# Objective
Make it easier to create pipelines derived from the `Material2dPipeline`. Currently this is made difficult because the fields of `Material2dKey` are private.
## Solution
Make the fields public.
# Objective
- To implement `Reflect` for more glam types.
## Solution
insert `impl_reflect_struct` invocations for more glam types. I am not sure about the boolean vectors, since none of them implement `Serde::Serialize/Deserialize`, and the SIMD versions don't have public fields.
I do still think implementing reflection is useful for BVec's since then they can be incorporated into `Reflect`'ed components and set dynamically even if as a whole + it's more consistent.
## Changelog
Implemented `Reflect` for the following types
- BVec2
- BVec3
- **BVec3A** (on simd supported platforms only)
- BVec4
- **BVec4A** (on simd supported platforms only)
- Mat2
- Mat3A
- DMat2
- Affine2
- Affine3A
- DAffine2
- DAffine3
- EulerRot
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
`glam` is an optional feature in `bevy_reflect` and there is a separate `mod test { #[cfg(feature = "glam")] mod glam { .. }}`.
The `reflect_downcast` test is not in that module and doesn't depend on glam, which breaks `cargo test -p bevy_reflect` without the `glam` feature.
## Solution
- Remove the glam types from the test, they're not relevant to it
# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
This is a rebase of #3701 which is currently scheduled for 0.8 but is marked for adoption.
> Fixes https://github.com/bevyengine/bevy/discussions/3609
## Solution
> - add an `insert_boxed()` method on the `Map` trait
> - implement it for `HashMap` using a new `FromReflect` generic bound
> - add a `map_apply()` helper method to implement `Map::apply()`, that inserts new values instead of ignoring them
---
## Changelog
TODO
Co-authored-by: james7132 <contact@jamessliu.com>
# Objective
- I think our codebase is hit badly by rust-lang/rust-analyzer#11410
- None of our uses of cyclic dependencies are remotely necessary
- Note that these are false positives in rust-analyzer, however it's probably easier for us to work around this
- Note also that I haven't confirmed that this is causing rust-analyzer to not work very well, but it's not a bad guess.
## Solution
- Remove our cyclic dependencies
- Import the trick from #2851 for no-op plugin groups.
# Objective
This is a common and useful type. I frequently use this when working with `Events` resource directly, typically when caching the data or manipulating the `World` directly.
This is also useful when manually configuring the cleanup strategy for events.
# Objective
Transform screen-space coordinates into world space in shaders. (My use case is for generating rays for ray tracing with the same perspective as the 3d camera).
## Solution
Add `inverse_projection` and `inverse_view_proj` fields to shader view uniform
---
## Changelog
### Added
`inverse_projection` and `inverse_view_proj` fields to shader view uniform
## Note
It'd probably be good to double-check that I did the matrix multiplication in the right order for `inverse_proj_view`. Thanks!
# Objective
- Fixes#4993
## Solution
- ~~Add `centered` property to `WindowDescriptor`~~
- Add `WindowPosition` enum
- `WindowDescriptor.position` is now `WindowPosition` instead of `Option<Vec2>`
- Add `center_window` function to `Window`
## Migration Guide
- If using `WindowDescriptor`, replace `position: None` with `position: WindowPosition::Default` and `position: Some(vec2)` with `WindowPosition::At(vec2)`.
I'm not sure if this is the best approach, so feel free to give any feedback.
Also I'm not sure how `Option`s should be handled in `bevy_winit/src/lib.rs:161`.
Also, on window creation we can't (or at least I couldn't) get `outer_size`, so this doesn't include decorations in calculations.
* Cleanup redundant code
* Use a type alias to make sure the `caster_query` and
`not_caster_query` really do the same thing and access the same things
**Objective**
Cleanup code that would otherwise be difficult to understand
**Solution**
* `extract_meshes` had two for loops which are functionally identical,
just copy-pasted code. I extracted the common code between the two
and put them into an anonymous function.
* I flattened the tuple literal for the bundle batch, it looks much
less nested and the code is much more readable as a result.
* The parameters of `extract_meshes` were also very daunting, but they
turned out to be the same query repeated twice. I extracted the query
into a type alias.
EDIT: I reworked the PR to **not do anything breaking**, and keep the old allocation behavior. Removing the memorized length was clearly a performance loss, so I kept it.
# Objective
- Enable `wgpu` profiling spans
## Solution
- `wgpu` uses the `profiling` crate to add profiling span instrumentation to their code
- `profiling` offers multiple 'backends' for profiling, including `tracing`
- When the `bevy` `trace` feature is used, add the `profiling` crate with its `profile-with-tracing` feature to enable appropriate profiling spans in `wgpu` using `tracing` which fits nicely into our infrastructure
- Bump our default `tracing` subscriber filter to `wgpu=info` from `wgpu=error` so that the profiling spans are not filtered out as they are created at the `info` level.
---
## Changelog
- Added: `tracing` profiling support for `wgpu` when using bevy's `trace` feature
- Changed: The default `tracing` filter statement for `wgpu` has been changed from the `error` level to the `info` level to not filter out the wgpu profiling spans
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Summary
This method strips a long type name like `bevy::render:📷:PerspectiveCameraBundle` down into the bare type name (`PerspectiveCameraBundle`). This is generally useful utility method, needed by #4299 and #5121.
As a result:
- This method was moved to `bevy_utils` for easier reuse.
- The legibility and robustness of this method has been significantly improved.
- Harder test cases have been added.
This change was split out of #4299 to unblock it and make merging / reviewing the rest of those changes easier.
## Changelog
- added `bevy_utils::get_short_name`, which strips the path from a type name for convenient display.
- removed the `TypeRegistry::get_short_name` method. Use the function in `bevy_utils` instead.
The first leak:
```rust
#[test]
fn blob_vec_drop_empty_capacity() {
let item_layout = Layout:🆕:<Foo>();
let drop = drop_ptr::<Foo>;
let _ = unsafe { BlobVec::new(item_layout, Some(drop), 0) };
}
```
this is because we allocate the swap scratch in blobvec regardless of what the capacity is, but we only deallocate if capacity is > 0
The second leak:
```rust
#[test]
fn panic_while_overwriting_component() {
let helper = DropTestHelper::new();
let res = panic::catch_unwind(|| {
let mut world = World::new();
world
.spawn()
.insert(helper.make_component(true, 0))
.insert(helper.make_component(false, 1));
println!("Done inserting! Dropping world...");
});
let drop_log = helper.finish(res);
assert_eq!(
&*drop_log,
[
DropLogItem::Create(0),
DropLogItem::Create(1),
DropLogItem::Drop(0),
]
);
}
```
this is caused by us not running the drop impl on the to-be-inserted component if the drop impl of the overwritten component panics
---
managed to figure out where the leaks were by using this 10/10 command
```
cargo --quiet test --lib -- --list | sed 's/: test$//' | MIRIFLAGS="-Zmiri-disable-isolation" xargs -n1 cargo miri test --lib -- --exact
```
which runs every test one by one rather than all at once which let miri actually tell me which test had the leak 🙃
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make Bevy work on android
## Solution
- Update android metadata and add a few more
- Set the target sdk to 31 as it will soon (in august) be the minimum sdk level for play store
- Remove the custom code to create an activity and use ndk-glue macro instead
- Delay window creation event on android
- Set the example with compatibility settings for wgpu. Those are needed for Bevy to work on my 2019 android tablet
- Add a few details on how to debug in case of failures
- Fix running the example on emulator. This was failing because of the name of the example
Bevy still doesn't work on android with this, audio features need to be disabled because of an ndk-glue version mismatch: rodio depends on 0.6.2, winit on 0.5.2. You can test with:
```
cargo apk run --release --example android_example --no-default-features --features "bevy_winit,render"
```
# Objective
CI is now failing with some changes that landed in 1.62.
## Solution
* Fix an unused lifetime by using it (we double-used the `w` lifetime).
* Update compile_fail error messages
* temporarily disable check-unused-dependencies
# Objective
- Provide a way to see the components of an entity.
- Fixes#1467
## Solution
- Add `World::inspect_entity`. It accepts an `Entity` and returns a vector of `&ComponentInfo` that the entity has.
- Add `EntityCommands::log_components`. It logs the component names of the entity. (info level)
---
## Changelog
### Added
- Ability to inspect components of an entity through `World::inspect_entity` or `EntityCommands::log_components`
# Objective
Fix some typos in bevy_reflect's readme
## Solution
- Change `Foo`'s `d` field to be of type `Vec<Baz>`
- Format `&dyn Reflect` to be monospace
# Objective
This fixes https://github.com/bevyengine/bevy/issues/5127
## Solution
- Moved texture sample out of branch in `prepare_normal()`.
Co-authored-by: DGriffin91 <github@dgdigital.net>
There are some outdated error messages for when a resource is not found. It references `add_resource` and `add_non_send_resource` which were renamed to `insert_resource` and `insert_non_send_resource`.
# Objective
- Fixes#3142
## Solution
- Done according to #3142
- Created new marker trait `ArchetypeFilter`
- Implement said trait to:
- `With<T>`
- `Without<T>`
- tuples containing only types that implement `ArchetypeFilter`, from 0 to 15 elements
- `Or<T>` where T is a tuple as described previously
- Changed `ExactSizeIterator` impl to include a new generic that must implement `WorldQuery` and `ArchetypeFilter`
- Added new tests
---
## Changelog
### Added
- `Query`s with archetypal filters can now use `.iter().len()` to get the exact size of the iterator.
# Objective
Documents the `BufferVec` render resource.
`BufferVec` is a fairly low level object, that will likely be managed by a higher level API (e.g. through [`encase`](https://github.com/bevyengine/bevy/issues/4272)) in the future. For now, since it is still used by some simple
example crates (e.g. [bevy-vertex-pulling](https://github.com/superdump/bevy-vertex-pulling)), it will be helpful
to provide some simple documentation on what `BufferVec` does.
## Solution
I looked through Discord discussion on `BufferVec`, and found [a comment](https://discord.com/channels/691052431525675048/953222550568173580/956596218857918464 ) by @superdump to be particularly helpful, in the general discussion around `encase`.
I have taken care to clarify where the data is stored (host-side), when the device-side buffer is created (through calls to `reserve`), and when data writes from host to device are scheduled (using `write_buffer` calls).
---
## Changelog
- Added doc string for `BufferVec` and two of its methods: `reserve` and `write_buffer`.
Co-authored-by: Brian Merchant <bhmerchant@gmail.com>
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
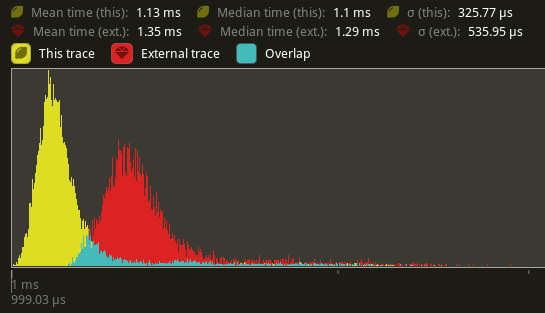
The command heavy `Extract` stage also saw a smaller overall improvement:
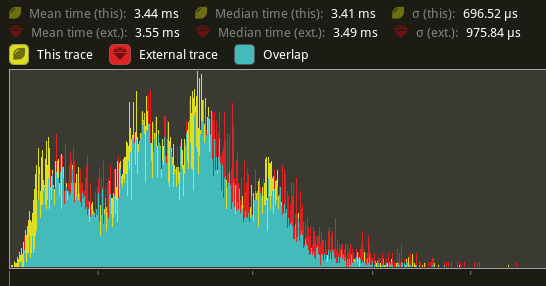
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
Currently, `Reflect` is unsafe to implement because of a contract in which `any` and `any_mut` must return `self`, or `downcast` will cause UB. This PR makes `Reflect` safe, makes `downcast` not use unsafe, and eliminates this contract.
## Solution
This PR adds a method to `Reflect`, `any`. It also renames the old `any` to `as_any`.
`any` now takes a `Box<Self>` and returns a `Box<dyn Any>`.
---
## Changelog
### Added:
- `any()` method
- `represents()` method
### Changed:
- `Reflect` is now a safe trait
- `downcast()` is now safe
- The old `any` is now called `as_any`, and `any_mut` is now `as_mut_any`
## Migration Guide
- Reflect derives should not have to change anything
- Manual reflect impls will need to remove the `unsafe` keyword, add `any()` implementations, and rename the old `any` and `any_mut` to `as_any` and `as_mut_any`.
- Calls to `any`/`any_mut` must be changed to `as_any`/`as_mut_any`
## Points of discussion:
- Should renaming `any` be avoided and instead name the new method `any_box`?
- ~~Could there be a performance regression from avoiding the unsafe? I doubt it, but this change does seem to introduce redundant checks.~~
- ~~Could/should `is` and `type_id()` be implemented differently? For example, moving `is` onto `Reflect` as an `fn(&self, TypeId) -> bool`~~
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
# Objective
Add support for custom `AssetIo` implementations to trigger reloading of an asset.
## Solution
- Add a public method to `AssetServer` to allow forcing the reloading of an asset.
---
## Changelog
- Add method `reload_asset` to `AssetServer`.
Co-authored-by: Robert G. Jakabosky <rjakabosky+neopallium@neoawareness.com>
# Objective
- Fixes#5083
## Solution
I looked at the implementation of those events. I noticed that they both are adaptations of `winit`'s `DeviceEvent`/`WindowEvent` enum variants. Therefore I based the description of the items on the documentation provided by the upstream crate. I also added a link to `CursorMoved`, just like `MouseMotion` already has.
## Observations
- Looking at the implementation of `MouseMotion`, I noticed the `DeviceId` field of the `winit` event is discarded by `bevy_input`. This means that in the case a machine has multiple pointing devices, it is impossible to distinguish to which one the event is referring to. **EDIT:** just tested, `MouseMotion` events are emitted for movement of both mice.
# Objective
Attempt to more clearly document `ImageSettings` and setting a default sampler for new images, as per #5046
## Changelog
- Moved ImageSettings into image.rs, image::* is already exported. Makes it simpler for linking docs.
- Renamed "DefaultImageSampler" to "RenderDefaultImageSampler". Not a great name, but more consistent with other render resources.
- Added/updated related docs
# Objective
- Allow custom shaders to reuse the HDR results of PBR.
## Solution
- Separate `pbr()` and `tone_mapping()` into 2 functions in `pbr_functions.wgsl`.
# Objective
- Simplify the process of obtaining a `ComponentId` instance corresponding to a `Component`.
- Resolves#5060.
## Solution
- Add a `component_id::<T: Component>(&self)` function to both `World` and `Components` to retrieve the `ComponentId` associated with `T` from a immutable reference.
---
## Changelog
- Added `World::component_id::<C>()` and `Components::component_id::<C>()` to retrieve a `Component`'s corresponding `ComponentId` if it exists.
# Objective
Update pbr mesh shader to use correct normals for skinned meshes.
## Solution
Only use `mesh_normal_local_to_world` for normals if `SKINNED` is not defined.
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
DioxusLabs and Bevy have taken over maintaining what was our abandoned ui layout dependency [stretch](https://github.com/vislyhq/stretch). Dioxus' fork has had a lot of work done on it by @alice-i-cecile, @Weibye , @jkelleyrtp, @mockersf, @HackerFoo, @TimJentzsch and a dozen other contributors and now is in much better shape than stretch was. The updated crate is called taffy and is available on github [here](https://github.com/DioxusLabs/taffy) ([taffy](https://crates.io/crates/taffy) on crates.io). The goal of this PR is to replace stretch v0.3.2 with taffy v0.1.0.
## Solution
I changed the bevy_ui Cargo.toml to depend on taffy instead of stretch and fixed all the errors rustc complained about.
---
## Changelog
Changed bevy_ui layout dependency from stretch to taffy (the maintained fork of stretch).
fixes#677
## Migration Guide
The public api of taffy is different from that of stretch so please advise me on what to do here @alice-i-cecile.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}