# Objective
Fixes#2823.
## Solution
This PR adds notes to the `HashMap` and `HashSet` docs explaining why `HashMap::new()` (resp. `HashSet::new()`) is not available, and guiding the user toward using the `Default` implementation for an empty collection.
# Objective
- Improve error descriptions and help understand how to fix them
- I noticed one today that could be expanded, it seemed like a good starting point
## Solution
- Start something like https://github.com/rust-lang/rust/tree/master/compiler/rustc_error_codes/src/error_codes
- Remove sentence about Rust mutability rules which is not very helpful in the error message
I decided to start the error code with B for Bevy so that they're not confused with error code from rust (which starts with E)
Longer term, there are a few more evolutions that can continue this:
- the code samples should be compiled check, and even executed for some of them to check they have the correct error code in a panic
- the error could be build on a page in the website like https://doc.rust-lang.org/error-index.html
- most panic should have their own error code
Mention the fact that the UI layout system is based on the CSS layout
model through a docstring comment on the `Style` type.
# Objective
Explain to new users that the Bevy UI uses the CSS layout model, to lower the barrier to entry given the fact documentation (book and code) is fairly limited on the topic.
## Solution
Fix as discussed with @alice-i-cecile on #2918.
# Objective
Set initial position of the window, so I can start it at the left side of the view automatically, used with `cargo watch`
## Solution
add window position to WindowDescriptor
# Objective
- Support tangent vertex attributes, and normal maps
- Support loading these from glTF models
## Solution
- Make two pipelines in both the shadow and pbr passes, one for without normal maps, one for with normal maps
- Select the correct pipeline to bind based on the presence of the normal map texture
- Share the vertex attribute layout between shadow and pbr passes
- Refactored pbr.wgsl to share a bunch of common code between the normal map and non-normal map entry points. I tried to do this in a way that will allow custom shader reuse.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the following:
* **Sprite Batching**: Collects sprites in a vertex buffer to draw many sprites with a single draw call. Sprites are batched by their `Handle<Image>` within a specific z-level. When possible, sprites are opportunistically batched _across_ z-levels (when no sprites with a different texture exist between two sprites with the same texture on different z levels). With these changes, I can now get ~130,000 sprites at 60fps on the `bevymark_pipelined` example.
* **Sprite Color Tints**: The `Sprite` type now has a `color` field. Non-white color tints result in a specialized render pipeline that passes the color in as a vertex attribute. I chose to specialize this because passing vertex colors has a measurable price (without colors I get ~130,000 sprites on bevymark, with colors I get ~100,000 sprites). "Colored" sprites cannot be batched with "uncolored" sprites, but I think this is fine because the chance of a "colored" sprite needing to batch with other "colored" sprites is generally probably way higher than an "uncolored" sprite needing to batch with a "colored" sprite.
* **Sprite Flipping**: Sprites can be flipped on their x or y axis using `Sprite::flip_x` and `Sprite::flip_y`. This is also true for `TextureAtlasSprite`.
* **Simpler BufferVec/UniformVec/DynamicUniformVec Clearing**: improved the clearing interface by removing the need to know the size of the final buffer at the initial clear.
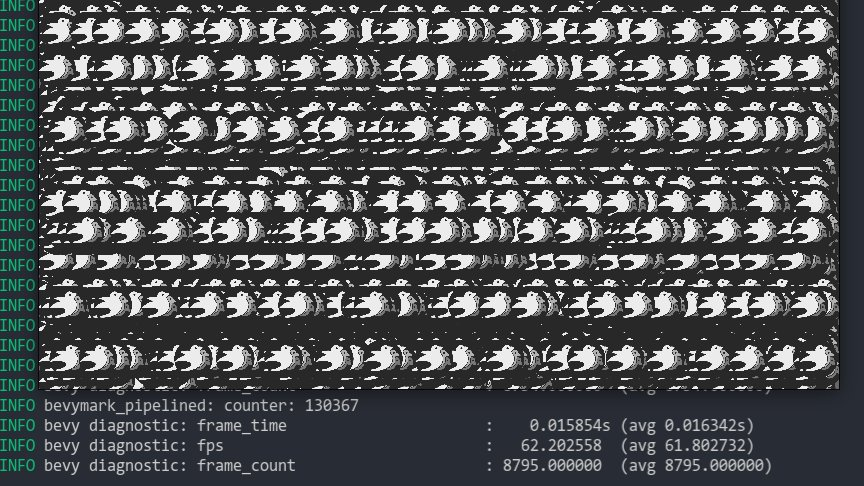
Note that this moves sprites away from entity-driven rendering and back to extracted lists. We _could_ use entities here, but it necessitates that an intermediate list is allocated / populated to collect and sort extracted sprites. This redundant copy, combined with the normal overhead of spawning extracted sprite entities, brings bevymark down to ~80,000 sprites at 60fps. I think making sprites a bit more fixed (by default) is worth it. I view this as acceptable because batching makes normal entity-driven rendering pretty useless anyway (and we would want to batch most custom materials too). We can still support custom shaders with custom bindings, we'll just need to define a specific interface for it.
Add an example that demonstrates the difference between no MSAA and MSAA 4x. This is also useful for testing panics when resizing the window using MSAA. This is on top of #3042 .
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds support for MSAA to the new renderer. This is done using the new [pipeline specialization](#3031) support to specialize on sample count. This is an alternative implementation to #2541 that cuts out the need for complicated render graph edge management by moving the relevant target information into View entities. This reuses @superdump's clever MSAA bitflag range code from #2541.
Note that wgpu currently only supports 1 or 4 samples due to those being the values supported by WebGPU. However they do plan on exposing ways to [enable/query for natively supported sample counts](https://github.com/gfx-rs/wgpu/issues/1832). When this happens we should integrate
# Objective
Make possible to use wgpu gles backend on in the browser (wasm32 + WebGL2).
## Solution
It is built on top of old @cart patch initializing windows before wgpu. Also:
- initializes wgpu with `Backends::GL` and proper `wgpu::Limits` on wasm32
- changes default texture format to `wgpu::TextureFormat::Rgba8UnormSrgb`
Co-authored-by: Mariusz Kryński <mrk@sed.pl>
# Objective
- Fixes#2919
- Initial pixel was hard coded and not dependent on texture format
- Replace #2920 as I noticed this needed to be done also on pipeline rendering branch
## Solution
- Replace the hard coded pixel with one using the texture pixel size
# Objective
while testing wgpu/WebGL on mobile GPU I've noticed bevy always forces vertex index format to 32bit (and ignores mesh settings).
## Solution
the solution is to pass proper vertex index format in GpuIndexInfo to render_pass
## New Features
This adds the following to the new renderer:
* **Shader Assets**
* Shaders are assets again! Users no longer need to call `include_str!` for their shaders
* Shader hot-reloading
* **Shader Defs / Shader Preprocessing**
* Shaders now support `# ifdef NAME`, `# ifndef NAME`, and `# endif` preprocessor directives
* **Bevy RenderPipelineDescriptor and RenderPipelineCache**
* Bevy now provides its own `RenderPipelineDescriptor` and the wgpu version is now exported as `RawRenderPipelineDescriptor`. This allows users to define pipelines with `Handle<Shader>` instead of needing to manually compile and reference `ShaderModules`, enables passing in shader defs to configure the shader preprocessor, makes hot reloading possible (because the descriptor can be owned and used to create new pipelines when a shader changes), and opens the doors to pipeline specialization.
* The `RenderPipelineCache` now handles compiling and re-compiling Bevy RenderPipelineDescriptors. It has internal PipelineLayout and ShaderModule caches. Users receive a `CachedPipelineId`, which can be used to look up the actual `&RenderPipeline` during rendering.
* **Pipeline Specialization**
* This enables defining per-entity-configurable pipelines that specialize on arbitrary custom keys. In practice this will involve specializing based on things like MSAA values, Shader Defs, Bind Group existence, and Vertex Layouts.
* Adds a `SpecializedPipeline` trait and `SpecializedPipelines<MyPipeline>` resource. This is a simple layer that generates Bevy RenderPipelineDescriptors based on a custom key defined for the pipeline.
* Specialized pipelines are also hot-reloadable.
* This was the result of experimentation with two different approaches:
1. **"generic immediate mode multi-key hash pipeline specialization"**
* breaks up the pipeline into multiple "identities" (the core pipeline definition, shader defs, mesh layout, bind group layout). each of these identities has its own key. looking up / compiling a specific version of a pipeline requires composing all of these keys together
* the benefit of this approach is that it works for all pipelines / the pipeline is fully identified by the keys. the multiple keys allow pre-hashing parts of the pipeline identity where possible (ex: pre compute the mesh identity for all meshes)
* the downside is that any per-entity data that informs the values of these keys could require expensive re-hashes. computing each key for each sprite tanked bevymark performance (sprites don't actually need this level of specialization yet ... but things like pbr and future sprite scenarios might).
* this is the approach rafx used last time i checked
2. **"custom key specialization"**
* Pipelines by default are not specialized
* Pipelines that need specialization implement a SpecializedPipeline trait with a custom key associated type
* This allows specialization keys to encode exactly the amount of information required (instead of needing to be a combined hash of the entire pipeline). Generally this should fit in a small number of bytes. Per-entity specialization barely registers anymore on things like bevymark. It also makes things like "shader defs" way cheaper to hash because we can use context specific bitflags instead of strings.
* Despite the extra trait, it actually generally makes pipeline definitions + lookups simpler: managing multiple keys (and making the appropriate calls to manage these keys) was way more complicated.
* I opted for custom key specialization. It performs better generally and in my opinion is better UX. Fortunately the way this is implemented also allows for custom caches as this all builds on a common abstraction: the RenderPipelineCache. The built in custom key trait is just a simple / pre-defined way to interact with the cache
## Callouts
* The SpecializedPipeline trait makes it easy to inherit pipeline configuration in custom pipelines. The changes to `custom_shader_pipelined` and the new `shader_defs_pipelined` example illustrate how much simpler it is to define custom pipelines based on the PbrPipeline.
* The shader preprocessor is currently pretty naive (it just uses regexes to process each line). Ultimately we might want to build a more custom parser for more performance + better error handling, but for now I'm happy to optimize for "easy to implement and understand".
## Next Steps
* Port compute pipelines to the new system
* Add more preprocessor directives (else, elif, import)
* More flexible vertex attribute specialization / enable cheaply specializing on specific mesh vertex layouts
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
# Objective
The current TODO comment is out of date
## Solution
I switched up the comment
Co-authored-by: William Batista <45850508+billyb2@users.noreply.github.com>
## Objective
Looking though the new pipelined example I stumbled on an issue with the example shader :
```
Oct 20 12:38:44.891 INFO bevy_render2::renderer: AdapterInfo { name: "Intel(R) UHD Graphics 620 (KBL GT2)", vendor: 32902, device: 22807, device_type: IntegratedGpu, backend: Vulkan }
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_point_shadow")
Oct 20 12:38:44.894 INFO naga:🔙:spv::writer: Skip function Some("fetch_directional_shadow")
Oct 20 12:38:44.898 ERROR wgpu::backend::direct: Handling wgpu errors as fatal by default
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In Device::create_shader_module
Global variable [1] 'view' is invalid
Type isn't compatible with the storage class
```
## Solution
added `<uniform>` here and there.
Note : my current mastery of shaders is about 2 days old, so this still kinda look likes wizardry
# Objective
- Bevy has several `compile_fail` test
- #2254 added `#[derive(Component)]`
- Those tests now fail for a different reason.
- This was not caught as these test still "successfully" failed to compile.
## Solution
- Add `#[derive(Component)]` to the doctest
- Also changed their cfg attribute from `doc` to `doctest`, so that these tests don't appear when running `cargo doc` with `--document-private-items`
# Objective
- Fixes#2501
- Builds up on #2639 taking https://github.com/bevyengine/bevy/pull/2639#issuecomment-898701047 into account
## Solution
- keep the physical cursor position in `Window`, and expose it.
- still convert to logical position in event, and when getting `cursor_position`
Co-authored-by: Ahmed Charles <acharles@outlook.com>
# Objective
The update to wgpu 0.11 broke CI for android. This was due to a confusion between `bevy::render::ShaderStage` and `wgpu::ShaderStage`.
## Solution
Revert the incorrect change
#2605 changed the lifetime annotations on `get_component` introducing unsoundness as you could keep the returned borrow even after using the query.
Example unsoundness:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_startup_system(startup)
.add_system(unsound)
.run();
}
#[derive(Debug, Component, PartialEq, Eq)]
struct Foo(Vec<u32>);
fn startup(mut c: Commands) {
let e = c.spawn().insert(Foo(vec![10])).id();
c.insert_resource(e);
}
fn unsound(mut q: Query<&mut Foo>, res: Res<Entity>) {
let foo = q.get_component::<Foo>(*res).unwrap();
let mut foo2 = q.iter_mut().next().unwrap();
let first_elem = &foo.0[0];
for _ in 0..16 {
foo2.0.push(12);
}
dbg!(*first_elem);
}
```
output:
`[src/main.rs:26] *first_elem = 0`
Add the entity ID and generation to the expect() message of two
world accessors, to make it easier to debug use-after-free issues.
Coupled with e.g. bevy-inspector-egui which also displays the entity ID,
this makes it much easier to identify what entity is being misused.
# Objective
Make it easier to identity an entity being accessed after being deleted.
## Solution
Augment the error message of some `expect()` call with the entity ID and
generation. Combined with some external tool like `bevy-inspector-egui`, which
also displays the entity ID, this increases the chances to be able to identify
the entity, and therefore find the error that led to a use-after-despawn.
Upgrades both the old and new renderer to wgpu 0.11 (and naga 0.7). This builds on @zicklag's work here #2556.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Remove duplicate `Events::update` call in `gilrs_event_system` (fixes#2893)
- See #2893 for context
- While there, make the systems no longer exclusive, as that is not required of them
## Solution
- Do the change
r? @alice-i-cecile
Using RenderQueue in BufferVec allows removal of the staging buffer entirely, as well as removal of the SpriteNode.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR adds a ControlNode which marks an entity as "transparent" to the UI layout system, meaning the children of this entity will be treated as the children of this entity s parent by the layout system(s).
# Objective
- Fixes#2904 (see for context)
## Solution
- Simply hoist span creation out of the threaded task
- Confirmed to solve the issue locally
Now all events have the full span parent tree up through `bevy_ecs::schedule::stage` all the way to `bevy_app::app::bevy_app` (and its parents in bevy-consumer code, if any).
# Objective
- Avoid usages of `format!` that ~immediately get passed to another `format!`. This avoids a temporary allocation and is just generally cleaner.
## Solution
- `bevy_derive::shader_defs` does a `format!("{}", val.to_string())`, which is better written as just `format!("{}", val)`
- `bevy_diagnostic::log_diagnostics_plugin` does a `format!("{:>}", format!(...))`, which is better written as `format!("{:>}", format_args!(...))`
- `bevy_ecs::schedule` does `tracing::info!(..., name = &*format!("{:?}", val))`, which is better written with the tracing shorthand `tracing::info!(..., name = ?val)`
- `bevy_reflect::reflect` does `f.write_str(&format!(...))`, which is better written as `write!(f, ...)` (this could also be written using `f.debug_tuple`, but I opted to maintain alt debug behavior)
- `bevy_reflect::serde::{ser, de}` do `serde::Error::custom(format!(...))`, which is better written as `Error::custom(format_args!(...))`, as `Error::custom` takes `impl Display` and just immediately calls `format!` again
# Objective
- removed unused RenderResourceId and SwapChainFrame (already unified with TextureView)
- added deref to BindGroup, this makes conversion to wgpu::BindGroup easier
## Solution
- cleans up the API
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes these issues:
- `WorldId`s currently aren't necessarily unique
- I want to guarantee that they're unique to safeguard my librarified version of https://github.com/bevyengine/bevy/discussions/2805
- There probably hasn't been a collision yet, but they could technically collide
- `SystemId` isn't used for anything
- It's no longer used now that `Locals` are stored within the `System`.
- `bevy_ecs` depends on rand
## Solution
- Instead of randomly generating `WorldId`s, just use an incrementing atomic counter, panicing on overflow.
- Remove `SystemId`
- We do need to allow Locals for exclusive systems at some point, but exclusive systems couldn't access their own `SystemId` anyway.
- Now that these don't depend on rand, move it to a dev-dependency
## Todo
Determine if `WorldId` should be `u32` based instead
If you need to build a texture atlas from an already created texture that is not match a grid, you need to use new_empty and add_texture to create it. However it is not straight forward to get the index to be used with TextureAtlasSprite. add_texture should be changed to return the index to the texture.
Currently you can do something like this:
```rs
let texture = asset_server.load::<Texture>::("texture.png");
let texture_atlas = TextureAtlas::new_empty(texture, Vec2::new(40.0, 40.0));
texture_atlas.add_texture(Rect {
min: Vec2::new(20.0, 20.0),
max: Vec2::new(40.0, 40.0),
});
let index = (texture_atlas.len() - 1) as u32;
let texture_atlas_sprite = TextureAtlasSprite {
index,
Default::default()
};
```
But this is more clear
```rs
let index = texture_atlas.add_texture(Rect {
min: Vec2::new(20.0, 20.0),
max: Vec2::new(40.0, 40.0),
});
```
Updates the requirements on [hexasphere](https://github.com/OptimisticPeach/hexasphere) to permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/OptimisticPeach/hexasphere/commits">compare view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
# Objective
Noticed a comment saying changed detection should be enabled for hierarchy maintenance once stable
Fixes#891
## Solution
Added `Changed<Parent>` filter on the query
Changed out unwraps to use if let syntax instead. Returning false when None.
Also modified an existing test to encompass these methods
This PR fixes#2828
# Objective
Using fullscreen or trying to resize a window caused a panic. Fix that.
## Solution
- Don't wholesale overwrite the ExtractedWindows resource when extracting windows
- This could cause an accumulation of unused windows that are holding onto swap chain frames?
- Check the if width and/or height changed since the last frame
- If the size changed, recreate the swap chain
- Ensure dimensions are >= 1 to avoid panics due to any dimension being 0
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
## Objective
The upcoming Bevy Book makes many references to the API documentation of bevy.
Most references belong to the first two chapters of the Bevy Book:
- bevyengine/bevy-website#176
- bevyengine/bevy-website#182
This PR attempts to improve the documentation of `bevy_ecs` and `bevy_app` in order to help readers of the Book who want to delve deeper into technical details.
## Solution
- Add crate and level module documentation
- Document the most important items (basically those included in the preludes), with the following style, where applicable:
- **Summary.** Short description of the item.
- **Second paragraph.** Detailed description of the item, without going too much in the implementation.
- **Code example(s).**
- **Safety or panic notes.**
## Collaboration
Any kind of collaboration is welcome, especially corrections, wording, new ideas and guidelines on where the focus should be put in.
---
### Related issues
- Fixes#2246
# Objective
[Tracy](https://github.com/wolfpld/tracy) is:
> A real time, nanosecond resolution, remote telemetry, hybrid frame and sampling profiler for games and other applications.
With the `trace_tracy` feature enabled, you run your bevy app and either a headless server (`capture`) or a live, interactive profiler UI (`Tracy`), and connect that to your bevy application to then stream the metric data and events, and save it or inspect it live/offline.
Previously when I implemented the spans across systems and stages and I was trying out different profiling tools, Tracy was too unstable on macOS to use. But now, quite some months later, it is working stably with Tracy 0.7.8. You can see timelines, aggregate statistics of mean system/stage execution times, and much more. It's very useful!
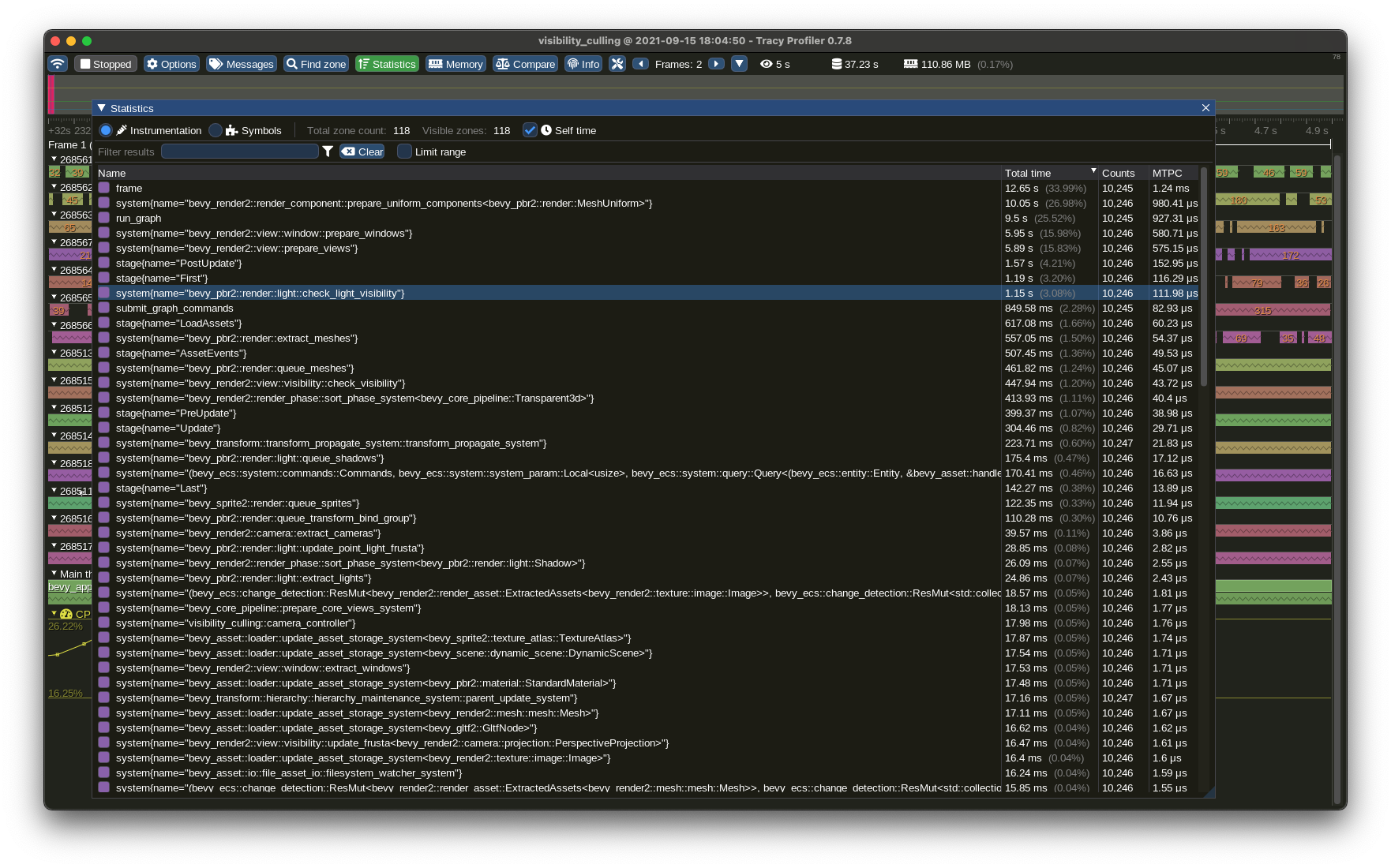
## Solution
- Use the `tracing-tracy` crate which supports our tracing spans
- Expose via the non-default feature `trace_tracy` for consistency with other `trace*` features
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}