# Objective
Fix#8267.
Fixes half of #7840.
The `ComputedVisibility` component contains two flags: hierarchy
visibility, and view visibility (whether its visible to any cameras).
Due to the modular and open-ended way that view visibility is computed,
it triggers change detection every single frame, even when the value
does not change. Since hierarchy visibility is stored in the same
component as view visibility, this means that change detection for
inherited visibility is completely broken.
At the company I work for, this has become a real issue. We are using
change detection to only re-render scenes when necessary. The broken
state of change detection for computed visibility means that we have to
to rely on the non-inherited `Visibility` component for now. This is
workable in the early stages of our project, but since we will
inevitably want to use the hierarchy, we will have to either:
1. Roll our own solution for computed visibility.
2. Fix the issue for everyone.
## Solution
Split the `ComputedVisibility` component into two: `InheritedVisibilty`
and `ViewVisibility`.
This allows change detection to behave properly for
`InheritedVisibility`.
View visiblity is still erratic, although it is less useful to be able
to detect changes
for this flavor of visibility.
Overall, this actually simplifies the API. Since the visibility system
consists of
self-explaining components, it is much easier to document the behavior
and usage.
This approach is more modular and "ECS-like" -- one could
strip out the `ViewVisibility` component entirely if it's not needed,
and rely only on inherited visibility.
---
## Changelog
- `ComputedVisibility` has been removed in favor of:
`InheritedVisibility` and `ViewVisiblity`.
## Migration Guide
The `ComputedVisibilty` component has been split into
`InheritedVisiblity` and
`ViewVisibility`. Replace any usages of
`ComputedVisibility::is_visible_in_hierarchy`
with `InheritedVisibility::get`, and replace
`ComputedVisibility::is_visible_in_view`
with `ViewVisibility::get`.
```rust
// Before:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
computed_visibility: ComputedVisibility::default(),
});
// After:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
inherited_visibility: InheritedVisibility::default(),
view_visibility: ViewVisibility::default(),
});
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_hierarchy() {
// After:
fn my_system(q: Query<&InheritedVisibility>) {
for inherited_visibility in &q {
if inherited_visibility.get() {
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_view() {
// After:
fn my_system(q: Query<&ViewVisibility>) {
for view_visibility in &q {
if view_visibility.get() {
```
```rust
// Before:
fn my_system(mut q: Query<&mut ComputedVisibilty>) {
for vis in &mut q {
vis.set_visible_in_view();
// After:
fn my_system(mut q: Query<&mut ViewVisibility>) {
for view_visibility in &mut q {
view_visibility.set();
```
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
This is a continuation of this PR: #8062
# Objective
- Reorder render schedule sets to allow data preparation when phase item
order is known to support improved batching
- Part of the batching/instancing etc plan from here:
https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074
- The original idea came from @inodentry and proved to be a good one.
Thanks!
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new
ordering
## Solution
- Move `Prepare` and `PrepareFlush` after `PhaseSortFlush`
- Add a `PrepareAssets` set that runs in parallel with other systems and
sets in the render schedule.
- Put prepare_assets systems in the `PrepareAssets` set
- If explicit dependencies are needed on Mesh or Material RenderAssets
then depend on the appropriate system.
- Add `ManageViews` and `ManageViewsFlush` sets between
`ExtractCommands` and Queue
- Move `queue_mesh*_bind_group` to the Prepare stage
- Rename them to `prepare_`
- Put systems that prepare resources (buffers, textures, etc.) into a
`PrepareResources` set inside `Prepare`
- Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set
after `PrepareResources`
- Move `prepare_lights` to the `ManageViews` set
- `prepare_lights` creates views and this must happen before `Queue`
- This system needs refactoring to stop handling all responsibilities
- Gather lights, sort, and create shadow map views. Store sorted light
entities in a resource
- Remove `BatchedPhaseItem`
- Replace `batch_range` with `batch_size` representing how many items to
skip after rendering the item or to skip the item entirely if
`batch_size` is 0.
- `queue_sprites` has been split into `queue_sprites` for queueing phase
items and `prepare_sprites` for batching after the `PhaseSort`
- `PhaseItem`s are still inserted in `queue_sprites`
- After sorting adjacent compatible sprite phase items are accumulated
into `SpriteBatch` components on the first entity of each batch,
containing a range of vertex indices. The associated `PhaseItem`'s
`batch_size` is updated appropriately.
- `SpriteBatch` items are then drawn skipping over the other items in
the batch based on the value in `batch_size`
- A very similar refactor was performed on `bevy_ui`
---
## Changelog
Changed:
- Reordered and reworked render app schedule sets. The main change is
that data is extracted, queued, sorted, and then prepared when the order
of data is known.
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the
reordering.
## Migration Guide
- Assets such as materials and meshes should now be created in
`PrepareAssets` e.g. `prepare_assets<Mesh>`
- Queueing entities to `RenderPhase`s continues to be done in `Queue`
e.g. `queue_sprites`
- Preparing resources (textures, buffers, etc.) should now be done in
`PrepareResources`, e.g. `prepare_prepass_textures`,
`prepare_mesh_uniforms`
- Prepare bind groups should now be done in `PrepareBindGroups` e.g.
`prepare_mesh_bind_group`
- Any batching or instancing can now be done in `Prepare` where the
order of the phase items is known e.g. `prepare_sprites`
## Next Steps
- Introduce some generic mechanism to ensure items that can be batched
are grouped in the phase item order, currently you could easily have
`[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching.
- Investigate improved orderings for building the MeshUniform buffer
- Implementing batching across the rest of bevy
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
- Better consistency with `add_systems`.
- Deprecating `add_plugin` in favor of a more powerful `add_plugins`.
- Allow passing `Plugin` to `add_plugins`.
- Allow passing tuples to `add_plugins`.
## Solution
- `App::add_plugins` now takes an `impl Plugins` parameter.
- `App::add_plugin` is deprecated.
- `Plugins` is a new sealed trait that is only implemented for `Plugin`,
`PluginGroup` and tuples over `Plugins`.
- All examples, benchmarks and tests are changed to use `add_plugins`,
using tuples where appropriate.
---
## Changelog
### Changed
- `App::add_plugins` now accepts all types that implement `Plugins`,
which is implemented for:
- Types that implement `Plugin`.
- Types that implement `PluginGroup`.
- Tuples (up to 16 elements) over types that implement `Plugins`.
- Deprecated `App::add_plugin` in favor of `App::add_plugins`.
## Migration Guide
- Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
- fix clippy lints early to make sure CI doesn't break when they get
promoted to stable
- have a noise-free `clippy` experience for nightly users
## Solution
- `cargo clippy --fix`
- replace `filter_map(|x| x.ok())` with `map_while(|x| x.ok())` to fix
potential infinite loop in case of IO error
# Objective
The objective is to be able to load data from "application-specific"
(see glTF spec 3.7.2.1.) vertex attribute semantics from glTF files into
Bevy meshes.
## Solution
Rather than probe the glTF for the specific attributes supported by
Bevy, this PR changes the loader to iterate through all the attributes
and map them onto `MeshVertexAttribute`s. This mapping includes all the
previously supported attributes, plus it is now possible to add mappings
using the `add_custom_vertex_attribute()` method on `GltfPlugin`.
## Changelog
- Add support for loading custom vertex attributes from glTF files.
- Add the `custom_gltf_vertex_attribute.rs` example to illustrate
loading custom vertex attributes.
## Migration Guide
- If you were instantiating `GltfPlugin` using the unit-like struct
syntax, you must instead use `GltfPlugin::default()` as the type is no
longer unit-like.
# Objective
- Have a default font
## Solution
- Add a font based on FiraMono containing only ASCII characters and use
it as the default font
- It is behind a feature `default_font` enabled by default
- I also updated examples to use it, but not UI examples to still show
how to use a custom font
---
## Changelog
* If you display text without using the default handle provided by
`TextStyle`, the text will be displayed
# Objective
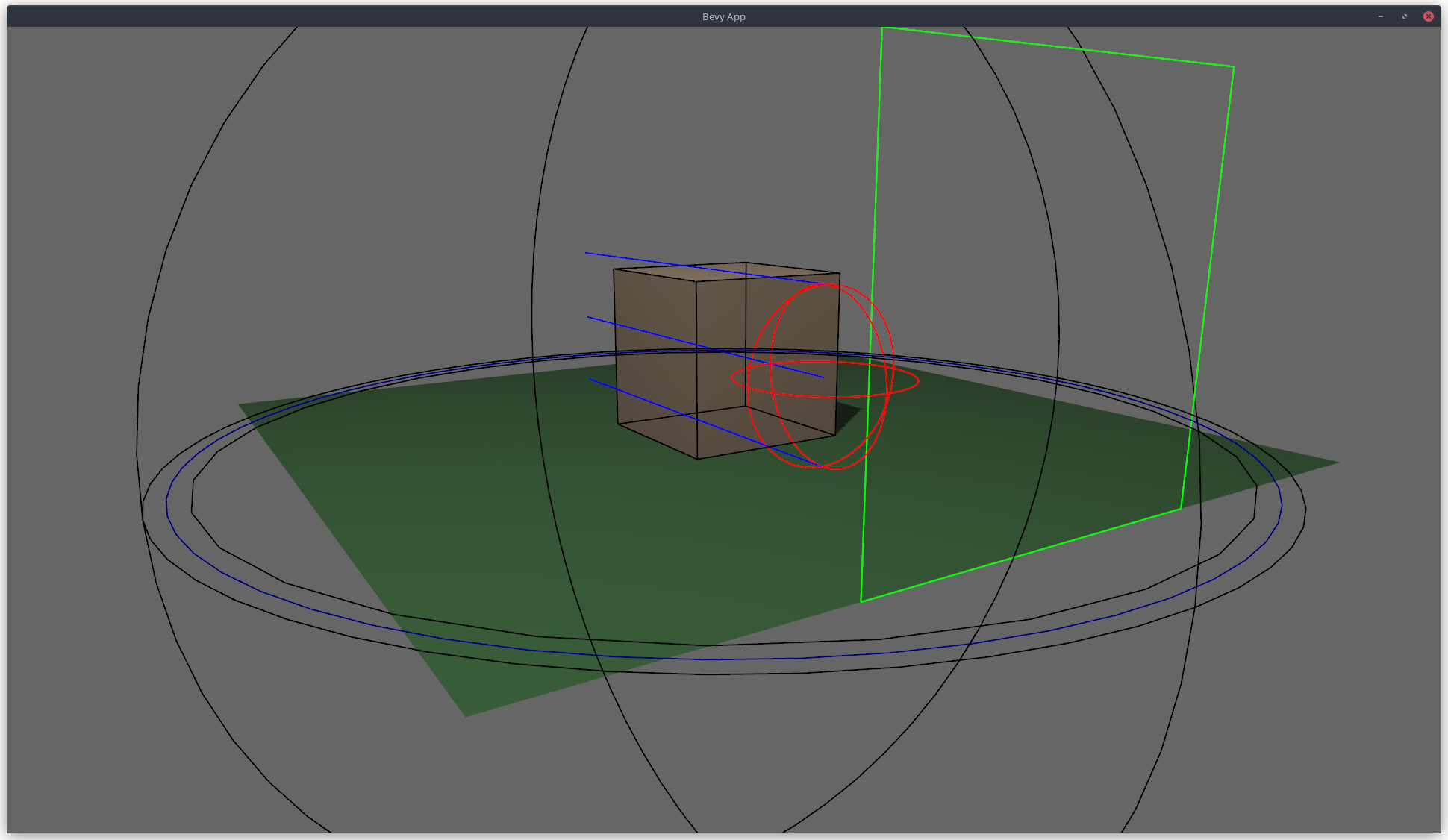
Added the possibility to draw arcs in 2d via gizmos
## Solution
- Added `arc_2d` function to `Gizmos`
- Added `arc_inner` function
- Added `Arc2dBuilder<'a, 's>`
- Updated `2d_gizmos.rs` example to draw an arc
---------
Co-authored-by: kjolnyr <kjolnyr@protonmail.ch>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ira <JustTheCoolDude@gmail.com>
# Objective
Fixes#8367
## Solution
Added a comment explaining why linear filtering is required in this
example, with formatting focused specifically on `ImagePlugin` to avoid
confusion
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
In the
[`Text`](3442a13d2c/crates/bevy_text/src/text.rs (L18))
struct the field is named: `linebreak_behaviour`, the British spelling
of _behavior_.
**Update**, also found:
- `FileDragAndDrop::HoveredFileCancelled`
- `TouchPhase::Cancelled`
- `Touches.just_cancelled`
The majority of all spelling is in the US but when you have a lot of
contributors across the world, sometimes
spelling differences can pop up in APIs such as in this case.
For consistency, I think it would be worth a while to ensure that the
API is persistent.
Some examples:
`from_reflect.rs` has `DefaultBehavior`
TextStyle has `color` and uses the `Color` struct.
In `bevy_input/src/Touch.rs` `TouchPhase::Cancelled` and _canceled_ are
used interchangeably in the documentation
I've found that there is also the same type of discrepancies in the
documentation, though this is a low priority but is worth checking.
**Update**: I've now checked the documentation (See #8291)
## Solution
I've only renamed the inconsistencies that have breaking changes and
documentation pertaining to them. The rest of the documentation will be
changed via #8291.
Do note that the winit API is written with UK spelling, thus this may be
a cause for confusion:
`winit::event::TouchPhase::Cancelled => TouchPhase::Canceled`
`winit::event::WindowEvent::HoveredFileCancelled` -> Related to
`FileDragAndDrop::HoveredFileCanceled`
But I'm hoping to maybe outline other spelling inconsistencies in the
API, and maybe an addition to the contribution guide.
---
## Changelog
- `Text` field `linebreak_behaviour` has been renamed to
`linebreak_behavior`.
- Event `FileDragAndDrop::HoveredFileCancelled` has been renamed to
`HoveredFileCanceled`
- Function `Touches.just_cancelled` has been renamed to
`Touches.just_canceled`
- Event `TouchPhase::Cancelled` has been renamed to
`TouchPhase::Canceled`
## Migration Guide
Update where `linebreak_behaviour` is used to `linebreak_behavior`
Updated the event `FileDragAndDrop::HoveredFileCancelled` where used to
`HoveredFileCanceled`
Update `Touches.just_cancelled` where used as `Touches.just_canceled`
The event `TouchPhase::Cancelled` is now called `TouchPhase::Canceled`
# Objective
Some examples still manually implement the States trait, even though
manual implementation is no longer needed as there is now the derive
macro for that.
---------
Signed-off-by: Natalia Asteria <fortressnordlys@outlook.com>
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
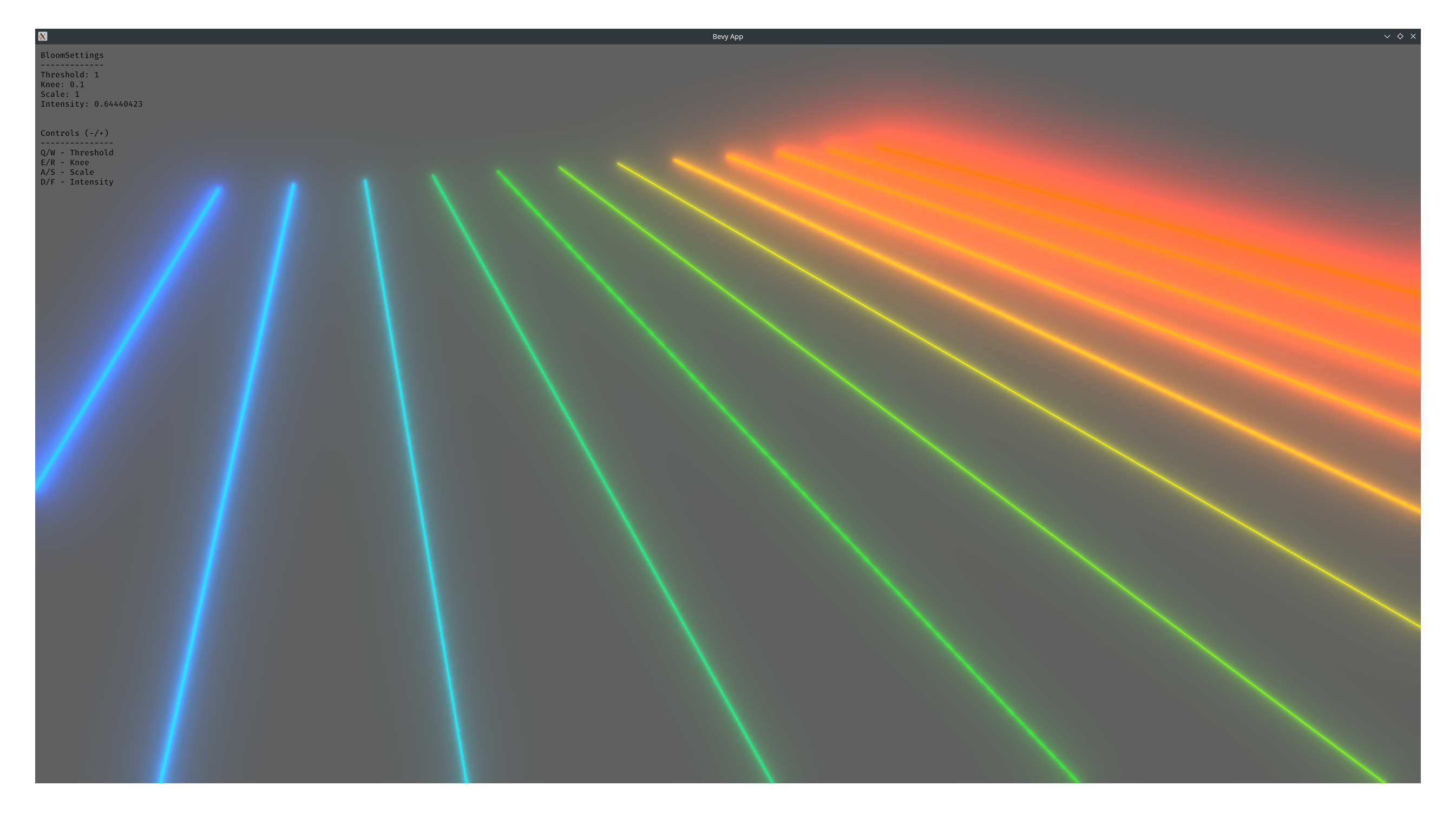
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
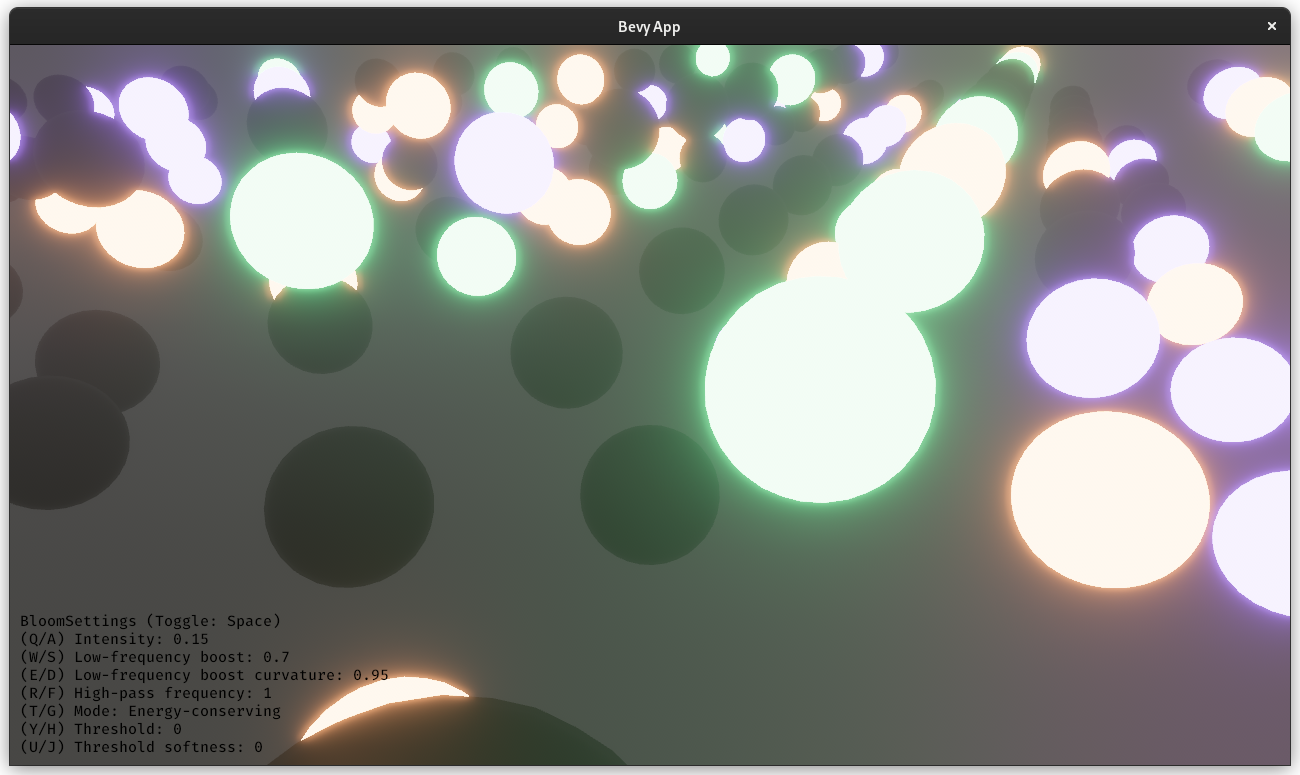
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
Fixes#7632.
As discussed in #7634, it can be quite challenging for users to intuit the mental model of how states now work.
## Solution
Rather than change the behavior of the `OnUpdate` system set, instead work on making sure it's easy to understand what's going on.
Two things have been done:
1. Remove the `.on_update` method from our bevy of system building traits. This was special-cased and made states feel much more magical than they need to.
2. Improve the docs for the `OnUpdate` system set.
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
Currently, Text always uses the default linebreaking behaviour in glyph_brush_layout `BuiltInLineBreaker::Unicode` which breaks lines at word boundaries. However, glyph_brush_layout also supports breaking lines at any character by setting the linebreaker to `BuiltInLineBreaker::AnyChar`. Having text wrap character-by-character instead of at word boundaries is desirable in some cases - consider that consoles/terminals usually wrap this way.
As a side note, the default Unicode linebreaker does not seem to handle emergency cases, where there is no word boundary on a line to break at. In that case, the text runs out of bounds. Issue #1867 shows an example of this.
## Solution
Basically just copies how TextAlignment is exposed, but for a new enum TextLineBreakBehaviour.
This PR exposes glyph_brush_layout's two simple linebreaking options (Unicode, AnyChar) to users of Text via the enum TextLineBreakBehaviour (which just translates those 2 aforementioned options), plus a method 'with_linebreak_behaviour' on Text and TextBundle.
## Changelog
Added `Text::with_linebreak_behaviour`
Added `TextBundle::with_linebreak_behaviour`
`TextPipeline::queue_text` and `GlyphBrush::compute_glyphs` now need a TextLineBreakBehaviour argument, in order to pass through the new field.
Modified the `text2d` example to show both linebreaking behaviours.
## Example
Here's what the modified example looks like

# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
It is currently possible to break reference counting for assets by creating a strong `HandleUntyped` and then modifying the `id` field before dropping the handle. This should not be allowed.
## Solution
Change the `id` field visibility to private and add a getter instead. The same change was previously done for `Handle<T>` in #6176, but `HandleUntyped` was forgotten.
---
## Migration Guide
- Instead of directly accessing the ID of a `HandleUntyped` as `handle.id`, use the new getter `handle.id()`.
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode.
# Objective
The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching.
Additionally as it stands Bevy only has two settings for visibility of an entity:
- "unconditionally hidden" `Visibility { is_visible: false }`,
- "inherit visibility from parent" `Visibility { is_visible: true }`
where a root level entity set to "inherit" is visible.
Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear.
Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode.
--
The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants.
## Solution
Change the Visibility component into
```rust
enum Visibility {
Hidden, // unconditionally hidden
Visible, // unconditionally visible
Inherited, // inherit visibility from parent
}
```
---
## Changelog
### Changed
`Visibility` is now an enum
## Migration Guide
- evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`.
- setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`.
- usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively.
- `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make running animation fluid skipping 'idle' frame.
## Solution
- Loop through the specified indices instead of through the whole sprite sheet.
The example is correct, is just the feeling that the animation loop is not seamless.
Based on the solution suggested by @mockersf in #5429.
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- Fix an awkwardly phrased/typoed error message
- Actually tell users which file caused the error
- IMO we don't need to panic
## Solution
- Add a warning including the involved asset path when a non-image is found by `load_folder`
- Note: uses `let else` which is stable now
```
2022-11-03T14:17:59.006861Z WARN texture_atlas: Some(AssetPath { path: "textures/rpg/tiles/whatisthisdoinghere.ogg", label: None }) did not resolve to an `Image` asset.
```
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Build on #6336 for more plugin configurations
## Solution
- `LogSettings`, `ImageSettings` and `DefaultTaskPoolOptions` are now plugins settings rather than resources
---
## Changelog
- `LogSettings` plugin settings have been move to `LogPlugin`, `ImageSettings` to `ImagePlugin` and `DefaultTaskPoolOptions` to `CorePlugin`
## Migration Guide
The `LogSettings` settings have been moved from a resource to `LogPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(LogSettings {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(LogPlugin {
level: Level::DEBUG,
filter: "wgpu=error,bevy_render=info,bevy_ecs=trace".to_string(),
}))
```
The `ImageSettings` settings have been moved from a resource to `ImagePlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(ImageSettings::default_nearest())
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(ImagePlugin::default_nearest()))
```
The `DefaultTaskPoolOptions` settings have been moved from a resource to `CorePlugin::task_pool_options`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(DefaultTaskPoolOptions::with_num_threads(4))
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(CorePlugin {
task_pool_options: TaskPoolOptions::with_num_threads(4),
}))
```
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
Fixes#6272
## Solution
Revert to old way of positioning text for Text2D rendered text.
Co-authored-by: Michel van der Hulst <hulstmichel@gmail.com>
As mentioned in #2926, it's better to have an explicit type that clearly communicates the intent of the timer mode rather than an opaque boolean, which can be only understood when knowing the signature or having to look up the documentation.
This also opens up a way to merge different timers, such as `Stopwatch`, and possibly future ones, such as `DiscreteStopwatch` and `DiscreteTimer` from #2683, into one struct.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Fixes#2926.
## Solution
Introduce `TimerMode` which replaces the `bool` argument of `Timer` constructors. A `Default` value for `TimerMode` is `Once`.
---
## Changelog
### Added
- `TimerMode` enum, along with variants `TimerMode::Once` and `TimerMode::Repeating`
### Changed
- Replace `bool` argument of `Timer::new` and `Timer::from_seconds` with `TimerMode`
- Change `repeating: bool` field of `Timer` with `mode: TimerMode`
## Migration Guide
- Replace `Timer::new(duration, false)` with `Timer::new(duration, TimerMode::Once)`.
- Replace `Timer::new(duration, true)` with `Timer::new(duration, TimerMode::Repeating)`.
- Replace `Timer::from_seconds(seconds, false)` with `Timer::from_seconds(seconds, TimerMode::Once)`.
- Replace `Timer::from_seconds(seconds, true)` with `Timer::from_seconds(seconds, TimerMode::Repeating)`.
- Change `timer.repeating()` to `timer.mode() == TimerMode::Repeating`.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}