# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
Transform screen-space coordinates into world space in shaders. (My use case is for generating rays for ray tracing with the same perspective as the 3d camera).
## Solution
Add `inverse_projection` and `inverse_view_proj` fields to shader view uniform
---
## Changelog
### Added
`inverse_projection` and `inverse_view_proj` fields to shader view uniform
## Note
It'd probably be good to double-check that I did the matrix multiplication in the right order for `inverse_proj_view`. Thanks!
# Objective
- Enable `wgpu` profiling spans
## Solution
- `wgpu` uses the `profiling` crate to add profiling span instrumentation to their code
- `profiling` offers multiple 'backends' for profiling, including `tracing`
- When the `bevy` `trace` feature is used, add the `profiling` crate with its `profile-with-tracing` feature to enable appropriate profiling spans in `wgpu` using `tracing` which fits nicely into our infrastructure
- Bump our default `tracing` subscriber filter to `wgpu=info` from `wgpu=error` so that the profiling spans are not filtered out as they are created at the `info` level.
---
## Changelog
- Added: `tracing` profiling support for `wgpu` when using bevy's `trace` feature
- Changed: The default `tracing` filter statement for `wgpu` has been changed from the `error` level to the `info` level to not filter out the wgpu profiling spans
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
Documents the `BufferVec` render resource.
`BufferVec` is a fairly low level object, that will likely be managed by a higher level API (e.g. through [`encase`](https://github.com/bevyengine/bevy/issues/4272)) in the future. For now, since it is still used by some simple
example crates (e.g. [bevy-vertex-pulling](https://github.com/superdump/bevy-vertex-pulling)), it will be helpful
to provide some simple documentation on what `BufferVec` does.
## Solution
I looked through Discord discussion on `BufferVec`, and found [a comment](https://discord.com/channels/691052431525675048/953222550568173580/956596218857918464 ) by @superdump to be particularly helpful, in the general discussion around `encase`.
I have taken care to clarify where the data is stored (host-side), when the device-side buffer is created (through calls to `reserve`), and when data writes from host to device are scheduled (using `write_buffer` calls).
---
## Changelog
- Added doc string for `BufferVec` and two of its methods: `reserve` and `write_buffer`.
Co-authored-by: Brian Merchant <bhmerchant@gmail.com>
# Objective
Attempt to more clearly document `ImageSettings` and setting a default sampler for new images, as per #5046
## Changelog
- Moved ImageSettings into image.rs, image::* is already exported. Makes it simpler for linking docs.
- Renamed "DefaultImageSampler" to "RenderDefaultImageSampler". Not a great name, but more consistent with other render resources.
- Added/updated related docs
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
Further speed up visibility checking by removing the main sources of contention for the system.
## Solution
- ~~Make `ComputedVisibility` a resource wrapping a `FixedBitset`.~~
- ~~Remove `ComputedVisibility` as a component.~~
~~This adds a one-bit overhead to every entity in the app world. For a game with 100,000 entities, this is 12.5KB of memory. This is still small enough to fit entirely in most L1 caches. Also removes the need for a per-Entity change detection tick. This reduces the memory footprint of ComputedVisibility 72x.~~
~~The decreased memory usage and less fragmented memory locality should provide significant performance benefits.~~
~~Clearing visible entities should be significantly faster than before:~~
- ~~Setting one `u32` to 0 clears 32 entities per cycle.~~
- ~~No archetype fragmentation to contend with.~~
- ~~Change detection is applied to the resource, so there is no per-Entity update tick requirement.~~
~~The side benefit of this design is that it removes one more "computed component" from userspace. Though accessing the values within it are now less ergonomic.~~
This PR changes `crossbeam_channel` in `check_visibility` to use a `Local<ThreadLocal<Cell<Vec<Entity>>>` to mark down visible entities instead.
Co-Authored-By: TheRawMeatball <therawmeatball@gmail.com>
Co-Authored-By: Aevyrie <aevyrie@gmail.com>
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
# Objective
- KTX2 UASTC format mapping was incorrect. For some reason I had written it to map to a set of data formats based on the count of KTX2 sample information blocks, but the mapping should be done based on the channel type in the sample information.
- This is a valid change pulled out from #4514 as the attempt to fix the array textures there was incorrect
## Solution
- Fix the KTX2 UASTC `DataFormat` enum to contain the correct formats based on the channel types in section 3.10.2 of https://github.khronos.org/KTX-Specification/ (search for "Basis Universal UASTC Format")
- Correctly map from the sample information channel type to `DataFormat`
- Correctly configure transcoding and the resulting texture format based on the `DataFormat`
---
## Changelog
- Fixed: KTX2 UASTC format handling
# Use Case
Seems generally useful, but specifically motivated by my work on the [`bevy_datasize`](https://github.com/BGR360/bevy_datasize) crate.
For that project, I'm implementing "heap size estimators" for all of the Bevy internal types. To do this accurately for `Mesh`, I need to get the lengths of all of the mesh's attribute vectors.
Currently, in order to accomplish this, I am doing the following:
* Checking all of the attributes that are mentioned in the `Mesh` class ([see here](0531ec2d02/src/builtins/render/mesh.rs (L46-L54)))
* Providing the user with an option to configure additional attributes to check ([see here](0531ec2d02/src/config.rs (L7-L21)))
This is both overly complicated and a bit wasteful (since I have to check every attribute name that I know about in case there are attributes set for it).
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Working with a large number of entities with `Aabbs`, rendered with an instanced shader, I found the bottleneck became the frustum culling system. The goal of this PR is to significantly improve culling performance without any major changes. We should consider constructing a BVH for more substantial improvements.
## Solution
- Convert the inner entity query to a parallel iterator with `par_for_each_mut` using a batch size of 1,024.
- This outperforms single threaded culling when there are more than 1,000 entities.
- Below this they are approximately equal, with <= 10 microseconds of multithreading overhead.
- Above this, the multithreaded version is significantly faster, scaling linearly with core count.
- In my million-entity-workload, this PR improves my framerate by 200% - 300%.
## log-log of `check_visibility` time vs. entities for single/multithreaded
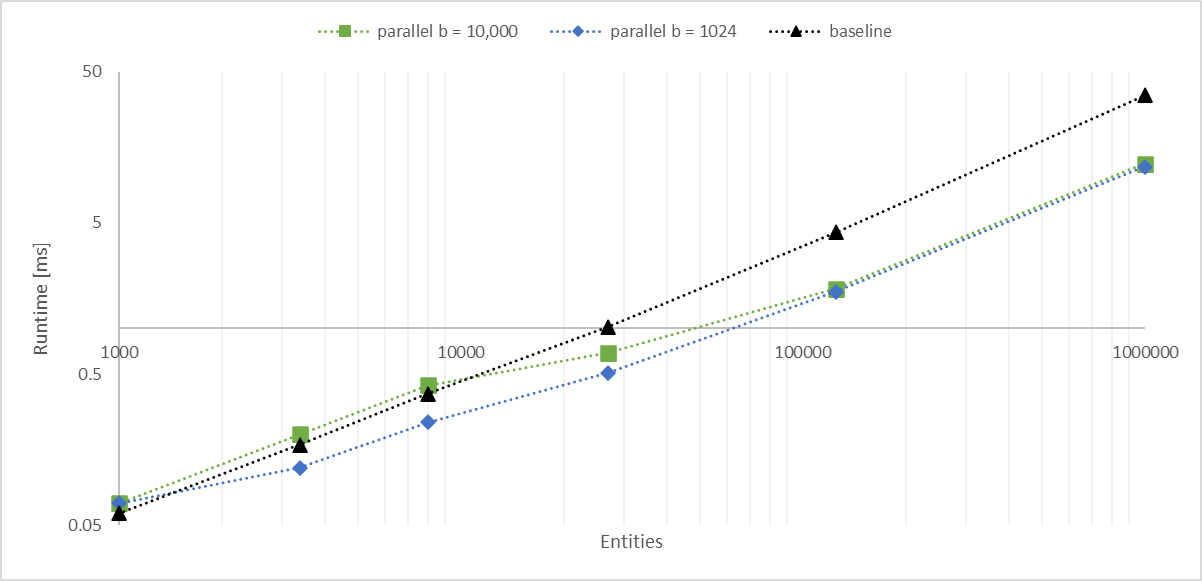
---
## Changelog
Frustum culling is now run with a parallel query. When culling more than a thousand entities, this is faster than the previous method, scaling proportionally with the number of available cores.
# Objective
Fix#4958
There was 4 issues:
- this is not true in WASM and on macOS: f28b921209/examples/3d/split_screen.rs (L90)
- ~~I made sure the system was running at least once~~
- I'm sending the event on window creation
- in webgl, setting a viewport has impacts on other render passes
- only in webgl and when there is a custom viewport, I added a render pass without a custom viewport
- shaderdef NO_ARRAY_TEXTURES_SUPPORT was not used by the 2d pipeline
- webgl feature was used but not declared in bevy_sprite, I added it to the Cargo.toml
- shaderdef NO_STORAGE_BUFFERS_SUPPORT was not used by the 2d pipeline
- I added it based on the BufferBindingType
The last commit changes the two last fixes to add the shaderdefs in the shader cache directly instead of needing to do it in each pipeline
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Most of our `Iterator` impls satisfy the requirements of `std::iter::FusedIterator`, which has internal specialization that optimizes `Interator::fuse`. The std lib iterator combinators do have a few that rely on `fuse`, so this could optimize those use cases. I don't think we're using any of them in the engine itself, but beyond a light increase in compile time, it doesn't hurt to implement the trait.
## Solution
Implement the trait for all eligible iterators in first party crates. Also add a missing `ExactSizeIterator` on an iterator that could use it.
While working on a refactor of `bevy_mod_picking` to include viewport-awareness, I found myself writing these functions to test if a cursor coordinate was inside the camera's rendered area.
# Objective
- Simplify conversion from physical to logical pixels
- Add methods that returns the dimensions of the viewport as a min-max rect
---
## Changelog
- Added `Camera::to_logical`
- Added `Camera::physical_viewport_rect`
- Added `Camera::logical_viewport_rect`
# Objective
Currently, providing the wrong number of inputs to a render graph node triggers this assertion:
```
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `2`', /[redacted]/bevy/crates/bevy_render/src/renderer/graph_runner.rs:164:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
This does not provide the user any context.
## Solution
Add a new `RenderGraphRunnerError` variant to handle this case. The new message looks like this:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > node (name: 'Some("outline_pass")') has 2 input slots, but was provided 1 values
```
---
## Changelog
### Changed
`RenderGraphRunnerError` now has a new variant, `MismatchedInputCount`.
## Migration Guide
Exhaustive matches on `RenderGraphRunnerError` will need to add a branch to handle the new `MismatchedInputCount` variant.
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
# Objective
At the moment all extra capabilities are disabled when validating shaders with naga:
c7c08f95cb/crates/bevy_render/src/render_resource/shader.rs (L146-L149)
This means these features can't be used even if the corresponding wgpu features are active.
## Solution
With these changes capabilities are now set corresponding to `RenderDevice::features`.
---
I have validated these changes for push constants with a project I am currently working on. Though bevy does not support creating pipelines with push constants yet, so I was only able to see that shaders are validated and compiled as expected.
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
Models can be produced that do not have vertex tangents but do have normal map textures. The tangents can be generated. There is a way that the vertex tangents can be generated to be exactly invertible to avoid introducing error when recreating the normals in the fragment shader.
## Solution
- After attempts to get https://github.com/gltf-rs/mikktspace to integrate simple glam changes and version bumps, and releases of that crate taking weeks / not being made (no offense intended to the authors/maintainers, bevy just has its own timelines and needs to take care of) it was decided to fork that repository. The following steps were taken:
- mikktspace was forked to https://github.com/bevyengine/mikktspace in order to preserve the repository's history in case the original is ever taken down
- The README in that repo was edited to add a note stating from where the repository was forked and explaining why
- The repo was locked for changes as its only purpose is historical
- The repo was integrated into the bevy repo using `git subtree add --prefix crates/bevy_mikktspace git@github.com:bevyengine/mikktspace.git master`
- In `bevy_mikktspace`:
- The travis configuration was removed
- `cargo fmt` was run
- The `Cargo.toml` was conformed to bevy's (just adding bevy to the keywords, changing the homepage and repository, changing the version to 0.7.0-dev - importantly the license is exactly the same)
- Remove the features, remove `nalgebra` entirely, only use `glam`, suppress clippy.
- This was necessary because our CI runs clippy with `--all-features` and the `nalgebra` and `glam` features are mutually exclusive, plus I don't want to modify this highly numerically-sensitive code just to appease clippy and diverge even more from upstream.
- Rebase https://github.com/bevyengine/bevy/pull/1795
- @jakobhellermann said it was fine to copy and paste but it ended up being almost exactly the same with just a couple of adjustments when validating correctness so I decided to actually rebase it and then build on top of it.
- Use the exact same fragment shader code to ensure correct normal mapping.
- Tested with both https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentMirrorTest which has vertex tangents and https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentTest which requires vertex tangent generation
Co-authored-by: alteous <alteous@outlook.com>
Adds ability to specify scaling factor for `WindowSize`, size of the fixed axis for `FixedVertical` and `FixedHorizontal` and a new `ScalingMode` that is a mix of `FixedVertical` and `FixedHorizontal`
# The issue
Currently, only available options are to:
* Have one of the axes fixed to value 1
* Have viewport size match the window size
* Manually adjust viewport size
In most of the games these options are not enough and more advanced scaling methods have to be used
## Solution
The solution is to provide additional parameters to current scaling modes, like scaling factor for `WindowSize`. Additionally, a more advanced `Auto` mode is added, which dynamically switches between behaving like `FixedVertical` and `FixedHorizontal` depending on the window's aspect ratio.
Co-authored-by: Daniikk1012 <49123959+Daniikk1012@users.noreply.github.com>
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
This was first done in 7b4e3a5, but was then reverted when the new
renderer for 0.6 was merged (ffecb05).
I'm assuming it was simply a mistake when merging.
# Objective
- Same as #2740, I think it was reverted by mistake when merging.
> # Objective
>
> - Make it easy to use HexColorError with `thiserror`, i.e. converting it into other error types.
>
> Makes this possible:
>
> ```rust
> #[derive(Debug, thiserror::Error)]
> pub enum LdtkError {
> #[error("An error occured while deserializing")]
> Json(#[from] serde_json::Error),
> #[error("An error occured while parsing a color")]
> HexColor(#[from] bevy::render::color::HexColorError),
> }
> ```
>
> ## Solution
>
> - Derive thiserror::Error the same way we do elsewhere (see query.rs for instance)
# Objective
One way to avoid texture atlas bleeding is to ensure that every vertex is
placed at an integer pixel coordinate. This is a particularly appealing
solution for regular structures like tile maps.
Doing so is currently harder than necessary when the WindowSize scaling
mode and Center origin are used: For odd window width or height, the
origin of the coordinate system is placed in the middle of a pixel at
some .5 offset.
## Solution
Avoid this issue by rounding the half width and height values.
# Objective
Make the function consistent with returned values and `as_hsla` method
Fixes#4826
## Solution
- Rename the method
## Migration Guide
- Rename the method
# Objective
- We do a lot of function pointer calls in a hot loop (clearing entities in render). This is slow, since calling function pointers cannot be optimised out. We can avoid that in the cases where the function call is a no-op.
- Alternative to https://github.com/bevyengine/bevy/pull/2897
- On my machine, in `many_cubes`, this reduces dropping time from ~150μs to ~80μs.
## Solution
- Make `drop` in `BlobVec` an `Option`, recording whether the given drop impl is required or not.
- Note that this does add branching in some cases - we could consider splitting this into two fields, i.e. unconditionally call the `drop` fn pointer.
- My intuition of how often types stored in `World` should have non-trivial drops makes me think that would be slower, however.
N.B. Even once this lands, we should still test having a 'drop_multiple' variant - for types with a real `Drop` impl, the current implementation is definitely optimal.
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
The frame marker event was emitted in the loop of presenting all the windows. This would mark the frame as finished multiple times if more than one window is used.
## Solution
Move the frame marker to after the `for`-loop, so that it gets executed only once.
# Objective
Make it easy to get position and index data from Meshes.
## Solution
It was previously possible to get the mesh data by manually matching on `Mesh::VertexAttributeValues` and `Mesh::Indices`as in the bodies of these two methods (`VertexAttributeValues::as_float3(&self)` and `Indices::iter(&self)`), but that's needless duplication that making these methods `pub` fixes.
# Objective
Fixes#3180, builds from https://github.com/bevyengine/bevy/pull/2898
## Solution
Support requesting a window to be closed and closing a window in `bevy_window`, and handle this in `bevy_winit`.
This is a stopgap until we move to windows as entites, which I'm sure I'll get around to eventually.
## Changelog
### Added
- `Window::close` to allow closing windows.
- `WindowClosed` to allow reacting to windows being closed.
### Changed
Replaced `bevy::system::exit_on_esc_system` with `bevy:🪟:close_on_esc`.
## Fixed
The app no longer exits when any window is closed. This difference is only observable when there are multiple windows.
## Migration Guide
`bevy::input::system::exit_on_esc_system` has been removed. Use `bevy:🪟:close_on_esc` instead.
`CloseWindow` has been removed. Use `Window::close` instead.
The `Close` variant has been added to `WindowCommand`. Handle this by closing the relevant window.
# Objective
Fixes#4556
## Solution
StorageBuffer must use the Size of the std430 representation to calculate the buffer size, as the std430 representation is the data that will be written to it.
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
Bevy users often want to create circles and other simple shapes.
All the machinery is in place to accomplish this, and there are external crates that help. But when writing code for e.g. a new bevy example, it's not really possible to draw a circle without bringing in a new asset, writing a bunch of scary looking mesh code, or adding a dependency.
In particular, this PR was inspired by this interaction in another PR: https://github.com/bevyengine/bevy/pull/3721#issuecomment-1016774535
## Solution
This PR adds `shape::RegularPolygon` and `shape::Circle` (which is just a `RegularPolygon` that defaults to a large number of sides)
## Discussion
There's a lot of ongoing discussion about shapes in <https://github.com/bevyengine/rfcs/pull/12> and at least one other lingering shape PR (although it seems incomplete).
That RFC currently includes `RegularPolygon` and `Circle` shapes, so I don't think that having working mesh generation code in the engine for those shapes would add much burden to an author of an implementation.
But if we'd prefer not to add additional shapes until after that's sorted out, I'm happy to close this for now.
## Alternatives for users
For any users stumbling on this issue, here are some plugins that will help if you need more shapes.
https://github.com/Nilirad/bevy_prototype_lyonhttps://github.com/johanhelsing/bevy_smudhttps://github.com/Weasy666/bevy_svghttps://github.com/redpandamonium/bevy_more_shapeshttps://github.com/ForesightMiningSoftwareCorporation/bevy_polyline
# Objective
- After #3412, `Camera::world_to_screen` got a little bit uglier to use by needing to provide both `Windows` and `Assets<Image>`, even though only one would be needed b697e73c3d/crates/bevy_render/src/camera/camera.rs (L117-L123)
- Some time, exact coordinates are not needed but normalized device coordinates is enough
## Solution
- Add a function to just get NDC
### Problem
It currently isn't possible to construct the default value of a reflected type. Because of that, it isn't possible to use `add_component` of `ReflectComponent` to add a new component to an entity because you can't know what the initial value should be.
### Solution
1. add `ReflectDefault` type
```rust
#[derive(Clone)]
pub struct ReflectDefault {
default: fn() -> Box<dyn Reflect>,
}
impl ReflectDefault {
pub fn default(&self) -> Box<dyn Reflect> {
(self.default)()
}
}
impl<T: Reflect + Default> FromType<T> for ReflectDefault {
fn from_type() -> Self {
ReflectDefault {
default: || Box::new(T::default()),
}
}
}
```
2. add `#[reflect(Default)]` to all component types that implement `Default` and are user facing (so not `ComputedSize`, `CubemapVisibleEntities` etc.)
This makes it possible to add the default value of a component to an entity without any compile-time information:
```rust
fn main() {
let mut app = App::new();
app.register_type::<Camera>();
let type_registry = app.world.get_resource::<TypeRegistry>().unwrap();
let type_registry = type_registry.read();
let camera_registration = type_registry.get(std::any::TypeId::of::<Camera>()).unwrap();
let reflect_default = camera_registration.data::<ReflectDefault>().unwrap();
let reflect_component = camera_registration
.data::<ReflectComponent>()
.unwrap()
.clone();
let default = reflect_default.default();
drop(type_registry);
let entity = app.world.spawn().id();
reflect_component.add_component(&mut app.world, entity, &*default);
let camera = app.world.entity(entity).get::<Camera>().unwrap();
dbg!(&camera);
}
```
### Open questions
- should we have `ReflectDefault` or `ReflectFromWorld` or both?
# Objective
- While optimising many_cubes, I noticed that all material handles are extracted regardless of whether the entity to which the handle belongs is visible or not. As such >100k handles are extracted when only <20k are visible.
## Solution
- Only extract material handles of visible entities.
- This improves `many_cubes -- sphere` from ~42fps to ~48fps. It reduces not only the extraction time but also system commands time. `Handle<StandardMaterial>` extraction and its system commands went from 0.522ms + 3.710ms respectively, to 0.267ms + 0.227ms an 88% reduction for this system for this case. It's very view dependent but...
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
# Objective
Reduce from scratch build time.
## Solution
Reduce the size of the critical path by removing dependencies between crates where not necessary. For `cargo check --no-default-features` this reduced build time from ~51s to ~45s. For some commits I am not completely sure if the tradeoff between build time reduction and convenience caused by the commit is acceptable. If not, I can drop them.
# Objective
Fix wonky torus normals.
## Solution
I attempted this previously in #3549, but it looks like I botched it. It seems like I mixed up the y/z axes. Somehow, the result looked okay from that particular camera angle.
This video shows toruses generated with
- [left, orange] original torus mesh code
- [middle, pink] PR 3549
- [right, purple] This PR
https://user-images.githubusercontent.com/200550/164093183-58a7647c-b436-4512-99cd-cf3b705cefb0.mov
# Objective
- Related #4276.
- Part of the splitting process of #3503.
## Solution
- Move `Size` to `bevy_ui`.
## Reasons
- `Size` is only needed in `bevy_ui` (because it needs to use `Val` instead of `f32`), but it's also used as a worse `Vec2` replacement in other areas.
- `Vec2` is more powerful than `Size` so it should be used whenever possible.
- Discussion in #3503.
## Changelog
### Changed
- The `Size` type got moved from `bevy_math` to `bevy_ui`.
## Migration Guide
- The `Size` type got moved from `bevy::math` to `bevy::ui`. To migrate you just have to import `bevy::ui::Size` instead of `bevy::math::Math` or use the `bevy::prelude` instead.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- The `OrthographicCameraBundle` constructor for 2d cameras uses a hardcoded value for Z position and scale of the camera. It could be useful to be able to customize these values.
## Solution
- Add a new constructor `custom_2d` that takes `far` (Z position) and `scale` as parameters. The default constructor `new_2d` uses this constructor with `far = 1000.0` and `scale = 1.0`.
# Objective
- Fixes#4234
- Fixes#4473
- Built on top of #3989
- Improve performance of `assign_lights_to_clusters`
## Solution
- Remove the OBB-based cluster light assignment algorithm and calculation of view space AABBs
- Implement the 'iterative sphere refinement' algorithm used in Just Cause 3 by Emil Persson as documented in the Siggraph 2015 Practical Clustered Shading talk by Persson, on pages 42-44 http://newq.net/dl/pub/s2015_practical.pdf
- Adapt to also support orthographic projections
- Add `many_lights -- orthographic` for testing many lights using an orthographic projection
## Results
- `assign_lights_to_clusters` in `many_lights` before this PR on an M1 Max over 1500 frames had a median execution time of 1.71ms. With this PR it is 1.51ms, a reduction of 0.2ms or 11.7% for this system.
---
## Changelog
- Changed: Improved cluster light assignment performance
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3499
## Solution
Uses a `HashMap` from `RenderTarget` to sampled textures when preparing `ViewTarget`s to ensure that two passes with the same render target get sampled to the same texture.
This builds on and depends on https://github.com/bevyengine/bevy/pull/3412, so this will be a draft PR until #3412 is merged. All changes for this PR are in the last commit.
# Objective
glTF files can contain cameras. Currently the scene viewer example uses _a_ camera defined in the file if possible, otherwise it spawns a new one. It would be nice if instead it could load all the cameras and cycle through them, while also having a separate user-controller camera.
## Solution
- instead of just a camera that is already defined, always spawn a new separate user-controller camera
- maintain a list of loaded cameras and cycle through them (wrapping to the user-controller camera) when pressing `C`
This matches the behavious that https://github.khronos.org/glTF-Sample-Viewer-Release/ has.
## Implementation notes
- The gltf scene asset loader just spawns the cameras into the world, but does not return a mapping of camera index to bevy entity. So instead the scene_viewer example just collects all spawned cameras with a good old `query.iter().collect()`, so the order is unspecified and may change between runs.
## Demo
https://user-images.githubusercontent.com/22177966/161826637-40161482-5b3b-4df5-aae8-1d5e9b918393.mp4
using the virtual city glTF sample file: https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/VC
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
Currently `tracy` interprets the entire trace as one frame because the marker for frames isn't being recorded.
~~When an event with `tracy.trace_marker=true` is recorded, `tracing-tracy` will mark the frame as finished:
<aa0b96b2ae/tracing-tracy/src/lib.rs (L240)>~~
~~Unfortunately this leads to~~
```rs
INFO bevy_app:frame: bevy_app::app: finished frame tracy.frame_mark=true
```
~~being printed every frame (we can't use DEBUG because bevy_log sets `max_release_level_info`.~~
Instead of emitting an event that gets logged every frame, we can depend on tracy-client itself and call `finish_continuous_frame!();`
# Objective
- Make `set_active_camera` system correctly respond to camera deletion, while preserving its correct behavior on first ever frame and any consequent frame, and with multiple cameras of the same type available in the world.
- Fixes#4227
## Solution
- Add a check that the entity referred to by `ActiveCamera` still exists in the world.
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Avoid crashing if `RenderDevice` doesn't exist (required for headless mode).
Fixes#4392.
## Solution
Use `CompressedImageFormats::all()` if there is no `RenderDevice`.
https://en.wikipedia.org/wiki/HSL_and_HSV#From_RGB
# Objective
Fixes#4382
## Solution
- Describe the solution used to achieve the objective above.
Fixed conversion formula to account for red and green component being max and equal
---
## Changelog
Fixed RGB -> HSL colorspace conversion
## Migration Guide
Co-authored-by: Francesco Giordana <fgiordana@netflix.com>
# Objective
Make it so that loading in a mesh without normals that is not a `TriangleList` succeeds.
## Solution
Flat normals can only be calculated on a mesh made of triangles.
Check whether the mesh is a `TriangleList` before trying to compute missing normals.
## Additional changes
The panic condition in `duplicate_vertices` did not make sense to me. I moved it to `compute_flat_normals` where the algorithm would produce incorrect results if the mesh is not a `TriangleList`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
make bevy ecs a lil bit less unsound
## Solution
make unsound API unsafe so that there is an unsafe block to blame:
```rust
use bevy_ecs::prelude::*;
#[derive(Debug, Component)]
struct Foo(u8);
fn main() {
let mut world = World::new();
let e1 = world.spawn().id();
let e2 = world.spawn().insert(Foo(2)).id();
world.entities_mut().meta[0] = world.entities_mut().meta[1].clone();
let foo = world.entity(e1).get::<Foo>().unwrap();
// whoo i love having components i dont have
dbg!(foo);
}
```
This is not _strictly_ speaking UB, however:
- `Query::get_multiple` cannot work if this is allowed
- bevy_ecs is a pile of unsafe code whose soundness generally depends on the world being in a "correct" state with "no funny business" so it seems best to disallow this
- it is trivial to get bevy to panic inside of functions with safety invariants that have been violated (the entity location is not valid)
- it seems to violate what the safety invariant on `Entities::flush` is trying to ensure
# Objective
Add a system parameter `ParamSet` to be used as container for conflicting parameters.
## Solution
Added two methods to the SystemParamState trait, which gives the access used by the parameter. Did the implementation. Added some convenience methods to FilteredAccessSet. Changed `get_conflicts` to return every conflicting component instead of breaking on the first conflicting `FilteredAccess`.
Co-authored-by: bilsen <40690317+bilsen@users.noreply.github.com>
related: https://github.com/bevyengine/bevy/pull/3289
In addition to validating shaders early when debug assertions are enabled, use the new [error scopes](https://gpuweb.github.io/gpuweb/#error-scopes) API when creating a shader module.
I chose to keep the early validation (and thereby parsing twice) when debug assertions are enabled in, because it lets as handle errors ourselves and display them with pretty colors, while the error scopes API just gives us a string we can display.
This change pulls in `futures-util` as a new dependency for `future.now_or_never()`. I can inline that part of futures-lite into `bevy_render` to keep the compilation time lower if that's preferred.
# Objective
Fixes `StandardMaterial` texture update (see sample code below).
Most probably fixes#3674 (did not test)
## Solution
Material updates, such as PBR update, reference the underlying `GpuImage`. Like here: 9a7852db0f/crates/bevy_pbr/src/pbr_material.rs (L177)
However, currently the `GpuImage` update may actually happen *after* the material update fetches the gpu image. Resulting in the material actually not being updated for the correct gpu image.
In this pull req, I introduce new systemlabels for the renderassetplugin. Also assigned the RenderAssetPlugin::<Image> to the `PreAssetExtract` stage, so that it is executed before any material updates.
Code to test.
Expected behavior:
* should update to red texture
Unexpected behavior (before this merge):
* texture stays randomly as green one (depending on the execution order of systems)
```rust
use bevy::{
prelude::*,
render::render_resource::{Extent3d, TextureDimension, TextureFormat},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_startup_system(setup)
.add_system(changes)
.run();
}
struct Iteration(usize);
#[derive(Component)]
struct MyComponent;
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
mut images: ResMut<Assets<Image>>,
) {
commands.spawn_bundle(PointLightBundle {
point_light: PointLight {
..Default::default()
},
transform: Transform::from_xyz(4.0, 8.0, 4.0),
..Default::default()
});
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(-2.0, 0.0, 5.0)
.looking_at(Vec3::new(0.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
commands.insert_resource(Iteration(0));
commands
.spawn_bundle(PbrBundle {
mesh: meshes.add(Mesh::from(shape::Quad::new(Vec2::new(3., 2.)))),
material: materials.add(StandardMaterial {
base_color_texture: Some(images.add(Image::new(
Extent3d {
width: 600,
height: 400,
depth_or_array_layers: 1,
},
TextureDimension::D2,
[0, 255, 0, 128].repeat(600 * 400), // GREEN
TextureFormat::Rgba8Unorm,
))),
..Default::default()
}),
..Default::default()
})
.insert(MyComponent);
}
fn changes(
mut materials: ResMut<Assets<StandardMaterial>>,
mut images: ResMut<Assets<Image>>,
mut iteration: ResMut<Iteration>,
webview_query: Query<&Handle<StandardMaterial>, With<MyComponent>>,
) {
if iteration.0 == 2 {
let material = materials.get_mut(webview_query.single()).unwrap();
let image = images
.get_mut(material.base_color_texture.as_ref().unwrap())
.unwrap();
image
.data
.copy_from_slice(&[255, 0, 0, 255].repeat(600 * 400));
}
iteration.0 += 1;
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add a helper for storage buffers similar to `UniformVec`
## Solution
- Add a `StorageBuffer<T, U>` where `T` is the main body of the shader struct without any final variable-sized array member, and `U` is the type of the items in a variable-sized array.
- Use `()` as the type for unwanted parts, e.g. `StorageBuffer<(), Vec4>::default()` would construct a binding that would work with `struct MyType { data: array<vec4<f32>>; }` in WGSL and `StorageBuffer<MyType, ()>::default()` would work with `struct MyType { ... }` in WGSL as long as there are no variable-sized arrays.
- Std430 requires that there is at most one variable-sized array in a storage buffer, that if there is one it is the last member of the binding, and that it has at least one item. `StorageBuffer` handles all of these constraints.
Add support for removing nodes, edges, and subgraphs. This enables live re-wiring of the render graph.
This was something I did to support the MSAA implementation, but it turned out to be unnecessary there. However, it is still useful so here it is in its own PR.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
When loading a gltf scene with a camera, bevy will panic at ``thread 'main' panicked at 'scene contains the unregistered type `bevy_render:📷:bundle::Camera3d`. consider registering the type using `app.register_type::<T>()`', /home/jakob/dev/rust/contrib/bevy/bevy/crates/bevy_scene/src/scene_spawner.rs:332:35``.
## Solution
Register the camera types to fix the panic.
# Objective
- Reduce time spent in the `check_visibility` system
## Solution
- Use `Vec3A` for all bounding volume types to leverage SIMD optimisations and to avoid repeated runtime conversions from `Vec3` to `Vec3A`
- Inline all bounding volume intersection methods
- Add on-the-fly calculated `Aabb` -> `Sphere` and do `Sphere`-`Frustum` intersection tests before `Aabb`-`Frustum` tests. This is faster for `many_cubes` but could be slower in other cases where the sphere test gives a false-positive that the `Aabb` test discards. Also, I tested precalculating the `Sphere`s and inserting them alongside the `Aabb` but this was slower.
- Do not test meshes against the far plane. Apparently games don't do this anymore with infinite projections, and it's one fewer plane to test against. I made it optional and still do the test for culling lights but that is up for discussion.
- These collectively reduce `check_visibility` execution time in `many_cubes -- sphere` from 2.76ms to 1.48ms and increase frame rate from ~42fps to ~44fps
Tracing added support for "inline span entering", which cuts down on a lot of complexity:
```rust
let span = info_span!("my_span").entered();
```
This adapts our code to use this pattern where possible, and updates our docs to recommend it.
This produces equivalent tracing behavior. Here is a side by side profile of "before" and "after" these changes.
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
- Fixes#3300
- `RunSystem` is messy
## Solution
- Adds the trick theorised in https://github.com/bevyengine/bevy/issues/3300#issuecomment-991791234
P.S. I also want this for an experimental refactoring of `Assets`, to remove the duplication of `Events<AssetEvent<T>>`
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Hierarchy tools are not just used for `Transform`: they are also used for scenes.
- In the future there's interest in using them for other features, such as visiibility inheritance.
- The fact that these tools are found in `bevy_transform` causes a great deal of user and developer confusion
- Fixes#2758.
## Solution
- Split `bevy_transform` into two!
- Make everything work again.
Note that this is a very tightly scoped PR: I *know* there are code quality and docs issues that existed in bevy_transform that I've just moved around. We should fix those in a seperate PR and try to merge this ASAP to reduce the bitrot involved in splitting an entire crate.
## Frustrations
The API around `GlobalTransform` is a mess: we have massive code and docs duplication, no link between the two types and no clear way to extend this to other forms of inheritance.
In the medium-term, I feel pretty strongly that `GlobalTransform` should be replaced by something like `Inherited<Transform>`, which lives in `bevy_hierarchy`:
- avoids code duplication
- makes the inheritance pattern extensible
- links the types at the type-level
- allows us to remove all references to inheritance from `bevy_transform`, making it more useful as a standalone crate and cleaning up its docs
## Additional context
- double-blessed by @cart in https://github.com/bevyengine/bevy/issues/4141#issuecomment-1063592414 and https://github.com/bevyengine/bevy/issues/2758#issuecomment-913810963
- preparation for more advanced / cleaner hierarchy tools: go read https://github.com/bevyengine/rfcs/pull/53 !
- originally attempted by @finegeometer in #2789. It was a great idea, just needed more discussion!
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
**Problem**
- whenever you want more than one of the builtin cameras (for example multiple windows, split screen, portals), you need to add a render graph node that executes the correct sub graph, extract the camera into the render world and add the correct `RenderPhase<T>` components
- querying for the 3d camera is annoying because you need to compare the camera's name to e.g. `CameraPlugin::CAMERA_3d`
**Solution**
- Introduce the marker types `Camera3d`, `Camera2d` and `CameraUi`
-> `Query<&mut Transform, With<Camera3d>>` works
- `PerspectiveCameraBundle::new_3d()` and `PerspectiveCameraBundle::<Camera3d>::default()` contain the `Camera3d` marker
- `OrthographicCameraBundle::new_3d()` has `Camera3d`, `OrthographicCameraBundle::new_2d()` has `Camera2d`
- remove `ActiveCameras`, `ExtractedCameraNames`
- run 2d, 3d and ui passes for every camera of their respective marker
-> no custom setup for multiple windows example needed
**Open questions**
- do we need a replacement for `ActiveCameras`? What about a component `ActiveCamera { is_active: bool }` similar to `Visibility`?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make insertion of uniform components faster
## Solution
- Use batch insertion in the prepare_uniform_components system
- Improves `many_cubes -- sphere` from ~42fps to ~43fps
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#3744
## Solution
The old code used the formula `normal . center + d + radius <= 0` to determine if the sphere with center `center` and radius `radius` is outside the plane with normal `normal` and distance from origin `d`. This only works if `normal` is normalized, which is not necessarily the case. Instead, `normal` and `d` are both multiplied by some factor that `radius` isn't multiplied by. So the additional code multiplied `radius` by that factor.
# Objective
Currently, errors in the render graph runner are exposed via a `Result::unwrap()` panic message, which dumps the debug representation of the error.
## Solution
This PR updates `render_system` to log the chain of errors, followed by an explicit panic:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > encountered an error when running a sub-graph
ERROR bevy_render::renderer: > tried to pass inputs to sub-graph "outline_graph", which has no input slots
thread 'main' panicked at 'Error running render graph: encountered an error when running a sub-graph', /[redacted]/bevy/crates/bevy_render/src/renderer/mod.rs:44:9
```
Some errors' `Display` impls (via `thiserror`) have also been updated to provide more detail about the cause of the error.
# Objective
- Currently there is now way of making an indirect draw call from a tracked render pass.
- This is a very useful feature for GPU based rendering.
## Solution
- Expose the `draw_indirect` and `draw_indexed_indirect` methods from the wgpu `RenderPass` in the `TrackedRenderPass`.
## Alternative
- #3595: Expose the underlying `RenderPass` directly
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
Will fix#3377 and #3254
## Solution
Use an enum to represent either a `WindowId` or `Handle<Image>` in place of `Camera::window`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds "hot reloading" of internal assets, which is normally not possible because they are loaded using `include_str` / direct Asset collection access.
This is accomplished via the following:
* Add a new `debug_asset_server` feature flag
* When that feature flag is enabled, create a second App with a second AssetServer that points to a configured location (by default the `crates` folder). Plugins that want to add hot reloading support for their assets can call the new `app.add_debug_asset::<T>()` and `app.init_debug_asset_loader::<T>()` functions.
* Load "internal" assets using the new `load_internal_asset` macro. By default this is identical to the current "include_str + register in asset collection" approach. But if the `debug_asset_server` feature flag is enabled, it will also load the asset dynamically in the debug asset server using the file path. It will then set up a correlation between the "debug asset" and the "actual asset" by listening for asset change events.
This is an alternative to #3673. The goal was to keep the boilerplate and features flags to a minimum for bevy plugin authors, and allow them to home their shaders near relevant code.
This is a draft because I haven't done _any_ quality control on this yet. I'll probably rename things and remove a bunch of unwraps. I just got it working and wanted to use it to start a conversation.
Fixes#3660
This enables shaders to (optionally) define their import path inside their source. This has a number of benefits:
1. enables users to define their own custom paths directly in their assets
2. moves the import path "close" to the asset instead of centralized in the plugin definition, which seems "better" to me.
3. makes "internal hot shader reloading" way more reasonable (see #3966)
4. logically opens the door to importing "parts" of a shader by defining "import_path blocks".
```rust
#define_import_path bevy_pbr::mesh_struct
struct Mesh {
model: mat4x4<f32>;
inverse_transpose_model: mat4x4<f32>;
// 'flags' is a bit field indicating various options. u32 is 32 bits so we have up to 32 options.
flags: u32;
};
let MESH_FLAGS_SHADOW_RECEIVER_BIT: u32 = 1u;
```
For some keys, it is too expensive to hash them on every lookup. Historically in Bevy, we have regrettably done the "wrong" thing in these cases (pre-computing hashes, then re-hashing them) because Rust's built in hashed collections don't give us the tools we need to do otherwise. Doing this is "wrong" because two different values can result in the same hash. Hashed collections generally get around this by falling back to equality checks on hash collisions. You can't do that if the key _is_ the hash. Additionally, re-hashing a hash increase the odds of collision!
#3959 needs pre-hashing to be viable, so I decided to finally properly solve the problem. The solution involves two different changes:
1. A new generalized "pre-hashing" solution in bevy_utils: `Hashed<T>` types, which store a value alongside a pre-computed hash. And `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . `PreHashMap` is just an alias for a normal HashMap that uses `Hashed<T>` as the key and a new `PassHash` implementation as the Hasher.
2. Replacing the `std::collections` re-exports in `bevy_utils` with equivalent `hashbrown` impls. Avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. The latest version of `hashbrown` adds support for the `entity_ref` api, so we can move to that in preparation for an std migration, if thats the direction they seem to be going in. Note that adding hashbrown doesn't increase our dependency count because it was already in our tree.
In addition to providing these core tools, I also ported the "table identity hashing" in `bevy_ecs` to `raw_entry_mut`, which was a particularly egregious case.
The biggest outstanding case is `AssetPathId`, which stores a pre-hash. We need AssetPathId to be cheaply clone-able (and ideally Copy), but `Hashed<AssetPath>` requires ownership of the AssetPath, which makes cloning ids way more expensive. We could consider doing `Hashed<Arc<AssetPath>>`, but cloning an arc is still a non-trivial expensive that needs to be considered. I would like to handle this in a separate PR. And given that we will be re-evaluating the Bevy Assets implementation in the very near future, I'd prefer to hold off until after that conversation is concluded.
# Objective
- `WgpuOptions` is mutated to be updated with the actual device limits and features, but this information is readily available to both the main and render worlds through the `RenderDevice` which has .limits() and .features() methods
- Information about the adapter in terms of its name, the backend in use, etc were not being exposed but have clear use cases for being used to take decisions about what rendering code to use. For example, if something works well on AMD GPUs but poorly on Intel GPUs. Or perhaps something works well in Vulkan but poorly in DX12.
## Solution
- Stop mutating `WgpuOptions `and don't insert the updated values into the main and render worlds
- Return `AdapterInfo` from `initialize_renderer` and insert it into the main and render worlds
- Use `RenderDevice` limits in the lighting code that was using `WgpuOptions.limits`.
- Renamed `WgpuOptions` to `WgpuSettings`
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Support overriding wgpu features and limits that were calculated from default values or queried from the adapter/backend.
- Fixes#3686
## Solution
- Add `disabled_features: Option<wgpu::Features>` to `WgpuOptions`
- Add `constrained_limits: Option<wgpu::Limits>` to `WgpuOptions`
- After maybe obtaining updated features and limits from the adapter/backend in the case of `WgpuOptionsPriority::Functionality`, enable the `WgpuOptions` `features`, disable the `disabled_features`, and constrain the `limits` by `constrained_limits`.
- Note that constraining the limits means for `wgpu::Limits` members named `max_.*` we take the minimum of that which was configured/queried for the backend/adapter and the specified constrained limit value. This means the configured/queried value is used if the constrained limit is larger as that is as much as the device/API supports, or the constrained limit value is used if it is smaller as we are imposing an artificial constraint. For members named `min_.*` we take the maximum instead. For example, a minimum stride might be 256 but we set constrained limit value of 1024, then 1024 is the more conservative value. If the constrained limit value were 16, then 256 would be the more conservative.
# Objective
If a user attempts to `.add_render_command::<P, C>()` on a world that does not contain `DrawFunctions<P>`, the engine panics with a generic `Option::unwrap` message:
```
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:318:76
```
## Solution
This PR adds a panic message describing the problem:
```
thread 'main' panicked at 'DrawFunctions<outline::MeshStencil> must be added to the world as a resource before adding render commands to it', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:322:17
```
# Objective
The documentation was unclear but it seemed like it was intended to _only_ flip the texture coordinates of the quad. However, it was also swapping the vertex positions, which resulted in inverted winding order so the front became a back face, and the normal was pointing into the face instead of out of it.
## Solution
- This change makes the only difference the UVs being horizontally flipped.
(cherry picked from commit de943381bd2a8b242c94db99e6c7bbd70006d7c3)
# Objective
The view uniform lacks view transform information. The inverse transform is currently provided but this is not sufficient if you do not have access to an `inverse` function (such as in WGSL).
## Solution
Grab the view transform, put it in the view uniform, use the same matrix to compute the inverse as well.
# Objective
The docs for `{VertexState, FragmentState}::entry_point` stipulate that the entry point function in the shader must return void. This seems to be specific to GLSL; WGSL has no `void` type and its entry point functions return values that describe their output.
## Solution
Remove the mention of the `void` return type.
# Objective
Enable the user to specify any presentation modes (including `Mailbox`).
Fixes#3807
## Solution
I've added a new `PresentMode` enum in `bevy_window` that mirrors the `wgpu` enum 1:1. Alternatively, I could add a new dependency on `wgpu-types` if that would be preferred.
## Objective
When print shader validation error messages, we didn't print the sources and error message text, which led to some confusing error messages.
```cs
error:
┌─ wgsl:15:11
│
15 │ return material.color + 1u;
│ ^^^^^^^^^^^^^^^^^^^^ naga::Expression [11]
```
## Solution
New error message:
```cs
error: Entry point fragment at Vertex is invalid
┌─ wgsl:15:11
│
15 │ return material.color + 1u;
│ ^^^^^^^^^^^^^^^^^^^^ naga::Expression [11]
│
= Expression [11] is invalid
= Operation Add can't work with [8] and [10]
```
# Objective
Add a simple way for user to get the size of a loaded texture in an Image object.
Aims to solve #3689
## Solution
Add a `size() -> Vec2` method
Add two simple tests for this method.
Updates:
. method named changed from `size_2d` to `size`
# Objective
- While it is not safe to enable mappable primary buffers for all GPUs, it should be preferred for integrated GPUs where an integrated GPU is one that is sharing system memory.
## Solution
- Auto-disable mappable primary buffers only for discrete GPUs. If the GPU is integrated and mappable primary buffers are supported, use them.
# Objective
In order to create a glsl shader, we must provide the `naga::ShaderStage` type which is not exported by bevy, meaning a user would have to manually include naga just to access this type.
`pub fn from_glsl(source: impl Into<Cow<'static, str>>, stage: naga::ShaderStage) -> Shader {`
## Solution
Re-rexport naga::ShaderStage from `render_resources`
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
# Objective
- When using `WgpuOptionsPriority::Functionality`, which is the default, wgpu::Features::MAPPABLE_PRIMARY_BUFFERS would be automatically enabled. This feature can and does have a significant negative impact on performance for discrete GPUs where resizable bar is not supported, which is a common case. As such, this feature should not be automatically enabled.
- Fixes the performance regression part of https://github.com/bevyengine/bevy/issues/3686 and at least some, if not all cases of https://github.com/bevyengine/bevy/issues/3687
## Solution
- When using `WgpuOptionsPriority::Functionality`, use the adapter-supported features, enable `TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` and disable `MAPPABLE_PRIMARY_BUFFERS`
Fixed doc comment where render Node input/output methods refered to using `RenderContext` for interaction instead of `RenderGraphContext`
# Objective
The doc comments for `Node` refer to `RenderContext` for slots instead of `RenderGraphContext`, which is only confusing because `Node::run` is passed both `RenderContext` and `RenderGraphContext`
## Solution
Fixed the typo
Super tiny thing. Found this while reviewing #3479.
# Objective
- Simplify code
- Fix the link in the doc comment
## Solution
- Import a single item :)
Co-authored-by: Pascal Hertleif <pascal@technocreatives.com>
# Objective
CI should check for missing backticks in doc comments.
Fixes#3435
## Solution
`clippy` has a lint for this: `doc_markdown`. This enables that lint in the CI script.
Of course, enabling this lint in CI causes a bunch of lint errors, so I've gone through and fixed all of them. This was a huge edit that touched a ton of files, so I split the PR up by crate.
When all of the following are merged, the CI should pass and this can be merged.
+ [x] #3467
+ [x] #3468
+ [x] #3470
+ [x] #3469
+ [x] #3471
+ [x] #3472
+ [x] #3473
+ [x] #3474
+ [x] #3475
+ [x] #3476
+ [x] #3477
+ [x] #3478
+ [x] #3479
+ [x] #3480
+ [x] #3481
+ [x] #3482
+ [x] #3483
+ [x] #3484
+ [x] #3485
+ [x] #3486
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_render` crate.
# Objective
In this PR I added the ability to opt-out graphical backends. Closes#3155.
## Solution
I turned backends into `Option` ~~and removed panicking sub app API to force users handle the error (was suggested by `@cart`)~~.
# Objective
The current 2d rendering is specialized to render sprites, we need a generic way to render 2d items, using meshes and materials like we have for 3d.
## Solution
I cloned a good part of `bevy_pbr` into `bevy_sprite/src/mesh2d`, removed lighting and pbr itself, adapted it to 2d rendering, added a `ColorMaterial`, and modified the sprite rendering to break batches around 2d meshes.
~~The PR is a bit crude; I tried to change as little as I could in both the parts copied from 3d and the current sprite rendering to make reviewing easier. In the future, I expect we could make the sprite rendering a normal 2d material, cleanly integrated with the rest.~~ _edit: see <https://github.com/bevyengine/bevy/pull/3460#issuecomment-1003605194>_
## Remaining work
- ~~don't require mesh normals~~ _out of scope_
- ~~add an example~~ _done_
- support 2d meshes & materials in the UI?
- bikeshed names (I didn't think hard about naming, please check if it's fine)
## Remaining questions
- ~~should we add a depth buffer to 2d now that there are 2d meshes?~~ _let's revisit that when we have an opaque render phase_
- ~~should we add MSAA support to the sprites, or remove it from the 2d meshes?~~ _I added MSAA to sprites since it's really needed for 2d meshes_
- ~~how to customize vertex attributes?~~ _#3120_
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Allow the user to specify the priority when configuring wgpu features/limits and by default use the maximum capabilities of the chosen adapter.
## Solution
- Add a `WgpuOptionsPriority` enum with `Compatibility`, `Functionality` and `WebGL2` options.
- Add a `priority: WgpuOptionsPriority` member to `WgpuOptions`.
- When initialising the renderer, if `WgpuOptions::priority == WgpuOptionsPriority::Functionality`, query the adapter for the available features and limits, use them when creating a device, and update `WgpuOptions` with those values. If `Compatibility` use the behaviour as before this PR. If `WebGL2` then use the WebGL2 downlevel limits as used when when building for wasm, for convenience of testing WebGL2 limits without having to build for wasm.
- Add an environment variable `WGPU_OPTIONS_PRIO` that takes `compatibility`, `functionality`, `webgl2`.
- Default to `WgpuOptionsPriority::Functionality`.
- Insert updated `WgpuOptions` into render app world as well. This is useful for applying the limits when rendering, such as limiting the directional light shadow map texture to 2048x2048 when using WebGL2 downlevel limits but not on wasm.
- Reduced `draw_state` logs from `debug` to `trace` and added `debug` level logs for the wgpu features and limits. Use `RUST_LOG=bevy_render=debug` to see the output.
# Objective
- Add support for loading lights from glTF 2.0 files
## Solution
- This adds support for the KHR_punctual_lights extension which supports point, directional, and spot lights, though we don't yet support spot lights.
- Inserting light bundles when creating scenes required registering some more light bundle component types.
This PR is part of the issue #3492.
# Objective
- Clean up dead code in `bevy_core`.
- Add and update the `bevy_core` documentation to achieve a 100% documentation coverage.
- Add the #![warn(missing_docs)] lint to keep the documentation coverage for the future.
# Solution
- Remove unused `Bytes`, `FromBytes`, `Labels`, and `EntityLabels` types and associated systems.
- Made several types private that really only have use as internal types, mostly pertaining to fixed timestep execution.
- Add and update the bevy_core documentation.
- Add the #![warn(missing_docs)] lint.
# Open Questions
Should more of the internal states of `FixedTimestep` be public? Seems mostly to be an implementation detail unless someone really needs that fixed timestep state.
# Objective
Docs updates.
## Solution
- Detail what `OrthographicCameraBundle::new_2d()` creates.
- Fix a few renamed parameters in comments of `TrackedRenderPass`.
- Add missing comments for viewport and debug markers.
Co-authored-by: Jerome Humbert <djeedai@gmail.com>
# Objective
- `Msaa` was disabled in webgl due to a bug in wgpu
- Bug has been fixed (https://github.com/gfx-rs/wgpu/pull/2307) and backported (https://github.com/gfx-rs/wgpu/pull/2327), and updates for [`wgpu-core`](https://crates.io/crates/wgpu-core/0.12.1) and [`wgpu-hal`](https://crates.io/crates/wgpu-hal/0.12.1) have been released
## Solution
- Remove custom config for `Msaa` in webgl
- I also changed two options that were using the arch instead of the `webgl` feature. it shouldn't change much for webgl, but could help if someone wants to target wasm but not webgl2
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Dynamic types (`DynamicStruct`, `DynamicTupleStruct`, `DynamicTuple`, `DynamicList` and `DynamicMap`) are used when deserializing scenes, but currently they can only be applied to existing concrete types. This leads to issues when trying to spawn non trivial deserialized scene.
For components, the issue is avoided by requiring that reflected components implement ~~`FromResources`~~ `FromWorld` (or `Default`). When spawning, a new concrete type is created that way, and the dynamic type is applied to it. Unfortunately, some components don't have any valid implementation of these traits.
In addition, any `Vec` or `HashMap` inside a component will panic when a dynamic type is pushed into it (for instance, `Text` panics when adding a text section).
To solve this issue, this PR adds the `FromReflect` trait that creates a concrete type from a dynamic type that represent it, derives the trait alongside the `Reflect` trait, drops the ~~`FromResources`~~ `FromWorld` requirement on reflected components, ~~and enables reflection for UI and Text bundles~~. It also adds the requirement that fields ignored with `#[reflect(ignore)]` implement `Default`, since we need to initialize them somehow.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- I want to port `bevy_egui` to Bevy main and only reuse re-exports from Bevy
## Solution
- Add exports for `BufferBinding` and `BufferDescriptor`
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
Fixes#3422
## Solution
Adds the existing `Visibility` component to UI bundles and checks for it in the extract phase of the render app.
The `ComputedVisibility` component was not added. I don't think the UI camera needs frustum culling, but having `RenderLayers` work may be desirable. However I think we would need to change `check_visibility()` to differentiate between 2d, 3d and UI entities.
# Objective
- Our crevice is still called "crevice", which we can't use for a release
- Users would need to use our "crevice" directly to be able to use the derive macro
## Solution
- Rename crevice to bevy_crevice, and crevice-derive to bevy-crevice-derive
- Re-export it from bevy_render, and use it from bevy_render everywhere
- Fix derive macro to work either from bevy_render, from bevy_crevice, or from bevy
## Remaining
- It is currently re-exported as `bevy::render::bevy_crevice`, is it the path we want?
- After a brief suggestion to Cart, I changed the version to follow Bevy version instead of crevice, do we want that?
- Crevice README.md need to be updated
- in the `Cargo.toml`, there are a few things to change. How do we want to change them? How do we keep attributions to original Crevice?
```
authors = ["Lucien Greathouse <me@lpghatguy.com>"]
documentation = "https://docs.rs/crevice"
homepage = "https://github.com/LPGhatguy/crevice"
repository = "https://github.com/LPGhatguy/crevice"
```
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Instead of panicking when the `indices` field of a mesh is `None`, actually manage it.
This is just a question of keeping track of the vertex buffer size.
## Notes
* Relying on this change to improve performance on [bevy_debug_lines using the new renderer](https://github.com/Toqozz/bevy_debug_lines/pull/10)
* I'm still new to rendering, my only expertise with wgpu is the learn-wgpu tutorial, likely I'm overlooking something.
### Problem
- shader processing errors are not displayed
- during hot reloading when encountering a shader with errors, the whole app crashes
### Solution
- log `error!`s for shader processing errors
- when `cfg(debug_assertions)` is enabled (i.e. you're running in `debug` mode), parse shaders before passing them to wgpu. This lets us handle errors early.
# Objective
- 3d examples fail to run in webgl2 because of unsupported texture formats or texture too large
## Solution
- switch to supported formats if a feature is enabled. I choose a feature instead of a build target to not conflict with a potential webgpu support
Very inspired by 6813b2edc5, and need #3290 to work.
I named the feature `webgl2`, but it's only needed if one want to use PBR in webgl2. Examples using only 2D already work.
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- I want to be able to use `#ifdef` and other processor directives in an imported shader
## Solution
- Process imported shader strings
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
Add missing methods to `TrackedRenderPass`
- `set_push_constants`
- `set_viewport`
- `insert_debug_marker`
- `push_debug_group`
- `pop_debug_group`
- `set_blend_constant`
https://docs.rs/wgpu/0.12.0/wgpu/struct.RenderPass.html
I need `set_push_constants` but started adding the others as I noticed they were also missing. The `draw indirect` family of methods are still missing as are the `timestamp query` methods.
# Objective
- Only bevy_render should depend directly on wgpu
- This helps to make sure bevy_render re-exports everything needed from wgpu
## Solution
- Remove bevy_pbr, bevy_sprite and bevy_ui dependency on wgpu
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
Fixes#3352Fixes#3208
## Solution
- Update wgpu to 0.12
- Update naga to 0.8
- Resolve compilation errors
- Remove [[block]] from WGSL shaders (because it is depracated and now wgpu cant parse it)
- Replace `elseif` with `else if` in pbr.wgsl
# Objective
- The multiple windows example which was viciously murdered in #3175.
- cart asked me to
## Solution
- Rework the example to work on pipelined-rendering, based on the work from #2898
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}