# Objective
#5703 caused the normal prepass to fail as the prepass uses
`pbr_functions::apply_normal_mapping`, which uses
`mesh_view_bindings::view` to determine mip bias, which conflicts with
`prepass_bindings::view`.
## Solution
pass the mip bias to the `apply_normal_mapping` function explicitly.
# Objective
Fixes#8967
## Solution
I think this example was just missed in #5703. I made the same sort of
changes to `fallback_image` that were made in other examples in that PR.
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
Fixes#6920
## Solution
From the issue discussion:
> From looking at the `AsBindGroup` derive macro implementation, the
fallback image's `TextureView` is used when the binding's
`Option<Handle<Image>>` is `None`. Because this relies on already having
a view that matches the desired binding dimensions, I think the solution
will require creating a separate `GpuImage` for each possible
`TextureViewDimension`.
---
## Changelog
Users can now rely on `FallbackImage` to work with a texture binding of
any dimension.
# Objective
Since #8446, example `shader_prepass` logs the following error on my mac
m1:
```
ERROR bevy_render::render_resource::pipeline_cache: failed to process shader:
error: Entry point fragment at Fragment is invalid
= Argument 1 varying error
= Capability MULTISAMPLED_SHADING is not supported
```
The example display the 3d scene but doesn't change with the preps
selected
Maybe related to this update in naga:
cc3a8ac737
## Solution
- Disable MSAA in the example, and check if it's enabled in the shader
# Objective
Fix the screenspace_texture example not working on the WebGPU examples
page. Currently it fails with the following error in the browser
console:
```
1 error(s) generated while compiling the shader:
:213:9 error: redeclaration of 'uv'
let uv = coords_to_viewport_uv(position.xy, view.viewport);
^^
:211:14 note: 'uv' previously declared here
@location(2) uv: vec2<f32>,
```
## Solution
Rename the shader variable `uv` to `viewport_uv` to prevent variable
redeclaration error.
# Objective
The objective is to be able to load data from "application-specific"
(see glTF spec 3.7.2.1.) vertex attribute semantics from glTF files into
Bevy meshes.
## Solution
Rather than probe the glTF for the specific attributes supported by
Bevy, this PR changes the loader to iterate through all the attributes
and map them onto `MeshVertexAttribute`s. This mapping includes all the
previously supported attributes, plus it is now possible to add mappings
using the `add_custom_vertex_attribute()` method on `GltfPlugin`.
## Changelog
- Add support for loading custom vertex attributes from glTF files.
- Add the `custom_gltf_vertex_attribute.rs` example to illustrate
loading custom vertex attributes.
## Migration Guide
- If you were instantiating `GltfPlugin` using the unit-like struct
syntax, you must instead use `GltfPlugin::default()` as the type is no
longer unit-like.
# Objective
- The old post processing example doesn't use the actual post processing
features of bevy. It also has some issues with resizing. It's also
causing some confusion for people because accessing the prepass textures
from it is not easy.
- There's already a render to texture example
- At this point, it's mostly obsolete since the post_process_pass
example is more complete and shows the recommended way to do post
processing in bevy. It's a bit more complicated, but it's well
documented and I'm working on simplifying it even more
## Solution
- Remove the old post_processing example
- Rename post_process_pass to post_processing
## Reviewer Notes
The diff is really noisy because of the rename, but I didn't change any
code in the example.
---------
Co-authored-by: James Liu <contact@jamessliu.com>

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Shader error cause by a missing import.
- `pbr_functions.wgsl` was missing an import for the `ambient_light()` function, as `array_texture` doesn't import it.
- Closes#7542.
## Solution
- Add`#import bevy_pbr::pbr_ambient` into `array_texture`
# Objective
- Fix `post_processing` and `shader_prepass` examples as they fail when compiling shaders due to missing shader defs
- Fixes#6799
- Fixes#6996
- Fixes#7375
- Supercedes #6997
- Supercedes #7380
## Solution
- The prepass was broken due to a missing `MAX_CASCADES_PER_LIGHT` shader def. Add it.
- The shader used in the `post_processing` example is applied to a 2D mesh, so use the correct mesh2d_view_bindings shader import.
# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
# Objective
- The functions added to utils.wgsl by the prepass assume that mesh_view_bindings are present, which isn't always the case
- Fixes https://github.com/bevyengine/bevy/issues/7353
## Solution
- Move these functions to their own `prepass_utils.wgsl` file
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
# Objective
fixes#5946
## Solution
adjust cluster index calculation for viewport origin.
from reading point 2 of the rasterization algorithm description in https://gpuweb.github.io/gpuweb/#rasterization, it looks like framebuffer space (and so @bulitin(position)) is not meant to be adjusted for viewport origin, so we need to subtract that to get the right cluster index.
- add viewport origin to rust `ExtractedView` and wgsl `View` structs
- subtract from frag coord for cluster index calculation
# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make `game_of_life.wgsl` easier to read and understand
## Solution
- Remove unused code in the shader
- `location_f32` was unused in `init`
- `color` was unused in `update`
# Objective
- Showcase how to use a `Material` and `Mesh` to spawn 3d lines
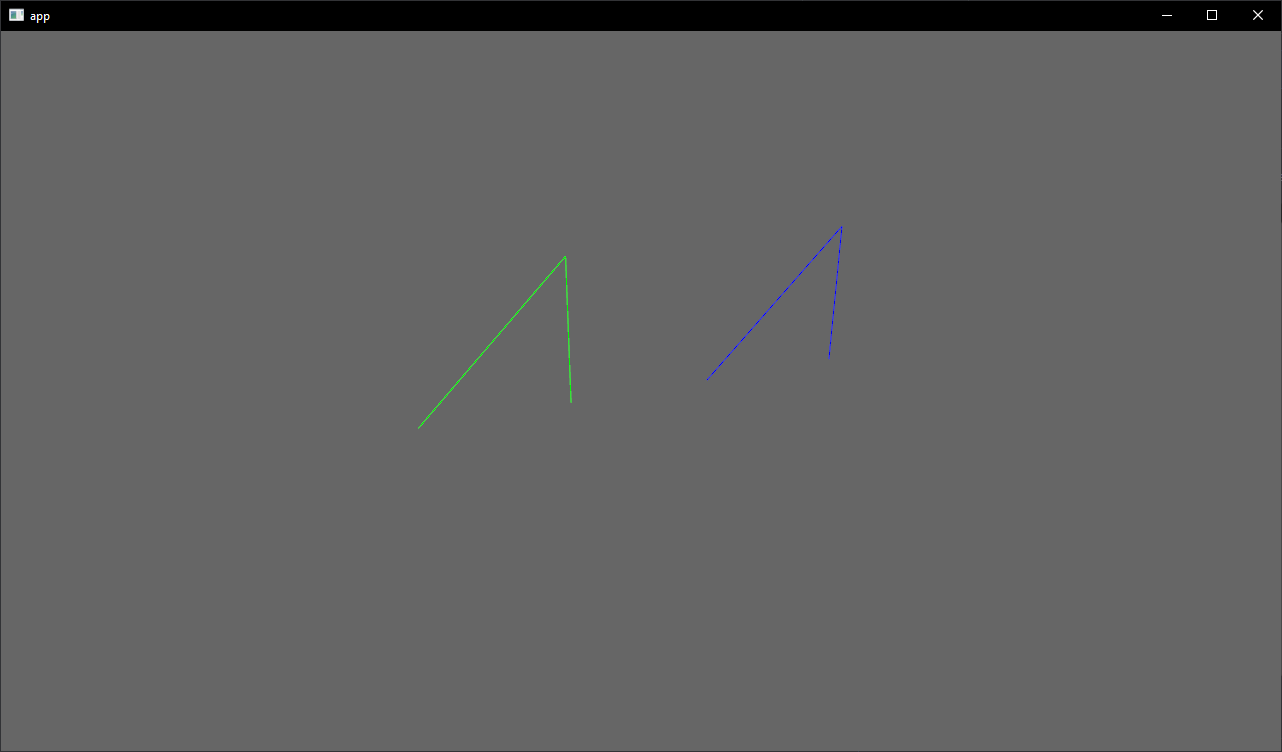
## Solution
- Add an example using a simple `Material` and `Mesh` definition to draw a 3d line
- Shows how to use `LineList` and `LineStrip` in combination with a specialized `Material`
## Notes
This isn't just a primitive shape because it needs a special Material, but I think it's a good showcase of the power of the `Material` and `AsBindGroup` abstractions. All of this is easy to figure out when you know these options are a thing, but I think they are hard to discover which is why I think this should be an example and not shipped with bevy.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
Add texture sampling to the GLSL shader example, as naga does not support the commonly used sampler2d type.
Fixes#5059
## Solution
- Align the shader_material_glsl example behaviour with the shader_material example, as the later includes texture sampling.
- Update the GLSL shader to do texture sampling the way naga supports it, and document the way naga does not support it.
## Changelog
- The shader_material_glsl example has been updated to demonstrate texture sampling using the GLSL shading language.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
- Split PBR and 2D mesh shaders into types and bindings to prepare the shaders to be more reusable.
- See #3969 for details. I'm doing this in multiple steps to make review easier.
---
## Changelog
- Changed: 2D and PBR mesh shaders are now split into types and bindings, the following shader imports are available: `bevy_pbr::mesh_view_types`, `bevy_pbr::mesh_view_bindings`, `bevy_pbr::mesh_types`, `bevy_pbr::mesh_bindings`, `bevy_sprite::mesh2d_view_types`, `bevy_sprite::mesh2d_view_bindings`, `bevy_sprite::mesh2d_types`, `bevy_sprite::mesh2d_bindings`
## Migration Guide
- In shaders for 3D meshes:
- `#import bevy_pbr::mesh_view_bind_group` -> `#import bevy_pbr::mesh_view_bindings`
- `#import bevy_pbr::mesh_struct` -> `#import bevy_pbr::mesh_types`
- NOTE: If you are using the mesh bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_pbr::mesh_bindings` which itself imports the mesh types needed for the bindings.
- In shaders for 2D meshes:
- `#import bevy_sprite::mesh2d_view_bind_group` -> `#import bevy_sprite::mesh2d_view_bindings`
- `#import bevy_sprite::mesh2d_struct` -> `#import bevy_sprite::mesh2d_types`
- NOTE: If you are using the mesh2d bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_sprite::mesh2d_bindings` which itself imports the mesh2d types needed for the bindings.
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The `custom_material.vert` shader used by the `shader_material_glsl` example is missing a `mat4 View` in `CameraViewProj` (added in [#3885](https://github.com/bevyengine/bevy/pull/3885))
## Solution
Update the definition of `CameraViewProj`
# Objective
Fixes#3352Fixes#3208
## Solution
- Update wgpu to 0.12
- Update naga to 0.8
- Resolve compilation errors
- Remove [[block]] from WGSL shaders (because it is depracated and now wgpu cant parse it)
- Replace `elseif` with `else if` in pbr.wgsl
## Shader Imports
This adds "whole file" shader imports. These come in two flavors:
### Asset Path Imports
```rust
// /assets/shaders/custom.wgsl
#import "shaders/custom_material.wgsl"
[[stage(fragment)]]
fn fragment() -> [[location(0)]] vec4<f32> {
return get_color();
}
```
```rust
// /assets/shaders/custom_material.wgsl
[[block]]
struct CustomMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CustomMaterial;
```
### Custom Path Imports
Enables defining custom import paths. These are intended to be used by crates to export shader functionality:
```rust
// bevy_pbr2/src/render/pbr.wgsl
#import bevy_pbr::mesh_view_bind_group
#import bevy_pbr::mesh_bind_group
[[block]]
struct StandardMaterial {
base_color: vec4<f32>;
emissive: vec4<f32>;
perceptual_roughness: f32;
metallic: f32;
reflectance: f32;
flags: u32;
};
/* rest of PBR fragment shader here */
```
```rust
impl Plugin for MeshRenderPlugin {
fn build(&self, app: &mut bevy_app::App) {
let mut shaders = app.world.get_resource_mut::<Assets<Shader>>().unwrap();
shaders.set_untracked(
MESH_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_bind_group"),
);
shaders.set_untracked(
MESH_VIEW_BIND_GROUP_HANDLE,
Shader::from_wgsl(include_str!("mesh_view_bind_group.wgsl"))
.with_import_path("bevy_pbr::mesh_view_bind_group"),
);
```
By convention these should use rust-style module paths that start with the crate name. Ultimately we might enforce this convention.
Note that this feature implements _run time_ import resolution. Ultimately we should move the import logic into an asset preprocessor once Bevy gets support for that.
## Decouple Mesh Logic from PBR Logic via MeshRenderPlugin
This breaks out mesh rendering code from PBR material code, which improves the legibility of the code, decouples mesh logic from PBR logic, and opens the door for a future `MaterialPlugin<T: Material>` that handles all of the pipeline setup for arbitrary shader materials.
## Removed `RenderAsset<Shader>` in favor of extracting shaders into RenderPipelineCache
This simplifies the shader import implementation and removes the need to pass around `RenderAssets<Shader>`.
## RenderCommands are now fallible
This allows us to cleanly handle pipelines+shaders not being ready yet. We can abort a render command early in these cases, preventing bevy from trying to bind group / do draw calls for pipelines that couldn't be bound. This could also be used in the future for things like "components not existing on entities yet".
# Next Steps
* Investigate using Naga for "partial typed imports" (ex: `#import bevy_pbr::material::StandardMaterial`, which would import only the StandardMaterial struct)
* Implement `MaterialPlugin<T: Material>` for low-boilerplate custom material shaders
* Move shader import logic into the asset preprocessor once bevy gets support for that.
Fixes#3132
Adds new `EntityRenderCommand`, `EntityPhaseItem`, and `CachedPipelinePhaseItem` traits to make it possible to reuse RenderCommands across phases. This should be helpful for features like #3072 . It also makes the trait impls slightly less generic-ey in the common cases.
This also fixes the custom shader examples to account for the recent Frustum Culling and MSAA changes (the UX for these things will be improved later).
## New Features
This adds the following to the new renderer:
* **Shader Assets**
* Shaders are assets again! Users no longer need to call `include_str!` for their shaders
* Shader hot-reloading
* **Shader Defs / Shader Preprocessing**
* Shaders now support `# ifdef NAME`, `# ifndef NAME`, and `# endif` preprocessor directives
* **Bevy RenderPipelineDescriptor and RenderPipelineCache**
* Bevy now provides its own `RenderPipelineDescriptor` and the wgpu version is now exported as `RawRenderPipelineDescriptor`. This allows users to define pipelines with `Handle<Shader>` instead of needing to manually compile and reference `ShaderModules`, enables passing in shader defs to configure the shader preprocessor, makes hot reloading possible (because the descriptor can be owned and used to create new pipelines when a shader changes), and opens the doors to pipeline specialization.
* The `RenderPipelineCache` now handles compiling and re-compiling Bevy RenderPipelineDescriptors. It has internal PipelineLayout and ShaderModule caches. Users receive a `CachedPipelineId`, which can be used to look up the actual `&RenderPipeline` during rendering.
* **Pipeline Specialization**
* This enables defining per-entity-configurable pipelines that specialize on arbitrary custom keys. In practice this will involve specializing based on things like MSAA values, Shader Defs, Bind Group existence, and Vertex Layouts.
* Adds a `SpecializedPipeline` trait and `SpecializedPipelines<MyPipeline>` resource. This is a simple layer that generates Bevy RenderPipelineDescriptors based on a custom key defined for the pipeline.
* Specialized pipelines are also hot-reloadable.
* This was the result of experimentation with two different approaches:
1. **"generic immediate mode multi-key hash pipeline specialization"**
* breaks up the pipeline into multiple "identities" (the core pipeline definition, shader defs, mesh layout, bind group layout). each of these identities has its own key. looking up / compiling a specific version of a pipeline requires composing all of these keys together
* the benefit of this approach is that it works for all pipelines / the pipeline is fully identified by the keys. the multiple keys allow pre-hashing parts of the pipeline identity where possible (ex: pre compute the mesh identity for all meshes)
* the downside is that any per-entity data that informs the values of these keys could require expensive re-hashes. computing each key for each sprite tanked bevymark performance (sprites don't actually need this level of specialization yet ... but things like pbr and future sprite scenarios might).
* this is the approach rafx used last time i checked
2. **"custom key specialization"**
* Pipelines by default are not specialized
* Pipelines that need specialization implement a SpecializedPipeline trait with a custom key associated type
* This allows specialization keys to encode exactly the amount of information required (instead of needing to be a combined hash of the entire pipeline). Generally this should fit in a small number of bytes. Per-entity specialization barely registers anymore on things like bevymark. It also makes things like "shader defs" way cheaper to hash because we can use context specific bitflags instead of strings.
* Despite the extra trait, it actually generally makes pipeline definitions + lookups simpler: managing multiple keys (and making the appropriate calls to manage these keys) was way more complicated.
* I opted for custom key specialization. It performs better generally and in my opinion is better UX. Fortunately the way this is implemented also allows for custom caches as this all builds on a common abstraction: the RenderPipelineCache. The built in custom key trait is just a simple / pre-defined way to interact with the cache
## Callouts
* The SpecializedPipeline trait makes it easy to inherit pipeline configuration in custom pipelines. The changes to `custom_shader_pipelined` and the new `shader_defs_pipelined` example illustrate how much simpler it is to define custom pipelines based on the PbrPipeline.
* The shader preprocessor is currently pretty naive (it just uses regexes to process each line). Ultimately we might want to build a more custom parser for more performance + better error handling, but for now I'm happy to optimize for "easy to implement and understand".
## Next Steps
* Port compute pipelines to the new system
* Add more preprocessor directives (else, elif, import)
* More flexible vertex attribute specialization / enable cheaply specializing on specific mesh vertex layouts
## Objective
Looking though the new pipelined example I stumbled on an issue with the example shader :
```
Oct 20 12:38:44.891 INFO bevy_render2::renderer: AdapterInfo { name: "Intel(R) UHD Graphics 620 (KBL GT2)", vendor: 32902, device: 22807, device_type: IntegratedGpu, backend: Vulkan }
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_point_shadow")
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_directional_shadow")
Oct 20 12:38:44.898 ERROR wgpu::backend::direct: Handling wgpu errors as fatal by default
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_shader_module
Global variable [1] 'view' is invalid
Type isn't compatible with the storage class
```
## Solution
added `<uniform>` here and there.
Note : my current mastery of shaders is about 2 days old, so this still kinda look likes wizardry
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
Alternative to #1203 and #1611
Camera bindings have historically been "hacked in". They were _required_ in all shaders and only supported a single Mat4. PBR (#1554) requires the CameraView matrix, but adding this using the "hacked" method forced users to either include all possible camera data in a single binding (#1203) or include all possible bindings (#1611).
This approach instead assigns each "active camera" its own RenderResourceBindings, which are populated by CameraNode. The PassNode then retrieves (and initializes) the relevant bind groups for all render pipelines used by visible entities.
* Enables any number of camera bindings , including zero (with any set or binding number ... set 0 should still be used to avoid rebinds).
* Renames Camera binding to CameraViewProj
* Adds CameraView binding
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}