# Objective
- Fixes#16469.
## Solution
- Make the picking backend features not enabled by default in each
sub-crate.
- Make features in `bevy_internal` to set the backend features
- Make the root `bevy` crate set the features by default.
## Testing
- The mesh and sprite picking examples still work correctly.
# Objective
Closes#15545.
`bevy_picking` supports UI and sprite picking, but not mesh picking.
Being able to pick meshes would be extremely useful for various games,
tools, and our own examples, as well as scene editors and inspectors.
So, we need a mesh picking backend!
Luckily,
[`bevy_mod_picking`](https://github.com/aevyrie/bevy_mod_picking) (which
`bevy_picking` is based on) by @aevyrie already has a [backend for
it](74f0c3c0fb/backends/bevy_picking_raycast/src/lib.rs)
using [`bevy_mod_raycast`](https://github.com/aevyrie/bevy_mod_raycast).
As a side product of adding mesh picking, we also get support for
performing ray casts on meshes!
## Solution
Upstream a large chunk of the immediate-mode ray casting functionality
from `bevy_mod_raycast`, and add a mesh picking backend based on
`bevy_mod_picking`. Huge thanks to @aevyrie who did all the hard work on
these incredible crates!
All meshes are pickable by default. Picking can be disabled for
individual entities by adding `PickingBehavior::IGNORE`, like normal.
Or, if you want mesh picking to be entirely opt-in, you can set
`MeshPickingBackendSettings::require_markers` to `true` and add a
`RayCastPickable` component to the desired camera and target entities.
You can also use the new `MeshRayCast` system parameter to cast rays
into the world manually:
```rust
fn ray_cast_system(mut ray_cast: MeshRayCast, foo_query: Query<(), With<Foo>>) {
let ray = Ray3d::new(Vec3::ZERO, Dir3::X);
// Only ray cast against entities with the `Foo` component.
let filter = |entity| foo_query.contains(entity);
// Never early-exit. Note that you can change behavior per-entity.
let early_exit_test = |_entity| false;
// Ignore the visibility of entities. This allows ray casting hidden entities.
let visibility = RayCastVisibility::Any;
let settings = RayCastSettings::default()
.with_filter(&filter)
.with_early_exit_test(&early_exit_test)
.with_visibility(visibility);
// Cast the ray with the settings, returning a list of intersections.
let hits = ray_cast.cast_ray(ray, &settings);
}
```
This is largely a direct port, but I did make several changes to match
our APIs better, remove things we don't need or that I think are
unnecessary, and do some general improvements to code quality and
documentation.
### Changes Relative to `bevy_mod_raycast` and `bevy_mod_picking`
- Every `Raycast` and "raycast" has been renamed to `RayCast` and "ray
cast" (similar reasoning as the "Naming" section in #15724)
- `Raycast` system param has been renamed to `MeshRayCast` to avoid
naming conflicts and to be explicit that it is not for colliders
- `RaycastBackend` has been renamed to `MeshPickingBackend`
- `RayCastVisibility` variants are now `Any`, `Visible`, and
`VisibleInView` instead of `Ignore`, `MustBeVisible`, and
`MustBeVisibleAndInView`
- `NoBackfaceCulling` has been renamed to `RayCastBackfaces`, to avoid
implying that it affects the rendering of backfaces for meshes (it
doesn't)
- `SimplifiedMesh` and `RayCastBackfaces` live near other ray casting
API types, not in their own 10 LoC module
- All intersection logic and types are in the same `intersections`
module, not split across several modules
- Some intersection types have been renamed to be clearer and more
consistent
- `IntersectionData` -> `RayMeshHit`
- `RayHit` -> `RayTriangleHit`
- General documentation and code quality improvements
### Removed / Not Ported
- Removed unused ray helpers and types, like `PrimitiveIntersection`
- Removed getters on intersection types, and made their properties
public
- There is no `2d` feature, and `Raycast::mesh_query` and
`Raycast::mesh2d_query` have been merged into `MeshRayCast::mesh_query`,
which handles both 2D and 3D
- I assume this existed previously because `Mesh2dHandle` used to be in
`bevy_sprite`. Now both the 2D and 3D mesh are in `bevy_render`.
- There is no `debug` feature or ray debug rendering
- There is no deferred API (`RaycastSource`)
- There is no `CursorRayPlugin` (the picking backend handles this)
### Note for Reviewers
In case it's helpful, the [first
commit](281638ef10)
here is essentially a one-to-one port. The rest of the commits are
primarily refactoring and cleaning things up in the ways listed earlier,
as well as changes to the module structure.
It may also be useful to compare the original [picking
backend](74f0c3c0fb/backends/bevy_picking_raycast/src/lib.rs)
and [`bevy_mod_raycast`](https://github.com/aevyrie/bevy_mod_raycast) to
this PR. Feel free to mention if there are any changes that I should
revert or something I should not include in this PR.
## Testing
I tested mesh picking and relevant components in some examples, for both
2D and 3D meshes, and added a new `mesh_picking` example. I also
~~stole~~ ported over the [ray-mesh intersection
benchmark](dbc5ef32fe/benches/ray_mesh_intersection.rs)
from `bevy_mod_raycast`.
---
## Showcase
Below is a version of the `2d_shapes` example modified to demonstrate 2D
mesh picking. This is not included in this PR.
https://github.com/user-attachments/assets/7742528c-8630-4c00-bacd-81576ac432bf
And below is the new `mesh_picking` example:
https://github.com/user-attachments/assets/b65c7a5a-fa3a-4c2d-8bbd-e7a2c772986e
There is also a really cool new `mesh_ray_cast` example ported over from
`bevy_mod_raycast`:
https://github.com/user-attachments/assets/3c5eb6c0-bd94-4fb0-bec6-8a85668a06c9
---------
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Trent <2771466+tbillington@users.noreply.github.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
# Objective
Updating ``glam`` to 0.29, ``encase`` to 0.10.
## Solution
Update the necessary ``Cargo.toml`` files.
## Testing
Ran ``cargo run -p ci`` on Windows; no issues came up.
---------
Co-authored-by: aecsocket <aecsocket@tutanota.com>
# Objective
It would be good to have benchmarks handy for function reflection as it
continues to be worked on.
## Solution
Add some basic benchmarks for function reflection.
## Testing
To test locally, run the following in the `benches` directory:
```
cargo bench --bench reflect_function
```
## Results
Here are a couple of the results (M1 Max MacBook Pro):
<img width="936" alt="Results of benching calling functions vs closures
via reflection. Closures average about 40ns, while functions average
about 55ns"
src="https://github.com/user-attachments/assets/b9a6c585-5fbe-43db-9a7b-f57dbd3815e3">
<img width="936" alt="Results of benching converting functions vs
closures into their dynamic representations. Closures average about
34ns, while functions average about 37ns"
src="https://github.com/user-attachments/assets/4614560a-7192-4c1e-9ade-7bc5a4ca68e3">
Currently, it seems `DynamicClosure` is just a bit more performant. This
is likely due to the fact that `DynamicFunction` stores its function
object in an `Arc` instead of a `Box` so that it can be `Send + Sync`
(and also `Clone`).
We'll likely need to do the same for `DynamicClosure` so I suspect these
results to change in the near future.
Basically it's https://github.com/bevyengine/bevy/pull/13792 with the
bumped versions of `encase` and `hexasphere`.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Add basic bubbling to observers, modeled off `bevy_eventlistener`.
## Solution
- Introduce a new `Traversal` trait for components which point to other
entities.
- Provide a default `TraverseNone: Traversal` component which cannot be
constructed.
- Implement `Traversal` for `Parent`.
- The `Event` trait now has an associated `Traversal` which defaults to
`TraverseNone`.
- Added a field `bubbling: &mut bool` to `Trigger` which can be used to
instruct the runner to bubble the event to the entity specified by the
event's traversal type.
- Added an associated constant `SHOULD_BUBBLE` to `Event` which
configures the default bubbling state.
- Added logic to wire this all up correctly.
Introducing the new associated information directly on `Event` (instead
of a new `BubblingEvent` trait) lets us dispatch both bubbling and
non-bubbling events through the same api.
## Testing
I have added several unit tests to cover the common bugs I identified
during development. Running the unit tests should be enough to validate
correctness. The changes effect unsafe portions of the code, but should
not change any of the safety assertions.
## Changelog
Observers can now bubble up the entity hierarchy! To create a bubbling
event, change your `Derive(Event)` to something like the following:
```rust
#[derive(Component)]
struct MyEvent;
impl Event for MyEvent {
type Traverse = Parent; // This event will propagate up from child to parent.
const AUTO_PROPAGATE: bool = true; // This event will propagate by default.
}
```
You can dispatch a bubbling event using the normal
`world.trigger_targets(MyEvent, entity)`.
Halting an event mid-bubble can be done using
`trigger.propagate(false)`. Events with `AUTO_PROPAGATE = false` will
not propagate by default, but you can enable it using
`trigger.propagate(true)`.
If there are multiple observers attached to a target, they will all be
triggered by bubbling. They all share a bubbling state, which can be
accessed mutably using `trigger.propagation_mut()` (`trigger.propagate`
is just sugar for this).
You can choose to implement `Traversal` for your own types, if you want
to bubble along a different structure than provided by `bevy_hierarchy`.
Implementers must be careful never to produce loops, because this will
cause bevy to hang.
## Migration Guide
+ Manual implementations of `Event` should add associated type `Traverse
= TraverseNone` and associated constant `AUTO_PROPAGATE = false`;
+ `Trigger::new` has new field `propagation: &mut Propagation` which
provides the bubbling state.
+ `ObserverRunner` now takes the same `&mut Propagation` as a final
parameter.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#12966
## Solution
Renaming multi_threaded feature to match snake case
## Migration Guide
Bevy feature multi-threaded should be refered to multi_threaded from now
on.
# Objective
- Update glam version requirement to latest version.
## Solution
- Updated `glam` version requirement from 0.25 to 0.27.
- Updated `encase` and `encase_derive_impl` version requirement from 0.7
to 0.8.
- Updated `hexasphere` version requirement from 10.0 to 12.0.
- Breaking changes from glam changelog:
- [0.26.0] Minimum Supported Rust Version bumped to 1.68.2 for impl
From<bool> for {f32,f64} support.
- [0.27.0] Changed implementation of vector fract method to match the
Rust implementation instead of the GLSL implementation, that is self -
self.trunc() instead of self - self.floor().
---
## Migration Guide
- When using `glam` exports, keep in mind that `vector` `fract()` method
now matches Rust implementation (that is `self - self.trunc()` instead
of `self - self.floor()`). If you want to use the GLSL implementation
you should now use `fract_gl()`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- The [`version`] field in `Cargo.toml` is optional for crates not
published on <https://crates.io>.
- We have several `publish = false` tools in this repository that still
have a version field, even when it's not useful.
[`version`]:
https://doc.rust-lang.org/cargo/reference/manifest.html#the-version-field
## Solution
- Remove the [`version`] field for all crates where `publish = false`.
- Update the description on a few crates and remove extra newlines as
well.
# Objective
- Primitive meshing is suboptimal
- Improve primitive meshing
## Solution
- Add primitive meshing benchmark
- Allows measuring future improvements
---
First of a few PRs to refactor and improve primitive meshing.
# Objective
Reduce the size of `bevy_utils`
(https://github.com/bevyengine/bevy/issues/11478)
## Solution
Move `EntityHash` related types into `bevy_ecs`. This also allows us
access to `Entity`, which means we no longer need `EntityHashMap`'s
first generic argument.
---
## Changelog
- Moved `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` into `bevy::ecs::entity::hash` .
- Removed `EntityHashMap`'s first generic argument. It is now hardcoded
to always be `Entity`.
## Migration Guide
- Uses of `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` now have to be imported from `bevy::ecs::entity::hash`.
- Uses of `EntityHashMap` no longer have to specify the first generic
parameter. It is now hardcoded to always be `Entity`.
Update to `glam` 0.25, `encase` 0.7 and `hexasphere` to 10.0
## Changelog
Added the `FloatExt` trait to the `bevy_math` prelude which adds `lerp`,
`inverse_lerp` and `remap` methods to the `f32` and `f64` types.
(This is my first PR here, so I've probably missed some things. Please
let me know what else I should do to help you as a reviewer!)
# Objective
Due to https://github.com/rust-lang/rust/issues/117800, the `derive`'d
`PartialEq::eq` on `Entity` isn't as good as it could be. Since that's
used in hashtable lookup, let's improve it.
## Solution
The derived `PartialEq::eq` short-circuits if the generation doesn't
match. However, having a branch there is sub-optimal, especially on
64-bit systems like x64 that could just load the whole `Entity` in one
load anyway.
Due to complications around `poison` in LLVM and the exact details of
what unsafe code is allowed to do with reference in Rust
(https://github.com/rust-lang/unsafe-code-guidelines/issues/346), LLVM
isn't allowed to completely remove the short-circuiting. `&Entity` is
marked `dereferencable(8)` so LLVM knows it's allowed to *load* all 8
bytes -- and does so -- but it has to assume that the `index` might be
undef/poison if the `generation` doesn't match, and thus while it finds
a way to do it without needing a branch, it has to do something slightly
more complicated than optimal to combine the results. (LLVM is allowed
to change non-short-circuiting code to use branches, but not the other
way around.)
Here's a link showing the codegen today:
<https://rust.godbolt.org/z/9WzjxrY7c>
```rust
#[no_mangle]
pub fn demo_eq_ref(a: &Entity, b: &Entity) -> bool {
a == b
}
```
ends up generating the following assembly:
```asm
demo_eq_ref:
movq xmm0, qword ptr [rdi]
movq xmm1, qword ptr [rsi]
pcmpeqd xmm1, xmm0
pshufd xmm0, xmm1, 80
movmskpd eax, xmm0
cmp eax, 3
sete al
ret
```
(It's usually not this bad in real uses after inlining and LTO, but it
makes a strong demo.)
This PR manually implements `PartialEq::eq` *without* short-circuiting,
and because that tells LLVM that neither the generations nor the index
can be poison, it doesn't need to be so careful and can generate the
"just compare the two 64-bit values" code you'd have probably already
expected:
```asm
demo_eq_ref:
mov rax, qword ptr [rsi]
cmp qword ptr [rdi], rax
sete al
ret
```
Since this doesn't change the representation of `Entity`, if it's
instead passed by *value*, then each `Entity` is two `u32` registers,
and the old and the new code do exactly the same thing. (Other
approaches, like changing `Entity` to be `[u32; 2]` or `u64`, affect
this case.)
This should hopefully merge easily with changes like
https://github.com/bevyengine/bevy/pull/9907 that also want to change
`Entity`.
## Benchmarks
I'm not super-confident that I got my machine fully consistent for
benchmarking, but whether I run the old or the new one first I get
reasonably consistent results.
Here's a fairly typical example of the benchmarks I added in this PR:

Building the sets seems to be basically the same. It's usually reported
as noise, but sometimes I see a few percent slower or faster.
But lookup hits in particular -- since a hit checks that the key is
equal -- consistently shows around 10% improvement.
`cargo run --example many_cubes --features bevy/trace_tracy --release --
--benchmark` showed as slightly faster with this change, though if I had
to bet I'd probably say it's more noise than meaningful (but at least
it's not worse either):

This is my first PR here -- and my first time running Tracy -- so please
let me know what else I should run, or run things on your own more
reliable machines to double-check.
---
## Changelog
(probably not worth including)
Changed: micro-optimized `Entity::eq` to help LLVM slightly.
## Migration Guide
(I really hope nobody was using this on uninitialized entities where
sufficiently tortured `unsafe` could could technically notice that this
has changed.)
# Objective
We want to measure performance on path reflection parsing.
## Solution
Benchmark path-based reflection:
- Add a benchmark for `ParsedPath::parse`
It's fairly noisy, this is why I added the 3% threshold.
Ideally we would fix the noisiness though. Supposedly I'm seeding the
RNG correctly, so there shouldn't be much observable variance. Maybe
someone can help spot the issue.
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
- Adds foundational math for Bezier curves, useful for UI/2D/3D animation and smooth paths.
https://user-images.githubusercontent.com/2632925/218883143-e138f994-1795-40da-8c59-21d779666991.mp4
## Solution
- Adds the generic `Bezier` type, and a `Point` trait. The `Point` trait allows us to use control points of any dimension, as long as they support vector math. I've implemented it for `f32`(1D), `Vec2`(2D), and `Vec3`/`Vec3A`(3D).
- Adds `CubicBezierEasing` on top of `Bezier` with the addition of an implementation of cubic Bezier easing, which is a foundational tool for UI animation.
- This involves solving for $t$ in the parametric Bezier function $B(t)$ using the Newton-Raphson method to find a value with error $\leq$ 1e-7, capped at 8 iterations.
- Added type aliases for common Bezier curves: `CubicBezier2d`, `CubicBezier3d`, `QuadraticBezier2d`, and `QuadraticBezier3d`. These types use `Vec3A` to represent control points, as this was found to have an 80-90% speedup over using `Vec3`.
- Benchmarking shows quadratic/cubic Bezier evaluations $B(t)$ take \~1.8/2.4ns respectively. Easing, which requires an iterative solve takes \~50ns for cubic Beziers.
---
## Changelog
- Added `CubicBezier2d`, `CubicBezier3d`, `QuadraticBezier2d`, and `QuadraticBezier3d` types with methods for sampling position, velocity, and acceleration. The generic `Bezier` type is also available, and generic over any degree of Bezier curve.
- Added `CubicBezierEasing`, with additional methods to allow for smooth easing animations.
## Objective
Fixes: #5110
## Solution
- Moved benches into separate modules according to the part of ECS they are testing.
- Made so all ECS benches are included in one `benches.rs` so they don’t need to be added separately in `Cargo.toml`.
- Renamed a bunch of files to have more coherent names.
- Merged `schedule.rs` and `system_schedule.rs` into one file.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Add benchmarks to test the performance of `Schedule`'s system dependency resolution.
## Solution
- Do a series of benchmarks while increasing the number of systems in the schedule to see how the run-time scales.
- Split the benchmarks into a group with no dependencies, and a group with many dependencies.
# Objective
Partially addresses #3594.
## Solution
This adds basic benchmarks for `List`, `Map`, and `Struct` implementors, both concrete (`Vec`, `HashMap`, and defined struct types) and dynamic (`DynamicList`, `DynamicMap` and `DynamicStruct`).
A few insights from the benchmarks (all measurements are local on my machine):
- Applying a list with many elements to a list with no elements is slower than applying to a list of the same length:
- 3-4x slower when applying to a `Vec`
- 5-6x slower when applying to a `DynamicList`
I suspect this could be improved by `reserve()`ing the correct length up front, but haven't tested.
- Applying a `DynamicMap` to another `Map` is linear in the number of elements, but applying a `HashMap` seems to be at least quadratic. No intuition on this one.
- Applying like structs (concrete -> concrete, `DynamicStruct` -> `DynamicStruct`) seems to be faster than applying unlike structs.
# Objective
- Add benches for run criteria. This is in anticipation of run criteria being redone in stageless.
## Solution
- Benches run criteria that don't access anything to test overhead
- Test run criteria that use a query
- Test run criteria that use a resource
# Objective
- Make it possible to use `System`s outside of the scheduler/executor without having to define logic to track new archetypes and call `System::add_archetype()` for each.
## Solution
- Replace `System::add_archetype(&Archetype)` with `System::update_archetypes(&World)`, making systems responsible for tracking their own most recent archetype generation the way that `SystemState` already does.
This has minimal (or simplifying) effect on most of the code with the exception of `FunctionSystem`, which must now track the latest `ArchetypeGeneration` it saw instead of relying on the executor to do it.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Benchmarks are good.
- Licensing situation appears to be [cleared up](https://github.com/bevyengine/bevy/pull/4225#issuecomment-1078710209).
## Solution
- Add the benchmark suite back in
- Suggested PR title: "Revert "Revert "Add cart's fork of ecs_bench_suite (#4225)" (#4252)"
Co-authored-by: Daniel McNab <36049421+DJMcNab@users.noreply.github.com>
This reverts commit 08ef2f0a28.
# Objective
- #4225 was merged without considering the licensing considerations.
- It merges in code taken from https://github.com/cart/ecs_bench_suite/tree/bevy-benches/src/bevy.
- We can safely assume that we do have a license to cart's contributions. However, these build upon 377e96e69a, for which we have no license.
- This has been verified by looking in the Cargo.toml, the root folder and the readme, none of which mention a license. Additionally, the string "license" [doesn't appear](https://github.com/rust-gamedev/ecs_bench_suite/search?q=license) in the repository.
- This means the code is all rights reserved.
- (The author of these commits also hasn't commented in #2373, though even if they had, it would be legally *dubious* to rely on that to license any code they ever wrote)
- (Note that the latest commit on the head at https://github.com/rust-gamedev/ecs_bench_suite hasn't had a license added either.)
- We are currently incorrectly claiming to be able to give an MIT/Apache 2.0 license to this code.
## Solution
- Revert it
# Objective
Better benchmarking for ECS. Fix#2062.
## Solution
Port @cart's fork of ecs_bench_suite to the official bench suite for bevy_ecs, replace cgmath with glam, update to latest bevy.
# Objective
- Document that the error codes will be rendered on the bevy website (see bevyengine/bevy-website#216)
- Some Cargo.toml files did not include the license or a description field
## Solution
- Readme for the errors crate
- Mark internal/development crates with `publish = false`
- Add missing license/descriptions to some crates
- [x] merge bevyengine/bevy-website#216
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
# Objective
While looking at the code of `World`, I noticed two basic functions (`get` and `get_mut`) that are probably called a lot and with simple code that are not `inline`
## Solution
- Add benchmark to check impact
- Add `#[inline]`
```
group this pr main
----- ---- ----
world_entity/50000_entities 1.00 115.9±11.90µs ? ?/sec 1.71 198.5±29.54µs ? ?/sec
world_get/50000_entities_SparseSet 1.00 409.9±46.96µs ? ?/sec 1.18 483.5±36.41µs ? ?/sec
world_get/50000_entities_Table 1.00 391.3±29.83µs ? ?/sec 1.16 455.6±57.85µs ? ?/sec
world_query_for_each/50000_entities_SparseSet 1.02 121.3±18.36µs ? ?/sec 1.00 119.4±13.88µs ? ?/sec
world_query_for_each/50000_entities_Table 1.03 13.8±0.96µs ? ?/sec 1.00 13.3±0.54µs ? ?/sec
world_query_get/50000_entities_SparseSet 1.00 666.9±54.36µs ? ?/sec 1.03 687.1±57.77µs ? ?/sec
world_query_get/50000_entities_Table 1.01 584.4±55.12µs ? ?/sec 1.00 576.3±36.13µs ? ?/sec
world_query_iter/50000_entities_SparseSet 1.01 169.7±19.50µs ? ?/sec 1.00 168.6±32.56µs ? ?/sec
world_query_iter/50000_entities_Table 1.00 26.2±1.38µs ? ?/sec 1.91 50.0±4.40µs ? ?/sec
```
I didn't add benchmarks for the mutable path but I don't see how it could hurt to make it inline too...
# Objective
- Currently the `Commands` and `CommandQueue` have no performance testing.
- As `Commands` are quite expensive due to the `Box<dyn Command>` allocated for each command, there should be perf tests for implementations that attempt to improve the performance.
## Solution
- Add some benchmarking for `Commands` and `CommandQueue`.
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes#1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
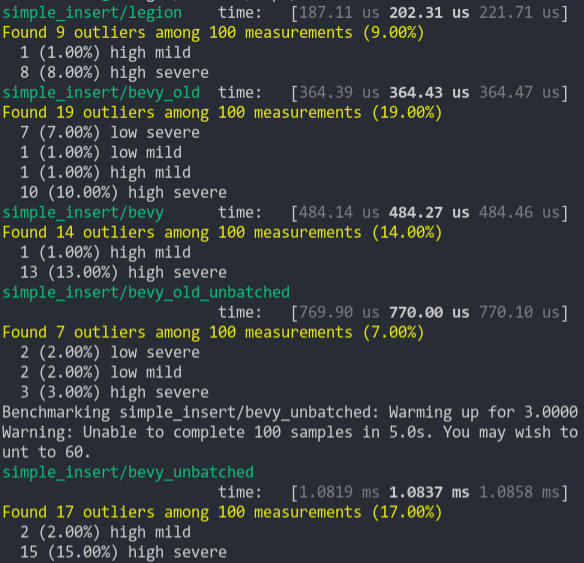
### Simple Insert (from ecs_bench_suite)
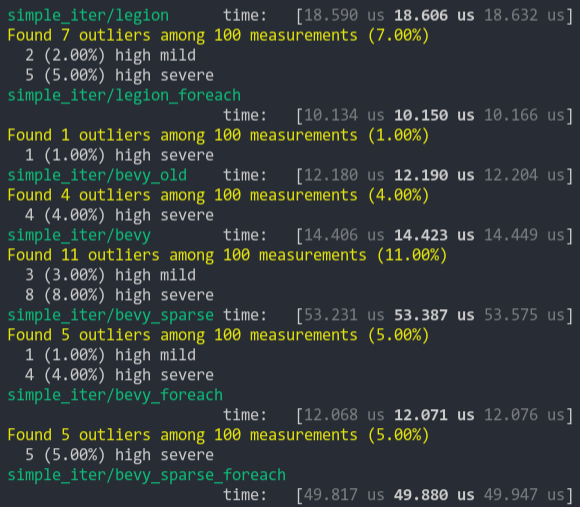
### Simpler Iter (from ecs_bench_suite)
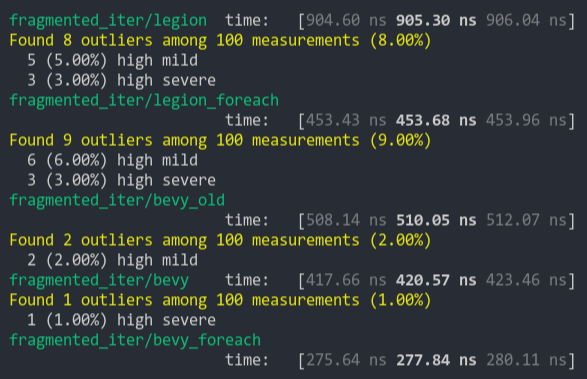
### Fragment Iter (from ecs_bench_suite)
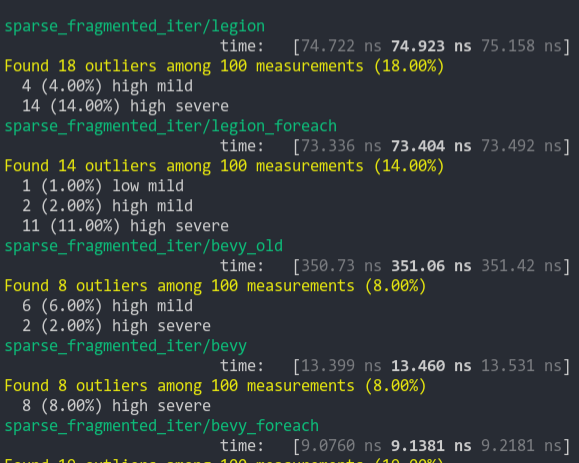
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
### Schedule (from ecs_bench_suite)
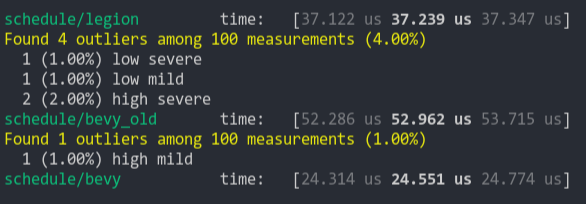
### Add Remove Component (from ecs_bench_suite)
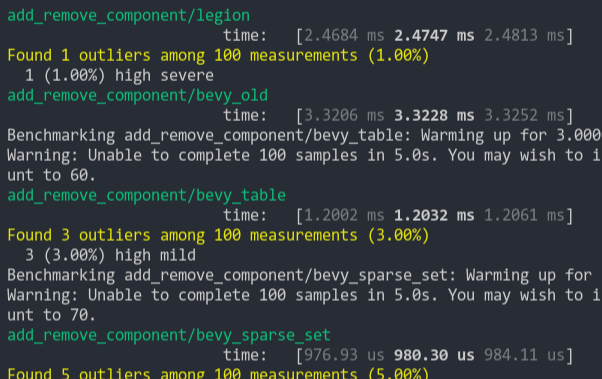
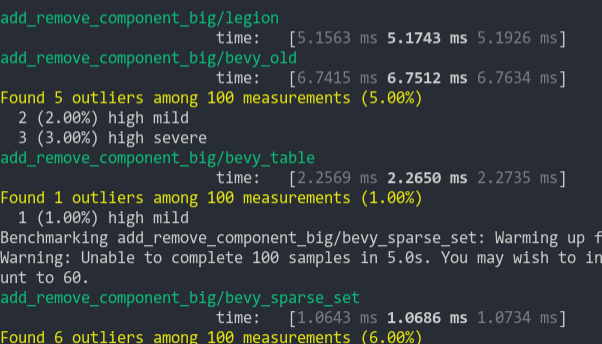
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
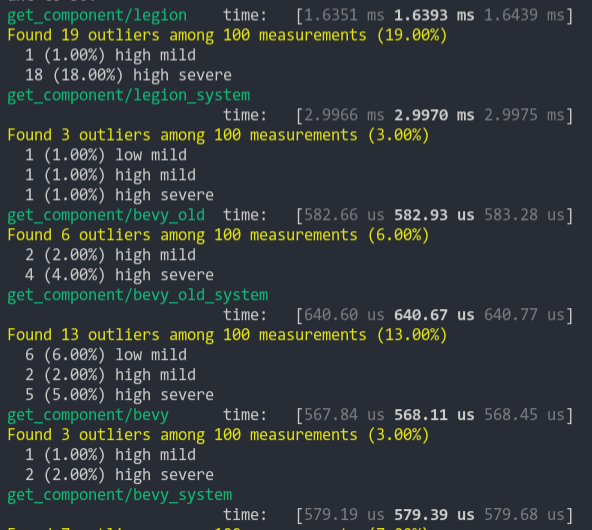
### Get Component
Looks up a single component value a large number of times
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}