# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
- Closes https://github.com/bevyengine/bevy/issues/8008
## Solution
- Add a skybox plugin that renders a fullscreen triangle, and then
modifies the vertices in a vertex shader to enforce that it renders as a
skybox background.
- Skybox is run at the end of MainOpaquePass3dNode.
- In the future, it would be nice to get something like bevy_atmosphere
built-in, and have a default skybox+environment map light.
---
## Changelog
- Added `Skybox`.
- `EnvironmentMapLight` now renders in the correct orientation.
## Migration Guide
- Flip `EnvironmentMapLight` maps if needed to match how they previously
rendered (which was backwards).
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
- We support enabling a normal prepass, but the main pass never actually
uses it and recomputes the normals in the main pass. This isn't ideal
since it's doing redundant work.
## Solution
- Use the normal texture from the prepass in the main pass
## Notes
~~I used `NORMAL_PREPASS_ENABLED` as a shader_def because
`NORMAL_PREPASS` is currently used to signify that it is running in the
prepass while this shader_def need to indicate the prepass is done and
the normal prepass was ran before. I'm not sure if there's a better way
to name this.~~
# Objective
Fixes#8089.
## Solution
Splits the MainPass3dNode into 2 nodes, one for the opaque + alpha
passes and one for the transparent pass.
---
## Changelog
- Split MainPass3dNode into MainOpaquePass3dNode and
MainTransparentPass3dNode
- Combine opaque and alpha phases in MainOpaquePass3dNode into one pass
- Create `START_MAIN_PASS` and `END_MAIN_PASS` empty nodes as labels
- Main pass becomes `START_MAIN_PASS -> MAIN_OPAQUE_PASS ->
MAIN_TRANSPARENT_PASS -> END_MAIN_PASS`
## Migration Guide
Nodes that previously added edges involving `MAIN_PASS` should now add
edges to or from `START_MAIN_PASS` or `END_MAIN_PASS` respectively.

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
- Fixes#7965
- Code quality improvements.
- Removes the unreferenced function `dither` in pbr_functions.wgsl
introduced in 72fbcc7, but made obsolete in c069c54.
- Makes the reference to `screen_space_dither` in pbr.wgsl conditional
on `#ifdef TONEMAP_IN_SHADER`, as the required import is conditional on
the same, as deband dithering can only occur if tonemapping is also
occurring.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
revert combining pipelines for AlphaMode::Blend and AlphaMode::Premultiplied & Add
the recent blend state pr changed `AlphaMode::Blend` to use a blend state of `Blend::PREMULTIPLIED_ALPHA_BLENDING`, and recovered the original behaviour by multiplying colour by alpha in the standard material's fragment shader.
this had some advantages (specifically it means more material instances can be batched together in future), but this also means that custom materials that specify `AlphaMode::Blend` now get a premultiplied blend state, so they must also multiply colour by alpha.
## Solution
revert that combination to preserve 0.9 behaviour for custom materials with AlphaMode::Blend.
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
the current depth bias only adjusts ordering, so it doesn't work for opaque meshes vs alpha-blend meshes, and it doesn't help when two meshes are infinitesimally offset from one another.
## Solution
pass the material's depth bias into the pipeline depth stencil `constant` field.
# Objective
Unfortunately, there are three issues with my changes introduced by #7784.
1. The changes left some dead code. This is already taken care of here: #7875.
2. Disabling prepass causes failures because the shadow mapping relies on the `PrepassPlugin` now.
3. Custom materials use the `prepass.wgsl` shader, but this does not always define a fragment entry point.
This PR fixes 2. and 3. and resolves#7879.
## Solution
- Add a regression test with disabled prepass.
- Split `PrepassPlugin` into two plugins:
- `PrepassPipelinePlugin` contains the part that is required for the shadow mapping to work and is unconditionally added.
- `PrepassPlugin` now only adds the systems and resources required for the "real" prepasses.
- Add a noop fragment entry point to `prepass.wgsl`, used if `NORMAL_PASS` is not defined.
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
- Remove dead code after #7784
# Changelog
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Migration Guide
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Objective
- Fixes#4372.
## Solution
- Use the prepass shaders for the shadow passes.
- Move `DEPTH_CLAMP_ORTHO` from `ShadowPipelineKey` to `MeshPipelineKey` and the associated clamp operation from `depth.wgsl` to `prepass.wgsl`.
- Remove `depth.wgsl` .
- Replace `ShadowPipeline` with `ShadowSamplers`.
Instead of running the custom `ShadowPipeline` we run the `PrepassPipeline` with the `DEPTH_PREPASS` flag and additionally the `DEPTH_CLAMP_ORTHO` flag for directional lights as well as the `ALPHA_MASK` flag for materials that use `AlphaMode::Mask(_)`.
# Objective
Fixes#7797
## Solution
This **seems** like a simple fix, but I'm not 100% confident and I may have messed up the math in some way. In particular, I'm not sure what I should be using for an FOV value.
However, this seems to be producing similar results to 0.9.
Here's the `orthographic` example with a default directional light.
edit: better screen grab below.
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
- ambiguities bad
## Solution
- solve ambiguities
- by either ignoring (e.g. on `queue_mesh_view_bind_groups` since `LightMeta` access is different)
- by introducing a dependency (`prepare_windows -> prepare_*` because the latter use the fallback Msaa)
- make `prepare_assets` public so that we can do a proper `.after`
# Objective
Currently, it is quite awkward to use the `pbr` function in a custom shader without binding a mesh bind group.
This is because the `pbr` function depends on the `MESH_FLAGS_SHADOW_RECEIVER_BIT` flag.
## Solution
I have removed this dependency by adding the flag as a parameter to the `PbrInput` struct.
I am not sure if this is the ideal solution since the mesh flag indicates both `MESH_FLAGS_SIGN_DETERMINANT_MODEL_3X3_BIT` and `MESH_FLAGS_SHADOW_RECEIVER_BIT`.
The former seems to be unrelated to PBR. Maybe the flag should be split.
# Objective
- Fix the environment map shader not working under webgl due to textureNumLevels() not being supported
- Fixes https://github.com/bevyengine/bevy/issues/7722
## Solution
- Instead of using textureNumLevels(), put an extra field in the GpuLights uniform to store the mip count
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
Standard material defaults are currently strange, and the docs are wrong re: metallic.
## Solution
Change the defaults to be similar to [Godot](https://github.com/godotengine/godot/pull/62756).
---
## Changelog
#### Changed
- `StandardMaterial` now defaults to a dielectric material (0.0 `metallic`) with 0.5 `perceptual_roughness`.
## Migration Guide
`StandardMaterial`'s default have now changed to be a fully dielectric material with medium roughness. If you want to use the old defaults, you can set `perceptual_roughness = 0.089` and `metallic = 0.01` (though metallic should generally only be set to 0.0 or 1.0).
# Objective
- rebased version of #6155
The `MaterialPipeline` cannot be integrated into other pipelines like the `MeshPipeline`.
## Solution
Implement `Clone` for `MaterialPipeline`. Expose systems and resources part of the `MaterialPlugin` to allow custom assembly - especially combining existing systems and resources with a custom `queue_material_meshes` system.
# Changelog
## Added
- Clone impl for MaterialPipeline
## Changed
- ExtractedMaterials, extract_materials and prepare_materials are now public
fixes#6799
# Objective
We should be able to reuse the `Globals` or `View` shader struct definitions from anywhere (including third party plugins) without needing to worry about defining unrelated shader defs.
Also we'd like to refactor these structs to not be repeatedly defined.
## Solution
Refactor both `Globals` and `View` into separate importable shaders.
Use the imports throughout.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
(Before)

(After)

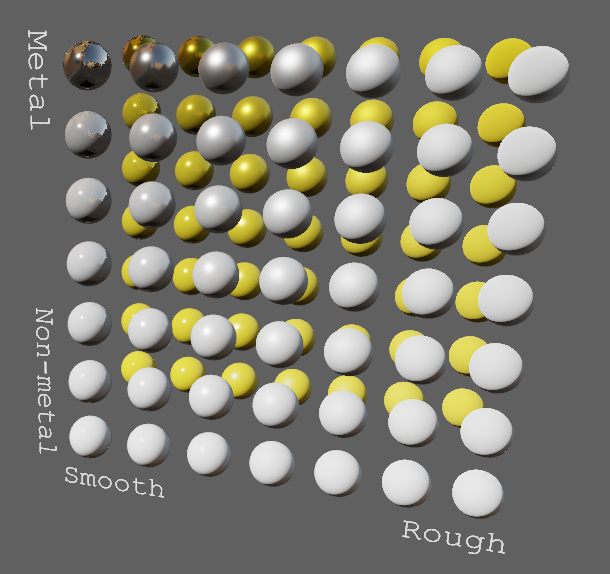
# Objective
- Improve lighting; especially reflections.
- Closes https://github.com/bevyengine/bevy/issues/4581.
## Solution
- Implement environment maps, providing better ambient light.
- Add microfacet multibounce approximation for specular highlights from Filament.
- Occlusion is no longer incorrectly applied to direct lighting. It now only applies to diffuse indirect light. Unsure if it's also supposed to apply to specular indirect light - the glTF specification just says "indirect light". In the case of ambient occlusion, for instance, that's usually only calculated as diffuse though. For now, I'm choosing to apply this just to indirect diffuse light, and not specular.
- Modified the PBR example to use an environment map, and have labels.
- Added `FallbackImageCubemap`.
## Implementation
- IBL technique references can be found in environment_map.wgsl.
- It's more accurate to use a LUT for the scale/bias. Filament has a good reference on generating this LUT. For now, I just used an analytic approximation.
- For now, environment maps must first be prefiltered outside of bevy using a 3rd party tool. See the `EnvironmentMap` documentation.
- Eventually, we should have our own prefiltering code, so that we can have dynamically changing environment maps, as well as let users drop in an HDR image and use asset preprocessing to create the needed textures using only bevy.
---
## Changelog
- Added an `EnvironmentMapLight` camera component that adds additional ambient light to a scene.
- StandardMaterials will now appear brighter and more saturated at high roughness, due to internal material changes. This is more physically correct.
- Fixed StandardMaterial occlusion being incorrectly applied to direct lighting.
- Added `FallbackImageCubemap`.
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
Fix#7377Fix#7513
## Solution
Record the changes made to the Bevy `Window` from `winit` as 'canon' to avoid Bevy sending those changes back to `winit` again, causing a feedback loop.
## Changelog
* Removed `ModifiesWindows` system label.
Neither `despawn_window` nor `changed_window` actually modify the `Window` component so all the `.after(ModifiesWindows)` shouldn't be necessary.
* Moved `changed_window` and `despawn_window` systems to `CoreStage::Last` to avoid systems making changes to the `Window` between `changed_window` and the end of the frame as they would be ignored.
## Migration Guide
The `ModifiesWindows` system label was removed.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
add a hook for ambient occlusion to the pbr shader
## Solution
add a hook for ambient occlusion to the pbr shader
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
Some render systems that have system set used as a label so that they can be referenced from somewhere else.
The 1:1 translation from `add_system_to_stage(Prepare, prepare_lights.label(PrepareLights))` is `add_system(prepare_lights.in_set(Prepare).in_set(PrepareLights)`, but configuring the `PrepareLights` set to be in `Prepare` would match the intention better (there are no systems in `PrepareLights` outside of `Prepare`) and it is easier for visualization tools to deal with.
# Solution
- replace
```rust
prepare_lights in PrepareLights
prepare_lights in Prepare
```
with
```rs
prepare_lights in PrepareLights
PrepareLights in Prepare
```
**Before**

**After**

# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Improve ergonomics / documentation of cascaded shadow maps
- Allow for the customization of the nearest shadowing distance.
- Fixes#7393
- Fixes#7362
## Solution
- Introduce `CascadeShadowConfigBuilder`
- Tweak various example cascade settings for better quality.
---
## Changelog
- Made examples look nicer under cascaded shadow maps.
- Introduce `CascadeShadowConfigBuilder` to help with creating `CascadeShadowConfig`
## Migration Guide
- Configure settings for cascaded shadow maps for directional lights using the newly introduced `CascadeShadowConfigBuilder`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
- Bevy should not have any "internal" execution order ambiguities. These clutter the output of user-facing error reporting, and can result in nasty, nondetermistic, very difficult to solve bugs.
- Verifying this currently involves repeated non-trivial manual work.
## Solution
- [x] add an example to quickly check this
- ~~[ ] ensure that this example panics if there are any unresolved ambiguities~~
- ~~[ ] run the example in CI 😈~~
There's one tricky ambiguity left, between UI and animation. I don't have the tools to fix this without system set configuration, so the remaining work is going to be left to #7267 or another PR after that.
```
2023-01-27T18:38:42.989405Z INFO bevy_ecs::schedule::ambiguity_detection: Execution order ambiguities detected, you might want to add an explicit dependency relation between some of these systems:
* Parallel systems:
-- "bevy_animation::animation_player" and "bevy_ui::flex::flex_node_system"
conflicts: ["bevy_transform::components::transform::Transform"]
```
## Changelog
Resolved internal execution order ambiguities for:
1. Transform propagation (ignored, we need smarter filter checking).
2. Gamepad processing (fixed).
3. bevy_winit's window handling (fixed).
4. Cascaded shadow maps and perspectives (fixed).
Also fixed a desynchronized state bug that could occur when the `Window` component is removed and then added to the same entity in a single frame.
# Objective
- Fix a bug causing performance to drop over time because the GPU fog buffer was endlessly growing
## Solution
- Clear the fog buffer every frame before populating it
# Objective
- Fix `post_processing` and `shader_prepass` examples as they fail when compiling shaders due to missing shader defs
- Fixes#6799
- Fixes#6996
- Fixes#7375
- Supercedes #6997
- Supercedes #7380
## Solution
- The prepass was broken due to a missing `MAX_CASCADES_PER_LIGHT` shader def. Add it.
- The shader used in the `post_processing` example is applied to a 2D mesh, so use the correct mesh2d_view_bindings shader import.
# Objective
In simple cases we might want to derive the `ExtractComponent` trait.
This adds symmetry to the existing `ExtractResource` derive.
## Solution
Add an implementation of `#[derive(ExtractComponent)]`.
The implementation is adapted from the existing `ExtractResource` derive macro.
Additionally, there is an attribute called `extract_component_filter`. This allows specifying a query filter type used when extracting.
If not specified, no filter (equal to `()`) is used.
So:
```rust
#[derive(Component, Clone, ExtractComponent)]
#[extract_component_filter(With<Fuel>)]
pub struct Car {
pub wheels: usize,
}
```
would expand to (a bit cleaned up here):
```rust
impl ExtractComponent for Car
{
type Query = &'static Self;
type Filter = With<Fuel>;
type Out = Self;
fn extract_component(item: QueryItem<'_, Self::Query>) -> Option<Self::Out> {
Some(item.clone())
}
}
```
---
## Changelog
- Added the ability to `#[derive(ExtractComponent)]` with an optional filter.
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873533-44c029af-13b7-4740-8ea3-af96bd5867c9.png">
<img width="1392" alt="image" src="https://user-images.githubusercontent.com/418473/203873549-36be7a23-b341-42a2-8a9f-ceea8ac7a2b8.png">
# Objective
- Add support for the “classic” distance fog effect, as well as a more advanced atmospheric fog effect.
## Solution
This PR:
- Introduces a new `FogSettings` component that controls distance fog per-camera.
- Adds support for three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
- Adds support for directional light influence over fog color;
- Extracts fog via `ExtractComponent`, then uses a prepare system that sets up a new dynamic uniform struct (`Fog`), similar to other mesh view types;
- Renders fog in PBR material shader, as a final adjustment to the `output_color`, after PBR is computed (but before tone mapping);
- Adds a new `StandardMaterial` flag to enable fog; (`fog_enabled`)
- Adds convenience methods for easier artistic control when creating non-linear fog types;
- Adds documentation around fog.
---
## Changelog
### Added
- Added support for distance-based fog effects for PBR materials, controllable per-camera via the new `FogSettings` component;
- Added `FogFalloff` enum for selecting between three widely used “traditional” fog falloff modes: `Linear`, `Exponential` and `ExponentialSquared`, as well as a more advanced `Atmospheric` fog;
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
# Objective
Prevent things from breaking tomorrow when rust 1.67 is released.
## Solution
Fix a few `uninlined_format_args` lints in recently introduced code.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps.
Fixes#3629
Before

After
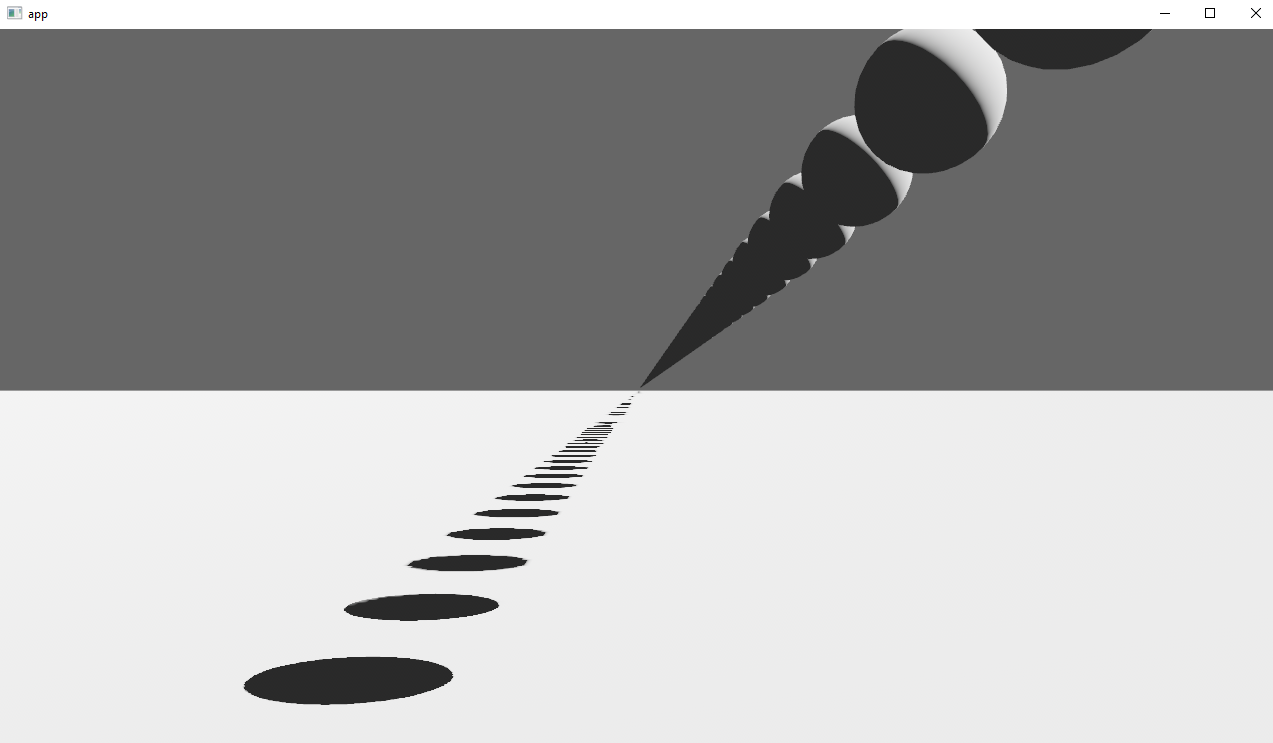
## Solution
Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination.
---
## Changelog
Directional lights now use cascaded shadow maps for improved shadow quality.
## Migration Guide
You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
# Objective
- The functions added to utils.wgsl by the prepass assume that mesh_view_bindings are present, which isn't always the case
- Fixes https://github.com/bevyengine/bevy/issues/7353
## Solution
- Move these functions to their own `prepass_utils.wgsl` file
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
Pipelines can be customized by wrapping an existing pipeline in a newtype and adding custom logic to its implementation of `SpecializedMeshPipeline::specialize`. To make that easier, the wrapped pipeline type needs to implement `Clone`.
For example, the current non-cloneable pipelines require wrapper pipelines to pull apart the wrapped pipeline like this:
```rust
impl FromWorld for Wireframe2dPipeline {
fn from_world(world: &mut World) -> Self {
let p = &world.resource::<Material2dPipeline<ColorMaterial>>();
Self {
mesh2d_pipeline: p.mesh2d_pipeline.clone(),
material2d_layout: p.material2d_layout.clone(),
vertex_shader: p.vertex_shader.clone(),
fragment_shader: p.fragment_shader.clone(),
}
}
}
```
## Solution
Derive or implement `Clone` on all built-in pipeline types. This is easy to do since they mostly just contain cheaply clonable reference-counted types.
---
## Changelog
Implement `Clone` for all pipeline types.
# Objective
fix error with shadow shader's spotlight direction calculation when direction.y ~= 0
fixes#7152
## Solution
same as #6167: in shadows.wgsl, clamp 1-x^2-z^2 to >= 0 so that we can safely sqrt it
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
- Avoid slower than necessary first frame after spawning many entities due to them not having `Aabb`s and so being marked visible
- Avoids unnecessarily large system and VRAM allocations as a consequence
## Solution
- I noticed when debugging the `many_cubes` stress test in Xcode that the `MeshUniform` binding was much larger than it needed to be. I realised that this was because initially, all mesh entities are marked as being visible because they don't have `Aabb`s because `calculate_bounds` is being run in `PostUpdate` and there are no system commands applications before executing the visibility check systems that need the `Aabb`s. The solution then is to run the `calculate_bounds` system just before the previous system commands are applied which is at the end of the `Update` stage.
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
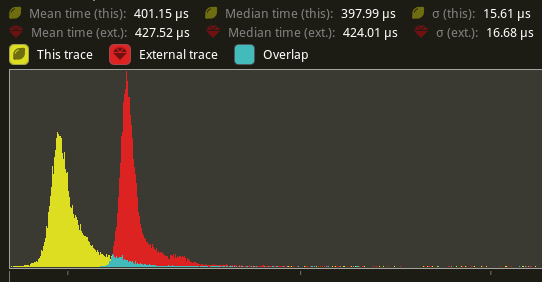
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
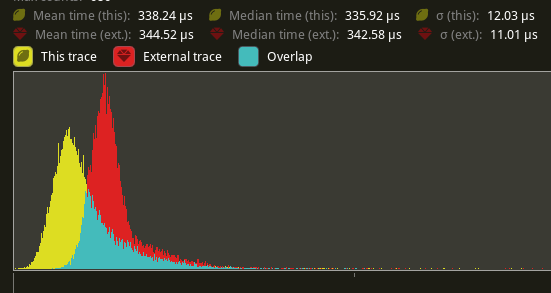
The shadow pass node is also slightly faster (344.52 -> 338.24us)
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
- The #7064 PR had poor performance on an M1 Max in MacOS due to significant overuse of registers resulting in 'register spilling' where data that would normally be stored in registers on the GPU is instead stored in VRAM. The latency to read from/write to VRAM instead of registers incurs a significant performance penalty.
- Use of registers is a limiting factor in shader performance. Assignment of a struct from memory to a local variable can incur copies. Passing a variable that has struct type as an argument to a function can also incur copies. As such, these two cases can incur increased register usage and decreased performance.
## Solution
- Remove/avoid a number of assignments of light struct type data to local variables.
- Remove/avoid a number of passing light struct type variables/data as value arguments to shader functions.
# Objective
- The recently merged PR #7013 does not allow multiple `RenderPhase`s to share the same `RenderPass`.
- Due to the introduced overhead we want to minimize the number of `RenderPass`es recorded during each frame.
## Solution
- Take a constructed `TrackedRenderPass` instead of a `RenderPassDiscriptor` as a parameter to the `RenderPhase::render` method.
---
## Changelog
To enable multiple `RenderPhases` to share the same `TrackedRenderPass`,
the `RenderPhase::render` signature has changed.
```rust
pub fn render<'w>(
&self,
render_pass: &mut TrackedRenderPass<'w>,
world: &'w World,
view: Entity)
```
Co-authored-by: Kurt Kühnert <51823519+kurtkuehnert@users.noreply.github.com>
# Objective
All `RenderPhases` follow the same render procedure.
The same code is duplicated multiple times across the codebase.
## Solution
I simply extracted this code into a method on the `RenderPhase`.
This avoids code duplication and makes setting up new `RenderPhases` easier.
---
## Changelog
### Changed
You can now set up the rendering code of a `RenderPhase` directly using the `RenderPhase::render` method, instead of implementing it manually in your render graph node.
# Objective
Following #4402, extract systems run on the render world instead of the main world, and allow retained state operations on it's resources. We're currently extracting to `ExtractedJoints` and then copying it twice during Prepare. Once into `SkinnedMeshJoints` and again into the actual GPU buffer.
This makes #4902 obsolete.
## Solution
Cut out the middle copy and directly extract joints into `SkinnedMeshJoints` and remove `ExtractedJoints` entirely.
This also removes the per-frame allocation that is being made to send `ExtractedJoints` into the render world.
## Performance
On my local machine, this halves the time for `prepare_skinned _meshes` on `many_foxes` (195.75us -> 93.93us on average).
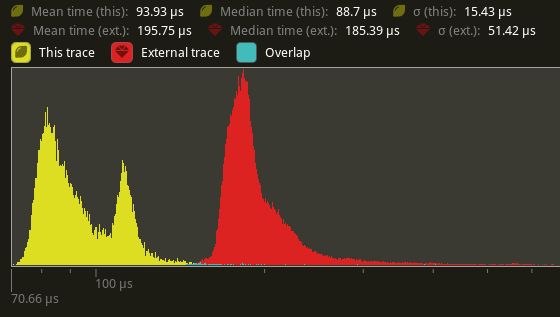
---
## Changelog
Added: `BufferVec::truncate`
Added: `BufferVec::extend`
Changed: `SkinnedMeshJoints::build` now takes a `&mut BufferVec` instead of a `&mut Vec` as a parameter.
Removed: `ExtractedJoints`.
## Migration Guide
`ExtractedJoints` has been removed. Read the bound bones from `SkinnedMeshJoints` instead.
# Objective
- Fixes#6841
- In some case, the number of maximum storage buffers is `u32::MAX` which doesn't fit in a `i32`
## Solution
- Add an option to have a `u32` in a `ShaderDefVal`
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- Reduce confusion around uniform bindings in materials. I've seen multiple people on discord get confused by it because it uses a struct that is named the same in the rust code and the wgsl code, but doesn't contain the same data. Also, the only reason this works is mostly by chance because the memory happens to align correctly.
## Solution
- Remove the confusing parts of the doc
## Notes
It's not super clear in the diff why this causes confusion, but essentially, the rust code defines a `CustomMaterial` struct with a color and a texture, but in the wgsl code the struct with the same name only contains the color. People are confused by it because the struct in wgsl doesn't need to be there.
You _can_ have complex structs on each side and the macro will even combine it for you if you reuse a binding index, but as it is now, this example seems to confuse more than help people.
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- Closes#5262
- Fix color banding caused by quantization.
## Solution
- Adds dithering to the tonemapping node from #3425.
- This is inspired by Godot's default "debanding" shader: https://gist.github.com/belzecue/
- Unlike Godot:
- debanding happens after tonemapping. My understanding is that this is preferred, because we are running the debanding at the last moment before quantization (`[f32, f32, f32, f32]` -> `f32`). This ensures we aren't biasing the dithering strength by applying it in a different (linear) color space.
- This code instead uses and reference the origin source, Valve at GDC 2015


## Additional Notes
Real time rendering to standard dynamic range outputs is limited to 8 bits of depth per color channel. Internally we keep everything in full 32-bit precision (`vec4<f32>`) inside passes and 16-bit between passes until the image is ready to be displayed, at which point the GPU implicitly converts our `vec4<f32>` into a single 32bit value per pixel, with each channel (rgba) getting 8 of those 32 bits.
### The Problem
8 bits of color depth is simply not enough precision to make each step invisible - we only have 256 values per channel! Human vision can perceive steps in luma to about 14 bits of precision. When drawing a very slight gradient, the transition between steps become visible because with a gradient, neighboring pixels will all jump to the next "step" of precision at the same time.
### The Solution
One solution is to simply output in HDR - more bits of color data means the transition between bands will become smaller. However, not everyone has hardware that supports 10+ bit color depth. Additionally, 10 bit color doesn't even fully solve the issue, banding will result in coherent bands on shallow gradients, but the steps will be harder to perceive.
The solution in this PR adds noise to the signal before it is "quantized" or resampled from 32 to 8 bits. Done naively, it's easy to add unneeded noise to the image. To ensure dithering is correct and absolutely minimal, noise is adding *within* one step of the output color depth. When converting from the 32bit to 8bit signal, the value is rounded to the nearest 8 bit value (0 - 255). Banding occurs around the transition from one value to the next, let's say from 50-51. Dithering will never add more than +/-0.5 bits of noise, so the pixels near this transition might round to 50 instead of 51 but will never round more than one step. This means that the output image won't have excess variance:
- in a gradient from 49 to 51, there will be a step between each band at 49, 50, and 51.
- Done correctly, the modified image of this gradient will never have a adjacent pixels more than one step (0-255) from each other.
- I.e. when scanning across the gradient you should expect to see:
```
|-band-| |-band-| |-band-|
Baseline: 49 49 49 50 50 50 51 51 51
Dithered: 49 50 49 50 50 51 50 51 51
Dithered (wrong): 49 50 51 49 50 51 49 51 50
```


You can see from above how correct dithering "fuzzes" the transition between bands to reduce distinct steps in color, without adding excess noise.
### HDR
The previous section (and this PR) assumes the final output is to an 8-bit texture, however this is not always the case. When Bevy adds HDR support, the dithering code will need to take the per-channel depth into account instead of assuming it to be 0-255. Edit: I talked with Rob about this and it seems like the current solution is okay. We may need to revisit once we have actual HDR final image output.
---
## Changelog
### Added
- All pipelines now support deband dithering. This is enabled by default in 3D, and can be toggled in the `Tonemapping` component in camera bundles. Banding is a graphical artifact created when the rendered image is crunched from high precision (f32 per color channel) down to the final output (u8 per channel in SDR). This results in subtle gradients becoming blocky due to the reduced color precision. Deband dithering applies a small amount of noise to the signal before it is "crunched", which breaks up the hard edges of blocks (bands) of color. Note that this does not add excess noise to the image, as the amount of noise is less than a single step of a color channel - just enough to break up the transition between color blocks in a gradient.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make the many foxes not unnecessarily bright. Broken since #5666.
- Fixes#6528
## Solution
- In #5666 normalisation of normals was moved from the fragment stage to the vertex stage. However, it was not added to the vertex stage for skinned normals. The many foxes are skinned and their skinned normals were not unit normals. which made them brighter. Normalising the skinned normals fixes this.
---
## Changelog
- Fixed: Non-unit length skinned normals are now normalized.
# Objective
- it would be useful to inspect these structs using reflection
## Solution
- derive and register reflect
- Note that `#[reflect(Component)]` requires `Default` (or `FromWorld`) until #6060, so I implemented `Default` for `Tonemapping` with `is_enabled: false`
# Objective
Fixes#5393
## Solution
- Add padding to `GlobalsUniform` / `Globals` to make it 16-byte aligned.
Still not super clear on whether this is a `naga` thing or an `encase` thing or what. But now that we're offering `globals` up to users and #5393 is not just breaking an example, maybe we should do this sort of workaround?
# Objective
This PR fixes#5789, by enabling movable (and scalable) directional light shadow volumes.
## Solution
This PR changes `ExtractedDirectionalLight` to hold a copy of the `DirectionalLight` entity's `GlobalTransform`, instead of just a `direction` vector. This allows the shadow map volume (as defined by the light's `shadow_projection` field) to be transformed honoring translation _and_ scale transforms, and not just rotation.
It also augments the texel size calculation (used to determine the `shadow_normal_bias`) so that it now takes into account the upper bound of the x/y/z scale of the `GlobalTransform`.
This change makes the directional light extraction code more consistent with point and spot lights (that already use `transform`), and allows easily moving and scaling the shadow volume along with a player entity based on camera distance/angle, immediately enabling more real world use cases until we have a more sophisticated adaptive implementation, such as the one described in #3629.
**Note:** While it was previously possible to update the projection achieving a similar effect, depending on the light direction and distance to the origin, the fact that the shadow map camera was always positioned at the origin with a hardcoded `Vec3::Y` up value meant you would get sub-optimal or inconsistent/incorrect results.
---
## Changelog
### Changed
- `DirectionalLight` shadow volumes now honor translation and scale transforms
## Migration Guide
- If your directional lights were positioned at the origin and not scaled (the default, most common scenario) no changes are needed on your part; it just works as before;
- If you previously had a system for dynamically updating directional light shadow projections, you might now be able to simplify your code by updating the directional light entity's transform instead;
- In the unlikely scenario that a scene with directional lights that previously rendered shadows correctly has missing shadows, make sure your directional lights are positioned at (0, 0, 0) and are not scaled to a size that's too large or too small.
# Objective
- Adds a bloom pass for HDR-enabled Camera3ds.
- Supersedes (and all credit due to!) https://github.com/bevyengine/bevy/pull/3430 and https://github.com/bevyengine/bevy/pull/2876

## Solution
- A threshold is applied to isolate emissive samples, and then a series of downscale and upscaling passes are applied and composited together.
- Bloom is applied to 2d or 3d Cameras with hdr: true and a BloomSettings component.
---
## Changelog
- Added a `core_pipeline::bloom::BloomSettings` component.
- Added `BloomNode` that runs between the main pass and tonemapping.
- Added a `BloomPlugin` that is loaded as part of CorePipelinePlugin.
- Added a bloom example project.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
# Objective
Currently we are limiting the amount of direction lights in a scene to one.
## Solution
Increase the amount of direction lights from 1 to 10.
This still is not a perfect solution, but should unblock many use cases.
We could probably just store the directional lights similar to the point lights in an storage buffer, allowing for an variable amount of directional lights.
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
- Add post processing passes for FXAA (Fast Approximate Anti-Aliasing)
- Add example comparing MSAA and FXAA
## Solution
When the FXAA plugin is added, passes for FXAA are inserted between the main pass and the tonemapping pass. Supports using either HDR or LDR output from the main pass.
---
## Changelog
- Add a new FXAANode that runs after the main pass when the FXAA plugin is added.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
- Freeing unused memory held by visible entities
- Fixed comment style
# Objective
With Rust 1.56 it's possible to shrink vectors to a specified capacity. Visibility system had a comment before asking for that feature to free unused memory by a vector if its capacity is two times larger than the length.
## Solution
Shrinking the vector of visible entities to the nearest power of 2 elements next to `len()`, if capacity exceeds it more than two times.
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective

^ enable this
Concretely, I need to
- list all handle ids for an asset type
- fetch the asset as `dyn Reflect`, given a `HandleUntyped`
- when encountering a `Handle<T>`, find out what asset type that handle refers to (`T`'s type id) and turn the handle into a `HandleUntyped`
## Solution
- add `ReflectAsset` type containing function pointers for working with assets
```rust
pub struct ReflectAsset {
type_uuid: Uuid,
assets_resource_type_id: TypeId, // TypeId of the `Assets<T>` resource
get: fn(&World, HandleUntyped) -> Option<&dyn Reflect>,
get_mut: fn(&mut World, HandleUntyped) -> Option<&mut dyn Reflect>,
get_unchecked_mut: unsafe fn(&World, HandleUntyped) -> Option<&mut dyn Reflect>,
add: fn(&mut World, &dyn Reflect) -> HandleUntyped,
set: fn(&mut World, HandleUntyped, &dyn Reflect) -> HandleUntyped,
len: fn(&World) -> usize,
ids: for<'w> fn(&'w World) -> Box<dyn Iterator<Item = HandleId> + 'w>,
remove: fn(&mut World, HandleUntyped) -> Option<Box<dyn Reflect>>,
}
```
- add `ReflectHandle` type relating the handle back to the asset type and providing a way to create a `HandleUntyped`
```rust
pub struct ReflectHandle {
type_uuid: Uuid,
asset_type_id: TypeId,
downcast_handle_untyped: fn(&dyn Any) -> Option<HandleUntyped>,
}
```
- add the corresponding `FromType` impls
- add a function `app.register_asset_reflect` which is supposed to be called after `.add_asset` and registers `ReflectAsset` and `ReflectHandle` in the type registry
---
## Changelog
- add `ReflectAsset` and `ReflectHandle` types, which allow code to use reflection to manipulate arbitrary assets without knowing their types at compile time
# Objective
Bevy's internal plugins have lots of execution-order ambiguities, which makes the ambiguity detection tool very noisy for our users.
## Solution
Silence every last ambiguity that can currently be resolved.
Each time an ambiguity is silenced, it is accompanied by a comment describing why it is correct. This description should be based on the public API of the respective systems. Thus, I have added documentation to some systems describing how they use some resources.
# Future work
Some ambiguities remain, due to issues out of scope for this PR.
* The ambiguity checker does not respect `Without<>` filters, leading to false positives.
* Ambiguities between `bevy_ui` and `bevy_animation` cannot be resolved, since neither crate knows that the other exists. We will need a general solution to this problem.
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Improve ergonomics by passing on the `IntoIterator` impl of the underlying type to wrapper types.
## Solution
Implement `IntoIterator` for ECS wrapper types (Mut, Local, Res, etc.).
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Use saturate wgsl function now implemented in naga (version 0.10.0). There is now no need for one in utils.wgsl.
naga's version allows usage for not only scalars but vectors as well.
## Solution
Remove the utils.wgsl saturate function.
## Changelog
Remove saturate function from utils.wgsl in favor of saturate in naga v0.10.0.
# Objective
- It's possible to create a mesh without positions or normals, but currently bevy forces these attributes to be present on any mesh.
## Solution
- Don't assume these attributes are present and add a shader defs for each attributes
- I updated 2d and 3d meshes to use the same logic.
---
## Changelog
- Meshes don't require any attributes
# Notes
I didn't update the pbr.wgsl shader because I'm not sure how to handle it. It doesn't really make sense to use it without positions or normals.
# Objective
There is no Srgb support on some GPU and display protocols with `winit` (for example, Nvidia's GPUs with Wayland). Thus `TextureFormat::bevy_default()` which returns `Rgba8UnormSrgb` or `Bgra8UnormSrgb` will cause panics on such platforms. This patch will resolve this problem. Fix https://github.com/bevyengine/bevy/issues/3897.
## Solution
Make `initialize_renderer` expose `wgpu::Adapter` and `first_available_texture_format`, use the `first_available_texture_format` by default.
## Changelog
* Fixed https://github.com/bevyengine/bevy/issues/3897.
# Objective
fix error with pbr shader's spotlight direction calculation when direction.y ~= 0
## Solution
in pbr_lighting.wgsl, clamp `1-x^2-z^2` to `>= 0` so that we can safely `sqrt` it
# Objective
The `Wireframe` type implements `Reflect`, but is never registered, making its reflection inaccessible.
## Solution
Call `App::register_type::<Wireframe>()` in the `Plugin::build` implementation of `WireframePlugin`.
---
## Changelog
Fixed `Wireframe` type reflection not getting registered.
# Objective
Add more documentation on `StandardMaterial` and improve
consistency on existing doc.
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- Alpha mask was previously ignored when using an unlit material.
- Fixes https://github.com/bevyengine/bevy/issues/4479
## Solution
- Extract the alpha discard to a separate function and use it when unlit is true
## Notes
I tried calling `alpha_discard()` before the `if` in pbr.wgsl, but I had errors related to having a `discard` at the beginning before doing the texture sampling. I'm not sure if there's a way to fix that instead of having the function being called in 2 places.
# Objective
Simple docs/comments only PR that just fixes some outdated file references left over from the render rewrite.
## Solution
- Change the references to point to the correct files
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
Implement `IntoIterator` for `&Extract<P>` if the system parameter it wraps implements `IntoIterator`.
Enables the use of `IntoIterator` with an extracted query.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
fixes#5946
## Solution
adjust cluster index calculation for viewport origin.
from reading point 2 of the rasterization algorithm description in https://gpuweb.github.io/gpuweb/#rasterization, it looks like framebuffer space (and so @bulitin(position)) is not meant to be adjusted for viewport origin, so we need to subtract that to get the right cluster index.
- add viewport origin to rust `ExtractedView` and wgsl `View` structs
- subtract from frag coord for cluster index calculation
# Objective
Since `identity` is a const fn that takes no arguments it seems logical to make it an associated constant.
This is also more in line with types from glam (eg. `Quat::IDENTITY`).
## Migration Guide
The method `identity()` on `Transform`, `GlobalTransform` and `TransformBundle` has been deprecated.
Use the associated constant `IDENTITY` instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Morten Mikkelsen clarified that the world normal and tangent must be normalized in the vertex stage and the interpolated values must not be normalized in the fragment stage. This is in order to match the mikktspace approach exactly.
- Fixes#5514 by ensuring the tangent basis matrix (TBN) is orthonormal
## Solution
- Normalize the world normal in the vertex stage and not the fragment stage
- Normalize the world tangent xyz in the vertex stage
- Take into account the sign of the determinant of the local to world matrix when calculating the bitangent
---
## Changelog
- Fixed - scaling a model that uses normal mapping now has correct lighting again
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
fix an error in shadow map indexing that occurs when point lights without shadows are used in conjunction with spotlights with shadows
## Solution
calculate point_light_count correctly
# Objective
the bevy pbr shader doesn't handle at all normal maps
if a mesh doesn't have backed tangents. This is a pitfall
(that I fell into) and needs to be documented.
# Solution
Document the behavior. (Also document a few other
`StandardMaterial` fields)
## Changelog
* Add documentation to `emissive`, `normal_map_texture` and `occlusion_texture` fields of `StandardMaterial`.
# Objective
[This unwrap()](de484c1e41/crates/bevy_pbr/src/pbr_material.rs (L195)) in pbr_material.rs will be hit if a StandardMaterial normal_map image has not finished loading, resulting in an error message that is hard to debug.
## Solution
~~This PR improves the error message including a potential indication of why the unwrap() could have panic'd by using expect() instead of unwrap().~~
This PR removes the panic by only proceeding if the image is found.
---
## Changelog
Don't panic when StandardMaterial normal_map images have not finished loading.
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Wireframes are currently not rendering on main because they aren't being extracted correctly
## Solution
- Extract the wireframes correctly
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy requires meshes to include UV coordinates, even if the material does not use any textures, and will fail with an error `ERROR bevy_pbr::material: Mesh is missing requested attribute: Vertex_Uv (MeshVertexAttributeId(2), pipeline type: Some("bevy_pbr::material::MaterialPipeline<bevy_pbr::pbr_material::StandardMaterial>"))` otherwise. The objective of this PR is to permit this.
## Solution
This PR follows the design of #4528, which added support for per-vertex colours. It adds a shader define called VERTEX_UVS which indicates the presence of UV coordinates to the shader.
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
Transform screen-space coordinates into world space in shaders. (My use case is for generating rays for ray tracing with the same perspective as the 3d camera).
## Solution
Add `inverse_projection` and `inverse_view_proj` fields to shader view uniform
---
## Changelog
### Added
`inverse_projection` and `inverse_view_proj` fields to shader view uniform
## Note
It'd probably be good to double-check that I did the matrix multiplication in the right order for `inverse_proj_view`. Thanks!
* Cleanup redundant code
* Use a type alias to make sure the `caster_query` and
`not_caster_query` really do the same thing and access the same things
**Objective**
Cleanup code that would otherwise be difficult to understand
**Solution**
* `extract_meshes` had two for loops which are functionally identical,
just copy-pasted code. I extracted the common code between the two
and put them into an anonymous function.
* I flattened the tuple literal for the bundle batch, it looks much
less nested and the code is much more readable as a result.
* The parameters of `extract_meshes` were also very daunting, but they
turned out to be the same query repeated twice. I extracted the query
into a type alias.
EDIT: I reworked the PR to **not do anything breaking**, and keep the old allocation behavior. Removing the memorized length was clearly a performance loss, so I kept it.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
This fixes https://github.com/bevyengine/bevy/issues/5127
## Solution
- Moved texture sample out of branch in `prepare_normal()`.
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Allow custom shaders to reuse the HDR results of PBR.
## Solution
- Separate `pbr()` and `tone_mapping()` into 2 functions in `pbr_functions.wgsl`.
# Objective
Update pbr mesh shader to use correct normals for skinned meshes.
## Solution
Only use `mesh_normal_local_to_world` for normals if `SKINNED` is not defined.
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
- Builds on top of #4938
- Make clustered-forward PBR lighting/shadows functionality callable
- See #3969 for details
## Solution
- Add `PbrInput` struct type containing a `StandardMaterial`, occlusion, world_position, world_normal, and frag_coord
- Split functionality to calculate the unit view vector, and normal-mapped normal into `bevy_pbr::pbr_functions`
- Split high-level shading flow into `pbr(in: PbrInput, N: vec3<f32>, V: vec3<f32>, is_orthographic: bool)` function in `bevy_pbr::pbr_functions`
- Rework `pbr.wgsl` fragment stage entry point to make use of the new functions
- This has been benchmarked on an M1 Max using `many_cubes -- sphere`. `main` had a median frame time of 15.88ms, this PR 15.99ms, which is a 0.69% frame time increase, which is within noise in my opinion.
---
## Changelog
- Added: PBR shading code is now callable. Import `bevy_pbr::pbr_functions` and its dependencies, create a `PbrInput`, calculate the unit view and normal-mapped normal vectors and whether the projection is orthographic, and call `pbr()`!
# Objective
- `.x` is not the correct syntax to access a column in a matrix in WGSL: https://www.w3.org/TR/WGSL/#matrix-access-expr
- naga accepts it and translates it correctly, but it's not valid when shaders are kept as is and used directly in WGSL
## Solution
- Use the correct syntax
# Objective
- Builds on top of #4901
- Separate out PBR lighting, shadows, clustered forward, and utils from `pbr.wgsl` as part of making the PBR code more reusable and extensible.
- See #3969 for details.
## Solution
- Add `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
---
## Changelog
- Added: `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
Fix#4958
There was 4 issues:
- this is not true in WASM and on macOS: f28b921209/examples/3d/split_screen.rs (L90)
- ~~I made sure the system was running at least once~~
- I'm sending the event on window creation
- in webgl, setting a viewport has impacts on other render passes
- only in webgl and when there is a custom viewport, I added a render pass without a custom viewport
- shaderdef NO_ARRAY_TEXTURES_SUPPORT was not used by the 2d pipeline
- webgl feature was used but not declared in bevy_sprite, I added it to the Cargo.toml
- shaderdef NO_STORAGE_BUFFERS_SUPPORT was not used by the 2d pipeline
- I added it based on the BufferBindingType
The last commit changes the two last fixes to add the shaderdefs in the shader cache directly instead of needing to do it in each pipeline
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- fix#4946
- fix running 3d in wasm
## Solution
- since #4867, the imports are splitter differently, and this shader def was not always set correctly depending on the shader used
- add it when needed
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Split PBR and 2D mesh shaders into types and bindings to prepare the shaders to be more reusable.
- See #3969 for details. I'm doing this in multiple steps to make review easier.
---
## Changelog
- Changed: 2D and PBR mesh shaders are now split into types and bindings, the following shader imports are available: `bevy_pbr::mesh_view_types`, `bevy_pbr::mesh_view_bindings`, `bevy_pbr::mesh_types`, `bevy_pbr::mesh_bindings`, `bevy_sprite::mesh2d_view_types`, `bevy_sprite::mesh2d_view_bindings`, `bevy_sprite::mesh2d_types`, `bevy_sprite::mesh2d_bindings`
## Migration Guide
- In shaders for 3D meshes:
- `#import bevy_pbr::mesh_view_bind_group` -> `#import bevy_pbr::mesh_view_bindings`
- `#import bevy_pbr::mesh_struct` -> `#import bevy_pbr::mesh_types`
- NOTE: If you are using the mesh bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_pbr::mesh_bindings` which itself imports the mesh types needed for the bindings.
- In shaders for 2D meshes:
- `#import bevy_sprite::mesh2d_view_bind_group` -> `#import bevy_sprite::mesh2d_view_bindings`
- `#import bevy_sprite::mesh2d_struct` -> `#import bevy_sprite::mesh2d_types`
- NOTE: If you are using the mesh2d bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_sprite::mesh2d_bindings` which itself imports the mesh2d types needed for the bindings.
# Objective
Models can be produced that do not have vertex tangents but do have normal map textures. The tangents can be generated. There is a way that the vertex tangents can be generated to be exactly invertible to avoid introducing error when recreating the normals in the fragment shader.
## Solution
- After attempts to get https://github.com/gltf-rs/mikktspace to integrate simple glam changes and version bumps, and releases of that crate taking weeks / not being made (no offense intended to the authors/maintainers, bevy just has its own timelines and needs to take care of) it was decided to fork that repository. The following steps were taken:
- mikktspace was forked to https://github.com/bevyengine/mikktspace in order to preserve the repository's history in case the original is ever taken down
- The README in that repo was edited to add a note stating from where the repository was forked and explaining why
- The repo was locked for changes as its only purpose is historical
- The repo was integrated into the bevy repo using `git subtree add --prefix crates/bevy_mikktspace git@github.com:bevyengine/mikktspace.git master`
- In `bevy_mikktspace`:
- The travis configuration was removed
- `cargo fmt` was run
- The `Cargo.toml` was conformed to bevy's (just adding bevy to the keywords, changing the homepage and repository, changing the version to 0.7.0-dev - importantly the license is exactly the same)
- Remove the features, remove `nalgebra` entirely, only use `glam`, suppress clippy.
- This was necessary because our CI runs clippy with `--all-features` and the `nalgebra` and `glam` features are mutually exclusive, plus I don't want to modify this highly numerically-sensitive code just to appease clippy and diverge even more from upstream.
- Rebase https://github.com/bevyengine/bevy/pull/1795
- @jakobhellermann said it was fine to copy and paste but it ended up being almost exactly the same with just a couple of adjustments when validating correctness so I decided to actually rebase it and then build on top of it.
- Use the exact same fragment shader code to ensure correct normal mapping.
- Tested with both https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentMirrorTest which has vertex tangents and https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentTest which requires vertex tangent generation
Co-authored-by: alteous <alteous@outlook.com>
# Objective
allow meshes with equal z-depth to be rendered in a chosen order / avoid z-fighting
## Solution
add a depth_bias to SpecializedMaterial that is added to the mesh depth used for render-ordering.
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
- noticed a few Vec3 and Vec2 that could be const
## Solution
- Declared them as const
- It seems to make a tiny improvement in example `many_light`, but given that the change is not complex at all it could still be worth it
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
- When spawning a sprite the alpha is used for transparency, but when using the `Color::into()` implementation to spawn a `StandardMaterial`, the alpha is ignored.
- Pretty much everytime I want to make something transparent I started with a `Color::rgb().into()` and I'm always surprised that it doesn't work when changing it to `Color::rgba().into()`
- It's possible there's an issue with this approach I am not thinking of, but I'm not sure what's the point of setting an alpha value without the goal of making a color transparent.
## Solution
- Set the alpha_mode to AlphaMode::Blend when the alpha is not the default value.
---
## Migration Guide
This is not a breaking change, but it can easily be migrated to reduce boilerplate
```rust
commands.spawn_bundle(PbrBundle {
mesh: meshes.add(shape::Cube::default().into()),
material: materials.add(StandardMaterial {
base_color: Color::rgba(1.0, 0.0, 0.0, 0.75),
alpha_mode: AlphaMode::Blend,
..default()
}),
..default()
});
// becomes
commands.spawn_bundle(PbrBundle {
mesh: meshes.add(shape::Cube::default().into()),
material: materials.add(Color::rgba(1.0, 0.0, 0.0, 0.75).into()),
..default()
});
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
### Problem
It currently isn't possible to construct the default value of a reflected type. Because of that, it isn't possible to use `add_component` of `ReflectComponent` to add a new component to an entity because you can't know what the initial value should be.
### Solution
1. add `ReflectDefault` type
```rust
#[derive(Clone)]
pub struct ReflectDefault {
default: fn() -> Box<dyn Reflect>,
}
impl ReflectDefault {
pub fn default(&self) -> Box<dyn Reflect> {
(self.default)()
}
}
impl<T: Reflect + Default> FromType<T> for ReflectDefault {
fn from_type() -> Self {
ReflectDefault {
default: || Box::new(T::default()),
}
}
}
```
2. add `#[reflect(Default)]` to all component types that implement `Default` and are user facing (so not `ComputedSize`, `CubemapVisibleEntities` etc.)
This makes it possible to add the default value of a component to an entity without any compile-time information:
```rust
fn main() {
let mut app = App::new();
app.register_type::<Camera>();
let type_registry = app.world.get_resource::<TypeRegistry>().unwrap();
let type_registry = type_registry.read();
let camera_registration = type_registry.get(std::any::TypeId::of::<Camera>()).unwrap();
let reflect_default = camera_registration.data::<ReflectDefault>().unwrap();
let reflect_component = camera_registration
.data::<ReflectComponent>()
.unwrap()
.clone();
let default = reflect_default.default();
drop(type_registry);
let entity = app.world.spawn().id();
reflect_component.add_component(&mut app.world, entity, &*default);
let camera = app.world.entity(entity).get::<Camera>().unwrap();
dbg!(&camera);
}
```
### Open questions
- should we have `ReflectDefault` or `ReflectFromWorld` or both?
# Objective
- While optimising many_cubes, I noticed that all material handles are extracted regardless of whether the entity to which the handle belongs is visible or not. As such >100k handles are extracted when only <20k are visible.
## Solution
- Only extract material handles of visible entities.
- This improves `many_cubes -- sphere` from ~42fps to ~48fps. It reduces not only the extraction time but also system commands time. `Handle<StandardMaterial>` extraction and its system commands went from 0.522ms + 3.710ms respectively, to 0.267ms + 0.227ms an 88% reduction for this system for this case. It's very view dependent but...
# Objective
- Creating and executing render passes has GPU overhead. If there are no phase items in the render phase to draw, then this overhead should not be incurred as it has no benefit.
## Solution
- Check if there are no phase items to draw, and if not, do not construct not execute the render pass
---
## Changelog
- Changed: Do not create nor execute empty render passes
# Objective
- Meshes are queued in opaque phase instead of transparent phase when drawing wireframes.
- There is a name mismatch.
## Solution
- Rename `transparent_phase` to `opaque_phase` in `wireframe.rs`.
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by moving FloatOrd to bevy_utils.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Move FloatOrd into bevy_utils. Fix the compile errors.
As a result, bevy_core_pipeline, bevy_pbr, bevy_sprite, bevy_text, and bevy_ui no longer depend on bevy_core (they were only using it for `FloatOrd` previously).
# Objective
- Related #4276.
- Part of the splitting process of #3503.
## Solution
- Move `Size` to `bevy_ui`.
## Reasons
- `Size` is only needed in `bevy_ui` (because it needs to use `Val` instead of `f32`), but it's also used as a worse `Vec2` replacement in other areas.
- `Vec2` is more powerful than `Size` so it should be used whenever possible.
- Discussion in #3503.
## Changelog
### Changed
- The `Size` type got moved from `bevy_math` to `bevy_ui`.
## Migration Guide
- The `Size` type got moved from `bevy::math` to `bevy::ui`. To migrate you just have to import `bevy::ui::Size` instead of `bevy::math::Math` or use the `bevy::prelude` instead.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Fix `ClusterConfig::None`
- This fix is from @robtfm but they didn't have time to submit it, so I am.
## Solution
- Always clear clusters and skip processing when `ClusterConfig::None`
- Conditionally remove `VisiblePointLights` from the view if it is present
# Objective
- https://github.com/bevyengine/bevy/pull/4098 still hasn't fixed minimisation on Windows.
- `Clusters.lights` is assumed to have the number of items given by the product of `Clusters.dimensions`'s axes.
## Solution
- Make that true in `clear`.
# Objective
- Fixes#4234
- Fixes#4473
- Built on top of #3989
- Improve performance of `assign_lights_to_clusters`
## Solution
- Remove the OBB-based cluster light assignment algorithm and calculation of view space AABBs
- Implement the 'iterative sphere refinement' algorithm used in Just Cause 3 by Emil Persson as documented in the Siggraph 2015 Practical Clustered Shading talk by Persson, on pages 42-44 http://newq.net/dl/pub/s2015_practical.pdf
- Adapt to also support orthographic projections
- Add `many_lights -- orthographic` for testing many lights using an orthographic projection
## Results
- `assign_lights_to_clusters` in `many_lights` before this PR on an M1 Max over 1500 frames had a median execution time of 1.71ms. With this PR it is 1.51ms, a reduction of 0.2ms or 11.7% for this system.
---
## Changelog
- Changed: Improved cluster light assignment performance
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- While animating 501 https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/BrainStem, I noticed things were getting a little slow
- Looking in tracy, the system `extract_skinned_meshes` is taking a lot of time, with a mean duration of 15.17ms
## Solution
- ~~Use `Vec` instead of a `SmallVec`~~
- ~~Don't use an temporary variable~~
- Compute the affine matrix as an `Affine3A` instead
- Remove the `temp` vec
| |mean|
|---|---|
|base|15.17ms|
|~~vec~~|~~9.31ms~~|
|~~no temp variable~~|~~11.31ms~~|
|removing the temp vector|8.43ms|
|affine|13.21ms|
|all together|7.23ms|
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Animation with shadows crashes with:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_render_pipeline
note: label = `shadow_pipeline`
error matching VERTEX shader requirements against the pipeline
shader global ResourceBinding { group: 1, binding: 1 } is not available in the layout pipeline layout
visibility flags don't include the shader stage
```
Animation with wireframe crashes with:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_render_pipeline
note: label = `opaque_mesh_pipeline`
error matching VERTEX shader requirements against the pipeline
shader global ResourceBinding { group: 2, binding: 0 } is not available in the layout pipeline layout
binding is missing from the pipeline layout
```
## Solution
- Fix the bindings
# Objective
Add a system parameter `ParamSet` to be used as container for conflicting parameters.
## Solution
Added two methods to the SystemParamState trait, which gives the access used by the parameter. Did the implementation. Added some convenience methods to FilteredAccessSet. Changed `get_conflicts` to return every conflicting component instead of breaking on the first conflicting `FilteredAccess`.
Co-authored-by: bilsen <40690317+bilsen@users.noreply.github.com>
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
* Refactor assign_lights_to_clusters to always clear + update clusters, even if the screen size isn't available yet / is zero. This fixes#4167. We still avoid the "expensive" per-light work when the screen size isn't available yet. I also consolidated some logic to eliminate some redundancies.
* Removed _a ton_ of (potentially very large) per-frame reallocations
* Removed `Res<VisiblePointLights>` (a vec) in favor of `Res<GlobalVisiblePointLights>` (a hashmap). We were allocating a new hashmap every frame, the collecting it into a vec every frame, then in another system _re-generating the hashmap_. It is always used like a hashmap, might as well embrace that. We now reuse the same hashmap every frame and dont use any intermediate collections.
* We were re-allocating Clusters aabb and light vectors every frame by re-constructing Clusters every frame. We now re-use the existing collections.
* Reuse per-camera VisiblePointLight vecs when possible instead of allocating them every frame. We now only insert VisiblePointLights if the component doesn't exist yet.
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Reduce time spent in the `check_visibility` system
## Solution
- Use `Vec3A` for all bounding volume types to leverage SIMD optimisations and to avoid repeated runtime conversions from `Vec3` to `Vec3A`
- Inline all bounding volume intersection methods
- Add on-the-fly calculated `Aabb` -> `Sphere` and do `Sphere`-`Frustum` intersection tests before `Aabb`-`Frustum` tests. This is faster for `many_cubes` but could be slower in other cases where the sphere test gives a false-positive that the `Aabb` test discards. Also, I tested precalculating the `Sphere`s and inserting them alongside the `Aabb` but this was slower.
- Do not test meshes against the far plane. Apparently games don't do this anymore with infinite projections, and it's one fewer plane to test against. I made it optional and still do the test for culling lights but that is up for discussion.
- These collectively reduce `check_visibility` execution time in `many_cubes -- sphere` from 2.76ms to 1.48ms and increase frame rate from ~42fps to ~44fps
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
fix cluster tilesize and tilecount calculations.
Fixes https://github.com/bevyengine/bevy/issues/4127 & https://github.com/bevyengine/bevy/issues/3596
## Solution
- calculate tilesize as smallest integers such that dimensions.xy() tiles will cover the screen
- calculate final dimensions as smallest integers such that final dimensions * tilesize will cover the screen
there is more cleanup that could be done in these functions. a future PR will likely remove the tilesize completely, so this is just a minimal change set to fix the current bug at small screen sizes
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
provide some customisation for default cluster setup
avoid "cluster index lists is full" in all cases (using a strategy outlined by @superdump)
## Solution
Add ClusterConfig enum (which can be inserted into a view at any time) to allow specifying cluster setup with variants:
- None (do not do any light assignment - for views which do not require light info, e.g. minimaps etc)
- Single (one cluster)
- XYZ (explicit cluster counts in each dimension)
- FixedZ (most similar to current - specify Z-slices and total, then x and y counts are dynamically determined to give approximately square clusters based on current aspect ratio)
Defaults to FixedZ { total: 4096, z: 24 } which is similar to the current setup.
Per frame, estimate the number of indices that would be required for the current config and decrease the cluster counts / increase the cluster sizes in the x and y dimensions if the index list would be too small.
notes:
- I didn't put ClusterConfig in the camera bundles to avoid introducing a dependency from bevy_render to bevy_pbr. the ClusterConfig enum comes with a pbr-centric impl block so i didn't want to move that into bevy_render either.
- ~Might want to add None variant to cluster config for views that don't care about lights?~
- Not well tested for orthographic
- ~there's a cluster_muck branch on my repo which includes some diagnostics / a modified lighting example which may be useful for tyre-kicking~ (outdated, i will bring it up to date if required)
anecdotal timings:
FPS on the lighting demo is negligibly better (~5%), maybe due to a small optimisation constraining the light aabb to be in front of the camera
FPS on the lighting demo with 100 extra lights added is ~33% faster, and also renders correctly as the cluster index count is no longer exceeded
## Objective
Currently, all directional and point lights have their viewing frusta recalculated every frame, even if they have not moved or been disabled/enabled.
## Solution
The relevant systems now make use of change detection to only update those lights whose viewing frusta may have changed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}