# Objective
- Closes#786
- Closes#2252
- Closes#2588
This PR implements a derive macro that allows users to define their queries as structs with named fields.
## Example
```rust
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct NumQuery<'w, T: Component, P: Component> {
entity: Entity,
u: UNumQuery<'w>,
generic: GenericQuery<'w, T, P>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct UNumQuery<'w> {
u_16: &'w u16,
u_32_opt: Option<&'w u32>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct GenericQuery<'w, T: Component, P: Component> {
generic: (&'w T, &'w P),
}
#[derive(WorldQuery)]
#[world_query(filter)]
struct NumQueryFilter<T: Component, P: Component> {
_u_16: With<u16>,
_u_32: With<u32>,
_or: Or<(With<i16>, Changed<u16>, Added<u32>)>,
_generic_tuple: (With<T>, With<P>),
_without: Without<Option<u16>>,
_tp: PhantomData<(T, P)>,
}
fn print_nums_readonly(query: Query<NumQuery<u64, i64>, NumQueryFilter<u64, i64>>) {
for num in query.iter() {
println!("{:#?}", num);
}
}
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct MutNumQuery<'w, T: Component, P: Component> {
i_16: &'w mut i16,
i_32_opt: Option<&'w mut i32>,
}
fn print_nums(mut query: Query<MutNumQuery, NumQueryFilter<u64, i64>>) {
for num in query.iter_mut() {
println!("{:#?}", num);
}
}
```
## TODOs:
- [x] Add support for `&T` and `&mut T`
- [x] Test
- [x] Add support for optional types
- [x] Test
- [x] Add support for `Entity`
- [x] Test
- [x] Add support for nested `WorldQuery`
- [x] Test
- [x] Add support for tuples
- [x] Test
- [x] Add support for generics
- [x] Test
- [x] Add support for query filters
- [x] Test
- [x] Add support for `PhantomData`
- [x] Test
- [x] Refactor `read_world_query_field_type_info`
- [x] Properly document `readonly` attribute for nested queries and the static assertions that guarantee safety
- [x] Test that we never implement `ReadOnlyFetch` for types that need mutable access
- [x] Test that we insert static assertions for nested `WorldQuery` that a user marked as readonly
# Objective
`all_tuples` panics when the start count is set to anything other than 0 or 1. Fix this bug.
## Solution
Originally part of #2381, this PR fixes the slice indexing used by the proc macro.
For some keys, it is too expensive to hash them on every lookup. Historically in Bevy, we have regrettably done the "wrong" thing in these cases (pre-computing hashes, then re-hashing them) because Rust's built in hashed collections don't give us the tools we need to do otherwise. Doing this is "wrong" because two different values can result in the same hash. Hashed collections generally get around this by falling back to equality checks on hash collisions. You can't do that if the key _is_ the hash. Additionally, re-hashing a hash increase the odds of collision!
#3959 needs pre-hashing to be viable, so I decided to finally properly solve the problem. The solution involves two different changes:
1. A new generalized "pre-hashing" solution in bevy_utils: `Hashed<T>` types, which store a value alongside a pre-computed hash. And `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . `PreHashMap` is just an alias for a normal HashMap that uses `Hashed<T>` as the key and a new `PassHash` implementation as the Hasher.
2. Replacing the `std::collections` re-exports in `bevy_utils` with equivalent `hashbrown` impls. Avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. The latest version of `hashbrown` adds support for the `entity_ref` api, so we can move to that in preparation for an std migration, if thats the direction they seem to be going in. Note that adding hashbrown doesn't increase our dependency count because it was already in our tree.
In addition to providing these core tools, I also ported the "table identity hashing" in `bevy_ecs` to `raw_entry_mut`, which was a particularly egregious case.
The biggest outstanding case is `AssetPathId`, which stores a pre-hash. We need AssetPathId to be cheaply clone-able (and ideally Copy), but `Hashed<AssetPath>` requires ownership of the AssetPath, which makes cloning ids way more expensive. We could consider doing `Hashed<Arc<AssetPath>>`, but cloning an arc is still a non-trivial expensive that needs to be considered. I would like to handle this in a separate PR. And given that we will be re-evaluating the Bevy Assets implementation in the very near future, I'd prefer to hold off until after that conversation is concluded.
# Objective
- `SystemStates` rock for dealing with exclusive world access, but are hard to figure out how to use.
- Fixes#3341.
## Solution
- Clearly document how to use `SystemState`, and why they're useful as an end-user.
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Fixes#3078
- Fixes#1397
## Solution
- Implement Commands::init_resource.
- Also implement for World, for consistency and to simplify internal structure.
- While we're here, clean up some of the docs for Command and World resource modification.
# Objective
- `serde_json` assumes that numbers being deserialized are either u64 or i64.
- `Entity` serializes and deserializes as a u32.
- Deserializing an `Entity` with `serde_json` fails with: `Error("invalid type: integer 10947, expected expected Entity"`
## Solution
- Implemented a visitor for u64 that allows an `Entity` to be deserialized in this case.
- While I was here, also fixed the redundant "expected expected Entity" in the error message
- Tested the change in a local project which now correctly deserializes `Entity` structs with `serde_json` when it couldn't before
Implements a new Queryable called AnyOf, which will return an item as long as at least one of it's requested Queryables returns something. For example, a `Query<AnyOf<(&A, &B, &C)>>` will return items with type `(Option<&A>, Option<&B>, Option<&C>)`, and will guarantee that for every element at least one of the option s is Some. This is a shorthand for queries like `Query<(Option<&A>, Option<&B>, Option<&C>), Or<(With<A>, With<B>, With&C>)>>`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Provide impls for mutable types to relevant immutable types.
- Closes#2005
## Solution
- impl From<ResMut> for Res
- impl From<NonSendMut> for NonSend
- Mut to &/&mut already impl'd in change_detection_impl! macro
# Objective
It would be useful to be able to restart a state (such as if an operation fails and needs to be retried from `on_enter`). Currently, it seems the way to restart a state is to transition to a dummy state and then transition back.
## Solution
The solution is to add a `restart` method on `State<T>` that allows for transitioning to the already-active state.
## Context
Based on [this](https://discord.com/channels/691052431525675048/742884593551802431/920335041756815441) question from the Discord.
Closes#2385
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
When using empty events, it can feel redundant to have to specify the type of the event when sending it.
## Solution
Add a new `fire()` function that sends the default value of the event. This requires that the event derives Default.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make it possible to use `&World` as a system parameter
## Solution
It seems like all the pieces were already in place, very simple impl
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Provide a non-consuming method of checking if there are events in an `EventReader`.
Fixes#2967
## Solution
Implements the `len` and `is_empty` functions for `EventReader` and `ManualEventReader`, giving users the ability to check for the presence of new events without consuming any.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Calling forget would invalidate the data pointer before it is used.
## Solution
Use `ManuallyDrop` to prevent the value from being dropped without moving it.
This is my first contribution to this exciting project! Thanks so much for your wonderful work. If there is anything that I can improve about this PR, please let me know :)
# Objective
- Fixes#2899
- If a simple one-off command is needed to be added within a System, this simplifies that process so that we can simply do `commands.add(|world: &mut World| { /* code here */ })` instead of defining a custom type implementing `Command`.
## Solution
- This is achieved by `impl Command for F where F: FnOnce(&mut World) + Send + Sync + 'static` as just calling the function.
I am not sure if the bounds can be further relaxed but needed the whole `Send`, `Sync`, and `'static` to get it to compile.
# Objective
A user on Discord couldn't derive SystemParam for this Struct:
```rs
#[derive(SystemParam)]
pub struct SpatialQuery<'w, 's, Q: WorldQuery + Send + Sync + 'static, F: WorldQuery + Send + Sync + 'static = ()>
where
F::Fetch: FilterFetch,
{
query: Query<'w, 's, (C, &'static Transform), F>,
}
```
## Solution
1. The `where`-clause is now also copied to the `SystemParamFetch` impl Block.
2. The `SystemParamState` impl Block no longer gets any defaults for generics
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
# Objective
Fixes#3566
## Solution
- [x] Fix broken links in private docs.
- [x] Add the `--document-private-items` flag to the CI.
## Note
The following was said by @killercup in #3566:
> I don't have time to confirm this but I assume that linking to private items throws an error/warning when just running cargo doc, and --document-private-item might actually hide that warning. So to test this, you'd have to run it twice.
I tested this and this is thankfully not the case. If you are linking to a private item you will get a warning no matter if you run `cargo doc` or `cargo doc --document-private-items`.
### Example
I added `struct Test;` to `bevy_core/src/name.rs` and linked to it inside of a doc comment using ``[`Test`]``. After that I ran `cargo doc -p bevy_core --document-private-items` using `RUSTDOCFLAGS="-D warnings"` and got the following output (note the last sentence):
```rust
error: public documentation for `Name` links to private item `Test`
--> crates/bevy_core/src/name.rs:11:82
|
11 | /// Component used to identify an entity. Stores a hash for faster comparisons [`Test`]
| ^^^^ this item is private
|
= note: `-D rustdoc::private-intra-doc-links` implied by `-D warnings`
= note: this link resolves only because you passed `--document-private-items`, but will break without
```
# Objective
Currently, simply calling `iter` on an event reader will mark all of it's events as read, even if the returned iterator is never used
## Solution
With this, the cursor will simply move to the last unread, but available event when iter is called, and incremented by one per `next` call.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Calling .id() has no purpose unless you use the Entity returned
- This is an easy source of confusion for beginners.
- This is easily missed during refactors.
## Solution
- Mark the appropriate methods as #[must_use]
# Objective
Emitting compile errors produces cleaner messages than panicking in a proc-macro.
## Solution
- Replace match-with-panic code with call to new `bevy_macro_utils::get_named_struct_fields` function
- Replace one use of match-with-panic for enums with inline match
_Aside:_ I'm also the maintainer of [`darling`](https://docs.rs/darling), a crate which provides a serde-like API for parsing macro inputs. I avoided using it here because it seemed like overkill, but if there are plans to add lots more attributes/macros then that might be a good way of offloading macro error handling.
# Objective
- Fixes#3616
## Solution
- As described in the issue, documentation for `iter_manual` was copied from `iter_combinations` and did not reflect the behavior of the method. I've pulled some information from #2351 to create a more accurate description.
# Objective
- Removes warning about accidently inserting bundles with `EntityCommands::insert`, but since a component now needs to implement `Component` it is unnecessary.
# Objective
This PR extends the `Events` documentation by:
- informing user about the possible race condition
- explicitly explaining the unusual double buffer implementation
Fixes#3305
Co-authored-by: MiniaczQ <jakub.motyka.2000@gmail.com>
Co-authored-by: MiniaczQ <MiniaczQ@gmail.com>
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
# Objective
- Fixes#1920.
- Users often want to know how to get the values of removed components (#1655).
- Stand-alone `bevy_ecs` behavior is very unintuitive, as `World::clear_trackers()` must be manually called.
- Fixes#2999 by extending the existing test (thanks @hymm for pointing me to it) to be clearer and check for component removal as well.
## Solution
- Better docs!
- Better tests!
# Objective
Remove the `StorageType` parameter from `ComponentDescriptor::new_resource` as discussed in #3361.
- fixes#3361
## Solution
- Parameter removed.
- Basic docs added.
## Note
Left a [comment](https://github.com/bevyengine/bevy/issues/3361#issuecomment-996433346) about `SparseStorage` being the more reasonable choice.
Co-authored-by: r4gus <david@thesugar.de>
Dynamic types (`DynamicStruct`, `DynamicTupleStruct`, `DynamicTuple`, `DynamicList` and `DynamicMap`) are used when deserializing scenes, but currently they can only be applied to existing concrete types. This leads to issues when trying to spawn non trivial deserialized scene.
For components, the issue is avoided by requiring that reflected components implement ~~`FromResources`~~ `FromWorld` (or `Default`). When spawning, a new concrete type is created that way, and the dynamic type is applied to it. Unfortunately, some components don't have any valid implementation of these traits.
In addition, any `Vec` or `HashMap` inside a component will panic when a dynamic type is pushed into it (for instance, `Text` panics when adding a text section).
To solve this issue, this PR adds the `FromReflect` trait that creates a concrete type from a dynamic type that represent it, derives the trait alongside the `Reflect` trait, drops the ~~`FromResources`~~ `FromWorld` requirement on reflected components, ~~and enables reflection for UI and Text bundles~~. It also adds the requirement that fields ignored with `#[reflect(ignore)]` implement `Default`, since we need to initialize them somehow.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- While reading code, found some queries that are `mut` and not used as such
## Solution
- Remove `mut` when possible
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- Storages are used to store the ECS data.
- They're undocumented.
## Solution
- Add some very basic docs.
## Notes
- Some of this was hard to immediately understand when reading the code, so suggestions on improvements / things to add are particularly welcome.
Fixes#2566Fixes#3005
There are only READMEs in the 4 crates here (with the exception of bevy itself).
Those 4 crates are ecs, reflect, tasks, and transform.
These should each now include their respective README files.
Co-authored-by: Hoidigan <57080125+Hoidigan@users.noreply.github.com>
Co-authored-by: Daniel Nelsen <57080125+Hoidigan@users.noreply.github.com>
# Objective
I thought I'd have a go a trying to fix#2597.
Hopefully fixes#2597.
## Solution
I reused the memory pointed to by the value parameter, that is already required by `insert` to not be dropped, to contain the extracted value while dropping it.
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
Fills in some gaps we had in our Bevy ECS tracing spans:
* Exclusive systems
* System Commands (for `apply_buffers = true` cases)
* System archetype updates
* Parallel system execution prep
# Objective
- New clippy lints with rust 1.57 are failing
## Solution
- Fixed clippy lints following suggestions
- I ignored clippy in old renderer because there was many and it will be removed soon
A sample implementation of how to have `iter()` work on mutable queries without breaking aliasing rules.
# Objective
- Fixes#753
## Solution
- Added a ReadOnlyFetch to WorldQuery that is the `&T` version of `&mut T` that is used to specify the return type for read only operations like `iter()`.
- ~~As the comment suggests specifying the bound doesn't work due to restrictions on defining recursive implementations (like `Or`). However bounds on the functions are fine~~ Never mind I misread how `Or` was constructed, bounds now exist.
- Note that the only mutable one has a new `Fetch` for readonly as the `State` has to be the same for any of this to work
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This is a squash-and-rebase of @Ku95's documentation of the new renderer onto the latest `pipelined-rendering` branch.
Original PR is #2884.
Co-authored-by: dataphract <dataphract@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
bevy_ecs has several compile_fail tests that assert lifetime safety. In the past, these tests have been green for the wrong reasons (see e.g. #2984). This PR makes sure, that they will fail if the compiler error changes.
## Solution
Use [trybuild](https://crates.io/crates/trybuild) to assert the compiler errors.
The UI tests are in a separate crate that is not part of the Bevy workspace. This is to ensure that they do not break Bevy's crater builds. The tests get executed by the CI workflow on the stable toolchain.
# Objective
- `bevy_ecs` exposes as an optional feature `bevy_reflect`. Disabling it doesn't compile.
- `bevy_asset` exposes as an optional feature `filesystem_watcher`. Disabling it doesn't compile. It is also not possible to disable this feature from Bevy
## Solution
- Fix compilation errors when disabling the default features. Make it possible to disable the feature `filesystem_watcher` from Bevy
# Objective
- Improve error descriptions and help understand how to fix them
- I noticed one today that could be expanded, it seemed like a good starting point
## Solution
- Start something like https://github.com/rust-lang/rust/tree/master/compiler/rustc_error_codes/src/error_codes
- Remove sentence about Rust mutability rules which is not very helpful in the error message
I decided to start the error code with B for Bevy so that they're not confused with error code from rust (which starts with E)
Longer term, there are a few more evolutions that can continue this:
- the code samples should be compiled check, and even executed for some of them to check they have the correct error code in a panic
- the error could be build on a page in the website like https://doc.rust-lang.org/error-index.html
- most panic should have their own error code
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
# Objective
- Bevy has several `compile_fail` test
- #2254 added `#[derive(Component)]`
- Those tests now fail for a different reason.
- This was not caught as these test still "successfully" failed to compile.
## Solution
- Add `#[derive(Component)]` to the doctest
- Also changed their cfg attribute from `doc` to `doctest`, so that these tests don't appear when running `cargo doc` with `--document-private-items`
#2605 changed the lifetime annotations on `get_component` introducing unsoundness as you could keep the returned borrow even after using the query.
Example unsoundness:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_startup_system(startup)
.add_system(unsound)
.run();
}
#[derive(Debug, Component, PartialEq, Eq)]
struct Foo(Vec<u32>);
fn startup(mut c: Commands) {
let e = c.spawn().insert(Foo(vec![10])).id();
c.insert_resource(e);
}
fn unsound(mut q: Query<&mut Foo>, res: Res<Entity>) {
let foo = q.get_component::<Foo>(*res).unwrap();
let mut foo2 = q.iter_mut().next().unwrap();
let first_elem = &foo.0[0];
for _ in 0..16 {
foo2.0.push(12);
}
dbg!(*first_elem);
}
```
output:
`[src/main.rs:26] *first_elem = 0`
Add the entity ID and generation to the expect() message of two
world accessors, to make it easier to debug use-after-free issues.
Coupled with e.g. bevy-inspector-egui which also displays the entity ID,
this makes it much easier to identify what entity is being misused.
# Objective
Make it easier to identity an entity being accessed after being deleted.
## Solution
Augment the error message of some `expect()` call with the entity ID and
generation. Combined with some external tool like `bevy-inspector-egui`, which
also displays the entity ID, this increases the chances to be able to identify
the entity, and therefore find the error that led to a use-after-despawn.
# Objective
- Fixes#2904 (see for context)
## Solution
- Simply hoist span creation out of the threaded task
- Confirmed to solve the issue locally
Now all events have the full span parent tree up through `bevy_ecs::schedule::stage` all the way to `bevy_app::app::bevy_app` (and its parents in bevy-consumer code, if any).
# Objective
- Avoid usages of `format!` that ~immediately get passed to another `format!`. This avoids a temporary allocation and is just generally cleaner.
## Solution
- `bevy_derive::shader_defs` does a `format!("{}", val.to_string())`, which is better written as just `format!("{}", val)`
- `bevy_diagnostic::log_diagnostics_plugin` does a `format!("{:>}", format!(...))`, which is better written as `format!("{:>}", format_args!(...))`
- `bevy_ecs::schedule` does `tracing::info!(..., name = &*format!("{:?}", val))`, which is better written with the tracing shorthand `tracing::info!(..., name = ?val)`
- `bevy_reflect::reflect` does `f.write_str(&format!(...))`, which is better written as `write!(f, ...)` (this could also be written using `f.debug_tuple`, but I opted to maintain alt debug behavior)
- `bevy_reflect::serde::{ser, de}` do `serde::Error::custom(format!(...))`, which is better written as `Error::custom(format_args!(...))`, as `Error::custom` takes `impl Display` and just immediately calls `format!` again
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes these issues:
- `WorldId`s currently aren't necessarily unique
- I want to guarantee that they're unique to safeguard my librarified version of https://github.com/bevyengine/bevy/discussions/2805
- There probably hasn't been a collision yet, but they could technically collide
- `SystemId` isn't used for anything
- It's no longer used now that `Locals` are stored within the `System`.
- `bevy_ecs` depends on rand
## Solution
- Instead of randomly generating `WorldId`s, just use an incrementing atomic counter, panicing on overflow.
- Remove `SystemId`
- We do need to allow Locals for exclusive systems at some point, but exclusive systems couldn't access their own `SystemId` anyway.
- Now that these don't depend on rand, move it to a dev-dependency
## Todo
Determine if `WorldId` should be `u32` based instead
Changed out unwraps to use if let syntax instead. Returning false when None.
Also modified an existing test to encompass these methods
This PR fixes#2828
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
## Objective
The upcoming Bevy Book makes many references to the API documentation of bevy.
Most references belong to the first two chapters of the Bevy Book:
- bevyengine/bevy-website#176
- bevyengine/bevy-website#182
This PR attempts to improve the documentation of `bevy_ecs` and `bevy_app` in order to help readers of the Book who want to delve deeper into technical details.
## Solution
- Add crate and level module documentation
- Document the most important items (basically those included in the preludes), with the following style, where applicable:
- **Summary.** Short description of the item.
- **Second paragraph.** Detailed description of the item, without going too much in the implementation.
- **Code example(s).**
- **Safety or panic notes.**
## Collaboration
Any kind of collaboration is welcome, especially corrections, wording, new ideas and guidelines on where the focus should be put in.
---
### Related issues
- Fixes#2246
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
- CI is failing again
- These failures result from https://github.com/rust-lang/rust/pull/85200
## Solution
- Fix the errors which result from this by using the given fields
- I also removed the now unused `Debug` impl.
I suspect that we shouldn't use -D warnings for nightly CI - ideally we'd get a discord webhook message into some (non-#github) dedicated channel on warnings.
But this does not implement that.
# Objective
The vast majority of `.single()` usage I've seen is immediately followed by a `.unwrap()`. Since it seems most people use it without handling the error, I think making it easier to just get what you want fast while also having a more verbose alternative when you want to handle the error could help.
## Solution
Instead of having a lot of `.unwrap()` everywhere, this PR introduces a `try_single()` variant that behaves like the current `.single()` and make the new `.single()` panic on error.
# Objective
Sometimes, the unwraps in `entity_mut` could fail here, if the entity was despawned *before* this command was applied.
The simplest case involves two command buffers:
```rust
use bevy::prelude::*;
fn b(mut commands1: Commands, mut commands2: Commands) {
let id = commands2.spawn().insert_bundle(()).id();
commands1.entity(id).despawn();
}
fn main() {
App::build().add_system(b.system()).run();
}
```
However, a more complicated version arises in the case of ambiguity:
```rust
use std::time::Duration;
use bevy::{app::ScheduleRunnerPlugin, prelude::*};
use rand::Rng;
fn cleanup(mut e: ResMut<Option<Entity>>) {
*e = None;
}
fn sleep_randomly() {
let mut rng = rand::thread_rng();
std:🧵:sleep(Duration::from_millis(rng.gen_range(0..50)));
}
fn spawn(mut commands: Commands, mut e: ResMut<Option<Entity>>) {
*e = Some(commands.spawn().insert_bundle(()).id());
}
fn despawn(mut commands: Commands, e: Res<Option<Entity>>) {
let mut rng = rand::thread_rng();
std:🧵:sleep(Duration::from_millis(rng.gen_range(0..50)));
if let Some(e) = *e {
commands.entity(e).despawn();
}
}
fn main() {
App::build()
.add_system(cleanup.system().label("cleanup"))
.add_system(sleep_randomly.system().label("before_despawn"))
.add_system(despawn.system().after("cleanup").after("before_despawn"))
.add_system(sleep_randomly.system().label("before_spawn"))
.add_system(spawn.system().after("cleanup").after("before_spawn"))
.insert_resource(None::<Entity>)
.add_plugin(ScheduleRunnerPlugin::default())
.run();
}
```
In the cases where this example crashes, it's because `despawn` was ordered before `spawn` in the topological ordering of systems (which determines when buffers are applied). However, `despawn` actually ran *after* `spawn`, because these systems are ambiguous, so the jiggles in the sleeping time triggered a case where this works.
## Solution
- Give a better error message
# Objective
Fix `Option<NonSend<T>>` to work when T isn't `Send`
Fix `Option<NonSendMut<T>>` to work when T isnt in the world.
## Solution
Simple two row fix, properly initialize T in `OptionNonSendState` and remove `T: Component` bound for `Option<NonSendMut<T>>`
also added a rudimentary test
Co-authored-by: Ïvar Källström <ivar.kallstrom@gmail.com>
# Objective
- QueryState is lacking documentation.
Fixes#2090
## Solution
- Provide documentation that mirrors Query (as suggested in #2090) and modify as needed.
Co-authored-by: James Leflang <59455417+jleflang@users.noreply.github.com>
This upstreams the code changes used by the new renderer to enable cross-app Entity reuse:
* Spawning at specific entities
* get_or_spawn: spawns an entity if it doesn't already exist and returns an EntityMut
* insert_or_spawn_batch: the batched equivalent to `world.get_or_spawn(entity).insert_bundle(bundle)`
* Clearing entities and storages
* Allocating Entities with "invalid" archetypes. These entities cannot be queried / are treated as "non existent". They serve as "reserved" entities that won't show up when calling `spawn()`. They must be "specifically spawned at" using apis like `get_or_spawn(entity)`.
In combination, these changes enable the "render world" to clear entities / storages each frame and reserve all "app world entities". These can then be spawned during the "render extract step".
This refactors "spawn" and "insert" code in a way that I think is a massive improvement to legibility and re-usability. It also yields marginal performance wins by reducing some duplicate lookups (less than a percentage point improvement on insertion benchmarks). There is also some potential for future unsafe reduction (by making BatchSpawner and BatchInserter generic). But for now I want to cut down generic usage to a minimum to encourage smaller binaries and faster compiles.
This is currently a draft because it needs more tests (although this code has already had some real-world testing on my custom-shaders branch).
I also fixed the benchmarks (which currently don't compile!) / added new ones to illustrate batching wins.
After these changes, Bevy ECS is basically ready to accommodate the new renderer. I think the biggest missing piece at this point is "sub apps".
This is a rather simple but wide change, and it involves adding a new `bevy_app_macros` crate. Let me know if there is a better way to do any of this!
---
# Objective
- Allow adding and accessing sub-apps by using a label instead of an index
## Solution
- Migrate the bevy label implementation and derive code to the `bevy_utils` and `bevy_macro_utils` crates and then add a new `SubAppLabel` trait to the `bevy_app` crate that is used when adding or getting a sub-app from an app.
# Objective
While implementing a plugin for my rollback networking library, I needed to load/save parts of the world. For this, I made a WorldSnapshot that works quite like the current DynamicScene. Using a TypeRegistry to register component types I want to save/load and then using ReflectComponents methods to add or apply components of the given types.
However, I noticed there is no method to remove components from entities through the ReflectComponent.
## Solution
I added a `remove_component` field to the `ReflectComponent` struct, as well as a `pub fn remove_component(&self, world: &mut World, entity: Entity)` to call that function in `remove_component`. This follows exactly the same pattern all other methods/fields in this struct look like.
This is an example how it could be used (at least how I would use it):
6c003f86f1/src/world_snapshot.rs (L133)
# Objective
Enable using exact World lifetimes during read-only access . This is motivated by the new renderer's need to allow read-only world-only queries to outlive the query itself (but still be constrained by the world lifetime).
For example:
115b170d1f/pipelined/bevy_pbr2/src/render/mod.rs (L774)
## Solution
Split out SystemParam state and world lifetimes and pipe those lifetimes up to read-only Query ops (and add into_inner for Res). According to every safety test I've run so far (except one), this is safe (see the temporary safety test commit). Note that changing the mutable variants to the new lifetimes would allow aliased mutable pointers (try doing that to see how it affects the temporary safety tests).
The new state lifetime on SystemParam does make `#[derive(SystemParam)]` more cumbersome (the current impl requires PhantomData if you don't use both lifetimes). We can make this better by detecting whether or not a lifetime is used in the derive and adjusting accordingly, but that should probably be done in its own pr.
## Why is this a draft?
The new lifetimes break QuerySet safety in one very specific case (see the query_set system in system_safety_test). We need to solve this before we can use the lifetimes given.
This is due to the fact that QuerySet is just a wrapper over Query, which now relies on world lifetimes instead of `&self` lifetimes to prevent aliasing (but in systems, each Query has its own implied lifetime, not a centralized world lifetime). I believe the fix is to rewrite QuerySet to have its own World lifetime (and own the internal reference). This will complicate the impl a bit, but I think it is doable. I'm curious if anyone else has better ideas.
Personally, I think these new lifetimes need to happen. We've gotta have a way to directly tie read-only World queries to the World lifetime. The new renderer is the first place this has come up, but I doubt it will be the last. Worst case scenario we can come up with a second `WorldLifetimeQuery<Q, F = ()>` parameter to enable these read-only scenarios, but I'd rather not add another type to the type zoo.
# Objective
This:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_system(test)
.run();
}
fn test(entities: Query<Entity>) {
let mut combinations = entities.iter_combinations_mut();
while let Some([e1, e2]) = combinations.fetch_next() {
dbg!(e1);
}
}
```
fails with the message "the trait bound `bevy::ecs::query::EntityFetch: std::clone::Clone` is not satisfied".
## Solution
It works after adding the naive clone implementation to EntityFetch. I'm not super familiar with ECS internals, so I'd appreciate input on this.
This is an updated version of #1434 PR. I've encountered this macro problem while trying to use @woubuc's bevy-event-set crate.
Co-authored-by: Piotr Balcer <piotr@balcer.eu>
# Objective
There is currently a 1-to-1 mapping between components and real rust types. This means that it is impossible for multiple components to be represented by the same rust type or for a component to not have a rust type at all. This means that component types can't be defined in languages other than rust like necessary for scripting or sandboxed (wasm?) plugins.
## Solution
Refactor `ComponentDescriptor` and `Bundle` to remove `TypeInfo`. `Bundle` now uses `ComponentId` instead. `ComponentDescriptor` is now always created from a rust type instead of through the `TypeInfo` indirection. A future PR may make it possible to construct a `ComponentDescriptor` from it's fields without a rust type being involved.
# Objective
- Remove all the `.system()` possible.
- Check for remaining missing cases.
## Solution
- Remove all `.system()`, fix compile errors
- 32 calls to `.system()` remains, mostly internals, the few others should be removed after #2446
# Objective
While looking at the code of `World`, I noticed two basic functions (`get` and `get_mut`) that are probably called a lot and with simple code that are not `inline`
## Solution
- Add benchmark to check impact
- Add `#[inline]`
```
group this pr main
----- ---- ----
world_entity/50000_entities 1.00 115.9±11.90µs ? ?/sec 1.71 198.5±29.54µs ? ?/sec
world_get/50000_entities_SparseSet 1.00 409.9±46.96µs ? ?/sec 1.18 483.5±36.41µs ? ?/sec
world_get/50000_entities_Table 1.00 391.3±29.83µs ? ?/sec 1.16 455.6±57.85µs ? ?/sec
world_query_for_each/50000_entities_SparseSet 1.02 121.3±18.36µs ? ?/sec 1.00 119.4±13.88µs ? ?/sec
world_query_for_each/50000_entities_Table 1.03 13.8±0.96µs ? ?/sec 1.00 13.3±0.54µs ? ?/sec
world_query_get/50000_entities_SparseSet 1.00 666.9±54.36µs ? ?/sec 1.03 687.1±57.77µs ? ?/sec
world_query_get/50000_entities_Table 1.01 584.4±55.12µs ? ?/sec 1.00 576.3±36.13µs ? ?/sec
world_query_iter/50000_entities_SparseSet 1.01 169.7±19.50µs ? ?/sec 1.00 168.6±32.56µs ? ?/sec
world_query_iter/50000_entities_Table 1.00 26.2±1.38µs ? ?/sec 1.91 50.0±4.40µs ? ?/sec
```
I didn't add benchmarks for the mutable path but I don't see how it could hurt to make it inline too...
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet.
You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away.
Co-Authored-By: Carter Anderson <mcanders1@gmail.com>
This logic was in both `remove_bundle` and ` remove_bundle_intersection` but only differed by whether we call `.._forget_missing_..` or `.._drop_missing_..`
* bevy_pbr2: Add support for most of the StandardMaterial textures
Normal maps are not included here as they require tangents in a vertex attribute.
* bevy_pbr2: Ensure RenderCommandQueue is ready for PbrShaders init
* texture_pipelined: Add a light to the scene so we can see stuff
* WIP bevy_pbr2: back to front sorting hack
* bevy_pbr2: Uniform control flow for texture sampling in pbr.frag
From 'fintelia' on the Bevy Render Rework Round 2 discussion:
"My understanding is that GPUs these days never use the "execute both branches
and select the result" strategy. Rather, what they do is evaluate the branch
condition on all threads of a warp, and jump over it if all of them evaluate to
false. If even a single thread needs to execute the if statement body, however,
then the remaining threads are paused until that is completed."
* bevy_pbr2: Simplify texture and sampler names
The StandardMaterial_ prefix is no longer needed
* bevy_pbr2: Match default 'AmbientColor' of current bevy_pbr for now
* bevy_pbr2: Convert from non-linear to linear sRGB for the color uniform
* bevy_pbr2: Add pbr_pipelined example
* Fix view vector in pbr frag to work in ortho
* bevy_pbr2: Use a 90 degree y fov and light range projection for lights
* bevy_pbr2: Add AmbientLight resource
* bevy_pbr2: Convert PointLight color to linear sRGB for use in fragment shader
* bevy_pbr2: pbr.frag: Rename PointLight.projection to view_projection
The uniform contains the view_projection matrix so this was incorrect.
* bevy_pbr2: PointLight is an OmniLight as it has a radius
* bevy_pbr2: Factoring out duplicated code
* bevy_pbr2: Implement RenderAsset for StandardMaterial
* Remove unnecessary texture and sampler clones
* fix comment formatting
* remove redundant Buffer:from
* Don't extract meshes when their material textures aren't ready
* make missing textures in the queue step an error
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This relicenses Bevy under the dual MIT or Apache-2.0 license. For rationale, see #2373.
* Changes the LICENSE file to describe the dual license. Moved the MIT license to docs/LICENSE-MIT. Added the Apache-2.0 license to docs/LICENSE-APACHE. I opted for this approach over dumping both license files at the root (the more common approach) for a number of reasons:
* Github links to the "first" license file (LICENSE-APACHE) in its license links (you can see this in the wgpu and rust-analyzer repos). People clicking these links might erroneously think that the apache license is the only option. Rust and Amethyst both use COPYRIGHT or COPYING files to solve this problem, but this creates more file noise (if you do everything at the root) and the naming feels way less intuitive.
* People have a reflex to look for a LICENSE file. By providing a single license file at the root, we make it easy for them to understand our licensing approach.
* I like keeping the root clean and noise free
* There is precedent for putting the apache and mit license text in sub folders (amethyst)
* Removed the `Copyright (c) 2020 Carter Anderson` copyright notice from the MIT license. I don't care about this attribution, it might make license compliance more difficult in some cases, and it didn't properly attribute other contributors. We shoudn't replace it with something like "Copyright (c) 2021 Bevy Contributors" because "Bevy Contributors" is not a legal entity. Instead, we just won't include the copyright line (which has precedent ... Rust also uses this approach).
* Updates crates to use the new "MIT OR Apache-2.0" license value
* Removes the old legion-transform license file from bevy_transform. bevy_transform has been its own, fully custom implementation for a long time and that license no longer applies.
* Added a License section to the main readme
* Updated our Bevy Plugin licensing guidelines.
As a follow-up we should update the website to properly describe the new license.
Closes#2373
# Objective
- Continue work of #2398 and friends.
- Make `.system()` optional in chaining.
## Solution
- Slight change to `IntoChainSystem` signature and implementation.
- Remove some usages of `.system()` in the chaining example, to verify the implementation.
---
I swear, I'm not splitting these up on purpose, I just legit forgot about most of the things where `System` appears in public API, and my trait usage explorer mingles that with the gajillion internal uses.
In case you're wondering what happened to part 5, #2446 ate it.
# Objective
- Currently `Commands` are quite slow due to the need to allocate for each command and wrap it in a `Box<dyn Command>`.
- For example:
```rust
fn my_system(mut cmds: Commands) {
cmds.spawn().insert(42).insert(3.14);
}
```
will have 3 separate `Box<dyn Command>` that need to be allocated and ran.
## Solution
- Utilize a specialized data structure keyed `CommandQueueInner`.
- The purpose of `CommandQueueInner` is to hold a collection of commands in contiguous memory.
- This allows us to store each `Command` type contiguously in memory and quickly iterate through them and apply the `Command::write` trait function to each element.
# Objective
Reduce compilation time
# Solution
Remove unused dependencies. While this PR doesn't remove any crates from `Cargo.lock`, it may unlock more build parallelism.
In #2034, the `Remove` Command did not get the same treatment as the rest of the commands. There's no discussion saying it shouldn't have public fields, so I am assuming it was an oversight. This fixes that oversight.
# Objective
- Continue work of #2398 and friends.
- Make `.system()` optional in run criteria APIs.
## Solution
- Slight change to `RunCriteriaDescriptorCoercion` signature and implementors.
- Implement `IntoRunCriteria` for `IntoSystem` rather than `System`.
- Remove some usages of `.system()` with run criteria in tests of `stage.rs`, to verify the implementation.
# Objective
I wanted to send the Bevy discord link to someone but couldn't find a pretty link to copy paste
## Solution
Use the vanity link we have for discord
# Objective
Beginners semi-regularly appear on the Discord asking for help with using `QuerySet` when they have a system with conflicting data access.
This happens because the Resulting Panic message only mentions `QuerySet` as a solution, even if in most cases `Without<T>` was enough to solve the problem.
## Solution
Mention the usage of `Without<T>` to create disjoint queries as an alternative to `QuerySet`
## Open Questions
- Is `disjoint` a too technical/mathematical word?
- Should `Without<T>` be mentioned before or after `QuerySet`?
- Before: Using `Without<T>` should be preferred and mentioning it first reinforces this for a reader.
- After: The Panics can be very long and a Reader could skip to end and only see the `QuerySet`
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
# Objective
- Continue work of #2398 and #2403.
- Make `.system()` syntax optional when using `.config()` API.
## Solution
- Introduce new prelude trait, `ConfigurableSystem`, that shorthands `my_system.system().config(...)` as `my_system.config(...)`.
- Expand `configure_system_local` test to also cover the new syntax.
# Objective
- Add inline documentation for `StorageType`.
- Currently the README in `bevy_ecs` provides docs for `StorageType`, however, adding addition inline docs makes it simpler for users who are actively reading the source code.
## Solution
- Add inline docs.
# Objective
- Extend work done in #2398.
- Make `.system()` syntax optional when using system descriptor API.
## Solution
- Slight change to `ParallelSystemDescriptorCoercion` signature and implementors.
---
I haven't touched exclusive systems, because it looks like the only two other solutions are going back to doubling our system insertion methods, or starting to lean into stageless. The latter will invalidate the former, so I think exclusive systems should remian pariahs until stageless.
I can grep & nuke `.system()` thorughout the codebase now, which might take a while, or we can do that in subsequent PR(s).
This can be your 6 months post-christmas present.
# Objective
- Make `.system` optional
- yeet
- It's ugly
- Alternative title: `.system` is dead; long live `.system`
- **yeet**
## Solution
- Use a higher ranked lifetime, and some trait magic.
N.B. This PR does not actually remove any `.system`s, except in a couple of examples. Once this is merged we can do that piecemeal across crates, and decide on syntax for labels.
# Objective
Currently, you can add `Option<Res<T>` or `Option<ResMut<T>` as a SystemParam, if the Resource could potentially not exist, but this functionality doesn't exist for `NonSend` and `NonSendMut`
## Solution
Adds implementations to use `Option<NonSend<T>>` and Option<NonSendMut<T>> as SystemParams.
# Objective
- CI jobs are starting to fail due to `clippy::bool-assert-comparison` and `clippy::single_component_path_imports` being triggered.
## Solution
- Fix all uses where `asset_eq!(<condition>, <bool>)` could be replace by `assert!`
- Move the `#[allow()]` for `single_component_path_imports` to `#![allow()]` at the start of the files.
# Objective
- The `DetectChanges` trait is used for types that detect change on mutable access (such as `ResMut`, `Mut`, etc...)
- `DetectChanges` was not implemented for `NonSendMut`
## Solution
- implement `NonSendMut` in terms of `DetectChanges`
# Objective
Currently, you can't call `is_added` or `is_changed` on a `NonSend` SystemParam, unless the Resource is a Component (implements `Send` and `Sync`).
This defeats the purpose of providing change detection for NonSend Resources.
While fixing this, I also noticed that `NonSend` does not have a bound at all on its struct.
## Solution
Change the bounds of `T` to always be `'static`.
[RENDERED](https://github.com/NiklasEi/bevy/blob/ecs_readme/crates/bevy_ecs/README.md)
Since I am trying to learn more about Bevy ECS at the moment, I thought this issue is a perfect fit.
This PR adds a readme to the `bevy_ecs` crate containing a minimal running example of stand alone `bevy_ecs`. Unique features like customizable component storage, Resources or change detection are introduced. For each of these features the readme links to an example in a newly created examples directory inside the `bevy_esc` crate.
Resolves#2008
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Problem
- The `Query` struct does not provide an easy way to check if it is empty.
- Specifically, users have to use `.iter().peekable()` or `.iter().next().is_none()` which is not very ergonomic.
- Fixes: #2270
## Solution
- Implement an `is_empty` function for queries to more easily check if the query is empty.
This enables `SystemParams` to be used outside of function systems. Anything can create and store `SystemState`, which enables efficient "param state cached" access to `SystemParams`.
It adds a `ReadOnlySystemParamFetch` trait, which enables safe `SystemState::get` calls without unique world access.
I renamed the old `SystemState` to `SystemMeta` to enable us to mirror the `QueryState` naming convention (but I'm happy to discuss alternative names if people have other ideas). I initially pitched this as `ParamState`, but given that it needs to include full system metadata, that doesn't feel like a particularly accurate name.
```rust
#[derive(Eq, PartialEq, Debug)]
struct A(usize);
#[derive(Eq, PartialEq, Debug)]
struct B(usize);
let mut world = World::default();
world.insert_resource(A(42));
world.spawn().insert(B(7));
// we get nice lifetime elision when declaring the type on the left hand side
let mut system_state: SystemState<(Res<A>, Query<&B>)> = SystemState::new(&mut world);
let (a, query) = system_state.get(&world);
assert_eq!(*a, A(42), "returned resource matches initial value");
assert_eq!(
*query.single().unwrap(),
B(7),
"returned component matches initial value"
);
// mutable system params require unique world access
let mut system_state: SystemState<(ResMut<A>, Query<&mut B>)> = SystemState::new(&mut world);
let (a, query) = system_state.get_mut(&mut world);
// static lifetimes are required when declaring inside of structs
struct SomeContainer {
state: SystemState<(Res<'static, A>, Res<'static, B>)>
}
// this can be shortened using type aliases, which will be useful for complex param tuples
type MyParams<'a> = (Res<'a, A>, Res<'a, B>);
struct SomeContainer {
state: SystemState<MyParams<'static>>
}
// It is the user's responsibility to call SystemState::apply(world) for parameters that queue up work
let mut system_state: SystemState<(Commands, Query<&B>)> = SystemState::new(&mut world);
{
let (mut commands, query) = system_state.get(&world);
commands.insert_resource(3.14);
}
system_state.apply(&mut world);
```
## Future Work
* Actually use SystemState inside FunctionSystem. This would be trivial, but it requires FunctionSystem to wrap SystemState in Option in its current form (which complicates system metadata lookup). I'd prefer to hold off until we adopt something like the later designs linked in #1364, which enable us to contruct Systems using a World reference (and also remove the need for `.system`).
* Consider a "scoped" approach to automatically call SystemState::apply when systems params are no longer being used (either a container type with a Drop impl, or a function that takes a closure for user logic operating on params).
When dropping the data, we originally only checked the size of an individual item instead of the size of the allocation. However with a capacity of 0, we attempt to deallocate a pointer which was not the result of allocation. That is, an item of `Layout { size_: 8, align_: 8 }` produces an array of `Layout { size_: 0, align_: 8 }` when `capacity = 0`.
Fixes#2294
## Objective
- Fixes: #2275
- `Assets` were being flagged as 'changed' each frame regardless of if the assets were actually being updated.
## Solution
- Only have `Assets` change detection be triggered when the collection is actually modified.
- This includes utilizing `ResMut` further down the stack instead of a `&mut Assets` directly.
Continuing the work on reducing the safety footguns in the code, I've removed one extra `UnsafeCell` in favour of safe `Cell` usage inisde `ComponentTicks`. That change led to discovery of misbehaving component insert logic, where data wasn't properly dropped when overwritten. Apart from that being fixed, some method names were changed to better convey the "initialize new allocation" and "replace existing allocation" semantic.
Depends on #2221, I will rebase this PR after the dependency is merged. For now, review just the last commit.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
`ResMut`, `Mut` and `ReflectMut` all share very similar code for change detection.
This PR is a first pass at refactoring these implementation and removing a lot of the duplicated code.
Note, this introduces a new trait `ChangeDetectable`.
Please feel free to comment away and let me know what you think!
I've noticed that we are overusing interior mutability of the Table data, where in many cases we already own a unique reference to it. That prompted a slight refactor aiming to reduce number of safety constraints that must be manually upheld. Now the majority of those are just about avoiding bound checking, which is relatively easy to prove right.
Another aspect is reducing the complexity of Table struct. Notably, we don't ever use archetypes stored there, so this whole thing goes away. Capacity and grow amount were mostly superficial, as we are already using Vecs inside anyway, so I've got rid of those too. Now the overall table capacity is being driven by the internal entity Vec capacity. This has a side effect of automatically implementing exponential growth pattern for BitVecs reallocations inside Table, which to my measurements slightly improves performance in tests that are heavy on inserts. YMMV, but I hope that those tests were at least remotely correct.
The previous implementation of `Events::extend` iterated through each event and manually `sent` it via `Events:;send`.
However, this could be a minor performance hit since calling `Vec::push` in a loop is not optimal.
This refactors the code to use `Vec::extend`.
This new api stems from this [discord conversation](https://discord.com/channels/691052431525675048/742569353878437978/844057268172357663).
This exposes a public facing `set_changed` method on `ResMut` and `Mut`.
As a side note: `ResMut` and `Mut` have a lot of duplicated code, I have a PR I may put up later that refactors these commonalities into a trait.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
- simplified code around archetype generations a little bit, as the special case value is not actually needed
- removed unnecessary UnsafeCell around pointer value that is never updated through shared references
- fixed and added a test for correct drop behaviour when removing sparse components through remove_bundle command
While trying to figure out how to implement a `SystemParam`, I spent a
long time looking for a feature that would do exactly what `Config`
does. I ignored it at first because all the examples I could find used
`()` and I couldn't see a way to modify it.
This is documented in other places, but `Config` is a logical place to
include some breadcrumbs. I've added some text that gives a brief
overview of what `Config` is for, and links to the existing docs on
`FunctionSystem::config` for more details.
This would have saved me from embarrassing myself by filing https://github.com/bevyengine/bevy/issues/2178.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
During PR #2046 @cart suggested that the `(): ()` notation is less legible than `_input: ()`. The first notation still managed to slip in though. This PR applies the second writing.
Related to [discussion on discord](https://discord.com/channels/691052431525675048/742569353878437978/824731187724681289)
With const generics, it is now possible to write generic iterator over multiple entities at once.
This enables patterns of query iterations like
```rust
for [e1, e2, e3] in query.iter_combinations() {
// do something with relation of all three entities
}
```
The compiler is able to infer the correct iterator for given size of array, so either of those work
```rust
for [e1, e2] in query.iter_combinations() { ... }
for [e1, e2, e3] in query.iter_combinations() { ... }
```
This feature can be very useful for systems like collision detection.
When you ask for permutations of size K of N entities:
- if K == N, you get one result of all entities
- if K < N, you get all possible subsets of N with size K, without repetition
- if K > N, the result set is empty (no permutation of size K exist)
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This can save users from having to type `&*X` all the time at the cost of some complexity in the type signature. For instance, this allows me to accommodate @jakobhellermann's suggestion in #1799 without requiring users to type `&*windows` 99% of the time.
`ParallelSystemContainer`'s `system` pointer was extracted from box, but it was never deallocated. This change adds missing drop implementation that cleans up that memory.
The first commit monomorphizes `add_system_inner` which I think was intended to be monomorphized anyway. The second commit moves the type argument of `GraphNode` to an associated type.
In response to #2023, here is a draft for a PR.
Fixes#2023
I've added an example to show how to use `WithBundle`, and also to test it out.
Right now there is a bug: If a bundle and a query are "the same", then it doesn't filter out
what it needs to filter out.
Example:
```
Print component initated from bundle.
[examples/ecs/query_bundle.rs:57] x = Dummy( <========= This should not get printed
111,
)
[examples/ecs/query_bundle.rs:57] x = Dummy(
222,
)
Show all components
[examples/ecs/query_bundle.rs:50] x = Dummy(
111,
)
[examples/ecs/query_bundle.rs:50] x = Dummy(
222,
)
```
However, it behaves the right way, if I add one more component to the bundle,
so the query and the bundle doesn't look the same:
```
Print component initated from bundle.
[examples/ecs/query_bundle.rs:57] x = Dummy(
222,
)
Show all components
[examples/ecs/query_bundle.rs:50] x = Dummy(
111,
)
[examples/ecs/query_bundle.rs:50] x = Dummy(
222,
)
```
I hope this helps. I'm definitely up for tinkering with this, and adding anything that I'm asked to add
or change.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I'm using Bevy ECS in a project of mine and I'd like to do world changes asynchronously.
The current public API for creating entities, `Commands` , has a lifetime that restricts it from being sent across threads. `CommandQueue` on the other hand is a Vec of commands that can be later ran on a World.
So far this is all public, but the commands themselves are private API. I know the intented use is with `Commands`, but that's not possible for my use case as I mentioned, and so I simply copied over the code for the commands I need and it works. Obviously, this isn't a nice solution, so I'd like to ask if it's not out of scope to make the commands public?
The documentation for `ShouldRun` doesn't completely explain what each of the variants you can return does. For instance, it isn't very clear that looping systems aren't executed again until after all the systems in a stage have had a chance to run.
This PR adds to the documentation for `ShouldRun`, and hopefully clarifies what is happening during a stage's execution when run criteria are checked and systems are being executed.
Some panic messages for systems include the system name, but there's a few panic messages which do not. This PR adds the system name for the remaining panic messages.
This is a continuation of the work done in #1864.
Related: #1846
This shrinks breakout from 316k to 310k when using `--feature dynamic`.
I haven't run the ecs benchmark to test performance as my laptop is too noisy for reliable benchmarking.
We discussed with @alice-i-cecile privately on iterators and agreed that making a custom ordered iterator over query makes no sense since materialization is required anyway and it's better to reuse existing components or code. Therefore, just adding an example to the documentation as requested.
Fixes#1470.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This includes a lot of single line comments where either saying more wasn't helpful or due to me not knowing enough about things yet to be able to go more indepth. Proofreading is very much welcome.
Fixes#1846
Got scared of the other "Requested resource does not exist" error at line 395 in `system_param.rs`, under `impl<'a, T: Component> SystemParamFetch<'a> for ResMutState<T> {`. Someone with better knowledge of the code might be able to go in and improve that one.
Fixes#1809. It makes it also possible to use `derive` for `SystemParam` inside ECS and avoid manual implementation. An alternative solution to macro changes is to use `use crate as bevy_ecs;` in `event.rs`.
fixes#1772
1st commit: the limit was at 11 as the macro was not using a range including the upper end. I changed that as it feels the purpose of the macro is clearer that way.
2nd commit: as suggested in the `// TODO`, I added a `Config` trait to go to 16 elements tuples. This means that if someone has a custom system parameter with a config that is not a tuple or an `Option`, they will have to implement `Config` for it instead of the standard `Default`.
I think [collection, thing_removed_from_collection] is a more natural order than [thing_removed_from_collection, collection]. Just a small tweak that I think we should include in 0.5.
Fixes#1753.
The problem was introduced while reworking the logic around stages' own criteria. Before #1675 they used to be stored and processed inline with the systems' criteria, and systems without criteria used that of their stage. After, criteria-less systems think they should run, always. This PR more or less restores previous behavior; a less cludge solution can wait until after 0.5 - ideally, until stageless.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This is intended to help protect users against #1671. It doesn't resolve the issue, but I think its a good stop-gap solution for 0.5. A "full" fix would be very involved (and maybe not worth the added complexity).
Removing the checks on this line https://github.com/bevyengine/bevy/blob/main/crates/bevy_sprite/src/frustum_culling.rs#L64 and running the "many_sprites" example revealed two corner case bugs in bevy_ecs. The first, a simple and honest missed line introduced in #1471. The other, an insidious monster that has been there since the ECS v2 rewrite, just waiting for the time to strike:
1. #1471 accidentally removed the "insert" line for sparse set components with the "mutated" bundle state. Re-adding it fixes the problem. I did a slight refactor here to make the implementation simpler and remove a branch.
2. The other issue is nastier. ECS v2 added an "archetype graph". When determining what components were added/mutated during an archetype change, we read the FromBundle edge (which encodes this state) on the "new" archetype. The problem is that unlike "add edges" which are guaranteed to be unique for a given ("graph node", "bundle id") pair, FromBundle edges are not necessarily unique:
```rust
// OLD_ARCHETYPE -> NEW_ARCHETYPE
// [] -> [usize]
e.insert(2usize);
// [usize] -> [usize, i32]
e.insert(1i32);
// [usize, i32] -> [usize, i32]
e.insert(1i32);
// [usize, i32] -> [usize]
e.remove::<i32>();
// [usize] -> [usize, i32]
e.insert(1i32);
```
Note that the second `e.insert(1i32)` command has a different "archetype graph edge" than the first, but they both lead to the same "new archetype".
The fix here is simple: just remove FromBundle edges because they are broken and store the information in the "add edges", which are guaranteed to be unique.
FromBundle edges were added to cut down on the number of archetype accesses / make the archetype access patterns nicer. But benching this change resulted in no significant perf changes and the addition of get_2_mut() for archetypes resolves the access pattern issue.
In the current impl, next clears out the entire stack and replaces it with a new state. This PR moves this functionality into a replace method, and changes the behavior of next to only change the top state.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I'm opening this prematurely; consider this an RFC that predates RFCs and therefore not super-RFC-like.
This PR does two "big" things: decouple run criteria from system sets, reimagine system sets as weapons of mass system description.
### What it lets us do:
* Reuse run criteria within a stage.
* Pipe output of one run criteria as input to another.
* Assign labels, dependencies, run criteria, and ambiguity sets to many systems at the same time.
### Things already done:
* Decoupled run criteria from system sets.
* Mass system description superpowers to `SystemSet`.
* Implemented `RunCriteriaDescriptor`.
* Removed `VirtualSystemSet`.
* Centralized all run criteria of `SystemStage`.
* Extended system descriptors with per-system run criteria.
* `.before()` and `.after()` for run criteria.
* Explicit order between state driver and related run criteria. Fixes#1672.
* Opt-in run criteria deduplication; default behavior is to panic.
* Labels (not exposed) for state run criteria; state run criteria are deduplicated.
### API issues that need discussion:
* [`FixedTimestep::step(1.0).label("my label")`](eaccf857cd/crates/bevy_ecs/src/schedule/run_criteria.rs (L120-L122)) and [`FixedTimestep::step(1.0).with_label("my label")`](eaccf857cd/crates/bevy_core/src/time/fixed_timestep.rs (L86-L89)) are both valid but do very different things.
---
I will try to maintain this post up-to-date as things change. Do check the diffs in "edited" thingy from time to time.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Resolves#1253#1562
This makes the Commands apis consistent with World apis. This moves to a "type state" pattern (like World) where the "current entity" is stored in an `EntityCommands` builder.
In general this tends to cuts down on indentation and line count. It comes at the cost of needing to type `commands` more and adding more semicolons to terminate expressions.
I also added `spawn_bundle` to Commands because this is a common enough operation that I think its worth providing a shorthand.
Updates the requirements on [fixedbitset](https://github.com/bluss/fixedbitset) to permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/bluss/fixedbitset/commits">compare view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Fixes#1692
Alternative to #1696
This ensures that the capacity actually grows in increments of grow_amount, and also ensures that Table capacity is always <= column and entity vec capacity.
Debug logs that describe the new logic (running the example in #1692)
[out.txt](https://github.com/bevyengine/bevy/files/6173808/out.txt)
# Problem Definition
The current change tracking (via flags for both components and resources) fails to detect changes made by systems that are scheduled to run earlier in the frame than they are.
This issue is discussed at length in [#68](https://github.com/bevyengine/bevy/issues/68) and [#54](https://github.com/bevyengine/bevy/issues/54).
This is very much a draft PR, and contributions are welcome and needed.
# Criteria
1. Each change is detected at least once, no matter the ordering.
2. Each change is detected at most once, no matter the ordering.
3. Changes should be detected the same frame that they are made.
4. Competitive ergonomics. Ideally does not require opting-in.
5. Low CPU overhead of computation.
6. Memory efficient. This must not increase over time, except where the number of entities / resources does.
7. Changes should not be lost for systems that don't run.
8. A frame needs to act as a pure function. Given the same set of entities / components it needs to produce the same end state without side-effects.
**Exact** change-tracking proposals satisfy criteria 1 and 2.
**Conservative** change-tracking proposals satisfy criteria 1 but not 2.
**Flaky** change tracking proposals satisfy criteria 2 but not 1.
# Code Base Navigation
There are three types of flags:
- `Added`: A piece of data was added to an entity / `Resources`.
- `Mutated`: A piece of data was able to be modified, because its `DerefMut` was accessed
- `Changed`: The bitwise OR of `Added` and `Changed`
The special behavior of `ChangedRes`, with respect to the scheduler is being removed in [#1313](https://github.com/bevyengine/bevy/pull/1313) and does not need to be reproduced.
`ChangedRes` and friends can be found in "bevy_ecs/core/resources/resource_query.rs".
The `Flags` trait for Components can be found in "bevy_ecs/core/query.rs".
`ComponentFlags` are stored in "bevy_ecs/core/archetypes.rs", defined on line 446.
# Proposals
**Proposal 5 was selected for implementation.**
## Proposal 0: No Change Detection
The baseline, where computations are performed on everything regardless of whether it changed.
**Type:** Conservative
**Pros:**
- already implemented
- will never miss events
- no overhead
**Cons:**
- tons of repeated work
- doesn't allow users to avoid repeating work (or monitoring for other changes)
## Proposal 1: Earlier-This-Tick Change Detection
The current approach as of Bevy 0.4. Flags are set, and then flushed at the end of each frame.
**Type:** Flaky
**Pros:**
- already implemented
- simple to understand
- low memory overhead (2 bits per component)
- low time overhead (clear every flag once per frame)
**Cons:**
- misses systems based on ordering
- systems that don't run every frame miss changes
- duplicates detection when looping
- can lead to unresolvable circular dependencies
## Proposal 2: Two-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in either the current frame's list of changes or the previous frame's.
**Type:** Conservative
**Pros:**
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- can result in a great deal of duplicated work
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 3: Last-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in the previous frame's list of changes.
**Type:** Exact
**Pros:**
- exact
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- change detection is always delayed, possibly causing painful chained delays
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 4: Flag-Doubling Change Detection
Combine Proposal 2 and Proposal 3. Differentiate between `JustChanged` (current behavior) and `Changed` (Proposal 3).
Pack this data into the flags according to [this implementation proposal](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804).
**Type:** Flaky + Exact
**Pros:**
- allows users to acc
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- users must specify the type of change detection required
- still quite fragile to system ordering effects when using the flaky `JustChanged` form
- cannot get immediate + exact results
- systems that don't run every frame miss changes
- duplicates detection when looping
## [SELECTED] Proposal 5: Generation-Counter Change Detection
A global counter is increased after each system is run. Each component saves the time of last mutation, and each system saves the time of last execution. Mutation is detected when the component's counter is greater than the system's counter. Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804). How to handle addition detection is unsolved; the current proposal is to use the highest bit of the counter as in proposal 1.
**Type:** Exact (for mutations), flaky (for additions)
**Pros:**
- low time overhead (set component counter on access, set system counter after execution)
- robust to systems that don't run every frame
- robust to systems that loop
**Cons:**
- moderately complex implementation
- must be modified as systems are inserted dynamically
- medium memory overhead (4 bytes per component + system)
- unsolved addition detection
## Proposal 6: System-Data Change Detection
For each system, track which system's changes it has seen. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- conceptually simple
**Cons:**
- requires storing data on each system
- implementation is complex
- must be modified as systems are inserted dynamically
## Proposal 7: Total-Order Change Detection
Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-754326523). This proposal is somewhat complicated by the new scheduler, but I believe it should still be conceptually feasible. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- efficient data storage relative to other exact proposals
**Cons:**
- requires access to the scheduler
- complex implementation and difficulty grokking
- must be modified as systems are inserted dynamically
# Tests
- We will need to verify properties 1, 2, 3, 7 and 8. Priority: 1 > 2 = 3 > 8 > 7
- Ideally we can use identical user-facing syntax for all proposals, allowing us to re-use the same syntax for each.
- When writing tests, we need to carefully specify order using explicit dependencies.
- These tests will need to be duplicated for both components and resources.
- We need to be sure to handle cases where ambiguous system orders exist.
`changing_system` is always the system that makes the changes, and `detecting_system` always detects the changes.
The component / resource changed will be simple boolean wrapper structs.
## Basic Added / Mutated / Changed
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 2
## At Least Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs after `detecting_system`
- verify at the end of tick 2
## At Most Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs once before `detecting_system`
- increment a counter based on the number of changes detected
- verify at the end of tick 2
## Fast Detection
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 1
## Ambiguous System Ordering Robustness
2 x 3 x 2 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs [before/after] `detecting_system` in tick 1
- `changing_system` runs [after/before] `detecting_system` in tick 2
## System Pausing
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs in tick 1, then is disabled by run criteria
- `detecting_system` is disabled by run criteria until it is run once during tick 3
- verify at the end of tick 3
## Addition Causes Mutation
2 design:
- Resources vs. Components
- `adding_system_1` adds a component / resource
- `adding system_2` adds the same component / resource
- verify the `Mutated` flag at the end of the tick
- verify the `Added` flag at the end of the tick
First check tests for: https://github.com/bevyengine/bevy/issues/333
Second check tests for: https://github.com/bevyengine/bevy/issues/1443
## Changes Made By Commands
- `adding_system` runs in Update in tick 1, and sends a command to add a component
- `detecting_system` runs in Update in tick 1 and 2, after `adding_system`
- We can't detect the changes in tick 1, since they haven't been processed yet
- If we were to track these changes as being emitted by `adding_system`, we can't detect the changes in tick 2 either, since `detecting_system` has already run once after `adding_system` :(
# Benchmarks
See: [general advice](https://github.com/bevyengine/bevy/blob/master/docs/profiling.md), [Criterion crate](https://github.com/bheisler/criterion.rs)
There are several critical parameters to vary:
1. entity count (1 to 10^9)
2. fraction of entities that are changed (0% to 100%)
3. cost to perform work on changed entities, i.e. workload (1 ns to 1s)
1 and 2 should be varied between benchmark runs. 3 can be added on computationally.
We want to measure:
- memory cost
- run time
We should collect these measurements across several frames (100?) to reduce bootup effects and accurately measure the mean, variance and drift.
Entity-component change detection is much more important to benchmark than resource change detection, due to the orders of magnitude higher number of pieces of data.
No change detection at all should be included in benchmarks as a second control for cases where missing changes is unacceptable.
## Graphs
1. y: performance, x: log_10(entity count), color: proposal, facet: performance metric. Set cost to perform work to 0.
2. y: run time, x: cost to perform work, color: proposal, facet: fraction changed. Set number of entities to 10^6
3. y: memory, x: frames, color: proposal
# Conclusions
1. Is the theoretical categorization of the proposals correct according to our tests?
2. How does the performance of the proposals compare without any load?
3. How does the performance of the proposals compare with realistic loads?
4. At what workload does more exact change tracking become worth the (presumably) higher overhead?
5. When does adding change-detection to save on work become worthwhile?
6. Is there enough divergence in performance between the best solutions in each class to ship more than one change-tracking solution?
# Implementation Plan
1. Write a test suite.
2. Verify that tests fail for existing approach.
3. Write a benchmark suite.
4. Get performance numbers for existing approach.
5. Implement, test and benchmark various solutions using a Git branch per proposal.
6. Create a draft PR with all solutions and present results to team.
7. Select a solution and replace existing change detection.
Co-authored-by: Brice DAVIER <bricedavier@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
An alternative to StateStages that uses SystemSets. Also includes pop and push operations since this was originally developed for my personal project which needed them.
Fixes all warnings from `cargo doc --all`.
Those related to code blocks were introduced in #1612, but re-formatting using the experimental features in `rustfmt.toml` doesn't seem to reintroduce them.
These are largely targeted at beginners, as `Entity`, `Component` and `System` are the most obvious terms to search when first getting introduced to Bevy.
Removes `get_unchecked` and `get_unchecked_mut` from `Tables` and `Archetypes` collections in favor of safe Index implementations. This fixes a safety error in `Archetypes::get_id_or_insert()` (which previously relied on TableId being valid to be safe ... the alternative was to make that method unsafe too). It also cuts down on a lot of unsafe and makes the code easier to look at. I'm not sure what changed since the last benchmark, but these numbers are more favorable than my last tests of similar changes. I didn't include the Components collection as those severely killed perf last time I tried. But this does inspire me to try again (just in a separate pr)!
Note that the `simple_insert/bevy_unbatched` benchmark fluctuates a lot on both branches (this was also true for prior versions of bevy). It seems like the allocator has more variance for many small allocations. And `sparse_frag_iter/bevy` operates on such a small scale that 10% fluctuations are common.
Some benches do take a small hit here, but I personally think its worth it.
This also fixes a safety error in Query::for_each_mut, which needed to mutably borrow Query (aaahh!).
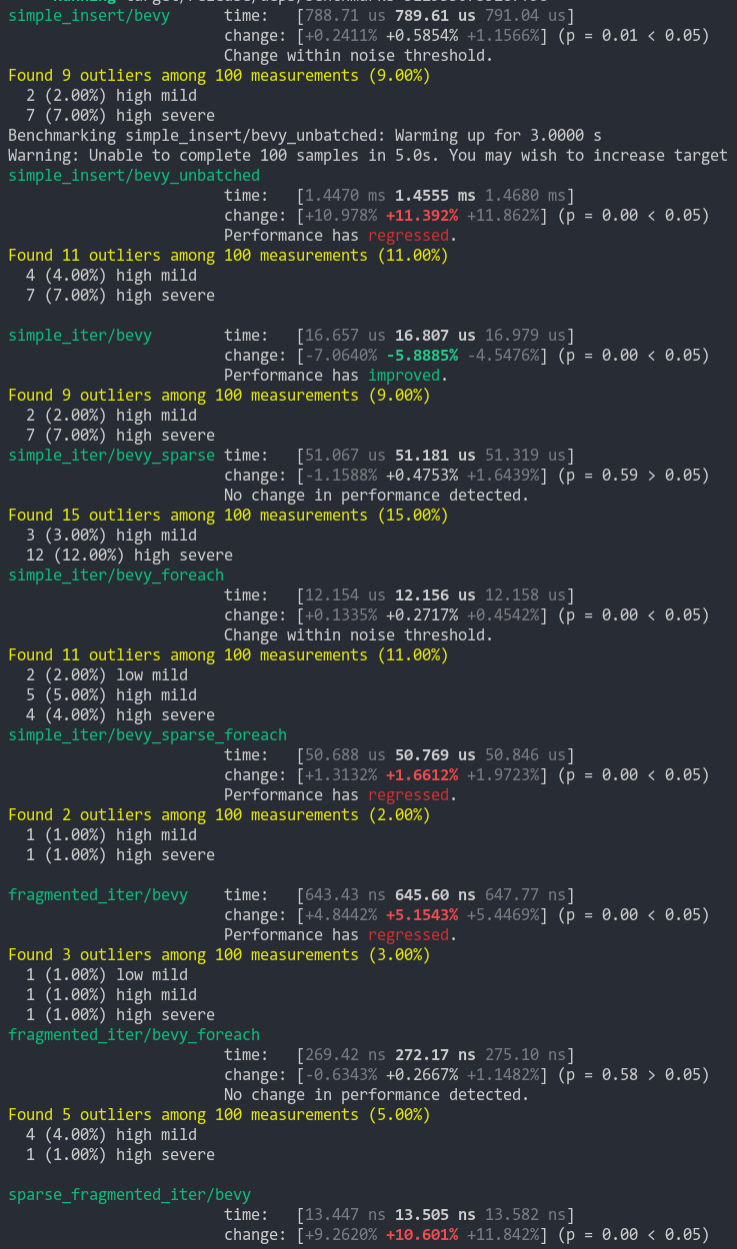
* Adds labels and orderings to systems that need them (uses the new many-to-many labels for InputSystem)
* Removes the Event, PreEvent, Scene, and Ui stages in favor of First, PreUpdate, and PostUpdate (there is more collapsing potential, such as the Asset stages and _maybe_ removing First, but those have more nuance so they should be handled separately)
* Ambiguity detection now prints component conflicts
* Removed broken change filters from flex calculation (which implicitly relied on the z-update system always modifying translation.z). This will require more work to make it behave as expected so i just removed it (and it was already doing this work every frame).
* Systems can now have more than one label attached to them.
* System labels no longer have to be unique in the stage.
Code like this is now possible:
```rust
SystemStage::parallel()
.with_system(system_0.system().label("group one").label("first"))
.with_system(system_1.system().label("group one").after("first"))
.with_system(system_2.system().after("group one"))
```
I've opted to use only the system name in ambiguity reporting, which previously was only a fallback; this, obviously, is because labels aren't one-to-one with systems anymore. We could allow users to name systems to improve this; we'll then have to think about whether or not we want to allow using the name as a label (this would, effectively, introduce implicit labelling, not all implications of which are clear to me yet wrt many-to-many labels).
Dependency cycle errors are reported using the system names and only the labels that form the cycle, with each system-system "edge" in the cycle represented as one or several labels.
Slightly unrelated: `.before()` and `.after()` with a label not attached to any system no longer crashes, and logs a warning instead. This is necessary to, for example, allow plugins to specify execution order with systems of potentially missing other plugins.
Adds `get_unique` and `get_unique_mut` to extend the query api and cover a common use case. Also establishes a second impl block where non-core APIs that don't access the internal fields of queries can live.
This allows users to write systems that do not panic if a resource does not exist at runtime (such as if it has not been inserted yet).
This is a copy-paste of the impls for `Res` and `ResMut`, with an extra check to see if the resource exists.
There might be a cleaner way to do it than this check. I don't know.
I've also added a clearer description of what bundles are used for, and explained that you can't query for bundles (a very common beginner confusion).
Co-authored-by: MinerSebas <scherthan_sebastian@web.de>
Co-authored-by: Renato Caldas <renato@calgera.com>
The bevy ecs v2 rewrite seems to have removed the `Or` query filter from the prelude, which I assume was done on accident, since `With` and `Without` are still there.
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes#1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
### Simple Insert (from ecs_bench_suite)
### Simpler Iter (from ecs_bench_suite)
### Fragment Iter (from ecs_bench_suite)
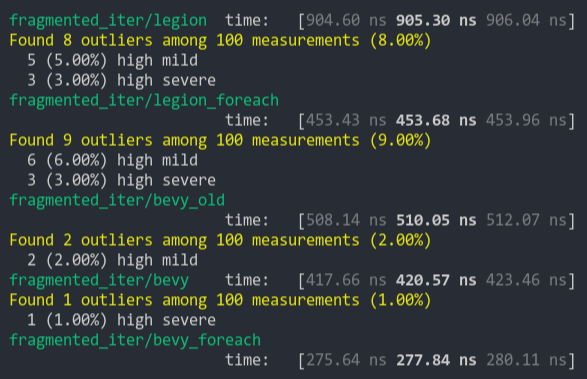
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
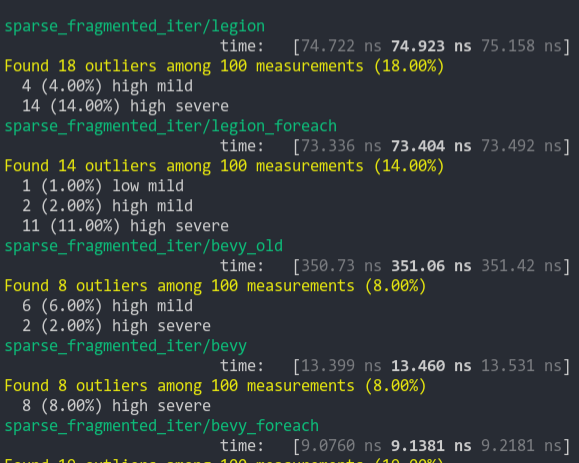
### Schedule (from ecs_bench_suite)
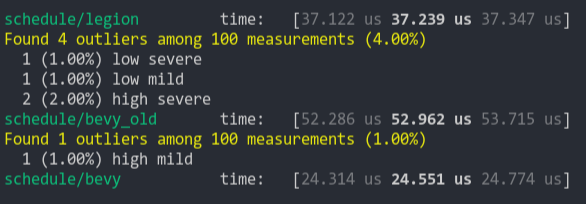
### Add Remove Component (from ecs_bench_suite)
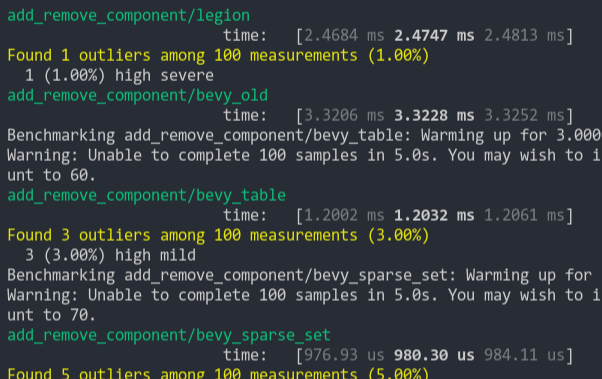
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
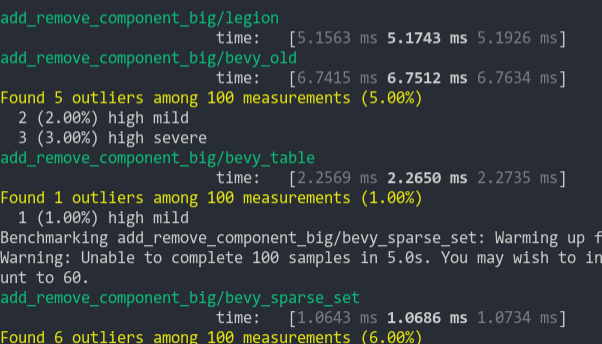
### Get Component
Looks up a single component value a large number of times
It took me a little while to figure out how to use the `SystemParam` derive macro to easily create my own params. So I figured I'd add some docs and an example with what I learned.
- Fixed a bug in the `SystemParam` derive macro where it didn't detect the correct crate name when used in an example (no longer relevant, replaced by #1426 - see further)
- Added some doc comments and a short example code block in the docs for the `SystemParam` trait
- Added a more complete example with explanatory comments in examples
This replaces `ChangedRes` with simple associated methods that return the same info, but don't block execution. Also, since ChangedRes was infectious and was the only reason `FetchSystemParam::get_params` and `System::run_unsafe` returned `Option`s, their implementation could be simplified after this PR is merged, or as part of it with a future commit.
This PR is easiest to review commit by commit.
Followup on https://github.com/bevyengine/bevy/pull/1309#issuecomment-767310084
- [x] Switch from a bash script to an xtask rust workspace member.
- Results in ~30s longer CI due to compilation of the xtask itself
- Enables Bevy contributors on any platform to run `cargo ci` to run linting -- if the default available Rust is the same version as on CI, then the command should give an identical result.
- [x] Use the xtask from official CI so there's only one place to update.
- [x] Bonus: Run clippy on the _entire_ workspace (existing CI setup was missing the `--workspace` flag
- [x] Clean up newly-exposed clippy errors
~#1388 builds on this to clean up newly discovered clippy errors -- I thought it might be nicer as a separate PR.~ Nope, merged it into this one so CI would pass.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I have run the VSCode Extension [markdownlint](https://marketplace.visualstudio.com/items?itemName=DavidAnson.vscode-markdownlint) on all Markdown Files in the Repo.
The provided Rules are documented here: https://github.com/DavidAnson/markdownlint/blob/v0.23.1/doc/Rules.md
Rules I didn't follow/fix:
* MD024/no-duplicate-heading
* Changelog: Here Heading will always repeat.
* Examples Readme: Platform-specific documentation should be symmetrical.
* MD025/single-title
* MD026/no-trailing-punctuation
* Caused by the ! in "Hello, World!".
* MD033/no-inline-html
* The plugins_guidlines file does need HTML, so the shown badges aren't downscaled too much.
* ~~MD036/no-emphasis-as-heading:~~
* ~~This Warning only Appears in the Github Issue Templates and can be ignored.~~
* ~~MD041/first-line-heading~~
* ~~Only appears in the Readme for the AlienCake example Assets, which is unimportant.~~
---
I also sorted the Examples in the Readme and Cargo.toml in this order/Priority:
* Topic/Folder
* Introductionary Examples
* Alphabetical Order
The explanation for each case, where it isn't Alphabetical :
* Diagnostics
* log_diagnostics: The usage of inbuild Diagnostics is more important than creating your own.
* ECS (Entity Component System)
* ecs_guide: The guide should be read, before diving into other Features.
* Reflection
* reflection: Basic Explanation should be read, before more advanced Topics.
* WASM Examples
* hello_wasm: It's "Hello, World!".
Before, when deriving `SystemLabel` for a type without `Clone`, the error message was:
```
the trait `SystemLabel` is not implemented for `&TransformSystem`
```
Now it is
```
the trait `Clone` is not implemented for `TransformSystem`
```
which directly shows what's needed to fix the problem.
The existing snippet fails to compile with:
```
no method named `system` found for fn item `fn(bevy::prelude::Commands) {example_system}` in the current scope
```
Relying on TypeId being some hash internally isn't future-proof because there is no guarantee about internal layout or structure of TypeId. I benchmarked TypeId noop hasher vs fxhash and found that there is very little difference.
Also fxhash is likely to be better supported because it is widely used in rustc itself.
[Benchmarks of hashers](https://github.com/bevyengine/bevy/issues/1097)
[Engine wide benchmarks](https://github.com/bevyengine/bevy/pull/1119#issuecomment-751361215)
* move print diagnostics to log
* entity count diagnostic
* asset count diagnostic
* remove useless `pub`s
* use `BTreeMap` instead of `HashMap`
* get entity count from world
* keep ordered list of diagnostics
* only update global transforms when they (or their ancestors) have changed
* only update render resource nodes when they have changed (quality check plz)
* only update entity mesh specialization when mesh (or mesh component) has changed
* only update sprite size when changed
* remove stale bind groups
* fix setting size of loading sprites
* store unmatched render resource binding results
* reduce state changes
* cargo fmt + clippy
* remove cached "NoMatch" results when new bindings are added to RenderResourceBindings
* inline current_entity in world_builder
* try creating bind groups even when they havent changed
* render_resources_node: update all entities when resized
* fmt
`ArchetypeAccess` was tracking `immutable` and `mutable` separately.
This means that checking is_compatible requires three checks:
m+m, m+i, i+m.
Instead, continue tracking `mutable` accesses, but instead of
`immutable` track `immutable | mutable` as another `accessed` bit mask.
This drops the comparisons to two (m+a, a+m) and turns out to be
what the rest of the code base wants too, unifying various duplicated
checks and loops.
* Add mutated tracker on resources and ChangedRes query for added or mutated resources.
* ResMut:::new() now takes a reference to a 'mutated' flag in its archetype.
* Change FetchResource so that get() returns an Option. Systems using Resources will only be called if all fetched Resources are Some(). This is done to implement ChangedRes, which is Some iff the Resource has been changed.
* Add OrRes for a logical or in tuples of Resource queries.
* Separate resource query get() in is_some() and get() methods for clarity
* Remove unneeded unsafe
* Change ResMut::new()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}