# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
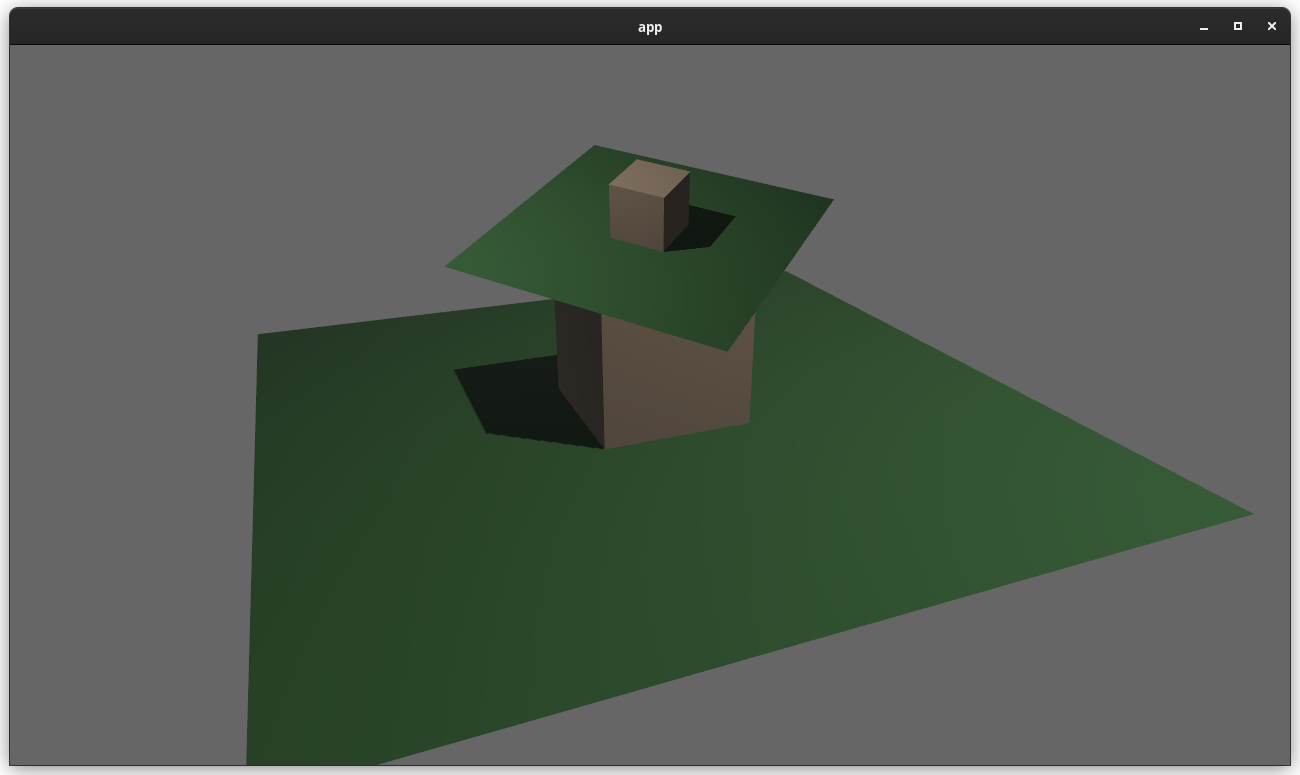
### two_passes example with the "second pass" camera configured to "load" the depth
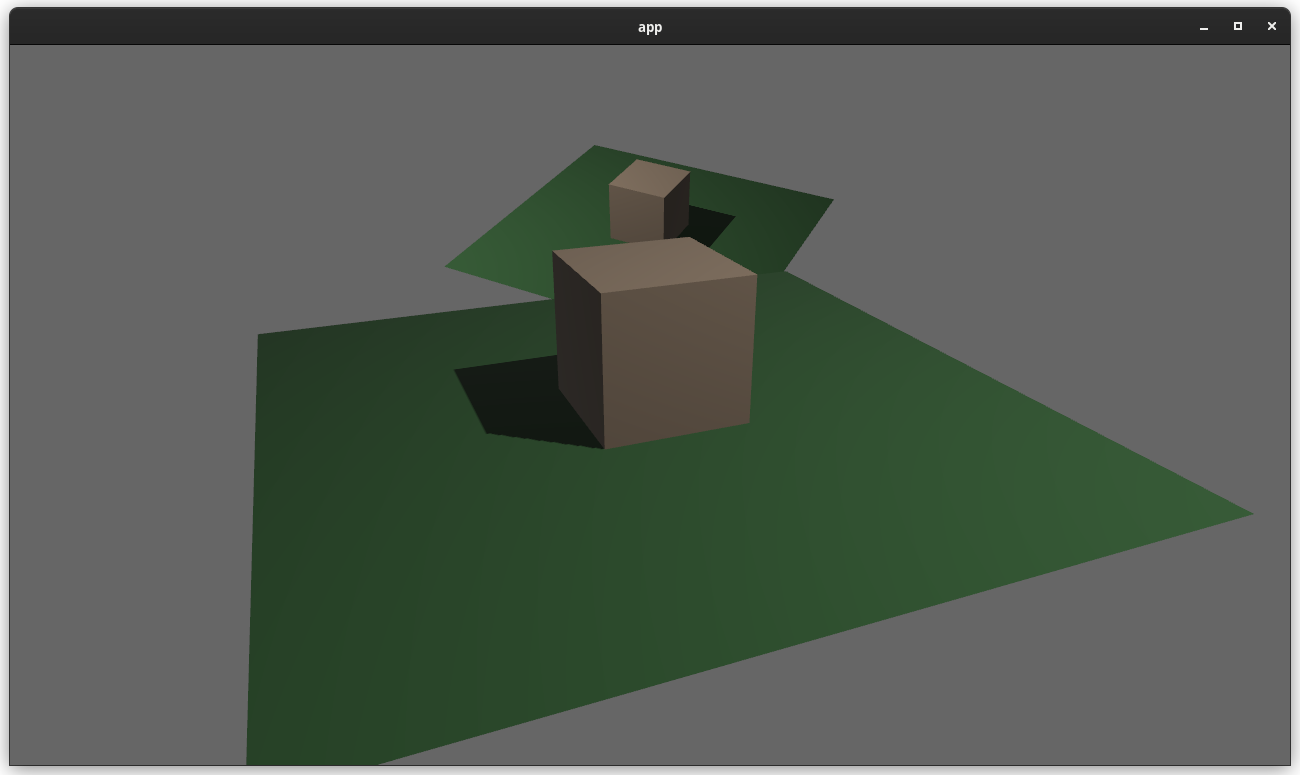
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
# Objective
In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access.
## Solution
Remove the `With<Handle<Mesh>>` filter
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
- To fix the broken commented code in `examples/shader/compute_shader_game_of_life.rs` for disabling frame throttling
## Solution
- Change the commented code from using the old `WindowDescriptor::vsync` to the new `WindowDescriptor::present_mode`
### Note
I chose to use the fully qualified scope `bevy:🪟:PresentWindow::Immediate` rather than explicitly including `PresentWindow` to avoid an unused import when the code is commented.
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
## Objective
The [`DrawMeshInstanced`] command in the example sets vertex buffer 0 twice, with two identical calls to:
```rs
pass.set_vertex_buffer(0, gpu_mesh.vertex_buffer.slice(..));
```
## Solution
Remove the second call as it is unecessary.
[`DrawMeshInstanced`]: f3de12bc5e/examples/shader/shader_instancing.rs (L217-L258)
# Objective
While trying to learn how to use custom shaders, I had difficulty figuring out how to use a vertex shader. My confusion was mostly because all the other shader examples used a custom pipeline, but I didn't want a custom pipeline. After digging around I realised that I simply needed to add a function to the `impl Material` block. I also searched what was the default shader used, because it wasn't obvious to me where to find it.
## Solution
Added a few comments explaining what is going on in the example and a link to the default shader.
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
This adds "high level" `Material` and `SpecializedMaterial` traits, which can be used with a `MaterialPlugin<T: SpecializedMaterial>`. `MaterialPlugin` automatically registers the appropriate resources, draw functions, and queue systems. The `Material` trait is simpler, and should cover most use cases. `SpecializedMaterial` is like `Material`, but it also requires defining a "specialization key" (see #3031). `Material` has a trivial blanket impl of `SpecializedMaterial`, which allows us to use the same types + functions for both.
This makes defining custom 3d materials much simpler (see the `shader_material` example diff) and ensures consistent behavior across all 3d materials (both built in and custom). I ported the built in `StandardMaterial` to `MaterialPlugin`. There is also a new `MaterialMeshBundle<T: SpecializedMaterial>`, which `PbrBundle` aliases to.
# Objective
- Our crevice is still called "crevice", which we can't use for a release
- Users would need to use our "crevice" directly to be able to use the derive macro
## Solution
- Rename crevice to bevy_crevice, and crevice-derive to bevy-crevice-derive
- Re-export it from bevy_render, and use it from bevy_render everywhere
- Fix derive macro to work either from bevy_render, from bevy_crevice, or from bevy
## Remaining
- It is currently re-exported as `bevy::render::bevy_crevice`, is it the path we want?
- After a brief suggestion to Cart, I changed the version to follow Bevy version instead of crevice, do we want that?
- Crevice README.md need to be updated
- in the `Cargo.toml`, there are a few things to change. How do we want to change them? How do we keep attributions to original Crevice?
```
authors = ["Lucien Greathouse <me@lpghatguy.com>"]
documentation = "https://docs.rs/crevice"
homepage = "https://github.com/LPGhatguy/crevice"
repository = "https://github.com/LPGhatguy/crevice"
```
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#3379
## Solution
The custom mesh pipelines needed to be specialized on each mesh's primitive topology, as done in `queue_meshes()`
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
## Shader Imports
This adds "whole file" shader imports. These come in two flavors:
### Asset Path Imports
```rust
// /assets/shaders/custom.wgsl
#import "shaders/custom_material.wgsl"
[[stage(fragment)]]
fn fragment() -> [[location(0)]] vec4<f32> {
return get_color();
}
```
```rust
// /assets/shaders/custom_material.wgsl
[[block]]
struct CustomMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CustomMaterial;
```
### Custom Path Imports
Enables defining custom import paths. These are intended to be used by crates to export shader functionality:
```rust
// bevy_pbr2/src/render/pbr.wgsl
#import bevy_pbr::mesh_view_bind_group
#import bevy_pbr::mesh_bind_group
[[block]]
struct StandardMaterial {
base_color: vec4<f32>;
emissive: vec4<f32>;
perceptual_roughness: f32;
metallic: f32;
reflectance: f32;
flags: u32;
};
/* rest of PBR fragment shader here */
```
```rust
impl Plugin for MeshRenderPlugin {
fn build(&self, app: &mut bevy_app::App) {
let mut shaders = app.world.get_resource_mut::<Assets<Shader>>().unwrap();
shaders.set_untracked(
MESH_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_bind_group"),
);
shaders.set_untracked(
MESH_VIEW_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_view_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_view_bind_group"),
);
```
By convention these should use rust-style module paths that start with the crate name. Ultimately we might enforce this convention.
Note that this feature implements _run time_ import resolution. Ultimately we should move the import logic into an asset preprocessor once Bevy gets support for that.
## Decouple Mesh Logic from PBR Logic via MeshRenderPlugin
This breaks out mesh rendering code from PBR material code, which improves the legibility of the code, decouples mesh logic from PBR logic, and opens the door for a future `MaterialPlugin<T: Material>` that handles all of the pipeline setup for arbitrary shader materials.
## Removed `RenderAsset<Shader>` in favor of extracting shaders into RenderPipelineCache
This simplifies the shader import implementation and removes the need to pass around `RenderAssets<Shader>`.
## RenderCommands are now fallible
This allows us to cleanly handle pipelines+shaders not being ready yet. We can abort a render command early in these cases, preventing bevy from trying to bind group / do draw calls for pipelines that couldn't be bound. This could also be used in the future for things like "components not existing on entities yet".
# Next Steps
* Investigate using Naga for "partial typed imports" (ex: `#import bevy_pbr::material::StandardMaterial`, which would import only the StandardMaterial struct)
* Implement `MaterialPlugin<T: Material>` for low-boilerplate custom material shaders
* Move shader import logic into the asset preprocessor once bevy gets support for that.
Fixes#3132
Adds new `EntityRenderCommand`, `EntityPhaseItem`, and `CachedPipelinePhaseItem` traits to make it possible to reuse RenderCommands across phases. This should be helpful for features like #3072 . It also makes the trait impls slightly less generic-ey in the common cases.
This also fixes the custom shader examples to account for the recent Frustum Culling and MSAA changes (the UX for these things will be improved later).
## New Features
This adds the following to the new renderer:
* **Shader Assets**
* Shaders are assets again! Users no longer need to call `include_str!` for their shaders
* Shader hot-reloading
* **Shader Defs / Shader Preprocessing**
* Shaders now support `# ifdef NAME`, `# ifndef NAME`, and `# endif` preprocessor directives
* **Bevy RenderPipelineDescriptor and RenderPipelineCache**
* Bevy now provides its own `RenderPipelineDescriptor` and the wgpu version is now exported as `RawRenderPipelineDescriptor`. This allows users to define pipelines with `Handle<Shader>` instead of needing to manually compile and reference `ShaderModules`, enables passing in shader defs to configure the shader preprocessor, makes hot reloading possible (because the descriptor can be owned and used to create new pipelines when a shader changes), and opens the doors to pipeline specialization.
* The `RenderPipelineCache` now handles compiling and re-compiling Bevy RenderPipelineDescriptors. It has internal PipelineLayout and ShaderModule caches. Users receive a `CachedPipelineId`, which can be used to look up the actual `&RenderPipeline` during rendering.
* **Pipeline Specialization**
* This enables defining per-entity-configurable pipelines that specialize on arbitrary custom keys. In practice this will involve specializing based on things like MSAA values, Shader Defs, Bind Group existence, and Vertex Layouts.
* Adds a `SpecializedPipeline` trait and `SpecializedPipelines<MyPipeline>` resource. This is a simple layer that generates Bevy RenderPipelineDescriptors based on a custom key defined for the pipeline.
* Specialized pipelines are also hot-reloadable.
* This was the result of experimentation with two different approaches:
1. **"generic immediate mode multi-key hash pipeline specialization"**
* breaks up the pipeline into multiple "identities" (the core pipeline definition, shader defs, mesh layout, bind group layout). each of these identities has its own key. looking up / compiling a specific version of a pipeline requires composing all of these keys together
* the benefit of this approach is that it works for all pipelines / the pipeline is fully identified by the keys. the multiple keys allow pre-hashing parts of the pipeline identity where possible (ex: pre compute the mesh identity for all meshes)
* the downside is that any per-entity data that informs the values of these keys could require expensive re-hashes. computing each key for each sprite tanked bevymark performance (sprites don't actually need this level of specialization yet ... but things like pbr and future sprite scenarios might).
* this is the approach rafx used last time i checked
2. **"custom key specialization"**
* Pipelines by default are not specialized
* Pipelines that need specialization implement a SpecializedPipeline trait with a custom key associated type
* This allows specialization keys to encode exactly the amount of information required (instead of needing to be a combined hash of the entire pipeline). Generally this should fit in a small number of bytes. Per-entity specialization barely registers anymore on things like bevymark. It also makes things like "shader defs" way cheaper to hash because we can use context specific bitflags instead of strings.
* Despite the extra trait, it actually generally makes pipeline definitions + lookups simpler: managing multiple keys (and making the appropriate calls to manage these keys) was way more complicated.
* I opted for custom key specialization. It performs better generally and in my opinion is better UX. Fortunately the way this is implemented also allows for custom caches as this all builds on a common abstraction: the RenderPipelineCache. The built in custom key trait is just a simple / pre-defined way to interact with the cache
## Callouts
* The SpecializedPipeline trait makes it easy to inherit pipeline configuration in custom pipelines. The changes to `custom_shader_pipelined` and the new `shader_defs_pipelined` example illustrate how much simpler it is to define custom pipelines based on the PbrPipeline.
* The shader preprocessor is currently pretty naive (it just uses regexes to process each line). Ultimately we might want to build a more custom parser for more performance + better error handling, but for now I'm happy to optimize for "easy to implement and understand".
## Next Steps
* Port compute pipelines to the new system
* Add more preprocessor directives (else, elif, import)
* More flexible vertex attribute specialization / enable cheaply specializing on specific mesh vertex layouts
Upgrades both the old and new renderer to wgpu 0.11 (and naga 0.7). This builds on @zicklag's work here #2556.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
The vast majority of `.single()` usage I've seen is immediately followed by a `.unwrap()`. Since it seems most people use it without handling the error, I think making it easier to just get what you want fast while also having a more verbose alternative when you want to handle the error could help.
## Solution
Instead of having a lot of `.unwrap()` everywhere, this PR introduces a `try_single()` variant that behaves like the current `.single()` and make the new `.single()` panic on error.
# Objective
- Remove all the `.system()` possible.
- Check for remaining missing cases.
## Solution
- Remove all `.system()`, fix compile errors
- 32 calls to `.system()` remains, mostly internals, the few others should be removed after #2446
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet.
You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away.
Co-Authored-By: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}