# Objective
Fixes#6952
## Solution
- Request WGPU capabilities `SAMPLED_TEXTURE_AND_STORAGE_BUFFER_ARRAY_NON_UNIFORM_INDEXING`, `SAMPLER_NON_UNIFORM_INDEXING` and `UNIFORM_BUFFER_AND_STORAGE_TEXTURE_ARRAY_NON_UNIFORM_INDEXING` when corresponding features are enabled.
- Add an example (`shaders/texture_binding_array`) illustrating (and testing) the use of non-uniform indexed textures and samplers.
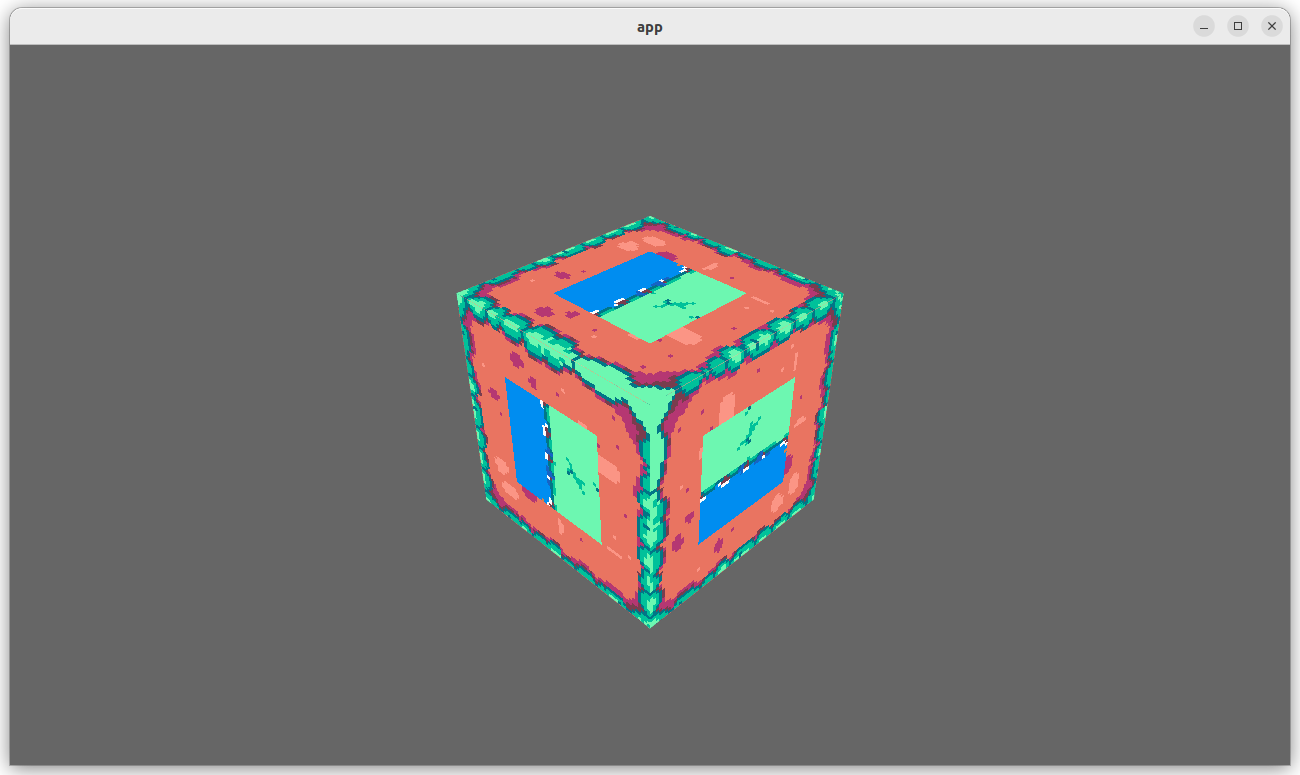
## Changelog
- Added new capabilities for shader validation.
- Added example `shaders/texture_binding_array`.
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
# Objective
- The changes to the MeshPipeline done for the prepass broke the shader_instancing example. The issue is that the view_layout changes based on if MSAA is enabled or not, but the example hardcoded the view_layout.
## Solution
- Don't overwrite the bind_group_layout of the descriptor since the MeshPipeline already takes care of this in the specialize function.
Closes https://github.com/bevyengine/bevy/issues/7285
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
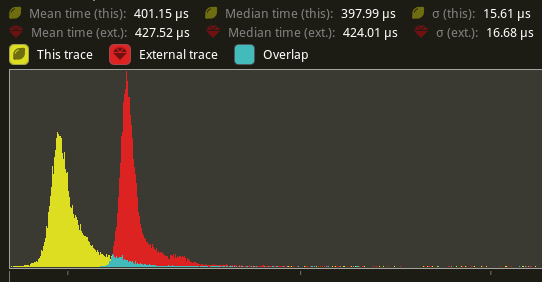
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
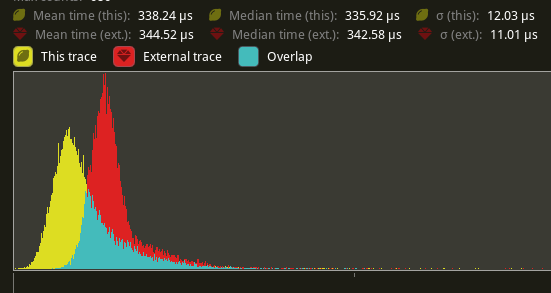
The shadow pass node is also slightly faster (344.52 -> 338.24us)
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
The documentation for camera priority is very confusing at the moment, it requires a bit of "double negative" kind of thinking.
# Solution
Flipping the wording on the documentation to reflect more common usecases like having an overlay camera and also renaming it to "order", since priority implies that it will override the other camera rather than have both run.
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode.
# Objective
The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching.
Additionally as it stands Bevy only has two settings for visibility of an entity:
- "unconditionally hidden" `Visibility { is_visible: false }`,
- "inherit visibility from parent" `Visibility { is_visible: true }`
where a root level entity set to "inherit" is visible.
Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear.
Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode.
--
The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants.
## Solution
Change the Visibility component into
```rust
enum Visibility {
Hidden, // unconditionally hidden
Visible, // unconditionally visible
Inherited, // inherit visibility from parent
}
```
---
## Changelog
### Changed
`Visibility` is now an enum
## Migration Guide
- evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`.
- setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`.
- usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively.
- `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
Allow more use cases where the user may benefit from both `ExtractComponentPlugin` _and_ `UniformComponentPlugin`.
## Solution
Add an associated type to `ExtractComponent` in order to allow specifying the output component (or bundle).
Make `extract_component` return an `Option<_>` such that components can be extracted only when needed.
What problem does this solve?
`ExtractComponentPlugin` allows extracting components, but currently the output type is the same as the input.
This means that use cases such as having a settings struct which turns into a uniform is awkward.
For example we might have:
```rust
struct MyStruct {
enabled: bool,
val: f32
}
struct MyStructUniform {
val: f32
}
```
With the new approach, we can extract `MyStruct` only when it is enabled, and turn it into its related uniform.
This chains well with `UniformComponentPlugin`.
The user may then:
```rust
app.add_plugin(ExtractComponentPlugin::<MyStruct>::default());
app.add_plugin(UniformComponentPlugin::<MyStructUniform>::default());
```
This then saves the user a fair amount of boilerplate.
## Changelog
### Changed
- `ExtractComponent` can specify output type, and outputting is optional.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- Using the instancing example as reference, I found it was breaking when enabling HDR on the camera. I found that this was because, unlike in internal code, this was not updating the specialization key with `view.hdr`.
## Solution
- Add the missing HDR bit.
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
# Objective
Fixes#5884#2879
Alternative to #2988#5885#2886
"Immutable" Plugin settings are currently represented as normal ECS resources, which are read as part of plugin init. This presents a number of problems:
1. If a user inserts the plugin settings resource after the plugin is initialized, it will be silently ignored (and use the defaults instead)
2. Users can modify the plugin settings resource after the plugin has been initialized. This creates a false sense of control over settings that can no longer be changed.
(1) and (2) are especially problematic and confusing for the `WindowDescriptor` resource, but this is a general problem.
## Solution
Immutable Plugin settings now live on each Plugin struct (ex: `WindowPlugin`). PluginGroups have been reworked to support overriding plugin values. This also removes the need for the `add_plugins_with` api, as the `add_plugins` api can use the builder pattern directly. Settings that can be used at runtime continue to be represented as ECS resources.
Plugins are now configured like this:
```rust
app.add_plugin(AssetPlugin {
watch_for_changes: true,
..default()
})
```
PluginGroups are now configured like this:
```rust
app.add_plugins(DefaultPlugins
.set(AssetPlugin {
watch_for_changes: true,
..default()
})
)
```
This is an alternative to #2988, which is similar. But I personally prefer this solution for a couple of reasons:
* ~~#2988 doesn't solve (1)~~ #2988 does solve (1) and will panic in that case. I was wrong!
* This PR directly ties plugin settings to Plugin types in a 1:1 relationship, rather than a loose "setup resource" <-> plugin coupling (where the setup resource is consumed by the first plugin that uses it).
* I'm not a huge fan of overloading the ECS resource concept and implementation for something that has very different use cases and constraints.
## Changelog
- PluginGroups can now be configured directly using the builder pattern. Individual plugin values can be overridden by using `plugin_group.set(SomePlugin {})`, which enables overriding default plugin values.
- `WindowDescriptor` plugin settings have been moved to `WindowPlugin` and `AssetServerSettings` have been moved to `AssetPlugin`
- `app.add_plugins_with` has been replaced by using `add_plugins` with the builder pattern.
## Migration Guide
The `WindowDescriptor` settings have been moved from a resource to `WindowPlugin::window`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(WindowDescriptor {
width: 400.0,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(WindowPlugin {
window: WindowDescriptor {
width: 400.0,
..default()
},
..default()
}))
```
The `AssetServerSettings` resource has been removed in favor of direct `AssetPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(AssetPlugin {
watch_for_changes: true,
..default()
}))
```
`add_plugins_with` has been replaced by `add_plugins` in combination with the builder pattern:
```rust
// Old (Bevy 0.8)
app.add_plugins_with(DefaultPlugins, |group| group.disable::<AssetPlugin>());
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.build().disable::<AssetPlugin>());
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
`AssetServer::watch_for_changes()` is racy and redundant with `AssetServerSettings`.
Closes#5964.
## Changelog
* Remove `AssetServer::watch_for_changes()`
* Add `AssetServerSettings` to the prelude.
* Minor cleanup.
## Migration Guide
`AssetServer::watch_for_changes()` was removed.
Instead, use the `AssetServerSettings` resource.
```rust
app // AssetServerSettings must be inserted before adding the AssetPlugin or DefaultPlugins.
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Provide better compile-time errors and diagnostics.
- Add more options to allow more textures types and sampler types.
- Update array_texture example to use upgraded AsBindGroup derive macro.
## Solution
Split out the parsing of the inner struct/field attributes (the inside part of a `#[foo(...)]` attribute) for better clarity
Parse the binding index for all inner attributes, as it is part of all attributes (`#[foo(0, ...)`), then allow each attribute implementer to parse the rest of the attribute metadata as needed. This should make it very trivial to extend/change if needed in the future.
Replaced invocations of `panic!` with the `syn::Error` type, providing fine-grained errors that retains span information. This provides much nicer compile-time errors, and even better IDE errors.

Updated the array_texture example to demonstrate the new changes.
## New AsBindGroup attribute options
### `#[texture(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|-------------- |---------------------------------------------------------------- | ----------- |
| dimension = "..." | `"1d"`, `"2d"`, `"2d_array"`, `"3d"`, `"cube"`, `"cube_array"` | `"2d"` |
| sample_type = "..." | `"float"`, `"depth"`, `"s_int"` or `"u_int"` | `"float"` |
| filterable = ... | `true`, `false` | `true` |
| multisampled = ... | `true`, `false` | `false` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[texture(0, dimension = "2d_array", visibility(vertex, fragment))]`
### `#[sampler(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|----------- |--------------------------------------------------- | ----------- |
| sampler_type = "..." | `"filtering"`, `"non_filtering"`, `"comparison"`. | `"filtering"` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[sampler(0, sampler_type = "filtering", visibility(vertex, fragment)]`
## Changelog
- Added more options to `#[texture(...)]` and `#[sampler(...)]` attributes, supporting more kinds of materials. See above for details.
- Upgraded IDE and compile-time error messages.
- Updated array_texture example using the new options.
Port changes made to Material in #5053 to Material2d as well.
This is more or less an exact copy of the implementation in bevy_pbr; I
simply pretended the API existed, then copied stuff over until it
started building and the shapes example was working again.
# Objective
The changes in #5053 makes it possible to add custom materials with a lot less boiler plate. However, the implementation isn't shared with Material 2d as it's a kind of fork of the bevy_pbr version. It should be possible to use AsBindGroup on the 2d version as well.
## Solution
This makes the same kind of changes in Material2d in bevy_sprite.
This makes the following work:
```rust
//! Draws a circular purple bevy in the middle of the screen using a custom shader
use bevy::{
prelude::*,
reflect::TypeUuid,
render::render_resource::{AsBindGroup, ShaderRef},
sprite::{Material2d, Material2dPlugin, MaterialMesh2dBundle},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(Material2dPlugin::<CustomMaterial>::default())
.add_startup_system(setup)
.run();
}
/// set up a simple 2D scene
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<CustomMaterial>>,
asset_server: Res<AssetServer>,
) {
commands.spawn_bundle(MaterialMesh2dBundle {
mesh: meshes.add(shape::Circle::new(50.).into()).into(),
material: materials.add(CustomMaterial {
color: Color::PURPLE,
color_texture: Some(asset_server.load("branding/icon.png")),
}),
transform: Transform::from_translation(Vec3::new(-100., 0., 0.)),
..default()
});
commands.spawn_bundle(Camera2dBundle::default());
}
/// The Material2d trait is very configurable, but comes with sensible defaults for all methods.
/// You only need to implement functions for features that need non-default behavior. See the Material api docs for details!
impl Material2d for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"shaders/custom_material.wgsl".into()
}
}
// This is the struct that will be passed to your shader
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add texture sampling to the GLSL shader example, as naga does not support the commonly used sampler2d type.
Fixes#5059
## Solution
- Align the shader_material_glsl example behaviour with the shader_material example, as the later includes texture sampling.
- Update the GLSL shader to do texture sampling the way naga supports it, and document the way naga does not support it.
## Changelog
- The shader_material_glsl example has been updated to demonstrate texture sampling using the GLSL shading language.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
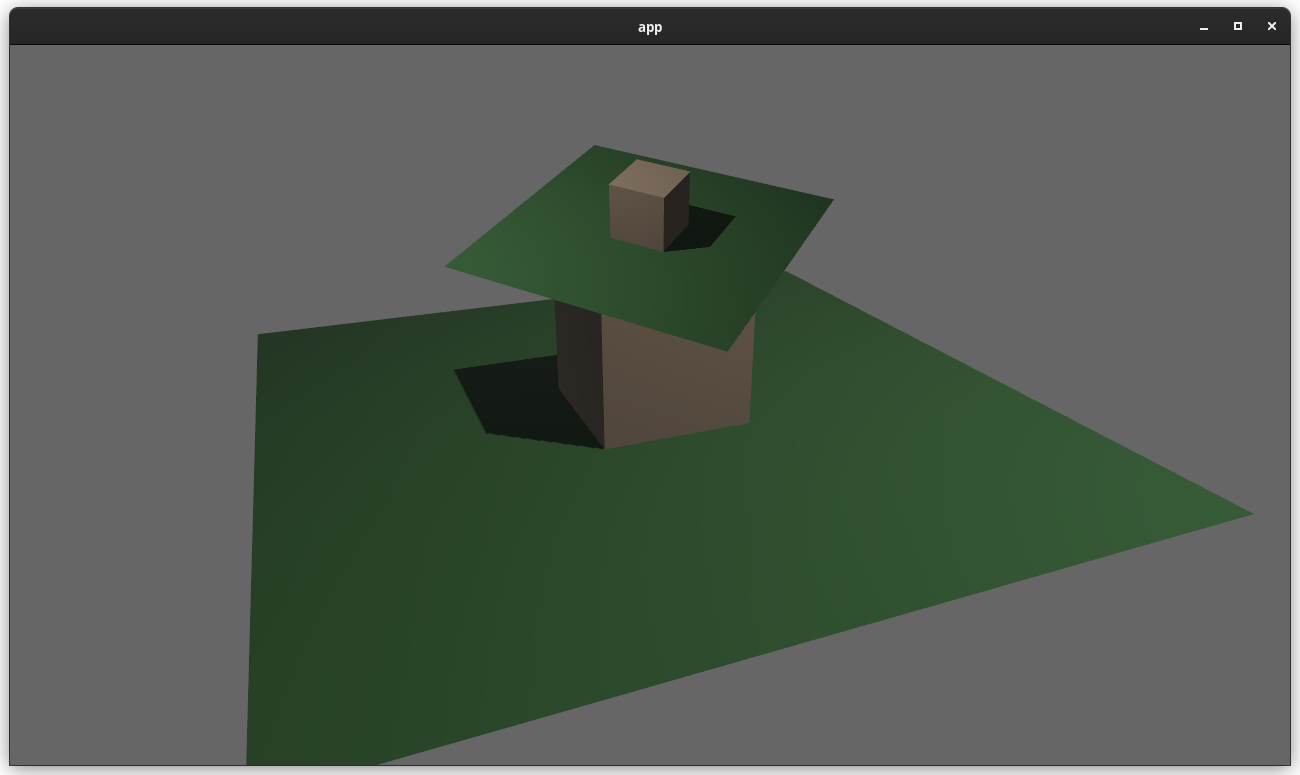
### two_passes example with the "second pass" camera configured to "load" the depth
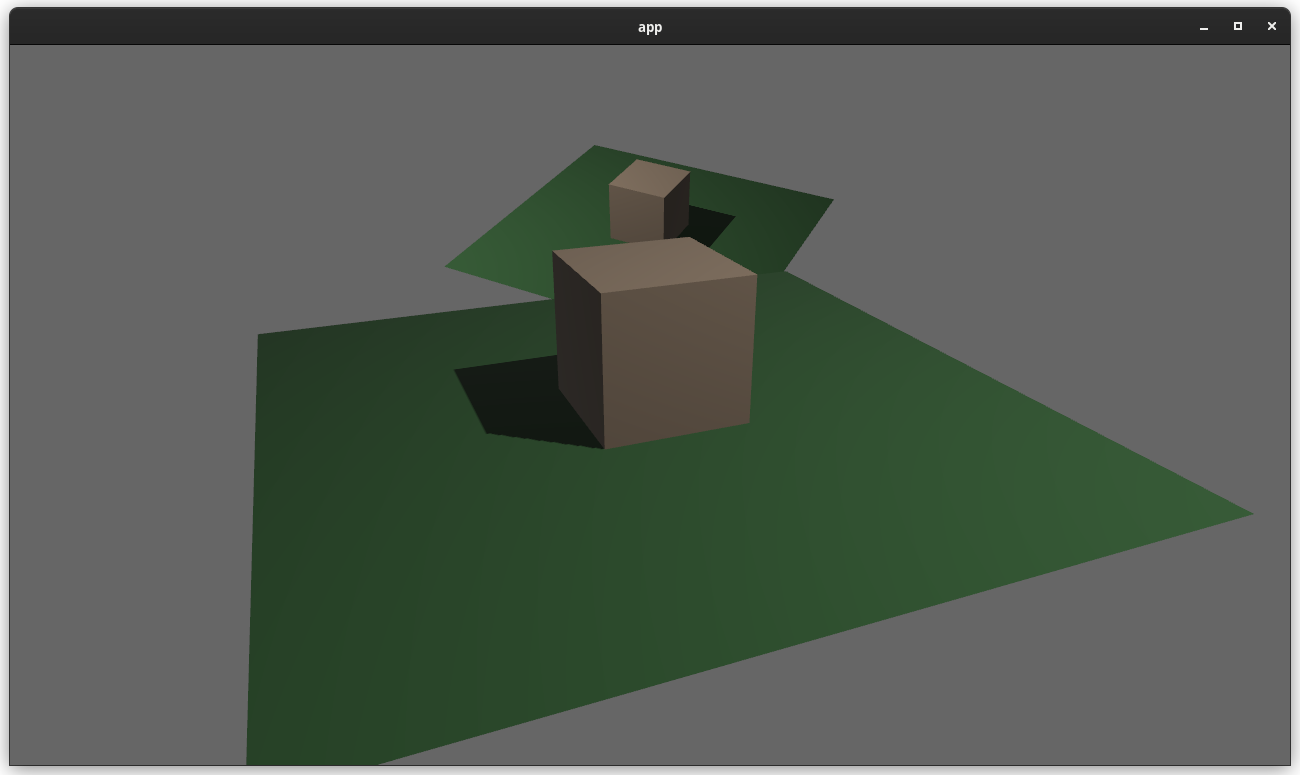
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
# Objective
In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access.
## Solution
Remove the `With<Handle<Mesh>>` filter
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
- To fix the broken commented code in `examples/shader/compute_shader_game_of_life.rs` for disabling frame throttling
## Solution
- Change the commented code from using the old `WindowDescriptor::vsync` to the new `WindowDescriptor::present_mode`
### Note
I chose to use the fully qualified scope `bevy:🪟:PresentWindow::Immediate` rather than explicitly including `PresentWindow` to avoid an unused import when the code is commented.
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}