# Objective
- Fixes a hurdle encountered when debugging a panic caused by the file
watcher loading a `.gitignore` file, which was hard to debug because
there was no file name in the report, only `asset paths must have
extensions`
## Solution
- Panic with a formatted message that includes the asset path, e.g.
`missing expected extension for asset path .gitignore`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Doonv <58695417+doonv@users.noreply.github.com>
Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>Even better no_std</h2>
<p>Switching from thiserror to derive_more allows for no_std builds on
stable rust</p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/blob/master/Changelog.md">ruzstd's
changelog</a>.</em></p>
<blockquote>
<h1>After 0.5.0</h1>
<ul>
<li>Make the hashing checksum optional (thanks to <a
href="https://github.com/tamird"><code>@tamird</code></a>)
<ul>
<li>breaking change as the public API changes based on features</li>
</ul>
</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="e620d2a856"><code>e620d2a</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/50">#50</a>
from KillingSpark/remove_thiserror</li>
<li><a
href="9e9d204c63"><code>9e9d204</code></a>
make clippy happy</li>
<li><a
href="f4a6fc0cc1"><code>f4a6fc0</code></a>
bump the version, this is an incompatible change</li>
<li><a
href="64d65b5c4f"><code>64d65b5</code></a>
fix test compile...</li>
<li><a
href="07bbda98c8"><code>07bbda9</code></a>
remove the error_in_core feature and switch the io_nostd to use the
Display t...</li>
<li><a
href="e15eb1e568"><code>e15eb1e</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/49">#49</a>
from tamird/clippy</li>
<li><a
href="92a3f2e6b2"><code>92a3f2e</code></a>
Avoid unnecessary cast</li>
<li><a
href="f588d5c362"><code>f588d5c</code></a>
Avoid slow zero-filling initialization</li>
<li><a
href="e79f09876f"><code>e79f098</code></a>
Avoid single-match expression</li>
<li><a
href="c75cc2fbb9"><code>c75cc2f</code></a>
Remove useless assertion</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.4.0...v0.5.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- `AssetPath` implements reflection, but is not registered as a type in
the plugin.
- Fixes#11481.
## Solution
- Register the `AssetPath` type when `AssetPlugin::build` is called.
---
## Changelog
- Registered `AssetPath` type for use in reflection.
# Objective
- `World::get_resource`'s comment on it's `unsafe` usage meant to say
"mutably" but instead said "immutably."
- Fixes#11430.
## Solution
- Replace "immutably" with "mutably."
# Objective
#10946 added bounding volume types and an `IntersectsVolume` trait, but
didn't actually implement intersections between bounding volumes.
This PR implements AABB-AABB, circle-circle / sphere-sphere, and
AABB-circle / AABB-sphere intersections.
## Solution
Implement `IntersectsVolume` for bounding volume pairs. I also added
`closest_point` methods to return the closest point on the surface /
inside of bounding volumes. This is used for AABB-circle / AABB-sphere
intersections.
---------
Co-authored-by: IQuick 143 <IQuick143cz@gmail.com>
# Objective
TextureAtlases are commonly used to drive animations described as a
consecutive range of indices. The current TextureAtlasBuilder uses the
AssetId of the image to determine the index of the texture in the
TextureAtlas. The AssetId of an Image Asset can change between runs.
The TextureAtlas exposes
[`get_texture_index`](https://docs.rs/bevy/latest/bevy/sprite/struct.TextureAtlas.html#method.get_texture_index)
to get the index from a given AssetId, but this needlessly complicates
the process of creating a simple TextureAtlas animation.
Fixes#2459
## Solution
- Use the (ordered) image_ids of the 'texture to place' vector to
retrieve the packed locations and compose the textures of the
TextureAtlas.
# Objective
It would be convenient to be able to call functions with `Commands` as a
parameter without having to move your own instance of `Commands`. Since
this struct is composed entirely of references, we can easily get an
owned instance of `Commands` by shortening the lifetime.
## Solution
Add `Commands::reborrow`, `EntiyCommands::reborrow`, and
`Deferred::reborrow`, which returns an owned version of themselves with
a shorter lifetime.
Remove unnecessary lifetimes from `EntityCommands`. The `'w` and `'s`
lifetimes only have to be separate for `Commands` because it's used as a
`SystemParam` -- this is not the case for `EntityCommands`.
---
## Changelog
Added `Commands::reborrow`. This is useful if you have `&mut Commands`
but need `Commands`. Also added `EntityCommands::reborrow` and
`Deferred:reborrow` which serve the same purpose.
## Migration Guide
The lifetimes for `EntityCommands` have been simplified.
```rust
// Before (Bevy 0.12)
struct MyStruct<'w, 's, 'a> {
commands: EntityCommands<'w, 's, 'a>,
}
// After (Bevy 0.13)
struct MyStruct<'a> {
commands: EntityCommands<'a>,
}
```
The method `EntityCommands::commands` now returns `Commands` rather than
`&mut Commands`.
```rust
// Before (Bevy 0.12)
let commands = entity_commands.commands();
commands.spawn(...);
// After (Bevy 0.13)
let mut commands = entity_commands.commands();
commands.spawn(...);
```
# Objective
Document a few common cases of which lifetime is required when using
SystemParam Derive
## Solution
Added a table in the doc comment
---------
Co-authored-by: laund <me@laund.moe>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Prep for https://github.com/bevyengine/bevy/pull/10164
- Make deferred_lighting_pass_id a ColorAttachment
- Correctly extract shadow view frusta so that the view uniforms get
populated
- Make some needed things public
- Misc formatting
# Objective
- Extend reflection to the standard library's `Wrapping` and
`Saturating` generic types.
This wasn't my use-case but someone in the discord was surprised that
this wasn't already done. I decided to make a PR because the other
`std::num` items were reflected and if there's a reason to exclude
`Wrapping` and `Saturating`, I am unaware of it.
## Solution
Trivial fix
---
## Changelog
Implemented `Reflect` for `Wrapping<T>` and `Saturating<T>` from
`std::num`.
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- Add the ability to describe storage texture bindings when deriving
`AsBindGroup`.
- This is especially valuable for the compute story of bevy which
deserves some extra love imo.
## Solution
- This add the ability to annotate struct fields with a
`#[storage_texture(0)]` annotation.
- Instead of adding specific option parsing for all the image formats
and access modes, I simply accept a token stream and defer checking to
see if the option is valid to the compiler. This still results in useful
and friendly errors and is free to maintain and always compatible with
wgpu changes.
---
## Changelog
- The `#[storage_texture(..)]` annotation is now accepted for fields of
`Handle<Image>` in structs that derive `AsBindGroup`.
- The game_of_life compute shader example has been updated to use
`AsBindGroup` together with `[storage_texture(..)]` to obtain the
`BindGroupLayout`.
## Migration Guide
# Objective
#8219 changed the target type of a `transmute` without changing the one
transmuting from ([see the relevant
diff](55e9ab7c92 (diff-11413fb2eeba97978379d325353d32aa76eefd0af0c8e9b50b7f394ddfda7a26R351-R355))),
making them incompatible. This PR fixes this by changing the initial
type to match the target one (modulo lifetimes).
## Solution
Change the type to be transmuted from to match the one transmuting into
(modulo lifetimes)
# Objective
- This PR makes it so that `ReflectSerialize` and `ReflectDeserialize`
traits are properly derived on `Name`. This avoids having the internal
hash “leak” into the serialization when using reflection.
## Solution
- Added a conditional derive for `ReflectDeserialize` and
`ReflectSerialize` via `#[cfg_attr()]`
---
## Changelog
- `Name` now implements `ReflectDeserialize` and `ReflectSerialize`
whenever the `serialize` feature is enabled.
# Objective
Fix weird visuals when drawing a gizmo with a non-normed normal.
Fixes#11401
## Solution
Just normalize right before we draw. Could do it when constructing the
builder but that seems less consistent.
## Changelog
- gizmos.circle normal is now a Direction3d instead of a Vec3.
## Migration Guide
- Pass a Direction3d for gizmos.circle normal, eg.
`Direction3d::new(vec).unwrap_or(default)` or potentially
`Direction3d::new_unchecked(vec)` if you know your vec is definitely
normalized.
# Objective
- Since #11218, example `asset_processing` fails:
```
thread 'main' panicked at crates/bevy_asset/src/io/source.rs:489:18:
Failed to create file watcher: Error { kind: PathNotFound, paths: ["examples/asset/processing/imported_assets/Default"] }
```
start from a fresh git clone or delete the folder before running to
reproduce, it is in gitignore and should not be present on a fresh run
a657478675/.gitignore (L18)
## Solution
- Auto create the `imported_assets` folder if it is configured
---------
Co-authored-by: Kyle <37520732+nvdaz@users.noreply.github.com>
# Objective
`Direction2d::from_normalized` & `Direction3d::from_normalized` don't
emphasize that importance of the vector being normalized enough.
## Solution
Rename `from_normalized` to `new_unchecked` and add more documentation.
---
`Direction2d` and `Direction3d` were added somewhat recently in
https://github.com/bevyengine/bevy/pull/10466 (after 0.12), so I don't
think documenting the changelog and migration guide is necessary (Since
there is no major previous version to migrate from).
But here it is anyway in case it's needed:
## Changelog
- Renamed `Direction2d::from_normalized` and
`Direction3d::from_normalized` to `new_unchecked`.
## Migration Guide
- Renamed `Direction2d::from_normalized` and
`Direction3d::from_normalized` to `new_unchecked`.
---------
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
# Objective
Currently, the `primitives` module is inside of the prelude for
`bevy_math`, but the actual primitives are not. This requires either
importing the shapes everywhere that uses them, or adding the
`primitives::` prefix:
```rust
let rectangle = meshes.add(primitives::Rectangle::new(5.0, 2.5));
```
(Note: meshing isn't actually implemented yet, but it's in #11431)
The primitives are meant to be used for a variety of tasks across
several crates, like for meshing, bounding volumes, gizmos, colliders,
and so on, so I think having them in the prelude is justified. It would
make several common tasks a lot more ergonomic.
```rust
let rectangle = meshes.add(Rectangle::new(5.0, 2.5));
```
## Solution
Add `primitives::*` to `bevy_math::prelude`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Currently, the only way to create an AABB is to specify its `min` and
`max` coordinates. However, it's often more useful to use the center and
half-size instead.
## Solution
Add `new` constructors for `Aabb2d` and `Aabb3d`.
This:
```rust
let aabb = Aabb3d {
min: center - half_size,
max: center + half_size,
}
```
becomes this:
```rust
let aabb = Aabb3d::new(center, half_size);
```
I also made the usage of "half-extents" vs. "half-size" a bit more
consistent.
# Objective
Currently, the `Ellipse` primitive is represented by a `half_width` and
`half_height`. To improve consistency (similarly to #11434), it might
make more sense to use a `Vec2` `half_size` instead.
Alternatively, to make the elliptical nature clearer, the properties
could also be called `radius_x` and `radius_y`.
Secondly, `Ellipse::new` currently takes a *full* width and height
instead of two radii. I would expect it to take the half-width and
half-height because ellipses and circles are almost always defined using
radii. I wouldn't expect `Circle::new` to take a diameter (if we had
that method).
## Solution
Change `Ellipse` to store a `half_size` and `new` to take the half-width
and half-height.
I also added a `from_size` method similar to `Rectangle::from_size`, and
added the `semi_minor` and `semi_major` helpers to get the
semi-minor/major radius.
# Objective
The `Rectangle` and `Cuboid` primitives currently use different
representations:
```rust
pub struct Rectangle {
/// The half width of the rectangle
pub half_width: f32,
/// The half height of the rectangle
pub half_height: f32,
}
pub struct Cuboid {
/// Half of the width, height and depth of the cuboid
pub half_extents: Vec3,
}
```
The property names and helpers are also inconsistent. `Cuboid` has
`half_extents`, but it also has a method called `from_size`. Most
existing code also uses "size" instead of "extents".
## Solution
Represent both `Rectangle` and `Cuboid` with `half_size` properties.
# Objective
Implements #9216
## Solution
- Replace `DiagnosticId` by `DiagnosticPath`. It's pre-hashed using
`const-fnv1a-hash` crate, so it's possible to create path in const
contexts.
---
## Changelog
- Replaced `DiagnosticId` by `DiagnosticPath`
- Set default history length to 120 measurements (2 seconds on 60 fps).
I've noticed hardcoded constant 20 everywhere and decided to change it
to `DEFAULT_MAX_HISTORY_LENGTH` , which is set to new diagnostics by
default. To override it, use `with_max_history_length`.
## Migration Guide
```diff
- const UNIQUE_DIAG_ID: DiagnosticId = DiagnosticId::from_u128(42);
+ const UNIQUE_DIAG_PATH: DiagnosticPath = DiagnosticPath::const_new("foo/bar");
- Diagnostic::new(UNIQUE_DIAG_ID, "example", 10)
+ Diagnostic::new(UNIQUE_DIAG_PATH).with_max_history_length(10)
- diagnostics.add_measurement(UNIQUE_DIAG_ID, || 42);
+ diagnostics.add_measurement(&UNIQUE_DIAG_ID, || 42);
```
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
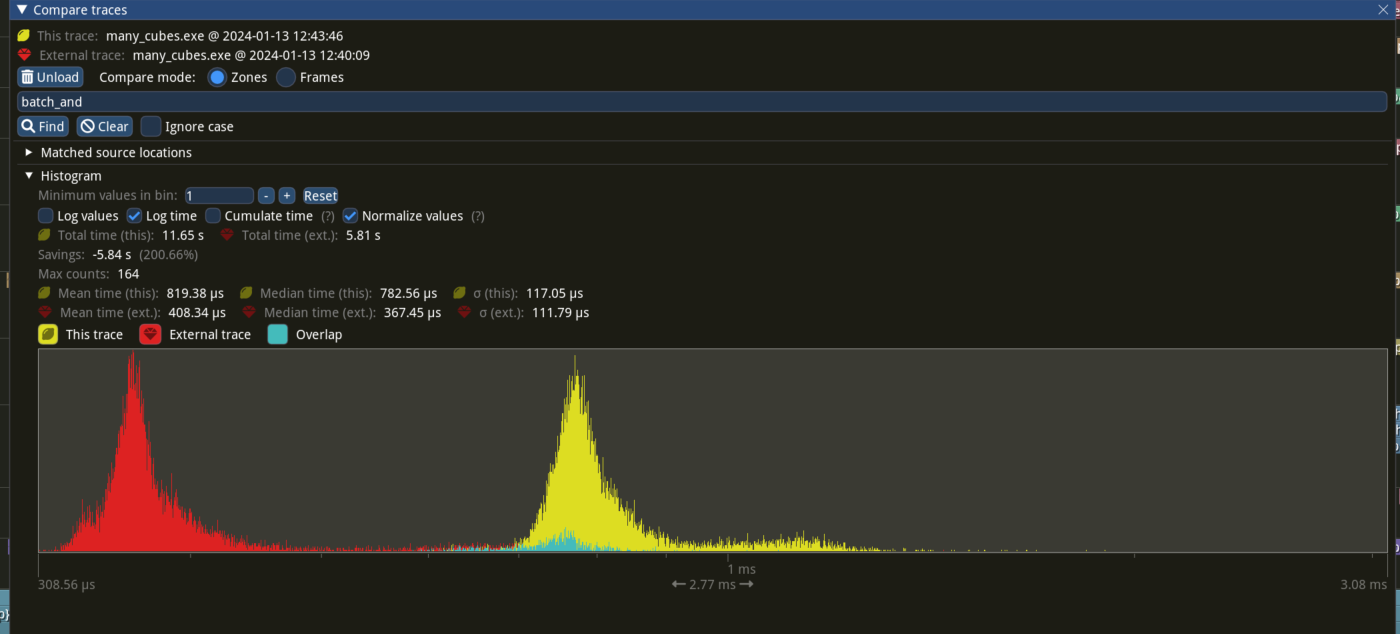
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
# Objective
Adjust bevy internals to utilize `Option<Res<State<S>>>` instead of
`Res<State<S>>`, to allow for adding/removing states at runtime and
avoid unexpected panics.
As requested here:
https://github.com/bevyengine/bevy/pull/10088#issuecomment-1869185413
---
## Changelog
- Changed the use of `world.resource`/`world.resource_mut` to
`world.get_resource`/`world.get_resource_mut` in the
`run_enter_schedule` and `apply_state_transition` systems and handled
the `None` option.
- `in_state` now returns a ` FnMut(Option<Res<State<S>>>) -> bool +
Clone`, returning `false` if the resource doesn't exist.
- `state_exists_and_equals` was marked as deprecated, and now just runs
and returns `in_state`, since their bevhaviour is now identical
- `state_changed` now takes an `Option<Res<State<S>>>` and returns
`false` if it does not exist.
I would like to remove `state_exists_and_equals` fully, but wanted to
ensure that is acceptable before doing so.
---------
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
- `FromType<T>` for `ReflectComponent` and `ReflectBundle` currently
require `T: FromWorld` for two reasons:
- they include a `from_world` method;
- they create dummy `T`s using `FromWorld` and then `apply` a `&dyn
Reflect` to it to simulate `FromReflect`.
- However `FromWorld`/`Default` may be difficult/weird/impractical to
implement, while `FromReflect` is easier and also more natural for the
job.
- See also
https://discord.com/channels/691052431525675048/1146022009554337792
## Solution
- Split `from_world` from `ReflectComponent` and `ReflectBundle` into
its own `ReflectFromWorld` struct.
- Replace the requirement on `FromWorld` in `ReflectComponent` and
`ReflectBundle` with `FromReflect`
---
## Changelog
- `ReflectComponent` and `ReflectBundle` no longer offer a `from_world`
method.
- `ReflectComponent` and `ReflectBundle`'s `FromType<T>` implementation
no longer requires `T: FromWorld`, but now requires `FromReflect`.
- `ReflectComponent::insert`, `ReflectComponent::apply_or_insert` and
`ReflectComponent::copy` now take an extra `&TypeRegistry` parameter.
- There is now a new `ReflectFromWorld` struct.
## Migration Guide
- Existing uses of `ReflectComponent::from_world` and
`ReflectBundle::from_world` will have to be changed to
`ReflectFromWorld::from_world`.
- Users of `#[reflect(Component)]` and `#[reflect(Bundle)]` will need to
also implement/derive `FromReflect`.
- Users of `#[reflect(Component)]` and `#[reflect(Bundle)]` may now want
to also add `FromWorld` to the list of reflected traits in case their
`FromReflect` implementation may fail.
- Users of `ReflectComponent` will now need to pass a `&TypeRegistry` to
its `insert`, `apply_or_insert` and `copy` methods.
This pull request re-submits #10057, which was backed out for breaking
macOS, iOS, and Android. I've tested this version on macOS and Android
and on the iOS simulator.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
When working within `bevy_ecs`, we can't use the `log_once` macros due
to their placement in `bevy_log` - which depends on `bevy_ecs`. All this
create does is migrate those macros to the `bevy_utils` crate, while
still re-exporting them in `bevy_log`.
created to resolve this:
https://github.com/bevyengine/bevy/pull/11417#discussion_r1458100211
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
After the Gizmos changes, `App::init_gizmos_group` turned into a
important function that for sure mustn't panic. The problem is: the
actual implementation causes a panic if somehow the code is runned
before `GizmoPlugin` was added to the App
- The error occurs here for example:
```rust
fn main() {
App::new()
.init_gizmo_group::<MyGizmoConfig>()
.add_plugins(DefaultPlugins)
.run();
}
#[derive(Default, Reflect, GizmoConfigGroup)]
struct MyGizmoConfig;
```

## Solution
- Instead of panicking when getting `GizmoConfigStore`, insert the store
in `App::init_gizmos_group` if needed
---
## Changelog
### Changed
- Changed App::init_gizmos_group to insert the resource if it don't
exist
### Removed
- Removed explicit init of `GizmoConfigStore`
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Some users want to change the default texture usage of the main camera
but they are currently hardcoded
## Solution
- Add a component that is used to configure the main texture usage field
---
## Changelog
Added `CameraMainTextureUsage`
Added `CameraMainTextureUsage` to `Camera3dBundle` and `Camera2dBundle`
## Migration Guide
Add `main_texture_usages: Default::default()` to your camera bundle.
# Notes
Inspired by: #6815
# Objective
- Tests are manually checking whether derived types implement certain
traits. (Specifically in `bevy_reflect.)
- #11182 introduces
[`static_assertions`](https://docs.rs/static_assertions/) to
automatically check this.
- Simplifies `Reflect` test in #11195.
- Closes#11196.
## Solution
- Add `static_assertions` and replace current tests.
---
I wasn't sure whether to remove the existing test or not. What do you
think?
# Objective
- Add methods to get Change Ticks for a given resource by type or
ComponentId
- Fixes#11390
The `is_resource_id_changed` requested in the Issue already exists, this
adds their request for `get_resource_change_ticks`
## Solution
- Added two methods to get change ticks by Type or ComponentId
# Objective
Closes#10570.
#10946 added bounding volume types and traits, but didn't use them for
anything yet. This PR implements `Bounded2d` and `Bounded3d` for Bevy's
primitive shapes.
## Solution
Implement `Bounded2d` and `Bounded3d` for primitive shapes. This allows
computing AABBs and bounding circles/spheres for them.
For most shapes, there are several ways of implementing bounding
volumes. I took inspiration from [Parry's bounding
volumes](https://github.com/dimforge/parry/tree/master/src/bounding_volume),
[Inigo Quilez](http://iquilezles.org/articles/diskbbox/), and figured
out the rest myself using geometry. I tried to comment all slightly
non-trivial or unclear math to make it understandable.
Parry uses support mapping (finding the farthest point in some direction
for convex shapes) for some AABBs like cones, cylinders, and line
segments. This involves several quat operations and normalizations, so I
opted for the simpler and more efficient geometric approaches shown in
[Quilez's article](http://iquilezles.org/articles/diskbbox/).
Below you can see some of the bounding volumes working in 2D and 3D.
Note that I can't conveniently add these examples yet because they use
primitive shape meshing, which is still WIP.
https://github.com/bevyengine/bevy/assets/57632562/4465cbc6-285b-4c71-b62d-a2b3ee16f8b4https://github.com/bevyengine/bevy/assets/57632562/94b4ac84-a092-46d7-b438-ce2e971496a4
---
## Changelog
- Implemented `Bounded2d`/`Bounded3d` for primitive shapes
- Added `from_point_cloud` method for bounding volumes (used by many
bounding implementations)
- Added `point_cloud_2d/3d_center` and `rotate_vec2` utility functions
- Added `RegularPolygon::vertices` method (used in regular polygon AABB
construction)
- Added `Triangle::circumcenter` method (used in triangle bounding
circle construction)
- Added bounding circle/sphere creation from AABBs and vice versa
## Extra
Do we want to implement `Bounded2d` for some "3D-ish" shapes too? For
example, capsules are sort of dimension-agnostic and useful for 2D, so I
think that would be good to implement. But a cylinder in 2D is just a
rectangle, and a cone is a triangle, so they wouldn't make as much sense
to me. A conical frustum would be an isosceles trapezoid, which could be
useful, but I'm not sure if computing the 2D AABB of a 3D frustum makes
semantic sense.
# Objective
This PR aims to implement multiple configs for gizmos as discussed in
#9187.
## Solution
Configs for the new `GizmoConfigGroup`s are stored in a
`GizmoConfigStore` resource and can be accesses using a type based key
or iterated over. This type based key doubles as a standardized location
where plugin authors can put their own configuration not covered by the
standard `GizmoConfig` struct. For example the `AabbGizmoGroup` has a
default color and toggle to show all AABBs. New configs can be
registered using `app.init_gizmo_group::<T>()` during startup.
When requesting the `Gizmos<T>` system parameter the generic type
determines which config is used. The config structs are available
through the `Gizmos` system parameter allowing for easy access while
drawing your gizmos.
Internally, resources and systems used for rendering (up to an including
the extract system) are generic over the type based key and inserted on
registering a new config.
## Alternatives
The configs could be stored as components on entities with markers which
would make better use of the ECS. I also implemented this approach
([here](https://github.com/jeliag/bevy/tree/gizmo-multiconf-comp)) and
believe that the ergonomic benefits of a central config store outweigh
the decreased use of the ECS.
## Unsafe Code
Implementing system parameter by hand is unsafe but seems to be required
to access the config store once and not on every gizmo draw function
call. This is critical for performance. ~Is there a better way to do
this?~
## Future Work
New gizmos (such as #10038, and ideas from #9400) will require custom
configuration structs. Should there be a new custom config for every
gizmo type, or should we group them together in a common configuration?
(for example `EditorGizmoConfig`, or something more fine-grained)
## Changelog
- Added `GizmoConfigStore` resource and `GizmoConfigGroup` trait
- Added `init_gizmo_group` to `App`
- Added early returns to gizmo drawing increasing performance when
gizmos are disabled
- Changed `GizmoConfig` and aabb gizmos to use new `GizmoConfigStore`
- Changed `Gizmos` system parameter to use type based key to retrieve
config
- Changed resources and systems used for gizmo rendering to be generic
over type based key
- Changed examples (3d_gizmos, 2d_gizmos) to showcase new API
## Migration Guide
- `GizmoConfig` is no longer a resource and has to be accessed through
`GizmoConfigStore` resource. The default config group is
`DefaultGizmoGroup`, but consider using your own custom config group if
applicable.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
This adds events for assets that fail to load along with minor utility
methods to make them useful. This paves the way for users writing their
own error handling and retry systems, plus Bevy including robust retry
handling: #11349.
* Addresses #11288
* Needed for #11349
# Solution
```rust
/// An event emitted when a specific [`Asset`] fails to load.
#[derive(Event, Clone, Debug)]
pub struct AssetLoadFailedEvent<A: Asset> {
pub id: AssetId<A>,
/// The original handle returned when the asset load was requested.
pub handle: Option<Handle<A>>,
/// The asset path that was attempted.
pub path: AssetPath<'static>,
/// Why the asset failed to load.
pub error: AssetLoadError,
}
```
I started implementing `AssetEvent::Failed` like suggested in #11288,
but decided it was better as its own type because:
* I think it makes sense for `AssetEvent` to only refer to assets that
actually exist.
* In order to return `AssetLoadError` in the event (which is useful
information for error handlers that might attempt a retry) we would have
to remove `Copy` from `AssetEvent`.
* There are numerous places in the render app that match against
`AssetEvent`, and I don't think it's worth introducing extra noise about
assets that don't exist.
I also introduced `UntypedAssetLoadErrorEvent`, which is very useful in
places that need to support type flexibility, like an Asset-agnostic
retry plugin.
# Changelog
* **Added:** `AssetLoadFailedEvent<A>`
* **Added**: `UntypedAssetLoadFailedEvent`
* **Added:** `AssetReaderError::Http` for status code information on
HTTP errors. Before this, status codes were only available by parsing
the error message of generic `Io` errors.
* **Added:** `asset_server.get_path_id(path)`. This method simply gets
the asset id for the path. Without this, one was left using
`get_path_handle(path)`, which has the overhead of returning a strong
handle.
* **Fixed**: Made `AssetServer` loads return the same handle for assets
that already exist in a failed state. Now, when you attempt a `load`
that's in a `LoadState::Failed` state, it'll re-use the original asset
id. The advantage of this is that any dependent assets created using the
original handle will "unbreak" if a retry succeeds.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
fix an occasional crash when moving ui root nodes between cameras.
occasionally, updating the TargetCamera of a ui element and then
removing the element causes a crash.
i believe that is because when we assign a child in taffy, the old
parent doesn't remove that child from it's children, so we have:
```
user: create root node N1, camera A
-> layout::set_camera_children(A) :
- create implicit node A1
- assign 1 as child -> taffy.children[A1] = [N1], taffy.parents[1] = A1
user: move root node N1 to camera B
-> layout::set_camera_children(B) :
- create implicit node B1
- assign 1 as child -> taffy.children[A1] = [N1], taffy.children[B1] = [N1], taffy.parents[1] = B1
-> layout::set_camera_children(A) :
- remove implicit node A1 (which still has N1 as a child) ->
-> taffy sets parent[N1] = None ***
-> taffy.children[B1] = [N1], taffy.parents[1] = None
user: remove N1
-> layout::remove_entities(N1)
- since parent[N1] is None, it's not removed from B1 -> taffy.children[B1] = [N1], taffy.parents[1] is removed
-> layout::set_camera_children(B)
- remove implicit node B1
- taffy crash accessing taffy.parents[N1]
```
## Solution
we can work around this by making sure to remove the child from the old
parent if one exists (this pr).
i think a better fix may be for taffy to check in `Taffy::remove` and
only set the child's parent to None if it is currently equal to the node
being removed but i'm not sure if there's an explicit assumption we're
violating here (@nicoburns).
# Objective
- `DynamicUniformBuffer::push` takes an owned `T` but only uses a shared
reference to it
- This in turn requires users of `DynamicUniformBuffer::push` to
potentially unecessarily clone data
## Solution
- Have `DynamicUniformBuffer::push` take a shared reference to `T`
---
## Changelog
- `DynamicUniformBuffer::push` now takes a `&T` instead of `T`
## Migration Guide
- Users of `DynamicUniformBuffer::push` now need to pass references to
`DynamicUniformBuffer::push` (e.g. existing `uniforms.push(value)` will
now become `uniforms.push(&value)`)
# Objective
Expand the existing `Query` API to support more dynamic use cases i.e.
scripting.
## Prior Art
- #6390
- #8308
- #10037
## Solution
- Create a `QueryBuilder` with runtime methods to define the set of
component accesses for a built query.
- Create new `WorldQueryData` implementations `FilteredEntityMut` and
`FilteredEntityRef` as variants of `EntityMut` and `EntityRef` that
provide run time checked access to the components included in a given
query.
- Add new methods to `Query` to create "query lens" with a subset of the
access of the initial query.
### Query Builder
The `QueryBuilder` API allows you to define a query at runtime. At it's
most basic use it will simply create a query with the corresponding type
signature:
```rust
let query = QueryBuilder::<Entity, With<A>>::new(&mut world).build();
// is equivalent to
let query = QueryState::<Entity, With<A>>::new(&mut world);
```
Before calling `.build()` you also have the opportunity to add
additional accesses and filters. Here is a simple example where we add
additional filter terms:
```rust
let entity_a = world.spawn((A(0), B(0))).id();
let entity_b = world.spawn((A(0), C(0))).id();
let mut query_a = QueryBuilder::<Entity>::new(&mut world)
.with::<A>()
.without::<C>()
.build();
assert_eq!(entity_a, query_a.single(&world));
```
This alone is useful in that allows you to decide which archetypes your
query will match at runtime. However it is also very limited, consider a
case like the following:
```rust
let query_a = QueryBuilder::<&A>::new(&mut world)
// Add an additional access
.data::<&B>()
.build();
```
This will grant the query an additional read access to component B
however we have no way of accessing the data while iterating as the type
signature still only includes &A. For an even more concrete example of
this consider dynamic components:
```rust
let query_a = QueryBuilder::<Entity>::new(&mut world)
// Adding a filter is easy since it doesn't need be read later
.with_id(component_id_a)
// How do I access the data of this component?
.ref_id(component_id_b)
.build();
```
With this in mind the `QueryBuilder` API seems somewhat incomplete by
itself, we need some way method of accessing the components dynamically.
So here's one:
### Query Transmutation
If the problem is not having the component in the type signature why not
just add it? This PR also adds transmute methods to `QueryBuilder` and
`QueryState`. Here's a simple example:
```rust
world.spawn(A(0));
world.spawn((A(1), B(0)));
let mut query = QueryBuilder::<()>::new(&mut world)
.with::<B>()
.transmute::<&A>()
.build();
query.iter(&world).for_each(|a| assert_eq!(a.0, 1));
```
The `QueryState` and `QueryBuilder` transmute methods look quite similar
but are different in one respect. Transmuting a builder will always
succeed as it will just add the additional accesses needed for the new
terms if they weren't already included. Transmuting a `QueryState` will
panic in the case that the new type signature would give it access it
didn't already have, for example:
```rust
let query = QueryState::<&A, Option<&B>>::new(&mut world);
/// This is fine, the access for Option<&A> is less restrictive than &A
query.transmute::<Option<&A>>(&world);
/// Oh no, this would allow access to &B on entities that might not have it, so it panics
query.transmute::<&B>(&world);
/// This is right out
query.transmute::<&C>(&world);
```
This is quite an appealing API to also have available on `Query` however
it does pose one additional wrinkle: In order to to change the iterator
we need to create a new `QueryState` to back it. `Query` doesn't own
it's own state though, it just borrows it, so we need a place to borrow
it from. This is why `QueryLens` exists, it is a place to store the new
state so it can be borrowed when you call `.query()` leaving you with an
API like this:
```rust
fn function_that_takes_a_query(query: &Query<&A>) {
// ...
}
fn system(query: Query<(&A, &B)>) {
let lens = query.transmute_lens::<&A>();
let q = lens.query();
function_that_takes_a_query(&q);
}
```
Now you may be thinking: Hey, wait a second, you introduced the problem
with dynamic components and then described a solution that only works
for static components! Ok, you got me, I guess we need a bit more:
### Filtered Entity References
Currently the only way you can access dynamic components on entities
through a query is with either `EntityMut` or `EntityRef`, however these
can access all components and so conflict with all other accesses. This
PR introduces `FilteredEntityMut` and `FilteredEntityRef` as
alternatives that have additional runtime checking to prevent accessing
components that you shouldn't. This way you can build a query with a
`QueryBuilder` and actually access the components you asked for:
```rust
let mut query = QueryBuilder::<FilteredEntityRef>::new(&mut world)
.ref_id(component_id_a)
.with(component_id_b)
.build();
let entity_ref = query.single(&world);
// Returns Some(Ptr) as we have that component and are allowed to read it
let a = entity_ref.get_by_id(component_id_a);
// Will return None even though the entity does have the component, as we are not allowed to read it
let b = entity_ref.get_by_id(component_id_b);
```
For the most part these new structs have the exact same methods as their
non-filtered equivalents.
Putting all of this together we can do some truly dynamic ECS queries,
check out the `dynamic` example to see it in action:
```
Commands:
comp, c Create new components
spawn, s Spawn entities
query, q Query for entities
Enter a command with no parameters for usage.
> c A, B, C, Data 4
Component A created with id: 0
Component B created with id: 1
Component C created with id: 2
Component Data created with id: 3
> s A, B, Data 1
Entity spawned with id: 0v0
> s A, C, Data 0
Entity spawned with id: 1v0
> q &Data
0v0: Data: [1, 0, 0, 0]
1v0: Data: [0, 0, 0, 0]
> q B, &mut Data
0v0: Data: [2, 1, 1, 1]
> q B || C, &Data
0v0: Data: [2, 1, 1, 1]
1v0: Data: [0, 0, 0, 0]
```
## Changelog
- Add new `transmute_lens` methods to `Query`.
- Add new types `QueryBuilder`, `FilteredEntityMut`, `FilteredEntityRef`
and `QueryLens`
- `update_archetype_component_access` has been removed, archetype
component accesses are now determined by the accesses set in
`update_component_access`
- Added method `set_access` to `WorldQuery`, this is called before
`update_component_access` for queries that have a restricted set of
accesses, such as those built by `QueryBuilder` or `QueryLens`. This is
primarily used by the `FilteredEntity*` variants and has an empty trait
implementation.
- Added method `get_state` to `WorldQuery` as a fallible version of
`init_state` when you don't have `&mut World` access.
## Future Work
Improve performance of `FilteredEntityMut` and `FilteredEntityRef`,
currently they have to determine the accesses a query has in a given
archetype during iteration which is far from ideal, especially since we
already did the work when matching the archetype in the first place. To
avoid making more internal API changes I have left it out of this PR.
---------
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
Tried using "embedded_watcher" feature and `embedded_asset!()` from
another crate. The assets embedded fine but were not "watched." The
problem appears to be that checking for the feature was done inside the
macro, so rather than checking if "embedded_watcher" was enabled for
bevy, it would check if it was enabled for the current crate.
## Solution
I extracted the checks for the "embedded_watcher" feature into its own
function called `watched_path()`. No external changes.
### Alternative Solution
An alternative fix would be to not do any feature checking in
`embedded_asset!()` or an extracted function and always send the
full_path to `insert_asset()` where it's promptly dropped when the
feature isn't turned on. That would be simpler.
```
($app: ident, $source_path: expr, $path: expr) => {{
let mut embedded = $app
.world
.resource_mut::<$crate::io::embedded::EmbeddedAssetRegistry>();
let path = $crate::embedded_path!($source_path, $path);
//#[cfg(feature = "embedded_watcher")]
let full_path = std::path::Path::new(file!()).parent().unwrap().join($path);
//#[cfg(not(feature = "embedded_watcher"))]
//let full_path = std::path::PathBuf::new();
embedded.insert_asset(full_path, &path, include_bytes!($path));
}};
```
## Changelog
> Fix embedded_watcher feature to work with external crates
Rebased and finished version of
https://github.com/bevyengine/bevy/pull/8407. Huge thanks to @GitGhillie
for adjusting all the examples, and the many other people who helped
write this PR (@superdump , @coreh , among others) :)
Fixes https://github.com/bevyengine/bevy/issues/8369
---
## Changelog
- Added a `brightness` control to `Skybox`.
- Added an `intensity` control to `EnvironmentMapLight`.
- Added `ExposureSettings` and `PhysicalCameraParameters` for
controlling exposure of 3D cameras.
- Removed the baked-in `DirectionalLight` exposure Bevy previously
hardcoded internally.
## Migration Guide
- If using a `Skybox` or `EnvironmentMapLight`, use the new `brightness`
and `intensity` controls to adjust their strength.
- All 3D scene will now have different apparent brightnesses due to Bevy
implementing proper exposure controls. You will have to adjust the
intensity of your lights and/or your camera exposure via the new
`ExposureSettings` component to compensate.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
Co-authored-by: Marco Buono <thecoreh@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
gltf-rs does its own computations when accessing `transform.matrix()`
which does not use glam types, rendering #11238 useless if people were
to load gltf models and expecting the results to be deterministic across
platforms.
## Solution
Move the computation to bevy side which uses glam types, it was already
used in one place, so I created one common function to handle the two
cases.
The added benefit this has, is that some gltf files can have
translation, rotation and scale directly instead of matrix which skips
the transform computation completely, win-win.
# Objective
> Old MR: #5072
> ~~Associated UI MR: #5070~~
> Adresses #1618
Unify sprite management
## Solution
- Remove the `Handle<Image>` field in `TextureAtlas` which is the main
cause for all the boilerplate
- Remove the redundant `TextureAtlasSprite` component
- Renamed `TextureAtlas` asset to `TextureAtlasLayout`
([suggestion](https://github.com/bevyengine/bevy/pull/5103#discussion_r917281844))
- Add a `TextureAtlas` component, containing the atlas layout handle and
the section index
The difference between this solution and #5072 is that instead of the
`enum` approach is that we can more easily manipulate texture sheets
without any breaking changes for classic `SpriteBundle`s (@mockersf
[comment](https://github.com/bevyengine/bevy/pull/5072#issuecomment-1165836139))
Also, this approach is more *data oriented* extracting the
`Handle<Image>` and avoiding complex texture atlas manipulations to
retrieve the texture in both applicative and engine code.
With this method, the only difference between a `SpriteBundle` and a
`SpriteSheetBundle` is an **additional** component storing the atlas
handle and the index.
~~This solution can be applied to `bevy_ui` as well (see #5070).~~
EDIT: I also applied this solution to Bevy UI
## Changelog
- (**BREAKING**) Removed `TextureAtlasSprite`
- (**BREAKING**) Renamed `TextureAtlas` to `TextureAtlasLayout`
- (**BREAKING**) `SpriteSheetBundle`:
- Uses a `Sprite` instead of a `TextureAtlasSprite` component
- Has a `texture` field containing a `Handle<Image>` like the
`SpriteBundle`
- Has a new `TextureAtlas` component instead of a
`Handle<TextureAtlasLayout>`
- (**BREAKING**) `DynamicTextureAtlasBuilder::add_texture` takes an
additional `&Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasLayout::from_grid` no longer takes a
`Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasBuilder::finish` now returns a
`Result<(TextureAtlasLayout, Handle<Image>), _>`
- `bevy_text`:
- `GlyphAtlasInfo` stores the texture `Handle<Image>`
- `FontAtlas` stores the texture `Handle<Image>`
- `bevy_ui`:
- (**BREAKING**) Removed `UiAtlasImage` , the atlas bundle is now
identical to the `ImageBundle` with an additional `TextureAtlas`
## Migration Guide
* Sprites
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(SpriteSheetBundle {
- sprite: TextureAtlasSprite::new(0),
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ texture: texture_handle,
..Default::default()
});
}
```
* UI
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(AtlasImageBundle {
- texture_atlas_image: UiTextureAtlasImage {
- index: 0,
- flip_x: false,
- flip_y: false,
- },
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ image: UiImage {
+ texture: texture_handle,
+ flip_x: false,
+ flip_y: false,
+ },
..Default::default()
});
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- The
[`build-templated-pages`](4778fbeb65/tools/build-templated-pages)
tool is used to render the Markdown templates in the
[docs-template](4778fbeb65/docs-template)
folder.
- It depends on out outdated version of `toml_edit`.
## Solution
- Bump `toml_edit` to 0.21, disabling all features except `parse`.
# Objective
Add support for presenting each UI tree on a specific window and
viewport, while making as few breaking changes as possible.
This PR is meant to resolve the following issues at once, since they're
all related.
- Fixes#5622
- Fixes#5570
- Fixes#5621
Adopted #5892 , but started over since the current codebase diverged
significantly from the original PR branch. Also, I made a decision to
propagate component to children instead of recursively iterating over
nodes in search for the root.
## Solution
Add a new optional component that can be inserted to UI root nodes and
propagate to children to specify which camera it should render onto.
This is then used to get the render target and the viewport for that UI
tree. Since this component is optional, the default behavior should be
to render onto the single camera (if only one exist) and warn of
ambiguity if multiple cameras exist. This reduces the complexity for
users with just one camera, while giving control in contexts where it
matters.
## Changelog
- Adds `TargetCamera(Entity)` component to specify which camera should a
node tree be rendered into. If only one camera exists, this component is
optional.
- Adds an example of rendering UI to a texture and using it as a
material in a 3D world.
- Fixes recalculation of physical viewport size when target scale factor
changes. This can happen when the window is moved between displays with
different DPI.
- Changes examples to demonstrate assigning UI to different viewports
and windows and make interactions in an offset viewport testable.
- Removes `UiCameraConfig`. UI visibility now can be controlled via
combination of explicit `TargetCamera` and `Visibility` on the root
nodes.
---------
Co-authored-by: davier <bricedavier@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
- Update async channel to v2.
## Solution
- async channel doesn't support `send_blocking` on wasm anymore. So
don't compile the pipelined rendering plugin on wasm anymore.
- Replaces https://github.com/bevyengine/bevy/pull/10405
## Migration Guide
- The `PipelinedRendering` plugin is no longer exported on wasm. If you
are including it in your wasm builds you should remove it.
```rust
#[cfg(all(not(target_arch = "wasm32"))]
app.add_plugins(bevy_render::pipelined_rendering::PipelinedRenderingPlugin);
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Partial fix for #11235
- Fixes#11274
- Fixes#11320
- Fixes#11273
## Solution
- check update mode to trigger redraw request, instead of once a redraw
request has been triggered
- don't ignore device event in case of `Reactive` update mode
- make sure that at least 5 updates are triggered on application start
to ensure everything is correctly initialized
- trigger manual updates instead of relying on redraw requests when
there are no window or they are not visible
> Replaces #5213
# Objective
Implement sprite tiling and [9 slice
scaling](https://en.wikipedia.org/wiki/9-slice_scaling) for
`bevy_sprite`.
Allowing slice scaling and texture tiling.
Basic scaling vs 9 slice scaling:

Slicing example:
<img width="481" alt="Screenshot 2022-07-05 at 15 05 49"
src="https://user-images.githubusercontent.com/26703856/177336112-9e961af0-c0af-4197-aec9-430c1170a79d.png">
Tiling example:
<img width="1329" alt="Screenshot 2023-11-16 at 13 53 32"
src="https://github.com/bevyengine/bevy/assets/26703856/14db39b7-d9e0-4bc3-ba0e-b1f2db39ae8f">
# Solution
- `SpriteBundlue` now has a `scale_mode` component storing a
`SpriteScaleMode` enum with three variants:
- `Stretched` (default)
- `Tiled` to have sprites tile horizontally and/or vertically
- `Sliced` allowing 9 slicing the texture and optionally tile some
sections with a `Textureslicer`.
- `bevy_sprite` has two extra systems to compute a
`ComputedTextureSlices` if necessary,:
- One system react to changes on `Sprite`, `Handle<Image>` or
`SpriteScaleMode`
- The other listens to `AssetEvent<Image>` to compute slices on sprites
when the texture is ready or changed
- I updated the `bevy_sprite` extraction stage to extract potentially
multiple textures instead of one, depending on the presence of
`ComputedTextureSlices`
- I added two examples showcasing the slicing and tiling feature.
The addition of `ComputedTextureSlices` as a cache is to avoid querying
the image data, to retrieve its dimensions, every frame in a extract or
prepare stage. Also it reacts to changes so we can have stuff like this
(tiling example):
https://github.com/bevyengine/bevy/assets/26703856/a349a9f3-33c3-471f-8ef4-a0e5dfce3b01
# Related
- [ ] Once #5103 or #10099 is merged I can enable tiling and slicing for
texture sheets as ui
# To discuss
There is an other option, to consider slice/tiling as part of the asset,
using the new asset preprocessing but I have no clue on how to do it.
Also, instead of retrieving the Image dimensions, we could use the same
system as the sprite sheet and have the user give the image dimensions
directly (grid). But I think it's less user friendly
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
Adds support for accessing raw extension data of loaded GLTF assets
## Solution
Via the GLTF loader settings, you can specify whether or not to include
the GLTF source. While not the ideal way of solving this problem,
modeling all of GLTF within Bevy just for extensions adds a lot of
complexity to the way Bevy handles GLTF currently. See the example GLTF
meta file and code
```
(
meta_format_version: "1.0",
asset: Load(
loader: "bevy_gltf::loader::GltfLoader",
settings: (
load_meshes: true,
load_cameras: true,
load_lights: true,
include_source: true,
),
),
)
```
```rs
pub fn load_gltf(mut commands: Commands, assets: Res<AssetServer>) {
let my_gltf = assets.load("test_platform.gltf");
commands.insert_resource(MyAssetPack {
spawned: false,
handle: my_gltf,
});
}
#[derive(Resource)]
pub struct MyAssetPack {
pub spawned: bool,
pub handle: Handle<Gltf>,
}
pub fn spawn_gltf_objects(
mut commands: Commands,
mut my: ResMut<MyAssetPack>,
assets_gltf: Res<Assets<Gltf>>,
) {
// This flag is used to because this system has to be run until the asset is loaded.
// If there's a better way of going about this I am unaware of it.
if my.spawned {
return;
}
if let Some(gltf) = assets_gltf.get(&my.handle) {
info!("spawn");
my.spawned = true;
// spawn the first scene in the file
commands.spawn(SceneBundle {
scene: gltf.scenes[0].clone(),
..Default::default()
});
let source = gltf.source.as_ref().unwrap();
info!("materials count {}", &source.materials().size_hint().0);
info!(
"materials ext is some {}",
&source.materials().next().unwrap().extensions().is_some()
);
}
}
```
---
## Changelog
Added support for GLTF extensions through including raw GLTF source via
loader flag `GltfLoaderSettings::include_source == true`, stored in
`Gltf::source: Option<gltf::Gltf>`
## Migration Guide
This will have issues with "asset migrations", as there is currently no
way for .meta files to be migrated. Attempting to migrate .meta files
without the new flag will yield the following error:
```
bevy_asset::server: Failed to deserialize meta for asset test_platform.gltf: Failed to deserialize asset meta: SpannedError { code: MissingStructField { field: "include_source", outer: Some("GltfLoaderSettings") }, position: Position { line: 9, col: 9 } }
```
This means users who want to migrate their .meta files will have to add
the `include_source: true,` setting to their meta files by hand.
# Objective
The ability to ignore the global volume doesn't seem desirable and
complicates the API.
#7706 added global volume and the ability to ignore it, but there was no
further discussion about whether that's useful. Feel free to discuss
here :)
## Solution
Replace the `Volume` type's functionality with the `VolumeLevel`. Remove
`VolumeLevel`.
I also removed `DerefMut` derive that effectively made the volume `pub`
and actually ensured that the volume isn't set below `0` even in release
builds.
## Migration Guide
The option to ignore the global volume using `Volume::Absolute` has been
removed and `Volume` now stores the volume level directly, removing the
need for the `VolumeLevel` struct.
# Objective
This PR is heavily inspired by
https://github.com/bevyengine/bevy/pull/7682
It aims to solve the same problem: allowing the user to extend the
tracing subscriber with extra layers.
(in my case, I'd like to use `use
metrics_tracing_context::{MetricsLayer, TracingContextLayer};`)
## Solution
I'm proposing a different api where the user has the opportunity to take
the existing `subscriber` and apply any transformations on it.
---
## Changelog
- Added a `update_subscriber` option on the `LogPlugin` that lets the
user modify the `subscriber` (for example to extend it with more tracing
`Layers`
## Migration Guide
> This section is optional. If there are no breaking changes, you can
delete this section.
- Added a new field `update_subscriber` in the `LogPlugin`
---------
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>
# Objective
The table [here](https://github.com/nagisa/rust_tracy_client) shows
which versions of [Tracy](https://github.com/wolfpld/tracy) should be
used combined with which Rust deps.
Reading `bevy_log`'s `Cargo.toml` can be slightly confusing since the
exact versions are not picked from the same row.
Reading the produced `Cargo.lock` when building a Bevy example shows
that it's the most recent row that is resolved, but this should be more
clearly understood without needing to check the lock file.
## Solution
- Specify versions from the compatibility table including patch version
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- `bevy_gizmos` cannot work if both `bevy_sprite` and `bevy_pbr` are
disabled.
- It silently fails to render, making it difficult to debug.
- Fixes#10984
## Solution
- Log an error message when `GizmoPlugin` is registered.
## Alternatives
I chose to log an error message, since it seemed the least intrusive of
potential solutions. Some alternatives include:
- Choosing one dependency as the default, neglecting the other. (#11035)
- Raising a compile error when neither dependency is enabled. ([See my
original
comment](https://github.com/bevyengine/bevy/issues/10984#issuecomment-1873420426))
- Raising a compile warning using a macro hack. ([Pre-RFC - Add
compile_warning!
macro](https://internals.rust-lang.org/t/pre-rfc-add-compile-warning-macro/9370/7?u=bd103))
- Logging a warning instead of an error.
- _This might be the better option. Let me know if I should change it._
---
## Changelog
- `bevy_gizmos` will now log an error if neither `bevy_pbr` nor
`bevy_sprite` are enabled.
# Objective
- Implementing `Default` for
[`CubicCurve`](https://docs.rs/bevy/latest/bevy/math/cubic_splines/struct.CubicCurve.html)
does not make sense because it cannot be mutated after creation.
- Closes#11209.
- Alternative to #11211.
## Solution
- Remove `Default` from `CubicCurve`'s derive statement.
Based off of @mockersf comment
(https://github.com/bevyengine/bevy/pull/11211#issuecomment-1880088036):
> CubicCurve can't be updated once created... I would prefer to remove
the Default impl as it doesn't make sense
---
## Changelog
- Removed the `Default` implementation for `CubicCurve`.
## Migration Guide
- Remove `CubicCurve` from any structs that implement `Default`.
- Wrap `CubicCurve` in a new type and provide your own default.
```rust
#[derive(Deref)]
struct MyCubicCurve<P: Point>(pub CubicCurve<P>);
impl Default for MyCubicCurve<Vec2> {
fn default() -> Self {
let points = [[
vec2(-1.0, -20.0),
vec2(3.0, 2.0),
vec2(5.0, 3.0),
vec2(9.0, 8.0),
]];
Self(CubicBezier::new(points).to_curve())
}
}
```
Based on discussion after #11268 was merged:
Instead of panicking should the impl of `TypeId::hash` change
significantly, have a fallback and detect this in a test.
# Objective
In #11330 I found out that `Parent::get` didn't get inlined, **even with
LTO on**!
This means that just to access a field, we have an instruction cache
invalidation, we will move some registers to the stack, will jump to new
instructions, move the field into a register, then do the same dance in
the other direction to go back to the call site.
## Solution
Mark trivial functions as `#[inline]`.
`inline(always)` may increase compilation time proportional to how many
time the function is called **and the size of the function marked with
`inline`**. Since we mark as `inline` functions that consists in a
single instruction, the cost is absolutely negligible.
I also took the opportunity to `inline` other functions. I'm not as
confident that marking functions calling other functions as `inline`
works similarly to very simple functions, so I used `inline` over
`inline(always)`, which doesn't have the same downsides as
`inline(always)`.
More information on inlining in rust:
https://nnethercote.github.io/perf-book/inlining.html
Not always, but skip it if the new length is smaller.
For context, `path_cache` is a `Vec<Vec<Option<Entity>>>`.
# Objective
Previously, when setting a new length to the `path_cache`, we would:
1. Deallocate all existing `Vec<Option<Entity>>`
2. Deallocate the `path_cache`
3. Allocate a new `Vec<Vec<Option<Entity>>>`, where each item is an
empty `Vec`, and would have to be allocated when pushed to.
This is a lot of allocations!
## Solution
Use
[`Vec::resize_with`](https://doc.rust-lang.org/stable/std/vec/struct.Vec.html#method.resize_with).
With this change, what occurs is:
1. We `clear` each `Vec<Option<Entity>>`, keeping the allocation, but
making the memory of each `Vec` re-usable
2. We only append new `Vec` to `path_cache` when it is too small.
* Fixes#11328
### Note on performance
I didn't benchmark it, I just ran a diff on the generated assembly (ran
with `--profile stress-test` and `--native`). I found this PR has 20
less instructions in `apply_animation` (out of 2504).
Though on a purely abstract level, I can deduce this leads to less
allocation.
More information on profiling allocations in rust:
https://nnethercote.github.io/perf-book/heap-allocations.html
## Future work
I think a [jagged vec](https://en.wikipedia.org/wiki/Jagged_array) would
be much more pertinent. Because it allocates everything in a single
contiguous buffer.
This would avoid dancing around allocations, and reduces the overhead of
one `*mut T` and two `usize` per row, also removes indirection,
improving cache efficiency. I think it would both improve code quality
and performance.
# Objective
`TypeId` contains a high-quality hash. Whenever a lookup based on a
`TypeId` is performed (e.g. to insert/remove components), the hash is
run through a second hash function. This is unnecessary.
## Solution
Skip re-hashing `TypeId`s.
In my
[testing](https://gist.github.com/SpecificProtagonist/4b49ad74c6b82b0aedd3b4ea35121be8),
this improves lookup performance consistently by 10%-15% (of course, the
lookup is only a small part of e.g. a bundle insertion).
# Objective
While working on #10832, I found this code very dense and hard to
understand.
I was not confident in my fix (or the correctness of the existing code).
## Solution
Clean up, test and document the code used in the `apply_animation`
system.
I also added a pair of length-related utility methods to `Keyframes` for
easier testing. They seemed generically useful, so I made them pub.
## Changelog
- Added `VariableCurve::find_current_keyframe` method.
- Added `Keyframes::len` and `is_empty` methods.
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
The purpose of this PR is to begin putting together a unified identifier
structure that can be used by entities and later components (as
entities) as well as relationship pairs for relations, to enable all of
these to be able to use the same storages. For the moment, to keep
things small and focused, only `Entity` is being changed to make use of
the new `Identifier` type, keeping `Entity`'s API and
serialization/deserialization the same. Further changes are for
follow-up PRs.
## Solution
`Identifier` is a wrapper around `u64` split into two `u32` segments
with the idea of being generalised to not impose restrictions on
variants. That is for `Entity` to do. Instead, it is a general API for
taking bits to then merge and map into a `u64` integer. It exposes
low/high methods to return the two value portions as `u32` integers,
with then the MSB masked for usage as a type flag, enabling entity kind
discrimination and future activation/deactivation semantics.
The layout in this PR for `Identifier` is described as below, going from
MSB -> LSB.
```
|F| High value | Low value |
|_|_______________________________|________________________________|
|1| 31 | 32 |
F = Bit Flags
```
The high component in this implementation has only 31 bits, but that
still leaves 2^31 or 2,147,483,648 values that can be stored still, more
than enough for any generation/relation kinds/etc usage. The low part is
a full 32-bit index. The flags allow for 1 bit to be used for
entity/pair discrimination, as these have different usages for the
low/high portions of the `Identifier`. More bits can be reserved for
more variants or activation/deactivation purposes, but this currently
has no use in bevy.
More bits could be reserved for future features at the cost of bits for
the high component, so how much to reserve is up for discussion. Also,
naming of the struct and methods are also subject to further
bikeshedding and feedback.
Also, because IDs can have different variants, I wonder if
`Entity::from_bits` needs to return a `Result` instead of potentially
panicking on receiving an invalid ID.
PR is provided as an early WIP to obtain feedback and notes on whether
this approach is viable.
---
## Changelog
### Added
New `Identifier` struct for unifying IDs.
### Changed
`Entity` changed to use new `Identifier`/`IdentifierMask` as the
underlying ID logic.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
# Objective
- It is common to run a system only when the clock is paused or not
paused, but this run condition doesn't exist.
## Solution
- Add the "paused" run condition.
---
## Changelog
- Systems can now be scheduled to run only if the clock is paused or not
using `.run_if(paused())` or `.run_if(not(paused()))`.
---------
Co-authored-by: radiish <cb.setho@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/11222
## Solution
SSAO's sample_mip_level was always giving negative values because it was
in UV space (0..1) when it needed to be in pixel units (0..resolution).
Fixing it so it properly samples lower mip levels when appropriate is a
pretty large speedup (~3.2ms -> ~1ms at 4k, ~507us-> 256us at 1080p on a
6800xt), and I didn't notice any obvious visual quality differences.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Implement bounding volume trait and the 4 types from
https://github.com/bevyengine/bevy/issues/10570. I will add intersection
tests in a future PR.
## Solution
Implement mostly everything as written in the issue, except:
- Intersection is no longer a method on the bounding volumes, but a
separate trait.
- I implemented a `visible_area` since it's the most common usecase to
care about the surface that could collide with cast rays.
- Maybe we want both?
---
## Changelog
- Added bounding volume types to bevy_math
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
In the past `winit:🪟:Window` was not Send + Sync on web.
https://github.com/rust-windowing/winit/pull/2834 made
`winit:🪟:Window` Sync + Send so Bevy's `unsafe impl` is no longer
necessary.
## Solution
Remove the unsafe impls.
# Objective
This dependency is seemingly no longer used directly after #7267.
Unfortunately, this doesn't fix us having versions of `event-listener`
in our tree.
Closes#10654
## Solution
Remove it, see if anything breaks.
# Objective
- Since #11227, Bevy doesn't work on mobile anymore. Windows are not
created.
## Solution
- Create initial window on mobile after the initial `Resume` event.
macOS is included because it's excluded from the other initial window
creation and I didn't want it to feel alone. Also, it makes sense. this
is needed for Android
cfcb6885e3/crates/bevy_winit/src/lib.rs (L152)
- request redraw during plugin initialisation (needed for WebGPU)
- request redraw when receiving `AboutToWait` instead of at the end of
the event handler. request to redraw during a `RedrawRequested` event
are ignored on iOS
# Objective
Issue #10243: rendering multiple triangles in the same place results in
flickering.
## Solution
Considered these alternatives:
- `depth_bias` may not work, because of high number of entities, so
creating a material per entity is practically not possible
- rendering at slightly different positions does not work, because when
camera is far, float rounding causes the same issues (edit: assuming we
have to use the same `depth_bias`)
- considered implementing deterministic operation like
`query.par_iter().flat_map(...).collect()` to be used in
`check_visibility` system (which would solve the issue since query is
deterministic), and could not figure out how to make it as cheap as
current approach with thread-local collectors (#11249)
So adding an option to sort entities after `check_visibility` system
run.
Should not be too bad, because after visibility check, only a handful
entities remain.
This is probably not the only source of non-determinism in Bevy, but
this is one I could find so far. At least it fixes the repro example.
## Changelog
- `DeterministicRenderingConfig` option to enable deterministic
rendering
## Test
<img width="1392" alt="image"
src="https://github.com/bevyengine/bevy/assets/28969/c735bce1-3a71-44cd-8677-c19f6c0ee6bd">
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
I want to run a system once after a given delay.
- First, I tried using the `on_timer` run condition, but it uses a
repeating timer, causing the system to run multiple times.
- Next, I tried combining the `on_timer` with the `run_once` run
condition. However, this causes the timer to *tick* only once, so the
system is never executed.
## Solution
- ~~Replace `on_timer` by `on_time_interval` and `on_real_timer` by
`on_real_time_interval` to clarify the meaning (the old ones are
deprecated to avoid a breaking change).~~ (Reverted according to
feedback)
- Add `once_after_delay` and `once_after_real_delay` to run the system
exactly once after the delay, using `TimerMode::Once`.
- Add `repeating_after_delay` and `repeating_after_real_delay` to run
the system indefinitely after the delay, using `Timer::finished` instead
of `Timer::just_finished`.
---
## Changelog
### Added
- `once_after_delay` and `once_after_real_delay` run conditions to run
the system exactly once after the delay, using `TimerMode::Once`.
- `repeating_after_delay` and `repeating_after_real_delay` run
conditions to run the system indefinitely after the delay, using
`Timer::finished` instead of `Timer::just_finished`.
# Objective
- Implements change described in
https://github.com/bevyengine/bevy/issues/3022
- Goal is to allow Entity to benefit from niche optimization, especially
in the case of Option<Entity> to reduce memory overhead with structures
with empty slots
## Discussion
- First PR attempt: https://github.com/bevyengine/bevy/pull/3029
- Discord:
https://discord.com/channels/691052431525675048/1154573759752183808/1154573764240093224
## Solution
- Change `Entity::generation` from u32 to NonZeroU32 to allow for niche
optimization.
- The reason for changing generation rather than index is so that the
costs are only encountered on Entity free, instead of on Entity alloc
- There was some concern with generations being used, due to there being
some desire to introduce flags. This was more to do with the original
retirement approach, however, in reality even if generations were
reduced to 24-bits, we would still have 16 million generations available
before wrapping and current ideas indicate that we would be using closer
to 4-bits for flags.
- Additionally, another concern was the representation of relationships
where NonZeroU32 prevents us using the full address space, talking with
Joy it seems unlikely to be an issue. The majority of the time these
entity references will be low-index entries (ie. `ChildOf`, `Owes`),
these will be able to be fast lookups, and the remainder of the range
can use slower lookups to map to the address space.
- It has the additional benefit of being less visible to most users,
since generation is only ever really set through `from_bits` type
methods.
- `EntityMeta` was changed to match
- On free, generation now explicitly wraps:
- Originally, generation would panic in debug mode and wrap in release
mode due to using regular ops.
- The first attempt at this PR changed the behavior to "retire" slots
and remove them from use when generations overflowed. This change was
controversial, and likely needs a proper RFC/discussion.
- Wrapping matches current release behaviour, and should therefore be
less controversial.
- Wrapping also more easily migrates to the retirement approach, as
users likely to exhaust the exorbitant supply of generations will code
defensively against aliasing and that defensive code is less likely to
break than code assuming that generations don't wrap.
- We use some unsafe code here when wrapping generations, to avoid
branch on NonZeroU32 construction. It's guaranteed safe due to how we
perform wrapping and it results in significantly smaller ASM code.
- https://godbolt.org/z/6b6hj8PrM
## Migration
- Previous `bevy_scene` serializations have a high likelihood of being
broken, as they contain 0th generation entities.
## Current Issues
- `Entities::reserve_generations` and `EntityMapper` wrap now, even in
debug - although they technically did in release mode already so this
probably isn't a huge issue. It just depends if we need to change
anything here?
---------
Co-authored-by: Natalie Baker <natalie.baker@advancednavigation.com>
Update to `glam` 0.25, `encase` 0.7 and `hexasphere` to 10.0
## Changelog
Added the `FloatExt` trait to the `bevy_math` prelude which adds `lerp`,
`inverse_lerp` and `remap` methods to the `f32` and `f64` types.
# Objective
When you have no idea what to put after `#` when loading an asset, error
message may help.
## Solution
Add all labels to the error message.
## Test plan
Modified `anti_alias` example to put incorrect label, the error is:
```
2024-01-08T07:41:25.462287Z ERROR bevy_asset::server: The file at 'models/FlightHelmet/FlightHelmet.gltf' does not contain the labeled asset 'Rrrr'; it contains the following 25 assets: 'Material0', 'Material1', 'Material2', 'Material3', 'Material4', 'Material5', 'Mesh0', 'Mesh0/Primitive0', 'Mesh1', 'Mesh1/Primitive0', 'Mesh2', 'Mesh2/Primitive0', 'Mesh3', 'Mesh3/Primitive0', 'Mesh4', 'Mesh4/Primitive0', 'Mesh5', 'Mesh5/Primitive0', 'Node0', 'Node1', 'Node2', 'Node3', 'Node4', 'Node5', 'Scene0'
```
# Objective
`Column` unconditionally requires three separate allocations: one for
the data, and two for the tick Vecs. The tick Vecs aren't really needed
for Resources, so we're allocating a bunch of one-element Vecs, and it
costs two extra dereferences when fetching/inserting/removing resources.
## Solution
Drop one level lower in `ResourceData` and directly store a `BlobVec`
and two `UnsafeCell<Tick>`s. This should significantly shrink
`ResourceData` (exchanging 6 usizes for 2 u32s), removes the need to
dereference two separate ticks when inserting/removing/fetching
resources, and can significantly decrease the number of small
allocations the ECS makes by default.
This tentatively might have a non-insignificant impact on the CPU cost
for rendering since we're constantly fetching resources in draw
functions, depending on how aggressively inlined the functions are.
This requires reimplementing some of the unsafe functions that `Column`
wraps, but it also allows us to delete a few Column APIs that were only
used for Resources, so the total amount of unsafe we're maintaining
shouldn't change significantly.
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
When creating a normalized direction from a vector, it can be useful to
get both the direction *and* the original length of the vector.
This came up when I was recreating some Parry APIs using bevy_math, and
doing it manually is quite painful. Nalgebra calls this method
[`Unit::try_new_and_get`](https://docs.rs/nalgebra/latest/nalgebra/base/struct.Unit.html#method.try_new_and_get).
## Solution
Add a `new_and_length` method to `Direction2d` and `Direction3d`.
Usage:
```rust
if let Ok((direction, length)) = Direction2d::new_and_length(Vec2::X * 10.0) {
assert_eq!(direction, Vec2::X);
assert_eq!(length, 10.0);
}
```
I'm open to different names, couldn't come up with a perfectly clear one
that isn't too long. My reasoning with the current name is that it's
like using `new` and calling `length` on the original vector.
# Objective
In #9604 we removed the ability to define an `EntityCommand` as
`fn(Entity, &mut World)`. However I have since realized that `fn(Entity,
&mut World)` is an incredibly expressive and powerful way to define a
command for an entity that may or may not exist (`fn(EntityWorldMut)`
only works on entities that are alive).
## Solution
Support `EntityCommand`s in the style of `fn(Entity, &mut World)`, as
well as `fn(EntityWorldMut)`. Use a marker generic on the
`EntityCommand` trait to allow multiple impls.
The second commit in this PR replaces all of the internal command
definitions with ones using `fn` definitions. This is mostly just to
show off how expressive this style of command is -- we can revert this
commit if we'd rather avoid breaking changes.
---
## Changelog
Re-added support for expressively defining an `EntityCommand` as a
function that takes `Entity, &mut World`.
## Migration Guide
All `Command` types in `bevy_ecs`, such as `Spawn`, `SpawnBatch`,
`Insert`, etc., have been made private. Use the equivalent methods on
`Commands` or `EntityCommands` instead.
# Objective
- Make it possible to react to arbitrary state changes
- this will be useful regardless of the other changes to states
currently being discussed
## Solution
- added `StateTransitionEvent<S>` struct
- previously, this would have been impossible:
```rs
#[derive(States, Eq, PartialEq, Hash, Copy, Clone, Default)]
enum MyState {
#[default]
Foo,
Bar(MySubState),
}
enum MySubState {
Spam,
Eggs,
}
app.add_system(Update, on_enter_bar);
fn on_enter_bar(trans: EventReader<StateTransition<MyState>>){
for (befoare, after) in trans.read() {
match before, after {
MyState::Foo, MyState::Bar(_) => info!("detected transition foo => bar");
_, _ => ();
}
}
}
```
---
## Changelog
- Added
- `StateTransitionEvent<S>` - Fired on state changes of `S`
## Migration Guide
N/A no breaking changes
---------
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
# Motivation
When spawning entities into a scene, it is very common to create assets
like meshes and materials and to add them via asset handles. A common
setup might look like this:
```rust
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
) {
commands.spawn(PbrBundle {
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
..default()
});
}
```
Let's take a closer look at the part that adds the assets using `add`.
```rust
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
```
Here, "mesh" and "material" are both repeated three times. It's very
explicit, but I find it to be a bit verbose. In addition to being more
code to read and write, the extra characters can sometimes also lead to
the code being formatted to span multiple lines even though the core
task, adding e.g. a primitive mesh, is extremely simple.
A way to address this is by using `.into()`:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }.into()),
material: materials.add(Color::RED.into()),
```
This is fine, but from the names and the type of `meshes`, we already
know what the type should be. It's very clear that `Cube` should be
turned into a `Mesh` because of the context it's used in. `.into()` is
just seven characters, but it's so common that it quickly adds up and
gets annoying.
It would be nice if you could skip all of the conversion and let Bevy
handle it for you:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
```
# Objective
Make adding assets more ergonomic by making `Assets::add` take an `impl
Into<A>` instead of `A`.
## Solution
`Assets::add` now takes an `impl Into<A>` instead of `A`, so e.g. this
works:
```rust
commands.spawn(PbrBundle {
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
..default()
});
```
I also changed all examples to use this API, which increases consistency
as well because `Mesh::from` and `into` were being used arbitrarily even
in the same file. This also gets rid of some lines of code because
formatting is nicer.
---
## Changelog
- `Assets::add` now takes an `impl Into<A>` instead of `A`
- Examples don't use `T::from(K)` or `K.into()` when adding assets
## Migration Guide
Some `into` calls that worked previously might now be broken because of
the new trait bounds. You need to either remove `into` or perform the
conversion explicitly with `from`:
```rust
// Doesn't compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }.into()),
// These compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }),
let mesh_handle = meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
```
## Concerns
I believe the primary concerns might be:
1. Is this too implicit?
2. Does this increase codegen bloat?
Previously, the two APIs were using `into` or `from`, and now it's
"nothing" or `from`. You could argue that `into` is slightly more
explicit than "nothing" in cases like the earlier examples where a
`Color` gets converted to e.g. a `StandardMaterial`, but I personally
don't think `into` adds much value even in this case, and you could
still see the actual type from the asset type.
As for codegen bloat, I doubt it adds that much, but I'm not very
familiar with the details of codegen. I personally value the user-facing
code reduction and ergonomics improvements that these changes would
provide, but it might be worth checking the other effects in more
detail.
Another slight concern is migration pain; apps might have a ton of
`into` calls that would need to be removed, and it did take me a while
to do so for Bevy itself (maybe around 20-40 minutes). However, I think
the fact that there *are* so many `into` calls just highlights that the
API could be made nicer, and I'd gladly migrate my own projects for it.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
{kind=link}
{kind=link}