# Objective
bevy_ecs has several compile_fail tests that assert lifetime safety. In the past, these tests have been green for the wrong reasons (see e.g. #2984). This PR makes sure, that they will fail if the compiler error changes.
## Solution
Use [trybuild](https://crates.io/crates/trybuild) to assert the compiler errors.
The UI tests are in a separate crate that is not part of the Bevy workspace. This is to ensure that they do not break Bevy's crater builds. The tests get executed by the CI workflow on the stable toolchain.
# Objective
Document that `AssetServer::load()` is asynchronous.
## Solution
Document that `AssetServer::load()` is asynchronous, and that the asset
will not be immediately available once the call returns. Instead,
explain that the user must call `AssetServer::get_load_state()` to
monitor the loading state of an asset.
# Objective
- `bevy_ecs` exposes as an optional feature `bevy_reflect`. Disabling it doesn't compile.
- `bevy_asset` exposes as an optional feature `filesystem_watcher`. Disabling it doesn't compile. It is also not possible to disable this feature from Bevy
## Solution
- Fix compilation errors when disabling the default features. Make it possible to disable the feature `filesystem_watcher` from Bevy
I just updated profiling.md (and accidentally skipped the pr process by not checking "create new branch" in the github ui). The markdown wasn't properly formatted, which broke the build.
Adds new `EntityRenderCommand`, `EntityPhaseItem`, and `CachedPipelinePhaseItem` traits to make it possible to reuse RenderCommands across phases. This should be helpful for features like #3072 . It also makes the trait impls slightly less generic-ey in the common cases.
This also fixes the custom shader examples to account for the recent Frustum Culling and MSAA changes (the UX for these things will be improved later).
# Objective
- Update vendor crevice to have the latest update from crevice 0.8.0
- Using https://github.com/ElectronicRU/crevice/tree/arrays which has the changes to make arrays work
## Solution
- Also updated glam and hexasphere to only have one version of glam
- From the original PR, using crevice to write GLSL code containing arrays would probably not work but it's not something used by Bevy
# Objective
Clarify the fact that setting the `RUST_LOG` environment variable
overrides any setting from the `LogSettings` resource.
## Solution
Update docstring comment for `LogSettings`.
- Requires #2997
- Removes `wasm_audio` feature as discussed in #2397
- Closes only task in #2479
Open questions:
Should we enable wasm audio by default or only when building for wasm using `cfg`?
Maybe there should be a global wasm feature for bevy?
# Objective
Implement frustum culling for much better performance on more complex scenes. With the Amazon Lumberyard Bistro scene, I was getting roughly 15fps without frustum culling and 60+fps with frustum culling on a MacBook Pro 16 with i9 9980HK 8c/16t CPU and Radeon Pro 5500M.
macOS does weird things with vsync so even though vsync was off, it really looked like sometimes other applications or the desktop window compositor were interfering, but the difference could be even more as I even saw up to 90+fps sometimes.
## Solution
- Until the https://github.com/bevyengine/rfcs/pull/12 RFC is completed, I wanted to implement at least some of the bounding volume functionality we needed to be able to unblock a bunch of rendering features and optimisations such as frustum culling, fitting the directional light orthographic projection to the relevant meshes in the view, clustered forward rendering, etc.
- I have added `Aabb`, `Frustum`, and `Sphere` types with only the necessary intersection tests for the algorithms used. I also added `CubemapFrusta` which contains a `[Frustum; 6]` and can be used by cube maps such as environment maps, and point light shadow maps.
- I did do a bit of benchmarking and optimisation on the intersection tests. I compared the [rafx parallel-comparison bitmask approach](c91bd5fcfd/rafx-visibility/src/geometry/frustum.rs (L64-L92)) with a naïve loop that has an early-out in case of a bounding volume being outside of any one of the `Frustum` planes and found them to be very similar, so I chose the simpler and more readable option. I also compared using Vec3 and Vec3A and it turned out that promoting Vec3s to Vec3A improved performance of the culling significantly due to Vec3A operations using SIMD optimisations where Vec3 uses plain scalar operations.
- When loading glTF models, the vertex attribute accessors generally store the minimum and maximum values, which allows for adding AABBs to meshes loaded from glTF for free.
- For meshes without an AABB (`PbrBundle` deliberately does not have an AABB by default), a system is executed that scans over the vertex positions to find the minimum and maximum values along each axis. This is used to construct the AABB.
- The `Frustum::intersects_obb` and `Sphere::insersects_obb` algorithm is from Foundations of Game Engine Development 2: Rendering by Eric Lengyel. There is no OBB type, yet, rather an AABB and the model matrix are passed in as arguments. This calculates a 'relative radius' of the AABB with respect to the plane normal (the plane normal in the Sphere case being something I came up with as the direction pointing from the centre of the sphere to the centre of the AABB) such that it can then do a sphere-sphere intersection test in practice.
- `RenderLayers` were copied over from the current renderer.
- `VisibleEntities` was copied over from the current renderer and a `CubemapVisibleEntities` was added to support `PointLight`s for now. `VisibleEntities` are added to views (cameras and lights) and contain a `Vec<Entity>` that is populated by culling/visibility systems that run in PostUpdate of the app world, and are iterated over in the render world for, for example, queuing up meshes to be drawn by lights for shadow maps and the main pass for cameras.
- `Visibility` and `ComputedVisibility` components were added. The `Visibility` component is user-facing so that, for example, the entity can be marked as not visible in an editor. `ComputedVisibility` on the other hand is the result of the culling/visibility systems and takes `Visibility` into account. So if an entity is marked as not being visible in its `Visibility` component, that will skip culling/visibility intersection tests and just mark the `ComputedVisibility` as false.
- The `ComputedVisibility` is used to decide which meshes to extract.
- I had to add a way to get the far plane from the `CameraProjection` in order to define an explicit far frustum plane for culling. This should perhaps be optional as it is not always desired and in that case, testing 5 planes instead of 6 is a performance win.
I think that's about all. I discussed some of the design with @cart on Discord already so hopefully it's not too far from being mergeable. It works well at least. 😄
# Objective
Fixes#2823.
## Solution
This PR adds notes to the `HashMap` and `HashSet` docs explaining why `HashMap::new()` (resp. `HashSet::new()`) is not available, and guiding the user toward using the `Default` implementation for an empty collection.
# Objective
- Improve error descriptions and help understand how to fix them
- I noticed one today that could be expanded, it seemed like a good starting point
## Solution
- Start something like https://github.com/rust-lang/rust/tree/master/compiler/rustc_error_codes/src/error_codes
- Remove sentence about Rust mutability rules which is not very helpful in the error message
I decided to start the error code with B for Bevy so that they're not confused with error code from rust (which starts with E)
Longer term, there are a few more evolutions that can continue this:
- the code samples should be compiled check, and even executed for some of them to check they have the correct error code in a panic
- the error could be build on a page in the website like https://doc.rust-lang.org/error-index.html
- most panic should have their own error code
Mention the fact that the UI layout system is based on the CSS layout
model through a docstring comment on the `Style` type.
# Objective
Explain to new users that the Bevy UI uses the CSS layout model, to lower the barrier to entry given the fact documentation (book and code) is fairly limited on the topic.
## Solution
Fix as discussed with @alice-i-cecile on #2918.
# Objective
Set initial position of the window, so I can start it at the left side of the view automatically, used with `cargo watch`
## Solution
add window position to WindowDescriptor
# Objective
- Support tangent vertex attributes, and normal maps
- Support loading these from glTF models
## Solution
- Make two pipelines in both the shadow and pbr passes, one for without normal maps, one for with normal maps
- Select the correct pipeline to bind based on the presence of the normal map texture
- Share the vertex attribute layout between shadow and pbr passes
- Refactored pbr.wgsl to share a bunch of common code between the normal map and non-normal map entry points. I tried to do this in a way that will allow custom shader reuse.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the following:
* **Sprite Batching**: Collects sprites in a vertex buffer to draw many sprites with a single draw call. Sprites are batched by their `Handle<Image>` within a specific z-level. When possible, sprites are opportunistically batched _across_ z-levels (when no sprites with a different texture exist between two sprites with the same texture on different z levels). With these changes, I can now get ~130,000 sprites at 60fps on the `bevymark_pipelined` example.
* **Sprite Color Tints**: The `Sprite` type now has a `color` field. Non-white color tints result in a specialized render pipeline that passes the color in as a vertex attribute. I chose to specialize this because passing vertex colors has a measurable price (without colors I get ~130,000 sprites on bevymark, with colors I get ~100,000 sprites). "Colored" sprites cannot be batched with "uncolored" sprites, but I think this is fine because the chance of a "colored" sprite needing to batch with other "colored" sprites is generally probably way higher than an "uncolored" sprite needing to batch with a "colored" sprite.
* **Sprite Flipping**: Sprites can be flipped on their x or y axis using `Sprite::flip_x` and `Sprite::flip_y`. This is also true for `TextureAtlasSprite`.
* **Simpler BufferVec/UniformVec/DynamicUniformVec Clearing**: improved the clearing interface by removing the need to know the size of the final buffer at the initial clear.
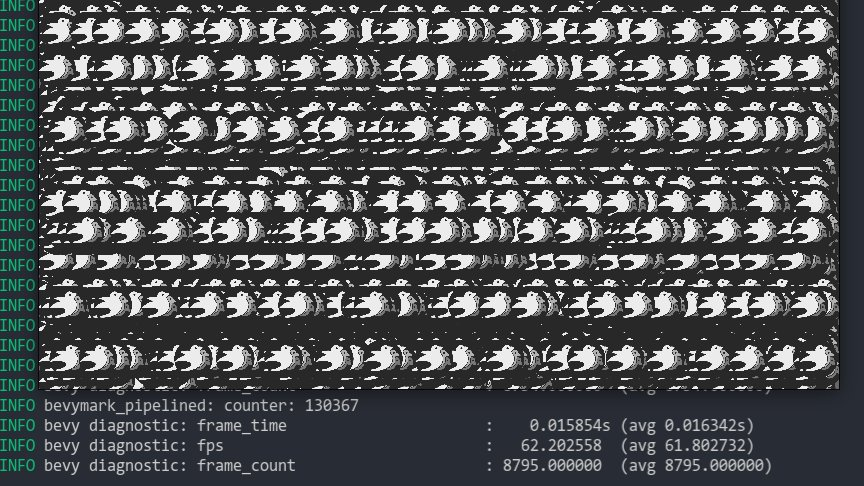
Note that this moves sprites away from entity-driven rendering and back to extracted lists. We _could_ use entities here, but it necessitates that an intermediate list is allocated / populated to collect and sort extracted sprites. This redundant copy, combined with the normal overhead of spawning extracted sprite entities, brings bevymark down to ~80,000 sprites at 60fps. I think making sprites a bit more fixed (by default) is worth it. I view this as acceptable because batching makes normal entity-driven rendering pretty useless anyway (and we would want to batch most custom materials too). We can still support custom shaders with custom bindings, we'll just need to define a specific interface for it.
Add an example that demonstrates the difference between no MSAA and MSAA 4x. This is also useful for testing panics when resizing the window using MSAA. This is on top of #3042 .
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds support for MSAA to the new renderer. This is done using the new [pipeline specialization](#3031) support to specialize on sample count. This is an alternative implementation to #2541 that cuts out the need for complicated render graph edge management by moving the relevant target information into View entities. This reuses @superdump's clever MSAA bitflag range code from #2541.
Note that wgpu currently only supports 1 or 4 samples due to those being the values supported by WebGPU. However they do plan on exposing ways to [enable/query for natively supported sample counts](https://github.com/gfx-rs/wgpu/issues/1832). When this happens we should integrate
# Objective
Make possible to use wgpu gles backend on in the browser (wasm32 + WebGL2).
## Solution
It is built on top of old @cart patch initializing windows before wgpu. Also:
- initializes wgpu with `Backends::GL` and proper `wgpu::Limits` on wasm32
- changes default texture format to `wgpu::TextureFormat::Rgba8UnormSrgb`
Co-authored-by: Mariusz Kryński <mrk@sed.pl>
# Objective
- Fixes#2919
- Initial pixel was hard coded and not dependent on texture format
- Replace #2920 as I noticed this needed to be done also on pipeline rendering branch
## Solution
- Replace the hard coded pixel with one using the texture pixel size
# Objective
while testing wgpu/WebGL on mobile GPU I've noticed bevy always forces vertex index format to 32bit (and ignores mesh settings).
## Solution
the solution is to pass proper vertex index format in GpuIndexInfo to render_pass
## New Features
This adds the following to the new renderer:
* **Shader Assets**
* Shaders are assets again! Users no longer need to call `include_str!` for their shaders
* Shader hot-reloading
* **Shader Defs / Shader Preprocessing**
* Shaders now support `# ifdef NAME`, `# ifndef NAME`, and `# endif` preprocessor directives
* **Bevy RenderPipelineDescriptor and RenderPipelineCache**
* Bevy now provides its own `RenderPipelineDescriptor` and the wgpu version is now exported as `RawRenderPipelineDescriptor`. This allows users to define pipelines with `Handle<Shader>` instead of needing to manually compile and reference `ShaderModules`, enables passing in shader defs to configure the shader preprocessor, makes hot reloading possible (because the descriptor can be owned and used to create new pipelines when a shader changes), and opens the doors to pipeline specialization.
* The `RenderPipelineCache` now handles compiling and re-compiling Bevy RenderPipelineDescriptors. It has internal PipelineLayout and ShaderModule caches. Users receive a `CachedPipelineId`, which can be used to look up the actual `&RenderPipeline` during rendering.
* **Pipeline Specialization**
* This enables defining per-entity-configurable pipelines that specialize on arbitrary custom keys. In practice this will involve specializing based on things like MSAA values, Shader Defs, Bind Group existence, and Vertex Layouts.
* Adds a `SpecializedPipeline` trait and `SpecializedPipelines<MyPipeline>` resource. This is a simple layer that generates Bevy RenderPipelineDescriptors based on a custom key defined for the pipeline.
* Specialized pipelines are also hot-reloadable.
* This was the result of experimentation with two different approaches:
1. **"generic immediate mode multi-key hash pipeline specialization"**
* breaks up the pipeline into multiple "identities" (the core pipeline definition, shader defs, mesh layout, bind group layout). each of these identities has its own key. looking up / compiling a specific version of a pipeline requires composing all of these keys together
* the benefit of this approach is that it works for all pipelines / the pipeline is fully identified by the keys. the multiple keys allow pre-hashing parts of the pipeline identity where possible (ex: pre compute the mesh identity for all meshes)
* the downside is that any per-entity data that informs the values of these keys could require expensive re-hashes. computing each key for each sprite tanked bevymark performance (sprites don't actually need this level of specialization yet ... but things like pbr and future sprite scenarios might).
* this is the approach rafx used last time i checked
2. **"custom key specialization"**
* Pipelines by default are not specialized
* Pipelines that need specialization implement a SpecializedPipeline trait with a custom key associated type
* This allows specialization keys to encode exactly the amount of information required (instead of needing to be a combined hash of the entire pipeline). Generally this should fit in a small number of bytes. Per-entity specialization barely registers anymore on things like bevymark. It also makes things like "shader defs" way cheaper to hash because we can use context specific bitflags instead of strings.
* Despite the extra trait, it actually generally makes pipeline definitions + lookups simpler: managing multiple keys (and making the appropriate calls to manage these keys) was way more complicated.
* I opted for custom key specialization. It performs better generally and in my opinion is better UX. Fortunately the way this is implemented also allows for custom caches as this all builds on a common abstraction: the RenderPipelineCache. The built in custom key trait is just a simple / pre-defined way to interact with the cache
## Callouts
* The SpecializedPipeline trait makes it easy to inherit pipeline configuration in custom pipelines. The changes to `custom_shader_pipelined` and the new `shader_defs_pipelined` example illustrate how much simpler it is to define custom pipelines based on the PbrPipeline.
* The shader preprocessor is currently pretty naive (it just uses regexes to process each line). Ultimately we might want to build a more custom parser for more performance + better error handling, but for now I'm happy to optimize for "easy to implement and understand".
## Next Steps
* Port compute pipelines to the new system
* Add more preprocessor directives (else, elif, import)
* More flexible vertex attribute specialization / enable cheaply specializing on specific mesh vertex layouts
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
# Objective
The current TODO comment is out of date
## Solution
I switched up the comment
Co-authored-by: William Batista <45850508+billyb2@users.noreply.github.com>
## Objective
Looking though the new pipelined example I stumbled on an issue with the example shader :
```
Oct 20 12:38:44.891 INFO bevy_render2::renderer: AdapterInfo { name: "Intel(R) UHD Graphics 620 (KBL GT2)", vendor: 32902, device: 22807, device_type: IntegratedGpu, backend: Vulkan }
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_point_shadow")
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_directional_shadow")
Oct 20 12:38:44.898 ERROR wgpu::backend::direct: Handling wgpu errors as fatal by default
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_shader_module
Global variable [1] 'view' is invalid
Type isn't compatible with the storage class
```
## Solution
added `<uniform>` here and there.
Note : my current mastery of shaders is about 2 days old, so this still kinda look likes wizardry
# Objective
- Bevy has several `compile_fail` test
- #2254 added `#[derive(Component)]`
- Those tests now fail for a different reason.
- This was not caught as these test still "successfully" failed to compile.
## Solution
- Add `#[derive(Component)]` to the doctest
- Also changed their cfg attribute from `doc` to `doctest`, so that these tests don't appear when running `cargo doc` with `--document-private-items`
# Objective
- Fixes#2501
- Builds up on #2639 taking https://github.com/bevyengine/bevy/pull/2639#issuecomment-898701047 into account
## Solution
- keep the physical cursor position in `Window`, and expose it.
- still convert to logical position in event, and when getting `cursor_position`
Co-authored-by: Ahmed Charles <acharles@outlook.com>
# Objective
The update to wgpu 0.11 broke CI for android. This was due to a confusion between `bevy::render::ShaderStage` and `wgpu::ShaderStage`.
## Solution
Revert the incorrect change
#2605 changed the lifetime annotations on `get_component` introducing unsoundness as you could keep the returned borrow even after using the query.
Example unsoundness:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_startup_system(startup)
.add_system(unsound)
.run();
}
#[derive(Debug, Component, PartialEq, Eq)]
struct Foo(Vec<u32>);
fn startup(mut c: Commands) {
let e = c.spawn().insert(Foo(vec![10])).id();
c.insert_resource(e);
}
fn unsound(mut q: Query<&mut Foo>, res: Res<Entity>) {
let foo = q.get_component::<Foo>(*res).unwrap();
let mut foo2 = q.iter_mut().next().unwrap();
let first_elem = &foo.0[0];
for _ in 0..16 {
foo2.0.push(12);
}
dbg!(*first_elem);
}
```
output:
`[src/main.rs:26] *first_elem = 0`
Add the entity ID and generation to the expect() message of two
world accessors, to make it easier to debug use-after-free issues.
Coupled with e.g. bevy-inspector-egui which also displays the entity ID,
this makes it much easier to identify what entity is being misused.
# Objective
Make it easier to identity an entity being accessed after being deleted.
## Solution
Augment the error message of some `expect()` call with the entity ID and
generation. Combined with some external tool like `bevy-inspector-egui`, which
also displays the entity ID, this increases the chances to be able to identify
the entity, and therefore find the error that led to a use-after-despawn.
Upgrades both the old and new renderer to wgpu 0.11 (and naga 0.7). This builds on @zicklag's work here #2556.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Remove duplicate `Events::update` call in `gilrs_event_system` (fixes#2893)
- See #2893 for context
- While there, make the systems no longer exclusive, as that is not required of them
## Solution
- Do the change
r? @alice-i-cecile
Using RenderQueue in BufferVec allows removal of the staging buffer entirely, as well as removal of the SpriteNode.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR adds a ControlNode which marks an entity as "transparent" to the UI layout system, meaning the children of this entity will be treated as the children of this entity s parent by the layout system(s).
# Objective
- Fixes#2904 (see for context)
## Solution
- Simply hoist span creation out of the threaded task
- Confirmed to solve the issue locally
Now all events have the full span parent tree up through `bevy_ecs::schedule::stage` all the way to `bevy_app::app::bevy_app` (and its parents in bevy-consumer code, if any).
# Objective
- Avoid usages of `format!` that ~immediately get passed to another `format!`. This avoids a temporary allocation and is just generally cleaner.
## Solution
- `bevy_derive::shader_defs` does a `format!("{}", val.to_string())`, which is better written as just `format!("{}", val)`
- `bevy_diagnostic::log_diagnostics_plugin` does a `format!("{:>}", format!(...))`, which is better written as `format!("{:>}", format_args!(...))`
- `bevy_ecs::schedule` does `tracing::info!(..., name = &*format!("{:?}", val))`, which is better written with the tracing shorthand `tracing::info!(..., name = ?val)`
- `bevy_reflect::reflect` does `f.write_str(&format!(...))`, which is better written as `write!(f, ...)` (this could also be written using `f.debug_tuple`, but I opted to maintain alt debug behavior)
- `bevy_reflect::serde::{ser, de}` do `serde::Error::custom(format!(...))`, which is better written as `Error::custom(format_args!(...))`, as `Error::custom` takes `impl Display` and just immediately calls `format!` again
{kind=link}