# Objective
Some examples still manually implement the States trait, even though
manual implementation is no longer needed as there is now the derive
macro for that.
---------
Signed-off-by: Natalia Asteria <fortressnordlys@outlook.com>
# Objective
- Test mobile example on real devices
## Solution
- Use [BrowserStack](https://www.browserstack.com) to have access to
[real
devices](https://www.browserstack.com/list-of-browsers-and-platforms/app_automate)
- [App Automate](https://www.browserstack.com/app-automate) to run the
example
- [App Percy](https://www.browserstack.com/app-percy) to compare the
screenshot
- Added a daily/manual CI job that will build for iOS and Android, send
the apps to BrowserStack, run the app on one iOS device and one Android
device, capture a screenshot, send it for visual validation, and archive
it in the GitHub action
Example run: https://github.com/mockersf/bevy/actions/runs/4521883534
They currently have a bug with the settings to view snapshots, they
should be public. I'll raise it to them, and if they don't fix it in
time it's possible to work around for everyone to view the results
through their API.
@cart to get this to work, you'll need
- to set up an account on BrowserStack
- add the secrets `BROWSERSTACK_USERNAME` and `BROWSERSTACK_ACCESS_KEY`
to the Bevy repo
- create a project in Percy
- add the secret `PERCY_TOKEN` to the Bevy repo and modify the project
name line 122 in the `Daily.yml` file

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
- Rename `text_layout` example to `flex_layout` to better reflect the
example purpose
- `AlignItems`/`JustifyContent` is not related to text layout, it's
about child nodes positioning
## Solution
- Rename the example
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
Co-Authored-By: davier
[bricedavier@gmail.com](mailto:bricedavier@gmail.com)
Fixes#3576.
Adds a `resources` field in scene serialization data to allow
de/serializing resources that have reflection enabled.
## Solution
Most of this code is taken from a previous closed PR:
https://github.com/bevyengine/bevy/pull/3580. Most of the credit goes to
@Davier , what I did was mostly getting it to work on the latest main
branch of Bevy, along with adding a few asserts in the currently
existing tests to be sure everything is working properly.
This PR changes the scene format to include resources in this way:
```
(
resources: {
// List of resources here, keyed by resource type name.
},
entities: [
// Previous scene format here
],
)
```
An example taken from the tests:
```
(
resources: {
"bevy_scene::serde::tests::MyResource": (
foo: 123,
),
},
entities: {
// Previous scene format here
},
)
```
For this, a `resources` fields has been added on the `DynamicScene` and
the `DynamicSceneBuilder` structs. The latter now also has a method
named `extract_resources` to properly extract the existing resources
registered in the local type registry, in a similar way to
`extract_entities`.
---
## Changelog
Added: Reflect resources registered in the type registry used by dynamic
scenes will now be properly de/serialized in scene data.
## Migration Guide
Since the scene format has been changed, the user may not be able to use
scenes saved prior to this PR due to the `resources` scene field being
missing. ~~To preserve backwards compatibility, I will try to make the
`resources` fully optional so that old scenes can be loaded without
issue.~~
## TODOs
- [x] I may have to update a few doc blocks still referring to dynamic
scenes as mere container of entities, since they now include resources
as well.
- [x] ~~I want to make the `resources` key optional, as specified in the
Migration Guide, so that old scenes will be compatible with this
change.~~ Since this would only be trivial for ron format, I think it
might be better to consider it in a separate PR/discussion to figure out
if it could be done for binary serialization too.
- [x] I suppose it might be a good idea to add a resources in the scene
example so that users will quickly notice they can serialize resources
just like entities.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
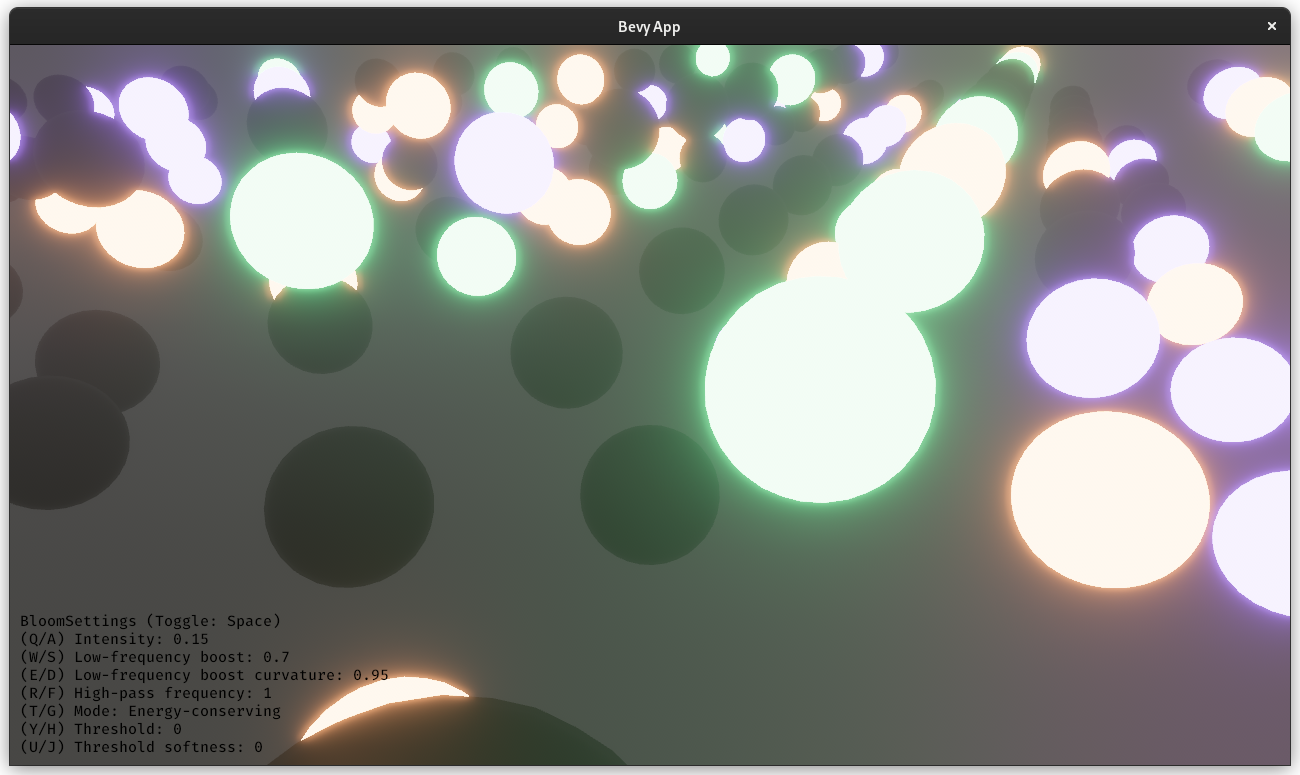
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
- Example `transparent_window` doesn't display a transparent window on macOS
- Fixes#6330
## Solution
- Set the `composite_alpha_mode` of the window to the correct value
- Update docs
# Objective
Simple text pipeline benchmark. It's quite expensive but current examples don't capture the performance of `queue_text` as it only runs on changes to the text.
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
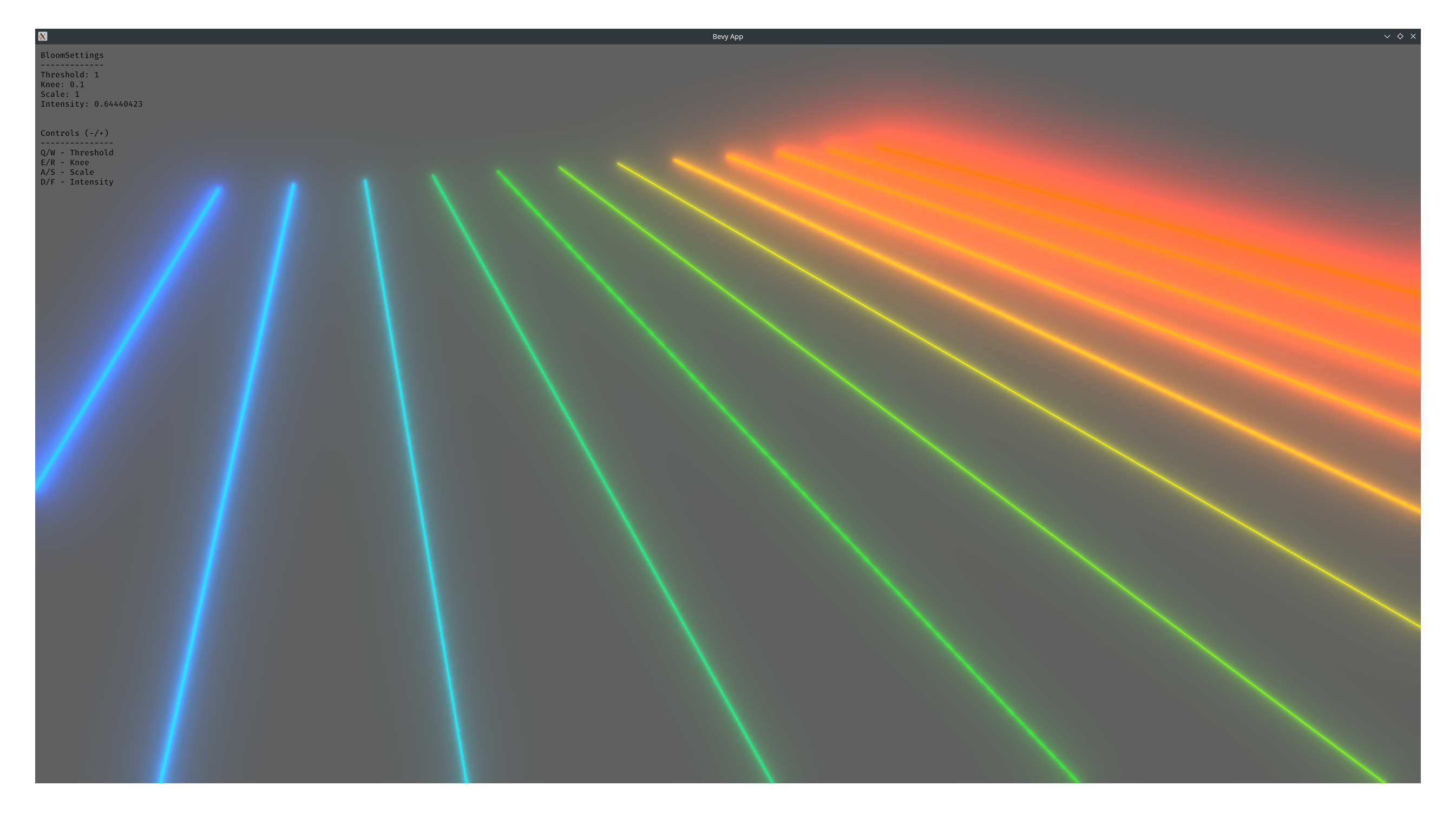
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
Fixes#6780
## Solution
- record the asset path of each watched file
- call `AssetIo::watch_for_changes` in `LoadContext::read_asset_bytes`
---
## Changelog
### Fixed
- fixed hot reloading for `LoadContext::read_asset_bytes`
### Changed
- `AssetIo::watch_path_for_changes` allows watched path and path to reload to differ
## Migration Guide
- for custom `AssetIo`s, differentiate paths to watch and asset paths to reload as a consequence
Co-authored-by: Vincent Junge <specificprotagonist@posteo.org>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
UIs created for Bevy cannot currently be made accessible. This PR aims to address that.
## Solution
Integrate AccessKit as a dependency, adding accessibility support to existing bevy_ui widgets.
## Changelog
### Added
* Integrate with and expose [AccessKit](https://accesskit.dev) for platform accessibility.
* Add `Label` for marking text specifically as a label for UI controls.
# Objective
- Fixes#1800, fixes#6984
- Alternative to #7196
- Ensure feature list is always up to date and that all are documented
- Help discovery of features
## Solution
- Use a template to update the cargo feature list
- Use the comment just above the feature declaration as the description
- Add the checks to CI
- Add the features to the base crate doc
# Objective
This PR adds an example that shows how to use `apply_system_buffers` and how to order it with respect to the relevant systems. It also shows how not ordering the systems can lead to unexpected behaviours.
## Solution
Add the example.
# Objective
This adds small comment to window fall through example that it won't work on specific platforms. This information is documented in `Cursor` api but I think it is worth to add it in example description for clarity sake.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
Fix#7584.
## Solution
Add an abstraction for creating custom system combinators with minimal boilerplate. Use this to implement AND/OR combinators. Use this to simplify the implementation of `PipeSystem`.
## Example
Feel free to bikeshed on the syntax.
I chose the names `and_then`/`or_else` to emphasize the fact that these short-circuit, while I chose method syntax to empasize that the arguments are *not* treated equally.
```rust
app.add_systems((
my_system.run_if(resource_exists::<R>().and_then(resource_equals(R(0)))),
our_system.run_if(resource_exists::<R>().or_else(resource_exists::<S>())),
));
```
---
## Todo
- [ ] Decide on a syntax
- [x] Write docs
- [x] Write tests
## Changelog
+ Added the extension methods `.and_then(...)` and `.or_else(...)` to run conditions, which allows combining run conditions with short-circuiting behavior.
+ Added the trait `Combine`, which can be used with the new `CombinatorSystem` to create system combinators with custom behavior.
# Objective
- Add basic spatial audio support to Bevy
- this is what rodio supports, so no HRTF, just simple stereo channel manipulation
- no "built-in" ECS support: `Emitter` and `Listener` should be components that would automatically update the positions
This PR goal is to just expose rodio functionality, made possible with the recent update to rodio 0.16. A proper ECS integration opens a lot more questions, and would probably require an RFC
Also updates rodio and fixes#6122
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
`ChangeTrackers<>` is a `WorldQuery` type that lets you access the change ticks for a component. #7097 has added `Ref<>`, which gives access to a component's value in addition to its change ticks. Since bevy's access model does not separate a component's value from its change ticks, there is no benefit to using `ChangeTrackers<T>` over `Ref<T>`.
## Solution
Deprecate `ChangeTrackers<>`.
---
## Changelog
* `ChangeTrackers<T>` has been deprecated. It will be removed in Bevy 0.11.
## Migration Guide
`ChangeTrackers<T>` has been deprecated, and will be removed in the next release. Any usage should be replaced with `Ref<T>`.
```rust
// Before (0.9)
fn my_system(q: Query<(&MyComponent, ChangeTrackers<MyComponent>)>) {
for (value, trackers) in &q {
if trackers.is_changed() {
// Do something with `value`.
}
}
}
// After (0.10)
fn my_system(q: Query<Ref<MyComponent>>) {
for value in &q {
if value.is_changed() {
// Do something with `value`.
}
}
}
```
# Objective
Fixes#7735
## Solution
Use `spawn_batch` instead of `spawn` repeatedly in a for loop
I have decided to switch from using rands `thread_rng()` to its `StdRng`, this allows us to avoid calling `collect()` on the bundle iterator, if collecting is fine then I can revert it back to using `thread_rng()`.
# Objective
Fix#7440. Fix#7441.
## Solution
* Remove builder functions on `ScheduleBuildSettings` in favor of public fields, move docs to the fields.
* Add `use_shortnames` and use it in `get_node_name` to feed it through `bevy_utils::get_short_name`.
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
Fixes#7295
Should we maybe default to 4x if 2x/8x is selected but not supported?
---
## Changelog
- Added 2x and 8x sample counts for MSAA.
# Objective
- Environment maps use these formats, and in the future rendering LUTs will need textures loaded by default in the engine
## Solution
- Make ktx2 and zstd part of the default feature
- Let examples assume these features are enabled
---
## Changelog
- `ktx2` and `zstd` are now party of bevy's default enabled features
## Migration Guide
- If you used the `ktx2` or `zstd` features, you no longer need to explicitly enable them, as they are now part of bevy's default enabled features
# Objective
Fixes#7632.
As discussed in #7634, it can be quite challenging for users to intuit the mental model of how states now work.
## Solution
Rather than change the behavior of the `OnUpdate` system set, instead work on making sure it's easy to understand what's going on.
Two things have been done:
1. Remove the `.on_update` method from our bevy of system building traits. This was special-cased and made states feel much more magical than they need to.
2. Improve the docs for the `OnUpdate` system set.
# Objective
- Required features were added to some examples in #7051 even though those features aren't the main focus of the examples
- Don't require features on examples that are useful without them
## Solution
- Remove required features on examples `load_gltf` and `scene_viewer`, but log a warning when they are not enabled
# Objective
There was issue #191 requesting subdivisions on the shape::Plane.
I also could have used this recently. I then write the solution.
Fixes #191
## Solution
I changed the shape::Plane to include subdivisions field and the code to create the subdivisions. I don't know how people are counting subdivisions so as I put in the doc comments 0 subdivisions results in the original geometry of the Plane.
Greater then 0 results in the number of lines dividing the plane.
I didn't know if it would be better to create a new struct that implemented this feature, say SubdivisionPlane or change Plane. I decided on changing Plane as that was what the original issue was.
It would be trivial to alter this to use another struct instead of altering Plane.
The issues of migration, although small, would be eliminated if a new struct was implemented.
## Changelog
### Added
Added subdivisions field to shape::Plane
## Migration Guide
All the examples needed to be updated to initalize the subdivisions field.
Also there were two tests in tests/window that need to be updated.
A user would have to update all their uses of shape::Plane to initalize the subdivisions field.
# Objective
`Size::width` sets the `height` field to `Val::DEFAULT` which is `Val::Undefined`, but the default for `Size` `height` is `Val::Auto`.
`Size::height` has the same problem, but with the `width` field.
The UI examples specify numeric values in many places where they could either be elided or replaced by composition of the Flex enum properties.
related: https://github.com/bevyengine/bevy/pull/7468
fixes: https://github.com/bevyengine/bevy/issues/6498
## Solution
Change `Size::width` so it sets `height` to `Val::AUTO` and change `Size::height` so it sets `width` to `Val::AUTO`.
Added some tests so this doesn't happen again.
## Changelog
Changed `Size::width` so it sets the `height` to `Val::AUTO`.
Changed `Size::height` so it sets the `width` to `Val::AUTO`.
Added tests to `geometry.rs` for `Size` and `UiRect` to ensure correct behaviour.
Simplified the UI examples. Replaced numeric values with the Flex property enums or elided them where possible, and removed the remaining use of auto margins.
## Migration Guide
The `Size::width` constructor function now sets the `height` to `Val::Auto` instead of `Val::Undefined`.
The `Size::height` constructor function now sets the `width` to `Val::Auto` instead of `Val::Undefined`.
(Before)

(After)

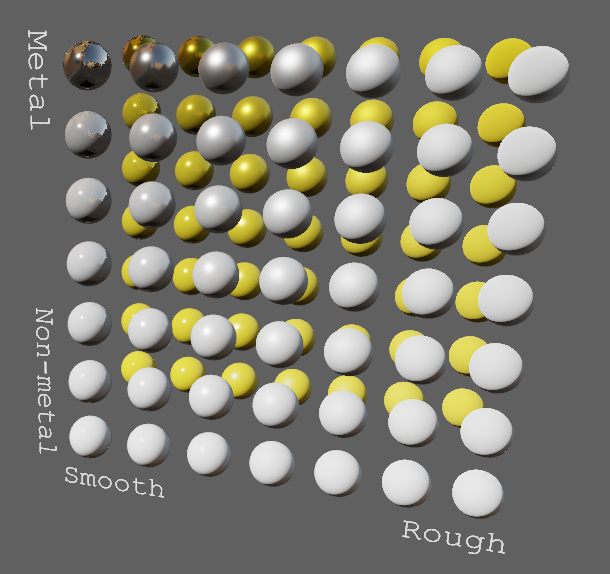
# Objective
- Improve lighting; especially reflections.
- Closes https://github.com/bevyengine/bevy/issues/4581.
## Solution
- Implement environment maps, providing better ambient light.
- Add microfacet multibounce approximation for specular highlights from Filament.
- Occlusion is no longer incorrectly applied to direct lighting. It now only applies to diffuse indirect light. Unsure if it's also supposed to apply to specular indirect light - the glTF specification just says "indirect light". In the case of ambient occlusion, for instance, that's usually only calculated as diffuse though. For now, I'm choosing to apply this just to indirect diffuse light, and not specular.
- Modified the PBR example to use an environment map, and have labels.
- Added `FallbackImageCubemap`.
## Implementation
- IBL technique references can be found in environment_map.wgsl.
- It's more accurate to use a LUT for the scale/bias. Filament has a good reference on generating this LUT. For now, I just used an analytic approximation.
- For now, environment maps must first be prefiltered outside of bevy using a 3rd party tool. See the `EnvironmentMap` documentation.
- Eventually, we should have our own prefiltering code, so that we can have dynamically changing environment maps, as well as let users drop in an HDR image and use asset preprocessing to create the needed textures using only bevy.
---
## Changelog
- Added an `EnvironmentMapLight` camera component that adds additional ambient light to a scene.
- StandardMaterials will now appear brighter and more saturated at high roughness, due to internal material changes. This is more physically correct.
- Fixed StandardMaterial occlusion being incorrectly applied to direct lighting.
- Added `FallbackImageCubemap`.
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Fixes#7565
`ecs_guide` example is currently panicking. This seems to just be a problem with the example only caused by the base sets PR.
## Solution
First, changed a few `in_set` to `in_base_set` to fix a few of
```
thread 'main' panicked at 'Systems cannot be added to 'base' system sets using 'in_set'. Use 'in_base_set' instead.', examples/ecs/ecs_guide.rs:301:45
```
And then added an `in_base_set` to fix the resulting (confusing) cycle error
```
2023-02-06T13:54:29.213843Z ERROR bevy_ecs::schedule_v3::schedule: schedule contains at least 1 cycle(s) -- cycle(s) found within:
---- 0: ["ecs_guide::game_over_system", "ecs_guide::score_check_system"]
```
I also changed this `add_system` call so the comment above and below make sense:
```diff
// add_system(system) adds systems to the Update system set by default
// However we can manually specify the set if we want to. The following is equivalent to
// add_system(score_system)
- .add_system(score_system)
+ .add_system(score_system.in_base_set(CoreSet::Update))
// There are other `CoreSets`, such as `Last` which runs at the very end of each run.
```
## Notes
- Does `MySet` even need to be a base set? Seems like yes.
- Is that cycle error when there is no explicit `in_base_set` actually expected?
# Objective
Implementing `States` manually is repetitive, so let's not.
One thing I'm unsure of is whether the macro import statement is in the right place.
# Objective
- Merge the examples on iOS and Android
- Make sure they both work from the same code
## Solution
- don't create window when not in an active state (from #6830)
- exit on suspend on Android (from #6830)
- automatically enable dependency feature of bevy_audio on android so that it works out of the box
- don't inverse y position of touch events
- reuse the same example for both Android and iOS
Fixes#4616Fixes#4103Fixes#3648Fixes#3458Fixes#3249Fixes#86
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Improve ergonomics / documentation of cascaded shadow maps
- Allow for the customization of the nearest shadowing distance.
- Fixes#7393
- Fixes#7362
## Solution
- Introduce `CascadeShadowConfigBuilder`
- Tweak various example cascade settings for better quality.
---
## Changelog
- Made examples look nicer under cascaded shadow maps.
- Introduce `CascadeShadowConfigBuilder` to help with creating `CascadeShadowConfig`
## Migration Guide
- Configure settings for cascaded shadow maps for directional lights using the newly introduced `CascadeShadowConfigBuilder`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Removal events are unwieldy and require some knowledge of when to put systems that need to catch events for them, it is very easy to end up missing one and end up with memory leak-ish issues where you don't clean up after yourself.
## Solution
Consolidate removals with the benefits of `Events<...>` (such as double buffering and per system ticks for reading the events) and reduce the special casing of it, ideally I was hoping to move the removals to a `Resource` in the world, but that seems a bit more rough to implement/maintain because of double mutable borrowing issues.
This doesn't go the full length of change detection esque removal detection a la https://github.com/bevyengine/rfcs/pull/44.
Just tries to make the current workflow a bit more user friendly so detecting removals isn't such a scheduling nightmare.
---
## Changelog
- RemovedComponents<T> is now backed by an `Events<Entity>` for the benefits of double buffering.
## Migration Guide
- Add a `mut` for `removed: RemovedComponents<T>` since we are now modifying an event reader internally.
- Iterating over removed components now requires `&mut removed_components` or `removed_components.iter()` instead of `&removed_components`.
# Objective
- Update winit to 0.28
## Solution
- Small API change
- A security advisory has been added for a unmaintained crate used by a dependency of winit build script for wayland
I didn't do anything for Android support in this PR though it should be fixable, it should be done in a separate one, maybe https://github.com/bevyengine/bevy/pull/6830
---
## Changelog
- `window.always_on_top` has been removed, you can now use `window.window_level`
## Migration Guide
before:
```rust
app.new()
.add_plugins(DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
always_on_top: true,
..default()
}),
..default()
}));
```
after:
```rust
app.new()
.add_plugins(DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
window_level: bevy:🪟:WindowLevel::AlwaysOnTop,
..default()
}),
..default()
}));
```
## Objective
A common easy to miss mistake is to write something like:
``` rust
Size::new(Val::Percent(100.), Val::Px(100.));
```
`UiRect` has the `left`, `right`, `all`, `vertical`, etc constructor functions, `Size` is used a lot more frequently but lacks anything similar.
## Solution
Implement `all`, `width` and `height` functions for `Size`.
## Changelog
* Added `all`, `width` and `height` functions to `Size`.
Since the new renderer, no frustum culling is applied to 2d components
(be it Sprite or Mesh2d), the stress_tests docs is therefore misleading
and should be updated.
Furthermore, the `many_animated_sprites` example, unlike `many_sprites`
kept vsync enabled, making the stress test less useful than it could be.
We now disable vsync for `many_animated_sprites`.
Also, `many_animated_sprites` didn't have the stress_tests warning
message, instead, it had a paragraph in the module doc. I replaced the
module doc paragraph by the warning message, to be more in line with
other examples.
## Solution
- Remove the paragraph about frustum culling in the `many_sprites`
and `many_animated_sprites` stress tests
# Objective
- Bevy should not have any "internal" execution order ambiguities. These clutter the output of user-facing error reporting, and can result in nasty, nondetermistic, very difficult to solve bugs.
- Verifying this currently involves repeated non-trivial manual work.
## Solution
- [x] add an example to quickly check this
- ~~[ ] ensure that this example panics if there are any unresolved ambiguities~~
- ~~[ ] run the example in CI 😈~~
There's one tricky ambiguity left, between UI and animation. I don't have the tools to fix this without system set configuration, so the remaining work is going to be left to #7267 or another PR after that.
```
2023-01-27T18:38:42.989405Z INFO bevy_ecs::schedule::ambiguity_detection: Execution order ambiguities detected, you might want to add an explicit dependency relation between some of these systems:
* Parallel systems:
-- "bevy_animation::animation_player" and "bevy_ui::flex::flex_node_system"
conflicts: ["bevy_transform::components::transform::Transform"]
```
## Changelog
Resolved internal execution order ambiguities for:
1. Transform propagation (ignored, we need smarter filter checking).
2. Gamepad processing (fixed).
3. bevy_winit's window handling (fixed).
4. Cascaded shadow maps and perspectives (fixed).
Also fixed a desynchronized state bug that could occur when the `Window` component is removed and then added to the same entity in a single frame.
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
# Objective
- Fix#7315
- Add IME support
## Solution
- Add two new fields to `Window`, to control if IME is enabled and the candidate box position
This allows the use of dead keys which are needed in French, or the full IME experience to type using Pinyin
I also added a basic general text input example that can handle IME input.
https://user-images.githubusercontent.com/8672791/213941353-5ed73a73-5dd1-4e66-a7d6-a69b49694c52.mp4
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873533-44c029af-13b7-4740-8ea3-af96bd5867c9.png">
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873549-36be7a23-b341-42a2-8a9f-ceea8ac7a2b8.png">
# Objective
- Add support for the “classic” distance fog effect, as well as a more advanced atmospheric fog effect.
## Solution
This PR:
- Introduces a new `FogSettings` component that controls distance fog per-camera.
- Adds support for three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
- Adds support for directional light influence over fog color;
- Extracts fog via `ExtractComponent`, then uses a prepare system that sets up a new dynamic uniform struct (`Fog`), similar to other mesh view types;
- Renders fog in PBR material shader, as a final adjustment to the `output_color`, after PBR is computed (but before tone mapping);
- Adds a new `StandardMaterial` flag to enable fog; (`fog_enabled`)
- Adds convenience methods for easier artistic control when creating non-linear fog types;
- Adds documentation around fog.
---
## Changelog
### Added
- Added support for distance-based fog effects for PBR materials, controllable per-camera via the new `FogSettings` component;
- Added `FogFalloff` enum for selecting between three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
# Objective
Prevent things from breaking tomorrow when rust 1.67 is released.
## Solution
Fix a few `uninlined_format_args` lints in recently introduced code.
# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
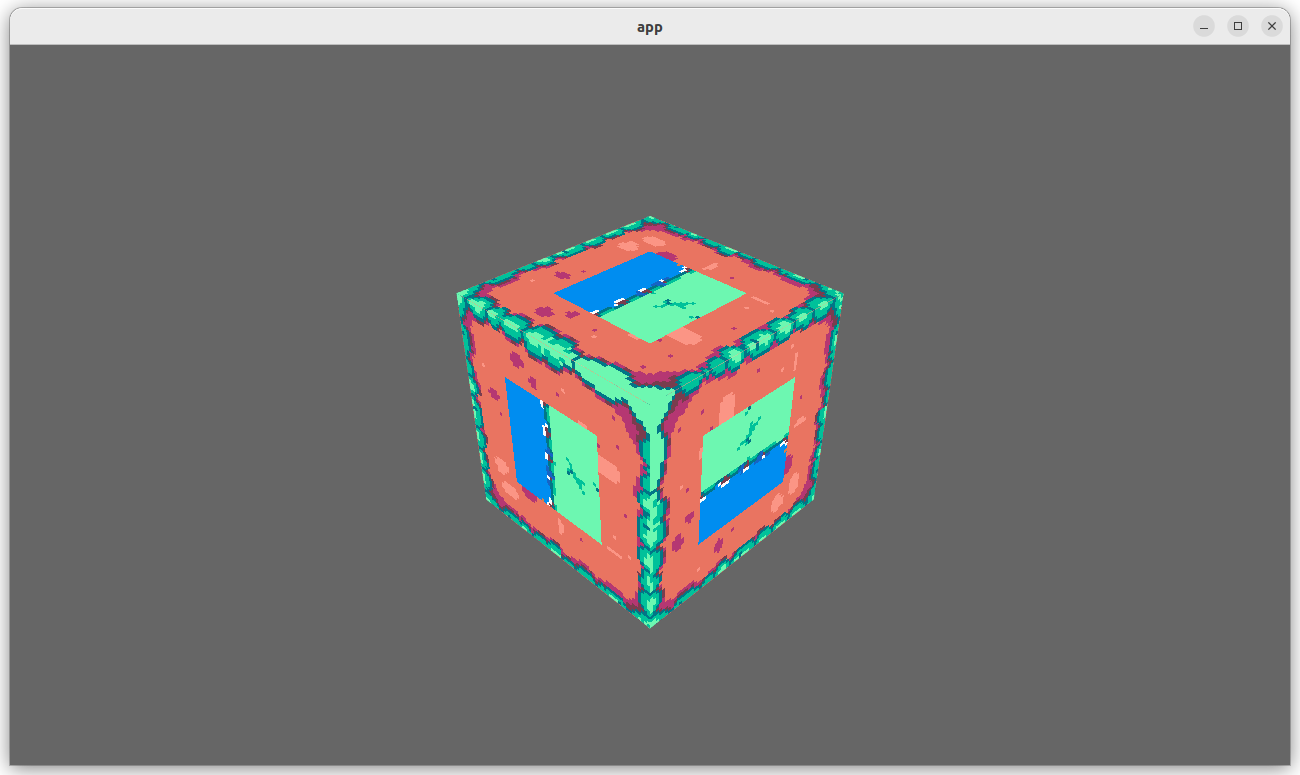
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps.
Fixes#3629
Before

After
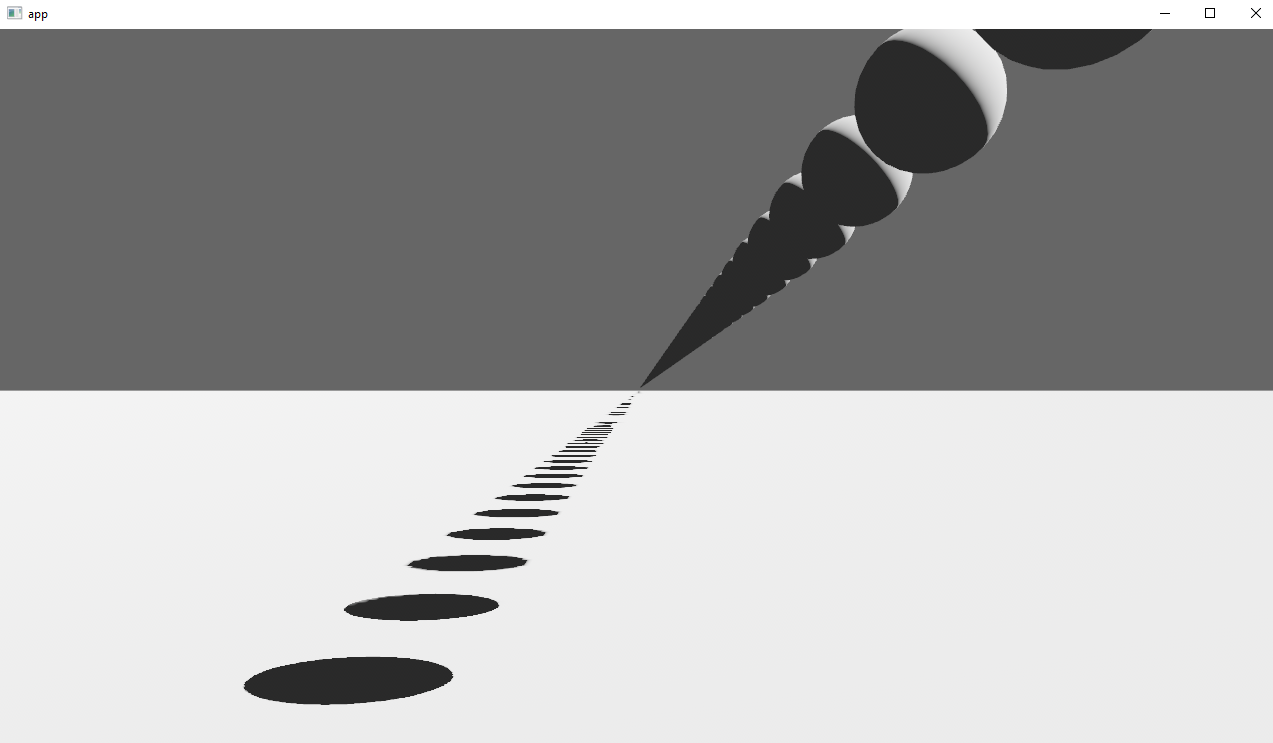
## Solution
Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination.
---
## Changelog
Directional lights now use cascaded shadow maps for improved shadow quality.
## Migration Guide
You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
# Objective
Shadows are broken on many_foxes on AMD GPUs. This seems to be due to rounding or floating point precision issues combined with the absolute unit of a plane that it's currently using.
Related: https://github.com/bevyengine/bevy/issues/6542
I'm not sure if we want to close that issue, as there's still the underlying issue of shadows breaking on overly large planes.
## Solution
Make the plane smaller.
# Objective
On wasm, bevy applications currently prevent any of the normal browser hotkeys from working normally (Ctrl+R, F12, F5, Ctrl+F5, tab, etc.).
Some of those events you may want to override, perhaps you can hold the tab key for showing in-game stats?
However, if you want to make a well-behaved game, you probably don't want to needlessly prevent that behavior unless you have a good reason.
Secondary motivation: Also, consider the workaround presented here to get audio working: https://developer.chrome.com/blog/web-audio-autoplay/#moving-forward ; It won't work (for keydown events) if we stop event propagation.
## Solution
- Winit has a field that allows it to not stop event propagation, expose it on the window settings to allow the user to choose the desired behavior. Default to `true` for backwards compatibility.
---
## Changelog
- Added `Window::prevent_default_event_handling` . This allows bevy apps to not override default browser behavior on hotkeys like F5, F12, Ctrl+R etc.
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
# Objective
Currently, Text always uses the default linebreaking behaviour in glyph_brush_layout `BuiltInLineBreaker::Unicode` which breaks lines at word boundaries. However, glyph_brush_layout also supports breaking lines at any character by setting the linebreaker to `BuiltInLineBreaker::AnyChar`. Having text wrap character-by-character instead of at word boundaries is desirable in some cases - consider that consoles/terminals usually wrap this way.
As a side note, the default Unicode linebreaker does not seem to handle emergency cases, where there is no word boundary on a line to break at. In that case, the text runs out of bounds. Issue #1867 shows an example of this.
## Solution
Basically just copies how TextAlignment is exposed, but for a new enum TextLineBreakBehaviour.
This PR exposes glyph_brush_layout's two simple linebreaking options (Unicode, AnyChar) to users of Text via the enum TextLineBreakBehaviour (which just translates those 2 aforementioned options), plus a method 'with_linebreak_behaviour' on Text and TextBundle.
## Changelog
Added `Text::with_linebreak_behaviour`
Added `TextBundle::with_linebreak_behaviour`
`TextPipeline::queue_text` and `GlyphBrush::compute_glyphs` now need a TextLineBreakBehaviour argument, in order to pass through the new field.
Modified the `text2d` example to show both linebreaking behaviours.
## Example
Here's what the modified example looks like

# Objective
- Fixes#7294
## Solution
- Do not trigger change detection when setting the cursor position from winit
When moving the cursor continuously, Winit sends events:
- CursorMoved(0)
- CursorMoved(1)
- => start of Bevy schedule execution
- CursorMoved(2)
- CursorMoved(3)
- <= End of Bevy schedule execution
if Bevy schedule runs after the event 1, events 2 and 3 would happen during the execution but would be read only on the next system run. During the execution, the system would detect a change on cursor position, and send back an order to winit to move it back to 1, so event 2 and 3 would be ignored. By bypassing change detection when setting the cursor from winit event, it doesn't trigger sending back that change to winit out of order.
# Objective
- The changes to the MeshPipeline done for the prepass broke the shader_instancing example. The issue is that the view_layout changes based on if MSAA is enabled or not, but the example hardcoded the view_layout.
## Solution
- Don't overwrite the bind_group_layout of the descriptor since the MeshPipeline already takes care of this in the specialize function.
Closes https://github.com/bevyengine/bevy/issues/7285
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
See:
- https://github.com/bevyengine/bevy/issues/7067#issuecomment-1381982285
- (This does not fully close that issue in my opinion.)
- https://discord.com/channels/691052431525675048/1063454009769340989
## Solution
This merge request adds documentation:
1. Alert users to the fact that `App::run()` might never return and code placed after it might never be executed.
2. Makes `winit::WinitSettings::return_from_run` discoverable.
3. Better explains why `winit::WinitSettings::return_from_run` is discouraged and better links to up-stream docs. on that topic.
4. Adds notes to the `app/return_after_run.rs` example which otherwise promotes a feature that carries caveats.
Furthermore, w.r.t `winit::WinitSettings::return_from_run`:
- Broken links to `winit` docs are fixed.
- Links now point to BOTH `EventLoop::run()` and `EventLoopExtRunReturn::run_return()` which are the salient up-stream pages and make more sense, taken together.
- Collateral damage: "Supported platforms" heading; disambiguation of "run" → `App::run()`; links.
## Future Work
I deliberately structured the "`run()` might not return" section under `App::run()` to allow for alternative patterns (e.g. `AppExit` event, `WindowClosed` event) to be listed or mentioned, beneath it, in the future.
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
# Objective
- Fixes#6361
- Fixes#6362
- Fixes#6364
## Solution
- Added an example for creating a custom `Decodable` type
- Clarified the documentation on `Decodable`
- Added an `AddAudioSource` trait and implemented it for `App`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
Add useful information about cursor position relative to a UI node. Fixes#7079.
## Solution
- Added a new `RelativeCursorPosition` component
---
## Changelog
- Added
- `RelativeCursorPosition`
- an example showcasing the new component
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
It is possible to manually update `GlobalTransform`.
The engine actually assumes this is not possible.
For example, `propagate_transform` does not update children
of an `Entity` which **`GlobalTransform`** changed,
leading to unexpected behaviors.
A `GlobalTransform` set by the user may also be blindly
overwritten by the propagation system.
## Solution
- Remove `translation_mut`
- Explain to users that they shouldn't manually update the `GlobalTransform`
- Remove `global_vs_local.rs` example, since it misleads users
in believing that it is a valid use-case to manually update the
`GlobalTransform`
---
## Changelog
- Remove `GlobalTransform::translation_mut`
## Migration Guide
`GlobalTransform::translation_mut` has been removed without alternative,
if you were relying on this, update the `Transform` instead. If the given entity
had children or parent, you may need to remove its parent to make its transform
independent (in which case the new `Commands::set_parent_in_place` and
`Commands::remove_parent_in_place` may be of interest)
Bevy may add in the future a way to toggle transform propagation on
an entity basis.
# Objective
- Remove redundant gamepad events
- Simplify consuming gamepad events.
- Refactor: Separate handling of gamepad events into multiple systems.
## Solution
- Removed `GamepadEventRaw`, and `GamepadEventType`.
- Added bespoke `GamepadConnectionEvent`, `GamepadAxisChangedEvent`, and `GamepadButtonChangedEvent`.
- Refactored `gamepad_event_system`.
- Added `gamepad_button_event_system`, `gamepad_axis_event_system`, and `gamepad_connection_system`, which update the `Input` and `Axis` resources using their corresponding event type.
Gamepad events are now handled in their own systems and have their own types.
This allows for querying for gamepad events without having to match on `GamepadEventType` and makes creating handlers for specific gamepad event types, like a `GamepadConnectionEvent` or `GamepadButtonChangedEvent` possible.
We remove `GamepadEventRaw` by filtering the gamepad events, using `GamepadSettings`, _at the source_, in `bevy_gilrs`. This way we can create `GamepadEvent`s directly and avoid creating `GamepadEventRaw` which do not pass the user defined filters.
We expose ordered `GamepadEvent`s and we can respond to individual gamepad event types.
## Migration Guide
- Replace `GamepadEvent` and `GamepadEventRaw` types with their specific gamepad event type.
# Objective
- Fixes https://github.com/bevyengine/bevy/discussions/6338
This PR allows for smooth transitions between different animations.
## Solution
- This PR uses very simple linear blending of animations.
- When starting a new animation, you can give it a duration, and throughout that duration, the previous and the new animation are being linearly blended, until only the new animation is running.
- I'm aware of https://github.com/bevyengine/rfcs/pull/49 and https://github.com/bevyengine/rfcs/pull/51, which are more complete solutions to this problem, but they seem still far from being implemented. Until they're ready, this PR allows for the most basic use case of blending, i.e. smoothly transitioning between different animations.
## Migration Guide
- no bc breaking changes
# Objective
- Fixes#7081.
## Solution
- Moved functionality from kitchen sink plugin `CorePlugin` to separate plugins, `TaskPoolPlugin`, `TypeRegistrationPlugin`, `FrameCountPlugin`. `TaskPoolOptions` resource should now be used with `TaskPoolPlugin`.
## Changelog
Minimal changes made (code kept in `bevy_core/lib.rs`).
## Migration Guide
- `CorePlugin` broken into separate plugins. If not using `DefaultPlugins` or `MinimalPlugins` `PluginGroup`s, the replacement for `CorePlugin` is now to add `TaskPoolPlugin`, `TypeRegistrationPlugin`, and `FrameCountPlugin` to the app.
## Notes
- Consistent with Bevy goal "modularity over deep integration" but the functionality of `TypeRegistrationPlugin` and `FrameCountPlugin` is weak (the code has to go somewhere, though!).
- No additional tests written.
# Objective
It is currently possible to break reference counting for assets by creating a strong `HandleUntyped` and then modifying the `id` field before dropping the handle. This should not be allowed.
## Solution
Change the `id` field visibility to private and add a getter instead. The same change was previously done for `Handle<T>` in #6176, but `HandleUntyped` was forgotten.
---
## Migration Guide
- Instead of directly accessing the ID of a `HandleUntyped` as `handle.id`, use the new getter `handle.id()`.
# Objective
- When using `Color::hex` for the first time, I was confused by the fact that I can't specify colors using #, which is much more familiar.
- In the code editor (if there is support) there is a preview of the color, which is very convenient.

## Solution
- Allow you to enter colors like `#ff33f2` and use the `.strip_prefix` method to delete the `#` character.
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
The shadow pass node is also slightly faster (344.52 -> 338.24us)
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
Solve #5464
## Solution
Adds a `SystemInformationDiagnosticsPlugin` to add diagnostics.
Adds `Cargo.toml` flags to fix building on different platforms.
---
## Changelog
Adds `sysinfo` crate to `bevy-diagnostics`.
Changes in import order are due to clippy.
Co-authored-by: l1npengtul <35755164+l1npengtul@users.noreply.github.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
# Objective
I am new to Bevy. And during my development, I noticed that the `iOS` example doesn't work.
Example panics with next message: ```panicked at 'Resource requested by bevy_ui::widget::text::text_system does not exist: bevy_asset::assets::Assets```.
I have asked for help in a `discord` iOS chat and there I receive a recommendation that it is possible that some bevy features missing.
## Solution
So, I used ```bevy``` with default features.
# Objective
Scene viewer mouse sensitivity/cursor usage isn't the best it could be atm, so just adding some quick, maybe opinionated, tweaks to make it feel more at home in usage.
## Solution
- Mouse delta shouldn't be affected by delta time, it should be more expected that if I move my mouse 1 inch to the right that it should move the in game camera/whatever is controlled the same regardless of FPS.
- Uses a magic number of 180.0 for a nice default sensitivity, modeled after Valorant's default sensitivity.
- Cursor now gets locked/hidden when rotating the camera to give it more of the effect that you are grabbing the camera.
# Objective
The documentation for camera priority is very confusing at the moment, it requires a bit of "double negative" kind of thinking.
# Solution
Flipping the wording on the documentation to reflect more common usecases like having an overlay camera and also renaming it to "order", since priority implies that it will override the other camera rather than have both run.
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode.
# Objective
The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching.
Additionally as it stands Bevy only has two settings for visibility of an entity:
- "unconditionally hidden" `Visibility { is_visible: false }`,
- "inherit visibility from parent" `Visibility { is_visible: true }`
where a root level entity set to "inherit" is visible.
Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear.
Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode.
--
The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants.
## Solution
Change the Visibility component into
```rust
enum Visibility {
Hidden, // unconditionally hidden
Visible, // unconditionally visible
Inherited, // inherit visibility from parent
}
```
---
## Changelog
### Changed
`Visibility` is now an enum
## Migration Guide
- evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`.
- setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`.
- usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively.
- `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
This PR reorganizes majority of the scene viewer example into a module of plugins which then allows reuse of functionality among new or existing examples. In addition, this enables the scene viewer to be more succinct and showcase the distinct cases of camera control and scene control.
This work is to support future work in organization and future examples. A more complicated 3D scene example has been requested by the community (#6551) which requests functionality currently included in scene_viewer, but previously inaccessible. The future example can now just utilize the two plugins created here. The existing example [animated_fox example] can utilize the scene creation and animation control functionality of `SceneViewerPlugin`.
## Solution
- Created a `scene_viewer` module inside the `tools` example folder.
- Created two plugins: `SceneViewerPlugin` (gltf scene loading, animation control, camera tracking control, light control) and `CameraControllerPlugin` (controllable camera).
- Original `scene_viewer.rs` moved to `scene_viewer/main.rs` and now utilizes the two plugins.
# Objective
The `WgpuSettings` resource is only used during plugin build. Move it into the `RenderPlugin` struct.
Changing these settings requires re-initializing the render context, which is currently not supported.
If it is supported in the future it should probably be more explicit than changing a field on a resource, maybe something similar to the `CreateWindow` event.
## Migration Guide
```rust
// Before (0.9)
App::new()
.insert_resource(WgpuSettings { .. })
.add_plugins(DefaultPlugins)
// After (0.10)
App::new()
.add_plugins(DefaultPlugins.set(RenderPlugin {
wgpu_settings: WgpuSettings { .. },
}))
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This adds a custom profile for testing against stress tests. Bevy seemingly gets notably faster with LTO turned on. To more accurately depict production level performance, LTO and other rustc-level optimizations should be enabled when performance testing on stress tests.
Also updated the stress test docs to reflect that users should be using it.
# Objective
`AsBindGroup` can't be used as a trait object because of the constraint `Sized` and because of the associated function.
This is a problem for [`bevy_atmosphere`](https://github.com/JonahPlusPlus/bevy_atmosphere) because it needs to use a trait that depends on `AsBindGroup` as a trait object, for switching out different shaders at runtime. The current solution it employs is reimplementing the trait and derive macro into that trait, instead of constraining to `AsBindGroup`.
## Solution
Remove the `Sized` constraint from `AsBindGroup` and add the constraint `where Self: Sized` to the associated function `bind_group_layout`. Also change `PreparedBindGroup<T: AsBindGroup>` to `PreparedBindGroup<T>` and use it as `PreparedBindGroup<Self::Data>` instead of `PreparedBindGroup<Self>`.
This weakens the constraints, but increases the flexibility of `AsBindGroup`.
I'm not entirely sure why the `Sized` constraint was there, because it worked fine without it (maybe @cart wasn't aware of use cases for `AsBindGroup` as a trait object or this was just leftover from legacy code?).
---
## Changelog
- `AsBindGroup` can be used as a trait object.
# Objective
[Rust 1.66](https://blog.rust-lang.org/inside-rust/2022/12/12/1.66.0-prerelease.html) is coming in a few days, and bevy doesn't build with it.
Fix that.
## Solution
Replace output from a trybuild test, and fix a few new instances of `needless_borrow` and `unnecessary_cast` that are now caught.
## Note
Due to the trybuild test, this can't be merged until 1.66 is released.
# Objective
Change detection can be spuriously triggered by setting a field to the same value as before. As a result, a common pattern is to write:
```rust
if *foo != value {
*foo = value;
}
```
This is confusing to read, and heavy on boilerplate.
Adopted from #5373, but untangled and rebased to current `bevy/main`.
## Solution
1. Add a method to the `DetectChanges` trait that implements this boilerplate when the appropriate trait bounds are met.
2. Document this minor footgun, and point users to it.
## Changelog
* added the `set_if_neq` method to avoid triggering change detection when the new and previous values are equal. This will work on both components and resources.
## Migration Guide
If you are manually checking if a component or resource's value is equal to its new value before setting it to avoid triggering change detection, migrate to the clearer and more convenient `set_if_neq` method.
## Context
Related to #2363 as it avoids triggering change detection, but not a complete solution (as it still requires triggering it when real changes are made).
Co-authored-by: Zoey <Dessix@Dessix.net>
# Objective
The feature doesn't have any use case in libraries or applications and many users use this feature incorrectly. See the issue for details.
Closes#5753.
## Solution
Remove it.
---
## Changelog
### Removed
- `render` feature group.
## Migration Guide
Instead of using `render` feature group use dependencies directly. This group consisted of `bevy_core_pipeline`, `bevy_pbr`, `bevy_gltf`, `bevy_render`, `bevy_sprite`, `bevy_text` and `bevy_ui`. You probably want to check if you need all of them.
# Objective
- Fixes#6630, fixes#6679
- Improve scene viewer in cases where there are more than one scene in a gltf file
## Solution
- Can select which scene to display using `#SceneN`, defaults to scene 0 if not present
- Display the number of scenes available if there are more than one
# Objective
- Make running animation fluid skipping 'idle' frame.
## Solution
- Loop through the specified indices instead of through the whole sprite sheet.
The example is correct, is just the feeling that the animation loop is not seamless.
Based on the solution suggested by @mockersf in #5429.
# Objective
Adds a cylinder shape. Fixes#2282.
## Solution
- I added a custom cylinder shape, taken from [here](https://github.com/rparrett/typey_birb/blob/main/src/cylinder.rs) with permission from @rparrett.
- I also added the cylinder shape to the `3d_shapes` example scene.
---
## Changelog
- Added cylinder shape
Co-Authored-By: Rob Parrett <robparrett@gmail.com>
Co-Authored-By: davidhof <7483215+davidhof@users.noreply.github.com>
# Objective
Fixes#6224, add ``dbg``, ``info``, ``warn`` and ``error`` system piping adapter variants to expand #5776, which call the corresponding re-exported [bevy_log macros](https://docs.rs/bevy/latest/bevy/log/macro.info.html) when the result is an error.
## Solution
* Added ``dbg``, ``info``, ``warn`` and ``error`` system piping adapter variants to ``system_piping.rs``.
* Modified and added tests for these under examples in ``system_piping.rs``.
The PR fixes the interface of `EventReader::clear`. Currently, the method consumes the reader, which makes it unusable.
## Changelog
- `EventReader::clear` now takes a mutable reference instead of consuming the event reader.
## Migration Guide
`EventReader::clear` now takes a mutable reference instead of consuming the event reader. This means that `clear` now needs explicit mutable access to the reader variable, which previously could have been omitted in some cases:
```rust
// Old (0.9)
fn clear_events(reader: EventReader<SomeEvent>) {
reader.clear();
}
// New (0.10)
fn clear_events(mut reader: EventReader<SomeEvent>) {
reader.clear();
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The global_vs_local_translation example tries to use transparency to identify static cubes, but the materials of those cubes aren't transparent.
## Solution
Change material alpha_mode to `AlphaMode::Blend` for those cubes.
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- Fix CI issue with updated `cargo-app`
## Solution
- Move the Android example to its own package. It's not necessary for the CI fix, but it's cleaner, mimic the iOS example, and easier to reuse for someone wanting to setup android support in their project
- Build the package in CI instead of the example
The Android example is still working on my android device with this change 👍
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
Fixes#6498.
## Solution
Adding a parent node with properties AlignItems::Center and JustifyContent::Center to centered child nodes and removing their auto-margin properties.
# Objective
Allow more use cases where the user may benefit from both `ExtractComponentPlugin` _and_ `UniformComponentPlugin`.
## Solution
Add an associated type to `ExtractComponent` in order to allow specifying the output component (or bundle).
Make `extract_component` return an `Option<_>` such that components can be extracted only when needed.
What problem does this solve?
`ExtractComponentPlugin` allows extracting components, but currently the output type is the same as the input.
This means that use cases such as having a settings struct which turns into a uniform is awkward.
For example we might have:
```rust
struct MyStruct {
enabled: bool,
val: f32
}
struct MyStructUniform {
val: f32
}
```
With the new approach, we can extract `MyStruct` only when it is enabled, and turn it into its related uniform.
This chains well with `UniformComponentPlugin`.
The user may then:
```rust
app.add_plugin(ExtractComponentPlugin::<MyStruct>::default());
app.add_plugin(UniformComponentPlugin::<MyStructUniform>::default());
```
This then saves the user a fair amount of boilerplate.
## Changelog
### Changed
- `ExtractComponent` can specify output type, and outputting is optional.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- Bevy should be usable to create 'overlay' type apps, where the input is not captured by Bevy, but passed down/into a target app, or to allow passive displays/widgets etc.
## Solution
- the `winit:🪟:Window` already has a `set_cursor_hittest()` which basically does this for mouse input events, so I've exposed it (trying to copy the style laid out in the existing wrappings, and added a simple demo.
---
## Changelog
- Added `hittest` to `WindowAttributes`
- Added the `hittest`'s setters/getters
- Modified the `WindowBuilder`
- Modifed the `WindowDescriptor`'s `Default` impl.
- Added an example `cargo run --example fallthrough`
# Objective
- The `contributors` example panics when attempting to generate an empty range if the window height is smaller than the sprites
- Don't do that
## Solution
- Clamp the bounce height to be 0 minimum, and generate an inclusive range when passing it to `rng.gen_range`
# Objective
I needed a window which is always on top, to create a overlay app.
## Solution
expose the `always_on_top` property of winit in bevy's `WindowDescriptor` as a boolean flag
---
## Changelog
### Added
- add `WindowDescriptor.always_on_top` which configures a window to stay on top.
# Objective
Fixes #3225, Allow for flippable UI Images
## Solution
Add flip_x and flip_y fields to UiImage, and swap the UV coordinates accordingly in ui_prepare_nodes.
## Changelog
* Changes UiImage to a struct with texture, flip_x, and flip_y fields.
* Adds flip_x and flip_y fields to ExtractedUiNode.
* Changes extract_uinodes to extract the flip_x and flip_y values from UiImage.
* Changes prepare_uinodes to swap the UV coordinates as required.
* Changes UiImage derefs to texture field accesses.
# Objective
- Using the instancing example as reference, I found it was breaking when enabling HDR on the camera. I found that this was because, unlike in internal code, this was not updating the specialization key with `view.hdr`.
## Solution
- Add the missing HDR bit.
# Objective
- Fix an awkwardly phrased/typoed error message
- Actually tell users which file caused the error
- IMO we don't need to panic
## Solution
- Add a warning including the involved asset path when a non-image is found by `load_folder`
- Note: uses `let else` which is stable now
```
2022-11-03T14:17:59.006861Z WARN texture_atlas: Some(AssetPath { path: "textures/rpg/tiles/whatisthisdoinghere.ogg", label: None }) did not resolve to an `Image` asset.
```
# Objective
Fixes: https://github.com/bevyengine/bevy/issues/6466
Summary: The UI Scaling example dynamically scales the UI which will dynamically allocate fonts to the font atlas surpassing the protective limit, throwing a panic.
## Solution
- Set TextSettings.allow_dynamic_font_size = true for the UI Scaling example. This is the ideal solution since the dynamic changes to the UI are not continuous yet still discrete.
- Update the panic text to reflect ui scaling as a potential cause
# Objective
The bloom example has a 2d camera for the UI. This is an artifact of an older version of bevy. All cameras can render the UI now.
## Solution
Remove the 2d camera
Allow passing `Vec`s of glam vector types as vertex attributes.
Alternative to #4548 and #2719
Also used some macros to cut down on all the repetition.
# Migration Guide
Implementations of `From<Vec<[u16; 4]>>` and `From<Vec<[u8; 4]>>` for `VertexAttributeValues` have been removed.
I you're passing either `Vec<[u16; 4]>` or `Vec<[u8; 4]>` into `Mesh::insert_attribute` it will now require wrapping it with right the `VertexAttributeValues` enum variant.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Adds a bloom pass for HDR-enabled Camera3ds.
- Supersedes (and all credit due to!) https://github.com/bevyengine/bevy/pull/3430 and https://github.com/bevyengine/bevy/pull/2876

## Solution
- A threshold is applied to isolate emissive samples, and then a series of downscale and upscaling passes are applied and composited together.
- Bloom is applied to 2d or 3d Cameras with hdr: true and a BloomSettings component.
---
## Changelog
- Added a `core_pipeline::bloom::BloomSettings` component.
- Added `BloomNode` that runs between the main pass and tonemapping.
- Added a `BloomPlugin` that is loaded as part of CorePipelinePlugin.
- Added a bloom example project.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
# Objective
Add consistent UI rendering and interaction where deep nodes inside two different hierarchies will never render on top of one-another by default and offer an escape hatch (z-index) for nodes to change their depth.
## The problem with current implementation
The current implementation of UI rendering is broken in that regard, mainly because [it sets the Z value of the `Transform` component based on a "global Z" space](https://github.com/bevyengine/bevy/blob/main/crates/bevy_ui/src/update.rs#L43) shared by all nodes in the UI. This doesn't account for the fact that each node's final `GlobalTransform` value will be relative to its parent. This effectively makes the depth unpredictable when two deep trees are rendered on top of one-another.
At the moment, it's also up to each part of the UI code to sort all of the UI nodes. The solution that's offered here does the full sorting of UI node entities once and offers the result through a resource so that all systems can use it.
## Solution
### New ZIndex component
This adds a new optional `ZIndex` enum component for nodes which offers two mechanism:
- `ZIndex::Local(i32)`: Overrides the depth of the node relative to its siblings.
- `ZIndex::Global(i32)`: Overrides the depth of the node relative to the UI root. This basically allows any node in the tree to "escape" the parent and be ordered relative to the entire UI.
Note that in the current implementation, omitting `ZIndex` on a node has the same result as adding `ZIndex::Local(0)`. Additionally, the "global" stacking context is essentially a way to add your node to the root stacking context, so using `ZIndex::Local(n)` on a root node (one without parent) will share that space with all nodes using `Index::Global(n)`.
### New UiStack resource
This adds a new `UiStack` resource which is calculated from both hierarchy and `ZIndex` during UI update and contains a vector of all node entities in the UI, ordered by depth (from farthest from camera to closest). This is exposed publicly by the bevy_ui crate with the hope that it can be used for consistent ordering and to reduce the amount of sorting that needs to be done by UI systems (i.e. instead of sorting everything by `global_transform.z` in every system, this array can be iterated over).
### New z_index example
This also adds a new z_index example that showcases the new `ZIndex` component. It's also a good general demo of the new UI stack system, because making this kind of UI was very broken with the old system (e.g. nodes would render on top of each other, not respecting hierarchy or insert order at all).

---
## Changelog
- Added the `ZIndex` component to bevy_ui.
- Added the `UiStack` resource to bevy_ui, and added implementation in a new `stack.rs` module.
- Removed the previous Z updating system from bevy_ui, because it was replaced with the above.
- Changed bevy_ui rendering to use UiStack instead of z ordering.
- Changed bevy_ui focus/interaction system to use UiStack instead of z ordering.
- Added a new z_index example.
## ZIndex demo
Here's a demo I wrote to test these features
https://user-images.githubusercontent.com/1060971/188329295-d7beebd6-9aee-43ab-821e-d437df5dbe8a.mp4
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#6059, changing all incorrect occurrences of ``id`` in the ``entity`` module to ``index``:
* struct level documentation,
* ``id`` struct field,
* ``id`` method and its documentation.
## Solution
Renaming and verifying using CI.
Co-authored-by: Edvin Kjell <43633999+Edwox@users.noreply.github.com>
# Objective
- Add post processing passes for FXAA (Fast Approximate Anti-Aliasing)
- Add example comparing MSAA and FXAA
## Solution
When the FXAA plugin is added, passes for FXAA are inserted between the main pass and the tonemapping pass. Supports using either HDR or LDR output from the main pass.
---
## Changelog
- Add a new FXAANode that runs after the main pass when the FXAA plugin is added.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes #6311
- Make it clearer what should be done in the example (close the Bevy app window)
## Solution
- Remove the second windowed Bevy App [since winit does not support this](https://github.com/rust-windowing/winit/blob/v0.27.4/src/event_loop.rs#L82-L83)
- Add title to the Bevy window asking the user to close it
This is more of a quick fix to have a working example. It would be nicer if we had a small real usecase for this functionality.
Another alternativ that I tried out: If we want to showcase a second Bevy app as it was before, we could still do this as long as one of them does not have a window. But I don't see how this is helpful in the context of the example, so I stuck with only one Bevy app and a simple print afterwards.
# Objective
- Make it impossible to add a plugin twice
- This is going to be more a risk for plugins with configurations, to avoid things like `App::new().add_plugins(DefaultPlugins).add_plugin(ImagePlugin::default_nearest())`
## Solution
- Panic when a plugin is added twice
- It's still possible to mark a plugin as not unique by overriding `is_unique`
- ~~Simpler version of~~ #3988 (not simpler anymore because of how `PluginGroupBuilder` implements `PluginGroup`)
# Objective
Currently toggling an `AudioSink` (for example from a game menu) requires writing
```rs
if sink.is_paused() {
sink.play();
} else {
sink.pause();
}
```
It would be nicer if we could reduce this down to a single line
```rs
sink.toggle();
```
## Solution
Add an `AudioSink::toggle` method which does exactly that.
---
## Changelog
- Added `AudioSink::toggle` which can be used to toggle state of a sink.
# Objective
Add methods to `Query<&Children>` and `Query<&Parent>` to iterate over descendants and ancestors, respectively.
## Changelog
* Added extension trait for `Query` in `bevy_hierarchy`, `HierarchyQueryExt`
* Added method `iter_descendants` to `Query<&Children>` via `HierarchyQueryExt` for iterating over the descendants of an entity.
* Added method `iter_ancestors` to `Query<&Parent>` via `HierarchyQueryExt` for iterating over the ancestors of an entity.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
Following discussion on #3536 and #3522, `Handle::as_weak()` takes a type `U`, reinterpreting the handle as of another asset type while keeping the same ID. This is mainly used today in font atlas code. This PR does two things:
- Rename the method to `cast_weak()` to make its intent more clear
- Actually change the type uuid in the handle if it's not an asset path variant.
## Migration Guide
- Rename `Handle::as_weak` uses to `Handle::cast_weak`
The method now properly sets the associated type uuid if the handle is a direct reference (e.g. not a reference to an `AssetPath`), so adjust you code accordingly if you relied on the previous behavior.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Proactive changing of code to comply with warnings generated by beta of rustlang version of cargo clippy.
## Solution
- Code changed as recommended by `rustup update`, `rustup default beta`, `cargo run -p ci -- clippy`.
- Tested using `beta` and `stable`. No clippy warnings in either after changes made.
---
## Changelog
- Warnings fixed were: `clippy::explicit-auto-deref` (present in 11 files), `clippy::needless-borrow` (present in 2 files), and `clippy::only-used-in-recursion` (only 1 file).
# Objective
- Build on #6336 for more plugin configurations
## Solution
- `LogSettings`, `ImageSettings` and `DefaultTaskPoolOptions` are now plugins settings rather than resources
---
## Changelog
- `LogSettings` plugin settings have been move to `LogPlugin`, `ImageSettings` to `ImagePlugin` and `DefaultTaskPoolOptions` to `CorePlugin`
## Migration Guide
The `LogSettings` settings have been moved from a resource to `LogPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(LogSettings {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(LogPlugin {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
}))
```
The `ImageSettings` settings have been moved from a resource to `ImagePlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(ImageSettings::default_nearest())
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(ImagePlugin::default_nearest()))
```
The `DefaultTaskPoolOptions` settings have been moved from a resource to `CorePlugin::task_pool_options`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(DefaultTaskPoolOptions::with_num_threads(4))
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(CorePlugin {
task_pool_options: TaskPoolOptions::with_num_threads(4),
}))
```
# Objective
Fixes#5884#2879
Alternative to #2988#5885#2886
"Immutable" Plugin settings are currently represented as normal ECS resources, which are read as part of plugin init. This presents a number of problems:
1. If a user inserts the plugin settings resource after the plugin is initialized, it will be silently ignored (and use the defaults instead)
2. Users can modify the plugin settings resource after the plugin has been initialized. This creates a false sense of control over settings that can no longer be changed.
(1) and (2) are especially problematic and confusing for the `WindowDescriptor` resource, but this is a general problem.
## Solution
Immutable Plugin settings now live on each Plugin struct (ex: `WindowPlugin`). PluginGroups have been reworked to support overriding plugin values. This also removes the need for the `add_plugins_with` api, as the `add_plugins` api can use the builder pattern directly. Settings that can be used at runtime continue to be represented as ECS resources.
Plugins are now configured like this:
```rust
app.add_plugin(AssetPlugin {
watch_for_changes: true,
..default()
})
```
PluginGroups are now configured like this:
```rust
app.add_plugins(DefaultPlugins
.set(AssetPlugin {
watch_for_changes: true,
..default()
})
)
```
This is an alternative to #2988, which is similar. But I personally prefer this solution for a couple of reasons:
* ~~#2988 doesn't solve (1)~~ #2988 does solve (1) and will panic in that case. I was wrong!
* This PR directly ties plugin settings to Plugin types in a 1:1 relationship, rather than a loose "setup resource" <-> plugin coupling (where the setup resource is consumed by the first plugin that uses it).
* I'm not a huge fan of overloading the ECS resource concept and implementation for something that has very different use cases and constraints.
## Changelog
- PluginGroups can now be configured directly using the builder pattern. Individual plugin values can be overridden by using `plugin_group.set(SomePlugin {})`, which enables overriding default plugin values.
- `WindowDescriptor` plugin settings have been moved to `WindowPlugin` and `AssetServerSettings` have been moved to `AssetPlugin`
- `app.add_plugins_with` has been replaced by using `add_plugins` with the builder pattern.
## Migration Guide
The `WindowDescriptor` settings have been moved from a resource to `WindowPlugin::window`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(WindowDescriptor {
width: 400.0,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(WindowPlugin {
window: WindowDescriptor {
width: 400.0,
..default()
},
..default()
}))
```
The `AssetServerSettings` resource has been removed in favor of direct `AssetPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(AssetPlugin {
watch_for_changes: true,
..default()
}))
```
`add_plugins_with` has been replaced by `add_plugins` in combination with the builder pattern:
```rust
// Old (Bevy 0.8)
app.add_plugins_with(DefaultPlugins, |group| group.disable::<AssetPlugin>());
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.build().disable::<AssetPlugin>());
```
# Objective
Fixes#6339.
## Solution
This PR adds a new type, `GamepadInfo`, which holds metadata associated with a particular `Gamepad`. The `Gamepads` resource now holds a `HashMap<Gamepad, GamepadInfo>`. The `GamepadInfo` is created when the gamepad backend (by default `bevy_gilrs`) emits a "gamepad connected" event.
The `gamepad_viewer` example has been updated to showcase the new functionality.
Before:

After:

---
## Changelog
### Added
- Added `GamepadInfo`.
- Added `Gamepads::name()`, which returns the name of the specified gamepad if it exists.
### Changed
- `GamepadEventType::Connected` is now a tuple variant with a single field of type `GamepadInfo`.
- Since `GamepadInfo` is not `Copy`, `GamepadEventType` is no longer `Copy`. The same is true of `GamepadEvent` and `GamepadEventRaw`.
## Migration Guide
- Pattern matches on `GamepadEventType::Connected` will need to be updated, as the form of the variant has changed.
- Code that requires `GamepadEvent`, `GamepadEventRaw` or `GamepadEventType` to be `Copy` will need to be updated.
# Objective
- Add Time-Adjusted Rolling EMA-based smoothing to diagnostics.
- Closes#4983; see that issue for more more information.
## Terms
- EMA - [Exponential Moving Average](https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average)
- SMA - [Simple Moving Average](https://en.wikipedia.org/wiki/Moving_average#Simple_moving_average)
## Solution
- We use a fairly standard approximation of a true EMA where $EMA_{\text{frame}} = EMA_{\text{previous}} + \alpha \left( x_{\text{frame}} - EMA_{\text{previous}} \right)$ where $\alpha = \Delta t / \tau$ and $\tau$ is an arbitrary smoothness factor. (See #4983 for more discussion of the math.)
- The smoothness factor is here defaulted to $2 / 21$; this was chosen fairly arbitrarily as supposedly related to the existing 20-bucket SMA.
- The smoothness factor can be set on a per-diagnostic basis via `Diagnostic::with_smoothing_factor`.
---
## Changelog
### Added
- `Diagnostic::smoothed` - provides an exponentially smoothed view of a recorded diagnostic, to e.g. reduce jitter in frametime readings.
### Changed
- `LogDiagnosticsPlugin` now records the smoothed value rather than the raw value.
- For diagnostics recorded less often than every 0.1 seconds, this change to defaults will have no visible effect.
- For discrete diagnostics where this smoothing is not desirable, set a smoothing factor of 0 to disable smoothing.
- The average of the recent history is still shown when available.
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
- Update `wgpu` to 0.14.0, `naga` to `0.10.0`, `winit` to 0.27.4, `raw-window-handle` to 0.5.0, `ndk` to 0.7.
## Solution
---
## Changelog
### Changed
- Changed `RawWindowHandleWrapper` to `RawHandleWrapper` which wraps both `RawWindowHandle` and `RawDisplayHandle`, which satisfies the `impl HasRawWindowHandle and HasRawDisplayHandle` that `wgpu` 0.14.0 requires.
- Changed `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, change its type from `bool` to `bevy_window::CursorGrabMode`.
## Migration Guide
- Adjust usage of `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, and adjust its type from `bool` to `bevy_window::CursorGrabMode`.
# Objective
Fix a camera ambiguity warning in the IOS example
## Solution
I'm assuming that this was accidentally added when UI cameras stopped being a thing. So just delete the extra camera.
# Objective
To be consistent like other examples, it's better to keep file name and example name same, so we don't need to find correct example name in Cargo.toml.
## Solution
Rename example file scaling.rs to ui_scaling.rs.
# Objective
Fixes#6272
## Solution
Revert to old way of positioning text for Text2D rendered text.
Co-authored-by: Michel van der Hulst <hulstmichel@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3418
## Solution
Originally a rebase of https://github.com/bevyengine/bevy/pull/3446. Work was originally done by mfdorst, who should receive considerable credit. Then the error types were extensively reworked by targrub.
## Migration Guide
`AxisSettings` now has a `new()`, which may return an `AxisSettingsError`.
`AxisSettings` fields made private; now must be accessed through getters and setters. There's a dead zone, from `.deadzone_upperbound()` to `.deadzone_lowerbound()`, and a live zone, from `.deadzone_upperbound()` to `.livezone_upperbound()` and from `.deadzone_lowerbound()` to `.livezone_lowerbound()`.
`AxisSettings` setters no longer panic.
`ButtonSettings` fields made private; now must be accessed through getters and setters.
`ButtonSettings` now has a `new()`, which may return a `ButtonSettingsError`.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
As mentioned in #2926, it's better to have an explicit type that clearly communicates the intent of the timer mode rather than an opaque boolean, which can be only understood when knowing the signature or having to look up the documentation.
This also opens up a way to merge different timers, such as `Stopwatch`, and possibly future ones, such as `DiscreteStopwatch` and `DiscreteTimer` from #2683, into one struct.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Fixes#2926.
## Solution
Introduce `TimerMode` which replaces the `bool` argument of `Timer` constructors. A `Default` value for `TimerMode` is `Once`.
---
## Changelog
### Added
- `TimerMode` enum, along with variants `TimerMode::Once` and `TimerMode::Repeating`
### Changed
- Replace `bool` argument of `Timer::new` and `Timer::from_seconds` with `TimerMode`
- Change `repeating: bool` field of `Timer` with `mode: TimerMode`
## Migration Guide
- Replace `Timer::new(duration, false)` with `Timer::new(duration, TimerMode::Once)`.
- Replace `Timer::new(duration, true)` with `Timer::new(duration, TimerMode::Repeating)`.
- Replace `Timer::from_seconds(seconds, false)` with `Timer::from_seconds(seconds, TimerMode::Once)`.
- Replace `Timer::from_seconds(seconds, true)` with `Timer::from_seconds(seconds, TimerMode::Repeating)`.
- Change `timer.repeating()` to `timer.mode() == TimerMode::Repeating`.
# Objective
Fixes#5820
## Solution
Change field name and documentation from `bevy::ui::Node` struct
---
## Changelog
`bevy::ui::Node` `size` field has renamed to `calculated_size`
## Migration Guide
All references to the old `size` name has been changed, to access `bevy::ui::Node` `size` field use `calculated_size`
# Objective
> System chaining is a confusing name: it implies the ability to construct non-linear graphs, and suggests a sense of system ordering that is only incidentally true. Instead, it actually works by passing data from one system to the next, much like the pipe operator.
> In the accepted [stageless RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/45-stageless.md), this concept is renamed to piping, and "system chaining" is used to construct groups of systems with ordering dependencies between them.
Fixes#6225.
## Changelog
System chaining has been renamed to system piping to improve clarity (and free up the name for new ordering APIs).
## Migration Guide
The `.chain(handler_system)` method on systems is now `.pipe(handler_system)`.
The `IntoChainSystem` trait is now `IntoPipeSystem`, and the `ChainSystem` struct is now `PipeSystem`.
The docs ended up quite verbose :v
Also added a missing `#[inline]` to `GlobalTransform::mul_transform`.
I'd say this resolves#5500
# Migration Guide
`Transform::mul_vec3` has been renamed to `transform_point`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Closes#6202.
The default background color for `NodeBundle` is currently white.
However, it's very rare that you actually want a white background color.
Instead, you often want a background color specific to the style of your game or a transparent background (e.g. for UI layout nodes).
## Solution
`Default` is not derived for `NodeBundle` anymore, but explicitly specified.
The default background color is now transparent (`Color::NONE.into()`) as this is the most common use-case, is familiar from the web and makes specifying a layout for your UI less tedious.
---
## Changelog
- Changed the default `NodeBundle.background_color` to be transparent (`Color::NONE.into()`).
## Migration Guide
If you want a `NodeBundle` with a white background color, you must explicitly specify it:
Before:
```rust
let node = NodeBundle {
..default()
}
```
After:
```rust
let node = NodeBundle {
background_color: Color::WHITE.into(),
..default()
}
```
# Objective
- Reduce code duplication in the `gamepad_viewer` example.
- Fixes#6164
## Solution
- Added a custom Bundle called `GamepadButtonBundle` to avoid repeating similar code throughout the example.
- Created a `new()` method on `GamepadButtonBundle`.
Co-authored-by: Alvin Philips <alvinphilips257@gmail.com>
# Objective
Scene viewer example has switch camera keys defined, but only one camera was instantiated on the scene.
## Solution
More explicit help how to cycle the cameras, explaining that more cameras must be present in loaded scene.
Co-authored-by: Fanda Vacek <fvacek@elektroline.cz>
# Objective
Examples should use the correct tools for the job.
## Solution
A fixed timestep, by design, can step multiple times consecutively in a single update.
That property used to crash the `alien_cake_addict` example (#2525), which was "fixed" in #3411 (by just not panicking). The proper fix is to use a timer instead, since the system is supposed to spawn a cake every 5 seconds.
---
A timer guarantees a minimum duration. A fixed timestep guarantees a fixed number of steps per second.
Each one works by essentially sacrificing the other's guarantee.
You can use them together, but no other systems are timestep-based in this example, so the timer is enough.
# Objective
- Alpha mask was previously ignored when using an unlit material.
- Fixes https://github.com/bevyengine/bevy/issues/4479
## Solution
- Extract the alpha discard to a separate function and use it when unlit is true
## Notes
I tried calling `alpha_discard()` before the `if` in pbr.wgsl, but I had errors related to having a `discard` at the beginning before doing the texture sampling. I'm not sure if there's a way to fix that instead of having the function being called in 2 places.
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
Fixes#6077
# Objective
- Make many_sprites and many_animated_sprites work again
## Solution
- Removed the extra transform from the camera bundle - not sure why it was necessary, since `Camera2dBundle::default()` already contains a transform with the same parameters.
---
# Objective
I was about to submit a PR to add these two examples to `bevy-website` and re-discovered the inconsistency.
Although it's not a major issue on the website where only the filenames are shown, this would help to visually distinguish the two examples in the list because the names are very prominent.
This also helps out when fuzzy-searching the codebase for these files.
## Solution
Rename `shapes` to `2d_shapes`. Now the filename matches the example name, and the naming structure matches the 3d example.
## Notes
@Nilirad proposed this in https://github.com/bevyengine/bevy/pull/4613#discussion_r862455631 but it had slipped away from my brain at that time.
# Objective
Fixes#6078. The `UiColor` component is unhelpfully named: it is unclear, ambiguous with border color and
## Solution
Rename the `UiColor` component (and associated fields) to `BackgroundColor` / `background_colorl`.
## Migration Guide
`UiColor` has been renamed to `BackgroundColor`. This change affects `NodeBundle`, `ButtonBundle` and `ImageBundle`. In addition, the corresponding field on `ExtractedUiNode` has been renamed to `background_color` for consistency.
This is an adoption of #3775
This merges `TextureAtlas` `from_grid_with_padding` into `from_grid` , adding optional padding and optional offset.
Since the orignal PR, the offset had already been added to from_grid_with_padding through #4836
## Changelog
- Added `padding` and `offset` arguments to `TextureAtlas::from_grid`
- Removed `TextureAtlas::from_grid_with_padding`
## Migration Guide
`TextureAtlas::from_grid_with_padding` was merged into `from_grid` which takes two additional parameters for padding and an offset.
```
// 0.8
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1);
// 0.9
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1, None, None)
// 0.8
TextureAtlas::from_grid_with_padding(texture_handle, Vec2::new(24.0, 24.0), 7, 1, Vec2::new(4.0, 4.0));
// 0.9
TextureAtlas::from_grid(texture_handle, Vec2::new(24.0, 24.0), 7, 1, Some(Vec2::new(4.0, 4.0)), None)
```
Co-authored-by: olefish <88390729+oledfish@users.noreply.github.com>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
- Reconfigure surface after present mode changes. It seems that this is not done currently at runtime. It's pretty common for games to change such graphical settings at runtime.
- Fixes present mode issue in #5111
## Solution
- Exactly like resolution change gets tracked when extracting window, do the same for present mode.
Additionally, I added present mode (vsync) toggling to window settings example.
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
@BoxyUwU this is your fault.
Also cart didn't arrive in time to tell us not to do this.
# Objective
- Fix#2974
## Solution
- The first commit just does the actual change
- Follow up commits do steps to prove that this method works to unify as required, but this does not remove `insert_bundle`.
## Changelog
### Changed
Nested bundles now collapse automatically, and every `Component` now implements `Bundle`.
This means that you can combine bundles and components arbitrarily, for example:
```rust
// before:
.insert(A).insert_bundle(MyBBundle{..})
// after:
.insert_bundle((A, MyBBundle {..}))
```
Note that there will be a follow up PR that removes the current `insert` impl and renames `insert_bundle` to `insert`.
### Removed
The `bundle` attribute in `derive(Bundle)`.
## Migration guide
In `derive(Bundle)`, the `bundle` attribute has been removed. Nested bundles are not collapsed automatically. You should remove `#[bundle]` attributes.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
> Note: This is rebased off #4561 and can be viewed as a competitor to that PR. See `Comparison with #4561` section for details.
# Objective
The current serialization format used by `bevy_reflect` is both verbose and error-prone. Taking the following structs[^1] for example:
```rust
// -- src/inventory.rs
#[derive(Reflect)]
struct Inventory {
id: String,
max_storage: usize,
items: Vec<Item>
}
#[derive(Reflect)]
struct Item {
name: String
}
```
Given an inventory of a single item, this would serialize to something like:
```rust
// -- assets/inventory.ron
{
"type": "my_game::inventory::Inventory",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "inv001",
},
"max_storage": {
"type": "usize",
"value": 10
},
"items": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "my_game::inventory::Item",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Pickaxe"
},
},
},
],
},
},
}
```
Aside from being really long and difficult to read, it also has a few "gotchas" that users need to be aware of if they want to edit the file manually. A major one is the requirement that you use the proper keys for a given type. For structs, you need `"struct"`. For lists, `"list"`. For tuple structs, `"tuple_struct"`. And so on.
It also ***requires*** that the `"type"` entry come before the actual data. Despite being a map— which in programming is almost always orderless by default— the entries need to be in a particular order. Failure to follow the ordering convention results in a failure to deserialize the data.
This makes it very prone to errors and annoyances.
## Solution
Using #4042, we can remove a lot of the boilerplate and metadata needed by this older system. Since we now have static access to type information, we can simplify our serialized data to look like:
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
name: "Pickaxe"
),
],
),
}
```
This is much more digestible and a lot less error-prone (no more key requirements and no more extra type names).
Additionally, it is a lot more familiar to users as it follows conventional serde mechanics. For example, the struct is represented with `(...)` when serialized to RON.
#### Custom Serialization
Additionally, this PR adds the opt-in ability to specify a custom serde implementation to be used rather than the one created via reflection. For example[^1]:
```rust
// -- src/inventory.rs
#[derive(Reflect, Serialize)]
#[reflect(Serialize)]
struct Item {
#[serde(alias = "id")]
name: String
}
```
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
id: "Pickaxe"
),
],
),
},
```
By allowing users to define their own serialization methods, we do two things:
1. We give more control over how data is serialized/deserialized to the end user
2. We avoid having to re-define serde's attributes and forcing users to apply both (e.g. we don't need a `#[reflect(alias)]` attribute).
### Improved Formats
One of the improvements this PR provides is the ability to represent data in ways that are more conventional and/or familiar to users. Many users are familiar with RON so here are some of the ways we can now represent data in RON:
###### Structs
```js
{
"my_crate::Foo": (
bar: 123
)
}
// OR
{
"my_crate::Foo": Foo(
bar: 123
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Foo",
"struct": {
"bar": {
"type": "usize",
"value": 123
}
}
}
```
</details>
###### Tuples
```js
{
"(f32, f32)": (1.0, 2.0)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "(f32, f32)",
"tuple": [
{
"type": "f32",
"value": 1.0
},
{
"type": "f32",
"value": 2.0
}
]
}
```
</details>
###### Tuple Structs
```js
{
"my_crate::Bar": ("Hello World!")
}
// OR
{
"my_crate::Bar": Bar("Hello World!")
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Bar",
"tuple_struct": [
{
"type": "alloc::string::String",
"value": "Hello World!"
}
]
}
```
</details>
###### Arrays
It may be a bit surprising to some, but arrays now also use the tuple format. This is because they essentially _are_ tuples (a sequence of values with a fixed size), but only allow for homogenous types. Additionally, this is how RON handles them and is probably a result of the 32-capacity limit imposed on them (both by [serde](https://docs.rs/serde/latest/serde/trait.Serialize.html#impl-Serialize-for-%5BT%3B%2032%5D) and by [bevy_reflect](https://docs.rs/bevy/latest/bevy/reflect/trait.GetTypeRegistration.html#impl-GetTypeRegistration-for-%5BT%3B%2032%5D)).
```js
{
"[i32; 3]": (1, 2, 3)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "[i32; 3]",
"array": [
{
"type": "i32",
"value": 1
},
{
"type": "i32",
"value": 2
},
{
"type": "i32",
"value": 3
}
]
}
```
</details>
###### Enums
To make things simple, I'll just put a struct variant here, but the style applies to all variant types:
```js
{
"my_crate::ItemType": Consumable(
name: "Healing potion"
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::ItemType",
"enum": {
"variant": "Consumable",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Healing potion"
}
}
}
}
```
</details>
### Comparison with #4561
This PR is a rebased version of #4561. The reason for the split between the two is because this PR creates a _very_ different scene format. You may notice that the PR descriptions for either PR are pretty similar. This was done to better convey the changes depending on which (if any) gets merged first. If #4561 makes it in first, I will update this PR description accordingly.
---
## Changelog
* Re-worked serialization/deserialization for reflected types
* Added `TypedReflectDeserializer` for deserializing data with known `TypeInfo`
* Renamed `ReflectDeserializer` to `UntypedReflectDeserializer`
* ~~Replaced usages of `deserialize_any` with `deserialize_map` for non-self-describing formats~~ Reverted this change since there are still some issues that need to be sorted out (in a separate PR). By reverting this, crates like `bincode` can throw an error when attempting to deserialize non-self-describing formats (`bincode` results in `DeserializeAnyNotSupported`)
* Structs, tuples, tuple structs, arrays, and enums are now all de/serialized using conventional serde methods
## Migration Guide
* This PR reduces the verbosity of the scene format. Scenes will need to be updated accordingly:
```js
// Old format
{
"type": "my_game::item::Item",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "bevycraft:stone",
},
"tags": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "alloc::string::String",
"value": "material"
},
],
},
}
// New format
{
"my_game::item::Item": (
id: "bevycraft:stone",
tags: ["material"]
)
}
```
[^1]: Some derives omitted for brevity.
# Objective
Implement `IntoIterator` for `&Extract<P>` if the system parameter it wraps implements `IntoIterator`.
Enables the use of `IntoIterator` with an extracted query.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`AssetServer::watch_for_changes()` is racy and redundant with `AssetServerSettings`.
Closes#5964.
## Changelog
* Remove `AssetServer::watch_for_changes()`
* Add `AssetServerSettings` to the prelude.
* Minor cleanup.
## Migration Guide
`AssetServer::watch_for_changes()` was removed.
Instead, use the `AssetServerSettings` resource.
```rust
app // AssetServerSettings must be inserted before adding the AssetPlugin or DefaultPlugins.
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- To address problems outlined in https://github.com/bevyengine/bevy/issues/5245
## Solution
- Introduce `reflect(skip_serializing)` on top of `reflect(ignore)` which disables automatic serialisation to scenes, but does not disable reflection of the field.
---
## Changelog
- Adds:
- `bevy_reflect::serde::type_data` module
- `SerializationData` structure for describing which fields are to be/not to be ignored, automatically registers as type_data for struct-based types
- the `skip_serialization` flag for `#[reflect(...)]`
- Removes:
- ability to ignore Enum variants in serialization, since that didn't work anyway
## Migration Guide
- Change `#[reflect(ignore)]` to `#[reflect(skip_serializing)]` where disabling reflection is not the intended effect.
- Remove ignore/skip attributes from enum variants as these won't do anything anymore
# Objective
Alice says to make this PR: https://discord.com/channels/691052431525675048/745805740274614303/1018554340841107477
- The "scene" example in the examples folder has a TODO comment about writing the serialized data to a file. This PR implements that.
## Solution
The `AssetIo` trait in the `AssetServer` only supports reading data, not writing it. So, I used `std::io::File` for the implementation. This way, every time you run the example, it will mutate the file in-place.
I had thought about adding a UUID string to the example Component, so that every time you run the example, the file will be guaranteed to change (currently, it just writes the same numbers over and over). However, I didn't bother because it was beyond the scope of the TODO comment.
One thing to note is that the logic for serializing the scene into RON data has changed since the existing RON file was created, and so even though the data is the same, it's rendered in a different order for whatever reason.
I left the changed output to the example file, because it's presumably trivial. I can remove it and force-push if you don't want that included in here.
# Objective
- The `Gamepad` type is a tiny value-containing type that implements `Copy`.
- By convention, references to `Copy` types should be avoided, as they can introduce overhead and muddle the semantics of what's going on.
- This allows us to reduce boilerplate reference manipulation and lifetimes in user facing code.
## Solution
- Make assorted methods on `Gamepads` take / return a raw `Gamepad`, rather than `&Gamepad`.
## Migration Guide
- `Gamepads::iter` now returns an iterator of `Gamepad`. rather than an iterator of `&Gamepad`.
- `Gamepads::contains` now accepts a `Gamepad`, rather than a `&Gamepad`.
# Objective
Since `identity` is a const fn that takes no arguments it seems logical to make it an associated constant.
This is also more in line with types from glam (eg. `Quat::IDENTITY`).
## Migration Guide
The method `identity()` on `Transform`, `GlobalTransform` and `TransformBundle` has been deprecated.
Use the associated constant `IDENTITY` instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Examples inconsistently use either `TAU`, `PI`, `FRAC_PI_2` or `FRAC_PI_4`.
Often in odd ways and without `use`ing the constants, making it difficult to parse.
* Use `PI` to specify angles.
* General code-quality improvements.
* Fix borked `hierarchy` example.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Adopted from #3836
- Example showcases how to request a new resolution
- Example showcases how to react to resolution changes
Co-authored-by: Andreas Weibye <13300393+Weibye@users.noreply.github.com>
# Objective
- Allow users to change the scaling of the UI
- Adopted from #2808
## Solution
- This is an accessibility feature for fixed-size UI elements, allowing the developer to expose a range of UI scales for the player to set a scale that works for their needs.
> - The user can modify the UiScale struct to change the scaling at runtime. This multiplies the Px values by the scale given, while not touching any others.
> - The example showcases how this even allows for fluid transitions
> Here's how the example looks like:
https://user-images.githubusercontent.com/1631166/132979069-044161a9-8e85-45ab-9e93-fcf8e3852c2b.mp4
---
## Changelog
- Added a `UiScale` which can be used to scale all of UI
Co-authored-by: Andreas Weibye <13300393+Weibye@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Very small convenience constructors added to `Size`.
Does not change current examples too much but I'm working on a rather complex UI use-case where this cuts down on some extra typing :)
# Objective
- Replace the square with a circle in the breakout example.
- Fixes#4324, adopted from #4682 by @shaderduck.
## Solution
- Uses the Mesh2D APIs to draw a circle. The collision still uses the AABB algorithm, but it seems to be working fine, and I haven't seen any odd looking cases.
# Objective
This PR changes it possible to use vertex colors without a texture using the bevy_sprite ColorMaterial.
Fixes#5679
## Solution
- Made multiplication of the output color independent of the COLOR_MATERIAL_FLAGS_TEXTURE_BIT bit
- Extended mesh2d_vertex_color_texture example to show off both vertex colors and tinting
Not sure if extending the existing example was the right call but it seems to be reasonable to me.
I couldn't find any tests for the shaders and I think adding shader testing would be beyond the scope of this PR. So no tests in this PR. 😬
Co-authored-by: Jonas Wagner <jonas@29a.ch>
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`bevy::render::texture::ImageSettings` was added to prelude in #5566, so these `use` statements are unnecessary and the examples can be made a bit more concise.
## Solution
Remove `use bevy::render::texture::ImageSettings`
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Change frametimediagnostic from seconds to milliseconds because this will always be less than one seconds and is the common diagnostic display unit for game engines.
## Solution
- multiplied the existing value by 1000
---
## Changelog
Frametimes are now reported in milliseconds
Co-authored-by: Syama Mishra <38512086+SyamaMishra@users.noreply.github.com>
Co-authored-by: McSpidey <mcspidey@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
> This is a revival of #1347. Credit for the original PR should go to @Davier.
Currently, enums are treated as `ReflectRef::Value` types by `bevy_reflect`. Obviously, there needs to be better a better representation for enums using the reflection API.
## Solution
Based on prior work from @Davier, an `Enum` trait has been added as well as the ability to automatically implement it via the `Reflect` derive macro. This allows enums to be expressed dynamically:
```rust
#[derive(Reflect)]
enum Foo {
A,
B(usize),
C { value: f32 },
}
let mut foo = Foo::B(123);
assert_eq!("B", foo.variant_name());
assert_eq!(1, foo.field_len());
let new_value = DynamicEnum::from(Foo::C { value: 1.23 });
foo.apply(&new_value);
assert_eq!(Foo::C{value: 1.23}, foo);
```
### Features
#### Derive Macro
Use the `#[derive(Reflect)]` macro to automatically implement the `Enum` trait for enum definitions. Optionally, you can use `#[reflect(ignore)]` with both variants and variant fields, just like you can with structs. These ignored items will not be considered as part of the reflection and cannot be accessed via reflection.
```rust
#[derive(Reflect)]
enum TestEnum {
A,
// Uncomment to ignore all of `B`
// #[reflect(ignore)]
B(usize),
C {
// Uncomment to ignore only field `foo` of `C`
// #[reflect(ignore)]
foo: f32,
bar: bool,
},
}
```
#### Dynamic Enums
Enums may be created/represented dynamically via the `DynamicEnum` struct. The main purpose of this struct is to allow enums to be deserialized into a partial state and to allow dynamic patching. In order to ensure conversion from a `DynamicEnum` to a concrete enum type goes smoothly, be sure to add `FromReflect` to your derive macro.
```rust
let mut value = TestEnum::A;
// Create from a concrete instance
let dyn_enum = DynamicEnum::from(TestEnum::B(123));
value.apply(&dyn_enum);
assert_eq!(TestEnum::B(123), value);
// Create a purely dynamic instance
let dyn_enum = DynamicEnum::new("TestEnum", "A", ());
value.apply(&dyn_enum);
assert_eq!(TestEnum::A, value);
```
#### Variants
An enum value is always represented as one of its variants— never the enum in its entirety.
```rust
let value = TestEnum::A;
assert_eq!("A", value.variant_name());
// Since we are using the `A` variant, we cannot also be the `B` variant
assert_ne!("B", value.variant_name());
```
All variant types are representable within the `Enum` trait: unit, struct, and tuple.
You can get the current type like:
```rust
match value.variant_type() {
VariantType::Unit => println!("A unit variant!"),
VariantType::Struct => println!("A struct variant!"),
VariantType::Tuple => println!("A tuple variant!"),
}
```
> Notice that they don't contain any values representing the fields. These are purely tags.
If a variant has them, you can access the fields as well:
```rust
let mut value = TestEnum::C {
foo: 1.23,
bar: false
};
// Read/write specific fields
*value.field_mut("bar").unwrap() = true;
// Iterate over the entire collection of fields
for field in value.iter_fields() {
println!("{} = {:?}", field.name(), field.value());
}
```
#### Variant Swapping
It might seem odd to group all variant types under a single trait (why allow `iter_fields` on a unit variant?), but the reason this was done ~~is to easily allow *variant swapping*.~~ As I was recently drafting up the **Design Decisions** section, I discovered that other solutions could have been made to work with variant swapping. So while there are reasons to keep the all-in-one approach, variant swapping is _not_ one of them.
```rust
let mut value: Box<dyn Enum> = Box::new(TestEnum::A);
value.set(Box::new(TestEnum::B(123))).unwrap();
```
#### Serialization
Enums can be serialized and deserialized via reflection without needing to implement `Serialize` or `Deserialize` themselves (which can save thousands of lines of generated code). Below are the ways an enum can be serialized.
> Note, like the rest of reflection-based serialization, the order of the keys in these representations is important!
##### Unit
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "A"
}
}
```
##### Tuple
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "B",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
<details>
<summary>Effects on Option</summary>
This ends up making `Option` look a little ugly:
```json
{
"type": "core::option::Option<usize>",
"enum": {
"variant": "Some",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
</details>
##### Struct
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "C",
"struct": {
"foo": {
"type": "f32",
"value": 1.23
},
"bar": {
"type": "bool",
"value": false
}
}
}
}
```
## Design Decisions
<details>
<summary><strong>View Section</strong></summary>
This section is here to provide some context for why certain decisions were made for this PR, alternatives that could have been used instead, and what could be improved upon in the future.
### Variant Representation
One of the biggest decisions was to decide on how to represent variants. The current design uses a "all-in-one" design where unit, tuple, and struct variants are all simultaneously represented by the `Enum` trait. This is not the only way it could have been done, though.
#### Alternatives
##### 1. Variant Traits
One way of representing variants would be to define traits for each variant, implementing them whenever an enum featured at least one instance of them. This would allow us to define variants like:
```rust
pub trait Enum: Reflect {
fn variant(&self) -> Variant;
}
pub enum Variant<'a> {
Unit,
Tuple(&'a dyn TupleVariant),
Struct(&'a dyn StructVariant),
}
pub trait TupleVariant {
fn field_len(&self) -> usize;
// ...
}
```
And then do things like:
```rust
fn get_tuple_len(foo: &dyn Enum) -> usize {
match foo.variant() {
Variant::Tuple(tuple) => tuple.field_len(),
_ => panic!("not a tuple variant!")
}
}
```
The reason this PR does not go with this approach is because of the fact that variants are not separate types. In other words, we cannot implement traits on specific variants— these cover the *entire* enum. This means we offer an easy footgun:
```rust
let foo: Option<i32> = None;
let my_enum = Box::new(foo) as Box<dyn TupleVariant>;
```
Here, `my_enum` contains `foo`, which is a unit variant. However, since we need to implement `TupleVariant` for `Option` as a whole, it's possible to perform such a cast. This is obviously wrong, but could easily go unnoticed. So unfortunately, this makes it not a good candidate for representing variants.
##### 2. Variant Structs
To get around the issue of traits necessarily needing to apply to both the enum and its variants, we could instead use structs that are created on a per-variant basis. This was also considered but was ultimately [[removed](71d27ab3c6) due to concerns about allocations.
Each variant struct would probably look something like:
```rust
pub trait Enum: Reflect {
fn variant_mut(&self) -> VariantMut;
}
pub enum VariantMut<'a> {
Unit,
Tuple(TupleVariantMut),
Struct(StructVariantMut),
}
struct StructVariantMut<'a> {
fields: Vec<&'a mut dyn Reflect>,
field_indices: HashMap<Cow<'static, str>, usize>
}
```
This allows us to isolate struct variants into their own defined struct and define methods specifically for their use. It also prevents users from casting to it since it's not a trait. However, this is not an optimal solution. Both `field_indices` and `fields` will require an allocation (remember, a `Box<[T]>` still requires a `Vec<T>` in order to be constructed). This *might* be a problem if called frequently enough.
##### 3. Generated Structs
The original design, implemented by @Davier, instead generates structs specific for each variant. So if we had a variant path like `Foo::Bar`, we'd generate a struct named `FooBarWrapper`. This would be newtyped around the original enum and forward tuple or struct methods to the enum with the chosen variant.
Because it involved using the `Tuple` and `Struct` traits (which are also both bound on `Reflect`), this meant a bit more code had to be generated. For a single struct variant with one field, the generated code amounted to ~110LoC. However, each new field added to that variant only added ~6 more LoC.
In order to work properly, the enum had to be transmuted to the generated struct:
```rust
fn variant(&self) -> crate::EnumVariant<'_> {
match self {
Foo::Bar {value: i32} => {
let wrapper_ref = unsafe {
std::mem::transmute::<&Self, &FooBarWrapper>(self)
};
crate::EnumVariant::Struct(wrapper_ref as &dyn crate::Struct)
}
}
}
```
This works because `FooBarWrapper` is defined as `repr(transparent)`.
Out of all the alternatives, this would probably be the one most likely to be used again in the future. The reasons for why this PR did not continue to use it was because:
* To reduce generated code (which would hopefully speed up compile times)
* To avoid cluttering the code with generated structs not visible to the user
* To keep bevy_reflect simple and extensible (these generated structs act as proxies and might not play well with current or future systems)
* To avoid additional unsafe blocks
* My own misunderstanding of @Davier's code
That last point is obviously on me. I misjudged the code to be too unsafe and unable to handle variant swapping (which it probably could) when I was rebasing it. Looking over it again when writing up this whole section, I see that it was actually a pretty clever way of handling variant representation.
#### Benefits of All-in-One
As stated before, the current implementation uses an all-in-one approach. All variants are capable of containing fields as far as `Enum` is concerned. This provides a few benefits that the alternatives do not (reduced indirection, safer code, etc.).
The biggest benefit, though, is direct field access. Rather than forcing users to have to go through pattern matching, we grant direct access to the fields contained by the current variant. The reason we can do this is because all of the pattern matching happens internally. Getting the field at index `2` will automatically return `Some(...)` for the current variant if it has a field at that index or `None` if it doesn't (or can't).
This could be useful for scenarios where the variant has already been verified or just set/swapped (or even where the type of variant doesn't matter):
```rust
let dyn_enum: &mut dyn Enum = &mut Foo::Bar {value: 123};
// We know it's the `Bar` variant
let field = dyn_enum.field("value").unwrap();
```
Reflection is not a type-safe abstraction— almost every return value is wrapped in `Option<...>`. There are plenty of places to check and recheck that a value is what Reflect says it is. Forcing users to have to go through `match` each time they want to access a field might just be an extra step among dozens of other verification processes.
Some might disagree, but ultimately, my view is that the benefit here is an improvement to the ergonomics and usability of reflected enums.
</details>
---
## Changelog
### Added
* Added `Enum` trait
* Added `Enum` impl to `Reflect` derive macro
* Added `DynamicEnum` struct
* Added `DynamicVariant`
* Added `EnumInfo`
* Added `VariantInfo`
* Added `StructVariantInfo`
* Added `TupleVariantInfo`
* Added `UnitVariantInfo`
* Added serializtion/deserialization support for enums
* Added `EnumSerializer`
* Added `VariantType`
* Added `VariantFieldIter`
* Added `VariantField`
* Added `enum_partial_eq(...)`
* Added `enum_hash(...)`
### Changed
* `Option<T>` now implements `Enum`
* `bevy_window` now depends on `bevy_reflect`
* Implemented `Reflect` and `FromReflect` for `WindowId`
* Derive `FromReflect` on `PerspectiveProjection`
* Derive `FromReflect` on `OrthographicProjection`
* Derive `FromReflect` on `WindowOrigin`
* Derive `FromReflect` on `ScalingMode`
* Derive `FromReflect` on `DepthCalculation`
## Migration Guide
* Enums no longer need to be treated as values and usages of `#[reflect_value(...)]` can be removed or replaced by `#[reflect(...)]`
* Enums (including `Option<T>`) now take a different format when serializing. The format is described above, but this may cause issues for existing scenes that make use of enums.
---
Also shout out to @nicopap for helping clean up some of the code here! It's a big feature so help like this is really appreciated!
Co-authored-by: Gino Valente <gino.valente.code@gmail.com>
# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add a section to the example's README on how
to reduce generated wasm executable size.
Add a `wasm-release` profile to bevy's `Cargo.toml`
in order to use it when building bevy-website.
Notes:
- We do not recommend `strip = "symbols"` since it breaks bindgen
- see https://github.com/bevyengine/bevy-website/pull/402
# Objective
Bevy need a way to benchmark UI rendering code,
this PR adds a stress test that spawns a lot of buttons.
## Solution
- Add the `many_buttons` stress test.
---
## Changelog
- Add the `many_buttons` stress test.
If users try to implement a custom asset loader, they must manually import anyhow::error as it's used by the asset loader trait but not exported.
2b93ab5812/examples/asset/custom_asset.rs (L25)Fixes#3138
Co-authored-by: sark <sarkahn@hotmail.com>
# Objective
Creating UI elements is very boilerplate-y with lots of indentation.
This PR aims to reduce boilerplate around creating text elements.
## Changelog
* Renamed `Text::with_section` to `from_section`.
It no longer takes a `TextAlignment` as argument, as the vast majority of cases left it `Default::default()`.
* Added `Text::from_sections` which creates a `Text` from a list of `TextSections`.
Reduces line-count and reduces indentation by one level.
* Added `Text::with_alignment`.
A builder style method for setting the `TextAlignment` of a `Text`.
* Added `TextSection::new`.
Does not reduce line count, but reduces character count and made it easier to read. No more `.to_string()` calls!
* Added `TextSection::from_style` which creates an empty `TextSection` with a style.
No more empty strings! Reduces indentation.
* Added `TextAlignment::CENTER` and friends.
* Added methods to `TextBundle`. `from_section`, `from_sections`, `with_text_alignment` and `with_style`.
## Note for reviewers.
Because of the nature of these changes I recommend setting diff view to 'split'.
~~Look for the book icon~~ cog in the top-left of the Files changed tab.
Have fun reviewing ❤️
<sup> >:D </sup>
## Migration Guide
`Text::with_section` was renamed to `from_section` and no longer takes a `TextAlignment` as argument.
Use `with_alignment` to set the alignment instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Provide better compile-time errors and diagnostics.
- Add more options to allow more textures types and sampler types.
- Update array_texture example to use upgraded AsBindGroup derive macro.
## Solution
Split out the parsing of the inner struct/field attributes (the inside part of a `#[foo(...)]` attribute) for better clarity
Parse the binding index for all inner attributes, as it is part of all attributes (`#[foo(0, ...)`), then allow each attribute implementer to parse the rest of the attribute metadata as needed. This should make it very trivial to extend/change if needed in the future.
Replaced invocations of `panic!` with the `syn::Error` type, providing fine-grained errors that retains span information. This provides much nicer compile-time errors, and even better IDE errors.

Updated the array_texture example to demonstrate the new changes.
## New AsBindGroup attribute options
### `#[texture(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|-------------- |---------------------------------------------------------------- | ----------- |
| dimension = "..." | `"1d"`, `"2d"`, `"2d_array"`, `"3d"`, `"cube"`, `"cube_array"` | `"2d"` |
| sample_type = "..." | `"float"`, `"depth"`, `"s_int"` or `"u_int"` | `"float"` |
| filterable = ... | `true`, `false` | `true` |
| multisampled = ... | `true`, `false` | `false` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[texture(0, dimension = "2d_array", visibility(vertex, fragment))]`
### `#[sampler(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|----------- |--------------------------------------------------- | ----------- |
| sampler_type = "..." | `"filtering"`, `"non_filtering"`, `"comparison"`. | `"filtering"` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[sampler(0, sampler_type = "filtering", visibility(vertex, fragment)]`
## Changelog
- Added more options to `#[texture(...)]` and `#[sampler(...)]` attributes, supporting more kinds of materials. See above for details.
- Upgraded IDE and compile-time error messages.
- Updated array_texture example using the new options.
# Objective
- Help user when they need to add both a `TransformBundle` and a `VisibilityBundle`
## Solution
- Add a `SpatialBundle` adding all components
Birbs no longer bounce too low, not coming close to their true bouncy potential.
Birbs also no longer bonk head when window is smaller. (Will still bonk head when window is made smaller too fast! pls no)
*cough cough*
Make the height of the birb-bounces dependent on the window size so they always bounce elegantly towards the top of the window.
Also no longer panics when closing the window q:
~~Might put a video here if I figure out how to.~~
<sup> rendering video is hard. birbrate go brr
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Port changes made to Material in #5053 to Material2d as well.
This is more or less an exact copy of the implementation in bevy_pbr; I
simply pretended the API existed, then copied stuff over until it
started building and the shapes example was working again.
# Objective
The changes in #5053 makes it possible to add custom materials with a lot less boiler plate. However, the implementation isn't shared with Material 2d as it's a kind of fork of the bevy_pbr version. It should be possible to use AsBindGroup on the 2d version as well.
## Solution
This makes the same kind of changes in Material2d in bevy_sprite.
This makes the following work:
```rust
//! Draws a circular purple bevy in the middle of the screen using a custom shader
use bevy::{
prelude::*,
reflect::TypeUuid,
render::render_resource::{AsBindGroup, ShaderRef},
sprite::{Material2d, Material2dPlugin, MaterialMesh2dBundle},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(Material2dPlugin::<CustomMaterial>::default())
.add_startup_system(setup)
.run();
}
/// set up a simple 2D scene
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<CustomMaterial>>,
asset_server: Res<AssetServer>,
) {
commands.spawn_bundle(MaterialMesh2dBundle {
mesh: meshes.add(shape::Circle::new(50.).into()).into(),
material: materials.add(CustomMaterial {
color: Color::PURPLE,
color_texture: Some(asset_server.load("branding/icon.png")),
}),
transform: Transform::from_translation(Vec3::new(-100., 0., 0.)),
..default()
});
commands.spawn_bundle(Camera2dBundle::default());
}
/// The Material2d trait is very configurable, but comes with sensible defaults for all methods.
/// You only need to implement functions for features that need non-default behavior. See the Material api docs for details!
impl Material2d for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"shaders/custom_material.wgsl".into()
}
}
// This is the struct that will be passed to your shader
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Showcase how to use a `Material` and `Mesh` to spawn 3d lines
## Solution
- Add an example using a simple `Material` and `Mesh` definition to draw a 3d line
- Shows how to use `LineList` and `LineStrip` in combination with a specialized `Material`
## Notes
This isn't just a primitive shape because it needs a special Material, but I think it's a good showcase of the power of the `Material` and `AsBindGroup` abstractions. All of this is easy to figure out when you know these options are a thing, but I think they are hard to discover which is why I think this should be an example and not shipped with bevy.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Reduce confusion as the example opens a window and isn't truly "headless"
- Fixes https://github.com/bevyengine/bevy/issues/5260.
## Solution
- Rename the example and add to the docs that the window is expected.
## Objective
Implement absolute minimum viable product for the changes proposed in bevyengine/rfcs#53.
## Solution
- Remove public mutative access to `Parent` (Children is already publicly read-only). This includes public construction methods like `Copy`, `Clone`, and `Default`.
- Remove `PreviousParent`
- Remove `parent_update_system`
- Update all hierarchy related commands to immediately update both `Parent` and `Children` references.
## Remaining TODOs
- [ ] Update documentation for both `Parent` and `Children`. Discourage using `EntityCommands::remove`
- [x] Add `HierarchyEvent` to notify listeners of hierarchy updates. This is meant to replace listening on `PreviousParent`
## Followup
- These changes should be best moved to the hooks mentioned in #3742.
- Backing storage for both might be best moved to indexes mentioned in the same relations.
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Add texture sampling to the GLSL shader example, as naga does not support the commonly used sampler2d type.
Fixes#5059
## Solution
- Align the shader_material_glsl example behaviour with the shader_material example, as the later includes texture sampling.
- Update the GLSL shader to do texture sampling the way naga supports it, and document the way naga does not support it.
## Changelog
- The shader_material_glsl example has been updated to demonstrate texture sampling using the GLSL shading language.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
Intended to close#5073
## Solution
Adds a stress test that use TextureAtlas based on the existing many_sprites test using the animated sprite implementation from the sprite_sheet example.
In order to satisfy the goals described in #5073 the animations are all slightly offset.
Of note is that the original stress test was designed to test fullstrum culling. I kept this test similar as to facilitate easy comparisons between the use of TextureAtlas and without.
# Objective
Currently stress tests are vsynced. This is undesirable for a stress test, as you want to run them with uncapped framerates.
## Solution
Ensure all stress tests are using PresentMode::Immediate if they render anything.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make Bevy work on android
## Solution
- Update android metadata and add a few more
- Set the target sdk to 31 as it will soon (in august) be the minimum sdk level for play store
- Remove the custom code to create an activity and use ndk-glue macro instead
- Delay window creation event on android
- Set the example with compatibility settings for wgpu. Those are needed for Bevy to work on my 2019 android tablet
- Add a few details on how to debug in case of failures
- Fix running the example on emulator. This was failing because of the name of the example
Bevy still doesn't work on android with this, audio features need to be disabled because of an ndk-glue version mismatch: rodio depends on 0.6.2, winit on 0.5.2. You can test with:
```
cargo apk run --release --example android_example --no-default-features --features "bevy_winit,render"
```
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Small bug in the example game given in examples/ecs/ecs_guide
Currently, if there are 2 players in this example game, the function exclusive_player_system can add a player with the name "Player 2". However, the name should be "Player 3". This PR fixes this. I also add a message to inform that a new player has arrived in the mock game.
Co-authored-by: Dilyan Kostov <dilyanks@amazon.com>
# Objective
- Have information about examples only in one place that can be used for the repo and for the website (and remove the need to keep a list of example to build for wasm in the website 75acb73040/generate-wasm-examples/generate_wasm_examples.sh (L92-L99))
## Solution
- Add metadata about examples in `Cargo.toml`
- Build the `examples/README.md` from a template using those metadata. I used tera as the template engine to use the same tech as the website.
- Make CI fail if an example is missing metadata, or if the readme file needs to be updated (the command to update it is displayed in the failed step in CI)
## Remaining To Do
- After the next release with this merged in, the website will be able to be updated to use those metadata too
- I would like to build the examples in wasm and make them available at http://dev-docs.bevyengine.org/ but that will require more design
- https://github.com/bevyengine/bevy-website/issues/299 for other ToDos
Co-authored-by: Readme <github-actions@github.com>
# Objective
`bevy_ui` doesn't support correctly touch inputs because of two problems in the focus system:
- It attempts to retrieve touch input with a specific `0` id
- It doesn't retrieve touch positions and bases its focus solely on mouse position, absent from mobile devices
## Solution
I added a few methods to the `Touches` resource, allowing to check if **any** touch input was pressed, released or cancelled and to retrieve the *position* of the first pressed touch input and adapted the focus system.
I added a test button to the *iOS* example and it works correclty on emulator. I did not test on a real touch device as:
- Android is not working (https://github.com/bevyengine/bevy/issues/3249)
- I don't have an iOS device
- changed `EntityCountDiagnosticsPlugin` to not use an exclusive system to get its entity count
- removed mention of `WgpuResourceDiagnosticsPlugin` in example `log_diagnostics` as it doesn't exist anymore
- added ability to enable, disable ~~or toggle~~ a diagnostic (fix#3767)
- made diagnostic values lazy, so they are only computed if the diagnostic is enabled
- do not log an average for diagnostics with only one value
- removed `sum` function from diagnostic as it isn't really useful
- ~~do not keep an average of the FPS diagnostic. it is already an average on the last 20 frames, so the average FPS was an average of the last 20 frames over the last 20 frames~~
- do not compute the FPS value as an average over the last 20 frames but give the actual "instant FPS"
- updated log format to use variable capture
- added some doc
- the frame counter diagnostic value can be reseted to 0
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
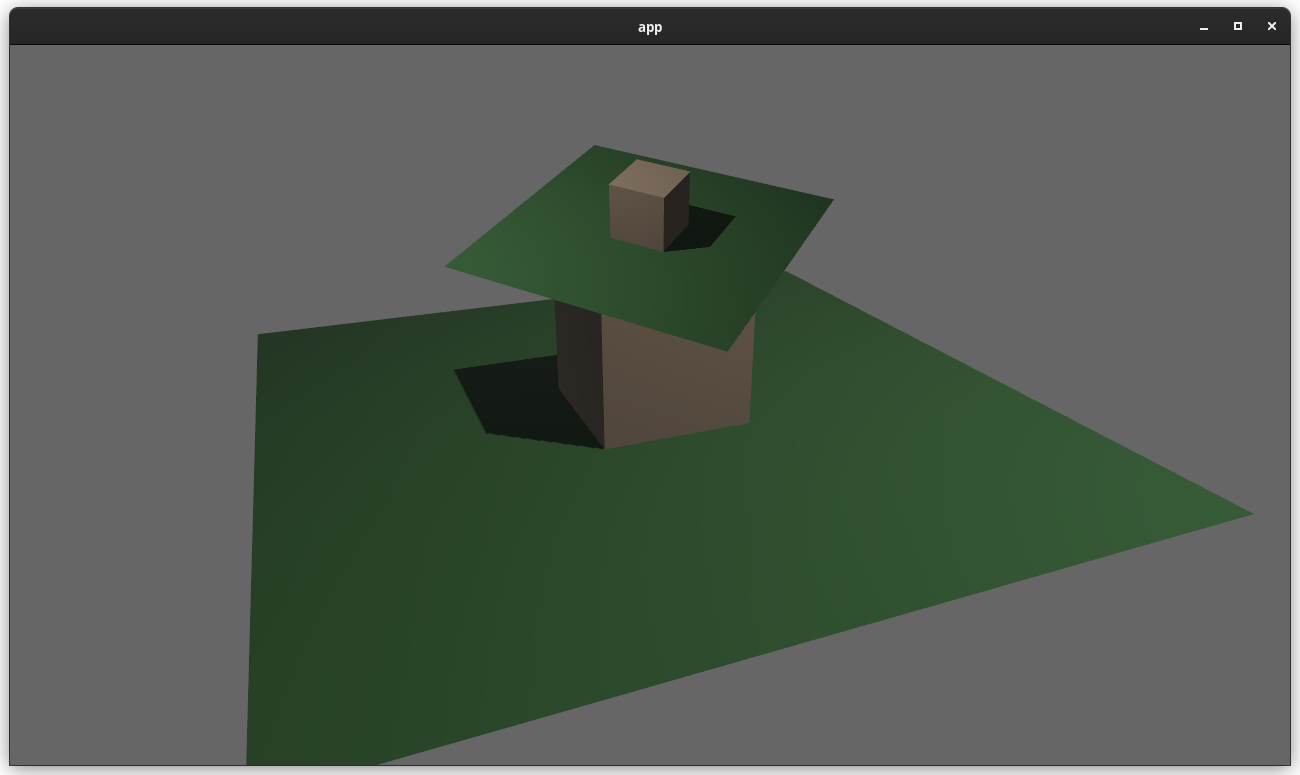
### two_passes example with the "second pass" camera configured to "load" the depth
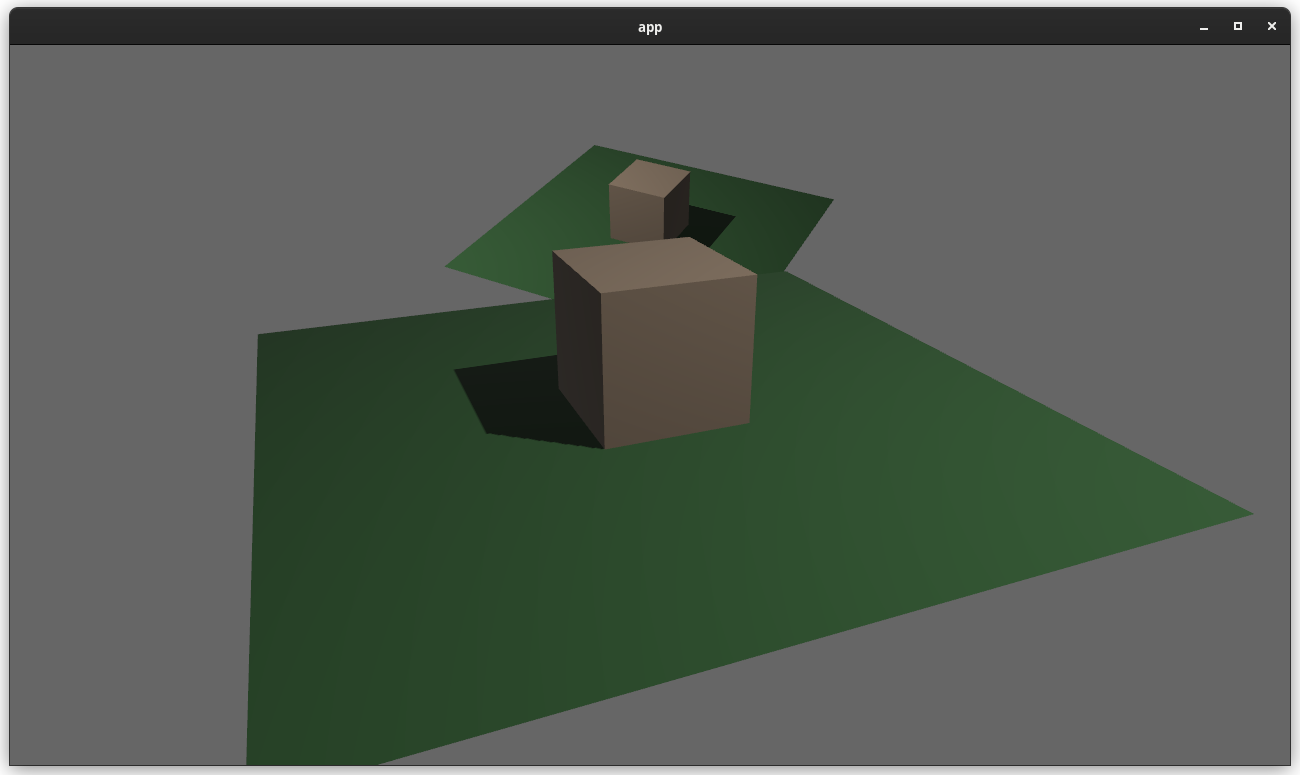
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
# Objective
In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access.
## Solution
Remove the `With<Handle<Mesh>>` filter
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
# Objective
- To fix the broken commented code in `examples/shader/compute_shader_game_of_life.rs` for disabling frame throttling
## Solution
- Change the commented code from using the old `WindowDescriptor::vsync` to the new `WindowDescriptor::present_mode`
### Note
I chose to use the fully qualified scope `bevy:🪟:PresentWindow::Immediate` rather than explicitly including `PresentWindow` to avoid an unused import when the code is commented.
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Split PBR and 2D mesh shaders into types and bindings to prepare the shaders to be more reusable.
- See #3969 for details. I'm doing this in multiple steps to make review easier.
---
## Changelog
- Changed: 2D and PBR mesh shaders are now split into types and bindings, the following shader imports are available: `bevy_pbr::mesh_view_types`, `bevy_pbr::mesh_view_bindings`, `bevy_pbr::mesh_types`, `bevy_pbr::mesh_bindings`, `bevy_sprite::mesh2d_view_types`, `bevy_sprite::mesh2d_view_bindings`, `bevy_sprite::mesh2d_types`, `bevy_sprite::mesh2d_bindings`
## Migration Guide
- In shaders for 3D meshes:
- `#import bevy_pbr::mesh_view_bind_group` -> `#import bevy_pbr::mesh_view_bindings`
- `#import bevy_pbr::mesh_struct` -> `#import bevy_pbr::mesh_types`
- NOTE: If you are using the mesh bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_pbr::mesh_bindings` which itself imports the mesh types needed for the bindings.
- In shaders for 2D meshes:
- `#import bevy_sprite::mesh2d_view_bind_group` -> `#import bevy_sprite::mesh2d_view_bindings`
- `#import bevy_sprite::mesh2d_struct` -> `#import bevy_sprite::mesh2d_types`
- NOTE: If you are using the mesh2d bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_sprite::mesh2d_bindings` which itself imports the mesh2d types needed for the bindings.
# Objective
- The `scene_viewer` example assumes the `animation` feature is enabled, which it is by default. However, animations may have a performance cost that is undesirable when testing performance, for example. Then it is useful to be able to disable the `animation` feature and one would still like the `scene_viewer` example to work.
## Solution
- Gate animation code in `scene_viewer` on the `animation` feature being enabled.
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
- Add Vertex Color support to 2D meshes and ColorMaterial. This extends the work from #4528 (which in turn builds on the excellent tangent handling).
## Solution
- Added `#ifdef` wrapped support for vertex colors in the 2D mesh shader and `ColorMaterial` shader.
- Added an example, `mesh2d_vertex_color_texture` to demonstrate it in action.

---
## Changelog
- Added optional (ifdef wrapped) vertex color support to the 2dmesh and color material systems.
# Objective
- Sometimes, people might load an asset as one type, then use it with an `Asset`s for a different type.
- See e.g. #4784.
- This is especially likely with the Gltf types, since users may not have a clear conceptual model of what types the assets will be.
- We had an instance of this ourselves, in the `scene_viewer` example
## Solution
- Make `Assets::get` require a type safe handle.
---
## Changelog
### Changed
- `Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles.
### Added
- `HandleUntyped::typed_weak`, a helper function for creating a weak typed version of an exisitng `HandleUntyped`.
## Migration Guide
`Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles. If you were previously passing in:
- a `HandleId`, use `&Handle::weak(id)` instead, to create a weak handle. You may have been able to store a type safe `Handle` instead.
- a `HandleUntyped`, use `&handle_untyped.typed_weak()` to create a weak handle of the specified type. This is most likely to be the useful when using [load_folder](https://docs.rs/bevy_asset/latest/bevy_asset/struct.AssetServer.html#method.load_folder)
- a `Handle<U>` of of a different type, consider whether this is the correct handle type to store. If it is (i.e. the same handle id is used for multiple different Asset types) use `Handle::weak(handle.id)` to cast to a different type.
# Objective
Fixes#3183. Requiring a `&TaskPool` parameter is sort of meaningless if the only correct one is to use the one provided by `Res<ComputeTaskPool>` all the time.
## Solution
Have `QueryState` save a clone of the `ComputeTaskPool` which is used for all `par_for_each` functions.
~~Adds a small overhead of the internal `Arc` clone as a part of the startup, but the ergonomics win should be well worth this hardly-noticable overhead.~~
Updated the docs to note that it will panic the task pool is not present as a resource.
# Future Work
If https://github.com/bevyengine/rfcs/pull/54 is approved, we can replace these resource lookups with a static function call instead to get the `ComputeTaskPool`.
---
## Changelog
Removed: The `task_pool` parameter of `Query(State)::par_for_each(_mut)`. These calls will use the `World`'s `ComputeTaskPool` resource instead.
## Migration Guide
The `task_pool` parameter for `Query(State)::par_for_each(_mut)` has been removed. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(
task_pool: Res<ComputeTaskPool>,
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
If using `Query(State)` outside of a system run by the scheduler, you may need to manually configure and initialize a `ComputeTaskPool` as a resource in the `World`.
# Objective
- Coming from 7a596f1910 (r876310734)
- Simplify the examples regarding addition of `Msaa` Resource with default value.
## Solution
- Remove addition of `Msaa` Resource with default value from examples,
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by minimally splitting off time functionality into bevy_time. Functionality like that provided by #3002 would increase the complexity of bevy_time, so this is a good candidate for pulling into its own unit.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Pull the time module of bevy_core into a new crate, bevy_time.
# Migration guide
- Time related types (e.g. `Time`, `Timer`, `Stopwatch`, `FixedTimestep`, etc.) should be imported from `bevy::time::*` rather than `bevy::core::*`.
- If you were adding `CorePlugin` manually, you'll also want to add `TimePlugin` from `bevy::time`.
- The `bevy::core::CorePlugin::Time` system label is replaced with `bevy::time::TimeSystem`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
> ℹ️ **Note**: This is a rebased version of #2383. A large portion of it has not been touched (only a few minor changes) so that any additional discussion may happen here. All credit should go to @NathanSWard for their work on the original PR.
- Currently reflection is not supported for arrays.
- Fixes#1213
## Solution
* Implement reflection for arrays via the `Array` trait.
* Note, `Array` is different from `List` in the way that you cannot push elements onto an array as they are statically sized.
* Now `List` is defined as a sub-trait of `Array`.
---
## Changelog
* Added the `Array` reflection trait
* Allows arrays up to length 32 to be reflected via the `Array` trait
## Migration Guide
* The `List` trait now has the `Array` supertrait. This means that `clone_dynamic` will need to specify which version to use:
```rust
// Before
let cloned = my_list.clone_dynamic();
// After
let cloned = List::clone_dynamic(&my_list);
```
* All implementers of `List` will now need to implement `Array` (this mostly involves moving the existing methods to the `Array` impl)
Co-authored-by: NathanW <nathansward@comcast.net>
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- It's pretty common to want to check if an EventReader has received one or multiple events while also needing to consume the iterator to "clear" the EventReader.
- The current approach is to do something like `events.iter().count() > 0` or `events.iter().last().is_some()`. It's not immediately obvious that the purpose of that is to consume the events and check if there were any events. My solution doesn't really solve that part, but it encapsulates the pattern.
## Solution
- Add a `.clear()` method that consumes the iterator.
- It takes the EventReader by value to make sure it isn't used again after it has been called.
---
## Migration Guide
Not a breaking change, but if you ever found yourself in a situation where you needed to consume the EventReader and check if there was any events you can now use
```rust
fn system(events: EventReader<MyEvent>) {
if !events.is_empty {
events.clear();
// Process the fact that one or more event was received
}
}
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
Fixes#3180, builds from https://github.com/bevyengine/bevy/pull/2898
## Solution
Support requesting a window to be closed and closing a window in `bevy_window`, and handle this in `bevy_winit`.
This is a stopgap until we move to windows as entites, which I'm sure I'll get around to eventually.
## Changelog
### Added
- `Window::close` to allow closing windows.
- `WindowClosed` to allow reacting to windows being closed.
### Changed
Replaced `bevy::system::exit_on_esc_system` with `bevy:🪟:close_on_esc`.
## Fixed
The app no longer exits when any window is closed. This difference is only observable when there are multiple windows.
## Migration Guide
`bevy::input::system::exit_on_esc_system` has been removed. Use `bevy:🪟:close_on_esc` instead.
`CloseWindow` has been removed. Use `Window::close` instead.
The `Close` variant has been added to `WindowCommand`. Handle this by closing the relevant window.
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
Bevy users often want to create circles and other simple shapes.
All the machinery is in place to accomplish this, and there are external crates that help. But when writing code for e.g. a new bevy example, it's not really possible to draw a circle without bringing in a new asset, writing a bunch of scary looking mesh code, or adding a dependency.
In particular, this PR was inspired by this interaction in another PR: https://github.com/bevyengine/bevy/pull/3721#issuecomment-1016774535
## Solution
This PR adds `shape::RegularPolygon` and `shape::Circle` (which is just a `RegularPolygon` that defaults to a large number of sides)
## Discussion
There's a lot of ongoing discussion about shapes in <https://github.com/bevyengine/rfcs/pull/12> and at least one other lingering shape PR (although it seems incomplete).
That RFC currently includes `RegularPolygon` and `Circle` shapes, so I don't think that having working mesh generation code in the engine for those shapes would add much burden to an author of an implementation.
But if we'd prefer not to add additional shapes until after that's sorted out, I'm happy to close this for now.
## Alternatives for users
For any users stumbling on this issue, here are some plugins that will help if you need more shapes.
https://github.com/Nilirad/bevy_prototype_lyonhttps://github.com/johanhelsing/bevy_smudhttps://github.com/Weasy666/bevy_svghttps://github.com/redpandamonium/bevy_more_shapeshttps://github.com/ForesightMiningSoftwareCorporation/bevy_polyline
This is a replacement for #2106
This adds a `Metadata` struct which contains metadata information about a file, at the moment only the file type.
It also adds a `get_metadata` to `AssetIo` trait and an `asset_io` accessor method to `AssetServer` and `LoadContext`
I am not sure about the changes in `AndroidAssetIo ` and `WasmAssetIo`.
# Objective
- As requested here: https://github.com/bevyengine/bevy/pull/4520#issuecomment-1109302039
- Make it easier to spot issues with built-in shapes
## Solution
https://user-images.githubusercontent.com/200550/165624709-c40dfe7e-0e1e-4bd3-ae52-8ae66888c171.mp4
- Add an example showcasing the built-in 3d shapes with lighting/shadows
- Rotate objects in such a way that all faces are seen by the camera
- Add a UV debug texture
## Discussion
I'm not sure if this is what @alice-i-cecile had in mind, but I adapted the little "torus playground" from the issue linked above to include all built-in shapes.
This exact arrangement might not be particularly scalable if many more shapes are added. Maybe a slow camera pan, or cycling with the keyboard or on a timer, or a sidebar with buttons would work better. If one of the latter options is used, options for showing wireframes or computed flat normals might add some additional utility.
Ideally, I think we'd have a better way of visualizing normals.
Happy to rework this or close it if there's not a consensus around it being useful.
# Objective
- Part of the splitting process of #3692.
## Solution
- Remove / change the tuple structs inside of `gamepad.rs` of `bevy_input` to normal structs.
## Reasons
- It made the `gamepad_connection_system` cleaner.
- It made the `gamepad_input_events.rs` example cleaner (which is probably the most notable change for the user facing API).
- Tuple structs are not descriptive (`.0`, `.1`).
- Using tuple structs for more than 1 field is a bad idea (This means that the `Gamepad` type might be fine as a tuple struct, but I still prefer normal structs over tuple structs).
Feel free to discuss this change as this is more or less just a matter of taste.
## Changelog
### Changed
- The `Gamepad`, `GamepadButton`, `GamepadAxis`, `GamepadEvent` and `GamepadEventRaw` types are now normal structs instead of tuple structs and have a `new()` function.
## Migration Guide
- The `Gamepad`, `GamepadButton`, `GamepadAxis`, `GamepadEvent` and `GamepadEventRaw` types are now normal structs instead of tuple structs and have a `new()` function. To migrate change every instantiation to use the `new()` function instead and use the appropriate field names instead of `.0` and `.1`.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by moving FloatOrd to bevy_utils.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Move FloatOrd into bevy_utils. Fix the compile errors.
As a result, bevy_core_pipeline, bevy_pbr, bevy_sprite, bevy_text, and bevy_ui no longer depend on bevy_core (they were only using it for `FloatOrd` previously).
# Objective
- Closes#335.
- Related #4285.
- Part of the splitting process of #3503.
## Solution
- Move `Rect` to `bevy_ui` and rename it to `UiRect`.
## Reasons
- `Rect` is only used in `bevy_ui` and therefore calling it `UiRect` makes the intent clearer.
- We have two types that are called `Rect` currently and it's missleading (see `bevy_sprite::Rect` and #335).
- Discussion in #3503.
## Changelog
### Changed
- The `Rect` type got moved from `bevy_math` to `bevy_ui` and renamed to `UiRect`.
## Migration Guide
- The `Rect` type got renamed to `UiRect`. To migrate you just have to change every occurrence of `Rect` to `UiRect`.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Related #4276.
- Part of the splitting process of #3503.
## Solution
- Move `Size` to `bevy_ui`.
## Reasons
- `Size` is only needed in `bevy_ui` (because it needs to use `Val` instead of `f32`), but it's also used as a worse `Vec2` replacement in other areas.
- `Vec2` is more powerful than `Size` so it should be used whenever possible.
- Discussion in #3503.
## Changelog
### Changed
- The `Size` type got moved from `bevy_math` to `bevy_ui`.
## Migration Guide
- The `Size` type got moved from `bevy::math` to `bevy::ui`. To migrate you just have to import `bevy::ui::Size` instead of `bevy::math::Math` or use the `bevy::prelude` instead.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Fixes#4234
- Fixes#4473
- Built on top of #3989
- Improve performance of `assign_lights_to_clusters`
## Solution
- Remove the OBB-based cluster light assignment algorithm and calculation of view space AABBs
- Implement the 'iterative sphere refinement' algorithm used in Just Cause 3 by Emil Persson as documented in the Siggraph 2015 Practical Clustered Shading talk by Persson, on pages 42-44 http://newq.net/dl/pub/s2015_practical.pdf
- Adapt to also support orthographic projections
- Add `many_lights -- orthographic` for testing many lights using an orthographic projection
## Results
- `assign_lights_to_clusters` in `many_lights` before this PR on an M1 Max over 1500 frames had a median execution time of 1.71ms. With this PR it is 1.51ms, a reduction of 0.2ms or 11.7% for this system.
---
## Changelog
- Changed: Improved cluster light assignment performance
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Continue the effort to clean up this example
## Solution
- Store contributor name as component to avoid awkward vec of tuples
- Name the variable storing the Random Number Generator "rng"
- Use init_resource for resource implementing default
- Fix a few spots where an Entity was unnecessarily referenced and immediately dereferenced
- Fix up an awkward comment
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3499
## Solution
Uses a `HashMap` from `RenderTarget` to sampled textures when preparing `ViewTarget`s to ensure that two passes with the same render target get sampled to the same texture.
This builds on and depends on https://github.com/bevyengine/bevy/pull/3412, so this will be a draft PR until #3412 is merged. All changes for this PR are in the last commit.
# Objective
glTF files can contain cameras. Currently the scene viewer example uses _a_ camera defined in the file if possible, otherwise it spawns a new one. It would be nice if instead it could load all the cameras and cycle through them, while also having a separate user-controller camera.
## Solution
- instead of just a camera that is already defined, always spawn a new separate user-controller camera
- maintain a list of loaded cameras and cycle through them (wrapping to the user-controller camera) when pressing `C`
This matches the behavious that https://github.khronos.org/glTF-Sample-Viewer-Release/ has.
## Implementation notes
- The gltf scene asset loader just spawns the cameras into the world, but does not return a mapping of camera index to bevy entity. So instead the scene_viewer example just collects all spawned cameras with a good old `query.iter().collect()`, so the order is unspecified and may change between runs.
## Demo
https://user-images.githubusercontent.com/22177966/161826637-40161482-5b3b-4df5-aae8-1d5e9b918393.mp4
using the virtual city glTF sample file: https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/VC
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Several examples are useful for qualitative tests of Bevy's performance
- By contrast, these are less useful for learning material: they are often relatively complex and have large amounts of setup and are performance optimized.
## Solution
- Move bevymark, many_sprites and many_cubes into the new stress_tests example folder
- Move contributors into the games folder: unlike the remaining examples in the 2d folder, it is not focused on demonstrating a clear feature.
Remove the 'chaining' api, as it's peculiar
~~Implement the label traits for `Box<dyn ThatTrait>` (n.b. I'm not confident about this change, but it was the quickest path to not regressing)~~
Remove the need for '`.system`' when using run criteria piping
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Changing animation mid animation can leave the model not in its original position
- ~~The movement speed is fixed, no matter the size of the model~~
## Solution
- when changing animation, set it to its initial state and wait for one frame before changing the animation
- ~~when settings the camera controller, use the camera transform to know how far it is from the origin and use the distance for the speed~~
The scene viewer example doesn't run on wasm because it sets the asset folder to `std::env::var("CARGO_MANIFEST_DIR").unwrap()`, which isn't supported on the web.
Solution: set the asset folder to `"."` instead.
# Objective
- `Local`s can no longer be accessed outside of their creating system, but these docs say they can be.
- There's also little reason to have a pure wrapper type for `Local`s; they can just use the real type. The parameter name should be sufficiently documenting.
# Objective
- Only move the camera when explicitly wanted, otherwise the camera goes crazy if the cursor isn't already in the middle of the window when it opens.
## Solution
- Check if the Left mouse button is pressed before updating the mouse delta
- Input is configurable
The example was broken in #3635 when the `ActiveCamera` logic was introduced, after which there could only be one active `Camera3d` globally.
Ideally there could be one `Camera3d` per render target, not globally, but that isn't the case yet.
To fix the example, we need to
- don't use `Camera3d` twice, add a new `SecondWindowCamera3d` marker
- add the `CameraTypePlugin::<SecondWindowCamera3d>`
- extract the correct `RenderPhase`s
- add a 3d pass driver node for the secondary camera
Fixes#4378
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Since #4224, using labels which only refer to one system doesn't make sense.
## Solution
- Remove some of those.
## Future work
- We should remove the ability to use strings as system labels entirely. I haven't in this PR because there are tests which use this, and that's a lot of code to change.
- The only use cases for labels are either intra-crate, which use #4224, or inter-crate, which should either use #4224 or explicit types. Neither of those should use strings.
# Objective
Add a system parameter `ParamSet` to be used as container for conflicting parameters.
## Solution
Added two methods to the SystemParamState trait, which gives the access used by the parameter. Did the implementation. Added some convenience methods to FilteredAccessSet. Changed `get_conflicts` to return every conflicting component instead of breaking on the first conflicting `FilteredAccess`.
Co-authored-by: bilsen <40690317+bilsen@users.noreply.github.com>
# Objective
Fixes#4344.
## Solution
Add a new component `Text2dBounds` to `Text2dBundle` that specifies the maximum width and height of text. Text will wrap according to this size.
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
1. Spawning walls in the Breakout example was hard to follow and error-prone.
2. The strategy used in `paddle_movement_system` was somewhat convoluted.
3. Correctly modifying the size of the arena was hard, due to implicit coupling between the bounds and the bounds that the paddle can move in.
## Solution
1. Refactor this to use a WallBundle struct with a builder; neatly demonstrating some essential patterns along the way.
2. Use clamp and avoid using weird &mut strategies.
3. Refactor logic to allow users to tweak the brick size, and automatically adjust the number of rows and columns to match.
4. Make the brick layout more like classic breakout!
# Objective
- The Breakout example uses system names like `paddle_movement_system`
- _system syntax is redundant
- the [community has spoken](https://github.com/bevyengine/bevy/discussions/2804), and prefers to avoid `_system` system names by a more than 2:1 ratio
- existing system names were not terribly descriptive
## Solution
- rename the systems to take the form of `verb`, rather than `noun_system` to better capture the behavior they are implenting
- yeet `_system`
This adds the concept of "default labels" for systems (currently scoped to "parallel systems", but this could just as easily be implemented for "exclusive systems"). Function systems now include their function's `SystemTypeIdLabel` by default.
This enables the following patterns:
```rust
// ordering two systems without manually defining labels
app
.add_system(update_velocity)
.add_system(movement.after(update_velocity))
// ordering sets of systems without manually defining labels
app
.add_system(foo)
.add_system_set(
SystemSet::new()
.after(foo)
.with_system(bar)
.with_system(baz)
)
```
Fixes: #4219
Related to: #4220
Credit to @aevyrie @alice-i-cecile @DJMcNab (and probably others) for proposing (and supporting) this idea about a year ago. I was a big dummy that both shut down this (very good) idea and then forgot I did that. Sorry. You all were right!
# Objective
- The components in the Breakout game are defined in a strange fashion.
- Components should decouple behavior wherever possible.
- Systems should be as general as possible, to make extending behavior easier.
- Marker components are idiomatic and useful, but marker components and query filters were not used.
- The existing design makes it challenging for beginners to extend the example into a high-quality game.
## Solution
- Refactor component definitions in the Breakout example to reflect principles above.
## Context
A small portion of the changes made in #2094. Interacts with changes in #4255; merge conflicts will have to be resolved.
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Objective
There recently was a discussion on Discord about a possible test case for stress-testing transform hierarchies.
## Solution
Create a test case for stress testing transform propagation.
*Edit:* I have scrapped my previous example and built something more functional and less focused on visuals.
There are three test setups:
- `TestCase::Tree` recursively creates a tree with a specified depth and branch width
- `TestCase::NonUniformTree` is the same as `Tree` but omits nodes in a way that makes the tree "lean" towards one side, like this:
<details>
<summary></summary>
</details>
- `TestCase::Humanoids` creates one or more separate hierarchies based on the structure of common humanoid rigs
- this can both insert `active` and `inactive` instances of the human rig
It's possible to parameterize which parts of the hierarchy get updated (transform change) and which remain unchanged. This is based on @james7132 suggestion:
There's a probability to decide which entities should remain static. On top of that these changes can be limited to a certain range in the hierarchy (min_depth..max_depth).
# Objective
- The Breakout example has a lot of configurable constant values for setup, but these are buried in the source code.
- Magic numbers scattered in the source code are hard to follow.
- Providing constants up front makes tweaking examples very approachable.
## Solution
- Move magic numbers into constants
## Context
Part of the changes made in #2094; split out for easier review.
# Objective
- Allow quick and easy testing of scenes
## Solution
- Add a `scene-viewer` tool based on `load_gltf`.
- Run it with e.g. `cargo run --release --example scene_viewer --features jpeg -- ../some/path/assets/models/Sponza/glTF/Sponza.gltf#Scene0`
- Configure the asset path as pointing to the repo root for convenience (paths specified relative to current working directory)
- Copy over the camera controller from the `shadow_biases` example
- Support toggling the light animation
- Support toggling shadows
- Support adjusting the directional light shadow projection (cascaded shadow maps will remove the need for this later)
I don't want to do too much on it up-front. Rather we can add features over time as we need them.
# Objective
- Make the example a little easier to follow by removing unnecessary steps.
## Solution
- `Assets<Image>` will give us a handle for our render texture if we call `add()` instead of `set()`. No need to set it manually; one less thing to think about while reading the example.
# Add Transform Examples
- Adding examples for moving/rotating entities (with its own section) to resolve#2400
I've stumbled upon this project and been fiddling around a little. Saw the issue and thought I might just add some examples for the proposed transformations.
Mind to check if I got the gist correctly and suggest anything I can improve?
**Problem**
- whenever you want more than one of the builtin cameras (for example multiple windows, split screen, portals), you need to add a render graph node that executes the correct sub graph, extract the camera into the render world and add the correct `RenderPhase<T>` components
- querying for the 3d camera is annoying because you need to compare the camera's name to e.g. `CameraPlugin::CAMERA_3d`
**Solution**
- Introduce the marker types `Camera3d`, `Camera2d` and `CameraUi`
-> `Query<&mut Transform, With<Camera3d>>` works
- `PerspectiveCameraBundle::new_3d()` and `PerspectiveCameraBundle::<Camera3d>::default()` contain the `Camera3d` marker
- `OrthographicCameraBundle::new_3d()` has `Camera3d`, `OrthographicCameraBundle::new_2d()` has `Camera2d`
- remove `ActiveCameras`, `ExtractedCameraNames`
- run 2d, 3d and ui passes for every camera of their respective marker
-> no custom setup for multiple windows example needed
**Open questions**
- do we need a replacement for `ActiveCameras`? What about a component `ActiveCamera { is_active: bool }` similar to `Visibility`?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Use the low power, reactive rendering settings for UI examples.
- Make the feature more discoverable by using it in an applicable context.
# Objective
Fixes#4036
## Solution
- Use `VertexBufferLayout::from_vertex_formats`
- Actually put a u32 into `ATTRIBUTE_COLOR` and convert it in the shader
I'm not 100% sure about the color stuff. It seems like `ATTRIBUTE_COLOR` has been `Uint32` this whole time, but this example previously worked with `[f32; 4]` somehow, perhaps because the vertex layout was manually specified.
Let me know if that can be improved, or feel free to close for an alternative fix.
# Objective
- Improve documentation.
- Provide helper functions for common uses of `Windows` relating to getting the primary `Window`.
- Reduce repeated `Window` code.
# Solution
- Adds infallible `primary()` and `primary_mut()` functions with standard error text. This replaces the commonly used `get_primary().unwrap()` seen throughout bevy which has inconsistent or nonexistent error messages.
- Adds `scale_factor(WindowId)` to replace repeated code blocks throughout.
# Considerations
- The added functions can panic if the primary window does not exist.
- It is very uncommon for the primary window to not exist, as seen by the regular use of `get_primary().unwrap()`. Most users will have a single window and will need to reference the primary window in their code multiple times.
- The panic provides a consistent error message to make this class of error easy to spot from the panic text.
- This follows the established standard of short names for infallible-but-unlikely-to-panic functions in bevy.
- Removes line noise for common usage of `Windows`.
# Objective
- Reduce power usage for games when not focused.
- Reduce power usage to ~0 when a desktop application is minimized (opt-in).
- Reduce power usage when focused, only updating on a `winit` event, or the user sends a redraw request. (opt-in)
https://user-images.githubusercontent.com/2632925/156904387-ec47d7de-7f06-4c6f-8aaf-1e952c1153a2.mp4
Note resource usage in the Task Manager in the above video.
## Solution
- Added a type `UpdateMode` that allows users to specify how the winit event loop is updated, without exposing winit types.
- Added two fields to `WinitConfig`, both with the `UpdateMode` type. One configures how the application updates when focused, and the other configures how the application behaves when it is not focused. Users can modify this resource manually to set the type of event loop control flow they want.
- For convenience, two functions were added to `WinitConfig`, that provide reasonable presets: `game()` (default) and `desktop_app()`.
- The `game()` preset, which is used by default, is unchanged from current behavior with one exception: when the app is out of focus the app updates at a minimum of 10fps, or every time a winit event is received. This has a huge positive impact on power use and responsiveness on my machine, which will otherwise continue running the app at many hundreds of fps when out of focus or minimized.
- The `desktop_app()` preset is fully reactive, only updating when user input (winit event) is supplied or a `RedrawRequest` event is sent. When the app is out of focus, it only updates on `Window` events - i.e. any winit event that directly interacts with the window. What this means in practice is that the app uses *zero* resources when minimized or not interacted with, but still updates fluidly when the app is out of focus and the user mouses over the application.
- Added a `RedrawRequest` event so users can force an update even if there are no events. This is useful in an application when you want to, say, run an animation even when the user isn't providing input.
- Added an example `low_power` to demonstrate these changes
## Usage
Configuring the event loop:
```rs
use bevy::winit::{WinitConfig};
// ...
.insert_resource(WinitConfig::desktop_app()) // preset
// or
.insert_resource(WinitConfig::game()) // preset
// or
.insert_resource(WinitConfig{ .. }) // manual
```
Requesting a redraw:
```rs
use bevy:🪟:RequestRedraw;
// ...
fn request_redraw(mut event: EventWriter<RequestRedraw>) {
event.send(RequestRedraw);
}
```
## Other details
- Because we have a single event loop for multiple windows, every time I've mentioned "focused" above, I more precisely mean, "if at least one bevy window is focused".
- Due to a platform bug in winit (https://github.com/rust-windowing/winit/issues/1619), we can't simply use `Window::request_redraw()`. As a workaround, this PR will temporarily set the window mode to `Poll` when a redraw is requested. This is then reset to the user's `WinitConfig` setting on the next frame.
# Objective
- Make the many_cubes example more interesting (and look more like many_sprites)
## Solution
- Actually display many cubes
- Move the camera around
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
# Objective
- Add ways to control how audio is played
## Solution
- playing a sound will return a (weak) handle to an asset that can be used to control playback
- if the asset is dropped, it will detach the sink (same behaviour as now)
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
Will fix#3377 and #3254
## Solution
Use an enum to represent either a `WindowId` or `Handle<Image>` in place of `Camera::window`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#786
- Closes#2252
- Closes#2588
This PR implements a derive macro that allows users to define their queries as structs with named fields.
## Example
```rust
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct NumQuery<'w, T: Component, P: Component> {
entity: Entity,
u: UNumQuery<'w>,
generic: GenericQuery<'w, T, P>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct UNumQuery<'w> {
u_16: &'w u16,
u_32_opt: Option<&'w u32>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct GenericQuery<'w, T: Component, P: Component> {
generic: (&'w T, &'w P),
}
#[derive(WorldQuery)]
#[world_query(filter)]
struct NumQueryFilter<T: Component, P: Component> {
_u_16: With<u16>,
_u_32: With<u32>,
_or: Or<(With<i16>, Changed<u16>, Added<u32>)>,
_generic_tuple: (With<T>, With<P>),
_without: Without<Option<u16>>,
_tp: PhantomData<(T, P)>,
}
fn print_nums_readonly(query: Query<NumQuery<u64, i64>, NumQueryFilter<u64, i64>>) {
for num in query.iter() {
println!("{:#?}", num);
}
}
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct MutNumQuery<'w, T: Component, P: Component> {
i_16: &'w mut i16,
i_32_opt: Option<&'w mut i32>,
}
fn print_nums(mut query: Query<MutNumQuery, NumQueryFilter<u64, i64>>) {
for num in query.iter_mut() {
println!("{:#?}", num);
}
}
```
## TODOs:
- [x] Add support for `&T` and `&mut T`
- [x] Test
- [x] Add support for optional types
- [x] Test
- [x] Add support for `Entity`
- [x] Test
- [x] Add support for nested `WorldQuery`
- [x] Test
- [x] Add support for tuples
- [x] Test
- [x] Add support for generics
- [x] Test
- [x] Add support for query filters
- [x] Test
- [x] Add support for `PhantomData`
- [x] Test
- [x] Refactor `read_world_query_field_type_info`
- [x] Properly document `readonly` attribute for nested queries and the static assertions that guarantee safety
- [x] Test that we never implement `ReadOnlyFetch` for types that need mutable access
- [x] Test that we insert static assertions for nested `WorldQuery` that a user marked as readonly
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- `WgpuOptions` is mutated to be updated with the actual device limits and features, but this information is readily available to both the main and render worlds through the `RenderDevice` which has .limits() and .features() methods
- Information about the adapter in terms of its name, the backend in use, etc were not being exposed but have clear use cases for being used to take decisions about what rendering code to use. For example, if something works well on AMD GPUs but poorly on Intel GPUs. Or perhaps something works well in Vulkan but poorly in DX12.
## Solution
- Stop mutating `WgpuOptions `and don't insert the updated values into the main and render worlds
- Return `AdapterInfo` from `initialize_renderer` and insert it into the main and render worlds
- Use `RenderDevice` limits in the lighting code that was using `WgpuOptions.limits`.
- Renamed `WgpuOptions` to `WgpuSettings`
I wanted to try one of the new examples but it felt so clunky that I wanted to improve it.
It did make me feel like maybe some input axes abstraction like Unity has might be useful.
Also, eating cake should probably be a separate system from movement.
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
My attempt at fixing #2142. My very first attempt at contributing to Bevy so more than open to any feedback.
I borrowed heavily from the [Bevy Cheatbook page](https://bevy-cheatbook.github.io/patterns/generic-systems.html?highlight=generic#generic-systems).
## Solution
Fairly straightforward example using a clean up system to delete entities that are coupled with app state after exiting that state.
Co-authored-by: B-Janson <brandon@canva.com>
# Objective
- Bevy currently has no simple way to make an "empty" Entity work correctly in a Hierachy.
- The current Solution is to insert a Tuple instead:
```rs
.insert_bundle((Transform::default(), GlobalTransform::default()))
```
## Solution
* Add a `TransformBundle` that combines the Components:
```rs
.insert_bundle(TransformBundle::default())
```
* The code is based on #2331, except for missing the more controversial usage of `TransformBundle` as a Sub-bundle in preexisting Bundles.
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Add two examples on how to communicate with a task that is running either in another thread or in a thread from `AsyncComputeTaskPool`.
Loosely based on https://github.com/bevyengine/bevy/discussions/1150
# Objective
Enable the user to specify any presentation modes (including `Mailbox`).
Fixes#3807
## Solution
I've added a new `PresentMode` enum in `bevy_window` that mirrors the `wgpu` enum 1:1. Alternatively, I could add a new dependency on `wgpu-types` if that would be preferred.
## Objective
The [`DrawMeshInstanced`] command in the example sets vertex buffer 0 twice, with two identical calls to:
```rs
pass.set_vertex_buffer(0, gpu_mesh.vertex_buffer.slice(..));
```
## Solution
Remove the second call as it is unecessary.
[`DrawMeshInstanced`]: f3de12bc5e/examples/shader/shader_instancing.rs (L217-L258)
# Objective
- `asset_server.watch_for_changes().unwrap()` only watches changes for assets loaded **_after_** that call.
- Technically, the `hot_asset_reloading` example is racey as the watch on the asset path is set up in an async task scheduled from the asset `load()`, but the filesystem watcher is only constructed in a call that comes **_after_** the call to `load()`.
## Solution
- It feels safest to allow enabling watching the filesystem for changes on the asset server from the point of its construction. Therefore, adding such an option to `AssetServerSettings` seemed to be the correct solution.
- Fix `hot_asset_reloading` by inserting the `AssetServerSettings` resource with `watch_for_changes: true` instead of calling `asset_server.watch_for_changes().unwrap()`.
- Document the shortcomings of `.watch_for_changes()`
# Objective
When using empty events, it can feel redundant to have to specify the type of the event when sending it.
## Solution
Add a new `fire()` function that sends the default value of the event. This requires that the event derives Default.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Objective
There is no bevy example that shows how to transform a sprite. At least as its singular purpose. This creates an example of how to use transform.translate to move a sprite up and down. The last pull request had issues that I couldn't fix so I created a new one
### Solution
I created move_sprite example.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
I think the 'collide' function inside the 'bevy/crates/bevy_sprite/src/collide_aabb.rs' file should return 'Some' if the two rectangles are fully overlapping or one is inside the other. This can happen on low-end machines when a lot of time passes between two frames because of a stutter, so a bullet for example gets inside its target. I can also think of situations where this is a valid use case even without stutters.
## Solution
I added an 'Inside' version to the Collision enum declared in the file. And I use it, when the two rectangles are overlapping, but we can't say from which direction it happened. I gave a 'penetration depth' of minus Infinity to these cases, so that this variant only appears, when the two rectangles overlap from each side fully. I am not sure if this is the right thing to do.
Fixes#1980
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
While trying to learn how to use custom shaders, I had difficulty figuring out how to use a vertex shader. My confusion was mostly because all the other shader examples used a custom pipeline, but I didn't want a custom pipeline. After digging around I realised that I simply needed to add a function to the `impl Material` block. I also searched what was the default shader used, because it wasn't obvious to me where to find it.
## Solution
Added a few comments explaining what is going on in the example and a link to the default shader.
# Objective
Some new bevy users are unfamiliar with quaternions and have trouble working with rotations in 2D.
There has been an [issue](https://github.com/bitshifter/glam-rs/issues/226) raised with glam to add helpers to better support these users, however for now I feel could be better to provide examples of how to do this in Bevy as a starting point for new users.
## Solution
I've added a 2d_rotation example which demonstrates 3 different rotation examples to try help get people started:
- Rotating and translating a player ship based on keyboard input
- An enemy ship type that rotates to face the player ship immediately
- An enemy ship type that rotates to face the player at a fixed angular velocity
I also have a standalone version of this example here https://github.com/bitshifter/bevy-2d-rotation-example but I think it would be more discoverable if it's included with Bevy.
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
# Objective
- There are wasm specific examples, which is misleading as now it works by default
- I saw a few people on discord trying to work through those examples that are very limited
## Solution
- Remove them and update the instructions
adds an example using UI for something more related to a game than the current UI examples.
Example with a game menu:
* new game - will display settings for 5 seconds before returning to menu
* preferences - can modify the settings, with two sub menus
* quit - will quit the game
I wanted a more complex UI example before starting the UI rewrite to have ground for comparison
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
In this PR I added the ability to opt-out graphical backends. Closes#3155.
## Solution
I turned backends into `Option` ~~and removed panicking sub app API to force users handle the error (was suggested by `@cart`)~~.
# Objective
The current 2d rendering is specialized to render sprites, we need a generic way to render 2d items, using meshes and materials like we have for 3d.
## Solution
I cloned a good part of `bevy_pbr` into `bevy_sprite/src/mesh2d`, removed lighting and pbr itself, adapted it to 2d rendering, added a `ColorMaterial`, and modified the sprite rendering to break batches around 2d meshes.
~~The PR is a bit crude; I tried to change as little as I could in both the parts copied from 3d and the current sprite rendering to make reviewing easier. In the future, I expect we could make the sprite rendering a normal 2d material, cleanly integrated with the rest.~~ _edit: see <https://github.com/bevyengine/bevy/pull/3460#issuecomment-1003605194>_
## Remaining work
- ~~don't require mesh normals~~ _out of scope_
- ~~add an example~~ _done_
- support 2d meshes & materials in the UI?
- bikeshed names (I didn't think hard about naming, please check if it's fine)
## Remaining questions
- ~~should we add a depth buffer to 2d now that there are 2d meshes?~~ _let's revisit that when we have an opaque render phase_
- ~~should we add MSAA support to the sprites, or remove it from the 2d meshes?~~ _I added MSAA to sprites since it's really needed for 2d meshes_
- ~~how to customize vertex attributes?~~ _#3120_
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- More colours
## Solution
- Various changes
- Would have a video here, but don't have an easy way to record one before I go to sleep
- I intend to additionally change the distribution of the satellites, to be more uniform in space.
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `examples` folder.
This adds "high level" `Material` and `SpecializedMaterial` traits, which can be used with a `MaterialPlugin<T: SpecializedMaterial>`. `MaterialPlugin` automatically registers the appropriate resources, draw functions, and queue systems. The `Material` trait is simpler, and should cover most use cases. `SpecializedMaterial` is like `Material`, but it also requires defining a "specialization key" (see #3031). `Material` has a trivial blanket impl of `SpecializedMaterial`, which allows us to use the same types + functions for both.
This makes defining custom 3d materials much simpler (see the `shader_material` example diff) and ensures consistent behavior across all 3d materials (both built in and custom). I ported the built in `StandardMaterial` to `MaterialPlugin`. There is also a new `MaterialMeshBundle<T: SpecializedMaterial>`, which `PbrBundle` aliases to.
# Objective
- Our crevice is still called "crevice", which we can't use for a release
- Users would need to use our "crevice" directly to be able to use the derive macro
## Solution
- Rename crevice to bevy_crevice, and crevice-derive to bevy-crevice-derive
- Re-export it from bevy_render, and use it from bevy_render everywhere
- Fix derive macro to work either from bevy_render, from bevy_crevice, or from bevy
## Remaining
- It is currently re-exported as `bevy::render::bevy_crevice`, is it the path we want?
- After a brief suggestion to Cart, I changed the version to follow Bevy version instead of crevice, do we want that?
- Crevice README.md need to be updated
- in the `Cargo.toml`, there are a few things to change. How do we want to change them? How do we keep attributions to original Crevice?
```
authors = ["Lucien Greathouse <me@lpghatguy.com>"]
documentation = "https://docs.rs/crevice"
homepage = "https://github.com/LPGhatguy/crevice"
repository = "https://github.com/LPGhatguy/crevice"
```
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- mp3 feature of rodio has dependencies that are not maintained with security issues
- mp3 feature of rodio doesn't build in wasm
- mp3 feature of rodio uses internal memory allocation that cause rejection from Apple appstore
## Solution
- Use vorbis instead of mp3 by default
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- Tentatively fixes#2525.
## Solution
- The panic seems to occur when the game-over state occurs nearly instantly.
- Discard the `Result`, rather than panicking. We could probably handle this better, but I want to see if this works first. Ping @qarmin.
# Objective
The window's cursor should be settable without having to implement a custom cursor icon solution. This will especially be helpful when creating user-interfaces that might like to use the cursor to denote some meaning (e.g., _clickable_, _resizable_, etc.).
## Solution
Added a `CursorIcon` enum that maps one-to-one to winit's `CursorIcon` enum, as well as a method to set/get it for the given `Window`.
# Objective
Fixes#3379
## Solution
The custom mesh pipelines needed to be specialized on each mesh's primitive topology, as done in `queue_meshes()`
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
This PR implements the `overflow` style property in `bevy_ui`. When set to `Overflow::Hidden`, the children of that node are clipped so that overflowing parts are not rendered. This is an important building block for UI widgets.
## Solution
Clipping is done on the CPU so that it does not break batching.
The clip regions update was implemented as a separate system for clarity, but it could be merged with the other UI systems to avoid doing an additional tree traversal. (I don't think it's important until we fix the layout performance issues though).
A scrolling list was added to the `ui_pipelined` example to showcase `Overflow::Hidden`. For the sake of simplicity, it can only be scrolled with a mouse.
# Objective
- The multiple windows example which was viciously murdered in #3175.
- cart asked me to
## Solution
- Rework the example to work on pipelined-rendering, based on the work from #2898
# Objective
Every time I come back to Bevy I face the same issue: how do I draw a rectangle again? How did that work? So I go to https://github.com/bevyengine/bevy/tree/main/examples in the hope of finding literally the simplest possible example that draws something on the screen without any dependency such as an image. I don't want to have to add some image first, I just quickly want to get something on the screen with `main.rs` alone so that I can continue building on from that point on. Such an example is particularly helpful for a quick start for smaller projects that don't even need any assets such as images (this is my case currently).
Currently every single example of https://github.com/bevyengine/bevy/tree/main/examples#2d-rendering (which is the first section after hello world that beginners will look for for very minimalistic and quick examples) depends on at least an asset or is too complex. This PR solves this.
It also serves as a great comparison for a beginner to realize what Bevy is really like and how different it is from what they may expect Bevy to be. For example for someone coming from [LÖVE](https://love2d.org/), they will have something like this in their head when they think of drawing a rectangle:
```lua
function love.draw()
love.graphics.setColor(0.25, 0.25, 0.75);
love.graphics.rectangle("fill", 0, 0, 50, 50);
end
```
This, of course, differs quite a lot from what you do in Bevy. I imagine there will be people that just want to see something as simple as this in comparison to have a better understanding for the amount of differences.
## Solution
Add a dead simple example drawing a blue 50x50 rectangle in the center with no more and no less than needed.
# Objective
Have the bird spawning/collision systems in bevymark use the proper window size, instead of the size set in WindowDescriptor which isn't updated when the window is resized.
## Solution
Use the Windows resource to grab the width/height from the primary window. This is consistent with the other examples.
# Objective
This PR fixes a crash when winit is enabled when there is a camera in the world. Part of #3155
## Solution
In this PR, I removed two unwraps and added an example for regression testing.
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
# Objective
Port bevy_ui to pipelined-rendering (see #2535 )
## Solution
I did some changes during the port:
- [X] separate color from the texture asset (as suggested [here](https://discord.com/channels/691052431525675048/743663924229963868/874353914525413406))
- [X] ~give the vertex shader a per-instance buffer instead of per-vertex buffer~ (incompatible with batching)
Remaining features to implement to reach parity with the old renderer:
- [x] textures
- [X] TextBundle
I'd also like to add these features, but they need some design discussion:
- [x] batching
- [ ] separate opaque and transparent phases
- [ ] multiple windows
- [ ] texture atlases
- [ ] (maybe) clipping
Applogies, had to recreate this pr because of branching issue.
Old PR: https://github.com/bevyengine/bevy/pull/3033
# Objective
Fixes#3032
Allowing a user to create a transparent window
## Solution
I've allowed the transparent bool to be passed to the winit window builder
# Objective
Fixes#3181
## Solution
Refactored `contributors.rs` example:
- Renamed unclear variables
- Split setup system into two separate systems
Co-authored-by: CrazyRoka <rokarostuk@gmail.com>
# Objective
- iOS CI has linker issues https://github.com/bevyengine/bevy/runs/4388921574?check_suite_focus=true
## Solution
- Building for iOS actually requires ~~both iOS SDK for target and~~ macOS SDK for build scripts. ~~I added them both when needed~~ I replaced the iOS SDK with the maOS. This was not an issue on m1 as they are compatible enough to make the build pass.
- This completely confused `shader-sys` which fails to build in this configuration. Luckily as the example now uses the new renderer, I was able to remove the old renderer and depend no more on this lib.
This is confirmed to work:
- on intel mac with simulator
- on m1 mac with simulator
- on m1 mac with real iphone
# Objective
- With #3109 I broke iOS CI: https://github.com/bevyengine/bevy/runs/4374891646?check_suite_focus=true
## Solution
- Fix indentation in makefile
- Adds scheme that is now needed
With this, `make install` works on my m1 Mac but still fails on my intel Mac unless I run something like `make install; cargo build --target x86_64-apple-ios; make install; cargo build --target x86_64-apple-ios; make install`. It seems something is off when executing cargo through `xcodebuild` on my setup but not sure what. So this PR will probably not fix iOS CI 😞
# Objective
- Remove `cargo-lipo` as [it's deprecated](https://github.com/TimNN/cargo-lipo#maintenance-status) and doesn't work on new Apple processors
- Fix CI that will fail as soon as GitHub update the worker used by Bevy to macOS 11
## Solution
- Replace `cargo-lipo` with building with the correct target
- Setup the correct path to libraries by using `xcrun --show-sdk-path`
- Also try and fix path to cmake in case it's not found but available through homebrew
## Shader Imports
This adds "whole file" shader imports. These come in two flavors:
### Asset Path Imports
```rust
// /assets/shaders/custom.wgsl
#import "shaders/custom_material.wgsl"
[[stage(fragment)]]
fn fragment() -> [[location(0)]] vec4<f32> {
return get_color();
}
```
```rust
// /assets/shaders/custom_material.wgsl
[[block]]
struct CustomMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CustomMaterial;
```
### Custom Path Imports
Enables defining custom import paths. These are intended to be used by crates to export shader functionality:
```rust
// bevy_pbr2/src/render/pbr.wgsl
#import bevy_pbr::mesh_view_bind_group
#import bevy_pbr::mesh_bind_group
[[block]]
struct StandardMaterial {
base_color: vec4<f32>;
emissive: vec4<f32>;
perceptual_roughness: f32;
metallic: f32;
reflectance: f32;
flags: u32;
};
/* rest of PBR fragment shader here */
```
```rust
impl Plugin for MeshRenderPlugin {
fn build(&self, app: &mut bevy_app::App) {
let mut shaders = app.world.get_resource_mut::<Assets<Shader>>().unwrap();
shaders.set_untracked(
MESH_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_bind_group"),
);
shaders.set_untracked(
MESH_VIEW_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_view_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_view_bind_group"),
);
```
By convention these should use rust-style module paths that start with the crate name. Ultimately we might enforce this convention.
Note that this feature implements _run time_ import resolution. Ultimately we should move the import logic into an asset preprocessor once Bevy gets support for that.
## Decouple Mesh Logic from PBR Logic via MeshRenderPlugin
This breaks out mesh rendering code from PBR material code, which improves the legibility of the code, decouples mesh logic from PBR logic, and opens the door for a future `MaterialPlugin<T: Material>` that handles all of the pipeline setup for arbitrary shader materials.
## Removed `RenderAsset<Shader>` in favor of extracting shaders into RenderPipelineCache
This simplifies the shader import implementation and removes the need to pass around `RenderAssets<Shader>`.
## RenderCommands are now fallible
This allows us to cleanly handle pipelines+shaders not being ready yet. We can abort a render command early in these cases, preventing bevy from trying to bind group / do draw calls for pipelines that couldn't be bound. This could also be used in the future for things like "components not existing on entities yet".
# Next Steps
* Investigate using Naga for "partial typed imports" (ex: `#import bevy_pbr::material::StandardMaterial`, which would import only the StandardMaterial struct)
* Implement `MaterialPlugin<T: Material>` for low-boilerplate custom material shaders
* Move shader import logic into the asset preprocessor once bevy gets support for that.
Fixes#3132
# Objective
- Document that the error codes will be rendered on the bevy website (see bevyengine/bevy-website#216)
- Some Cargo.toml files did not include the license or a description field
## Solution
- Readme for the errors crate
- Mark internal/development crates with `publish = false`
- Add missing license/descriptions to some crates
- [x] merge bevyengine/bevy-website#216
Adds new `EntityRenderCommand`, `EntityPhaseItem`, and `CachedPipelinePhaseItem` traits to make it possible to reuse RenderCommands across phases. This should be helpful for features like #3072 . It also makes the trait impls slightly less generic-ey in the common cases.
This also fixes the custom shader examples to account for the recent Frustum Culling and MSAA changes (the UX for these things will be improved later).
This implements the following:
* **Sprite Batching**: Collects sprites in a vertex buffer to draw many sprites with a single draw call. Sprites are batched by their `Handle<Image>` within a specific z-level. When possible, sprites are opportunistically batched _across_ z-levels (when no sprites with a different texture exist between two sprites with the same texture on different z levels). With these changes, I can now get ~130,000 sprites at 60fps on the `bevymark_pipelined` example.
* **Sprite Color Tints**: The `Sprite` type now has a `color` field. Non-white color tints result in a specialized render pipeline that passes the color in as a vertex attribute. I chose to specialize this because passing vertex colors has a measurable price (without colors I get ~130,000 sprites on bevymark, with colors I get ~100,000 sprites). "Colored" sprites cannot be batched with "uncolored" sprites, but I think this is fine because the chance of a "colored" sprite needing to batch with other "colored" sprites is generally probably way higher than an "uncolored" sprite needing to batch with a "colored" sprite.
* **Sprite Flipping**: Sprites can be flipped on their x or y axis using `Sprite::flip_x` and `Sprite::flip_y`. This is also true for `TextureAtlasSprite`.
* **Simpler BufferVec/UniformVec/DynamicUniformVec Clearing**: improved the clearing interface by removing the need to know the size of the final buffer at the initial clear.
Note that this moves sprites away from entity-driven rendering and back to extracted lists. We _could_ use entities here, but it necessitates that an intermediate list is allocated / populated to collect and sort extracted sprites. This redundant copy, combined with the normal overhead of spawning extracted sprite entities, brings bevymark down to ~80,000 sprites at 60fps. I think making sprites a bit more fixed (by default) is worth it. I view this as acceptable because batching makes normal entity-driven rendering pretty useless anyway (and we would want to batch most custom materials too). We can still support custom shaders with custom bindings, we'll just need to define a specific interface for it.
Add an example that demonstrates the difference between no MSAA and MSAA 4x. This is also useful for testing panics when resizing the window using MSAA. This is on top of #3042 .
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## New Features
This adds the following to the new renderer:
* **Shader Assets**
* Shaders are assets again! Users no longer need to call `include_str!` for their shaders
* Shader hot-reloading
* **Shader Defs / Shader Preprocessing**
* Shaders now support `# ifdef NAME`, `# ifndef NAME`, and `# endif` preprocessor directives
* **Bevy RenderPipelineDescriptor and RenderPipelineCache**
* Bevy now provides its own `RenderPipelineDescriptor` and the wgpu version is now exported as `RawRenderPipelineDescriptor`. This allows users to define pipelines with `Handle<Shader>` instead of needing to manually compile and reference `ShaderModules`, enables passing in shader defs to configure the shader preprocessor, makes hot reloading possible (because the descriptor can be owned and used to create new pipelines when a shader changes), and opens the doors to pipeline specialization.
* The `RenderPipelineCache` now handles compiling and re-compiling Bevy RenderPipelineDescriptors. It has internal PipelineLayout and ShaderModule caches. Users receive a `CachedPipelineId`, which can be used to look up the actual `&RenderPipeline` during rendering.
* **Pipeline Specialization**
* This enables defining per-entity-configurable pipelines that specialize on arbitrary custom keys. In practice this will involve specializing based on things like MSAA values, Shader Defs, Bind Group existence, and Vertex Layouts.
* Adds a `SpecializedPipeline` trait and `SpecializedPipelines<MyPipeline>` resource. This is a simple layer that generates Bevy RenderPipelineDescriptors based on a custom key defined for the pipeline.
* Specialized pipelines are also hot-reloadable.
* This was the result of experimentation with two different approaches:
1. **"generic immediate mode multi-key hash pipeline specialization"**
* breaks up the pipeline into multiple "identities" (the core pipeline definition, shader defs, mesh layout, bind group layout). each of these identities has its own key. looking up / compiling a specific version of a pipeline requires composing all of these keys together
* the benefit of this approach is that it works for all pipelines / the pipeline is fully identified by the keys. the multiple keys allow pre-hashing parts of the pipeline identity where possible (ex: pre compute the mesh identity for all meshes)
* the downside is that any per-entity data that informs the values of these keys could require expensive re-hashes. computing each key for each sprite tanked bevymark performance (sprites don't actually need this level of specialization yet ... but things like pbr and future sprite scenarios might).
* this is the approach rafx used last time i checked
2. **"custom key specialization"**
* Pipelines by default are not specialized
* Pipelines that need specialization implement a SpecializedPipeline trait with a custom key associated type
* This allows specialization keys to encode exactly the amount of information required (instead of needing to be a combined hash of the entire pipeline). Generally this should fit in a small number of bytes. Per-entity specialization barely registers anymore on things like bevymark. It also makes things like "shader defs" way cheaper to hash because we can use context specific bitflags instead of strings.
* Despite the extra trait, it actually generally makes pipeline definitions + lookups simpler: managing multiple keys (and making the appropriate calls to manage these keys) was way more complicated.
* I opted for custom key specialization. It performs better generally and in my opinion is better UX. Fortunately the way this is implemented also allows for custom caches as this all builds on a common abstraction: the RenderPipelineCache. The built in custom key trait is just a simple / pre-defined way to interact with the cache
## Callouts
* The SpecializedPipeline trait makes it easy to inherit pipeline configuration in custom pipelines. The changes to `custom_shader_pipelined` and the new `shader_defs_pipelined` example illustrate how much simpler it is to define custom pipelines based on the PbrPipeline.
* The shader preprocessor is currently pretty naive (it just uses regexes to process each line). Ultimately we might want to build a more custom parser for more performance + better error handling, but for now I'm happy to optimize for "easy to implement and understand".
## Next Steps
* Port compute pipelines to the new system
* Add more preprocessor directives (else, elif, import)
* More flexible vertex attribute specialization / enable cheaply specializing on specific mesh vertex layouts
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
Upgrades both the old and new renderer to wgpu 0.11 (and naga 0.7). This builds on @zicklag's work here #2556.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
The vast majority of `.single()` usage I've seen is immediately followed by a `.unwrap()`. Since it seems most people use it without handling the error, I think making it easier to just get what you want fast while also having a more verbose alternative when you want to handle the error could help.
## Solution
Instead of having a lot of `.unwrap()` everywhere, this PR introduces a `try_single()` variant that behaves like the current `.single()` and make the new `.single()` panic on error.
# Objective
My attempt at fixing #2075 .
This is my very first contribution to this repo. Also, I'm very new to both Rust and bevy, so any feedback is *deeply* appreciated.
## Solution
- Changed `move_camera_system` so it only targets the camera entity. My approach here differs from the one used in the [cheatbook](https://bevy-cheatbook.github.io/cookbook/cursor2world.html?highlight=maincamera#2d-games) (in which a marker component is used to track the camera), so please, let me know which of them is more idiomatic.
- `move_camera_system` does not require both `Position` and `Transform` anymore (I used `rotate` for rotating the `Transform` in place, but couldn't find an equivalent `translate` method).
- Changed `tick_system` so it only targets the timer entity.
- Sprites are now spawned via a single `spawn_batch` instead of multiple `spawn`s.
# Objective
- The breakout scoreboard was not using the correct text section to display the score integer.
## Solution
- This updates the code to use the correct text section.
# Objective
Make it easier to check if some set of inputs matches a key, such as if you want to allow all of space or up or w for jumping.
Currently, this requires:
```rust
if keyboard.pressed(KeyCode::Space)
|| keyboard.pressed(KeyCode::Up)
|| keyboard.pressed(KeyCode::W) {
// ...
```
## Solution
Add an implementation of the helper methods, which very simply iterate through the items, used as:
```rust
if keyboard.any_pressed([KeyCode::Space, KeyCode::Up, KeyCode::W]) {
```
# Objective
Forward perspective projections have poor floating point precision distribution over the depth range. Reverse projections fair much better, and instead of having to have a far plane, with the reverse projection, using an infinite far plane is not a problem. The infinite reverse perspective projection has become the industry standard. The renderer rework is a great time to migrate to it.
## Solution
All perspective projections, including point lights, have been moved to using `glam::Mat4::perspective_infinite_reverse_rh()` and so have no far plane. As various depth textures are shared between orthographic and perspective projections, a quirk of this PR is that the near and far planes of the orthographic projection are swapped when the Mat4 is computed. This has no impact on 2D/3D orthographic projection usage, and provides consistency in shaders, texture clear values, etc. throughout the codebase.
## Known issues
For some reason, when looking along -Z, all geometry is black. The camera can be translated up/down / strafed left/right and geometry will still be black. Moving forward/backward or rotating the camera away from looking exactly along -Z causes everything to work as expected.
I have tried to debug this issue but both in macOS and Windows I get crashes when doing pixel debugging. If anyone could reproduce this and debug it I would be very grateful. Otherwise I will have to try to debug it further without pixel debugging, though the projections and such all looked fine to me.
# Objective
- Prevent the need to have a system that synchronizes sprite sizes with their images
## Solution
- Read the sprite size from the image asset when rendering the sprite
- Replace the `size` and `resize_mode` fields of `Sprite` with a `custom_size: Option<Vec2>` that will modify the sprite's rendered size to be different than the image size, but only if it is `Some(Vec2)`
# Objective
Allow marking meshes as not casting / receiving shadows.
## Solution
- Added `NotShadowCaster` and `NotShadowReceiver` zero-sized type components.
- Extract these components into `bool`s in `ExtractedMesh`
- Only generate `DrawShadowMesh` `Drawable`s for meshes _without_ `NotShadowCaster`
- Add a `u32` bit `flags` member to `MeshUniform` with one flag indicating whether the mesh is a shadow receiver
- If a mesh does _not_ have the `NotShadowReceiver` component, then it is a shadow receiver, and so the bit in the `MeshUniform` is set, otherwise it is not set.
- Added an example illustrating the functionality.
NOTE: I wanted to have the default state of a mesh as being a shadow caster and shadow receiver, hence the `Not*` components. However, I am on the fence about this. I don't want to have a negative performance impact, nor have people wondering why their custom meshes don't have shadows because they forgot to add `ShadowCaster` and `ShadowReceiver` components, but I also really don't like the double negatives the `Not*` approach incurs. What do you think?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
A question was raised on Discord about the units of the `PointLight` `intensity` member.
After digging around in the bevy_pbr2 source code and [Google Filament documentation](https://google.github.io/filament/Filament.html#mjx-eqn-pointLightLuminousPower) I discovered that the intention by Filament was that the 'intensity' value for point lights would be in lumens. This makes a lot of sense as these are quite relatable units given basically all light bulbs I've seen sold over the past years are rated in lumens as people move away from thinking about how bright a bulb is relative to a non-halogen incandescent bulb.
However, it seems that the derivation of the conversion between luminous power (lumens, denoted `Φ` in the Filament formulae) and luminous intensity (lumens per steradian, `I` in the Filament formulae) was missed and I can see why as it is tucked right under equation 58 at the link above. As such, while the formula states that for a point light, `I = Φ / 4 π` we have been using `intensity` as if it were luminous intensity `I`.
Before this PR, the intensity field is luminous intensity in lumens per steradian. After this PR, the intensity field is luminous power in lumens, [as suggested by Filament](https://google.github.io/filament/Filament.html#table_lighttypesunits) (unfortunately the link jumps to the table's caption so scroll up to see the actual table).
I appreciate that it may be confusing to call this an intensity, but I think this is intended as more of a non-scientific, human-relatable general term with a bit of hand waving so that most light types can just have an intensity field and for most of them it works in the same way or at least with some relatable value. I'm inclined to think this is reasonable rather than throwing terms like luminous power, luminous intensity, blah at users.
## Solution
- Documented the `PointLight` `intensity` member as 'luminous power' in units of lumens.
- Added a table of examples relating from various types of household lighting to lumen values.
- Added in the mapping from luminous power to luminous intensity when premultiplying the intensity into the colour before it is made into a graphics uniform.
- Updated the documentation in `pbr.wgsl` to clarify the earlier confusion about the missing `/ 4 π`.
- Bumped the intensity of the point lights in `3d_scene_pipelined` to 1600 lumens.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Allow the user to set the clear color when using the pipelined renderer
## Solution
- Add a `ClearColor` resource that can be added to the world to configure the clear color
## Remaining Issues
Currently the `ClearColor` resource is cloned from the app world to the render world every frame. There are two ways I can think of around this:
1. Figure out why `app_world.is_resource_changed::<ClearColor>()` always returns `true` in the `extract` step and fix it so that we are only updating the resource when it changes
2. Require the users to add the `ClearColor` resource to the render sub-app instead of the parent app. This is currently sub-optimal until we have labled sub-apps, and probably a helper funciton on `App` such as `app.with_sub_app(RenderApp, |app| { ... })`. Even if we had that, I think it would be more than we want the user to have to think about. They shouldn't have to know about the render sub-app I don't think.
I think the first option is the best, but I could really use some help figuring out the nuance of why `is_resource_changed` is always returning true in that context.
# Objective
Enable using exact World lifetimes during read-only access . This is motivated by the new renderer's need to allow read-only world-only queries to outlive the query itself (but still be constrained by the world lifetime).
For example:
115b170d1f/pipelined/bevy_pbr2/src/render/mod.rs (L774)
## Solution
Split out SystemParam state and world lifetimes and pipe those lifetimes up to read-only Query ops (and add into_inner for Res). According to every safety test I've run so far (except one), this is safe (see the temporary safety test commit). Note that changing the mutable variants to the new lifetimes would allow aliased mutable pointers (try doing that to see how it affects the temporary safety tests).
The new state lifetime on SystemParam does make `#[derive(SystemParam)]` more cumbersome (the current impl requires PhantomData if you don't use both lifetimes). We can make this better by detecting whether or not a lifetime is used in the derive and adjusting accordingly, but that should probably be done in its own pr.
## Why is this a draft?
The new lifetimes break QuerySet safety in one very specific case (see the query_set system in system_safety_test). We need to solve this before we can use the lifetimes given.
This is due to the fact that QuerySet is just a wrapper over Query, which now relies on world lifetimes instead of `&self` lifetimes to prevent aliasing (but in systems, each Query has its own implied lifetime, not a centralized world lifetime). I believe the fix is to rewrite QuerySet to have its own World lifetime (and own the internal reference). This will complicate the impl a bit, but I think it is doable. I'm curious if anyone else has better ideas.
Personally, I think these new lifetimes need to happen. We've gotta have a way to directly tie read-only World queries to the World lifetime. The new renderer is the first place this has come up, but I doubt it will be the last. Worst case scenario we can come up with a second `WorldLifetimeQuery<Q, F = ()>` parameter to enable these read-only scenarios, but I'd rather not add another type to the type zoo.
## Objective
- Clean up remaining references to the trait `FromResources`, which was replaced in favor of `FromWorld` during the ECS rework.
## Solution
- Remove the derive macro for `FromResources`
- Change doc references of `FromResources` to `FromWorld`
(this is the first item in #2576)
# Objective
- Prevent the need to specify a sprite size when using the pipelined sprite renderer
## Solution
- Re-introduce the sprite auto resize system from the old renderer
# Objective
Restore the functionality of sprite atlases in the new renderer.
### **Note:** This PR relies on #2555
## Solution
Mostly just a copy paste of the existing sprite atlas implementation, however I unified the rendering between sprites and atlases.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Port bevy_gltf to the pipelined-rendering branch.
## Solution
crates/bevy_gltf has been copied and pasted into pipelined/bevy_gltf2 and modifications were made to work with the pipelined-rendering branch. Notably vertex tangents and vertex colours are not supported.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Remove all the `.system()` possible.
- Check for remaining missing cases.
## Solution
- Remove all `.system()`, fix compile errors
- 32 calls to `.system()` remains, mostly internals, the few others should be removed after #2446
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet.
You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away.
Co-Authored-By: Carter Anderson <mcanders1@gmail.com>
* 3d_scene_pipelined: Use a shallower directional light angle to provoke acne
* cornell_box_pipelined: Remove bias tweaks
* bevy_pbr2: Simplify shadow biases by moving them to linear depth
* bevy_pbr2: Do not use DepthBiasState
* bevy_pbr2: Do not use bilinear filtering for sampling depth textures
* pbr.wgsl: Remove unnecessary comment
* bevy_pbr2: Do manual shadow map depth comparisons for more flexibility
* examples: Add shadow_biases_pipelined example
This is useful for stress testing biases.
* bevy_pbr2: Scale the point light normal bias by the shadow map texel size
This allows the normal bias to be small close to the light source where the
shadow map texel to screen texel ratio is high, but is appropriately large
further away from the light source where the shadow map texel can easily cover
multiple screen texels.
* shadow_biases_pipelined: Add support for toggling directional / point light
* shadow_biases_pipelined: Cleanup
* bevy_pbr2: Scale the directional light normal bias by the shadow map texel size
* shadow_biases_pipelined: Fit the orthographic projection around the scene
* bevy_pbr2: Directional lights should have no shadows outside their projection
Before this change, sampling a fragment position from outside the ndc volume
would result in the return sample being clamped to the edge in x,y or possibly
always casting a shadow for fragment positions past the orthographic
projection's far plane.
* bevy_pbr2: Fix the default directional light normal bias
* Revert "bevy_pbr2: Do manual shadow map depth comparisons for more flexibility"
This reverts commit 7df1bab38a42d8a33bc50ca583d4be37bd9c9f0d.
* shadow_biases_pipelined: Adjust directional light normal bias in 0.1 increments
* pbr.wgsl: Add a couple of clarifying comments
* Revert "bevy_pbr2: Do not use bilinear filtering for sampling depth textures"
This reverts commit f53baab0232ce218866a45cad6902b470f4cf2c4.
* shadow_biases_pipelined: Print usage to terminal
* 3d_scene_pipelined: Use a shallower directional light angle to provoke acne
* cornell_box_pipelined: Remove bias tweaks
* bevy_pbr2: Simplify shadow biases by moving them to linear depth
* bevy_pbr2: Add support for most of the StandardMaterial textures
Normal maps are not included here as they require tangents in a vertex attribute.
* bevy_pbr2: Ensure RenderCommandQueue is ready for PbrShaders init
* texture_pipelined: Add a light to the scene so we can see stuff
* WIP bevy_pbr2: back to front sorting hack
* bevy_pbr2: Uniform control flow for texture sampling in pbr.frag
From 'fintelia' on the Bevy Render Rework Round 2 discussion:
"My understanding is that GPUs these days never use the "execute both branches
and select the result" strategy. Rather, what they do is evaluate the branch
condition on all threads of a warp, and jump over it if all of them evaluate to
false. If even a single thread needs to execute the if statement body, however,
then the remaining threads are paused until that is completed."
* bevy_pbr2: Simplify texture and sampler names
The StandardMaterial_ prefix is no longer needed
* bevy_pbr2: Match default 'AmbientColor' of current bevy_pbr for now
* bevy_pbr2: Convert from non-linear to linear sRGB for the color uniform
* bevy_pbr2: Add pbr_pipelined example
* Fix view vector in pbr frag to work in ortho
* bevy_pbr2: Use a 90 degree y fov and light range projection for lights
* bevy_pbr2: Add AmbientLight resource
* bevy_pbr2: Convert PointLight color to linear sRGB for use in fragment shader
* bevy_pbr2: pbr.frag: Rename PointLight.projection to view_projection
The uniform contains the view_projection matrix so this was incorrect.
* bevy_pbr2: PointLight is an OmniLight as it has a radius
* bevy_pbr2: Factoring out duplicated code
* bevy_pbr2: Implement RenderAsset for StandardMaterial
* Remove unnecessary texture and sampler clones
* fix comment formatting
* remove redundant Buffer:from
* Don't extract meshes when their material textures aren't ready
* make missing textures in the queue step an error
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Noticed a warning when running tests:
```
> cargo test --workspace
warning: output filename collision.
The example target `change_detection` in package `bevy_ecs v0.5.0 (/bevy/crates/bevy_ecs)` has the same output filename as the example target `change_detection` in package `bevy v0.5.0 (/bevy)`.
Colliding filename is: /bevy/target/debug/examples/change_detection
The targets should have unique names.
Consider changing their names to be unique or compiling them separately.
This may become a hard error in the future; see <https://github.com/rust-lang/cargo/issues/6313>.
warning: output filename collision.
The example target `change_detection` in package `bevy_ecs v0.5.0 (/bevy/crates/bevy_ecs)` has the same output filename as the example target `change_detection` in package `bevy v0.5.0 (/bevy)`.
Colliding filename is: /bevy/target/debug/examples/change_detection.dSYM
The targets should have unique names.
Consider changing their names to be unique or compiling them separately.
This may become a hard error in the future; see <https://github.com/rust-lang/cargo/issues/6313>.
```
## Solution
I renamed example `change_detection` to `component_change_detection`
# Objective
- Extend work done in #2398.
- Make `.system()` syntax optional when using system descriptor API.
## Solution
- Slight change to `ParallelSystemDescriptorCoercion` signature and implementors.
---
I haven't touched exclusive systems, because it looks like the only two other solutions are going back to doubling our system insertion methods, or starting to lean into stageless. The latter will invalidate the former, so I think exclusive systems should remian pariahs until stageless.
I can grep & nuke `.system()` thorughout the codebase now, which might take a while, or we can do that in subsequent PR(s).
This can be your 6 months post-christmas present.
# Objective
- Make `.system` optional
- yeet
- It's ugly
- Alternative title: `.system` is dead; long live `.system`
- **yeet**
## Solution
- Use a higher ranked lifetime, and some trait magic.
N.B. This PR does not actually remove any `.system`s, except in a couple of examples. Once this is merged we can do that piecemeal across crates, and decide on syntax for labels.
I'm still here :) will try to land the ios audio support in cpal soon and then we can land this.
This PR also adds in assets as a directory reference and avoids the "Xcode is optimizing and breaking my PNGs" issue that I had earlier on during iOS testing on Bevy.
Re-testing this now.
Related to [discussion on discord](https://discord.com/channels/691052431525675048/742569353878437978/824731187724681289)
With const generics, it is now possible to write generic iterator over multiple entities at once.
This enables patterns of query iterations like
```rust
for [e1, e2, e3] in query.iter_combinations() {
// do something with relation of all three entities
}
```
The compiler is able to infer the correct iterator for given size of array, so either of those work
```rust
for [e1, e2] in query.iter_combinations() { ... }
for [e1, e2, e3] in query.iter_combinations() { ... }
```
This feature can be very useful for systems like collision detection.
When you ask for permutations of size K of N entities:
- if K == N, you get one result of all entities
- if K < N, you get all possible subsets of N with size K, without repetition
- if K > N, the result set is empty (no permutation of size K exist)
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Fixes the frag shader for unlit materials by correcting the scope of the `#ifndef` to include the light functions. Closes#2190, introduced in #2112.
Tested by changing materials in the the `3d_scene` example to be unlit. Unsure how to prevent future regressions without creating a test case scene that will catch these runtime panics.
This covers issue #2110
It adds the line `.add_system(bevy::input::system::exit_on_esc_system.system())` before `.run()`
to every example that uses a window, so users have a quick way to close the examples.
I used the full name `bevy::input::system::exit_on_esc_system`, I thought it gave clarity about being a built-in system.
The examples excluded from the change are the ones in the android, ios, wasm folders, the headless
examples and the ecs/system_sets example because it closes itself.
Changes to get Bevy to compile with wgpu master.
With this, on a Mac:
* 2d examples look fine
* ~~3d examples crash with an error specific to metal about a compilation error~~
* 3d examples work fine after enabling feature `wgpu/cross`
Feature `wgpu/cross` seems to be needed only on some platforms, not sure how to know which. It was introduced in https://github.com/gfx-rs/wgpu-rs/pull/826
Adds an GitHub Action to check all local (non http://, https:// ) links in all Markdown files of the repository for liveness.
Fails if a file is not found.
# Goal
This should help maintaining the quality of the documentation.
# Impact
Takes ~24 seconds currently and found 3 dead links (pull requests already created).
# Dependent PRs
* #2064
* #2065
* #2066
# Info
See [markdown-link-check](https://github.com/marketplace/actions/markdown-link-check).
# Example output
```
FILE: ./docs/profiling.md
1 links checked.
FILE: ./docs/plugins_guidelines.md
37 links checked.
FILE: ./docs/linters.md
[✖] ../.github/linters/markdown-lint.yml → Status: 400 [Error: ENOENT: no such file or directory, access '/github/workspace/.github/linters/markdown-lint.yml'] {
errno: -2,
code: 'ENOENT',
syscall: 'access',
path: '/github/workspace/.github/linters/markdown-lint.yml'
}
```
# Improvements
* Can also be used to check external links, but fails because of:
* Too many requests (429) responses:
```
FILE: ./CHANGELOG.md
[✖] https://github.com/bevyengine/bevy/pull/1762 → Status: 429
```
* crates.io links respond 404
```
FILE: ./README.md
[✖] https://crates.io/crates/bevy → Status: 404
```
In response to #2023, here is a draft for a PR.
Fixes#2023
I've added an example to show how to use `WithBundle`, and also to test it out.
Right now there is a bug: If a bundle and a query are "the same", then it doesn't filter out
what it needs to filter out.
Example:
```
Print component initated from bundle.
[examples/ecs/query_bundle.rs:57] x = Dummy( <========= This should not get printed
111,
)
[examples/ecs/query_bundle.rs:57] x = Dummy(
222,
)
Show all components
[examples/ecs/query_bundle.rs:50] x = Dummy(
111,
)
[examples/ecs/query_bundle.rs:50] x = Dummy(
222,
)
```
However, it behaves the right way, if I add one more component to the bundle,
so the query and the bundle doesn't look the same:
```
Print component initated from bundle.
[examples/ecs/query_bundle.rs:57] x = Dummy(
222,
)
Show all components
[examples/ecs/query_bundle.rs:50] x = Dummy(
111,
)
[examples/ecs/query_bundle.rs:50] x = Dummy(
222,
)
```
I hope this helps. I'm definitely up for tinkering with this, and adding anything that I'm asked to add
or change.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
If accepted, fixes#1694 .
I wanted to explore system sets and run criteria a bit, so made an example expanding a bit on the snippets shown in the 0.5 release post.
Shows a couple of system sets, uses system labels, run criterion, and a use of the interesting `RunCriterion::pipe` functionality.
Fixes#1895
Changed most `println` to `info` in examples, some to `warn` when it was useful to differentiate from other more noisy logs.
Added doc on `LogPlugin`, how to configure it, and why (and how) you may need to disable it
This was nowhere documented inside Bevy.
Should I also mention the use case of debugging a project?
Closes#810
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Just to avoid confusion to close readers of the example, this fix ensures cake is transformed to the height at the cake's cell, rather than the height at the player's cell.
Without this, cake may be floating or buried, depending on where the player is standing at time of spawning.
Love your work!
This PR adds an example on how to animate a shader by passing the global `time.seconds_since_startup()` to a component, and accessing that component inside the shader.
Hopefully this is the current proper solution, please let me know if it should be solved in another way.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Direction of movement was reversed, previously.
(i.e. Left arrow key moved sprite to the right; Right arrow key moved sprite to the left.)
This PR changes the code to now be consistent with, for example, the breakout example: 81b53d15d4/examples/game/breakout.rs (L184-L190)
i.e. AFAICT it's not an issue with the keycode being different/wrong.
After an inquiry on Reddit about support for Directional Lights and the unused properties on Light, I wanted to clean it up, to hopefully make it ever so slightly more clear for anyone wanting to add additional light types.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I was looking into "lower level" rendering and I saw no example on how to do that. Yet, I think it's something relevant to show, so I set up a simple example on how to do that. I hope it's welcome.
I'm not confident about the code and a review is definitely nice to have, especially because there are a few things that are not great.
Specifically, I think it would be nice to see how to render with a completely custom set of attributes (position and color, in this case), but I couldn't manage to get it working without normals and uv.
It makes sense if bevy Meshes need these two attributes, but I'm not sure about it.
Co-authored-by: Alessandro Re <ale@ale-re.net>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR fixes https://github.com/bevyengine/bevy/issues/1240, where the ball is escaping the playing field at low framerates. I did this by moving the movement and physics system into a Fixed Timestep system set and changing the movement steps to a constant. So we lose the example use of delta_time for changing position, but gain a use of FixedTimestep.
If this is accepted https://github.com/bevyengine/bevy-website/pull/102 will need to be updated to match.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR adds normal maps on top of PBR #1554. Once that PR lands, the changes should look simpler.
Edit: Turned out to be so little extra work, I added metallic/roughness texture too. And occlusion and emissive.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
In the current impl, next clears out the entire stack and replaces it with a new state. This PR moves this functionality into a replace method, and changes the behavior of next to only change the top state.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This adds a new project for showing off Frustum Culling.
(Master runs this at sub 1 FPS while with the frustum culling it runs at 144 FPS on my system)
Short clip of the project running:
https://streamable.com/vvzh2u
I'm opening this prematurely; consider this an RFC that predates RFCs and therefore not super-RFC-like.
This PR does two "big" things: decouple run criteria from system sets, reimagine system sets as weapons of mass system description.
### What it lets us do:
* Reuse run criteria within a stage.
* Pipe output of one run criteria as input to another.
* Assign labels, dependencies, run criteria, and ambiguity sets to many systems at the same time.
### Things already done:
* Decoupled run criteria from system sets.
* Mass system description superpowers to `SystemSet`.
* Implemented `RunCriteriaDescriptor`.
* Removed `VirtualSystemSet`.
* Centralized all run criteria of `SystemStage`.
* Extended system descriptors with per-system run criteria.
* `.before()` and `.after()` for run criteria.
* Explicit order between state driver and related run criteria. Fixes#1672.
* Opt-in run criteria deduplication; default behavior is to panic.
* Labels (not exposed) for state run criteria; state run criteria are deduplicated.
### API issues that need discussion:
* [`FixedTimestep::step(1.0).label("my label")`](eaccf857cd/crates/bevy_ecs/src/schedule/run_criteria.rs (L120-L122)) and [`FixedTimestep::step(1.0).with_label("my label")`](eaccf857cd/crates/bevy_core/src/time/fixed_timestep.rs (L86-L89)) are both valid but do very different things.
---
I will try to maintain this post up-to-date as things change. Do check the diffs in "edited" thingy from time to time.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Fixes#1736
There seemed to be an obvious transcription error where `setup_pipeline` was being called during `on_update` of `AppState::CreateWindow` instead of `AppState::Setup`.
However, the example still panicked after fixing that.
I'm not sure if there's some intended or unintended change in event processing during state transitions or something, but this PR make the example work again.
Cleaned up an unused `Stage` label while I was in there.
Please feel free to close this in favor of another approach.
Resolves#1253#1562
This makes the Commands apis consistent with World apis. This moves to a "type state" pattern (like World) where the "current entity" is stored in an `EntityCommands` builder.
In general this tends to cuts down on indentation and line count. It comes at the cost of needing to type `commands` more and adding more semicolons to terminate expressions.
I also added `spawn_bundle` to Commands because this is a common enough operation that I think its worth providing a shorthand.
So I think that the underlying issue is actually a system order ambiguity thing between `spawn_bonus` and `rotate_bonus`, but I'm not confident enough about `run_criteria`, `FixedTimeStep`, etc. to sort that out.
This is a rebase of StarArawns PBR work from #261 with IngmarBitters work from #1160 cherry-picked on top.
I had to make a few minor changes to make some intermediate commits compile and the end result is not yet 100% what I expected, so there's a bit more work to do.
Co-authored-by: John Mitchell <toasterthegamer@gmail.com>
Co-authored-by: Ingmar Bitter <ingmar.bitter@gmail.com>
Alternative to #1203 and #1611
Camera bindings have historically been "hacked in". They were _required_ in all shaders and only supported a single Mat4. PBR (#1554) requires the CameraView matrix, but adding this using the "hacked" method forced users to either include all possible camera data in a single binding (#1203) or include all possible bindings (#1611).
This approach instead assigns each "active camera" its own RenderResourceBindings, which are populated by CameraNode. The PassNode then retrieves (and initializes) the relevant bind groups for all render pipelines used by visible entities.
* Enables any number of camera bindings , including zero (with any set or binding number ... set 0 should still be used to avoid rebinds).
* Renames Camera binding to CameraViewProj
* Adds CameraView binding
# Problem Definition
The current change tracking (via flags for both components and resources) fails to detect changes made by systems that are scheduled to run earlier in the frame than they are.
This issue is discussed at length in [#68](https://github.com/bevyengine/bevy/issues/68) and [#54](https://github.com/bevyengine/bevy/issues/54).
This is very much a draft PR, and contributions are welcome and needed.
# Criteria
1. Each change is detected at least once, no matter the ordering.
2. Each change is detected at most once, no matter the ordering.
3. Changes should be detected the same frame that they are made.
4. Competitive ergonomics. Ideally does not require opting-in.
5. Low CPU overhead of computation.
6. Memory efficient. This must not increase over time, except where the number of entities / resources does.
7. Changes should not be lost for systems that don't run.
8. A frame needs to act as a pure function. Given the same set of entities / components it needs to produce the same end state without side-effects.
**Exact** change-tracking proposals satisfy criteria 1 and 2.
**Conservative** change-tracking proposals satisfy criteria 1 but not 2.
**Flaky** change tracking proposals satisfy criteria 2 but not 1.
# Code Base Navigation
There are three types of flags:
- `Added`: A piece of data was added to an entity / `Resources`.
- `Mutated`: A piece of data was able to be modified, because its `DerefMut` was accessed
- `Changed`: The bitwise OR of `Added` and `Changed`
The special behavior of `ChangedRes`, with respect to the scheduler is being removed in [#1313](https://github.com/bevyengine/bevy/pull/1313) and does not need to be reproduced.
`ChangedRes` and friends can be found in "bevy_ecs/core/resources/resource_query.rs".
The `Flags` trait for Components can be found in "bevy_ecs/core/query.rs".
`ComponentFlags` are stored in "bevy_ecs/core/archetypes.rs", defined on line 446.
# Proposals
**Proposal 5 was selected for implementation.**
## Proposal 0: No Change Detection
The baseline, where computations are performed on everything regardless of whether it changed.
**Type:** Conservative
**Pros:**
- already implemented
- will never miss events
- no overhead
**Cons:**
- tons of repeated work
- doesn't allow users to avoid repeating work (or monitoring for other changes)
## Proposal 1: Earlier-This-Tick Change Detection
The current approach as of Bevy 0.4. Flags are set, and then flushed at the end of each frame.
**Type:** Flaky
**Pros:**
- already implemented
- simple to understand
- low memory overhead (2 bits per component)
- low time overhead (clear every flag once per frame)
**Cons:**
- misses systems based on ordering
- systems that don't run every frame miss changes
- duplicates detection when looping
- can lead to unresolvable circular dependencies
## Proposal 2: Two-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in either the current frame's list of changes or the previous frame's.
**Type:** Conservative
**Pros:**
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- can result in a great deal of duplicated work
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 3: Last-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in the previous frame's list of changes.
**Type:** Exact
**Pros:**
- exact
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- change detection is always delayed, possibly causing painful chained delays
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 4: Flag-Doubling Change Detection
Combine Proposal 2 and Proposal 3. Differentiate between `JustChanged` (current behavior) and `Changed` (Proposal 3).
Pack this data into the flags according to [this implementation proposal](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804).
**Type:** Flaky + Exact
**Pros:**
- allows users to acc
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- users must specify the type of change detection required
- still quite fragile to system ordering effects when using the flaky `JustChanged` form
- cannot get immediate + exact results
- systems that don't run every frame miss changes
- duplicates detection when looping
## [SELECTED] Proposal 5: Generation-Counter Change Detection
A global counter is increased after each system is run. Each component saves the time of last mutation, and each system saves the time of last execution. Mutation is detected when the component's counter is greater than the system's counter. Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804). How to handle addition detection is unsolved; the current proposal is to use the highest bit of the counter as in proposal 1.
**Type:** Exact (for mutations), flaky (for additions)
**Pros:**
- low time overhead (set component counter on access, set system counter after execution)
- robust to systems that don't run every frame
- robust to systems that loop
**Cons:**
- moderately complex implementation
- must be modified as systems are inserted dynamically
- medium memory overhead (4 bytes per component + system)
- unsolved addition detection
## Proposal 6: System-Data Change Detection
For each system, track which system's changes it has seen. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- conceptually simple
**Cons:**
- requires storing data on each system
- implementation is complex
- must be modified as systems are inserted dynamically
## Proposal 7: Total-Order Change Detection
Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-754326523). This proposal is somewhat complicated by the new scheduler, but I believe it should still be conceptually feasible. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- efficient data storage relative to other exact proposals
**Cons:**
- requires access to the scheduler
- complex implementation and difficulty grokking
- must be modified as systems are inserted dynamically
# Tests
- We will need to verify properties 1, 2, 3, 7 and 8. Priority: 1 > 2 = 3 > 8 > 7
- Ideally we can use identical user-facing syntax for all proposals, allowing us to re-use the same syntax for each.
- When writing tests, we need to carefully specify order using explicit dependencies.
- These tests will need to be duplicated for both components and resources.
- We need to be sure to handle cases where ambiguous system orders exist.
`changing_system` is always the system that makes the changes, and `detecting_system` always detects the changes.
The component / resource changed will be simple boolean wrapper structs.
## Basic Added / Mutated / Changed
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 2
## At Least Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs after `detecting_system`
- verify at the end of tick 2
## At Most Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs once before `detecting_system`
- increment a counter based on the number of changes detected
- verify at the end of tick 2
## Fast Detection
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 1
## Ambiguous System Ordering Robustness
2 x 3 x 2 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs [before/after] `detecting_system` in tick 1
- `changing_system` runs [after/before] `detecting_system` in tick 2
## System Pausing
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs in tick 1, then is disabled by run criteria
- `detecting_system` is disabled by run criteria until it is run once during tick 3
- verify at the end of tick 3
## Addition Causes Mutation
2 design:
- Resources vs. Components
- `adding_system_1` adds a component / resource
- `adding system_2` adds the same component / resource
- verify the `Mutated` flag at the end of the tick
- verify the `Added` flag at the end of the tick
First check tests for: https://github.com/bevyengine/bevy/issues/333
Second check tests for: https://github.com/bevyengine/bevy/issues/1443
## Changes Made By Commands
- `adding_system` runs in Update in tick 1, and sends a command to add a component
- `detecting_system` runs in Update in tick 1 and 2, after `adding_system`
- We can't detect the changes in tick 1, since they haven't been processed yet
- If we were to track these changes as being emitted by `adding_system`, we can't detect the changes in tick 2 either, since `detecting_system` has already run once after `adding_system` :(
# Benchmarks
See: [general advice](https://github.com/bevyengine/bevy/blob/master/docs/profiling.md), [Criterion crate](https://github.com/bheisler/criterion.rs)
There are several critical parameters to vary:
1. entity count (1 to 10^9)
2. fraction of entities that are changed (0% to 100%)
3. cost to perform work on changed entities, i.e. workload (1 ns to 1s)
1 and 2 should be varied between benchmark runs. 3 can be added on computationally.
We want to measure:
- memory cost
- run time
We should collect these measurements across several frames (100?) to reduce bootup effects and accurately measure the mean, variance and drift.
Entity-component change detection is much more important to benchmark than resource change detection, due to the orders of magnitude higher number of pieces of data.
No change detection at all should be included in benchmarks as a second control for cases where missing changes is unacceptable.
## Graphs
1. y: performance, x: log_10(entity count), color: proposal, facet: performance metric. Set cost to perform work to 0.
2. y: run time, x: cost to perform work, color: proposal, facet: fraction changed. Set number of entities to 10^6
3. y: memory, x: frames, color: proposal
# Conclusions
1. Is the theoretical categorization of the proposals correct according to our tests?
2. How does the performance of the proposals compare without any load?
3. How does the performance of the proposals compare with realistic loads?
4. At what workload does more exact change tracking become worth the (presumably) higher overhead?
5. When does adding change-detection to save on work become worthwhile?
6. Is there enough divergence in performance between the best solutions in each class to ship more than one change-tracking solution?
# Implementation Plan
1. Write a test suite.
2. Verify that tests fail for existing approach.
3. Write a benchmark suite.
4. Get performance numbers for existing approach.
5. Implement, test and benchmark various solutions using a Git branch per proposal.
6. Create a draft PR with all solutions and present results to team.
7. Select a solution and replace existing change detection.
Co-authored-by: Brice DAVIER <bricedavier@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
`Color` can now be from different color spaces or representation:
- sRGB
- linear RGB
- HSL
This fixes#1193 by allowing the creation of const colors of all types, and writing it to the linear RGB color space for rendering.
I went with an enum after trying with two different types (`Color` and `LinearColor`) to be able to use the different variants in all place where a `Color` is expected.
I also added the HLS representation because:
- I like it
- it's useful for some case, see example `contributors`: I can just change the saturation and lightness while keeping the hue of the color
- I think adding another variant not using `red`, `green`, `blue` makes it clearer there are differences
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
An alternative to StateStages that uses SystemSets. Also includes pop and push operations since this was originally developed for my personal project which needed them.
it's a followup of #1550
I think calling explicit methods/values instead of default makes the code easier to read: "what is `Quat::default()`" vs "Oh, it's `Quat::IDENTITY`"
`Transform::identity()` and `GlobalTransform::identity()` can also be consts and I replaced the calls to their `default()` impl with `identity()`
Fixes all warnings from `cargo doc --all`.
Those related to code blocks were introduced in #1612, but re-formatting using the experimental features in `rustfmt.toml` doesn't seem to reintroduce them.
1. The instructions in the main README used to point users to the git main version. This has likely misdirected and confused many new users. Update to direct users to the latest release instead.
2. Rewrite the notice in the examples README to make it clearer and more concise, and to show the `latest` git branch.
See also: https://github.com/bevyengine/bevy-website/pull/109 for similar changes to the website and official book.
This only affected 2 Examples:
* `generic_reflection`: For some reason, a `pub use` statement was used. This was removed, and alphabetically ordered.
* `wireframe`: This example used the `bevy_internal` crate directly. Changed to use `bevy` instead.
All other Example Imports are correct.
One potential subjective change is the `removel_detection` example.
Unlike all other Examples, it has its (first) explanatory comment before the Imports.
Adds `get_unique` and `get_unique_mut` to extend the query api and cover a common use case. Also establishes a second impl block where non-core APIs that don't access the internal fields of queries can live.
This adds a `EventWriter<T>` `SystemParam` that is just a thin wrapper around `ResMut<Events<T>>`. This is primarily to have API symmetry between the reader and writer, and has the added benefit of easily improving the API later with no breaking changes.
Since 89217171b4, some birds in example `contributors` where not colored.
Fix is to use `flip_x` of `Sprite` instead of setting `transform.scale.x` to `-1` as described in #1407.
It may be an unintended side effect, as now we can't easily display a colored sprite while changing it's scale from `1` to `-1`, we would have to change it's scale from `1` to `0`, then flip it, then change scale from `0` to `1`.
This pull request is following the discussion on the issue #1127. Additionally, it integrates the change proposed by #1112.
The list of change of this pull request:
* ✨ Add `Timer::times_finished` method that counts the number of wraps for repeating timers.
* ♻️ Refactored `Timer`
* 🐛 Fix a bug where 2 successive calls to `Timer::tick` which makes a repeating timer to finish makes `Timer::just_finished` to return `false` where it should return `true`. Minimal failing example:
```rust
use bevy::prelude::*;
let mut timer: Timer<()> = Timer::from_seconds(1.0, true);
timer.tick(1.5);
assert!(timer.finished());
assert!(timer.just_finished());
timer.tick(1.5);
assert!(timer.finished());
assert!(timer.just_finished()); // <- This fails where it should not
```
* 📚 Add extensive documentation for Timer with doc examples.
* ✨ Add a `Stopwatch` struct similar to `Timer` with extensive doc and tests.
Even if the type specialization is not retained for bevy, the doc, bugfix and added method are worth salvaging 😅.
This is my first PR for bevy, please be kind to me ❤️ .
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes#1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
### Simple Insert (from ecs_bench_suite)
### Simpler Iter (from ecs_bench_suite)
### Fragment Iter (from ecs_bench_suite)
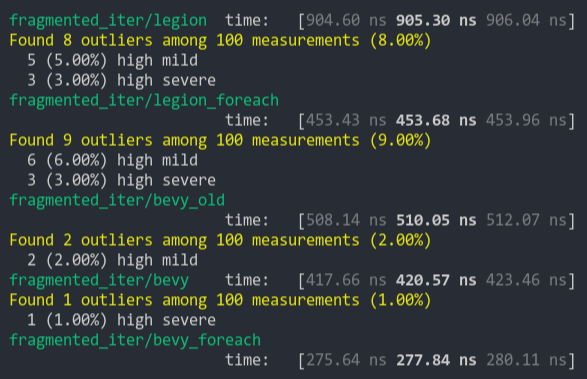
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
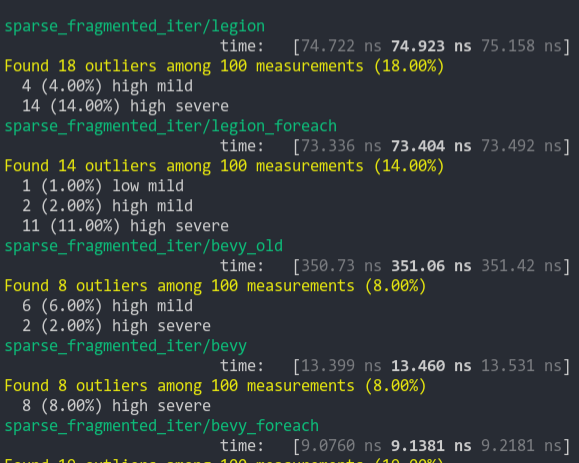
### Schedule (from ecs_bench_suite)
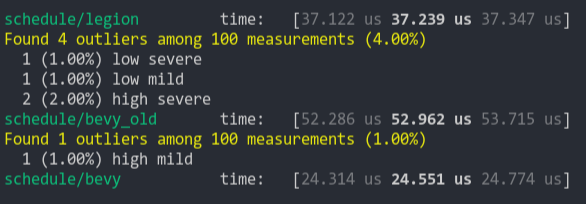
### Add Remove Component (from ecs_bench_suite)
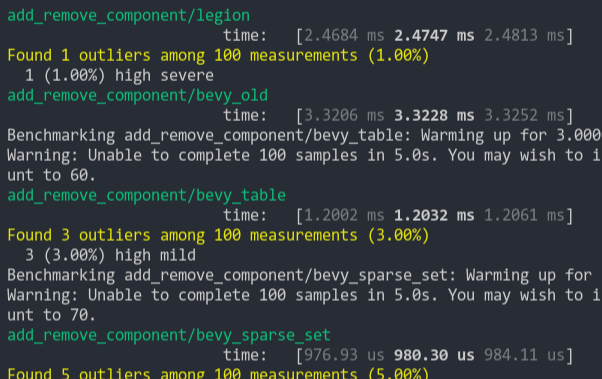
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
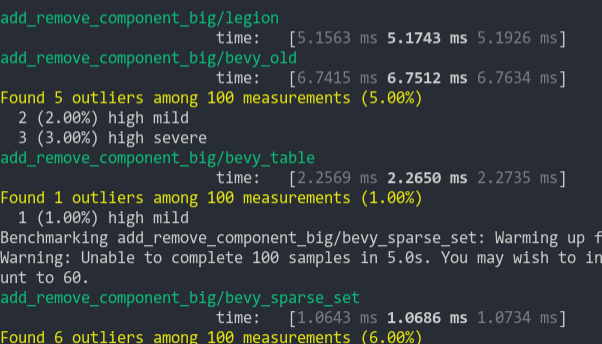
### Get Component
Looks up a single component value a large number of times
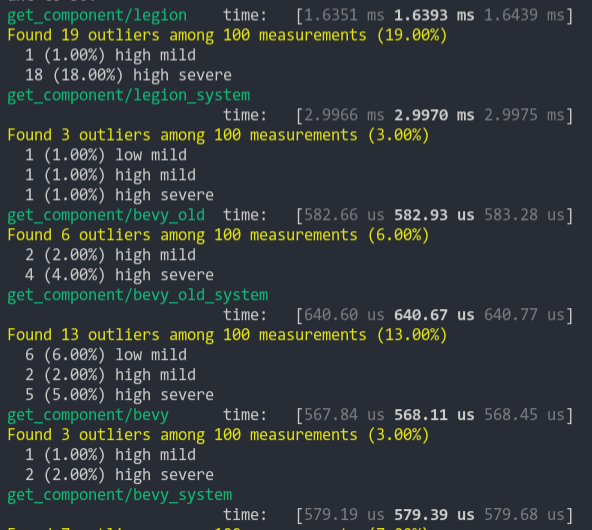
This PR implements wireframe rendering.
Usage:
This is now ready as soon as #1401 gets merged.
Usage:
```rust
app
.insert_resource(WgpuOptions {
name: Some("3d_scene"),
features: WgpuFeatures::NON_FILL_POLYGON_MODE,
..Default::default()
}) // To enable the NON_FILL_POLYGON_MODE feature
.add_plugin(WireframePlugin)
.run();
```
Now we just need to add the Wireframe component on an entity, and it'll draw. its wireframe.
We can also enable wireframe drawing globally by setting the global property in the `WireframeConfig` resource to `true`.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
OK, here's my attempt at sprite flipping. There are a couple of points that I need review/help on, but I think the UX is about ideal:
```rust
.spawn(SpriteBundle {
material: materials.add(texture_handle.into()),
sprite: Sprite {
// Flip the sprite along the x axis
flip: SpriteFlip { x: true, y: false },
..Default::default()
},
..Default::default()
});
```
Now for the issues. The big issue is that for some reason, when flipping the UVs on the sprite, there is a light "bleeding" or whatever you call it where the UV tries to sample past the texture boundry and ends up clipping. This is only noticed when resizing the window, though. You can see a screenshot below.

I am quite baffled why the texture sampling is overrunning like it is and could use some guidance if anybody knows what might be wrong.
The other issue, which I just worked around, is that I had to remove the `#[render_resources(from_self)]` annotation from the Spritesheet because the `SpriteFlip` render resource wasn't being picked up properly in the shader when using it. I'm not sure what the cause of that was, but by removing the annotation and re-organizing the shader inputs accordingly the problem was fixed.
I'm not sure if this is the most efficient way to do this or if there is a better way, but I wanted to try it out if only for the learning experience. Let me know what you think!
It took me a little while to figure out how to use the `SystemParam` derive macro to easily create my own params. So I figured I'd add some docs and an example with what I learned.
- Fixed a bug in the `SystemParam` derive macro where it didn't detect the correct crate name when used in an example (no longer relevant, replaced by #1426 - see further)
- Added some doc comments and a short example code block in the docs for the `SystemParam` trait
- Added a more complete example with explanatory comments in examples
I have run the VSCode Extension [markdownlint](https://marketplace.visualstudio.com/items?itemName=DavidAnson.vscode-markdownlint) on all Markdown Files in the Repo.
The provided Rules are documented here: https://github.com/DavidAnson/markdownlint/blob/v0.23.1/doc/Rules.md
Rules I didn't follow/fix:
* MD024/no-duplicate-heading
* Changelog: Here Heading will always repeat.
* Examples Readme: Platform-specific documentation should be symmetrical.
* MD025/single-title
* MD026/no-trailing-punctuation
* Caused by the ! in "Hello, World!".
* MD033/no-inline-html
* The plugins_guidlines file does need HTML, so the shown badges aren't downscaled too much.
* ~~MD036/no-emphasis-as-heading:~~
* ~~This Warning only Appears in the Github Issue Templates and can be ignored.~~
* ~~MD041/first-line-heading~~
* ~~Only appears in the Readme for the AlienCake example Assets, which is unimportant.~~
---
I also sorted the Examples in the Readme and Cargo.toml in this order/Priority:
* Topic/Folder
* Introductionary Examples
* Alphabetical Order
The explanation for each case, where it isn't Alphabetical :
* Diagnostics
* log_diagnostics: The usage of inbuild Diagnostics is more important than creating your own.
* ECS (Entity Component System)
* ecs_guide: The guide should be read, before diving into other Features.
* Reflection
* reflection: Basic Explanation should be read, before more advanced Topics.
* WASM Examples
* hello_wasm: It's "Hello, World!".
* use `length_squared` for visible entities
* ortho projection 2d/3d different depth calculation
* use ScalingMode::FixedVertical for 3d ortho
* new example: 3d orthographic
* add normalized orthographic projection
* custom scale for ScaledOrthographicProjection
* allow choosing base axis for ScaledOrthographicProjection
* cargo fmt
* add general (scaled) orthographic camera bundle
FIXME: does the same "far" trick from Camera2DBundle make any sense here?
* fixes
* camera bundles: rename and new ortho constructors
* unify orthographic projections
* give PerspectiveCameraBundle constructors like those of OrthographicCameraBundle
* update examples with new camera bundle syntax
* rename CameraUiBundle to UiCameraBundle
* update examples
* ScalingMode::None
* remove extra blank lines
* sane default bounds for orthographic projection
* fix alien_cake_addict example
* reorder ScalingMode enum variants
* ios example fix
- added some missing examples
- changed the order of a few examples (app/empty came after app/empty_default for example)
- added a table with the examples for Android and iOS, like it was done for wasm
see [`issue 1326`](https://github.com/bevyengine/bevy/issues/1326)
{kind=link}
{kind=link}
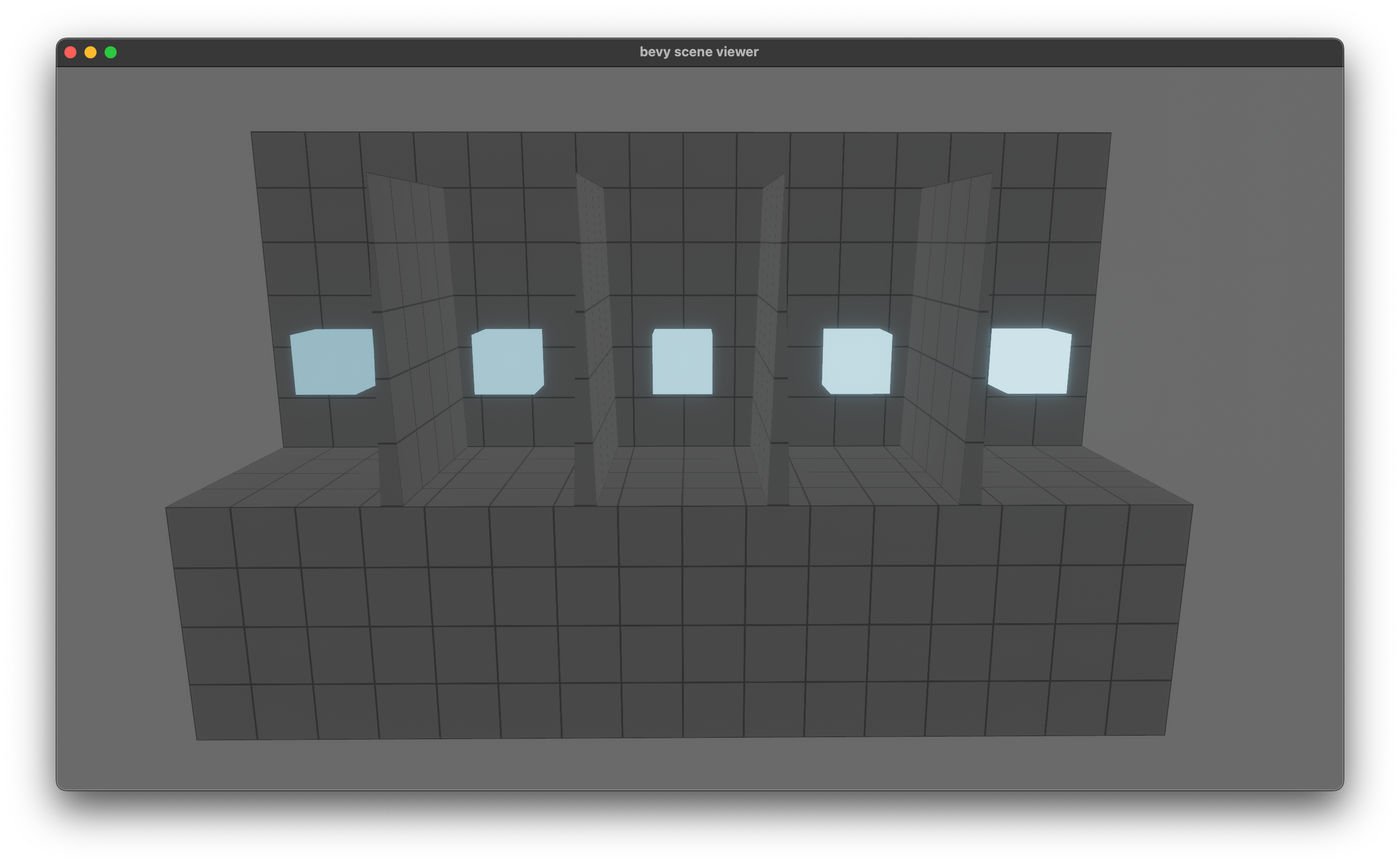{kind=link}
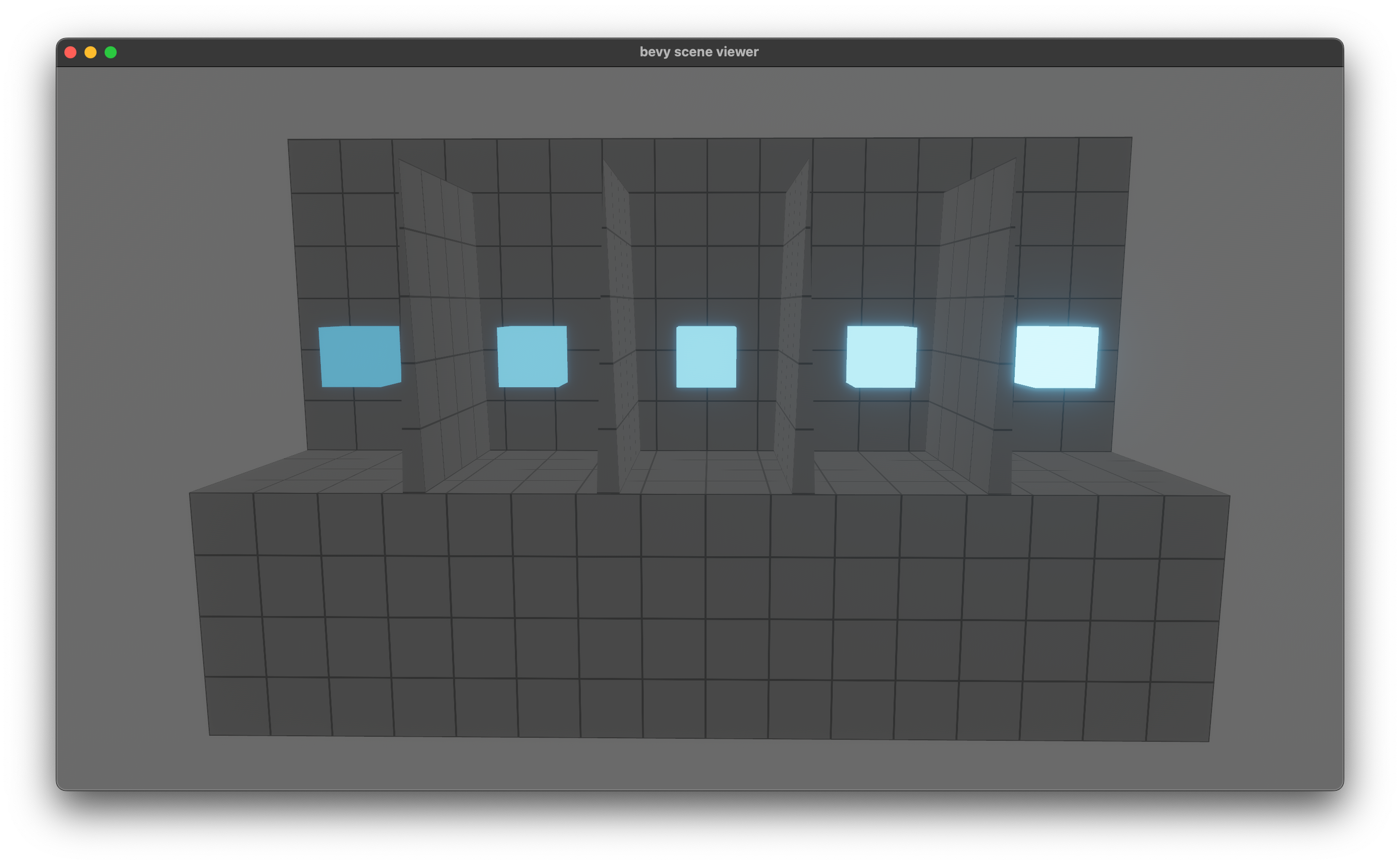{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
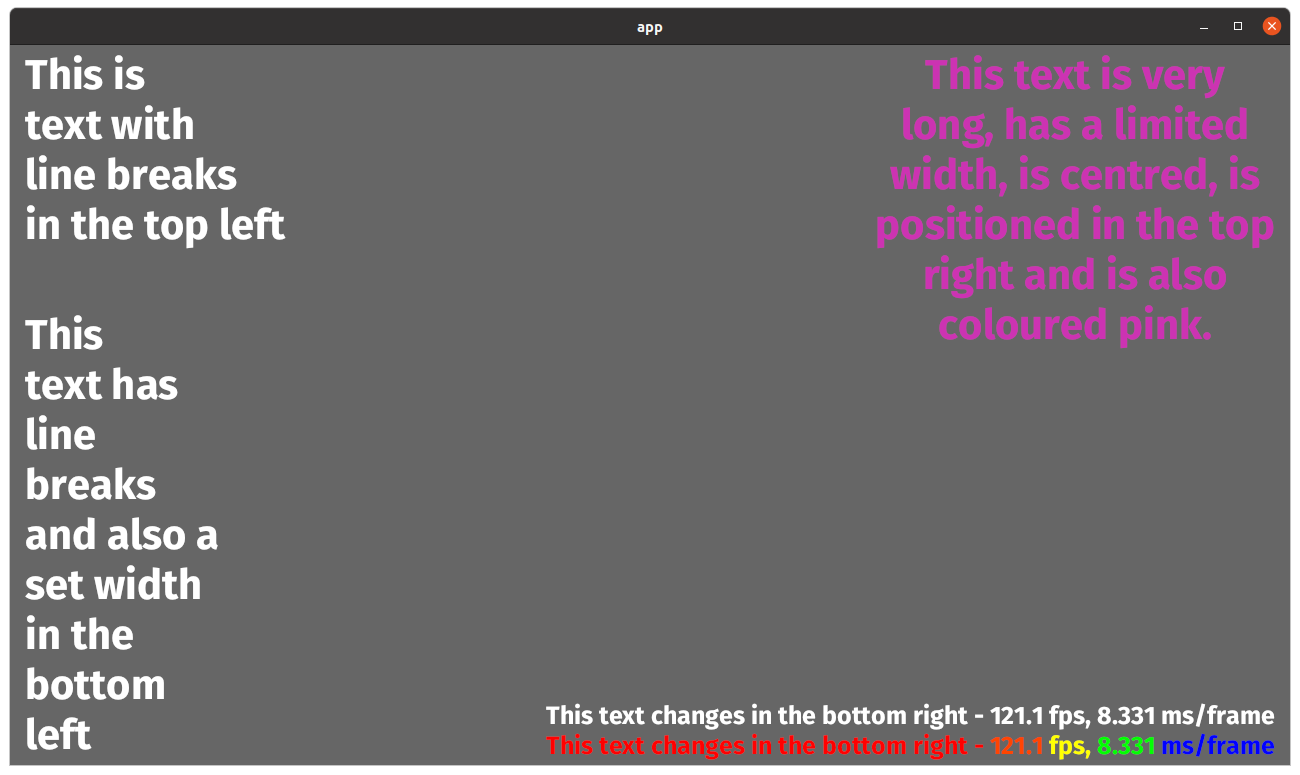{kind=link}
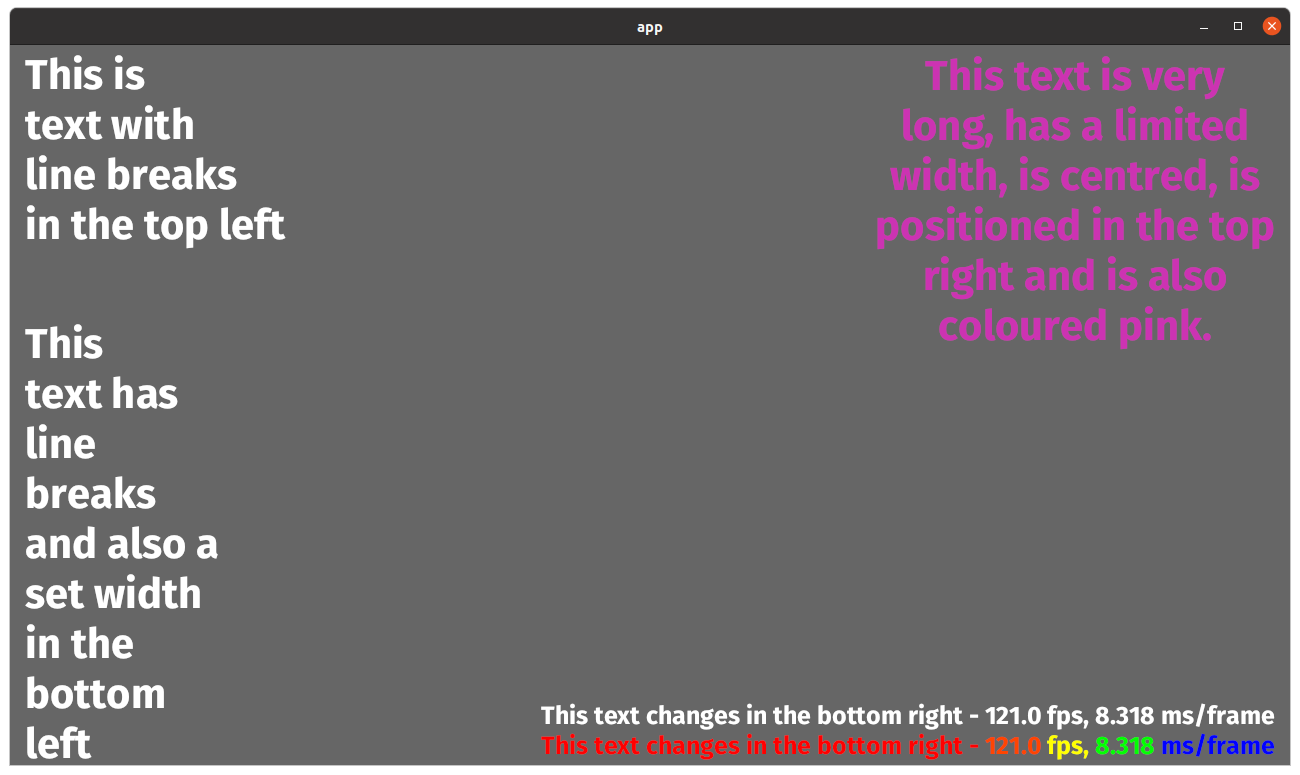{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}