# Objective
Promote the `Rect` utility of `sprite::Rect`, which defines a rectangle
by its minimum and maximum corners, to the `bevy_math` crate to make it
available as a general math type to all crates without the need to
depend on the `bevy_sprite` crate.
Fixes#5575
## Solution
Move `sprite::Rect` into `bevy_math` and fix all uses.
Implement `Reflect` for `Rect` directly into the `bevy_reflect` crate by
having `bevy_reflect` depend on `bevy_math`. This looks like a new
dependency, but the `bevy_reflect` was "cheating" for other math types
by directly depending on `glam` to reflect other math types, thereby
giving the illusion that there was no dependency on `bevy_math`. In
practice conceptually Bevy's math types are reflected into the
`bevy_reflect` crate to avoid a dependency of that crate to a "lower
level" utility crate like `bevy_math` (which in turn would make
`bevy_reflect` be a dependency of most other crates, and increase the
risk of circular dependencies). So this change simply formalizes that
dependency in `Cargo.toml`.
The `Rect` struct is also augmented in this change with a collection of
utility methods to improve its usability. A few uses cases are updated
to use those new methods, resulting is more clear and concise syntax.
---
## Changelog
### Changed
- Moved the `sprite::Rect` type into `bevy_math`.
### Added
- Added several utility methods to the `math::Rect` type.
## Migration Guide
The `bevy::sprite::Rect` type moved to the math utility crate as
`bevy::math::Rect`. You should change your imports from `use
bevy::sprite::Rect` to `use bevy::math::Rect`.
# Objective
- While generating https://github.com/jakobhellermann/bevy_reflect_ts_type_export/blob/main/generated/types.ts, I noticed that some types that implement `Reflect` did not register themselves
- `Viewport` isn't reflect but can be (there's a TODO)
## Solution
- register all reflected types
- derive `Reflect` for `Viewport`
## Changelog
- more types are not registered in the type registry
- remove `Serialize`, `Deserialize` impls from `Viewport`
I also decided to remove the `Serialize, Deserialize` from the `Viewport`, since they were (AFAIK) only used for reflection, which now is done without serde. So this is technically a breaking change for people who relied on that impl directly.
Personally I don't think that every bevy type should implement `Serialize, Deserialize`, as that would lead to a ton of code generation that mostly isn't necessary because we can do the same with `Reflect`, but if this is deemed controversial I can remove it from this PR.
## Migration Guide
- `KeyCode` now implements `Reflect` not as `reflect_value`, but with proper struct reflection. The `Serialize` and `Deserialize` impls were removed, now that they are no longer required for scene serialization.
# Objective
This PR changes it possible to use vertex colors without a texture using the bevy_sprite ColorMaterial.
Fixes#5679
## Solution
- Made multiplication of the output color independent of the COLOR_MATERIAL_FLAGS_TEXTURE_BIT bit
- Extended mesh2d_vertex_color_texture example to show off both vertex colors and tinting
Not sure if extending the existing example was the right call but it seems to be reasonable to me.
I couldn't find any tests for the shaders and I think adding shader testing would be beyond the scope of this PR. So no tests in this PR. 😬
Co-authored-by: Jonas Wagner <jonas@29a.ch>
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Similar to #5512 , the `View` struct definition in the shaders in `bevy_sprite` and `bevy_ui` were out of sync with the rust-side `ViewUniform`. Only `view_proj` was being used and is the first member and as those shaders are not customisable it makes little difference in practice, unlike for `Mesh2d`.
## Solution
- Sync shader `View` struct definition in `bevy_sprite` and `bevy_ui` with the correct definition that matches `ViewUniform`
# Objective
View mesh2d_view_types.wgsl was missing a couple of fields present in bevy::render::ViewUniform, causing rendering issues for shaders using later fields.
## Solution
Solved by adding the fields in question
# Objective
I've found there is a duplicated line, probably left after some copy paste.
## Solution
- removed it
---
Co-authored-by: adsick <vadimgangsta73@gmail.com>
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Port changes made to Material in #5053 to Material2d as well.
This is more or less an exact copy of the implementation in bevy_pbr; I
simply pretended the API existed, then copied stuff over until it
started building and the shapes example was working again.
# Objective
The changes in #5053 makes it possible to add custom materials with a lot less boiler plate. However, the implementation isn't shared with Material 2d as it's a kind of fork of the bevy_pbr version. It should be possible to use AsBindGroup on the 2d version as well.
## Solution
This makes the same kind of changes in Material2d in bevy_sprite.
This makes the following work:
```rust
//! Draws a circular purple bevy in the middle of the screen using a custom shader
use bevy::{
prelude::*,
reflect::TypeUuid,
render::render_resource::{AsBindGroup, ShaderRef},
sprite::{Material2d, Material2dPlugin, MaterialMesh2dBundle},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(Material2dPlugin::<CustomMaterial>::default())
.add_startup_system(setup)
.run();
}
/// set up a simple 2D scene
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<CustomMaterial>>,
asset_server: Res<AssetServer>,
) {
commands.spawn_bundle(MaterialMesh2dBundle {
mesh: meshes.add(shape::Circle::new(50.).into()).into(),
material: materials.add(CustomMaterial {
color: Color::PURPLE,
color_texture: Some(asset_server.load("branding/icon.png")),
}),
transform: Transform::from_translation(Vec3::new(-100., 0., 0.)),
..default()
});
commands.spawn_bundle(Camera2dBundle::default());
}
/// The Material2d trait is very configurable, but comes with sensible defaults for all methods.
/// You only need to implement functions for features that need non-default behavior. See the Material api docs for details!
impl Material2d for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"shaders/custom_material.wgsl".into()
}
}
// This is the struct that will be passed to your shader
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make it easier to create pipelines derived from the `Material2dPipeline`. Currently this is made difficult because the fields of `Material2dKey` are private.
## Solution
Make the fields public.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
Fix#4958
There was 4 issues:
- this is not true in WASM and on macOS: f28b921209/examples/3d/split_screen.rs (L90)
- ~~I made sure the system was running at least once~~
- I'm sending the event on window creation
- in webgl, setting a viewport has impacts on other render passes
- only in webgl and when there is a custom viewport, I added a render pass without a custom viewport
- shaderdef NO_ARRAY_TEXTURES_SUPPORT was not used by the 2d pipeline
- webgl feature was used but not declared in bevy_sprite, I added it to the Cargo.toml
- shaderdef NO_STORAGE_BUFFERS_SUPPORT was not used by the 2d pipeline
- I added it based on the BufferBindingType
The last commit changes the two last fixes to add the shaderdefs in the shader cache directly instead of needing to do it in each pipeline
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Split PBR and 2D mesh shaders into types and bindings to prepare the shaders to be more reusable.
- See #3969 for details. I'm doing this in multiple steps to make review easier.
---
## Changelog
- Changed: 2D and PBR mesh shaders are now split into types and bindings, the following shader imports are available: `bevy_pbr::mesh_view_types`, `bevy_pbr::mesh_view_bindings`, `bevy_pbr::mesh_types`, `bevy_pbr::mesh_bindings`, `bevy_sprite::mesh2d_view_types`, `bevy_sprite::mesh2d_view_bindings`, `bevy_sprite::mesh2d_types`, `bevy_sprite::mesh2d_bindings`
## Migration Guide
- In shaders for 3D meshes:
- `#import bevy_pbr::mesh_view_bind_group` -> `#import bevy_pbr::mesh_view_bindings`
- `#import bevy_pbr::mesh_struct` -> `#import bevy_pbr::mesh_types`
- NOTE: If you are using the mesh bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_pbr::mesh_bindings` which itself imports the mesh types needed for the bindings.
- In shaders for 2D meshes:
- `#import bevy_sprite::mesh2d_view_bind_group` -> `#import bevy_sprite::mesh2d_view_bindings`
- `#import bevy_sprite::mesh2d_struct` -> `#import bevy_sprite::mesh2d_types`
- NOTE: If you are using the mesh2d bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_sprite::mesh2d_bindings` which itself imports the mesh2d types needed for the bindings.
# Objective
Increase compatibility with a fairly common format of padded spritesheets, in which half the padding value occurs before the first sprite box begins. The original behaviour falls out when `Vec2::ZERO` is used for `offset`.
See below unity screenshot for an example of a spritesheet with padding
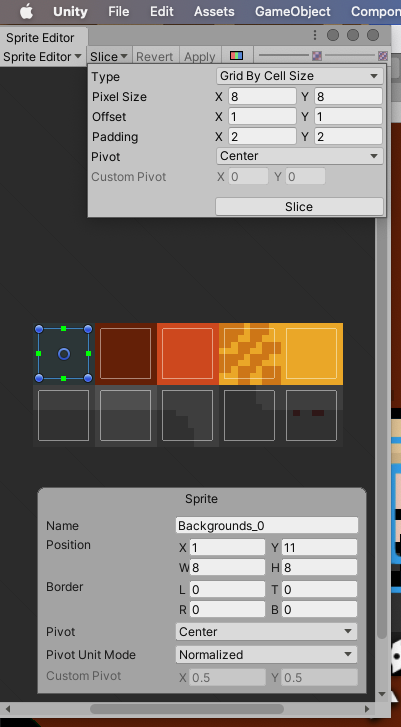
## Solution
Tiny change to `crates/bevy_sprite/src/texture_atlas.rs`
## Migration Guide
Calls to `TextureAtlas::from_grid_with_padding` should be modified to include a new parameter, which can be set to `Vec2::ZERO` to retain old behaviour.
```rust
from_grid_with_padding(texture, tile_size, columns, rows, padding)
|
V
from_grid_with_padding(texture, tile_size, columns, rows, padding, Vec2::ZERO)
```
Co-authored-by: FraserLee <30442265+FraserLee@users.noreply.github.com>
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
- Add Vertex Color support to 2D meshes and ColorMaterial. This extends the work from #4528 (which in turn builds on the excellent tangent handling).
## Solution
- Added `#ifdef` wrapped support for vertex colors in the 2D mesh shader and `ColorMaterial` shader.
- Added an example, `mesh2d_vertex_color_texture` to demonstrate it in action.

---
## Changelog
- Added optional (ifdef wrapped) vertex color support to the 2dmesh and color material systems.
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
- While optimising many_cubes, I noticed that all material handles are extracted regardless of whether the entity to which the handle belongs is visible or not. As such >100k handles are extracted when only <20k are visible.
## Solution
- Only extract material handles of visible entities.
- This improves `many_cubes -- sphere` from ~42fps to ~48fps. It reduces not only the extraction time but also system commands time. `Handle<StandardMaterial>` extraction and its system commands went from 0.522ms + 3.710ms respectively, to 0.267ms + 0.227ms an 88% reduction for this system for this case. It's very view dependent but...
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by moving FloatOrd to bevy_utils.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Move FloatOrd into bevy_utils. Fix the compile errors.
As a result, bevy_core_pipeline, bevy_pbr, bevy_sprite, bevy_text, and bevy_ui no longer depend on bevy_core (they were only using it for `FloatOrd` previously).
# Objective
- Related #4276.
- Part of the splitting process of #3503.
## Solution
- Move `Size` to `bevy_ui`.
## Reasons
- `Size` is only needed in `bevy_ui` (because it needs to use `Val` instead of `f32`), but it's also used as a worse `Vec2` replacement in other areas.
- `Vec2` is more powerful than `Size` so it should be used whenever possible.
- Discussion in #3503.
## Changelog
### Changed
- The `Size` type got moved from `bevy_math` to `bevy_ui`.
## Migration Guide
- The `Size` type got moved from `bevy::math` to `bevy::ui`. To migrate you just have to import `bevy::ui::Size` instead of `bevy::math::Math` or use the `bevy::prelude` instead.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#1616, fixes#2225
- Let user specify an anchor for a sprite
## Solution
- Add an enum for an anchor point for most common values, with a variant for a custom point
- Defaults to Center to not change current behaviour
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
An entity spawned with `MaterialMesh2dBundle<M>` cannot be saved and spawned using `DynamicScene` because the `Mesh2dHandle` component does not `impl Reflect`.
## Solution
Add `#[derive(Reflect)]` and `#[reflect(Component)]` to `Mesh2dHandle`, and call `register_type` in `SpritePlugin`. Also add `#[derive(Debug)]` since I'm touching the `derive`s anyway.
# Objective
Cleans up some duplicated color -> u32 conversion code in `bevy_sprite` and `bevy_ui`
## Solution
Use `as_linear_rgba_u32` which was added recently by #4088
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}