# Objective
I noticed while working on #5366 that the documentation for label types wasn't working correctly. Having experimented with this for a few weeks, I believe that generating docs in macros is more effort than it's worth.
## Solution
Add more boilerplate, copy-paste and edit the docs across types. This also lets us add custom doctests for specific types. Also, we don't need `concat_idents` as a dependency anymore.
# Objective
- Closes#4954
- Reduce the complexity of the `{System, App, *}Label` APIs.
## Solution
For the sake of brevity I will only refer to `SystemLabel`, but everything applies to all of the other label types as well.
- Add `SystemLabelId`, a lightweight, `copy` struct.
- Convert custom types into `SystemLabelId` using the trait `SystemLabel`.
## Changelog
- String literals implement `SystemLabel` for now, but this should be changed with #4409 .
## Migration Guide
- Any previous use of `Box<dyn SystemLabel>` should be replaced with `SystemLabelId`.
- `AsSystemLabel` trait has been modified.
- No more output generics.
- Method `as_system_label` now returns `SystemLabelId`, removing an unnecessary level of indirection.
- If you *need* a label that is determined at runtime, you can use `Box::leak`. Not recommended.
## Questions for later
* Should we generate a `Debug` impl along with `#[derive(*Label)]`?
* Should we rename `as_str()`?
* Should we remove the extra derives (such as `Hash`) from builtin `*Label` types?
* Should we automatically derive types like `Clone, Copy, PartialEq, Eq`?
* More-ergonomic comparisons between `Label` and `LabelId`.
* Move `Dyn{Eq, Hash,Clone}` somewhere else.
* Some API to make interning dynamic labels easier.
* Optimize string representation
* Empty string for unit structs -- no debug info but faster comparisons
* Don't show enum types -- same tradeoffs as asbove.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Fixes#4271
## Solution
- Check for a pending transition in addition to a scheduled operation.
- I don't see a valid reason for updating the state unless both `scheduled` and `transition` are empty.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
## Objective
- ~~Make absurdly long-lived changes stay detectable for even longer (without leveling up to `u64`).~~
- Give all changes a consistent maximum lifespan.
- Improve code clarity.
## Solution
- ~~Increase the frequency of `check_tick` scans to increase the oldest reliably-detectable change.~~
(Deferred until we can benchmark the cost of a scan.)
- Ignore changes older than the maximum reliably-detectable age.
- General refactoring—name the constants, use them everywhere, and update the docs.
- Update test cases to check for the specified behavior.
## Related
This PR addresses (at least partially) the concerns raised in:
- #3071
- #3082 (and associated PR #3084)
## Background
- #1471
Given the minimum interval between `check_ticks` scans, `N`, the oldest reliably-detectable change is `u32::MAX - (2 * N - 1)` (or `MAX_CHANGE_AGE`). Reducing `N` from ~530 million (current value) to something like ~2 million would extend the lifetime of changes by a billion.
| minimum `check_ticks` interval | oldest reliably-detectable change | usable % of `u32::MAX` |
| --- | --- | --- |
| `u32::MAX / 8` (536,870,911) | `(u32::MAX / 4) * 3` | 75.0% |
| `2_000_000` | `u32::MAX - 3_999_999` | 99.9% |
Similarly, changes are still allowed to be between `MAX_CHANGE_AGE`-old and `u32::MAX`-old in the interim between `check_tick` scans. While we prevent their age from overflowing, the test to detect changes still compares raw values. This makes failure ultimately unreliable, since when ancient changes stop being detected varies depending on when the next scan occurs.
## Open Question
Currently, systems and system states are incorrectly initialized with their `last_change_tick` set to `0`, which doesn't handle wraparound correctly.
For consistent behavior, they should either be initialized to the world's `last_change_tick` (and detect no changes) or to `MAX_CHANGE_AGE` behind the world's current `change_tick` (and detect everything as a change). I've currently gone with the latter since that was closer to the existing behavior.
## Follow-up Work
(Edited: entire section)
We haven't actually profiled how long a `check_ticks` scan takes on a "large" `World` , so we don't know if it's safe to increase their frequency. However, we are currently relying on play sessions not lasting long enough to trigger a scan and apps not having enough entities/archetypes for it to be "expensive" (our assumption). That isn't a real solution. (Either scanning never costs enough to impact frame times or we provide an option to use `u64` change ticks. Nobody will accept random hiccups.)
To further extend the lifetime of changes, we actually only need to increment the world tick if a system has `Fetch: !ReadOnlySystemParamFetch`. The behavior will be identical because all writes are sequenced, but I'm not sure how to implement that in a way that the compiler can optimize the branch out.
Also, since having no false positives depends on a `check_ticks` scan running at least every `2 * N - 1` ticks, a `last_check_tick` should also be stored in the `World` so that any lull in system execution (like a command flush) could trigger a scan if needed. To be completely robust, all the systems initialized on the world should be scanned, not just those in the current stage.
# Objective
- `RunOnce` was a manual `System` implementation.
- Adding run criteria to stages was yet to be systemyoten
## Solution
- Make it a normal function
- yeet
## Changelog
- Replaced `RunOnce` with `ShouldRun::once`
## Migration guide
The run criterion `RunOnce`, which would make the controlled systems run only once, has been replaced with a new run criterion function `ShouldRun::once`. Replace all instances of `RunOnce` with `ShouldRun::once`.
# Objective
Reduce from scratch build time.
## Solution
Reduce the size of the critical path by removing dependencies between crates where not necessary. For `cargo check --no-default-features` this reduced build time from ~51s to ~45s. For some commits I am not completely sure if the tradeoff between build time reduction and convenience caused by the commit is acceptable. If not, I can drop them.
# Objective
`AsSystemLabel` has been introduced on system descriptors to make ordering systems more convenient, but `SystemSet::before` and `SystemSet::after` still take `SystemLabels` directly:
use bevy::ecs::system::AsSystemLabel;
/*…*/ SystemSet::new().before(foo.as_system_label()) /*…*/
is currently necessary instead of
/*…*/ SystemSet::new().before(foo) /*…*/
## Solution
Use `AsSystemLabel` for `SystemSet`
# Objective
- Make it possible to use `System`s outside of the scheduler/executor without having to define logic to track new archetypes and call `System::add_archetype()` for each.
## Solution
- Replace `System::add_archetype(&Archetype)` with `System::update_archetypes(&World)`, making systems responsible for tracking their own most recent archetype generation the way that `SystemState` already does.
This has minimal (or simplifying) effect on most of the code with the exception of `FunctionSystem`, which must now track the latest `ArchetypeGeneration` it saw instead of relying on the executor to do it.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Remove the 'chaining' api, as it's peculiar
~~Implement the label traits for `Box<dyn ThatTrait>` (n.b. I'm not confident about this change, but it was the quickest path to not regressing)~~
Remove the need for '`.system`' when using run criteria piping
This adds the concept of "default labels" for systems (currently scoped to "parallel systems", but this could just as easily be implemented for "exclusive systems"). Function systems now include their function's `SystemTypeIdLabel` by default.
This enables the following patterns:
```rust
// ordering two systems without manually defining labels
app
.add_system(update_velocity)
.add_system(movement.after(update_velocity))
// ordering sets of systems without manually defining labels
app
.add_system(foo)
.add_system_set(
SystemSet::new()
.after(foo)
.with_system(bar)
.with_system(baz)
)
```
Fixes: #4219
Related to: #4220
Credit to @aevyrie @alice-i-cecile @DJMcNab (and probably others) for proposing (and supporting) this idea about a year ago. I was a big dummy that both shut down this (very good) idea and then forgot I did that. Sorry. You all were right!
Tracing added support for "inline span entering", which cuts down on a lot of complexity:
```rust
let span = info_span!("my_span").entered();
```
This adapts our code to use this pattern where possible, and updates our docs to recommend it.
This produces equivalent tracing behavior. Here is a side by side profile of "before" and "after" these changes.
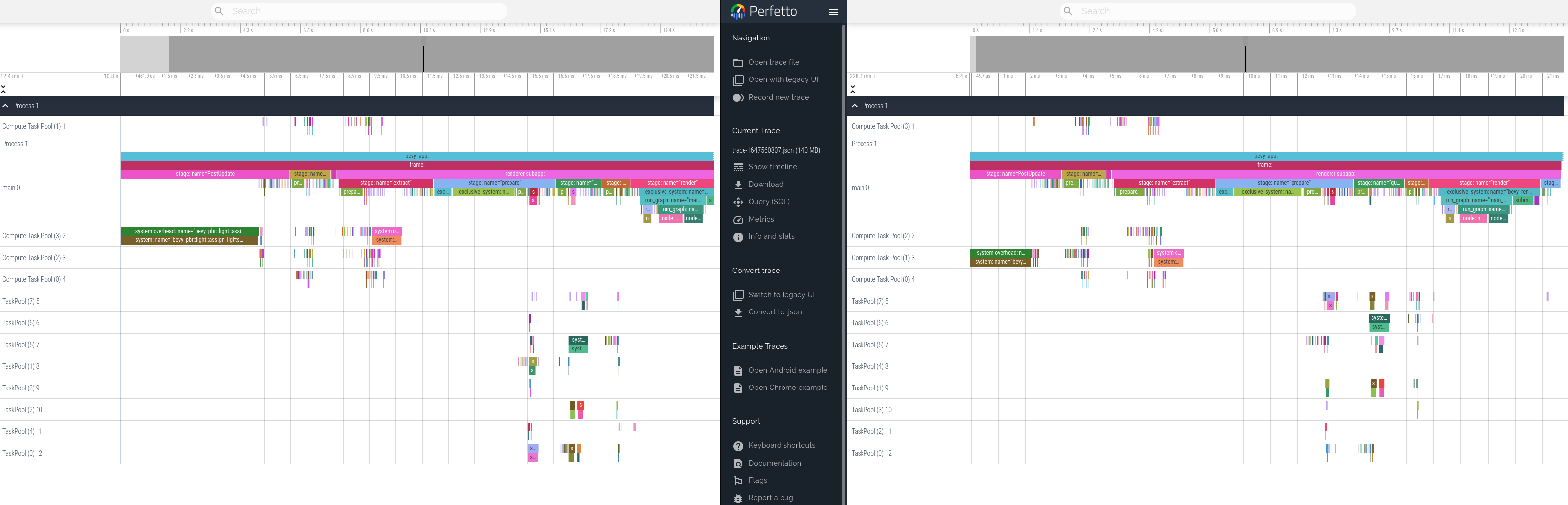
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
- Fix the ugliness of the `config` api.
- Supercedes #2440, #2463, #2491
## Solution
- Since #2398, capturing closure systems have worked.
- Use those instead where we needed config before
- Remove the rest of the config api.
- Related: #2777
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Fixes#3078
- Fixes#1397
## Solution
- Implement Commands::init_resource.
- Also implement for World, for consistency and to simplify internal structure.
- While we're here, clean up some of the docs for Command and World resource modification.
# Objective
It would be useful to be able to restart a state (such as if an operation fails and needs to be retried from `on_enter`). Currently, it seems the way to restart a state is to transition to a dummy state and then transition back.
## Solution
The solution is to add a `restart` method on `State<T>` that allows for transitioning to the already-active state.
## Context
Based on [this](https://discord.com/channels/691052431525675048/742884593551802431/920335041756815441) question from the Discord.
Closes#2385
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make it possible to use `&World` as a system parameter
## Solution
It seems like all the pieces were already in place, very simple impl
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
Fills in some gaps we had in our Bevy ECS tracing spans:
* Exclusive systems
* System Commands (for `apply_buffers = true` cases)
* System archetype updates
* Parallel system execution prep
# Objective
- New clippy lints with rust 1.57 are failing
## Solution
- Fixed clippy lints following suggestions
- I ignored clippy in old renderer because there was many and it will be removed soon
# Objective
- Fixes#2904 (see for context)
## Solution
- Simply hoist span creation out of the threaded task
- Confirmed to solve the issue locally
Now all events have the full span parent tree up through `bevy_ecs::schedule::stage` all the way to `bevy_app::app::bevy_app` (and its parents in bevy-consumer code, if any).
# Objective
- Avoid usages of `format!` that ~immediately get passed to another `format!`. This avoids a temporary allocation and is just generally cleaner.
## Solution
- `bevy_derive::shader_defs` does a `format!("{}", val.to_string())`, which is better written as just `format!("{}", val)`
- `bevy_diagnostic::log_diagnostics_plugin` does a `format!("{:>}", format!(...))`, which is better written as `format!("{:>}", format_args!(...))`
- `bevy_ecs::schedule` does `tracing::info!(..., name = &*format!("{:?}", val))`, which is better written with the tracing shorthand `tracing::info!(..., name = ?val)`
- `bevy_reflect::reflect` does `f.write_str(&format!(...))`, which is better written as `write!(f, ...)` (this could also be written using `f.debug_tuple`, but I opted to maintain alt debug behavior)
- `bevy_reflect::serde::{ser, de}` do `serde::Error::custom(format!(...))`, which is better written as `Error::custom(format_args!(...))`, as `Error::custom` takes `impl Display` and just immediately calls `format!` again
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes these issues:
- `WorldId`s currently aren't necessarily unique
- I want to guarantee that they're unique to safeguard my librarified version of https://github.com/bevyengine/bevy/discussions/2805
- There probably hasn't been a collision yet, but they could technically collide
- `SystemId` isn't used for anything
- It's no longer used now that `Locals` are stored within the `System`.
- `bevy_ecs` depends on rand
## Solution
- Instead of randomly generating `WorldId`s, just use an incrementing atomic counter, panicing on overflow.
- Remove `SystemId`
- We do need to allow Locals for exclusive systems at some point, but exclusive systems couldn't access their own `SystemId` anyway.
- Now that these don't depend on rand, move it to a dev-dependency
## Todo
Determine if `WorldId` should be `u32` based instead
## Objective
The upcoming Bevy Book makes many references to the API documentation of bevy.
Most references belong to the first two chapters of the Bevy Book:
- bevyengine/bevy-website#176
- bevyengine/bevy-website#182
This PR attempts to improve the documentation of `bevy_ecs` and `bevy_app` in order to help readers of the Book who want to delve deeper into technical details.
## Solution
- Add crate and level module documentation
- Document the most important items (basically those included in the preludes), with the following style, where applicable:
- **Summary.** Short description of the item.
- **Second paragraph.** Detailed description of the item, without going too much in the implementation.
- **Code example(s).**
- **Safety or panic notes.**
## Collaboration
Any kind of collaboration is welcome, especially corrections, wording, new ideas and guidelines on where the focus should be put in.
---
### Related issues
- Fixes#2246
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
This is a rather simple but wide change, and it involves adding a new `bevy_app_macros` crate. Let me know if there is a better way to do any of this!
---
# Objective
- Allow adding and accessing sub-apps by using a label instead of an index
## Solution
- Migrate the bevy label implementation and derive code to the `bevy_utils` and `bevy_macro_utils` crates and then add a new `SubAppLabel` trait to the `bevy_app` crate that is used when adding or getting a sub-app from an app.
{kind=link}
{kind=link}
{kind=link}