metadata + asset bytes is guaranteed to be transactional
/ correctly paired.
* **Portable / Run anywhere / Database-free**: The processor does not
rely on an in-memory database (although it uses some database techniques
for reliability). This is important because pretty much all in-memory
databases have unsupported platforms or build complications.
* **Configure Processor Defaults Per File Type**: You can say "use this
processor for all files of this type".
* **Custom Processors**: The `Processor` trait is flexible and
unopinionated. It can be implemented by downstream plugins.
* **LoadAndSave Processors**: Most asset processing scenarios can be
expressed as "run AssetLoader A, save the results using AssetSaver X,
and then load the result using AssetLoader B". For example, load this
png image using `PngImageLoader`, which produces an `Image` asset and
then save it using `CompressedImageSaver` (which also produces an
`Image` asset, but in a compressed format), which takes an `Image` asset
as input. This means if you have an `AssetLoader` for an asset, you are
already half way there! It also means that you can share AssetSavers
across multiple loaders. Because `CompressedImageSaver` accepts Bevy's
generic Image asset as input, it means you can also use it with some
future `JpegImageLoader`.
* **Loader and Saver Settings**: Asset Loaders and Savers can now define
their own settings types, which are passed in as input when an asset is
loaded / saved. Each asset can define its own settings.
* **Asset `.meta` files**: configure asset loaders, their settings,
enable/disable processing, and configure processor settings
* **Runtime Asset Dependency Tracking** Runtime asset dependencies (ex:
if an asset contains a `Handle<Image>`) are tracked by the asset server.
An event is emitted when an asset and all of its dependencies have been
loaded
* **Unprocessed Asset Loading**: Assets do not require preprocessing.
They can be loaded directly. A processed asset is just a "normal" asset
with some extra metadata. Asset Loaders don't need to know or care about
whether or not an asset was processed.
* **Async Asset IO**: Asset readers/writers use async non-blocking
interfaces. Note that because Rust doesn't yet support async traits,
there is a bit of manual Boxing / Future boilerplate. This will
hopefully be removed in the near future when Rust gets async traits.
* **Pluggable Asset Readers and Writers**: Arbitrary asset source
readers/writers are supported, both by the processor and the asset
server.
* **Better Asset Handles**
* **Single Arc Tree**: Asset Handles now use a single arc tree that
represents the lifetime of the asset. This makes their implementation
simpler, more efficient, and allows us to cheaply attach metadata to
handles. Ex: the AssetPath of a handle is now directly accessible on the
handle itself!
* **Const Typed Handles**: typed handles can be constructed in a const
context. No more weird "const untyped converted to typed at runtime"
patterns!
* **Handles and Ids are Smaller / Faster To Hash / Compare**: Typed
`Handle<T>` is now much smaller in memory and `AssetId<T>` is even
smaller.
* **Weak Handle Usage Reduction**: In general Handles are now considered
to be "strong". Bevy features that previously used "weak `Handle<T>`"
have been ported to `AssetId<T>`, which makes it statically clear that
the features do not hold strong handles (while retaining strong type
information). Currently Handle::Weak still exists, but it is very
possible that we can remove that entirely.
* **Efficient / Dense Asset Ids**: Assets now have efficient dense
runtime asset ids, which means we can avoid expensive hash lookups.
Assets are stored in Vecs instead of HashMaps. There are now typed and
untyped ids, which means we no longer need to store dynamic type
information in the ID for typed handles. "AssetPathId" (which was a
nightmare from a performance and correctness standpoint) has been
entirely removed in favor of dense ids (which are retrieved for a path
on load)
* **Direct Asset Loading, with Dependency Tracking**: Assets that are
defined at runtime can still have their dependencies tracked by the
Asset Server (ex: if you create a material at runtime, you can still
wait for its textures to load). This is accomplished via the (currently
optional) "asset dependency visitor" trait. This system can also be used
to define a set of assets to load, then wait for those assets to load.
* **Async folder loading**: Folder loading also uses this system and
immediately returns a handle to the LoadedFolder asset, which means
folder loading no longer blocks on directory traversals.
* **Improved Loader Interface**: Loaders now have a specific "top level
asset type", which makes returning the top-level asset simpler and
statically typed.
* **Basic Image Settings and Processing**: Image assets can now be
processed into the gpu-friendly Basic Universal format. The ImageLoader
now has a setting to define what format the image should be loaded as.
Note that this is just a minimal MVP ... plenty of additional work to do
here. To demo this, enable the `basis-universal` feature and turn on
asset processing.
* **Simpler Audio Play / AudioSink API**: Asset handle providers are
cloneable, which means the Audio resource can mint its own handles. This
means you can now do `let sink_handle = audio.play(music)` instead of
`let sink_handle = audio_sinks.get_handle(audio.play(music))`. Note that
this might still be replaced by
https://github.com/bevyengine/bevy/pull/8424.
**Removed Handle Casting From Engine Features**: Ex: FontAtlases no
longer use casting between handle types
## Using The New Asset System
### Normal Unprocessed Asset Loading
By default the `AssetPlugin` does not use processing. It behaves pretty
much the same way as the old system.
If you are defining a custom asset, first derive `Asset`:
```rust
#[derive(Asset)]
struct Thing {
value: String,
}
```
Initialize the asset:
```rust
app.init_asset:<Thing>()
```
Implement a new `AssetLoader` for it:
```rust
#[derive(Default)]
struct ThingLoader;
#[derive(Serialize, Deserialize, Default)]
pub struct ThingSettings {
some_setting: bool,
}
impl AssetLoader for ThingLoader {
type Asset = Thing;
type Settings = ThingSettings;
fn load<'a>(
&'a self,
reader: &'a mut Reader,
settings: &'a ThingSettings,
load_context: &'a mut LoadContext,
) -> BoxedFuture<'a, Result<Thing, anyhow::Error>> {
Box::pin(async move {
let mut bytes = Vec::new();
reader.read_to_end(&mut bytes).await?;
// convert bytes to value somehow
Ok(Thing {
value
})
})
}
fn extensions(&self) -> &[&str] {
&["thing"]
}
}
```
Note that this interface will get much cleaner once Rust gets support
for async traits. `Reader` is an async futures_io::AsyncRead. You can
stream bytes as they come in or read them all into a `Vec<u8>`,
depending on the context. You can use `let handle =
load_context.load(path)` to kick off a dependency load, retrieve a
handle, and register the dependency for the asset.
Then just register the loader in your Bevy app:
```rust
app.init_asset_loader::<ThingLoader>()
```
Now just add your `Thing` asset files into the `assets` folder and load
them like this:
```rust
fn system(asset_server: Res<AssetServer>) {
let handle = Handle<Thing> = asset_server.load("cool.thing");
}
```
You can check load states directly via the asset server:
```rust
if asset_server.load_state(&handle) == LoadState::Loaded { }
```
You can also listen for events:
```rust
fn system(mut events: EventReader<AssetEvent<Thing>>, handle: Res<SomeThingHandle>) {
for event in events.iter() {
if event.is_loaded_with_dependencies(&handle) {
}
}
}
```
Note the new `AssetEvent::LoadedWithDependencies`, which only fires when
the asset is loaded _and_ all dependencies (and their dependencies) have
loaded.
Unlike the old asset system, for a given asset path all `Handle<T>`
values point to the same underlying Arc. This means Handles can cheaply
hold more asset information, such as the AssetPath:
```rust
// prints the AssetPath of the handle
info!("{:?}", handle.path())
```
### Processed Assets
Asset processing can be enabled via the `AssetPlugin`. When developing
Bevy Apps with processed assets, do this:
```rust
app.add_plugins(DefaultPlugins.set(AssetPlugin::processed_dev()))
```
This runs the `AssetProcessor` in the background with hot-reloading. It
reads assets from the `assets` folder, processes them, and writes them
to the `.imported_assets` folder. Asset loads in the Bevy App will wait
for a processed version of the asset to become available. If an asset in
the `assets` folder changes, it will be reprocessed and hot-reloaded in
the Bevy App.
When deploying processed Bevy apps, do this:
```rust
app.add_plugins(DefaultPlugins.set(AssetPlugin::processed()))
```
This does not run the `AssetProcessor` in the background. It behaves
like `AssetPlugin::unprocessed()`, but reads assets from
`.imported_assets`.
When the `AssetProcessor` is running, it will populate sibling `.meta`
files for assets in the `assets` folder. Meta files for assets that do
not have a processor configured look like this:
```rust
(
meta_format_version: "1.0",
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: FromExtension,
),
),
)
```
This is metadata for an image asset. For example, if you have
`assets/my_sprite.png`, this could be the metadata stored at
`assets/my_sprite.png.meta`. Meta files are totally optional. If no
metadata exists, the default settings will be used.
In short, this file says "load this asset with the ImageLoader and use
the file extension to determine the image type". This type of meta file
is supported in all AssetPlugin modes. If in `Unprocessed` mode, the
asset (with the meta settings) will be loaded directly. If in
`ProcessedDev` mode, the asset file will be copied directly to the
`.imported_assets` folder. The meta will also be copied directly to the
`.imported_assets` folder, but with one addition:
```rust
(
meta_format_version: "1.0",
processed_info: Some((
hash: 12415480888597742505,
full_hash: 14344495437905856884,
process_dependencies: [],
)),
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: FromExtension,
),
),
)
```
`processed_info` contains `hash` (a direct hash of the asset and meta
bytes), `full_hash` (a hash of `hash` and the hashes of all
`process_dependencies`), and `process_dependencies` (the `path` and
`full_hash` of every process_dependency). A "process dependency" is an
asset dependency that is _directly_ used when processing the asset.
Images do not have process dependencies, so this is empty.
When the processor is enabled, you can use the `Process` metadata
config:
```rust
(
meta_format_version: "1.0",
asset: Process(
processor: "bevy_asset::processor::process::LoadAndSave<bevy_render::texture::image_loader::ImageLoader, bevy_render::texture::compressed_image_saver::CompressedImageSaver>",
settings: (
loader_settings: (
format: FromExtension,
),
saver_settings: (
generate_mipmaps: true,
),
),
),
)
```
This configures the asset to use the `LoadAndSave` processor, which runs
an AssetLoader and feeds the result into an AssetSaver (which saves the
given Asset and defines a loader to load it with). (for terseness
LoadAndSave will likely get a shorter/friendlier type name when [Stable
Type Paths](#7184) lands). `LoadAndSave` is likely to be the most common
processor type, but arbitrary processors are supported.
`CompressedImageSaver` saves an `Image` in the Basis Universal format
and configures the ImageLoader to load it as basis universal. The
`AssetProcessor` will read this meta, run it through the LoadAndSave
processor, and write the basis-universal version of the image to
`.imported_assets`. The final metadata will look like this:
```rust
(
meta_format_version: "1.0",
processed_info: Some((
hash: 905599590923828066,
full_hash: 9948823010183819117,
process_dependencies: [],
)),
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: Format(Basis),
),
),
)
```
To try basis-universal processing out in Bevy examples, (for example
`sprite.rs`), change `add_plugins(DefaultPlugins)` to
`add_plugins(DefaultPlugins.set(AssetPlugin::processed_dev()))` and run
with the `basis-universal` feature enabled: `cargo run
--features=basis-universal --example sprite`.
To create a custom processor, there are two main paths:
1. Use the `LoadAndSave` processor with an existing `AssetLoader`.
Implement the `AssetSaver` trait, register the processor using
`asset_processor.register_processor::<LoadAndSave<ImageLoader,
CompressedImageSaver>>(image_saver.into())`.
2. Implement the `Process` trait directly and register it using:
`asset_processor.register_processor(thing_processor)`.
You can configure default processors for file extensions like this:
```rust
asset_processor.set_default_processor::<ThingProcessor>("thing")
```
There is one more metadata type to be aware of:
```rust
(
meta_format_version: "1.0",
asset: Ignore,
)
```
This will ignore the asset during processing / prevent it from being
written to `.imported_assets`.
The AssetProcessor stores a transaction log at `.imported_assets/log`
and uses it to gracefully recover from unexpected stops. This means you
can force-quit the processor (and Bevy Apps running the processor in
parallel) at arbitrary times!
`.imported_assets` is "local state". It should _not_ be checked into
source control. It should also be considered "read only". In practice,
you _can_ modify processed assets and processed metadata if you really
need to test something. But those modifications will not be represented
in the hashes of the assets, so the processed state will be "out of
sync" with the source assets. The processor _will not_ fix this for you.
Either revert the change after you have tested it, or delete the
processed files so they can be re-populated.
## Open Questions
There are a number of open questions to be discussed. We should decide
if they need to be addressed in this PR and if so, how we will address
them:
### Implied Dependencies vs Dependency Enumeration
There are currently two ways to populate asset dependencies:
* **Implied via AssetLoaders**: if an AssetLoader loads an asset (and
retrieves a handle), a dependency is added to the list.
* **Explicit via the optional Asset::visit_dependencies**: if
`server.load_asset(my_asset)` is called, it will call
`my_asset.visit_dependencies`, which will grab dependencies that have
been manually defined for the asset via the Asset trait impl (which can
be derived).
This means that defining explicit dependencies is optional for "loaded
assets". And the list of dependencies is always accurate because loaders
can only produce Handles if they register dependencies. If an asset was
loaded with an AssetLoader, it only uses the implied dependencies. If an
asset was created at runtime and added with
`asset_server.load_asset(MyAsset)`, it will use
`Asset::visit_dependencies`.
However this can create a behavior mismatch between loaded assets and
equivalent "created at runtime" assets if `Assets::visit_dependencies`
doesn't exactly match the dependencies produced by the AssetLoader. This
behavior mismatch can be resolved by completely removing "implied loader
dependencies" and requiring `Asset::visit_dependencies` to supply
dependency data. But this creates two problems:
* It makes defining loaded assets harder and more error prone: Devs must
remember to manually annotate asset dependencies with `#[dependency]`
when deriving `Asset`. For more complicated assets (such as scenes), the
derive likely wouldn't be sufficient and a manual `visit_dependencies`
impl would be required.
* Removes the ability to immediately kick off dependency loads: When
AssetLoaders retrieve a Handle, they also immediately kick off an asset
load for the handle, which means it can start loading in parallel
_before_ the asset finishes loading. For large assets, this could be
significant. (although this could be mitigated for processed assets if
we store dependencies in the processed meta file and load them ahead of
time)
### Eager ProcessorDev Asset Loading
I made a controversial call in the interest of fast startup times ("time
to first pixel") for the "processor dev mode configuration". When
initializing the AssetProcessor, current processed versions of unchanged
assets are yielded immediately, even if their dependencies haven't been
checked yet for reprocessing. This means that
non-current-state-of-filesystem-but-previously-valid assets might be
returned to the App first, then hot-reloaded if/when their dependencies
change and the asset is reprocessed.
Is this behavior desirable? There is largely one alternative: do not
yield an asset from the processor to the app until all of its
dependencies have been checked for changes. In some common cases (load
dependency has not changed since last run) this will increase startup
time. The main question is "by how much" and is that slower startup time
worth it in the interest of only yielding assets that are true to the
current state of the filesystem. Should this be configurable? I'm
starting to think we should only yield an asset after its (historical)
dependencies have been checked for changes + processed as necessary, but
I'm curious what you all think.
### Paths Are Currently The Only Canonical ID / Do We Want Asset UUIDs?
In this implementation AssetPaths are the only canonical asset
identifier (just like the previous Bevy Asset system and Godot). Moving
assets will result in re-scans (and currently reprocessing, although
reprocessing can easily be avoided with some changes). Asset
renames/moves will break code and assets that rely on specific paths,
unless those paths are fixed up.
Do we want / need "stable asset uuids"? Introducing them is very
possible:
1. Generate a UUID and include it in .meta files
2. Support UUID in AssetPath
3. Generate "asset indices" which are loaded on startup and map UUIDs to
paths.
4 (maybe). Consider only supporting UUIDs for processed assets so we can
generate quick-to-load indices instead of scanning meta files.
The main "pro" is that assets referencing UUIDs don't need to be
migrated when a path changes. The main "con" is that UUIDs cannot be
"lazily resolved" like paths. They need a full view of all assets to
answer the question "does this UUID exist". Which means UUIDs require
the AssetProcessor to fully finish startup scans before saying an asset
doesnt exist. And they essentially require asset pre-processing to use
in apps, because scanning all asset metadata files at runtime to resolve
a UUID is not viable for medium-to-large apps. It really requires a
pre-generated UUID index, which must be loaded before querying for
assets.
I personally think this should be investigated in a separate PR. Paths
aren't going anywhere ... _everyone_ uses filesystems (and
filesystem-like apis) to manage their asset source files. I consider
them permanent canonical asset information. Additionally, they behave
well for both processed and unprocessed asset modes. Given that Bevy is
supporting both, this feels like the right canonical ID to start with.
UUIDS (and maybe even other indexed-identifier types) can be added later
as necessary.
### Folder / File Naming Conventions
All asset processing config currently lives in the `.imported_assets`
folder. The processor transaction log is in `.imported_assets/log`.
Processed assets are added to `.imported_assets/Default`, which will
make migrating to processed asset profiles (ex: a
`.imported_assets/Mobile` profile) a non-breaking change. It also allows
us to create top-level files like `.imported_assets/log` without it
being interpreted as an asset. Meta files currently have a `.meta`
suffix. Do we like these names and conventions?
### Should the `AssetPlugin::processed_dev` configuration enable
`watch_for_changes` automatically?
Currently it does (which I think makes sense), but it does make it the
only configuration that enables watch_for_changes by default.
### Discuss on_loaded High Level Interface:
This PR includes a very rough "proof of concept" `on_loaded` system
adapter that uses the `LoadedWithDependencies` event in combination with
`asset_server.load_asset` dependency tracking to support this pattern
```rust
fn main() {
App::new()
.init_asset::<MyAssets>()
.add_systems(Update, on_loaded(create_array_texture))
.run();
}
#[derive(Asset, Clone)]
struct MyAssets {
#[dependency]
picture_of_my_cat: Handle<Image>,
#[dependency]
picture_of_my_other_cat: Handle<Image>,
}
impl FromWorld for ArrayTexture {
fn from_world(world: &mut World) -> Self {
picture_of_my_cat: server.load("meow.png"),
picture_of_my_other_cat: server.load("meeeeeeeow.png"),
}
}
fn spawn_cat(In(my_assets): In<MyAssets>, mut commands: Commands) {
commands.spawn(SpriteBundle {
texture: my_assets.picture_of_my_cat.clone(),
..default()
});
commands.spawn(SpriteBundle {
texture: my_assets.picture_of_my_other_cat.clone(),
..default()
});
}
```
The implementation is _very_ rough. And it is currently unsafe because
`bevy_ecs` doesn't expose some internals to do this safely from inside
`bevy_asset`. There are plenty of unanswered questions like:
* "do we add a Loadable" derive? (effectively automate the FromWorld
implementation above)
* Should `MyAssets` even be an Asset? (largely implemented this way
because it elegantly builds on `server.load_asset(MyAsset { .. })`
dependency tracking).
We should think hard about what our ideal API looks like (and if this is
a pattern we want to support). Not necessarily something we need to
solve in this PR. The current `on_loaded` impl should probably be
removed from this PR before merging.
## Clarifying Questions
### What about Assets as Entities?
This Bevy Asset V2 proposal implementation initially stored Assets as
ECS Entities. Instead of `AssetId<T>` + the `Assets<T>` resource it used
`Entity` as the asset id and Asset values were just ECS components.
There are plenty of compelling reasons to do this:
1. Easier to inline assets in Bevy Scenes (as they are "just" normal
entities + components)
2. More flexible queries: use the power of the ECS to filter assets (ex:
`Query<Mesh, With<Tree>>`).
3. Extensible. Users can add arbitrary component data to assets.
4. Things like "component visualization tools" work out of the box to
visualize asset data.
However Assets as Entities has a ton of caveats right now:
* We need to be able to allocate entity ids without a direct World
reference (aka rework id allocator in Entities ... i worked around this
in my prototypes by just pre allocating big chunks of entities)
* We want asset change events in addition to ECS change tracking ... how
do we populate them when mutations can come from anywhere? Do we use
Changed queries? This would require iterating over the change data for
all assets every frame. Is this acceptable or should we implement a new
"event based" component change detection option?
* Reconciling manually created assets with asset-system managed assets
has some nuance (ex: are they "loaded" / do they also have that
component metadata?)
* "how do we handle "static" / default entity handles" (ties in to the
Entity Indices discussion:
https://github.com/bevyengine/bevy/discussions/8319). This is necessary
for things like "built in" assets and default handles in things like
SpriteBundle.
* Storing asset information as a component makes it easy to "invalidate"
asset state by removing the component (or forcing modifications).
Ideally we have ways to lock this down (some combination of Rust type
privacy and ECS validation)
In practice, how we store and identify assets is a reasonably
superficial change (porting off of Assets as Entities and implementing
dedicated storage + ids took less than a day). So once we sort out the
remaining challenges the flip should be straightforward. Additionally, I
do still have "Assets as Entities" in my commit history, so we can reuse
that work. I personally think "assets as entities" is a good endgame,
but it also doesn't provide _significant_ value at the moment and it
certainly isn't ready yet with the current state of things.
### Why not Distill?
[Distill](https://github.com/amethyst/distill) is a high quality fully
featured asset system built in Rust. It is very natural to ask "why not
just use Distill?".
It is also worth calling out that for awhile, [we planned on adopting
Distill / I signed off on
it](https://github.com/bevyengine/bevy/issues/708).
However I think Bevy has a number of constraints that make Distill
adoption suboptimal:
* **Architectural Simplicity:**
* Distill's processor requires an in-memory database (lmdb) and RPC
networked API (using Cap'n Proto). Each of these introduces API
complexity that increases maintenance burden and "code grokability".
Ignoring tests, documentation, and examples, Distill has 24,237 lines of
Rust code (including generated code for RPC + database interactions). If
you ignore generated code, it has 11,499 lines.
* Bevy builds the AssetProcessor and AssetServer using pluggable
AssetReader/AssetWriter Rust traits with simple io interfaces. They do
not necessitate databases or RPC interfaces (although Readers/Writers
could use them if that is desired). Bevy Asset V2 (at the time of
writing this PR) is 5,384 lines of Rust code (ignoring tests,
documentation, and examples). Grain of salt: Distill does have more
features currently (ex: Asset Packing, GUIDS, remote-out-of-process
asset processor). I do plan to implement these features in Bevy Asset V2
and I personally highly doubt they will meaningfully close the 6115
lines-of-code gap.
* This complexity gap (which while illustrated by lines of code, is much
bigger than just that) is noteworthy to me. Bevy should be hackable and
there are pillars of Distill that are very hard to understand and
extend. This is a matter of opinion (and Bevy Asset V2 also has
complicated areas), but I think Bevy Asset V2 is much more approachable
for the average developer.
* Necessary disclaimer: counting lines of code is an extremely rough
complexity metric. Read the code and form your own opinions.
* **Optional Asset Processing:** Not all Bevy Apps (or Bevy App
developers) need / want asset preprocessing. Processing increases the
complexity of the development environment by introducing things like
meta files, imported asset storage, running processors in the
background, waiting for processing to finish, etc. Distill _requires_
preprocessing to work. With Bevy Asset V2 processing is fully opt-in.
The AssetServer isn't directly aware of asset processors at all.
AssetLoaders only care about converting bytes to runtime Assets ... they
don't know or care if the bytes were pre-processed or not. Processing is
"elegantly" (forgive my self-congratulatory phrasing) layered on top and
builds on the existing Asset system primitives.
* **Direct Filesystem Access to Processed Asset State:** Distill stores
processed assets in a database. This makes debugging / inspecting the
processed outputs harder (either requires special tooling to query the
database or they need to be "deployed" to be inspected). Bevy Asset V2,
on the other hand, stores processed assets in the filesystem (by default
... this is configurable). This makes interacting with the processed
state more natural. Note that both Godot and Unity's new asset system
store processed assets in the filesystem.
* **Portability**: Because Distill's processor uses lmdb and RPC
networking, it cannot be run on certain platforms (ex: lmdb is a
non-rust dependency that cannot run on the web, some platforms don't
support running network servers). Bevy should be able to process assets
everywhere (ex: run the Bevy Editor on the web, compile + process
shaders on mobile, etc). Distill does partially mitigate this problem by
supporting "streaming" assets via the RPC protocol, but this is not a
full solve from my perspective. And Bevy Asset V2 can (in theory) also
stream assets (without requiring RPC, although this isn't implemented
yet)
Note that I _do_ still think Distill would be a solid asset system for
Bevy. But I think the approach in this PR is a better solve for Bevy's
specific "asset system requirements".
### Doesn't async-fs just shim requests to "sync" `std::fs`? What is the
point?
"True async file io" has limited / spotty platform support. async-fs
(and the rust async ecosystem generally ... ex Tokio) currently use
async wrappers over std::fs that offload blocking requests to separate
threads. This may feel unsatisfying, but it _does_ still provide value
because it prevents our task pools from blocking on file system
operations (which would prevent progress when there are many tasks to
do, but all threads in a pool are currently blocking on file system
ops).
Additionally, using async APIs for our AssetReaders and AssetWriters
also provides value because we can later add support for "true async
file io" for platforms that support it. _And_ we can implement other
"true async io" asset backends (such as networked asset io).
## Draft TODO
- [x] Fill in missing filesystem event APIs: file removed event (which
is expressed as dangling RenameFrom events in some cases), file/folder
renamed event
- [x] Assets without loaders are not moved to the processed folder. This
breaks things like referenced `.bin` files for GLTFs. This should be
configurable per-non-asset-type.
- [x] Initial implementation of Reflect and FromReflect for Handle. The
"deserialization" parity bar is low here as this only worked with static
UUIDs in the old impl ... this is a non-trivial problem. Either we add a
Handle::AssetPath variant that gets "upgraded" to a strong handle on
scene load or we use a separate AssetRef type for Bevy scenes (which is
converted to a runtime Handle on load). This deserves its own discussion
in a different pr.
- [x] Populate read_asset_bytes hash when run by the processor (a bit of
a special case .. when run by the processor the processed meta will
contain the hash so we don't need to compute it on the spot, but we
don't want/need to read the meta when run by the main AssetServer)
- [x] Delay hot reloading: currently filesystem events are handled
immediately, which creates timing issues in some cases. For example hot
reloading images can sometimes break because the image isn't finished
writing. We should add a delay, likely similar to the [implementation in
this PR](https://github.com/bevyengine/bevy/pull/8503).
- [x] Port old platform-specific AssetIo implementations to the new
AssetReader interface (currently missing Android and web)
- [x] Resolve on_loaded unsafety (either by removing the API entirely or
removing the unsafe)
- [x] Runtime loader setting overrides
- [x] Remove remaining unwraps that should be error-handled. There are
number of TODOs here
- [x] Pretty AssetPath Display impl
- [x] Document more APIs
- [x] Resolve spurious "reloading because it has changed" events (to
repro run load_gltf with `processed_dev()`)
- [x] load_dependency hot reloading currently only works for processed
assets. If processing is disabled, load_dependency changes are not hot
reloaded.
- [x] Replace AssetInfo dependency load/fail counters with
`loading_dependencies: HashSet<UntypedAssetId>` to prevent reloads from
(potentially) breaking counters. Storing this will also enable
"dependency reloaded" events (see [Next Steps](#next-steps))
- [x] Re-add filesystem watcher cargo feature gate (currently it is not
optional)
- [ ] Migration Guide
- [ ] Changelog
## Followup TODO
- [ ] Replace "eager unchanged processed asset loading" behavior with
"don't returned unchanged processed asset until dependencies have been
checked".
- [ ] Add true `Ignore` AssetAction that does not copy the asset to the
imported_assets folder.
- [ ] Finish "live asset unloading" (ex: free up CPU asset memory after
uploading an image to the GPU), rethink RenderAssets, and port renderer
features. The `Assets` collection uses `Option<T>` for asset storage to
support its removal. (1) the Option might not actually be necessary ...
might be able to just remove from the collection entirely (2) need to
finalize removal apis
- [ ] Try replacing the "channel based" asset id recycling with
something a bit more efficient (ex: we might be able to use raw atomic
ints with some cleverness)
- [ ] Consider adding UUIDs to processed assets (scoped just to helping
identify moved assets ... not exposed to load queries ... see [Next
Steps](#next-steps))
- [ ] Store "last modified" source asset and meta timestamps in
processed meta files to enable skipping expensive hashing when the file
wasn't changed
- [ ] Fix "slow loop" handle drop fix
- [ ] Migrate to TypeName
- [x] Handle "loader preregistration". See #9429
## Next Steps
* **Configurable per-type defaults for AssetMeta**: It should be
possible to add configuration like "all png image meta should default to
using nearest sampling" (currently this hard-coded per-loader/processor
Settings::default() impls). Also see the "Folder Meta" bullet point.
* **Avoid Reprocessing on Asset Renames / Moves**: See the "canonical
asset ids" discussion in [Open Questions](#open-questions) and the
relevant bullet point in [Draft TODO](#draft-todo). Even without
canonical ids, folder renames could avoid reprocessing in some cases.
* **Multiple Asset Sources**: Expand AssetPath to support "asset source
names" and support multiple AssetReaders in the asset server (ex:
`webserver://some_path/image.png` backed by an Http webserver
AssetReader). The "default" asset reader would use normal
`some_path/image.png` paths. Ideally this works in combination with
multiple AssetWatchers for hot-reloading
* **Stable Type Names**: this pr removes the TypeUuid requirement from
assets in favor of `std::any::type_name`. This makes defining assets
easier (no need to generate a new uuid / use weird proc macro syntax).
It also makes reading meta files easier (because things have "friendly
names"). We also use type names for components in scene files. If they
are good enough for components, they are good enough for assets. And
consistency across Bevy pillars is desirable. However,
`std::any::type_name` is not guaranteed to be stable (although in
practice it is). We've developed a [stable type
path](https://github.com/bevyengine/bevy/pull/7184) to resolve this,
which should be adopted when it is ready.
* **Command Line Interface**: It should be possible to run the asset
processor in a separate process from the command line. This will also
require building a network-server-backed AssetReader to communicate
between the app and the processor. We've been planning to build a "bevy
cli" for awhile. This seems like a good excuse to build it.
* **Asset Packing**: This is largely an additive feature, so it made
sense to me to punt this until we've laid the foundations in this PR.
* **Per-Platform Processed Assets**: It should be possible to generate
assets for multiple platforms by supporting multiple "processor
profiles" per asset (ex: compress with format X on PC and Y on iOS). I
think there should probably be arbitrary "profiles" (which can be
separate from actual platforms), which are then assigned to a given
platform when generating the final asset distribution for that platform.
Ex: maybe devs want a "Mobile" profile that is shared between iOS and
Android. Or a "LowEnd" profile shared between web and mobile.
* **Versioning and Migrations**: Assets, Loaders, Savers, and Processors
need to have versions to determine if their schema is valid. If an asset
/ loader version is incompatible with the current version expected at
runtime, the processor should be able to migrate them. I think we should
try using Bevy Reflect for this, as it would allow us to load the old
version as a dynamic Reflect type without actually having the old Rust
type. It would also allow us to define "patches" to migrate between
versions (Bevy Reflect devs are currently working on patching). The
`.meta` file already has its own format version. Migrating that to new
versions should also be possible.
* **Real Copy-on-write AssetPaths**: Rust's actual Cow (clone-on-write
type) currently used by AssetPath can still result in String clones that
aren't actually necessary (cloning an Owned Cow clones the contents).
Bevy's asset system requires cloning AssetPaths in a number of places,
which result in actual clones of the internal Strings. This is not
efficient. AssetPath internals should be reworked to exhibit truer
cow-like-behavior that reduces String clones to the absolute minimum.
* **Consider processor-less processing**: In theory the AssetServer
could run processors "inline" even if the background AssetProcessor is
disabled. If we decide this is actually desirable, we could add this.
But I don't think its a priority in the short or medium term.
* **Pre-emptive dependency loading**: We could encode dependencies in
processed meta files, which could then be used by the Asset Server to
kick of dependency loads as early as possible (prior to starting the
actual asset load). Is this desirable? How much time would this save in
practice?
* **Optimize Processor With UntypedAssetIds**: The processor exclusively
uses AssetPath to identify assets currently. It might be possible to
swap these out for UntypedAssetIds in some places, which are smaller /
cheaper to hash and compare.
* **One to Many Asset Processing**: An asset source file that produces
many assets currently must be processed into a single "processed" asset
source. If labeled assets can be written separately they can each have
their own configured savers _and_ they could be loaded more granularly.
Definitely worth exploring!
* **Automatically Track "Runtime-only" Asset Dependencies**: Right now,
tracking "created at runtime" asset dependencies requires adding them
via `asset_server.load_asset(StandardMaterial::default())`. I think with
some cleverness we could also do this for
`materials.add(StandardMaterial::default())`, making tracking work
"everywhere". There are challenges here relating to change detection /
ensuring the server is made aware of dependency changes. This could be
expensive in some cases.
* **"Dependency Changed" events**: Some assets have runtime artifacts
that need to be re-generated when one of their dependencies change (ex:
regenerate a material's bind group when a Texture needs to change). We
are generating the dependency graph so we can definitely produce these
events. Buuuuut generating these events will have a cost / they could be
high frequency for some assets, so we might want this to be opt-in for
specific cases.
* **Investigate Storing More Information In Handles**: Handles can now
store arbitrary information, which makes it cheaper and easier to
access. How much should we move into them? Canonical asset load states
(via atomics)? (`handle.is_loaded()` would be very cool). Should we
store the entire asset and remove the `Assets<T>` collection?
(`Arc<RwLock<Option<Image>>>`?)
* **Support processing and loading files without extensions**: This is a
pretty arbitrary restriction and could be supported with very minimal
changes.
* **Folder Meta**: It would be nice if we could define per folder
processor configuration defaults (likely in a `.meta` or `.folder_meta`
file). Things like "default to linear filtering for all Images in this
folder".
* **Replace async_broadcast with event-listener?** This might be
approximately drop-in for some uses and it feels more light weight
* **Support Running the AssetProcessor on the Web**: Most of the hard
work is done here, but there are some easy straggling TODOs (make the
transaction log an interface instead of a direct file writer so we can
write a web storage backend, implement an AssetReader/AssetWriter that
reads/writes to something like LocalStorage).
* **Consider identifying and preventing circular dependencies**: This is
especially important for "processor dependencies", as processing will
silently never finish in these cases.
* **Built-in/Inlined Asset Hot Reloading**: This PR regresses
"built-in/inlined" asset hot reloading (previously provided by the
DebugAssetServer). I'm intentionally punting this because I think it can
be cleanly implemented with "multiple asset sources" by registering a
"debug asset source" (ex: `debug://bevy_pbr/src/render/pbr.wgsl` asset
paths) in combination with an AssetWatcher for that asset source and
support for "manually loading pats with asset bytes instead of
AssetReaders". The old DebugAssetServer was quite nasty and I'd love to
avoid that hackery going forward.
* **Investigate ways to remove double-parsing meta files**: Parsing meta
files currently involves parsing once with "minimal" versions of the
meta file to extract the type name of the loader/processor config, then
parsing again to parse the "full" meta. This is suboptimal. We should be
able to define custom deserializers that (1) assume the loader/processor
type name comes first (2) dynamically looks up the loader/processor
registrations to deserialize settings in-line (similar to components in
the bevy scene format). Another alternative: deserialize as dynamic
Reflect objects and then convert.
* **More runtime loading configuration**: Support using the Handle type
as a hint to select an asset loader (instead of relying on AssetPath
extensions)
* **More high level Processor trait implementations**: For example, it
might be worth adding support for arbitrary chains of "asset transforms"
that modify an in-memory asset representation between loading and
saving. (ex: load a Mesh, run a `subdivide_mesh` transform, followed by
a `flip_normals` transform, then save the mesh to an efficient
compressed format).
* **Bevy Scene Handle Deserialization**: (see the relevant [Draft TODO
item](#draft-todo) for context)
* **Explore High Level Load Interfaces**: See [this
discussion](#discuss-on_loaded-high-level-interface) for one prototype.
* **Asset Streaming**: It would be great if we could stream Assets (ex:
stream a long video file piece by piece)
* **ID Exchanging**: In this PR Asset Handles/AssetIds are bigger than
they need to be because they have a Uuid enum variant. If we implement
an "id exchanging" system that trades Uuids for "efficient runtime ids",
we can cut down on the size of AssetIds, making them more efficient.
This has some open design questions, such as how to spawn entities with
"default" handle values (as these wouldn't have access to the exchange
api in the current system).
* **Asset Path Fixup Tooling**: Assets that inline asset paths inside
them will break when an asset moves. The asset system provides the
functionality to detect when paths break. We should build a framework
that enables formats to define "path migrations". This is especially
important for scene files. For editor-generated files, we should also
consider using UUIDs (see other bullet point) to avoid the need to
migrate in these cases.
---------
Co-authored-by: BeastLe9enD <beastle9end@outlook.de>
Co-authored-by: Mike <mike.hsu@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
fix #8185, #6710
replace #7005 (closed)
rgb and rgba 16 bit textures currently default to `Rgba16Uint`, the more
common use is `Rgba16Unorm`, which also matches the default type of rgb8
and rgba8 textures.
## Solution
Change default to `Rgba16Unorm`
# Objective
Bevy currently crashes when meshes with different vertex counts for
attributes are provided.
## Solution
Instead of crashing we can warn and take the min length of all the given
attributes.
# Objective
- Fixes#9244.
## Solution
- Changed the `(Into)SystemSetConfigs` traits and structs be more like
the `(Into)SystemConfigs` traits and structs.
- Replaced uses of `IntoSystemSetConfig` with `IntoSystemSetConfigs`
- Added generic `ItemConfig` and `ItemConfigs` types.
- Changed `SystemConfig(s)` and `SystemSetConfig(s)` to be type aliases
to `ItemConfig(s)`.
- Added generic `process_configs` to `ScheduleGraph`.
- Changed `configure_sets_inner` and `add_systems_inner` to reuse
`process_configs`.
---
## Changelog
- Added `run_if` to `IntoSystemSetConfigs`
- Deprecated `Schedule::configure_set` and `App::configure_set`
- Removed `IntoSystemSetConfig`
## Migration Guide
- Use `App::configure_sets` instead of `App::configure_set`
- Use `Schedule::configure_sets` instead of `Schedule::configure_set`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently, the depth textures are cached based on the target. If
multiple camera have the same target but a different
`depth_texture_usage` bevy will just use the same texture and ignore
that setting.
## Solution
- Add the usage as a cache key
# Objective
- Currently we don't have panicking alternative for getting components
from `Query` like for resources. Partially addresses #9443.
## Solution
- Add these functions.
---
## Changelog
### Added
- `Query::component` and `Query::component_mut` to get specific
component from query and panic on error.
# Objective
The recently introduced check that the cursor position returned by
`Window::cursor_position()` is within the bounds of the window
(3cf94e7c9d)
has the following issue:
If *w* is the window width, points within the window satisfy the
condition 0 ≤ *x* < *w*, but the code assumes the condition 0 ≤ *x* ≤
*w*. In other words, if *x* = *w*, the point is not within the window
bounds. Likewise for the height. This program demonstrates the issue:
```rust
use bevy::{prelude::*, window::WindowResolution};
fn main() {
let mut window = Window {
resolution: WindowResolution::new(100.0, 100.0),
..default()
};
window.set_cursor_position(Some(Vec2::new(100.0, 0.0)));
println!("{:?}", window.cursor_position());
}
```
It prints `Some(Vec2(100.0, 0.0))` instead of the expected `None`.
## Solution
- Exclude the upper bound, i.e., the window width for the *x* position
and the window height for the *y* position.
# Objective
Allow mutably iterating over all registered diagnostics. This is a
useful utility method when exposing bevy's diagnostics in an editor that
allows toggling whether the diagnostic is enabled.
## Solution
- Add `iter_mut`, mirroring what `iter` does, just mutably.
---
## Changelog
### Added
- Added `DiagnosticsStore::iter_mut` for mutably iterating over all
registered diagnostics.
# Objective
This PR aims to fix a handful of problems with the `SpatialBundle` docs:
The docs describe the role of the single components of the bundle,
overshadowing the purpose of `SpatialBundle` itself. Also, those items
may be added, removed or changed over time, as it happened with #9497,
requiring a higher maintenance effort, which will often result in
errors, as it happened.
## Solution
Just describe the role of `SpatialBundle` and of the transform and
visibility concepts, without mentioning the specific component types.
Since the bundle has public fields, the reader can easily click them and
read the documentation if they need to know more. I removed the mention
of numbers of components since they were four, now they are five, and
who knows how many they will be in the future. In this process, I
removed the bullet points, which are no longer needed, and were
contextually wrong in the first place, since they were meant to list the
components, but ended up describing use-cases and requirements for
hierarchies.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.
The WGSL spec says that all scalar or vector integer vertex stage
outputs and fragment stage inputs must be marked as @interpolate(flat).
I think wgpu fixed this up for us, but being explicit is more correct.
# Objective
- Supercedes #8872
- Improve sprite rendering performance after the regression in #9236
## Solution
- Use an instance-rate vertex buffer to store per-instance data.
- Store color, UV offset and scale, and a transform per instance.
- Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine
3x4 matrix and store the transpose of that in the per-instance data.
This is similar to how MeshUniform uses transpose affine matrices.
- Use a special index buffer that has batches of 6 indices referencing 4
vertices. The lower 2 bits indicate the x and y of a quad such that the
corners are:
```
10 11
00 01
```
UVs are implicit but get modified by UV offset and scale The remaining
upper bits contain the instance index.
## Benchmarks
I will compare versus `main` before #9236 because the results should be
as good as or faster than that. Running `bevymark -- 10000 16` on an M1
Max with `main` at `e8b38925` in yellow, this PR in red:
Looking at the median frame times, that's a 37% reduction from before.
---
## Changelog
- Changed: Improved sprite rendering performance by leveraging an
instance-rate vertex buffer.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
Fix#8267.
Fixes half of #7840.
The `ComputedVisibility` component contains two flags: hierarchy
visibility, and view visibility (whether its visible to any cameras).
Due to the modular and open-ended way that view visibility is computed,
it triggers change detection every single frame, even when the value
does not change. Since hierarchy visibility is stored in the same
component as view visibility, this means that change detection for
inherited visibility is completely broken.
At the company I work for, this has become a real issue. We are using
change detection to only re-render scenes when necessary. The broken
state of change detection for computed visibility means that we have to
to rely on the non-inherited `Visibility` component for now. This is
workable in the early stages of our project, but since we will
inevitably want to use the hierarchy, we will have to either:
1. Roll our own solution for computed visibility.
2. Fix the issue for everyone.
## Solution
Split the `ComputedVisibility` component into two: `InheritedVisibilty`
and `ViewVisibility`.
This allows change detection to behave properly for
`InheritedVisibility`.
View visiblity is still erratic, although it is less useful to be able
to detect changes
for this flavor of visibility.
Overall, this actually simplifies the API. Since the visibility system
consists of
self-explaining components, it is much easier to document the behavior
and usage.
This approach is more modular and "ECS-like" -- one could
strip out the `ViewVisibility` component entirely if it's not needed,
and rely only on inherited visibility.
---
## Changelog
- `ComputedVisibility` has been removed in favor of:
`InheritedVisibility` and `ViewVisiblity`.
## Migration Guide
The `ComputedVisibilty` component has been split into
`InheritedVisiblity` and
`ViewVisibility`. Replace any usages of
`ComputedVisibility::is_visible_in_hierarchy`
with `InheritedVisibility::get`, and replace
`ComputedVisibility::is_visible_in_view`
with `ViewVisibility::get`.
```rust
// Before:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
computed_visibility: ComputedVisibility::default(),
});
// After:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
inherited_visibility: InheritedVisibility::default(),
view_visibility: ViewVisibility::default(),
});
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_hierarchy() {
// After:
fn my_system(q: Query<&InheritedVisibility>) {
for inherited_visibility in &q {
if inherited_visibility.get() {
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_view() {
// After:
fn my_system(q: Query<&ViewVisibility>) {
for view_visibility in &q {
if view_visibility.get() {
```
```rust
// Before:
fn my_system(mut q: Query<&mut ComputedVisibilty>) {
for vis in &mut q {
vis.set_visible_in_view();
// After:
fn my_system(mut q: Query<&mut ViewVisibility>) {
for view_visibility in &mut q {
view_visibility.set();
```
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
- Fixes#9641
- Anonymous sets are named by their system members. When
`ScheduleBuildSettings::report_sets` is on, systems are named by their
sets. So when getting the anonymous set name this would cause an
infinite recursion.
## Solution
- When getting the anonymous system set name, don't get their system's
names with the sets the systems belong to.
## Other Possible solutions
- An alternate solution might be to skip anonymous sets when getting the
system's name for an anonymous set's name.
# Objective
- I broke ambiguity reporting in one of my refactors.
`conflicts_to_string` should have been using the passed in parameter
rather than the one stored on self.
# Objective
I've been collecting some mistakes in the documentation and fixed them
---------
Co-authored-by: Emi <emanuel.boehm@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
`Window::physical_cursor_position` checks to see if the cursor's
position is inside the window but it constructs the bounding rect for
the window using its logical size and then checks to see if it contains
the cursor's physical position. When the physical size is smaller than
the logical size, this leaves a dead zone where the cursor is over the
window but its position is unreported.
fixes: #9656
## Solution
Use the physical size of the window.
# Objective
Make it easier to create bounding boxes in user code by providing a
constructor that computes a box surrounding an arbitrary number of
points.
## Solution
Add `Aabb::enclosing`, which accepts iterators, slices, or arrays.
---------
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
- The current `EventReader::iter` has been determined to cause confusion
among new Bevy users. It was suggested by @JoJoJet to rename the method
to better clarify its usage.
- Solves #9624
## Solution
- Rename `EventReader::iter` to `EventReader::read`.
- Rename `EventReader::iter_with_id` to `EventReader::read_with_id`.
- Rename `ManualEventReader::iter` to `ManualEventReader::read`.
- Rename `ManualEventReader::iter_with_id` to
`ManualEventReader::read_with_id`.
---
## Changelog
- `EventReader::iter` has been renamed to `EventReader::read`.
- `EventReader::iter_with_id` has been renamed to
`EventReader::read_with_id`.
- `ManualEventReader::iter` has been renamed to
`ManualEventReader::read`.
- `ManualEventReader::iter_with_id` has been renamed to
`ManualEventReader::read_with_id`.
- Deprecated `EventReader::iter`
- Deprecated `EventReader::iter_with_id`
- Deprecated `ManualEventReader::iter`
- Deprecated `ManualEventReader::iter_with_id`
## Migration Guide
- Existing usages of `EventReader::iter` and `EventReader::iter_with_id`
will have to be changed to `EventReader::read` and
`EventReader::read_with_id` respectively.
- Existing usages of `ManualEventReader::iter` and
`ManualEventReader::iter_with_id` will have to be changed to
`ManualEventReader::read` and `ManualEventReader::read_with_id`
respectively.
# Objective
The latest `clippy` release has a much more aggressive application of
the
[`explicit_iter_loop`](https://rust-lang.github.io/rust-clippy/master/index.html#/explicit_into_iter_loop?groups=pedantic)
pedantic lint.
As a result, clippy now suggests the following:
```diff
-for event in events.iter() {
+for event in &mut events {
```
I'm generally in favor of this lint. Using `for mut item in &mut query`
is also recommended over `for mut item in query.iter_mut()` for good
reasons IMO.
But, it is my personal belief that `&mut events` is much less clear than
`events.iter()`.
Why? The reason is that the events from `EventReader` **are not
mutable**, they are immutable references to each event in the event
reader. `&mut events` suggests we are getting mutable access to events —
similarly to `&mut query` — which is not the case. Using `&mut events`
is therefore misleading.
`IntoIterator` requires a mutable `EventReader` because it updates the
internal `last_event_count`, not because it let you mutate it.
So clippy's suggested improvement is a downgrade.
## Solution
Do not implement `IntoIterator` for `&mut events`.
Without the impl, clippy won't suggest its "fix". This also prevents
generally people from using `&mut events` for iterating `EventReader`s,
which makes the ecosystem every-so-slightly better.
---
## Changelog
- Removed `IntoIterator` impl for `&mut EventReader`
## Migration Guide
- `&mut EventReader` does not implement `IntoIterator` anymore. replace
`for foo in &mut events` by `for foo in events.iter()`
# Objective
- Some of the old ambiguity tests didn't get ported over during schedule
v3.
## Solution
- Port over tests from
15ee98db8d/crates/bevy_ecs/src/schedule/ambiguity_detection.rs (L279-L612)
with minimal changes
- Make a method to convert the ambiguity conflicts to a string for
easier verification of correct results.
# Objective
As far as I can tell, this is no longer needed since the switch to
fancier shader imports via `naga_oil`.
This shouldn't have any affect on compile times because it's in our tree
from `naga_oil`, `tracing-subscriber`, and `rodio`.
# Objective
Rename `Val`'s `evaluate` method to `resolve`.
Implement `resolve` support for `Val`'s viewport variants.
fixes#9535
---
## Changelog
`bevy_ui::ui_node::Val`:
* Renamed the following methods and added a `viewport_size` parameter:
- `evaluate` to `resolve`
- `try_add_with_size` to `try_add_with_context`
- `try_add_assign_with_size` to `try_add_assign_with_context`
- `try_sub_with_size` to `try_sub_with_context`
- `try_sub_assign_with_size` to `try_sub_assign_with_context`
* Implemented `resolve` support for `Val`'s viewport coordinate types
## Migration Guide
* Renamed the following `Val` methods and added a `viewport_size`
parameter:
- `evaluate` to `resolve`
- `try_add_with_size` to `try_add_with_context`
- `try_add_assign_with_size` to `try_add_assign_with_context`
- `try_sub_with_size` to `try_sub_with_context`
- `try_sub_assign_with_size` to `try_sub_assign_with_context`
Legitimately, bevy emits a WARN when encountering entities in UI trees
without NodeBunlde components.
Bevy pretty much always panics when such a thing happens, due to the
update_clipping system.
However, sometimes, it's perfectly legitimate to have a child without UI
nodes in a UI tree. For example, as a "seed" entity that is consumed by
a 3rd party plugin, which will later spawn a valid UI tree. In loading
scenarios, you are pretty much guaranteed to have incomplete children.
The presence of the WARN hints that bevy does not intend to panic on
such occasion (otherwise the warn! would be a panic!) so I assume panic
is an unintended behavior, aka a bug.
## Solution
Early-return instead of panicking.
I did only test that it indeed fixed the panic, not checked for UI
inconsistencies. Though on a logical level, it can only have changed
code that would otherwise panic.
## Alternatives
Instead of early-returning on invalid entity in `update_clipping`, do
not call it with invalid entity in its recursive call.
---
## Changelog
- Do not panic on non-UI child of UI entity
# Objective
Fix#4278Fix#5504Fix#9422
Provide safe ways to borrow an entire entity, while allowing disjoint
mutable access. `EntityRef` and `EntityMut` are not suitable for this,
since they provide access to the entire world -- they are just helper
types for working with `&World`/`&mut World`.
This has potential uses for reflection and serialization
## Solution
Remove `EntityRef::world`, which allows it to soundly be used within
queries.
`EntityMut` no longer supports structural world mutations, which allows
multiple instances of it to exist for different entities at once.
Structural world mutations are performed using the new type
`EntityWorldMut`.
```rust
fn disjoint_system(
q2: Query<&mut A>,
q1: Query<EntityMut, Without<A>>,
) { ... }
let [entity1, entity2] = world.many_entities_mut([id1, id2]);
*entity1.get_mut::<T>().unwrap() = *entity2.get().unwrap();
for entity in world.iter_entities_mut() {
...
}
```
---
## Changelog
- Removed `EntityRef::world`, to fix a soundness issue with queries.
+ Removed the ability to structurally mutate the world using
`EntityMut`, which allows it to be used in queries.
+ Added `EntityWorldMut`, which is used to perform structural mutations
that are no longer allowed using `EntityMut`.
## Migration Guide
**Note for maintainers: ensure that the guide for #9604 is updated
accordingly.**
Removed the method `EntityRef::world`, to fix a soundness issue with
queries. If you need access to `&World` while using an `EntityRef`,
consider passing the world as a separate parameter.
`EntityMut` can no longer perform 'structural' world mutations, such as
adding or removing components, or despawning the entity. Additionally,
`EntityMut::world`, `EntityMut::world_mut` , and
`EntityMut::world_scope` have been removed.
Instead, use the newly-added type `EntityWorldMut`, which is a helper
type for working with `&mut World`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Move schedule name into `Schedule` to allow the schedule name to be
used for errors and tracing in Schedule methods
- Fixes#9510
## Solution
- Move label onto `Schedule` and adjust api's on `World` and `Schedule`
to not pass explicit label where it makes sense to.
- add name to errors and tracing.
- `Schedule::new` now takes a label so either add the label or use
`Schedule::default` which uses a default label. `default` is mostly used
in doc examples and tests.
---
## Changelog
- move label onto `Schedule` to improve error message and logging for
schedules.
## Migration Guide
`Schedule::new` and `App::add_schedule`
```rust
// old
let schedule = Schedule::new();
app.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
app.add_schedule(schedule);
```
if you aren't using a label and are using the schedule struct directly
you can use the default constructor.
```rust
// old
let schedule = Schedule::new();
schedule.run(world);
// new
let schedule = Schedule::default();
schedule.run(world);
```
`Schedules:insert`
```rust
// old
let schedule = Schedule::new();
schedules.insert(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
schedules.insert(schedule);
```
`World::add_schedule`
```rust
// old
let schedule = Schedule::new();
world.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
world.add_schedule(schedule);
```
# Objective
Every frame, `Events::update` gets called, which clears out any old
events from the buffer. There should be a way of taking ownership of
these old events instead of throwing them away. My use-case is dumping
old events into a debug menu so they can be inspected later.
One potential workaround is to just have a system that clones any
incoming events and stores them in a list -- however, this requires the
events to implement `Clone`.
## Solution
Add `Events::update_drain`, which returns an iterator of the events that
were removed from the buffer.
# Objective
Doc comment for the `global_transform` field in `NodeBundle` says:
```
/// This field is automatically managed by the UI layout system.
```
The `GlobalTransform` component is the thing being managed, not the
`global_transform` field, and the `TransformPropagate` systems do the
managing, not the UI layout system.
# Objective
- Fixes: #9508
- Fixes: #9526
## Solution
- Adds
```rust
fn configure_schedules(&mut self, schedule_build_settings: ScheduleBuildSettings)
```
to `Schedules`, and `App` to simplify applying `ScheduleBuildSettings`
to all schedules.
---
## Migration Guide
- No breaking changes.
- Adds `Schedule::get_build_settings()` getter for the schedule's
`ScheduleBuildSettings`.
- Can replaced manual configuration of all schedules:
```rust
// Old
for (_, schedule) in app.world.resource_mut::<Schedules>().iter_mut() {
schedule.set_build_settings(build_settings);
}
// New
app.configure_schedules(build_settings);
```
# Objective
To enable non exclusive system usage of reflected components and make
reflection more ergonomic to use by making it more in line with standard
entity commands.
## Solution
- Implements a new `EntityCommands` extension trait for reflection
related functions in the reflect module of bevy_ecs.
- Implements 4 new commands, `insert_reflect`,
`insert_reflect_with_registry`, `remove_reflect`, and
`remove_reflect_with_registry`. Both insert commands take a `Box<dyn
Reflect>` component while the remove commands take the component type
name.
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module. (Might be worth making these just public to enable user end
custom entity commands in a different pr)
- Added basic tests to ensure the commands are actually working.
- Documentation of functions.
---
## Changelog
Added:
- Implements 4 new commands on the new entity commands extension.
- `insert_reflect`
- `remove_reflect`
- `insert_reflect_with_registry`
- `remove_reflect_with_registry`
The commands operate the same except the with_registry commands take a
generic parameter for a resource that implements `AsRef<TypeRegistry>`.
Otherwise the default commands use the `AppTypeRegistry` for reflection
data.
Changed:
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module.
> Hopefully this time it works. Please don't make me rebase again ☹
# Objective
- Fixes [#8835](https://github.com/bevyengine/bevy/issues/8835)
## Solution
- Added a note to the `set_volume` docstring which explains how volume
is interpreted.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fixes#4917
- Replaces #9602
## Solution
- Replaced `EntityCommand` implementation for `FnOnce` to apply to
`FnOnce(EntityMut)` instead of `FnOnce(Entity, &mut World)`
---
## Changelog
- `FnOnce(Entity, &mut World)` no longer implements `EntityCommand`.
This is a breaking change.
## Migration Guide
### 1. New-Type `FnOnce`
Create an `EntityCommand` type which implements the method you
previously wrote:
```rust
pub struct ClassicEntityCommand<F>(pub F);
impl<F> EntityCommand for ClassicEntityCommand<F>
where
F: FnOnce(Entity, &mut World) + Send + 'static,
{
fn apply(self, id: Entity, world: &mut World) {
(self.0)(id, world);
}
}
commands.add(ClassicEntityCommand(|id: Entity, world: &mut World| {
/* ... */
}));
```
### 2. Extract `(Entity, &mut World)` from `EntityMut`
The method `into_world_mut` can be used to gain access to the `World`
from an `EntityMut`.
```rust
let old = |id: Entity, world: &mut World| {
/* ... */
};
let new = |mut entity: EntityMut| {
let id = entity.id();
let world = entity.into_world_mut();
/* ... */
};
```
# Objective
The name `ManualEventIterator` is long and unnecessary, as this is the
iterator type used for both `EventReader` and `ManualEventReader`.
## Solution
Rename `ManualEventIterator` to `EventIterator`. To ease migration, add
a deprecated type alias with the old name.
---
## Changelog
- The types `ManualEventIterator{WithId}` have been renamed to
`EventIterator{WithId}`.
## Migration Guide
The type `ManualEventIterator` has been renamed to `EventIterator`.
Additonally, `ManualEventIteratorWithId` has been renamed to
`EventIteratorWithId`.
# Objective
#5483 allows for the creation of non-`Sync` locals. However, it's not
actually possible to use these types as there is a `Sync` bound on the
`Deref` impls.
## Solution
Remove the unnecessary bounds.
# Objective
- have errors in configure_set and configure_sets show the line number
of the user calling location rather than pointing to schedule.rs
- use display formatting for the errors
## Example Error Text
```text
// dependency loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: DependencyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:39
// after
thread 'main' panicked at 'System set `A` depends on itself.', examples/stress_tests/bevymark.rs:16:9
// hierarchy loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: HierarchyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:3
// after
thread 'main' panicked at 'System set `A` contains itself.', examples/stress_tests/bevymark.rs:16:9
// configuring a system type set
// before
thread 'main' panicked at 'configuring system type sets is not allowed', crates\bevy_ecs\src\schedule\config.rs:394:9
//after
thread 'main' panicked at 'configuring system type sets is not allowed', examples/stress_tests/bevymark.rs:16:9
```
Code to produce errors:
```rust
use bevy::prelude::*;
#[derive(SystemSet, Clone, Debug, PartialEq, Eq, Hash)]
enum TestSet {
A,
}
fn main() {
fn foo() {}
let mut app = App::empty();
// Hierarchy Loop
app.configure_set(Main, TestSet::A.in_set(TestSet::A));
// Dependency Loop
app.configure_set(Main, TestSet::A.after(TestSet::A));
// Configure System Type Set
app.configure_set(Main, foo.into_system_set());
}
```
# Objective
A Bezier curve is a curve defined by two or more control points. In the
simplest form, it's just a line. The (arguably) most common type of
Bezier curve is a cubic Bezier, defined by four control points. These
are often used in animation, etc. Bevy has a Bezier curve struct called
`Bezier`. However, this is technically a misnomer as it only represents
cubic Bezier curves.
## Solution
This PR changes the struct name to `CubicBezier` to more accurately
reflect the struct's usage. Since it's exposed in Bevy's prelude, it can
potentially collide with other `Bezier` implementations. While that
might instead be an argument for removing it from the prelude, there's
also something to be said for adding a more general `Bezier` into Bevy,
in which case we'd likely want to use the name `Bezier`. As a final
motivator, not only is the struct located in `cubic_spines.rs`, there
are also several other spline-related structs which follow the
`CubicXxx` naming convention where applicable. For example,
`CubicSegment` represents a cubic Bezier curve (with coefficients
pre-baked).
---
## Migration Guide
- Change all `Bezier` references to `CubicBezier`
# Objective
Fixes#9550
## Solution
Removes a check that asserts that _all_ attribute metas are path-only,
rather than just the `#[deref]` attribute itself.
---
## Changelog
- Fixes an issue where deriving `Deref` with `#[deref]` on a field
causes other attributes to sometimes result in a compile error
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
These new defaults match what is used by `Camera2dBundle::default()`,
removing a potential footgun from overriding a field in the projection
component of the bundle.
## Solution
Adjusted the near clipping plane of `OrthographicProjection::default()`
to `-1000.`.
---
## Changelog
Changed: `OrthographicProjection::default()` now matches the value used
in `Camera2dBundle::default()`
## Migration Guide
Workarounds used to keep the projection consistent with the bundle
defaults are no longer required. Meanwhile, uses of
`OrthographicProjection` in 2D scenes may need to be adjusted; the
`near` clipping plane default was changed from `0.0` to `-1000.0`.
# Objective
`sync_simple_transforms` only checks for removed parents and doesn't
filter for `Without<Parent>`, so it overwrites the `GlobalTransform` of
non-orphan entities that were orphaned and then reparented since the
last update.
Introduced by #7264
## Solution
Filter for `Without<Parent>`.
Fixes#9517, #9492
## Changelog
`sync_simple_transforms`:
* Added a `Without<Parent>` filter to the orphaned entities query.
Fixes https://github.com/bevyengine/bevy/issues/9458.
On case-insensitive filesystems (Windows, Mac, NTFS mounted in Linux,
etc.), a path can be represented in a multiple ways:
- `c:\users\user\rust\assets\hello\world`
- `c:/users/user/rust/assets/hello/world`
- `C:\USERS\USER\rust\assets\hello\world`
If user specifies a path variant that doesn't match asset folder path
bevy calculates, `path.strip_prefix()` will fail, as demonstrated below:
```rs
dbg!(Path::new("c:/foo/bar/baz").strip_prefix("c:/foo"));
// Ok("bar/baz")
dbg!(Path::new("c:/FOO/bar/baz").strip_prefix("c:/foo"));
// StripPrefixError(())
```
This commit rewrites the code in question in a way that prefix stripping
is no longer necessary.
I've tested with the following paths on my computer:
```rs
let res = asset_server.load_folder("C:\\Users\\user\\rust\\assets\\foo\\bar");
dbg!(res);
let res = asset_server.load_folder("c:\\users\\user\\rust\\assets\\foo\\bar");
dbg!(res);
let res = asset_server.load_folder("C:/Users/user/rust/assets/foo/bar");
dbg!(res);
```
# Objective
* There is no way to read the fields of `GridPlacement` once set.
* Values of `0` for `GridPlacement`'s fields are invalid but can be set.
* A non-zero representation would be half the size.
fixes#9474
## Solution
* Add `get_start`, `get_end` and `get_span` accessor methods.
* Change`GridPlacement`'s constructor functions to panic on arguments of
zero.
* Use non-zero types instead of primitives for `GridPlacement`'s fields.
---
## Changelog
`bevy_ui::ui_node::GridPlacement`:
* Field types have been changed to `Option<NonZeroI16>` and
`Option<NonZeroU16>`. This is because zero values are not valid for
`GridPlacement`. Previously, Taffy interpreted these as auto variants.
* Constructor functions for `GridPlacement` panic on arguments of `0`.
* Added accessor functions: `get_start`, `get_end`, and `get_span`.
These return the inner primitive value (if present) of the respective
fields.
## Migration Guide
`GridPlacement`'s constructor functions no longer accept values of `0`.
Given any argument of `0` they will panic with a `GridPlacementError`.
# Objective
- Fixes#9321
## Solution
- `EntityMap` has been replaced by a simple `HashMap<Entity, Entity>`.
---
## Changelog
- `EntityMap::world_scope` has been replaced with `World::world_scope`
to avoid creating a new trait. This is a public facing change to the
call semantics, but has no effect on results or behaviour.
- `EntityMap`, as a `HashMap`, now operates on `&Entity` rather than
`Entity`. This changes many standard access functions (e.g, `.get`) in a
public-facing way.
## Migration Guide
- Calls to `EntityMap::world_scope` can be directly replaced with the
following:
`map.world_scope(&mut world)` -> `world.world_scope(&mut map)`
- Calls to legacy `EntityMap` methods such as `EntityMap::get` must
explicitly include de/reference symbols:
`let entity = map.get(parent);` -> `let &entity = map.get(&parent);`
# Objective
Fixes#9420
## Solution
Remove one of the two `AppExit` event checks in the
`ScheduleRunnerPlugin`'s main loop. Specificially, the check that
happens immediately before calling `App.update()`, to be consistent with
the `WinitPlugin`.
# Objective
fixes#8357
gltf animations can affect multiple "root" nodes (i.e. top level nodes
within a gltf scene).
the current loader adds an AnimationPlayer to each root node which is
affected by any animation. when a clip which affects multiple root nodes
is played on a root node player, the root node name is not checked,
leading to potentially incorrect weights being applied.
also, the `AnimationClip::compatible_with` method will never return true
for those clips, as it checks that all paths start with the root node
name - not all paths start with the same name so it can't return true.
## Solution
- check the first path node name matches the given root
- change compatible_with to return true if `any` match is found
a better alternative would probably be to attach the player to the scene
root instead of the first child, and then walk the full path from there.
this would be breaking (and would stop multiple animations that *don't*
overlap from being played concurrently), but i'm happy to modify to that
if it's preferred.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- Meshes with a higher number of joints than `MAX_JOINTS` are crashing
- Fixes partly #9021 (doesn't crash anymore, but the mesh is not
correctly displayed)
## Solution
- Only take up to `MAX_JOINTS` joints when extending the buffer
# Objective
Make code relating to event more readable.
Currently the `impl` block of `Events` is split in two, and the big part
of its implementations are put at the end of the file, far from the
definition of the `struct`.
## Solution
- Move and merge the `impl` blocks of `Events` next to its definition.
- Move the `EventSequence` definition and implementations before the
`Events`, because they're pretty trivial and help understand how
`Events` work, rather than being buried bellow `Events`.
I separated those two steps in two commits to not be too confusing. I
didn't modify any code of documentation. I want to do a second PR with
such modifications after this one is merged.
# Objective
Similar to #6344, but contains only `ReflectBundle` changes. Useful for
scripting. The implementation has also been updated to look exactly like
`ReflectComponent`.
---
## Changelog
### Added
- Reflection for bundles.
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
This PR's first aim is to fix a mistake in `HalfSpace`'s documentation.
When defining a `Frustum` myself in bevy_basic_portals, I realised that
the "distance" of the `HalfSpace` is not, as the current doc defines,
the "distance from the origin along the normal", but actually the
opposite of that.
See the example I gave in this PR.
This means one of two things:
1. The documentation about `HalfSpace` is wrong (it is either way
because of the `n.p + d > 0` formula given later anyway, which is how it
behaves, but in that formula `d` is indeed the opposite of the "distance
from the origin along the normal", otherwise it should be `n.p > d`)
2. The distance is supposed to be the "distance from the origin along
the normal" but when used in a Frustum it's used as the opposite, and it
is a mistake
3. Same as 2, but it is somehow intended
Since I think `HalfSpace` is only used for `Frustum`, and it's easier to
fix documentation than code, I assumed for this PR we're in case number
1. If we're in case number 3, the documentation of `Frustum` needs to
change, and in case number 2, the code needs to be fixed.
While I was at it, I also :
- Tried to improve the documentation for `Frustum`, `Aabb`, and
`VisibilitySystems`, among others, since they're all related to
`Frustum`.
- Fixed documentation about frustum culling not applying to 2d objects,
which is not true since https://github.com/bevyengine/bevy/pull/7885
## Remarks and questions
- What about a `HalfSpace` with an infinite distance, is it allowed and
does it represents the whole space? If so it should probably be
mentioned.
- I referenced the `update_frusta` system in
`bevy_render::view::visibility` directly instead of referencing its
system set, should I reference the system set instead? It's a bit
annoying since it's in 3 sets.
- `visibility_propagate` is not public for some reason, I think it
probably should be, but for now I only documented its system set, should
I make it public? I don't think that would count as a breaking change?
- Why is `Aabb` inserted by a system, with `NoFrustumCulling` as an
opt-out, instead of having it inserted by default in `PbrBundle` for
example and then the system calculating it when it's added? Is it
because there is still no way to have an optional component inside a
bundle?
---------
Co-authored-by: SpecificProtagonist <vincentjunge@posteo.net>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
- `bevy_text/src/pipeline.rs` had some crufty code.
## Solution
Remove the cruft.
- `&mut self` argument was unused by
`TextPipeline::create_text_measure`, so we replace it with a constructor
`TextMeasureInfo::from_text`.
- We also pass a `&Text` to `from_text` since there is no reason to
split the struct before passing it as argument.
- from_text also checks beforehand that every Font exist in the
Assets<Font>. This allows rust to skip the drop code on the Vecs we
create in the method, since there is no early exit.
- We also remove the scaled_fonts field on `TextMeasureInfo`. This
avoids an additional allocation. We can re-use the font on `fonts`
instead in `compute_size`. Building a `ScaledFont` seems fairly cheap,
when looking at the ab_glyph internals.
- We also implement ToSectionText on TextMeasureSection, this let us
skip creating a whole new Vec each time we call compute_size.
- This let us remove compute_size_from_section_text, since its only
purpose was to not have to allocate the Vec we just made redundant.
- Make some immutabe `Vec<T>` into `Box<[T]>` and `String` into
`Box<str>`
- `{min,max}_width_content_size` fields of `TextMeasureInfo` have name
`width` in them, yet the contain information on both width and height.
- `TextMeasureInfo::linebreak_behaviour` -> `linebreak_behavior`
## Migration Guide
- The `ResMut<TextPipeline>` argument to `measure_text_system` doesn't
exist anymore. If you were calling this system manually, you should
remove the argument.
- The `{min,max}_width_content_size` fields of `TextMeasureInfo` are
renamed to `min` and `max` respectively
- Other changes to `TextMeasureInfo` may also break your code if you
were manually building it. Please consider using the new
`TextMeasureInfo::from_text` to build one instead.
- `TextPipeline::create_text_measure` has been removed in favor of
`TextMeasureInfo::from_text`
# Objective
Added `AnimationPlayer` API UX improvements.
- Succestor to https://github.com/bevyengine/bevy/pull/5912
- Fixes https://github.com/bevyengine/bevy/issues/5848
_(Credits to @asafigan for filing #5848, creating the initial pull
request, and the discussion in #5912)_
## Solution
- Created `RepeatAnimation` enum to describe an animation repetition
behavior.
- Added `is_finished()`, `set_repeat()`, and `is_playback_reversed()`
methods to the animation player.
- ~~Made the animation clip optional as per the comment from #5912~~
> ~~My problem is that the default handle [used the initialize a
`PlayingAnimation`] could actually refer to an actual animation if an
AnimationClip is set for the default handle, which leads me to ask,
"Should animation_clip should be an Option?"~~
- Added an accessor for the animation clip `animation_clip()` to the
animation player.
To determine if an animation is finished, we use the number of times the
animation has completed and the repetition behavior. If the animation is
playing in reverse then `elapsed < 0.0` counts as a completion.
Otherwise, `elapsed > animation.duration` counts as a completion. This
is what I would expect, personally. If there's any ambiguity, perhaps we
could add some `AnimationCompletionBehavior`, to specify that kind of
completion behavior to use.
Update: Previously `PlayingAnimation::elapsed` was being used as the
seek time into the animation clip. This was misleading because if you
increased the speed of the animation it would also increase (or
decrease) the elapsed time. In other words, the elapsed time was not
actually the elapsed time. To solve this, we introduce
`PlayingAnimation::seek_time` to serve as the value we manipulate the
move between keyframes. Consequently, `elapsed()` now returns the actual
elapsed time, and is not effected by the animation speed. Because
`set_elapsed` was being used to manipulate the displayed keyframe, we
introduce `AnimationPlayer::seek_to` and `AnimationPlayer::replay` to
provide this functionality.
## Migration Guide
- Removed `set_elapsed`.
- Removed `stop_repeating` in favour of
`AnimationPlayer::set_repeat(RepeatAnimation::Never)`.
- Introduced `seek_to` to seek to a given timestamp inside of the
animation.
- Introduced `seek_time` accessor for the `PlayingAnimation::seek_to`.
- Introduced `AnimationPlayer::replay` to reset the `PlayingAnimation`
to a state where no time has elapsed.
---------
Co-authored-by: Hennadii Chernyshchyk <genaloner@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#8840
Make the cursor position more consistent, right now the cursor position
is *sometimes* outside of the window and returns the position and
*sometimes* `None`.
Even in the cases where someone might be using that position that is
outside of the window, it'll probably require some manual
transformations for it to actually be useful.
## Solution
Check the windows width and height for out of bounds positions.
---
## Changelog
- Cursor position is now always `None` when outside of the window.
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
Any time we wish to transform the output of a system, we currently use
system piping to do so:
```rust
my_system.pipe(|In(x)| do_something(x))
```
Unfortunately, system piping is not a zero cost abstraction. Each call
to `.pipe` requires allocating two extra access sets: one for the second
system and one for the combined accesses of both systems. This also adds
extra work to each call to `update_archetype_component_access`, which
stacks as one adds multiple layers of system piping.
## Solution
Add the `AdapterSystem` abstraction: similar to `CombinatorSystem`, this
allows you to implement a trait to generically control how a system is
run and how its inputs and outputs are processed. Unlike
`CombinatorSystem`, this does not have any overhead when computing world
accesses which makes it ideal for simple operations such as inverting or
ignoring the output of a system.
Add the extension method `.map(...)`: this is similar to `.pipe(...)`,
only it accepts a closure as an argument instead of an `In<T>` system.
```rust
my_system.map(do_something)
```
This has the added benefit of making system names less messy: a system
that ignores its output will just be called `my_system`, instead of
`Pipe(my_system, ignore)`
---
## Changelog
TODO
## Migration Guide
The `system_adapter` functions have been deprecated: use `.map` instead,
which is a lightweight alternative to `.pipe`.
```rust
// Before:
my_system.pipe(system_adapter::ignore)
my_system.pipe(system_adapter::unwrap)
my_system.pipe(system_adapter::new(T::from))
// After:
my_system.map(std::mem::drop)
my_system.map(Result::unwrap)
my_system.map(T::from)
// Before:
my_system.pipe(system_adapter::info)
my_system.pipe(system_adapter::dbg)
my_system.pipe(system_adapter::warn)
my_system.pipe(system_adapter::error)
// After:
my_system.map(bevy_utils::info)
my_system.map(bevy_utils::dbg)
my_system.map(bevy_utils::warn)
my_system.map(bevy_utils::error)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fix the `borders`, `ui` and `text_wrap_debug` examples.
## Solution
- Swap `TransparentUi` to use a stable sort
---
This is the smallest change to fix the examples but ideally this is
fixed by setting better sort keys for the UI elements such that we can
swap back to an unstable sort.
# Objective
- break up large build_schedule system to make it easier to read
- Clean up related error messages.
- I have a follow up PR that adds the schedule name to the error
messages, but wanted to break this up from that.
## Changelog
- refactor `build_schedule` to be easier to read
## Sample Error Messages
Dependency Cycle
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
Hierarchy Cycle
```text
thread 'main' panicked at 'System set hierarchy contains cycle(s).
schedule has 1 in_set cycle(s):
cycle 1: set 'A' contains itself
set 'A'
... which contains set 'B'
... which contains set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
System Type Set
```text
thread 'main' panicked at 'Tried to order against `SystemTypeSet(fn foo())` in a schedule that has more than one `SystemTypeSet(fn foo())` instance. `SystemTypeSet(fn foo())` is a `SystemTypeSet` and cannot be used for ordering if ambiguous. Use a different set without this restriction.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Hierarchy Redundancy
```text
thread 'main' panicked at 'System set hierarchy contains redundant edges.
hierarchy contains redundant edge(s) -- system set 'X' cannot be child of set 'A', longer path exists
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Systems have ordering but interset
```text
thread 'main' panicked at '`A` and `C` have a `before`-`after` relationship (which may be transitive) but share systems.', crates\bevy_ecs\src\schedule\schedule.rs:227:51
```
Cross Dependency
```text
thread 'main' panicked at '`A` and `B` have both `in_set` and `before`-`after` relationships (these might be transitive). This combination is unsolvable as a system cannot run before or after a set it belongs to.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Ambiguity
```text
thread 'main' panicked at 'Systems with conflicting access have indeterminate run order.
1 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- res_mut and res_ref
conflict on: ["bevymark::ambiguity::X"]
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
# Objective
Sometimes you want to create a plugin with a custom run condition. In a
function, you take the `Condition` trait and then make a
`BoxedCondition` from it to store it. And then you want to add that
condition to a system, but you can't, because there is only the `run_if`
function available which takes `impl Condition<M>` instead of
`BoxedCondition`. So you have to create a wrapper type for the
`BoxedCondition` and implement the `System` and `ReadOnlySystem` traits
for the wrapper (Like it's done in the picture below). It's very
inconvenient and boilerplate. But there is an easy solution for that:
make the `run_if_inner` system that takes a `BoxedCondition` public.
Also, it makes sense to make `in_set_inner` function public as well with
the same motivation.

A chunk of the source code of the `bevy-inspector-egui` crate.
## Solution
Make `run_if_inner` function public.
Rename `run_if_inner` to `run_if_dyn`.
Make `in_set_inner` function public.
Rename `in_set_inner` to `in_set_dyn`.
## Changelog
Changed visibility of `run_if_inner` from `pub(crate)` to `pub`.
Renamed `run_if_inner` to `run_if_dyn`.
Changed visibility of `in_set_inner` from `pub(crate)` to `pub`.
Renamed `in_set_inner` to `in_set_dyn`.
## Migration Guide
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
This is a continuation of this PR: #8062
# Objective
- Reorder render schedule sets to allow data preparation when phase item
order is known to support improved batching
- Part of the batching/instancing etc plan from here:
https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074
- The original idea came from @inodentry and proved to be a good one.
Thanks!
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new
ordering
## Solution
- Move `Prepare` and `PrepareFlush` after `PhaseSortFlush`
- Add a `PrepareAssets` set that runs in parallel with other systems and
sets in the render schedule.
- Put prepare_assets systems in the `PrepareAssets` set
- If explicit dependencies are needed on Mesh or Material RenderAssets
then depend on the appropriate system.
- Add `ManageViews` and `ManageViewsFlush` sets between
`ExtractCommands` and Queue
- Move `queue_mesh*_bind_group` to the Prepare stage
- Rename them to `prepare_`
- Put systems that prepare resources (buffers, textures, etc.) into a
`PrepareResources` set inside `Prepare`
- Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set
after `PrepareResources`
- Move `prepare_lights` to the `ManageViews` set
- `prepare_lights` creates views and this must happen before `Queue`
- This system needs refactoring to stop handling all responsibilities
- Gather lights, sort, and create shadow map views. Store sorted light
entities in a resource
- Remove `BatchedPhaseItem`
- Replace `batch_range` with `batch_size` representing how many items to
skip after rendering the item or to skip the item entirely if
`batch_size` is 0.
- `queue_sprites` has been split into `queue_sprites` for queueing phase
items and `prepare_sprites` for batching after the `PhaseSort`
- `PhaseItem`s are still inserted in `queue_sprites`
- After sorting adjacent compatible sprite phase items are accumulated
into `SpriteBatch` components on the first entity of each batch,
containing a range of vertex indices. The associated `PhaseItem`'s
`batch_size` is updated appropriately.
- `SpriteBatch` items are then drawn skipping over the other items in
the batch based on the value in `batch_size`
- A very similar refactor was performed on `bevy_ui`
---
## Changelog
Changed:
- Reordered and reworked render app schedule sets. The main change is
that data is extracted, queued, sorted, and then prepared when the order
of data is known.
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the
reordering.
## Migration Guide
- Assets such as materials and meshes should now be created in
`PrepareAssets` e.g. `prepare_assets<Mesh>`
- Queueing entities to `RenderPhase`s continues to be done in `Queue`
e.g. `queue_sprites`
- Preparing resources (textures, buffers, etc.) should now be done in
`PrepareResources`, e.g. `prepare_prepass_textures`,
`prepare_mesh_uniforms`
- Prepare bind groups should now be done in `PrepareBindGroups` e.g.
`prepare_mesh_bind_group`
- Any batching or instancing can now be done in `Prepare` where the
order of the phase items is known e.g. `prepare_sprites`
## Next Steps
- Introduce some generic mechanism to ensure items that can be batched
are grouped in the phase item order, currently you could easily have
`[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching.
- Investigate improved orderings for building the MeshUniform buffer
- Implementing batching across the rest of bevy
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
* `Local` and `SystemName` implement `Debug` manually, but they could
derive it.
* `QueryState` and `dyn System` have unconventional debug formatting.
# Objective
Fixes#9509
## Solution
We use the assumption, that enum types are uppercase in contrast to
module names.
[`collapse_type_name`](crates/bevy_util/src/short_names) is now
retaining the second last segment, if it starts with a uppercase
character.
---------
Co-authored-by: Emi <emanuel.boehm@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- Fixes#9533
## Solution
* Added `Val::ZERO` as a constant which is defined as `Val::Px(0.)`.
* Added manual `PartialEq` implementation for `Val` which allows any
zero value to equal any other zero value. E.g., `Val::Px(0.) ==
Val::Percent(0.)` etc. This is technically a breaking change, as
`Val::Px(0.) == Val::Percent(0.)` now equals `true` instead of `false`
(as an example)
* Replaced instances of `Val::Px(0.)`, `Val::Percent(0.)`, etc. with
`Val::ZERO`
* Fixed `bevy_ui::layout::convert::tests::test_convert_from` test to
account for Taffy not equating `Points(0.)` and `Percent(0.)`. These
tests now use `assert_eq!(...)` instead of `assert!(matches!(...))`
which gives easier to diagnose error messages.
# Objective
All delimiter symbols used by the path parser are ASCII, this means we
can entirely ignore UTF8 handling. This may improve performance.
## Solution
Instead of storing the path as an `&str` + the parser offset, and
reading the path using `&self.path[self.offset..]`, we store the parser
state in a `&[u8]`. This allows two optimizations:
1. Avoid UTF8 checking on `&self.path[self.offset..]`
2. Avoid any kind of bound checking, since the length of what is left to
read is stored in the `&[u8]`'s reference metadata, and is assumed valid
by the compiler.
This is a major improvement when comparing to the previous parser.
1. `access_following` and `next_token` now inline in `PathParser::next`
2. Benchmarking show a 20% performance increase (#9364)
Please note that while we ignore UTF-8 handling, **utf-8 is still
supported**. This is because we only handle "at the edges" what happens
exactly before and after a recognized `SYMBOL`. utf-8 is handled
transparently beyond that.
# Objective
- Unify the `ParsedPath` and `GetPath` APIs. They weirdly didn't play
well together.
- Make `ParsedPath` and `GetPath` API easier to use
## Solution
- Add the `ReflectPath` trait.
- `GetPath` methods now accept an `impl ReflectPath<'a>` instead of a
`&'a str`, this mean it also can accepts a `&ParsedPath`
- Make `GetPath: Reflect` and use default impl for `Reflect` types.
- Add `GetPath` and `ReflectPath` to the `bevy_reflect` prelude
---
## Changelog
- Add the `ReflectPath` trait.
- `GetPath` methods now accept an `impl ReflectPath<'a>` instead of a
`&'a str`, this mean it also can accept a `&ParsedPath`
- Make `GetPath: Reflect` and use default impl for `Reflect` types.
- Add `GetPath` and `ReflectPath` to the `bevy_reflect` prelude
## Migration Guide
`GetPath` now requires `Reflect`. This reduces a lot of boilerplate on
bevy's side. If you were implementing manually `GetPath` on your own
type, please get in touch!
`ParsedPath::element[_mut]` isn't an inherent method of `ParsedPath`,
you must now import `ReflectPath`. This is only relevant if you weren't
importing the bevy prelude.
```diff
-use bevy::reflect::ParsedPath;
+use bevy::reflect::{ParsedPath, ReflectPath};
parsed_path.element(reflect_type).unwrap()
parsed_path.element(reflect_type).unwrap()
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fixes#9552
## Solution
- Only n_pixels bytes of data was being copied instead of 1 byte per
component, i.e. n_pixels * 4
---
## Changelog
- Fixed: loading of Rgb8 ktx2 files.
# Objective
- Fix blender gltf imports with emissive materials
- Progress towards https://github.com/bevyengine/bevy/issues/5178
## Solution
- Upgrade to gltf-rs 1.3 supporiting
[KHR_materials_emissive_strength](https://github.com/KhronosGroup/glTF/blob/main/extensions/2.0/Khronos/KHR_materials_emissive_strength/README.md)
---
## Changelog
- GLTF files using `emissiveStrength` (such as those exported by
blender) are now supported
## Migration Guide
- The GLTF asset loader will now factor in `emissiveStrength` when
converting to Bevy's `StandardMaterial::emissive`. Blender will export
emissive materials using this field. Remove the field from your GLTF
files or manually modify your materials post-asset-load to match how
Bevy would load these files in previous versions.
# Objective
Fixes incorrect docs in `bevy_ui` for `JustifyItems` and `JustifySelf`.
## Solution
`JustifyItems` and `JustifySelf` target the main axis and not the cross
axis.
# Objective
`round_ties_up` checks the predicate:
```rust
0. <= value || value.fract() != 0.5
```
which is meant to determine if the value is negative with a fractional
part of `0.5`.
However given a negative value, `fract` returns a negative fraction so
the predicate is true for all numeric values and `ceil` is never called.
## Solution
Changed the predicate to `value.fract() != -0.5` and added a test.
Also improved the comments a bit.
# Objective
- A few of the `const DEFAULT` properties of the grid feature are not
marked as pub. This is an issue because it means you can't have a
`const` `Style` declaration anymore. Most of the existing properties are
already pub.
## Solution
- add the missing pub
# Objective
- Wireframe currently don't display since #9416
- There is an error
```
2023-08-20T10:06:54.190347Z ERROR bevy_render::render_resource::pipeline_cache: failed to process shader:
error: no definition in scope for identifier: 'vertex_no_morph'
┌─ crates/bevy_pbr/src/render/wireframe.wgsl:26:94
│
26 │ let model = bevy_pbr::mesh_functions::get_model_matrix(vertex_no_morph.instance_index);
│ ^^^^^^^^^^^^^^^ unknown identifier
│
= no definition in scope for identifier: 'vertex_no_morph'
```
## Solution
- Use the correct identifier
# Objective
- Resolves https://github.com/bevyengine/bevy/issues/9440
## Solution
- Remove the doc string mentioning the position of a `NodeBundle`, since
the doc string for the `style` component already explains this ability.
# Objective
- When spawning a window, it will be white until the GPU is ready to
draw the app. To avoid this, we can make the window invisible and then
make it visible once the gpu is ready. Unfortunately, the visible flag
is not available to users.
## Solution
- Let users change the visible flag
## Notes
This is only user controlled. It would be nice if it was done
automatically by bevy instead but I want to keep this PR simple.
# Objective
PR #6360 changed `TaskPoolOptions` so it is no longer used as a
Resource, but didn't remove the `Resource` derive.
## Solution
Remove the Resource derive from `TaskPoolOptions`, as it is no longer
needed. Also add a Debug derive, because it didn't have it before.
---
## Changelog
- `TaskPoolOptions` no longer derives Resource, and `TaskPoolOptions` &
`TaskPoolThreadAssignmentPolicy` now derive Debug.
## Migration Guide
If for some reason anyone is still using `TaskPoolOptions` as a
Resource, they would now have to use a wrapper type:
```rust
#[derive(Resource)]
pub struct MyTaskPoolOptions(pub TaskPoolOptions);
```
# Objective
Add `GamepadButtonInput` event
Resolves#8988
## Solution
- Add `GamepadButtonInput` type
- Emit `GamepadButtonInput` events whenever `Input<GamepadButton>` is
written to
- Update example
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#9488
## Solution
Set point light radius to always be 0.0. Reading this value from glTF
would require using application specific extras property.
---
## Changelog
### Fixed
- #9488 Point Lights use Range for Radius when importing from GLTF
# Objective
Allow users to specify the power preference when selecting a wgpu
adapter, which is useful for testing or workaround purposes, and makes
the behaviour consistent with the already present check for
`WGPU_BACKEND`.
## Solution
In `WgpuSettings::default()`, allow users to specify the
`WGPU_POWER_PREF` to affect the wgpu adapter choice.
# Objective
fix#9452
when multiple assets are queued to a preregistered loader, only one gets
unblocked when the real loader is registered.
## Solution
i thought async_channel receivers worked like broadcast channels, but in
fact the notification is only received by a single receiver, so only a
single waiting asset is unblocked. close the sender instead so that all
blocked receivers are unblocked.
If a line has one point behind the camera(near plane) then it would
deform or, if the `depth_bias` setting was set to a negative value,
disappear.
## Solution
The issue is that performing a perspective divide does not work
correctly for points behind the near plane and a perspective divide is
used inside the shader to define the line width in screen space.
The solution is to perform near plane clipping manually inside the
shader before the perspective divide is done.
# Objective
Fixes#9455
This change has probably been forgotten in
https://github.com/bevyengine/bevy/pull/8306.
## Solution
Remove the inversion of the Y axis when propagates window change back to
winit.
# Objective
Inconvenient initialization of `UiScale`
## Solution
Change `UiScale` to a tuple struct
## Migration Guide
Replace initialization of `UiScale` like ```UiScale { scale: 1.0 }```
with ```UiScale(1.0)```
# Objective
- Fixes part of #9021
## Solution
- Joint mesh are in format `Unorm8x4` in some gltf file, but Bevy
expects a `Float32x4`. Converts them. Also converts `Unorm16x4`
- According to gltf spec:
https://registry.khronos.org/glTF/specs/2.0/glTF-2.0.html#skinned-mesh-attributes
> WEIGHTS_n: float, or normalized unsigned byte, or normalized unsigned
short
# Objective
Fix#9089
## Solution
Don't try to draw lines with less than 2 vertices. These would not be
visible either way.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Currently, (AFAIC, accidentally) after registering an event for a
Gilrs button event, we ignore all subsequent events for the same button
in the same frame, because we don't update our filter. This is rare, but
I noticed it while adding gamepad support to a terminal app rendering at
15fps.
- Related to #4664, but does not quite fix it.
## Solution
- Move the edit to the `Axis<GamepadButton>` resource to when we read
the events from Gilrs.
# Objective
Closes#9115, replaces #9117.
## Solution
Emit event when scene is ready.
---
## Changelog
### Added
- `SceneInstanceReady` event when scene becomes ready.
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/9250
## Changelog
- Move scene spawner systems to a new SpawnScene schedule which is after
Update and before PostUpdate (schedule order:
[PreUpdate][Update][SpawnScene][PostUpdate])
## Migration Guide
- Move scene spawner systems to a new SpawnScene schedule which is after
Update and before PostUpdate (schedule order:
[PreUpdate][Update][SpawnScene][PostUpdate]), you might remove system
ordering code related to scene spawning as the execution order has been
guaranteed by bevy engine.
---------
Co-authored-by: Hennadii Chernyshchyk <genaloner@gmail.com>
Updates the requirements on
[tracy-client](https://github.com/nagisa/rust_tracy_client) to permit
the latest version.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f38da93ff1"><code>f38da93</code></a>
Test with 1.63.0 for MSRV</li>
<li><a
href="3621e20ccd"><code>3621e20</code></a>
tracing-client-sys: 0.21.1</li>
<li><a
href="bccf04b152"><code>bccf04b</code></a>
tracing-tracy: 0.10.3</li>
<li><a
href="bff27b5218"><code>bff27b5</code></a>
tracy-client: 0.15.2 -> 0.16.0 + fix auto update</li>
<li><a
href="9ed943bd6b"><code>9ed943b</code></a>
Add safe GPU API</li>
<li><a
href="60443cc55c"><code>60443cc</code></a>
Benches fell out of sync</li>
<li><a
href="c346a10998"><code>c346a10</code></a>
Fix version table typo</li>
<li><a
href="0763d2d16c"><code>0763d2d</code></a>
Bump MSRV to 1.60.0</li>
<li><a
href="d483998d48"><code>d483998</code></a>
Update Tracy client bindings to v0.9.1</li>
<li><a
href="dce363444f"><code>dce3634</code></a>
client-sys: 0.20.0, client: 0.15.1, tracing: 0.10.2</li>
<li>Additional commits viewable in <a
href="https://github.com/nagisa/rust_tracy_client/compare/tracy-client-v0.15.0...tracy-client-v0.16.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- Significantly reduce the size of MeshUniform by only including
necessary data.
## Solution
Local to world, model transforms are affine. This means they only need a
4x3 matrix to represent them.
`MeshUniform` stores the current, and previous model transforms, and the
inverse transpose of the current model transform, all as 4x4 matrices.
Instead we can store the current, and previous model transforms as 4x3
matrices, and we only need the upper-left 3x3 part of the inverse
transpose of the current model transform. This change allows us to
reduce the serialized MeshUniform size from 208 bytes to 144 bytes,
which is over a 30% saving in data to serialize, and VRAM bandwidth and
space.
## Benchmarks
On an M1 Max, running `many_cubes -- sphere`, main is in yellow, this PR
is in red:
<img width="1484" alt="Screenshot 2023-08-11 at 02 36 43"
src="https://github.com/bevyengine/bevy/assets/302146/7d99c7b3-f2bb-4004-a8d0-4c00f755cb0d">
A reduction in frame time of ~14%.
---
## Changelog
- Changed: Redefined `MeshUniform` to improve performance by using 4x3
affine transforms and reconstructing 4x4 matrices in the shader. Helper
functions were added to `bevy_pbr::mesh_functions` to unpack the data.
`affine_to_square` converts the packed 4x3 in 3x4 matrix data to a 4x4
matrix. `mat2x4_f32_to_mat3x3` converts the 3x3 in mat2x4 + f32 matrix
data back into a 3x3.
## Migration Guide
Shader code before:
```
var model = mesh[instance_index].model;
```
Shader code after:
```
#import bevy_pbr::mesh_functions affine_to_square
var model = affine_to_square(mesh[instance_index].model);
```
# Objective
- When loading gltf files during app creation (for example using a
FromWorld impl and adding that as a resource), no loader was found.
- As the gltf loader can load compressed formats, it needs to know what
the GPU supports so it's not available at app creation time.
## Solution
alternative to #9426
- add functionality to preregister the loader. loading assets with
matching extensions will block until a real loader is registered.
- preregister "gltf" and "glb".
- prereigster image formats.
the way this is set up, if a set of extensions are all registered with a
single preregistration call, then later a loader is added that matches
some of the extensions, assets using the remaining extensions will then
fail. i think that should work well for image formats that we don't know
are supported until later.
While being nobody other's issue as far I can tell, I want to create a
trait I plan to implement on `App` where more than one schedule is
modified.
My workaround so far was working with a closure that returns an
`ExecutorKind` from a match of the method variable.
It makes it easier for me to being able to clone `ExecutorKind` and I
don't see this being controversial for others working with Bevy.
I did nothing more than adding `Clone` to the derived traits, no
migration guide needed.
(If this worked out then the GitHub editor is not too shabby.)
# Objective
Bevy prefers `mod.rs` inside `module_name` files over `module_name.rs`
collocated with `module_name`. In `bevy_render`, it seems the `window`
modules didn't follow this convention
## Solution
- Follow the `mod.rs` convention.
# Objective
- Fixes#9324
- Audio sinks used to have a custom drop implementation to detach the
sinks because it was not required to keep a reference to it
- With the new audio api, a reference is kept as a component of an
entity
## Solution
- Remove that custom drop implementation, and the option wrapping that
was required for it.
# Objective
Just like
[`set_if_neq`](https://docs.rs/bevy_ecs/latest/bevy_ecs/change_detection/trait.DetectChangesMut.html#method.set_if_neq),
being able to express the "I don't want to unnecessarily trigger the
change detection" but with the ability to handle the previous value if
change occurs.
## Solution
Add `replace_if_neq` to `DetectChangesMut`.
---
## Changelog
- Added `DetectChangesMut::replace_if_neq`: like `set_if_neq` change the
value only if the new value if different from the current one, but
return the previous value if the change occurs.
# Objective
I found it very difficult to understand how bevy tasks work, and I
concluded that the documentation should be improved for beginners like
me.
## Solution
These changes to the documentation were written from my beginner's
perspective after
some extremely helpful explanations by nil on Discord.
I am not familiar enough with rustdoc yet; when looking at the source, I
found the documentation at the very top of `usages.rs` helpful, but I
don't know where they are rendered. They should probably be linked to
from the main `bevy_tasks` README.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
In `bevy_sprite`, the `Anchor` type is not `Copy`. It makes interacting
with it more difficult than necessary.
## Solution
Derive `Copy` on it. The rust API guidelines are that you should derive
`Copy` when possible.
<https://rust-lang.github.io/api-guidelines/interoperability.html#types-eagerly-implement-common-traits-c-common-traits>
Regardless, `Anchor` is a very small `enum` which warrants `Copy`.
---
## Changelog
- In `bevy_sprite` `Anchor` is now `Copy`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Need this for a custom `AnimationPlayer` that I tick in `FixedUpdate`
# Objective
- Need access to an animation clip's `paths` from outside the module
## Solution
- Add a getter method to return a reference to `paths`
---------
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
Add a `RunSystem` extension trait to allow for immediate execution of
systems on a `World` for debugging and/or testing purposes.
# Objective
Fixes#6184
Initially, I made this CL as `ApplyCommands`. After a discussion with
@cart , we decided a more generic implementation would be better to
support all systems. This is the new revised CL. Sorry for the long
delay! 😅
This CL allows users to do this:
```rust
use bevy::prelude::*;
use bevy::ecs::system::RunSystem;
struct T(usize);
impl Resource for T {}
fn system(In(n): In<usize>, mut commands: Commands) -> usize {
commands.insert_resource(T(n));
n + 1
}
let mut world = World::default();
let n = world.run_system_with(1, system);
assert_eq!(n, 2);
assert_eq!(world.resource::<T>().0, 1);
```
## Solution
This is implemented as a trait extension and not included in any
preludes to ensure it's being used consciously.
Internally, it just initializes and runs a systems, and applies any
deferred parameters all "in place".
The trait has 2 functions (one of which calls the other by default):
- `run_system_with` is the general implementation, which allows user to
pass system input parameters
- `run_system` is the ergonomic wrapper for systems with no input
parameter (to avoid having the user pass `()` as input).
~~Additionally, this trait is also implemented for `&mut App`. I added
this mainly for ergonomics (`app.run_system` vs.
`app.world.run_system`).~~ (Removed based on feedback)
---------
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
Add possibility to use the glam's swizzles traits without having to
manually import them.
```diff
use bevy::prelude::*;
- use bevy::math::Vec3Swizzles;
fn foo(x: Vec3) {
let y: Vec2 = x.xy();
}
```
## Solution
Add the swizzles traits to bevy's prelude.
---
## Changelog
- `Vec2Swizzles`, `Vec3Swizzles` and `Vec4Swizzles` are now part of the
prelude.
# Objective
Fixes#9094
## Solution
Takes a bit from
[this](https://github.com/bevyengine/bevy/issues/9094#issuecomment-1629333851)
comment as well as a
[comment](https://discord.com/channels/691052431525675048/1002362493634629796/1128024873260810271)
from @soqb.
This allows users to opt-out of the `TypePath` implementation that is
automatically generated by the `Reflect` derive macro, allowing custom
`TypePath` implementations.
```rust
#[derive(Reflect)]
#[reflect(type_path = false)]
struct Foo<T> {
#[reflect(ignore)]
_marker: PhantomData<T>,
}
struct NotTypePath;
impl<T: 'static> TypePath for Foo<T> {
fn type_path() -> &'static str {
std::any::type_name::<Self>()
}
fn short_type_path() -> &'static str {
static CELL: GenericTypePathCell = GenericTypePathCell::new();
CELL.get_or_insert::<Self, _>(|| {
bevy_utils::get_short_name(std::any::type_name::<Self>())
})
}
fn crate_name() -> Option<&'static str> {
Some("my_crate")
}
fn module_path() -> Option<&'static str> {
Some("my_crate::foo")
}
fn type_ident() -> Option<&'static str> {
Some("Foo")
}
}
// Can use `TypePath`
let _ = <Foo<NotTypePath> as TypePath>::type_path();
// Can register the type
let mut registry = TypeRegistry::default();
registry.register::<Foo<NotTypePath>>();
```
#### Type Path Stability
The stability of type paths mainly come into play during serialization.
If a type is moved between builds, an unstable type path may become
invalid.
Users that opt-out of `TypePath` and rely on something like
`std::any::type_name` as in the example above, should be aware that this
solution removes the stability guarantees. Deserialization thus expects
that type to never move. If it does, then the serialized type paths will
need to be updated accordingly.
If a user depends on stability, they will need to implement that
stability logic manually (probably by looking at the expanded output of
a typical `Reflect`/`TypePath` derive). This could be difficult for type
parameters that don't/can't implement `TypePath`, and will need to make
heavy use of string parsing and manipulation to achieve the same effect
(alternatively, they can choose to simply exclude any type parameter
that doesn't implement `TypePath`).
---
## Changelog
- Added the `#[reflect(type_path = false)]` attribute to opt out of the
`TypePath` impl when deriving `Reflect`
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Update a camera's frustum only when needed.
- Maybe a performance gain from not having to compute frusta when not
needed, at the cost of change detection (?)
- Making "fighting" with `update_frusta` less tedious, see
https://github.com/bevyengine/bevy/issues/9077 and
https://discord.com/channels/691052431525675048/743663924229963868/1127566087966433322
## Solution
Add change detection filter for `GlobalTransform` or `T:
CameraProjection` in `update_frusta`, since those are the cases when the
frustum needs to be updated.
## Note
I don't think a migration guide and changelog are needed, but I'm not
100% sure, I could put something like "if you're fighting against
`update_frusta`, you can do it only when there is a change to
`GlobalTransform` or `CameraProjection` now", what do you think? It's
not really a breaking change with a normal use case.
naga and wgpu should polyfill WGSL instance_index functionality where it
is not available in GLSL. Until that is done, we can work around it in
bevy using a push constant which is converted to a uniform by naga and
wgpu.
# Objective
- Fixes#9375
## Solution
- Use a push constant to pass in the base instance to the shader on
WebGL2 so that base instance + gl_InstanceID is used to correctly
represent the instance index.
## TODO
- [ ] Benchmark vs per-object dynamic offset MeshUniform as this will
now push a uniform value per-draw as well as update the dynamic offset
per-batch.
- [x] Test on DX12 AMD/NVIDIA to check that this PR does not regress any
problems that were observed there. (@Elabajaba @robtfm were testing that
last time - help appreciated. <3 )
---
## Changelog
- Added: `bevy_render::instance_index` shader import which includes a
workaround for the lack of a WGSL `instance_index` polyfill for WebGL2
in naga and wgpu for the time being. It uses a push_constant which gets
converted to a plain uniform by naga and wgpu.
## Migration Guide
Shader code before:
```
struct Vertex {
@builtin(instance_index) instance_index: u32,
...
}
@vertex
fn vertex(vertex_no_morph: Vertex) -> VertexOutput {
...
var model = mesh[vertex_no_morph.instance_index].model;
```
After:
```
#import bevy_render::instance_index
struct Vertex {
@builtin(instance_index) instance_index: u32,
...
}
@vertex
fn vertex(vertex_no_morph: Vertex) -> VertexOutput {
...
var model = mesh[bevy_render::instance_index::get_instance_index(vertex_no_morph.instance_index)].model;
```
# Objective
The default for `ContentSize` should have the `measure_func` field set
to `None`, instead of a fixed size of zero. This means that until a
measure func is set the size of the UI node will be determined by its
`Style` constraints. This is preferable as it allows users to specify
the space the Node should take up in the layout while waiting for
content to load.
## Solution
Derive `Default` for `ContentSize`.
The PR also adds a `fixed_size` helper function to make it a bit easier
to access the old behaviour.
## Changelog
* Derived `Default` for `ContentSize`
* Added a `fixed_size` helper function to `ContentSize` that creates a
new `ContentSize` with a `MeasureFunc` that always returns the same
value, regardless of layout constraints.
## Migration Guide
The default for `ContentSize` now sets its `measure_func` to `None`,
instead of a fixed size measure that returns `Vec2::ZERO`.
The helper function `fixed_size` can be called with
`ContentSize::fixed_size(Vec2::ZERO)` to get the previous behaviour.
# Objective
It seems the behavior of field attributes was accidentally broken at
some point. Take the following code:
```rust
#[derive(Reflect)]
struct Foo {
#[reflect(ignore, default)]
value: usize
}
```
The above code should simply mark `value` as ignored and specify a
default behavior. However, what this actually does is discard both.
That's especially a problem when we don't want the field to be be given
a `Reflect` or `FromReflect` bound (which is why we ignore it in the
first place).
This only happens when the attributes are combined into one. The
following code works properly:
```rust
#[derive(Reflect)]
struct Foo {
#[reflect(ignore)]
#[reflect(default)]
value: usize
}
```
## Solution
Cleaned up the field attribute parsing logic to support combined field
attributes.
---
## Changelog
- Fixed a bug where `Reflect` derive attributes on fields are not able
to be combined into a single attribute
# Objective
- Follow up to #8887
- The parsing code in `bevy_reflect/src/path/mod.rs` could also do with
some cleanup
## Solution
- Create the `parse.rs` module, move all parsing code to this module
- The parsing errors also now keep track of the whole parsed string, and
are much more fine-grained
### Detailed changes
- Move `PathParser` to `parse.rs` submodule
- Rename `token_to_access` to `access_following` (yep, goes from 132
lines to 16)
- Move parsing tests into the `parse.rs` file
# Objective
The doc comment for `text_system` is not quite correct. It implies that
a new `TextLayoutInfo` is generated on changes to `Text` and `Style`.
While changes to those components might indirectly trigger a
regeneration of the text layout, `text_system` itself only queries for
changes to `Node`
Also added details to `measure_text_system`'s doc comments explaining
how it reacts to changes.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- `bevy_tasks` emits warnings under certain conditions
When I run `cargo clippy -p bevy_tasks` the warning doesn't show up,
while if I run it with `cargo clippy -p bevy_asset` the warning shows
up.
## Solution
- Fix the warnings.
## Longer term solution
We should probably fix CI so that those warnings do not slip through.
But that's not the goal of this PR.
# Objective
This doc comment for the `set` method of `ContentSize`:
```
Set a `Measure` for this function
```
doesn't seem to make sense, `ContentSize` is not a function.
# Solution
Replace it.
# Objective
When an `AudioSink` is removed from an entity, the audio player will
automatically start any `AudioSource` still attached, which normally is
the one used to start playback in the first place.
## Solution
Long story short, the default behavior is restarting the audio, and this
commit documents that.
---
## Changelog
Fixed documentation on `AudioSink` to clarify removal behavior.
# Objective
shader defs associated with a shader via `load_internal_asset!` or
`Shader::from_xxx_with_defs` were being accidentally ignored for
top-level shaders.
## Solution
include the defs for top level shaders.
# Objective
- Fixes#9114
## Solution
Inside `ScheduleGraph::build_schedule()` the variable `node_count =
self.systems.len() + self.system_sets.len()` is used to calculate the
indices for the `reachable` bitset derived from `self.hierarchy.graph`.
However, the number of nodes inside `self.hierarchy.graph` does not
always correspond to `self.systems.len() + self.system_sets.len()` when
`ambiguous_with` is used, because an ambiguous set is added to
`system_sets` (because we need an `NodeId` for the ambiguity graph)
without adding a node to `self.hierarchy`.
In this PR, we rename `node_count` to the more descriptive name
`hg_node_count` and set it to `self.hierarchy.graph.node_count()`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fixes#9113
## Solution
disable `multi-threaded` default feature
## Migration Guide
The `multi-threaded` feature in `bevy_ecs` and `bevy_tasks` is no longer
enabled by default. However, this remains a default feature for the
umbrella `bevy` crate. If you depend on `bevy_ecs` or `bevy_tasks`
directly, you should consider enabling this to allow systems to run in
parallel.
Fixes#5856. Fixes#8080. Fixes#9040.
# Objective
We need to limit the update rate of games whose windows are not visible
(minimized or completely occluded). Compositors typically ignore the
VSync settings of windows that aren't visible. That, combined with the
lack of rendering work, results in a scenario where an app becomes
completely CPU-bound and starts updating without limit.
There are currently three update modes.
- `Continuous` updates an app as often as possible.
- `Reactive` updates when new window or device events have appeared, a
timer expires, or a redraw is requested.
- `ReactiveLowPower` is the same as `Reactive` except it ignores device
events (e.g. general mouse movement).
The problem is that the default "game" settings are set to `Contiuous`
even when no windows are visible.
### More Context
- https://github.com/libsdl-org/SDL/issues/1871
- https://github.com/glfw/glfw/issues/680
- https://github.com/godotengine/godot/issues/19741
- https://github.com/godotengine/godot/issues/64708
## Solution
Change the default "unfocused" `UpdateMode` for games to
`ReactiveLowPower` just like desktop apps. This way, even when the
window is occluded, the app still updates at a sensible rate or if
something about the window changes. I chose 20Hz arbitrarily.
# Objective
The `lifetimeless` module has been a source of confusion for bevy users
for a while now.
## Solution
Add a couple paragraph explaining that, yes, you can use one of the type
alias safely, without ever leaking any memory.
Redo of #7590 since I messed up my branch.
# Objective
- Revise docs.
- Refactor event loop code a little bit to make it easier to follow.
## Solution
- Do the above.
---
### Migration Guide
- `UpdateMode::Reactive { max_wait: .. }` -> `UpdateMode::Reactive {
wait: .. }`
- `UpdateMode::ReactiveLowPower { max_wait: .. }` ->
`UpdateMode::ReactiveLowPower { wait: .. }`
---------
Co-authored-by: Sélène Amanita <134181069+Selene-Amanita@users.noreply.github.com>
# Objective
Remove the `With<Parent>` query filter from the `parent_node_query`
parameter of the `bevy_ui::render::extract_uinode_borders` function.
This is a bug, the query is only used to retrieve the size of the
current node's parent. We don't care if that parent node has a `Parent`
or not.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fixes#9138
## Solution
- Calling `Camera2dBundle::default()` will now result in a
`Camera2dBundle` with `Vec3::ZERO` transform, `far` value of `1000.` and
`near` value of `-1000.`.
- This will enable the rendering of 2d entities in negative z space by
default.
- I did not modify `new_with_far` as moving the camera to `Vec3::ZERO`
in that function will cause entities in the positive z space to become
hidden without further changes. And the further changes cannot be
applied without it being a breaking change.
# Objective
Glam 0.24 added new glam types (```I64Vec``` and ```U64Vec```). However
these are not reflectable unlike the other glam types
## Solution
Implement reflect for these new types
---
## Changelog
Implements reflect with the impl_reflect_struct macro on ```I64Vec2```,
```I64Vec3```, ```I64Vec4```, ```U64Vec2```, ```U64Vec3```, and
```U64Vec4``` types
# Objective
- Repeat in `Gizmos` that they are drawned in immediate mode, which is
said at the module level but not here, and detail what it means.
- Clarify for every method of `Gizmos` that they should be called for
every frame.
- Clarify which methods belong to 3D or 2D space (kinda obvious for 2D
but still)
The first time I used gizmos I didn't understand how they work and was
confused as to why nothing showed up.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: SpecificProtagonist <vincentjunge@posteo.net>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- In bevy_polyline, we discovered an issue that happens when line width
is smaller than 1.0 and using perspective. It would sometimes end up
negative or NaN. I'm not entirely sure _why_ it happens.
## Solution
- Make sure the width doesn't go below 0 before multiplying it with the
alpha
# Notes
Here's a link to the bevy_polyline issue
https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline/issues/46
I'm not sure if the solution is correct but it solved the issue in my
testing.
Co-authored-by: François <mockersf@gmail.com>
# Objective
This PR continues https://github.com/bevyengine/bevy/pull/8885
It aims to improve the `Mesh` documentation in the following ways:
- Put everything at the "top level" instead of the "impl".
- Explain better what is a Mesh, how it can be created, and that it can
be edited.
- Explain it can be used with a `Material`, and mention
`StandardMaterial`, `PbrBundle`, `ColorMaterial`, and
`ColorMesh2dBundle` since those cover most cases
- Mention the glTF/Bevy vocabulary discrepancy for "Mesh"
- Add an image for the example
- Various nitpicky modifications
## Note
- The image I added is 90.3ko which I think is small enough?
- Since rustdoc doesn't allow cross-reference not in dependencies of a
subcrate [yet](https://github.com/rust-lang/rust/issues/74481), I have a
lot of backtick references that are not links :(
- Since rustdoc doesn't allow linking to code in the crate (?) I put
link to github directly.
- Since rustdoc doesn't allow embed images in doc
[yet](https://github.com/rust-lang/rust/issues/32104), maybe
[soon](https://github.com/rust-lang/rfcs/pull/3397), I had to put only a
link to the image. I don't think it's worth adding
[embed_doc_image](https://docs.rs/embed-doc-image/latest/embed_doc_image/)
as a dependency for this.
# Objective
- Fix shader_material_glsl example
## Solution
- Expose the `PER_OBJECT_BUFFER_BATCH_SIZE` shader def through the
default `MeshPipeline` specialization.
- Make use of it in the `custom_material.vert` shader to access the mesh
binding.
---
## Changelog
- Added: Exposed the `PER_OBJECT_BUFFER_BATCH_SIZE` shader def through
the default `MeshPipeline` specialization to use in custom shaders not
using bevy_pbr::mesh_bindings that still want to use the mesh binding in
some way.
# Objective
- The `path` module was getting fairly large.
- The code in `AccessRef::read_element` and mut equivalent was very
complex and difficult to understand.
- The `ReflectPathError` had a lot of variants, and was difficult to
read.
## Solution
- Split the file in two, `access` now has its own module
- Rewrite the `read_element` methods, they were ~200 lines long, they
are now ~70 lines long — I didn't change any of the logic. It's really
just the same code, but error handling is separated.
- Split the `ReflectPathError` error
- Merge `AccessRef` and `Access`
- A few other changes that aim to reduce code complexity
### Fully detailed change list
- `Display` impl of `ParsedPath` now includes prefix dots — this allows
simplifying its implementation, and IMO `.path.to.field` is a better way
to express a "path" than `path.to.field` which could suggest we are
reading the `to` field of a variable named `path`
- Add a test to check that dot prefixes and other are correctly parsed —
Until now, no test contained a prefixing dot
- Merge `Access` and `AccessRef`, using a `Cow<'a, str>`. Generated code
seems to agree with this decision (`ParsedPath::parse` sheds 5% of
instructions)
- Remove `Access::as_ref` since there is no such thing as an `AccessRef`
anymore.
- Rename `AccessRef::to_owned` into `AccessRef::into_owned()` since it
takes ownership of `self` now.
- Add a `parse_static` that doesn't allocate new strings for named
fields!
- Add a section about path reflection in the `bevy_reflect` crate root
doc — I saw a few people that weren't aware of path reflection, so I
thought it was pertinent to add it to the root doc
- a lot of nits
- rename `index` to `offset` when it refers to offset in the path string
— There is no more confusion with the other kind of indices in this
context, also it's a common naming convention for parsing.
- Make a dedicated enum for parsing errors
- rename the `read_element` methods to `element` — shorter, but also
`read_element_mut` was a fairly poor name
- The error values now not only contain the expected type but also the
actual type.
- Remove lifetimes that could be inferred from the `GetPath` trait
methods.
---
## Change log
- Added the `ParsedPath::parse_static` method, avoids allocating when
parsing `&'static str`.
## Migration Guide
If you were matching on the `Err(ReflectPathError)` value returned by
`GetPath` and `ParsedPath` methods, now only the parse-related errors
and the offset are publicly accessible. You can always use the
`fmt::Display` to get a clear error message, but if you need
programmatic access to the error types, please open an issue.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
- attempt to clarify with better docstrings the default behaviour of
WindowPlugin and the component type it accepts.
# Objective
- I'm new to Rust and Bevy, I got a bit confused about how to customise
some window parameters (title, height, width etc) and while the docs do
show the struct code for that field `Option<Window>` I was a bit of a
doofus and skipped that to read the docstring entry for `primary_window`
and then the `Window` component directly which aren't linked together.
This is a minor improvement which I think will help in-case others, like
me, have a doofus moment.
---------
Co-authored-by: Sélène Amanita <134181069+Selene-Amanita@users.noreply.github.com>
# Objective
This PR updates the name of the enum variant used in the docs for
`OrthographicProjection`.
## Solution
- Change the outdated 'WindowScale` to `WindowSize`.
# Objective
- Reduce the number of rebindings to enable batching of draw commands
## Solution
- Use the new `GpuArrayBuffer` for `MeshUniform` data to store all
`MeshUniform` data in arrays within fewer bindings
- Sort opaque/alpha mask prepass, opaque/alpha mask main, and shadow
phases also by the batch per-object data binding dynamic offset to
improve performance on WebGL2.
---
## Changelog
- Changed: Per-object `MeshUniform` data is now managed by
`GpuArrayBuffer` as arrays in buffers that need to be indexed into.
## Migration Guide
Accessing the `model` member of an individual mesh object's shader
`Mesh` struct the old way where each `MeshUniform` was stored at its own
dynamic offset:
```rust
struct Vertex {
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh.model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
The new way where one needs to index into the array of `Mesh`es for the
batch:
```rust
struct Vertex {
@builtin(instance_index) instance_index: u32,
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh[vertex.instance_index].model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
Note that using the instance_index is the default way to pass the
per-object index into the shader, but if you wish to do custom rendering
approaches you can pass it in however you like.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
# Objective
My attempt at implementing #7515
## Solution
Added struct `Pitch` and implemented on it `Source` trait.
## Changelog
### Added
- File pitch.rs to bevy_audio crate
- Struct `Pitch` and type aliases for `AudioSourceBundle<Pitch>` and
`SpatialAudioSourceBundle<Pitch>`
- New example showing how to use `PitchBundle`
### Changed
- `AudioPlugin` now adds system for `Pitch` audio
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
The previous formatting didn't render as you'd expect, with 'For CSS
Grid containers' getting adopted by the prior bullet point. Rather than
fixing that directly I opted for a slight reformatting for consistency
with other fields, notably left/right/top/bottom.
# Objective
Fixes#9298 - Default window title leaks "bevy" context
## Solution
I just replaced the literal string "Bevy App" with "App" in Window's
Default trait implementation.
# Objective
Cloning a `WorldQuery` type's "fetch" struct was made unsafe in #5593,
by adding the `unsafe fn clone_fetch` to `WorldQuery`. However, as that
method's documentation explains, it is not the right place to put the
safety invariant:
> While calling this method on its own cannot cause UB it is marked
`unsafe` as the caller must ensure that the returned value is not used
in any way that would cause two `QueryItem<Self>` for the same
`archetype_index` or `table_row` to be alive at the same time.
You can clone a fetch struct all you want and it will never cause
undefined behavior -- in order for something to go wrong, you need to
improperly call `WorldQuery::fetch` with it (which is marked unsafe).
Additionally, making it unsafe to clone a fetch struct does not even
prevent undefined behavior, since there are other ways to incorrectly
use a fetch struct. For example, you could just call fetch more than
once for the same entity, which is not currently forbidden by any
documented invariants.
## Solution
Document a safety invariant on `WorldQuery::fetch` that requires the
caller to not create aliased `WorldQueryItem`s for mutable types. Remove
the `clone_fetch` function, and add the bound `Fetch: Clone` instead.
---
## Changelog
- Removed the associated function `WorldQuery::clone_fetch`, and added a
`Clone` bound to `WorldQuery::Fetch`.
## Migration Guide
### `fetch` invariants
The function `WorldQuery::fetch` has had the following safety invariant
added:
> If this type does not implement `ReadOnlyWorldQuery`, then the caller
must ensure that it is impossible for more than one `Self::Item` to
exist for the same entity at any given time.
This invariant was always required for soundness, but was previously
undocumented. If you called this function manually anywhere, you should
check to make sure that this invariant is not violated.
### Removed `clone_fetch`
The function `WorldQuery::clone_fetch` has been removed. The associated
type `WorldQuery::Fetch` now has the bound `Clone`.
Before:
```rust
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>
unsafe fn clone_fetch<'w>(fetch: &Self::Fetch<'w>) -> Self::Fetch<'w> {
MyFetch {
field1: fetch.field1,
field2: fetch.field2.clone(),
...
}
}
}
```
After:
```rust
#[derive(Clone)]
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>;
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/9234
re-breaks: The issues that were linked in #9169
## Solution
Revert the PR that broke tonemapping/postprocessing/etc.
Any passes that are post msaa resolve need to use the main textures, not
the msaa texture.
## Changelog
Idk what to put here since it's a revert.
# Objective
Fixes#9097
## Solution
Reorder the `ExtractSchedule` so that the `extract_text_uinodes` and
`extract_uinode_borders` systems are run after `extract_atlas_uinodes`.
## Changelog
`bevy_ui::render`:
* Added the `ExtractAtlasNode` variant to `RenderUiSystem`.
* Changed `ExtractSchedule` so that `extract_uinode_borders` and
`extract_text_uinodes` run after `extract_atlas_uinodes`.
This is not used directly within the rendering code.
# Objective
- Remove extraneous dependency on `wgpu-hal` as it is not used.
## Solution
- The dependency has been removed and should have no externally visible
impact.
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
# Objective
Fixes#9121
Context:
- `ImageTextureLoader` depends on `RenderDevice` to work out which
compressed image formats it can support
- `RenderDevice` is initialised by `RenderPlugin`
- https://github.com/bevyengine/bevy/pull/8336 made `RenderPlugin`
initialisation async
- This caused `RenderDevice` to be missing at the time of
`ImageTextureLoader` initialisation, which in turn meant UASTC encoded
ktx2 textures were being converted to unsupported formats, and thus
caused panics
## Solution
- Delay `ImageTextureLoader` initialisation
---
## Changelog
- Moved `ImageTextureLoader` initialisation from `ImagePlugin::build()`
to `ImagePlugin::finish()`
- Default to `CompressedImageFormats::NONE` if `RenderDevice` resource
is missing
---------
Co-authored-by: 66OJ66 <hi0obxud@anonaddy.me>
### **Adopted #6430**
# Objective
`MutUntyped` is the untyped variant of `Mut<T>` that stores a `PtrMut`
instead of a `&mut T`. Working with a `MutUntyped` is a bit annoying,
because as soon you want to use the ptr e.g. as a `&mut dyn Reflect` you
cannot use a type like `Mut<dyn Reflect>` but instead need to carry
around a `&mut dyn Reflect` and a `impl FnMut()` to mark the value as
changed.
## Solution
* Provide a method `map_unchanged` to turn a `MutUntyped` into a
`Mut<T>` by mapping the `PtrMut<'a>` to a `&'a mut T`
This can be used like this:
```rust
// SAFETY: ptr is of type `u8`
let val: Mut<u8> = mut_untyped.map_unchanged(|ptr| unsafe { ptr.deref_mut::<u8>() });
// SAFETY: from the context it is known that `ReflectFromPtr` was made for the type of the `MutUntyped`
let val: Mut<dyn Reflect> = mut_untyped.map_unchanged(|ptr| unsafe { reflect_from_ptr.as_reflect_ptr_mut(ptr) });
```
Note that nothing prevents you from doing
```rust
mut_untyped.map_unchanged(|ptr| &mut ());
```
or using any other mutable reference you can get, but IMO that is fine
since that will only result in a `Mut` that will dereference to that
value and mark the original value as changed. The lifetimes here prevent
anything bad from happening.
## Alternatives
1. Make `Ticks` public and provide a method to get construct a `Mut`
from `Ticks` and `&mut T`. More powerful and more easy to misuse.
2. Do nothing. People can still do everything they want, but they need
to pass (`&mut dyn Reflect, impl FnMut() + '_)` around instead of
`Mut<dyn Reflect>`
## Changelog
- add `MutUntyped::map_unchanged` to turn a `MutUntyped` into its typed
counterpart
---------
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
Fix#8936.
## Solution
Stop using `unwrap` in the core pipelined rendering logic flow.
Separately also scoped the `sub app` span to just running the render app
instead of including the blocking send.
Current unknowns: should we use `std::panic::catch_unwind` around
running the render app? Other engine threads use it defensively, but
we're letting it bubble up here, and a user-created panic could cause a
deadlock if it kills the thread.
---
## Changelog
Fixed: Pipelined rendering should no longer have spurious panics upon
app exit.
# Objective
Implements #9082 but with an option to toggle minimize and close buttons
too.
## Solution
- Added an `enabled_buttons` member to the `Window` struct through which
users can enable or disable specific window control buttons.
---
## Changelog
- Added an `enabled_buttons` member to the `Window` struct through which
users can enable or disable specific window control buttons.
- Added a new system to the `window_settings` example which demonstrates
the toggling functionality.
---
## Migration guide
- Added an `enabled_buttons` member to the `Window` struct through which
users can enable or disable specific window control buttons.
# Objective
Currently the panic message if a duplicate plugin is added isn't really
helpful or at least can be made more useful if it includes the location
where the plugin was added a second time.
## Solution
Add `track_caller` to `add_plugins` and it's called dependencies.
# Objective
This attempts to make the new IRect and URect structs in bevy_math more
similar to the existing Rect struct.
## Solution
Add reflect implementations for IRect and URect, since one already
exists for Rect.
# Objective
- #8960 isn't optimal for very distinct AABB colors, it can be improved
## Solution
We want a function that maps sequential values (entities concurrently
living in a scene _usually_ have ids that are sequential) into very
different colors (the hue component of the color, to be specific)
What we are looking for is a [so-called "low discrepancy"
sequence](https://en.wikipedia.org/wiki/Low-discrepancy_sequence). ie: a
function `f` such as for integers in a given range (eg: 101, 102, 103…),
`f(i)` returns a rational number in the [0..1] range, such as `|f(i) -
f(i±1)| ≈ 0.5` (maximum difference of images for neighboring preimages)
AHash is a good random hasher, but it has relatively high discrepancy,
so we need something else.
Known good low discrepancy sequences are:
#### The [Van Der Corput
sequence](https://en.wikipedia.org/wiki/Van_der_Corput_sequence)
<details><summary>Rust implementation</summary>
```rust
fn van_der_corput(bits: u64) -> f32 {
let leading_zeros = if bits == 0 { 0 } else { bits.leading_zeros() };
let nominator = bits.reverse_bits() >> leading_zeros;
let denominator = bits.next_power_of_two();
nominator as f32 / denominator as f32
}
```
</details>
#### The [Gold Kronecker
sequence](https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/)
<details><summary>Rust implementation</summary>
Note that the implementation suggested in the linked post assumes
floats, we have integers
```rust
fn gold_kronecker(bits: u64) -> f32 {
const U64_MAX_F: f32 = u64::MAX as f32;
// (u64::MAX / Φ) rounded down
const FRAC_U64MAX_GOLDEN_RATIO: u64 = 11400714819323198485;
bits.wrapping_mul(FRAC_U64MAX_GOLDEN_RATIO) as f32 / U64_MAX_F
}
```
</details>
### Comparison of the sequences
So they are both pretty good. Both only have a single (!) division and
two `u32 as f32` conversions.
- Kronecker is resilient to regular sequence (eg: 100, 102, 104, 106)
while this kills Van Der Corput (consider that potentially one entity
out of two spawned might be a mesh)
I made a small app to compare the two sequences, available at:
https://gist.github.com/nicopap/5dd9bd6700c6a9a9cf90c9199941883e
At the top, we have Van Der Corput, at the bottom we have the Gold
Kronecker. In the video, we spawn a vertical line at the position on
screen where the x coordinate is the image of the sequence. The
preimages are 1,2,3,4,… The ideal algorithm would always have the
largest possible gap between each line (imagine the screen x coordinate
as the color hue):
https://github.com/bevyengine/bevy/assets/26321040/349aa8f8-f669-43ba-9842-f9a46945e25c
Here, we repeat the experiment, but with with `entity.to_bits()` instead
of a sequence:
https://github.com/bevyengine/bevy/assets/26321040/516cea27-7135-4daa-a4e7-edfd1781d119
Notice how Van Der Corput tend to bunch the lines on a single side of
the screen. This is because we always skip odd-numbered entities.
Gold Kronecker seems always worse than Van Der Corput, but it is
resilient to finicky stuff like entity indices being multiples of a
number rather than purely sequential, so I prefer it over Van Der
Corput, since we can't really predict how distributed the entity indices
will be.
### Chosen implementation
You'll notice this PR's implementation is not the Golden ratio-based
Kronecker sequence as described in
[tueoqs](https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/).
Why?
tueoqs R function multiplies a rational/float and takes the fractional
part of the result `(x/Φ) % 1`. We start with an integer `u32`. So
instead of converting into float and dividing by Φ (mod 1) we directly
divide by Φ as integer (mod 2³²) both operations are equivalent, the
integer division (which is actually a multiplication by `u32::MAX / Φ`)
is probably faster.
## Acknowledgements
- `inspi` on discord linked me to
https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/
and the wikipedia article.
- [this blog
post](https://probablydance.com/2018/06/16/fibonacci-hashing-the-optimization-that-the-world-forgot-or-a-better-alternative-to-integer-modulo/)
for the idea of multiplying the `u32` rather than the `f32`.
- `nakedible` for suggesting the `index()` over `to_bits()` which
considerably reduces generated code (goes from 50 to 11 instructions)
# Objective
- Add a type for uploading a Rust `Vec<T>` to a GPU `array<T>`.
- Makes progress towards https://github.com/bevyengine/bevy/issues/89.
## Solution
- Port @superdump's `BatchedUniformBuffer` to bevy main, as a fallback
for WebGL2, which doesn't support storage buffers.
- Rather than getting an `array<T>` in a shader, you get an `array<T,
N>`, and have to rebind every N elements via dynamic offsets.
- Add `GpuArrayBuffer` to abstract over
`StorageBuffer<Vec<T>>`/`BatchedUniformBuffer`.
## Future Work
Add a shader macro kinda thing to abstract over the following
automatically:
https://github.com/bevyengine/bevy/pull/8204#pullrequestreview-1396911727
---
## Changelog
* Added `GpuArrayBuffer`, `GpuComponentArrayBufferPlugin`,
`GpuArrayBufferable`, and `GpuArrayBufferIndex` types.
* Added `DynamicUniformBuffer::new_with_alignment()`.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Teodor Tanasoaia <28601907+teoxoy@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Vincent <9408210+konsolas@users.noreply.github.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Fixes#9200
Switches ()'s to []'s when talking about the optional `_mut` suffix in
the ECS Query Struct page to have more idiomatic docs.
## Solution
Replace `()` with `[]` in appropriate doc pages.
When building Bevy using Bazel, you don't need a 'Cargo.toml'... except
Bevy requires it currently. Hopefully this can help illuminate the
requirement.
# Objective
I recently started exploring Bazel and Buck2. Currently Bazel has some
great advantages over Cargo for me and I was pretty happy to find that
things generally work quite well!
Once I added a target to my test project that depended on bevy but
didn't use Cargo, I didn't create a Cargo.toml file for it and things
appeared to work, but as soon as I went to derive from Component the
build failed with the cryptic error:
```
ERROR: /Users/photex/workspaces/personal/mb-rogue/scratch/BUILD:24:12: Compiling Rust bin hello_bevy (0 files) failed: (Exit 1): process_wrapper failed: error executing command (from target //scratch:hello_bevy) bazel-out/darwin_arm64-opt-exec-2B5CBBC6/bin/external/rules_rust/util/process_wrapper/process_wrapper --arg-file ... (remaining 312 arguments skipped)
error: proc-macro derive panicked
--> scratch/hello_bevy.rs:5:10
|
5 | #[derive(Component)]
| ^^^^^^^^^
|
= help: message: called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
error: proc-macro derive panicked
--> scratch/hello_bevy.rs:8:10
|
8 | #[derive(Component)]
| ^^^^^^^^^
|
= help: message: called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
```
## Solution
After poking around I realized that the proc macros in Bevy all use
bevy_macro_utils::BevyManifest, which was attempting to load a Cargo
manifest that doesn't exist.
This PR doesn't address the Cargo requirement (I'd love to see if there
was a way to support more than Cargo transparently), but it *does*
replace some calls to unwrap with expect and hopefully the error
messages will be more helpful for other folks like me hoping to pat down
a new trail:
```
ERROR: /Users/photex/workspaces/personal/mb-rogue/scratch/BUILD:23:12: Compiling Rust bin hello_bevy (0 files) failed: (Exit 1): process_wrapper failed: error executing command (from target //scratch:hello_bevy) bazel-out/darwin_arm64-opt-exec-2B5CBBC6/bin/external/rules_rust/util/process_wrapper/process_wrapper --arg-file ... (remaining 312 arguments skipped)
error: proc-macro derive panicked
--> scratch/hello_bevy.rs:5:10
|
5 | #[derive(Component)]
| ^^^^^^^^^
|
= help: message: Unable to read cargo manifest: /private/var/tmp/_bazel_photex/135f23dc56826c24d6c3c9f6b688b2fe/execroot/__main__/scratch/Cargo.toml: Os { code: 2, kind: NotFound, message: "No such file or directory" }
error: proc-macro derive panicked
--> scratch/hello_bevy.rs:8:10
|
8 | #[derive(Component)]
| ^^^^^^^^^
|
= help: message: Unable to read cargo manifest: /private/var/tmp/_bazel_photex/135f23dc56826c24d6c3c9f6b688b2fe/execroot/__main__/scratch/Cargo.toml: Os { code: 2, kind: NotFound, message: "No such file or directory" }
```
Co-authored-by: Chip Collier <chip.collier@avid.com>
# Objective
Fixes#8894Fixes#7944
## Solution
The UI pipeline's `MultisampleState::count` is set to 1 whereas the
`MultisampleState::count` for the camera's ViewTarget is taken from the
`Msaa` resource, and corruption occurs when these two values are
different.
This PR solves the problem by setting `MultisampleState::count` for the
UI pipeline to the value from the Msaa resource too.
I don't know much about Bevy's rendering internals or graphics hardware,
so maybe there is a better solution than this. UI MSAA was probably
disabled for a good reason (performance?).
## Changelog
* Enabled multisampling for the UI pipeline.
# Objective
AssetPath shader imports check if the shader is added using the path
without quotes. this causes them to be re-added even if already present,
which can cause previous dependents to get unloaded leading to a
"missing import" error.
## Solution
fix the module name of AssetPath shaders used for checking if it's
already added to correctly use the quoted name.
# Objective
In
[`AssetLoader::load()`](https://docs.rs/bevy/0.11.0/bevy/asset/trait.AssetLoader.html#tymethod.load),
I have an
[`AssetPath`](https://docs.rs/bevy/0.11.0/bevy/asset/struct.AssetPath.html)
to a dependency asset.
I get a handle to this dependency asset using
[`LoadContext::get_handle()`](https://docs.rs/bevy/0.11.0/bevy/asset/struct.LoadContext.html#method.get_handle)
passing the `AssetPath`. But I also need to pass this `AssetPath` to
[`LoadedAsset::with_dependency()`](https://docs.rs/bevy/0.11.0/bevy/asset/struct.LoadedAsset.html#method.with_dependency)
later.
The current solution for this problem is either use `clone()`, but
`AssetPath` may contains owned data.
```rust
let dependency_path: AssetPath = _;
let dependency = load_context.get_handle(dependency_path.clone());
// ...
load_context.set_default_asset(LoadedAsset::new(my_asset).with_dependency(dependency_path));
```
Or to use `AssetPathId::from(&path)` which is a bit verbose.
```rust
let dependency_path: AssetPath = _;
let dependency = load_context.get_handle(AssetPathId::from(&dependency_path));
// ...
load_context.set_default_asset(LoadedAsset::new(my_asset).with_dependency(dependency_path));
```
Ideal solution (introduced by this PR) is to pass a reference to
`get_handle()`.
```rust
let dependency_path: AssetPath = _;
let dependency = load_context.get_handle(&dependency_path);
// ...
load_context.set_default_asset(LoadedAsset::new(my_asset).with_dependency(dependency_path));
```
## Solution
Implement `From<&AssetPath>` for `HandleId`
---
## Changelog
- Added: `HandleId` can be build from a reference to `AssetPath`.
# Objective
Continue #7867 now that we have URect #7984
- Return `URect` instead of `(UVec2, UVec2)` in
`Camera::physical_viewport_rect`
- Add `URect` and `IRect` to prelude
## Changelog
- Changed `Camera::physical_viewport_rect` return type from `(UVec2,
UVec2)` to `URect`
- `URect` and `IRect` were added to prelude
## Migration Guide
Before:
```rust
fn view_physical_camera_rect(camera_query: Query<&Camera>) {
let camera = camera_query.single();
let Some((min, max)) = camera.physical_viewport_rect() else { return };
dbg!(min, max);
}
```
After:
```rust
fn view_physical_camera_rect(camera_query: Query<&Camera>) {
let camera = camera_query.single();
let Some(URect { min, max }) = camera.physical_viewport_rect() else { return };
dbg!(min, max);
}
```
# Objective
Gizmos are intended to draw over everything but for some reason I set
the sort key to `0` during #8427 :v
I didn't catch this mistake because it still draws over sprites with a Z
translation of `0`.
## Solution
Set the sort key to `f32::INFINITY`.
# Objective
Some of the conversion methods on the new rect types introduced in #7984
have misleading names.
## Solution
Rename all methods returning an `IRect` to `as_irect` and all methods
returning a `URect` to `as_urect`.
## Migration Guide
Replace uses of the old method names with the new method names.
# Objective
In my application, I'm manually wrapping the built-in Bevy loaders with
a wrapper loader that stores some metadata before calling into the inner
Bevy loader. This worked for the glTF loader in Bevy 0.10, but in Bevy
0.11 it became impossible to do this because the glTF loader became
unconstructible outside Bevy due to the new private fields within it.
It's now in fact impossible to get a reference to a GltfLoader at all
from outside Bevy, because the only way to construct a GltfLoader is to
add the GltfPlugin to an App, and the GltfPlugin only hands out
references to its GltfLoader to the asset server, which provides no
public access to the loaders it manages.
## Solution
This commit fixes the problem by adding a public `new` method to allow
manual construction of a glTF loader.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
In both Text2d and Bevy UI text because of incorrect text size and
alignment calculations if a block of text has empty leading lines then
those lines are ignored. Also, depending on the font size when leading
empty lines are ignored the same number of lines of text can go missing
from the bottom of the text block.
## Example (from murtaugh on discord)
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.run();
}
fn setup(mut commands: Commands) {
commands.spawn(Camera2dBundle::default());
let text = "\nfirst line\nsecond line\nthird line\n";
commands.spawn(TextBundle {
text: Text::from_section(
text.to_string(),
TextStyle {
font_size: 60.0,
color: Color::YELLOW,
..Default::default()
},
),
style: Style {
position_type: PositionType::Absolute,
..Default::default()
},
background_color: BackgroundColor(Color::RED),
..Default::default()
});
}
```

## Solution
`TextPipeline::queue_text`,
`TextMeasureInfo::compute_size_from_section_texts` and
`GlyphBrush::process_glyphs` each have a nearly duplicate section of
code that calculates the minimum bounds around a list of text sections.
The first two functions don't apply any rounding, but `process_glyphs`
also floors all the values. It seems like this difference can cause
conflicts where the text gets incorrectly shaped.
Also when Bevy computes the text bounds it chooses the smallest possible
rect that fits all the glyphs, ignoring white space. The glyphs are then
realigned vertically so the first glyph is on the top line. Any empty
leading lines are missed.
This PR adds a function `compute_text_bounds` that replaces the
duplicate code, so the text bounds are rounded the same way by each
function. Also, since Bevy doesn't use `ab_glyph` to control vertical
alignment, the minimum y bound is just always set to 0 which ensures no
leading empty lines will be missed.
There is another problem in that trailing empty lines are also ignored,
but that's more difficult to deal with and much less important than the
other issues, so I'll leave it for another PR.
<img width="462" alt="fixed_text_align_bounds"
src="https://github.com/bevyengine/bevy/assets/27962798/85e32e2c-d68f-4677-8e87-38e27ade4487">
---
## Changelog
Added a new function `compute_text_bounds` to the `glyph_brush` module
that replaces the text size and bounds calculations in
`TextPipeline::queue_text`,
`TextMeasureInfo::compute_size_from_section_texts` and
`GlyphBrush::process_glyphs`. The text bounds are calculated identically
in each function and the minimum y bound is not derived from the glyphs
but is always set to 0.
# Objective
`ExtractedUiNodes` is cleared by the `extract_uinodes` function during
the extraction schedule. Because the Bevy UI renderer uses a painters
algorithm, this makes it impossible for users to create a custom
extraction function that adds items for a node to be drawn behind the
rectangle added by `extract_uniodes`.
## Solution
Drain `ExtractedUiNodes` in `prepare_ui_nodes` instead, after the
extraction schedule has finished.
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
`GlobalTransform` after insertion will be updated only on `Transform` or
hierarchy change.
Fixes#9075
## Solution
Update `GlobalTransform` after insertion too.
---
## Changelog
- `GlobalTransform` is now updated not only on `Transform` or hierarchy
change, but also on insertion.
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
fixes#8911, #7712
## Solution
Rounding was added to Taffy which fixed issue #7712.
The implementation uses the f32 `round` method which rounds ties
(fractional part is a half) away from zero. Issue #8911 occurs when a
node's min and max bounds on either axis are "ties" and zero is between
them. Then the bounds are rounded away from each other, and the node
grows by a pixel. This alone shouldn't cause the node to expand
continuously, but I think there is some interaction with the way Taffy
recomputes a layout from its cached data that I didn't identify.
This PR fixes#8911 by first disabling Taffy's internal rounding and
using an alternative rounding function that rounds ties up.
Then, instead of rounding the values of the internal layout tree as
Taffy's built-in rounding does, we leave those values unmodified and
only the values stored in the components are rounded. This requires
walking the tree for the UI node geometry update rather than iterating
through a query.
Because the component values are regenerated each update, that should
mean that UI updates are idempotent (ish) now and make the growing node
behaviour seen in issue #8911 impossible.
I expected a performance regression, but it's an improvement on main:
```
cargo run --profile stress-test --features trace_tracy --example many_buttons
```
<img width="461" alt="ui-rounding-fix-compare"
src="https://github.com/bevyengine/bevy/assets/27962798/914bfd50-e18a-4642-b262-fafa69005432">
I guess it makes sense to do the rounding together with the node size
and position updates.
---
## Changelog
`bevy_ui::layout`:
* Taffy's built-in rounding is disabled and rounding is now performed by
`ui_layout_system`.
* Instead of rounding the values of the internal layout tree as Taffy's
built-in rounding does, we leave those values unmodified and only the
values stored in the components are rounded. This requires walking the
tree for the UI node geometry update rather than iterating through a
query. Because the component values are regenerated each update, that
should mean that UI updates are idempotent now and make the growing node
behaviour seen in issue #8911 impossible.
* Added two helper functions `round_ties_up` and
`round_layout_coordinates`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This pull request is mutually exclusive with #9066.
# Objective
Complete the initialization of the plugin in `ScheduleRunnerPlugin`.
## Solution
Wait for asynchronous tasks to complete, then `App::finish` and
`App::cleanup` in the runner function.
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- accesskit_unix is not optional anymore
## Solution
- Enable `async-io` feature of `accesskit_winit` only when
`accesskit_unix` is enabled
# Objective
Improve the `bevy_audio` API to make it more user-friendly and
ECS-idiomatic. This PR is a first-pass at addressing some of the most
obvious (to me) problems. In the interest of keeping the scope small,
further improvements can be done in future PRs.
The current `bevy_audio` API is very clunky to work with, due to how it
(ab)uses bevy assets to represent audio sinks.
The user needs to write a lot of boilerplate (accessing
`Res<Assets<AudioSink>>`) and deal with a lot of cognitive overhead
(worry about strong vs. weak handles, etc.) in order to control audio
playback.
Audio playback is initiated via a centralized `Audio` resource, which
makes it difficult to keep track of many different sounds playing in a
typical game.
Further, everything carries a generic type parameter for the sound
source type, making it difficult to mix custom sound sources (such as
procedurally generated audio or unofficial formats) with regular audio
assets.
Let's fix these issues.
## Solution
Refactor `bevy_audio` to a more idiomatic ECS API. Remove the `Audio`
resource. Do everything via entities and components instead.
Audio playback data is now stored in components:
- `PlaybackSettings`, `SpatialSettings`, `Handle<AudioSource>` are now
components. The user inserts them to tell Bevy to play a sound and
configure the initial playback parameters.
- `AudioSink`, `SpatialAudioSink` are now components instead of special
magical "asset" types. They are inserted by Bevy when it actually begins
playing the sound, and can be queried for by the user in order to
control the sound during playback.
Bundles: `AudioBundle` and `SpatialAudioBundle` are available to make it
easy for users to play sounds. Spawn an entity with one of these bundles
(or insert them to a complex entity alongside other stuff) to play a
sound.
Each entity represents a sound to be played.
There is also a new "auto-despawn" feature (activated using
`PlaybackSettings`), which, if enabled, tells Bevy to despawn entities
when the sink playback finishes. This allows for "fire-and-forget" sound
playback. Users can simply
spawn entities whenever they want to play sounds and not have to worry
about leaking memory.
## Unsolved Questions
I think the current design is *fine*. I'd be happy for it to be merged.
It has some possibly-surprising usability pitfalls, but I think it is
still much better than the old `bevy_audio`. Here are some discussion
questions for things that we could further improve. I'm undecided on
these questions, which is why I didn't implement them. We should decide
which of these should be addressed in this PR, and what should be left
for future PRs. Or if they should be addressed at all.
### What happens when sounds start playing?
Currently, the audio sink components are inserted and the bundle
components are kept. Should Bevy remove the bundle components? Something
else?
The current design allows an entity to be reused for playing the same
sound with the same parameters repeatedly. This is a niche use case I'd
like to be supported, but if we have to give it up for a simpler design,
I'd be fine with that.
### What happens if users remove any of the components themselves?
As described above, currently, entities can be reused. Removing the
audio sink causes it to be "detached" (I kept the old `Drop` impl), so
the sound keeps playing. However, if the audio bundle components are not
removed, Bevy will detect this entity as a "queued" sound entity again
(has the bundle compoenents, without a sink component), just like before
playing the sound the first time, and start playing the sound again.
This behavior might be surprising? Should we do something different?
### Should mutations to `PlaybackSettings` be applied to the audio sink?
We currently do not do that. `PlaybackSettings` is just for the initial
settings when the sound starts playing. This is clearly documented.
Do we want to keep this behavior, or do we want to allow users to use
`PlaybackSettings` instead of `AudioSink`/`SpatialAudioSink` to control
sounds during playback too?
I think I prefer for them to be kept separate. It is not a bad mental
model once you understand it, and it is documented.
### Should `AudioSink` and `SpatialAudioSink` be unified into a single
component type?
They provide a similar API (via the `AudioSinkPlayback` trait) and it
might be annoying for users to have to deal with both of them. The
unification could be done using an enum that is matched on internally by
the methods. Spatial audio has extra features, so this might make it
harder to access. I think we shouldn't.
### Automatic synchronization of spatial sound properties from
Transforms?
Should Bevy automatically apply changes to Transforms to spatial audio
entities? How do we distinguish between listener and emitter? Which one
does the transform represent? Where should the other one come from?
Alternatively, leave this problem for now, and address it in a future
PR. Or do nothing, and let users deal with it, as shown in the
`spatial_audio_2d` and `spatial_audio_3d` examples.
---
## Changelog
Added:
- `AudioBundle`/`SpatialAudioBundle`, add them to entities to play
sounds.
Removed:
- The `Audio` resource.
- `AudioOutput` is no longer `pub`.
Changed:
- `AudioSink`, `SpatialAudioSink` are now components instead of assets.
## Migration Guide
// TODO: write a more detailed migration guide, after the "unsolved
questions" are answered and this PR is finalized.
Before:
```rust
/// Need to store handles somewhere
#[derive(Resource)]
struct MyMusic {
sink: Handle<AudioSink>,
}
fn play_music(
asset_server: Res<AssetServer>,
audio: Res<Audio>,
audio_sinks: Res<Assets<AudioSink>>,
mut commands: Commands,
) {
let weak_handle = audio.play_with_settings(
asset_server.load("music.ogg"),
PlaybackSettings::LOOP.with_volume(0.5),
);
// upgrade to strong handle and store it
commands.insert_resource(MyMusic {
sink: audio_sinks.get_handle(weak_handle),
});
}
fn toggle_pause_music(
audio_sinks: Res<Assets<AudioSink>>,
mymusic: Option<Res<MyMusic>>,
) {
if let Some(mymusic) = &mymusic {
if let Some(sink) = audio_sinks.get(&mymusic.sink) {
sink.toggle();
}
}
}
```
Now:
```rust
/// Marker component for our music entity
#[derive(Component)]
struct MyMusic;
fn play_music(
mut commands: Commands,
asset_server: Res<AssetServer>,
) {
commands.spawn((
AudioBundle::from_audio_source(asset_server.load("music.ogg"))
.with_settings(PlaybackSettings::LOOP.with_volume(0.5)),
MyMusic,
));
}
fn toggle_pause_music(
// `AudioSink` will be inserted by Bevy when the audio starts playing
query_music: Query<&AudioSink, With<MyMusic>>,
) {
if let Ok(sink) = query.get_single() {
sink.toggle();
}
}
```
# Objective
`accesskit` and `accesskit_winit` need to be upgraded.
## Solution
Upgrade `accesskit` and `accesskit_winit`.
---
## Changelog
### Changed
* Upgrade accesskit to v0.11.
* Upgrade accesskit_winit to v0.14.
# Objective
Currently, `DynamicScene`s extract all components listed in the given
(or the world's) type registry. This acts as a quasi-filter of sorts.
However, it can be troublesome to use effectively and lacks decent
control.
For example, say you need to serialize only the following component over
the network:
```rust
#[derive(Reflect, Component, Default)]
#[reflect(Component)]
struct NPC {
name: Option<String>
}
```
To do this, you'd need to:
1. Create a new `AppTypeRegistry`
2. Register `NPC`
3. Register `Option<String>`
If we skip Step 3, then the entire scene might fail to serialize as
`Option<String>` requires registration.
Not only is this annoying and easy to forget, but it can leave users
with an impossible task: serializing a third-party type that contains
private types.
Generally, the third-party crate will register their private types
within a plugin so the user doesn't need to do it themselves. However,
this means we are now unable to serialize _just_ that type— we're forced
to allow everything!
## Solution
Add the `SceneFilter` enum for filtering components to extract.
This filter can be used to optionally allow or deny entire sets of
components/resources. With the `DynamicSceneBuilder`, users have more
control over how their `DynamicScene`s are built.
To only serialize a subset of components, use the `allow` method:
```rust
let scene = builder
.allow::<ComponentA>()
.allow::<ComponentB>()
.extract_entity(entity)
.build();
```
To serialize everything _but_ a subset of components, use the `deny`
method:
```rust
let scene = builder
.deny::<ComponentA>()
.deny::<ComponentB>()
.extract_entity(entity)
.build();
```
Or create a custom filter:
```rust
let components = HashSet::from([type_id]);
let filter = SceneFilter::Allowlist(components);
// let filter = SceneFilter::Denylist(components);
let scene = builder
.with_filter(Some(filter))
.extract_entity(entity)
.build();
```
Similar operations exist for resources:
<details>
<summary>View Resource Methods</summary>
To only serialize a subset of resources, use the `allow_resource`
method:
```rust
let scene = builder
.allow_resource::<ResourceA>()
.extract_resources()
.build();
```
To serialize everything _but_ a subset of resources, use the
`deny_resource` method:
```rust
let scene = builder
.deny_resource::<ResourceA>()
.extract_resources()
.build();
```
Or create a custom filter:
```rust
let resources = HashSet::from([type_id]);
let filter = SceneFilter::Allowlist(resources);
// let filter = SceneFilter::Denylist(resources);
let scene = builder
.with_resource_filter(Some(filter))
.extract_resources()
.build();
```
</details>
### Open Questions
- [x] ~~`allow` and `deny` are mutually exclusive. Currently, they
overwrite each other. Should this instead be a panic?~~ Took @soqb's
suggestion and made it so that the opposing method simply removes that
type from the list.
- [x] ~~`DynamicSceneBuilder` extracts entity data as soon as
`extract_entity`/`extract_entities` is called. Should this behavior
instead be moved to the `build` method to prevent ordering mixups (e.g.
`.allow::<Foo>().extract_entity(entity)` vs
`.extract_entity(entity).allow::<Foo>()`)? The tradeoff would be
iterating over the given entities twice: once at extraction and again at
build.~~ Based on the feedback from @Testare it sounds like it might be
better to just keep the current functionality (if anything we can open a
separate PR that adds deferred methods for extraction, so the
choice/performance hit is up to the user).
- [ ] An alternative might be to remove the filter from
`DynamicSceneBuilder` and have it as a separate parameter to the
extraction methods (either in the existing ones or as added
`extract_entity_with_filter`-type methods). Is this preferable?
- [x] ~~Should we include constructors that include common types to
allow/deny? For example, a `SceneFilter::standard_allowlist` that
includes things like `Parent` and `Children`?~~ Consensus suggests we
should. I may split this out into a followup PR, though.
- [x] ~~Should we add the ability to remove types from the filter
regardless of whether an allowlist or denylist (e.g.
`filter.remove::<Foo>()`)?~~ See the first list item
- [x] ~~Should `SceneFilter` be an enum? Would it make more sense as a
struct that contains an `is_denylist` boolean?~~ With the added
`SceneFilter::None` state (replacing the need to wrap in an `Option` or
rely on an empty `Denylist`), it seems an enum is better suited now
- [x] ~~Bikeshed: Do we like the naming convention? Should we instead
use `include`/`exclude` terminology?~~ Sounds like we're sticking with
`allow`/`deny`!
- [x] ~~Does this feature need a new example? Do we simply include it in
the existing one (maybe even as a comment?)? Should this be done in a
followup PR instead?~~ Example will be added in a followup PR
### Followup Tasks
- [ ] Add a dedicated `SceneFilter` example
- [ ] Possibly add default types to the filter (e.g. deny things like
`ComputedVisibility`, allow `Parent`, etc)
---
## Changelog
- Added the `SceneFilter` enum for filtering components and resources
when building a `DynamicScene`
- Added methods:
- `DynamicSceneBuilder::with_filter`
- `DynamicSceneBuilder::allow`
- `DynamicSceneBuilder::deny`
- `DynamicSceneBuilder::allow_all`
- `DynamicSceneBuilder::deny_all`
- `DynamicSceneBuilder::with_resource_filter`
- `DynamicSceneBuilder::allow_resource`
- `DynamicSceneBuilder::deny_resource`
- `DynamicSceneBuilder::allow_all_resources`
- `DynamicSceneBuilder::deny_all_resources`
- Removed methods:
- `DynamicSceneBuilder::from_world_with_type_registry`
- `DynamicScene::from_scene` and `DynamicScene::from_world` no longer
require an `AppTypeRegistry` reference
## Migration Guide
- `DynamicScene::from_scene` and `DynamicScene::from_world` no longer
require an `AppTypeRegistry` reference:
```rust
// OLD
let registry = world.resource::<AppTypeRegistry>();
let dynamic_scene = DynamicScene::from_world(&world, registry);
// let dynamic_scene = DynamicScene::from_scene(&scene, registry);
// NEW
let dynamic_scene = DynamicScene::from_world(&world);
// let dynamic_scene = DynamicScene::from_scene(&scene);
```
- Removed `DynamicSceneBuilder::from_world_with_type_registry`. Now the
registry is automatically taken from the given world:
```rust
// OLD
let registry = world.resource::<AppTypeRegistry>();
let builder = DynamicSceneBuilder::from_world_with_type_registry(&world,
registry);
// NEW
let builder = DynamicSceneBuilder::from_world(&world);
```
# Objective
After the UI layout is computed when the coordinates are converted back
from physical coordinates to logical coordinates the `UiScale` is
ignored. This results in a confusing situation where we have two
different systems of logical coordinates.
Example:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.add_systems(Update, update)
.run();
}
fn setup(mut commands: Commands, mut ui_scale: ResMut<UiScale>) {
ui_scale.scale = 4.;
commands.spawn(Camera2dBundle::default());
commands.spawn(NodeBundle {
style: Style {
align_items: AlignItems::Center,
justify_content: JustifyContent::Center,
width: Val::Percent(100.),
..Default::default()
},
..Default::default()
})
.with_children(|builder| {
builder.spawn(NodeBundle {
style: Style {
width: Val::Px(100.),
height: Val::Px(100.),
..Default::default()
},
background_color: Color::MAROON.into(),
..Default::default()
}).with_children(|builder| {
builder.spawn(TextBundle::from_section("", TextStyle::default());
});
});
}
fn update(
mut text_query: Query<(&mut Text, &Parent)>,
node_query: Query<Ref<Node>>,
) {
for (mut text, parent) in text_query.iter_mut() {
let node = node_query.get(parent.get()).unwrap();
if node.is_changed() {
text.sections[0].value = format!("size: {}", node.size());
}
}
}
```
result:

We asked for a 100x100 UI node but the Node's size is multiplied by the
value of `UiScale` to give a logical size of 400x400.
## Solution
Divide the output physical coordinates by `UiScale` in
`ui_layout_system` and multiply the logical viewport size by `UiScale`
when creating the projection matrix for the UI's `ExtractedView` in
`extract_default_ui_camera_view`.
---
## Changelog
* The UI layout's physical coordinates are divided by both the window
scale factor and `UiScale` when converting them back to logical
coordinates. The logical size of Ui nodes now matches the values given
to their size constraints.
* Multiply the logical viewport size by `UiScale` before creating the
projection matrix for the UI's `ExtractedView` in
`extract_default_ui_camera_view`.
* In `ui_focus_system` the cursor position returned from `Window` is
divided by `UiScale`.
* Added a scale factor parameter to `Node::physical_size` and
`Node::physical_rect`.
* The example `viewport_debug` now uses a `UiScale` of 2. to ensure that
viewport coordinates are working correctly with a non-unit `UiScale`.
## Migration Guide
Physical UI coordinates are now divided by both the `UiScale` and the
window's scale factor to compute the logical sizes and positions of UI
nodes.
This ensures that UI Node size and position values, held by the `Node`
and `GlobalTransform` components, conform to the same logical coordinate
system as the style constraints from which they are derived,
irrespective of the current `scale_factor` and `UiScale`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#8630.
## Solution
Since a camera's view and projection matrices are modified during
`PostUpdate` in `camera_system` and `propagate_transforms`, it is fine
to move `update_previous_view_projections` from `Update` to `PreUpdate`.
Doing so adds consistence with `update_mesh_previous_global_transforms`
and allows systems in `Update` to use `PreviousViewProjection` correctly
without explicit ordering.
# Objective
I'm creating an iOS game and had to find a way to persist game state
when the application is terminated. This required listening to the
[`applicationWillTerminate()`
method](https://developer.apple.com/documentation/uikit/uiapplicationdelegate/1623111-applicationwillterminate),
but I cannot do so myself anymore since `winit` already set up a
delegate to listen for it, and there can be only one delegate.
So I had to move up the stack and try to respond to one of the events
from `winit` instead. It appears `winit` fires two events that could
serve my purpose: `WindowEvent::Destroyed` and `Event::LoopDestroyed`.
It seemed to me the former might be slightly more generally useful, and
I also found a past discussion that suggested it would be appropriate
for Bevy to have a `WindowDestroyed` event:
https://github.com/bevyengine/bevy/pull/5589#discussion_r942811021
## Solution
- I've added the `WindowDestroyed` event, which fires when `winit` fires
`WindowEvent::Destroyed`.
---
## Changelog
### Added
- Introduced a new `WindowDestroyed` event type. It is used to indicate
a window has been destroyed by the windowing system.
# Objective
bevy_render currently has a dependency on a random older version of
once_cell which is not used anywhere.
## Solution
Remove the dependency
## Changelog
N/A
## Migration Guide
N/A
# Objective
- Remove need to call `.get()` on two ticks to compare them for
equality.
## Solution
- Derive `Eq` and `PartialEq`.
---
## Changelog
> `Tick` now implements `Eq` and `PartialEq`
# Objective
- Fix#8984
### Solution
- Address compilation errors
I admit: I did sneak it an unrelated mini-refactor. of the
`measurment.rs` module. it seemed to me that directly importing `taffy`
types helped reduce a lot of boilerplate, so I did it.
# Objective
The bounding box colors are from bevy_gizmo are randomized between app
runs. This can get confusing for users.
## Solution
Use a fixed seed with `RandomState::with_seeds` rather than initializing
a `AHash`.
The random number was chose so that the first few colors are clearly
distinct.
According to the `RandomState::hash_one` documentation, it's also
faster.

---
## Changelog
* bevy_gizmo: Keep a consistent color for AABBs of identical entities
between runs
# Objective
Since 10f5c92, shadows were broken for models with morph target.
When #5703 was merged, the morph target code in `render/mesh.wgsl` was
correctly updated to use the new import syntax. However, similar code
exists in `prepass/prepass.wgsl`, but it was never update. (the reason
code is duplicated is that the `Vertex` struct is different for both
files).
## Solution
Update the code, so that shadows render correctly with morph targets.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/8925
## Solution
~~Clamp the bad values.~~
Normalize the prepass normals when we get them in the `prepass_normal()`
function.
## More Info
The issue is that NdotV is sometimes very slightly greater than 1 (maybe
FP rounding issues?), which caused `F_Schlick()` to return NANs in
`pow(1.0 - NdotV, 5.0)` (call stack looked like`pbr()` ->
`directional_light()` -> `Fd_Burley()` -> `F_Schlick()`)
# Objective
Since 10f5c92, parallax mapping was broken.
When #5703 was merged, the change from `in.uv` to `uv` in the pbr shader
was reverted. So the shader would use the wrong coordinate to sample the
various textures.
## Solution
We revert to using the correct uv.
# Objective
Followup bugfix for #5703. Without this we get the following error when
CAS (Contrast Adaptive Sharpening) is enabled:
```
2023-06-29T01:31:23.829331Z ERROR bevy_render::render_resource::pipeline_cache: failed to process shader:
error: unknown type: 'FullscreenVertexOutput'
┌─ crates/bevy_core_pipeline/src/contrast_adaptive_sharpening/robust_contrast_adaptive_sharpening.wgsl:63:17
│
63 │ fn fragment(in: FullscreenVertexOutput) -> @location(0) vec4<f32> {
│ ^^^^^^^^^^^^^^^^^^^^^^ unknown type
│
= unknown type: 'FullscreenVertexOutput'
```
@robtfm I wouldn't expect this to fail. I was under the impression the
`#import bevy_core_pipeline::fullscreen_vertex_shader` would pull
"everything" from that file into this one?
# Objective
- This fixes a crash when loading shaders, when running an Adreno GPU
and using WebGL mode.
- Fixes#8506
- Fixes#8047
## Solution
- The shader pbr_functions.wgsl, will fail in apply_fog function, trying
to access values that are null on Adreno chipsets using WebGL, these
devices are commonly found in android handheld devices.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title. This is necessary in order to update
[`bevy-trait-query`](https://crates.io/crates/bevy-trait-query) to Bevy
0.11.
---
## Changelog
Added the unsafe function `UnsafeWorldCell::storages`, which provides
unchecked access to the internal data stores of a `World`.
Added `GizmoConfig::render_layers`, which will ensure Gizmos are only
rendered on cameras that can see those `RenderLayers`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Relax unnecessary type restrictions on `App.runner` function.
## Solution
Changed the type of `App.runner` from `Fn(App)` to `FnOnce(App)`.
# Objective
#5703 caused the normal prepass to fail as the prepass uses
`pbr_functions::apply_normal_mapping`, which uses
`mesh_view_bindings::view` to determine mip bias, which conflicts with
`prepass_bindings::view`.
## Solution
pass the mip bias to the `apply_normal_mapping` function explicitly.
# Objective
Currently `App::edit_schedule` takes in `impl FnMut(&mut Schedule)`, but
it calls the function only once. It is probably the intention has been
to have it take `FnOnce` instead.
## Solution
- Relax the parameter to take `FnOnce` instead of `FnMut`
# Objective
- There was a deadlock discovered in the implementation of
`bevy_reflect::utility::GenericTypeCell`, when called on a recursive
type, e.g. `Vec<Vec<VariableCurve>>`
## Solution
- Drop the lock before calling the initialisation function, and then
pick it up again afterwards.
## Additional Context
- [Discussed on
Discord](https://discord.com/channels/691052431525675048/1002362493634629796/1122706835284185108)
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
Currently when `UntypedReflectDeserializerVisitor` deserializes a
`Box<dyn Reflect>` it only considers the first entry of the map,
silently ignoring any additional entries. For example the following RON
data:
```json
{
"f32": 1.23,
"u32": 1,
}
```
is successfully deserialized as a `f32`, completly ignoring the `"u32":
1` part.
## Solution
`UntypedReflectDeserializerVisitor` was changed to check if any other
key could be deserialized, and in that case returns an error.
---
## Changelog
`UntypedReflectDeserializer` now errors on malformed inputs instead of
silently disgarding additional data.
## Migration Guide
If you were deserializing `Box<dyn Reflect>` values with multiple
entries (i.e. entries other than `"type": { /* fields */ }`) you should
remove them or deserialization will fail.
# Objective
`World::entity`, `World::entity_mut` and `Commands::entity` should be
marked with `track_caller` to display where (in user code) the call with
the invalid `Entity` was made. `Commands::entity` already has the
attibute, but it does nothing due to the call to `unwrap_or_else`.
## Solution
- Apply the `track_caller` attribute to the `World::entity_mut` and
`World::entity`.
- Remove the call to `unwrap_or_else` which makes the `track_caller`
attribute useless (because `unwrap_or_else` is not `track_caller`
itself). The avoid eager evaluation of the panicking branch it is never
inlined.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
`color_from_entity` uses the poor man's hash to get a fixed random color
for an entity.
While the poor man's hash is succinct, it has a tendency to clump. As a
result, bevy_gizmos has a tendency to re-use very similar colors for
different entities.
This is bad, we would want non-similar colors that take the whole range
of possible hues. This way, each bevy_gizmos aabb gizmo is easy to
identify.
## Solution
AHash is a nice and fast hash that just so happen to be available to
use, so we use it.
# Objective
In Bevy 10.1 and before, the only way to enable text wrapping was to set
a local `Val::Px` width constraint on the text node itself.
`Val::Percent` constraints and constraints on the text node's ancestors
did nothing.
#7779 fixed those problems. But perversely displaying unwrapped text is
really difficult now, and requires users to nest each `TextBundle` in a
`NodeBundle` and apply `min_width` and `max_width` constraints. Some
constructions may even need more than one layer of nesting. I've seen
several people already who have really struggled with this when porting
their projects to main in advance of 0.11.
## Solution
Add a `NoWrap` variant to the `BreakLineOn` enum.
If `NoWrap` is set, ignore any constraints on the width for the text and
call `TextPipeline::queue_text` with a width bound of `f32::INFINITY`.
---
## Changelog
* Added a `NoWrap` variant to the `BreakLineOn` enum.
* If `NoWrap` is set, any constraints on the width for the text are
ignored and `TextPipeline::queue_text` is called with a width bound of
`f32::INFINITY`.
* Changed the `size` field of `FixedMeasure` to `pub`. This shouldn't
have been private, it was always intended to have `pub` visibility.
* Added a `with_no_wrap` method to `TextBundle`.
## Migration Guide
`bevy_text::text::BreakLineOn` has a new variant `NoWrap` that disables
text wrapping for the `Text`.
Text wrapping can also be disabled using the `with_no_wrap` method of
`TextBundle`.
# Objective
- Fix this error to be able to run UI examples in WebGPU
```
1 error(s) generated while compiling the shader:
:31:18 error: integral user-defined vertex outputs must have a flat interpolation attribute
@location(3) mode: u32,
^^^^
:36:1 note: while analyzing entry point 'vertex'
fn vertex(
^^
```
It was introduce in #8793
## Solution
- Add `@interpolate(flat)` to the `mode` field
# Objective
In Bevy main, the unconstrained size of an `ImageBundle` or
`AtlasImageBundle` UI node is based solely on the size of its texture
and doesn't change with window scale factor or `UiScale`.
## Solution
* The size field of each `ImageMeasure` should be multiplied by the
current combined scale factor.
* Each `ImageMeasure` should be updated when the combined scale factor
is changed.
## Example:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.insert_resource(UiScale { scale: 1.5 })
.add_systems(Startup, setup)
.run();
}
fn setup(mut commands: Commands, asset_server: Res<AssetServer>) {
commands.spawn(Camera2dBundle::default());
commands.spawn(NodeBundle {
style: Style {
// The size of the "bevy_logo_dark.png" texture is 520x130 pixels
width: Val::Px(520.),
height: Val::Px(130.),
..Default::default()
},
background_color: Color::RED.into(),
..Default::default()
});
commands
.spawn(ImageBundle {
style: Style {
position_type: PositionType::Absolute,
..Default::default()
},
image: UiImage::new(asset_server.load("bevy_logo_dark.png")),
..Default::default()
});
}
```
The red node is given a size with the same dimensions as the texture. So
we would expect the texture to fill the node exactly.
* Result with Bevy main branch bb59509d44:
<img width="400" alt="image-size-broke"
src="https://github.com/bevyengine/bevy/assets/27962798/19fd927d-ecc5-49a7-be05-c121a8df163f">
* Result with this PR (and Bevy 0.10.1):
<img width="400" alt="image-size-fixed"
src="https://github.com/bevyengine/bevy/assets/27962798/40b47820-5f2d-408f-88ef-9e2beb9c92a0">
---
## Changelog
`bevy_ui::widget::image`
* Update all `ImageMeasure`s on changes to the window scale factor or
`UiScale`.
* Multiply `ImageMeasure::size` by the window scale factor and
`UiScale`.
## Migration Guide
# Objective
- Change despawn descendants to return self (#8883).
## Solution
- Change function signature `despawn_descendants` under trait
`DespawnRecursiveExt`.
- Add single extra test `spawn_children_after_despawn_descendants` (May
be unnecessary)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Partially address #5504. Fix#4278. Provide "whole entity" access in
queries. This can be useful when you don't know at compile time what
you're accessing (i.e. reflection via `ReflectComponent`).
## Solution
Implement `WorldQuery` for `EntityRef`.
- This provides read-only access to the entire entity, and supports
anything that `EntityRef` can normally do.
- It matches all archetypes and tables and will densely iterate when
possible.
- It marks all of the ArchetypeComponentIds of a matched archetype as
read.
- Adding it to a query will cause it to panic if used in conjunction
with any other mutable access.
- Expanded the docs on Query to advertise this feature.
- Added tests to ensure the panics were working as intended.
- Added `EntityRef` to the ECS prelude.
To make this safe, `EntityRef::world` was removed as it gave potential
`UnsafeCell`-like access to other parts of the `World` including aliased
mutable access to the components it would otherwise read safely.
## Performance
Not great beyond the additional parallelization opportunity over
exclusive systems. The `EntityRef` is fetched from `Entities` like any
other call to `World::entity`, which can be very random access heavy.
This could be simplified if `ArchetypeRow` is available in
`WorldQuery::fetch`'s arguments, but that's likely not something we
should optimize for.
## Future work
An equivalent API where it gives mutable access to all components on a
entity can be done with a scoped version of `EntityMut` where it does
not provide `&mut World` access nor allow for structural changes to the
entity is feasible as well. This could be done as a safe alternative to
exclusive system when structural mutation isn't required or the target
set of entities is scoped.
---
## Changelog
Added: `Access::has_any_write`
Added: `EntityRef` now implements `WorldQuery`. Allows read-only access
to the entire entity, incompatible with any other mutable access, can be
mixed with `With`/`Without` filters for more targeted use.
Added: `EntityRef` to `bevy::ecs::prelude`.
Removed: `EntityRef::world`
## Migration Guide
TODO
---------
Co-authored-by: Carter Weinberg <weinbergcarter@gmail.com>
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#7323
- Reduce texture blurriness for TAA
## Solution
- Add a `MipBias` component and view uniform.
- Switch material `textureSample()` calls to `textureSampleBias()`.
- Add a `-1.0` bias to TAA.
---
## Changelog
- Added `MipBias` camera component, mostly for internal use.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add morph targets to `bevy_pbr` (closes#5756) & load them from glTF
- Supersedes #3722
- Fixes#6814
[Morph targets][1] (also known as shape interpolation, shape keys, or
blend shapes) allow animating individual vertices with fine grained
controls. This is typically used for facial expressions. By specifying
multiple poses as vertex offset, and providing a set of weight of each
pose, it is possible to define surprisingly realistic transitions
between poses. Blending between multiple poses also allow composition.
Morph targets are part of the [gltf standard][2] and are a feature of
Unity and Unreal, and babylone.js, it is only natural to implement them
in bevy.
## Solution
This implementation of morph targets uses a 3d texture where each pixel
is a component of an animated attribute. Each layer is a different
target. We use a 2d texture for each target, because the number of
attribute×components×animated vertices is expected to always exceed the
maximum pixel row size limit of webGL2. It copies fairly closely the way
skinning is implemented on the CPU side, while on the GPU side, the
shader morph target implementation is a relatively trivial detail.
We add an optional `morph_texture` to the `Mesh` struct. The
`morph_texture` is built through a method that accepts an iterator over
attribute buffers.
The `MorphWeights` component, user-accessible, controls the blend of
poses used by mesh instances (so that multiple copy of the same mesh may
have different weights), all the weights are uploaded to a uniform
buffer of 256 `f32`. We limit to 16 poses per mesh, and a total of 256
poses.
More literature:
* Old babylone.js implementation (vertex attribute-based):
https://www.eternalcoding.com/dev-log-1-morph-targets/
* Babylone.js implementation (similar to ours):
https://www.youtube.com/watch?v=LBPRmGgU0PE
* GPU gems 3:
https://developer.nvidia.com/gpugems/gpugems3/part-i-geometry/chapter-3-directx-10-blend-shapes-breaking-limits
* Development discord thread
https://discord.com/channels/691052431525675048/1083325980615114772https://user-images.githubusercontent.com/26321040/231181046-3bca2ab2-d4d9-472e-8098-639f1871ce2e.mp4https://github.com/bevyengine/bevy/assets/26321040/d2a0c544-0ef8-45cf-9f99-8c3792f5a258
## Acknowledgements
* Thanks to `storytold` for sponsoring the feature
* Thanks to `superdump` and `james7132` for guidance and help figuring
out stuff
## Future work
- Handling of less and more attributes (eg: animated uv, animated
arbitrary attributes)
- Dynamic pose allocation (so that zero-weighted poses aren't uploaded
to GPU for example, enables much more total poses)
- Better animation API, see #8357
----
## Changelog
- Add morph targets to bevy meshes
- Support up to 64 poses per mesh of individually up to 116508 vertices,
animation currently strictly limited to the position, normal and tangent
attributes.
- Load a morph target using `Mesh::set_morph_targets`
- Add `VisitMorphTargets` and `VisitMorphAttributes` traits to
`bevy_render`, this allows defining morph targets (a fairly complex and
nested data structure) through iterators (ie: single copy instead of
passing around buffers), see documentation of those traits for details
- Add `MorphWeights` component exported by `bevy_render`
- `MorphWeights` control mesh's morph target weights, blending between
various poses defined as morph targets.
- `MorphWeights` are directly inherited by direct children (single level
of hierarchy) of an entity. This allows controlling several mesh
primitives through a unique entity _as per GLTF spec_.
- Add `MorphTargetNames` component, naming each indices of loaded morph
targets.
- Load morph targets weights and buffers in `bevy_gltf`
- handle morph targets animations in `bevy_animation` (previously, it
was a `warn!` log)
- Add the `MorphStressTest.gltf` asset for morph targets testing, taken
from the glTF samples repo, CC0.
- Add morph target manipulation to `scene_viewer`
- Separate the animation code in `scene_viewer` from the rest of the
code, reducing `#[cfg(feature)]` noise
- Add the `morph_targets.rs` example to show off how to manipulate morph
targets, loading `MorpStressTest.gltf`
## Migration Guide
- (very specialized, unlikely to be touched by 3rd parties)
- `MeshPipeline` now has a single `mesh_layouts` field rather than
separate `mesh_layout` and `skinned_mesh_layout` fields. You should
handle all possible mesh bind group layouts in your implementation
- You should also handle properly the new `MORPH_TARGETS` shader def and
mesh pipeline key. A new function is exposed to make this easier:
`setup_moprh_and_skinning_defs`
- The `MeshBindGroup` is now `MeshBindGroups`, cached bind groups are
now accessed through the `get` method.
[1]: https://en.wikipedia.org/wiki/Morph_target_animation
[2]:
https://registry.khronos.org/glTF/specs/2.0/glTF-2.0.html#morph-targets
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fix#8908.
## Solution
Assign the vertex buffers twice with a single item offset instead of
setting the array_stride lower than the vertex layout's size for
linestrips.
# Objective
Improve the documentation relating to windows, and update the parts that
have not been updated since version 0.8.
Version 0.9 introduced `Window` as a component, before that
`WindowDescriptor` (which would become `Window` later) was used to store
information about how a window will be created. Since version 0.9, from
my understanding, this information will also be synchronised with the
current state of the window, and can be used to modify this state.
However, some of the documentation has not been updated to reflect that,
here is an example:
https://docs.rs/bevy/0.8.0/bevy/window/enum.WindowMode.html /
https://docs.rs/bevy/latest/bevy/window/enum.WindowMode.html (notice
that the verb "Creates" is still there).
This PR aims at improving the documentation relating to windows.
## Solution
- Change "will" for "should" when relevant, "should" implies that the
information should in both direction (from the window state to the
`Window` component and vice-versa) and can be used to get and set, will
implies it is only used to set a state.
- Remove references to "creation" or be more clear about it.
- Reference back the `Window` component for most of its sub-structs.
- Clarify what needs to be clarified
- A lot of other minor changes, including fixing the link to W3schools
in `bevy_winit`
## Warning
Please note that my knowledge about how winit and bevy_winit work is
limited and some of the informations I added in the doc may be
inaccurate. A person who knows better how it works should review some of
my claims, in particular:
- How fullscreen works:
https://github.com/bevyengine/bevy/pull/8858#discussion_r1232413155
- How WindowResolution / sizes work:
https://github.com/bevyengine/bevy/pull/8858#discussion_r1233010719
- What happens when `WindowPosition` is set to `Centered` or
`Automatic`. From my understanding of the code, it should always be set
back to `At`, but is it really the case? For example [when creating the
window](https://github.com/bevyengine/bevy/blob/main/crates/bevy_winit/src/winit_windows.rs#L74),
or when [a `WindowEvent::Moved` is
triggered](https://github.com/bevyengine/bevy/blob/main/crates/bevy_winit/src/lib.rs#L602)
or when [Centered/Automatic by the code after the window is
created](https://github.com/bevyengine/bevy/blob/main/crates/bevy_winit/src/system.rs#L243),
am I missing some cases and do the codes I linked do that in all of
them?
- Are there any field in the `Window` component that can't be used to
modify the state of the window, only at creation?
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Jerome Humbert <djeedai@gmail.com>
# Objective
- Fix the AsBindGroup texture attribute visibility flag parsing
- This appears to have been caused by a syn crate update which then the
visibility code got updated
- Also I noticed that by default the vertex and fragment flags were on,
so visibility(compute) would actually make the texture visible to
vertex, fragment and compute shaders, I fixed this too
## Solution
- Update flag parsing to use MetaList.parse_nested_meta function, which
loads the flags into a Vec then loop through those flags
- Change initial visibility flags to use VisibilityFlags::default()
rather than VisibilityFlags::vertex_fragment()
# Objective
`prepare_uinodes` creates a new `UiBatch` whenever the texture changes,
when most often it's just queuing untextured quads. Instead of switching
textures, we can reduce the number of batches generated significantly by
adding a condition to the fragment shader so that it only multiplies by
the `textureSample` value when drawing a textured quad.
# Solution
Add a `mode` field to `UiVertex`.
In `prepare_uinodes` set `mode` to 0 if the quad is textured or 1 if
untextured.
Add a condition to the fragment shader that only multiplies by the
`color` value from `textureSample` if `mode` is set to 1.
---
## Changelog
* Added a `mode` field to `UiVertex`, and added an extra `u32` vertex
attribute to the shader and vertex buffer layout.
* In `prepare_uinodes` mode is set to 0 for the vertices of textured
quads, and 1 if untextured.
* Added a condition to the fragment shader in `ui.wgsl` that only
multiplies by the `color` value from `textureSample` if the mode is
equal to 0.
# Objective
- Fixes#8645
## Solution
Cascaded shadow maps use a technique commonly called shadow pancaking to
enhance shadow map resolution by restricting the orthographic projection
used in creating the shadow maps to the frustum slice for the cascade.
The implication of this restriction is that shadow casters can be closer
than the near plane of the projection volume.
Prior to this PR, we address clamp the depth of the prepass vertex
output to ensure that these shadow casters do not get clipped, resulting
in shadow loss. However, a flaw / bug of the prior approach is that the
depth that gets written to the shadow map isn't quite correct - the
depth was previously derived by interpolated the clamped clip position,
resulting in depths that are further than they should be. This creates
artifacts that are particularly noticeable when a very 'long' object
intersects the near plane close to perpendicularly.
The fix in this PR is to propagate the unclamped depth to the prepass
fragment shader and use that depth value directly.
A complementary solution would be to use
[DEPTH_CLIP_CONTROL](https://docs.rs/wgpu/latest/wgpu/struct.Features.html#associatedconstant.DEPTH_CLIP_CONTROL)
to request `unclipped_depth`. However due to the relatively low support
of the feature on Vulkan (I believe it's ~38%), I went with this
solution for now to get the broadest fix out first.
---
## Changelog
- Fixed: Shadows from directional lights were sometimes incorrectly
omitted when the shadow caster was partially out of view.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Better consistency with `add_systems`.
- Deprecating `add_plugin` in favor of a more powerful `add_plugins`.
- Allow passing `Plugin` to `add_plugins`.
- Allow passing tuples to `add_plugins`.
## Solution
- `App::add_plugins` now takes an `impl Plugins` parameter.
- `App::add_plugin` is deprecated.
- `Plugins` is a new sealed trait that is only implemented for `Plugin`,
`PluginGroup` and tuples over `Plugins`.
- All examples, benchmarks and tests are changed to use `add_plugins`,
using tuples where appropriate.
---
## Changelog
### Changed
- `App::add_plugins` now accepts all types that implement `Plugins`,
which is implemented for:
- Types that implement `Plugin`.
- Types that implement `PluginGroup`.
- Tuples (up to 16 elements) over types that implement `Plugins`.
- Deprecated `App::add_plugin` in favor of `App::add_plugins`.
## Migration Guide
- Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fix broken normals when the NormalPrepass is enabled
## Solution
- Don't use the normal prepass for the world_normal
- Only loadthe normal prepass
- when msaa is disabled
- for opaque or alpha mask meshes and only for use it for N not
world_normal
# Objective
- Use `AppTypeRegistry` on API defined in `bevy_ecs`
(https://github.com/bevyengine/bevy/pull/8895#discussion_r1234748418)
A lot of the API on `Reflect` depends on a registry. When it comes to
the ECS. We should use `AppTypeRegistry` in the general case.
This is however impossible in `bevy_ecs`, since `AppTypeRegistry` is
defined in `bevy_app`.
## Solution
- Move `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
- Still add the resource in the `App` plugin, since bevy_ecs itself
doesn't know of plugins
Note that `bevy_ecs` is a dependency of `bevy_app`, so nothing
revolutionary happens.
## Alternative
- Define the API as a trait in `bevy_app` over `bevy_ecs`. (though this
prevents us from using bevy_ecs internals)
- Do not rely on `AppTypeRegistry` for the API in question, requring
users to extract themselves the resource and pass it to the API methods.
---
## Changelog
- Moved `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
## Migration Guide
- If you were **not** using a `prelude::*` to import `AppTypeRegistry`,
you should update your imports:
```diff
- use bevy::app::AppTypeRegistry;
+ use bevy::ecs::reflect::AppTypeRegistry
```
# Objective
The "bevy_text" feature attributes for the `PrimaryWindow`, `Window` and
`TextureAtlas` imports in `bevy_ui::render` are used by non-text systems
(`extract_uinode_borders` and `extract_atlas_uinodes`) and need to be
removed.
For those who wish to be able to `#[reflect]` stuff using the `Uuid`
type
I'm very unfamiliar with the codebase, so please tell me if I'm missing
something
# Objective
- Providing a "noob-friendly" example since not many people are
proficient in 3D modeling / rendering concepts.
## Solution
- Adding more information to the example, with an explanation.
~~~~
_Thanks to Nocta on discord for helping out when I didn't understand the
subject well._
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- `bevy_log` writes logs to `stdout` (with ANSI formatting), which gets
in the way with program output and complicates parsing.
- Closes#8869
## Solution
- Change `bevy_log` to write to `stderr` instead of `stdout`
---
## Changelog
Changed:
- Logs write to `stderr` rather than `stdout` on desktop targets
## Migration Guide
- Capture logs from `stderr` instead of from `stdout`
- Use `2> output.log` on the command line to save `stderr` to a file
# Objective
Add a get_unclamped method to
[Axis](https://docs.rs/bevy/0.10.1/bevy/input/struct.Axis.html) to allow
it to be used in cases where being able to get a precise relative
movement is important. For example, camera zoom with the mouse wheel.
This would make it possible for libraries like leafwing input manager to
leverage `Axis` for mouse motion and mouse wheel axis mapping. I tried
to use it my PR here
https://github.com/Leafwing-Studios/leafwing-input-manager/pull/346 but
will likely have to revert that and read the mouse wheel events for now
which is what prompted this PR.
## Solution
Instead of clamping the axis value when it is set, it now stores the raw
value and clamps it in the `get` method. This allows a simple
get_unclamped method that just returns the raw value.
## Changelog
- Added a get_unclamped method to Axis that can return values outside of
-1.0 to 1.0
# Objective
Fixes#6920
## Solution
From the issue discussion:
> From looking at the `AsBindGroup` derive macro implementation, the
fallback image's `TextureView` is used when the binding's
`Option<Handle<Image>>` is `None`. Because this relies on already having
a view that matches the desired binding dimensions, I think the solution
will require creating a separate `GpuImage` for each possible
`TextureViewDimension`.
---
## Changelog
Users can now rely on `FallbackImage` to work with a texture binding of
any dimension.
# Objective
- Document android code that is currently causing clippy warnings due to
not being documented
## Solution
- Document the two previously undocumented items
# Objective
`WorldQuery::Fetch` is a type used to optimize the implementation of
queries. These types are hidden and not intended to be outside of the
engine, so there is no need to provide type aliases to make it easier to
refer to them. If a user absolutely needs to refer to one of these
types, they can always just refer to the associated type directly.
## Solution
Deprecate these type aliases.
---
## Changelog
- Deprecated the type aliases `QueryFetch` and `ROQueryFetch`.
## Migration Guide
The type aliases `bevy_ecs::query::QueryFetch` and `ROQueryFetch` have
been deprecated. If you need to refer to a `WorldQuery` struct's fetch
type, refer to the associated type defined on `WorldQuery` directly:
```rust
// Before:
type MyFetch<'w> = QueryFetch<'w, MyQuery>;
type MyFetchReadOnly<'w> = ROQueryFetch<'w, MyQuery>;
// After:
type MyFetch<'w> = <MyQuery as WorldQuery>::Fetch;
type MyFetchReadOnly<'w> = <<MyQuery as WorldQuery>::ReadOnly as WorldQuery>::Fetch;
```
# Objective
This adds support for using texture atlas sprites in UI. From
discussions today in the ui-dev discord it seems this is a much wanted
feature.
This was previously attempted in #5070 by @ManevilleF however that was
blocked #5103. This work can be easily modified to support #5103 changes
after that merges.
## Solution
I created a new UI bundle that reuses the existing texture atlas
infrastructure. I create a new atlas image component to prevent it from
being drawn by the existing non-UI systems and to remove unused
parameters.
In extract I added new system to calculate the required values for the
texture atlas image, this extracts into the same resource as the
existing UI Image and Text components.
This should have minimal performance impact because if texture atlas is
not present then the exact same code path is followed. Also there should
be no unintended behavior changes because without the new components the
existing systems write the extract same resulting data.
I also added an example showing the sprite working and a system to
advance the animation on space bar presses.
Naming is hard and I would accept any feedback on the bundle name!
---
## Changelog
> Added TextureAtlasImageBundle
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
Discovered that PointLight did not implement FromReflect. Adding
FromReflect where Reflect is used. I overreached and applied this rule
everywhere there was a Reflect without a FromReflect, except from where
the compiler wouldn't allow me.
Based from question: https://github.com/bevyengine/bevy/discussions/8774
## Solution
- Adding FromReflect where Reflect was already derived
## Notes
First PR I do in this ecosystem, so not sure if this is the usual
approach, that is, to touch many files at once.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
`ParsedPath` does not need to be mut to access a field of a `Reflect`.
Be that access mutable or not. Yet `element_mut` requires a mutable
borrow on `self`.
## Solution
- Make `element_mut` take a `&self` over a `&mut self`.
#8887 fixes this, but this is a major limitation in the API and I'd
rather see it merged before 0.11.
---
## Changelog
- `ParsedPath::element_mut` and `ParsedPath::reflect_element_mut` now
accept a non-mutable `ParsedPath` (only the accessed `Reflect` needs to
be mutable)
# Objective
- Implementing reflection for Cow<'static, [T]>
- Hopefully fixes#7429
## Solution
- Implementing Reflect, Typed, GetTypeRegistration, and FromReflect for
Cow<'static, [T]>
---
## Notes
I have not used bevy_reflection much yet, so I may not fully understand
all the use cases. This is also my first attempt at contributing, so I
would appreciate any feedback or recommendations for changes. I tried to
add cases for using Cow<'static, str> and Cow<'static, [u8]> to some of
the bevy_reflect tests, but I can't guarantee those tests are
comprehensive enough.
---------
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Repetitively fetching ReflectResource and ReflectComponent from the
TypeRegistry is costly.
We want to access the underlying `fn`s. to do so, we expose the
`ReflectResourceFns` and `ReflectComponentFns` stored in ReflectResource
and ReflectComponent.
---
## Changelog
- Add the `fn_pointers` methods to `ReflectResource` and
`ReflectComponent` returning the underlying `ReflectResourceFns` and
`ReflectComponentFns`
# Objective
Make the UI code more concise.
## Solution
Add two utility methods to make manipulating `UiRect` from code more
concise:
- `UiRect::px()` create a new `UiRect` like the `new()` function, but
with values in logical pixels directly.
- `UiRect::percent()` is similar, with values as percentages.
This saves a lot of typing and makes UI code more compact while
retaining readability.
---
## Changelog
### Added
Added two new constructors `UiRect::px()` and `UiRect::percent()` to
create a new `UiRect` from values directly specified in logical pixels
and percentages, respectively. The argument order is the same as
`UiRect::new()`, but avoids having to repeat `Val::Px` and
`Val::Percent`, respectively.
# Objective
- Fixes#7811
## Solution
- I added `Has<T>` (and `HasFetch<T>` ) and implemented `WorldQuery`,
`ReadonlyWorldQuery`, and `ArchetypeFilter` it
- I also added documentation with an example and a unit test
I believe I've done everything right but this is my first contribution
and I'm not an ECS expert so someone who is should probably check my
implementation. I based it on what `Or<With<T>,>`, would do. The only
difference is that `Has` does not update component access - adding `Has`
to a query should never affect whether or not it is disjoint with
another query *I think*.
---
## Changelog
## Added
- Added `Has<T>` WorldQuery to find out whether or not an entity has a
particular component.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
We can currently set `camera.target` to either an `Image` or `Window`.
For OpenXR & WebXR we need to be able to render to a `TextureView`.
This partially addresses #115 as with the addition we can create
internal and external xr crates.
## Solution
A `TextureView` item is added to the `RenderTarget` enum. It holds an id
which is looked up by a `ManualTextureViews` resource, much like how
`Assets<Image>` works.
I believe this approach was first used by @kcking in their [xr
fork](eb39afd51b/crates/bevy_render/src/camera/camera.rs (L322)).
The only change is that a `u32` is used to index the textures as
`FromReflect` does not support `uuid` and I don't know how to implement
that.
---
## Changelog
### Added
Render: Added `RenderTarget::TextureView` as a `camera.target` option,
enabling rendering directly to a `TextureView`.
## Migration Guide
References to the `RenderTarget` enum will need to handle the additional
field, ie in `match` statements.
---
## Comments
- The [wgpu
work](c039a74884)
done by @expenses allows us to create framebuffer texture views from
`wgpu v0.15, bevy 0.10`.
- I got the WebXR techniques from the [xr
fork](https://github.com/dekuraan/xr-bevy) by @dekuraan.
- I have tested this with a wip [external webxr
crate](018e22bb06/crates/bevy_webxr/src/bevy_utils/xr_render.rs (L50))
on an Oculus Quest 2.

---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: Paul Hansen <mail@paul.rs>
# Objective
- Cleanup the `reflect.rs` file in `bevy_ecs`, it's very large and can
get difficult to navigate
## Solution
- Split the file into 3 modules, re-export the types in the
`reflect/mod.rs` to keep a perfectly identical API.
- Add **internal** architecture doc explaining how `ReflectComponent`
works. Note that this doc is internal only, since `component.rs` is not
exposed publicly.
### Tips to reviewers
To review this change properly, you need to compare it to the previous
version of `reflect.rs`. The diff from this PR does not help at all!
What you will need to do is compare `reflect.rs` individually with each
newly created file.
Here is how I did it:
- Adding my fork as remote `git remote add nicopap
https://github.com/nicopap/bevy.git`
- Checkout out the branch `git checkout nicopap/split_ecs_reflect`
- Checkout the old `reflect.rs` by running `git checkout HEAD~1 --
crates/bevy_ecs/src/reflect.rs`
- Compare the old with the new with `git diff --no-index
crates/bevy_ecs/src/reflect.rs crates/bevy_ecs/src/reflect/component.rs`
You could also concatenate everything into a single file and compare
against it:
- `cat
crates/bevy_ecs/src/reflect/{component,resource,map_entities,mod}.rs >
new_reflect.rs`
- `git diff --no-index crates/bevy_ecs/src/reflect.rs new_reflect.rs`
# Objective
Fix https://github.com/bevyengine/bevy/issues/1018 (Textures on the
`Plane` shape appear flipped).
This bug have been around for a very long time apparently, I tested it
was still there (see test code bellow) and sure enough, this image:

... is flipped vertically when used as a texture on a plane (in main,
0.10.1 and 0.9):

I'm pretty confused because this bug is so easy to fix, it has been
around for so long, it is easy to encounter, and PRs touching this code
still didn't fix it: https://github.com/bevyengine/bevy/pull/7546 To the
point where I'm wondering if it's actually intended. If it is, please
explain why and this PR can be changed to "mention that in the doc".
## Solution
Fix the UV mapping on the Plane shape
Here is how it looks after the PR

## Test code
```rust
use bevy::{
prelude::*,
};
fn main () {
App::new()
.add_plugins(DefaultPlugins)
.add_startup_system(setup)
.run();
}
fn setup(
mut commands: Commands,
assets: ResMut<AssetServer>,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
) {
commands.spawn(Camera3dBundle {
transform: Transform::from_xyz(0., 3., 0.).looking_at(Vec3::ZERO, Vec3::NEG_Z),
..default()
});
let mesh = meshes.add(Mesh::from(shape::Plane::default()));
let texture_image = assets.load("test.png");
let material = materials.add(StandardMaterial {
base_color_texture: Some(texture_image),
..default()
});
commands.spawn(PbrBundle {
mesh,
material,
..default()
});
}
```
## Changelog
Fix textures on `Plane` shapes being flipped vertically.
## Migration Guide
Flip the textures you use on `Plane` shapes.
# Objective
Resolves#7558.
Systems that are known to never modify the world implement the trait
`ReadOnlySystem`. This is a perfect place to add a safe API for running
a system with a shared reference to a World.
---
## Changelog
- Added the trait method `ReadOnlySystem::run_readonly`, which allows a
system to be run using `&World`.
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
`ComponentIdFor` is a type that gives you access to a component's
`ComponentId` in a system. It is currently awkward to use, since it must
be wrapped in a `Local<>` to be used.
## Solution
Make `ComponentIdFor` a proper SystemParam.
---
## Changelog
- Refactored the type `ComponentIdFor` in order to simplify how it is
used.
## Migration Guide
The type `ComponentIdFor<T>` now implements `SystemParam` instead of
`FromWorld` -- this means it should be used as the parameter for a
system directly instead of being used in a `Local`.
```rust
// Before:
fn my_system(
component_id: Local<ComponentIdFor<MyComponent>>,
) {
let component_id = **component_id;
}
// After:
fn my_system(
component_id: ComponentIdFor<MyComponent>,
) {
let component_id = component_id.get();
}
```
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
Implement borders for UI nodes.
Relevant discussion: #7785
Related: #5924, #3991
<img width="283" alt="borders"
src="https://user-images.githubusercontent.com/27962798/220968899-7661d5ec-6f5b-4b0f-af29-bf9af02259b5.PNG">
## Solution
Add an extraction function to draw the borders.
---
Can only do one colour rectangular borders due to the limitations of the
Bevy UI renderer.
Maybe it can be combined with #3991 eventually to add curved border
support.
## Changelog
* Added a component `BorderColor`.
* Added the `extract_uinode_borders` system to the UI Render App.
* Added the UI example `borders`
---------
Co-authored-by: Nico Burns <nico@nicoburns.com>
# Objective
The method `UnsafeWorldCell::read_change_tick` was renamed in #8588, but
I forgot to update a usage of this method in a doctest.
## Solution
Update the method call.
# Objective
To mirror the `Ref` added as `WorldQuery`, and the `Mut` in
`EntityMut::get_mut`, we add `EntityRef::get_ref`, which retrieves `T`
with tick information, but *immutably*.
## Solution
- Add the method in question, also add it to`UnsafeEntityCell` since
this seems to be the best way of getting that information.
Also update/add safety comments to neighboring code.
---
## Changelog
- Add `EntityRef::get_ref` to get an `Option<Ref<T>>` from `EntityRef`
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The method `QueryState::par_iter` does not currently force the query to
be read-only. This means you can unsoundly mutate a world through an
immutable reference in safe code.
```rust
fn bad_system(world: &World, mut query: Local<QueryState<&mut T>>) {
query.par_iter(world).for_each_mut(|mut x| *x = unsoundness);
}
```
## Solution
Use read-only versions of the `WorldQuery` types.
---
## Migration Guide
The function `QueryState::par_iter` now forces any world accesses to be
read-only, similar to how `QueryState::iter` works. Any code that
previously mutated the world using this method was *unsound*. If you
need to mutate the world, use `par_iter_mut` instead.
# Objective
Make a combined system cloneable if both systems are cloneable on their
own. This is necessary for using chained conditions (e.g
`cond1.and_then(cond2)`) with `distributive_run_if()`.
## Solution
Implement `Clone` for `CombinatorSystem<Func, A, B>` where `A, B:
Clone`.
# Objective
- Fixes#8782
## Solution
- Call `init_resource` on `register_diagnostic` so that a
`DiagnosticStore` gets initialized if it does not exist.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
The `extract` function is given the main app world, and the subapp, not
vice versa as the comment would lead us to believe.
## Solution
Fix the doc.
# Objective
- Rename the `render::primitives::Plane` struct as to not confuse it
with `bevy_render::mesh::shape::Plane`
- Fixes https://github.com/bevyengine/bevy/issues/8730
## Solution
- Refactor the `render::primitives::Plane` struct to
`render::primitives::HalfSpace`
- Modify documentation to reflect this change
## Changelog
- Renamed `Plane` to `HalfSpace` to more accurately represent it's use
- Renamed `planes` member in `Frustum` to `half_spaces` to reflect
changes
## Migration Guide
- `Plane` has been renamed to `HalfSpace`
- `planes` member in `Frustum` has been renamed to `half_spaces`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
When browsing the bevy source code to try and learn about
`bevy_core_pipeline`, I noticed that the `DrawFunctions` resources,
`sort_phase_system`s and texture preparation for the `Opaque3d` and
`AlphaMask3d` phase items are all set up in `bevy_core_pipeline`, while
the `Opaque3dPrepass` and `AlphaMask3dPrepass` phase items are only
*declared* in `bevy_core_pipeline`, and actually registered properly
with the renderer in `bevy_pbr`.
This means that, if I am trying to make crate that replaces `bevy_pbr`,
I need to make sure I manually fix this unfinished setup the same way
that `bevy_pbr` does. Worse, it means that if I try to use the
`PrepassNode` `bevy_core_pipeline` adds *without* fixing this, the
engine will simply crash because the `DrawFunctions<T>` resources cannot
be accessed.
The only advantage I can think of for bevy doing it this way is an
ambiguous performance save due to the prepass render phases not being
present unless you are using prepass materials with PBR.
## Solution
I have moved the registration of `DrawFunctions<T>`,
`sort_phase_system::<T>`, camera `RenderPhase` extraction, and texture
preparation for prepass's phase items into `bevy_core_pipeline`
alongside the equivalent code that sets up the `Opaque3d`, `AlphaMask3d`
and `Transparent3d` phase items.
Am open to tweaking this to improve the performance impact of prepass
things being around if the app doesn't use them if needed.
I've tested that the `shader_prepass` example still works with this
change.
# Objective
EntityRef::get_change_ticks mentions that ComponentTicks is useful to
create change detection for your own runtime.
However, ComponentTicks doesn't even expose enough data to create
something that implements DetectChanges. Specifically, we need to be
able to extract the last change tick.
## Solution
We add a method to get the last change tick. We also add a method to get
the added tick.
## Changelog
- Add `last_changed_tick` and `added_tick` to `ComponentTicks`
# Objective
- Fixes#8811 .
## Solution
- Rename "write" method to "apply" in Command trait definition.
- Rename other implementations of command trait throughout bevy's code
base.
---
## Changelog
- Changed: `Command::write` has been changed to `Command::apply`
- Changed: `EntityCommand::write` has been changed to
`EntityCommand::apply`
## Migration Guide
- `Command::write` implementations need to be changed to implement
`Command::apply` instead. This is a mere name change, with no further
actions needed.
- `EntityCommand::write` implementations need to be changed to implement
`EntityCommand::apply` instead. This is a mere name change, with no
further actions needed.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- I can't map unsized type using `Ref::map` (for example `dyn Reflect`)
## Solution
- Allow unsized types (this is possible because `Ref` stores a reference
to `T`)
# Objective
`QueryState` exposes a `get_manual` and `iter_manual` method. However,
there is now `iter_many_manual`.
`iter_many_manual` is useful when you have a `&World` (eg: the `world`
in a `Scene`) and want to run a query several times on it (eg:
iteratively navigate a hierarchy by calling `iter_many` on `Children`
component).
`iter_many`'s need for a `&mut World` makes the API much less flexible.
The exclusive access pattern requires doing some very funky dance and
excludes a category of algorithms for hierarchy traversal.
## Solution
- Add a `iter_many_manual` method to `QueryState`
### Alternative
My current workaround is to use `get_manual`. However, this doesn't
benefit from the optimizations on `QueryManyIter`.
---
## Changelog
- Add a `iter_many_manual` method to `QueryState`
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
`Ref` is a useful way of accessing change detection data.
However, unlike `Mut`, it doesn't expose a constructor or even a way to
go from `Ref<A>` to `Ref<B>`.
Such methods could be useful, for example, to 3rd party crates that want
to expose change detection information in a clean way.
My use case is to map a `Ref<T>` into a `Ref<dyn Reflect>`, and keep
change detection info to avoid running expansive routines.
## Solution
We add the `new` and `map` methods. Since similar methods exist on `Mut`
where they are much more footgunny to use, I judged that it was
acceptable to create such methods.
## Workaround
Currently, it's not possible to create/project `Ref`s. One can define
their own `Ref` and implement `ChangeDetection` on it. One would then
use `ChangeTrackers` to populate the custom `Ref` with tick data.
---
## Changelog
- Added the `Ref::map` and `Ref::new` methods for more ergonomic `Ref`s
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Some reflect components weren't properly registered.
## Solution
- We register them
- I also sorted the register lines in `Plugin::build` in `bevy_ui`
### Note
How I did I find them:
- I picked up the list of `Component`s from the `Component` trait page
in rustdoc.
- Then I tried to register all of them. Removing the registration when
it doesn't implement `Reflect` to pass compilation.
- Then I added `app.register_type_data::<T, Foo>()`, for all Reflect
components. It panics if `T` is not registered.
- I repeated the last line N times until bevy stopped panicking at
startup
---
## Changelog
- Register the following components: `PrimaryWindow` `Fxaa`
`FogSettings` `NotShadowCaster` `NotShadowReceiver` `CalculatedClip`
`RelativeCursorPosition`
`AlphaMode` is not used as a component anywhere in the engine. It
shouldn't implement `Component`. It might mislead users into thinking it
has any effect as a component.
---
## Changelog
- Remove `Component` implementation for `AlphaMode`. It wasn't used by
anything.
## Migration Guide
`AlphaMode` is not a component anymore.
It wasn't used anywhere in the engine. If you were using it as a
component for your own purposes, you should use a newtype instead, as
follow:
```rust
#[derive(Component, Deref)]
struct MyAlphaMode(AlphaMode);
```
Then replace uses of `AlphaMode` with `MyAlphaMode`
```diff
- Query<&AlphaMode, …>,
+ Query<&MyAlphaMode, …>,
```
# Objective
- When a window is closed, the associated camera keeps rendering even if
the RenderTarget isn't valid anymore.
- This is essentially just wasting a lot of performance.
## Solution
- Detect the window close event and disable any camera that used the
window has a RenderTarget.
## Notes
It's possible a similar thing could be done for camera that use an image
handle, but I would fix that in a separate PR.
# Objective
`NoFrustumCulling` doesn't implement `Reflect`, while nothing prevents
it from implementing it.
## Solution
Implement `Reflect` for it.
---
## Changelog
- Add `Reflect` derive to `NoFrustrumCulling`.
- Add `FromReflect` derive to `Visibility`.
# Objective
This calculation is performed componentwise but all the values are
vectors so it should be using vector operations.
Works correctly with the `relative_cursor_position` example.
# Objective
To upgrade winit's dependency, it's useful to reuse SmolStr, which
replaces/improves the too restrictive Key letter enums.
As Input<Key> is a resource it should implement Reflect through all its
fields.
## Solution
Add smol_str to bevy_reflect supported types, behind a feature flag.
This PR blocks winit's upgrade PR:
https://github.com/bevyengine/bevy/pull/8745.
# Current state
- I'm discovering bevy_reflect, I appreciate all feedbacks, and send me
your nitpicks!
- Lacking more tests
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
The goal of this PR is to receive touchpad magnification and rotation
events.
## Solution
Implement pendants for winit's `TouchpadMagnify` and `TouchpadRotate`
events.
Adjust the `mouse_input_events.rs` example to debug magnify and rotate
events.
Since winit only reports these events on macOS, the Bevy events for
touchpad magnification and rotation are currently only fired on macOS.
Updates the requirements on
[notify](https://github.com/notify-rs/notify) to permit the latest
version.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/notify-rs/notify/blob/main/CHANGELOG.md">notify's
changelog</a>.</em></p>
<blockquote>
<h2>notify 6.0.0 (2023-05-17)</h2>
<ul>
<li>CHANGE: files and directories moved into a watch folder on Linux
will now be reported as <code>rename to</code> events instead of
<code>create</code> events <a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a></li>
<li>CHANGE: on Linux <code>rename from</code> events will be emitted
immediately without starting a new thread <a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a></li>
<li>CHANGE: raise MSRV to 1.60 <a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a></li>
</ul>
<h2>debouncer-mini 0.3.0 (2023-05-17)</h2>
<ul>
<li>CHANGE: upgrade to notify 6.0.0, pushing MSRV to 1.60 <a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a></li>
</ul>
<h2>debouncer-full 0.1.0 (2023-05-17)</h2>
<p>Newly introduced alternative debouncer with more features. <a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a></p>
<ul>
<li>FEATURE: only emit a single <code>rename</code> event if the rename
<code>From</code> and <code>To</code> events can be matched</li>
<li>FEATURE: merge multiple <code>rename</code> events</li>
<li>FEATURE: keep track of the file system IDs all files and stiches
rename events together (FSevents, Windows)</li>
<li>FEATURE: emit only one <code>remove</code> event when deleting a
directory (inotify)</li>
<li>FEATURE: don't emit duplicate create events</li>
<li>FEATURE: don't emit <code>Modify</code> events after a
<code>Create</code> event</li>
</ul>
<p><a
href="https://redirect.github.com/notify-rs/notify/issues/480">#480</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/480">notify-rs/notify#480</a></p>
<h2>notify 5.2.0 (2023-05-17)</h2>
<ul>
<li>CHANGE: implement <code>Copy</code> for <code>EventKind</code> and
<code>ModifyKind</code> <a
href="https://redirect.github.com/notify-rs/notify/issues/481">#481</a></li>
</ul>
<p><a
href="https://redirect.github.com/notify-rs/notify/issues/481">#481</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/481">notify-rs/notify#481</a></p>
<h2>notify 5.1.0 (2023-01-15)</h2>
<ul>
<li>CHANGE: switch from winapi to windows-sys <a
href="https://redirect.github.com/notify-rs/notify/issues/457">#457</a></li>
<li>FIX: kqueue-backend: batch file-watching together to improve
performance <a
href="https://redirect.github.com/notify-rs/notify/issues/454">#454</a></li>
<li>DOCS: include license file in crate again <a
href="https://redirect.github.com/notify-rs/notify/issues/461">#461</a></li>
<li>DOCS: typo and examples fixups</li>
</ul>
<p><a
href="https://redirect.github.com/notify-rs/notify/issues/454">#454</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/454">notify-rs/notify#454</a>
<a
href="https://redirect.github.com/notify-rs/notify/issues/461">#461</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/461">notify-rs/notify#461</a>
<a
href="https://redirect.github.com/notify-rs/notify/issues/457">#457</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/457">notify-rs/notify#457</a></p>
<h2>debouncer-mini 0.2.1 (2022-09-05)</h2>
<ul>
<li>DOCS: correctly document the <code>crossbeam</code> feature <a
href="https://redirect.github.com/notify-rs/notify/issues/440">#440</a></li>
</ul>
<p><a
href="https://redirect.github.com/notify-rs/notify/issues/440">#440</a>:
<a
href="https://redirect.github.com/notify-rs/notify/pull/440">notify-rs/notify#440</a></p>
<h2>debouncer-mini 0.2.0 (2022-08-30)</h2>
<p>Upgrade notify dependency to 5.0.0</p>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/notify-rs/notify/commits">compare view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>No-std support and better dict API</h2>
<p>This release features no-std support with big thanks to <a
href="https://github.com/antangelo"><code>@antangelo</code></a>!</p>
<p>Also the API for dictionaries has been revised, which required some
breaking changes in that department</p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="fa7bd9c7b3"><code>fa7bd9c</code></a>
allow streaming decoder to also be used with a &mut FrameDecoder for
easier r...</li>
<li><a
href="3b6403b8e7"><code>3b6403b</code></a>
reenable forcing a different dict</li>
<li><a
href="2be7fbb01b"><code>2be7fbb</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/40">#40</a>
from KillingSpark/overhaul_dicts</li>
<li><a
href="343d69b339"><code>343d69b</code></a>
no need to check that the dict still matches at the start of each decode
call</li>
<li><a
href="d73f5e689a"><code>d73f5e6</code></a>
cargo fmt</li>
<li><a
href="f3f09c76f0"><code>f3f09c7</code></a>
improve initing the decoder from a dict</li>
<li><a
href="0b9331dd19"><code>0b9331d</code></a>
make clippy happy</li>
<li><a
href="06433dec34"><code>06433de</code></a>
start overhauling dict API</li>
<li><a
href="1256944604"><code>1256944</code></a>
Update ci.yml</li>
<li><a
href="3449d0a2bf"><code>3449d0a</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/39">#39</a>
from antangelo/no_std</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.3.1...v0.4.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Followup to #7184
This makes `Reflect: DynamicTypePath` which allows us to remove
`Reflect::get_type_path`, reducing unnecessary codegen and simplifying
`Reflect` implementations.
# Objective
Be consistent with `Resource`s and `Components` and have `Event` types
be more self-documenting.
Although not susceptible to accidentally using a function instead of a
value due to `Event`s only being initialized by their type, much of the
same reasoning for removing the blanket impl on `Resource` also applies
here.
* Not immediately obvious if a type is intended to be an event
* Prevent invisible conflicts if the same third-party or primitive types
are used as events
* Allows for further extensions (e.g. opt-in warning for missed events)
## Solution
Remove the blanket impl for the `Event` trait. Add a derive macro for
it.
---
## Changelog
- `Event` is no longer implemented for all applicable types. Add the
`#[derive(Event)]` macro for events.
## Migration Guide
* Add the `#[derive(Event)]` macro for events. Third-party types used as
events should be wrapped in a newtype.
# Objective
It was accidentally found that rustc is unable to parse certain
constructs in `where` clauses properly. `bevy_reflect::Reflect`'s habit
of copying and pasting the field types in a type's definition to its
`where` clauses made it very easy to accidentally run into this
behaviour - particularly with the construct
```rust
where
for<'a> fn(&'a T) -> &'a T: Trait1 + Trait2
```
which was incorrectly parsed as
```rust
where
for<'a> (fn(&'a T) -> &'a T: Trait1 + Trait2)
^ ^ incorrect syntax grouping
```
instead of
```rust
where
(for<'a> fn(&'a T) -> &'a T): Trait1 + Trait2
^ ^ correct syntax grouping
```
Fixes#8759
## Solution
This commit fixes the issue by inserting explicit parentheses to
disambiguate types from their bound lists.
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/8586.
## Solution
- Add `preferred_theme` field to `Window` and set it when window
creation
- Add `window_theme` field to `InternalWindowState` to store current
window theme
- Expose winit `WindowThemeChanged` event
---------
Co-authored-by: hate <15314665+hate@users.noreply.github.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#8751
## Solution
The doc string for the `primary_window` field on `Window` now mentions
that the default spawned primary window is spawned with the
`PrimaryWindow` marker component.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fix#8658
- `without_winit` example panics `thread 'Compute Task Pool (2)'
panicked at 'called `Option::unwrap()` on a `None` value',
crates/bevy_render/src/pipelined_rendering.rs:134:84`
## Solution
- In the default runner method `run_once`, correctly finish the
initialisation of the plugins. `run_once` can't be called twice so it's
ok to do it there
# Objective
I was trying to add some `Diagnostics` to have a better break down of
performance but I noticed that the current implementation uses a
`ResMut` which forces the functions to all run sequentially whereas
before they could run in parallel. This created too great a performance
penalty to be usable.
## Solution
This PR reworks how the diagnostics work with a couple of breaking
changes. The idea is to change how `Diagnostics` works by changing it to
a `SystemParam`. This allows us to hold a `Deferred` buffer of
measurements that can be applied later, avoiding the need for multiple
mutable references to the hashmap. This means we can run systems that
write diagnostic measurements in parallel.
Firstly, we rename the old `Diagnostics` to `DiagnosticsStore`. This
clears up the original name for the new interface while allowing us to
preserve more closely the original API.
Then we create a new `Diagnostics` struct which implements `SystemParam`
and contains a deferred `SystemBuffer`. This can be used very similar to
the old `Diagnostics` for writing new measurements.
```rust
fn system(diagnostics: ResMut<Diagnostics>) { diagnostics.new_measurement(ID, || 10.0)}
// changes to
fn system(mut diagnostics: Diagnostics) { diagnostics.new_measurement(ID, || 10.0)}
```
For reading the diagnostics, the user needs to change from `Diagnostics`
to `DiagnosticsStore` but otherwise the function calls are the same.
Finally, we add a new method to the `App` for registering diagnostics.
This replaces the old method of creating a startup system and adding it
manually.
Testing it, this PR does indeed allow Diagnostic systems to be run in
parallel.
## Changelog
- Change `Diagnostics` to implement `SystemParam` which allows
diagnostic systems to run in parallel.
## Migration Guide
- Register `Diagnostic`'s using the new
`app.register_diagnostic(Diagnostic::new(DIAGNOSTIC_ID,
"diagnostic_name", 10));`
- In systems for writing new measurements, change `mut diagnostics:
ResMut<Diagnostics>` to `mut diagnostics: Diagnostics` to allow the
systems to run in parallel.
- In systems for reading measurements, change `diagnostics:
Res<Diagnostics>` to `diagnostics: Res<DiagnosticsStore>`.
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
- Continue with #8685 to make `TonyMcMapface` the default tonemapping
## Solution
- Change the default value `Camera3dBundle::tonemapping` from
`Tonemapping::ReinhardLuminance` to `Default::default()`
(`Tonemapping::TonyMcMapface`)
# Objective
- `apply_system_buffers` is an unhelpful name: it introduces a new
internal-only concept
- this is particularly rough for beginners as reasoning about how
commands work is a critical stumbling block
## Solution
- rename `apply_system_buffers` to the more descriptive `apply_deferred`
- rename related fields, arguments and methods in the internals fo
bevy_ecs for consistency
- update the docs
## Changelog
`apply_system_buffers` has been renamed to `apply_deferred`, to more
clearly communicate its intent and relation to `Deferred` system
parameters like `Commands`.
## Migration Guide
- `apply_system_buffers` has been renamed to `apply_deferred`
- the `apply_system_buffers` method on the `System` trait has been
renamed to `apply_deferred`
- the `is_apply_system_buffers` function has been replaced by
`is_apply_deferred`
- `Executor::set_apply_final_buffers` is now
`Executor::set_apply_final_deferred`
- `Schedule::apply_system_buffers` is now `Schedule::apply_deferred`
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
Fixes#8596
## Solution
Change interface of the trait Map. Adjust implementations of this trait
---
## Changelog
### Changed
- Interface of Map trait
### Added
- `Map::get_at_mut`
## Migration Guide
Every implementor of Map trait would need to implement `get_at_mut`.
Which, judging by changes in this PR, should be fairly trivial.
- Supress false positive `redundant_clone` lints.
- Supress inactionable `result_large_err` lint.
Most of the size(50 out of 68 bytes) is coming from
`naga::WithSpan<naga::valid::ValidationError>`
# Objective
- Make the dependency job successful again
## Solution
- Update the list of duplicates
- Remove a security issue exception not needed anymore
- Also update a dependency that was missed by dependabot
# Objective
Right now it's impossible to construct a MapIter outside of the
bevy_reflect crate, making it impossible to implement the Map trait for
custom map types.
## Solution
Addition of a pub constructor to MapIter.
Updates the requirements on
[android_log-sys](https://github.com/nercury/android_log-sys-rs) to
permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/nercury/android_log-sys-rs/commits">compare
view</a></li>
</ul>
</details>
<br />
You can trigger a rebase of this PR by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>> **Note**
> Automatic rebases have been disabled on this pull request as it has
been open for over 30 days.
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
The `Condition` trait is only implemented for systems and system
functions that take no input. This can make it awkward to write
conditions that are intended to be used with system piping.
## Solution
Add an `In` generic to the trait. It defaults to `()`.
---
## Changelog
- Made the `Condition` trait generic over system inputs.
# Objective
- Fix Wayland window client side decorations issue on Gnome Wayland,
fixes#3301.
## Solution
- One simple one line solution: Add winit's `wayland-csd-adwaita`
feature to Bevy's `wayland` feature.
Copied from
https://github.com/bevyengine/bevy/issues/3301#issuecomment-1569611257:
### Investigation
1. Gnome forced Wayland apps to implement CSD, whether on their own or
using some libraries like Gnome's official solution
[libdecor](https://gitlab.freedesktop.org/libdecor/libdecor). Many Linux
apps do this with libdecor, like blender, kitty... I think it's not
comfortable for Bevy to fix this problem this way.
2. Winit has support for CSD on
wayland(8bb004a1d9/Cargo.toml (L42)),
but Bevy disabled Winit's default features, thus no winit's
`wayland-csd-adwaita` feature. And Bevy's `wayland` feature doesn't
include winit's `wayland-csd-adwaita` feature so users can't get window
decorations on Wayland even with Bevy's `wayland` feature enabled.
3. Many rust UI toolkit, like iced, doesn't disable winit's
`wayland-csd-adwaita` feature.
### Conclusion and one Possible solution
Bevy disabled `winit`'s default features in order to decrease package
size. But I think it's acceptable to add `winit`'s `wayland-csd-adwaita`
feature to Bevy's `wayland` feature gate to fix this issue easily for
this only add on crate: sctk-adwaita.
# Objective
Several of our built-in `Command` types are too public:
- `GetOrSpawn` is public, even though it only makes sense to call it
from within `Commands::get_or_spawn`.
- `Remove` and `RemoveResource` contain public `PhantomData` marker
fields.
## Solution
Remove `GetOrSpawn` and use an anonymous command. Make the marker fields
private.
---
## Migration Guide
The `Command` types `Remove` and `RemoveResource` may no longer be
constructed manually.
```rust
// Before:
commands.add(Remove::<T> {
entity: id,
phantom: PhantomData,
});
// After:
commands.add(Remove::<T>::new(id));
// Before:
commands.add(RemoveResource::<T> { phantom: PhantomData });
// After:
commands.add(RemoveResource::<T>::new());
```
The command type `GetOrSpawn` has been removed. It was not possible to
use this type outside of `bevy_ecs`.
## Objective
- Provide a way to use `CubicCurve` non-iter methods
- Accept a `FnMut` over a `fn` pointer on `iter_samples`
- Improve `build_*_cubic_100_points` benchmark by -45% (this means they
are twice as fast)
### Solution
Previously, the only way to iterate over an evenly spaced set of points
on a `CubicCurve` was to use one of the `iter_*` methods.
The return value of those methods were bound by `&self` lifetime, making
them unusable in certain contexts.
Furthermore, other `CubicCurve` methods (`position`, `velocity`,
`acceleration`) required normalizing `t` over the `CubicCurve`'s
internal segment count.
There were no way to access this segment count, making those methods
pretty much unusable.
The newly added `segment_count` allows accessing the segment count.
`iter_samples` used to accept a `fn`, a function pointer. This is
surprising and contrary to the rust stdlib APIs, which accept `Fn`
traits for `Iterator` combinators.
`iter_samples` now accepts a `FnMut`.
I don't trust a bit the bevy benchmark suit, but according to it, this
doubles (-45%) the performance on the `build_pos_cubic_100_points` and
`build_accel_cubic_100_points` benchmarks.
---
## Changelog
- Added the `CubicCurve::segments` method to access the underlying
segments of a cubic curve
- Allow closures as `CubicCurve::iter_samples` `sample_function`
argument.
# Objective
Add documentation to `Query` and `QueryState` errors in bevy_ecs
(`QuerySingleError`, `QueryEntityError`, `QueryComponentError`)
## Solution
- Change display message for `QueryEntityError::QueryDoesNotMatch`: this
error can also happen when the entity has a component which is filtered
out (with `Without<C>`)
- Fix wrong reference in the documentation of `Query::get_component` and
`Query::get_component_mut` from `QueryEntityError` to
`QueryComponentError`
- Complete the documentation of the three error enum variants.
- Add examples for `QueryComponentError::MissingReadAccess` and
`QueryComponentError::MissingWriteAccess`
- Add reference to `QueryState` in `QueryEntityError`'s documentation.
---
## Migration Guide
Expect `QueryEntityError::QueryDoesNotMatch`'s display message to
change? Not sure that counts.
---------
Co-authored-by: harudagondi <giogdeasis@gmail.com>
# Objective
- Make #8015 easier to review;
## Solution
- This commit contains changes not directly related to transmission
required by #8015, in easier-to-review, one-change-per-commit form.
---
## Changelog
### Fixed
- Clear motion vector prepass using `0.0` instead of `1.0`, to avoid TAA
artifacts on transparent objects against the background;
### Added
- The `E` mathematical constant is now available for use in shaders,
exposed under `bevy_pbr::utils`;
- A new `TAA` shader def is now available, for conditionally enabling
shader logic via `#ifdef` when TAA is enabled; (e.g. for jittering
texture samples)
- A new `FallbackImageZero` resource is introduced, for when a fallback
image filled with zeroes is required;
- A new `RenderPhase<I>::render_range()` method is introduced, for
render phases that need to render their items in multiple parceled out
“steps”;
### Changed
- The `MainTargetTextures` struct now holds both `Texture` and
`TextureViews` for the main textures;
- The fog shader functions under `bevy_pbr::fog` now take the a `Fog`
structure as their first argument, instead of relying on the global
`fog` uniform;
- The main textures can now be used as copy sources;
## Migration Guide
- `ViewTarget::main_texture()` and `ViewTarget::main_texture_other()`
now return `&Texture` instead of `&TextureView`. If you were relying on
these methods, replace your usage with
`ViewTarget::main_texture_view()`and
`ViewTarget::main_texture_other_view()`, respectively;
- `ViewTarget::sampled_main_texture()` now returns `Option<&Texture>`
instead of a `Option<&TextureView>`. If you were relying on this method,
replace your usage with `ViewTarget::sampled_main_texture_view()`;
- The `apply_fog()`, `linear_fog()`, `exponential_fog()`,
`exponential_squared_fog()` and `atmospheric_fog()` functions now take a
configurable `Fog` struct. If you were relying on them, update your
usage by adding the global `fog` uniform as their first argument;
Change the default tonemapping method from ReinhardLuminance to
TonyMcMapface, which generally looks nicer and works out of the box with
bloom.
---
## Changelog
- TonyMcMapface is now the default tonemapper, instead of
ReinhardLuminance.
## Migration Guide
- The default tonemapper has been changed from ReinhardLuminance to
TonyMcMapface. Explicitly set ReinhardLuminance on your cameras to get
back the previous look.
# Objective
When using `FromReflect`, fields can be optionally left out if they are
marked with `#[reflect(default)]`. This is very handy for working with
serialized data as giant structs only need to list a subset of defined
fields in order to be constructed.
<details>
<summary>Example</summary>
Take the following struct:
```rust
#[derive(Reflect, FromReflect)]
struct Foo {
#[reflect(default)]
a: usize,
#[reflect(default)]
b: usize,
#[reflect(default)]
c: usize,
#[reflect(default)]
d: usize,
}
```
Since all the fields are default-able, we can successfully call
`FromReflect` on deserialized data like:
```rust
(
"foo::Foo": (
// Only set `b` and default the rest
b: 123
)
)
```
</details>
Unfortunately, this does not work with fields in enum variants. Marking
a variant field as `#[reflect(default)]` does nothing when calling
`FromReflect`.
## Solution
Allow enum variant fields to define a default value using
`#[reflect(default)]`.
### `#[reflect(Default)]`
One thing that structs and tuple structs can do is use their `Default`
implementation when calling `FromReflect`. Adding `#[reflect(Default)]`
to the struct or tuple struct both registers `ReflectDefault` and alters
the `FromReflect` implementation to use `Default` to generate any
missing fields.
This works well enough for structs and tuple structs, but for enums it's
not as simple. Since the `Default` implementation for an enum only
covers a single variant, it's not as intuitive as to what the behavior
will be. And (imo) it feels weird that we would be able to specify
default values in this way for one variant but not the others.
Because of this, I chose to not implement that behavior here. However,
I'm open to adding it in if anyone feels otherwise.
---
## Changelog
- Allow enum variant fields to define a default value using
`#[reflect(default)]`
# Objective
Fix#7833.
Safety comments in the multi-threaded executor don't really talk about
system world accesses, which makes it unclear if the code is actually
valid.
## Solution
Update the `System` trait to use `UnsafeWorldCell`. This type's API is
written in a way that makes it much easier to cleanly maintain safety
invariants. Use this type throughout the multi-threaded executor, with a
liberal use of safety comments.
---
## Migration Guide
The `System` trait now uses `UnsafeWorldCell` instead of `&World`. This
type provides a robust API for interior mutable world access.
- The method `run_unsafe` uses this type to manage world mutations
across multiple threads.
- The method `update_archetype_component_access` uses this type to
ensure that only world metadata can be used.
```rust
let mut system = IntoSystem::into_system(my_system);
system.initialize(&mut world);
// Before:
system.update_archetype_component_access(&world);
unsafe { system.run_unsafe(&world) }
// After:
system.update_archetype_component_access(world.as_unsafe_world_cell_readonly());
unsafe { system.run_unsafe(world.as_unsafe_world_cell()) }
```
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Right now we can't really benefit from [early depth
testing](https://www.khronos.org/opengl/wiki/Early_Fragment_Test) in our
PBR shader because it includes codepaths with `discard`, even for
situations where they are not necessary.
## Solution
- This PR introduces a new `MeshPipelineKey` and shader def,
`MAY_DISCARD`;
- All possible material/mesh options that that may result in `discard`s
being needed must set `MAY_DISCARD` ahead of time:
- Right now, this is only `AlphaMode::Mask(f32)`, but in the future
might include other options/effects; (e.g. one effect I'm personally
interested in is bayer dither pseudo-transparency for LOD transitions of
opaque meshes)
- Shader codepaths that can `discard` are guarded by an `#ifdef
MAY_DISCARD` preprocessor directive:
- Right now, this is just one branch in `alpha_discard()`;
- If `MAY_DISCARD` is _not_ set, the `@early_depth_test` attribute is
added to the PBR fragment shader. This is a not yet documented, possibly
non-standard WGSL extension I found browsing Naga's source code. [I
opened a PR to document it
there](https://github.com/gfx-rs/naga/pull/2132). My understanding is
that for backends where this attribute is supported, it will force an
explicit opt-in to early depth test. (e.g. via
`layout(early_fragment_tests) in;` in GLSL)
## Caveats
- I included `@early_depth_test` for the sake of us being explicit, and
avoiding the need for the driver to be “smart” about enabling this
feature. That way, if we make a mistake and include a `discard`
unguarded by `MAY_DISCARD`, it will either produce errors or noticeable
visual artifacts so that we'll catch early, instead of causing a
performance regression.
- I'm not sure explicit early depth test is supported on the naga Metal
backend, which is what I'm currently using, so I can't really test the
explicit early depth test enable, I would like others with Vulkan/GL
hardware to test it if possible;
- I would like some guidance on how to measure/verify the performance
benefits of this;
- If I understand it correctly, this, or _something like this_ is needed
to fully reap the performance gains enabled by #6284;
- This will _most definitely_ conflict with #6284 and #6644. I can fix
the conflicts as needed, depending on whether/the order they end up
being merging in.
---
## Changelog
### Changed
- Early depth tests are now enabled whenever possible for meshes using
`StandardMaterial`, reducing the number of fragments evaluated for
scenes with lots of occlusions.
# Objective
Fix#8604
## Solution
Use `.add_srgb_suffix()` when creating the screenshot texture.
Allow converting `Bgra8Unorm` images.
Only a two line change for the fix, the `screenshot.rs` changes are just
a bit of cleanup.
# Objective
Fix warnings:
```rs
warning: variable does not need to be mutable
--> /bevy/crates/bevy_app/src/plugin_group.rs:147:13
|
147 | let mut plugin_entry = self
| ----^^^^^^^^^^^^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
warning: variable does not need to be mutable
--> /bevy/crates/bevy_app/src/plugin_group.rs:161:13
|
161 | let mut plugin_entry = self
| ----^^^^^^^^^^^^
| |
| help: remove this `mut`
warning: `bevy_app` (lib) generated 2 warnings (run `cargo fix --lib -p bevy_app` to apply 2 suggestions)
warning: variable does not need to be mutable
--> /bevy/crates/bevy_render/src/view/window.rs:126:13
|
126 | ... let mut extracted_window = extracted_windows.entry(entity).or_insert(Extracte...
| ----^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_mut)]` on by default
warning: `bevy_render` (lib) generated 1 warning (run `cargo fix --lib -p bevy_render` to apply 1 suggestion)
```
## Solution
- Remove the mut keyword in those variables.
# Objective
Reduce missing docs warning noise when building examples for wasm
## Solution
Added "#[allow(missing_docs)]" on the wasm specific version of
BoxedFuture
# Objective
- Allow for directly call methods on states without first calling
`state.get().my_method()`
## Solution
- Implement `Deref` for `State<S>` with `Target = S`
---
*I did not implement `DerefMut` because states hold no data and should
only be changed via `NextState::set()`*
# Objective
- If I understand correctly, forward points in `direction`, so the
negative of `direction` should be back.
## Migration Guide
- `Transform::look_to` method changed default value of
`direction.try_normalize()` from `Vec3::Z` to `Vec3::NEG_Z`
# Objective
- Since the `RequestRedraw` event triggers the bevy app to run `update`
in `bevy_app::app::App`, the documentation should state that all the
windows in the application and its sub-apps are going to get redrawn,
rather than a single window.
## Solution
- Change `RequestRedraw` documentation in `bevy_window` to mention every
window.
# Objective
Make `Material2dPipeline` reusable. This was already done for PBR
materials in #7548.
## Solution
Expose `extract_materials_2d`, `prepare_materials_2d` and
`ExtractedMaterials2d`.
---
## Changelog
- bevy_sprite: Make `prepare_materials_2d`, `extract_materials_2d` and
`ExtractedMaterials2d` public.
Updates the requirements on
[libloading](https://github.com/nagisa/rust_libloading) to permit the
latest version.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="83b1037f21"><code>83b1037</code></a>
Release 0.8.0</li>
<li><a
href="a6a394a7ef"><code>a6a394a</code></a>
bump MSRV to 1.48</li>
<li><a
href="c7955a761e"><code>c7955a7</code></a>
Replace winapi with windows-sys</li>
<li><a
href="95d03a1ddf"><code>95d03a1</code></a>
Add support for QNX Neutrino</li>
<li><a
href="6e284984ae"><code>6e28498</code></a>
Fix CI</li>
<li><a
href="95a0f62e8f"><code>95a0f62</code></a>
Placate clippy</li>
<li><a
href="224a3def35"><code>224a3de</code></a>
Release 0.7.4</li>
<li><a
href="bd17713dcc"><code>bd17713</code></a>
Support AIX dyld constants</li>
<li><a
href="6e07929736"><code>6e07929</code></a>
fix typo</li>
<li><a
href="6b33651a90"><code>6b33651</code></a>
Construct a PathBuf</li>
<li>Additional commits viewable in <a
href="https://github.com/nagisa/rust_libloading/compare/0.7.0...0.8.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Updates the requirements on
[sysinfo](https://github.com/GuillaumeGomez/sysinfo) to permit the
latest version.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/GuillaumeGomez/sysinfo/blob/master/CHANGELOG.md">sysinfo's
changelog</a>.</em></p>
<blockquote>
<h1>0.29.0</h1>
<ul>
<li>Add <code>ProcessExt::effective_user_id</code> and
<code>ProcessExt::effective_group_id</code>.</li>
<li>Rename <code>DiskType</code> into <code>DiskKind</code>.</li>
<li>Rename <code>DiskExt::type_</code> into
<code>DiskExt::kind</code>.</li>
<li>macOS: Correctly handle <code>ProcessStatus</code> and remove public
<code>ThreadStatus</code> field.</li>
<li>Windows 11: Fix CPU core usage.</li>
</ul>
<h1>0.28.4</h1>
<ul>
<li>macOS: Improve CPU computation.</li>
<li>Strengthen a process test (needed for debian).</li>
</ul>
<h1>0.28.3</h1>
<ul>
<li>FreeBSD/Windows: Add missing frequency for global CPU.</li>
<li>macOS: Fix used memory computation.</li>
<li>macOS: Improve available memory computation.</li>
<li>Windows: Fix potential panic when getting process data.</li>
</ul>
<h1>0.28.2</h1>
<ul>
<li>Linux: Improve CPU usage computation.</li>
</ul>
<h1>0.28.1</h1>
<ul>
<li>macOS: Fix overflow when computing CPU usage.</li>
</ul>
<h1>0.28.0</h1>
<ul>
<li>Linux: Fix name and CPU usage for processes tasks.</li>
<li>unix: Keep all users, even "not real" accounts.</li>
<li>Windows: Use SID for Users ID.</li>
<li>Fix C API.</li>
<li>Disable default cdylib compilation.</li>
<li>Add <code>serde</code> feature to enable serialization.</li>
<li>Linux: Handle <code>Idle</code> state in
<code>ProcessStatus</code>.</li>
<li>Linux: Add brand and name of ARM CPUs.</li>
</ul>
<h1>0.27.8</h1>
<ul>
<li>macOS: Fix overflow when computing CPU usage.</li>
</ul>
<h1>0.27.7</h1>
<ul>
<li>macOS: Fix process CPU usage computation</li>
<li>Linux: Improve ARM CPU <code>brand</code> and <code>name</code>
information.</li>
<li>Windows: Fix resource leak.</li>
<li>Documentation improvements.</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/GuillaumeGomez/sysinfo/commits">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- Fixes#7352
## Solution
GLES doesn't support binding specific mip levels for sampling. Fallback
to using separate textures instead.
-
[wgpu-hal/src/gles/device.rs](628a95cd1c/wgpu-hal/src/gles/device.rs (L1038))
---
---------
Co-authored-by: Wilhelm Vallrand <>
# Objective
This method has no documentation and it's extremely unclear what it
does, or what the returned tick represents.
## Solution
Write documentation.
# Objective
- Update dependencies `ruzstd` and `basis-universal`
- Alternative to #5278 and #8133
## Solution
- Update the dependencies, fix the code
- Bevy now also depend on `syn@2` so it's not a blocker to update
`ruzstd` anymore
# Objective
Fix an out-of-date doc string.
The old doc string says "returns None if …" and "for a given
descriptor",
but this method neither takes an argument or returns an `Option`.
# Objective
Add support for the [Netpbm](https://en.wikipedia.org/wiki/Netpbm) image
formats, behind a `pnm` feature flag.
My personal use case for this was robotics applications, with `pgm`
being a popular format used in the field to represent world maps in
robots.
I chose the formats and feature name by checking the logic in
[image.rs](a35ed552fa/crates/bevy_render/src/texture/image.rs (L76))
## Solution
Quite straightforward, the `pnm` feature flag already exists in the
`image` crate so it's just creating and exposing a `pnm` feature flag in
the root `Cargo.toml` and forwarding it through `bevy_internal` and
`bevy_render` all the way to the `image` crate.
---
## Changelog
### Added
`pnm` feature to add support for `pam`, `pbm`, `pgm` and `ppm` image
formats.
---------
Signed-off-by: Luca Della Vedova <lucadv@intrinsic.ai>
# Objective
Bevy code tends to make heavy use of the [newtype](
https://doc.rust-lang.org/rust-by-example/generics/new_types.html)
pattern, which is why we have a dedicated derive for
[`Deref`](https://doc.rust-lang.org/std/ops/trait.Deref.html) and
[`DerefMut`](https://doc.rust-lang.org/std/ops/trait.DerefMut.html).
This derive works for any struct with a single field:
```rust
#[derive(Component, Deref, DerefMut)]
struct MyNewtype(usize);
```
One reason for the single-field limitation is to prevent confusion and
footguns related that would arise from allowing multi-field structs:
<table align="center">
<tr>
<th colspan="2">
Similar structs, different derefs
</th>
</tr>
<tr>
<td>
```rust
#[derive(Deref, DerefMut)]
struct MyStruct {
foo: usize, // <- Derefs usize
bar: String,
}
```
</td>
<td>
```rust
#[derive(Deref, DerefMut)]
struct MyStruct {
bar: String, // <- Derefs String
foo: usize,
}
```
</td>
</tr>
<tr>
<th colspan="2">
Why `.1`?
</th>
</tr>
<tr>
<td colspan="2">
```rust
#[derive(Deref, DerefMut)]
struct MyStruct(Vec<usize>, Vec<f32>);
let mut foo = MyStruct(vec![123], vec![1.23]);
// Why can we skip the `.0` here?
foo.push(456);
// But not here?
foo.1.push(4.56);
```
</td>
</tr>
</table>
However, there are certainly cases where it's useful to allow for
structs with multiple fields. Such as for structs with one "real" field
and one `PhantomData` to allow for generics:
```rust
#[derive(Deref, DerefMut)]
struct MyStruct<T>(
// We want use this field for the `Deref`/`DerefMut` impls
String,
// But we need this field so that we can make this struct generic
PhantomData<T>
);
// ERROR: Deref can only be derived for structs with a single field
// ERROR: DerefMut can only be derived for structs with a single field
```
Additionally, the possible confusion and footguns are mainly an issue
for newer Rust/Bevy users. Those familiar with `Deref` and `DerefMut`
understand what adding the derive really means and can anticipate its
behavior.
## Solution
Allow users to opt into multi-field `Deref`/`DerefMut` derives using a
`#[deref]` attribute:
```rust
#[derive(Deref, DerefMut)]
struct MyStruct<T>(
// Use this field for the `Deref`/`DerefMut` impls
#[deref] String,
// We can freely include any other field without a compile error
PhantomData<T>
);
```
This prevents the footgun pointed out in the first issue described in
the previous section, but it still leaves the possible confusion
surrounding `.0`-vs-`.#`. However, the idea is that by making this
behavior explicit with an attribute, users will be more aware of it and
can adapt appropriately.
---
## Changelog
- Added `#[deref]` attribute to `Deref` and `DerefMut` derives
# Objective
The unit test `chang_tick_wraparound` is meant to ensure that change
ticks correctly deal with wrapping by setting the world's
`last_change_tick` to `u32::MAX`. However, since systems don't use* the
value of `World::last_change_tick`, this test doesn't actually involve
any wrapping behavior.
*exclusive systems do use `World::last_change_tick`; however it gets
overwritten by the system's own last tick in `System::run`.
## Solution
Use `QueryState` instead of systems in the unit test. This approach
actually uses `World::last_change_tick`, so it properly tests that
change ticks deal with wrapping correctly.
# Objective
- Simplify API and make authoring styles easier
See:
https://github.com/bevyengine/bevy/issues/8540#issuecomment-1536177102
## Solution
- The `size`, `min_size`, `max_size`, and `gap` properties have been
replaced by `width`, `height`, `min_width`, `min_height`, `max_width`,
`max_height`, `row_gap`, and `column_gap` properties
---
## Changelog
- Flattened `Style` properties that have a `Size` value directly into
`Style`
## Migration Guide
- The `size`, `min_size`, `max_size`, and `gap` properties have been
replaced by the `width`, `height`, `min_width`, `min_height`,
`max_width`, `max_height`, `row_gap`, and `column_gap` properties. Use
the new properties instead.
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
- Fix#5631
## Solution
- Wait 50ms (configurable) after the last modification event before
reloading an asset.
---
## Changelog
- `AssetPlugin::watch_for_changes` is now a `ChangeWatcher` instead of a
`bool`
- Fixed https://github.com/bevyengine/bevy/issues/5631
## Migration Guide
- Replace `AssetPlugin::watch_for_changes: true` with e.g.
`ChangeWatcher::with_delay(Duration::from_millis(200))`
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
* `Node::physical_rect` divides the logical size of the node by the
scale factor, when it should multiply.
* Add a `physical_size` method to `Node` that calculates the physical
size of a node.
---
## Changelog
* Added a method `physical_size` to `Node` that calculates the physical
size of the `Node` based on the given scale factor.
* Fixed the `Node::physical_rect` method, the logical size should be
multiplied by the scale factor to get the physical size.
* Removed the `scale_value` function from the `text` widget module and
replaced its usage with `Node::physical_size`.
* Derived `Copy` for `Node` (since it's only a wrapped `Vec2`).
* Made `Node::size` const.
# Objective
`ScheduleGraph` currently stores run conditions in a
`Option<Vec<BoxedCondition>>`. The `Option` is unnecessary, since we can
just use an empty vector instead of `None`.
# Objective
The method `UnsafeWorldCell::world_mut` is a special case, since its
safety contract is more difficult to satisfy than the other methods on
`UnsafeWorldCell`. Rewrite its documentation to be specific about when
it can and cannot be used. Provide examples and emphasize that it is
unsound to call in most cases.
# Objective
The method `UnsafeWorldCell::read_change_tick` is longer than it needs
to be. `World` only has a method called this because it has two methods
for getting a change tick: one that takes `&self` and one that takes
`&mut self`. Since this distinction is not applicable to
`UnsafeWorldCell`, we should just call this method `change_tick`.
## Solution
Deprecate the current method and add a new one called `change_tick`.
---
## Changelog
- Renamed `UnsafeWorldCell::read_change_tick` to `change_tick`.
## Migration Guide
The `UnsafeWorldCell` method `read_change_tick` has been renamed to
`change_tick`.
# Objective
`ScheduleRunnerPlugin` was still configured via a resource, meaning
users would be able to change the settings while the app is running, but
the changes wouldn't have an effect.
## Solution
Configure plugin directly
---
## Changelog
- Changed: merged `ScheduleRunnerSettings` into `ScheduleRunnerPlugin`
## Migration Guide
- instead of inserting the `ScheduleRunnerSettings` resource, configure
the `ScheduleRunnerPlugin`
# Objective
- Fixes#3531
## Solution
- Added an append wrapper to BufferVec based on the function signature
for vec.append()
---
First PR to Bevy. I didn't see any tests for other BufferVec methods
(could have missed them) and currently this method is not used anywhere
in the project. Let me know if there are tests to add or if I should
find somewhere to use append so it is not dead code. The issue mentions
implementing `truncate` and `extend` which were already implemented and
merged
[here](https://github.com/bevyengine/bevy/pull/6833/files#diff-c8fb332382379e383f1811e30c31991b1e0feb38ca436c357971755368012ced)
# Objective
Replace `Query<&T, Changed<T>>` style queries with the more efficient
`Query<Ref<T>>` form in two of the UI systems.
---
## Changelog
Replaced use of `Changed` with `Ref` in queries in the
`ui_layout_system` and `calc_bounds` UI systems.
# Objective
- When writing render nodes that need a view, you always need to define
a `Query` on the associated view and make sure to update it manually and
query it manually. This is verbose and error prone.
## Solution
- Introduce a new `ViewNode` trait and `ViewNodeRunner` `Node` that will
take care of managing the associated view query automatically.
- The trait is currently a passthrough of the `Node` trait. So it still
has the update/run with all the same data passed in.
- The `ViewNodeRunner` is the actual node that is added to the render
graph and it contains the custom node. This is necessary because it's
the one that takes care of updating the node.
---
## Changelog
- Add `ViewNode`
- Add `ViewNodeRunner`
## Notes
Currently, this only handles the view query, but it could probably have
a ReadOnlySystemState that would also simplify querying all the readonly
resources that most render nodes currently query manually. The issue is
that I don't know how to do that without a `&mut self`.
At first, I tried making this a default feature of all `Node`, but I
kept hitting errors related to traits and generics and stuff I'm not
super comfortable with. This implementations is much simpler and keeps
the default Node behaviour so isn't a breaking change
## Reviewer Notes
The PR looks quite big, but the core of the PR is the changes in
`render_graph/node.rs`. Every other change is simply updating existing
nodes to use this new feature.
## Open questions
~~- Naming is not final, I'm opened to anything. I named it
ViewQueryNode because it's a node with a managed Query on a View.~~
~~- What to do when the query fails? All nodes using this pattern
currently just `return Ok(())` when it fails, so I chose that, but
should it be more flexible?~~
~~- Is the ViewQueryFilter actually necessary? All view queries run on
the entity that is already guaranteed to be a view. Filtering won't do
much, but maybe someone wants to control an effect with the presence of
a component instead of a flag.~~
~~- What to do with Nodes that are empty struct? Implementing
`FromWorld` is pretty verbose but not implementing it means there's 2
ways to create a `ViewNodeRunner` which seems less ideal. This is an
issue now because most node simply existed to hold the query, but now
that they don't hold the query state we are left with a bunch of empty
structs.~~
- Should we have a `RenderGraphApp::add_render_graph_view_node()`, this
isn't necessary, but it could make the code a bit shorter.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add Reflect and FromReflect for AssetPath
- Fixes#8458
## Solution
- Straightforward derive of `Reflect` and `FromReflect` for `AssetPath`
- Implement `Reflect` and `FromReflect` for `Cow<'static, Path>` as to
satisfy the 'static lifetime requierments of bevy_reflect.
Implementation is a direct copy of that for `Cow<'static, str>` so maybe
it begs the question that was already asked in #7429 - maybe it would be
benefitial to write a general implementation for `Reflect` for
`Cow<'static, T>`.
# Objective
Sometimes we might want to read from the depth texture in some custom
rendering features. We must then add `STORAGE_BINDING` or
`TEXTURE_BINDING` to the texture usage flags when creating them.
## Solution
This PR allows one to customize the usage flags in the `Camera3d`
component.
# Objective
- Fixes#8563
## Solution
~~- Implement From<Color> for [u8; 4]~~
~~- also implement From<[u8; 4]> for Color because why not.~~
- implement method `as_rgba_u8` in Color
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
`text_system` and `measure_text_system` both keep local queues to keep
track of text node entities that need recomputations/remeasurement,
which scales very badly with large numbers of text entities (O(n^2)) and
makes the code quite difficult to understand.
Also `text_system` filters for `Changed<Text>`, this isn't something
that it should do. When a text node entity fails to be processed by
`measure_text_system` because a font can't be found, the text node will
still be added to `text_system`'s local queue for recomputation. `Text`
should only ever be queued by `text_system` when a text node's geometry
is modified or a new measure is added.
## Solution
Remove the local text queues and use a component `TextFlags` to schedule
remeasurements and recomputations.
## Changelog
* Created a component `TextFlags` with fields `remeasure` and
`recompute`, which can be used to schedule a text `remeasure` or
`recomputation` respectively and added it to `TextBundle`.
* Removed the local text queues from `measure_text_system` and
`text_system` and instead use the `TextFlags` component to schedule
remeasurements and recomputations.
## Migration Guide
The component `TextFlags` has been added to `TextBundle`.
# Objective
Copy the `debug::print_tree` function from Taffy except display entity
ids instead of Taffy's node ids and indicate which ui nodes have a
measure func.
# Objective
Ensure future consistency between the two compare functions for all
types with manual `Ord` and `PartialOrd` implementations.
## Solution
Use `Self::cpm` in the implementation of `partial_cpm` for types
`Handle` and `Name`.
# Objective
there were typos in AxisSettings livezone/deadzone get/set function doc
comments.
## Solution
I changed the comments to be (hopefully) correct this time. I could be
wrong though.
# Objective
- Support WebGPU
- alternative to #5027 that doesn't need any async / await
- fixes#8315
- Surprise fix#7318
## Solution
### For async renderer initialisation
- Update the plugin lifecycle:
- app builds the plugin
- calls `plugin.build`
- registers the plugin
- app starts the event loop
- event loop waits for `ready` of all registered plugins in the same
order
- returns `true` by default
- then call all `finish` then all `cleanup` in the same order as
registered
- then execute the schedule
In the case of the renderer, to avoid anything async:
- building the renderer plugin creates a detached task that will send
back the initialised renderer through a mutex in a resource
- `ready` will wait for the renderer to be present in the resource
- `finish` will take that renderer and place it in the expected
resources by other plugins
- other plugins (that expect the renderer to be available) `finish` are
called and they are able to set up their pipelines
- `cleanup` is called, only custom one is still for pipeline rendering
### For WebGPU support
- update the `build-wasm-example` script to support passing `--api
webgpu` that will build the example with WebGPU support
- feature for webgl2 was always enabled when building for wasm. it's now
in the default feature list and enabled on all platforms, so check for
this feature must also check that the target_arch is `wasm32`
---
## Migration Guide
- `Plugin::setup` has been renamed `Plugin::cleanup`
- `Plugin::finish` has been added, and plugins adding pipelines should
do it in this function instead of `Plugin::build`
```rust
// Before
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.insert_resource::<MyResource>
.add_systems(Update, my_system);
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<RenderResourceNeedingDevice>()
.init_resource::<OtherRenderResource>();
}
}
// After
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.insert_resource::<MyResource>
.add_systems(Update, my_system);
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<OtherRenderResource>();
}
fn finish(&self, app: &mut App) {
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<RenderResourceNeedingDevice>();
}
}
```
# Objective
Fixes#8528
## Solution
Manually implement `PartialEq`, `Eq`, `PartialOrd`, `Ord`, and `Hash`
for `bevy_ecs::event::EventId`. These new implementations do not rely on
the `Event` implementing the same traits allowing `EventId` to be used
in more cases.
# Objective
there was a typo in AxisSettings. It said "Values that are higher than
`livezone_upperbound` will be rounded up to -1.0." which I'm pretty
confident should be "1.0".
## Solution
I removed the '-'
# Objective
After fixing dynamic scene to only map specific entities, we want
map_entities to default to the less error prone behavior and have the
previous behavior renamed to "map_all_entities." As this is a breaking
change, it could not be pushed out with the bug fix.
## Solution
Simple rename and refactor.
## Changelog
### Changed
- `map_entities` now accepts a list of entities to apply to, with
`map_all_entities` retaining previous behavior of applying to all
entities in the map.
## Migration Guide
- In `bevy_ecs`, `ReflectMapEntities::map_entites` now requires an
additional `entities` parameter to specify which entities it applies to.
To keep the old behavior, use the new
`ReflectMapEntities::map_all_entities`, but consider if passing the
entities in specifically might be better for your use case to avoid
bugs.
# Objective
- I want to take screenshots of examples in CI to help with validation
of changes
## Solution
- Can override how much time is updated per frame
- Can specify on which frame to take a screenshots
- Save screenshots in CI
I reused the `TimeUpdateStrategy::ManualDuration` to be able to set the
time update strategy to a fixed duration every frame. Its previous
meaning didn't make much sense to me. This change makes it possible to
have screenshots that are exactly the same across runs.
If this gets merged, I'll add visual comparison of screenshots between
runs to ensure nothing gets broken
## Migration Guide
* `TimeUpdateStrategy::ManualDuration` meaning has changed. Instead of
setting time to `Instant::now()` plus the given duration, it sets time
to last update plus the given duration.
# Objective
- For many UI use cases (e.g. tree views, lists), it is important to be
able to imperatively sort child nodes.
- This also enables us to eventually support something like the
[`order`](https://developer.mozilla.org/en-US/docs/Web/CSS/order) CSS
property, that declaratively re-orders flex box items by a numeric
value, similar to z-index, but in space.
## Solution
We removed the ability to directly construct `Children` from `&[Entity]`
some time ago (#4197#5532) to enforce consistent hierarchies ([RFC
53](https://github.com/bevyengine/rfcs/blob/main/rfcs/53-consistent-hierarchy.md)).
If I understand it correctly, it's currently possible to re-order
children by using `Children::swap()` or
`commands.entity(id).replace_children(...)`, however these are either
too cumbersome, needlessly inefficient, and/or don't take effect
immediately.
This PR exposes the in-place sorting methods from the `slice` primitive
in `Children`, enabling imperatively sorting children in place via `&mut
Children`, while still preserving consistent hierarchies.
---
## Changelog
### Added
- The sorting methods from the `slice` primitive are now exposed by the
`Children` component, allowing imperatively sorting children in place
(Useful for UI scenarios such as lists)
# Objective
- Handle dangling entity references inside scenes
- Handle references to entities with generation > 0 inside scenes
- Fix a latent bug in `Parent`'s `MapEntities` implementation, which
would, if the parent was outside the scene, cause the scene to be loaded
into the new world with a parent reference potentially pointing to some
random entity in that new world.
- Fixes#4793 and addresses #7235
## Solution
- DynamicScenes now identify entities with a `Entity` instead of a u32,
therefore including generation
- `World` exposes a new `reserve_generations` function that despawns an
entity and advances its generation by some extra amount.
- `MapEntities` implementations have a new `get_or_reserve` function
available that will always return an `Entity`, establishing a new
mapping to a dead entity when the entity they are called with is not in
the `EntityMap`. Subsequent calls with that same `Entity` will return
the same newly created dead entity reference, preserving equality
semantics.
- As a result, after loading a scene containing references to dead
entities (or entities otherwise outside the scene), those references
will all point to different generations on a single entity id in the new
world.
---
## Changelog
### Changed
- In serialized scenes, entities are now identified by a u64 instead of
a u32.
- In serialized scenes, components with entity references now have those
references serialize as u64s instead of structs.
### Fixed
- Scenes containing components with entity references will now
deserialize and add to a world reliably.
## Migration Guide
- `MapEntities` implementations must change from a `&EntityMap`
parameter to a `&mut EntityMapper` parameter and can no longer return a
`Result`. Finally, they should switch from calling `EntityMap::get` to
calling `EntityMapper::get_or_reserve`.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
fixes#8516
* Give `CalculatedSize` a more specific and intuitive name.
* `MeasureFunc`s should only be updated when their `CalculatedSize` is
modified by the systems managing their content.
For example, suppose that you have a UI displaying an image using an
`ImageNode`. When the window is resized, the node's `MeasureFunc` will
be updated even though the dimensions of the texture contained by the
node are unchanged.
* Fix the `CalculatedSize` API so that it no longer requires the extra
boxing and the `dyn_clone` method.
## Solution
* Rename `CalculatedSize` to `ContentSize`
* Only update `MeasureFunc`s on `CalculatedSize` changes.
* Remove the `dyn_clone` method from `Measure` and move the `Measure`
from the `ContentSize` component rather than cloning it.
* Change the measure_func field of `ContentSize` to type
`Option<taffy::node::MeasureFunc>`. Add a `set` method that wraps the
given measure appropriately.
---
## Changelog
* Renamed `CalculatedSize` to `ContentSize`.
* Replaced `upsert_leaf` with a function `update_measure` that only
updates the node's `MeasureFunc`.
* `MeasureFunc`s are only updated when the `ContentSize` changes and not
when the layout changes.
* Scale factor is no longer applied to the size values passed to the
`MeasureFunc`.
* Remove the `ContentSize` scaling in `text_system`.
* The `dyn_clone` method has been removed from the `Measure` trait.
* `Measure`s are moved from the `ContentSize` component instead of
cloning them.
* Added `set` method to `ContentSize` that replaces the `new` function.
## Migration Guide
* `CalculatedSize` has been renamed to `ContentSize`.
* The `upsert_leaf` function has been removed from `UiSurface` and
replaced with `update_measure` which updates the `MeasureFunc` without
node insertion.
* The `dyn_clone` method has been removed from the `Measure` trait.
* The new function of `CalculatedSize` has been replaced with the method
`set`.
# Objective
after calling `SceneSpawner::spawn_as_child`, the scene spawner system
will always try to attach the scene instance to the parent once it is
loaded, even if the parent has been deleted, causing a panic.
## Solution
check if the parent is still alive, and don't spawn the scene instance
if not.
# Objective
- Enable taking a screenshot in wasm
- Followup on #7163
## Solution
- Create a blob from the image data, generate a url to that blob, add an
`a` element to the document linking to that url, click on that element,
then revoke the url
- This will automatically trigger a download of the screenshot file in
the browser
# Objective
This is just an oversight on my part when I implemented this in
https://github.com/bevyengine/bevy/pull/7186, there isn't much reason to
print out the hash of a `Name` like it does currently:
```
Name { hash: 1608798714325729304, name: "Suzanne" } (7v0)
```
## Solution
Instead it would be better if we just printed out the string like so:
```
"Suzanne" (7v0)
```
As it conveys all of the information in a less cluttered and immediately
intuitive way which was the original purpose of `DebugName`. Which I
also think translates to `Name` as well since I mostly see it as a thin
wrapper around a string.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Updated to wgpu 0.16.0 and wgpu-hal 0.16.0
---
## Changelog
1. Upgrade wgpu to 0.16.0 and wgpu-hal to 0.16.0
2. Fix the error in native when using a filterable
`TextureSampleType::Float` on a multisample `BindingType::Texture`.
([https://github.com/gfx-rs/wgpu/pull/3686](https://github.com/gfx-rs/wgpu/pull/3686))
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
> This PR is based on discussion from #6601
The Dynamic types (e.g. `DynamicStruct`, `DynamicList`, etc.) act as
both:
1. Dynamic containers which may hold any arbitrary data
2. Proxy types which may represent any other type
Currently, the only way we can represent the proxy-ness of a Dynamic is
by giving it a name.
```rust
// This is just a dynamic container
let mut data = DynamicStruct::default();
// This is a "proxy"
data.set_name(std::any::type_name::<Foo>());
```
This type name is the only way we check that the given Dynamic is a
proxy of some other type. When we need to "assert the type" of a `dyn
Reflect`, we call `Reflect::type_name` on it. However, because we're
only using a string to denote the type, we run into a few gotchas and
limitations.
For example, hashing a Dynamic proxy may work differently than the type
it proxies:
```rust
#[derive(Reflect, Hash)]
#[reflect(Hash)]
struct Foo(i32);
let concrete = Foo(123);
let dynamic = concrete.clone_dynamic();
let concrete_hash = concrete.reflect_hash();
let dynamic_hash = dynamic.reflect_hash();
// The hashes are not equal because `concrete` uses its own `Hash` impl
// while `dynamic` uses a reflection-based hashing algorithm
assert_ne!(concrete_hash, dynamic_hash);
```
Because the Dynamic proxy only knows about the name of the type, it's
unaware of any other information about it. This means it also differs on
`Reflect::reflect_partial_eq`, and may include ignored or skipped fields
in places the concrete type wouldn't.
## Solution
Rather than having Dynamics pass along just the type name of proxied
types, we can instead have them pass around the `TypeInfo`.
Now all Dynamic types contain an `Option<&'static TypeInfo>` rather than
a `String`:
```diff
pub struct DynamicTupleStruct {
- type_name: String,
+ represented_type: Option<&'static TypeInfo>,
fields: Vec<Box<dyn Reflect>>,
}
```
By changing `Reflect::get_type_info` to
`Reflect::represented_type_info`, hopefully we make this behavior a
little clearer. And to account for `None` values on these dynamic types,
`Reflect::represented_type_info` now returns `Option<&'static
TypeInfo>`.
```rust
let mut data = DynamicTupleStruct::default();
// Not proxying any specific type
assert!(dyn_tuple_struct.represented_type_info().is_none());
let type_info = <Foo as Typed>::type_info();
dyn_tuple_struct.set_represented_type(Some(type_info));
// Alternatively:
// let dyn_tuple_struct = foo.clone_dynamic();
// Now we're proxying `Foo`
assert!(dyn_tuple_struct.represented_type_info().is_some());
```
This means that we can have full access to all the static type
information for the proxied type. Future work would include
transitioning more static type information (trait impls, attributes,
etc.) over to the `TypeInfo` so it can actually be utilized by Dynamic
proxies.
### Alternatives & Rationale
> **Note**
> These alternatives were written when this PR was first made using a
`Proxy` trait. This trait has since been removed.
<details>
<summary>View</summary>
#### Alternative: The `Proxy<T>` Approach
I had considered adding something like a `Proxy<T>` type where `T` would
be the Dynamic and would contain the proxied type information.
This was nice in that it allows us to explicitly determine whether
something is a proxy or not at a type level. `Proxy<DynamicStruct>`
proxies a struct. Makes sense.
The reason I didn't go with this approach is because (1) tuples, (2)
complexity, and (3) `PartialReflect`.
The `DynamicTuple` struct allows us to represent tuples at runtime. It
also allows us to do something you normally can't with tuples: add new
fields. Because of this, adding a field immediately invalidates the
proxy (e.g. our info for `(i32, i32)` doesn't apply to `(i32, i32,
NewField)`). By going with this PR's approach, we can just remove the
type info on `DynamicTuple` when that happens. However, with the
`Proxy<T>` approach, it becomes difficult to represent this behavior—
we'd have to completely control how we access data for `T` for each `T`.
Secondly, it introduces some added complexities (aside from the manual
impls for each `T`). Does `Proxy<T>` impl `Reflect`? Likely yes, if we
want to represent it as `dyn Reflect`. What `TypeInfo` do we give it?
How would we forward reflection methods to the inner type (remember, we
don't have specialization)? How do we separate this from Dynamic types?
And finally, how do all this in a way that's both logical and intuitive
for users?
Lastly, introducing a `Proxy` trait rather than a `Proxy<T>` struct is
actually more inline with the [Unique Reflect
RFC](https://github.com/bevyengine/rfcs/pull/56). In a way, the `Proxy`
trait is really one part of the `PartialReflect` trait introduced in
that RFC (it's technically not in that RFC but it fits well with it),
where the `PartialReflect` serves as a way for proxies to work _like_
concrete types without having full access to everything a concrete
`Reflect` type can do. This would help bridge the gap between the
current state of the crate and the implementation of that RFC.
All that said, this is still a viable solution. If the community
believes this is the better path forward, then we can do that instead.
These were just my reasons for not initially going with it in this PR.
#### Alternative: The Type Registry Approach
The `Proxy` trait is great and all, but how does it solve the original
problem? Well, it doesn't— yet!
The goal would be to start moving information from the derive macro and
its attributes to the generated `TypeInfo` since these are known
statically and shouldn't change. For example, adding `ignored: bool` to
`[Un]NamedField` or a list of impls.
However, there is another way of storing this information. This is, of
course, one of the uses of the `TypeRegistry`. If we're worried about
Dynamic proxies not aligning with their concrete counterparts, we could
move more type information to the registry and require its usage.
For example, we could replace `Reflect::reflect_hash(&self)` with
`Reflect::reflect_hash(&self, registry: &TypeRegistry)`.
That's not the _worst_ thing in the world, but it is an ergonomics loss.
Additionally, other attributes may have their own requirements, further
restricting what's possible without the registry. The `Reflect::apply`
method will require the registry as well now. Why? Well because the
`map_apply` function used for the `Reflect::apply` impls on `Map` types
depends on `Map::insert_boxed`, which (at least for `DynamicMap`)
requires `Reflect::reflect_hash`. The same would apply when adding
support for reflection-based diffing, which will require
`Reflect::reflect_partial_eq`.
Again, this is a totally viable alternative. I just chose not to go with
it for the reasons above. If we want to go with it, then we can close
this PR and we can pursue this alternative instead.
#### Downsides
Just to highlight a quick potential downside (likely needs more
investigation): retrieving the `TypeInfo` requires acquiring a lock on
the `GenericTypeInfoCell` used by the `Typed` impls for generic types
(non-generic types use a `OnceBox which should be faster). I am not sure
how much of a performance hit that is and will need to run some
benchmarks to compare against.
</details>
### Open Questions
1. Should we use `Cow<'static, TypeInfo>` instead? I think that might be
easier for modding? Perhaps, in that case, we need to update
`Typed::type_info` and friends as well?
2. Are the alternatives better than the approach this PR takes? Are
there other alternatives?
---
## Changelog
### Changed
- `Reflect::get_type_info` has been renamed to
`Reflect::represented_type_info`
- This method now returns `Option<&'static TypeInfo>` rather than just
`&'static TypeInfo`
### Added
- Added `Reflect::is_dynamic` method to indicate when a type is dynamic
- Added a `set_represented_type` method on all dynamic types
### Removed
- Removed `TypeInfo::Dynamic` (use `Reflect::is_dynamic` instead)
- Removed `Typed` impls for all dynamic types
## Migration Guide
- The Dynamic types no longer take a string type name. Instead, they
require a static reference to `TypeInfo`:
```rust
#[derive(Reflect)]
struct MyTupleStruct(f32, f32);
let mut dyn_tuple_struct = DynamicTupleStruct::default();
dyn_tuple_struct.insert(1.23_f32);
dyn_tuple_struct.insert(3.21_f32);
// BEFORE:
let type_name = std::any::type_name::<MyTupleStruct>();
dyn_tuple_struct.set_name(type_name);
// AFTER:
let type_info = <MyTupleStruct as Typed>::type_info();
dyn_tuple_struct.set_represented_type(Some(type_info));
```
- `Reflect::get_type_info` has been renamed to
`Reflect::represented_type_info` and now also returns an
`Option<&'static TypeInfo>` (instead of just `&'static TypeInfo`):
```rust
// BEFORE:
let info: &'static TypeInfo = value.get_type_info();
// AFTER:
let info: &'static TypeInfo = value.represented_type_info().unwrap();
```
- `TypeInfo::Dynamic` and `DynamicInfo` has been removed. Use
`Reflect::is_dynamic` instead:
```rust
// BEFORE:
if matches!(value.get_type_info(), TypeInfo::Dynamic) {
// ...
}
// AFTER:
if value.is_dynamic() {
// ...
}
```
---------
Co-authored-by: radiish <cb.setho@gmail.com>
# Objective
A lot of items in `bevy_ui` could be `FromReflect` but aren't. This
prevents users and library authors from being able to convert from a
`dyn Reflect` to one of these items.
## Solution
Derive `FromReflect` where possible. Also register the
`ReflectFromReflect` type data.
# Objective
Considering that `FromReflect` is a very common trait to derive, it
would make sense to include `ReflectFromReflect` in the `bevy_reflect`
prelude so users don't need to import it separately.
## Solution
Add `ReflectFromReflect` to the prelude.
# Objective
Currently, there isn't a clean way of getting an untyped handle to an
asset during asset loading. This is useful for when an asset needs to
reference other assets, but may not know the concrete type of each
asset.
We could "hack" this together by just using some random asset:
```rust
// We don't care what `bar.baz` is, so we "pretend" it's an `Image`
let handle: Handle<Image> = load_context.get_handle("foo/bar.baz");
```
This should work since we don't actually care about the underlying type
in this case. However, we can do better.
## Solution
Add the `LoadContext::get_handle_untyped` method to get untyped handles
to assets.
# Objective
- Reduce compilation time
## Solution
- Make `spirv` and `glsl` shader format support optional. They are not
needed for Bevy shaders.
- on my mac (where shaders are compiled to `msl`), this reduces the
total build time by 2 to 5 seconds, improvement should be even better
with less cores
There is a big reduction in compile time for `naga`, and small
improvements on `wgpu` and `bevy_render`
This PR with optional shader formats enabled timings:
<img width="1478" alt="current main"
src="https://user-images.githubusercontent.com/8672791/234347032-cbd5c276-a9b0-49c3-b793-481677391c18.png">
This PR:
<img width="1479" alt="this pr"
src="https://user-images.githubusercontent.com/8672791/234347059-a67412a9-da8d-4356-91d8-7b0ae84ca100.png">
---
## Migration Guide
- If you want to use shaders in `spirv`, enable the
`shader_format_spirv` feature
- If you want to use shaders in `glsl`, enable the `shader_format_glsl`
feature
# Objective
- Fixes#8484
## Solution
Since #8445 fonts need to register a debug asset, otherwise the
`debug_asset_server` feature doesn't work. This adds the debug asset
registration
# Objective
Provide the ability to trigger controller rumbling (force-feedback) with
a cross-platform API.
## Solution
This adds the `GamepadRumbleRequest` event to `bevy_input` and adds a
system in `bevy_gilrs` to read them and rumble controllers accordingly.
It's a relatively primitive API with a `duration` in seconds and
`GamepadRumbleIntensity` with values for the weak and strong gamepad
motors. It's is an almost 1-to-1 mapping to platform APIs. Some
platforms refer to these motors as left and right, and low frequency and
high frequency, but by convention, they're usually the same.
I used #3868 as a starting point, updated to main, removed the low-level
gilrs effect API, and moved the requests to `bevy_input` and exposed the
strong and weak intensities.
I intend this to hopefully be a non-controversial cross-platform
starting point we can build upon to eventually support more fine-grained
control (closer to the gilrs effect API)
---
## Changelog
### Added
- Gamepads can now be rumbled by sending the `GamepadRumbleRequest`
event.
---------
Co-authored-by: Nicola Papale <nico@nicopap.ch>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
Co-authored-by: Bruce Reif (Buswolley) <bruce.reif@dynata.com>
# Objective
`Camera::logical_viewport_rect()` returns `Option<(Vec2, Vec2)>` which
is a tuple of vectors representing the `(min, max)` bounds of the
viewport rect. Since the function says it returns a rect and there is a
`Rect { min, max }` struct in `bevy_math`, using the struct will be
clearer.
## Solution
Replaced `Option<(Vec2, Vec2)>` with `Option<Rect>` for
`Camera::logical_viewport_rect()`.
---
## Changelog
- Changed `Camera::logical_viewport_rect` return type from `(Vec2,
Vec2)` to `Rect`
## Migration Guide
Before:
```
fn view_logical_camera_rect(camera_query: Query<&Camera>) {
let camera = camera_query.single();
let Some((min, max)) = camera.logical_viewport_rect() else { return };
dbg!(min, max);
}
```
After:
```
fn view_logical_camera_rect(camera_query: Query<&Camera>) {
let camera = camera_query.single();
let Some(Rect { min, max }) = camera.logical_viewport_rect() else { return };
dbg!(min, max);
}
```
# Objective
Add a bounding box gizmo
## Changes
- Added the `AabbGizmo` component that will draw the `Aabb` component on
that entity.
- Added an option to draw all bounding boxes in a scene on the
`GizmoConfig` resource.
- Added `TransformPoint` trait to generalize over the point
transformation methods on various transform types (e.g `Transform` and
`GlobalTransform`).
- Changed the `Gizmos::cuboid` method to accept an `impl TransformPoint`
instead of separate translation, rotation, and scale.
# Objective
Timer with zero `Duration` panics at `tick()` because of division by
zero. This PR Fixes#8463 .
## Solution
- Handle division by zero separately with `checked_div` and
`checked_rem`.
---
## Changelog
- Replace division with `checked_div`. Set `times_finished_this_tick` to
u32::MAX when duration is zero.
- Set `elapsed` to `Duration::ZERO` when timer duration is zero.
- Set `percent` to `1.0` when duration is zero.
- `times_finished_this_tick` is [not used
anywhere](https://github.com/bevyengine/bevy/search?q=times_finished_this_tick),
that's why this change will not affect other parts of the project.
- `times_finished_this_tick` is set to `0` after `reset()` and before
first `tick()` call.
# Objective
- Add `Aabb` calculation for `Sprite`, `TextureAtlasSprite` and
`Mesh2d`.
- Enable frustum culling for 2D entities since frustum culling requires
a `Aabb` component in the entity to function.
- Improve 2D performance massively when there are many sprites out of
view. (ex: `many_sprites`)
## Solution
- Derived from @Weasy666's #3944 pull request, which had no activity
since multiple months.
- Adapted the code to the latest version of Bevy.
- Added support for sprites with non-center `Anchor`s to avoid culling
prematurely when part of the sprite is still in view or not culling when
sprite is already out of view.
### Note
- Gives 15.8x performance boosts in some scenarios. (5 fps vs 79 fps
with 409600 sprites in `many_sprites`)
---------
Co-authored-by: ira <JustTheCoolDude@gmail.com>
# Objective
The objective is to be able to load data from "application-specific"
(see glTF spec 3.7.2.1.) vertex attribute semantics from glTF files into
Bevy meshes.
## Solution
Rather than probe the glTF for the specific attributes supported by
Bevy, this PR changes the loader to iterate through all the attributes
and map them onto `MeshVertexAttribute`s. This mapping includes all the
previously supported attributes, plus it is now possible to add mappings
using the `add_custom_vertex_attribute()` method on `GltfPlugin`.
## Changelog
- Add support for loading custom vertex attributes from glTF files.
- Add the `custom_gltf_vertex_attribute.rs` example to illustrate
loading custom vertex attributes.
## Migration Guide
- If you were instantiating `GltfPlugin` using the unit-like struct
syntax, you must instead use `GltfPlugin::default()` as the type is no
longer unit-like.
This line does not appear to be an intended part of the `Panics`
section, but instead looks like it was missed when copy-pasting a
`Panics` section from above.
It confused me when I was reading the docs. At first I read it as if it
was an imperative statement saying not to use `match` statements which
seemed odd and out of place. Once I saw the code it was clearly in err.
# Objective
- Cleanup documentation string to reduce end-user confusion.
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Enabling AlphaMode::Opaque in the shader_prepass example crashes. The
issue seems to be that enabling opaque also generates vertex_uvs
Fixes https://github.com/bevyengine/bevy/issues/8273
## Solution
- Use the vertex_uvs in the shader if they are present
# Objective
The first query of `measure_text_system`'s `text_queries` `ParamSet`
queries for all changed `Text` meaning that non-UI `Text` entities could
be added to its queue.
## Solution
Add a `With<Node>` query filter.
---
## Changelog
changes:
* Added a `With<Node>` query filter to first query of
`measure_text_system`'s `text_queries` `ParamSet` to ensure that only UI
node entities are added to its local queue.
* Fixed comment (text is not computed on changes to style).
# Objective
- Fix the issue described in #8183: Box<dyn Reflect> structs with a
hashmap in them will panic when clone_value is called on it
- Fixes: #8183
## Solution
- Updates the implementation of Reflect for Hashmaps to make clone_value
call from_reflect on the key before inserting it into the new struct
# Objective
- Have a default font
## Solution
- Add a font based on FiraMono containing only ASCII characters and use
it as the default font
- It is behind a feature `default_font` enabled by default
- I also updated examples to use it, but not UI examples to still show
how to use a custom font
---
## Changelog
* If you display text without using the default handle provided by
`TextStyle`, the text will be displayed
# Objective
Added the possibility to draw arcs in 2d via gizmos
## Solution
- Added `arc_2d` function to `Gizmos`
- Added `arc_inner` function
- Added `Arc2dBuilder<'a, 's>`
- Updated `2d_gizmos.rs` example to draw an arc
---------
Co-authored-by: kjolnyr <kjolnyr@protonmail.ch>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ira <JustTheCoolDude@gmail.com>
# Objective
If a UI node has a changed `CalculatedSize` component and either the UI
does a full update or the node also has a changed `Style` component, the
node's corresponding Taffy node will be updated twice by
`flex_node_system`.
## Solution
Add a `Without<Calculated>` query filter so that the two changed node
queries in `flex_node_system` are mutually exclusive and move the
`CalculatedSize` node updater into the else block of the full-update if
conditional.
# Objective
- Mesh entities should cast shadows when not having Aabbs and having
NoFrustumCulling
- Fixes#8442
## Solution
- Mesh entities with NoFrustumCulling get no automatic Aabbs added
- Point and spot lights do not cull mesh entities for their shadow
mapping if they do not have an Aabb, but directional lights do
- Make directional lights not cull mesh entities from cascades if the do
not have Aabbs. So no Aabb as a consequence of a NoFrustumCulling
component will mean that those mesh entities are not culled and so are
visible to the light.
---
## Changelog
- Fixed: Mesh entities with NoFrustumCulling will cast shadows for
directional light shadow maps
Fixes https://github.com/bevyengine/bevy/issues/1207
# Objective
Right now, it's impossible to capture a screenshot of the entire window
without forking bevy. This is because
- The swapchain texture never has the COPY_SRC usage
- It can't be accessed without taking ownership of it
- Taking ownership of it breaks *a lot* of stuff
## Solution
- Introduce a dedicated api for taking a screenshot of a given bevy
window, and guarantee this screenshot will always match up with what
gets put on the screen.
---
## Changelog
- Added the `ScreenshotManager` resource with two functions,
`take_screenshot` and `save_screenshot_to_disk`
# Objective
Methods for interacting with world schedules currently have two
variants: one that takes `impl ScheduleLabel` and one that takes `&dyn
ScheduleLabel`. Operations such as `run_schedule` or `schedule_scope`
only use the label by reference, so there is little reason to have an
owned variant of these functions.
## Solution
Decrease maintenance burden by merging the `ref` variants of these
functions with the owned variants.
---
## Changelog
- Deprecated `World::run_schedule_ref`. It is now redundant, since
`World::run_schedule` can take values by reference.
## Migration Guide
The method `World::run_schedule_ref` has been deprecated, and will be
removed in the next version of Bevy. Use `run_schedule` instead.
# Objective
Label traits such as `ScheduleLabel` currently have a major footgun: the
trait is implemented for `Box<dyn ScheduleLabel>`, but the
implementation does not function as one would expect since `Box<T>` is
considered to be a distinct type from `T`. This is because the behavior
of the `ScheduleLabel` trait is specified mainly through blanket
implementations, which prevents `Box<dyn ScheduleLabel>` from being
properly special-cased.
## Solution
Replace the blanket-implemented behavior with a series of methods
defined on `ScheduleLabel`. This allows us to fully special-case
`Box<dyn ScheduleLabel>` .
---
## Changelog
Fixed a bug where boxed label types (such as `Box<dyn ScheduleLabel>`)
behaved incorrectly when compared with concretely-typed labels.
## Migration Guide
The `ScheduleLabel` trait has been refactored to no longer depend on the
traits `std::any::Any`, `bevy_utils::DynEq`, and `bevy_utils::DynHash`.
Any manual implementations will need to implement new trait methods in
their stead.
```rust
impl ScheduleLabel for MyType {
// Before:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
// After:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
fn as_dyn_eq(&self) -> &dyn DynEq {
self
}
// No, `mut state: &mut` is not a typo.
fn dyn_hash(&self, mut state: &mut dyn Hasher) {
self.hash(&mut state);
// Hashing the TypeId isn't strictly necessary, but it prevents collisions.
TypeId::of::<Self>().hash(&mut state);
}
}
```
Added helper extracted from #7711. that PR contains some controversy
conditions, but this one should be good to go.
---
## Changelog
### Added
- `any_component_removed` condition.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Split the UI overflow enum so that overflow can be set for each axis
separately.
## Solution
Change `Overflow` from an enum to a struct with `x` and `y`
`OverflowAxis` fields, where `OverflowAxis` is an enum with `Clip` and
`Visible` variants. Modify `update_clipping` to calculate clipping for
each axis separately. If only one axis is clipped, the other axis is
given infinite bounds.
<img width="642" alt="overflow"
src="https://user-images.githubusercontent.com/27962798/227592983-568cf76f-7e40-48c4-a511-43c886f5e431.PNG">
---
## Changelog
* Split the UI overflow implementation so overflow can be set for each
axis separately.
* Added the enum `OverflowAxis` with `Clip` and `Visible` variants.
* Changed `Overflow` to a struct with `x` and `y` fields of type
`OverflowAxis`.
* `Overflow` has new methods `visible()` and `hidden()` that replace its
previous `Clip` and `Visible` variants.
* Added `Overflow` helper methods `clip_x()` and `clip_y()` that return
a new `Overflow` value with the given axis clipped.
* Modified `update_clipping` so it calculates clipping for each axis
separately. If a node is only clipped on a single axis, the other axis
is given `-f32::INFINITY` to `f32::INFINITY` clipping bounds.
## Migration Guide
The `Style` property `Overflow` is now a struct with `x` and `y` fields,
that allow for per-axis overflow control.
Use these helper functions to replace the variants of `Overflow`:
* Replace `Overflow::Visible` with `Overflow::visible()`
* Replace `Overflow::Hidden` with `Overflow::clip()`
# Objective
Avoid queuing empty meshes for rendering.
Should prevent #8144 from triggering when no gizmos are in use. Not a
real fix, unfortunately.
## Solution
Add an `in_use` field to `GizmoStorage` and only set it to true when
there are gizmos to draw.
# Objective
Follow-up to #8377.
As the system module has been refactored, there are many types that no
longer make sense to live in the files that they do:
- The `IntoSystem` trait is in `function_system.rs`, even though this
trait is relevant to all kinds of systems. Same for the `In<T>` type.
- `PipeSystem` is now just an implementation of `CombinatorSystem`, so
`system_piping.rs` no longer needs its own file.
## Solution
- Move `IntoSystem`, `In<T>`, and system piping combinators & tests into
the top-level `mod.rs` file for `bevy_ecs::system`.
- Move `PipeSystem` into `combinator.rs`.
# Objective
Add Reflection to `TextureAtlasSprite` to bring it inline with `Sprite`
## Solution
Addition of appropriate macros to the type
---
## Changelog
`#[reflect(Component)]` and derive `FromReflect` for
`TextureAtlasSprite`
Added `TextureAtlasSprite` to the TypeRegistry
# Objective
Fixes#8415.
## Solution
I simply added the missing types to the type registry.
## Changelog
Added `#[reflect(Component]` to `bevi_ui::ui_node::ZIndex`, since it
impls `Component` and `Reflect.`
The following types have been added to the type registry:
1. `bevy_ui::ZIndex`
2. `bevy_math::Rect`
3. `bevy_text::BreakLineOn`
4. `bevy_text::Text2dBounds`
# Objective
Followup to #7779 which tweaks the actual text measurement algorithm to
be more robust.
Before:
<img width="822" alt="Screenshot 2023-04-17 at 18 12 05"
src="https://user-images.githubusercontent.com/1007307/232566858-3d3f0fd5-f3d4-400a-8371-3c2a3f541e56.png">
After:
<img width="810" alt="Screenshot 2023-04-17 at 18 41 40"
src="https://user-images.githubusercontent.com/1007307/232566919-4254cbfa-1cc3-4ea7-91ed-8ca1b759bacf.png">
(note extra space taken up in header in before example)
## Solution
- Text layout of horizontal text (currently the only kind of text we
support) is now based solely on the layout constraints in the horizontal
axis. It ignores constraints in the vertical axis and computes vertical
size based on wrapping subject to the horizontal axis constraints.
- I've also added a paragraph to the `grid` example for testing / demo
purposes.
# Objective
When changing an Entity's `Parent` to a new one from an old `Parent`
that doesn't exist, Bevy panics. Fixes#8337.
## Solution
Use `get_entity_mut` instead of `entity_mut` in `remove_from_children`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Incorrectly resolved merge conflicts in
https://github.com/bevyengine/bevy/pull/8026 have caused UI text to not
render at all.
## Solution
Restore correct system schedule for text systems
# Objective
An easy way to create 2D grid layouts
## Solution
Enable the `grid` feature in Taffy and add new style types for defining
grids.
## Notes
- ~I'm having a bit of trouble getting `#[derive(Reflect)]` to work
properly. Help with that would be appreciated (EDIT: got it to compile
by ignoring the problematic fields, but this presumably can't be
merged).~ This is now fixed
- ~The alignment types now have a `Normal` variant because I couldn't
get reflect to work with `Option`.~ I've decided to stick with the
flattened variant, as it saves a level of wrapping when authoring
styles. But I've renamed the variants from `Normal` to `Default`.
- ~This currently exposes a simplified API on top of grid. In particular
the following is not currently supported:~
- ~Negative grid indices~ Now supported.
- ~Custom `end` values for grid placement (you can only use `start` and
`span`)~ Now supported
- ~`minmax()` track sizing functions~ minmax is now support through a
`GridTrack::minmax()` constructor
- ~`repeat()`~ repeat is now implemented as `RepeatedGridTrack`
- ~Documentation still needs to be improved.~ An initial pass over the
documentation has been completed.
## Screenshot
<img width="846" alt="Screenshot 2023-03-10 at 17 56 21"
src="https://user-images.githubusercontent.com/1007307/224435332-69aa9eac-123d-4856-b75d-5449d3f1d426.png">
---
## Changelog
- Support for CSS Grid layout added to `bevy_ui`
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: Andreas Weibye <13300393+Weibye@users.noreply.github.com>
# Objective
- Currently, it is not possible to call `.pipe` on a system that takes
any input other than `()`.
- The `IntoPipeSystem` trait is currently very difficult to parse due to
its use of generics.
## Solution
Remove the `IntoPipeSystem` trait, and move the `pipe` method to
`IntoSystem`.
---
## Changelog
- System piping has been made more flexible: it is now possible to call
`.pipe` on a system that takes an input.
## Migration Guide
The `IntoPipeSystem` trait has been removed, and the `pipe` method has
been moved to the `IntoSystem` trait.
```rust
// Before:
use bevy_ecs::system::IntoPipeSystem;
schedule.add_systems(first.pipe(second));
// After:
use bevy_ecs::system::IntoSystem;
schedule.add_systems(first.pipe(second));
```
# Objective
- Fixes unclear warning when `insert_non_send_resource` is called on a
Send resource
## Solution
- Add a message to the asssert statement that checks this
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
`text_system` runs before the UI layout is calculated and the size of
the text node is determined, so it cannot correctly shape the text to
fit the layout, and has no way of determining if the text needs to be
wrapped.
The function `text_constraint` attempts to determine the size of the
node from the local size constraints in the `Style` component. It can't
be made to work, you have to compute the whole layout to get the correct
size. A simple example of where this fails completely is a text node set
to stretch to fill the empty space adjacent to a node with size
constraints set to `Val::Percent(50.)`. The text node will take up half
the space, even though its size constraints are `Val::Auto`
Also because the `text_system` queries for changes to the `Style`
component, when a style value is changed that doesn't affect the node's
geometry the text is recomputed unnecessarily.
Querying on changes to `Node` is not much better. The UI layout is
changed to fit the `CalculatedSize` of the text, so the size of the node
is changed and so the text and UI layout get recalculated multiple times
from a single change to a `Text`.
Also, the `MeasureFunc` doesn't work at all, it doesn't have enough
information to fit the text correctly and makes no attempt.
Fixes#7663, #6717, #5834, #1490,
## Solution
Split the `text_system` into two functions:
* `measure_text_system` which calculates the size constraints for the
text node and runs before `UiSystem::Flex`
* `text_system` which runs after `UiSystem::Flex` and generates the
actual text.
* Fix the `MeasureFunc` calculations.
---
Text wrapping in main:
<img width="961" alt="Capturemain"
src="https://user-images.githubusercontent.com/27962798/220425740-4fe4bf46-24fb-4685-a1cf-bc01e139e72d.PNG">
With this PR:
<img width="961" alt="captured_wrap"
src="https://user-images.githubusercontent.com/27962798/220425807-949996b0-f127-4637-9f33-56a6da944fb0.PNG">
## Changelog
* Removed the previous fields from `CalculatedSize`. `CalculatedSize`
now contains a boxed `Measure`.
* Added `measurement` module to `bevy_ui`.
* Added the method `create_text_measure` to `TextPipeline`.
* Added a new system `measure_text_system` that runs before
`UiSystem::Flex` that creates a `MeasureFunc` for the text.
* Rescheduled `text_system` to run after `UiSystem::Flex`.
* Added a trait `Measure`. A `Measure` is used to compute the size of a
UI node when the size of that node is based on its content.
* Added `ImageMeasure` and `TextMeasure` which implement `Measure`.
* Added a new component `UiImageSize` which is used by
`update_image_calculated_size_system` to track image size changes.
* Added a `UiImageSize` component to `ImageBundle`.
## Migration Guide
`ImageBundle` has a new component `UiImageSize` which contains the size
of the image bundle's texture and is updated automatically by
`update_image_calculated_size_system`
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
The implementation of `System::run_unsafe` for `FunctionSystem` requires
that the world is the same one used to initialize the system. However,
the `System` trait has no requirements that the world actually matches,
which makes this implementation unsound.
This was previously mentioned in
https://github.com/bevyengine/bevy/pull/7605#issuecomment-1426491871
Fixes part of #7833.
## Solution
Add the safety invariant that
`System::update_archetype_component_access` must be called prior to
`System::run_unsafe`. Since
`FunctionSystem::update_archetype_component_access` properly validates
the world, this ensures that `run_unsafe` is not called with a
mismatched world.
Most exclusive systems are not required to be run on the same world that
they are initialized with, so this is not a concern for them. Systems
formed by combining an exclusive system with a regular system *do*
require the world to match, however the validation is done inside of
`System::run` when needed.
# Objective
This PR attempts to improve query compatibility checks in scenarios
involving `Or` filters.
Currently, for the following two disjoint queries, Bevy will throw a
panic:
```
fn sys(_: Query<&mut C, Or<(With<A>, With<B>)>>, _: Query<&mut C, (Without<A>, Without<B>)>) {}
```
This PR addresses this particular scenario.
## Solution
`FilteredAccess::with` now stores a vector of `AccessFilters`
(representing a pair of `with` and `without` bitsets), where each member
represents an `Or` "variant".
Filters like `(With<A>, Or<(With<B>, Without<C>)>` are expected to be
expanded into `A * B + A * !C`.
When calculating whether queries are compatible, every `AccessFilters`
of a query is tested for incompatibility with every `AccessFilters` of
another query.
---
## Changelog
- Improved system and query data access compatibility checks in
scenarios involving `Or` filters
---------
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
If you want to execute a schedule on the world using arbitrarily complex
behavior, you currently need to use "hokey-pokey strats": remove the
schedule from the world, do your thing, and add it back to the world.
Not only is this cumbersome, it's potentially error-prone as one might
forget to re-insert the schedule.
## Solution
Add the `World::{try}schedule_scope{ref}` family of functions, which is
a convenient abstraction over hokey pokey strats. This method
essentially works the same way as `World::resource_scope`.
### Example
```rust
// Run the schedule five times.
world.schedule_scope(MySchedule, |world, schedule| {
for _ in 0..5 {
schedule.run(world);
}
});
```
---
## Changelog
Added the `World::schedule_scope` family of methods, which provide a way
to get mutable access to a world and one of its schedules at the same
time.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The default StandardMaterial values of `pbr_material.rs` and
`pbr_types.wgsl` are out of sync.
I think they are out of sync since
https://github.com/bevyengine/bevy/pull/7664.
## Solution
Adapt the values: `metallic = 0.0`, `perceptual_roughness = 0.5`.
# Objective
We don't have a constructor function for `UiRect` that sets uniform
horizontal and vertical values, even though it is a common pattern.
## Solution
Add a constructor function to `UiRect` called `axes`, that sets both
`left` and `right` to the same given horizontal value,
and sets both `top` and `bottom` to same given vertical value.
## Changelog
* Added a constructor function `axes` to `UiRect`.
# Objective
fixes#8348
## Solution
- Uses multi-line string with backslashes allowing rustfmt to work
properly in the surrounding area.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
The behavior of change detection within `PipeSystem` is very tricky and
subtle, and is not currently covered by any of our tests as far as I'm
aware.
# Objective
Upon closer inspection, there are a few functions in the ECS that are
not being inlined, even with the highest optimizations and LTO enabled:
- Almost all
[WorldQuery::init_fetch](9fd5f20e25/results/query_get.s (L57))
calls. Affects `Query::get` calls in hot loops. In particular, the
`WorldQuery` implementation for `()` is used *everywhere* as the default
filter and is effectively a no-op.
-
[Entities::get](9fd5f20e25/results/query_get.s (L39)).
Affects `Query::get`, `World::get`, and any component insertion or
removal.
-
[Entities::set](9fd5f20e25/results/entity_remove.s (L2487)).
Affects any component insertion or removal.
-
[Tick::new](9fd5f20e25/results/entity_insert.s (L1368)).
I've only seen this in component insertion and spawning.
- ArchetypeRow::new
- BlobVec::set_len
Almost all of these have trivial or even empty implementations or have
significant opportunity to be optimized into surrounding code when
inlined with LTO enabled.
## Solution
Inline them
# Objective
The method `World::try_run_schedule` currently panics if the `Schedules`
resource does not exist, but it should just return an `Err`. Similarly,
`World::add_schedule` panics unnecessarily if the resource does not
exist.
Also, the documentation for `World::add_schedule` is completely wrong.
## Solution
When the `Schedules` resource does not exist, we now treat it the same
as if it did exist but was empty. When calling `add_schedule`, we
initialize it if it does not exist.
# Objective
Fixes#8215 and #8152. When systems panic, it causes the main thread to
panic as well, which clutters the output.
## Solution
Resolves the panic in the multi-threaded scheduler. Also adds an extra
message that tells the user the system that panicked.
Using the example from the issue, here is what the messages now look
like:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Update, panicking_system)
.run();
}
fn panicking_system() {
panic!("oooh scary");
}
```
### Before
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2m 58s
Running `target\debug\bevy_test.exe`
2023-03-30T22:19:09.234932Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'Compute Task Pool (5)' panicked at 'A system has panicked so the executor cannot continue.: RecvError', E:\Projects\Rust\bevy\crates\bevy_ecs\src\schedule\executor\multi_threaded.rs:194:60
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', E:\Projects\Rust\bevy\crates\bevy_tasks\src\task_pool.rs:376:49
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
### After
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2.39s
Running `target\debug\bevy_test.exe`
2023-03-30T22:11:24.748513Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Encountered a panic in system `bevy_test::panicking_system`!
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix#8191.
Currently, a state transition will be triggered whenever the `NextState`
resource has a value, even if that "transition" is to the same state as
the previous one. This caused surprising/meaningless behavior, such as
the existence of an `OnTransition { from: A, to: A }` schedule.
## Solution
State transition schedules now only run if the new state is not equal to
the old state. Change detection works the same way, only being triggered
when the states compare not equal.
---
## Changelog
- State transition schedules are no longer run when transitioning to and
from the same state.
## Migration Guide
State transitions are now only triggered when the exited and entered
state differ. This means that if the world is currently in state `A`,
the `OnEnter(A)` schedule (or `OnExit`) will no longer be run if you
queue up a state transition to the same state `A`.
# Objective
Noticed while writing #7728 that we are using `trace!` logs in our event
functions. This has shown to have significant overhead, even trace level
logs are disabled globally, as seen in #7639.
## Solution
Use the `detailed_trace!` macro introduced in #7639. Also removed the
`event_trace` function that was only used in one location.
---
## Changelog
Changed: Event trace logs are now feature gated behind the
`detailed-trace` feature.
# Objective
Fix#8321
## Solution
The `old_viewport_size` that is used to detect whether the viewport has
changed was not being updated and thus always `None`.
# Objective
Adds a new resource to control a global volume.
Fixes#7690
---
## Solution
Added a new resource to control global volume, this is then multiplied
with an audio sources volume to get the output volume, individual audio
sources can opt out of this my enabling the `absolute_volume` field in
`PlaybackSettings`.
---
## Changelog
### Added
- `GlobalVolume` a resource to control global volume (in prelude).
- `global_volume` field to `AudioPlugin` or setting the initial value of
`GlobalVolume`.
- `Volume` enum that can be `Relative` or `Absolute`.
- `VolumeLevel` struct for defining a volume level.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
when a mesh uses zero for all bone weights, vertices end up in the
middle of the screen.
## Solution
we can address this by explicitly setting the first bone weight to 1
when the weights are given as zero. this is the approach taken by
[unity](https://forum.unity.com/threads/whats-the-problem-with-this-import-fbx-warning.133736/)
(although that also sets the bone index to zero) and
[three.js](94c1a4b86f/src/objects/SkinnedMesh.js (L98)),
and likely other engines.
## Alternatives
it does add a bit of overhead, and users can always fix this themselves,
though it's a bit awkward particularly with gltfs.
(note - this is for work so my sme status shouldn't apply)
---------
Co-authored-by: ira <JustTheCoolDude@gmail.com>
# Objective
- Fix#7263
This has nothing to do with #7024. This is for the case where the
user opted to **not** keep the same global transform on update.
## Solution
- Add a `RemovedComponent<Parent>` to `propagate_transforms`
- Add a `RemovedComponent<Parent>` and `Local<Vec<Entity>>` to
`sync_simple_transforms`
- Add test to make sure all of this works.
### Performance note
This should only incur a cost in cases where a parent is removed.
A minimal overhead (one look up in the `removed_components`
sparse set) per root entities without children which transform didn't
change. A `Vec` the size of the largest number of entities removed
with a `Parent` component in a single frame, and a binary search on
a `Vec` per root entities.
It could slow up considerably in situations where a lot of entities are
orphaned consistently during every frame, since
`sync_simple_transforms` is not parallel. But in this situation,
it is likely that the overhead of archetype updates overwhelms
everything.
---
## Changelog
- Fix the `GlobalTransform` not getting updated when `Parent` is removed
## Migration Guide
- If you called `bevy_transform::systems::sync_simple_transforms` and
`bevy_transform::systems::propagate_transforms` (which is not
re-exported by bevy) you need to account for the additional
`RemovedComponents<Parent>` parameter.
---------
Co-authored-by: vyb <vyb@users.noreply.github.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Fixes#8333
# Objective
Fixes issue which causes failure to compile if using
`#![deny(missing_docs)]`.
## Solution
Added some very basic commenting to the generated read-only fields.
honestly I feel this to be up for debate since the comments are very
basic and give very little useful information but the purpose of this PR
is to fix the issue at hand.
---
## Changelog
Added comments to the derive macro and the projects now successfully
compile.
---------
Co-authored-by: lupan <kallll5@hotmail.com>
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
Make the coordinate systems of screen-space items (cursor position, UI,
viewports, etc.) consistent.
## Solution
Remove the weird double inversion of the cursor position's Y origin.
Once in bevy_winit to the bottom and then again in bevy_ui back to the
top.
This leaves the origin at the top left like it is in every other popular
app framework.
Update the `world_to_viewport`, `viewport_to_world`, and
`viewport_to_world_2d` methods to flip the Y origin (as they should
since the viewport coordinates were always relative to the top left).
## Migration Guide
`Window::cursor_position` now returns the position of the cursor
relative to the top left instead of the bottom left.
This now matches other screen-space coordinates like
`RelativeCursorPosition`, UI, and viewports.
The `world_to_viewport`, `viewport_to_world`, and `viewport_to_world_2d`
methods on `Camera` now return/take the viewport position relative to
the top left instead of the bottom left.
If you were using `world_to_viewport` to position a UI node the returned
`y` value should now be passed into the `top` field on `Style` instead
of the `bottom` field.
Note that this might shift the position of the UI node as it is now
anchored at the top.
If you were passing `Window::cursor_position` to `viewport_to_world` or
`viewport_to_world_2d` no change is necessary.
# Objective
Text glyphs that were clipped were not sized correctly because the
transform extracted from the `extract_text_uinodes` had a scaling on it
that wasn't accounted for.
fixes#8167
## Solution
Remove the scaling from the transform and multiply the size of the
glyphs by the inverse of the scale factor.
# Objective
Add helper functions to `UiImage` for creating flipped images.
## Changelog
* Added `with_flip_x` and `with_flip_y` methods to `UiImage` that return
the `UiImage` flipped along the respective axis.
# Objective
Exposes `empty()` method for `AudioSink`.
Based on `0.10.0`, should be a non-breaking change.
---
## Changelog
- Expose `empty()` method for `AudioSink`
- Add `AudioSink::empty()` example
---------
Co-authored-by: hank <hank@hank.co.in>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
When a `CalculatedSize` component from a UI Node entity is removed, the
corresponding Taffy measure isn't removed which will mess up the layout
in confusing, unpredictable ways.
## Solution
Iterate through all the entities with removed `CalculatedSize`
components and remove the corresponding Taffy measures.
# Objective
In the
[`Text`](3442a13d2c/crates/bevy_text/src/text.rs (L18))
struct the field is named: `linebreak_behaviour`, the British spelling
of _behavior_.
**Update**, also found:
- `FileDragAndDrop::HoveredFileCancelled`
- `TouchPhase::Cancelled`
- `Touches.just_cancelled`
The majority of all spelling is in the US but when you have a lot of
contributors across the world, sometimes
spelling differences can pop up in APIs such as in this case.
For consistency, I think it would be worth a while to ensure that the
API is persistent.
Some examples:
`from_reflect.rs` has `DefaultBehavior`
TextStyle has `color` and uses the `Color` struct.
In `bevy_input/src/Touch.rs` `TouchPhase::Cancelled` and _canceled_ are
used interchangeably in the documentation
I've found that there is also the same type of discrepancies in the
documentation, though this is a low priority but is worth checking.
**Update**: I've now checked the documentation (See #8291)
## Solution
I've only renamed the inconsistencies that have breaking changes and
documentation pertaining to them. The rest of the documentation will be
changed via #8291.
Do note that the winit API is written with UK spelling, thus this may be
a cause for confusion:
`winit::event::TouchPhase::Cancelled => TouchPhase::Canceled`
`winit::event::WindowEvent::HoveredFileCancelled` -> Related to
`FileDragAndDrop::HoveredFileCanceled`
But I'm hoping to maybe outline other spelling inconsistencies in the
API, and maybe an addition to the contribution guide.
---
## Changelog
- `Text` field `linebreak_behaviour` has been renamed to
`linebreak_behavior`.
- Event `FileDragAndDrop::HoveredFileCancelled` has been renamed to
`HoveredFileCanceled`
- Function `Touches.just_cancelled` has been renamed to
`Touches.just_canceled`
- Event `TouchPhase::Cancelled` has been renamed to
`TouchPhase::Canceled`
## Migration Guide
Update where `linebreak_behaviour` is used to `linebreak_behavior`
Updated the event `FileDragAndDrop::HoveredFileCancelled` where used to
`HoveredFileCanceled`
Update `Touches.just_cancelled` where used as `Touches.just_canceled`
The event `TouchPhase::Cancelled` is now called `TouchPhase::Canceled`
# Objective
- RenderGraphExt was merged, but only used in limited situations
## Solution
- Fix some remaining issues with the existing api
- Use the new api in the main pass and mass writeback
- Add CORE_2D and CORE_3D constant to make render_graph code shorter
# Objective
While working on #8299, I noticed that we're using a `capacity` field,
even though `wgpu::Buffer` exposes a `size` accessor that does the same
thing.
## Solution
Remove it from all buffer wrappers. Use `wgpu::Buffer::size` instead.
Default to 0 if no buffer has been allocated yet.
# Objective
Fixes#8284. `values` is being pushed to separately from the actual
scratch buffer in `DynamicUniformBuffer::push` and
`DynamicStorageBuffer::push`. In both types, `values` is really only
used to track the number of elements being added to the buffer, yet is
causing extra allocations, size increments and excess copies.
## Solution
Remove it and its remaining uses. Replace it with accesses to `scratch`
instead.
I removed the `len` accessor, as it may be non-trivial to compute just
from `scratch`. If this is still desirable to have, we can keep a `len`
member field to track it instead of relying on `scratch`.
# Objective
State requires a kind of awkward `state.0` to get the current state and
exposes the field directly to manipulation.
## Solution
Make it accessible through a getter method as well as privatize the
field to make sure false assumptions about setting the state aren't
made.
## Migration Guide
- Use `State::get` instead of accessing the tuple field directly.
# Objective
- Adding a node to the render_graph can be quite verbose and error prone
because there's a lot of moving parts to it.
## Solution
- Encapsulate this in a simple utility method
- Mostly intended for optional nodes that have specific ordering
- Requires that the `Node` impl `FromWorld`, but every internal node is
built using a new function taking a `&mut World` so it was essentially
already `FromWorld`
- Use it for the bloom, fxaa and taa, nodes.
- The main nodes don't use it because they rely more on the order of
many nodes being added
---
## Changelog
- Impl `FromWorld` for `BloomNode`, `FxaaNode` and `TaaNode`
- Added `RenderGraph::add_node_edges()`
- Added `RenderGraph::sub_graph()`
- Added `RenderGraph::sub_graph_mut()`
- Added `RenderGraphApp`, `RenderGraphApp::add_render_graph_node`,
`RenderGraphApp::add_render_graph_edges`,
`RenderGraphApp::add_render_graph_edge`
## Notes
~~This was taken out of https://github.com/bevyengine/bevy/pull/7995
because it works on it's own. Once the linked PR is done, the new
`add_node()` will be simplified a bit since the input/output params
won't be necessary.~~
This feature will be useful in most of the upcoming render nodes so it's
impact will be more relevant at that point.
Partially fixes#7985
## Future work
* Add a way to automatically label nodes or at least make it part of the
trait. This would remove one more field from the functions added in this
PR
* Use it in the main pass 2d/3d
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
bevy-scene does not have a reason to depend on bevy-render except to
include the `Visibility` and `ComputedVisibility` components. Including
that in the dependency chain is unnecessary for people not using
`bevy_render`.
Also fixed a problem where compilation fails when the `serialize`
feature was not enabled.
## Solution
This was added in #5335 to address some of the problems caused by #5310.
Imo the user just always have to remember to include `VisibilityBundle`
when they spawn `SceneBundle` or `DynamicSceneBundle`, but that will be
a breaking change. This PR makes `bevy_render` an optional dependency of
`bevy_scene` instead to respect the existing behavior.
# Objective
While migrating the engine to use the `Tick` type in #7905, I forgot to
update `UnsafeWorldCell::increment_change_tick`.
## Solution
Update the function.
---
## Changelog
- The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
## Migration Guide
The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
# Objective
TAA, FXAA, and some other post processing effects can cause the image to
become blurry. Sharpening helps to counteract that.
## Solution
~~This is a port of AMD's Contrast Adaptive Sharpening (I ported it from
the
[SweetFX](https://github.com/CeeJayDK/SweetFX/blob/master/Shaders/CAS.fx)
version, which is still MIT licensed). CAS is a good sharpening
algorithm that is better at avoiding the full screen oversharpening
artifacts that simpler algorithms tend to create.~~
This is a port of AMD's Robust Contrast Adaptive Sharpening (RCAS) which
they developed for FSR 1 ([and continue to use in FSR
2](149cf26e12/src/ffx-fsr2-api/shaders/ffx_fsr1.h (L599))).
RCAS is a good sharpening algorithm that is better at avoiding the full
screen oversharpening artifacts that simpler algorithms tend to create.
---
## Future Work
- Consider porting this to a compute shader for potentially better
performance. (In my testing it is currently ridiculously cheap (0.01ms
in Bistro at 1440p where I'm GPU bound), so this wasn't a priority,
especially since it would increase complexity due to still needing the
non-compute version for webgl2 support).
---
## Changelog
- Added Contrast Adaptive Sharpening.
---------
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Closes https://github.com/bevyengine/bevy/issues/8008
## Solution
- Add a skybox plugin that renders a fullscreen triangle, and then
modifies the vertices in a vertex shader to enforce that it renders as a
skybox background.
- Skybox is run at the end of MainOpaquePass3dNode.
- In the future, it would be nice to get something like bevy_atmosphere
built-in, and have a default skybox+environment map light.
---
## Changelog
- Added `Skybox`.
- `EnvironmentMapLight` now renders in the correct orientation.
## Migration Guide
- Flip `EnvironmentMapLight` maps if needed to match how they previously
rendered (which was backwards).
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
These traits are both implemented, but not reflected, requiring user
code to do `app.register_type_data::<BloomSettings,
ReflectDefault>().register_type_data::<BloomSettings,
ReflectComponent>()` to make these usable via reflection.
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
Fix typo in bevy_reflect README: `MyType` is a struct and not a trait,
so `&dyn MyType` is incorrect.
## Solution
Replace `&dyn MyType` with `&dyn DoThing`
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Fix `CubicCurve::iter_samples` iteration count.
## Solution
If I understand the function and the docs correctly, this should iterate
over `0..=subdivisions` instead of `0..subdivisions`.
For example: Now the iteration returns 3 points at `subdivisions = 2`,
as indicated in the documentation.
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
Our regression tests for `SystemParam` currently consist of a bunch of
loosely dispersed struct definitions. This is messy, and doesn't fully
test their functionality.
## Solution
Group the struct definitions into functions annotated with `#[test]`.
This not only makes the module more organized, but it allows us to call
`assert_is_system`, which has the potential to catch some bugs that
would have been missed with the old approach. Also, this approach is
consistent with how `WorldQuery` regression tests are organized.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
The type `ThinSlicePtr` has a manual implementation of `Clone` that
manually clones each field. Since this type implements `Copy`, we can
change this implementation to simply dereference `&self`.
# Objective
I ran into a case where I need to create a `CommandQueue` and push
standard `Command` actions like `Insert` or `Remove` to it manually. I
saw that `Remove` looked as follows:
```rust
struct Remove<T> {
entity: Entity,
phantom: PhantomData<T>
}
```
so naturally, I tried to use `Remove::<Foo>::from(entity)` but it didn't
exist. We need to specify the `PhantomData` explicitly when creating
this command action. The same goes for `RemoveResource` and
`InitResource`
## Solution
This PR implements the following:
- `From<Entity>` for `Remove<T>`
- `Default` for `RemoveResource` and `InitResource`
- use these traits in the implementation of methods of `Commands`
- rename `phantom` field on the structs above to `_phantom` to have a
more uniform field naming scheme for the command actions
---
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
- Added: implemented `From<Entity>` for `Remove<T>` and `Default` for
`RemoveResource` and `InitResource` for ergonomics
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- We support enabling a normal prepass, but the main pass never actually
uses it and recomputes the normals in the main pass. This isn't ideal
since it's doing redundant work.
## Solution
- Use the normal texture from the prepass in the main pass
## Notes
~~I used `NORMAL_PREPASS_ENABLED` as a shader_def because
`NORMAL_PREPASS` is currently used to signify that it is running in the
prepass while this shader_def need to indicate the prepass is done and
the normal prepass was ran before. I'm not sure if there's a better way
to name this.~~
# Objective
Fix#8179
## Solution
- Added `#![warn(missing_docs)]` and document all public items. All
methods on `Gizmos` have doc examples.
- Expanded the docs on the module/crate. Some unfortunate duplication
there :/
- Moved the methods from `GizmoBuffer` to be directly on `Gizmos` and
made `GizmoBuffer` private. This means the methods on `Gizmos` will show
up on its doc page.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow the use of the "glam _assert" feature to help catch runtime
errors and validate the arguments passed to glam.
e.g.
```rs
// Will panic if self is zero length when glam_assert is enabled.
pub fn normalize(self) -> Self {
let normalized = self.mul(self.length_recip());
glam_assert!(normalized.is_finite());
normalized
}
```
## Solution
- Re-export the optional feature glam_assert
---
## Changelog
Added: Optional feature "glam_assert"
# Objective
WebP is a modern image format developed by Google that offers a
significant reduction in file size compared to other image formats such
as PNG and JPEG, while still maintaining good image quality. This makes
it particularly useful for games with large numbers of images, such as
those with high-quality textures or detailed sprites, where file size
and loading times can have a significant impact on performance.
By adding support for WebP images in Bevy, game developers using this
engine can now take advantage of this modern image format and reduce the
memory usage and loading times of their games. This improvement can
ultimately result in a better gaming experience for players.
In summary, the objective of adding WebP image format support in Bevy is
to enable game developers to use a modern image format that provides
better compression rates and smaller file sizes, resulting in faster
loading times and reduced memory usage for their games.
## Solution
To add support for WebP images in Bevy, this pull request leverages the
existing `image` crate support for WebP. This implementation is easily
integrated into the existing Bevy asset-loading system. To maintain
compatibility with existing Bevy projects, WebP image support is
disabled by default, and developers can enable it by adding a feature
flag to their project's `Cargo.toml` file. With this feature, Bevy
becomes even more versatile for game developers and provides a valuable
addition to the game engine.
---
## Changelog
- Added support for WebP image format in Bevy game engine
## Migration Guide
To enable WebP image support in your Bevy project, add the following
line to your project's Cargo.toml file:
```toml
bevy = { version = "*", features = ["webp"]}
```
# Objective
Fixes#8089.
## Solution
Splits the MainPass3dNode into 2 nodes, one for the opaque + alpha
passes and one for the transparent pass.
---
## Changelog
- Split MainPass3dNode into MainOpaquePass3dNode and
MainTransparentPass3dNode
- Combine opaque and alpha phases in MainOpaquePass3dNode into one pass
- Create `START_MAIN_PASS` and `END_MAIN_PASS` empty nodes as labels
- Main pass becomes `START_MAIN_PASS -> MAIN_OPAQUE_PASS ->
MAIN_TRANSPARENT_PASS -> END_MAIN_PASS`
## Migration Guide
Nodes that previously added edges involving `MAIN_PASS` should now add
edges to or from `START_MAIN_PASS` or `END_MAIN_PASS` respectively.

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/7990.
## Solution
- Register needed types, verified pasted code in issue works.
Do I need to register more `Option<T>` types?
# Objective
Fixes#7989
Based on #7991 by @CoffeeVampir3
## Solution
There were three parts to this issue:
1. `extend_where_clause` did not account for the optionality of a where
clause's trailing comma
```rust
// OKAY
struct Foo<T> where T: Asset, {/* ... */}
// ERROR
struct Foo<T> where T: Asset {/* ... */}
```
2. `FromReflect` derive logic was not actively using
`extend_where_clause` which led to some inconsistencies (enums weren't
adding _any_ additional bounds even)
3. Using `extend_where_clause` in the `FromReflect` derive logic meant
we had to optionally add `Default` bounds to ignored fields iff the
entire item itself was not already `Default` (otherwise the definition
for `Handle<T>` wouldn't compile since `HandleType` doesn't impl
`Default` but `Handle<T>` itself does)
---
## Changelog
- Fixed issue where a missing trailing comma could break the reflection
derives
- Fixes#7965
- Code quality improvements.
- Removes the unreferenced function `dither` in pbr_functions.wgsl
introduced in 72fbcc7, but made obsolete in c069c54.
- Makes the reference to `screen_space_dither` in pbr.wgsl conditional
on `#ifdef TONEMAP_IN_SHADER`, as the required import is conditional on
the same, as deband dithering can only occur if tonemapping is also
occurring.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- `Sprite` components are not included in scene (de)serialization.
- Fixes#8206
## Solution
- Add `#[reflect(Component, Default)]` to `Sprite`
- Add `#[derive(FromReflect)]` to `Sprite` and `Anchor`
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy with
```
default-features = false
features = [
"trace_tracy"
]
```
will fail due to `error: The platform you're compiling for is not
supported by winit`
## Solution
- Make bevy_winit/trace optional in trace feature
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
A `RegularPolygon` is described by the circumscribed radius, not the
inscribed radius.
## Objective
- Correct documentation for `RegularPolygon`
## Solution
- Use the correct term
---------
Co-authored-by: Paul Hüber <phueber@kernsp.in>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
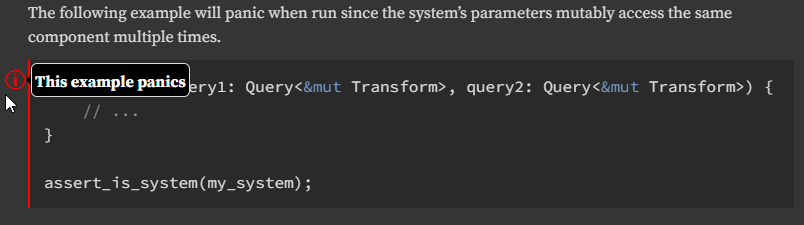
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
Add viewport variants to `Val` that specify a percentage length based on
the size of the window.
## Solution
Add the variants `Vw`, `Vh`, `VMin` and `VMax` to `Val`.
Add a physical window size parameter to the `from_style` function and
use it to convert the viewport variants to Taffy Points values.
One issue: It isn't responsive to window resizes. So `flex_node_system`
has to do a full update every time the window size changes. Perhaps this
can be fixed with support from Taffy.
---
## Changelog
* Added `Val` viewport unit variants `Vw`, `Vh`, `VMin` and `VMax`.
* Modified `convert` module to support the new `Val` variants.
* Changed `flex_node_system` to support the new `Val` variants.
* Perform full layout update on screen resizing, to propagate the new
viewport size to all nodes.
This MR is a rebased and alternative proposal to
https://github.com/bevyengine/bevy/pull/5602
# Objective
- https://github.com/bevyengine/bevy/pull/4447 implemented untyped
(using component ids instead of generics and TypeId) APIs for
inserting/accessing resources and accessing components, but left
inserting components for another PR (this one)
## Solution
- add `EntityMut::insert_by_id`
- split `Bundle` into `DynamicBundle` with `get_components` and `Bundle:
DynamicBundle`. This allows the `BundleInserter` machinery to be reused
for bundles that can only be written, not read, and have no statically
available `ComponentIds`
- Compared to the original MR this approach exposes unsafe endpoints and
requires the user to manage instantiated `BundleIds`. This is quite easy
for the end user to do and does not incur the performance penalty of
checking whether component input is correctly provided for the
`BundleId`.
- This MR does ensure that constructing `BundleId` itself is safe
---
## Changelog
- add methods for inserting bundles and components to:
`world.entity_mut(entity).insert_by_id`
# Objective
Add comments explaining:
* That `Val::Px` is a value in logical pixels
* That `Val::Percent` is based on the length of its parent along a
specific axis.
* How the layout algorithm determines which axis the percentage should
be based on.
# Objective
Co-Authored-By: davier
[bricedavier@gmail.com](mailto:bricedavier@gmail.com)
Fixes#3576.
Adds a `resources` field in scene serialization data to allow
de/serializing resources that have reflection enabled.
## Solution
Most of this code is taken from a previous closed PR:
https://github.com/bevyengine/bevy/pull/3580. Most of the credit goes to
@Davier , what I did was mostly getting it to work on the latest main
branch of Bevy, along with adding a few asserts in the currently
existing tests to be sure everything is working properly.
This PR changes the scene format to include resources in this way:
```
(
resources: {
// List of resources here, keyed by resource type name.
},
entities: [
// Previous scene format here
],
)
```
An example taken from the tests:
```
(
resources: {
"bevy_scene::serde::tests::MyResource": (
foo: 123,
),
},
entities: {
// Previous scene format here
},
)
```
For this, a `resources` fields has been added on the `DynamicScene` and
the `DynamicSceneBuilder` structs. The latter now also has a method
named `extract_resources` to properly extract the existing resources
registered in the local type registry, in a similar way to
`extract_entities`.
---
## Changelog
Added: Reflect resources registered in the type registry used by dynamic
scenes will now be properly de/serialized in scene data.
## Migration Guide
Since the scene format has been changed, the user may not be able to use
scenes saved prior to this PR due to the `resources` scene field being
missing. ~~To preserve backwards compatibility, I will try to make the
`resources` fully optional so that old scenes can be loaded without
issue.~~
## TODOs
- [x] I may have to update a few doc blocks still referring to dynamic
scenes as mere container of entities, since they now include resources
as well.
- [x] ~~I want to make the `resources` key optional, as specified in the
Migration Guide, so that old scenes will be compatible with this
change.~~ Since this would only be trivial for ron format, I think it
might be better to consider it in a separate PR/discussion to figure out
if it could be done for binary serialization too.
- [x] I suppose it might be a good idea to add a resources in the scene
example so that users will quickly notice they can serialize resources
just like entities.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6760
- adds line and position on line info to scene errors
```text
Before:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)`
After:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)` at scenes/test/scene.scn.ron:10:4
```
## Solution
- use span_error to get position info. This is what the ron crate does
internally to get the position info.
562963f887/src/options.rs (L158)
## Changelog
- added line numbers to scene errors
---------
Co-authored-by: Paul Hansen <mail@paul.rs>
# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
- Currently, https://github.com/vleue/bevy_bistro_playground crashes when enabling shadows, because this allocates a new buffer for the view uniforms, but the `TonemappingNode` uses a cached bind group that doesn't reference the new uniform buffer.
## Solution
- Check if the buffer id of the view uniforms buffer has changed and create a new bind group if it did.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
revert combining pipelines for AlphaMode::Blend and AlphaMode::Premultiplied & Add
the recent blend state pr changed `AlphaMode::Blend` to use a blend state of `Blend::PREMULTIPLIED_ALPHA_BLENDING`, and recovered the original behaviour by multiplying colour by alpha in the standard material's fragment shader.
this had some advantages (specifically it means more material instances can be batched together in future), but this also means that custom materials that specify `AlphaMode::Blend` now get a premultiplied blend state, so they must also multiply colour by alpha.
## Solution
revert that combination to preserve 0.9 behaviour for custom materials with AlphaMode::Blend.
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
Current `Node` doc comment:
```rust
/// The size of the node as width and height in pixels
/// automatically calculated by [`super::flex::flex_node_system`]
```
It should be changed to make it clear that `Node` stores the size in logical pixels, not physical.
# Objective
- Example `transparent_window` doesn't display a transparent window on macOS
- Fixes#6330
## Solution
- Set the `composite_alpha_mode` of the window to the correct value
- Update docs
# Objective
Upgrade to Taffy 0.3.3
Fixes: #7712
## Solution
Upgrade to Taffy 0.3.3 with the `grid` feature disabled.
---
## Changelog
* Changed Taffy version to 0.3.3 and disabled its `grid` feature.
* Added the `Start` and `End` variants to `AlignItems`, `AlignSelf`, `AlignContent` and `JustifyContent`.
* Added the `SpaceEvenly` variant to `AlignContent`.
* Updated `from_style` for Taffy 0.3.3.
# Objective
the current depth bias only adjusts ordering, so it doesn't work for opaque meshes vs alpha-blend meshes, and it doesn't help when two meshes are infinitesimally offset from one another.
## Solution
pass the material's depth bias into the pipeline depth stencil `constant` field.
# Objective
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
- Make cubic splines more flexible and more performant
- Remove the existing spline implementation that is generic over many degrees
- This is a potential performance footgun and adds type complexity for negligible gain.
- Add implementations of:
- Bezier splines
- Cardinal splines (inc. Catmull-Rom)
- B-Splines
- Hermite splines
https://user-images.githubusercontent.com/2632925/221780519-495d1b20-ab46-45b4-92a3-32c46da66034.mp4https://user-images.githubusercontent.com/2632925/221780524-2b154016-699f-404f-9c18-02092f589b04.mp4https://user-images.githubusercontent.com/2632925/221780525-f934f99d-9ad4-4999-bae2-75d675f5644f.mp4
## Solution
- Implements the concept that splines are curve generators (e.g. https://youtu.be/jvPPXbo87ds?t=3488) via the `CubicGenerator` trait.
- Common splines are bespoke data types that implement this trait. This gives us flexibility to add custom spline-specific methods on these types, while ultimately all generating a `CubicCurve`.
- All splines generate `CubicCurve`s, which are a chain of precomputed polynomial coefficients. This means that all splines have the same evaluation cost, as the calculations for determining position, velocity, and acceleration are all identical. In addition, `CubicCurve`s are simply a list of `CubicSegment`s, which are evaluated from t=0 to t=1. This also means cubic splines of different type can be chained together, as ultimately they all are simply a collection of `CubicSegment`s.
- Because easing is an operation on a singe segment of a Bezier curve, we can simply implement easing on `Beziers` that use the `Vec2` type for points. Higher level crates such as `bevy_ui` can wrap this in a more ergonomic interface as needed.
### Performance
Measured on a desktop i5 8600K (6-year-old CPU):
- easing: 2.7x faster (19ns)
- cubic vec2 position sample: 1.5x faster (1.8ns)
- cubic vec3 position sample: 1.5x faster (2.6ns)
- cubic vec3a position sample: 1.9x faster (1.4ns)
On a laptop i7 11800H:
- easing: 16ns
- cubic vec2 position sample: 1.6ns
- cubic vec3 position sample: 2.3ns
- cubic vec3a position sample: 1.2ns
---
## Changelog
- Added a generic cubic curve trait, and implementation for Cardinal splines (including Catmull-Rom), B-Splines, Beziers, and Hermite Splines. 2D cubic curve segments also implement easing functionality for animation.
# Objective
Unfortunately, there are three issues with my changes introduced by #7784.
1. The changes left some dead code. This is already taken care of here: #7875.
2. Disabling prepass causes failures because the shadow mapping relies on the `PrepassPlugin` now.
3. Custom materials use the `prepass.wgsl` shader, but this does not always define a fragment entry point.
This PR fixes 2. and 3. and resolves#7879.
## Solution
- Add a regression test with disabled prepass.
- Split `PrepassPlugin` into two plugins:
- `PrepassPipelinePlugin` contains the part that is required for the shadow mapping to work and is unconditionally added.
- `PrepassPlugin` now only adds the systems and resources required for the "real" prepasses.
- Add a noop fragment entry point to `prepass.wgsl`, used if `NORMAL_PASS` is not defined.
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
- Fixes#7874.
- The `bevy_text` dependency is optional for `bevy_ui`, but the `accessibility` module depended on it.
## Solution
- Guard the `accessibility` module behind the `bevy_text` feature and only add the plugin when it's enabled.
# Objective
- Remove dead code after #7784
# Changelog
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Migration Guide
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
# Objective
Fixes#7864
## Solution
Add the run conditions described in the issue. Also needed to add `bevy` as a dev dependency to `bevy_time` so the doctests can run.
---
## Changelog
- Add `on_timer` and `on_fixed_timer` run conditions
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
- Fixes#4372.
## Solution
- Use the prepass shaders for the shadow passes.
- Move `DEPTH_CLAMP_ORTHO` from `ShadowPipelineKey` to `MeshPipelineKey` and the associated clamp operation from `depth.wgsl` to `prepass.wgsl`.
- Remove `depth.wgsl` .
- Replace `ShadowPipeline` with `ShadowSamplers`.
Instead of running the custom `ShadowPipeline` we run the `PrepassPipeline` with the `DEPTH_PREPASS` flag and additionally the `DEPTH_CLAMP_ORTHO` flag for directional lights as well as the `ALPHA_MASK` flag for materials that use `AlphaMode::Mask(_)`.
# Objective
Fixes#7797
## Solution
This **seems** like a simple fix, but I'm not 100% confident and I may have messed up the math in some way. In particular, I'm not sure what I should be using for an FOV value.
However, this seems to be producing similar results to 0.9.
Here's the `orthographic` example with a default directional light.
edit: better screen grab below.
# Objective
Fixes#6780
## Solution
- record the asset path of each watched file
- call `AssetIo::watch_for_changes` in `LoadContext::read_asset_bytes`
---
## Changelog
### Fixed
- fixed hot reloading for `LoadContext::read_asset_bytes`
### Changed
- `AssetIo::watch_path_for_changes` allows watched path and path to reload to differ
## Migration Guide
- for custom `AssetIo`s, differentiate paths to watch and asset paths to reload as a consequence
Co-authored-by: Vincent Junge <specificprotagonist@posteo.org>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
UIs created for Bevy cannot currently be made accessible. This PR aims to address that.
## Solution
Integrate AccessKit as a dependency, adding accessibility support to existing bevy_ui widgets.
## Changelog
### Added
* Integrate with and expose [AccessKit](https://accesskit.dev) for platform accessibility.
* Add `Label` for marking text specifically as a label for UI controls.
# Objective
Alternative to #7490. I wrote all of the code in this PR, but I have added @robtfm as co-author on commits that build on ideas from #7490. I would not have been able to solve these problems on my own without much more time investment and I'm largely just rephrasing the ideas from that PR.
Fixes#7435Fixes#7361Fixes#5721
## Solution
This implements the solution I [outlined here](https://github.com/bevyengine/bevy/pull/7490#issuecomment-1426580633).
* Adds "msaa writeback" as an explicit "msaa camera feature" and default to msaa_writeback: true for each camera. If this is true, a camera has MSAA enabled, and it isn't the first camera for the target, add a writeback before the main pass for that camera.
* Adds a CameraOutputMode, which can be used to configure if (and how) the results of a camera's rendering will be written to the final RenderTarget output texture (via the upscaling node). The `blend_state` and `color_attachment_load_op` are now configurable, giving much more control over how a camera will write to the output texture.
* Made cameras with the same target share the same main_texture tracker by using `Arc<AtomicUsize>`, which ensures continuity across cameras. This was previously broken / could produce weird results in some cases. `ViewTarget::main_texture()` is now correct in every context.
* Added a new generic / specializable BlitPipeline, which the new MsaaWritebackNode uses internally. The UpscalingPipelineNode now uses BlitPipeline instead of its own pipeline. We might ultimately need to fork this back out if we choose to add more configurability to the upscaling, but for now this will save on binary size by not embedding the same shader twice.
* Moved the "camera sorting" logic from the camera driver node to its own system. The results are now stored in the `SortedCameras` resource, which can be used anywhere in the renderer. MSAA writeback makes use of this.
---
## Changelog
- Added `Camera::msaa_writeback` which can enable and disable msaa writeback.
- Added specializable `BlitPipeline` and ported the upscaling node to use this.
- Added SortedCameras, exposing information that was previously internal to the camera driver node.
- Made cameras with the same target share the same main_texture tracker, which ensures continuity across cameras.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
Text2d entity's text needs to be recomputed when their bounds are changed, but it isn't.
# Solution
Change `update_text2d_layout` to query for `Ref<Text2dBounds>` and recompute the text if the bounds have changed.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
# Objective
Implement `Reflect` for `std::collections::HashMap<K, V, S>` as well as `hashbrown::HashMap<K, V, S>` rather than just for `hashbrown::HashMap<K, V, RandomState>`. Fixes#7739.
## Solution
Rather than implementing on `HashMap<K, V>` I instead implemented most of the related traits on `HashMap<K, V, S> where S: BuildHasher + Send + Sync + 'static` and then `FromReflect` also needs the extra bound `S: Default` because it needs to use `with_capacity_and_hasher` so needs to be able to generate a default hasher.
As the API of `hashbrown::HashMap` is identical to `collections::HashMap` making them both work just required creating an `impl_reflect_for_hashmap` macro like the `impl_reflect_for_veclike` above and then applying this to both HashMaps.
---
## Changelog
`std::collections::HashMap` can now be reflected. Also more `State` generics than just `RandomState` can now be reflected for both `hashbrown::HashMap` and `collections::HashMap`
# Objective
Fix#7544. Update docs for `Window::transparent` regarding Windows 11 platform support. Following the update to winit 0.28, this has been fixed.
## Solution
Remove the mention in the docs.
`EntityMut::move_entity_from_remove` had two soundness bugs:
- When removing the entity from the archetype, the swapped entity had its table row updated to the same as the removed entity's
- When removing the entity from the table, the swapped entity did not have its table row updated
`BundleInsert::insert` had two/three soundness bugs
- When moving an entity to a new archetype from an `insert`, the swapped entity had its table row set to a different entities
- When moving an entity to a new table from an `insert`, the swapped entity did not have its table row updated
See added tests for examples that trigger those bugs
`EntityMut::despawn` had two soundness bugs
- When despawning an entity, the swapped entity had its table row set to a different entities even if the table didnt change
- When despawning an entity, the swapped entity did not have its table row updated
# Objective
- A more intuitive distinction between the two. `remove_intersection` is verbose and unclear.
- `EntityMut::remove` and `Commands::remove` should match.
## Solution
- What the title says.
---
## Migration Guide
Before
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).remove::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove_intersection::<Parent>();
}
}
}
```
After
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).take::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove::<Parent>();
}
}
}
```
# Objective
Common run conditions can be very useful for quick and ergonomic changes to when a system runs.
Specifically what I'd like to be able to do is
```rust
use bevy::prelude::*;
use bevy::input::common_conditions::input_toggle_active;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(
bevy_inspector_egui::quick::WorldInspectorPlugin::default()
.run_if(input_toggle_active(true, KeyCode::Escape)
)
.run();
}
```
## Solution
- add `bevy_input::common_conditions` module with `input_toggle_active`, `input_pressed`, `input_just_pressed`, `input_just_released`
## Changelog
- added common run conditions for `bevy_input`
- you can now use `.add_system(jump.run_if(input_just_pressed(KeyCode::Space)))`
# Objective
There were a couple primitive types missing from the default `TypeRegistry` constructor.
## Solution
Added the missing registrations for `char` and `String`.
# Objective
A couple of places in `bevy_app` use a scoped block that doesn't do anything. I imagine these are a relic from when `Mut<T>` implemented `Drop` in the early days of bevy.
## Solution
Remove the scopes.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
Alternative to #7804
Allows other instances of the `sync_simple_transforms` and `propagate_transforms` systems to be added.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
While working on #7784, I noticed that a `#define VAR` in a `.wgsl` file is always effective, even if it its scope is not accepting lines.
Example:
```c
#define A
#ifndef A
#define B
#endif
```
Currently, `B` will be defined although it shouldn't. This PR fixes that.
## Solution
Move the branch responsible for `#define` lines into the last else branch, which is only evaluated if the current scope is accepting lines.
# Objective
- `bevy_text` used to be "optional". the feature could be disabled, which meant that the systems were not added but `bevy_text` was still compiled because of a hard dependency in `bevy_ui`
- Running something without `bevy_text` enabled and with `bevy_ui` enabled now crashes:
```
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /bevy/crates/bevy_ecs/src/schedule/schedule.rs:1147:34
```
- This is because `bevy_ui` declares some of its systems in ambiguity sets with systems from `bevy_text`, which were not added if `bevy_text` is disabled
## Solution
- Make `bevy_text` completely optional
## Migration Guide
- feature `bevy_text` now completely removes `bevy_text` from the dependencies when not enabled. Enable feature `bevy_text` if you use Bevy to render text
# Objective
While we use `#[doc(hidden)]` to try and hide marker generics from the user, these types reveal themselves in compiler errors, adding visual noise and confusion.
## Solution
Replace the `AlreadyWasSystem` marker generic with `()`, to reduce visual noise in error messages. This also makes it possible to return `impl Condition<()>` from combinators.
For function systems, use their function signature as the marker type. This should drastically improve the legibility of some error messages.
The `InputMarker` type has been removed, since it is unnecessary.
# Objective
Several places in the ECS use marker generics to avoid overlapping trait implementations, but different places alternately refer to it as `Params` and `Marker`. This is potentially confusing, since it might not be clear that the same pattern is being used. Additionally, users might be misled into thinking that the `Params` type corresponds to the `SystemParam`s of a system.
## Solution
Rename `Params` to `Marker`.
# Objective
There was PR that introduced support for storage buffer is `AsBindGroup` macro [#6129](https://github.com/bevyengine/bevy/pull/6129), but it does not give more granular control over storage buffer, it will always copy all the data no matter which part of it was updated. There is also currently another open PR #6669 that tries to achieve exactly that, it is just not up to date and seems abandoned (Sorry if that is not right). In this PR I'm proposing a solution for both of these approaches to co-exist using `#[storage(n, buffer)]` and `#[storage(n)]` to distinguish between the cases.
We could also discuss in this PR if there is a need to extend this support to DynamicBuffers as well.
# Objective
Fixes#3980
## Solution
Added examples to show how to run a `Schedule`, one with a unique system, and another with several systems
---
## Changelog
- Added: examples in docs to show how to run a `Schedule`
Co-authored-by: remiCzn <77072160+remiCzn@users.noreply.github.com>
# Objective
The `BoxedCondition` type alias does not require the underlying system to be read-only.
## Solution
Define the type alias using `ReadOnlySystem` instead of `System`.
Graph theory make head hurty. Closes#7367.
Basically, when we topologically sort the dependency graph, we already find its strongly-connected components (a really [neat algorithm][1]). This PR adds an algorithm that can dissect those into simple cycles, giving us more useful error reports.
test: `system_build_errors::dependency_cycle`
```
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
```
```
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
```
test: `system_build_errors::hierarchy_cycle`
```
schedule has 1 in_set cycle(s):
cycle 1: system set 'A' contains itself
system set 'A'
... which contains system set 'B'
... which contains system set 'A'
```
[1]: https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
# Objective
`cargo run -p ci` is currently failing locally for me.
```
error: variables can be used directly in the `format!` string
--> crates/bevy_reflect/bevy_reflect_derive/src/type_uuid.rs:106:69
|
106 | let uuid = Uuid::parse_str(&uuid).map_err(|err| input.error(format!("{}", err)))?;
```
It's not clear to me why CI/clippy didn't pick this up in #6633.
Add some more useful common run conditions.
Some of these existed in `iyes_loopless`. I know people used them, and it would be a regression for those users, when they try to migrate to new Bevy stageless, if they are missing.
I also took the opportunity to add a few more new ones.
---
## Changelog
### Added
- More "common run conditions": on_event, resource change detection, state_changed, any_with_component
# Objective
`TextBundle` should have a `BackgroundColor` component.
Apart from adding emphasis etc to text, adding a background color to text nodes can be extremely useful for understanding how Bevy aligns, sizes and positions text, and identifying and debugging problems.
It's easy for users to insert the `BackgroundColor` component themselves but not immediately obvious or discoverable that it's possible. A `BackgroundColor` component allows us to add a `with_background_color` helper function to `TextBundle`.
related issue: #5935
## Solution
Add a `BackgroundColor` component to `TextBundle`.
---
## Changelog
* Added a `BackgroundColor` component to `TextBundle`.
* Added a helper method `with_background_color` to `TextBundle`.
## Migration Guide
`TextBundle` now has a `BackgroundColor` component.
Use `TextBundle`'s `background_color` field or the `with_background_color` method to set a background color for text when spawning a text node, in place of manual insertion of a `BackgroundColor` component.
# Objective
When working on #7750 I noticed that `CoreSchedule::Main` was explicitly used to get the schedule for the `OnUpdate` set. This can lead to failures or weird behavior if `add_state` is used with a differently configured `default_schedule_label`, because the other systems are added to the default schedule. This PR fixes that.
## Solution
Use `default_schedule_label` to retrieve a single schedule to which all systems are added.
# Objective
Fix#5026.
## Solution
Only make a `trace!` log if the event count changed.
---
## Changelog
Changed: `EventWriter::send_batch` will only log a TRACE level log if the batch is non-empty.
# Objective
- Adds foundational math for Bezier curves, useful for UI/2D/3D animation and smooth paths.
https://user-images.githubusercontent.com/2632925/218883143-e138f994-1795-40da-8c59-21d779666991.mp4
## Solution
- Adds the generic `Bezier` type, and a `Point` trait. The `Point` trait allows us to use control points of any dimension, as long as they support vector math. I've implemented it for `f32`(1D), `Vec2`(2D), and `Vec3`/`Vec3A`(3D).
- Adds `CubicBezierEasing` on top of `Bezier` with the addition of an implementation of cubic Bezier easing, which is a foundational tool for UI animation.
- This involves solving for $t$ in the parametric Bezier function $B(t)$ using the Newton-Raphson method to find a value with error $\leq$ 1e-7, capped at 8 iterations.
- Added type aliases for common Bezier curves: `CubicBezier2d`, `CubicBezier3d`, `QuadraticBezier2d`, and `QuadraticBezier3d`. These types use `Vec3A` to represent control points, as this was found to have an 80-90% speedup over using `Vec3`.
- Benchmarking shows quadratic/cubic Bezier evaluations $B(t)$ take \~1.8/2.4ns respectively. Easing, which requires an iterative solve takes \~50ns for cubic Beziers.
---
## Changelog
- Added `CubicBezier2d`, `CubicBezier3d`, `QuadraticBezier2d`, and `QuadraticBezier3d` types with methods for sampling position, velocity, and acceleration. The generic `Bezier` type is also available, and generic over any degree of Bezier curve.
- Added `CubicBezierEasing`, with additional methods to allow for smooth easing animations.
# Objective
Fix#7584.
## Solution
Add an abstraction for creating custom system combinators with minimal boilerplate. Use this to implement AND/OR combinators. Use this to simplify the implementation of `PipeSystem`.
## Example
Feel free to bikeshed on the syntax.
I chose the names `and_then`/`or_else` to emphasize the fact that these short-circuit, while I chose method syntax to empasize that the arguments are *not* treated equally.
```rust
app.add_systems((
my_system.run_if(resource_exists::<R>().and_then(resource_equals(R(0)))),
our_system.run_if(resource_exists::<R>().or_else(resource_exists::<S>())),
));
```
---
## Todo
- [ ] Decide on a syntax
- [x] Write docs
- [x] Write tests
## Changelog
+ Added the extension methods `.and_then(...)` and `.or_else(...)` to run conditions, which allows combining run conditions with short-circuiting behavior.
+ Added the trait `Combine`, which can be used with the new `CombinatorSystem` to create system combinators with custom behavior.
# Objective
- Fixes#7636.
## Solution
`apply_state_transitions::<S>` runs in `CoreSet::StateTransitions` which is already scheduled before `CoreSet::Update`. Therefore explicitly scheduling `OnUpdate` after `apply_state_transitions::<S>` is not necessary.
# Objective
- Fixes#7442.
## Solution
- Added `report_sets` option to `ScheduleBuildSettings` like described in the linked issue.
The output of the `3d_scene` example when reporting ambiguities with `report_sets` and `use_shortnames` set to `true` (and with #7755 applied) now looks like this:
```
82 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- filesystem_watcher_system (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<DynamicScene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Scene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Shader> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Mesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<SkinnedMeshInverseBindposes> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Image> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<TextureAtlas> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<ColorMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Font> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<FontAtlasSet> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<StandardMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Gltf> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfNode> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfPrimitive> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfMesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSource> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSink> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AnimationClip> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- scene_spawner_system (Update) and close_when_requested (Update)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- calculate_bounds (CalculateBounds, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and visibility_propagate_system (PostUpdate, VisibilityPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_text2d_layout (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and ui_stack_system (PostUpdate, Stack)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and text_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_image_calculated_size_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and flex_node_system (Flex, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and add_clusters (AddClusters, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- visibility_propagate_system (PostUpdate, VisibilityPropagate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_text2d_layout (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- ui_stack_system (PostUpdate, Stack) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- text_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_image_calculated_size_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and animation_player (PostUpdate)
conflict on: ["bevy_transform::components::transform::Transform"]
-- apply_system_buffers (AddClustersFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and check_visibility (CheckVisibility, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_frusta (PostUpdate, UpdateLightFrusta)
conflict on: bevy_ecs::world::World
-- Assets<Scene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Shader>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Mesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<SkinnedMeshInverseBindposes>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Image>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<TextureAtlas>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<ColorMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Font>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<FontAtlasSet>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<StandardMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Gltf>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfNode>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfPrimitive>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfMesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSource>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSink>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AnimationClip>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<DynamicScene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
```
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
While working on #7442 i discovered that `get_short_name` does not work well with sub paths after closing brackets. It currently turns `bevy_asset::assets::Assets<bevy_scene::dynamic_scene::DynamicScene>::asset_event_system` into `Assets<DynamicScene>asset_event_system`. This PR fixes that.
## Solution
- Retain `::` after a closing bracket like `>`, `)` or `]`.
- Add a test for all sub path after closing bracket cases.
# Objective
- Add basic spatial audio support to Bevy
- this is what rodio supports, so no HRTF, just simple stereo channel manipulation
- no "built-in" ECS support: `Emitter` and `Listener` should be components that would automatically update the positions
This PR goal is to just expose rodio functionality, made possible with the recent update to rodio 0.16. A proper ECS integration opens a lot more questions, and would probably require an RFC
Also updates rodio and fixes#6122
# Objective
Allow using `Local<WorldId>` in systems.
## Solution
- Describe the solution used to achieve the objective above.
---
## Changelog
+ `WorldId` now implements the `FromWorld` trait.
# Objective
- Nothing render
```
ERROR bevy_render::render_resource::pipeline_cache: failed to process shader: Invalid shader def definition for '_import_path': bevy_pbr
```
## Solution
- Fix define regex so that it must have one whitespace after `define`
# Objective
- Fixes#7494
- It is now possible to define a ShaderDef from inside a shader. This can be useful to centralise a value, or making sure an import is only interpreted once
## Solution
- Support `#define <SHADERDEF_NAME> <optional value>`
# Objective
- ambiguities bad
## Solution
- solve ambiguities
- by either ignoring (e.g. on `queue_mesh_view_bind_groups` since `LightMeta` access is different)
- by introducing a dependency (`prepare_windows -> prepare_*` because the latter use the fallback Msaa)
- make `prepare_assets` public so that we can do a proper `.after`
# Objective
Currently, it is quite awkward to use the `pbr` function in a custom shader without binding a mesh bind group.
This is because the `pbr` function depends on the `MESH_FLAGS_SHADOW_RECEIVER_BIT` flag.
## Solution
I have removed this dependency by adding the flag as a parameter to the `PbrInput` struct.
I am not sure if this is the ideal solution since the mesh flag indicates both `MESH_FLAGS_SIGN_DETERMINANT_MODEL_3X3_BIT` and `MESH_FLAGS_SHADOW_RECEIVER_BIT`.
The former seems to be unrelated to PBR. Maybe the flag should be split.
# Objective
- Fix the environment map shader not working under webgl due to textureNumLevels() not being supported
- Fixes https://github.com/bevyengine/bevy/issues/7722
## Solution
- Instead of using textureNumLevels(), put an extra field in the GpuLights uniform to store the mip count
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
…top sort. reduce mem alloc
# Objective
- Reduce alloc count.
- Improve code quality.
## Solution
- use `TarjanScc::run` directly, which calls a closure with each scc, in closure, we can detect cycles and flatten nodes
# Objective
`ChangeTrackers<>` is a `WorldQuery` type that lets you access the change ticks for a component. #7097 has added `Ref<>`, which gives access to a component's value in addition to its change ticks. Since bevy's access model does not separate a component's value from its change ticks, there is no benefit to using `ChangeTrackers<T>` over `Ref<T>`.
## Solution
Deprecate `ChangeTrackers<>`.
---
## Changelog
* `ChangeTrackers<T>` has been deprecated. It will be removed in Bevy 0.11.
## Migration Guide
`ChangeTrackers<T>` has been deprecated, and will be removed in the next release. Any usage should be replaced with `Ref<T>`.
```rust
// Before (0.9)
fn my_system(q: Query<(&MyComponent, ChangeTrackers<MyComponent>)>) {
for (value, trackers) in &q {
if trackers.is_changed() {
// Do something with `value`.
}
}
}
// After (0.10)
fn my_system(q: Query<Ref<MyComponent>>) {
for value in &q {
if value.is_changed() {
// Do something with `value`.
}
}
}
```
# Objective
- Updates list of plugins and feature information in `DefaultPlugins` doc comment
- Solve the short term issue of https://github.com/bevyengine/bevy/issues/7332
## Solution
- Update doc comment to reflect current implementation
- Sort plugins by appearance in implementation
# Objective
Fixes#7736
## Solution
Implement the `SystemParam` trait for `WorldId`
## Changelog
- `WorldId` can now be taken as a system parameter and will return the id of the world the system is running in
# Objective
Closes#7573
- Make `StartupSet` a base set
## Solution
- Add `#[system_set(base)]` to the enum declaration
- Replace `.in_set(StartupSet::...)` with `.in_base_set(StartupSet::...)`
**Note**: I don't really know what I'm doing and what exactly the difference between base and non-base sets are. I mostly opened this PR based on discussion in Discord. I also don't really know how to test that I didn't break everything. Your reviews are appreciated!
---
## Changelog
- `StartupSet` is now a base set
## Migration Guide
`StartupSet` is now a base set. This means that you have to use `.in_base_set` instead of `.in_set`:
### Before
```rs
app.add_system(foo.in_set(StartupSet::PreStartup))
```
### After
```rs
app.add_system(foo.in_base_set(StartupSet::PreStartup))
```
# Objective
-0.0 should typically be treated exactly the same as 0.0, but this assertion was rejecting it while allowing 0.0. The `Duration` API handles this correctly (on recent Rust versions) and returns a zero `Duration` for both -0.0 and 0.0.
## Solution
Check for `ratio >= 0.0`, which is true if `ratio` is `-0.0`.
---
## Changelog
Allow relative speed of -0.0 in the `Time::set_relative_speed_fXX` methods.
# Objective
- Fixes#7659.
## Solution
- This PR extracted the `distributive_run_if` part of #7676, because it does not require the controversial introduction of anonymous system sets.
- The distinctive name should make the user aware about the differences between `IntoSystemConfig::run_if` and `IntoSystemConfigs::distributive_run_if`.
- The documentation explains in detail the consequences of using the API and possible pit falls when using it.
- A test demonstrates the possibility of changing the condition result, resulting in some of the systems not being run.
---
## Changelog
### Added
- Add `distributive_run_if` to `IntoSystemConfigs` to enable adding a run condition to each system when using `add_systems`.
# Objective
`bevy_reflect` can be a moderately complex crate to try and understand. It has many moving parts, a handful of gotchas, and a few subtle contracts that aren't immediately obvious to users and even other contributors.
The current README does an okay job demonstrating how the crate can be used. However, the crate's actual documentation should give a better overview of the crate, its inner-workings, and show some of its own examples.
## Solution
Added crate-level documentation that attempts to summarize the main parts of `bevy_reflect` into small sections.
This PR also updates the documentation for:
- `Reflect`
- `FromReflect`
- The reflection subtraits
- Other important types and traits
- The reflection macros (including the derive macros)
- Crate features
### Open Questions
1. ~~Should I update the docs for the Dynamic types? I was originally going to, but I'm getting a little concerned about the size of this PR 😅~~ Decided to not do this in this PR. It'll be better served from its own PR.
2. Should derive macro documentation be moved to the trait itself? This could improve visibility and allow for better doc links, but could also clutter up the trait's documentation (as well as not being on the actual derive macro's documentation).
### TODO
- [ ] ~~Document Dynamic types (?)~~ I think this should be done in a separate PR.
- [x] Document crate features
- [x] Update docs for `GetTypeRegistration`
- [x] Update docs for `TypeRegistration`
- [x] Update docs for `derive_from_reflect`
- [x] Document `reflect_trait`
- [x] Document `impl_reflect_value`
- [x] Document `impl_from_reflect_value`
---
## Changelog
- Updated documentation across the `bevy_reflect` crate
- Removed `#[module]` helper attribute for `Reflect` derives (this is not currently used)
## Migration Guide
- Removed `#[module]` helper attribute for `Reflect` derives. If your code is relying on this attribute, please replace it with either `#[reflect]` or `#[reflect_value]` (dependent on use-case).
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
follow-up to https://github.com/bevyengine/bevy/pull/7716
# Objective
System access is only populated in `System::initialize`, so without calling `initialize` it's actually impossible to see most ambiguities.
## Solution
- make `initialize` public. The method is idempotent, so calling it multiple times doesn't hurt
# Objective
Continuation of https://github.com/bevyengine/bevy/pull/5719
Now that we have a definable type for the iterator.
---
## Changelog
- Implemented IntoIterator for EventReader so you can now do `&mut reader` instead of `reader.iter()` for events.
# Objective
- bevy_ggrs uses `reflect_hash` in order to produce checksums for its world snapshots. These checksums are sent between clients in order to detect desyncronization.
- However, since we currently use `async::AHasher` with the `std` feature, this means that hashes will always be different for different peers, even if the state is identical.
- This means bevy_ggrs needs a way to get a deterministic (fixed) hash.
## Solution
- ~~Add a feature to use `bevy_utils::FixedState` for the hasher used by bevy_reflect.~~
- Always use `bevy_utils::FixedState` for initializing the bevy_reflect hasher.
---
## Changelog
- bevy_reflect now uses a fixed state for its hasher, which means the output of `Reflect::reflect_hash` is now deterministic across processes.
# Objective
Fix#7440. Fix#7441.
## Solution
* Remove builder functions on `ScheduleBuildSettings` in favor of public fields, move docs to the fields.
* Add `use_shortnames` and use it in `get_node_name` to feed it through `bevy_utils::get_short_name`.
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
Fixes#7295
Should we maybe default to 4x if 2x/8x is selected but not supported?
---
## Changelog
- Added 2x and 8x sample counts for MSAA.
# Objective
- Environment maps use these formats, and in the future rendering LUTs will need textures loaded by default in the engine
## Solution
- Make ktx2 and zstd part of the default feature
- Let examples assume these features are enabled
---
## Changelog
- `ktx2` and `zstd` are now party of bevy's default enabled features
## Migration Guide
- If you used the `ktx2` or `zstd` features, you no longer need to explicitly enable them, as they are now part of bevy's default enabled features
# Objective
The type `SyncCell<T>` (added in #5483) is used to force any wrapped type to be `Sync`, by only allowing exclusive access to the wrapped value. This restriction is unnecessary for types which are already `Sync`.
---
## Changelog
+ Added the method `read` to `SyncCell`, which allows shared access to values that already implement the `Sync` trait.
# Objective
Web builds do not support running on multiple threads right now. Defaulting to the multi-threaded executor has significant overhead without any benefit.
## Solution
Default to the single threaded executor on wasm32 builds.
# Objective
- other tools (bevy_mod_debugdump) would like to have access to the ambiguities so that they can do their own reporting/visualization
## Solution
- store `conflicting_systems` in `ScheduleGraph` after calling `build_schedule`
The solution isn't very pretty and as pointed out it https://github.com/bevyengine/bevy/pull/7522, there may be a better way of exposing this, but this is the quick and dirty way if we want to have this functionality exposed in 0.10.
# Objective
- RemovedComponents is just a thin wrapper around Events/ManualEventReader which is the same as an EventReader, so most usecases that of an EventReader will probably be useful for RemovedComponents too.
I was thinking of making a trait for this but I don't think it is worth the overhead currently.
## Solution
- Mirror the api surface of EventReader
# Objective
Motivated by #7469.
`EventReader` iterators use the default implementations for `.nth()` and `.last()`, which includes iterating over and throwing out all events before the desired one.
## Solution
Add specialized implementations for these methods that directly updates the unread event counter and returns a reference to the desired event.
TODO:
- [x] Add a unit test.
- [x] ~~Add a benchmark, to see if the compiler was doing this automatically already.~~ *On second thought, this doesn't feel like a very useful thing to include in the benchmark suite.*
# Objective
- it would be nice to be able to associate a `NodeId` of a system type set to the `NodeId` of the actual system (used in bevy_mod_debugdump)
## Solution
- make `system_type` return the type id of the system
- that way you can check if a `dyn SystemSet` is the system type set of a `dyn System`
- I don't know if this information is already present somewhere else in the scheduler or if there is a better way to expose it
# Objective
Fixes#7702.
## Solution
- Added an test that ensures that no error is returned if a system or set is inside two different sets that share the same base set.
- Added an check to only return an error if the two base sets are not equal.
# Objective
The `ScheduleGraph` should be expose so that crates like [bevy_mod_debugdump](https://github.com/jakobhellermann/bevy_mod_debugdump/blob/stageless/docs/README.md) can access useful information.
## Solution
- expose `ScheduleGraph`, `NodeId`, `BaseSetMembership`, `Dag`
- add accessor functions for sets and systems
## Changelog
- expose `ScheduleGraph` for use in third party tools
This does expose our use of `petgraph` as a graph library, so we can only change that as a breaking change.
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
The trait `Condition<>` is implemented for any type that can be converted into a `ReadOnlySystem` which takes no inputs and returns a bool. However, due to the current implementation, consumers of the trait cannot rely on the fact that `<T as Condition>::System` implements `ReadOnlySystem`. In cases such as the `not` combinator (added in #7559), we are required to add redundant `T::System: ReadOnlySystem` trait bounds, even though this should be implied by the `Condition<>` trait.
## Solution
Add a hidden associated type which allows the compiler to figure out that the `System` associated type implements `ReadOnlySystem`.
…able like Table. Rename clear to clear_entities to clarify that metadata keeps, only value cleared
# Objective
- Provide some inspectability for SparseSets.
## Solution
- `Tables` has these three methods, len, is_empty and iter too. Add these methods to `SparseSets`, so user can print the shape of storage.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- Add `len`, `is_empty`, `iter` methods on SparseSets.
- Rename `clear` to `clear_entities` to clarify its purpose.
- Add `new_for_test` on `ComponentInfo` to make test code easy.
- Add test case covering new methods.
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- Simply adding new functionality is not a breaking change.
# Objective
This PR improves message that caused by duplicate components in bundle.
## Solution
Show names of duplicate components.
The solution is not very elegant, in my opinion, I will be happy to listen to suggestions for improving it
Co-authored-by: Саня Череп <41489405+SDesya74@users.noreply.github.com>
# Objective
While porting my crate `bevy_trait_query` to bevy 0.10, I ran into an issue with the `DetectChangesMut` trait. Due to the way that the `set_if_neq` method (added in #6853) is implemented, you are forced to write a nonsense implementation of it for dynamically sized types. This edge case shows up when implementing trait queries, since `DetectChangesMut` is implemented for `Mut<dyn Trait>`.
## Solution
Simplify the generics for `set_if_neq` and add the `where Self::Target: Sized` trait bound to it. Add a default implementation so implementers don't need to implement a method with nonsensical trait bounds.
# Objective
The `SystemParamFunction` (and `ExclusiveSystemParamFunction`) trait is very cumbersome to use, due to it requiring four generic type parameters. These are currently all used as marker parameters to satisfy rust's trait coherence rules.
### Example (before)
```rust
pub fn pipe<AIn, Shared, BOut, A, AParam, AMarker, B, BParam, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<AIn>, ParamSet<(AParam, BParam)>) -> BOut
where
A: SystemParamFunction<AIn, Shared, AParam, AMarker>,
B: SystemParamFunction<Shared, BOut, BParam, BMarker>,
AParam: SystemParam,
BParam: SystemParam,
```
## Solution
Turn the `In`, `Out`, and `Param` generics into associated types. Merge the marker types together to retain coherence.
### Example (after)
```rust
pub fn pipe<A, B, AMarker, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<A::In>, ParamSet<(A::Param, B::Param)>) -> B::Out
where
A: SystemParamFunction<AMarker>,
B: SystemParamFunction<BMarker, In = A::Out>,
```
---
## Changelog
+ Simplified the `SystemParamFunction` and `ExclusiveSystemParamFunction` traits.
## Migration Guide
For users of the `SystemParamFunction` trait, the generic type parameters `In`, `Out`, and `Param` have been turned into associated types. The same has been done with the `ExclusiveSystemParamFunction` trait.
# Objective
The current doc comment for `flex-basis` states that it is "The initial size of the item", which is a bit confusing since size in Bevy is mostly used to refer to two-dimensional extents but `flex-basis` is a one-dimensional value.
It also needs to explain that:
* `flex-basis` sets the initial length of the main axis.
* Overrides `size` on the main axis.
* Obeys the `min_size` and `max_size` constraints.
# Objective
- #6402 changed `World::fetch_table` (now `UnsafeWorldCell::fetch_table`) to access the archetype in order to get the `table_id` and `table_row` of the entity involved. However this is useless since those were already present in the `EntityLocation`
- Moreover it's useless for `UnsafeWorldCell::fetch_table` to return the `TableRow` too, since the caller must already have access to the `EntityLocation` which contains the `TableRow`.
- The result is that `UnsafeWorldCell::fetch_table` now only does 2 memory fetches instead of 4.
## Solution
- Revert the changes to the implementation of `UnsafeWorldCell::fetch_table` made in #6402
…u64, so hash safety is not a concern
# Objective
- While reading the code, just noticed the BundleInfo's HashMap is std::collections::HashMap, which uses a slow but safe hasher.
## Solution
- Use bevy_utils::HashMap instead
benchmark diff (I run several times in a linux box, the perf improvement is consistent, though numbers varies from time to time, I paste my last run result here):
``` bash
cargo bench -- spawn
Compiling bevy_ecs v0.9.0 (/home/lishuo/developer/pr/bevy/crates/bevy_ecs)
Compiling bevy_app v0.9.0 (/home/lishuo/developer/pr/bevy/crates/bevy_app)
Compiling benches v0.1.0 (/home/lishuo/developer/pr/bevy/benches)
Finished bench [optimized] target(s) in 1m 17s
Running benches/bevy_ecs/change_detection.rs (/home/lishuo/developer/pr/bevy/benches/target/release/deps/change_detection-86c5445d0dc34529)
Gnuplot not found, using plotters backend
Running benches/bevy_ecs/benches.rs (/home/lishuo/developer/pr/bevy/benches/target/release/deps/ecs-e49b3abe80bfd8c0)
Gnuplot not found, using plotters backend
spawn_commands/2000_entities
time: [153.94 µs 159.19 µs 164.37 µs]
change: [-14.706% -11.050% -6.9633%] (p = 0.00 < 0.05)
Performance has improved.
spawn_commands/4000_entities
time: [328.77 µs 339.11 µs 349.11 µs]
change: [-7.6331% -3.9932% +0.0487%] (p = 0.06 > 0.05)
No change in performance detected.
spawn_commands/6000_entities
time: [445.01 µs 461.29 µs 477.36 µs]
change: [-16.639% -13.358% -10.006%] (p = 0.00 < 0.05)
Performance has improved.
spawn_commands/8000_entities
time: [657.94 µs 677.71 µs 696.95 µs]
change: [-8.8708% -5.2591% -1.6847%] (p = 0.01 < 0.05)
Performance has improved.
get_or_spawn/individual time: [452.02 µs 466.70 µs 482.07 µs]
change: [-17.218% -14.041% -10.728%] (p = 0.00 < 0.05)
Performance has improved.
get_or_spawn/batched time: [291.12 µs 301.12 µs 311.31 µs]
change: [-12.281% -8.9163% -5.3660%] (p = 0.00 < 0.05)
Performance has improved.
spawn_world/1_entities time: [81.668 ns 84.284 ns 86.860 ns]
change: [-12.251% -6.7872% -1.5402%] (p = 0.02 < 0.05)
Performance has improved.
spawn_world/10_entities time: [789.78 ns 821.96 ns 851.95 ns]
change: [-19.738% -14.186% -8.0733%] (p = 0.00 < 0.05)
Performance has improved.
spawn_world/100_entities
time: [7.9906 µs 8.2449 µs 8.5013 µs]
change: [-12.417% -6.6837% -0.8766%] (p = 0.02 < 0.05)
Change within noise threshold.
spawn_world/1000_entities
time: [81.602 µs 84.161 µs 86.833 µs]
change: [-13.656% -8.6520% -3.0491%] (p = 0.00 < 0.05)
Performance has improved.
Found 1 outliers among 100 measurements (1.00%)
1 (1.00%) high mild
Benchmarking spawn_world/10000_entities: Warming up for 500.00 ms
Warning: Unable to complete 100 samples in 4.0s. You may wish to increase target time to 4.0s, enable flat sampling, or reduce sample count to 70.
spawn_world/10000_entities
time: [813.02 µs 839.76 µs 865.41 µs]
change: [-12.133% -6.1970% -0.2302%] (p = 0.05 < 0.05)
Change within noise threshold.
```
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- use bevy_utils::HashMap for Bundles::bundle_ids
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- Not a breaking change, hashmap is internal impl.
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
- Improve readability of the run condition for systems only running in a certain state
## Solution
- Rename `state_equals` to `in_state` (see [comment by cart](https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428740311) in #7634 )
- `.run_if(state_equals(variant))` now is `.run_if(in_state(variant))`
This breaks the naming pattern a bit with the related conditions `state_exists` and `state_exists_and_equals` but I could not think of better names for those and think the improved readability of `in_state` is worth it.
# Objective
- Fixes#7612
- Since #7493, windows started as unfocused
## Solution
- Creating the window at the end of the event loop after the resume event instead of at the beginning of the loop of the next event fixes the focus
# Objective
The text contained by a text node is only recomputed when its `Style` or `Text` components change, or when the scale factor changes. Not when the geometry of the text node is modified.
Make it so that any change in text node size triggers a text recomputation.
## Solution
Change `text_system` so that it queries for text nodes with changed `Node` components and recomputes their text.
---
Most users won't notice any difference but it should fix some confusing edge cases in more complicated and interactive layouts.
## Changelog
* Added `Changed<Node>` to the change detection query of `text_system`. This ensures that any change in the size of a text node will cause any text it contains to be recomputed.
# Objective
Standard material defaults are currently strange, and the docs are wrong re: metallic.
## Solution
Change the defaults to be similar to [Godot](https://github.com/godotengine/godot/pull/62756).
---
## Changelog
#### Changed
- `StandardMaterial` now defaults to a dielectric material (0.0 `metallic`) with 0.5 `perceptual_roughness`.
## Migration Guide
`StandardMaterial`'s default have now changed to be a fully dielectric material with medium roughness. If you want to use the old defaults, you can set `perceptual_roughness = 0.089` and `metallic = 0.01` (though metallic should generally only be set to 0.0 or 1.0).
# Objective
Fixes#7632.
As discussed in #7634, it can be quite challenging for users to intuit the mental model of how states now work.
## Solution
Rather than change the behavior of the `OnUpdate` system set, instead work on making sure it's easy to understand what's going on.
Two things have been done:
1. Remove the `.on_update` method from our bevy of system building traits. This was special-cased and made states feel much more magical than they need to.
2. Improve the docs for the `OnUpdate` system set.
# Objective
Resolves#7121
## Solution
Decouples `List` and `Array` by removing `Array` as a supertrait of `List`. Additionally, similar methods from `Array` have been added to `List` so that their usages can remain largely unchanged.
#### Possible Alternatives
##### `Sequence`
My guess for why we originally made `List` a subtrait of `Array` is that they share a lot of common operations. We could potentially move these overlapping methods to a `Sequence` (name taken from #7059) trait and make that a supertrait of both. This would allow functions to contain logic that simply operates on a sequence rather than "list vs array".
However, this means that we'd need to add methods for converting to a `dyn Sequence`. It also might be confusing since we wouldn't add a `ReflectRef::Sequence` or anything like that. Is such a trait worth adding (either in this PR or a followup one)?
---
## Changelog
- Removed `Array` as supertrait of `List`
- Added methods to `List` that were previously provided by `Array`
## Migration Guide
The `List` trait is no longer dependent on `Array`. Implementors of `List` can remove the `Array` impl and move its methods into the `List` impl (with only a couple tweaks).
```rust
// BEFORE
impl Array for Foo {
fn get(&self, index: usize) -> Option<&dyn Reflect> {/* ... */}
fn get_mut(&mut self, index: usize) -> Option<&mut dyn Reflect> {/* ... */}
fn len(&self) -> usize {/* ... */}
fn is_empty(&self) -> bool {/* ... */}
fn iter(&self) -> ArrayIter {/* ... */}
fn drain(self: Box<Self>) -> Vec<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicArray {/* ... */}
}
impl List for Foo {
fn insert(&mut self, index: usize, element: Box<dyn Reflect>) {/* ... */}
fn remove(&mut self, index: usize) -> Box<dyn Reflect> {/* ... */}
fn push(&mut self, value: Box<dyn Reflect>) {/* ... */}
fn pop(&mut self) -> Option<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicList {/* ... */}
}
// AFTER
impl List for Foo {
fn get(&self, index: usize) -> Option<&dyn Reflect> {/* ... */}
fn get_mut(&mut self, index: usize) -> Option<&mut dyn Reflect> {/* ... */}
fn insert(&mut self, index: usize, element: Box<dyn Reflect>) {/* ... */}
fn remove(&mut self, index: usize) -> Box<dyn Reflect> {/* ... */}
fn push(&mut self, value: Box<dyn Reflect>) {/* ... */}
fn pop(&mut self) -> Option<Box<dyn Reflect>> {/* ... */}
fn len(&self) -> usize {/* ... */}
fn is_empty(&self) -> bool {/* ... */}
fn iter(&self) -> ListIter {/* ... */}
fn drain(self: Box<Self>) -> Vec<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicList {/* ... */}
}
```
Some other small tweaks that will need to be made include:
- Use `ListIter` for `List::iter` instead of `ArrayIter` (the return type from `Array::iter`)
- Replace `array_hash` with `list_hash` in `Reflect::reflect_hash` for implementors of `List`
# Objective
- rebased version of #6155
The `MaterialPipeline` cannot be integrated into other pipelines like the `MeshPipeline`.
## Solution
Implement `Clone` for `MaterialPipeline`. Expose systems and resources part of the `MaterialPlugin` to allow custom assembly - especially combining existing systems and resources with a custom `queue_material_meshes` system.
# Changelog
## Added
- Clone impl for MaterialPipeline
## Changed
- ExtractedMaterials, extract_materials and prepare_materials are now public
# Objective
- Fixes: #7187
Since avoiding the `SRes::into_inner` call does not seem to be possible, this PR tries to at least document its usage.
I am not sure if I explained the lifetime issue correctly, please let me know if something is incorrect.
## Solution
- Add information about the `SRes::into_inner` usage on both `RenderCommand` and `Res`
# Objective
Add doc tests for the `Size` constructor functions.
Also changed the function descriptions so they explicitly state the values that elided values are given.
## Changelog
* Added doc tests for the `Size` constructor functions.
# Objective
The `size` field of `CalculatedSize` shouldn't be a `Size` as it only ever stores (unscaled) pixel values. By default its fields are `Val::Auto` but these are converted to `0`s before being sent to Taffy.
## Solution
Change the `size` field of `CalculatedSize` to a Vec2.
## Changelog
* Changed the `size` field of `CalculatedSize` to a Vec2.
* Removed the `Val` <-> `f32` conversion code for `CalculatedSize`.
## Migration Guide
* The size field of `CalculatedSize` has been changed to a `Vec2`.
Profiles show that in extremely hot loops, like the draw loops in the renderer, invoking the trace! macro has noticeable overhead, even if the trace log level is not enabled.
Solve this by introduce a 'wrapper' detailed_trace macro around trace, that wraps the trace! log statement in a trivially false if statement unless a cargo feature is enabled
# Objective
- Eliminate significant overhead observed with trace-level logging in render hot loops, even when trace log level is not enabled.
- This is an alternative solution to the one proposed in #7223
## Solution
- Introduce a wrapper around the `trace!` macro called `detailed_trace!`. This macro wraps the `trace!` macro with an if statement that is conditional on a new cargo feature, `detailed_trace`. When the feature is not enabled (the default), then the if statement is trivially false and should be optimized away at compile time.
- Convert the observed hot occurrences of trace logging in `TrackedRenderPass` with this new macro.
Testing the results of
```
cargo run --profile stress-test --features bevy/trace_tracy --example many_cubes -- spheres
```

shows significant improvement of the `main_opaque_pass_3d` of the renderer, a median time decrease from 6.0ms to 3.5ms.
---
## Changelog
- For performance reasons, some detailed renderer trace logs now require the use of cargo feature `detailed_trace` in addition to setting the log level to `TRACE` in order to be shown.
## Migration Guide
- Some detailed bevy trace events now require the use of the cargo feature `detailed_trace` in addition to enabling `TRACE` level logging to view. Should you wish to see these logs, please compile your code with the bevy feature `detailed_trace`. Currently, the only logs that are affected are the renderer logs pertaining to `TrackedRenderPass` functions
# Objective
Related to #7530.
`EventReader` iterators currently use the default impl for `.count()`, which unnecessarily loops over all unread events.
# Solution
Add specialized impls that mark the `EventReader` as consumed and return the number of unread events.
# Objective
There was issue #191 requesting subdivisions on the shape::Plane.
I also could have used this recently. I then write the solution.
Fixes #191
## Solution
I changed the shape::Plane to include subdivisions field and the code to create the subdivisions. I don't know how people are counting subdivisions so as I put in the doc comments 0 subdivisions results in the original geometry of the Plane.
Greater then 0 results in the number of lines dividing the plane.
I didn't know if it would be better to create a new struct that implemented this feature, say SubdivisionPlane or change Plane. I decided on changing Plane as that was what the original issue was.
It would be trivial to alter this to use another struct instead of altering Plane.
The issues of migration, although small, would be eliminated if a new struct was implemented.
## Changelog
### Added
Added subdivisions field to shape::Plane
## Migration Guide
All the examples needed to be updated to initalize the subdivisions field.
Also there were two tests in tests/window that need to be updated.
A user would have to update all their uses of shape::Plane to initalize the subdivisions field.
# Objective
- While working on scope recently, I ran into a missing invariant for the transmutes in scope. The references passed into Scope are active for the rest of the scope function, but rust doesn't know this so it allows using the owned `spawned` and `scope` after `f` returns.
## Solution
- Update the safety comment
- Shadow the owned values so they can't be used.
# Objective
In our project we parse `GltfNode` from `*.gltf` file, and we need extra properties information from Blender. Right now there is no way to get this properties from GltfNode (only through query when you spawn scene), so objective of this PR is to add extra properties to `GltfNode`
## Solution
Store extra properties inside `Gltf` structs
---
## Changelog
- Add pub field `extras` to `GltfNode`/`GltfMesh`/`GltfPrimitive` which store extras
- Add pub field `material_extras` to `GltfPrimitive` which store material extras
# Objective
`Size::width` sets the `height` field to `Val::DEFAULT` which is `Val::Undefined`, but the default for `Size` `height` is `Val::Auto`.
`Size::height` has the same problem, but with the `width` field.
The UI examples specify numeric values in many places where they could either be elided or replaced by composition of the Flex enum properties.
related: https://github.com/bevyengine/bevy/pull/7468
fixes: https://github.com/bevyengine/bevy/issues/6498
## Solution
Change `Size::width` so it sets `height` to `Val::AUTO` and change `Size::height` so it sets `width` to `Val::AUTO`.
Added some tests so this doesn't happen again.
## Changelog
Changed `Size::width` so it sets the `height` to `Val::AUTO`.
Changed `Size::height` so it sets the `width` to `Val::AUTO`.
Added tests to `geometry.rs` for `Size` and `UiRect` to ensure correct behaviour.
Simplified the UI examples. Replaced numeric values with the Flex property enums or elided them where possible, and removed the remaining use of auto margins.
## Migration Guide
The `Size::width` constructor function now sets the `height` to `Val::Auto` instead of `Val::Undefined`.
The `Size::height` constructor function now sets the `width` to `Val::Auto` instead of `Val::Undefined`.
# Objective
Make the name less verbose without sacrificing clarity.
---
## Migration Guide
*Note for maintainers:* This PR has no breaking changes relative to bevy 0.9. Instead of this PR having its own migration guide, we should just edit the changelog for #6404.
The type `UnsafeWorldCellEntityRef` has been renamed to `UnsafeEntityCell`.
# Objective
Continuation of #7560.
`MutUntyped::last_changed` and `set_last_changed` do not behave as described in their docs.
## Solution
Fix them using the same approach that was used for `Mut<>` in #7560.
fixes#6799
# Objective
We should be able to reuse the `Globals` or `View` shader struct definitions from anywhere (including third party plugins) without needing to worry about defining unrelated shader defs.
Also we'd like to refactor these structs to not be repeatedly defined.
## Solution
Refactor both `Globals` and `View` into separate importable shaders.
Use the imports throughout.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- This makes code a little more readable now.
## Solution
- Use `position` provided by `Iter` instead of `enumerating` indices and `map`ping to the index.
This was missed in #7205.
Should be fixed now. 😄
## Migration Guide
- `SpecializedComputePipelines::specialize` now takes a `&PipelineCache` instead of a `&mut PipelineCache`
# Objective
The current `AlignSelf` doc comments:
```rust
pub enum AlignSelf {
/// Use the value of [`AlignItems`]
Auto,
/// If the parent has [`AlignItems::Center`] only this item will be at the start
FlexStart,
/// If the parent has [`AlignItems::Center`] only this item will be at the end
FlexEnd,
/// If the parent has [`AlignItems::FlexStart`] only this item will be at the center
Center,
/// If the parent has [`AlignItems::Center`] only this item will be at the baseline
Baseline,
/// If the parent has [`AlignItems::Center`] only this item will stretch along the whole cross axis
Stretch,
}
```
Actual behaviour of `AlignSelf` in Bevy main:
<img width="642" alt="align_self" src="https://user-images.githubusercontent.com/27962798/217795178-7a82638f-118d-4474-b7f9-ca27f204731d.PNG">
The white label at the top of each column is the parent node's `AlignItems` setting.
`AlignSelf` is always applied, not (as the documentation states) only when the parent has `AlignItems::Center` or `AlignItems::FlexStart` set.
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_startup_system(setup)
.run();
}
fn setup(mut commands: Commands, asset_server: Res<AssetServer>) {
commands.spawn(Camera2dBundle::default());
commands.spawn(NodeBundle {
style: Style {
justify_content: JustifyContent::SpaceAround,
align_items: AlignItems::Center,
size: Size::new(Val::Percent(100.), Val::Percent(100.)),
..Default::default()
},
background_color: BackgroundColor(Color::NAVY),
..Default::default()
}).with_children(|builder| {
for align_items in [
AlignItems::Baseline,
AlignItems::FlexStart,
AlignItems::Center,
AlignItems::FlexEnd,
AlignItems::Stretch,
] {
builder.spawn(NodeBundle {
style: Style {
align_items,
flex_direction: FlexDirection::Column,
justify_content: JustifyContent::SpaceBetween,
size: Size::new(Val::Px(150.), Val::Px(500.)),
..Default::default()
},
background_color: BackgroundColor(Color::DARK_GRAY),
..Default::default()
}).with_children(|builder| {
builder.spawn((
TextBundle {
text: Text::from_section(
format!("AlignItems::{align_items:?}"),
TextStyle {
font: asset_server.load("fonts/FiraSans-Regular.ttf"),
font_size: 16.0,
color: Color::BLACK,
},
),
style: Style {
align_self: AlignSelf::Stretch,
..Default::default()
},
..Default::default()
},
BackgroundColor(Color::WHITE),
));
for align_self in [
AlignSelf::Auto,
AlignSelf::FlexStart,
AlignSelf::Center,
AlignSelf::FlexEnd,
AlignSelf::Baseline,
AlignSelf::Stretch,
] {
builder.spawn((
TextBundle {
text: Text::from_section(
format!("AlignSelf::{align_self:?}"),
TextStyle {
font: asset_server.load("fonts/FiraSans-Regular.ttf"),
font_size: 16.0,
color: Color::WHITE,
},
),
style: Style {
align_self,
..Default::default()
},
..Default::default()
},
BackgroundColor(Color::BLACK),
));
}
});
}
});
}
```
# Objective
Make `last_changed` behave as described in its docs.
## Solution
- Return `changed` instead of `last_change_tick`. `last_change_tick` is the system's previous tick and is just used for comparison.
- Update the docs of the similarly named `set_last_changed` (which does correctly interact with `last_change_tick`) to clarify that the two functions touch different data. (I advocate for renaming one or the other if anyone has any good suggestions).
It also might make sense to return a cloned `Tick` instead of `u32`.
---
## Changelog
- Fixed `DetectChanges::last_changed` returning the wrong value.
- Fixed `DetectChangesMut::set_last_changed` not actually updating the `changed` tick.
## Migration Guide
- The incorrect value that was being returned by `DetectChanges::last_changed` was the previous run tick of the system checking for changed values. If you depended on this value, you can get it from the `SystemChangeTick` `SystemParam` instead.
(Before)

(After)

# Objective
- Improve lighting; especially reflections.
- Closes https://github.com/bevyengine/bevy/issues/4581.
## Solution
- Implement environment maps, providing better ambient light.
- Add microfacet multibounce approximation for specular highlights from Filament.
- Occlusion is no longer incorrectly applied to direct lighting. It now only applies to diffuse indirect light. Unsure if it's also supposed to apply to specular indirect light - the glTF specification just says "indirect light". In the case of ambient occlusion, for instance, that's usually only calculated as diffuse though. For now, I'm choosing to apply this just to indirect diffuse light, and not specular.
- Modified the PBR example to use an environment map, and have labels.
- Added `FallbackImageCubemap`.
## Implementation
- IBL technique references can be found in environment_map.wgsl.
- It's more accurate to use a LUT for the scale/bias. Filament has a good reference on generating this LUT. For now, I just used an analytic approximation.
- For now, environment maps must first be prefiltered outside of bevy using a 3rd party tool. See the `EnvironmentMap` documentation.
- Eventually, we should have our own prefiltering code, so that we can have dynamically changing environment maps, as well as let users drop in an HDR image and use asset preprocessing to create the needed textures using only bevy.
---
## Changelog
- Added an `EnvironmentMapLight` camera component that adds additional ambient light to a scene.
- StandardMaterials will now appear brighter and more saturated at high roughness, due to internal material changes. This is more physically correct.
- Fixed StandardMaterial occlusion being incorrectly applied to direct lighting.
- Added `FallbackImageCubemap`.
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Clarify what the function is actually calculating.
The `Tick::is_older_than` function is actually calculating whether the tick is newer than the system's `last_change_tick`, not older. As far as I can tell, the engine was using it correctly everywhere already.
## Solution
- Rename the function.
---
## Changelog
- `Tick::is_older_than` was renamed to `Tick::is_newer_than`. This is not a functional change, since that was what was always being calculated, despite the wrong name.
## Migration Guide
- Replace usages of `Tick::is_older_than` with `Tick::is_newer_than`.
# Objective
Closes#7202
## Solution
~~Introduce a `not` helper to pipe conditions. Opened mostly for discussion. Maybe create an extension trait with `not` method? Please, advice.~~
Introduce `not(condition)` condition that inverses the result of the passed.
---
## Changelog
### Added
- `not` condition.
# Objective
- Terminology used in field names and docs aren't accurate
- `window_origin` doesn't have any effect when `scaling_mode` is `ScalingMode::None`
- `left`, `right`, `bottom`, and `top` are set automatically unless `scaling_mode` is `None`. Fields that only sometimes give feedback are confusing.
- `ScalingMode::WindowSize` has no arguments, which is inconsistent with other `ScalingMode`s. 1 pixel = 1 world unit is also typically way too wide.
- `OrthographicProjection` feels generally less streamlined than its `PerspectiveProjection` counterpart
- Fixes#5818
- Fixes#6190
## Solution
- Improve consistency in `OrthographicProjection`'s public fields (they should either always give feedback or never give feedback).
- Improve consistency in `ScalingMode`'s arguments
- General usability improvements
- Improve accuracy of terminology:
- "Window" should refer to the physical window on the desktop
- "Viewport" should refer to the component in the window that images are drawn on (typically all of it)
- "View frustum" should refer to the volume captured by the projection
---
## Changelog
### Added
- Added argument to `ScalingMode::WindowSize` that specifies the number of pixels that equals one world unit.
- Added documentation for fields and enums
### Changed
- Renamed `window_origin` to `viewport_origin`, which now:
- Affects all `ScalingMode`s
- Takes a fraction of the viewport's width and height instead of an enum
- Removed `WindowOrigin` enum as it's obsolete
- Renamed `ScalingMode::None` to `ScalingMode::Fixed`, which now:
- Takes arguments to specify the projection size
- Replaced `left`, `right`, `bottom`, and `top` fields with a single `area: Rect`
- `scale` is now applied before updating `area`. Reading from it will take `scale` into account.
- Documentation changes to make terminology more accurate and consistent
## Migration Guide
- Change `window_origin` to `viewport_origin`; replace `WindowOrigin::Center` with `Vec2::new(0.5, 0.5)` and `WindowOrigin::BottomLeft` with `Vec2::new(0.0, 0.0)`
- For shadow projections and such, replace `left`, `right`, `bottom`, and `top` with `area: Rect::new(left, bottom, right, top)`
- For camera projections, remove l/r/b/t values from `OrthographicProjection` instantiations, as they no longer have any effect in any `ScalingMode`
- Change `ScalingMode::None` to `ScalingMode::Fixed`
- Replace manual changes of l/r/b/t with:
- Arguments in `ScalingMode::Fixed` to specify size
- `viewport_origin` to specify offset
- Change `ScalingMode::WindowSize` to `ScalingMode::WindowSize(1.0)`
# Objective
Fix#7571
## Solution
* Removed the offending line.
***
## Changelog
* Removed
* * The line: ``\\ [`apply_system_buffers`]: bevy_ecs::prelude::apply_system_buffers`` from `bevy_app` crate, which overrides the link in that specific comment block.
Co-authored-by: lupan <kallll5@hotmail.com>
Small commit to remove an unused resource scoped within a single bevy_ecs unit test. Also rearranged the initialization to follow initialization conventions of surrounding tests. World/Schedule initialization followed by resource initialization.
This change was tested locally with `cargo test`, and `cargo fmt` was run.
Risk should be tiny as change is scoped to a single unit test and very tiny, and I can't see any way that this resource is being used in the test.
Thank you so much!
# Objective
One of the most important usages of plugin names is currently not mentioned in its documentation: the uniqueness check
## Solution
- Mention that the plugin name is used to check for uniqueness
# Objective
Run conditions are a special type of system that do not modify the world, and which return a bool. Due to the way they are currently implemented, you can *only* use bare function systems as a run condition. Among other things, this prevents the use of system piping with run conditions. This make very basic constructs impossible, such as `my_system.run_if(my_condition.pipe(not))`.
Unblocks a basic solution for #7202.
## Solution
Add the trait `ReadOnlySystem`, which is implemented for any system whose parameters all implement `ReadOnlySystemParam`. Allow any `-> bool` system implementing this trait to be used as a run condition.
---
## Changelog
+ Added the trait `ReadOnlySystem`, which is implemented for any `System` type whose parameters all implement `ReadOnlySystemParam`.
+ Added the function `bevy::ecs::system::assert_is_read_only_system`.
# Objective
Fix#7377Fix#7513
## Solution
Record the changes made to the Bevy `Window` from `winit` as 'canon' to avoid Bevy sending those changes back to `winit` again, causing a feedback loop.
## Changelog
* Removed `ModifiesWindows` system label.
Neither `despawn_window` nor `changed_window` actually modify the `Window` component so all the `.after(ModifiesWindows)` shouldn't be necessary.
* Moved `changed_window` and `despawn_window` systems to `CoreStage::Last` to avoid systems making changes to the `Window` between `changed_window` and the end of the frame as they would be ignored.
## Migration Guide
The `ModifiesWindows` system label was removed.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Implementing `States` manually is repetitive, so let's not.
One thing I'm unsure of is whether the macro import statement is in the right place.
# Objective
- Prepass opaque and alpha mask are incorrectly sorted back to front. This slipped through review by accident.
## Solution
- Sort prepass opaque and alpha mask front to back
# Objective
add a hook for ambient occlusion to the pbr shader
## Solution
add a hook for ambient occlusion to the pbr shader
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
Some render systems that have system set used as a label so that they can be referenced from somewhere else.
The 1:1 translation from `add_system_to_stage(Prepare, prepare_lights.label(PrepareLights))` is `add_system(prepare_lights.in_set(Prepare).in_set(PrepareLights)`, but configuring the `PrepareLights` set to be in `Prepare` would match the intention better (there are no systems in `PrepareLights` outside of `Prepare`) and it is easier for visualization tools to deal with.
# Solution
- replace
```rust
prepare_lights in PrepareLights
prepare_lights in Prepare
```
with
```rs
prepare_lights in PrepareLights
PrepareLights in Prepare
```
**Before**

**After**

# Objective
One pattern to increase parallelism is deferred mutation: instead of directly mutating the world (and preventing other systems from running at the same time), you queue up operations to be applied to the world at the end of the stage. The most common example of this pattern uses the `Commands` SystemParam.
In order to avoid the overhead associated with commands, some power users may want to add their own deferred mutation behavior. To do this, you must implement the unsafe trait `SystemParam`, which interfaces with engine internals in a way that we'd like users to be able to avoid.
## Solution
Add the `Deferred<T>` primitive `SystemParam`, which encapsulates the deferred mutation pattern.
This can be combined with other types of `SystemParam` to safely and ergonomically create powerful custom types.
Essentially, this is just a variant of `Local<T>` which can run code at the end of the stage.
This type is used in the engine to derive `Commands` and `ParallelCommands`, which removes a bunch of unsafe boilerplate.
### Example
```rust
use bevy_ecs::system::{Deferred, SystemBuffer};
/// Sends events with a delay, but may run in parallel with other event writers.
#[derive(SystemParam)]
pub struct BufferedEventWriter<'s, E: Event> {
queue: Deferred<'s, EventQueue<E>>,
}
struct EventQueue<E>(Vec<E>);
impl<'s, E: Event> BufferedEventWriter<'s, E> {
/// Queues up an event to be sent at the end of this stage.
pub fn send(&mut self, event: E) {
self.queue.0.push(event);
}
}
// The `SystemBuffer` trait controls how [`Deferred`] gets applied at the end of the stage.
impl<E: Event> SystemBuffer for EventQueue<E> {
fn apply(&mut self, world: &mut World) {
let mut events = world.resource_mut::<Events<E>>();
for e in self.0.drain(..) {
events.send(e);
}
}
}
```
---
## Changelog
+ Added the `SystemParam` type `Deferred<T>`, which can be used to defer `World` mutations. Powered by the new trait `SystemBuffer`.
# Objective
Buffers in bevy do not allow for setting buffer usage flags which can be useful for setting COPY_SRC, MAP_READ, MAP_WRITE, which allows for buffers to be copied from gpu to cpu for inspection.
## Solution
Add buffer_usage field to buffers and a set_usage function to set them
# Objective
Currently the `GetPath` documentation suggests it can be used with `Tuple` types (reflected tuples). However, this is not currently the case.
## Solution
Add reflection path support for `Tuple` types.
---
## Changelog
- Add reflection path support for `Tuple` types
# Objective
- There is a small perf cost for starting the multithreaded executor.
## Solution
- We can skip that cost when there are zero systems in the schedule. Overall not a big perf boost unless there are a lot of empty schedules that are trying to run, but it is something.
Below is a tracy trace of the run_fixed_update_schedule for many_foxes which has zero systems in it. Yellow is main and red is this pr. The time difference between the peaks of the humps is around 15us.
# Objective
- Implementing logic used by system params and `UnsafeWorldCell` on `&World` is sus since `&World` generally denotes shared read only access to world but this is a lie in the above situations. Move most/all logic that uses `&World` to mean `UnsafeWorldCell` onto `UnsafeWorldCell`
- Add a way to take a `&mut World` out of `UnsafeWorldCell` and use this in `WorldCell`'s `Drop` impl instead of a `UnsafeCell` field
---
## Changelog
- changed some `UnsafeWorldCell` methods to take `self` instead of `&self`/`&mut self` since there is literally no point to them doing that
- `UnsafeWorldCell::world` is now used to get immutable access to the whole world instead of just the metadata which can now be done via `UnsafeWorldCell::world_metadata`
- `UnsafeWorldCell::world_mut` now exists and can be used to get a `&mut World` out of `UnsafeWorldCell`
- removed `UnsafeWorldCell::storages` since that is probably unsound since storages contains the actual component/resource data not just metadata
## Migration guide
N/A none of the breaking changes here make any difference for a 0.9->0.10 transition since `UnsafeWorldCell` did not exist in 0.9
# Objective
- Merge the examples on iOS and Android
- Make sure they both work from the same code
## Solution
- don't create window when not in an active state (from #6830)
- exit on suspend on Android (from #6830)
- automatically enable dependency feature of bevy_audio on android so that it works out of the box
- don't inverse y position of touch events
- reuse the same example for both Android and iOS
Fixes#4616Fixes#4103Fixes#3648Fixes#3458Fixes#3249Fixes#86
# Objective
- Fixes#766
## Solution
- Add a new `Lcha` member to `bevy_render::color::Color` enum
---
## Changelog
- Add a new `Lcha` member to `bevy_render::color::Color` enum
- Add `bevy_render::color::LchRepresentation` struct
# Objective
[as noted](https://github.com/bevyengine/bevy/pull/5950#discussion_r1080762807) by james, transmuting arcs may be UB.
we now store a `*const ()` pointer internally, and only rely on `ptr.cast::<()>().cast::<T>() == ptr`.
as a happy side effect this removes the need for boxing the value, so todo: potentially use this for release mode as well
Implementing GetTypeRegistration in macro impl_reflect_for_veclike! had typos!
It only implement GetTypeRegistration for Vec<T>, but not for VecDeque<T>.
This will cause serialization and deserialization failure.
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Currently exclusive systems and applying buffers run outside of the multithreaded executor and just calls the funtions on the thread the schedule is running on. Stageless changes this to run these using tasks in a scope. Specifically It uses `spawn_on_scope` to run these. For the render thread this is incorrect as calling `spawn_on_scope` there runs tasks on the main thread. It should instead run these on the render thread and only run nonsend systems on the main thread.
## Solution
- Add another executor to `Scope` for spawning tasks on the scope. `spawn_on_scope` now always runs the task on the thread the scope is running on. `spawn_on_external` spawns onto the external executor than is optionally passed in. If None is passed `spawn_on_external` will spawn onto the scope executor.
- Eventually this new machinery will be able to be removed. This will happen once a fix for removing NonSend resources from the world lands. So this is a temporary fix to support stageless.
---
## Changelog
- add a spawn_on_external method to allow spawning on the scope's thread or an external thread
## Migration Guide
> No migration guide. The main thread executor was introduced in pipelined rendering which was merged for 0.10. spawn_on_scope now behaves the same way as on 0.9.
# Objective
Fixes#7476. UI scale was being incorrectly ignored when a primary window exists.
## Solution
Always take into account UI scale, regardless of whether a primary window exists.
Tested locally on @forbjok 's minimal repro project https://github.com/forbjok/bevy_ui_repro with this patch, and the issue is fixed on my machine.
# Objective
allow negatively-scaled mesh2ds to render correctly by disabling back-face culling. this brings the mesh2d pipeline into line with the sprite pipeline. i don't see any cases where backface-culling would be useful for 2d meshes.
# Objective
- Make the internals of `RemovedComponents` clearer
## Solution
- Add a wrapper around `Entity`, used in `RemovedComponents` as `Events<RemovedComponentsEntity>`
---
## Changelog
- `RemovedComponents` now internally uses an `Events<RemovedComponentsEntity>` instead of an `Events<Entity>`
The `DoubleEndedIterator` impls produce incorrect results on subsequent calls to `iter()` if the iterator is only partially consumed.
The following code shows what happens
```rust
fn next_back_is_bad() {
let mut events = Events::<TestEvent>::default();
events.send(TestEvent { i: 0 });
events.send(TestEvent { i: 1 });
events.send(TestEvent { i: 2 });
let mut reader = events.get_reader();
let mut iter = reader.iter(&events);
assert_eq!(iter.next_back(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), Some(&TestEvent { i: 0 }));
let mut iter = reader.iter(&events);
// `i: 2` event is returned twice! The `i: 1` event is missed.
assert_eq!(iter.next(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), None);
}
```
I don't think this can be fixed without adding some very convoluted bookkeeping.
## Migration Guide
`ManualEventIterator` and `ManualEventIteratorWithId` are no longer `DoubleEndedIterator`s.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Improve ergonomics / documentation of cascaded shadow maps
- Allow for the customization of the nearest shadowing distance.
- Fixes#7393
- Fixes#7362
## Solution
- Introduce `CascadeShadowConfigBuilder`
- Tweak various example cascade settings for better quality.
---
## Changelog
- Made examples look nicer under cascaded shadow maps.
- Introduce `CascadeShadowConfigBuilder` to help with creating `CascadeShadowConfig`
## Migration Guide
- Configure settings for cascaded shadow maps for directional lights using the newly introduced `CascadeShadowConfigBuilder`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Avoid ‘Unable to find a GPU! Make sure you have installed required drivers!’ .
Because many devices only support OpenGL without Vulkan.
Fixes#3191
## Solution
Use all backends supported by wgpu.
# Objective
Removal events are unwieldy and require some knowledge of when to put systems that need to catch events for them, it is very easy to end up missing one and end up with memory leak-ish issues where you don't clean up after yourself.
## Solution
Consolidate removals with the benefits of `Events<...>` (such as double buffering and per system ticks for reading the events) and reduce the special casing of it, ideally I was hoping to move the removals to a `Resource` in the world, but that seems a bit more rough to implement/maintain because of double mutable borrowing issues.
This doesn't go the full length of change detection esque removal detection a la https://github.com/bevyengine/rfcs/pull/44.
Just tries to make the current workflow a bit more user friendly so detecting removals isn't such a scheduling nightmare.
---
## Changelog
- RemovedComponents<T> is now backed by an `Events<Entity>` for the benefits of double buffering.
## Migration Guide
- Add a `mut` for `removed: RemovedComponents<T>` since we are now modifying an event reader internally.
- Iterating over removed components now requires `&mut removed_components` or `removed_components.iter()` instead of `&removed_components`.
# Objective
Currently, shaders may only have syntax such as
```wgsl
#ifdef FOO
// foo code
#else
#ifdef BAR
// bar code
#else
#ifdef BAZ
// baz code
#else
// fallback code
#endif
#endif
#endif
```
This is hard to read and follow.
Add a way to allow writing `#else ifdef DEFINE` to reduce the number of scopes introduced and to increase readability.
## Solution
Refactor the current preprocessing a bit and add logic to allow `#else ifdef DEFINE`.
This includes per-scope tracking of whether a branch has been accepted.
Add a few tests for this feature.
With these changes we may now write:
```wgsl
#ifdef FOO
// foo code
#else ifdef BAR
// bar code
#else ifdef BAZ
// baz code
#else
// fallback code
#endif
```
instead.
---
## Changelog
- Add `#else ifdef` to shader preprocessing.
# Objective
The trait method `SystemParam::apply` allows a `SystemParam` type to defer world mutations, which is internally used to apply `Commands` at the end of the stage. Any operations that require `&mut World` access must be deferred in this way, since parallel systems do not have exclusive access to the world.
The `ExclusiveSystemParam` trait (added in #6083) has an `apply` method which serves the same purpose. However, deferring mutations in this way does not make sense for exclusive systems since they already have `&mut World` access: there is no need to wait until a hard sync point, as the system *is* a hard sync point. World mutations can and should be performed within the body of the system.
## Solution
Remove the method. There were no implementations of this method in the engine.
---
## Changelog
*Note for maintainers: this changelog makes more sense if it's placed above the one for #6919.*
- Removed the method `ExclusiveSystemParamState::apply`.
## Migration Guide
*Note for maintainers: this migration guide makes more sense if it's placed above the one for #6919.*
The trait method `ExclusiveSystemParamState::apply` has been removed. If you have an exclusive system with buffers that must be applied, you should apply them within the body of the exclusive system.
# Objective
Fixes#7434.
This is my first time contributing to a Rust project, so please let me know if this wasn't the change intended by the linked issue.
## Solution
Adds a test with a system that panics to `bevy_ecs`.
I'm not sure if this is the intended panic message, but this is what the test currently results in:
```
thread 'system::tests::panic_inside_system' panicked at 'called `Option::unwrap()` on a `None` value', /Users/bjorn/workplace/bevy/crates/bevy_tasks/src/task_pool.rs:354:49
```
# Objective
- Update winit to 0.28
## Solution
- Small API change
- A security advisory has been added for a unmaintained crate used by a dependency of winit build script for wayland
I didn't do anything for Android support in this PR though it should be fixable, it should be done in a separate one, maybe https://github.com/bevyengine/bevy/pull/6830
---
## Changelog
- `window.always_on_top` has been removed, you can now use `window.window_level`
## Migration Guide
before:
```rust
app.new()
.add_plugins(DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
always_on_top: true,
..default()
}),
..default()
}));
```
after:
```rust
app.new()
.add_plugins(DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
window_level: bevy:🪟:WindowLevel::AlwaysOnTop,
..default()
}),
..default()
}));
```
# Objective
Fix#7447.
The `SystemParam` derive uses the wrong lifetimes for ignored fields.
## Solution
Use type inference instead of explicitly naming the types of ignored fields. This allows the compiler to automatically use the correct lifetime.
# Objective
- Fix panic_when_hierachy_cycle test hanging
- The problem is that the scope only awaits one task at a time in get_results. In stageless this task is the multithreaded executor. That tasks hangs when a system panics and cannot make anymore progress. This wasn't a problem before because the executor was spawned after all the system tasks had been spawned. But in stageless the executor is spawned before all the system tasks are spawned.
## Solution
- We can catch unwind on each system and close the finish channel if one panics. This then causes the receiver end of the finish channel to panic too.
- this might have a small perf impact, but when running many_foxes it seems to be within the noise. So less than 40us.
## Other possible solutions
- It might be possible to fairly poll all the tasks in get_results in the scope. If we could do that then the scope could panic whenever one of tasks panics. It would require a data structure that we could both poll the futures through a shared ref and also push to it. I tried FuturesUnordered, but it requires an exclusive ref to poll it.
- The catch unwind could be moved onto when we create the tasks for scope instead. We would then need something like a oneshot async channel to inform get_results if a task panics.
# Objective
Ability to use `ReflectComponent` methods in dynamic type contexts with no access to `&World`.
This problem occurred to me when wanting to apply reflected types to an entity where the `&World` reference was already consumed by query iterator leaving only `EntityMut`.
## Solution
- Remove redundant `EntityMut` or `EntityRef` lookup from `World` and `Entity` in favor of taking `EntityMut` directly in `ReflectComponentFns`.
- Added `RefectComponent::contains` to determine without panic whether `apply` can be used.
## Changelog
- Changed function signatures of `ReflectComponent` methods, `apply`, `remove`, `contains`, and `reflect`.
## Migration Guide
- Call `World::entity` before calling into the changed `ReflectComponent` methods, most likely user already has a `EntityRef` or `EntityMut` which was being queried redundantly.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
- After the multithreaded executor finishes running all the systems, we apply the buffers for any system that hasn't applied it's buffers. This is a courtesy apply for users who forget to order their systems before a apply_system_buffers. When checking stageless, it was found that this apply_system_buffers was running on the executor thread instead of the world's thread. This is a problem because anything with world access should be able to access nonsend resources.
## Solution
- Move the final apply_system_buffers outside of the executor and outside of the scope, so it runs on the same thread that schedule.run is called on.
# Objective
In CSS Flexbox width and height are auto by default, whereas in Bevy their default is `Size::Undefined`.
This means that, unlike in CSS, if you elide a height or width value for a node it will be given zero length (unless it has an explicitly sized child node). This has misled users into falsely assuming that they have to explicitly set a value for both height and width all the time.
relevant issue: #7120
## Solution
Change the `Size` `width` and `height` default values to `Val::Auto`
## Changelog
* Changed the `Size` `width` and `height` default values to `Val::Auto`
## Migration Guide
The default values for `Size` `width` and `height` have been changed from `Val::Undefined` to `Val::Auto`.
It's unlikely to cause any issues with existing code.
# Objective
- The stageless executor keeps track of systems that have run, but have not applied their system buffers. The bitset for that was being cloned into apply_system_buffers and cleared in that function, but we need to clear the original version instead of the cloned version
## Solution
- move the clear out of the apply_system_buffers function.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Clearing the reader doesn't require iterating the events. Updating the `last_event_count` of the reader is enough.
I rewrote part of the documentation as some of it was incorrect or harder to understand than necessary.
## Changelog
Added `ManualEventReader::clear()`
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
During testing, I observed that the `FrameCount` resource (`bevy_core`) was being incremented by `FrameCountPlugin` non-deterministically, during update, subject to the whims of the execution order.
The effect was that the counter could and did change while a frame was still in flight, while user-systems were still executing.
## Solution
I have delayed the incrementing of the `FrameCount` resource to `CoreStage::Last`. The resource was described in the documentation as "*a count of rendered frames*" and, after my change, it actually will match that description.
## Changes
- `CoreStage::Last` was chosen so that the counter will be `0` during all earlier stages of the very first execution of the schedule.
- Documentation added declaring *when* the counter is incremented.
- Hint added, directing users towards `u32::wrapping_sub()` because integer overflow is reasonable to expect.
## Note
Even though this change might have a short time-to-live in light of the upcoming *Stageless* changes, I think this is worthwhile – at least as an in-code reminder that this counter should behave predictably.
# Objective
- Resolve a Fixme to remove the `Default` impl for `HandleType`, once Reflection no longer requires it.
- Presumebly this Comment was made before the `FromReflect` Derive used the `#[reflect(Default)]`, to substitute for the requirment that a ignored field has a `Default`.
## Solution
- Just remove the `Default` derive and comment.
## Objective
A common easy to miss mistake is to write something like:
``` rust
Size::new(Val::Percent(100.), Val::Px(100.));
```
`UiRect` has the `left`, `right`, `all`, `vertical`, etc constructor functions, `Size` is used a lot more frequently but lacks anything similar.
## Solution
Implement `all`, `width` and `height` functions for `Size`.
## Changelog
* Added `all`, `width` and `height` functions to `Size`.
# Problem
The field is called `background_color` but it is also used to hold the colors of text glyphs and images.
It's mildly confusing and longer to type than just `color`.
## Solution
Rename `background_color` to `color`.
## Changelog
* Renamed the `background_color` field of `ExtractedUiNode` to `color`.
## Migration Guide
* The `background_color` field of `ExtractedUiNode` is now named `color`.
# Objective
- Fixes#7430.
## Solution
- Changed fields of `ArrayIter` to be private.
- Add a constructor `new` to `ArrayIter`.
- Replace normal struct creation with `new`.
---
## Changelog
- Add a constructor `new` to `ArrayIter`.
Co-authored-by: Elbert Ronnie <103196773+elbertronnie@users.noreply.github.com>
## Objective
Remove `QueuedText`.
`QueuedText` isn't useful. It's exposed in the `bevy_ui` public interface but can't be used for anything because its `entities` field is private.
## Solution
Remove the `QueuedText` struct and use a `Local<Vec<Entity>` in its place.
## Changelog
* Removed `QueuedText`
# Objective
- Bevy should not have any "internal" execution order ambiguities. These clutter the output of user-facing error reporting, and can result in nasty, nondetermistic, very difficult to solve bugs.
- Verifying this currently involves repeated non-trivial manual work.
## Solution
- [x] add an example to quickly check this
- ~~[ ] ensure that this example panics if there are any unresolved ambiguities~~
- ~~[ ] run the example in CI 😈~~
There's one tricky ambiguity left, between UI and animation. I don't have the tools to fix this without system set configuration, so the remaining work is going to be left to #7267 or another PR after that.
```
2023-01-27T18:38:42.989405Z INFO bevy_ecs::schedule::ambiguity_detection: Execution order ambiguities detected, you might want to add an explicit dependency relation between some of these systems:
* Parallel systems:
-- "bevy_animation::animation_player" and "bevy_ui::flex::flex_node_system"
conflicts: ["bevy_transform::components::transform::Transform"]
```
## Changelog
Resolved internal execution order ambiguities for:
1. Transform propagation (ignored, we need smarter filter checking).
2. Gamepad processing (fixed).
3. bevy_winit's window handling (fixed).
4. Cascaded shadow maps and perspectives (fixed).
Also fixed a desynchronized state bug that could occur when the `Window` component is removed and then added to the same entity in a single frame.
# Objective
- Fix a bug causing performance to drop over time because the GPU fog buffer was endlessly growing
## Solution
- Clear the fog buffer every frame before populating it
# Objective
- Fix `post_processing` and `shader_prepass` examples as they fail when compiling shaders due to missing shader defs
- Fixes#6799
- Fixes#6996
- Fixes#7375
- Supercedes #6997
- Supercedes #7380
## Solution
- The prepass was broken due to a missing `MAX_CASCADES_PER_LIGHT` shader def. Add it.
- The shader used in the `post_processing` example is applied to a 2D mesh, so use the correct mesh2d_view_bindings shader import.
# Objective
- Trying to make it easier to have a more user friendly debugging name for when you want to print out an entity.
## Solution
- Add a new `WorldQuery` struct `DebugName` to format the `Name` if the entity has one, otherwise formats the `Entity` id.
This means we can do this and get more descriptive errors without much more effort:
```rust
fn my_system(moving: Query<(DebugName, &mut Position, &Velocity)>) {
for (name, mut position, velocity) in &mut moving {
position += velocity;
if position.is_nan() {
error!("{:?} has an invalid position state", name);
}
}
}
```
---
## Changelog
- Added `DebugName` world query for more human friendly debug names of entities.
# Objective
In simple cases we might want to derive the `ExtractComponent` trait.
This adds symmetry to the existing `ExtractResource` derive.
## Solution
Add an implementation of `#[derive(ExtractComponent)]`.
The implementation is adapted from the existing `ExtractResource` derive macro.
Additionally, there is an attribute called `extract_component_filter`. This allows specifying a query filter type used when extracting.
If not specified, no filter (equal to `()`) is used.
So:
```rust
#[derive(Component, Clone, ExtractComponent)]
#[extract_component_filter(With<Fuel>)]
pub struct Car {
pub wheels: usize,
}
```
would expand to (a bit cleaned up here):
```rust
impl ExtractComponent for Car
{
type Query = &'static Self;
type Filter = With<Fuel>;
type Out = Self;
fn extract_component(item: QueryItem<'_, Self::Query>) -> Option<Self::Out> {
Some(item.clone())
}
}
```
---
## Changelog
- Added the ability to `#[derive(ExtractComponent)]` with an optional filter.
# Objective
- Fixes#4592
## Solution
- Implement `SrgbColorSpace` for `u8` via `f32`
- Convert KTX2 R8 and R8G8 non-linear sRGB to wgpu `R8Unorm` and `Rg8Unorm` as non-linear sRGB are not supported by wgpu for these formats
- Convert KTX2 R8G8B8 formats to `Rgba8Unorm` and `Rgba8UnormSrgb` by adding an alpha channel as the Rgb variants don't exist in wgpu
---
## Changelog
- Added: Support for KTX2 `R8_SRGB`, `R8_UNORM`, `R8G8_SRGB`, `R8G8_UNORM`, `R8G8B8_SRGB`, `R8G8B8_UNORM` formats by converting to supported wgpu formats as appropriate
# Objective
Add a `FromReflect` derive to the `Aabb` type, like all other math types, so we can reflect `Vec<Aabb>`.
## Solution
Just add it :)
---
## Changelog
### Added
- Implemented `FromReflect` for `Aabb`.
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
# Objective
- Fix#7315
- Add IME support
## Solution
- Add two new fields to `Window`, to control if IME is enabled and the candidate box position
This allows the use of dead keys which are needed in French, or the full IME experience to type using Pinyin
I also added a basic general text input example that can handle IME input.
https://user-images.githubusercontent.com/8672791/213941353-5ed73a73-5dd1-4e66-a7d6-a69b49694c52.mp4
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873533-44c029af-13b7-4740-8ea3-af96bd5867c9.png">
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873549-36be7a23-b341-42a2-8a9f-ceea8ac7a2b8.png">
# Objective
- Add support for the “classic” distance fog effect, as well as a more advanced atmospheric fog effect.
## Solution
This PR:
- Introduces a new `FogSettings` component that controls distance fog per-camera.
- Adds support for three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
- Adds support for directional light influence over fog color;
- Extracts fog via `ExtractComponent`, then uses a prepare system that sets up a new dynamic uniform struct (`Fog`), similar to other mesh view types;
- Renders fog in PBR material shader, as a final adjustment to the `output_color`, after PBR is computed (but before tone mapping);
- Adds a new `StandardMaterial` flag to enable fog; (`fog_enabled`)
- Adds convenience methods for easier artistic control when creating non-linear fog types;
- Adds documentation around fog.
---
## Changelog
### Added
- Added support for distance-based fog effects for PBR materials, controllable per-camera via the new `FogSettings` component;
- Added `FogFalloff` enum for selecting between three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
# Objective
Found while working on #7385.
The struct `EntityMut` has the safety invariant that it's cached `EntityLocation` must always accurately specify where the entity is stored. Thus, any time its location might be invalidated (such as by calling `EntityMut::world_mut` and moving archetypes), the cached location *must* be updated by calling `EntityMut::update_location`.
The method `world_scope` encapsulates this pattern in safe API by requiring world mutations to be done in a closure, after which `update_location` will automatically be called. However, this method has a soundness hole: if a panic occurs within the closure, then `update_location` will never get called. If the panic is caught in an outer scope, then the `EntityMut` will be left with an outdated location, which is undefined behavior.
An example of this can be seen in the unit test `entity_mut_world_scope_panic`, which has been added to this PR as a regression test. Without the other changes in this PR, that test will invoke undefined behavior in safe code.
## Solution
Call `EntityMut::update_location()` from within a `Drop` impl, which ensures that it will get executed even if `EntityMut::world_scope` unwinds.
# Objective
I recently had an issue, where I have a struct:
```
struct Property {
inner: T
}
```
that I use as a wrapper for internal purposes.
I don't want to update my struct definition to
```
struct Property<T: Reflect>{
inner: T
}
```
because I still want to be able to build `Property<T>` for types `T` that are not `Reflect`. (and also because I don't want to update my whole code base with `<T: Reflect>` bounds)
I still wanted to have reflection on it (for `bevy_inspector_egui`), but adding `derive(Reflect)` fails with the error:
`T cannot be sent between threads safely. T needs to implement Sync.`
I believe that `bevy_reflect` should adopt the model of other derives in the case of generics, which is to add the `Reflect` implementation only if the generics also implement `Reflect`. (That is the behaviour of other macros such as `derive(Clone)` or `derive(Debug)`.
It's also the current behavior of `derive(FromReflect)`.
Basically doing something like:
```
impl<T> Reflect for Foo<T>
where T: Reflect
```
## Solution
- I updated the derive macros for `Structs` and `TupleStructs` to add extra `where` bounds.
- Every type that is reflected will need a `T: Reflect` bound
- Ignored types will need a `T: 'static + Send + Sync` bound. Here's the reason. For cases like this:
```
#[derive(Reflect)]
struct Foo<T, U>{
a: T
#[reflect(ignore)]
b: U
}
```
I had to add the bound `'static + Send + Sync` to ignored generics like `U`.
The reason is that we want `Foo<T, U>` to be `Reflect: 'static + Send + Sync`, so `Foo<T, U>` must be able to implement those auto-traits. `Foo<T, U>` will only implement those auto-traits if every generic type implements them, including ignored types.
This means that the previously compile-fail case now compiles:
```
#[derive(Reflect)]
struct Foo<'a> {
#[reflect(ignore)]
value: &'a str,
}
```
But `Foo<'a>` will only be useable in the cases where `'a: 'static` and panic if we don't have `'a: 'static`, which is what we want (nice bonus from this PR ;) )
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
### Added
Possibility to add `derive(Reflect)` to structs and enums that contain generic types, like so:
```
#[derive(Reflect)]
struct Foo<T>{
a: T
}
```
Reflection will only be available if the generic type T also implements `Reflect`.
(previously, this would just return a compiler error)
# Objective
The function `EntityMut::world_scope` is a safe abstraction that allows you to temporarily get mutable access to the underlying `World` of an `EntityMut`. This function is purely stateful, meaning it is not easily possible to return a value from it.
## Solution
Allow returning a computed value from the closure. This is similar to how `World::resource_scope` works.
---
## Changelog
- The function `EntityMut::world_scope` now allows returning a value from the immediately-computed closure.
# Objective
## Use Case
A render node which calls `post_process_write()` on a `ViewTarget` multiple times during a single run of the node means both main textures of this view target is accessed.
If the source texture (which alternate between main textures **a** and **b**) is accessed in a shader during those iterations it means that those textures have to be bound using bind groups.
Preparing bind groups for both main textures ahead of time is desired, which means having access to the _other_ main texture is needed.
## Solution
Add a method on `ViewTarget` for accessing the other main texture.
---
## Changelog
### Added
- `main_texture_other` API on `ViewTarget`
# Objective
There's no period at the end of the first line of the `Name` documentation, and this messes up the grammar of the summary rustdoc creates:
```
↓
Component used to identify an entity. Stores a hash for faster comparisons The hash is eagerly re-computed upon each update to the name.
```
## Solution
I added it.
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
alternative to #5922, implements #5956
builds on top of https://github.com/bevyengine/bevy/pull/6402
# Objective
https://github.com/bevyengine/bevy/issues/5956 goes into more detail, but the TLDR is:
- bevy systems ensure disjoint accesses to resources and components, and for that to work there are methods `World::get_resource_unchecked_mut(&self)`, ..., `EntityRef::get_mut_unchecked(&self)` etc.
- we don't have these unchecked methods for `by_id` variants, so third-party crate authors cannot build their own safe disjoint-access abstractions with these
- having `_unchecked_mut` methods is not great, because in their presence safe code can accidentally violate subtle invariants. Having to go through `world.as_unsafe_world_cell().unsafe_method()` forces you to stop and think about what you want to write in your `// SAFETY` comment.
The alternative is to keep exposing `_unchecked_mut` variants for every operation that we want third-party crates to build upon, but we'd prefer to avoid using these methods alltogether: https://github.com/bevyengine/bevy/pull/5922#issuecomment-1241954543
Also, this is something that **cannot be implemented outside of bevy**, so having either this PR or #5922 as an escape hatch with lots of discouraging comments would be great.
## Solution
- add `UnsafeWorldCell` with `unsafe fn get_resource(&self)`, `unsafe fn get_resource_mut(&self)`
- add `fn World::as_unsafe_world_cell(&mut self) -> UnsafeWorldCell<'_>` (and `as_unsafe_world_cell_readonly(&self)`)
- add `UnsafeWorldCellEntityRef` with `unsafe fn get`, `unsafe fn get_mut` and the other utilities on `EntityRef` (no methods for spawning, despawning, insertion)
- use the `UnsafeWorldCell` abstraction in `ReflectComponent`, `ReflectResource` and `ReflectAsset`, so these APIs are easier to reason about
- remove `World::get_resource_mut_unchecked`, `EntityRef::get_mut_unchecked` and use `unsafe { world.as_unsafe_world_cell().get_mut() }` and `unsafe { world.as_unsafe_world_cell().get_entity(entity)?.get_mut() }` instead
This PR does **not** make use of `UnsafeWorldCell` for anywhere else in `bevy_ecs` such as `SystemParam` or `Query`. That is a much larger change, and I am convinced that having `UnsafeWorldCell` is already useful for third-party crates.
Implemented API:
```rust
struct World { .. }
impl World {
fn as_unsafe_world_cell(&self) -> UnsafeWorldCell<'_>;
}
struct UnsafeWorldCell<'w>(&'w World);
impl<'w> UnsafeWorldCell {
unsafe fn world(&self) -> &World;
fn get_entity(&self) -> UnsafeWorldCellEntityRef<'w>; // returns 'w which is `'self` of the `World::as_unsafe_world_cell(&'w self)`
unsafe fn get_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_resource_by_id(&self, ComponentId) -> Option<&'w T>;
unsafe fn get_resource_mut<T>(&self) -> Option<Mut<'w, T>>;
unsafe fn get_resource_mut_by_id(&self) -> Option<MutUntyped<'w>>;
unsafe fn get_non_send_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_non_send_resource_mut<T>(&self) -> Option<Mut<'w, T>>>;
// not included: remove, remove_resource, despawn, anything that might change archetypes
}
struct UnsafeWorldCellEntityRef<'w> { .. }
impl UnsafeWorldCellEntityRef<'w> {
unsafe fn get<T>(&self, Entity) -> Option<&'w T>;
unsafe fn get_by_id(&self, Entity, ComponentId) -> Option<Ptr<'w>>;
unsafe fn get_mut<T>(&self, Entity) -> Option<Mut<'w, T>>;
unsafe fn get_mut_by_id(&self, Entity, ComponentId) -> Option<MutUntyped<'w>>;
unsafe fn get_change_ticks<T>(&self, Entity) -> Option<Mut<'w, T>>;
// fn id, archetype, contains, contains_id, containts_type_id
}
```
<details>
<summary>UnsafeWorldCell docs</summary>
Variant of the [`World`] where resource and component accesses takes a `&World`, and the responsibility to avoid
aliasing violations are given to the caller instead of being checked at compile-time by rust's unique XOR shared rule.
### Rationale
In rust, having a `&mut World` means that there are absolutely no other references to the safe world alive at the same time,
without exceptions. Not even unsafe code can change this.
But there are situations where careful shared mutable access through a type is possible and safe. For this, rust provides the [`UnsafeCell`](std::cell::UnsafeCell)
escape hatch, which allows you to get a `*mut T` from a `&UnsafeCell<T>` and around which safe abstractions can be built.
Access to resources and components can be done uniquely using [`World::resource_mut`] and [`World::entity_mut`], and shared using [`World::resource`] and [`World::entity`].
These methods use lifetimes to check at compile time that no aliasing rules are being broken.
This alone is not enough to implement bevy systems where multiple systems can access *disjoint* parts of the world concurrently. For this, bevy stores all values of
resources and components (and [`ComponentTicks`](crate::component::ComponentTicks)) in [`UnsafeCell`](std::cell::UnsafeCell)s, and carefully validates disjoint access patterns using
APIs like [`System::component_access`](crate::system::System::component_access).
A system then can be executed using [`System::run_unsafe`](crate::system::System::run_unsafe) with a `&World` and use methods with interior mutability to access resource values.
access resource values.
### Example Usage
[`UnsafeWorldCell`] can be used as a building block for writing APIs that safely allow disjoint access into the world.
In the following example, the world is split into a resource access half and a component access half, where each one can
safely hand out mutable references.
```rust
use bevy_ecs::world::World;
use bevy_ecs::change_detection::Mut;
use bevy_ecs::system::Resource;
use bevy_ecs::world::unsafe_world_cell_world::UnsafeWorldCell;
// INVARIANT: existance of this struct means that users of it are the only ones being able to access resources in the world
struct OnlyResourceAccessWorld<'w>(UnsafeWorldCell<'w>);
// INVARIANT: existance of this struct means that users of it are the only ones being able to access components in the world
struct OnlyComponentAccessWorld<'w>(UnsafeWorldCell<'w>);
impl<'w> OnlyResourceAccessWorld<'w> {
fn get_resource_mut<T: Resource>(&mut self) -> Option<Mut<'w, T>> {
// SAFETY: resource access is allowed through this UnsafeWorldCell
unsafe { self.0.get_resource_mut::<T>() }
}
}
// impl<'w> OnlyComponentAccessWorld<'w> {
// ...
// }
// the two interior mutable worlds borrow from the `&mut World`, so it cannot be accessed while they are live
fn split_world_access(world: &mut World) -> (OnlyResourceAccessWorld<'_>, OnlyComponentAccessWorld<'_>) {
let resource_access = OnlyResourceAccessWorld(unsafe { world.as_unsafe_world_cell() });
let component_access = OnlyComponentAccessWorld(unsafe { world.as_unsafe_world_cell() });
(resource_access, component_access)
}
```
</details>
# Objective
Prevent things from breaking tomorrow when rust 1.67 is released.
## Solution
Fix a few `uninlined_format_args` lints in recently introduced code.
# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps.
Fixes#3629
Before

After
## Solution
Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination.
---
## Changelog
Directional lights now use cascaded shadow maps for improved shadow quality.
## Migration Guide
You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
# Objective
Fixes#7286. Both `App::add_sub_app` and `App::insert_sub_app` are rather redundant. Before 0.10 is shipped, one of them should be removed.
## Solution
Remove `App::add_sub_app` to prefer `App::insert_sub_app`.
Also hid away `SubApp::extract` since that can be a footgun if someone mutates it for whatever reason. Willing to revert this change if there are objections.
Perhaps we should make `SubApp: Deref<Target=App>`? Might change if we decide to move `!Send` resources into it.
---
## Changelog
Added: `SubApp::new`
Removed: `App::add_sub_app`
## Migration Guide
`App::add_sub_app` has been removed in favor of `App::insert_sub_app`. Use `SubApp::new` and insert it via `App::add_sub_app`
Old:
```rust
let mut sub_app = App::new()
// Build subapp here
app.add_sub_app(MySubAppLabel, sub_app);
```
New:
```rust
let mut sub_app = App::new()
// Build subapp here
app.insert_sub_app(MySubAppLabel, SubApp::new(sub_app, extract_fn));
```
# Objective
- The functions added to utils.wgsl by the prepass assume that mesh_view_bindings are present, which isn't always the case
- Fixes https://github.com/bevyengine/bevy/issues/7353
## Solution
- Move these functions to their own `prepass_utils.wgsl` file
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Problem
The `upsert_leaf` method creates a new `MeasureFunc` and, if required, a new leaf node, but then it only adds the new `MeasureFunc` to existing leaf nodes.
## Solution
Add the `MeasureFunc` to new leaf nodes as well.
# Objective
`add_system(system)` without any `.in_set` configuration should land in `CoreSet::Update`.
We check that the sets are empty, but for systems there is always the `SystemTypeset`.
## Solution
- instead of `is_empty()`, check that the only set it the `SystemTypeSet`
# Objective
The naming of the two plugin groups `DefaultPlugins` and `MinimalPlugins` suggests that one is a super-set of the other but this is not the case. Instead, the two plugin groups are intended for very different purposes.
Closes: https://github.com/bevyengine/bevy/issues/7173
## Solution
This merge request adds doc. comments that compensate for this and try save the user from confusion.
1. `DefaultPlugins` and `MinimalPlugins` intentions are described.
2. A strong emphasis on embracing `DefaultPlugins` as a whole but controlling what it contains with *Cargo* *features* is added – this is because the ordering in `DefaultPlugins` appears to be important so preventing users with "minimalist" foibles (That's Me!) from recreating the code seems worthwhile.
3. Notes are added explaining the confusing fact that `MinimalPlugins` contains `ScheduleRunnerPlugin` (which is very "important"-sounding) but `DefaultPlugins` does not.
# Objective
Help users understand how to write code that runs when the app is exiting.
See:
- #7067 (Partial resolution)
## Solution
Added documentation to `AppExit` class that mentions using the `Drop` trait for code that needs to run on program exit, as well as linking to the caveat about `App::run()` not being guaranteed to return.
# Objective
`bevy_ecs/system_param.rs` contains many seemingly-arbitrary struct definitions which serve as compile tests.
## Solution
Add a comment to each one, linking the issue or PR that motivated its addition.
# Objective
> ℹ️ **This is an adoption of #4081 by @james7132**
Fixes#4080.
Provide a way to pre-parse reflection paths so as to avoid having to parse at each call to `GetPath::path` (or similar method).
## Solution
Adds the `ParsedPath` struct (named `FieldPath` in the original PR) that parses and caches the sequence of accesses to a reflected element. This is functionally similar to the `GetPath` trait, but removes the need to parse an unchanged path more than once.
### Additional Changes
Included in this PR from the original is cleaner code as well as the introduction of a new pathing operation: field access by index. This allows struct and struct variant fields to be accessed in a more performant (albeit more fragile) way if needed. This operation is faster due to not having to perform string matching. As an example, if we wanted the third field on a struct, we'd write `#2`—where `#` denotes indexed access and `2` denotes the desired field index.
This PR also contains improved documentation for `GetPath` and friends, including renaming some of the methods to be more clear to the end-user with a reduced risk of getting them mixed up.
### Future Work
There are a few things that could be done as a separate PR (order doesn't matter— they could be followup PRs or done in parallel). These are:
- [x] ~~Add support for `Tuple`. Currently, we hint that they work but they do not.~~ See #7324
- [ ] Cleanup `ReflectPathError`. I think it would be nicer to give `ReflectPathError` two variants: `ReflectPathError::ParseError` and `ReflectPathError::AccessError`, with all current variants placed within one of those two. It's not obvious when one might expect to receive one type of error over the other, so we can help by explicitly categorizing them.
---
## Changelog
- Cleaned up `GetPath` logic
- Added `ParsedPath` for cached reflection paths
- Added new reflection path syntax: struct field access by index (example syntax: `foo#1`)
- Renamed methods on `GetPath`:
- `path` -> `reflect_path`
- `path_mut` -> `reflect_path_mut`
- `get_path` -> `path`
- `get_path_mut` -> `path_mut`
## Migration Guide
`GetPath` methods have been renamed according to the following:
- `path` -> `reflect_path`
- `path_mut` -> `reflect_path_mut`
- `get_path` -> `path`
- `get_path_mut` -> `path_mut`
Co-authored-by: Gino Valente <gino.valente.code@gmail.com>
# Objective
On wasm, bevy applications currently prevent any of the normal browser hotkeys from working normally (Ctrl+R, F12, F5, Ctrl+F5, tab, etc.).
Some of those events you may want to override, perhaps you can hold the tab key for showing in-game stats?
However, if you want to make a well-behaved game, you probably don't want to needlessly prevent that behavior unless you have a good reason.
Secondary motivation: Also, consider the workaround presented here to get audio working: https://developer.chrome.com/blog/web-audio-autoplay/#moving-forward ; It won't work (for keydown events) if we stop event propagation.
## Solution
- Winit has a field that allows it to not stop event propagation, expose it on the window settings to allow the user to choose the desired behavior. Default to `true` for backwards compatibility.
---
## Changelog
- Added `Window::prevent_default_event_handling` . This allows bevy apps to not override default browser behavior on hotkeys like F5, F12, Ctrl+R etc.
# Problemo
Some code in #5911 and #5454 does not compile with dynamic linking enabled.
The code is behind a feature gate to prevent dynamically linked builds from breaking, but it's not quite set up correctly.
## Solution
Forward the `dynamic` feature flag to the `bevy_diagnostic` crate and gate the code behind it.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes#5675. Replace `toml` with `toml_edit`
## Solution
Replace `toml` with `toml_edit`. This conveniently also removes the `serde` dependency from `bevy_macro_utils`, which may speed up cold compilation by removing the serde bottleneck from most of the macro crates in the engine.
# Objective
Speed up `prepare_uinodes`. The color `[f32; 4]` is being computed separately for every vertex in the UI, even though the color is the same for all 6 verticies.
## Solution
Avoid recomputing the color and cache it for all 6 verticies.
## Performance
On `many_buttons`, this shaved off 33% of the time in `prepare_uinodes` (7.67ms -> 5.09ms) on my local machine.
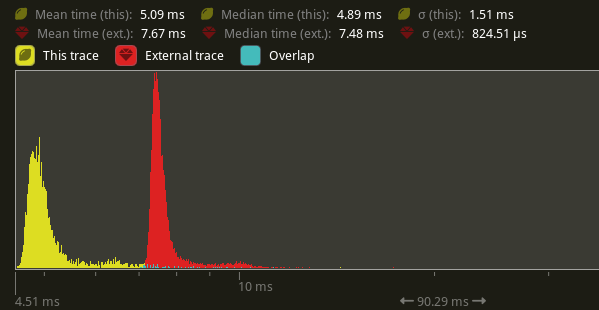
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
# Objective
Currently, Text always uses the default linebreaking behaviour in glyph_brush_layout `BuiltInLineBreaker::Unicode` which breaks lines at word boundaries. However, glyph_brush_layout also supports breaking lines at any character by setting the linebreaker to `BuiltInLineBreaker::AnyChar`. Having text wrap character-by-character instead of at word boundaries is desirable in some cases - consider that consoles/terminals usually wrap this way.
As a side note, the default Unicode linebreaker does not seem to handle emergency cases, where there is no word boundary on a line to break at. In that case, the text runs out of bounds. Issue #1867 shows an example of this.
## Solution
Basically just copies how TextAlignment is exposed, but for a new enum TextLineBreakBehaviour.
This PR exposes glyph_brush_layout's two simple linebreaking options (Unicode, AnyChar) to users of Text via the enum TextLineBreakBehaviour (which just translates those 2 aforementioned options), plus a method 'with_linebreak_behaviour' on Text and TextBundle.
## Changelog
Added `Text::with_linebreak_behaviour`
Added `TextBundle::with_linebreak_behaviour`
`TextPipeline::queue_text` and `GlyphBrush::compute_glyphs` now need a TextLineBreakBehaviour argument, in order to pass through the new field.
Modified the `text2d` example to show both linebreaking behaviours.
## Example
Here's what the modified example looks like

# Objective
- Fixes#7294
## Solution
- Do not trigger change detection when setting the cursor position from winit
When moving the cursor continuously, Winit sends events:
- CursorMoved(0)
- CursorMoved(1)
- => start of Bevy schedule execution
- CursorMoved(2)
- CursorMoved(3)
- <= End of Bevy schedule execution
if Bevy schedule runs after the event 1, events 2 and 3 would happen during the execution but would be read only on the next system run. During the execution, the system would detect a change on cursor position, and send back an order to winit to move it back to 1, so event 2 and 3 would be ignored. By bypassing change detection when setting the cursor from winit event, it doesn't trigger sending back that change to winit out of order.
# Objective
- `Components::resource_id` doesn't exist. Like `Components::component_id` but for resources.
## Solution
- Created `Components::resource_id` and added some docs.
---
## Changelog
- Added `Components::resource_id`.
- Changed `World::init_resource` to return the generated `ComponentId`.
- Changed `World::init_non_send_resource` to return the generated `ComponentId`.
# Objective
- Fixes#7288
- Do not expose access directly to cursor position as it is the physical position, ignoring scale
## Solution
- Make cursor position private
- Expose getter/setter on the window to have access to the scale
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
After #6503, bevy_render uses the `send_blocking` method introduced in async-channel 1.7, but depended only on ^1.4.
I saw this after pulling main without running cargo update.
# Objective
- Fix minimum dependency version of async-channel
## Solution
- Bump async-channel version constraint to ^1.8, which is currently the latest version.
NOTE: Both bevy_ecs and bevy_tasks also depend on async-channel but they didn't use any newer features.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
## Problem
`extract_uinodes` checks if an image is loaded for nodes without images
## Solution
Move the image loading skip check so that it is only performed for nodes with a `UiImage` component.
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Safety comments for the `CommandQueue` type are quite sparse and very imprecise. Sometimes, they are right for the wrong reasons or use circular reasoning.
## Solution
- Document previously-implicit safety invariants.
- Rewrite safety comments to actually reflect the specific invariants of each operation.
- Use `OwningPtr` instead of raw pointers, to encode an invariant in the type system instead of via comments.
- Use typed pointer methods when possible to increase reliability.
---
## Changelog
+ Added the function `OwningPtr::read_unaligned`.
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
See:
- https://github.com/bevyengine/bevy/issues/7067#issuecomment-1381982285
- (This does not fully close that issue in my opinion.)
- https://discord.com/channels/691052431525675048/1063454009769340989
## Solution
This merge request adds documentation:
1. Alert users to the fact that `App::run()` might never return and code placed after it might never be executed.
2. Makes `winit::WinitSettings::return_from_run` discoverable.
3. Better explains why `winit::WinitSettings::return_from_run` is discouraged and better links to up-stream docs. on that topic.
4. Adds notes to the `app/return_after_run.rs` example which otherwise promotes a feature that carries caveats.
Furthermore, w.r.t `winit::WinitSettings::return_from_run`:
- Broken links to `winit` docs are fixed.
- Links now point to BOTH `EventLoop::run()` and `EventLoopExtRunReturn::run_return()` which are the salient up-stream pages and make more sense, taken together.
- Collateral damage: "Supported platforms" heading; disambiguation of "run" → `App::run()`; links.
## Future Work
I deliberately structured the "`run()` might not return" section under `App::run()` to allow for alternative patterns (e.g. `AppExit` event, `WindowClosed` event) to be listed or mentioned, beneath it, in the future.
# Objective
- Fixes#7260
## Solution
- #6649 used `init_non_send_resource` for `AudioOutput`, but this is before #6436 was merged.
- Use `init_resource` instead.
# Objective
Repeated calls to `init_non_send_resource` currently overwrite the old value because the wrong storage is being checked.
## Solution
Use the correct storage. Add some tests.
## Notes
Without the fix, the new test fails with
```
thread 'world::tests::init_non_send_resource_does_not_overwrite' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `0`', crates/bevy_ecs/src/world/mod.rs:2267:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test world::tests::init_non_send_resource_does_not_overwrite ... FAILED
```
This was introduced by #7174 and it seems like a fairly straightforward oopsie.
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
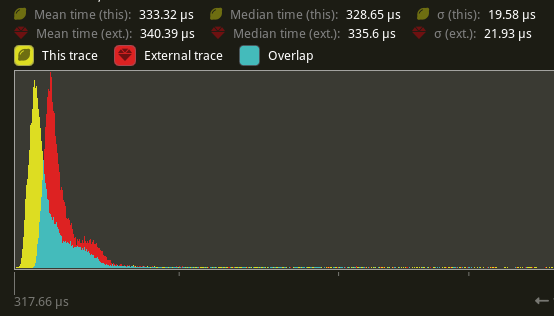
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
# Objective
- Enabling the `debug_asset_server` feature doesn't compile when using it with `load_internal_binary_asset!()`. The issue is because it assumes the loader takes an `&'static str` as a parameter, but binary assets loader expect `&'static [u8]`.
## Solution
- Add a generic type for the loader and use a different type in `load_internal_asset` and `load_internal_binary_asset`
# Objective
- Fixes#6361
- Fixes#6362
- Fixes#6364
## Solution
- Added an example for creating a custom `Decodable` type
- Clarified the documentation on `Decodable`
- Added an `AddAudioSource` trait and implemented it for `App`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
Fix#4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be.
## Solution
As `Parent` and `Children` are updated in tandem in hierarchy commands after #4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings.
Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it.
The tests from #4608 still pass, so the change detection here still works just fine under this approach.
# Objective
fix bloom when used on a camera with a viewport specified
## Solution
- pass viewport into the prefilter shader, and use it to read from the correct section of the original rendered screen
- don't apply viewport for the intermediate bloom passes, only for the final blend output
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes#7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
# Objective
Fixes#5859
## Solution
- Add `ClearChildren` and `ReplaceChildren` commands in the `crates/bevy_hierarchy/src/child_builder.rs`
---
## Changelog
- Added `ClearChildren` and `ReplaceChildren` struct
- Added `clear_children(&mut self) -> &mut Self` and `replace_children(&mut self, children: &[Entity]) -> &mut Self` function in `BuildChildren` trait
- Changed `PushChildren` `write` function body to a `push_children ` function to reused in `ReplaceChildren`
- Added `clear_children` function
- Added `push_and_replace_children_commands` and `push_and_clear_children_commands` test
Co-authored-by: ld000 <lidong9144@163.com>
Co-authored-by: lidong63 <lidong63@meituan.com>
# Objective
- Fixes a bug where `just_pressed` and `just_released` in `Input<GamepadButton>` might behave incorrectly due calling `clear` 3 times in a single frame through these three different systems: `gamepad_button_event_system`, `gamepad_axis_event_system` and `gamepad_connection_system` in any order
## Solution
- Call `clear` only once and before all the above three systems, i.e. in `gamepad_event_system`
## Additional Info
- Discussion in Discord: https://discord.com/channels/691052431525675048/768253008416342076/1064621963693273279
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
Currently, the `AxisSettings::new` function is unusable due to
an implementation quirk. It only allows `AxisSettings` where
the bounds that are supposed to be positive are negative!
## Solution
- We fix the bound check
- We add a test to make sure the method is usable
Seems like the error slipped through because of the relatively
verbose code style. With all those `if/else`, very long names,
range syntax, the bound check is actually hard to spot. I first
refactored a lot of code, but I left out the refactor because the
fix should be integrated independently.
---
## Changelog
- Fix `AxisSettings::new` only accepting invalid bounds
# Objective
Add useful information about cursor position relative to a UI node. Fixes#7079.
## Solution
- Added a new `RelativeCursorPosition` component
---
## Changelog
- Added
- `RelativeCursorPosition`
- an example showcasing the new component
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
Fix#5248.
## Solution
Support `In<T>` parameters and allow returning arbitrary types in exclusive systems.
---
## Changelog
- Exclusive systems may now be used with system piping.
## Migration Guide
Exclusive systems (systems that access `&mut World`) now support system piping, so the `ExclusiveSystemParamFunction` trait now has generics for the `In`put and `Out`put types.
```rust
// Before
fn my_generic_system<T, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<Param>
{ ... }
// After
fn my_generic_system<T, In, Out, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<In, Out, Param>
{ ... }
```
# Objective
Pipelines can be customized by wrapping an existing pipeline in a newtype and adding custom logic to its implementation of `SpecializedMeshPipeline::specialize`. To make that easier, the wrapped pipeline type needs to implement `Clone`.
For example, the current non-cloneable pipelines require wrapper pipelines to pull apart the wrapped pipeline like this:
```rust
impl FromWorld for Wireframe2dPipeline {
fn from_world(world: &mut World) -> Self {
let p = &world.resource::<Material2dPipeline<ColorMaterial>>();
Self {
mesh2d_pipeline: p.mesh2d_pipeline.clone(),
material2d_layout: p.material2d_layout.clone(),
vertex_shader: p.vertex_shader.clone(),
fragment_shader: p.fragment_shader.clone(),
}
}
}
```
## Solution
Derive or implement `Clone` on all built-in pipeline types. This is easy to do since they mostly just contain cheaply clonable reference-counted types.
---
## Changelog
Implement `Clone` for all pipeline types.
# Objective
fix error with shadow shader's spotlight direction calculation when direction.y ~= 0
fixes#7152
## Solution
same as #6167: in shadows.wgsl, clamp 1-x^2-z^2 to >= 0 so that we can safely sqrt it
# Objective
There are some utility functions for actually working with `Storages` inside `entity_ref.rs` that are used both for `EntityRef/EntityMut` and `World`, with a `// TODO: move to Storages`.
This PR moves them to private methods on `World`, because that's the safest API boundary. On `Storages` you would need to ensure that you pass `Components` from the same world.
## Solution
- move get_component[_with_type], get_ticks[_with_type], get_component_and_ticks[_with_type] to `World` (still pub(crate))
- replace `pub use entity_ref::*;` with `pub use entity_ref::{EntityRef, EntityMut}` and qualified `entity_ref::get_mut[_by_id]` in `world.rs`
- add safety comments to a bunch of methods
# Objective
* `World::init_resource` and `World::get_resource_or_insert_with` are implemented naively, and as such they perform duplicate `TypeId -> ComponentId` lookups.
* `World::get_resource_or_insert_with` contains an additional duplicate `ComponentId -> ResourceData` lookup.
* This function also contains an unnecessary panic branch, which we rely on the optimizer to be able to remove.
## Solution
Implement the functions using engine-internal code, instead of combining high-level functions. This allows computed variables to persist across different branches, instead of being recomputed.
# Objective
It is often necessary to update an entity's parent
while keeping its GlobalTransform static. Currently
it is cumbersome and error-prone (two questions in
the discord `#help` channel in the past week)
- Part 2, resolves#5475
- Builds on: #7020.
## Solution
- Added the `BuildChildrenTransformExt` trait, it is part
of `bevy::prelude` and adds the following methods to `EntityCommands`:
- `set_parent_in_place`: Change the parent of an entity and
update its `Transform` in order to preserve its `GlobalTransform` after the parent change
- `remove_parent_in_place`: Remove an entity from a hierarchy,
while preserving its `GlobalTransform`.
---
## Changelog
- Added the `BuildChildrenTransformExt` trait, it is part
of `bevy::prelude` and adds the following methods to `EntityCommands`:
- `set_parent_in_place`: Change the parent of an entity and
update its `Transform` in order to preserve its `GlobalTransform` after the parent change
- `remove_parent_in_place`: Remove an entity from a hierarchy,
while preserving its `GlobalTransform`.
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- While building UI, it makes more sense for most nodes to have a `FocusPolicy` of `Pass`, so that user interaction can correctly bubble
- Only `ButtonBundle` blocks by default
This change means that for someone adding children to a button, it's not needed to change the focus policy of those children to `Pass` for the button to continue to work.
---
## Changelog
- `FocusPolicy` default has changed from `FocusPolicy::Block` to `FocusPolicy::Pass`
## Migration Guide
- `FocusPolicy` default has changed from `FocusPolicy::Block` to `FocusPolicy::Pass`
# Objective
The documentation of the bevy_render crate is still pretty incomplete.
This PR follows up on #6885 and improves the documentation of the `render_phase` module.
This module contains one of our most important rendering abstractions and the current documentation is pretty confusing. This PR tries to clarify what all of these pieces are for and how they work together to form bevy`s modular rendering logic.
## Solution
### Code Reformating
- I have moved the `rangefinder` into the `render_phase` module since it is only used there.
- I have moved the `PhaseItem` (and the `BatchedPhaseItem`) from `render_phase::draw` over to `render_phase::mod`. This does not change the public-facing API since they are reexported anyway, but this change makes the relation between `RenderPhase` and `PhaseItem` clear and easier to discover.
### Documentation
- revised all documentation in the `render_phase` module
- added a module-level explanation of how `RenderPhase`s, `RenderPass`es, `PhaseItem`s, `Draw` functions, and `RenderCommands` relate to each other and how they are used
---
## Changelog
- The `rangefinder` module has been moved into the `render_phase` module.
## Migration Guide
- The `rangefinder` module has been moved into the `render_phase` module.
```rust
//old
use bevy::render::rangefinder::*;
// new
use bevy::render::render_phase::rangefinder::*;
```
# Objective
Following #6681, both `TableRow` and `TableId` are now part of `EntityLocation`. However, the safety invariant on `EntityLocation` requires that all of the constituent fields are `repr(transprent)` or `repr(C)` and the bit pattern of all 1s must be valid. This is not true for `TableRow` and `TableId` currently.
## Solution
Mark `TableRow` and `TableId` to satisfy the safety requirement. Add safety comments on `ArchetypeId`, `ArchetypeRow`, `TableId` and `TableRow`.
# Objective
Improve safety testing when using `bevy_ptr` types. This is a follow-up to #7113.
## Solution
Add a debug-only assertion that pointers are aligned when casting to a concrete type. This should very quickly catch any unsoundness from unaligned pointers, even without miri. However, this can have a large negative perf impact on debug builds.
---
## Changelog
Added: `Ptr::deref` will now panic in debug builds if the pointer is not aligned.
Added: `PtrMut::deref_mut` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::read` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::drop_as` will now panic in debug builds if the pointer is not aligned.
# Objective
- It can be useful for third party crates to work independently on how bevy is imported
## Solution
- Expose an helper to get a subcrate path for macros
# Objective
- There is a warning when building in release:
```
warning: unused import: `bevy_ecs::system::Local`
--> crates/bevy_render/src/extract_resource.rs:5:5
|
5 | use bevy_ecs::system::Local;
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
```
- It's used 59751d6e33/crates/bevy_render/src/extract_resource.rs (L47)
- Fix it
## Solution
- Gate the import
- repeat of #5320
# Objective
`MutUntyped` is a struct that stores a `PtrMut` alongside change tick metadata. Working with this type is cumbersome, and has few benefits over storing the pointer and change ticks separately.
Related: #6430 (title is out of date)
## Solution
Add a convenience method for transforming an untyped change detection pointer into its typed counterpart.
---
## Changelog
- Added the method `MutUntyped::with_type`.
As mentioned in https://github.com/bevyengine/bevy/pull/6530. It allows to not create a new constant and simply having it to show up in the documentation when someone is looking for "transparent" (case insensitive) in rustdoc search.
cc @alice-i-cecile
# Objective
Enums are now reflectable, but are not accessible via reflection paths.
This would allow us to do things like:
```rust
#[derive(Reflect)]
struct MyStruct {
data: MyEnum
}
#[derive(Reflect)]
struct MyEnum {
Foo(u32, u32),
Bar(bool)
}
let x = MyStruct {
data: MyEnum::Foo(123),
};
assert_eq!(*x.get_path::<u32>("data.1").unwrap(), 123);
```
## Solution
Added support for enums in reflection paths.
##### Note
This uses a simple approach of just getting the field with the given accessor. It does not do matching or anything else to ensure the enum is the intended variant. This means that the variant must be known ahead of time or matched outside the reflection path (i.e. path to variant, perform manual match, and continue pathing).
---
## Changelog
- Added support for enums in reflection paths
# Objective
There are times where we want to simply take an owned `dyn Reflect` and cast it to a type `T`.
Currently, this involves doing:
```rust
let value = value.take::<T>().unwrap_or_else(|value| {
T::from_reflect(&*value).unwrap_or_else(|| {
panic!(
"expected value of type {} to convert to type {}.",
value.type_name(),
std::any::type_name::<T>()
)
})
});
```
This is a common operation that could be easily be simplified.
## Solution
Add the `FromReflect::take_from_reflect` method. This first tries to `take` the value, calling `from_reflect` iff that fails.
```rust
let value = T::take_from_reflect(value).unwrap_or_else(|value| {
panic!(
"expected value of type {} to convert to type {}.",
value.type_name(),
std::any::type_name::<T>()
)
});
```
Based on suggestion from @soqb on [Discord](https://discord.com/channels/691052431525675048/1002362493634629796/1041046880316043374).
---
## Changelog
- Add `FromReflect::take_from_reflect` method
# Objective
- Fixes#7066
## Solution
- Split the ChangeDetection trait into ChangeDetection and ChangeDetectionMut
- Added Ref as equivalent to &T with change detection
---
## Changelog
- Support for Ref which allow inspecting change detection flags in an immutable way
## Migration Guide
- While bevy prelude includes both ChangeDetection and ChangeDetectionMut any code explicitly referencing ChangeDetection might need to be updated to ChangeDetectionMut or both. Specifically any reading logic requires ChangeDetection while writes requires ChangeDetectionMut.
use bevy_ecs::change_detection::DetectChanges -> use bevy_ecs::change_detection::{DetectChanges, DetectChangesMut}
- Previously Res had methods to access change detection `is_changed` and `is_added` those methods have been moved to the `DetectChanges` trait. If you are including bevy prelude you will have access to these types otherwise you will need to `use bevy_ecs::change_detection::DetectChanges` to continue using them.
# Objective
The types in the `bevy_ptr` accidentally did not document anything relating to alignment. This is unsound as many methods rely on the pointer being correctly aligned.
## Solution
This PR introduces new safety invariants on the `$ptr::new`, `$ptr::byte_offset` and `$ptr::byte_add` methods requiring them to keep the pointer aligned. This is consistent with the documentation of these pointer types which document them as being "type erased borrows".
As it was pointed out (by @JoJoJet in #7117) that working with unaligned pointers can be useful (for example our commands abstraction which does not try to align anything properly, see #7039) this PR also introduces a default type parameter to all the pointer types that specifies whether it has alignment requirements or not. I could not find any code in `bevy_ecs` that would need unaligned pointers right now so this is going unused.
---
## Changelog
- Correctly document alignment requirements on `bevy_ptr` types.
- Support variants of `bevy_ptr` types that do not require being correctly aligned for the pointee type.
## Migration Guide
- Safety invariants on `bevy_ptr` types' `new` `byte_add` and `byte_offset` methods have been changed. All callers should re-audit for soundness.
# Objective
- Spawn tasks from other threads onto an async executor, but limit those tasks to run on a specific thread.
- This is a continuation of trying to break up some of the changes in pipelined rendering.
- Eventually this will be used to allow `NonSend` systems to run on the main thread in pipelined rendering #6503 and also to solve #6552.
- For this specific PR this allows for us to store a thread executor in a thread local, rather than recreating a scope executor for every scope which should save on a little work.
## Solution
- We create a Executor that does a runtime check for what thread it's on before creating a !Send ticker. The ticker is the only way for the executor to make progress.
---
## Changelog
- create a ThreadExecutor that can only be ticked on one thread.
`Query`'s fields being `pub(crate)` means that the struct can be constructed via safe code from anywhere in `bevy_ecs` . This is Not Good since it is intended that all construction of this type goes through `Query::new` which is an `unsafe fn` letting various `Query` methods rely on those invariants holding even though they can be trivially bypassed.
This has no user facing impact
# Objective
It is possible to manually update `GlobalTransform`.
The engine actually assumes this is not possible.
For example, `propagate_transform` does not update children
of an `Entity` which **`GlobalTransform`** changed,
leading to unexpected behaviors.
A `GlobalTransform` set by the user may also be blindly
overwritten by the propagation system.
## Solution
- Remove `translation_mut`
- Explain to users that they shouldn't manually update the `GlobalTransform`
- Remove `global_vs_local.rs` example, since it misleads users
in believing that it is a valid use-case to manually update the
`GlobalTransform`
---
## Changelog
- Remove `GlobalTransform::translation_mut`
## Migration Guide
`GlobalTransform::translation_mut` has been removed without alternative,
if you were relying on this, update the `Transform` instead. If the given entity
had children or parent, you may need to remove its parent to make its transform
independent (in which case the new `Commands::set_parent_in_place` and
`Commands::remove_parent_in_place` may be of interest)
Bevy may add in the future a way to toggle transform propagation on
an entity basis.
# Objective
- Fix#7103.
- The issue is caused because I forgot to add a where clause to a generated struct in #7056.
## Solution
- Add the where clause.
`Query` relies on the `World` it stores being the same as the world used for creating the `QueryState` it stores. If they are not the same then everything is very unsound. This was not actually being checked anywhere, `Query::new` did not have a safety invariant or even an assertion that the `WorldId`'s are the same.
This shouldn't have any user facing impact unless we have really messed up in bevy and have unsoundness elsewhere (in which case we would now get a panic instead of being unsound).
# Objective
- In some cases, you need a `Mut<T>` pointer, but you only have a mutable reference to one. There is no easy way of converting `&'a mut Mut<'_, T>` -> `Mut<'a, T>` outside of the engine.
### Example (Before)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// The function expects a `Mut<T>`, so `x` gets moved here.
do_with_mut(x);
// Error: use of moved value.
do_a_thing(&x);
}
```
## Solution
- Add the function `reborrow`, which performs the mapping. This is analogous to `PtrMut::reborrow`.
### Example (After)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// We reborrow `x`, so the original does not get moved.
do_with_mut(x.reborrow());
// Works fine.
do_a_thing(&x);
}
```
---
## Changelog
- Added the method `reborrow` to `Mut`, `ResMut`, `NonSendMut`, and `MutUntyped`.
# Objective
This a follow-up to #6894, see https://github.com/bevyengine/bevy/pull/6894#discussion_r1045203113
The goal is to avoid cloning any string when getting a `&TypeRegistration` corresponding to a string which is being deserialized. As a bonus code duplication is also reduced.
## Solution
The manual deserialization of a string and lookup into the type registry has been moved into a separate `TypeRegistrationDeserializer` type, which implements `DeserializeSeed` with a `Visitor` that accepts any string with `visit_str`, even ones that may not live longer than that function call.
`BorrowedStr` has been removed since it's no longer used.
---
## Changelog
- The type `TypeRegistrationDeserializer` has been added, which simplifies getting a `&TypeRegistration` while deserializing a string.
# Objective
- Fix the name of function parameter name in docs
## Solution
- Change `f` to `sub_app_runner`
---
It confused me a bit when I was reading the docs in the autocomplete hint.
Hesitated about filing a PR since it's just a one single word change in the comment.
Is this the right process to change these docs?
# Objective
The type `Local<T>` unnecessarily has the bound `T: Sync` when the local is used in an exclusive system.
## Solution
Lift the bound.
---
## Changelog
Removed the bound `T: Sync` from `Local<T>` when used as an `ExclusiveSystemParam`.
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
- Fixes#7061
## Solution
- Add and implement `insert` and `remove` methods for `List`.
---
## Changelog
- Added `insert` and `remove` methods to `List`.
- Changed the `push` and `pop` methods on `List` to have default implementations.
## Migration Guide
- Manual implementors of `List` need to implement the new methods `insert` and `remove` and
consider whether to use the new default implementation of `push` and `pop`.
Co-authored-by: radiish <thesethskigamer@gmail.com>
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
- This pulls out some of the changes to Plugin setup and sub apps from #6503 to make that PR easier to review.
- Separate the extract stage from running the sub app's schedule to allow for them to be run on separate threads in the future
- Fixes#6990
## Solution
- add a run method to `SubApp` that runs the schedule
- change the name of `sub_app_runner` to extract to make it clear that this function is only for extracting data between the main app and the sub app
- remove the extract stage from the sub app schedule so it can be run separately. This is done by adding a `setup` method to the `Plugin` trait that runs after all plugin build methods run. This is required to allow the extract stage to be removed from the schedule after all the plugins have added their systems to the stage. We will also need the setup method for pipelined rendering to setup the render thread. See e3267965e1/crates/bevy_render/src/pipelined_rendering.rs (L57-L98)
## Changelog
- Separate SubApp Extract stage from running the sub app schedule.
## Migration Guide
### SubApp `runner` has conceptually been changed to an `extract` function.
The `runner` no longer is in charge of running the sub app schedule. It's only concern is now moving data between the main world and the sub app. The `sub_app.app.schedule` is now run for you after the provided function is called.
```rust
// before
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
render_app.app.schedule.run();
});
}
// after
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
// schedule is automatically called for you after extract is run
});
}
```
# Objective
- Remove redundant gamepad events
- Simplify consuming gamepad events.
- Refactor: Separate handling of gamepad events into multiple systems.
## Solution
- Removed `GamepadEventRaw`, and `GamepadEventType`.
- Added bespoke `GamepadConnectionEvent`, `GamepadAxisChangedEvent`, and `GamepadButtonChangedEvent`.
- Refactored `gamepad_event_system`.
- Added `gamepad_button_event_system`, `gamepad_axis_event_system`, and `gamepad_connection_system`, which update the `Input` and `Axis` resources using their corresponding event type.
Gamepad events are now handled in their own systems and have their own types.
This allows for querying for gamepad events without having to match on `GamepadEventType` and makes creating handlers for specific gamepad event types, like a `GamepadConnectionEvent` or `GamepadButtonChangedEvent` possible.
We remove `GamepadEventRaw` by filtering the gamepad events, using `GamepadSettings`, _at the source_, in `bevy_gilrs`. This way we can create `GamepadEvent`s directly and avoid creating `GamepadEventRaw` which do not pass the user defined filters.
We expose ordered `GamepadEvent`s and we can respond to individual gamepad event types.
## Migration Guide
- Replace `GamepadEvent` and `GamepadEventRaw` types with their specific gamepad event type.
# Objective
- Fixes https://github.com/bevyengine/bevy/discussions/6338
This PR allows for smooth transitions between different animations.
## Solution
- This PR uses very simple linear blending of animations.
- When starting a new animation, you can give it a duration, and throughout that duration, the previous and the new animation are being linearly blended, until only the new animation is running.
- I'm aware of https://github.com/bevyengine/rfcs/pull/49 and https://github.com/bevyengine/rfcs/pull/51, which are more complete solutions to this problem, but they seem still far from being implemented. Until they're ready, this PR allows for the most basic use case of blending, i.e. smoothly transitioning between different animations.
## Migration Guide
- no bc breaking changes
# Objective
- Storage buffers are useful and not currently supported by the `AsBindGroup` derive which means you need to expand the macro if you need a storage buffer
## Solution
- Add a new `#[storage]` attribute to the derive `AsBindGroup` macro.
- Support and optional `read_only` parameter that defaults to false when not present.
- Support visibility parameters like the texture and sampler attributes.
---
## Changelog
- Add a new `#[storage(index)]` attribute to the derive `AsBindGroup` macro.
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Avoid slower than necessary first frame after spawning many entities due to them not having `Aabb`s and so being marked visible
- Avoids unnecessarily large system and VRAM allocations as a consequence
## Solution
- I noticed when debugging the `many_cubes` stress test in Xcode that the `MeshUniform` binding was much larger than it needed to be. I realised that this was because initially, all mesh entities are marked as being visible because they don't have `Aabb`s because `calculate_bounds` is being run in `PostUpdate` and there are no system commands applications before executing the visibility check systems that need the `Aabb`s. The solution then is to run the `calculate_bounds` system just before the previous system commands are applied which is at the end of the `Update` stage.
Spiritual successor to #5205.
Actual successor to #6865.
# Objective
Currently, system params are defined using three traits: `SystemParam`, `ReadOnlySystemParam`, `SystemParamState`. The behavior for each param is specified by the `SystemParamState` trait, while `SystemParam` simply defers to the state.
Splitting the traits in this way makes it easier to implement within macros, but it increases the cognitive load. Worst of all, this approach requires each `MySystemParam` to have a public `MySystemParamState` type associated with it.
## Solution
* Merge the trait `SystemParamState` into `SystemParam`.
* Remove all trivial `SystemParam` state types.
* `OptionNonSendMutState<T>`: you will not be missed.
---
- [x] Fix/resolve the remaining test failure.
## Changelog
* Removed the trait `SystemParamState`, merging its functionality into `SystemParam`.
## Migration Guide
**Note**: this should replace the migration guide for #6865.
This is relative to Bevy 0.9, not main.
The traits `SystemParamState` and `SystemParamFetch` have been removed, and their functionality has been transferred to `SystemParam`.
```rust
// Before (0.9)
impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
}
unsafe impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
unsafe impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(&mut self, ...) -> Self::Item;
}
unsafe impl ReadOnlySystemParamFetch for MyParamState { }
// After (0.10)
unsafe impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
type Item<'w, 's> = MyParam<'w, 's>;
fn init_state(world: &mut World, system_meta: &mut SystemMeta) -> Self::State { ... }
fn get_param<'w, 's>(state: &mut Self::State, ...) -> Self::Item<'w, 's>;
}
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> { }
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> {}
```
# Objective
- The doctest for `Mut::map_unchanged` uses a fake function `set_if_not_equal` to demonstrate usage.
- Now that #6853 has been merged, we can use `Mut::set_if_neq` directly instead of mocking it.
(github made me type out a message for the commit which looked like it was for the pr, sorry)
# Objective
- Add a way to get all of the input devices of an `Axis`, primarily useful for looping through them
## Solution
- Adds `Axis<T>::devices()` which returns a `FixedSizeIterator<Item = &T>`
- Adds a (probably unneeded) `test_axis_devices` test because tests are cool.
---
## Changelog
- Added `Axis<T>::devices()` method
## Migration Guide
Not a breaking change.
# Objective
`SystemParam` `Local`s documentation currently leaves out information that should be documented.
- What happens when multiple `SystemParam`s within the same system have the same `Local` type.
- What lifetime parameter is expected by `Local`.
## Solution
- Added sentences to documentation to communicate this information.
- Renamed `Local` lifetimes in code to `'s` where they previously were not. Users can get complicated incorrect suggested fixes if they pass the wrong lifetime. Some instance of the code had `'w` indicating the expected lifetime might not have been known to those that wrote the code either.
Co-authored-by: iiYese <83026177+iiYese@users.noreply.github.com>
# Objective
- Fixes#7081.
## Solution
- Moved functionality from kitchen sink plugin `CorePlugin` to separate plugins, `TaskPoolPlugin`, `TypeRegistrationPlugin`, `FrameCountPlugin`. `TaskPoolOptions` resource should now be used with `TaskPoolPlugin`.
## Changelog
Minimal changes made (code kept in `bevy_core/lib.rs`).
## Migration Guide
- `CorePlugin` broken into separate plugins. If not using `DefaultPlugins` or `MinimalPlugins` `PluginGroup`s, the replacement for `CorePlugin` is now to add `TaskPoolPlugin`, `TypeRegistrationPlugin`, and `FrameCountPlugin` to the app.
## Notes
- Consistent with Bevy goal "modularity over deep integration" but the functionality of `TypeRegistrationPlugin` and `FrameCountPlugin` is weak (the code has to go somewhere, though!).
- No additional tests written.
# Objective
It is currently possible to break reference counting for assets by creating a strong `HandleUntyped` and then modifying the `id` field before dropping the handle. This should not be allowed.
## Solution
Change the `id` field visibility to private and add a getter instead. The same change was previously done for `Handle<T>` in #6176, but `HandleUntyped` was forgotten.
---
## Migration Guide
- Instead of directly accessing the ID of a `HandleUntyped` as `handle.id`, use the new getter `handle.id()`.
# Objective
- When using `Color::hex` for the first time, I was confused by the fact that I can't specify colors using #, which is much more familiar.
- In the code editor (if there is support) there is a preview of the color, which is very convenient.

## Solution
- Allow you to enter colors like `#ff33f2` and use the `.strip_prefix` method to delete the `#` character.
# Objective
- Fix#4200
Currently, `#[derive(SystemParam)]` publicly exposes each field type, which makes it impossible to encapsulate private fields.
## Solution
Previously, the fields were leaked because they were used as an input generic type to the macro-generated `SystemParam::State` struct. That type has been changed to store its state in a field with a specific type, instead of a generic type.
---
## Changelog
- Fixed a bug that caused `#[derive(SystemParam)]` to leak the types of private fields.
# Objective
- Set the cursor grab mode after the window is built, fix#7007, clean some conversion code.
## Solution
- Set the cursor grab mode after the window is built.
# Objective
Fixes#6891
## Solution
Replaces deserializing map keys as `&str` with deserializing them as `String`.
This bug seems to occur when using something like `File` or `BufReader` rather than bytes or a string directly (I only tested `File` and `BufReader` for `rmp-serde` and `serde_json`). This might be an issue with other `Read` impls as well (except `&[u8]` it seems).
We already had passing tests for Message Pack but none that use a `File` or `BufReader`. This PR also adds or modifies tests to check for this in the future.
This change was also based on [feedback](https://github.com/bevyengine/bevy/pull/4561#discussion_r957385136) I received in a previous PR.
---
## Changelog
- Fix bug where scene deserialization using certain readers could fail (e.g. `BufReader`, `File`, etc.)
# Objective
Speed up animation by leveraging all threads in `ComputeTaskPool`.
## Solution
This PR parallelizes animation sampling across all threads.
To ensure that this is safely done, all animation is predicated with an ancestor query to ensure that there is no conflicting `AnimationPlayer` above each animated hierarchy that may cause this to alias.
Unlike the RFC, this does not add support for reflect based "animate anything", but only extends the existing `AnimationPlayer` to support high numbers of animated characters on screen at once.
## Performance
This cuts `many_foxes`'s frame time on my machine by a full millisecond, from 7.49ms to 6.5ms. (yellow is this PR, red is main).
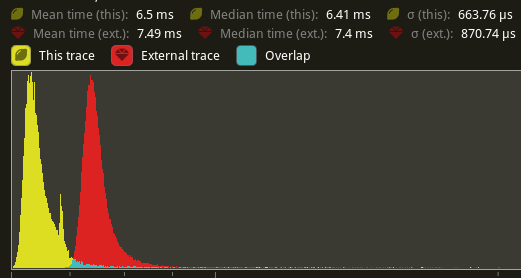
---
## Changelog
Changed: Animation sampling now runs fully multi-threaded using threads from `ComputeTaskPool`.
Changed: `AnimationPlayer` that are on a child or descendant of another entity with another player will no longer be run.
# Objective
- Fixes#5529
## Solution
- Add assosciated constants named DEFAULT to as many types as possible
- Add const to as many methods in bevy_ui as possible
I have not applied the same treatment to the bundles in bevy_ui as it would require going into other bevy crates to implement const defaults for structs in bevy_text or relies on UiImage which calls HandleUntyped.typed() which isn't const safe.
Alternatively the defaults could relatively easily be turned into a macro to regain some of the readability and conciseness at the cost of explicitness.
Such a macro that partially implements this exists as a crate here: [const-default](https://docs.rs/const-default/latest/const_default/derive.ConstDefault.html) but does not support enums.
Let me know if there's anything I've missed or if I should push further into other crates.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
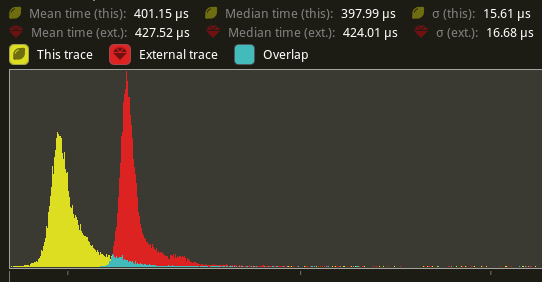
The shadow pass node is also slightly faster (344.52 -> 338.24us)
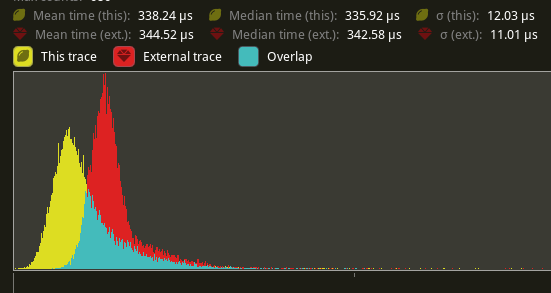
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
- The #7064 PR had poor performance on an M1 Max in MacOS due to significant overuse of registers resulting in 'register spilling' where data that would normally be stored in registers on the GPU is instead stored in VRAM. The latency to read from/write to VRAM instead of registers incurs a significant performance penalty.
- Use of registers is a limiting factor in shader performance. Assignment of a struct from memory to a local variable can incur copies. Passing a variable that has struct type as an argument to a function can also incur copies. As such, these two cases can incur increased register usage and decreased performance.
## Solution
- Remove/avoid a number of assignments of light struct type data to local variables.
- Remove/avoid a number of passing light struct type variables/data as value arguments to shader functions.
# Objective
- The recently merged PR #7013 does not allow multiple `RenderPhase`s to share the same `RenderPass`.
- Due to the introduced overhead we want to minimize the number of `RenderPass`es recorded during each frame.
## Solution
- Take a constructed `TrackedRenderPass` instead of a `RenderPassDiscriptor` as a parameter to the `RenderPhase::render` method.
---
## Changelog
To enable multiple `RenderPhases` to share the same `TrackedRenderPass`,
the `RenderPhase::render` signature has changed.
```rust
pub fn render<'w>(
&self,
render_pass: &mut TrackedRenderPass<'w>,
world: &'w World,
view: Entity)
```
Co-authored-by: Kurt Kühnert <51823519+kurtkuehnert@users.noreply.github.com>
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
There isn't really a way to test that code using bevy_reflect compiles or doesn't compile for certain scenarios. This would be especially useful for macro-centric PRs like #6511 and #6042.
## Solution
Using `bevy_ecs_compile_fail_tests` as reference, added the `bevy_reflect_compile_fail_tests` crate.
Currently, this crate contains a very simple test case. This is so that we can get the basic foundation of this crate agreed upon and merged so that more tests can be added by other PRs.
### Open Questions
- [x] Should this be added to CI? (Answer: Yes)
---
## Changelog
- Added the `bevy_reflect_compile_fail_tests` crate for testing compilation errors
# Objective
Solve #5464
## Solution
Adds a `SystemInformationDiagnosticsPlugin` to add diagnostics.
Adds `Cargo.toml` flags to fix building on different platforms.
---
## Changelog
Adds `sysinfo` crate to `bevy-diagnostics`.
Changes in import order are due to clippy.
Co-authored-by: l1npengtul <35755164+l1npengtul@users.noreply.github.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
# Objective
`TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` was already included in `adapter.features()` on non-wasm target, and since it is the default value for `WgpuSettings.features`, the subsequent code will also combine into this feature:
b6066c30b6/crates/bevy_render/src/renderer/mod.rs (L155-L156)
# Objective
Bevy uses custom `Ptr` types so the rust borrow checker can help ensure lifetimes are correct, even when types aren't known. However, these types don't benefit from the automatic lifetime coercion regular rust references enjoy
## Solution
Add a couple methods to Ptr, PtrMut, and MutUntyped to allow for easy usage of these types in more complex scenarios.
## Changelog
- Added `as_mut` and `as_ref` methods to `MutUntyped`.
- Added `shrink` and `as_ref` methods to `PtrMut`.
## Migration Guide
- `MutUntyped::into_inner` now marks things as changed.
# Objective
All `RenderPhases` follow the same render procedure.
The same code is duplicated multiple times across the codebase.
## Solution
I simply extracted this code into a method on the `RenderPhase`.
This avoids code duplication and makes setting up new `RenderPhases` easier.
---
## Changelog
### Changed
You can now set up the rendering code of a `RenderPhase` directly using the `RenderPhase::render` method, instead of implementing it manually in your render graph node.
# Objective
- Loading a gltf files prints many errors
```
ERROR bevy_ecs::world: Unable to send event `bevy_hierarchy::events::HierarchyEvent`
Event must be added to the app with `add_event()`
https://docs.rs/bevy/*/bevy/app/struct.App.html#method.add_event
```
- Loading a gltf file create a world for a scene where events are not registered. Executing hierarchy commands on that world should not print error
## Solution
- Revert part of #6921
- don't use `world.send_event` / `world.send_event_batch` from commands
# Objective
- We already log the adapter info on startup when bevy_render is present. It would be nice to have more info about the system to be able to ask users to submit it in bug reports
## Solution
- Use the `sysinfo` crate to get all the information
- I made sure it _only_ gets the required informations to avoid unnecessary system request
- Add a system that logs this on startup
- This system is currently in `bevy_diagnostics` because I didn't really know where to put it.
Here's an example log from my system:
```log
INFO bevy_diagnostic: SystemInformation { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 7 5800X 8-Core Processor", core_count: "8", memory: "34282242 KB" }
```
---
## Changelog
- Added a new default log when starting a bevy app that logs the system information
# Objective
It is often necessary to update an entity's parent while keeping its GlobalTransform static. Currently it is cumbersome and error-prone (two questions in the discord `#help` channel in the past week)
- Part 1 of #5475
- Part 2: #7024.
## Solution
- Add a `reparented_to` method to `GlobalTransform`
---
## Changelog
- Add a `reparented_to` method to `GlobalTransform`
# Objective
Resolve#6156.
The most common type of command is one that runs for a single entity. Built-in commands like this can be ergonomically added to the command queue using the `EntityCommands` struct. However, adding custom entity commands to the queue is quite cumbersome. You must first spawn an entity, store its ID in a local, then construct a command using that ID and add it to the queue. This prevents method chaining, which is the main benefit of using `EntityCommands`.
### Example (before)
```rust
struct MyCustomCommand(Entity);
impl Command for MyCustomCommand { ... }
let id = commands.spawn((...)).id();
commmands.add(MyCustomCommand(id));
```
## Solution
Add the `EntityCommand` trait, which allows directly adding per-entity commands to the `EntityCommands` struct.
### Example (after)
```rust
struct MyCustomCommand;
impl EntityCommand for MyCustomCommand { ... }
commands.spawn((...)).add(MyCustomCommand);
```
---
## Changelog
- Added the trait `EntityCommand`. This is a counterpart of `Command` for types that execute code for a single entity.
## Future Work
If we feel its necessary, we can simplify built-in commands (such as `Despawn`) to use this trait.
# Objective
Any closure with the signature `FnOnce(&mut World)` implicitly implements the trait `Command` due to a blanket implementation. However, this implementation unnecessarily has the `Sync` bound, which limits the types that can be used.
## Solution
Remove the bound.
---
## Changelog
- `Command` closures no longer need to implement the marker trait `std::marker::Sync`.
# Objective
The documentation for camera priority is very confusing at the moment, it requires a bit of "double negative" kind of thinking.
# Solution
Flipping the wording on the documentation to reflect more common usecases like having an overlay camera and also renaming it to "order", since priority implies that it will override the other camera rather than have both run.
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode.
# Objective
The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching.
Additionally as it stands Bevy only has two settings for visibility of an entity:
- "unconditionally hidden" `Visibility { is_visible: false }`,
- "inherit visibility from parent" `Visibility { is_visible: true }`
where a root level entity set to "inherit" is visible.
Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear.
Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode.
--
The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants.
## Solution
Change the Visibility component into
```rust
enum Visibility {
Hidden, // unconditionally hidden
Visible, // unconditionally visible
Inherited, // inherit visibility from parent
}
```
---
## Changelog
### Changed
`Visibility` is now an enum
## Migration Guide
- evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`.
- setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`.
- usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively.
- `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Be able to name the type that `ManualEventReader::iter/iter_with_id` returns and `EventReader::iter/iter_with_id` by proxy.
Currently for the purpose of https://github.com/bevyengine/bevy/pull/5719
## Solution
- Create a custom `Iterator` type.
# Objective
- alternative to #2895
- as mentioned in #2535 the uuid based ids in the render module should be replaced with atomic-counted ones
## Solution
- instead of generating a random UUID for each render resource, this implementation increases an atomic counter
- this might be replaced by the ids of wgpu if they expose them directly in the future
- I have not benchmarked this solution yet, but this should be slightly faster in theory.
- Bevymark does not seem to be affected much by this change, which is to be expected.
- Nothing of our API has changed, other than that the IDs have lost their IMO rather insignificant documentation.
- Maybe the documentation could be added back into the macro, but this would complicate the code.
# Objective
- Describe the objective or issue this PR addresses.
SpritePipelineKey could use more constification.
## Solution
Constify SpritePipelineKey implementation.
## Changelog
Co-authored-by: AxiomaticSemantics <117950168+AxiomaticSemantics@users.noreply.github.com>
# Objective
Align the hierarchy API between `EntityCommands` and `EntityMut`.
Added missing methods to `EntityMut`.
Replaced the duplicate `Command` implementations with the ones on `EntityMut` (e.g. The `AddChild` command is now just `world.entity_mut(..).add_child(..)`)
Fixed `update_old_parents` not sending `ChildAdded` events.
This PR does not add `add_children` to `EntityMut` as I would like to remove it from `EntityCommands` instead in #6942.
## Changelog
* Added `add_child`, `set_parent` and `remove_parent` to `EntityMut`
* Fixed missing `ChildAdded` events
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
* Currently, the `SystemParam` derive does not support types with const generic parameters.
* If you try to use const generics, the error message is cryptic and unhelpful.
* Continuation of the work started in #6867 and #6957.
## Solution
Allow const generic parameters to be used with `#[derive(SystemParam)]`.
# Objective
Fixes#4729.
Continuation of #4854.
## Solution
Add documentation to `ParamSet` and its methods. Includes examples suggested by community members in the original PR.
Co-authored-by: Nanox19435 <50684926+Nanox19435@users.noreply.github.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
Fixes#4231.
## Solution
This PR implements the solution suggested by @bjorn3 : Use an internal property within `App` to detect `App::run()` calls from `Plugin::build()`.
---
## Changelog
- panic when App::run() is called from Plugin::build()
# Objective
Upgrade to Taffy 0.2
## Solution
Do it
## Changelog
Upgraded to Taffy 0.2, improving UI layout performance significantly and adding the flexbox `gap` property and `AlignContent::SpaceEvenly`.
## Notes
`many_buttons` is 8% faster! speed improvements for more highly nested UIs will be much more dramatic. Great work, Team Taffy.
# Objective
* The `SystemParam` derive internally uses tuples, which means it is constrained by the 16-field limit on `all_tuples`.
* The error message if you exceed this limit is abysmal.
* Supercedes #5965 -- this does the same thing, but is simpler.
## Solution
If any tuples have more than 16 fields, they are folded into tuples of tuples until they are under the 16-field limit.
# Objective
Currently, only named structs can be used with the `SystemParam` derive macro.
## Solution
Remove the restriction. Tuple structs and unit structs are now supported.
---
## Changelog
+ Added support for tuple structs and unit structs to the `SystemParam` derive macro.
# Objective
Fixes#6862 (oh hey good catch @alice-i-cecile)
Bevy was failing to print events from `info!()` and friends to the console if the `trace_tracy` feature was enabled. It shouldn't be doing that.
## Solution
The problem was this per-layer filter that was added in #4320 to suppress a noisy per-frame event (which Tracy requires in order to properly close out a frame):
- The problem event's target was `"bevy_render::renderer"`, not `"tracy"`. - So, the filter wasn't specifically targeting the noisy event.
- Without a default, `tracing_subscriber::filter::Targets` will remove _everything_ that doesn't match an explicit target rule. - So, the filter _was_ silencing the noisy event, along with everything else.
This PR changes that filter to do what was probably intended in #4320: suppress ~any events more verbose than `ERROR` from `bevy_render::renderer`~ the one problematically noisy event, but allow anything else that already made it through the top-level filter_layer.
Also, adds a comment to clarify the intent of that filter, since it's otherwise a bit opaque and required some research.
---
## Changelog
Fixed a bug that hid console log messages when the `trace_tracy` feature was enabled.
The Camera link in the UiCameraConfig was not rendered properly by the documentation.
# Objective
- In the UiCameraConfig page (https://docs.rs/bevy/latest/bevy/prelude/struct.UiCameraConfig.html), a link to the Camera page (https://docs.rs/bevy/latest/bevy/render/camera/struct.Camera.html) is broken.
## Solution
- It seems that when using URL fragment specifiers, backtick should not be used. It might be an issue of rust itself. Replacing the URL fragment specifier `[`Camera`]: bevy_render:📷:Camera` with `[Camera]: bevy_render:📷:Camera` solves this.
# Objective
- `bevy_ptr::{Ptr, PtrMut, OwnedPtr}` wrap raw pointers and should be printable using pointer formatting.
## Solution
- Add a `core::fmt::Pointer` impl for `Ptr`, `PtrMut` and `OwnedPtr` based on the wrapped `NonNull` pointer.
---
## Changelog
- Added a `core::fmt::Pointer` impl to `Ptr`, `PtrMut` and `OwnedPtr`.
Co-authored-by: MrGunflame <mrgunflame@protonmail.com>
## Objective
Bevy UI uses a `MeasureFunc` that preserves the aspect ratio of text, not just images. This means that the extent of flex-items containing text may be calculated incorrectly depending on the ratio of the text size compared to the size of its containing node.
Fixes#6748
Related to #6724
with Bevy 0.9:
with this PR (accurately matching the behavior of Flexbox):
## Solution
Only perform the aspect ratio calculations if the uinode contains an image.
## Changelog
* Added a field `preserve_aspect_ratio` to `CalculatedSize`
* The `MeasureFunc` only preserves the aspect ratio when `preserve_aspect_ratio` is true.
* `update_image_calculated_size_system` sets `preserve_aspect_ratio` to true for nodes with images.
# Objective
The `WgpuSettings` resource is only used during plugin build. Move it into the `RenderPlugin` struct.
Changing these settings requires re-initializing the render context, which is currently not supported.
If it is supported in the future it should probably be more explicit than changing a field on a resource, maybe something similar to the `CreateWindow` event.
## Migration Guide
```rust
// Before (0.9)
App::new()
.insert_resource(WgpuSettings { .. })
.add_plugins(DefaultPlugins)
// After (0.10)
App::new()
.add_plugins(DefaultPlugins.set(RenderPlugin {
wgpu_settings: WgpuSettings { .. },
}))
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Following #4402, extract systems run on the render world instead of the main world, and allow retained state operations on it's resources. We're currently extracting to `ExtractedJoints` and then copying it twice during Prepare. Once into `SkinnedMeshJoints` and again into the actual GPU buffer.
This makes #4902 obsolete.
## Solution
Cut out the middle copy and directly extract joints into `SkinnedMeshJoints` and remove `ExtractedJoints` entirely.
This also removes the per-frame allocation that is being made to send `ExtractedJoints` into the render world.
## Performance
On my local machine, this halves the time for `prepare_skinned _meshes` on `many_foxes` (195.75us -> 93.93us on average).
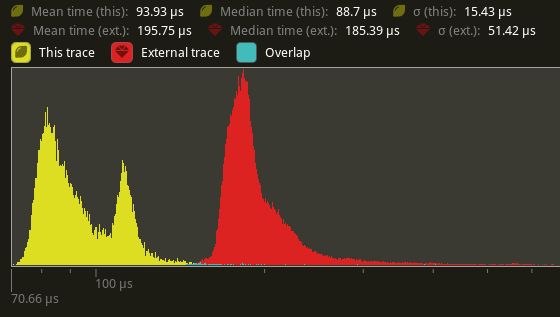
---
## Changelog
Added: `BufferVec::truncate`
Added: `BufferVec::extend`
Changed: `SkinnedMeshJoints::build` now takes a `&mut BufferVec` instead of a `&mut Vec` as a parameter.
Removed: `ExtractedJoints`.
## Migration Guide
`ExtractedJoints` has been removed. Read the bound bones from `SkinnedMeshJoints` instead.
# Objective
Fix#1991. Allow users to have a bit more control over the creation and finalization of the threads in `TaskPool`.
## Solution
Add new methods to `TaskPoolBuilder` that expose callbacks that are called to initialize and finalize each thread in the `TaskPool`.
Unlike the proposed solution in #1991, the callback is argument-less. If an an identifier is needed, `std:🧵:current` should provide that information easily.
Added a unit test to ensure that they're being called correctly.
# Objective
- Dynamic scene builder can build scenes without components, if they didn't have any matching the type registry
- Those entities are not really useful in the final `DynamicScene`
## Solution
- Add a method `remove_empty_entities` that will remove empty entities. It's not called by default when calling `build`, I'm not sure if that's a good idea or not.
# Objective
There is currently no way to iterate over key/value pairs inside an `EntityMap`, which makes the usage of this struct very awkward. I couldn't think of a good reason why the `iter()` function should not be exposed, considering the interface already exposes `keys()` and `values()`, so I made this PR.
## Solution
Implement `iter()` for `EntityMap` in terms of its inner map type.
# Objective
Some settings were only applied in windowed mode.
Fix the issue in #6933
# Solution
Always apply the settings.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Remove a method with an unfortunate name and questionable usefulness.
Added in #4708
It doesn't make sense to me for us to provide a method to work around a limitation of closures when we can simply, *not* use a closure.
The limitation in this case is not being able to initialize a variable from inside a closure:
```rust
let child_id;
commands.spawn_empty().with_children(|parent| {
// Error: passing uninitalized variable to a closure.
child_id = parent.spawn_empty().id();
});
// Do something with child_id
```
The docs for `add_children` suggest the following:
```rust
let child_id = commands
.spawn_empty()
.add_children(|parent| parent.spawn_empty().id());
```
I would instead suggest using the following snippet.
```rust
let parent_id = commands.spawn_empty().id();
let child_id = commands.spawn_empty().set_parent(parent_id).id();
// To be fair, at the time of #4708 this would have been a bit more cumbersome since `set_parent` did not exist.
```
Using `add_children` gets more unwieldy when you also want the `parent_id`.
```rust
let parent_commands = commands.spawn_empty();
let parent_id = parent_commands.id();
let child_id = parent_commands.add_children(|parent| parent.spawn_empty().id());
```
### The name
I see why `add_children` is named that way, it's the non-builder variant of `with_children` so it kinda makes sense,
but now the method name situation for `add_child`, `add_children` and `push_children` is *rather* unfortunate.
Removing `add_children` and renaming `push_children` to `add_children` in one go is kinda bleh, but that way we end up with the matching methods `add_child` and `add_children`.
Another reason to rename `push_children` is that it's trying to mimick the `Vec` api naming but fails because `push` is for single elements. I guess it should have been `extend_children_from_slice`, but lets not name it that :)
### Questions
~~Should `push_children` be renamed in this PR? This would make the migration guide easier to deal with.~~
Let's do that later.
Does anyone know of a way to do a simple text/regex search through all the github repos for usage of `add_children`?
That way we can have a better idea of how this will affect users. My guess is that usage of `add_children` is quite rare.
## Migration Guide
The method `add_children` on `EntityCommands` was removed.
If you were using `add_children` over `with_children` to return data out of the closure you can use `set_parent` or `add_child` to avoid the closure instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`AsBindGroup` can't be used as a trait object because of the constraint `Sized` and because of the associated function.
This is a problem for [`bevy_atmosphere`](https://github.com/JonahPlusPlus/bevy_atmosphere) because it needs to use a trait that depends on `AsBindGroup` as a trait object, for switching out different shaders at runtime. The current solution it employs is reimplementing the trait and derive macro into that trait, instead of constraining to `AsBindGroup`.
## Solution
Remove the `Sized` constraint from `AsBindGroup` and add the constraint `where Self: Sized` to the associated function `bind_group_layout`. Also change `PreparedBindGroup<T: AsBindGroup>` to `PreparedBindGroup<T>` and use it as `PreparedBindGroup<Self::Data>` instead of `PreparedBindGroup<Self>`.
This weakens the constraints, but increases the flexibility of `AsBindGroup`.
I'm not entirely sure why the `Sized` constraint was there, because it worked fine without it (maybe @cart wasn't aware of use cases for `AsBindGroup` as a trait object or this was just leftover from legacy code?).
---
## Changelog
- `AsBindGroup` can be used as a trait object.
# Objective
[Rust 1.66](https://blog.rust-lang.org/inside-rust/2022/12/12/1.66.0-prerelease.html) is coming in a few days, and bevy doesn't build with it.
Fix that.
## Solution
Replace output from a trybuild test, and fix a few new instances of `needless_borrow` and `unnecessary_cast` that are now caught.
## Note
Due to the trybuild test, this can't be merged until 1.66 is released.
# Objective
A separate `tracing` span for running a system's commands is created, even if the system doesn't have commands. This is adding extra measuring overhead (see #4892) where it's not needed.
## Solution
Move the span into `ParallelCommandState` and `CommandQueue`'s `SystemParamState::apply`. To get the right metadata for the span, a additional `&SystemMeta` parameter was added to `SystemParamState::apply`.
---
## Changelog
Added: `SystemMeta::name`
Changed: Systems without `Commands` and `ParallelCommands` will no longer show a "system_commands" span when profiling.
Changed: `SystemParamState::apply` now takes a `&SystemMeta` parameter in addition to the provided `&mut World`.
# Objective
Change detection can be spuriously triggered by setting a field to the same value as before. As a result, a common pattern is to write:
```rust
if *foo != value {
*foo = value;
}
```
This is confusing to read, and heavy on boilerplate.
Adopted from #5373, but untangled and rebased to current `bevy/main`.
## Solution
1. Add a method to the `DetectChanges` trait that implements this boilerplate when the appropriate trait bounds are met.
2. Document this minor footgun, and point users to it.
## Changelog
* added the `set_if_neq` method to avoid triggering change detection when the new and previous values are equal. This will work on both components and resources.
## Migration Guide
If you are manually checking if a component or resource's value is equal to its new value before setting it to avoid triggering change detection, migrate to the clearer and more convenient `set_if_neq` method.
## Context
Related to #2363 as it avoids triggering change detection, but not a complete solution (as it still requires triggering it when real changes are made).
Co-authored-by: Zoey <Dessix@Dessix.net>
# Objective
The following code:
```rs
use bevy::prelude::Image;
use image::{ DynamicImage, GenericImage, Rgba };
fn main() {
let mut dynamic_image = DynamicImage::new_rgb32f(1, 1);
dynamic_image.put_pixel(0, 0, Rgba([1, 1, 1, 1]));
let image = Image::from_dynamic(dynamic_image, false); // Panic!
println!("{image:?}");
}
```
Can cause an assertion failed:
```
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `16`,
right: `14`: Pixel data, size and format have to match', .../bevy_render-0.9.1/src/texture/image.rs:209:9
stack backtrace:
...
4: core::panicking::assert_failed<usize,usize>
at /rustc/897e37553bba8b42751c67658967889d11ecd120/library/core/src/panicking.rs:181
5: bevy_render::texture::image::Image::new
at .../bevy_render-0.9.1/src/texture/image.rs:209
6: bevy_render::texture::image::Image::from_dynamic
at .../bevy_render-0.9.1/src/texture/image_texture_conversion.rs:159
7: bevy_test::main
at ./src/main.rs:8
...
```
It seems to be cause by a copypasta in `crates/bevy_render/src/texture/image_texture_conversion.rs`. Let's fix it.
## Solution
```diff
// DynamicImage::ImageRgb32F(image) => {
- let a = u16::max_value();
+ let a = 1f32;
```
This will fix the conversion.
---
## Changelog
- Fixed the alpha channel of the `image::DynamicImage::ImageRgb32F` to `bevy_render::texture::Image` conversion in `bevy_render::texture::Image::from_dynamic()`.
# Objective
- https://github.com/bevyengine/bevy/pull/5364 Added a few features to the AsBindGroup derive, but if you don't know they exist they aren't documented anywhere.
## Solution
- Document the new arguments in the doc block for the derive.
# Objective
Speed up bundle insertion and spawning from a bundle.
## Solution
Use the same technique used in #6800 to remove the branch on storage type when writing components from a `Bundle` into storage.
- Add a `StorageType` argument to the closure on `Bundle::get_components`.
- Pass `C::Storage::STORAGE_TYPE` into that argument.
- Match on that argument instead of reading from a `Vec<StorageType>` in `BundleInfo`.
- Marked all implementations of `Bundle::get_components` as inline to encourage dead code elimination.
The `Vec<StorageType>` in `BundleInfo` was also removed as it's no longer needed. If users were reliant on this, they can either use the compile time constants or fetch the information from `Components`. Should save a rather negligible amount of memory.
## Performance
Microbenchmarks show a slight improvement to inserting components into existing entities, as well as spawning from a bundle. Ranging about 8-16% faster depending on the benchmark.
```
group main soft-constant-write-components
----- ---- ------------------------------
add_remove/sparse_set 1.08 1019.0±80.10µs ? ?/sec 1.00 944.6±66.86µs ? ?/sec
add_remove/table 1.07 1343.3±20.37µs ? ?/sec 1.00 1257.3±18.13µs ? ?/sec
add_remove_big/sparse_set 1.08 1132.4±263.10µs ? ?/sec 1.00 1050.8±240.74µs ? ?/sec
add_remove_big/table 1.02 2.6±0.05ms ? ?/sec 1.00 2.5±0.08ms ? ?/sec
get_or_spawn/batched 1.15 401.4±17.76µs ? ?/sec 1.00 349.3±11.26µs ? ?/sec
get_or_spawn/individual 1.13 732.1±43.35µs ? ?/sec 1.00 645.6±41.44µs ? ?/sec
insert_commands/insert 1.12 623.9±37.48µs ? ?/sec 1.00 557.4±34.99µs ? ?/sec
insert_commands/insert_batch 1.16 401.4±17.00µs ? ?/sec 1.00 347.4±12.87µs ? ?/sec
insert_simple/base 1.08 416.9±5.60µs ? ?/sec 1.00 385.2±4.14µs ? ?/sec
insert_simple/unbatched 1.06 934.5±44.58µs ? ?/sec 1.00 881.3±47.86µs ? ?/sec
spawn_commands/2000_entities 1.09 190.7±11.41µs ? ?/sec 1.00 174.7±9.15µs ? ?/sec
spawn_commands/4000_entities 1.10 386.5±25.33µs ? ?/sec 1.00 352.3±18.81µs ? ?/sec
spawn_commands/6000_entities 1.10 586.2±34.42µs ? ?/sec 1.00 535.3±27.25µs ? ?/sec
spawn_commands/8000_entities 1.08 778.5±45.15µs ? ?/sec 1.00 718.0±33.66µs ? ?/sec
spawn_world/10000_entities 1.04 1026.4±195.46µs ? ?/sec 1.00 985.8±253.37µs ? ?/sec
spawn_world/1000_entities 1.06 103.8±20.23µs ? ?/sec 1.00 97.6±18.22µs ? ?/sec
spawn_world/100_entities 1.15 11.4±4.25µs ? ?/sec 1.00 9.9±1.87µs ? ?/sec
spawn_world/10_entities 1.05 1030.8±229.78ns ? ?/sec 1.00 986.2±231.12ns ? ?/sec
spawn_world/1_entities 1.01 105.1±23.33ns ? ?/sec 1.00 104.6±31.84ns ? ?/sec
```
---
## Changelog
Changed: `Bundle::get_components` now takes a `FnMut(StorageType, OwningPtr)`. The provided storage type must be correct for the component being fetched.
# Objective
Partially address #3492.
## Solution
Document the remaining undocumented members of `bevy_utils` and set `warn(missing_docs)` on the crate level. Also enabled `clippy::undocumented_unsafe_blocks` as a warning on the crate to keep it in sync with `bevy_ecs`'s warnings.
# Objective
```rust
// makes clippy complain about 'taking a mutable reference to a `const` item'
let color = *Color::RED.set_a(0.5);
// Now you can do
let color = Color::RED.with_a(0.5);
```
## Changelog
Added `with_r`, `with_g`, `with_b`, and `with_a` to `Color`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6417
## Solution
- clear_trackers was not being called on the render world. This causes the removed components vecs to continuously grow. This PR adds clear trackers to the end of RenderStage::Cleanup
## Migration Guide
The call to `clear_trackers` in `App` has been moved from the schedule to App::update for the main world and calls to `clear_trackers` have been added for sub_apps in the same function. This was due to needing stronger guarantees. If clear_trackers isn't called on a world it can lead to memory leaks in `RemovedComponents`.
# Objective
* Implementing a custom `SystemParam` by hand requires implementing three traits -- four if it is read-only.
* The trait `SystemParamFetch<'w, 's>` is a workaround from before we had generic associated types, and is no longer necessary.
## Solution
* Combine the trait `SystemParamFetch` with `SystemParamState`.
* I decided to remove the `Fetch` name and keep the `State` name, since the former was consistently conflated with the latter.
* Replace the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`, which simplifies trait bounds in generic code.
---
## Changelog
- Removed the trait `SystemParamFetch`, moving its functionality to `SystemParamState`.
- Replaced the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`.
## Migration Guide
The trait `SystemParamFetch` has been removed, and its functionality has been transferred to `SystemParamState`.
```rust
// Before
impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(...) -> Self::Item;
}
// After
impl SystemParamState for MyParamState {
type Item<'w, 's> = MyParam<'w, 's>; // Generic associated types!
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
fn get_param<'w, 's>(...) -> Self::Item<'w, 's>;
}
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl<'w, 's> ReadOnlySystemParam for MyParam<'w, 's> {}
```
# Objective
It's not clear to users how to handle `!Sync` types as components and resources in the absence of engine level support for them.
## Solution
Added a section to `Component`'s and `Resource`'s type level docs on available options for making a type `Sync` when it holds `!Sync` fields, linking `bevy_utils::synccell::SyncCell` and the currently unstable `std::sync::Exclusive`.
Also added a compile_fail doctest that illustrates how to apply `SyncCell`. These will break when/if #6572 gets merged, at which point these docs should be updated.
# Objective
This is an adoption of #5792. Fixes#5791.
## Solution
Implemented all the required reflection traits for `VecDeque`, taking from `Vec`'s impls.
---
## Changelog
Added: `std::collections::VecDeque` now implements `Reflect` and all relevant traits.
Co-authored-by: james7132 <contact@jamessliu.com>
# Objective
- Get rid of giant match statement to get PixelInfo.
- This will allow for supporting any texture that is uncompressed, instead of people needing to PR in any textures that are supported in wgpu, but not bevy.
## Solution
- More conservative alternative to https://github.com/bevyengine/bevy/pull/6788, where we don't try to make some of the calculations correct for compressed types.
- Delete `PixelInfo` and get the pixel_size directly from wgpu. Data from wgpu is here: https://docs.rs/wgpu-types/0.14.0/src/wgpu_types/lib.rs.html#2359
- Panic if the texture is a compressed type. An integer byte size of a pixel is no longer a valid concept when talking about compressed textures.
- All internal usages use `pixel_size` and not `pixel_info` and are on uncompressed formats. Most of these usages are on either explicit texture formats or slightly indirectly through `TextureFormat::bevy_default()`. The other uses are in `TextureAtlas` and have other calculations that assumes the texture is uncompressed.
## Changelog
- remove `PixelInfo` and get `pixel_size` from wgpu
## Migration Guide
`PixelInfo` has been removed. `PixelInfo::components` is equivalent to `texture_format.describe().components`. `PixelInfo::type_size` can be gotten from `texture_format.describe().block_size/ texture_format.describe().components`. But note this can yield incorrect results for some texture types like Rg11b10Float.
# Objective
Adds a cylinder shape. Fixes#2282.
## Solution
- I added a custom cylinder shape, taken from [here](https://github.com/rparrett/typey_birb/blob/main/src/cylinder.rs) with permission from @rparrett.
- I also added the cylinder shape to the `3d_shapes` example scene.
---
## Changelog
- Added cylinder shape
Co-Authored-By: Rob Parrett <robparrett@gmail.com>
Co-Authored-By: davidhof <7483215+davidhof@users.noreply.github.com>
# Objective
Fixes#6224, add ``dbg``, ``info``, ``warn`` and ``error`` system piping adapter variants to expand #5776, which call the corresponding re-exported [bevy_log macros](https://docs.rs/bevy/latest/bevy/log/macro.info.html) when the result is an error.
## Solution
* Added ``dbg``, ``info``, ``warn`` and ``error`` system piping adapter variants to ``system_piping.rs``.
* Modified and added tests for these under examples in ``system_piping.rs``.
# Objective
- Make `AudioOutput` a `Resource`.
## Solution
- Do not store `OutputStream` in the struct.
- `mem::forget` `OutputStream`.
---
## Changelog
### Added
- `AudioOutput` is now a `Resource`.
## Migration Guide
- Use `Res<AudioOutput<Source>>` instead of `NonSend<AudioOutput<Source>>`. Same for `Mut` variants.
# Objective
Resolves#4597 (based on the work from #6056 and a refresh of #4147)
When using reflection, we may often end up in a scenario where we have a Dynamic representing a certain type. Unfortunately, we can't just call `MyType::from_reflect` as we do not have knowledge of the concrete type (`MyType`) at runtime.
Such scenarios happen when we call `Reflect::clone_value`, use the reflection deserializers, or create the Dynamic type ourselves.
## Solution
Add a `ReflectFromReflect` type data struct.
This struct allows us to easily convert Dynamic representations of our types into their respective concrete instances.
```rust
#[derive(Reflect, FromReflect)]
#[reflect(FromReflect)] // <- Register `ReflectFromReflect`
struct MyStruct(String);
let type_id = TypeId::of::<MyStruct>();
// Register our type
let mut registry = TypeRegistry::default();
registry.register::<MyStruct>();
// Create a concrete instance
let my_struct = MyStruct("Hello world".to_string());
// `Reflect::clone_value` will generate a `DynamicTupleStruct` for tuple struct types
let dynamic_value: Box<dyn Reflect> = my_struct.clone_value();
assert!(!dynamic_value.is::<MyStruct>());
// Get the `ReflectFromReflect` type data from the registry
let rfr: &ReflectFromReflect = registry
.get_type_data::<ReflectFromReflect>(type_id)
.unwrap();
// Call `FromReflect::from_reflect` on our Dynamic value
let concrete_value: Box<dyn Reflect> = rfr.from_reflect(&dynamic_value);
assert!(concrete_value.is::<MyStruct>());
```
### Why this PR?
###### Why now?
The three main reasons I closed#4147 were that:
1. Registering `ReflectFromReflect` is clunky (deriving `FromReflect` *and* registering `ReflectFromReflect`)
2. The ecosystem and Bevy itself didn't seem to pay much attention to deriving `FromReflect`
3. I didn't see a lot of desire from the community for such a feature
However, as time has passed it seems 2 and 3 are not really true anymore. Bevy is internally adding lots more `FromReflect` derives, which should make this feature all the more useful. Additionally, I have seen a growing number of people look for something like `ReflectFromReflect`.
I think 1 is still an issue, but not a horrible one. Plus it could be made much, much better using #6056. And I think splitting this feature out of #6056 could lead to #6056 being adopted sooner (or at least make the need more clear to users).
###### Why not just re-open #4147?
The main reason is so that this PR can garner more attention than simply re-opening the old one. This helps bring fresh eyes to the PR for potentially more perspectives/reviews.
---
## Changelog
* Added `ReflectFromReflect`
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
#6547 accidentally broke change detection for SparseSet components by using `Ticks::from_tick_cells` with the wrong argument order.
## Solution
Use the right argument order. Add a regression test.
# Objective
The window event types currently don't support reflection. This PR adds support to them (as requested [here](https://github.com/bevyengine/bevy/issues/6223#issuecomment-1273852329)).
## Solution
Implement `Reflect` + `FromReflect` for window event types. Relevant traits are also being reflected with `#[reflect(...)]` attributes.
Additionally, this PR derives `Reflect` + `FromReflect` for `WindowDescriptor` and the types it depends on so that `CreateWindow` events can be fully manipulated through reflection.
Finally, this PR adds `FromReflect` for `PathBuf` as a value type, which is needed for `FileDragAndDrop`.
This adds the "glam" feature to the `bevy_reflect` dependency for package `bevy_window`. Since `bevy_window` transitively depends on `glam` already, all this brings in are the reflection `impl`s.
## Open questions
Should `app.register_type::<PathBuf>();` be moved to `CorePlugin`? I added it to `WindowPlugin` because that's where it's used and `CorePlugin` doesn't seem to register all the missing std types, but it would also make sense in `CorePlugin` I believe since it's a commonly used type.
---
## Changelog
Added:
- Implemented `Reflect` + `FromReflect` for window events and related types. These types are automatically registered when adding the `WindowPlugin`.
# Objective
- Fixes#6841
- In some case, the number of maximum storage buffers is `u32::MAX` which doesn't fit in a `i32`
## Solution
- Add an option to have a `u32` in a `ShaderDefVal`
having `doc(hidden)` on the read only version of a generated mutable world query leads to docs on the readonly item having a dead link. It also makes it annoying to have nice docs for libraries attempting to expose derived `WorldQuery` structs as re-exporting the read only item does not cause it to appear in docs even though it would be intended for users to know about the read only world query and use it.
# Objective
Fixes#6866.
## Solution
Docs now should describe what the _front_, _first_, _back_, and _last_ elements are for an implementor of the `bevy::reflect::list::List` Trait. Further, the docs should describe how `bevy::reflect::list::List::push` and `bevy::reflect::list::List::pop` should act on these elements.
Co-authored-by: Linus Käll <linus.kall.business@gmail.com>
# Objective
Prevent future unsoundness that was seen in #6623.
## Solution
Newtype both indexes in `Archetype` and `Table` as `ArchetypeRow` and `TableRow`. This avoids weird numerical manipulation on the indices, and can be stored and treated opaquely. Also enforces the source and destination of where these indices at a type level.
---
## Changelog
Changed: `Archetype` indices and `Table` rows have been newtyped as `ArchetypeRow` and `TableRow`.
# Objective
`EntityRef::get` and friends all type erase calls to fetch the target components by using passing in the `TypeId` instead of using generics. This is forcing a lookup to `Components` to fetch the storage type. This adds an extra memory lookup and forces a runtime branch instead of allowing the compiler to optimize out the unused branch.
## Solution
Leverage `Component::Storage::STORAGE_TYPE` as a constant instead of fetching the metadata from `Components`.
## Performance
This has a near 2x speedup for all calls to `World::get`. Microbenchmark results from my local machine. `Query::get_component`, which uses `EntityRef::get` internally also show a slight speed up. This has closed the gap between `World::get` and `Query::get` for the same use case.
```
group entity-ref-generics main
----- ------------------- ----
query_get_component/50000_entities_sparse 1.00 890.6±40.42µs ? ?/sec 1.10 980.6±28.22µs ? ?/sec
query_get_component/50000_entities_table 1.00 968.5±73.73µs ? ?/sec 1.08 1048.8±31.76µs ? ?/sec
query_get_component_simple/system 1.00 703.2±4.37µs ? ?/sec 1.00 702.1±6.13µs ? ?/sec
query_get_component_simple/unchecked 1.02 855.8±8.98µs ? ?/sec 1.00 843.1±8.19µs ? ?/sec
world_get/50000_entities_sparse 1.00 202.3±3.15µs ? ?/sec 1.85 374.0±20.96µs ? ?/sec
world_get/50000_entities_table 1.00 193.0±1.78µs ? ?/sec 2.02 389.2±26.55µs ? ?/sec
world_query_get/50000_entities_sparse 1.01 162.4±2.23µs ? ?/sec 1.00 161.3±0.95µs ? ?/sec
world_query_get/50000_entities_table 1.00 199.9±0.63µs ? ?/sec 1.00 200.2±0.74µs ? ?/sec
```
This should also, by proxy, speed up the `ReflectComponent` APIs as most of those use `World::get` variants internally.
# Objective
- Fixes#3004
## Solution
- Replaced all the types with their fully quallified names
- Replaced all trait methods and inherent methods on dyn traits with their fully qualified names
- Made a new file `fq_std.rs` that contains structs corresponding to commonly used Structs and Traits from `std`. These structs are replaced by their respective fully qualified names when used inside `quote!`
# Objective
- Fixes#6711
## Solution
- Change the `path` function parameter of `dynamically_load_plugin` and `DynamicPluginExt::load_plugin` to a generic with `AsRef<OsStr>` bound
# Objective
`prepare_asset` for Image has an alternate path for texture creation that is used when the image is not compressed and does not contain mipmaps. This additional code path is unnecessary as `render_device.create_texture_with_data()` will handle both cases correctly.
## Solution
Use `render_device.create_texture_with_data()` in all cases.
Tested successfully with the following examples:
- load_gltf
- render_to_texture
- texture
- 3d_shapes
- sprite
- sprite_sheet
- array_texture
- shader_material_screenspace_texture
- skybox (though this already would use the `create_texture_with_data()` branch anyway)
# Objective
The methods `World::change_tick` and `World::read_change_tick` lack documentation and have confusingly similar behavior.
## Solution
Add documentation and clarify the distinction between the two functions.
The PR fixes the interface of `EventReader::clear`. Currently, the method consumes the reader, which makes it unusable.
## Changelog
- `EventReader::clear` now takes a mutable reference instead of consuming the event reader.
## Migration Guide
`EventReader::clear` now takes a mutable reference instead of consuming the event reader. This means that `clear` now needs explicit mutable access to the reader variable, which previously could have been omitted in some cases:
```rust
// Old (0.9)
fn clear_events(reader: EventReader<SomeEvent>) {
reader.clear();
}
// New (0.10)
fn clear_events(mut reader: EventReader<SomeEvent>) {
reader.clear();
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#6812.
## Solution
- Replaced `World::read_change_ticks` with `World::change_ticks` within `bevy_ecs` crate in places where `World` references were mutable.
---
# Objective
Partially addresses #5504. Allow users to get an `Iterator<Item = EntityRef<'a>>` over all entities in the `World`.
## Solution
Change `World::iter_entities` to return an iterator of `EntityRef` instead of `Entity`.
Not sure how to tackle making an `Iterator<Item = EntityMut<'_>>` without being horribly unsound. Might need to wait for `LendingIterator` to stabilize so we can ensure only one of them is valid at a given time.
---
## Changelog
Changed: `World::iter_entities` now returns an iterator of `EntityRef` instead of `Entity`.
# Objective
Currently, the `SystemParam` derive forces you to declare the lifetime parameters `<'w, 's>`, even if you don't use them.
If you don't follow this structure, the error message is quite nasty.
### Example (before):
```rust
#[derive(SystemParam)]
pub struct EventWriter<'w, 's, E: Event> {
events: ResMut<'w, Events<E>>,
// The derive forces us to declare the `'s` lifetime even though we don't use it,
// so we have to add this `PhantomData` to please rustc.
#[system_param(ignore)]
_marker: PhantomData<&'s ()>,
}
```
## Solution
* Allow the user to omit either lifetime.
* Emit a descriptive error if any lifetimes used are invalid.
### Example (after):
```rust
#[derive(SystemParam)]
pub struct EventWriter<'w, E: Event> {
events: ResMut<'w, Events<E>>,
}
```
---
## Changelog
* The `SystemParam` derive is now more flexible, allowing you to omit unused lifetime parameters.
Updates the requirements on [tracing-chrome](https://github.com/thoren-d/tracing-chrome) to permit the latest version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/thoren-d/tracing-chrome/releases">tracing-chrome's releases</a>.</em></p>
<blockquote>
<h2>Release v0.7.0</h2>
<ul>
<li>Add <code>start_new</code> to <code>FlushGuard</code>. You can now generate multiple traces in one run!</li>
<li>Clean up dependencies</li>
<li>Make events thread-scoped</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="8760d81206"><code>8760d81</code></a> Prepare for 0.7 (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/16">#16</a>)</li>
<li><a href="a30bfb78d2"><code>a30bfb7</code></a> Update documentation (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/15">#15</a>)</li>
<li><a href="3fe24ff44d"><code>3fe24ff</code></a> Save thread names for start_new (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/14">#14</a>)</li>
<li><a href="fa8a0ff8ba"><code>fa8a0ff</code></a> Adding "Start New" feature that allows a user to finalize writing to the (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/11">#11</a>)</li>
<li><a href="d3059d66b3"><code>d3059d6</code></a> Directly depend on crossbeam_channel (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/12">#12</a>)</li>
<li><a href="441dba5c21"><code>441dba5</code></a> change scope of instant events to thread (<a href="https://github-redirect.dependabot.com/thoren-d/tracing-chrome/issues/13">#13</a>)</li>
<li>See full diff in <a href="https://github.com/thoren-d/tracing-chrome/compare/v0.6.0...v0.7.0">compare view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
# Objective
Fixes#6827
## Solution
Use the `Color::rgba_linear` function instead of the `Color::rgba` function to correctly interpret colors from glTF files in the linear color space rather than the incorrect sRGB color space
# Objective
> Followup to [this](https://github.com/bevyengine/bevy/pull/6755#discussion_r1032671178) comment
Rearrange the impls in the `impls/std.rs` file.
The issue was that I had accidentally misplaced the impl for `Option<T>` and put it between the `Cow<'static, str>` impls. This is just a slight annoyance and readability issue.
## Solution
Move the `Option<T>` and `&'static Path` impls around to be more readable.
# Objective
The soundness of the ECS `World` partially relies on the correctness of the state of `Entities` stored within it. We're currently allowing users to (unsafely) mutate it, as well as readily construct it without using a `World`. While this is not strictly unsound so long as users (including `bevy_render`) safely use the APIs, it's a fairly easy path to unsoundness without much of a guard rail.
Addresses #3362 for `bevy_ecs::entity`. Incorporates the changes from #3985.
## Solution
Remove `Entities`'s `Default` implementation and force access to the type to only be through a properly constructed `World`.
Additional cleanup for other parts of `bevy_ecs::entity`:
- `Entity::index` and `Entity::generation` are no longer `pub(crate)`, opting to force the rest of bevy_ecs to use the public interface to access these values.
- `EntityMeta` is no longer `pub` and also not `pub(crate)` to attempt to cut down on updating `generation` without going through an `Entities` API. It's currently inaccessible except via the `pub(crate)` Vec on `Entities`, there was no way for an outside user to use it.
- Added `Entities::set`, an unsafe `pub(crate)` API for setting the location of an Entity (parallel to `Entities::get`) that replaces the internal case where we need to set the location of an entity when it's been spawned, moved, or despawned.
- `Entities::alloc_at_without_replacement` is only used in `World::get_or_spawn` within the first party crates, and I cannot find a public use of this API in any ecosystem crate that I've checked (via GitHub search).
- Attempted to document the few remaining undocumented public APIs in the module.
---
## Changelog
Removed: `Entities`'s `Default` implementation.
Removed: `EntityMeta`
Removed: `Entities::alloc_at_without_replacement` and `AllocAtWithoutReplacement`.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Since #5900 3d examples fail in wasm
```
ERROR crates/bevy_render/src/render_resource/pipeline_cache.rs:660 failed to process shader: Unknown shader def: 'AVAILABLE_STORAGE_BUFFER_BINDINGS'
```
## Solution
- Fix it by always adding the shaderdef `AVAILABLE_STORAGE_BUFFER_BINDINGS` with the actual value, instead of 3 when 3 or more were available
# Objective
- Support textures in `Rgb9e5Ufloat` format.
## Solution
- Add `TextureFormatPixelInfo` for `Rgb9e5Ufloat`.
Tested this with a `Rgb9e5Ufloat` encoded KTX2 texture.
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
Document `bevy_ecs::archetype` and and declutter the public documentation for the module by making types non-`pub`.
Addresses #3362 for `bevy_ecs::archetype`.
## Solution
- Add module level documentation.
- Add type and API level documentation for all public facing types.
- Make `ArchetypeId`, `ArchetypeGeneration`, and `ArchetypeComponentId` truly opaque IDs that are not publicly constructable.
- Make `AddBundle` non-pub, make `Edges::get_add_bundle` return a `Option<ArchetypeId>` and fork the existing function into `Edges::get_add_bundle_internal`.
- Remove `pub(crate)` on fields that have a corresponding pub accessor function.
- Removed the `Archetypes: Default` impl, opting for a `pub(crate) fn new` alternative instead.
---
## Changelog
Added: `ArchetypeGeneration` now implements `Ord` and `PartialOrd`.
Removed: `Archetypes`'s `Default` implementation.
Removed: `Archetype::new` and `Archetype::is_empty`.
Removed: `ArchetypeId::new` and `ArchetypeId::value`.
Removed: `ArchetypeGeneration::value`
Removed: `ArchetypeIdentity`.
Removed: `ArchetypeComponentId::new` and `ArchetypeComponentId::value`.
Removed: `AddBundle`. `Edges::get_add_bundle` now returns `Option<ArchetypeId>`
# Objective
- The documentation describing different ways to spawn an Entity is missing reference to "method" for "Spawn an entity with components".
## Solution
- Update the documentation to add the reference to `World::spawn`.
# Objective
* Fix#6668
* There is no need to panic when a parenting operation is redundant, as no invalid state is entered.
## Solution
Make `push_children` idempotent.
# Objective
One of the use-cases for the function `Entity::from_raw` is creating placeholder entity ids, which are meant to be overwritten later. If we use a constant for this instead of `from_raw`, it is more ergonomic and self-documenting.
## Solution
Add a constant that returns an entity ID with an index of `u32::MAX` and a generation of zero. Users are instructed to overwrite this value before using it.
# Objective
When a global tracing subscriber has already been set, `LogPlugin` panics with an error message explaining this. However, if a global logger has already been set, it simply panics on an unwrap.
#6426 mentiones the panic and has been fixed by unique plugins, but the panic can still occur if a logger has been set through different means or multiple apps are created, as in #4934. The solution to that specific case isn't clear; this PR only fixes the missing error message.
## Solution
- ~add error message to panic~
- turn into warning
# Objective
- Reduce confusion around uniform bindings in materials. I've seen multiple people on discord get confused by it because it uses a struct that is named the same in the rust code and the wgsl code, but doesn't contain the same data. Also, the only reason this works is mostly by chance because the memory happens to align correctly.
## Solution
- Remove the confusing parts of the doc
## Notes
It's not super clear in the diff why this causes confusion, but essentially, the rust code defines a `CustomMaterial` struct with a color and a texture, but in the wgsl code the struct with the same name only contains the color. People are confused by it because the struct in wgsl doesn't need to be there.
You _can_ have complex structs on each side and the macro will even combine it for you if you reuse a binding index, but as it is now, this example seems to confuse more than help people.
# Objective
Fixes#6739
## Solution
Implement the required traits. They cannot be implemented for `Path` directly, since it is a dynamically-sized type.
# Objective
Fixes#6642
In a way that doesn't create any breaking changes, as a possible way to fix the above in a patch release.
## Solution
Don't actually remove font atlases when `max_font_atlases` is exceeded. Add a warning instead.
Keep `TextError::ExceedMaxTextAtlases` and `TextSettings` as-is so we don't break anything.
This is a bit of a cop-out, but the problems revealed by #6642 seem very challenging to fix properly.
Maybe follow up later with something more like https://github.com/rparrett/bevy/commits/remove-max-font-atlases later, if this is the direction we want to go.
## Note
See previous attempt at a "simple fix" that only solved some of the issues: #6666
# Objective
> Part of #6573
When serializing a `DynamicScene` we end up treating almost all non-value types as though their type data doesn't exist. This is because when creating the `DynamicScene` we call `Reflect::clone_value` on the components, which generates a Dynamic type for all non-value types.
What this means is that the `glam` types are treated as though their `ReflectSerialize` registrations don't exist. However, the deserializer _does_ pick up the registration and attempts to use that instead. This results in the deserializer trying to operate on "malformed" data, causing this error:
```
WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected float
```
## Solution
Ideally, we should better handle the serialization of possibly-Dynamic types. However, this runs into issues where the `ReflectSerialize` expects the concrete type and not a Dynamic representation, resulting in a panic:
0aa4147af6/crates/bevy_reflect/src/type_registry.rs (L402-L413)
Since glam types are so heavily used in Bevy (specifically in `Transform` and `GlobalTransform`), it makes sense to just a quick fix in that enables them to be used properly in scenes while a proper solution is found.
This PR simply removes all `ReflectSerialize` and `ReflectDeserialize` registrations from the glam types that are reflected as structs.
---
## Changelog
- Remove `ReflectSerialize` and `ReflectDeserialize` registrations from most glam types
## Migration Guide
This PR removes `ReflectSerialize` and `ReflectDeserialize` registrations from most glam types. This means any code relying on either of those type data existing for those glam types will need to not do that.
This also means that some serialized glam types will need to be updated. For example, here is `Affine3A`:
```rust
// BEFORE
(
"glam::f32::affine3a::Affine3A": (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0),
// AFTER
"glam::f32::affine3a::Affine3A": (
matrix3: (
x_axis: (
x: 1.0,
y: 0.0,
z: 0.0,
),
y_axis: (
x: 0.0,
y: 1.0,
z: 0.0,
),
z_axis: (
x: 0.0,
y: 0.0,
z: 1.0,
),
),
translation: (
x: 0.0,
y: 0.0,
z: 0.0,
),
)
)
```
# Objective
Many types in `bevy_render` implemented `Reflect` but were not registered.
## Solution
Register all types in `bevy_render` that impl `Reflect`.
This also registers additional dependent types (i.e. field types).
> Note: Adding these dependent types would not be needed using something like #5781😉
---
## Changelog
- Register missing `bevy_render` types in the `TypeRegistry`:
- `camera::RenderTarget`
- `globals::GlobalsUniform`
- `texture::Image`
- `view::ComputedVisibility`
- `view::Visibility`
- `view::VisibleEntities`
- Register additional dependent types:
- `view::ComputedVisibilityFlags`
- `Vec<Entity>`
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6603
## Solution
- `Task`s will cancel when dropped, but wait until they return Pending before they actually get canceled. That means that if a task panics, it's possible for that error to get propagated to the scope and the scope gets dropped, while scoped tasks in other threads are still running. This is a big problem since scoped task can hold life-timed values that are dropped as the scope is dropped leading to UB.
---
## Changelog
- changed `Scope` to use `FallibleTask` and await the cancellation of all remaining tasks when it's dropped.
# Objective
- Reverts #5730.
- Fixes#6173, fixes#6596.
## Solution
Remove the warning entirely.
## Changelog
You will no longer be spammed about
> Missed 31 `bevy_input:🐭:MouseMotion` events. Consider
reading from the `EventReader` more often (generally the best
solution) or calling Events::update() less frequently
(normally this is called once per frame). This problem is most
likely due to run criteria/fixed timesteps or consuming events
conditionally. See the Events documentation for
more information.
when you miss events. These warnings were often (but not always) a false positive. You can still check this manually by using `ManualEventReader::missed_events`
# Objective
Remove an obscure and inconsistent bit of API.
Simplify the `WorldChildBuilder` code.
No idea why this even exists.
An example of the removed API:
```rust
world.spawn_empty().with_children(|parent| {
parent.spawn_empty();
parent.push_children(&[some_entity]); // Does *not* add children to the parent.
// It's actually identical to:
parent.spawn_empty().push_children(&[some_entity]);
});
world.spawn_empty().with_children(|parent| {
// This just panics.
parent.push_children(&[some_entity]);
});
```
This exists only on `WorldChildBuilder`; `ChildBuilder` does not have this API.
Yeet.
## Migration Guide
Hierarchy editing methods such as `with_children` and `push_children` have been removed from `WorldChildBuilder`.
You can edit the hierarchy via `EntityMut` instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes#6713
Binary deserialization is failing for unit structs as well as structs with all ignored/skipped fields.
## Solution
Add a check for the number of possible fields in a struct before deserializing. If empty, don't attempt to deserialize any fields (as there will be none).
Note: ~~This does not apply to enums as they do not properly handle skipped fields (see #6721).~~ Enums still do not properly handle skipped fields, but I decided to include the logic for it anyways to account for `#[reflect(ignore)]`'d fields in the meantime.
---
## Changelog
- Fix bug where deserializing unit structs would fail for non-self-describing formats
# Objective
Consider the test
```rust
let cell = world.cell();
let _value_a = cell.resource_mut::<A>();
let _value_b = cell.resource_mut::<A>();
```
Currently, this will roughly execute
```rust
// first call
let value = unsafe {
self.world
.get_non_send_unchecked_mut_with_id(component_id)?
};
return Some(WorldBorrowMut::new(value, archetype_component_id, self.access)))
// second call
let value = unsafe {
self.world
.get_non_send_unchecked_mut_with_id(component_id)?
};
return Some(WorldBorrowMut::new(value, archetype_component_id, self.access)))
```
where `WorldBorrowMut::new` will panic if the resource is already borrowed.
This means, that `_value_a` will be created, the access checked (OK), then `value_b` will be created, and the access checked (`panic`).
For a moment, both `_value_a` and `_value_b` existed as `&mut T` to the same location, which is insta-UB as far as I understand it.
## Solution
Flip the order so that `WorldBorrowMut::new` first checks the access, _then_ fetches creates the value. To do that, we pass a `impl FnOnce() -> Mut<T>` instead of the `Mut<T>` directly:
```rust
let get_value = || unsafe {
self.world
.get_non_send_unchecked_mut_with_id(component_id)?
};
return Some(WorldBorrowMut::new(get_value, archetype_component_id, self.access)))
```
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
Fixes#4697. Hierarchical propagation of properties, currently only Transform -> GlobalTransform, can be a very expensive operation. Transform propagation is a strict dependency for anything positioned in world-space. In large worlds, this can take quite a bit of time, so limiting it to a single thread can result in poor CPU utilization as it bottlenecks the rest of the frame's systems.
## Solution
- Move transforms without a parent or a child (free-floating (Global)Transform) entities into a separate parallel system.
- Chunk the hierarchy based on the root entities and process it in parallel with `Query::par_for_each_mut`.
- Utilize the hierarchy's specific properties introduced in #4717 to allow for safe use of `Query::get_unchecked` on multiple threads. Assuming each child is unique in the hierarchy, it is impossible to have an aliased `&mut GlobalTransform` so long as we verify that the parent for a child is the same one propagated from.
---
## Changelog
Removed: `transform_propagate_system` is no longer `pub`.
Without this fix, piped systems containing exclusive systems fail to run, giving a runtime panic.
With this PR, running piped systems that contain exclusive systems now works.
## Explanation of the bug
This is because, unless overridden, the default implementation of `run` from the `System` trait simply calls `run_unsafe`. That is not valid for exclusive systems. They must always be called via `run`, as `run_unsafe` takes `&World` instead of `&mut World`.
Trivial reproduction example:
```rust
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_system(exclusive.pipe(another))
.run();
}
fn exclusive(_world: &mut World) {}
fn another() {}
```
If you run this, you will get a panic 'Cannot run exclusive systems with a shared World reference' and the backtrace shows how bevy (correctly) tries to call the `run` method (because the system is exclusive), but it is the implementation from the `System` trait (because `PipeSystem` does not have its own), which calls `run_unsafe` (incorrect):
- 3: <bevy_ecs::system::system_piping::PipeSystem<SystemA,SystemB> as bevy_ecs::system::system::System>::run_unsafe
- 4: bevy_ecs::system::system::System::run
# Objective
Allow more use cases where the user may benefit from both `ExtractComponentPlugin` _and_ `UniformComponentPlugin`.
## Solution
Add an associated type to `ExtractComponent` in order to allow specifying the output component (or bundle).
Make `extract_component` return an `Option<_>` such that components can be extracted only when needed.
What problem does this solve?
`ExtractComponentPlugin` allows extracting components, but currently the output type is the same as the input.
This means that use cases such as having a settings struct which turns into a uniform is awkward.
For example we might have:
```rust
struct MyStruct {
enabled: bool,
val: f32
}
struct MyStructUniform {
val: f32
}
```
With the new approach, we can extract `MyStruct` only when it is enabled, and turn it into its related uniform.
This chains well with `UniformComponentPlugin`.
The user may then:
```rust
app.add_plugin(ExtractComponentPlugin::<MyStruct>::default());
app.add_plugin(UniformComponentPlugin::<MyStructUniform>::default());
```
This then saves the user a fair amount of boilerplate.
## Changelog
### Changed
- `ExtractComponent` can specify output type, and outputting is optional.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
Add a method to rotate a transform to point towards a direction.
Also updated the docs to link to `forward` and `up` instead of mentioning local negative `Z` and local `Y`.
Unfortunately, links to methods don't work in rust-analyzer :(
Co-authored-by: Devil Ira <justthecooldude@gmail.com>
# Objective
Latest Release, "bevy 0.9" move the FrameCount updater into RenderPlugin, it leads to user who only run app with Core/Minimal Plugin cannot get the right number of FrameCount, it always return 0.
As for use cases like a server app, we don't want to add render dependencies to the app.
More detail in #6656
## Solution
- Move the `update_frame_count` into CorePlugin
# Objective
This add a ctor to `Box` to aid the creation of non-centred boxes. The PR adopts @rezural's work on PR #3322, taking into account the feedback on that PR from @james7132.
## Solution
`Box::from_corners()` creates a `Box` from two opposing corners and automatically determines the min and max extents to ensure that the `Box` is well-formed.
Co-authored-by: rezural <rezural@protonmail.com>
# Objective
- Bevy should be usable to create 'overlay' type apps, where the input is not captured by Bevy, but passed down/into a target app, or to allow passive displays/widgets etc.
## Solution
- the `winit:🪟:Window` already has a `set_cursor_hittest()` which basically does this for mouse input events, so I've exposed it (trying to copy the style laid out in the existing wrappings, and added a simple demo.
---
## Changelog
- Added `hittest` to `WindowAttributes`
- Added the `hittest`'s setters/getters
- Modified the `WindowBuilder`
- Modifed the `WindowDescriptor`'s `Default` impl.
- Added an example `cargo run --example fallthrough`
# Objective
Fixes#4884. `ComponentTicks` stores both added and changed ticks contiguously in the same 8 bytes. This is convenient when passing around both together, but causes half the bytes fetched from memory for the purposes of change detection to effectively go unused. This is inefficient when most queries (no filter, mutating *something*) only write out to the changed ticks.
## Solution
Split the storage for change detection ticks into two separate `Vec`s inside `Column`. Fetch only what is needed during iteration.
This also potentially also removes one blocker from autovectorization of dense queries.
EDIT: This is confirmed to enable autovectorization of dense queries in `for_each` and `par_for_each` where possible. Unfortunately `iter` has other blockers that prevent it.
### TODO
- [x] Microbenchmark
- [x] Check if this allows query iteration to autovectorize simple loops.
- [x] Clean up all of the spurious tuples now littered throughout the API
### Open Questions
- ~~Is `Mut::is_added` absolutely necessary? Can we not just use `Added` or `ChangeTrackers`?~~ It's optimized out if unused.
- ~~Does the fetch of the added ticks get optimized out if not used?~~ Yes it is.
---
## Changelog
Added: `Tick`, a wrapper around a single change detection tick.
Added: `Column::get_added_ticks`
Added: `Column::get_column_ticks`
Added: `SparseSet::get_added_ticks`
Added: `SparseSet::get_column_ticks`
Changed: `Column` now stores added and changed ticks separately internally.
Changed: Most APIs returning `&UnsafeCell<ComponentTicks>` now returns `TickCells` instead, which contains two separate `&UnsafeCell<Tick>` for either component ticks.
Changed: `Query::for_each(_mut)`, `Query::par_for_each(_mut)` will now leverage autovectorization to speed up query iteration where possible.
## Migration Guide
TODO
# Objective
Fix#6453.
## Solution
Use the solution mentioned in the issue by catching the unwind and dropping the error. Wrap the `executor.try_tick` calls with `std::catch::unwind`.
Ideally this would be moved outside of the hot loop, but the mut ref to the `spawned` future is not `UnwindSafe`.
This PR only addresses the bug, we can address the perf issues (should there be any) later.
# Objective
Fix#5149
## Solution
Instead of returning the **total count** of elements in the `QueryIter` in
`size_hint`, we return the **count of remaining elements**. This
Fixes#5149 even when #5148 gets merged.
- https://github.com/bevyengine/bevy/issues/5149
- https://github.com/bevyengine/bevy/pull/5148
---
## Changelog
- Fix partially consumed `QueryIter` and `QueryCombinationIter` having invalid `size_hint`
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Make core pipeline graphic nodes, including `BloomNode`, `FxaaNode`, `TonemappingNode` and `UpscalingNode` public.
This will allow users to construct their own render graphs with these build-in nodes.
## Solution
Make them public.
Also put node names into bevy's core namespace (`core_2d::graph::node`, `core_3d::graph::node`) which makes them consistent.
# Objective
Fix android touch events being flipped. Only removed test for android, don't have ios device to test with. Tested with emulator and physical device.
## Solution
Remove check, no longer needed with coordinate change in 0.9
# Objective
Delete `ImageMode`. It doesn't do anything except mislead people into thinking it controls the aspect ratio of images somehow.
Fixes#3933 and #6637
## Solution
Delete `ImageMode`
## Changelog
Removes the `ImageMode` enum.
Removes the `image_mode` field from `ImageBundle`
Removes the `With<ImageMode>` query filter from `image_node_system`
Renames `image_node_system` to` update_image_calculated_size_system`
# Objective
Fixes#6661
## Solution
Make `SceneSpawner::spawn_dynamic` return `InstanceId` like other functions there.
---
## Changelog
Make `SceneSpawner::spawn_dynamic` return `InstanceId` instead of `()`.
When I was upgrading to 0.9 noticed there were some changes to the timer, mainly the `TimerMode`. When switching from the old `is_repeating()` and `set_repeating()` to the new `mode()` and `set_mode()` noticed the docs still had the old description.
# Objective
BlobVec currently relies on a scratch piece of memory allocated at initialization to make a temporary copy of a component when using `swap_remove_and_{forget/drop}`. This is potentially suboptimal as it writes to a, well-known, but random part of memory instead of using the stack.
## Solution
As the `FIXME` in the file states, replace `swap_scratch` with a call to `swap_nonoverlapping::<u8>`. The swapped last entry is returned as a `OwnedPtr`.
In theory, this should be faster as the temporary swap is allocated on the stack, `swap_nonoverlapping` allows for easier vectorization for bigger types, and the same memory is used between the swap and the returned `OwnedPtr`.
# Objective
* Enable `Res` and `Query` parameter mutual exclusion
* Required for https://github.com/bevyengine/bevy/pull/5080
The `FilteredAccessSet::get_conflicts` methods didn't work properly with
`Res` and `ResMut` parameters. Because those added their access by using
the `combined_access_mut` method and directly modifying the global
access state of the FilteredAccessSet. This caused an inconsistency,
because get_conflicts assumes that ALL added access have a corresponding
`FilteredAccess` added to the `filtered_accesses` field.
In practice, that means that SystemParam that adds their access through
the `Access` returned by `combined_access_mut` and the ones that add
their access using the `add` method lived in two different universes. As
a result, they could never be mutually exclusive.
## Solution
This commit fixes it by removing the `combined_access_mut` method. This
ensures that the `combined_access` field of FilteredAccessSet is always
updated consistently with the addition of a filter. When checking for
filtered access, it is now possible to account for `Res` and `ResMut`
invalid access. This is currently not needed, but might be in the
future.
We add the `add_unfiltered_{read,write}` methods to replace previous
usages of `combined_access_mut`.
We also add improved Debug implementations on FixedBitSet so that their
meaning is much clearer in debug output.
---
## Changelog
* Fix `Res` and `Query` parameter never being mutually exclusive.
## Migration Guide
Note: this mostly changes ECS internals, but since the API is public, it is technically breaking:
* Removed `FilteredAccessSet::combined_access_mut`
* Replace _immutable_ usage of those by `combined_access`
* For _mutable_ usages, use the new `add_unfiltered_{read,write}` methods instead of `combined_access_mut` followed by `add_{read,write}`
# Objective
Make core types in ECS smaller. The column sparse set in Tables is never updated after creation.
## Solution
Create `ImmutableSparseSet` which removes the capacity fields in the backing vec's and the APIs for inserting or removing elements. Drops the size of the sparse set by 3 usizes (24 bytes on 64-bit systems)
## Followup
~~After #4809, Archetype's component SparseSet should be replaced with it.~~ This has been done.
---
## Changelog
Removed: `Table::component_capacity`
## Migration Guide
`Table::component_capacity()` has been removed as Tables do not support adding/removing columns after construction.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities.
## Solution
Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices.
It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created.
## Additional Context
There are several other in-flight PRs that shrink Archetype:
- #4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype)
- #4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype)
---
## Changelog
Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs.
## Migration Guide
Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
# Objective
`ComputedVisibility` could afford to be smaller/faster. Optimizing the size and performance of operations on the component will positively benefit almost all extraction systems.
This was listed as one of the potential pieces of future work for #5310.
## Solution
Merge both internal booleans into a single `u8` bitflag field. Rely on bitmasks to evaluate local, hierarchical, and general visibility.
Pros:
- `ComputedVisibility::is_visible` should be a single bitmask test instead of two.
- `ComputedVisibility` is now only 1 byte. Should be able to fit 100% more per cache line when using dense iteration.
Cons:
- Harder to read.
- Setting individual values inside `ComputedVisiblity` require bitmask mutations.
This should be a non-breaking change. No public API was changed. The only publicly visible effect is that `ComputedVisibility` is now 1 byte instead of 2.
# Objective
Fixes#6594
## Solution
- `New` function for `Size` is now a `const` function :)
## Changelog
- `New` function for `Size` is now a `const` function
## Migration Guide
- Nothing has been changed
# Objective
In bevy 0.8 you could list all resources using `world.archetypes().resource().components()`. As far as I can tell the resource archetype has been replaced with the `Resources` storage, and it would be nice if it could be used to iterate over all resource component IDs as well.
## Solution
- add `fn Resources::iter(&self) -> impl Iterator<Item = (ComponentId, &ResourceData)>`
# Objective
- Derive Clone and Debug for `AssetPlugin`
- Make it possible to log asset server settings
- And get an owned instance if wrapping `AssetPlugin` in another plugin. See: 129224ef72/src/web_asset_plugin.rs (L45)
# Objective
> Part of #6573
`Children` was not being properly deserialized in scenes. This was due to a missing registration on `SmallVec<[Entity; 8]>`, which is used by `Children`.
## Solution
Register `SmallVec<[Entity; 8]>`.
---
## Changelog
- Registered `SmallVec<[Entity; 8]>`
# Objective
Fixes#6030, making ``serde`` optional.
## Solution
This was solved by making a ``serialize`` feature that can activate ``serde``, which is now optional.
When ``serialize`` is deactivated, the ``Plugin`` implementation for ``ScenePlugin`` does nothing.
Co-authored-by: Linus Käll <linus.kall.business@gmail.com>
# Objective
Currently, `Ptr` and `PtrMut` can only be constructed via unsafe code. This means that downgrading a reference to an untyped pointer is very cumbersome, despite being a very simple operation.
## Solution
Define conversions for easily and safely constructing untyped pointers. This is the non-owned counterpart to `OwningPtr::make`.
Before:
```rust
let ptr = unsafe { PtrMut::new(NonNull::from(&mut value).cast()) };
```
After:
```rust
let ptr = PtrMut::from(&mut value);
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
I needed a window which is always on top, to create a overlay app.
## Solution
expose the `always_on_top` property of winit in bevy's `WindowDescriptor` as a boolean flag
---
## Changelog
### Added
- add `WindowDescriptor.always_on_top` which configures a window to stay on top.
# Objective
`ScalingMode::Auto` for cameras only targets min_height and min_width, or as the docs say it `Use minimal possible viewport size while keeping the aspect ratio.`
But there is no ScalingMode that targets max_height and Max_width or `Use maximal possible viewport size while keeping the aspect ratio.`
## Solution
Added `ScalingMode::AutoMax` that does the exact opposite of `ScalingMode::Auto`
---
## Changelog
Renamed `ScalingMode::Auto` to `ScalingMode::AutoMin`.
## Migration Guide
just rename `ScalingMode::Auto` to `ScalingMode::AutoMin` if you are using it.
Co-authored-by: Lixou <82600264+DasLixou@users.noreply.github.com>
Add a method to get the focused window.
Use this instead of `WindowFocused` events in `close_on_esc`.
Seems that the OS/window manager might not always send focused events on application startup.
Sadly, not a fix for #5646.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes #3225, Allow for flippable UI Images
## Solution
Add flip_x and flip_y fields to UiImage, and swap the UV coordinates accordingly in ui_prepare_nodes.
## Changelog
* Changes UiImage to a struct with texture, flip_x, and flip_y fields.
* Adds flip_x and flip_y fields to ExtractedUiNode.
* Changes extract_uinodes to extract the flip_x and flip_y values from UiImage.
* Changes prepare_uinodes to swap the UV coordinates as required.
* Changes UiImage derefs to texture field accesses.
# Objective
Fixes#6615.
`BlobVec` does not respect alignment for zero-sized types, which results in UB whenever a ZST with alignment other than 1 is used in the world.
## Solution
Add the fn `bevy_ptr::dangling_with_align`.
---
## Changelog
+ Added the function `dangling_with_align` to `bevy_ptr`, which creates a well-aligned dangling pointer to a type whose alignment is not known at compile time.
# Objective
- Implements removal of entries from a `dyn Map`
- Fixes#6563
## Solution
- Adds a `remove` method to the `Map` trait which takes in a `&dyn Reflect` key and returns the value removed if it was present.
---
## Changelog
- Added `Map::remove`
## Migration Guide
- Implementors of `Map` will need to implement the `remove` method.
Co-authored-by: radiish <thesethskigamer@gmail.com>
# Objective
The [documentation for `ButtonSettingsError`](https://docs.rs/bevy/0.9.0/bevy/input/gamepad/enum.ButtonSettingsError.html) incorrectly describes the valid range of values as `0.0..=2.0`, probably because it was copied from `AxisSettingsError`. The actual range, as seen in the functions that return it and in its own `thiserror` description, is `0.0..=1.0`.
## Solution
Update the doc comments to reflect the correct range.
Co-authored-by: Sol Toder <ajaxgb@gmail.com>
# Objective
Fix#6548. Most of these methods were already made `const` in #5688. `Entity::to_bits` is the only one that remained.
## Solution
Make it const.
# Objective
- Fix#3606
- Fix#4579
- Fix#3380
## Solution
When running on a Linux machine with some AMD or Intel device, when calling
`surface.get_current_texture()`, ignore `wgpu::SurfaceError::Timeout` errors.
## Alternative
An alternative solution found in the `wgpu` examples is:
```rust
let frame = surface
.get_current_texture()
.or_else(|_| {
render_device.configure_surface(surface, &swap_chain_descriptor);
surface.get_current_texture()
})
.expect("Error reconfiguring surface");
window.swap_chain_texture = Some(TextureView::from(frame));
```
See: <94ce76391b/wgpu/examples/framework.rs (L362-L370)>
Veloren [handles the Timeout error the way this PR proposes to handle it](https://github.com/gfx-rs/wgpu/issues/1218#issuecomment-1092056971).
The reason I went with this PR's solution is that `configure_surface` seems to be quite an expensive operation, and it would run every frame with the wgpu framework solution, despite the fact it works perfectly fine without `configure_surface`.
I know this looks super hacky with the linux-specific line and the AMD check, but my understanding is that the `Timeout` occurrence is specific to a quirk of some AMD drivers on linux, and if otherwise met should be considered a bug.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#5262
- Fix color banding caused by quantization.
## Solution
- Adds dithering to the tonemapping node from #3425.
- This is inspired by Godot's default "debanding" shader: https://gist.github.com/belzecue/
- Unlike Godot:
- debanding happens after tonemapping. My understanding is that this is preferred, because we are running the debanding at the last moment before quantization (`[f32, f32, f32, f32]` -> `f32`). This ensures we aren't biasing the dithering strength by applying it in a different (linear) color space.
- This code instead uses and reference the origin source, Valve at GDC 2015


## Additional Notes
Real time rendering to standard dynamic range outputs is limited to 8 bits of depth per color channel. Internally we keep everything in full 32-bit precision (`vec4<f32>`) inside passes and 16-bit between passes until the image is ready to be displayed, at which point the GPU implicitly converts our `vec4<f32>` into a single 32bit value per pixel, with each channel (rgba) getting 8 of those 32 bits.
### The Problem
8 bits of color depth is simply not enough precision to make each step invisible - we only have 256 values per channel! Human vision can perceive steps in luma to about 14 bits of precision. When drawing a very slight gradient, the transition between steps become visible because with a gradient, neighboring pixels will all jump to the next "step" of precision at the same time.
### The Solution
One solution is to simply output in HDR - more bits of color data means the transition between bands will become smaller. However, not everyone has hardware that supports 10+ bit color depth. Additionally, 10 bit color doesn't even fully solve the issue, banding will result in coherent bands on shallow gradients, but the steps will be harder to perceive.
The solution in this PR adds noise to the signal before it is "quantized" or resampled from 32 to 8 bits. Done naively, it's easy to add unneeded noise to the image. To ensure dithering is correct and absolutely minimal, noise is adding *within* one step of the output color depth. When converting from the 32bit to 8bit signal, the value is rounded to the nearest 8 bit value (0 - 255). Banding occurs around the transition from one value to the next, let's say from 50-51. Dithering will never add more than +/-0.5 bits of noise, so the pixels near this transition might round to 50 instead of 51 but will never round more than one step. This means that the output image won't have excess variance:
- in a gradient from 49 to 51, there will be a step between each band at 49, 50, and 51.
- Done correctly, the modified image of this gradient will never have a adjacent pixels more than one step (0-255) from each other.
- I.e. when scanning across the gradient you should expect to see:
```
|-band-| |-band-| |-band-|
Baseline: 49 49 49 50 50 50 51 51 51
Dithered: 49 50 49 50 50 51 50 51 51
Dithered (wrong): 49 50 51 49 50 51 49 51 50
```


You can see from above how correct dithering "fuzzes" the transition between bands to reduce distinct steps in color, without adding excess noise.
### HDR
The previous section (and this PR) assumes the final output is to an 8-bit texture, however this is not always the case. When Bevy adds HDR support, the dithering code will need to take the per-channel depth into account instead of assuming it to be 0-255. Edit: I talked with Rob about this and it seems like the current solution is okay. We may need to revisit once we have actual HDR final image output.
---
## Changelog
### Added
- All pipelines now support deband dithering. This is enabled by default in 3D, and can be toggled in the `Tonemapping` component in camera bundles. Banding is a graphical artifact created when the rendered image is crunched from high precision (f32 per color channel) down to the final output (u8 per channel in SDR). This results in subtle gradients becoming blocky due to the reduced color precision. Deband dithering applies a small amount of noise to the signal before it is "crunched", which breaks up the hard edges of blocks (bands) of color. Note that this does not add excess noise to the image, as the amount of noise is less than a single step of a color channel - just enough to break up the transition between color blocks in a gradient.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make the many foxes not unnecessarily bright. Broken since #5666.
- Fixes#6528
## Solution
- In #5666 normalisation of normals was moved from the fragment stage to the vertex stage. However, it was not added to the vertex stage for skinned normals. The many foxes are skinned and their skinned normals were not unit normals. which made them brighter. Normalising the skinned normals fixes this.
---
## Changelog
- Fixed: Non-unit length skinned normals are now normalized.
This reverts commit 8429b6d6ca as discussed in #6522.
I tested that the game_menu example works as it should.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Attempting to build `bevy_tasks` produces the following error:
```
error[E0599]: no method named `is_finished` found for struct `async_executor::Task` in the current scope
--> /[...]]/bevy/crates/bevy_tasks/src/task.rs:51:16
|
51 | self.0.is_finished()
| ^^^^^^^^^^^ method not found in `async_executor::Task<T>`
```
It looks like this was introduced along with `Task::is_finished`, which delegates to `async_task::Task::is_finished`. However, the latter was only introduced in `async-task` 4.2.0; `bevy_tasks` does not explicitly depend on `async-task` but on `async-executor` ^1.3.0, which in turn depends on `async-task` ^4.0.0.
## Solution
Add an explicit dependency on `async-task` ^4.2.0.
# Objective
Copy `send_event` and friends from `World` to `WorldCell`.
Clean up `bevy_winit` using `WorldCell::send_event`.
## Changelog
Added `send_event`, `send_event_default`, and `send_event_batch` to `WorldCell`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- it would be useful to inspect these structs using reflection
## Solution
- derive and register reflect
- Note that `#[reflect(Component)]` requires `Default` (or `FromWorld`) until #6060, so I implemented `Default` for `Tonemapping` with `is_enabled: false`
# Objective
The `load_internal_asset` macro is helpful when creating rendering plugins, but it doesn't support load binary assets (like those compiled as spir-v).
## Solution
Add a `load_internal_binary_asset` macro that use `include_bytes!`.
# Objective
Fixes#5393
## Solution
- Add padding to `GlobalsUniform` / `Globals` to make it 16-byte aligned.
Still not super clear on whether this is a `naga` thing or an `encase` thing or what. But now that we're offering `globals` up to users and #5393 is not just breaking an example, maybe we should do this sort of workaround?
* Move the despawn debug log from `World::despawn` to `EntityMut::despawn`.
* Move the despawn non-existent warning log from `Commands::despawn` to `World::despawn`.
This should make logging consistent regardless of which of the three `despawn` methods is used.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Using `Reflect` we can easily switch between a specific reflection trait object, such as a `dyn Struct`, to a `dyn Reflect` object via `Reflect::as_reflect` or `Reflect::as_reflect_mut`.
```rust
fn do_something(value: &dyn Reflect) {/* ... */}
let foo: Box<dyn Struct> = Box::new(Foo::default());
do_something(foo.as_reflect());
```
However, there is no way to convert a _boxed_ reflection trait object to a `Box<dyn Reflect>`.
## Solution
Add a `Reflect::into_reflect` method which allows converting a boxed reflection trait object back into a boxed `Reflect` trait object.
```rust
fn do_something(value: Box<dyn Reflect>) {/* ... */}
let foo: Box<dyn Struct> = Box::new(Foo::default());
do_something(foo.into_reflect());
```
---
## Changelog
- Added `Reflect::into_reflect`
# Objective
Some render plugins, like [bevy-hikari](https://github.com/cryscan/bevy-hikari) require to set `CameraRenderGraph`. In order to switch between render graphs I need to insert a new `CameraRenderGraph` component. It's not very ergonomic.
## Solution
Add `CameraRenderGraph::set` like in [Name](https://docs.rs/bevy/latest/bevy/core/struct.Name.html).
---
## Changelog
### Added
- `CameraRenderGraph::set`.
# Objective
There is no way to gen an owned value of `Reflect`.
## Solution
Add it! This was originally a part of #6421, but @MrGVSV asked me to create a separate for it to implement reflect diffing.
---
## Changelog
### Added
- `Reflect::reflect_owned` to get an owned version of `Reflect`.
# Objective
`NodeBundle` contains an `image` field, which can be misleading, because if you do supply an image there, nothing will be shown to screen. You need to use an `ImageBundle` instead.
## Solution
* `image` (`UiImage`) field is removed from `NodeBundle`,
* extraction stage queries now make an optional query for `UiImage`, if one is not found, use the image handle that is used as a default by `UiImage`: c019a60b39/crates/bevy_ui/src/ui_node.rs (L464)
* touching up docs for `NodeBundle` to help guide what `NodeBundle` should be used for
* renamed `entity.rs` to `node_bundle.rs` as that gives more of a hint regarding the module's purpose
* separating `camera_config` stuff from the pre-made UI node bundles so that `node_bundle.rs` makes more sense as a module name.
# Objective
- adding a new `.register` should not overwrite old type data
- separate crates should both be able to register the same type
I ran into this while debugging why `register::<Handle<T>>` removed the `ReflectHandle` type data from a prior `register_asset_reflect`.
## Solution
- make `register` do nothing if called again for the same type
- I also removed some unnecessary duplicate registrations
# Objective
When an error causes `debug_checked_unreachable` to be called, the panic message unhelpfully points to the function definition instead of the place that caused the error.
## Solution
Add the `#[track_caller]` attribute in debug mode.
# Objective
Fixes: https://github.com/bevyengine/bevy/issues/6466
Summary: The UI Scaling example dynamically scales the UI which will dynamically allocate fonts to the font atlas surpassing the protective limit, throwing a panic.
## Solution
- Set TextSettings.allow_dynamic_font_size = true for the UI Scaling example. This is the ideal solution since the dynamic changes to the UI are not continuous yet still discrete.
- Update the panic text to reflect ui scaling as a potential cause
# Objective
Bevy UI (and third party plugins) currently have no good way to position themselves after all post processing effects. They currently use the tonemapping node, but this is not adequate if there is anything after tonemapping (such as FXAA).
## Solution
Add a logical `END_MAIN_PASS_POST_PROCESSING` RenderGraph node that main pass post processing effects position themselves before, and things like UIs can position themselves after.
# Objective
This PR fixes#5789, by enabling movable (and scalable) directional light shadow volumes.
## Solution
This PR changes `ExtractedDirectionalLight` to hold a copy of the `DirectionalLight` entity's `GlobalTransform`, instead of just a `direction` vector. This allows the shadow map volume (as defined by the light's `shadow_projection` field) to be transformed honoring translation _and_ scale transforms, and not just rotation.
It also augments the texel size calculation (used to determine the `shadow_normal_bias`) so that it now takes into account the upper bound of the x/y/z scale of the `GlobalTransform`.
This change makes the directional light extraction code more consistent with point and spot lights (that already use `transform`), and allows easily moving and scaling the shadow volume along with a player entity based on camera distance/angle, immediately enabling more real world use cases until we have a more sophisticated adaptive implementation, such as the one described in #3629.
**Note:** While it was previously possible to update the projection achieving a similar effect, depending on the light direction and distance to the origin, the fact that the shadow map camera was always positioned at the origin with a hardcoded `Vec3::Y` up value meant you would get sub-optimal or inconsistent/incorrect results.
---
## Changelog
### Changed
- `DirectionalLight` shadow volumes now honor translation and scale transforms
## Migration Guide
- If your directional lights were positioned at the origin and not scaled (the default, most common scenario) no changes are needed on your part; it just works as before;
- If you previously had a system for dynamically updating directional light shadow projections, you might now be able to simplify your code by updating the directional light entity's transform instead;
- In the unlikely scenario that a scene with directional lights that previously rendered shadows correctly has missing shadows, make sure your directional lights are positioned at (0, 0, 0) and are not scaled to a size that's too large or too small.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
`EntityMut::remove_children` does not call `self.update_location()` which is unsound.
Verified by adding the following assertion, which fails when running the tests.
```rust
let before = self.location();
self.update_location();
assert_eq!(before, self.location());
```
I also removed incorrect messages like "parent entity is not modified" and the unhelpful "Inserting a bundle in the children entities may change the parent entity's location if they were of the same archetype" which might lead people to think that's the *only* thing that can change the entity's location.
# Changelog
Added `EntityMut::world_scope`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Allow passing `Vec`s of glam vector types as vertex attributes.
Alternative to #4548 and #2719
Also used some macros to cut down on all the repetition.
# Migration Guide
Implementations of `From<Vec<[u16; 4]>>` and `From<Vec<[u8; 4]>>` for `VertexAttributeValues` have been removed.
I you're passing either `Vec<[u16; 4]>` or `Vec<[u8; 4]>` into `Mesh::insert_attribute` it will now require wrapping it with right the `VertexAttributeValues` enum variant.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Closes#5934
Currently it is not possible to de/serialize data to non-self-describing formats using reflection.
## Solution
Add support for non-self-describing de/serialization using reflection.
This allows us to use binary formatters, like [`postcard`](https://crates.io/crates/postcard):
```rust
#[derive(Reflect, FromReflect, Debug, PartialEq)]
struct Foo {
data: String
}
let mut registry = TypeRegistry::new();
registry.register::<Foo>();
let input = Foo {
data: "Hello world!".to_string()
};
// === Serialize! === //
let serializer = ReflectSerializer::new(&input, ®istry);
let bytes: Vec<u8> = postcard::to_allocvec(&serializer).unwrap();
println!("{:?}", bytes); // Output: [129, 217, 61, 98, ...]
// === Deserialize! === //
let deserializer = UntypedReflectDeserializer::new(®istry);
let dynamic_output = deserializer
.deserialize(&mut postcard::Deserializer::from_bytes(&bytes))
.unwrap();
let output = <Foo as FromReflect>::from_reflect(dynamic_output.as_ref()).unwrap();
assert_eq!(expected, output); // OK!
```
#### Crates Tested
- ~~[`rmp-serde`](https://crates.io/crates/rmp-serde)~~ Apparently, this _is_ self-describing
- ~~[`bincode` v2.0.0-rc.1](https://crates.io/crates/bincode/2.0.0-rc.1) (using [this PR](https://github.com/bincode-org/bincode/pull/586))~~ This actually works for the latest release (v1.3.3) of [`bincode`](https://crates.io/crates/bincode) as well. You just need to be sure to use fixed-int encoding.
- [`postcard`](https://crates.io/crates/postcard)
## Future Work
Ideally, we would refactor the `serde` module, but I don't think I'll do that in this PR so as to keep the diff relatively small (and to avoid any painful rebases). This should probably be done once this is merged, though.
Some areas we could improve with a refactor:
* Split deserialization logic across multiple files
* Consolidate helper functions/structs
* Make the logic more DRY
---
## Changelog
- Add support for non-self-describing de/serialization using reflection.
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Adds a bloom pass for HDR-enabled Camera3ds.
- Supersedes (and all credit due to!) https://github.com/bevyengine/bevy/pull/3430 and https://github.com/bevyengine/bevy/pull/2876

## Solution
- A threshold is applied to isolate emissive samples, and then a series of downscale and upscaling passes are applied and composited together.
- Bloom is applied to 2d or 3d Cameras with hdr: true and a BloomSettings component.
---
## Changelog
- Added a `core_pipeline::bloom::BloomSettings` component.
- Added `BloomNode` that runs between the main pass and tonemapping.
- Added a `BloomPlugin` that is loaded as part of CorePipelinePlugin.
- Added a bloom example project.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
Alternative to #6424Fixes#6226
Fixes spawning empty bundles
## Solution
Add `BundleComponentStatus` trait and implement it for `AddBundle` and a new `SpawnBundleStatus` type (which always returns an Added status). `write_components` is now generic on `BundleComponentStatus` instead of taking `AddBundle` directly. This means BundleSpawner can now avoid needing AddBundle from the Empty archetype, which means BundleSpawner no longer needs a reference to the original archetype.
In theory this cuts down on the work done in `write_components` when spawning, but I'm seeing no change in the spawn benchmarks.
# Objective
The UI pass in HDR breaks currently because the color attachment format does not match the HDR ViewTarget.
## Solution
Specialize the UI pipeline on "hdr-ness" and select the appropriate format (like we do in the other built in pipelines).
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
Respect mipmap_filter when create ImageDescriptor with linear()/nearest()
# Objective
Fixes#6348
## Migration Guide
This PR changes default `ImageSettings` and may lead to unexpected behaviour for existing projects with mipmapped textures. Users should provide custom `ImageSettings` resource with `mipmap_filter=FilterMode::Nearest` if they want to keep old behaviour.
Co-authored-by: Yakov Borevich <j.borevich@gmail.com>
# Objective
Currently we are limiting the amount of direction lights in a scene to one.
## Solution
Increase the amount of direction lights from 1 to 10.
This still is not a perfect solution, but should unblock many use cases.
We could probably just store the directional lights similar to the point lights in an storage buffer, allowing for an variable amount of directional lights.
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
# Objective
Right now, the `TaskPool` implementation allows panics to permanently kill worker threads upon panicking. This is currently non-recoverable without using a `std::panic::catch_unwind` in every scheduled task. This is poor ergonomics and even poorer developer experience. This is exacerbated by #2250 as these threads are global and cannot be replaced after initialization.
Removes the need for temporary fixes like #4998. Fixes#4996. Fixes#6081. Fixes#5285. Fixes#5054. Supersedes #2307.
## Solution
The current solution is to wrap `Executor::run` in `TaskPool` with a `catch_unwind`, and discarding the potential panic. This was taken straight from [smol](404c7bcc0a/src/spawn.rs (L44))'s current implementation. ~~However, this is not entirely ideal as:~~
- ~~the signaled to the awaiting task. We would need to change `Task<T>` to use `async_task::FallibleTask` internally, and even then it doesn't signal *why* it panicked, just that it did.~~ (See below).
- ~~no error is logged of any kind~~ (See below)
- ~~it's unclear if it drops other tasks in the executor~~ (it does not)
- ~~This allows the ECS parallel executor to keep chugging even though a system's task has been dropped. This inevitably leads to deadlock in the executor.~~ Assuming we don't catch the unwind in ParallelExecutor, this will naturally kill the main thread.
### Alternatives
A final solution likely will incorporate elements of any or all of the following.
#### ~~Log and Ignore~~
~~Log the panic, drop the task, keep chugging. This only addresses the discoverability of the panic. The process will continue to run, probably deadlocking the executor. tokio's detatched tasks operate in this fashion.~~
Panics already do this by default, even when caught by `catch_unwind`.
#### ~~`catch_unwind` in `ParallelExecutor`~~
~~Add another layer catching system-level panics into the `ParallelExecutor`. How the executor continues when a core dependency of many systems fails to run is up for debate.~~
`async_task::Task` bubbles up panics already, this will transitively push panics all the way to the main thread.
#### ~~Emulate/Copy `tokio::JoinHandle` with `Task<T>`~~
~~`tokio::JoinHandle<T>` bubbles up the panic from the underlying task when awaited. This can be transitively applied across other APIs that also use `Task<T>` like `Query::par_for_each` and `TaskPool::scope`, bubbling up the panic until it's either caught or it reaches the main thread.~~
`async_task::Task` bubbles up panics already, this will transitively push panics all the way to the main thread.
#### Abort on Panic
The nuclear option. Log the error, abort the entire process on any thread in the task pool panicking. Definitely avoids any additional infrastructure for passing the panic around, and might actually lead to more efficient code as any unwinding is optimized out. However gives the developer zero options for dealing with the issue, a seemingly poor choice for debuggability, and prevents graceful shutdown of the process. Potentially an option for handling very low-level task management (a la #4740). Roughly takes the shape of:
```rust
struct AbortOnPanic;
impl Drop for AbortOnPanic {
fn drop(&mut self) {
abort!();
}
}
let guard = AbortOnPanic;
// Run task
std::mem::forget(AbortOnPanic);
```
---
## Changelog
Changed: `bevy_tasks::TaskPool`'s threads will no longer terminate permanently when a task scheduled onto them panics.
Changed: `bevy_tasks::Task` and`bevy_tasks::Scope` will propagate panics in the spawned tasks/scopes to the parent thread.
# Objective
Add consistent UI rendering and interaction where deep nodes inside two different hierarchies will never render on top of one-another by default and offer an escape hatch (z-index) for nodes to change their depth.
## The problem with current implementation
The current implementation of UI rendering is broken in that regard, mainly because [it sets the Z value of the `Transform` component based on a "global Z" space](https://github.com/bevyengine/bevy/blob/main/crates/bevy_ui/src/update.rs#L43) shared by all nodes in the UI. This doesn't account for the fact that each node's final `GlobalTransform` value will be relative to its parent. This effectively makes the depth unpredictable when two deep trees are rendered on top of one-another.
At the moment, it's also up to each part of the UI code to sort all of the UI nodes. The solution that's offered here does the full sorting of UI node entities once and offers the result through a resource so that all systems can use it.
## Solution
### New ZIndex component
This adds a new optional `ZIndex` enum component for nodes which offers two mechanism:
- `ZIndex::Local(i32)`: Overrides the depth of the node relative to its siblings.
- `ZIndex::Global(i32)`: Overrides the depth of the node relative to the UI root. This basically allows any node in the tree to "escape" the parent and be ordered relative to the entire UI.
Note that in the current implementation, omitting `ZIndex` on a node has the same result as adding `ZIndex::Local(0)`. Additionally, the "global" stacking context is essentially a way to add your node to the root stacking context, so using `ZIndex::Local(n)` on a root node (one without parent) will share that space with all nodes using `Index::Global(n)`.
### New UiStack resource
This adds a new `UiStack` resource which is calculated from both hierarchy and `ZIndex` during UI update and contains a vector of all node entities in the UI, ordered by depth (from farthest from camera to closest). This is exposed publicly by the bevy_ui crate with the hope that it can be used for consistent ordering and to reduce the amount of sorting that needs to be done by UI systems (i.e. instead of sorting everything by `global_transform.z` in every system, this array can be iterated over).
### New z_index example
This also adds a new z_index example that showcases the new `ZIndex` component. It's also a good general demo of the new UI stack system, because making this kind of UI was very broken with the old system (e.g. nodes would render on top of each other, not respecting hierarchy or insert order at all).

---
## Changelog
- Added the `ZIndex` component to bevy_ui.
- Added the `UiStack` resource to bevy_ui, and added implementation in a new `stack.rs` module.
- Removed the previous Z updating system from bevy_ui, because it was replaced with the above.
- Changed bevy_ui rendering to use UiStack instead of z ordering.
- Changed bevy_ui focus/interaction system to use UiStack instead of z ordering.
- Added a new z_index example.
## ZIndex demo
Here's a demo I wrote to test these features
https://user-images.githubusercontent.com/1060971/188329295-d7beebd6-9aee-43ab-821e-d437df5dbe8a.mp4
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
Fixes#6059, changing all incorrect occurrences of ``id`` in the ``entity`` module to ``index``:
* struct level documentation,
* ``id`` struct field,
* ``id`` method and its documentation.
## Solution
Renaming and verifying using CI.
Co-authored-by: Edvin Kjell <43633999+Edwox@users.noreply.github.com>
# Objective
In some scenarios it can be useful to check if a task has been finished without polling it. I added a function called `is_finished` to check if a task has been finished.
## Solution
Since `async_task` supports it out of the box, it is just a simple wrapper function.
---
# Objective
- Add post processing passes for FXAA (Fast Approximate Anti-Aliasing)
- Add example comparing MSAA and FXAA
## Solution
When the FXAA plugin is added, passes for FXAA are inserted between the main pass and the tonemapping pass. Supports using either HDR or LDR output from the main pass.
---
## Changelog
- Add a new FXAANode that runs after the main pass when the FXAA plugin is added.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
For `derive(WorldQuery)`, there are three structs generated, `Item`, `Fetch` and `State`.
These inherit the visibility of the derived structure, thus `#![warn(missing_docs)]` would
warn about missing documentation for these structures.
- [ ] I'd like some advice on what to write here, as I personally don't really understand `Fetch` nor `State`.
# Objective
Currently, `bevy_dynamic_plugin` simply panics on error. This makes it impossible to handle failures in applications that use this feature.
For example, I'd like to build an optional expansion for my game, that may not be distributed to all users. I want to use `bevy_dynamic_plugin` for loading it. I want my game to try to load it on startup, but continue without it if it cannot be loaded.
## Solution
- Make the `dynamically_load_plugin` function return a `Result`, so it can gracefully return loading errors.
- Create an error enum type, to provide useful information about the kind of error. This adds `thiserror` to the dependencies of `bevy_dynamic_plugin`, but that dependency is already used in other parts of bevy (such as `bevy_asset`), so not a big deal.
I chose not to change the behavior of the builder method in the App extension trait. I kept it as panicking. There is no clean way (that I'm aware of) to make a builder-style API that has fallible methods. So it is either a panic or a warning. I feel the panic is more appropriate.
---
## Changelog
### Changed
- `bevy_dynamic_plugin::dynamically_load_plugin` now returns `Result` instead of panicking, to allow for error handling
# Objective
* Add benchmarks for `Query::get_many`.
* Speed up `Query::get_many`.
## Solution
Previously, `get_many` and `get_many_mut` used the method `array::map`, which tends to optimize very poorly. This PR replaces uses of that method with loops.
## Benchmarks
| Benchmark name | Execution time | Change from this PR |
|--------------------------------------|----------------|---------------------|
| query_get_many_2/50000_calls_table | 1.3732 ms | -24.967% |
| query_get_many_2/50000_calls_sparse | 1.3826 ms | -24.572% |
| query_get_many_5/50000_calls_table | 2.6833 ms | -30.681% |
| query_get_many_5/50000_calls_sparse | 2.9936 ms | -30.672% |
| query_get_many_10/50000_calls_table | 5.7771 ms | -36.950% |
| query_get_many_10/50000_calls_sparse | 7.4345 ms | -36.987% |
# Objective
Add documentation `#[world_query(ignore)]`. Fixes#6283.
---
I've only described it's behavior so far (which appears to be the same as with `system_param`). Is there another use-case for this besides with `PhantomData`? I could only find a single usage of this construct on GitHub, which is [here](ffcb816927/bevy/examples/ecs/custom_query_param.rs (L102)).
I was also wondering if it would make sense to add a usage example to the `custom_query_example`? 🤔 That's why it's currently still in there.
Co-authored-by: Lucas Jenß <243719+x3ro@users.noreply.github.com>
# Objective
`bevy_core` is missing a feature corresponding to the `serialize` feature on the `bevy` crate. Similar to #6378 and https://github.com/bevyengine/bevy/pull/6379 to serialize `Name` easily.
## Solution
Add this feature and hand-written serialization for `Name` (to avoid storing `hash` field).
---
## Changelog
### Added
* `Serialize` and `Deserialize` derives for `Name` under `serialize` feature.
# Objective
Post processing effects cannot read and write to the same texture. Currently they must own their own intermediate texture and redundantly copy from that back to the main texture. This is very inefficient.
Additionally, working with ViewTarget is more complicated than it needs to be, especially when working with HDR textures.
## Solution
`ViewTarget` now stores two copies of the "main texture". It uses an atomic value to track which is currently the "main texture" (this interior mutability is necessary to accommodate read-only RenderGraph execution).
`ViewTarget` now has a `post_process_write` method, which will return a source and destination texture. Each call to this method will flip between the two copies of the "main texture".
```rust
let post_process = render_target.post_process_write();
let source_texture = post_process.source;
let destination_texture = post_process.destination;
```
The caller _must_ read from the source texture and write to the destination texture, as it is assumed that the destination texture will become the new "main texture".
For simplicity / understandability `ViewTarget` is now a flat type. "hdr-ness" is a property of the `TextureFormat`. The internals are fully private in the interest of providing simple / consistent apis. Developers can now easily access the main texture by calling `view_target.main_texture()`.
HDR ViewTargets no longer have an "ldr texture" with `TextureFormat::bevy_default`. They _only_ have their two "hdr" textures. This simplifies the mental model. All we have is the "currently active hdr texture" and the "other hdr texture", which we flip between for post processing effects.
The tonemapping node has been rephrased to use this "post processing pattern". The blit pass has been removed, and it now only runs a pass when HDR is enabled. Notably, both the input and output texture are assumed to be HDR. This means that tonemapping behaves just like any other "post processing effect". It could theoretically be moved anywhere in the "effect chain" and continue to work.
In general, I think these changes will make the lives of people making post processing effects much easier. And they better position us to start building higher level / more structured "post processing effect stacks".
---
## Changelog
- `ViewTarget` now stores two copies of the "main texture". Calling `ViewTarget::post_process_write` will flip between copies of the main texture.
# Objective
- `ReflectDefault` can be used to create default values for reflected types
- `std` primitives that are `Default`-constructable should register `ReflectDefault`
## Solution
- register `ReflectDefault`
# Objective
- Fixes #6311
- Make it clearer what should be done in the example (close the Bevy app window)
## Solution
- Remove the second windowed Bevy App [since winit does not support this](https://github.com/rust-windowing/winit/blob/v0.27.4/src/event_loop.rs#L82-L83)
- Add title to the Bevy window asking the user to close it
This is more of a quick fix to have a working example. It would be nicer if we had a small real usecase for this functionality.
Another alternativ that I tried out: If we want to showcase a second Bevy app as it was before, we could still do this as long as one of them does not have a window. But I don't see how this is helpful in the context of the example, so I stuck with only one Bevy app and a simple print afterwards.
# Objective
Entities are unique, however, this is not reflected in the scene format. Currently, entities are stored in a list where a user could inadvertently create a duplicate of the same entity.
## Solution
Switch from the list representation to a map representation for entities.
---
## Changelog
* The `entities` field in the scene format is now a map of entity ID to entity data
## Migration Guide
The scene format now stores its collection of entities in a map rather than a list:
```rust
// OLD
(
entities: [
(
entity: 12,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
),
],
)
// NEW
(
entities: {
12: (
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
),
},
)
```
# Objective
- Make it impossible to add a plugin twice
- This is going to be more a risk for plugins with configurations, to avoid things like `App::new().add_plugins(DefaultPlugins).add_plugin(ImagePlugin::default_nearest())`
## Solution
- Panic when a plugin is added twice
- It's still possible to mark a plugin as not unique by overriding `is_unique`
- ~~Simpler version of~~ #3988 (not simpler anymore because of how `PluginGroupBuilder` implements `PluginGroup`)
# Objective
- Bevy main crashs on Safari mobile
- On Safari mobile, calling winit_window.set_cursor_grab(true) fails as the API is not implemented (as there is no cursor on Safari mobile, the api doesn't make sense there). I don't know about other mobile browsers
## Solution
- Do not call the api to release cursor grab on window creation, as the cursor is not grabbed anyway at this point
- This is #3617 which was lost in #6218
# Objective
Fixes#6378
`bevy_transform` is missing a feature corresponding to the `serialize` feature on the `bevy` crate.
## Solution
Adds a `serialize` feature to `bevy_transform`.
Derives `serde::Serialize` and `Deserialize` when feature is enabled.
# Objective
Currently toggling an `AudioSink` (for example from a game menu) requires writing
```rs
if sink.is_paused() {
sink.play();
} else {
sink.pause();
}
```
It would be nicer if we could reduce this down to a single line
```rs
sink.toggle();
```
## Solution
Add an `AudioSink::toggle` method which does exactly that.
---
## Changelog
- Added `AudioSink::toggle` which can be used to toggle state of a sink.
# Objective
Add methods to `Query<&Children>` and `Query<&Parent>` to iterate over descendants and ancestors, respectively.
## Changelog
* Added extension trait for `Query` in `bevy_hierarchy`, `HierarchyQueryExt`
* Added method `iter_descendants` to `Query<&Children>` via `HierarchyQueryExt` for iterating over the descendants of an entity.
* Added method `iter_ancestors` to `Query<&Parent>` via `HierarchyQueryExt` for iterating over the ancestors of an entity.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
- Freeing unused memory held by visible entities
- Fixed comment style
# Objective
With Rust 1.56 it's possible to shrink vectors to a specified capacity. Visibility system had a comment before asking for that feature to free unused memory by a vector if its capacity is two times larger than the length.
## Solution
Shrinking the vector of visible entities to the nearest power of 2 elements next to `len()`, if capacity exceeds it more than two times.
# Objective
- Time have `Reflect`, but doesn't have `FromReflect`.
## Solution
- Add it for `Timer`, `Stopwatch` and `TimerMode`.
---
## Changelog
### Added
* `FromReflect` derive for `Timer`, `Stopwatch` and `TimerMode`.
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
Fix the soundness issue outlined in #5866. In short the problem is that `query.to_readonly().get_component_mut::<T>()` can provide unsound mutable access to the component. This PR is an alternative to just removing the offending api. Given that `to_readonly` is a useful tool, I think this approach is a preferable short term solution. Long term I think theres a better solution out there, but we can find that on its own time.
## Solution
Add what amounts to a "dirty flag" that marks Queries that have been converted to their read-only variant via `to_readonly` as dirty. When this flag is set to true, `get_component_mut` will fail with an error, preventing the unsound access.
# Objective
Following discussion on #3536 and #3522, `Handle::as_weak()` takes a type `U`, reinterpreting the handle as of another asset type while keeping the same ID. This is mainly used today in font atlas code. This PR does two things:
- Rename the method to `cast_weak()` to make its intent more clear
- Actually change the type uuid in the handle if it's not an asset path variant.
## Migration Guide
- Rename `Handle::as_weak` uses to `Handle::cast_weak`
The method now properly sets the associated type uuid if the handle is a direct reference (e.g. not a reference to an `AssetPath`), so adjust you code accordingly if you relied on the previous behavior.
# Objective
Currently for entities we serialize only `id`. But this is not very expected behavior. For example, in networking, when the server sends its state, it contains entities and components. On the client, I create new objects and map them (using `EntityMap`) to those received from the server (to know which one matches which). And if `generation` field is missing, this mapping can be broken. Example:
1. Server sends an entity `Entity{ id: 2, generation: 1}` with components.
2. Client puts the received entity in a map and create a new entity that maps to this received entity. The new entity have different `id` and `generation`. Let's call it `Entity{ id: 12, generation: 4}`.
3. Client sends a command for `Entity{ id: 12, generation: 4}`. To do so, it maps local entity to the one from server. But `generation` field is 0 because it was omitted for serialization on the server. So it maps to `Entity{ id: 2, generation: 0}`.
4. Server receives `Entity{ id: 2, generation: 0}` which is invalid.
In my game I worked around it by [writing custom serialization](https://github.com/dollisgame/dollis/blob/master/src/core/network/entity_serde.rs) and using `serde(with = "...")`. But it feels like a bad default to me.
Using `Entity` over a custom `NetworkId` also have the following advantages:
1. Re-use `MapEntities` trait to map `Entity`s in replicated components.
2. Instead of server `Entity <-> NetworkId ` and `Entity <-> NetworkId`, we map entities only on client.
3. No need to handling uniqueness. It's a rare case, but makes things simpler. For example, I don't need to query for a resource to create an unique ID.
Closes#6143.
## Solution
Use default serde impls. If anyone want to avoid wasting memory on `generation`, they can create a new type that holds `u32`. This is what Bevy do for [DynamicEntity](https://docs.rs/bevy/latest/bevy/scene/struct.DynamicEntity.html) to serialize scenes. And I don't see any use case to serialize an entity id expect this one.
---
## Changelog
### Changed
- Entity now serializes / deserializes `generation` field.
## Migration Guide
- Entity now fully serialized. If you want to serialze only `id`, as it was before, you can create a new type that wraps `u32`.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective

^ enable this
Concretely, I need to
- list all handle ids for an asset type
- fetch the asset as `dyn Reflect`, given a `HandleUntyped`
- when encountering a `Handle<T>`, find out what asset type that handle refers to (`T`'s type id) and turn the handle into a `HandleUntyped`
## Solution
- add `ReflectAsset` type containing function pointers for working with assets
```rust
pub struct ReflectAsset {
type_uuid: Uuid,
assets_resource_type_id: TypeId, // TypeId of the `Assets<T>` resource
get: fn(&World, HandleUntyped) -> Option<&dyn Reflect>,
get_mut: fn(&mut World, HandleUntyped) -> Option<&mut dyn Reflect>,
get_unchecked_mut: unsafe fn(&World, HandleUntyped) -> Option<&mut dyn Reflect>,
add: fn(&mut World, &dyn Reflect) -> HandleUntyped,
set: fn(&mut World, HandleUntyped, &dyn Reflect) -> HandleUntyped,
len: fn(&World) -> usize,
ids: for<'w> fn(&'w World) -> Box<dyn Iterator<Item = HandleId> + 'w>,
remove: fn(&mut World, HandleUntyped) -> Option<Box<dyn Reflect>>,
}
```
- add `ReflectHandle` type relating the handle back to the asset type and providing a way to create a `HandleUntyped`
```rust
pub struct ReflectHandle {
type_uuid: Uuid,
asset_type_id: TypeId,
downcast_handle_untyped: fn(&dyn Any) -> Option<HandleUntyped>,
}
```
- add the corresponding `FromType` impls
- add a function `app.register_asset_reflect` which is supposed to be called after `.add_asset` and registers `ReflectAsset` and `ReflectHandle` in the type registry
---
## Changelog
- add `ReflectAsset` and `ReflectHandle` types, which allow code to use reflection to manipulate arbitrary assets without knowing their types at compile time
fixes https://github.com/bevyengine/bevy/issues/5944
Uses the second solution:
> 2. keep track of the old viewport in the computed_state, and if camera.viewport != camera.computed_state.old_viewport, then update the projection. This is more reliable, but needs to store two UVec2s more in the camera (probably not a big deal).
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
Currently, `DynamicSceneBuilder` keeps track of entities via a `HashMap`. This has an unintended side-effect in that, when building the full `DynamicScene`, we aren't guaranteed any particular order.
In other words, inserting Entity A then Entity B can result in either `[A, B]` or `[B, A]`. This can be rather annoying when running tests on scenes generated via the builder as it will work sometimes but not other times. There's also the potential that this might unnecessarily clutter up VCS diffs for scene files (assuming they had an intentional order).
## Solution
Store `DynamicSceneBuilder`'s entities in a `Vec` rather than a `HashMap`.
---
## Changelog
* Stablized entity order in `DynamicSceneBuilder` (0.9.0-dev)
# Objective
Bevy's internal plugins have lots of execution-order ambiguities, which makes the ambiguity detection tool very noisy for our users.
## Solution
Silence every last ambiguity that can currently be resolved.
Each time an ambiguity is silenced, it is accompanied by a comment describing why it is correct. This description should be based on the public API of the respective systems. Thus, I have added documentation to some systems describing how they use some resources.
# Future work
Some ambiguities remain, due to issues out of scope for this PR.
* The ambiguity checker does not respect `Without<>` filters, leading to false positives.
* Ambiguities between `bevy_ui` and `bevy_animation` cannot be resolved, since neither crate knows that the other exists. We will need a general solution to this problem.
# Objective
- Fixes#5876 .
## Solution
- added pub use statements to re-export the following traits in bevy_audio: rodio::source::Source, rodio::Sample, rodio::cpal::Sample.
- rodio::cpal::Sample was re-exported as CpalSample to avoid naming conflict with rodio::Sample.
# Objective
Currently scenes define components using a list:
```rust
[
(
entity: 0,
components: [
{
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
{
"my_crate::Foo": (
text: "Hello World",
),
},
{
"my_crate::Bar": (
baz: 123,
),
},
],
),
]
```
However, this representation has some drawbacks (as pointed out by @Metadorius in [this](https://github.com/bevyengine/bevy/pull/4561#issuecomment-1202215565) comment):
1. Increased nesting and more characters (minor effect on overall size)
2. More importantly, by definition, entities cannot have more than one instance of any given component. Therefore, such data is best stored as a map— where all values are meant to have unique keys.
## Solution
Change `components` to store a map of components rather than a list:
```rust
[
(
entity: 0,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
"my_crate::Foo": (
text: "Hello World",
),
"my_crate::Bar": (
baz: 123
),
},
),
]
```
#### Code Representation
This change only affects the scene format itself. `DynamicEntity` still stores its components as a list. The reason for this is that storing such data as a map is not really needed since:
1. The "key" of each value is easily found by just calling `Reflect::type_name` on it
2. We should be generating such structs using the `World` itself which upholds the one-component-per-entity rule
One could in theory create manually create a `DynamicEntity` with duplicate components, but this isn't something I think we should focus on in this PR. `DynamicEntity` can be broken in other ways (i.e. storing a non-component in the components list), and resolving its issues can be done in a separate PR.
---
## Changelog
* The scene format now uses a map to represent the collection of components rather than a list
## Migration Guide
The scene format now uses a map to represent the collection of components. Scene files will need to update from the old list format.
<details>
<summary>Example Code</summary>
```rust
// OLD
[
(
entity: 0,
components: [
{
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
{
"my_crate::Foo": (
text: "Hello World",
),
},
{
"my_crate::Bar": (
baz: 123,
),
},
],
),
]
// NEW
[
(
entity: 0,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
"my_crate::Foo": (
text: "Hello World",
),
"my_crate::Bar": (
baz: 123
),
},
),
]
```
</details>
# Objective
Currently, Bevy only supports rendering to the current "surface texture format". This means that "render to texture" scenarios must use the exact format the primary window's surface uses, or Bevy will crash. This is even harder than it used to be now that we detect preferred surface formats at runtime instead of using hard coded BevyDefault values.
## Solution
1. Look up and store each window surface's texture format alongside other extracted window information
2. Specialize the upscaling pass on the current `RenderTarget`'s texture format, now that we can cheaply correlate render targets to their current texture format
3. Remove the old `SurfaceTextureFormat` and `AvailableTextureFormats`: these are now redundant with the information stored on each extracted window, and probably should not have been globals in the first place (as in theory each surface could have a different format).
This means you can now use any texture format you want when rendering to a texture! For example, changing the `render_to_texture` example to use `R16Float` now doesn't crash / properly only stores the red component:
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Adds support for reflecting many more of the input types. This allows those types to be used via scripting, `bevy-inspector-egui`, etc. These types are registered by the `InputPlugin` so that they're automatically available to anyone who wants to use them
Closes#6223
## Solution
Many types now have `#[derive(Reflect, FromReflect)]` added to them in `bevy_input`. Additionally, `#[reflect(traits...)]` has been added for applicable traits to the types.
This PR does not add reflection support for types which have private fields. Notably, `Touch` and `Touches` don't implement `Reflect`/`FromReflect`.
This adds the "glam" feature to the `bevy_reflect` dependency for package `bevy_input`. Since `bevy_input` transitively depends on `glam` already, all this brings in are the reflection `impl`s.
## Migration Guide
- `Input<T>` now implements `Reflect` via `#[reflect]` instead of `#[reflect_value]`. This means it now exposes its private fields via the `Reflect` trait rather than being treated as a value type. For code that relies on the `Input<T>` struct being treated as a value type by reflection, it is still possible to wrap the `Input<T>` type with a wrapper struct and apply `#[reflect_value]` to it.
- As a reminder, private fields exposed via reflection are not subject to any stability guarantees.
---
## Changelog
Added
- Implemented `Reflect` + `FromReflect` for many input-related types. These types are automatically registered when adding the `InputPlugin`.
# Objective
- Proactive changing of code to comply with warnings generated by beta of rustlang version of cargo clippy.
## Solution
- Code changed as recommended by `rustup update`, `rustup default beta`, `cargo run -p ci -- clippy`.
- Tested using `beta` and `stable`. No clippy warnings in either after changes made.
---
## Changelog
- Warnings fixed were: `clippy::explicit-auto-deref` (present in 11 files), `clippy::needless-borrow` (present in 2 files), and `clippy::only-used-in-recursion` (only 1 file).
# Objective
- Some tests are very flaky on a m1
- m1 currently have a 41 ns precision
## Solution
- Do not run tests that compare a `Duration` or a `f64` on a m1 (and m2)
# Objective
- Make the settings of plugins readable during app building
## Solution
- Added a vector of added plugins to the app. Their settings can be accessed as read only
# Objective
- Do not implement `Copy` or `Clone` for `Fetch` types as this is kind of sus soundness wise (it feels like cloning an `IterMut` in safe code to me). Cloning a fetch seems important to think about soundness wise when doing it so I prefer this over adding a `Clone` bound to the assoc type definition (i.e. `type Fetch: Clone`) even though that would also solve the other listed things here.
- Remove a bunch of `QueryFetch<'w, Q>: Clone` bounds from our API as now all fetches can be "cloned" for use in `iter_combinations`. This should also help avoid the type inference regression ptrification introduced where `for<'a> QueryFetch<'a, Q>: Trait` bounds misbehave since we no longer need any of those kind of higher ranked bounds (although in practice we had none anyway).
- Stop being able to "forget" to implement clone for fetches, we've had a lot of issues where either `derive(Clone)` was used instead of a manual impl (so we ended up with too tight bounds on the impl) or flat out forgot to implement Clone at all. With this change all fetches are able to be cloned for `iter_combinations` so this will no longer be possible to mess up.
On an unrelated note, while making this PR I realised we probably want safety invariants on `archetype/table_fetch` that nothing aliases the table_row/archetype_index according to the access we set.
---
## Changelog
`Clone` and `Copy` were removed from all `Fetch` types.
## Migration Guide
- Call `WorldQuery::clone_fetch` instead of `fetch.clone()`. Make sure to add safety comments :)
# Objective
- Build on #6336 for more plugin configurations
## Solution
- `LogSettings`, `ImageSettings` and `DefaultTaskPoolOptions` are now plugins settings rather than resources
---
## Changelog
- `LogSettings` plugin settings have been move to `LogPlugin`, `ImageSettings` to `ImagePlugin` and `DefaultTaskPoolOptions` to `CorePlugin`
## Migration Guide
The `LogSettings` settings have been moved from a resource to `LogPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(LogSettings {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(LogPlugin {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
}))
```
The `ImageSettings` settings have been moved from a resource to `ImagePlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(ImageSettings::default_nearest())
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(ImagePlugin::default_nearest()))
```
The `DefaultTaskPoolOptions` settings have been moved from a resource to `CorePlugin::task_pool_options`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(DefaultTaskPoolOptions::with_num_threads(4))
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(CorePlugin {
task_pool_options: TaskPoolOptions::with_num_threads(4),
}))
```
# Objective
This is a follow-up to #6317, which makes use of a feature of the newest `trybuild` version, `1.0.71`, but does not specify the new patch version in `bevy_ecs_compile_fail_tests/Cargo.toml`.
The PR passed CI because CI downloaded the latest `trybuild` version satisfying the dependency specification. However, Cargo will not know an update is required if a user already has a `^1.0` version of `trybuild` cached locally, which causes the new `$N` syntax to fail the tests.
## Solution
Updated the `trybuild` requirement to `1.0.71`.
# Objective
- Reverts unnecessary version increase for `thiserror` caused by the following PR. 9066d51420
- The aforementioned PR should have increased `thiserrror` version uniformly across all bevy crates. As far as I can tell it was unneccessary to bump versions
## Solution
- Revert versions to the matching version used by other bevy "crates"
```
MBP-Larry-Du.local:~/Code/bevy:$ git grep thiserror
CHANGELOG.md:- [Derive thiserror::Error for HexColorError][2740]
crates/bevy_asset/Cargo.toml:thiserror = "1.0"
crates/bevy_asset/src/asset_server.rs:use thiserror::Error;
crates/bevy_asset/src/io/mod.rs:use thiserror::Error;
crates/bevy_gltf/Cargo.toml:thiserror = "1.0"
crates/bevy_gltf/src/loader.rs:use thiserror::Error;
crates/bevy_input/Cargo.toml:thiserror = "1.0"
crates/bevy_input/src/gamepad.rs:use thiserror::Error;
crates/bevy_reflect/Cargo.toml:thiserror = "1.0"
crates/bevy_reflect/src/path.rs:use thiserror::Error;
crates/bevy_render/Cargo.toml:thiserror = "1.0"
```
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- What changed as a result of this PR? Fixed dependency conflict for building projects.
Current build of StarRust runs successfully with the `thiserror` reversion: https://github.com/LarsDu/StarRust
But will run into dependency conflicts if `thiserror` is version 1.037
Co-authored-by: Larry Du <larry.du@freenome.com>
# Objective
I was trying to implement a collision system for my game, and believed that the iter_combinations method might be what I need. But I couldn't find a simple explanation of what a combination was in Bevy and thought it could use some more explanation.
## Solution
I added some description to the documentation that can hopefully further elaborate on what a combination is.
I also changed up the docs for the method because a combination is a different thing than a permutation but the Bevy docs seemed to use them interchangeably.
# Objective
- `QueryCombinationIter` can have sizes greater than `usize::MAX`.
- Fixes#5846
## Solution
- Only the implementation of `ExactSizeIterator` has been removed. Instead of using `query_combination.len()`, you can use `query_combination.size_hint().0` to get the same value as before.
---
## Migration Guide
- Switch to using other methods of getting the length.
# Objective
Fixes#5884#2879
Alternative to #2988#5885#2886
"Immutable" Plugin settings are currently represented as normal ECS resources, which are read as part of plugin init. This presents a number of problems:
1. If a user inserts the plugin settings resource after the plugin is initialized, it will be silently ignored (and use the defaults instead)
2. Users can modify the plugin settings resource after the plugin has been initialized. This creates a false sense of control over settings that can no longer be changed.
(1) and (2) are especially problematic and confusing for the `WindowDescriptor` resource, but this is a general problem.
## Solution
Immutable Plugin settings now live on each Plugin struct (ex: `WindowPlugin`). PluginGroups have been reworked to support overriding plugin values. This also removes the need for the `add_plugins_with` api, as the `add_plugins` api can use the builder pattern directly. Settings that can be used at runtime continue to be represented as ECS resources.
Plugins are now configured like this:
```rust
app.add_plugin(AssetPlugin {
watch_for_changes: true,
..default()
})
```
PluginGroups are now configured like this:
```rust
app.add_plugins(DefaultPlugins
.set(AssetPlugin {
watch_for_changes: true,
..default()
})
)
```
This is an alternative to #2988, which is similar. But I personally prefer this solution for a couple of reasons:
* ~~#2988 doesn't solve (1)~~ #2988 does solve (1) and will panic in that case. I was wrong!
* This PR directly ties plugin settings to Plugin types in a 1:1 relationship, rather than a loose "setup resource" <-> plugin coupling (where the setup resource is consumed by the first plugin that uses it).
* I'm not a huge fan of overloading the ECS resource concept and implementation for something that has very different use cases and constraints.
## Changelog
- PluginGroups can now be configured directly using the builder pattern. Individual plugin values can be overridden by using `plugin_group.set(SomePlugin {})`, which enables overriding default plugin values.
- `WindowDescriptor` plugin settings have been moved to `WindowPlugin` and `AssetServerSettings` have been moved to `AssetPlugin`
- `app.add_plugins_with` has been replaced by using `add_plugins` with the builder pattern.
## Migration Guide
The `WindowDescriptor` settings have been moved from a resource to `WindowPlugin::window`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(WindowDescriptor {
width: 400.0,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(WindowPlugin {
window: WindowDescriptor {
width: 400.0,
..default()
},
..default()
}))
```
The `AssetServerSettings` resource has been removed in favor of direct `AssetPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(AssetPlugin {
watch_for_changes: true,
..default()
}))
```
`add_plugins_with` has been replaced by `add_plugins` in combination with the builder pattern:
```rust
// Old (Bevy 0.8)
app.add_plugins_with(DefaultPlugins, |group| group.disable::<AssetPlugin>());
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.build().disable::<AssetPlugin>());
```
# Objective
Scenes are currently represented as a list of entities. This is all we need currently, but we may want to add more data to this format in the future (metadata, asset lists, etc.).
It would be nice to update the format in preparation of possible future changes. Doing so now (i.e., before 0.9) could mean reduced[^1] breakage for things added in 0.10.
[^1]: Obviously, adding features runs the risk of breaking things regardless. But if all features added are for whatever reason optional or well-contained, then users should at least have an easier time updating.
## Solution
Made the scene root a struct rather than a list.
```rust
(
entities: [
// Entity data here...
]
)
```
---
## Changelog
* The scene format now puts the entity list in a newly added `entities` field, rather than having it be the root object
## Migration Guide
The scene file format now uses a struct as the root object rather than a list of entities. The list of entities is now found in the `entities` field of this struct.
```rust
// OLD
[
(
entity: 0,
components: [
// Components...
]
),
]
// NEW
(
entities: [
(
entity: 0,
components: [
// Components...
]
),
]
)
```
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
- You usually want to say that a given animation *should* be playing, doing nothing if it's already playing.
## Solution
- Rename play to start and add new play method that won't overwrite the existing animation if it's already playing #6350
---
## Changelog
### Changed
`AnimationPlayer::play` will now not restart the animation if it's already playing
### Added
An `AnimationPlayer ::start` method, which has the old behavior of `play`
## Migration guide
- If you were using `play` to restart an animation that was already playing, that functionality has been moved to `start`. Now, `play` won't have any effect if the requested animation is already playing.
# Objective
Improve ergonomics by passing on the `IntoIterator` impl of the underlying type to wrapper types.
## Solution
Implement `IntoIterator` for ECS wrapper types (Mut, Local, Res, etc.).
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Improve #3953
## Solution
- The very specific circumstances under which the render world is reset meant that the flush_as_invalid function could be replaced with one that had a noop as its init method.
- This removes a double-writing issue leading to greatly increased performance.
Running the reproduction code in the linked issue, this change nearly doubles the framerate.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Avoids creating a `SurfaceConfiguration` for every window in every frame for the `prepare_windows` system
- As such also avoid calling `get_supported_formats` for every window in every frame
## Solution
- Construct `SurfaceConfiguration` lazyly in `prepare_windows`
---
This also changes the error message for failed initial surface configuration from "Failed to acquire next swapchain texture" to "Error configuring surface".
# Objective
When running the scene example, you might notice we end up printing out the following:
```ron
// ...
{
"scene::ComponentB": (
value: "hello",
_time_since_startup: (
secs: 0,
nanos: 0,
),
),
},
// ...
```
We should not be printing out `_time_since_startup` as the field is marked with `#[reflect(skip_serializing)]`:
```rust
#[derive(Component, Reflect)]
#[reflect(Component)]
struct ComponentB {
pub value: String,
#[reflect(skip_serializing)]
pub _time_since_startup: Duration,
}
```
This is because when we create the `DynamicScene`, we end up calling `Reflect::clone_value`:
82126697ee/crates/bevy_scene/src/dynamic_scene_builder.rs (L114-L114)
This results in non-Value types being cloned into Dynamic types, which means the `TypeId` returned from `reflected_value.type_id()` is not the same as the original component's.
And this meant we were not able to locate the correct `TypeRegistration`.
## Solution
Use `TypeInfo::type_id()` instead of calling `Any::type_id()` on the value directly.
---
## Changelog
* Fix a bug introduced in `0.9.0-dev` where scenes disregarded component's type registrations
# Objective
- Clipping (visible in the UI example with text scrolling) is funky
- Fixes#6287
## Solution
- Fix UV calculation:
- correct order for values (issue introduced in #6000)
- add the `y` values instead of subtracting them now that vertical order is reversed
- take scale factor into account (bug already present before reversing the order)
- While around clipping, I changed clip to only mutate when changed
No more funkiness! 😞
<img width="696" alt="Screenshot 2022-10-23 at 22 44 18" src="https://user-images.githubusercontent.com/8672791/197417721-30ad4150-5264-427f-ac82-e5265c1fb3a9.png">
# Objective
Fixes#6339.
## Solution
This PR adds a new type, `GamepadInfo`, which holds metadata associated with a particular `Gamepad`. The `Gamepads` resource now holds a `HashMap<Gamepad, GamepadInfo>`. The `GamepadInfo` is created when the gamepad backend (by default `bevy_gilrs`) emits a "gamepad connected" event.
The `gamepad_viewer` example has been updated to showcase the new functionality.
Before:

After:

---
## Changelog
### Added
- Added `GamepadInfo`.
- Added `Gamepads::name()`, which returns the name of the specified gamepad if it exists.
### Changed
- `GamepadEventType::Connected` is now a tuple variant with a single field of type `GamepadInfo`.
- Since `GamepadInfo` is not `Copy`, `GamepadEventType` is no longer `Copy`. The same is true of `GamepadEvent` and `GamepadEventRaw`.
## Migration Guide
- Pattern matches on `GamepadEventType::Connected` will need to be updated, as the form of the variant has changed.
- Code that requires `GamepadEvent`, `GamepadEventRaw` or `GamepadEventType` to be `Copy` will need to be updated.
I found myself doing
```rust
let child = commands.spawn(..).id();
commands.entity(parent).add_child(child);
```
When that could just be
```rust
commands.spawn(..).set_parent(parent);
```
Adding `set_parent` was trivial as it's just an `AddChild` command. Most of the changes are for `remove_parent`.
Also updated some outdated docs.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Adds a better interface for performing mathematical operations with UI unit `Val`. Fixes#6080.
## Solution
- Added `try_add` and `try_sub` methods to Val.
- Removed the `Add` and `AddAssign` impls for `Val` that introduced unintuitive and bug-prone behaviour.
- As a consequence of the prior, ~~changed the `Add` and `Sub` impls for the `Size` struct to take a `(Val, Val)` instead of `Vec2`~~ deleted the `Add` and `Sub` impls for the `Size` struct
- Added a `From<(Val, Val)>` impl for the `Size` struct
- Added `evaluate(size: f32)` method that converts from `Val::Percent` to `Val::Px`.
- Added `try_add_with_size` and `try_sub_with_size` methods to `Val`, which evaluate `Val::Percent` values into `Val::Px` values before adding.
---
## Migration Guide
Instead of using the + and - operators, perform calculations on `Val`s using the new `try_add` and `try_sub` methods. Multiplication and division remained unchanged. Also, when adding or subtracting from `Size`, ~~use a `Val` tuple instead of `Vec2`~~ perform the addition on `width` and `height` separately.
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
Fixes#5559
Replaces #5628
## Solution
Because the generated method from_components() creates an instance of Self my implementation requires any field type that is marked to be ignored to implement Default.
---
## Changelog
Added the possibility to ignore fields in a bundle with `#[bundle(ignore)]`. Typically used when `PhantomData` needs to be added to a `Bundle`.
# Objective
- #4466 broke local tasks running.
- Fixes https://github.com/bevyengine/bevy/issues/6120
## Solution
- Add system for ticking local executors on main thread into bevy_core where the tasks pools are initialized.
- Add ticking local executors into thread executors
## Changelog
- tick all thread local executors in task pool.
## Notes
- ~~Not 100% sure about this PR. Ticking the local executor for the main thread in scope feels a little kludgy as it requires users of bevy_tasks to be calling scope periodically for those tasks to make progress.~~ took this out in favor of a system that ticks the local executors.
# Objective
- Fix disabling features in bevy_ecs (broken by #5630)
- Add tests in CI for bevy_ecs, bevy_reflect and bevy as those crates could be use standalone
Add the following message:
```
Items are returned in the order of the list of entities.
Entities that don't match the query are skipped.
```
Additionally, the docs in `iter.rs` and `state.rs` were updated to match those in `query.rs`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Add Time-Adjusted Rolling EMA-based smoothing to diagnostics.
- Closes#4983; see that issue for more more information.
## Terms
- EMA - [Exponential Moving Average](https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average)
- SMA - [Simple Moving Average](https://en.wikipedia.org/wiki/Moving_average#Simple_moving_average)
## Solution
- We use a fairly standard approximation of a true EMA where $EMA_{\text{frame}} = EMA_{\text{previous}} + \alpha \left( x_{\text{frame}} - EMA_{\text{previous}} \right)$ where $\alpha = \Delta t / \tau$ and $\tau$ is an arbitrary smoothness factor. (See #4983 for more discussion of the math.)
- The smoothness factor is here defaulted to $2 / 21$; this was chosen fairly arbitrarily as supposedly related to the existing 20-bucket SMA.
- The smoothness factor can be set on a per-diagnostic basis via `Diagnostic::with_smoothing_factor`.
---
## Changelog
### Added
- `Diagnostic::smoothed` - provides an exponentially smoothed view of a recorded diagnostic, to e.g. reduce jitter in frametime readings.
### Changed
- `LogDiagnosticsPlugin` now records the smoothed value rather than the raw value.
- For diagnostics recorded less often than every 0.1 seconds, this change to defaults will have no visible effect.
- For discrete diagnostics where this smoothing is not desirable, set a smoothing factor of 0 to disable smoothing.
- The average of the recent history is still shown when available.
# Objective
At least partially addresses #6282.
Resources are currently stored as a dedicated Resource archetype (ID 1). This allows for easy code reusability, but unnecessarily adds 72 bytes (on 64-bit systems) to the struct that is only used for that one archetype. It also requires several fields to be `pub(crate)` which isn't ideal.
This should also remove one sparse-set lookup from fetching, inserting, and removing resources from a `World`.
## Solution
- Add `Resources` parallel to `Tables` and `SparseSets` and extract the functionality used by `Archetype` in it.
- Remove `unique_components` from `Archetype`
- Remove the `pub(crate)` on `Archetype::components`.
- Remove `ArchetypeId::RESOURCE`
- Remove `Archetypes::resource` and `Archetypes::resource_mut`
---
## Changelog
Added: `Resources` type to store resources.
Added: `Storages::resource`
Removed: `ArchetypeId::RESOURCE`
Removed: `Archetypes::resource` and `Archetypes::resources`
Removed: `Archetype::unique_components` and `Archetypes::unique_components_mut`
## Migration Guide
Resources have been moved to `Resources` under `Storages` in `World`. All code dependent on `Archetype::unique_components(_mut)` should access it via `world.storages().resources()` instead.
All APIs accessing the raw data of individual resources (mutable *and* read-only) have been removed as these APIs allowed for unsound unsafe code. All usages of these APIs should be changed to use `World::{get, insert, remove}_resource`.
# Objective
Speed up queries that are fragmented over many empty archetypes and tables.
## Solution
Add a early-out to check if the table or archetype is empty before iterating over it. This adds an extra branch for every archetype matched, but skips setting the archetype/table to the underlying state and any iteration over it.
This may not be worth it for the default `Query::iter` and maybe even the `Query::for_each` implementations, but this definitely avoids scheduling unnecessary tasks in the `Query::par_for_each` case.
Ideally, `matched_archetypes` should only contain archetypes where there's actually work to do, but this would add a `O(n)` flat cost to every call to `update_archetypes` that scales with the number of matched archetypes.
TODO: Benchmark
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
Use saturate wgsl function now implemented in naga (version 0.10.0). There is now no need for one in utils.wgsl.
naga's version allows usage for not only scalars but vectors as well.
## Solution
Remove the utils.wgsl saturate function.
## Changelog
Remove saturate function from utils.wgsl in favor of saturate in naga v0.10.0.
# Objective
I recently wanted to look at the possibility of adding `Mutated` and `Unchanged` query filters and was confronted with some seemingly unrelated broken tests.
These tests were written in such a way that changing the number of WorldQuery impls in the project would break them.
Fortunately, a [very recent release of trybuild](https://github.com/dtolnay/trybuild/releases/tag/1.0.70) has made this unnecessary.
## Solution
Replace hardcoded numbers in test output with `$N` placeholders.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/6306
## Solution
Change the failing assert and expand example to explain when ordering is deterministic or not.
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
The `RenderLayers` type is never registered, making it unavailable for reflection.
## Solution
Register it in `CameraPlugin`, the same plugin that registers the related `Visibility*` types.
# Objective
- Update `wgpu` to 0.14.0, `naga` to `0.10.0`, `winit` to 0.27.4, `raw-window-handle` to 0.5.0, `ndk` to 0.7.
## Solution
---
## Changelog
### Changed
- Changed `RawWindowHandleWrapper` to `RawHandleWrapper` which wraps both `RawWindowHandle` and `RawDisplayHandle`, which satisfies the `impl HasRawWindowHandle and HasRawDisplayHandle` that `wgpu` 0.14.0 requires.
- Changed `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, change its type from `bool` to `bevy_window::CursorGrabMode`.
## Migration Guide
- Adjust usage of `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, and adjust its type from `bool` to `bevy_window::CursorGrabMode`.
# Objective
Resolves#6197
Make it so that doc comments can be retrieved via reflection.
## Solution
Adds the new `documentation` feature to `bevy_reflect` (disabled by default).
When enabled, documentation can be found using `TypeInfo::doc` for reflected types:
```rust
/// Some struct.
///
/// # Example
///
/// ```ignore
/// let some_struct = SomeStruct;
/// ```
#[derive(Reflect)]
struct SomeStruct;
let info = <SomeStruct as Typed>::type_info();
assert_eq!(
Some(" Some struct.\n\n # Example\n\n ```ignore\n let some_struct = SomeStruct;\n ```"),
info.docs()
);
```
### Notes for Reviewers
The bulk of the files simply added the same 16 lines of code (with slightly different documentation). Most of the real changes occur in the `bevy_reflect_derive` files as well as in the added tests.
---
## Changelog
* Added `documentation` feature to `bevy_reflect`
* Added `TypeInfo::docs` method (and similar methods for all info types)
# Objective
Fixes#6272
## Solution
Revert to old way of positioning text for Text2D rendered text.
Co-authored-by: Michel van der Hulst <hulstmichel@gmail.com>
# Objective
Make toggling the visibility of an entity slightly more convenient.
## Solution
Add a mutating `toggle` method to the `Visibility` component
```rust
fn my_system(mut query: Query<&mut Visibility, With<SomeMarker>>) {
let mut visibility = query.single_mut();
// before:
visibility.is_visible = !visibility.is_visible;
// after:
visibility.toggle();
}
```
## Changelog
### Added
- Added a mutating `toggle` method to the `Visibility` component
# Objective
Fixes#6244
## Solution
Uses derive to implement `Serialize` and `Deserialize` for `Timer` and `Stopwatch`
### Things to consider
- Should fields such as `finished` and `times_finished_this_tick` in `Timer` be serialized?
- Does `Countdown` and `PrintOnCompletionTimer` need to be serialized and deserialized?
## Changelog
Added `Serialize` and `Deserialize` implementations to `Timer` and `Stopwatch`, `Countdown`.
# Objective
Currently, surprising behavior happens when specifying `#[reflect(...)]` or `#[reflect_value(...)]` multiple times. Rather than merging the traits lists from all attributes, only the trait list from the last attribute is used. For example, in the following code, only the `Debug` and `Hash` traits are reflected and not `Default` or `PartialEq`:
```rs
#[derive(Debug, PartialEq, Hash, Default, Reflect)]
#[reflect(PartialEq, Default)]
#[reflect(Debug, Hash)]
struct Foo;
```
This is especially important when some traits should only be reflected under certain circumstances. For example, this previously had surprisingly behavior when the "serialize" feature is enabled:
```rs
#[derive(Debug, Hash, Reflect)]
#[reflect(Debug, Hash)]
#[cfg_attr(
feature = "serialize",
derive(Serialize, Deserialize),
reflect(Serialize, Deserialize)
]
struct Foo;
```
In addition, compile error messages generated from using the derive macro often point to the `#[derive(Reflect)]` rather than to the source of the error. It would be a lot more helpful if the compiler errors pointed to what specifically caused the error rather than just to the derive macro itself.
## Solution
Merge the trait lists in all `#[reflect(...)]` and `#[reflect_value(...)]` attributes. Additionally, make `#[reflect]` and `#[reflect_value]` mutually exclusive.
Additionally, span information is carried throughout some parts of the code now to ensure that error messages point to more useful places and better indicate what caused those errors. For example, `#[reflect(Hash, Hash)]` points to the second `Hash` as the source of an error. Also, in the following example, the compiler error now points to the `Hash` in `#[reflect(Hash)]` rather than to the derive macro:
```rs
#[derive(Reflect)]
#[reflect(Hash)] // <-- compiler error points to `Hash` for lack of a `Hash` implementation
struct Foo;
```
---
## Changelog
Changed
- Using multiple `#[reflect(...)]` or `#[reflect_value(...)]` attributes now merges the trait lists. For example, `#[reflect(Debug, Hash)] #[reflect(PartialEq, Default)]` is equivalent to `#[reflect(Debug, Hash, PartialEq, Default)]`.
- Multiple `#[reflect(...)]` and `#[reflect_value(...)]` attributes were previously accepted, but only the last attribute was respected.
- Using both `#[reflect(...)]` and `#[reflect_value(...)]` was previously accepted, but had surprising behavior. This is no longer accepted.
- Improved error messages for `#[derive(Reflect)]` by propagating useful span information. Many errors should now point to the source of those errors rather than to the derive macro.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3418
## Solution
Originally a rebase of https://github.com/bevyengine/bevy/pull/3446. Work was originally done by mfdorst, who should receive considerable credit. Then the error types were extensively reworked by targrub.
## Migration Guide
`AxisSettings` now has a `new()`, which may return an `AxisSettingsError`.
`AxisSettings` fields made private; now must be accessed through getters and setters. There's a dead zone, from `.deadzone_upperbound()` to `.deadzone_lowerbound()`, and a live zone, from `.deadzone_upperbound()` to `.livezone_upperbound()` and from `.deadzone_lowerbound()` to `.livezone_lowerbound()`.
`AxisSettings` setters no longer panic.
`ButtonSettings` fields made private; now must be accessed through getters and setters.
`ButtonSettings` now has a `new()`, which may return a `ButtonSettingsError`.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
- Trying to make it possible to do write tests that don't require a raw window handle.
- Fixes https://github.com/bevyengine/bevy/issues/6106.
## Solution
- Make the interface and type changes. Avoid accessing `None`.
---
## Changelog
- Converted `raw_window_handle` field in both `Window` and `ExtractedWindow` to `Option<RawWindowHandleWrapper>`.
- Revised accessor function `Window::raw_window_handle()` to return `Option<RawWindowHandleWrapper>`.
- Skip conditions in loops that would require a raw window handle (to create a `Surface`, for example).
## Migration Guide
`Window::raw_window_handle()` now returns `Option<RawWindowHandleWrapper>`.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
As suggested in #6104, it would be nice to link directly to `linux_dependencies.md` file in the panic message when running on Linux. And when not compiling for Linux, we fall back to the old message.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Resolves#6104.
## Solution
Add link to `linux_dependencies.md` when compiling for Linux, and fall back to the old one when not.
# Objective
- Fixes#6206
## Solution
- Create a constructor for creating `ReflectComponent` and `ReflectResource`
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
### Added
- Created constructors for `ReflectComponent` and `ReflectResource`, allowing for advanced scripting use-cases.
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
As mentioned in #2926, it's better to have an explicit type that clearly communicates the intent of the timer mode rather than an opaque boolean, which can be only understood when knowing the signature or having to look up the documentation.
This also opens up a way to merge different timers, such as `Stopwatch`, and possibly future ones, such as `DiscreteStopwatch` and `DiscreteTimer` from #2683, into one struct.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Fixes#2926.
## Solution
Introduce `TimerMode` which replaces the `bool` argument of `Timer` constructors. A `Default` value for `TimerMode` is `Once`.
---
## Changelog
### Added
- `TimerMode` enum, along with variants `TimerMode::Once` and `TimerMode::Repeating`
### Changed
- Replace `bool` argument of `Timer::new` and `Timer::from_seconds` with `TimerMode`
- Change `repeating: bool` field of `Timer` with `mode: TimerMode`
## Migration Guide
- Replace `Timer::new(duration, false)` with `Timer::new(duration, TimerMode::Once)`.
- Replace `Timer::new(duration, true)` with `Timer::new(duration, TimerMode::Repeating)`.
- Replace `Timer::from_seconds(seconds, false)` with `Timer::from_seconds(seconds, TimerMode::Once)`.
- Replace `Timer::from_seconds(seconds, true)` with `Timer::from_seconds(seconds, TimerMode::Repeating)`.
- Change `timer.repeating()` to `timer.mode() == TimerMode::Repeating`.
# Objective
- Add a way to iterate over all entities from &World
## Solution
- Added a function `iter_entities` on World which returns an iterator of `Entity` derived from the entities in the `World`'s `archetypes`
---
## Changelog
- Added a function `iter_entities` on World, allowing iterating over all entities in contexts where you only have read-only access to the World.
# Objective
Fixes#5820
## Solution
Change field name and documentation from `bevy::ui::Node` struct
---
## Changelog
`bevy::ui::Node` `size` field has renamed to `calculated_size`
## Migration Guide
All references to the old `size` name has been changed, to access `bevy::ui::Node` `size` field use `calculated_size`
Bevy's coordinate system is right-handed Y up, so +Z points towards my nose and I'm looking in the -Z direction. Therefore, `Transform::looking_at/look_at` must be pointing towards -Z. Or am I wrong here?
# Objective
- make it easier to build dynamic scenes
## Solution
- add a builder to create a dynamic scene from a world. it can extract an entity or an iterator of entities
- alternative to #6013, leaving the "hierarchy iteration" part to #6185 which does it better
- alternative to #6004
- using a builder makes it easier to chain several extractions
# Objective
> System chaining is a confusing name: it implies the ability to construct non-linear graphs, and suggests a sense of system ordering that is only incidentally true. Instead, it actually works by passing data from one system to the next, much like the pipe operator.
> In the accepted [stageless RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/45-stageless.md), this concept is renamed to piping, and "system chaining" is used to construct groups of systems with ordering dependencies between them.
Fixes#6225.
## Changelog
System chaining has been renamed to system piping to improve clarity (and free up the name for new ordering APIs).
## Migration Guide
The `.chain(handler_system)` method on systems is now `.pipe(handler_system)`.
The `IntoChainSystem` trait is now `IntoPipeSystem`, and the `ChainSystem` struct is now `PipeSystem`.
# Objective
`RemoveChildren` could remove the `Parent` component from children belonging to a different parent, which breaks the hierarchy.
This change looks a little funny because I'm reusing the events to avoid needing to clone the parent's `Children`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Taking the API improvement out of #5431
- `iter_instance_entities` used to return an option of iterator, now it just returns an iterator
---
## Changelog
- If you use `SceneSpawner::iter_instance_entities`, it no longer returns an `Option`. The iterator will be empty if the return value used to be `None`
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
See commit message.
I noticed I couldn't use `globals.time` when using `Material2d`.
I copied the solution from 8073362039 , and now `Material2d` works for me.
Perhaps some of these struct definitions could be shared in the future, but for now I've just copy pasted it (it looked like the `View` struct was done that way).
Ping @IceSentry , I saw a comment on the linked commit that you intended to do this work at some point in the future.
# Objective
- It's possible to create a mesh without positions or normals, but currently bevy forces these attributes to be present on any mesh.
## Solution
- Don't assume these attributes are present and add a shader defs for each attributes
- I updated 2d and 3d meshes to use the same logic.
---
## Changelog
- Meshes don't require any attributes
# Notes
I didn't update the pbr.wgsl shader because I'm not sure how to handle it. It doesn't really make sense to use it without positions or normals.
# Objective
- `process_touch_event` in `bevy_input` don't update position info. `TouchPhase::Ended` and `TouchPhase::Cancelled` should use the position info from `pressed`. Otherwise, it'll not update. The position info is updated from `TouchPhase::Moved`.
## Solution
- Use updated touch info.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, feel free to skip this section.
- Fixed: bevy_input, fix process touch event, update touch info
# Objective
When designing an API, you may wish to provide access only to a specific field of a component or resource. The current options for doing this in safe code are
* `*Mut::into_inner`, which flags a change no matter what.
* `*Mut::bypass_change_detection`, which misses all changes.
## Solution
Add the method `map_unchanged`.
### Example
```rust
// When run, zeroes the translation of every entity.
fn reset_all(mut transforms: Query<&mut Transform>) {
for transform in &mut transforms {
// We pinky promise not to modify `t` within the closure.
let translation = transform.map_unchanged(|t| &mut t.translation);
// Only reset the translation if it isn't already zero.
translation.set_if_not_equal(Vec2::ZERO);
}
}
```
---
## Changelog
+ Added the method `map_unchanged` to types `Mut<T>`, `ResMut<T>`, and `NonSendMut<T>`.
This is a holdover from back when `Transform` was backed by a private `Mat4` two years ago.
Not particularly useful anymore :)
## Migration Guide
`Transform::apply_non_uniform_scale` has been removed.
It can be replaced with the following snippet:
```rust
transform.scale *= scale_factor;
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
The docs ended up quite verbose :v
Also added a missing `#[inline]` to `GlobalTransform::mul_transform`.
I'd say this resolves#5500
# Migration Guide
`Transform::mul_vec3` has been renamed to `transform_point`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Make `GlobalTransform` constructible from scripts, in the same vein as #6187.
## Solution
- Use the derive macro to reflect default
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- `GlobalTransform` now reflects the `Default` trait.
…
# Objective
- Fixes Camera not being serializable due to missing registrations in core functionality.
- Fixes#6169
## Solution
- Updated Bevy_Render CameraPlugin with registrations for Option<Viewport> and then Bevy_Core CorePlugin with registrations for ReflectSerialize and ReflectDeserialize for type data Range<f32> respectively according to the solution in #6169
Co-authored-by: Noah <noahshomette@gmail.com>
# Background
Incremental implementation of #4299. The code is heavily borrowed from that PR.
# Objective
The execution order ambiguity checker often emits false positives, since bevy is not aware of invariants upheld by the user.
## Solution
Title
---
## Changelog
+ Added methods `SystemDescriptor::ignore_all_ambiguities` and `::ambiguous_with`. These allow you to silence warnings for specific system-order ambiguities.
## Migration Guide
***Note for maintainers**: This should replace the migration guide for #5916*
Ambiguity sets have been replaced with a simpler API.
```rust
// These systems technically conflict, but we don't care which order they run in.
fn jump_on_click(mouse: Res<Input<MouseButton>>, mut transforms: Query<&mut Transform>) { ... }
fn jump_on_spacebar(keys: Res<Input<KeyCode>>, mut transforms: Query<&mut Transform>) { ... }
//
// Before
#[derive(AmbiguitySetLabel)]
struct JumpSystems;
app
.add_system(jump_on_click.in_ambiguity_set(JumpSystems))
.add_system(jump_on_spacebar.in_ambiguity_set(JumpSystems));
//
// After
app
.add_system(jump_on_click.ambiguous_with(jump_on_spacebar))
.add_system(jump_on_spacebar);
```
# Objective
There is no Srgb support on some GPU and display protocols with `winit` (for example, Nvidia's GPUs with Wayland). Thus `TextureFormat::bevy_default()` which returns `Rgba8UnormSrgb` or `Bgra8UnormSrgb` will cause panics on such platforms. This patch will resolve this problem. Fix https://github.com/bevyengine/bevy/issues/3897.
## Solution
Make `initialize_renderer` expose `wgpu::Adapter` and `first_available_texture_format`, use the `first_available_texture_format` by default.
## Changelog
* Fixed https://github.com/bevyengine/bevy/issues/3897.
# Objective
Closes#6202.
The default background color for `NodeBundle` is currently white.
However, it's very rare that you actually want a white background color.
Instead, you often want a background color specific to the style of your game or a transparent background (e.g. for UI layout nodes).
## Solution
`Default` is not derived for `NodeBundle` anymore, but explicitly specified.
The default background color is now transparent (`Color::NONE.into()`) as this is the most common use-case, is familiar from the web and makes specifying a layout for your UI less tedious.
---
## Changelog
- Changed the default `NodeBundle.background_color` to be transparent (`Color::NONE.into()`).
## Migration Guide
If you want a `NodeBundle` with a white background color, you must explicitly specify it:
Before:
```rust
let node = NodeBundle {
..default()
}
```
After:
```rust
let node = NodeBundle {
background_color: Color::WHITE.into(),
..default()
}
```
# Objective
Allow `Mesh2d` shaders to work with meshes that have vertex tangents
## Solution
Correctly pass `mesh.model` into `mesh2d_tangent_local_to_world`
# Objective
Fixes#6010
## Solution
As discussed in #6010, this makes it so the `Children` component is removed from the entity whenever all of its children are removed. The behavior is now consistent between all of the commands that may remove children from a parent, and this is tested via two new test functions (one for world functions and one for commands).
Documentation was also added to `insert_children`, `push_children`, `add_child` and `remove_children` commands to make this behavior clearer for users.
## Changelog
- Fixed `Children` component not getting removed from entity when all its children are moved to a new parent.
## Migration Guide
- Queries with `Changed<Children>` will no longer match entities that had all of their children removed using `remove_children`.
- `RemovedComponents<Children>` will now contain entities that had all of their children remove using `remove_children`.
# Objective
- Reflecting `Default` is required for scripts to create `Reflect` types at runtime with no static type information.
- Reflecting `Default` on `Handle<T>` and `ComputedVisibility` should allow scripts from `bevy_mod_js_scripting` to actually spawn sprites from scratch, without needing any hand-holding from the host-game.
## Solution
- Derive `ReflectDefault` for `Handle<T>` and `ComputedVisiblity`.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- The `Default` trait is now reflected for `Handle<T>` and `ComputedVisibility`
# Objective
- Field `id` of `Handle<T>` is public: https://docs.rs/bevy/latest/bevy/asset/struct.Handle.html#structfield.id
- Changing the value of this field doesn't make sense as it could mean changing the previous handle without dropping it, breaking asset cleanup detection for the old handle and the new one
## Solution
- Make the field private, and add a public getter
Opened after discussion in #6171. Pinging @zicklag
---
## Migration Guide
- If you were accessing the value `handle.id`, you can now do so with `handle.id()`
# Objective
Add a method for getting a world space ray from a viewport position.
Opted to add a `Ray` type to `bevy_math` instead of returning a tuple of `Vec3`'s as this is clearer and easier to document
The docs on `viewport_to_world` are okay, but I'm not super happy with them.
## Changelog
* Add `Camera::viewport_to_world`
* Add `Camera::ndc_to_world`
* Add `Ray` to `bevy_math`
* Some doc tweaks
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Fix#5285
## Solution
- Put the panicking system in a single threaded stage during the test
- This way only the main thread will panic, which is handled by `cargo test`
# Objective
- Fixes contradictory docs in Window::PresentMode partaining to PresentMode fallback behavior. Fix based on commit history showing the most recent update didn't remove old references to the gracefal fallback for Immediate and Mailbox.
- Fixes#5831
## Solution
- Updated the docs for Window::PresentMode itself and for each individual enum variant to clarify which will fallback and which will panic.
Co-authored-by: Noah <noahshomette@gmail.com>
# Objective
fix error with pbr shader's spotlight direction calculation when direction.y ~= 0
## Solution
in pbr_lighting.wgsl, clamp `1-x^2-z^2` to `>= 0` so that we can safely `sqrt` it
# Objective
The `Wireframe` type implements `Reflect`, but is never registered, making its reflection inaccessible.
## Solution
Call `App::register_type::<Wireframe>()` in the `Plugin::build` implementation of `WireframePlugin`.
---
## Changelog
Fixed `Wireframe` type reflection not getting registered.
# Objective
Add more documentation on `StandardMaterial` and improve
consistency on existing doc.
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Relaxes the trait bound for `World::resource_scope` to allow non-send resources. Fixes#6037.
## Solution
No big changes in code had to be made. Added a check so that the non-send resources won't be accessed from a different thread.
---
## Changelog
- `World::resource_scope` accepts non-send resources now
- `World::resource_scope` verifies non-send access if the resource is non-send
- Two new tests are added, one for valid use of `World::resource_scope` with a non-send resource, and one for invalid use (calling it from a different thread, resulting in panic)
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
As explained by #5960, `Commands::get_or_spawn` may return a dangling `EntityCommands` that references a non-existing entities. As explained in [this comment], it may be undesirable to make the method return an `Option`.
- Addresses #5960
- Alternative to #5961
## Solution
This PR adds a doc comment to the method to inform the user that the returned `EntityCommands` is not guaranteed to be valid. It also adds panic doc comments on appropriate `EntityCommands` methods.
[this comment]: https://github.com/bevyengine/bevy/pull/5961#issuecomment-1259870849
# Objective
- Alpha mask was previously ignored when using an unlit material.
- Fixes https://github.com/bevyengine/bevy/issues/4479
## Solution
- Extract the alpha discard to a separate function and use it when unlit is true
## Notes
I tried calling `alpha_discard()` before the `if` in pbr.wgsl, but I had errors related to having a `discard` at the beginning before doing the texture sampling. I'm not sure if there's a way to fix that instead of having the function being called in 2 places.
# Objective
- Currently, errors aren't logged as soon as they are found, they are logged only on the next frame. This means your shader could have an unreported error that could have been reported on the first frame.
## Solution
- Log the error as soon as they are found, don't wait until next frame
## Notes
I discovered this issue because I was simply unwrapping the `Result` from `PipelinCache::get_render_pipeline()` which caused it to fail without any explanations. Admittedly, this was a bit of a user error, I shouldn't have unwrapped that, but it seems a bit strange to wait until the next time the pipeline is processed to log the error instead of just logging it as soon as possible since we already have all the info necessary.
# Objective
- Add ability to create nested spawns. This is needed for stageless. The current executor spawns tasks for each system early and runs the system by communicating through a channel. In stageless we want to spawn the task late, so that archetypes can be updated right before the task is run. The executor is run on a separate task, so this enables the scope to be passed to the spawned executor.
- Fixes#4301
## Solution
- Instantiate a single threaded executor on the scope and use that instead of the LocalExecutor. This allows the scope to be Send, but still able to spawn tasks onto the main thread the scope is run on. This works because while systems can access nonsend data. The systems themselves are Send. Because of this change we lose the ability to spawn nonsend tasks on the scope, but I don't think this is being used anywhere. Users would still be able to use spawn_local on TaskPools.
- Steals the lifetime tricks the `std:🧵:scope` uses to allow nested spawns, but disallow scope to be passed to tasks or threads not associated with the scope.
- Change the storage for the tasks to a `ConcurrentQueue`. This is to allow a &Scope to be passed for spawning instead of a &mut Scope. `ConcurrentQueue` was chosen because it was already in our dependency tree because `async_executor` depends on it.
- removed the optimizations for 0 and 1 spawned tasks. It did improve those cases, but made the cases of more than 1 task slower.
---
## Changelog
Add ability to nest spawns
```rust
fn main() {
let pool = TaskPool::new();
pool.scope(|scope| {
scope.spawn(async move {
// calling scope.spawn from an spawn task was not possible before
scope.spawn(async move {
// do something
});
});
})
}
```
## Migration Guide
If you were using explicit lifetimes and Passing Scope you'll need to specify two lifetimes now.
```rust
fn scoped_function<'scope>(scope: &mut Scope<'scope, ()>) {}
// should become
fn scoped_function<'scope>(scope: &Scope<'_, 'scope, ()>) {}
```
`scope.spawn_local` changed to `scope.spawn_on_scope` this should cover cases where you needed to run tasks on the local thread, but does not cover spawning Nonsend Futures.
## TODO
* [x] think real hard about all the lifetimes
* [x] add doc about what 'env and 'scope mean.
* [x] manually check that the single threaded task pool still works
* [x] Get updated perf numbers
* [x] check and make sure all the transmutes are necessary
* [x] move commented out test into a compile fail test
* [x] look through the tests for scope on std and see if I should add any more tests
Co-authored-by: Michael Hsu <myhsu@benjaminelectric.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make `Res` cloneable
## Solution
Add an associated fn `clone(self: &Self) -. Self` instead of `Copy + Clone` trait impls to avoid `res.clone()` failing to clone out the underlying `T`
# Objective
Often one wants to create a `UiRect` with a value only specifying a single field. These ways are already available, but not the most ergonomic:
```rust
UiRect::new(Val::Undefined, Val::Undefined, Val::Percent(25.0), Val::Undefined)
```
```rust
UiRect {
top: Val::Percent(25.0),
..default()
}
```
## Solution
Introduce 6 new constructors:
- `horizontal`
- `vertical`
- `left`
- `right`
- `top`
- `bottom`
So the above code can be written instead as:
```rust
UiRect::top(Val::Percent(25.0))
```
This solution is similar to the style fields `margin-left`, `padding-top`, etc. that you would see in CSS, from which bevy's UI has other inspiration. Therefore, it should still feel intuitive to users coming from CSS.
---
## Changelog
### Added
- Additional constructors for `UiRect` to specify values for specific fields
# Objective
Currently, arrays cannot indexed using the reflection path API.
This change makes them behave like lists so `x.get_path("list[0]")` will behave the same way, whether x.list is a "List" (e.g. a Vec) or an array.
## Solution
When syntax is encounterd `[ <idx> ]` we check if the referenced type is either a `ReflectRef::List` or `ReflectRef::Array` (or `ReflectMut` for the mutable case). Since both provide the identical API for accessing entries, we do the same for both, although it requires code duplication as far as I can tell.
This was born from working on #5764, but since this seems to be an easier fix (and I am not sure if I can actually solve #5812) I figured it might be worth to split this out.
# Objective
Simple docs/comments only PR that just fixes some outdated file references left over from the render rewrite.
## Solution
- Change the references to point to the correct files
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
I was working with the TextBundle component bundle because I wanted to change the position of the text that the bundle was holding. I used the transform field on the TextBundle at first because that is normally what controls the position of sprites in Bevy and that's what I was used to working with.
But the actual way to change the position of text inside of a TextBundle is to use the Style's position field, not the TextBundle's transform field.
Anecdotally, it was mentioned on the discord that other users have had this issue too.
## Solution
I added a small doc comment to the TextBundle's transform telling users not to use it to set the position of text. And since this issue applies to the other UI bundles, I added comments there as well!
# Objective
Fixes#6078. The `UiColor` component is unhelpfully named: it is unclear, ambiguous with border color and
## Solution
Rename the `UiColor` component (and associated fields) to `BackgroundColor` / `background_colorl`.
## Migration Guide
`UiColor` has been renamed to `BackgroundColor`. This change affects `NodeBundle`, `ButtonBundle` and `ImageBundle`. In addition, the corresponding field on `ExtractedUiNode` has been renamed to `background_color` for consistency.
This is an adoption of #3775
This merges `TextureAtlas` `from_grid_with_padding` into `from_grid` , adding optional padding and optional offset.
Since the orignal PR, the offset had already been added to from_grid_with_padding through #4836
## Changelog
- Added `padding` and `offset` arguments to `TextureAtlas::from_grid`
- Removed `TextureAtlas::from_grid_with_padding`
## Migration Guide
`TextureAtlas::from_grid_with_padding` was merged into `from_grid` which takes two additional parameters for padding and an offset.
```
// 0.8
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1);
// 0.9
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1, None, None)
// 0.8
TextureAtlas::from_grid_with_padding(texture_handle, Vec2::new(24.0, 24.0), 7, 1, Vec2::new(4.0, 4.0));
// 0.9
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1, Some(Vec2::new(4.0, 4.0)), None)
```
Co-authored-by: olefish <88390729+oledfish@users.noreply.github.com>
# Objective
- Sometimes, like when using shaders, you can only use a time value in `f32`. Unfortunately this suffers from floating precision issues pretty quickly. The standard approach to this problem is to wrap the time after a given period
- This is necessary for https://github.com/bevyengine/bevy/pull/5409
## Solution
- Add a `seconds_since_last_wrapping_period` method on `Time` that returns a `f32` that is the `seconds_since_startup` modulo the `max_wrapping_period`
---
## Changelog
Added `seconds_since_last_wrapping_period` to `Time`
## Additional info
I'm very opened to hearing better names. I don't really like the current naming, I just went with something descriptive.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
- Add unit tests for ambiguity detection reporting.
- Incremental implementation of #4299.
## Solution
- Refactor ambiguity detection internals to make it testable. As a bonus, this should make it easier to extend in the future.
## Notes
* This code was copy-pasted from #4299 and modified. Credit goes to @alice-i-cecile and @afonsolage, though I'm not sure who wrote what at this point.
## Objective
Fixes https://github.com/bevyengine/bevy/issues/6063
## Solution
- Use `then_some(x)` instead of `then( || x)`.
- Updated error logs from `bevy_ecs_compile_fail_tests`.
## Migration Guide
From Rust 1.63 to 1.64, a new Clippy error was added; now one should use `then_some(x)` instead of `then( || x)`.
# Objective
Both components already derives `Reflect` and it would be nice to have `FromReflect` in order to ser/de between those types without relaying on `downcast`, since it can fail between different platforms, like WebAssembly.
## Solution
Derive `FromReflect` for `Transform` and `GlobalTransform`.
I thought if I should also derive `FromReflect` for `GlobalTransform`, since it's a computed component, but there may be some use cases where a `GlobalTransform` is needed to be sent over the wire, so I decided to do it.
# Objective
- Reconfigure surface after present mode changes. It seems that this is not done currently at runtime. It's pretty common for games to change such graphical settings at runtime.
- Fixes present mode issue in #5111
## Solution
- Exactly like resolution change gets tracked when extracting window, do the same for present mode.
Additionally, I added present mode (vsync) toggling to window settings example.
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
The doc comments for `Command` methods are a bit inconsistent on the format, they sometimes go out of scope, and most importantly they are wrong, in the sense that they claim to perform the action described by the command, while in reality, they just push a command to perform the action.
- Follow-up of #5938.
- Related to #5913.
## Solution
- Where applicable, only stated that a `Command` is pushed.
- Added a “See also” section for similar methods.
- Added a missing “Panics” section for `Commands::entity`.
- Removed a wrong comment about `Commands::get_or_spawn` returning `None` (It does not return an option).
- Removed polluting descriptions of other items.
- Misc formatting changes.
## Future possibilities
Since the `Command` implementors (`Spawn`, `InsertBundle`, `InitResource`, ...) are public, I thought that it might be appropriate to describe the action of the command there instead of the method, and to add a `method → command struct` link to fill the gap.
If that seems too far-fetched, we may opt to make them private, if possible, or `#[doc(hidden)]`.
# Objective
Working on issue #1934 , with linking examples to the documentation. PR for transform examples.
## Solution
Added to the documentation in bevy_transform transform.rs and global_transform.rs utilizing links from examples.
[X] 3d_rotations.rs linked to rotate in Transform
[X] global_vs_local_translation.rs linked to top of Transform and GlobalTransform documentation
[X] scale.rs linked to scale Struct in Transform
[X] transform.rs linked to top of Transform documentation
[X] translation.rs linked to from_translation in Transform
Co-authored-by: bwhitt7 <103079612+bwhitt7@users.noreply.github.com>
@BoxyUwU this is your fault.
Also cart didn't arrive in time to tell us not to do this.
# Objective
- Fix#2974
## Solution
- The first commit just does the actual change
- Follow up commits do steps to prove that this method works to unify as required, but this does not remove `insert_bundle`.
## Changelog
### Changed
Nested bundles now collapse automatically, and every `Component` now implements `Bundle`.
This means that you can combine bundles and components arbitrarily, for example:
```rust
// before:
.insert(A).insert_bundle(MyBBundle{..})
// after:
.insert_bundle((A, MyBBundle {..}))
```
Note that there will be a follow up PR that removes the current `insert` impl and renames `insert_bundle` to `insert`.
### Removed
The `bundle` attribute in `derive(Bundle)`.
## Migration guide
In `derive(Bundle)`, the `bundle` attribute has been removed. Nested bundles are not collapsed automatically. You should remove `#[bundle]` attributes.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
> Note: This is rebased off #4561 and can be viewed as a competitor to that PR. See `Comparison with #4561` section for details.
# Objective
The current serialization format used by `bevy_reflect` is both verbose and error-prone. Taking the following structs[^1] for example:
```rust
// -- src/inventory.rs
#[derive(Reflect)]
struct Inventory {
id: String,
max_storage: usize,
items: Vec<Item>
}
#[derive(Reflect)]
struct Item {
name: String
}
```
Given an inventory of a single item, this would serialize to something like:
```rust
// -- assets/inventory.ron
{
"type": "my_game::inventory::Inventory",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "inv001",
},
"max_storage": {
"type": "usize",
"value": 10
},
"items": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "my_game::inventory::Item",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Pickaxe"
},
},
},
],
},
},
}
```
Aside from being really long and difficult to read, it also has a few "gotchas" that users need to be aware of if they want to edit the file manually. A major one is the requirement that you use the proper keys for a given type. For structs, you need `"struct"`. For lists, `"list"`. For tuple structs, `"tuple_struct"`. And so on.
It also ***requires*** that the `"type"` entry come before the actual data. Despite being a map— which in programming is almost always orderless by default— the entries need to be in a particular order. Failure to follow the ordering convention results in a failure to deserialize the data.
This makes it very prone to errors and annoyances.
## Solution
Using #4042, we can remove a lot of the boilerplate and metadata needed by this older system. Since we now have static access to type information, we can simplify our serialized data to look like:
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
name: "Pickaxe"
),
],
),
}
```
This is much more digestible and a lot less error-prone (no more key requirements and no more extra type names).
Additionally, it is a lot more familiar to users as it follows conventional serde mechanics. For example, the struct is represented with `(...)` when serialized to RON.
#### Custom Serialization
Additionally, this PR adds the opt-in ability to specify a custom serde implementation to be used rather than the one created via reflection. For example[^1]:
```rust
// -- src/inventory.rs
#[derive(Reflect, Serialize)]
#[reflect(Serialize)]
struct Item {
#[serde(alias = "id")]
name: String
}
```
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
id: "Pickaxe"
),
],
),
},
```
By allowing users to define their own serialization methods, we do two things:
1. We give more control over how data is serialized/deserialized to the end user
2. We avoid having to re-define serde's attributes and forcing users to apply both (e.g. we don't need a `#[reflect(alias)]` attribute).
### Improved Formats
One of the improvements this PR provides is the ability to represent data in ways that are more conventional and/or familiar to users. Many users are familiar with RON so here are some of the ways we can now represent data in RON:
###### Structs
```js
{
"my_crate::Foo": (
bar: 123
)
}
// OR
{
"my_crate::Foo": Foo(
bar: 123
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Foo",
"struct": {
"bar": {
"type": "usize",
"value": 123
}
}
}
```
</details>
###### Tuples
```js
{
"(f32, f32)": (1.0, 2.0)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "(f32, f32)",
"tuple": [
{
"type": "f32",
"value": 1.0
},
{
"type": "f32",
"value": 2.0
}
]
}
```
</details>
###### Tuple Structs
```js
{
"my_crate::Bar": ("Hello World!")
}
// OR
{
"my_crate::Bar": Bar("Hello World!")
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Bar",
"tuple_struct": [
{
"type": "alloc::string::String",
"value": "Hello World!"
}
]
}
```
</details>
###### Arrays
It may be a bit surprising to some, but arrays now also use the tuple format. This is because they essentially _are_ tuples (a sequence of values with a fixed size), but only allow for homogenous types. Additionally, this is how RON handles them and is probably a result of the 32-capacity limit imposed on them (both by [serde](https://docs.rs/serde/latest/serde/trait.Serialize.html#impl-Serialize-for-%5BT%3B%2032%5D) and by [bevy_reflect](https://docs.rs/bevy/latest/bevy/reflect/trait.GetTypeRegistration.html#impl-GetTypeRegistration-for-%5BT%3B%2032%5D)).
```js
{
"[i32; 3]": (1, 2, 3)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "[i32; 3]",
"array": [
{
"type": "i32",
"value": 1
},
{
"type": "i32",
"value": 2
},
{
"type": "i32",
"value": 3
}
]
}
```
</details>
###### Enums
To make things simple, I'll just put a struct variant here, but the style applies to all variant types:
```js
{
"my_crate::ItemType": Consumable(
name: "Healing potion"
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::ItemType",
"enum": {
"variant": "Consumable",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Healing potion"
}
}
}
}
```
</details>
### Comparison with #4561
This PR is a rebased version of #4561. The reason for the split between the two is because this PR creates a _very_ different scene format. You may notice that the PR descriptions for either PR are pretty similar. This was done to better convey the changes depending on which (if any) gets merged first. If #4561 makes it in first, I will update this PR description accordingly.
---
## Changelog
* Re-worked serialization/deserialization for reflected types
* Added `TypedReflectDeserializer` for deserializing data with known `TypeInfo`
* Renamed `ReflectDeserializer` to `UntypedReflectDeserializer`
* ~~Replaced usages of `deserialize_any` with `deserialize_map` for non-self-describing formats~~ Reverted this change since there are still some issues that need to be sorted out (in a separate PR). By reverting this, crates like `bincode` can throw an error when attempting to deserialize non-self-describing formats (`bincode` results in `DeserializeAnyNotSupported`)
* Structs, tuples, tuple structs, arrays, and enums are now all de/serialized using conventional serde methods
## Migration Guide
* This PR reduces the verbosity of the scene format. Scenes will need to be updated accordingly:
```js
// Old format
{
"type": "my_game::item::Item",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "bevycraft:stone",
},
"tags": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "alloc::string::String",
"value": "material"
},
],
},
}
// New format
{
"my_game::item::Item": (
id: "bevycraft:stone",
tags: ["material"]
)
}
```
[^1]: Some derives omitted for brevity.
# Objective
Add traits to events in `bevy_input` and `bevy_windows`: `Copy`, `Serialize`/`Deserialize`, `PartialEq`, and `Eq`, as requested in https://github.com/bevyengine/bevy/issues/6022, https://github.com/bevyengine/bevy/issues/6023, https://github.com/bevyengine/bevy/issues/6024.
## Solution
Added the traits to events in `bevy_input` and `bevy_windows`. Added dependency of `serde` in `Cargo.toml` of `bevy_input`.
## Migration Guide
If one has been `.clone()`'ing `bevy_input` events, Clippy will now complain about that. Just remove `.clone()` to solve.
## Other Notes
Some events in `bevy_input` had `f32` fields, so `Eq` trait was not derived for them.
Some events in `bevy_windows` had `String` fields, so `Copy` trait was not derived for them.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
Implement `IntoIterator` for `&Extract<P>` if the system parameter it wraps implements `IntoIterator`.
Enables the use of `IntoIterator` with an extracted query.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`AssetServer::watch_for_changes()` is racy and redundant with `AssetServerSettings`.
Closes#5964.
## Changelog
* Remove `AssetServer::watch_for_changes()`
* Add `AssetServerSettings` to the prelude.
* Minor cleanup.
## Migration Guide
`AssetServer::watch_for_changes()` was removed.
Instead, use the `AssetServerSettings` resource.
```rust
app // AssetServerSettings must be inserted before adding the AssetPlugin or DefaultPlugins.
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
When trying derive `Debug` for type that has `DynamicEnum` it wasn't possible, since neither of `DynamicEnum`, `DynamicTuple`, `DynamicVariant` or `DynamicArray` implements `Debug`.
## Solution
Implement Debug for those types, using `derive` macro
---
## Changelog
- `DynamicEnum`, `DynamicTuple`, `DynamicVariant` and `DynamicArray` now implements `Debug`
# Objective
Fixes#5636
Summary: The FontAtlasSet caches generated font textures per font size. Since font size can be any arbitrary floating point number it is possible for the user to generate thousands of font texture inadvertently by changing the font size over time. This results in a memory leak as these generated font textures fill the available memory.
## Solution
We limit the number of possible font sizes that we will cache and throw an error if the user attempts to generate more. This error encourages the user to use alternative, less performance intensive methods to accomplish the same goal. If the user requires more font sizes and the alternative solutions wont work there is now a TextSettings Resource that the user can set to configure this limit.
---
## Changelog
The number of cached font sizes per font is now limited with a default limit of 100 font sizes per font. This limit is configurable via the new TextSettings struct.
# Objective
A common pitfall since 0.8 is the requirement on `ComputedVisibility`
being present on all ancestors of an entity that itself has
`ComputedVisibility`, without which, the entity becomes invisible.
I myself hit the issue and got very confused, and saw a few people hit
it as well, so it makes sense to provide a hint of what to do when such
a situation is encountered.
- Fixes#5849
- Closes#5616
- Closes#2277
- Closes#5081
## Solution
We now check that all entities with both a `Parent` and a
`ComputedVisibility` component have parents that themselves have a
`ComputedVisibility` component.
Note that the warning is only printed once.
We also add a similar warning to `GlobalTransform`.
This only emits a warning. Because sometimes it could be an intended
behavior.
Alternatives:
- Do nothing and keep repeating to newcomers how to avoid recurring
pitfalls
- Make the transform and visibility propagation tolerant to missing
components (#5616)
- Probably archetype invariants, though the current draft would not
allow detecting that kind of errors
---
## Changelog
- Add a warning when encountering dubious component hierarchy structure
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- To address problems outlined in https://github.com/bevyengine/bevy/issues/5245
## Solution
- Introduce `reflect(skip_serializing)` on top of `reflect(ignore)` which disables automatic serialisation to scenes, but does not disable reflection of the field.
---
## Changelog
- Adds:
- `bevy_reflect::serde::type_data` module
- `SerializationData` structure for describing which fields are to be/not to be ignored, automatically registers as type_data for struct-based types
- the `skip_serialization` flag for `#[reflect(...)]`
- Removes:
- ability to ignore Enum variants in serialization, since that didn't work anyway
## Migration Guide
- Change `#[reflect(ignore)]` to `#[reflect(skip_serializing)]` where disabling reflection is not the intended effect.
- Remove ignore/skip attributes from enum variants as these won't do anything anymore
# Objective
As of Rust 1.59, `std:🧵:available_parallelism` has been stabilized. As of Rust 1.61, the API matches `num_cpus::get` by properly handling Linux's cgroups and other sandboxing mechanisms.
As bevy does not have an established MSRV, we can replace `num_cpus` in `bevy_tasks` and reduce our dependency tree by one dep.
## Solution
Replace `num_cpus` with `std:🧵:available_parallelism`. Wrap it to have a fallback in the case it errors out and have it operate in the same manner as `num_cpus` did.
This however removes `physical_core_count` from the API, though we are currently not using it in any way in first-party crates.
---
## Changelog
Changed: `bevy_tasks::logical_core_count` -> `bevy_tasks::available_parallelism`.
Removed: `bevy_tasks::physical_core_count`.
## Migration Guide
`bevy_tasks::logical_core_count` and `bevy_tasks::physical_core_count` have been removed. `logical_core_count` has been replaced with `bevy_tasks::available_parallelism`, which works identically. If `bevy_tasks::physical_core_count` is required, the `num_cpus` crate can be used directly, as these two were just aliases for `num_cpus` APIs.
# Objective
Fixes Issue #6005.
## Solution
Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound.
## Migration Guide
Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead.
Very small change that improves the usability of `Sprite`.
Before this PR, the only way to render a portion of an `Image` was to create a `TextureAtlas` and use `TextureAtlasSprite`/`SpriteSheetBundle`. This can be very annoying for one-off use cases, like if you just want to remove a border from an image, or something. Using `Sprite`/`SpriteBundle` always meant that the entire full image would be rendered.
This PR adds an optional `rect` field to `Sprite`, allowing a sub-rectangle of the image to be rendered. This is similar to how texture atlases work, but does not require creating a texture atlas asset, making it much more convenient and efficient for quick one-off use cases.
Given how trivial this change is, it really felt like missing functionality in Bevy's sprites API. ;)
## Changelog
Added:
- `rect` field on `Sprite`: allows rendering a portion of the sprite's image; more convenient for one-off use cases, than creating a texture atlas.
# Objective
fixes#5946
## Solution
adjust cluster index calculation for viewport origin.
from reading point 2 of the rasterization algorithm description in https://gpuweb.github.io/gpuweb/#rasterization, it looks like framebuffer space (and so @bulitin(position)) is not meant to be adjusted for viewport origin, so we need to subtract that to get the right cluster index.
- add viewport origin to rust `ExtractedView` and wgsl `View` structs
- subtract from frag coord for cluster index calculation
# Objective
Currently some TextureFormats are not supported by the Image type.
The `TextureFormat::Rg16Unorm` format is useful for storing minmax heightmaps.
Similar to #5249 I now additionally require image to support the dual channel variant.
## Solution
Added `TextureFormat::Rg16Unorm` support to Image.
Additionally this PR derives `Resource` for `SpecializedComputePipelines`, because for some reason this was missing.
All other special pipelines do derive `Resource` already.
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
# Objective
Fixes#5963
## Solution
Add remaining fn in Timer class, this function only minus total duration with elapsed time.
Co-authored-by: Sergi-Ferrez <61662926+Sergi-Ferrez@users.noreply.github.com>
# Objective
While coding in bevy I needed to get the elapsed time of a stopwatch as f64.
I found it quite odd there are functions on Timer to get time as f64 but not on the Stopwatch.
## Solution
- added a function that returns the `Stopwatch` elapsed time as `f64`
---
## Changelog
### Added
- Added a function to get `Stopwatch` elapsed time as `f64`
### Fixed
- The Stopwatch elapsed function had a wrong docs link
# Objective
While using the ParallelExecutor, systems do not actually start until `prepare_systems` completes. In stages where there are large numbers of "empty" systems with very little work to do, this delay adds significant overhead, which can add up over many stages.
## Solution
Immediately and synchronously signal the start of systems that can run without dependencies inside `prepare_systems` instead of waiting for the first executor iteration after `prepare_systems` completes. Any system that is dependent on them still cannot run until after `prepare_systems` completes, but there are a large number of unconstrained systems in the base engine where this is a general benefit in almost every case.
## Performance
This change was tested against `many_foxes` in the default configuration. As this change is sensitive to the overhead around scheduling systems, the spans for measuring system timing, system overhead, and system commands were all commented out for these measurements.
The median stage timings between `main` and this PR are as follows:
|stage|main|this PR|
|:--|:--|:--|
|First|75.54 us|61.61 us|
|LoadAssets|51.05 us|42.32 us|
|PreUpdate|54.6 us|55.56 us|
|Update|61.89 us|51.5 us|
|PostUpdate|7.27 ms|6.71 ms|
|AssetEvents|47.82 us|35.95 us|
|Last|39.19 us|37.71 us|
|reserve_and_flush|57.83 us|48.2 us|
|Extract|1.41 ms|1.28 ms|
|Prepare|554.49 us|502.53 us|
|Queue|216.29 us|207.51 us|
|Sort|67.03 us|60.99 us|
|Render|1.73 ms|1.58 ms|
|Cleanup|33.55 us|30.76 us|
|Clear Entities|18.56 us|17.05 us|
|**full frame**|**11.9 ms**|**10.91 ms**|
For the first few stages, the benefit is small but cumulative over each. For PostUpdate in particular, this allows `parent_update` to run while prepare_systems is running, which is required for the animation and transform propagation systems, which dominate the time spent in the stage, but also frontloads the contention as the other "empty" systems are also running while `parent_update` is running. For Render, where there is just a single large exclusive system, the benefit comes from not waiting on a spuriously scheduled task on the task pool to kick off the system: it's immediately scheduled to run.
# Objective
EntityMut::world takes &mut self instead of &self I don't see any reason for this.
EntityRef is overly restrictive with fn world and could return &'w World
---
## Changelog
- EntityRef now implements Copy and Clone
- EntityRef::world is now fn(&self) -> &'w World instead of fn(&mut self) -> &World
- EntityMut::world is now fn(&self) -> &World instead of fn(&mut self) -> &World
# Objective
Currently, `Local` has a `Sync` bound. Theoretically this is unnecessary as a local can only ever be accessed from its own system, ensuring exclusive access on one thread. This PR removes this restriction.
## Solution
- By removing the `Resource` bound from `Local` and adding the new `SyncCell` threading primative, `Local` can have the `Sync` bound removed.
## Changelog
### Added
- Added `SyncCell` to `bevy_utils`
### Changed
- Removed `Resource` bound from `Local`
- `Local` is now wrapped in a `SyncCell`
## Migration Guide
- Any code relying on `Local<T>` having `T: Resource` may have to be changed, but this is unlikely.
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
While looking into `collide()`, I wrote some tests to confirm the behavior I read in the code. This PR adds those tests and improves the documentation.
Co-authored-by: robem <669201+robem@users.noreply.github.com>
# Objective
- Make people stop believing that commands are applied immediately (hopefully).
- Close#5913.
- Alternative to #5930.
## Solution
I added the clause “to perform impactful changes to the `World`” to the first line to subliminally help the reader accept the fact that some operations cannot be performed immediately without messing up everything.
Then I explicitely said that applying a command requires exclusive `World` access, and finally I proceeded to show when these commands are automatically applied.
I also added a brief paragraph about how commands can be applied manually, if they want.
---
### Further possibilities
If you agree, we can also change the text of the method documentation (in a separate PR) to stress about enqueueing an action instead of just performing it. For example, in `Commands::spawn`:
> Creates a new `Entity`
would be changed to something like:
> Issues a `Command` to spawn a new `Entity`
This may even have a greater effect, since when typing in an IDE, the docs of the method pop up and the programmer can read them on the fly.
# Objective
Without this we can inappropriately merge batches together without properly accounting for non-batch items between them, and the merged batch will then be sorted incorrectly later.
This change seems to reliably fix the issue I was seeing in #5919.
## Solution
Ensure the `batch_phase_system` runs after the `sort_phase_system`, so that batching can only look at actually adjacent phase items.
# Objective
I wanted to run the code
```rust
let reflect_resource: ReflectResource = ...;
let value: Mut<dyn Reflect> = reflect_resource.reflect(world);
value.deref();
// ^ ERROR: deref method doesn't exist because `dyn Reflect` doesnt satisfy `: Sized`.
```
## Solution
Relax `Sized` bounds in all the methods and trait implementations for `Mut` and friends.
# Objective
This code is very disjoint, and the `stage.rs` file that it's in is already very long.
All I've done is move the code and clean up the compiler errors that result.
Followup to #5916, split out from #4299.
# Objective
Ambiguity sets are used to ignore system order ambiguities between groups of systems. However, they are not very useful: they are clunky, poorly integrated, and generally hampered by the difficulty using (or discovering) the ambiguity detector.
As a first step to the work in #4299, we're removing them.
## Migration Guide
Ambiguity sets have been removed.
# Objective
- Our existing change detection API is not flexible enough for advanced users: particularly those attempting to do rollback networking.
- This is an important use case, and with adequate warnings we can make mucking about with change ticks scary enough that users generally won't do it.
- Fixes#5633.
- Closes#2363.
## Changelog
- added `ChangeDetection::set_last_changed` to manually mutate the `last_change_ticks` field"
- the `ChangeDetection` trait now requires an `Inner` associated type, which contains the value being wrapped.
- added `ChangeDetection::bypass_change_detection`, which hands out a raw `&mut Inner`
## Migration Guide
Add the `Inner` associated type and new methods to any type that you've implemented `DetectChanges` for.
# Objective
- I'm currently working on being able to call methods on reflect types (https://github.com/jakobhellermann/bevy_reflect_fns)
- for that, I'd like to add methods to the `Input<KeyCode>` resource (which I'm doing by registering type data)
- implementing `Reflect` is currently a requirement for having type data in the `TypeRegistry`
## Solution
- derive `Reflect` for `KeyCode` and `Input`
- uses `#[reflect_value]` for `Input`, since it's fields aren't supposed to be observable
- using reflect_value would need `Clone` bounds on `T`, but since all the methods (`.pressed` etc) already require `T: Copy`, I unified everything to requiring `Copy`
- add `Send + Sync + 'static` bounds, also required by reflect derive
## Unrelated improvements
I can extract into a separate PR if needed.
- the `Reflect` derive would previously ignore `#[reflect_value]` and only accept `#[reflect_value()]` which was a bit confusing
- the generated code used `val.clone()` on a reference, which is fine if `val` impls `Clone`, but otherwise also compiles with a worse error message. Change to `std::clone::Clone::clone(val)` instead which gives a neat `T does not implement Clone` error
Make API users aware that the type aliases `QueryItem` and `QueryFetch` can be used instead of the more bloated alternative with `WorldQueryGats`.
Fixes#5842
# Objective
Make `TextLayoutInfo` more accessible as a component, rather than internal to `TextPipeline`. I am working on a plugin that manipulates these and there is no (mutable) access to them right now.
## Solution
This changes `TextPipeline::queue_text` to return `TextLayoutInfo`'s rather than storing them in a map internally. `text2d_system` and `text_system` now take the returned `TextLayoutInfo` and store it as a component of the entity. I considered adding an accessor to `TextPipeline` (e.g. `get_glyphs_mut`) but this seems like it might be a little faster, and also has the added benefit of cleaning itself up when entities are removed. Right now nothing is ever removed from the glyphs map.
## Changelog
Removed `DefaultTextPipeline`. `TextPipeline` no longer has a generic key type. `TextPipeline::queue_text` returns `TextLayoutInfo` directly.
## Migration Guide
This might break a third-party crate? I could restore the orginal TextPipeline API as a wrapper around what's in this PR.
# Objective
Fixes#5882
## Solution
Per https://github.com/rust-windowing/winit/issues/1705, the root cause is "UIWindow should be created inside UIApplicationMain". Currently, there are two places to create UIWindow, one is Plugin's build function, which is not inside UIApplicationMain. Just comment it out, and it works.
# Objective
Support monitor selection for all window modes.
Fixes#5875.
## Changelog
* Moved `MonitorSelection` out of `WindowPosition::Centered`, into `WindowDescriptor`.
* `WindowPosition::At` is now relative to the monitor instead of being in 'desktop space'.
* Renamed `MonitorSelection::Number` to `MonitorSelection::Index` for clarity.
* Added `WindowMode` to the prelude.
* `Window::set_position` is now relative to a monitor and takes a `MonitorSelection` as argument.
## Migration Guide
`MonitorSelection` was moved out of `WindowPosition::Centered`, into `WindowDescriptor`.
`MonitorSelection::Number` was renamed to `MonitorSelection::Index`.
```rust
// Before
.insert_resource(WindowDescriptor {
position: WindowPosition::Centered(MonitorSelection::Number(1)),
..default()
})
// After
.insert_resource(WindowDescriptor {
monitor: MonitorSelection::Index(1),
position: WindowPosition::Centered,
..default()
})
```
`Window::set_position` now takes a `MonitorSelection` as argument.
```rust
window.set_position(MonitorSelection::Current, position);
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Clean up taffy nodes when the associated UI node gets removed. The current UI code will keep the taffy nodes around forever.
## Solution
Use `RemovedComponents<Node>` to iterate over nodes that are no longer valid UI nodes or that have been despawned, and remove them from taffy and the internal hash map.
## Implementation Notes
Do note that using `despawn()` instead of `despawn_recursive()` on a UI node that has children will result in a [warnings spam](https://github.com/bevyengine/bevy/blob/main/crates/bevy_ui/src/flex/mod.rs#L120) since the children will not be part of a proper UI hierarchy anymore.
---
## Changelog
- Fixed memory leak when nodes are removed in bevy_ui
# Objective
- The `Gamepad` type is a tiny value-containing type that implements `Copy`.
- By convention, references to `Copy` types should be avoided, as they can introduce overhead and muddle the semantics of what's going on.
- This allows us to reduce boilerplate reference manipulation and lifetimes in user facing code.
## Solution
- Make assorted methods on `Gamepads` take / return a raw `Gamepad`, rather than `&Gamepad`.
## Migration Guide
- `Gamepads::iter` now returns an iterator of `Gamepad`. rather than an iterator of `&Gamepad`.
- `Gamepads::contains` now accepts a `Gamepad`, rather than a `&Gamepad`.
## Solution
Exposes the image <-> "texture" as methods on `Image`.
## Extra
I'm wondering if `image_texture_conversion.rs` should be renamed to `image_conversion.rs`. That or the file be deleted altogether in favour of putting the code alongside the rest of the `Image` impl. Its kind-of weird to refer to the `Image` as a texture.
Also `Image::convert` is a public method so I didn't want to edit its signature, but it might be nice to have the function consume the image instead of just passing a reference to it because it would eliminate a clone.
## Changelog
> Rename `image_to_texture` to `Image::from_dynamic`
> Rename `texture_to_image` to `Image::try_into_dynamic`
> `Image::try_into_dynamic` now returns a `Result` (this is to make it easier for users who didn't read that only a few conversions are supported to figure it out.)
# Objective
Document most of the public items of the `bevy_render::camera` module and its
sub-modules.
## Solution
Add docs to most public items. Follow-up from #3447.
# Objective
- Increase consistency across documentation of `Query` methods.
- Fixes#5506
## Solution
- See #4989. This PR is derived from it. It just includes changes to the `Query` methods' docs.
# Objective
Document `PipelineCache` and a few other related types.
## Solution
Add documenting comments to `PipelineCache` and a few other related
types in the same file.
# Objective
https://github.com/bevyengine/bevy/pull/503 added these.
I don't know what problem it solved, the PR doesn't say and the code didn't make it obvious to me.
## Solution
AFAIK removing unsafe `Send`/`Sync` impls can't introduce unsoundness.
Yeet.
## Migration Guide
Why tho.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
The documentation on `Reflect` doesn't account for the recently added reflection traits: [`Array`](https://github.com/bevyengine/bevy/pull/4701) and [`Enum`](https://github.com/bevyengine/bevy/pull/4761).
## Solution
Updated the documentation for `Reflect` to account for the `Array` and `Enum`.
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Update notify dependency to 5.0.0 stable
- Fix breaking changes
- Closes#5861
## Solution
- RecommendedWatcher now takes a Config argument. Giving it the default Config should be the same behavior as before (check every 30 seconds)
# Objective
- Update ron to 0.8.0
- Fix breaking changes
- Closes#5862
## Solution
- Removed now non-existing method call (behavior is now the same without it)
# Objective
- Update `Query` docs with better terminology
- add some performance remarks (Fixes#4742)
## Solution
- See #4989. This PR is derived from it. It just includes changes to the `Query` struct docs.
# Objective
Promote the `Rect` utility of `sprite::Rect`, which defines a rectangle
by its minimum and maximum corners, to the `bevy_math` crate to make it
available as a general math type to all crates without the need to
depend on the `bevy_sprite` crate.
Fixes#5575
## Solution
Move `sprite::Rect` into `bevy_math` and fix all uses.
Implement `Reflect` for `Rect` directly into the `bevy_reflect` crate by
having `bevy_reflect` depend on `bevy_math`. This looks like a new
dependency, but the `bevy_reflect` was "cheating" for other math types
by directly depending on `glam` to reflect other math types, thereby
giving the illusion that there was no dependency on `bevy_math`. In
practice conceptually Bevy's math types are reflected into the
`bevy_reflect` crate to avoid a dependency of that crate to a "lower
level" utility crate like `bevy_math` (which in turn would make
`bevy_reflect` be a dependency of most other crates, and increase the
risk of circular dependencies). So this change simply formalizes that
dependency in `Cargo.toml`.
The `Rect` struct is also augmented in this change with a collection of
utility methods to improve its usability. A few uses cases are updated
to use those new methods, resulting is more clear and concise syntax.
---
## Changelog
### Changed
- Moved the `sprite::Rect` type into `bevy_math`.
### Added
- Added several utility methods to the `math::Rect` type.
## Migration Guide
The `bevy::sprite::Rect` type moved to the math utility crate as
`bevy::math::Rect`. You should change your imports from `use
bevy::sprite::Rect` to `use bevy::math::Rect`.
# Objective
- In WASM, creating a pipeline can easily take 2 seconds, freezing the game while doing so
- Preloading pipelines can be done during a "loading" state, but it is not trivial to know which pipeline to preload, or when it's done
## Solution
- Add a log with shaders being loaded and their shader defs
- add a function on `PipelineCache` to return the number of ready pipelines
# Objective
- Easier to work with model assets
- Models are often one mesh, many textures. This can be hard to use in Bevy as it's not possible to clone the scene to have one scene for each material. It's still possible to instantiate the texture-less scene, then modify the texture material once spawned but that means happening during play and is quite more painful
## Solution
- Expose the code to clone a scene. This code already existed but was only possible to use to spawn the scene
# Objective
Extend the scope of Gamepad to accommodate devices that have more inputs than a typical controller.
## Solution
Add additional enum variants to both _GamepadButtonType_ and _GamepadAxisType_ that supports up to 255 more non-standard buttons/axis respectively.
## Personal motivation
I have been writing an alternative to the GILRS crate, and with this simple change to the source code, It will be a trivial thing to direct new devices through the bevy systems, even when they do not always behave exactly like your typical controller.
# Objective
- Fixes#5850
## Solution
- As described in the issue, added a `get_entity` method on `Commands` that returns an `Option<EntityCommands>`
## Changelog
- Added the new method with a simple doc test
- I have re-used `get_entity` in `entity`, similarly to how `get_single` is used in `single` while additionally preserving the error message
- Add `#[inline]` to both functions
Entities that have commands queued to despawn system will still return commands when `get_entity` is called but that is representative of the fact that the entity is still around until those commands are flushed.
A potential `contains_entity` could also be added in this PR if desired, that would effectively be replacing Entities.contains but may be more discoverable if this is a common use case.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
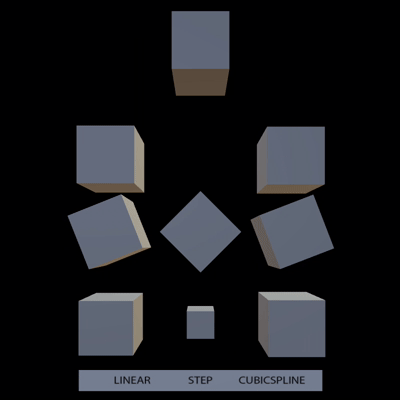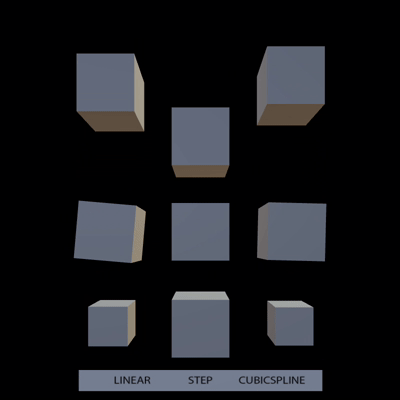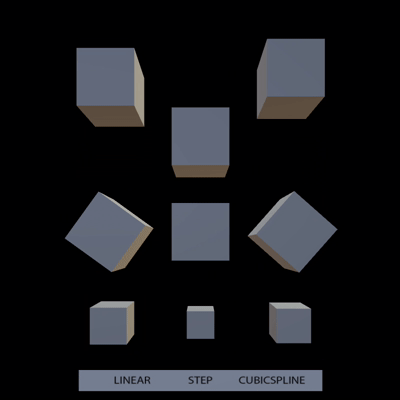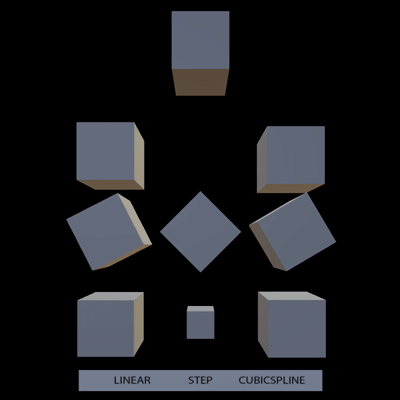{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}