# Objective
- break up large build_schedule system to make it easier to read
- Clean up related error messages.
- I have a follow up PR that adds the schedule name to the error
messages, but wanted to break this up from that.
## Changelog
- refactor `build_schedule` to be easier to read
## Sample Error Messages
Dependency Cycle
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
Hierarchy Cycle
```text
thread 'main' panicked at 'System set hierarchy contains cycle(s).
schedule has 1 in_set cycle(s):
cycle 1: set 'A' contains itself
set 'A'
... which contains set 'B'
... which contains set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
System Type Set
```text
thread 'main' panicked at 'Tried to order against `SystemTypeSet(fn foo())` in a schedule that has more than one `SystemTypeSet(fn foo())` instance. `SystemTypeSet(fn foo())` is a `SystemTypeSet` and cannot be used for ordering if ambiguous. Use a different set without this restriction.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Hierarchy Redundancy
```text
thread 'main' panicked at 'System set hierarchy contains redundant edges.
hierarchy contains redundant edge(s) -- system set 'X' cannot be child of set 'A', longer path exists
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Systems have ordering but interset
```text
thread 'main' panicked at '`A` and `C` have a `before`-`after` relationship (which may be transitive) but share systems.', crates\bevy_ecs\src\schedule\schedule.rs:227:51
```
Cross Dependency
```text
thread 'main' panicked at '`A` and `B` have both `in_set` and `before`-`after` relationships (these might be transitive). This combination is unsolvable as a system cannot run before or after a set it belongs to.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Ambiguity
```text
thread 'main' panicked at 'Systems with conflicting access have indeterminate run order.
1 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- res_mut and res_ref
conflict on: ["bevymark::ambiguity::X"]
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
# Objective
Sometimes you want to create a plugin with a custom run condition. In a
function, you take the `Condition` trait and then make a
`BoxedCondition` from it to store it. And then you want to add that
condition to a system, but you can't, because there is only the `run_if`
function available which takes `impl Condition<M>` instead of
`BoxedCondition`. So you have to create a wrapper type for the
`BoxedCondition` and implement the `System` and `ReadOnlySystem` traits
for the wrapper (Like it's done in the picture below). It's very
inconvenient and boilerplate. But there is an easy solution for that:
make the `run_if_inner` system that takes a `BoxedCondition` public.
Also, it makes sense to make `in_set_inner` function public as well with
the same motivation.

A chunk of the source code of the `bevy-inspector-egui` crate.
## Solution
Make `run_if_inner` function public.
Rename `run_if_inner` to `run_if_dyn`.
Make `in_set_inner` function public.
Rename `in_set_inner` to `in_set_dyn`.
## Changelog
Changed visibility of `run_if_inner` from `pub(crate)` to `pub`.
Renamed `run_if_inner` to `run_if_dyn`.
Changed visibility of `in_set_inner` from `pub(crate)` to `pub`.
Renamed `in_set_inner` to `in_set_dyn`.
## Migration Guide
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
While being nobody other's issue as far I can tell, I want to create a
trait I plan to implement on `App` where more than one schedule is
modified.
My workaround so far was working with a closure that returns an
`ExecutorKind` from a match of the method variable.
It makes it easier for me to being able to clone `ExecutorKind` and I
don't see this being controversial for others working with Bevy.
I did nothing more than adding `Clone` to the derived traits, no
migration guide needed.
(If this worked out then the GitHub editor is not too shabby.)
# Objective
- Fixes#9114
## Solution
Inside `ScheduleGraph::build_schedule()` the variable `node_count =
self.systems.len() + self.system_sets.len()` is used to calculate the
indices for the `reachable` bitset derived from `self.hierarchy.graph`.
However, the number of nodes inside `self.hierarchy.graph` does not
always correspond to `self.systems.len() + self.system_sets.len()` when
`ambiguous_with` is used, because an ambiguous set is added to
`system_sets` (because we need an `NodeId` for the ambiguity graph)
without adding a node to `self.hierarchy`.
In this PR, we rename `node_count` to the more descriptive name
`hg_node_count` and set it to `self.hierarchy.graph.node_count()`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Be consistent with `Resource`s and `Components` and have `Event` types
be more self-documenting.
Although not susceptible to accidentally using a function instead of a
value due to `Event`s only being initialized by their type, much of the
same reasoning for removing the blanket impl on `Resource` also applies
here.
* Not immediately obvious if a type is intended to be an event
* Prevent invisible conflicts if the same third-party or primitive types
are used as events
* Allows for further extensions (e.g. opt-in warning for missed events)
## Solution
Remove the blanket impl for the `Event` trait. Add a derive macro for
it.
---
## Changelog
- `Event` is no longer implemented for all applicable types. Add the
`#[derive(Event)]` macro for events.
## Migration Guide
* Add the `#[derive(Event)]` macro for events. Third-party types used as
events should be wrapped in a newtype.
# Objective
- `apply_system_buffers` is an unhelpful name: it introduces a new
internal-only concept
- this is particularly rough for beginners as reasoning about how
commands work is a critical stumbling block
## Solution
- rename `apply_system_buffers` to the more descriptive `apply_deferred`
- rename related fields, arguments and methods in the internals fo
bevy_ecs for consistency
- update the docs
## Changelog
`apply_system_buffers` has been renamed to `apply_deferred`, to more
clearly communicate its intent and relation to `Deferred` system
parameters like `Commands`.
## Migration Guide
- `apply_system_buffers` has been renamed to `apply_deferred`
- the `apply_system_buffers` method on the `System` trait has been
renamed to `apply_deferred`
- the `is_apply_system_buffers` function has been replaced by
`is_apply_deferred`
- `Executor::set_apply_final_buffers` is now
`Executor::set_apply_final_deferred`
- `Schedule::apply_system_buffers` is now `Schedule::apply_deferred`
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
The `Condition` trait is only implemented for systems and system
functions that take no input. This can make it awkward to write
conditions that are intended to be used with system piping.
## Solution
Add an `In` generic to the trait. It defaults to `()`.
---
## Changelog
- Made the `Condition` trait generic over system inputs.
# Objective
Fix#7833.
Safety comments in the multi-threaded executor don't really talk about
system world accesses, which makes it unclear if the code is actually
valid.
## Solution
Update the `System` trait to use `UnsafeWorldCell`. This type's API is
written in a way that makes it much easier to cleanly maintain safety
invariants. Use this type throughout the multi-threaded executor, with a
liberal use of safety comments.
---
## Migration Guide
The `System` trait now uses `UnsafeWorldCell` instead of `&World`. This
type provides a robust API for interior mutable world access.
- The method `run_unsafe` uses this type to manage world mutations
across multiple threads.
- The method `update_archetype_component_access` uses this type to
ensure that only world metadata can be used.
```rust
let mut system = IntoSystem::into_system(my_system);
system.initialize(&mut world);
// Before:
system.update_archetype_component_access(&world);
unsafe { system.run_unsafe(&world) }
// After:
system.update_archetype_component_access(world.as_unsafe_world_cell_readonly());
unsafe { system.run_unsafe(world.as_unsafe_world_cell()) }
```
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow for directly call methods on states without first calling
`state.get().my_method()`
## Solution
- Implement `Deref` for `State<S>` with `Target = S`
---
*I did not implement `DerefMut` because states hold no data and should
only be changed via `NextState::set()`*
# Objective
`ScheduleGraph` currently stores run conditions in a
`Option<Vec<BoxedCondition>>`. The `Option` is unnecessary, since we can
just use an empty vector instead of `None`.
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Methods for interacting with world schedules currently have two
variants: one that takes `impl ScheduleLabel` and one that takes `&dyn
ScheduleLabel`. Operations such as `run_schedule` or `schedule_scope`
only use the label by reference, so there is little reason to have an
owned variant of these functions.
## Solution
Decrease maintenance burden by merging the `ref` variants of these
functions with the owned variants.
---
## Changelog
- Deprecated `World::run_schedule_ref`. It is now redundant, since
`World::run_schedule` can take values by reference.
## Migration Guide
The method `World::run_schedule_ref` has been deprecated, and will be
removed in the next version of Bevy. Use `run_schedule` instead.
# Objective
Label traits such as `ScheduleLabel` currently have a major footgun: the
trait is implemented for `Box<dyn ScheduleLabel>`, but the
implementation does not function as one would expect since `Box<T>` is
considered to be a distinct type from `T`. This is because the behavior
of the `ScheduleLabel` trait is specified mainly through blanket
implementations, which prevents `Box<dyn ScheduleLabel>` from being
properly special-cased.
## Solution
Replace the blanket-implemented behavior with a series of methods
defined on `ScheduleLabel`. This allows us to fully special-case
`Box<dyn ScheduleLabel>` .
---
## Changelog
Fixed a bug where boxed label types (such as `Box<dyn ScheduleLabel>`)
behaved incorrectly when compared with concretely-typed labels.
## Migration Guide
The `ScheduleLabel` trait has been refactored to no longer depend on the
traits `std::any::Any`, `bevy_utils::DynEq`, and `bevy_utils::DynHash`.
Any manual implementations will need to implement new trait methods in
their stead.
```rust
impl ScheduleLabel for MyType {
// Before:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
// After:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
fn as_dyn_eq(&self) -> &dyn DynEq {
self
}
// No, `mut state: &mut` is not a typo.
fn dyn_hash(&self, mut state: &mut dyn Hasher) {
self.hash(&mut state);
// Hashing the TypeId isn't strictly necessary, but it prevents collisions.
TypeId::of::<Self>().hash(&mut state);
}
}
```
Added helper extracted from #7711. that PR contains some controversy
conditions, but this one should be good to go.
---
## Changelog
### Added
- `any_component_removed` condition.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
The implementation of `System::run_unsafe` for `FunctionSystem` requires
that the world is the same one used to initialize the system. However,
the `System` trait has no requirements that the world actually matches,
which makes this implementation unsound.
This was previously mentioned in
https://github.com/bevyengine/bevy/pull/7605#issuecomment-1426491871
Fixes part of #7833.
## Solution
Add the safety invariant that
`System::update_archetype_component_access` must be called prior to
`System::run_unsafe`. Since
`FunctionSystem::update_archetype_component_access` properly validates
the world, this ensures that `run_unsafe` is not called with a
mismatched world.
Most exclusive systems are not required to be run on the same world that
they are initialized with, so this is not a concern for them. Systems
formed by combining an exclusive system with a regular system *do*
require the world to match, however the validation is done inside of
`System::run` when needed.
# Objective
Fixes#8215 and #8152. When systems panic, it causes the main thread to
panic as well, which clutters the output.
## Solution
Resolves the panic in the multi-threaded scheduler. Also adds an extra
message that tells the user the system that panicked.
Using the example from the issue, here is what the messages now look
like:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Update, panicking_system)
.run();
}
fn panicking_system() {
panic!("oooh scary");
}
```
### Before
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2m 58s
Running `target\debug\bevy_test.exe`
2023-03-30T22:19:09.234932Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'Compute Task Pool (5)' panicked at 'A system has panicked so the executor cannot continue.: RecvError', E:\Projects\Rust\bevy\crates\bevy_ecs\src\schedule\executor\multi_threaded.rs:194:60
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', E:\Projects\Rust\bevy\crates\bevy_tasks\src\task_pool.rs:376:49
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
### After
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2.39s
Running `target\debug\bevy_test.exe`
2023-03-30T22:11:24.748513Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Encountered a panic in system `bevy_test::panicking_system`!
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix#8191.
Currently, a state transition will be triggered whenever the `NextState`
resource has a value, even if that "transition" is to the same state as
the previous one. This caused surprising/meaningless behavior, such as
the existence of an `OnTransition { from: A, to: A }` schedule.
## Solution
State transition schedules now only run if the new state is not equal to
the old state. Change detection works the same way, only being triggered
when the states compare not equal.
---
## Changelog
- State transition schedules are no longer run when transitioning to and
from the same state.
## Migration Guide
State transitions are now only triggered when the exited and entered
state differ. This means that if the world is currently in state `A`,
the `OnEnter(A)` schedule (or `OnExit`) will no longer be run if you
queue up a state transition to the same state `A`.
# Objective
State requires a kind of awkward `state.0` to get the current state and
exposes the field directly to manipulation.
## Solution
Make it accessible through a getter method as well as privatize the
field to make sure false assumptions about setting the state aren't
made.
## Migration Guide
- Use `State::get` instead of accessing the tuple field directly.
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
While we use `#[doc(hidden)]` to try and hide marker generics from the user, these types reveal themselves in compiler errors, adding visual noise and confusion.
## Solution
Replace the `AlreadyWasSystem` marker generic with `()`, to reduce visual noise in error messages. This also makes it possible to return `impl Condition<()>` from combinators.
For function systems, use their function signature as the marker type. This should drastically improve the legibility of some error messages.
The `InputMarker` type has been removed, since it is unnecessary.
# Objective
Several places in the ECS use marker generics to avoid overlapping trait implementations, but different places alternately refer to it as `Params` and `Marker`. This is potentially confusing, since it might not be clear that the same pattern is being used. Additionally, users might be misled into thinking that the `Params` type corresponds to the `SystemParam`s of a system.
## Solution
Rename `Params` to `Marker`.
# Objective
Fixes#3980
## Solution
Added examples to show how to run a `Schedule`, one with a unique system, and another with several systems
---
## Changelog
- Added: examples in docs to show how to run a `Schedule`
Co-authored-by: remiCzn <77072160+remiCzn@users.noreply.github.com>
# Objective
The `BoxedCondition` type alias does not require the underlying system to be read-only.
## Solution
Define the type alias using `ReadOnlySystem` instead of `System`.
Graph theory make head hurty. Closes#7367.
Basically, when we topologically sort the dependency graph, we already find its strongly-connected components (a really [neat algorithm][1]). This PR adds an algorithm that can dissect those into simple cycles, giving us more useful error reports.
test: `system_build_errors::dependency_cycle`
```
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
```
```
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
```
test: `system_build_errors::hierarchy_cycle`
```
schedule has 1 in_set cycle(s):
cycle 1: system set 'A' contains itself
system set 'A'
... which contains system set 'B'
... which contains system set 'A'
```
[1]: https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
Add some more useful common run conditions.
Some of these existed in `iyes_loopless`. I know people used them, and it would be a regression for those users, when they try to migrate to new Bevy stageless, if they are missing.
I also took the opportunity to add a few more new ones.
---
## Changelog
### Added
- More "common run conditions": on_event, resource change detection, state_changed, any_with_component
# Objective
Fix#7584.
## Solution
Add an abstraction for creating custom system combinators with minimal boilerplate. Use this to implement AND/OR combinators. Use this to simplify the implementation of `PipeSystem`.
## Example
Feel free to bikeshed on the syntax.
I chose the names `and_then`/`or_else` to emphasize the fact that these short-circuit, while I chose method syntax to empasize that the arguments are *not* treated equally.
```rust
app.add_systems((
my_system.run_if(resource_exists::<R>().and_then(resource_equals(R(0)))),
our_system.run_if(resource_exists::<R>().or_else(resource_exists::<S>())),
));
```
---
## Todo
- [ ] Decide on a syntax
- [x] Write docs
- [x] Write tests
## Changelog
+ Added the extension methods `.and_then(...)` and `.or_else(...)` to run conditions, which allows combining run conditions with short-circuiting behavior.
+ Added the trait `Combine`, which can be used with the new `CombinatorSystem` to create system combinators with custom behavior.
# Objective
- Fixes#7442.
## Solution
- Added `report_sets` option to `ScheduleBuildSettings` like described in the linked issue.
The output of the `3d_scene` example when reporting ambiguities with `report_sets` and `use_shortnames` set to `true` (and with #7755 applied) now looks like this:
```
82 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- filesystem_watcher_system (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<DynamicScene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Scene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Shader> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Mesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<SkinnedMeshInverseBindposes> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Image> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<TextureAtlas> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<ColorMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Font> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<FontAtlasSet> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<StandardMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Gltf> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfNode> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfPrimitive> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfMesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSource> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSink> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AnimationClip> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- scene_spawner_system (Update) and close_when_requested (Update)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- calculate_bounds (CalculateBounds, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and visibility_propagate_system (PostUpdate, VisibilityPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_text2d_layout (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and ui_stack_system (PostUpdate, Stack)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and text_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_image_calculated_size_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and flex_node_system (Flex, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and add_clusters (AddClusters, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- visibility_propagate_system (PostUpdate, VisibilityPropagate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_text2d_layout (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- ui_stack_system (PostUpdate, Stack) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- text_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_image_calculated_size_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and animation_player (PostUpdate)
conflict on: ["bevy_transform::components::transform::Transform"]
-- apply_system_buffers (AddClustersFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and check_visibility (CheckVisibility, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_frusta (PostUpdate, UpdateLightFrusta)
conflict on: bevy_ecs::world::World
-- Assets<Scene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Shader>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Mesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<SkinnedMeshInverseBindposes>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Image>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<TextureAtlas>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<ColorMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Font>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<FontAtlasSet>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<StandardMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Gltf>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfNode>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfPrimitive>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfMesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSource>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSink>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AnimationClip>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<DynamicScene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
```
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
…top sort. reduce mem alloc
# Objective
- Reduce alloc count.
- Improve code quality.
## Solution
- use `TarjanScc::run` directly, which calls a closure with each scc, in closure, we can detect cycles and flatten nodes
# Objective
- Fixes#7659.
## Solution
- This PR extracted the `distributive_run_if` part of #7676, because it does not require the controversial introduction of anonymous system sets.
- The distinctive name should make the user aware about the differences between `IntoSystemConfig::run_if` and `IntoSystemConfigs::distributive_run_if`.
- The documentation explains in detail the consequences of using the API and possible pit falls when using it.
- A test demonstrates the possibility of changing the condition result, resulting in some of the systems not being run.
---
## Changelog
### Added
- Add `distributive_run_if` to `IntoSystemConfigs` to enable adding a run condition to each system when using `add_systems`.
follow-up to https://github.com/bevyengine/bevy/pull/7716
# Objective
System access is only populated in `System::initialize`, so without calling `initialize` it's actually impossible to see most ambiguities.
## Solution
- make `initialize` public. The method is idempotent, so calling it multiple times doesn't hurt
# Objective
Fix#7440. Fix#7441.
## Solution
* Remove builder functions on `ScheduleBuildSettings` in favor of public fields, move docs to the fields.
* Add `use_shortnames` and use it in `get_node_name` to feed it through `bevy_utils::get_short_name`.
# Objective
Web builds do not support running on multiple threads right now. Defaulting to the multi-threaded executor has significant overhead without any benefit.
## Solution
Default to the single threaded executor on wasm32 builds.
# Objective
- other tools (bevy_mod_debugdump) would like to have access to the ambiguities so that they can do their own reporting/visualization
## Solution
- store `conflicting_systems` in `ScheduleGraph` after calling `build_schedule`
The solution isn't very pretty and as pointed out it https://github.com/bevyengine/bevy/pull/7522, there may be a better way of exposing this, but this is the quick and dirty way if we want to have this functionality exposed in 0.10.
# Objective
- it would be nice to be able to associate a `NodeId` of a system type set to the `NodeId` of the actual system (used in bevy_mod_debugdump)
## Solution
- make `system_type` return the type id of the system
- that way you can check if a `dyn SystemSet` is the system type set of a `dyn System`
- I don't know if this information is already present somewhere else in the scheduler or if there is a better way to expose it
# Objective
Fixes#7702.
## Solution
- Added an test that ensures that no error is returned if a system or set is inside two different sets that share the same base set.
- Added an check to only return an error if the two base sets are not equal.
# Objective
The `ScheduleGraph` should be expose so that crates like [bevy_mod_debugdump](https://github.com/jakobhellermann/bevy_mod_debugdump/blob/stageless/docs/README.md) can access useful information.
## Solution
- expose `ScheduleGraph`, `NodeId`, `BaseSetMembership`, `Dag`
- add accessor functions for sets and systems
## Changelog
- expose `ScheduleGraph` for use in third party tools
This does expose our use of `petgraph` as a graph library, so we can only change that as a breaking change.
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
The trait `Condition<>` is implemented for any type that can be converted into a `ReadOnlySystem` which takes no inputs and returns a bool. However, due to the current implementation, consumers of the trait cannot rely on the fact that `<T as Condition>::System` implements `ReadOnlySystem`. In cases such as the `not` combinator (added in #7559), we are required to add redundant `T::System: ReadOnlySystem` trait bounds, even though this should be implied by the `Condition<>` trait.
## Solution
Add a hidden associated type which allows the compiler to figure out that the `System` associated type implements `ReadOnlySystem`.
# Objective
The `SystemParamFunction` (and `ExclusiveSystemParamFunction`) trait is very cumbersome to use, due to it requiring four generic type parameters. These are currently all used as marker parameters to satisfy rust's trait coherence rules.
### Example (before)
```rust
pub fn pipe<AIn, Shared, BOut, A, AParam, AMarker, B, BParam, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<AIn>, ParamSet<(AParam, BParam)>) -> BOut
where
A: SystemParamFunction<AIn, Shared, AParam, AMarker>,
B: SystemParamFunction<Shared, BOut, BParam, BMarker>,
AParam: SystemParam,
BParam: SystemParam,
```
## Solution
Turn the `In`, `Out`, and `Param` generics into associated types. Merge the marker types together to retain coherence.
### Example (after)
```rust
pub fn pipe<A, B, AMarker, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<A::In>, ParamSet<(A::Param, B::Param)>) -> B::Out
where
A: SystemParamFunction<AMarker>,
B: SystemParamFunction<BMarker, In = A::Out>,
```
---
## Changelog
+ Simplified the `SystemParamFunction` and `ExclusiveSystemParamFunction` traits.
## Migration Guide
For users of the `SystemParamFunction` trait, the generic type parameters `In`, `Out`, and `Param` have been turned into associated types. The same has been done with the `ExclusiveSystemParamFunction` trait.
# Objective
- Improve readability of the run condition for systems only running in a certain state
## Solution
- Rename `state_equals` to `in_state` (see [comment by cart](https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428740311) in #7634 )
- `.run_if(state_equals(variant))` now is `.run_if(in_state(variant))`
This breaks the naming pattern a bit with the related conditions `state_exists` and `state_exists_and_equals` but I could not think of better names for those and think the improved readability of `in_state` is worth it.
# Objective
Fixes#7632.
As discussed in #7634, it can be quite challenging for users to intuit the mental model of how states now work.
## Solution
Rather than change the behavior of the `OnUpdate` system set, instead work on making sure it's easy to understand what's going on.
Two things have been done:
1. Remove the `.on_update` method from our bevy of system building traits. This was special-cased and made states feel much more magical than they need to.
2. Improve the docs for the `OnUpdate` system set.
# Objective
Closes#7202
## Solution
~~Introduce a `not` helper to pipe conditions. Opened mostly for discussion. Maybe create an extension trait with `not` method? Please, advice.~~
Introduce `not(condition)` condition that inverses the result of the passed.
---
## Changelog
### Added
- `not` condition.
Small commit to remove an unused resource scoped within a single bevy_ecs unit test. Also rearranged the initialization to follow initialization conventions of surrounding tests. World/Schedule initialization followed by resource initialization.
This change was tested locally with `cargo test`, and `cargo fmt` was run.
Risk should be tiny as change is scoped to a single unit test and very tiny, and I can't see any way that this resource is being used in the test.
Thank you so much!
# Objective
Run conditions are a special type of system that do not modify the world, and which return a bool. Due to the way they are currently implemented, you can *only* use bare function systems as a run condition. Among other things, this prevents the use of system piping with run conditions. This make very basic constructs impossible, such as `my_system.run_if(my_condition.pipe(not))`.
Unblocks a basic solution for #7202.
## Solution
Add the trait `ReadOnlySystem`, which is implemented for any system whose parameters all implement `ReadOnlySystemParam`. Allow any `-> bool` system implementing this trait to be used as a run condition.
---
## Changelog
+ Added the trait `ReadOnlySystem`, which is implemented for any `System` type whose parameters all implement `ReadOnlySystemParam`.
+ Added the function `bevy::ecs::system::assert_is_read_only_system`.
# Objective
Implementing `States` manually is repetitive, so let's not.
One thing I'm unsure of is whether the macro import statement is in the right place.
# Objective
- There is a small perf cost for starting the multithreaded executor.
## Solution
- We can skip that cost when there are zero systems in the schedule. Overall not a big perf boost unless there are a lot of empty schedules that are trying to run, but it is something.
Below is a tracy trace of the run_fixed_update_schedule for many_foxes which has zero systems in it. Yellow is main and red is this pr. The time difference between the peaks of the humps is around 15us.
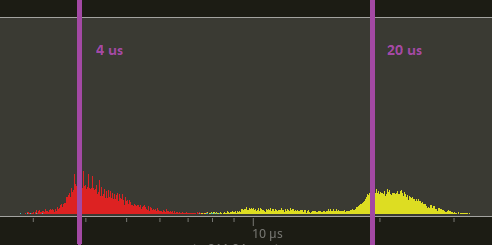
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Currently exclusive systems and applying buffers run outside of the multithreaded executor and just calls the funtions on the thread the schedule is running on. Stageless changes this to run these using tasks in a scope. Specifically It uses `spawn_on_scope` to run these. For the render thread this is incorrect as calling `spawn_on_scope` there runs tasks on the main thread. It should instead run these on the render thread and only run nonsend systems on the main thread.
## Solution
- Add another executor to `Scope` for spawning tasks on the scope. `spawn_on_scope` now always runs the task on the thread the scope is running on. `spawn_on_external` spawns onto the external executor than is optionally passed in. If None is passed `spawn_on_external` will spawn onto the scope executor.
- Eventually this new machinery will be able to be removed. This will happen once a fix for removing NonSend resources from the world lands. So this is a temporary fix to support stageless.
---
## Changelog
- add a spawn_on_external method to allow spawning on the scope's thread or an external thread
## Migration Guide
> No migration guide. The main thread executor was introduced in pipelined rendering which was merged for 0.10. spawn_on_scope now behaves the same way as on 0.9.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
- This pulls out some of the changes to Plugin setup and sub apps from #6503 to make that PR easier to review.
- Separate the extract stage from running the sub app's schedule to allow for them to be run on separate threads in the future
- Fixes#6990
## Solution
- add a run method to `SubApp` that runs the schedule
- change the name of `sub_app_runner` to extract to make it clear that this function is only for extracting data between the main app and the sub app
- remove the extract stage from the sub app schedule so it can be run separately. This is done by adding a `setup` method to the `Plugin` trait that runs after all plugin build methods run. This is required to allow the extract stage to be removed from the schedule after all the plugins have added their systems to the stage. We will also need the setup method for pipelined rendering to setup the render thread. See e3267965e1/crates/bevy_render/src/pipelined_rendering.rs (L57-L98)
## Changelog
- Separate SubApp Extract stage from running the sub app schedule.
## Migration Guide
### SubApp `runner` has conceptually been changed to an `extract` function.
The `runner` no longer is in charge of running the sub app schedule. It's only concern is now moving data between the main world and the sub app. The `sub_app.app.schedule` is now run for you after the provided function is called.
```rust
// before
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
render_app.app.schedule.run();
});
}
// after
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
// schedule is automatically called for you after extract is run
});
}
```
# Objective
A separate `tracing` span for running a system's commands is created, even if the system doesn't have commands. This is adding extra measuring overhead (see #4892) where it's not needed.
## Solution
Move the span into `ParallelCommandState` and `CommandQueue`'s `SystemParamState::apply`. To get the right metadata for the span, a additional `&SystemMeta` parameter was added to `SystemParamState::apply`.
---
## Changelog
Added: `SystemMeta::name`
Changed: Systems without `Commands` and `ParallelCommands` will no longer show a "system_commands" span when profiling.
Changed: `SystemParamState::apply` now takes a `&SystemMeta` parameter in addition to the provided `&mut World`.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
> System chaining is a confusing name: it implies the ability to construct non-linear graphs, and suggests a sense of system ordering that is only incidentally true. Instead, it actually works by passing data from one system to the next, much like the pipe operator.
> In the accepted [stageless RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/45-stageless.md), this concept is renamed to piping, and "system chaining" is used to construct groups of systems with ordering dependencies between them.
Fixes#6225.
## Changelog
System chaining has been renamed to system piping to improve clarity (and free up the name for new ordering APIs).
## Migration Guide
The `.chain(handler_system)` method on systems is now `.pipe(handler_system)`.
The `IntoChainSystem` trait is now `IntoPipeSystem`, and the `ChainSystem` struct is now `PipeSystem`.
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Background
Incremental implementation of #4299. The code is heavily borrowed from that PR.
# Objective
The execution order ambiguity checker often emits false positives, since bevy is not aware of invariants upheld by the user.
## Solution
Title
---
## Changelog
+ Added methods `SystemDescriptor::ignore_all_ambiguities` and `::ambiguous_with`. These allow you to silence warnings for specific system-order ambiguities.
## Migration Guide
***Note for maintainers**: This should replace the migration guide for #5916*
Ambiguity sets have been replaced with a simpler API.
```rust
// These systems technically conflict, but we don't care which order they run in.
fn jump_on_click(mouse: Res<Input<MouseButton>>, mut transforms: Query<&mut Transform>) { ... }
fn jump_on_spacebar(keys: Res<Input<KeyCode>>, mut transforms: Query<&mut Transform>) { ... }
//
// Before
#[derive(AmbiguitySetLabel)]
struct JumpSystems;
app
.add_system(jump_on_click.in_ambiguity_set(JumpSystems))
.add_system(jump_on_spacebar.in_ambiguity_set(JumpSystems));
//
// After
app
.add_system(jump_on_click.ambiguous_with(jump_on_spacebar))
.add_system(jump_on_spacebar);
```
# Objective
- Add ability to create nested spawns. This is needed for stageless. The current executor spawns tasks for each system early and runs the system by communicating through a channel. In stageless we want to spawn the task late, so that archetypes can be updated right before the task is run. The executor is run on a separate task, so this enables the scope to be passed to the spawned executor.
- Fixes#4301
## Solution
- Instantiate a single threaded executor on the scope and use that instead of the LocalExecutor. This allows the scope to be Send, but still able to spawn tasks onto the main thread the scope is run on. This works because while systems can access nonsend data. The systems themselves are Send. Because of this change we lose the ability to spawn nonsend tasks on the scope, but I don't think this is being used anywhere. Users would still be able to use spawn_local on TaskPools.
- Steals the lifetime tricks the `std:🧵:scope` uses to allow nested spawns, but disallow scope to be passed to tasks or threads not associated with the scope.
- Change the storage for the tasks to a `ConcurrentQueue`. This is to allow a &Scope to be passed for spawning instead of a &mut Scope. `ConcurrentQueue` was chosen because it was already in our dependency tree because `async_executor` depends on it.
- removed the optimizations for 0 and 1 spawned tasks. It did improve those cases, but made the cases of more than 1 task slower.
---
## Changelog
Add ability to nest spawns
```rust
fn main() {
let pool = TaskPool::new();
pool.scope(|scope| {
scope.spawn(async move {
// calling scope.spawn from an spawn task was not possible before
scope.spawn(async move {
// do something
});
});
})
}
```
## Migration Guide
If you were using explicit lifetimes and Passing Scope you'll need to specify two lifetimes now.
```rust
fn scoped_function<'scope>(scope: &mut Scope<'scope, ()>) {}
// should become
fn scoped_function<'scope>(scope: &Scope<'_, 'scope, ()>) {}
```
`scope.spawn_local` changed to `scope.spawn_on_scope` this should cover cases where you needed to run tasks on the local thread, but does not cover spawning Nonsend Futures.
## TODO
* [x] think real hard about all the lifetimes
* [x] add doc about what 'env and 'scope mean.
* [x] manually check that the single threaded task pool still works
* [x] Get updated perf numbers
* [x] check and make sure all the transmutes are necessary
* [x] move commented out test into a compile fail test
* [x] look through the tests for scope on std and see if I should add any more tests
Co-authored-by: Michael Hsu <myhsu@benjaminelectric.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
- Add unit tests for ambiguity detection reporting.
- Incremental implementation of #4299.
## Solution
- Refactor ambiguity detection internals to make it testable. As a bonus, this should make it easier to extend in the future.
## Notes
* This code was copy-pasted from #4299 and modified. Credit goes to @alice-i-cecile and @afonsolage, though I'm not sure who wrote what at this point.
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
While using the ParallelExecutor, systems do not actually start until `prepare_systems` completes. In stages where there are large numbers of "empty" systems with very little work to do, this delay adds significant overhead, which can add up over many stages.
## Solution
Immediately and synchronously signal the start of systems that can run without dependencies inside `prepare_systems` instead of waiting for the first executor iteration after `prepare_systems` completes. Any system that is dependent on them still cannot run until after `prepare_systems` completes, but there are a large number of unconstrained systems in the base engine where this is a general benefit in almost every case.
## Performance
This change was tested against `many_foxes` in the default configuration. As this change is sensitive to the overhead around scheduling systems, the spans for measuring system timing, system overhead, and system commands were all commented out for these measurements.
The median stage timings between `main` and this PR are as follows:
|stage|main|this PR|
|:--|:--|:--|
|First|75.54 us|61.61 us|
|LoadAssets|51.05 us|42.32 us|
|PreUpdate|54.6 us|55.56 us|
|Update|61.89 us|51.5 us|
|PostUpdate|7.27 ms|6.71 ms|
|AssetEvents|47.82 us|35.95 us|
|Last|39.19 us|37.71 us|
|reserve_and_flush|57.83 us|48.2 us|
|Extract|1.41 ms|1.28 ms|
|Prepare|554.49 us|502.53 us|
|Queue|216.29 us|207.51 us|
|Sort|67.03 us|60.99 us|
|Render|1.73 ms|1.58 ms|
|Cleanup|33.55 us|30.76 us|
|Clear Entities|18.56 us|17.05 us|
|**full frame**|**11.9 ms**|**10.91 ms**|
For the first few stages, the benefit is small but cumulative over each. For PostUpdate in particular, this allows `parent_update` to run while prepare_systems is running, which is required for the animation and transform propagation systems, which dominate the time spent in the stage, but also frontloads the contention as the other "empty" systems are also running while `parent_update` is running. For Render, where there is just a single large exclusive system, the benefit comes from not waiting on a spuriously scheduled task on the task pool to kick off the system: it's immediately scheduled to run.
# Objective
This code is very disjoint, and the `stage.rs` file that it's in is already very long.
All I've done is move the code and clean up the compiler errors that result.
Followup to #5916, split out from #4299.
# Objective
Ambiguity sets are used to ignore system order ambiguities between groups of systems. However, they are not very useful: they are clunky, poorly integrated, and generally hampered by the difficulty using (or discovering) the ambiguity detector.
As a first step to the work in #4299, we're removing them.
## Migration Guide
Ambiguity sets have been removed.
# Objective
Rust 1.63 resolved [an issue](https://github.com/rust-lang/rust/issues/83701) that prevents you from combining explicit generic arguments with `impl Trait` arguments.
Now, we no longer need to use dynamic dispatch to work around this.
## Migration Guide
The methods `Schedule::get_stage` and `get_stage_mut` now accept `impl StageLabel` instead of `&dyn StageLabel`.
### Before
```rust
let stage = schedule.get_stage_mut::<SystemStage>(&MyLabel)?;
```
### After
```rust
let stage = schedule.get_stage_mut::<SystemStage>(MyLabel)?;
```
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
I noticed while working on #5366 that the documentation for label types wasn't working correctly. Having experimented with this for a few weeks, I believe that generating docs in macros is more effort than it's worth.
## Solution
Add more boilerplate, copy-paste and edit the docs across types. This also lets us add custom doctests for specific types. Also, we don't need `concat_idents` as a dependency anymore.
# Objective
- Closes#4954
- Reduce the complexity of the `{System, App, *}Label` APIs.
## Solution
For the sake of brevity I will only refer to `SystemLabel`, but everything applies to all of the other label types as well.
- Add `SystemLabelId`, a lightweight, `copy` struct.
- Convert custom types into `SystemLabelId` using the trait `SystemLabel`.
## Changelog
- String literals implement `SystemLabel` for now, but this should be changed with #4409 .
## Migration Guide
- Any previous use of `Box<dyn SystemLabel>` should be replaced with `SystemLabelId`.
- `AsSystemLabel` trait has been modified.
- No more output generics.
- Method `as_system_label` now returns `SystemLabelId`, removing an unnecessary level of indirection.
- If you *need* a label that is determined at runtime, you can use `Box::leak`. Not recommended.
## Questions for later
* Should we generate a `Debug` impl along with `#[derive(*Label)]`?
* Should we rename `as_str()`?
* Should we remove the extra derives (such as `Hash`) from builtin `*Label` types?
* Should we automatically derive types like `Clone, Copy, PartialEq, Eq`?
* More-ergonomic comparisons between `Label` and `LabelId`.
* Move `Dyn{Eq, Hash,Clone}` somewhere else.
* Some API to make interning dynamic labels easier.
* Optimize string representation
* Empty string for unit structs -- no debug info but faster comparisons
* Don't show enum types -- same tradeoffs as asbove.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Fixes#4271
## Solution
- Check for a pending transition in addition to a scheduled operation.
- I don't see a valid reason for updating the state unless both `scheduled` and `transition` are empty.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
## Objective
- ~~Make absurdly long-lived changes stay detectable for even longer (without leveling up to `u64`).~~
- Give all changes a consistent maximum lifespan.
- Improve code clarity.
## Solution
- ~~Increase the frequency of `check_tick` scans to increase the oldest reliably-detectable change.~~
(Deferred until we can benchmark the cost of a scan.)
- Ignore changes older than the maximum reliably-detectable age.
- General refactoring—name the constants, use them everywhere, and update the docs.
- Update test cases to check for the specified behavior.
## Related
This PR addresses (at least partially) the concerns raised in:
- #3071
- #3082 (and associated PR #3084)
## Background
- #1471
Given the minimum interval between `check_ticks` scans, `N`, the oldest reliably-detectable change is `u32::MAX - (2 * N - 1)` (or `MAX_CHANGE_AGE`). Reducing `N` from ~530 million (current value) to something like ~2 million would extend the lifetime of changes by a billion.
| minimum `check_ticks` interval | oldest reliably-detectable change | usable % of `u32::MAX` |
| --- | --- | --- |
| `u32::MAX / 8` (536,870,911) | `(u32::MAX / 4) * 3` | 75.0% |
| `2_000_000` | `u32::MAX - 3_999_999` | 99.9% |
Similarly, changes are still allowed to be between `MAX_CHANGE_AGE`-old and `u32::MAX`-old in the interim between `check_tick` scans. While we prevent their age from overflowing, the test to detect changes still compares raw values. This makes failure ultimately unreliable, since when ancient changes stop being detected varies depending on when the next scan occurs.
## Open Question
Currently, systems and system states are incorrectly initialized with their `last_change_tick` set to `0`, which doesn't handle wraparound correctly.
For consistent behavior, they should either be initialized to the world's `last_change_tick` (and detect no changes) or to `MAX_CHANGE_AGE` behind the world's current `change_tick` (and detect everything as a change). I've currently gone with the latter since that was closer to the existing behavior.
## Follow-up Work
(Edited: entire section)
We haven't actually profiled how long a `check_ticks` scan takes on a "large" `World` , so we don't know if it's safe to increase their frequency. However, we are currently relying on play sessions not lasting long enough to trigger a scan and apps not having enough entities/archetypes for it to be "expensive" (our assumption). That isn't a real solution. (Either scanning never costs enough to impact frame times or we provide an option to use `u64` change ticks. Nobody will accept random hiccups.)
To further extend the lifetime of changes, we actually only need to increment the world tick if a system has `Fetch: !ReadOnlySystemParamFetch`. The behavior will be identical because all writes are sequenced, but I'm not sure how to implement that in a way that the compiler can optimize the branch out.
Also, since having no false positives depends on a `check_ticks` scan running at least every `2 * N - 1` ticks, a `last_check_tick` should also be stored in the `World` so that any lull in system execution (like a command flush) could trigger a scan if needed. To be completely robust, all the systems initialized on the world should be scanned, not just those in the current stage.
# Objective
- `RunOnce` was a manual `System` implementation.
- Adding run criteria to stages was yet to be systemyoten
## Solution
- Make it a normal function
- yeet
## Changelog
- Replaced `RunOnce` with `ShouldRun::once`
## Migration guide
The run criterion `RunOnce`, which would make the controlled systems run only once, has been replaced with a new run criterion function `ShouldRun::once`. Replace all instances of `RunOnce` with `ShouldRun::once`.
# Objective
Reduce from scratch build time.
## Solution
Reduce the size of the critical path by removing dependencies between crates where not necessary. For `cargo check --no-default-features` this reduced build time from ~51s to ~45s. For some commits I am not completely sure if the tradeoff between build time reduction and convenience caused by the commit is acceptable. If not, I can drop them.
# Objective
`AsSystemLabel` has been introduced on system descriptors to make ordering systems more convenient, but `SystemSet::before` and `SystemSet::after` still take `SystemLabels` directly:
use bevy::ecs::system::AsSystemLabel;
/*…*/ SystemSet::new().before(foo.as_system_label()) /*…*/
is currently necessary instead of
/*…*/ SystemSet::new().before(foo) /*…*/
## Solution
Use `AsSystemLabel` for `SystemSet`
# Objective
- Make it possible to use `System`s outside of the scheduler/executor without having to define logic to track new archetypes and call `System::add_archetype()` for each.
## Solution
- Replace `System::add_archetype(&Archetype)` with `System::update_archetypes(&World)`, making systems responsible for tracking their own most recent archetype generation the way that `SystemState` already does.
This has minimal (or simplifying) effect on most of the code with the exception of `FunctionSystem`, which must now track the latest `ArchetypeGeneration` it saw instead of relying on the executor to do it.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Remove the 'chaining' api, as it's peculiar
~~Implement the label traits for `Box<dyn ThatTrait>` (n.b. I'm not confident about this change, but it was the quickest path to not regressing)~~
Remove the need for '`.system`' when using run criteria piping
This adds the concept of "default labels" for systems (currently scoped to "parallel systems", but this could just as easily be implemented for "exclusive systems"). Function systems now include their function's `SystemTypeIdLabel` by default.
This enables the following patterns:
```rust
// ordering two systems without manually defining labels
app
.add_system(update_velocity)
.add_system(movement.after(update_velocity))
// ordering sets of systems without manually defining labels
app
.add_system(foo)
.add_system_set(
SystemSet::new()
.after(foo)
.with_system(bar)
.with_system(baz)
)
```
Fixes: #4219
Related to: #4220
Credit to @aevyrie @alice-i-cecile @DJMcNab (and probably others) for proposing (and supporting) this idea about a year ago. I was a big dummy that both shut down this (very good) idea and then forgot I did that. Sorry. You all were right!
Tracing added support for "inline span entering", which cuts down on a lot of complexity:
```rust
let span = info_span!("my_span").entered();
```
This adapts our code to use this pattern where possible, and updates our docs to recommend it.
This produces equivalent tracing behavior. Here is a side by side profile of "before" and "after" these changes.
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
- Fix the ugliness of the `config` api.
- Supercedes #2440, #2463, #2491
## Solution
- Since #2398, capturing closure systems have worked.
- Use those instead where we needed config before
- Remove the rest of the config api.
- Related: #2777
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Fixes#3078
- Fixes#1397
## Solution
- Implement Commands::init_resource.
- Also implement for World, for consistency and to simplify internal structure.
- While we're here, clean up some of the docs for Command and World resource modification.
# Objective
It would be useful to be able to restart a state (such as if an operation fails and needs to be retried from `on_enter`). Currently, it seems the way to restart a state is to transition to a dummy state and then transition back.
## Solution
The solution is to add a `restart` method on `State<T>` that allows for transitioning to the already-active state.
## Context
Based on [this](https://discord.com/channels/691052431525675048/742884593551802431/920335041756815441) question from the Discord.
Closes#2385
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make it possible to use `&World` as a system parameter
## Solution
It seems like all the pieces were already in place, very simple impl
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
Fills in some gaps we had in our Bevy ECS tracing spans:
* Exclusive systems
* System Commands (for `apply_buffers = true` cases)
* System archetype updates
* Parallel system execution prep
# Objective
- New clippy lints with rust 1.57 are failing
## Solution
- Fixed clippy lints following suggestions
- I ignored clippy in old renderer because there was many and it will be removed soon
# Objective
- Fixes#2904 (see for context)
## Solution
- Simply hoist span creation out of the threaded task
- Confirmed to solve the issue locally
Now all events have the full span parent tree up through `bevy_ecs::schedule::stage` all the way to `bevy_app::app::bevy_app` (and its parents in bevy-consumer code, if any).
# Objective
- Avoid usages of `format!` that ~immediately get passed to another `format!`. This avoids a temporary allocation and is just generally cleaner.
## Solution
- `bevy_derive::shader_defs` does a `format!("{}", val.to_string())`, which is better written as just `format!("{}", val)`
- `bevy_diagnostic::log_diagnostics_plugin` does a `format!("{:>}", format!(...))`, which is better written as `format!("{:>}", format_args!(...))`
- `bevy_ecs::schedule` does `tracing::info!(..., name = &*format!("{:?}", val))`, which is better written with the tracing shorthand `tracing::info!(..., name = ?val)`
- `bevy_reflect::reflect` does `f.write_str(&format!(...))`, which is better written as `write!(f, ...)` (this could also be written using `f.debug_tuple`, but I opted to maintain alt debug behavior)
- `bevy_reflect::serde::{ser, de}` do `serde::Error::custom(format!(...))`, which is better written as `Error::custom(format_args!(...))`, as `Error::custom` takes `impl Display` and just immediately calls `format!` again
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}