# Objective
- When using `Color::hex` for the first time, I was confused by the fact that I can't specify colors using #, which is much more familiar.
- In the code editor (if there is support) there is a preview of the color, which is very convenient.

## Solution
- Allow you to enter colors like `#ff33f2` and use the `.strip_prefix` method to delete the `#` character.
# Objective
The documentation for camera priority is very confusing at the moment, it requires a bit of "double negative" kind of thinking.
# Solution
Flipping the wording on the documentation to reflect more common usecases like having an overlay camera and also renaming it to "order", since priority implies that it will override the other camera rather than have both run.
# Objective
The `WgpuSettings` resource is only used during plugin build. Move it into the `RenderPlugin` struct.
Changing these settings requires re-initializing the render context, which is currently not supported.
If it is supported in the future it should probably be more explicit than changing a field on a resource, maybe something similar to the `CreateWindow` event.
## Migration Guide
```rust
// Before (0.9)
App::new()
.insert_resource(WgpuSettings { .. })
.add_plugins(DefaultPlugins)
// After (0.10)
App::new()
.add_plugins(DefaultPlugins.set(RenderPlugin {
wgpu_settings: WgpuSettings { .. },
}))
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`AsBindGroup` can't be used as a trait object because of the constraint `Sized` and because of the associated function.
This is a problem for [`bevy_atmosphere`](https://github.com/JonahPlusPlus/bevy_atmosphere) because it needs to use a trait that depends on `AsBindGroup` as a trait object, for switching out different shaders at runtime. The current solution it employs is reimplementing the trait and derive macro into that trait, instead of constraining to `AsBindGroup`.
## Solution
Remove the `Sized` constraint from `AsBindGroup` and add the constraint `where Self: Sized` to the associated function `bind_group_layout`. Also change `PreparedBindGroup<T: AsBindGroup>` to `PreparedBindGroup<T>` and use it as `PreparedBindGroup<Self::Data>` instead of `PreparedBindGroup<Self>`.
This weakens the constraints, but increases the flexibility of `AsBindGroup`.
I'm not entirely sure why the `Sized` constraint was there, because it worked fine without it (maybe @cart wasn't aware of use cases for `AsBindGroup` as a trait object or this was just leftover from legacy code?).
---
## Changelog
- `AsBindGroup` can be used as a trait object.
# Objective
Adds a cylinder shape. Fixes#2282.
## Solution
- I added a custom cylinder shape, taken from [here](https://github.com/rparrett/typey_birb/blob/main/src/cylinder.rs) with permission from @rparrett.
- I also added the cylinder shape to the `3d_shapes` example scene.
---
## Changelog
- Added cylinder shape
Co-Authored-By: Rob Parrett <robparrett@gmail.com>
Co-Authored-By: davidhof <7483215+davidhof@users.noreply.github.com>
# Objective
The bloom example has a 2d camera for the UI. This is an artifact of an older version of bevy. All cameras can render the UI now.
## Solution
Remove the 2d camera
Allow passing `Vec`s of glam vector types as vertex attributes.
Alternative to #4548 and #2719
Also used some macros to cut down on all the repetition.
# Migration Guide
Implementations of `From<Vec<[u16; 4]>>` and `From<Vec<[u8; 4]>>` for `VertexAttributeValues` have been removed.
I you're passing either `Vec<[u16; 4]>` or `Vec<[u8; 4]>` into `Mesh::insert_attribute` it will now require wrapping it with right the `VertexAttributeValues` enum variant.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Adds a bloom pass for HDR-enabled Camera3ds.
- Supersedes (and all credit due to!) https://github.com/bevyengine/bevy/pull/3430 and https://github.com/bevyengine/bevy/pull/2876

## Solution
- A threshold is applied to isolate emissive samples, and then a series of downscale and upscaling passes are applied and composited together.
- Bloom is applied to 2d or 3d Cameras with hdr: true and a BloomSettings component.
---
## Changelog
- Added a `core_pipeline::bloom::BloomSettings` component.
- Added `BloomNode` that runs between the main pass and tonemapping.
- Added a `BloomPlugin` that is loaded as part of CorePipelinePlugin.
- Added a bloom example project.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
- Add post processing passes for FXAA (Fast Approximate Anti-Aliasing)
- Add example comparing MSAA and FXAA
## Solution
When the FXAA plugin is added, passes for FXAA are inserted between the main pass and the tonemapping pass. Supports using either HDR or LDR output from the main pass.
---
## Changelog
- Add a new FXAANode that runs after the main pass when the FXAA plugin is added.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add methods to `Query<&Children>` and `Query<&Parent>` to iterate over descendants and ancestors, respectively.
## Changelog
* Added extension trait for `Query` in `bevy_hierarchy`, `HierarchyQueryExt`
* Added method `iter_descendants` to `Query<&Children>` via `HierarchyQueryExt` for iterating over the descendants of an entity.
* Added method `iter_ancestors` to `Query<&Parent>` via `HierarchyQueryExt` for iterating over the ancestors of an entity.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Build on #6336 for more plugin configurations
## Solution
- `LogSettings`, `ImageSettings` and `DefaultTaskPoolOptions` are now plugins settings rather than resources
---
## Changelog
- `LogSettings` plugin settings have been move to `LogPlugin`, `ImageSettings` to `ImagePlugin` and `DefaultTaskPoolOptions` to `CorePlugin`
## Migration Guide
The `LogSettings` settings have been moved from a resource to `LogPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(LogSettings {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(LogPlugin {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
}))
```
The `ImageSettings` settings have been moved from a resource to `ImagePlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(ImageSettings::default_nearest())
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(ImagePlugin::default_nearest()))
```
The `DefaultTaskPoolOptions` settings have been moved from a resource to `CorePlugin::task_pool_options`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(DefaultTaskPoolOptions::with_num_threads(4))
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(CorePlugin {
task_pool_options: TaskPoolOptions::with_num_threads(4),
}))
```
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
- Alpha mask was previously ignored when using an unlit material.
- Fixes https://github.com/bevyengine/bevy/issues/4479
## Solution
- Extract the alpha discard to a separate function and use it when unlit is true
## Notes
I tried calling `alpha_discard()` before the `if` in pbr.wgsl, but I had errors related to having a `discard` at the beginning before doing the texture sampling. I'm not sure if there's a way to fix that instead of having the function being called in 2 places.
# Objective
I was about to submit a PR to add these two examples to `bevy-website` and re-discovered the inconsistency.
Although it's not a major issue on the website where only the filenames are shown, this would help to visually distinguish the two examples in the list because the names are very prominent.
This also helps out when fuzzy-searching the codebase for these files.
## Solution
Rename `shapes` to `2d_shapes`. Now the filename matches the example name, and the naming structure matches the 3d example.
## Notes
@Nilirad proposed this in https://github.com/bevyengine/bevy/pull/4613#discussion_r862455631 but it had slipped away from my brain at that time.
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
Examples inconsistently use either `TAU`, `PI`, `FRAC_PI_2` or `FRAC_PI_4`.
Often in odd ways and without `use`ing the constants, making it difficult to parse.
* Use `PI` to specify angles.
* General code-quality improvements.
* Fix borked `hierarchy` example.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`bevy::render::texture::ImageSettings` was added to prelude in #5566, so these `use` statements are unnecessary and the examples can be made a bit more concise.
## Solution
Remove `use bevy::render::texture::ImageSettings`
# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Showcase how to use a `Material` and `Mesh` to spawn 3d lines
## Solution
- Add an example using a simple `Material` and `Mesh` definition to draw a 3d line
- Shows how to use `LineList` and `LineStrip` in combination with a specialized `Material`
## Notes
This isn't just a primitive shape because it needs a special Material, but I think it's a good showcase of the power of the `Material` and `AsBindGroup` abstractions. All of this is easy to figure out when you know these options are a thing, but I think they are hard to discover which is why I think this should be an example and not shipped with bevy.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
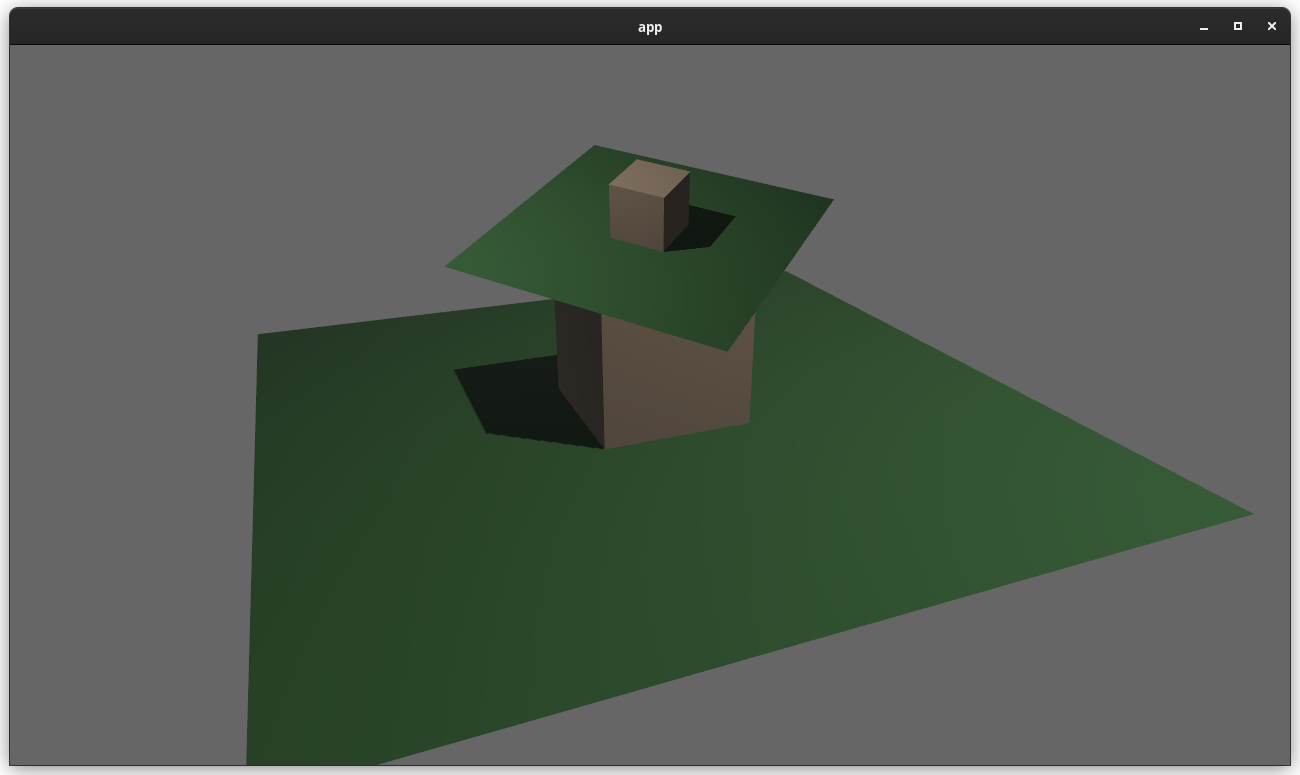
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
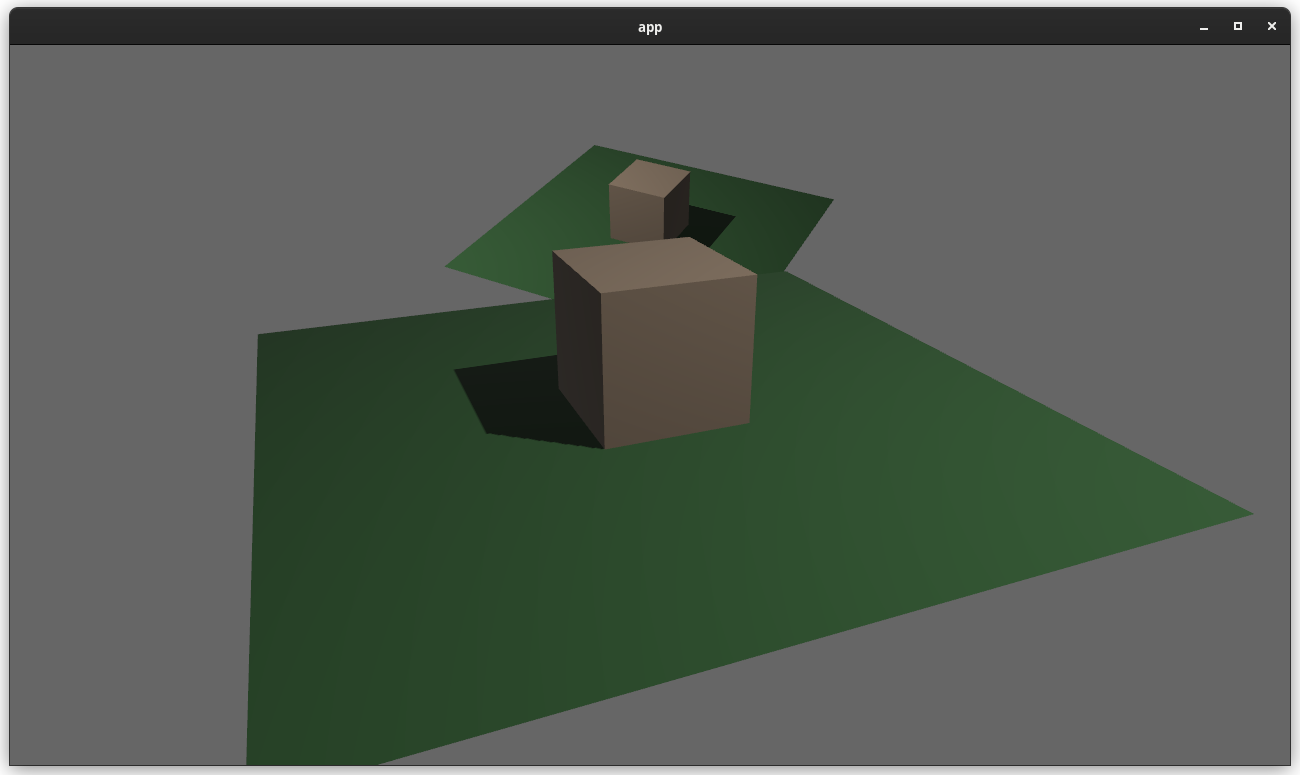
### two_passes example with the "second pass" camera configured to "load" the depth
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Coming from 7a596f1910 (r876310734)
- Simplify the examples regarding addition of `Msaa` Resource with default value.
## Solution
- Remove addition of `Msaa` Resource with default value from examples,
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
- As requested here: https://github.com/bevyengine/bevy/pull/4520#issuecomment-1109302039
- Make it easier to spot issues with built-in shapes
## Solution
https://user-images.githubusercontent.com/200550/165624709-c40dfe7e-0e1e-4bd3-ae52-8ae66888c171.mp4
- Add an example showcasing the built-in 3d shapes with lighting/shadows
- Rotate objects in such a way that all faces are seen by the camera
- Add a UV debug texture
## Discussion
I'm not sure if this is what @alice-i-cecile had in mind, but I adapted the little "torus playground" from the issue linked above to include all built-in shapes.
This exact arrangement might not be particularly scalable if many more shapes are added. Maybe a slow camera pan, or cycling with the keyboard or on a timer, or a sidebar with buttons would work better. If one of the latter options is used, options for showing wireframes or computed flat normals might add some additional utility.
Ideally, I think we'd have a better way of visualizing normals.
Happy to rework this or close it if there's not a consensus around it being useful.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3499
## Solution
Uses a `HashMap` from `RenderTarget` to sampled textures when preparing `ViewTarget`s to ensure that two passes with the same render target get sampled to the same texture.
This builds on and depends on https://github.com/bevyengine/bevy/pull/3412, so this will be a draft PR until #3412 is merged. All changes for this PR are in the last commit.
# Objective
- Several examples are useful for qualitative tests of Bevy's performance
- By contrast, these are less useful for learning material: they are often relatively complex and have large amounts of setup and are performance optimized.
## Solution
- Move bevymark, many_sprites and many_cubes into the new stress_tests example folder
- Move contributors into the games folder: unlike the remaining examples in the 2d folder, it is not focused on demonstrating a clear feature.
# Objective
Add a system parameter `ParamSet` to be used as container for conflicting parameters.
## Solution
Added two methods to the SystemParamState trait, which gives the access used by the parameter. Did the implementation. Added some convenience methods to FilteredAccessSet. Changed `get_conflicts` to return every conflicting component instead of breaking on the first conflicting `FilteredAccess`.
Co-authored-by: bilsen <40690317+bilsen@users.noreply.github.com>
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Make the example a little easier to follow by removing unnecessary steps.
## Solution
- `Assets<Image>` will give us a handle for our render texture if we call `add()` instead of `set()`. No need to set it manually; one less thing to think about while reading the example.
**Problem**
- whenever you want more than one of the builtin cameras (for example multiple windows, split screen, portals), you need to add a render graph node that executes the correct sub graph, extract the camera into the render world and add the correct `RenderPhase<T>` components
- querying for the 3d camera is annoying because you need to compare the camera's name to e.g. `CameraPlugin::CAMERA_3d`
**Solution**
- Introduce the marker types `Camera3d`, `Camera2d` and `CameraUi`
-> `Query<&mut Transform, With<Camera3d>>` works
- `PerspectiveCameraBundle::new_3d()` and `PerspectiveCameraBundle::<Camera3d>::default()` contain the `Camera3d` marker
- `OrthographicCameraBundle::new_3d()` has `Camera3d`, `OrthographicCameraBundle::new_2d()` has `Camera2d`
- remove `ActiveCameras`, `ExtractedCameraNames`
- run 2d, 3d and ui passes for every camera of their respective marker
-> no custom setup for multiple windows example needed
**Open questions**
- do we need a replacement for `ActiveCameras`? What about a component `ActiveCamera { is_active: bool }` similar to `Visibility`?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}