# Objective
- Address #10338
## Solution
- When implementing specular and diffuse transmission, I inadvertently
introduced a performance regression. On high-end hardware it is barely
noticeable, but **for lower-end hardware it can be pretty brutal**. If I
understand it correctly, this is likely due to use of masking by the GPU
to implement control flow, which means that you still pay the price for
the branches you don't take;
- To avoid that, this PR introduces new shader defs (controlled via
`StandardMaterialKey`) that conditionally include the transmission
logic, that way the shader code for both types of transmission isn't
even sent to the GPU if you're not using them;
- This PR also renames ~~`STANDARDMATERIAL_NORMAL_MAP`~~ to
`STANDARD_MATERIAL_NORMAL_MAP` for consistency with the naming
convention used elsewhere in the codebase. (Drive-by fix)
---
## Changelog
- Added new shader defs, set when using transmission in the
`StandardMaterial`:
- `STANDARD_MATERIAL_SPECULAR_TRANSMISSION`;
- `STANDARD_MATERIAL_DIFFUSE_TRANSMISSION`;
- `STANDARD_MATERIAL_SPECULAR_OR_DIFFUSE_TRANSMISSION`.
- Fixed performance regression caused by the introduction of
transmission, by gating transmission shader logic behind the newly
introduced shader defs;
- Renamed ~~`STANDARDMATERIAL_NORMAL_MAP`~~ to
`STANDARD_MATERIAL_NORMAL_MAP` for consistency;
## Migration Guide
- If you were using `#ifdef STANDARDMATERIAL_NORMAL_MAP` on your shader
code, make sure to update the name to `STANDARD_MATERIAL_NORMAL_MAP`;
(with an underscore between `STANDARD` and `MATERIAL`)
# Objective
- Materials should be a more frequent rebind then meshes (due to being
able to use a single vertex buffer, such as in #10164) and therefore
should be in a higher bind group.
---
## Changelog
- For 2d and 3d mesh/material setups (but not UI materials, or other
rendering setups such as gizmos, sprites, or text), mesh data is now in
bind group 1, and material data is now in bind group 2, which is swapped
from how they were before.
## Migration Guide
- Custom 2d and 3d mesh/material shaders should now use bind group 2
`@group(2) @binding(x)` for their bound resources, instead of bind group
1.
- Many internal pieces of rendering code have changed so that mesh data
is now in bind group 1, and material data is now in bind group 2.
Semi-custom rendering setups (that don't use the Material or Material2d
APIs) should adapt to these changes.
# Objective
- The current shader code is misleading since it makes it look like a
struct is passed to the bind group 0 but in reality only the color is
passed. They just happen to have the exact same memory layout so wgsl
doesn't complain and it works.
- The struct is defined after the `impl Material` block which is
backwards from pretty much every other usage of the `impl` block in
bevy.
## Solution
- Remove the unnecessary struct in the shader
- move the impl block
# Objective
- 2d materials have subtle differences with 3d materials that aren't
obvious to beginners
## Solution
- Add an example that shows how to make a 2d material
# Objective
- bump naga_oil to 0.10
- update shader imports to use rusty syntax
## Migration Guide
naga_oil 0.10 reworks the import mechanism to support more syntax to
make it more rusty, and test for item use before importing to determine
which imports are modules and which are items, which allows:
- use rust-style imports
```
#import bevy_pbr::{
pbr_functions::{alpha_discard as discard, apply_pbr_lighting},
mesh_bindings,
}
```
- import partial paths:
```
#import part::of::path
...
path::remainder::function();
```
which will call to `part::of::path::remainder::function`
- use fully qualified paths without importing:
```
// #import bevy_pbr::pbr_functions
bevy_pbr::pbr_functions::pbr()
```
- use imported items without qualifying
```
#import bevy_pbr::pbr_functions::pbr
// for backwards compatibility the old style is still supported:
// #import bevy_pbr::pbr_functions pbr
...
pbr()
```
- allows most imported items to end with `_` and numbers (naga_oil#30).
still doesn't allow struct members to end with `_` or numbers but it's
progress.
- the vast majority of existing shader code will work without changes,
but will emit "deprecated" warnings for old-style imports. these can be
suppressed with the `allow-deprecated` feature.
- partly breaks overrides (as far as i'm aware nobody uses these yet) -
now overrides will only be applied if the overriding module is added as
an additional import in the arguments to `Composer::make_naga_module` or
`Composer::add_composable_module`. this is necessary to support
determining whether imports are modules or items.
# Objective
allow extending `Material`s (including the built in `StandardMaterial`)
with custom vertex/fragment shaders and additional data, to easily get
pbr lighting with custom modifications, or otherwise extend a base
material.
# Solution
- added `ExtendedMaterial<B: Material, E: MaterialExtension>` which
contains a base material and a user-defined extension.
- added example `extended_material` showing how to use it
- modified AsBindGroup to have "unprepared" functions that return raw
resources / layout entries so that the extended material can combine
them
note: doesn't currently work with array resources, as i can't figure out
how to make the OwnedBindingResource::get_binding() work, as wgpu
requires a `&'a[&'a TextureView]` and i have a `Vec<TextureView>`.
# Migration Guide
manual implementations of `AsBindGroup` will need to be adjusted, the
changes are pretty straightforward and can be seen in the diff for e.g.
the `texture_binding_array` example.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
cleanup some pbr shader code. improve shader stage io consistency and
make pbr.wgsl (probably many people's first foray into bevy shader code)
a little more human-readable. also fix a couple of small issues with
deferred rendering.
## Solution
mesh_vertex_output:
- rename to forward_io (to align with prepass_io)
- rename `MeshVertexOutput` to `VertexOutput` (to align with prepass_io)
- move `Vertex` from mesh.wgsl into here (to align with prepass_io)
prepass_io:
- remove `FragmentInput`, use `VertexOutput` directly (to align with
forward_io)
- rename `VertexOutput::clip_position` to `position` (to align with
forward_io)
pbr.wgsl:
- restructure so we don't need `#ifdefs` on the actual entrypoint, use
VertexOutput and FragmentOutput in all cases and use #ifdefs to import
the right struct definitions.
- rearrange to make the flow clearer
- move alpha_discard up from `pbr_functions::pbr` to avoid needing to
call it on some branches and not others
- add a bunch of comments
deferred_lighting:
- move ssao into the `!unlit` block to reflect forward behaviour
correctly
- fix compile error with deferred + premultiply_alpha
## Migration Guide
in custom material shaders:
- `pbr_functions::pbr` no longer calls to
`pbr_functions::alpha_discard`. if you were using the `pbr` function in
a custom shader with alpha mask mode you now also need to call
alpha_discard manually
- rename imports of `bevy_pbr::mesh_vertex_output` to
`bevy_pbr::forward_io`
- rename instances of `MeshVertexOutput` to `VertexOutput`
in custom material prepass shaders:
- rename instances of `VertexOutput::clip_position` to
`VertexOutput::position`
# Objective
- Add a [Deferred
Renderer](https://en.wikipedia.org/wiki/Deferred_shading) to Bevy.
- This allows subsequent passes to access per pixel material information
before/during shading.
- Accessing this per pixel material information is needed for some
features, like GI. It also makes other features (ex. Decals) simpler to
implement and/or improves their capability. There are multiple
approaches to accomplishing this. The deferred shading approach works
well given the limitations of WebGPU and WebGL2.
Motivation: [I'm working on a GI solution for
Bevy](https://youtu.be/eH1AkL-mwhI)
# Solution
- The deferred renderer is implemented with a prepass and a deferred
lighting pass.
- The prepass renders opaque objects into the Gbuffer attachment
(`Rgba32Uint`). The PBR shader generates a `PbrInput` in mostly the same
way as the forward implementation and then [packs it into the
Gbuffer](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L168)).
- The deferred lighting pass unpacks the `PbrInput` and [feeds it into
the pbr()
function](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L65)),
then outputs the shaded color data.
- There is now a resource
[DefaultOpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L599))
that can be used to set the default render method for opaque materials.
If materials return `None` from
[opaque_render_method()](ec1465559f/crates/bevy_pbr/src/material.rs (L131))
the `DefaultOpaqueRendererMethod` will be used. Otherwise, custom
materials can also explicitly choose to only support Deferred or Forward
by returning the respective
[OpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L603))
- Deferred materials can be used seamlessly along with both opaque and
transparent forward rendered materials in the same scene. The [deferred
rendering
example](https://github.com/DGriffin91/bevy/blob/deferred/examples/3d/deferred_rendering.rs)
does this.
- The deferred renderer does not support MSAA. If any deferred materials
are used, MSAA must be disabled. Both TAA and FXAA are supported.
- Deferred rendering supports WebGL2/WebGPU.
## Custom deferred materials
- Custom materials can support both deferred and forward at the same
time. The
[StandardMaterial](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L166))
does this. So does [this
example](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56).
- Custom deferred materials that require PBR lighting can create a
`PbrInput`, write it to the deferred GBuffer and let it be rendered by
the `PBRDeferredLightingPlugin`.
- Custom deferred materials that require custom lighting have two
options:
1. Use the base_color channel of the `PbrInput` combined with the
`STANDARD_MATERIAL_FLAGS_UNLIT_BIT` flag.
[Example.](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56)
(If the unlit bit is set, the base_color is stored as RGB9E5 for extra
precision)
2. A Custom Deferred Lighting pass can be created, either overriding the
default, or running in addition. The a depth buffer is used to limit
rendering to only the required fragments for each deferred lighting
pass. Materials can set their respective depth id via the
[deferred_lighting_pass_id](b79182d2a3/crates/bevy_pbr/src/prepass/prepass_io.wgsl (L95))
attachment. The custom deferred lighting pass plugin can then set [its
corresponding
depth](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L37)).
Then with the lighting pass using
[CompareFunction::Equal](ec1465559f/crates/bevy_pbr/src/deferred/mod.rs (L335)),
only the fragments with a depth that equal the corresponding depth
written in the material will be rendered.
Custom deferred lighting plugins can also be created to render the
StandardMaterial. The default deferred lighting plugin can be bypassed
with `DefaultPlugins.set(PBRDeferredLightingPlugin { bypass: true })`
---------
Co-authored-by: nickrart <nickolas.g.russell@gmail.com>
# Objective
assets v2 broke custom shader imports. fix them
## Solution
store handles of any file dependencies in the `Shader` to avoid them
being immediately dropped.
also added a use into the `shader_material` example so that it'll be
harder to break support in future.
# Objective
- Implement the foundations of automatic batching/instancing of draw
commands as the next step from #89
- NOTE: More performance improvements will come when more data is
managed and bound in ways that do not require rebinding such as mesh,
material, and texture data.
## Solution
- The core idea for batching of draw commands is to check whether any of
the information that has to be passed when encoding a draw command
changes between two things that are being drawn according to the sorted
render phase order. These should be things like the pipeline, bind
groups and their dynamic offsets, index/vertex buffers, and so on.
- The following assumptions have been made:
- Only entities with prepared assets (pipelines, materials, meshes) are
queued to phases
- View bindings are constant across a phase for a given draw function as
phases are per-view
- `batch_and_prepare_render_phase` is the only system that performs this
batching and has sole responsibility for preparing the per-object data.
As such the mesh binding and dynamic offsets are assumed to only vary as
a result of the `batch_and_prepare_render_phase` system, e.g. due to
having to split data across separate uniform bindings within the same
buffer due to the maximum uniform buffer binding size.
- Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform
in arrays in GPU buffers rather than each one being at a dynamic offset
in a uniform buffer. This is the same optimisation that was made for 3D
not long ago.
- Change batch size for a range in `PhaseItem`, adding API for getting
or mutating the range. This is more flexible than a size as the length
of the range can be used in place of the size, but the start and end can
be otherwise whatever is needed.
- Add an optional mesh bind group dynamic offset to `PhaseItem`. This
avoids having to do a massive table move just to insert
`GpuArrayBufferIndex` components.
## Benchmarks
All tests have been run on an M1 Max on AC power. `bevymark` and
`many_cubes` were modified to use 1920x1080 with a scale factor of 1. I
run a script that runs a separate Tracy capture process, and then runs
the bevy example with `--features bevy_ci_testing,trace_tracy` and
`CI_TESTING_CONFIG=../benchmark.ron` with the contents of
`../benchmark.ron`:
```rust
(
exit_after: Some(1500)
)
```
...in order to run each test for 1500 frames.
The recent changes to `many_cubes` and `bevymark` added reproducible
random number generation so that with the same settings, the same rng
will occur. They also added benchmark modes that use a fixed delta time
for animations. Combined this means that the same frames should be
rendered both on main and on the branch.
The graphs compare main (yellow) to this PR (red).
### 3D Mesh `many_cubes --benchmark`
<img width="1411" alt="Screenshot 2023-09-03 at 23 42 10"
src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4">
The mesh and material are the same for all instances. This is basically
the best case for the initial batching implementation as it results in 1
draw for the ~11.7k visible meshes. It gives a ~30% reduction in median
frame time.
The 1000th frame is identical using the flip tool:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4615 seconds
```
### 3D Mesh `many_cubes --benchmark --material-texture-count 10`
<img width="1404" alt="Screenshot 2023-09-03 at 23 45 18"
src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf">
This run uses 10 different materials by varying their textures. The
materials are randomly selected, and there is no sorting by material
bind group for opaque 3D so any batching is 'random'. The PR produces a
~5% reduction in median frame time. If we were to sort the opaque phase
by the material bind group, then this should be a lot faster. This
produces about 10.5k draws for the 11.7k visible entities. This makes
sense as randomly selecting from 10 materials gives a chance that two
adjacent entities randomly select the same material and can be batched.
The 1000th frame is identical in flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4537 seconds
```
### 3D Mesh `many_cubes --benchmark --vary-per-instance`
<img width="1394" alt="Screenshot 2023-09-03 at 23 48 44"
src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f">
This run varies the material data per instance by randomly-generating
its colour. This is the worst case for batching and that it performs
about the same as `main` is a good thing as it demonstrates that the
batching has minimal overhead when dealing with ~11k visible mesh
entities.
The 1000th frame is identical according to flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4568 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d`
<img width="1412" alt="Screenshot 2023-09-03 at 23 59 56"
src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4">
This spawns 160 waves of 1000 quad meshes that are shaded with
ColorMaterial. Each wave has a different material so 160 waves currently
should result in 160 batches. This results in a 50% reduction in median
frame time.
Capturing a screenshot of the 1000th frame main vs PR gives:

```
Mean: 0.001222
Weighted median: 0.750432
1st weighted quartile: 0.453494
3rd weighted quartile: 0.969758
Min: 0.000000
Max: 0.990296
Evaluation time: 0.4255 seconds
```
So they seem to produce the same results. I also double-checked the
number of draws. `main` does 160000 draws, and the PR does 160, as
expected.
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --material-texture-count 10`
<img width="1392" alt="Screenshot 2023-09-04 at 00 09 22"
src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c">
This generates 10 textures and generates materials for each of those and
then selects one material per wave. The median frame time is reduced by
50%. Similar to the plain run above, this produces 160 draws on the PR
and 160000 on `main` and the 1000th frame is identical (ignoring the fps
counter text overlay).

```
Mean: 0.002877
Weighted median: 0.964980
1st weighted quartile: 0.668871
3rd weighted quartile: 0.982749
Min: 0.000000
Max: 0.992377
Evaluation time: 0.4301 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --vary-per-instance`
<img width="1396" alt="Screenshot 2023-09-04 at 00 13 53"
src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb">
This creates unique materials per instance by randomly-generating the
material's colour. This is the worst case for 2D batching. Somehow, this
PR manages a 7% reduction in median frame time. Both main and this PR
issue 160000 draws.
The 1000th frame is the same:

```
Mean: 0.001214
Weighted median: 0.937499
1st weighted quartile: 0.635467
3rd weighted quartile: 0.979085
Min: 0.000000
Max: 0.988971
Evaluation time: 0.4462 seconds
```
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite`
<img width="1396" alt="Screenshot 2023-09-04 at 12 21 12"
src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43">
This just spawns 160 waves of 1000 sprites. There should be and is no
notable difference between main and the PR.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --material-texture-count 10`
<img width="1389" alt="Screenshot 2023-09-04 at 12 36 08"
src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413">
This spawns the sprites selecting a texture at random per instance from
the 10 generated textures. This has no significant change vs main and
shouldn't.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --vary-per-instance`
<img width="1401" alt="Screenshot 2023-09-04 at 12 29 52"
src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6">
This sets the sprite colour as being unique per instance. This can still
all be drawn using one batch. There should be no difference but the PR
produces median frame times that are 4% higher. Investigation showed no
clear sources of cost, rather a mix of give and take that should not
happen. It seems like noise in the results.
### Summary
| Benchmark | % change in median frame time |
| ------------- | ------------- |
| many_cubes | 🟩 -30% |
| many_cubes 10 materials | 🟩 -5% |
| many_cubes unique materials | 🟩 ~0% |
| bevymark mesh2d | 🟩 -50% |
| bevymark mesh2d 10 materials | 🟩 -50% |
| bevymark mesh2d unique materials | 🟩 -7% |
| bevymark sprite | 🟥 2% |
| bevymark sprite 10 materials | 🟥 0.6% |
| bevymark sprite unique materials | 🟥 4.1% |
---
## Changelog
- Added: 2D and 3D mesh entities that share the same mesh and material
(same textures, same data) are now batched into the same draw command
for better performance.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective
- When adding/removing bindings in large binding lists, git would
generate very difficult-to-read diffs
## Solution
- Move the `@group(X) @binding(Y)` into the same line as the binding
type declaration
# Objective
- Significantly reduce the size of MeshUniform by only including
necessary data.
## Solution
Local to world, model transforms are affine. This means they only need a
4x3 matrix to represent them.
`MeshUniform` stores the current, and previous model transforms, and the
inverse transpose of the current model transform, all as 4x4 matrices.
Instead we can store the current, and previous model transforms as 4x3
matrices, and we only need the upper-left 3x3 part of the inverse
transpose of the current model transform. This change allows us to
reduce the serialized MeshUniform size from 208 bytes to 144 bytes,
which is over a 30% saving in data to serialize, and VRAM bandwidth and
space.
## Benchmarks
On an M1 Max, running `many_cubes -- sphere`, main is in yellow, this PR
is in red:
<img width="1484" alt="Screenshot 2023-08-11 at 02 36 43"
src="https://github.com/bevyengine/bevy/assets/302146/7d99c7b3-f2bb-4004-a8d0-4c00f755cb0d">
A reduction in frame time of ~14%.
---
## Changelog
- Changed: Redefined `MeshUniform` to improve performance by using 4x3
affine transforms and reconstructing 4x4 matrices in the shader. Helper
functions were added to `bevy_pbr::mesh_functions` to unpack the data.
`affine_to_square` converts the packed 4x3 in 3x4 matrix data to a 4x4
matrix. `mat2x4_f32_to_mat3x3` converts the 3x3 in mat2x4 + f32 matrix
data back into a 3x3.
## Migration Guide
Shader code before:
```
var model = mesh[instance_index].model;
```
Shader code after:
```
#import bevy_pbr::mesh_functions affine_to_square
var model = affine_to_square(mesh[instance_index].model);
```
naga and wgpu should polyfill WGSL instance_index functionality where it
is not available in GLSL. Until that is done, we can work around it in
bevy using a push constant which is converted to a uniform by naga and
wgpu.
# Objective
- Fixes#9375
## Solution
- Use a push constant to pass in the base instance to the shader on
WebGL2 so that base instance + gl_InstanceID is used to correctly
represent the instance index.
## TODO
- [ ] Benchmark vs per-object dynamic offset MeshUniform as this will
now push a uniform value per-draw as well as update the dynamic offset
per-batch.
- [x] Test on DX12 AMD/NVIDIA to check that this PR does not regress any
problems that were observed there. (@Elabajaba @robtfm were testing that
last time - help appreciated. <3 )
---
## Changelog
- Added: `bevy_render::instance_index` shader import which includes a
workaround for the lack of a WGSL `instance_index` polyfill for WebGL2
in naga and wgpu for the time being. It uses a push_constant which gets
converted to a plain uniform by naga and wgpu.
## Migration Guide
Shader code before:
```
struct Vertex {
@builtin(instance_index) instance_index: u32,
...
}
@vertex
fn vertex(vertex_no_morph: Vertex) -> VertexOutput {
...
var model = mesh[vertex_no_morph.instance_index].model;
```
After:
```
#import bevy_render::instance_index
struct Vertex {
@builtin(instance_index) instance_index: u32,
...
}
@vertex
fn vertex(vertex_no_morph: Vertex) -> VertexOutput {
...
var model = mesh[bevy_render::instance_index::get_instance_index(vertex_no_morph.instance_index)].model;
```
# Objective
The `post_processing` example is currently broken when run with webgl2.
```
cargo run --example post_processing --target=wasm32-unknown-unknown
```
```
wasm.js:387 panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_render_pipeline
note: label = `post_process_pipeline`
In the provided shader, the type given for group 0 binding 2 has a size of 4. As the device does not support `DownlevelFlags::BUFFER_BINDINGS_NOT_16_BYTE_ALIGNED`, the type must have a size that is a multiple of 16 bytes.
```
I bisected the breakage to c7eaedd6a1.
## Solution
Add padding when using webgl2
# Objective
- Fix shader_material_glsl example
## Solution
- Expose the `PER_OBJECT_BUFFER_BATCH_SIZE` shader def through the
default `MeshPipeline` specialization.
- Make use of it in the `custom_material.vert` shader to access the mesh
binding.
---
## Changelog
- Added: Exposed the `PER_OBJECT_BUFFER_BATCH_SIZE` shader def through
the default `MeshPipeline` specialization to use in custom shaders not
using bevy_pbr::mesh_bindings that still want to use the mesh binding in
some way.
# Objective
- Reduce the number of rebindings to enable batching of draw commands
## Solution
- Use the new `GpuArrayBuffer` for `MeshUniform` data to store all
`MeshUniform` data in arrays within fewer bindings
- Sort opaque/alpha mask prepass, opaque/alpha mask main, and shadow
phases also by the batch per-object data binding dynamic offset to
improve performance on WebGL2.
---
## Changelog
- Changed: Per-object `MeshUniform` data is now managed by
`GpuArrayBuffer` as arrays in buffers that need to be indexed into.
## Migration Guide
Accessing the `model` member of an individual mesh object's shader
`Mesh` struct the old way where each `MeshUniform` was stored at its own
dynamic offset:
```rust
struct Vertex {
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh.model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
The new way where one needs to index into the array of `Mesh`es for the
batch:
```rust
struct Vertex {
@builtin(instance_index) instance_index: u32,
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh[vertex.instance_index].model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
Note that using the instance_index is the default way to pass the
per-object index into the shader, but if you wish to do custom rendering
approaches you can pass it in however you like.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
# Objective
#5703 caused the normal prepass to fail as the prepass uses
`pbr_functions::apply_normal_mapping`, which uses
`mesh_view_bindings::view` to determine mip bias, which conflicts with
`prepass_bindings::view`.
## Solution
pass the mip bias to the `apply_normal_mapping` function explicitly.
# Objective
Fixes#8967
## Solution
I think this example was just missed in #5703. I made the same sort of
changes to `fallback_image` that were made in other examples in that PR.
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
Fixes#6920
## Solution
From the issue discussion:
> From looking at the `AsBindGroup` derive macro implementation, the
fallback image's `TextureView` is used when the binding's
`Option<Handle<Image>>` is `None`. Because this relies on already having
a view that matches the desired binding dimensions, I think the solution
will require creating a separate `GpuImage` for each possible
`TextureViewDimension`.
---
## Changelog
Users can now rely on `FallbackImage` to work with a texture binding of
any dimension.
# Objective
Since #8446, example `shader_prepass` logs the following error on my mac
m1:
```
ERROR bevy_render::render_resource::pipeline_cache: failed to process shader:
error: Entry point fragment at Fragment is invalid
= Argument 1 varying error
= Capability MULTISAMPLED_SHADING is not supported
```
The example display the 3d scene but doesn't change with the preps
selected
Maybe related to this update in naga:
cc3a8ac737
## Solution
- Disable MSAA in the example, and check if it's enabled in the shader
# Objective
Fix the screenspace_texture example not working on the WebGPU examples
page. Currently it fails with the following error in the browser
console:
```
1 error(s) generated while compiling the shader:
:213:9 error: redeclaration of 'uv'
let uv = coords_to_viewport_uv(position.xy, view.viewport);
^^
:211:14 note: 'uv' previously declared here
@location(2) uv: vec2<f32>,
```
## Solution
Rename the shader variable `uv` to `viewport_uv` to prevent variable
redeclaration error.
# Objective
The objective is to be able to load data from "application-specific"
(see glTF spec 3.7.2.1.) vertex attribute semantics from glTF files into
Bevy meshes.
## Solution
Rather than probe the glTF for the specific attributes supported by
Bevy, this PR changes the loader to iterate through all the attributes
and map them onto `MeshVertexAttribute`s. This mapping includes all the
previously supported attributes, plus it is now possible to add mappings
using the `add_custom_vertex_attribute()` method on `GltfPlugin`.
## Changelog
- Add support for loading custom vertex attributes from glTF files.
- Add the `custom_gltf_vertex_attribute.rs` example to illustrate
loading custom vertex attributes.
## Migration Guide
- If you were instantiating `GltfPlugin` using the unit-like struct
syntax, you must instead use `GltfPlugin::default()` as the type is no
longer unit-like.
# Objective
- The old post processing example doesn't use the actual post processing
features of bevy. It also has some issues with resizing. It's also
causing some confusion for people because accessing the prepass textures
from it is not easy.
- There's already a render to texture example
- At this point, it's mostly obsolete since the post_process_pass
example is more complete and shows the recommended way to do post
processing in bevy. It's a bit more complicated, but it's well
documented and I'm working on simplifying it even more
## Solution
- Remove the old post_processing example
- Rename post_process_pass to post_processing
## Reviewer Notes
The diff is really noisy because of the rename, but I didn't change any
code in the example.
---------
Co-authored-by: James Liu <contact@jamessliu.com>

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Shader error cause by a missing import.
- `pbr_functions.wgsl` was missing an import for the `ambient_light()` function, as `array_texture` doesn't import it.
- Closes#7542.
## Solution
- Add`#import bevy_pbr::pbr_ambient` into `array_texture`
# Objective
- Fix `post_processing` and `shader_prepass` examples as they fail when compiling shaders due to missing shader defs
- Fixes#6799
- Fixes#6996
- Fixes#7375
- Supercedes #6997
- Supercedes #7380
## Solution
- The prepass was broken due to a missing `MAX_CASCADES_PER_LIGHT` shader def. Add it.
- The shader used in the `post_processing` example is applied to a 2D mesh, so use the correct mesh2d_view_bindings shader import.
# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
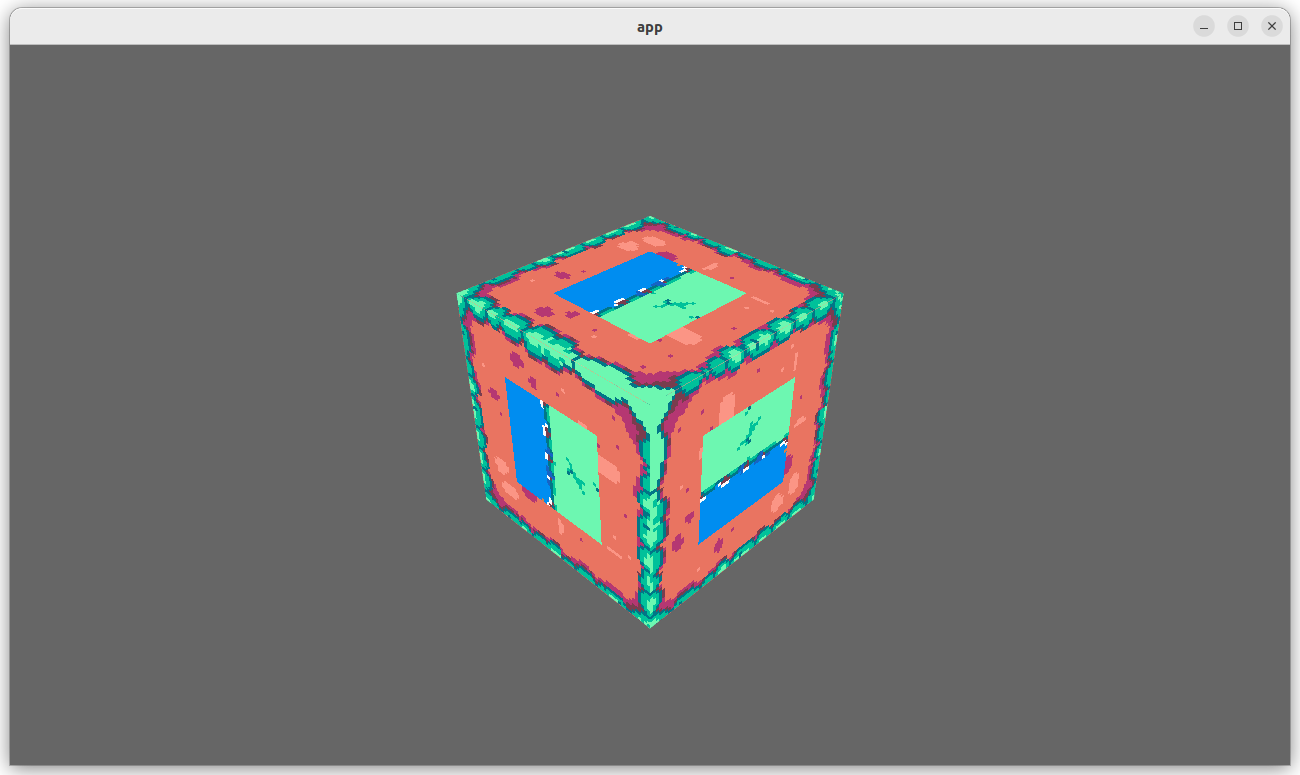
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
# Objective
- The functions added to utils.wgsl by the prepass assume that mesh_view_bindings are present, which isn't always the case
- Fixes https://github.com/bevyengine/bevy/issues/7353
## Solution
- Move these functions to their own `prepass_utils.wgsl` file
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
# Objective
fixes#5946
## Solution
adjust cluster index calculation for viewport origin.
from reading point 2 of the rasterization algorithm description in https://gpuweb.github.io/gpuweb/#rasterization, it looks like framebuffer space (and so @bulitin(position)) is not meant to be adjusted for viewport origin, so we need to subtract that to get the right cluster index.
- add viewport origin to rust `ExtractedView` and wgsl `View` structs
- subtract from frag coord for cluster index calculation
# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make `game_of_life.wgsl` easier to read and understand
## Solution
- Remove unused code in the shader
- `location_f32` was unused in `init`
- `color` was unused in `update`
{kind=link}
{kind=link}
{kind=link}
{kind=link}