# Objective
- RenderGraphExt was merged, but only used in limited situations
## Solution
- Fix some remaining issues with the existing api
- Use the new api in the main pass and mass writeback
- Add CORE_2D and CORE_3D constant to make render_graph code shorter
# Objective
While working on #8299, I noticed that we're using a `capacity` field,
even though `wgpu::Buffer` exposes a `size` accessor that does the same
thing.
## Solution
Remove it from all buffer wrappers. Use `wgpu::Buffer::size` instead.
Default to 0 if no buffer has been allocated yet.
# Objective
Fixes#8284. `values` is being pushed to separately from the actual
scratch buffer in `DynamicUniformBuffer::push` and
`DynamicStorageBuffer::push`. In both types, `values` is really only
used to track the number of elements being added to the buffer, yet is
causing extra allocations, size increments and excess copies.
## Solution
Remove it and its remaining uses. Replace it with accesses to `scratch`
instead.
I removed the `len` accessor, as it may be non-trivial to compute just
from `scratch`. If this is still desirable to have, we can keep a `len`
member field to track it instead of relying on `scratch`.
# Objective
- Adding a node to the render_graph can be quite verbose and error prone
because there's a lot of moving parts to it.
## Solution
- Encapsulate this in a simple utility method
- Mostly intended for optional nodes that have specific ordering
- Requires that the `Node` impl `FromWorld`, but every internal node is
built using a new function taking a `&mut World` so it was essentially
already `FromWorld`
- Use it for the bloom, fxaa and taa, nodes.
- The main nodes don't use it because they rely more on the order of
many nodes being added
---
## Changelog
- Impl `FromWorld` for `BloomNode`, `FxaaNode` and `TaaNode`
- Added `RenderGraph::add_node_edges()`
- Added `RenderGraph::sub_graph()`
- Added `RenderGraph::sub_graph_mut()`
- Added `RenderGraphApp`, `RenderGraphApp::add_render_graph_node`,
`RenderGraphApp::add_render_graph_edges`,
`RenderGraphApp::add_render_graph_edge`
## Notes
~~This was taken out of https://github.com/bevyengine/bevy/pull/7995
because it works on it's own. Once the linked PR is done, the new
`add_node()` will be simplified a bit since the input/output params
won't be necessary.~~
This feature will be useful in most of the upcoming render nodes so it's
impact will be more relevant at that point.
Partially fixes#7985
## Future work
* Add a way to automatically label nodes or at least make it part of the
trait. This would remove one more field from the functions added in this
PR
* Use it in the main pass 2d/3d
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
WebP is a modern image format developed by Google that offers a
significant reduction in file size compared to other image formats such
as PNG and JPEG, while still maintaining good image quality. This makes
it particularly useful for games with large numbers of images, such as
those with high-quality textures or detailed sprites, where file size
and loading times can have a significant impact on performance.
By adding support for WebP images in Bevy, game developers using this
engine can now take advantage of this modern image format and reduce the
memory usage and loading times of their games. This improvement can
ultimately result in a better gaming experience for players.
In summary, the objective of adding WebP image format support in Bevy is
to enable game developers to use a modern image format that provides
better compression rates and smaller file sizes, resulting in faster
loading times and reduced memory usage for their games.
## Solution
To add support for WebP images in Bevy, this pull request leverages the
existing `image` crate support for WebP. This implementation is easily
integrated into the existing Bevy asset-loading system. To maintain
compatibility with existing Bevy projects, WebP image support is
disabled by default, and developers can enable it by adding a feature
flag to their project's `Cargo.toml` file. With this feature, Bevy
becomes even more versatile for game developers and provides a valuable
addition to the game engine.
---
## Changelog
- Added support for WebP image format in Bevy game engine
## Migration Guide
To enable WebP image support in your Bevy project, add the following
line to your project's Cargo.toml file:
```toml
bevy = { version = "*", features = ["webp"]}
```

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
A `RegularPolygon` is described by the circumscribed radius, not the
inscribed radius.
## Objective
- Correct documentation for `RegularPolygon`
## Solution
- Use the correct term
---------
Co-authored-by: Paul Hüber <phueber@kernsp.in>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
Alternative to #7490. I wrote all of the code in this PR, but I have added @robtfm as co-author on commits that build on ideas from #7490. I would not have been able to solve these problems on my own without much more time investment and I'm largely just rephrasing the ideas from that PR.
Fixes#7435Fixes#7361Fixes#5721
## Solution
This implements the solution I [outlined here](https://github.com/bevyengine/bevy/pull/7490#issuecomment-1426580633).
* Adds "msaa writeback" as an explicit "msaa camera feature" and default to msaa_writeback: true for each camera. If this is true, a camera has MSAA enabled, and it isn't the first camera for the target, add a writeback before the main pass for that camera.
* Adds a CameraOutputMode, which can be used to configure if (and how) the results of a camera's rendering will be written to the final RenderTarget output texture (via the upscaling node). The `blend_state` and `color_attachment_load_op` are now configurable, giving much more control over how a camera will write to the output texture.
* Made cameras with the same target share the same main_texture tracker by using `Arc<AtomicUsize>`, which ensures continuity across cameras. This was previously broken / could produce weird results in some cases. `ViewTarget::main_texture()` is now correct in every context.
* Added a new generic / specializable BlitPipeline, which the new MsaaWritebackNode uses internally. The UpscalingPipelineNode now uses BlitPipeline instead of its own pipeline. We might ultimately need to fork this back out if we choose to add more configurability to the upscaling, but for now this will save on binary size by not embedding the same shader twice.
* Moved the "camera sorting" logic from the camera driver node to its own system. The results are now stored in the `SortedCameras` resource, which can be used anywhere in the renderer. MSAA writeback makes use of this.
---
## Changelog
- Added `Camera::msaa_writeback` which can enable and disable msaa writeback.
- Added specializable `BlitPipeline` and ported the upscaling node to use this.
- Added SortedCameras, exposing information that was previously internal to the camera driver node.
- Made cameras with the same target share the same main_texture tracker, which ensures continuity across cameras.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
While working on #7784, I noticed that a `#define VAR` in a `.wgsl` file is always effective, even if it its scope is not accepting lines.
Example:
```c
#define A
#ifndef A
#define B
#endif
```
Currently, `B` will be defined although it shouldn't. This PR fixes that.
## Solution
Move the branch responsible for `#define` lines into the last else branch, which is only evaluated if the current scope is accepting lines.
# Objective
There was PR that introduced support for storage buffer is `AsBindGroup` macro [#6129](https://github.com/bevyengine/bevy/pull/6129), but it does not give more granular control over storage buffer, it will always copy all the data no matter which part of it was updated. There is also currently another open PR #6669 that tries to achieve exactly that, it is just not up to date and seems abandoned (Sorry if that is not right). In this PR I'm proposing a solution for both of these approaches to co-exist using `#[storage(n, buffer)]` and `#[storage(n)]` to distinguish between the cases.
We could also discuss in this PR if there is a need to extend this support to DynamicBuffers as well.
# Objective
- Nothing render
```
ERROR bevy_render::render_resource::pipeline_cache: failed to process shader: Invalid shader def definition for '_import_path': bevy_pbr
```
## Solution
- Fix define regex so that it must have one whitespace after `define`
# Objective
- Fixes#7494
- It is now possible to define a ShaderDef from inside a shader. This can be useful to centralise a value, or making sure an import is only interpreted once
## Solution
- Support `#define <SHADERDEF_NAME> <optional value>`
# Objective
- ambiguities bad
## Solution
- solve ambiguities
- by either ignoring (e.g. on `queue_mesh_view_bind_groups` since `LightMeta` access is different)
- by introducing a dependency (`prepare_windows -> prepare_*` because the latter use the fallback Msaa)
- make `prepare_assets` public so that we can do a proper `.after`
# Objective
- Fix the environment map shader not working under webgl due to textureNumLevels() not being supported
- Fixes https://github.com/bevyengine/bevy/issues/7722
## Solution
- Instead of using textureNumLevels(), put an extra field in the GpuLights uniform to store the mip count
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Closes#7573
- Make `StartupSet` a base set
## Solution
- Add `#[system_set(base)]` to the enum declaration
- Replace `.in_set(StartupSet::...)` with `.in_base_set(StartupSet::...)`
**Note**: I don't really know what I'm doing and what exactly the difference between base and non-base sets are. I mostly opened this PR based on discussion in Discord. I also don't really know how to test that I didn't break everything. Your reviews are appreciated!
---
## Changelog
- `StartupSet` is now a base set
## Migration Guide
`StartupSet` is now a base set. This means that you have to use `.in_base_set` instead of `.in_set`:
### Before
```rs
app.add_system(foo.in_set(StartupSet::PreStartup))
```
### After
```rs
app.add_system(foo.in_base_set(StartupSet::PreStartup))
```
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
Fixes#7295
Should we maybe default to 4x if 2x/8x is selected but not supported?
---
## Changelog
- Added 2x and 8x sample counts for MSAA.
# Objective
- Environment maps use these formats, and in the future rendering LUTs will need textures loaded by default in the engine
## Solution
- Make ktx2 and zstd part of the default feature
- Let examples assume these features are enabled
---
## Changelog
- `ktx2` and `zstd` are now party of bevy's default enabled features
## Migration Guide
- If you used the `ktx2` or `zstd` features, you no longer need to explicitly enable them, as they are now part of bevy's default enabled features
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
- Fixes: #7187
Since avoiding the `SRes::into_inner` call does not seem to be possible, this PR tries to at least document its usage.
I am not sure if I explained the lifetime issue correctly, please let me know if something is incorrect.
## Solution
- Add information about the `SRes::into_inner` usage on both `RenderCommand` and `Res`
Profiles show that in extremely hot loops, like the draw loops in the renderer, invoking the trace! macro has noticeable overhead, even if the trace log level is not enabled.
Solve this by introduce a 'wrapper' detailed_trace macro around trace, that wraps the trace! log statement in a trivially false if statement unless a cargo feature is enabled
# Objective
- Eliminate significant overhead observed with trace-level logging in render hot loops, even when trace log level is not enabled.
- This is an alternative solution to the one proposed in #7223
## Solution
- Introduce a wrapper around the `trace!` macro called `detailed_trace!`. This macro wraps the `trace!` macro with an if statement that is conditional on a new cargo feature, `detailed_trace`. When the feature is not enabled (the default), then the if statement is trivially false and should be optimized away at compile time.
- Convert the observed hot occurrences of trace logging in `TrackedRenderPass` with this new macro.
Testing the results of
```
cargo run --profile stress-test --features bevy/trace_tracy --example many_cubes -- spheres
```

shows significant improvement of the `main_opaque_pass_3d` of the renderer, a median time decrease from 6.0ms to 3.5ms.
---
## Changelog
- For performance reasons, some detailed renderer trace logs now require the use of cargo feature `detailed_trace` in addition to setting the log level to `TRACE` in order to be shown.
## Migration Guide
- Some detailed bevy trace events now require the use of the cargo feature `detailed_trace` in addition to enabling `TRACE` level logging to view. Should you wish to see these logs, please compile your code with the bevy feature `detailed_trace`. Currently, the only logs that are affected are the renderer logs pertaining to `TrackedRenderPass` functions
# Objective
There was issue #191 requesting subdivisions on the shape::Plane.
I also could have used this recently. I then write the solution.
Fixes #191
## Solution
I changed the shape::Plane to include subdivisions field and the code to create the subdivisions. I don't know how people are counting subdivisions so as I put in the doc comments 0 subdivisions results in the original geometry of the Plane.
Greater then 0 results in the number of lines dividing the plane.
I didn't know if it would be better to create a new struct that implemented this feature, say SubdivisionPlane or change Plane. I decided on changing Plane as that was what the original issue was.
It would be trivial to alter this to use another struct instead of altering Plane.
The issues of migration, although small, would be eliminated if a new struct was implemented.
## Changelog
### Added
Added subdivisions field to shape::Plane
## Migration Guide
All the examples needed to be updated to initalize the subdivisions field.
Also there were two tests in tests/window that need to be updated.
A user would have to update all their uses of shape::Plane to initalize the subdivisions field.
fixes#6799
# Objective
We should be able to reuse the `Globals` or `View` shader struct definitions from anywhere (including third party plugins) without needing to worry about defining unrelated shader defs.
Also we'd like to refactor these structs to not be repeatedly defined.
## Solution
Refactor both `Globals` and `View` into separate importable shaders.
Use the imports throughout.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- This makes code a little more readable now.
## Solution
- Use `position` provided by `Iter` instead of `enumerating` indices and `map`ping to the index.
This was missed in #7205.
Should be fixed now. 😄
## Migration Guide
- `SpecializedComputePipelines::specialize` now takes a `&PipelineCache` instead of a `&mut PipelineCache`
(Before)

(After)

# Objective
- Improve lighting; especially reflections.
- Closes https://github.com/bevyengine/bevy/issues/4581.
## Solution
- Implement environment maps, providing better ambient light.
- Add microfacet multibounce approximation for specular highlights from Filament.
- Occlusion is no longer incorrectly applied to direct lighting. It now only applies to diffuse indirect light. Unsure if it's also supposed to apply to specular indirect light - the glTF specification just says "indirect light". In the case of ambient occlusion, for instance, that's usually only calculated as diffuse though. For now, I'm choosing to apply this just to indirect diffuse light, and not specular.
- Modified the PBR example to use an environment map, and have labels.
- Added `FallbackImageCubemap`.
## Implementation
- IBL technique references can be found in environment_map.wgsl.
- It's more accurate to use a LUT for the scale/bias. Filament has a good reference on generating this LUT. For now, I just used an analytic approximation.
- For now, environment maps must first be prefiltered outside of bevy using a 3rd party tool. See the `EnvironmentMap` documentation.
- Eventually, we should have our own prefiltering code, so that we can have dynamically changing environment maps, as well as let users drop in an HDR image and use asset preprocessing to create the needed textures using only bevy.
---
## Changelog
- Added an `EnvironmentMapLight` camera component that adds additional ambient light to a scene.
- StandardMaterials will now appear brighter and more saturated at high roughness, due to internal material changes. This is more physically correct.
- Fixed StandardMaterial occlusion being incorrectly applied to direct lighting.
- Added `FallbackImageCubemap`.
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
- Terminology used in field names and docs aren't accurate
- `window_origin` doesn't have any effect when `scaling_mode` is `ScalingMode::None`
- `left`, `right`, `bottom`, and `top` are set automatically unless `scaling_mode` is `None`. Fields that only sometimes give feedback are confusing.
- `ScalingMode::WindowSize` has no arguments, which is inconsistent with other `ScalingMode`s. 1 pixel = 1 world unit is also typically way too wide.
- `OrthographicProjection` feels generally less streamlined than its `PerspectiveProjection` counterpart
- Fixes#5818
- Fixes#6190
## Solution
- Improve consistency in `OrthographicProjection`'s public fields (they should either always give feedback or never give feedback).
- Improve consistency in `ScalingMode`'s arguments
- General usability improvements
- Improve accuracy of terminology:
- "Window" should refer to the physical window on the desktop
- "Viewport" should refer to the component in the window that images are drawn on (typically all of it)
- "View frustum" should refer to the volume captured by the projection
---
## Changelog
### Added
- Added argument to `ScalingMode::WindowSize` that specifies the number of pixels that equals one world unit.
- Added documentation for fields and enums
### Changed
- Renamed `window_origin` to `viewport_origin`, which now:
- Affects all `ScalingMode`s
- Takes a fraction of the viewport's width and height instead of an enum
- Removed `WindowOrigin` enum as it's obsolete
- Renamed `ScalingMode::None` to `ScalingMode::Fixed`, which now:
- Takes arguments to specify the projection size
- Replaced `left`, `right`, `bottom`, and `top` fields with a single `area: Rect`
- `scale` is now applied before updating `area`. Reading from it will take `scale` into account.
- Documentation changes to make terminology more accurate and consistent
## Migration Guide
- Change `window_origin` to `viewport_origin`; replace `WindowOrigin::Center` with `Vec2::new(0.5, 0.5)` and `WindowOrigin::BottomLeft` with `Vec2::new(0.0, 0.0)`
- For shadow projections and such, replace `left`, `right`, `bottom`, and `top` with `area: Rect::new(left, bottom, right, top)`
- For camera projections, remove l/r/b/t values from `OrthographicProjection` instantiations, as they no longer have any effect in any `ScalingMode`
- Change `ScalingMode::None` to `ScalingMode::Fixed`
- Replace manual changes of l/r/b/t with:
- Arguments in `ScalingMode::Fixed` to specify size
- `viewport_origin` to specify offset
- Change `ScalingMode::WindowSize` to `ScalingMode::WindowSize(1.0)`
# Objective
Fix#7377Fix#7513
## Solution
Record the changes made to the Bevy `Window` from `winit` as 'canon' to avoid Bevy sending those changes back to `winit` again, causing a feedback loop.
## Changelog
* Removed `ModifiesWindows` system label.
Neither `despawn_window` nor `changed_window` actually modify the `Window` component so all the `.after(ModifiesWindows)` shouldn't be necessary.
* Moved `changed_window` and `despawn_window` systems to `CoreStage::Last` to avoid systems making changes to the `Window` between `changed_window` and the end of the frame as they would be ignored.
## Migration Guide
The `ModifiesWindows` system label was removed.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Some render systems that have system set used as a label so that they can be referenced from somewhere else.
The 1:1 translation from `add_system_to_stage(Prepare, prepare_lights.label(PrepareLights))` is `add_system(prepare_lights.in_set(Prepare).in_set(PrepareLights)`, but configuring the `PrepareLights` set to be in `Prepare` would match the intention better (there are no systems in `PrepareLights` outside of `Prepare`) and it is easier for visualization tools to deal with.
# Solution
- replace
```rust
prepare_lights in PrepareLights
prepare_lights in Prepare
```
with
```rs
prepare_lights in PrepareLights
PrepareLights in Prepare
```
**Before**

**After**

# Objective
Buffers in bevy do not allow for setting buffer usage flags which can be useful for setting COPY_SRC, MAP_READ, MAP_WRITE, which allows for buffers to be copied from gpu to cpu for inspection.
## Solution
Add buffer_usage field to buffers and a set_usage function to set them
# Objective
- Fixes#766
## Solution
- Add a new `Lcha` member to `bevy_render::color::Color` enum
---
## Changelog
- Add a new `Lcha` member to `bevy_render::color::Color` enum
- Add `bevy_render::color::LchRepresentation` struct
# Objective
[as noted](https://github.com/bevyengine/bevy/pull/5950#discussion_r1080762807) by james, transmuting arcs may be UB.
we now store a `*const ()` pointer internally, and only rely on `ptr.cast::<()>().cast::<T>() == ptr`.
as a happy side effect this removes the need for boxing the value, so todo: potentially use this for release mode as well
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
Avoid ‘Unable to find a GPU! Make sure you have installed required drivers!’ .
Because many devices only support OpenGL without Vulkan.
Fixes#3191
## Solution
Use all backends supported by wgpu.
# Objective
Currently, shaders may only have syntax such as
```wgsl
#ifdef FOO
// foo code
#else
#ifdef BAR
// bar code
#else
#ifdef BAZ
// baz code
#else
// fallback code
#endif
#endif
#endif
```
This is hard to read and follow.
Add a way to allow writing `#else ifdef DEFINE` to reduce the number of scopes introduced and to increase readability.
## Solution
Refactor the current preprocessing a bit and add logic to allow `#else ifdef DEFINE`.
This includes per-scope tracking of whether a branch has been accepted.
Add a few tests for this feature.
With these changes we may now write:
```wgsl
#ifdef FOO
// foo code
#else ifdef BAR
// bar code
#else ifdef BAZ
// baz code
#else
// fallback code
#endif
```
instead.
---
## Changelog
- Add `#else ifdef` to shader preprocessing.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
In simple cases we might want to derive the `ExtractComponent` trait.
This adds symmetry to the existing `ExtractResource` derive.
## Solution
Add an implementation of `#[derive(ExtractComponent)]`.
The implementation is adapted from the existing `ExtractResource` derive macro.
Additionally, there is an attribute called `extract_component_filter`. This allows specifying a query filter type used when extracting.
If not specified, no filter (equal to `()`) is used.
So:
```rust
#[derive(Component, Clone, ExtractComponent)]
#[extract_component_filter(With<Fuel>)]
pub struct Car {
pub wheels: usize,
}
```
would expand to (a bit cleaned up here):
```rust
impl ExtractComponent for Car
{
type Query = &'static Self;
type Filter = With<Fuel>;
type Out = Self;
fn extract_component(item: QueryItem<'_, Self::Query>) -> Option<Self::Out> {
Some(item.clone())
}
}
```
---
## Changelog
- Added the ability to `#[derive(ExtractComponent)]` with an optional filter.
# Objective
- Fixes#4592
## Solution
- Implement `SrgbColorSpace` for `u8` via `f32`
- Convert KTX2 R8 and R8G8 non-linear sRGB to wgpu `R8Unorm` and `Rg8Unorm` as non-linear sRGB are not supported by wgpu for these formats
- Convert KTX2 R8G8B8 formats to `Rgba8Unorm` and `Rgba8UnormSrgb` by adding an alpha channel as the Rgb variants don't exist in wgpu
---
## Changelog
- Added: Support for KTX2 `R8_SRGB`, `R8_UNORM`, `R8G8_SRGB`, `R8G8_UNORM`, `R8G8B8_SRGB`, `R8G8B8_UNORM` formats by converting to supported wgpu formats as appropriate
# Objective
Add a `FromReflect` derive to the `Aabb` type, like all other math types, so we can reflect `Vec<Aabb>`.
## Solution
Just add it :)
---
## Changelog
### Added
- Implemented `FromReflect` for `Aabb`.
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
# Objective
## Use Case
A render node which calls `post_process_write()` on a `ViewTarget` multiple times during a single run of the node means both main textures of this view target is accessed.
If the source texture (which alternate between main textures **a** and **b**) is accessed in a shader during those iterations it means that those textures have to be bound using bind groups.
Preparing bind groups for both main textures ahead of time is desired, which means having access to the _other_ main texture is needed.
## Solution
Add a method on `ViewTarget` for accessing the other main texture.
---
## Changelog
### Added
- `main_texture_other` API on `ViewTarget`
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps.
Fixes#3629
Before

After
## Solution
Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination.
---
## Changelog
Directional lights now use cascaded shadow maps for improved shadow quality.
## Migration Guide
You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
# Objective
Fixes#7286. Both `App::add_sub_app` and `App::insert_sub_app` are rather redundant. Before 0.10 is shipped, one of them should be removed.
## Solution
Remove `App::add_sub_app` to prefer `App::insert_sub_app`.
Also hid away `SubApp::extract` since that can be a footgun if someone mutates it for whatever reason. Willing to revert this change if there are objections.
Perhaps we should make `SubApp: Deref<Target=App>`? Might change if we decide to move `!Send` resources into it.
---
## Changelog
Added: `SubApp::new`
Removed: `App::add_sub_app`
## Migration Guide
`App::add_sub_app` has been removed in favor of `App::insert_sub_app`. Use `SubApp::new` and insert it via `App::add_sub_app`
Old:
```rust
let mut sub_app = App::new()
// Build subapp here
app.add_sub_app(MySubAppLabel, sub_app);
```
New:
```rust
let mut sub_app = App::new()
// Build subapp here
app.insert_sub_app(MySubAppLabel, SubApp::new(sub_app, extract_fn));
```
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
After #6503, bevy_render uses the `send_blocking` method introduced in async-channel 1.7, but depended only on ^1.4.
I saw this after pulling main without running cargo update.
# Objective
- Fix minimum dependency version of async-channel
## Solution
- Bump async-channel version constraint to ^1.8, which is currently the latest version.
NOTE: Both bevy_ecs and bevy_tasks also depend on async-channel but they didn't use any newer features.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
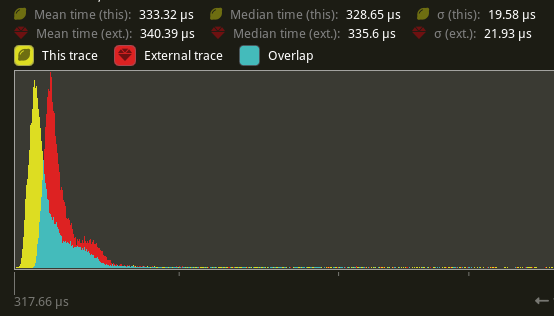
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
The documentation of the bevy_render crate is still pretty incomplete.
This PR follows up on #6885 and improves the documentation of the `render_phase` module.
This module contains one of our most important rendering abstractions and the current documentation is pretty confusing. This PR tries to clarify what all of these pieces are for and how they work together to form bevy`s modular rendering logic.
## Solution
### Code Reformating
- I have moved the `rangefinder` into the `render_phase` module since it is only used there.
- I have moved the `PhaseItem` (and the `BatchedPhaseItem`) from `render_phase::draw` over to `render_phase::mod`. This does not change the public-facing API since they are reexported anyway, but this change makes the relation between `RenderPhase` and `PhaseItem` clear and easier to discover.
### Documentation
- revised all documentation in the `render_phase` module
- added a module-level explanation of how `RenderPhase`s, `RenderPass`es, `PhaseItem`s, `Draw` functions, and `RenderCommands` relate to each other and how they are used
---
## Changelog
- The `rangefinder` module has been moved into the `render_phase` module.
## Migration Guide
- The `rangefinder` module has been moved into the `render_phase` module.
```rust
//old
use bevy::render::rangefinder::*;
// new
use bevy::render::render_phase::rangefinder::*;
```
# Objective
- There is a warning when building in release:
```
warning: unused import: `bevy_ecs::system::Local`
--> crates/bevy_render/src/extract_resource.rs:5:5
|
5 | use bevy_ecs::system::Local;
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
```
- It's used 59751d6e33/crates/bevy_render/src/extract_resource.rs (L47)
- Fix it
## Solution
- Gate the import
- repeat of #5320
As mentioned in https://github.com/bevyengine/bevy/pull/6530. It allows to not create a new constant and simply having it to show up in the documentation when someone is looking for "transparent" (case insensitive) in rustdoc search.
cc @alice-i-cecile
# Objective
- Fixes#7066
## Solution
- Split the ChangeDetection trait into ChangeDetection and ChangeDetectionMut
- Added Ref as equivalent to &T with change detection
---
## Changelog
- Support for Ref which allow inspecting change detection flags in an immutable way
## Migration Guide
- While bevy prelude includes both ChangeDetection and ChangeDetectionMut any code explicitly referencing ChangeDetection might need to be updated to ChangeDetectionMut or both. Specifically any reading logic requires ChangeDetection while writes requires ChangeDetectionMut.
use bevy_ecs::change_detection::DetectChanges -> use bevy_ecs::change_detection::{DetectChanges, DetectChangesMut}
- Previously Res had methods to access change detection `is_changed` and `is_added` those methods have been moved to the `DetectChanges` trait. If you are including bevy prelude you will have access to these types otherwise you will need to `use bevy_ecs::change_detection::DetectChanges` to continue using them.
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
- This pulls out some of the changes to Plugin setup and sub apps from #6503 to make that PR easier to review.
- Separate the extract stage from running the sub app's schedule to allow for them to be run on separate threads in the future
- Fixes#6990
## Solution
- add a run method to `SubApp` that runs the schedule
- change the name of `sub_app_runner` to extract to make it clear that this function is only for extracting data between the main app and the sub app
- remove the extract stage from the sub app schedule so it can be run separately. This is done by adding a `setup` method to the `Plugin` trait that runs after all plugin build methods run. This is required to allow the extract stage to be removed from the schedule after all the plugins have added their systems to the stage. We will also need the setup method for pipelined rendering to setup the render thread. See e3267965e1/crates/bevy_render/src/pipelined_rendering.rs (L57-L98)
## Changelog
- Separate SubApp Extract stage from running the sub app schedule.
## Migration Guide
### SubApp `runner` has conceptually been changed to an `extract` function.
The `runner` no longer is in charge of running the sub app schedule. It's only concern is now moving data between the main world and the sub app. The `sub_app.app.schedule` is now run for you after the provided function is called.
```rust
// before
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
render_app.app.schedule.run();
});
}
// after
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
// schedule is automatically called for you after extract is run
});
}
```
# Objective
- Storage buffers are useful and not currently supported by the `AsBindGroup` derive which means you need to expand the macro if you need a storage buffer
## Solution
- Add a new `#[storage]` attribute to the derive `AsBindGroup` macro.
- Support and optional `read_only` parameter that defaults to false when not present.
- Support visibility parameters like the texture and sampler attributes.
---
## Changelog
- Add a new `#[storage(index)]` attribute to the derive `AsBindGroup` macro.
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Avoid slower than necessary first frame after spawning many entities due to them not having `Aabb`s and so being marked visible
- Avoids unnecessarily large system and VRAM allocations as a consequence
## Solution
- I noticed when debugging the `many_cubes` stress test in Xcode that the `MeshUniform` binding was much larger than it needed to be. I realised that this was because initially, all mesh entities are marked as being visible because they don't have `Aabb`s because `calculate_bounds` is being run in `PostUpdate` and there are no system commands applications before executing the visibility check systems that need the `Aabb`s. The solution then is to run the `calculate_bounds` system just before the previous system commands are applied which is at the end of the `Update` stage.
Spiritual successor to #5205.
Actual successor to #6865.
# Objective
Currently, system params are defined using three traits: `SystemParam`, `ReadOnlySystemParam`, `SystemParamState`. The behavior for each param is specified by the `SystemParamState` trait, while `SystemParam` simply defers to the state.
Splitting the traits in this way makes it easier to implement within macros, but it increases the cognitive load. Worst of all, this approach requires each `MySystemParam` to have a public `MySystemParamState` type associated with it.
## Solution
* Merge the trait `SystemParamState` into `SystemParam`.
* Remove all trivial `SystemParam` state types.
* `OptionNonSendMutState<T>`: you will not be missed.
---
- [x] Fix/resolve the remaining test failure.
## Changelog
* Removed the trait `SystemParamState`, merging its functionality into `SystemParam`.
## Migration Guide
**Note**: this should replace the migration guide for #6865.
This is relative to Bevy 0.9, not main.
The traits `SystemParamState` and `SystemParamFetch` have been removed, and their functionality has been transferred to `SystemParam`.
```rust
// Before (0.9)
impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
}
unsafe impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
unsafe impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(&mut self, ...) -> Self::Item;
}
unsafe impl ReadOnlySystemParamFetch for MyParamState { }
// After (0.10)
unsafe impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
type Item<'w, 's> = MyParam<'w, 's>;
fn init_state(world: &mut World, system_meta: &mut SystemMeta) -> Self::State { ... }
fn get_param<'w, 's>(state: &mut Self::State, ...) -> Self::Item<'w, 's>;
}
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> { }
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> {}
```
# Objective
- When using `Color::hex` for the first time, I was confused by the fact that I can't specify colors using #, which is much more familiar.
- In the code editor (if there is support) there is a preview of the color, which is very convenient.

## Solution
- Allow you to enter colors like `#ff33f2` and use the `.strip_prefix` method to delete the `#` character.
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
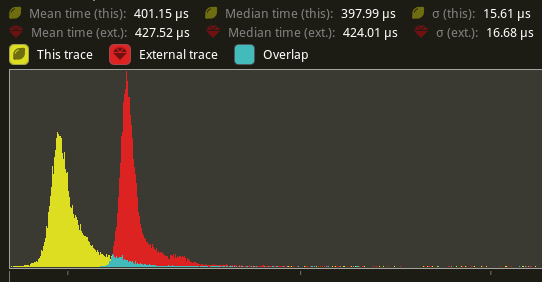
The shadow pass node is also slightly faster (344.52 -> 338.24us)
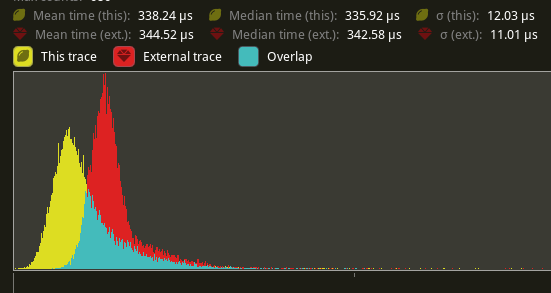
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
- The recently merged PR #7013 does not allow multiple `RenderPhase`s to share the same `RenderPass`.
- Due to the introduced overhead we want to minimize the number of `RenderPass`es recorded during each frame.
## Solution
- Take a constructed `TrackedRenderPass` instead of a `RenderPassDiscriptor` as a parameter to the `RenderPhase::render` method.
---
## Changelog
To enable multiple `RenderPhases` to share the same `TrackedRenderPass`,
the `RenderPhase::render` signature has changed.
```rust
pub fn render<'w>(
&self,
render_pass: &mut TrackedRenderPass<'w>,
world: &'w World,
view: Entity)
```
Co-authored-by: Kurt Kühnert <51823519+kurtkuehnert@users.noreply.github.com>
# Objective
`TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` was already included in `adapter.features()` on non-wasm target, and since it is the default value for `WgpuSettings.features`, the subsequent code will also combine into this feature:
b6066c30b6/crates/bevy_render/src/renderer/mod.rs (L155-L156)
# Objective
All `RenderPhases` follow the same render procedure.
The same code is duplicated multiple times across the codebase.
## Solution
I simply extracted this code into a method on the `RenderPhase`.
This avoids code duplication and makes setting up new `RenderPhases` easier.
---
## Changelog
### Changed
You can now set up the rendering code of a `RenderPhase` directly using the `RenderPhase::render` method, instead of implementing it manually in your render graph node.
# Objective
The documentation for camera priority is very confusing at the moment, it requires a bit of "double negative" kind of thinking.
# Solution
Flipping the wording on the documentation to reflect more common usecases like having an overlay camera and also renaming it to "order", since priority implies that it will override the other camera rather than have both run.
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode.
# Objective
The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching.
Additionally as it stands Bevy only has two settings for visibility of an entity:
- "unconditionally hidden" `Visibility { is_visible: false }`,
- "inherit visibility from parent" `Visibility { is_visible: true }`
where a root level entity set to "inherit" is visible.
Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear.
Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode.
--
The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants.
## Solution
Change the Visibility component into
```rust
enum Visibility {
Hidden, // unconditionally hidden
Visible, // unconditionally visible
Inherited, // inherit visibility from parent
}
```
---
## Changelog
### Changed
`Visibility` is now an enum
## Migration Guide
- evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`.
- setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`.
- usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively.
- `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- alternative to #2895
- as mentioned in #2535 the uuid based ids in the render module should be replaced with atomic-counted ones
## Solution
- instead of generating a random UUID for each render resource, this implementation increases an atomic counter
- this might be replaced by the ids of wgpu if they expose them directly in the future
- I have not benchmarked this solution yet, but this should be slightly faster in theory.
- Bevymark does not seem to be affected much by this change, which is to be expected.
- Nothing of our API has changed, other than that the IDs have lost their IMO rather insignificant documentation.
- Maybe the documentation could be added back into the macro, but this would complicate the code.
# Objective
The `WgpuSettings` resource is only used during plugin build. Move it into the `RenderPlugin` struct.
Changing these settings requires re-initializing the render context, which is currently not supported.
If it is supported in the future it should probably be more explicit than changing a field on a resource, maybe something similar to the `CreateWindow` event.
## Migration Guide
```rust
// Before (0.9)
App::new()
.insert_resource(WgpuSettings { .. })
.add_plugins(DefaultPlugins)
// After (0.10)
App::new()
.add_plugins(DefaultPlugins.set(RenderPlugin {
wgpu_settings: WgpuSettings { .. },
}))
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Following #4402, extract systems run on the render world instead of the main world, and allow retained state operations on it's resources. We're currently extracting to `ExtractedJoints` and then copying it twice during Prepare. Once into `SkinnedMeshJoints` and again into the actual GPU buffer.
This makes #4902 obsolete.
## Solution
Cut out the middle copy and directly extract joints into `SkinnedMeshJoints` and remove `ExtractedJoints` entirely.
This also removes the per-frame allocation that is being made to send `ExtractedJoints` into the render world.
## Performance
On my local machine, this halves the time for `prepare_skinned _meshes` on `many_foxes` (195.75us -> 93.93us on average).
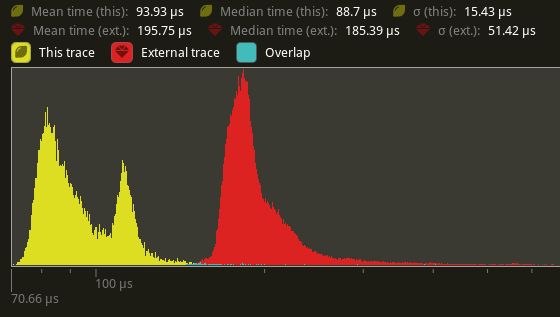
---
## Changelog
Added: `BufferVec::truncate`
Added: `BufferVec::extend`
Changed: `SkinnedMeshJoints::build` now takes a `&mut BufferVec` instead of a `&mut Vec` as a parameter.
Removed: `ExtractedJoints`.
## Migration Guide
`ExtractedJoints` has been removed. Read the bound bones from `SkinnedMeshJoints` instead.
# Objective
`AsBindGroup` can't be used as a trait object because of the constraint `Sized` and because of the associated function.
This is a problem for [`bevy_atmosphere`](https://github.com/JonahPlusPlus/bevy_atmosphere) because it needs to use a trait that depends on `AsBindGroup` as a trait object, for switching out different shaders at runtime. The current solution it employs is reimplementing the trait and derive macro into that trait, instead of constraining to `AsBindGroup`.
## Solution
Remove the `Sized` constraint from `AsBindGroup` and add the constraint `where Self: Sized` to the associated function `bind_group_layout`. Also change `PreparedBindGroup<T: AsBindGroup>` to `PreparedBindGroup<T>` and use it as `PreparedBindGroup<Self::Data>` instead of `PreparedBindGroup<Self>`.
This weakens the constraints, but increases the flexibility of `AsBindGroup`.
I'm not entirely sure why the `Sized` constraint was there, because it worked fine without it (maybe @cart wasn't aware of use cases for `AsBindGroup` as a trait object or this was just leftover from legacy code?).
---
## Changelog
- `AsBindGroup` can be used as a trait object.
# Objective
[Rust 1.66](https://blog.rust-lang.org/inside-rust/2022/12/12/1.66.0-prerelease.html) is coming in a few days, and bevy doesn't build with it.
Fix that.
## Solution
Replace output from a trybuild test, and fix a few new instances of `needless_borrow` and `unnecessary_cast` that are now caught.
## Note
Due to the trybuild test, this can't be merged until 1.66 is released.
# Objective
The following code:
```rs
use bevy::prelude::Image;
use image::{ DynamicImage, GenericImage, Rgba };
fn main() {
let mut dynamic_image = DynamicImage::new_rgb32f(1, 1);
dynamic_image.put_pixel(0, 0, Rgba([1, 1, 1, 1]));
let image = Image::from_dynamic(dynamic_image, false); // Panic!
println!("{image:?}");
}
```
Can cause an assertion failed:
```
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `16`,
right: `14`: Pixel data, size and format have to match', .../bevy_render-0.9.1/src/texture/image.rs:209:9
stack backtrace:
...
4: core::panicking::assert_failed<usize,usize>
at /rustc/897e37553bba8b42751c67658967889d11ecd120/library/core/src/panicking.rs:181
5: bevy_render::texture::image::Image::new
at .../bevy_render-0.9.1/src/texture/image.rs:209
6: bevy_render::texture::image::Image::from_dynamic
at .../bevy_render-0.9.1/src/texture/image_texture_conversion.rs:159
7: bevy_test::main
at ./src/main.rs:8
...
```
It seems to be cause by a copypasta in `crates/bevy_render/src/texture/image_texture_conversion.rs`. Let's fix it.
## Solution
```diff
// DynamicImage::ImageRgb32F(image) => {
- let a = u16::max_value();
+ let a = 1f32;
```
This will fix the conversion.
---
## Changelog
- Fixed the alpha channel of the `image::DynamicImage::ImageRgb32F` to `bevy_render::texture::Image` conversion in `bevy_render::texture::Image::from_dynamic()`.
# Objective
- https://github.com/bevyengine/bevy/pull/5364 Added a few features to the AsBindGroup derive, but if you don't know they exist they aren't documented anywhere.
## Solution
- Document the new arguments in the doc block for the derive.
# Objective
```rust
// makes clippy complain about 'taking a mutable reference to a `const` item'
let color = *Color::RED.set_a(0.5);
// Now you can do
let color = Color::RED.with_a(0.5);
```
## Changelog
Added `with_r`, `with_g`, `with_b`, and `with_a` to `Color`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
* Implementing a custom `SystemParam` by hand requires implementing three traits -- four if it is read-only.
* The trait `SystemParamFetch<'w, 's>` is a workaround from before we had generic associated types, and is no longer necessary.
## Solution
* Combine the trait `SystemParamFetch` with `SystemParamState`.
* I decided to remove the `Fetch` name and keep the `State` name, since the former was consistently conflated with the latter.
* Replace the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`, which simplifies trait bounds in generic code.
---
## Changelog
- Removed the trait `SystemParamFetch`, moving its functionality to `SystemParamState`.
- Replaced the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`.
## Migration Guide
The trait `SystemParamFetch` has been removed, and its functionality has been transferred to `SystemParamState`.
```rust
// Before
impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(...) -> Self::Item;
}
// After
impl SystemParamState for MyParamState {
type Item<'w, 's> = MyParam<'w, 's>; // Generic associated types!
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
fn get_param<'w, 's>(...) -> Self::Item<'w, 's>;
}
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl<'w, 's> ReadOnlySystemParam for MyParam<'w, 's> {}
```
# Objective
- Get rid of giant match statement to get PixelInfo.
- This will allow for supporting any texture that is uncompressed, instead of people needing to PR in any textures that are supported in wgpu, but not bevy.
## Solution
- More conservative alternative to https://github.com/bevyengine/bevy/pull/6788, where we don't try to make some of the calculations correct for compressed types.
- Delete `PixelInfo` and get the pixel_size directly from wgpu. Data from wgpu is here: https://docs.rs/wgpu-types/0.14.0/src/wgpu_types/lib.rs.html#2359
- Panic if the texture is a compressed type. An integer byte size of a pixel is no longer a valid concept when talking about compressed textures.
- All internal usages use `pixel_size` and not `pixel_info` and are on uncompressed formats. Most of these usages are on either explicit texture formats or slightly indirectly through `TextureFormat::bevy_default()`. The other uses are in `TextureAtlas` and have other calculations that assumes the texture is uncompressed.
## Changelog
- remove `PixelInfo` and get `pixel_size` from wgpu
## Migration Guide
`PixelInfo` has been removed. `PixelInfo::components` is equivalent to `texture_format.describe().components`. `PixelInfo::type_size` can be gotten from `texture_format.describe().block_size/ texture_format.describe().components`. But note this can yield incorrect results for some texture types like Rg11b10Float.
# Objective
Adds a cylinder shape. Fixes#2282.
## Solution
- I added a custom cylinder shape, taken from [here](https://github.com/rparrett/typey_birb/blob/main/src/cylinder.rs) with permission from @rparrett.
- I also added the cylinder shape to the `3d_shapes` example scene.
---
## Changelog
- Added cylinder shape
Co-Authored-By: Rob Parrett <robparrett@gmail.com>
Co-Authored-By: davidhof <7483215+davidhof@users.noreply.github.com>
# Objective
- Fixes#6841
- In some case, the number of maximum storage buffers is `u32::MAX` which doesn't fit in a `i32`
## Solution
- Add an option to have a `u32` in a `ShaderDefVal`
# Objective
`prepare_asset` for Image has an alternate path for texture creation that is used when the image is not compressed and does not contain mipmaps. This additional code path is unnecessary as `render_device.create_texture_with_data()` will handle both cases correctly.
## Solution
Use `render_device.create_texture_with_data()` in all cases.
Tested successfully with the following examples:
- load_gltf
- render_to_texture
- texture
- 3d_shapes
- sprite
- sprite_sheet
- array_texture
- shader_material_screenspace_texture
- skybox (though this already would use the `create_texture_with_data()` branch anyway)
# Objective
The soundness of the ECS `World` partially relies on the correctness of the state of `Entities` stored within it. We're currently allowing users to (unsafely) mutate it, as well as readily construct it without using a `World`. While this is not strictly unsound so long as users (including `bevy_render`) safely use the APIs, it's a fairly easy path to unsoundness without much of a guard rail.
Addresses #3362 for `bevy_ecs::entity`. Incorporates the changes from #3985.
## Solution
Remove `Entities`'s `Default` implementation and force access to the type to only be through a properly constructed `World`.
Additional cleanup for other parts of `bevy_ecs::entity`:
- `Entity::index` and `Entity::generation` are no longer `pub(crate)`, opting to force the rest of bevy_ecs to use the public interface to access these values.
- `EntityMeta` is no longer `pub` and also not `pub(crate)` to attempt to cut down on updating `generation` without going through an `Entities` API. It's currently inaccessible except via the `pub(crate)` Vec on `Entities`, there was no way for an outside user to use it.
- Added `Entities::set`, an unsafe `pub(crate)` API for setting the location of an Entity (parallel to `Entities::get`) that replaces the internal case where we need to set the location of an entity when it's been spawned, moved, or despawned.
- `Entities::alloc_at_without_replacement` is only used in `World::get_or_spawn` within the first party crates, and I cannot find a public use of this API in any ecosystem crate that I've checked (via GitHub search).
- Attempted to document the few remaining undocumented public APIs in the module.
---
## Changelog
Removed: `Entities`'s `Default` implementation.
Removed: `EntityMeta`
Removed: `Entities::alloc_at_without_replacement` and `AllocAtWithoutReplacement`.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Since #5900 3d examples fail in wasm
```
ERROR crates/bevy_render/src/render_resource/pipeline_cache.rs:660 failed to process shader: Unknown shader def: 'AVAILABLE_STORAGE_BUFFER_BINDINGS'
```
## Solution
- Fix it by always adding the shaderdef `AVAILABLE_STORAGE_BUFFER_BINDINGS` with the actual value, instead of 3 when 3 or more were available
# Objective
- Support textures in `Rgb9e5Ufloat` format.
## Solution
- Add `TextureFormatPixelInfo` for `Rgb9e5Ufloat`.
Tested this with a `Rgb9e5Ufloat` encoded KTX2 texture.
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- Reduce confusion around uniform bindings in materials. I've seen multiple people on discord get confused by it because it uses a struct that is named the same in the rust code and the wgsl code, but doesn't contain the same data. Also, the only reason this works is mostly by chance because the memory happens to align correctly.
## Solution
- Remove the confusing parts of the doc
## Notes
It's not super clear in the diff why this causes confusion, but essentially, the rust code defines a `CustomMaterial` struct with a color and a texture, but in the wgsl code the struct with the same name only contains the color. People are confused by it because the struct in wgsl doesn't need to be there.
You _can_ have complex structs on each side and the macro will even combine it for you if you reuse a binding index, but as it is now, this example seems to confuse more than help people.
# Objective
Many types in `bevy_render` implemented `Reflect` but were not registered.
## Solution
Register all types in `bevy_render` that impl `Reflect`.
This also registers additional dependent types (i.e. field types).
> Note: Adding these dependent types would not be needed using something like #5781😉
---
## Changelog
- Register missing `bevy_render` types in the `TypeRegistry`:
- `camera::RenderTarget`
- `globals::GlobalsUniform`
- `texture::Image`
- `view::ComputedVisibility`
- `view::Visibility`
- `view::VisibleEntities`
- Register additional dependent types:
- `view::ComputedVisibilityFlags`
- `Vec<Entity>`
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
Allow more use cases where the user may benefit from both `ExtractComponentPlugin` _and_ `UniformComponentPlugin`.
## Solution
Add an associated type to `ExtractComponent` in order to allow specifying the output component (or bundle).
Make `extract_component` return an `Option<_>` such that components can be extracted only when needed.
What problem does this solve?
`ExtractComponentPlugin` allows extracting components, but currently the output type is the same as the input.
This means that use cases such as having a settings struct which turns into a uniform is awkward.
For example we might have:
```rust
struct MyStruct {
enabled: bool,
val: f32
}
struct MyStructUniform {
val: f32
}
```
With the new approach, we can extract `MyStruct` only when it is enabled, and turn it into its related uniform.
This chains well with `UniformComponentPlugin`.
The user may then:
```rust
app.add_plugin(ExtractComponentPlugin::<MyStruct>::default());
app.add_plugin(UniformComponentPlugin::<MyStructUniform>::default());
```
This then saves the user a fair amount of boilerplate.
## Changelog
### Changed
- `ExtractComponent` can specify output type, and outputting is optional.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
Latest Release, "bevy 0.9" move the FrameCount updater into RenderPlugin, it leads to user who only run app with Core/Minimal Plugin cannot get the right number of FrameCount, it always return 0.
As for use cases like a server app, we don't want to add render dependencies to the app.
More detail in #6656
## Solution
- Move the `update_frame_count` into CorePlugin
# Objective
This add a ctor to `Box` to aid the creation of non-centred boxes. The PR adopts @rezural's work on PR #3322, taking into account the feedback on that PR from @james7132.
## Solution
`Box::from_corners()` creates a `Box` from two opposing corners and automatically determines the min and max extents to ensure that the `Box` is well-formed.
Co-authored-by: rezural <rezural@protonmail.com>
# Objective
`ComputedVisibility` could afford to be smaller/faster. Optimizing the size and performance of operations on the component will positively benefit almost all extraction systems.
This was listed as one of the potential pieces of future work for #5310.
## Solution
Merge both internal booleans into a single `u8` bitflag field. Rely on bitmasks to evaluate local, hierarchical, and general visibility.
Pros:
- `ComputedVisibility::is_visible` should be a single bitmask test instead of two.
- `ComputedVisibility` is now only 1 byte. Should be able to fit 100% more per cache line when using dense iteration.
Cons:
- Harder to read.
- Setting individual values inside `ComputedVisiblity` require bitmask mutations.
This should be a non-breaking change. No public API was changed. The only publicly visible effect is that `ComputedVisibility` is now 1 byte instead of 2.
# Objective
`ScalingMode::Auto` for cameras only targets min_height and min_width, or as the docs say it `Use minimal possible viewport size while keeping the aspect ratio.`
But there is no ScalingMode that targets max_height and Max_width or `Use maximal possible viewport size while keeping the aspect ratio.`
## Solution
Added `ScalingMode::AutoMax` that does the exact opposite of `ScalingMode::Auto`
---
## Changelog
Renamed `ScalingMode::Auto` to `ScalingMode::AutoMin`.
## Migration Guide
just rename `ScalingMode::Auto` to `ScalingMode::AutoMin` if you are using it.
Co-authored-by: Lixou <82600264+DasLixou@users.noreply.github.com>
# Objective
- Fix#3606
- Fix#4579
- Fix#3380
## Solution
When running on a Linux machine with some AMD or Intel device, when calling
`surface.get_current_texture()`, ignore `wgpu::SurfaceError::Timeout` errors.
## Alternative
An alternative solution found in the `wgpu` examples is:
```rust
let frame = surface
.get_current_texture()
.or_else(|_| {
render_device.configure_surface(surface, &swap_chain_descriptor);
surface.get_current_texture()
})
.expect("Error reconfiguring surface");
window.swap_chain_texture = Some(TextureView::from(frame));
```
See: <94ce76391b/wgpu/examples/framework.rs (L362-L370)>
Veloren [handles the Timeout error the way this PR proposes to handle it](https://github.com/gfx-rs/wgpu/issues/1218#issuecomment-1092056971).
The reason I went with this PR's solution is that `configure_surface` seems to be quite an expensive operation, and it would run every frame with the wgpu framework solution, despite the fact it works perfectly fine without `configure_surface`.
I know this looks super hacky with the linux-specific line and the AMD check, but my understanding is that the `Timeout` occurrence is specific to a quirk of some AMD drivers on linux, and if otherwise met should be considered a bug.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#5393
## Solution
- Add padding to `GlobalsUniform` / `Globals` to make it 16-byte aligned.
Still not super clear on whether this is a `naga` thing or an `encase` thing or what. But now that we're offering `globals` up to users and #5393 is not just breaking an example, maybe we should do this sort of workaround?
# Objective
Some render plugins, like [bevy-hikari](https://github.com/cryscan/bevy-hikari) require to set `CameraRenderGraph`. In order to switch between render graphs I need to insert a new `CameraRenderGraph` component. It's not very ergonomic.
## Solution
Add `CameraRenderGraph::set` like in [Name](https://docs.rs/bevy/latest/bevy/core/struct.Name.html).
---
## Changelog
### Added
- `CameraRenderGraph::set`.
Allow passing `Vec`s of glam vector types as vertex attributes.
Alternative to #4548 and #2719
Also used some macros to cut down on all the repetition.
# Migration Guide
Implementations of `From<Vec<[u16; 4]>>` and `From<Vec<[u8; 4]>>` for `VertexAttributeValues` have been removed.
I you're passing either `Vec<[u16; 4]>` or `Vec<[u8; 4]>` into `Mesh::insert_attribute` it will now require wrapping it with right the `VertexAttributeValues` enum variant.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
Respect mipmap_filter when create ImageDescriptor with linear()/nearest()
# Objective
Fixes#6348
## Migration Guide
This PR changes default `ImageSettings` and may lead to unexpected behaviour for existing projects with mipmapped textures. Users should provide custom `ImageSettings` resource with `mipmap_filter=FilterMode::Nearest` if they want to keep old behaviour.
Co-authored-by: Yakov Borevich <j.borevich@gmail.com>
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
Post processing effects cannot read and write to the same texture. Currently they must own their own intermediate texture and redundantly copy from that back to the main texture. This is very inefficient.
Additionally, working with ViewTarget is more complicated than it needs to be, especially when working with HDR textures.
## Solution
`ViewTarget` now stores two copies of the "main texture". It uses an atomic value to track which is currently the "main texture" (this interior mutability is necessary to accommodate read-only RenderGraph execution).
`ViewTarget` now has a `post_process_write` method, which will return a source and destination texture. Each call to this method will flip between the two copies of the "main texture".
```rust
let post_process = render_target.post_process_write();
let source_texture = post_process.source;
let destination_texture = post_process.destination;
```
The caller _must_ read from the source texture and write to the destination texture, as it is assumed that the destination texture will become the new "main texture".
For simplicity / understandability `ViewTarget` is now a flat type. "hdr-ness" is a property of the `TextureFormat`. The internals are fully private in the interest of providing simple / consistent apis. Developers can now easily access the main texture by calling `view_target.main_texture()`.
HDR ViewTargets no longer have an "ldr texture" with `TextureFormat::bevy_default`. They _only_ have their two "hdr" textures. This simplifies the mental model. All we have is the "currently active hdr texture" and the "other hdr texture", which we flip between for post processing effects.
The tonemapping node has been rephrased to use this "post processing pattern". The blit pass has been removed, and it now only runs a pass when HDR is enabled. Notably, both the input and output texture are assumed to be HDR. This means that tonemapping behaves just like any other "post processing effect". It could theoretically be moved anywhere in the "effect chain" and continue to work.
In general, I think these changes will make the lives of people making post processing effects much easier. And they better position us to start building higher level / more structured "post processing effect stacks".
---
## Changelog
- `ViewTarget` now stores two copies of the "main texture". Calling `ViewTarget::post_process_write` will flip between copies of the main texture.
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective

^ enable this
Concretely, I need to
- list all handle ids for an asset type
- fetch the asset as `dyn Reflect`, given a `HandleUntyped`
- when encountering a `Handle<T>`, find out what asset type that handle refers to (`T`'s type id) and turn the handle into a `HandleUntyped`
## Solution
- add `ReflectAsset` type containing function pointers for working with assets
```rust
pub struct ReflectAsset {
type_uuid: Uuid,
assets_resource_type_id: TypeId, // TypeId of the `Assets<T>` resource
get: fn(&World, HandleUntyped) -> Option<&dyn Reflect>,
get_mut: fn(&mut World, HandleUntyped) -> Option<&mut dyn Reflect>,
get_unchecked_mut: unsafe fn(&World, HandleUntyped) -> Option<&mut dyn Reflect>,
add: fn(&mut World, &dyn Reflect) -> HandleUntyped,
set: fn(&mut World, HandleUntyped, &dyn Reflect) -> HandleUntyped,
len: fn(&World) -> usize,
ids: for<'w> fn(&'w World) -> Box<dyn Iterator<Item = HandleId> + 'w>,
remove: fn(&mut World, HandleUntyped) -> Option<Box<dyn Reflect>>,
}
```
- add `ReflectHandle` type relating the handle back to the asset type and providing a way to create a `HandleUntyped`
```rust
pub struct ReflectHandle {
type_uuid: Uuid,
asset_type_id: TypeId,
downcast_handle_untyped: fn(&dyn Any) -> Option<HandleUntyped>,
}
```
- add the corresponding `FromType` impls
- add a function `app.register_asset_reflect` which is supposed to be called after `.add_asset` and registers `ReflectAsset` and `ReflectHandle` in the type registry
---
## Changelog
- add `ReflectAsset` and `ReflectHandle` types, which allow code to use reflection to manipulate arbitrary assets without knowing their types at compile time
fixes https://github.com/bevyengine/bevy/issues/5944
Uses the second solution:
> 2. keep track of the old viewport in the computed_state, and if camera.viewport != camera.computed_state.old_viewport, then update the projection. This is more reliable, but needs to store two UVec2s more in the camera (probably not a big deal).
# Objective
Bevy's internal plugins have lots of execution-order ambiguities, which makes the ambiguity detection tool very noisy for our users.
## Solution
Silence every last ambiguity that can currently be resolved.
Each time an ambiguity is silenced, it is accompanied by a comment describing why it is correct. This description should be based on the public API of the respective systems. Thus, I have added documentation to some systems describing how they use some resources.
# Future work
Some ambiguities remain, due to issues out of scope for this PR.
* The ambiguity checker does not respect `Without<>` filters, leading to false positives.
* Ambiguities between `bevy_ui` and `bevy_animation` cannot be resolved, since neither crate knows that the other exists. We will need a general solution to this problem.
# Objective
Currently, Bevy only supports rendering to the current "surface texture format". This means that "render to texture" scenarios must use the exact format the primary window's surface uses, or Bevy will crash. This is even harder than it used to be now that we detect preferred surface formats at runtime instead of using hard coded BevyDefault values.
## Solution
1. Look up and store each window surface's texture format alongside other extracted window information
2. Specialize the upscaling pass on the current `RenderTarget`'s texture format, now that we can cheaply correlate render targets to their current texture format
3. Remove the old `SurfaceTextureFormat` and `AvailableTextureFormats`: these are now redundant with the information stored on each extracted window, and probably should not have been globals in the first place (as in theory each surface could have a different format).
This means you can now use any texture format you want when rendering to a texture! For example, changing the `render_to_texture` example to use `R16Float` now doesn't crash / properly only stores the red component:
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Proactive changing of code to comply with warnings generated by beta of rustlang version of cargo clippy.
## Solution
- Code changed as recommended by `rustup update`, `rustup default beta`, `cargo run -p ci -- clippy`.
- Tested using `beta` and `stable`. No clippy warnings in either after changes made.
---
## Changelog
- Warnings fixed were: `clippy::explicit-auto-deref` (present in 11 files), `clippy::needless-borrow` (present in 2 files), and `clippy::only-used-in-recursion` (only 1 file).
# Objective
- Build on #6336 for more plugin configurations
## Solution
- `LogSettings`, `ImageSettings` and `DefaultTaskPoolOptions` are now plugins settings rather than resources
---
## Changelog
- `LogSettings` plugin settings have been move to `LogPlugin`, `ImageSettings` to `ImagePlugin` and `DefaultTaskPoolOptions` to `CorePlugin`
## Migration Guide
The `LogSettings` settings have been moved from a resource to `LogPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(LogSettings {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(LogPlugin {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
}))
```
The `ImageSettings` settings have been moved from a resource to `ImagePlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(ImageSettings::default_nearest())
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(ImagePlugin::default_nearest()))
```
The `DefaultTaskPoolOptions` settings have been moved from a resource to `CorePlugin::task_pool_options`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(DefaultTaskPoolOptions::with_num_threads(4))
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(CorePlugin {
task_pool_options: TaskPoolOptions::with_num_threads(4),
}))
```
# Objective
- Improve #3953
## Solution
- The very specific circumstances under which the render world is reset meant that the flush_as_invalid function could be replaced with one that had a noop as its init method.
- This removes a double-writing issue leading to greatly increased performance.
Running the reproduction code in the linked issue, this change nearly doubles the framerate.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Avoids creating a `SurfaceConfiguration` for every window in every frame for the `prepare_windows` system
- As such also avoid calling `get_supported_formats` for every window in every frame
## Solution
- Construct `SurfaceConfiguration` lazyly in `prepare_windows`
---
This also changes the error message for failed initial surface configuration from "Failed to acquire next swapchain texture" to "Error configuring surface".
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
The `RenderLayers` type is never registered, making it unavailable for reflection.
## Solution
Register it in `CameraPlugin`, the same plugin that registers the related `Visibility*` types.
# Objective
- Update `wgpu` to 0.14.0, `naga` to `0.10.0`, `winit` to 0.27.4, `raw-window-handle` to 0.5.0, `ndk` to 0.7.
## Solution
---
## Changelog
### Changed
- Changed `RawWindowHandleWrapper` to `RawHandleWrapper` which wraps both `RawWindowHandle` and `RawDisplayHandle`, which satisfies the `impl HasRawWindowHandle and HasRawDisplayHandle` that `wgpu` 0.14.0 requires.
- Changed `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, change its type from `bool` to `bevy_window::CursorGrabMode`.
## Migration Guide
- Adjust usage of `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, and adjust its type from `bool` to `bevy_window::CursorGrabMode`.
# Objective
Make toggling the visibility of an entity slightly more convenient.
## Solution
Add a mutating `toggle` method to the `Visibility` component
```rust
fn my_system(mut query: Query<&mut Visibility, With<SomeMarker>>) {
let mut visibility = query.single_mut();
// before:
visibility.is_visible = !visibility.is_visible;
// after:
visibility.toggle();
}
```
## Changelog
### Added
- Added a mutating `toggle` method to the `Visibility` component
# Objective
- Trying to make it possible to do write tests that don't require a raw window handle.
- Fixes https://github.com/bevyengine/bevy/issues/6106.
## Solution
- Make the interface and type changes. Avoid accessing `None`.
---
## Changelog
- Converted `raw_window_handle` field in both `Window` and `ExtractedWindow` to `Option<RawWindowHandleWrapper>`.
- Revised accessor function `Window::raw_window_handle()` to return `Option<RawWindowHandleWrapper>`.
- Skip conditions in loops that would require a raw window handle (to create a `Surface`, for example).
## Migration Guide
`Window::raw_window_handle()` now returns `Option<RawWindowHandleWrapper>`.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
As suggested in #6104, it would be nice to link directly to `linux_dependencies.md` file in the panic message when running on Linux. And when not compiling for Linux, we fall back to the old message.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Resolves#6104.
## Solution
Add link to `linux_dependencies.md` when compiling for Linux, and fall back to the old one when not.
…
# Objective
- Fixes Camera not being serializable due to missing registrations in core functionality.
- Fixes#6169
## Solution
- Updated Bevy_Render CameraPlugin with registrations for Option<Viewport> and then Bevy_Core CorePlugin with registrations for ReflectSerialize and ReflectDeserialize for type data Range<f32> respectively according to the solution in #6169
Co-authored-by: Noah <noahshomette@gmail.com>
# Objective
There is no Srgb support on some GPU and display protocols with `winit` (for example, Nvidia's GPUs with Wayland). Thus `TextureFormat::bevy_default()` which returns `Rgba8UnormSrgb` or `Bgra8UnormSrgb` will cause panics on such platforms. This patch will resolve this problem. Fix https://github.com/bevyengine/bevy/issues/3897.
## Solution
Make `initialize_renderer` expose `wgpu::Adapter` and `first_available_texture_format`, use the `first_available_texture_format` by default.
## Changelog
* Fixed https://github.com/bevyengine/bevy/issues/3897.
# Objective
- Reflecting `Default` is required for scripts to create `Reflect` types at runtime with no static type information.
- Reflecting `Default` on `Handle<T>` and `ComputedVisibility` should allow scripts from `bevy_mod_js_scripting` to actually spawn sprites from scratch, without needing any hand-holding from the host-game.
## Solution
- Derive `ReflectDefault` for `Handle<T>` and `ComputedVisiblity`.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- The `Default` trait is now reflected for `Handle<T>` and `ComputedVisibility`
# Objective
Add a method for getting a world space ray from a viewport position.
Opted to add a `Ray` type to `bevy_math` instead of returning a tuple of `Vec3`'s as this is clearer and easier to document
The docs on `viewport_to_world` are okay, but I'm not super happy with them.
## Changelog
* Add `Camera::viewport_to_world`
* Add `Camera::ndc_to_world`
* Add `Ray` to `bevy_math`
* Some doc tweaks
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, errors aren't logged as soon as they are found, they are logged only on the next frame. This means your shader could have an unreported error that could have been reported on the first frame.
## Solution
- Log the error as soon as they are found, don't wait until next frame
## Notes
I discovered this issue because I was simply unwrapping the `Result` from `PipelinCache::get_render_pipeline()` which caused it to fail without any explanations. Admittedly, this was a bit of a user error, I shouldn't have unwrapped that, but it seems a bit strange to wait until the next time the pipeline is processed to log the error instead of just logging it as soon as possible since we already have all the info necessary.
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
- Reconfigure surface after present mode changes. It seems that this is not done currently at runtime. It's pretty common for games to change such graphical settings at runtime.
- Fixes present mode issue in #5111
## Solution
- Exactly like resolution change gets tracked when extracting window, do the same for present mode.
Additionally, I added present mode (vsync) toggling to window settings example.
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
Implement `IntoIterator` for `&Extract<P>` if the system parameter it wraps implements `IntoIterator`.
Enables the use of `IntoIterator` with an extracted query.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
A common pitfall since 0.8 is the requirement on `ComputedVisibility`
being present on all ancestors of an entity that itself has
`ComputedVisibility`, without which, the entity becomes invisible.
I myself hit the issue and got very confused, and saw a few people hit
it as well, so it makes sense to provide a hint of what to do when such
a situation is encountered.
- Fixes#5849
- Closes#5616
- Closes#2277
- Closes#5081
## Solution
We now check that all entities with both a `Parent` and a
`ComputedVisibility` component have parents that themselves have a
`ComputedVisibility` component.
Note that the warning is only printed once.
We also add a similar warning to `GlobalTransform`.
This only emits a warning. Because sometimes it could be an intended
behavior.
Alternatives:
- Do nothing and keep repeating to newcomers how to avoid recurring
pitfalls
- Make the transform and visibility propagation tolerant to missing
components (#5616)
- Probably archetype invariants, though the current draft would not
allow detecting that kind of errors
---
## Changelog
- Add a warning when encountering dubious component hierarchy structure
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
fixes#5946
## Solution
adjust cluster index calculation for viewport origin.
from reading point 2 of the rasterization algorithm description in https://gpuweb.github.io/gpuweb/#rasterization, it looks like framebuffer space (and so @bulitin(position)) is not meant to be adjusted for viewport origin, so we need to subtract that to get the right cluster index.
- add viewport origin to rust `ExtractedView` and wgsl `View` structs
- subtract from frag coord for cluster index calculation
# Objective
Currently some TextureFormats are not supported by the Image type.
The `TextureFormat::Rg16Unorm` format is useful for storing minmax heightmaps.
Similar to #5249 I now additionally require image to support the dual channel variant.
## Solution
Added `TextureFormat::Rg16Unorm` support to Image.
Additionally this PR derives `Resource` for `SpecializedComputePipelines`, because for some reason this was missing.
All other special pipelines do derive `Resource` already.
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
## Solution
Exposes the image <-> "texture" as methods on `Image`.
## Extra
I'm wondering if `image_texture_conversion.rs` should be renamed to `image_conversion.rs`. That or the file be deleted altogether in favour of putting the code alongside the rest of the `Image` impl. Its kind-of weird to refer to the `Image` as a texture.
Also `Image::convert` is a public method so I didn't want to edit its signature, but it might be nice to have the function consume the image instead of just passing a reference to it because it would eliminate a clone.
## Changelog
> Rename `image_to_texture` to `Image::from_dynamic`
> Rename `texture_to_image` to `Image::try_into_dynamic`
> `Image::try_into_dynamic` now returns a `Result` (this is to make it easier for users who didn't read that only a few conversions are supported to figure it out.)
# Objective
Document most of the public items of the `bevy_render::camera` module and its
sub-modules.
## Solution
Add docs to most public items. Follow-up from #3447.
# Objective
Document `PipelineCache` and a few other related types.
## Solution
Add documenting comments to `PipelineCache` and a few other related
types in the same file.
# Objective
- In WASM, creating a pipeline can easily take 2 seconds, freezing the game while doing so
- Preloading pipelines can be done during a "loading" state, but it is not trivial to know which pipeline to preload, or when it's done
## Solution
- Add a log with shaders being loaded and their shader defs
- add a function on `PipelineCache` to return the number of ready pipelines
# Objective
Since `identity` is a const fn that takes no arguments it seems logical to make it an associated constant.
This is also more in line with types from glam (eg. `Quat::IDENTITY`).
## Migration Guide
The method `identity()` on `Transform`, `GlobalTransform` and `TransformBundle` has been deprecated.
Use the associated constant `IDENTITY` instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- While generating https://github.com/jakobhellermann/bevy_reflect_ts_type_export/blob/main/generated/types.ts, I noticed that some types that implement `Reflect` did not register themselves
- `Viewport` isn't reflect but can be (there's a TODO)
## Solution
- register all reflected types
- derive `Reflect` for `Viewport`
## Changelog
- more types are not registered in the type registry
- remove `Serialize`, `Deserialize` impls from `Viewport`
I also decided to remove the `Serialize, Deserialize` from the `Viewport`, since they were (AFAIK) only used for reflection, which now is done without serde. So this is technically a breaking change for people who relied on that impl directly.
Personally I don't think that every bevy type should implement `Serialize, Deserialize`, as that would lead to a ton of code generation that mostly isn't necessary because we can do the same with `Reflect`, but if this is deemed controversial I can remove it from this PR.
## Migration Guide
- `KeyCode` now implements `Reflect` not as `reflect_value`, but with proper struct reflection. The `Serialize` and `Deserialize` impls were removed, now that they are no longer required for scene serialization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}