# Objective
Closes#9955.
Use the same interface for all "pure" builder types: taking and
returning `Self` (and not `&mut Self`).
## Solution
Changed `DynamicSceneBuilder`, `SceneFilter` and `TableBuilder` to take
and return `Self`.
## Changelog
### Changed
- `DynamicSceneBuilder` and `SceneBuilder` methods in `bevy_ecs` now
take and return `Self`.
## Migration guide
When using `bevy_ecs::DynamicSceneBuilder` and `bevy_ecs::SceneBuilder`,
instead of binding the builder to a variable, directly use it. Methods
on those types now consume `Self`, so you will need to re-bind the
builder if you don't `build` it immediately.
Before:
```rust
let mut scene_builder = DynamicSceneBuilder::from_world(&world);
let scene = scene_builder.extract_entity(a).extract_entity(b).build();
```
After:
```rust
let scene = DynamicSceneBuilder::from_world(&world)
.extract_entity(a)
.extract_entity(b)
.build();
```
# Objective
- Followup to #7184.
- ~Deprecate `TypeUuid` and remove its internal references.~ No longer
part of this PR.
- Use `TypePath` for the type registry, and (de)serialisation instead of
`std::any::type_name`.
- Allow accessing type path information behind proxies.
## Solution
- Introduce methods on `TypeInfo` and friends for dynamically querying
type path. These methods supersede the old `type_name` methods.
- Remove `Reflect::type_name` in favor of `DynamicTypePath::type_path`
and `TypeInfo::type_path_table`.
- Switch all uses of `std::any::type_name` in reflection, non-debugging
contexts to use `TypePath`.
---
## Changelog
- Added `TypePathTable` for dynamically accessing methods on `TypePath`
through `TypeInfo` and the type registry.
- Removed `type_name` from all `TypeInfo`-like structs.
- Added `type_path` and `type_path_table` methods to all `TypeInfo`-like
structs.
- Removed `Reflect::type_name` in favor of
`DynamicTypePath::reflect_type_path` and `TypeInfo::type_path`.
- Changed the signature of all `DynamicTypePath` methods to return
strings with a static lifetime.
## Migration Guide
- Rely on `TypePath` instead of `std::any::type_name` for all stability
guarantees and for use in all reflection contexts, this is used through
with one of the following APIs:
- `TypePath::type_path` if you have a concrete type and not a value.
- `DynamicTypePath::reflect_type_path` if you have an `dyn Reflect`
value without a concrete type.
- `TypeInfo::type_path` for use through the registry or if you want to
work with the represented type of a `DynamicFoo`.
- Remove `type_name` from manual `Reflect` implementations.
- Use `type_path` and `type_path_table` in place of `type_name` on
`TypeInfo`-like structs.
- Use `get_with_type_path(_mut)` over `get_with_type_name(_mut)`.
## Note to reviewers
I think if anything we were a little overzealous in merging #7184 and we
should take that extra care here.
In my mind, this is the "point of no return" for `TypePath` and while I
think we all agree on the design, we should carefully consider if the
finer details and current implementations are actually how we want them
moving forward.
For example [this incorrect `TypePath` implementation for
`String`](3fea3c6c0b/crates/bevy_reflect/src/impls/std.rs (L90))
(note that `String` is in the default Rust prelude) snuck in completely
under the radar.
# Objective
- Fixes#8140
## Solution
- Added Explicit Error Typing for `AssetLoader` and `AssetSaver`, which
were the last instances of `anyhow` in use across Bevy.
---
## Changelog
- Added an associated type `Error` to `AssetLoader` and `AssetSaver` for
use with the `load` and `save` methods respectively.
- Changed `ErasedAssetLoader` and `ErasedAssetSaver` `load` and `save`
methods to use `Box<dyn Error + Send + Sync + 'static>` to allow for
arbitrary `Error` types from the non-erased trait variants. Note the
strict requirements match the pre-existing requirements around
`anyhow::Error`.
## Migration Guide
- `anyhow` is no longer exported by `bevy_asset`; Add it to your own
project (if required).
- `AssetLoader` and `AssetSaver` have an associated type `Error`; Define
an appropriate error type (e.g., using `thiserror`), or use a pre-made
error type (e.g., `anyhow::Error`). Note that using `anyhow::Error` is a
drop-in replacement.
- `AssetLoaderError` has been removed; Define a new error type, or use
an alternative (e.g., `anyhow::Error`)
- All the first-party `AssetLoader`'s and `AssetSaver`'s now return
relevant (and narrow) error types instead of a single ambiguous type;
Match over the specific error type, or encapsulate (`Box<dyn>`,
`thiserror`, `anyhow`, etc.)
## Notes
A simpler PR to resolve this issue would simply define a Bevy `Error`
type defined as `Box<dyn std::error::Error + Send + Sync + 'static>`,
but I think this type of error handling should be discouraged when
possible. Since only 2 traits required the use of `anyhow`, it isn't a
substantive body of work to solidify these error types, and remove
`anyhow` entirely. End users are still encouraged to use `anyhow` if
that is their preferred error handling style. Arguably, adding the
`Error` associated type gives more freedom to end-users to decide
whether they want more or less explicit error handling (`anyhow` vs
`thiserror`).
As an aside, I didn't perform any testing on Android or WASM. CI passed
locally, but there may be mistakes for those platforms I missed.
# Objective
Avert a panic when removing resources from Scenes.
### Reproduction Steps
```rust
let mut scene = Scene::new(World::default());
scene.world.init_resource::<Time>();
scene.world.remove_resource::<Time>();
scene.clone_with(&app.resource::<AppTypeRegistry>());
```
### Panic Message
```
thread 'Compute Task Pool (10)' panicked at 'Requested resource bevy_time::time::Time does not exist in the `World`.
Did you forget to add it using `app.insert_resource` / `app.init_resource`?
Resources are also implicitly added via `app.add_event`,
and can be added by plugins.', .../bevy/crates/bevy_ecs/src/reflect/resource.rs:203:52
```
## Solution
Check that the resource actually still exists before copying.
---
## Changelog
- resolved a panic caused by removing resources from scenes
# Objective
Finish documenting `bevy_scene`.
## Solution
Document the remaining items and add a crate-level `warn(missing_doc)`
attribute as for the other crates with completed documentation.
# Bevy Asset V2 Proposal
## Why Does Bevy Need A New Asset System?
Asset pipelines are a central part of the gamedev process. Bevy's
current asset system is missing a number of features that make it
non-viable for many classes of gamedev. After plenty of discussions and
[a long community feedback
period](https://github.com/bevyengine/bevy/discussions/3972), we've
identified a number missing features:
* **Asset Preprocessing**: it should be possible to "preprocess" /
"compile" / "crunch" assets at "development time" rather than when the
game starts up. This enables offloading expensive work from deployed
apps, faster asset loading, less runtime memory usage, etc.
* **Per-Asset Loader Settings**: Individual assets cannot define their
own loaders that override the defaults. Additionally, they cannot
provide per-asset settings to their loaders. This is a huge limitation,
as many asset types don't provide all information necessary for Bevy
_inside_ the asset. For example, a raw PNG image says nothing about how
it should be sampled (ex: linear vs nearest).
* **Asset `.meta` files**: assets should have configuration files stored
adjacent to the asset in question, which allows the user to configure
asset-type-specific settings. These settings should be accessible during
the pre-processing phase. Modifying a `.meta` file should trigger a
re-processing / re-load of the asset. It should be possible to configure
asset loaders from the meta file.
* **Processed Asset Hot Reloading**: Changes to processed assets (or
their dependencies) should result in re-processing them and re-loading
the results in live Bevy Apps.
* **Asset Dependency Tracking**: The current bevy_asset has no good way
to wait for asset dependencies to load. It punts this as an exercise for
consumers of the loader apis, which is unreasonable and error prone.
There should be easy, ergonomic ways to wait for assets to load and
block some logic on an asset's entire dependency tree loading.
* **Runtime Asset Loading**: it should be (optionally) possible to load
arbitrary assets dynamically at runtime. This necessitates being able to
deploy and run the asset server alongside Bevy Apps on _all platforms_.
For example, we should be able to invoke the shader compiler at runtime,
stream scenes from sources like the internet, etc. To keep deployed
binaries (and startup times) small, the runtime asset server
configuration should be configurable with different settings compared to
the "pre processor asset server".
* **Multiple Backends**: It should be possible to load assets from
arbitrary sources (filesystems, the internet, remote asset serves, etc).
* **Asset Packing**: It should be possible to deploy assets in
compressed "packs", which makes it easier and more efficient to
distribute assets with Bevy Apps.
* **Asset Handoff**: It should be possible to hold a "live" asset
handle, which correlates to runtime data, without actually holding the
asset in memory. Ex: it must be possible to hold a reference to a GPU
mesh generated from a "mesh asset" without keeping the mesh data in CPU
memory
* **Per-Platform Processed Assets**: Different platforms and app
distributions have different capabilities and requirements. Some
platforms need lower asset resolutions or different asset formats to
operate within the hardware constraints of the platform. It should be
possible to define per-platform asset processing profiles. And it should
be possible to deploy only the assets required for a given platform.
These features have architectural implications that are significant
enough to require a full rewrite. The current Bevy Asset implementation
got us this far, but it can take us no farther. This PR defines a brand
new asset system that implements most of these features, while laying
the foundations for the remaining features to be built.
## Bevy Asset V2
Here is a quick overview of the features introduced in this PR.
* **Asset Preprocessing**: Preprocess assets at development time into
more efficient (and configurable) representations
* **Dependency Aware**: Dependencies required to process an asset are
tracked. If an asset's processed dependency changes, it will be
reprocessed
* **Hot Reprocessing/Reloading**: detect changes to asset source files,
reprocess them if they have changed, and then hot-reload them in Bevy
Apps.
* **Only Process Changes**: Assets are only re-processed when their
source file (or meta file) has changed. This uses hashing and timestamps
to avoid processing assets that haven't changed.
* **Transactional and Reliable**: Uses write-ahead logging (a technique
commonly used by databases) to recover from crashes / forced-exits.
Whenever possible it avoids full-reprocessing / only uncompleted
transactions will be reprocessed. When the processor is running in
parallel with a Bevy App, processor asset writes block Bevy App asset
reads. Reading metadata + asset bytes is guaranteed to be transactional
/ correctly paired.
* **Portable / Run anywhere / Database-free**: The processor does not
rely on an in-memory database (although it uses some database techniques
for reliability). This is important because pretty much all in-memory
databases have unsupported platforms or build complications.
* **Configure Processor Defaults Per File Type**: You can say "use this
processor for all files of this type".
* **Custom Processors**: The `Processor` trait is flexible and
unopinionated. It can be implemented by downstream plugins.
* **LoadAndSave Processors**: Most asset processing scenarios can be
expressed as "run AssetLoader A, save the results using AssetSaver X,
and then load the result using AssetLoader B". For example, load this
png image using `PngImageLoader`, which produces an `Image` asset and
then save it using `CompressedImageSaver` (which also produces an
`Image` asset, but in a compressed format), which takes an `Image` asset
as input. This means if you have an `AssetLoader` for an asset, you are
already half way there! It also means that you can share AssetSavers
across multiple loaders. Because `CompressedImageSaver` accepts Bevy's
generic Image asset as input, it means you can also use it with some
future `JpegImageLoader`.
* **Loader and Saver Settings**: Asset Loaders and Savers can now define
their own settings types, which are passed in as input when an asset is
loaded / saved. Each asset can define its own settings.
* **Asset `.meta` files**: configure asset loaders, their settings,
enable/disable processing, and configure processor settings
* **Runtime Asset Dependency Tracking** Runtime asset dependencies (ex:
if an asset contains a `Handle<Image>`) are tracked by the asset server.
An event is emitted when an asset and all of its dependencies have been
loaded
* **Unprocessed Asset Loading**: Assets do not require preprocessing.
They can be loaded directly. A processed asset is just a "normal" asset
with some extra metadata. Asset Loaders don't need to know or care about
whether or not an asset was processed.
* **Async Asset IO**: Asset readers/writers use async non-blocking
interfaces. Note that because Rust doesn't yet support async traits,
there is a bit of manual Boxing / Future boilerplate. This will
hopefully be removed in the near future when Rust gets async traits.
* **Pluggable Asset Readers and Writers**: Arbitrary asset source
readers/writers are supported, both by the processor and the asset
server.
* **Better Asset Handles**
* **Single Arc Tree**: Asset Handles now use a single arc tree that
represents the lifetime of the asset. This makes their implementation
simpler, more efficient, and allows us to cheaply attach metadata to
handles. Ex: the AssetPath of a handle is now directly accessible on the
handle itself!
* **Const Typed Handles**: typed handles can be constructed in a const
context. No more weird "const untyped converted to typed at runtime"
patterns!
* **Handles and Ids are Smaller / Faster To Hash / Compare**: Typed
`Handle<T>` is now much smaller in memory and `AssetId<T>` is even
smaller.
* **Weak Handle Usage Reduction**: In general Handles are now considered
to be "strong". Bevy features that previously used "weak `Handle<T>`"
have been ported to `AssetId<T>`, which makes it statically clear that
the features do not hold strong handles (while retaining strong type
information). Currently Handle::Weak still exists, but it is very
possible that we can remove that entirely.
* **Efficient / Dense Asset Ids**: Assets now have efficient dense
runtime asset ids, which means we can avoid expensive hash lookups.
Assets are stored in Vecs instead of HashMaps. There are now typed and
untyped ids, which means we no longer need to store dynamic type
information in the ID for typed handles. "AssetPathId" (which was a
nightmare from a performance and correctness standpoint) has been
entirely removed in favor of dense ids (which are retrieved for a path
on load)
* **Direct Asset Loading, with Dependency Tracking**: Assets that are
defined at runtime can still have their dependencies tracked by the
Asset Server (ex: if you create a material at runtime, you can still
wait for its textures to load). This is accomplished via the (currently
optional) "asset dependency visitor" trait. This system can also be used
to define a set of assets to load, then wait for those assets to load.
* **Async folder loading**: Folder loading also uses this system and
immediately returns a handle to the LoadedFolder asset, which means
folder loading no longer blocks on directory traversals.
* **Improved Loader Interface**: Loaders now have a specific "top level
asset type", which makes returning the top-level asset simpler and
statically typed.
* **Basic Image Settings and Processing**: Image assets can now be
processed into the gpu-friendly Basic Universal format. The ImageLoader
now has a setting to define what format the image should be loaded as.
Note that this is just a minimal MVP ... plenty of additional work to do
here. To demo this, enable the `basis-universal` feature and turn on
asset processing.
* **Simpler Audio Play / AudioSink API**: Asset handle providers are
cloneable, which means the Audio resource can mint its own handles. This
means you can now do `let sink_handle = audio.play(music)` instead of
`let sink_handle = audio_sinks.get_handle(audio.play(music))`. Note that
this might still be replaced by
https://github.com/bevyengine/bevy/pull/8424.
**Removed Handle Casting From Engine Features**: Ex: FontAtlases no
longer use casting between handle types
## Using The New Asset System
### Normal Unprocessed Asset Loading
By default the `AssetPlugin` does not use processing. It behaves pretty
much the same way as the old system.
If you are defining a custom asset, first derive `Asset`:
```rust
#[derive(Asset)]
struct Thing {
value: String,
}
```
Initialize the asset:
```rust
app.init_asset:<Thing>()
```
Implement a new `AssetLoader` for it:
```rust
#[derive(Default)]
struct ThingLoader;
#[derive(Serialize, Deserialize, Default)]
pub struct ThingSettings {
some_setting: bool,
}
impl AssetLoader for ThingLoader {
type Asset = Thing;
type Settings = ThingSettings;
fn load<'a>(
&'a self,
reader: &'a mut Reader,
settings: &'a ThingSettings,
load_context: &'a mut LoadContext,
) -> BoxedFuture<'a, Result<Thing, anyhow::Error>> {
Box::pin(async move {
let mut bytes = Vec::new();
reader.read_to_end(&mut bytes).await?;
// convert bytes to value somehow
Ok(Thing {
value
})
})
}
fn extensions(&self) -> &[&str] {
&["thing"]
}
}
```
Note that this interface will get much cleaner once Rust gets support
for async traits. `Reader` is an async futures_io::AsyncRead. You can
stream bytes as they come in or read them all into a `Vec<u8>`,
depending on the context. You can use `let handle =
load_context.load(path)` to kick off a dependency load, retrieve a
handle, and register the dependency for the asset.
Then just register the loader in your Bevy app:
```rust
app.init_asset_loader::<ThingLoader>()
```
Now just add your `Thing` asset files into the `assets` folder and load
them like this:
```rust
fn system(asset_server: Res<AssetServer>) {
let handle = Handle<Thing> = asset_server.load("cool.thing");
}
```
You can check load states directly via the asset server:
```rust
if asset_server.load_state(&handle) == LoadState::Loaded { }
```
You can also listen for events:
```rust
fn system(mut events: EventReader<AssetEvent<Thing>>, handle: Res<SomeThingHandle>) {
for event in events.iter() {
if event.is_loaded_with_dependencies(&handle) {
}
}
}
```
Note the new `AssetEvent::LoadedWithDependencies`, which only fires when
the asset is loaded _and_ all dependencies (and their dependencies) have
loaded.
Unlike the old asset system, for a given asset path all `Handle<T>`
values point to the same underlying Arc. This means Handles can cheaply
hold more asset information, such as the AssetPath:
```rust
// prints the AssetPath of the handle
info!("{:?}", handle.path())
```
### Processed Assets
Asset processing can be enabled via the `AssetPlugin`. When developing
Bevy Apps with processed assets, do this:
```rust
app.add_plugins(DefaultPlugins.set(AssetPlugin::processed_dev()))
```
This runs the `AssetProcessor` in the background with hot-reloading. It
reads assets from the `assets` folder, processes them, and writes them
to the `.imported_assets` folder. Asset loads in the Bevy App will wait
for a processed version of the asset to become available. If an asset in
the `assets` folder changes, it will be reprocessed and hot-reloaded in
the Bevy App.
When deploying processed Bevy apps, do this:
```rust
app.add_plugins(DefaultPlugins.set(AssetPlugin::processed()))
```
This does not run the `AssetProcessor` in the background. It behaves
like `AssetPlugin::unprocessed()`, but reads assets from
`.imported_assets`.
When the `AssetProcessor` is running, it will populate sibling `.meta`
files for assets in the `assets` folder. Meta files for assets that do
not have a processor configured look like this:
```rust
(
meta_format_version: "1.0",
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: FromExtension,
),
),
)
```
This is metadata for an image asset. For example, if you have
`assets/my_sprite.png`, this could be the metadata stored at
`assets/my_sprite.png.meta`. Meta files are totally optional. If no
metadata exists, the default settings will be used.
In short, this file says "load this asset with the ImageLoader and use
the file extension to determine the image type". This type of meta file
is supported in all AssetPlugin modes. If in `Unprocessed` mode, the
asset (with the meta settings) will be loaded directly. If in
`ProcessedDev` mode, the asset file will be copied directly to the
`.imported_assets` folder. The meta will also be copied directly to the
`.imported_assets` folder, but with one addition:
```rust
(
meta_format_version: "1.0",
processed_info: Some((
hash: 12415480888597742505,
full_hash: 14344495437905856884,
process_dependencies: [],
)),
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: FromExtension,
),
),
)
```
`processed_info` contains `hash` (a direct hash of the asset and meta
bytes), `full_hash` (a hash of `hash` and the hashes of all
`process_dependencies`), and `process_dependencies` (the `path` and
`full_hash` of every process_dependency). A "process dependency" is an
asset dependency that is _directly_ used when processing the asset.
Images do not have process dependencies, so this is empty.
When the processor is enabled, you can use the `Process` metadata
config:
```rust
(
meta_format_version: "1.0",
asset: Process(
processor: "bevy_asset::processor::process::LoadAndSave<bevy_render::texture::image_loader::ImageLoader, bevy_render::texture::compressed_image_saver::CompressedImageSaver>",
settings: (
loader_settings: (
format: FromExtension,
),
saver_settings: (
generate_mipmaps: true,
),
),
),
)
```
This configures the asset to use the `LoadAndSave` processor, which runs
an AssetLoader and feeds the result into an AssetSaver (which saves the
given Asset and defines a loader to load it with). (for terseness
LoadAndSave will likely get a shorter/friendlier type name when [Stable
Type Paths](#7184) lands). `LoadAndSave` is likely to be the most common
processor type, but arbitrary processors are supported.
`CompressedImageSaver` saves an `Image` in the Basis Universal format
and configures the ImageLoader to load it as basis universal. The
`AssetProcessor` will read this meta, run it through the LoadAndSave
processor, and write the basis-universal version of the image to
`.imported_assets`. The final metadata will look like this:
```rust
(
meta_format_version: "1.0",
processed_info: Some((
hash: 905599590923828066,
full_hash: 9948823010183819117,
process_dependencies: [],
)),
asset: Load(
loader: "bevy_render::texture::image_loader::ImageLoader",
settings: (
format: Format(Basis),
),
),
)
```
To try basis-universal processing out in Bevy examples, (for example
`sprite.rs`), change `add_plugins(DefaultPlugins)` to
`add_plugins(DefaultPlugins.set(AssetPlugin::processed_dev()))` and run
with the `basis-universal` feature enabled: `cargo run
--features=basis-universal --example sprite`.
To create a custom processor, there are two main paths:
1. Use the `LoadAndSave` processor with an existing `AssetLoader`.
Implement the `AssetSaver` trait, register the processor using
`asset_processor.register_processor::<LoadAndSave<ImageLoader,
CompressedImageSaver>>(image_saver.into())`.
2. Implement the `Process` trait directly and register it using:
`asset_processor.register_processor(thing_processor)`.
You can configure default processors for file extensions like this:
```rust
asset_processor.set_default_processor::<ThingProcessor>("thing")
```
There is one more metadata type to be aware of:
```rust
(
meta_format_version: "1.0",
asset: Ignore,
)
```
This will ignore the asset during processing / prevent it from being
written to `.imported_assets`.
The AssetProcessor stores a transaction log at `.imported_assets/log`
and uses it to gracefully recover from unexpected stops. This means you
can force-quit the processor (and Bevy Apps running the processor in
parallel) at arbitrary times!
`.imported_assets` is "local state". It should _not_ be checked into
source control. It should also be considered "read only". In practice,
you _can_ modify processed assets and processed metadata if you really
need to test something. But those modifications will not be represented
in the hashes of the assets, so the processed state will be "out of
sync" with the source assets. The processor _will not_ fix this for you.
Either revert the change after you have tested it, or delete the
processed files so they can be re-populated.
## Open Questions
There are a number of open questions to be discussed. We should decide
if they need to be addressed in this PR and if so, how we will address
them:
### Implied Dependencies vs Dependency Enumeration
There are currently two ways to populate asset dependencies:
* **Implied via AssetLoaders**: if an AssetLoader loads an asset (and
retrieves a handle), a dependency is added to the list.
* **Explicit via the optional Asset::visit_dependencies**: if
`server.load_asset(my_asset)` is called, it will call
`my_asset.visit_dependencies`, which will grab dependencies that have
been manually defined for the asset via the Asset trait impl (which can
be derived).
This means that defining explicit dependencies is optional for "loaded
assets". And the list of dependencies is always accurate because loaders
can only produce Handles if they register dependencies. If an asset was
loaded with an AssetLoader, it only uses the implied dependencies. If an
asset was created at runtime and added with
`asset_server.load_asset(MyAsset)`, it will use
`Asset::visit_dependencies`.
However this can create a behavior mismatch between loaded assets and
equivalent "created at runtime" assets if `Assets::visit_dependencies`
doesn't exactly match the dependencies produced by the AssetLoader. This
behavior mismatch can be resolved by completely removing "implied loader
dependencies" and requiring `Asset::visit_dependencies` to supply
dependency data. But this creates two problems:
* It makes defining loaded assets harder and more error prone: Devs must
remember to manually annotate asset dependencies with `#[dependency]`
when deriving `Asset`. For more complicated assets (such as scenes), the
derive likely wouldn't be sufficient and a manual `visit_dependencies`
impl would be required.
* Removes the ability to immediately kick off dependency loads: When
AssetLoaders retrieve a Handle, they also immediately kick off an asset
load for the handle, which means it can start loading in parallel
_before_ the asset finishes loading. For large assets, this could be
significant. (although this could be mitigated for processed assets if
we store dependencies in the processed meta file and load them ahead of
time)
### Eager ProcessorDev Asset Loading
I made a controversial call in the interest of fast startup times ("time
to first pixel") for the "processor dev mode configuration". When
initializing the AssetProcessor, current processed versions of unchanged
assets are yielded immediately, even if their dependencies haven't been
checked yet for reprocessing. This means that
non-current-state-of-filesystem-but-previously-valid assets might be
returned to the App first, then hot-reloaded if/when their dependencies
change and the asset is reprocessed.
Is this behavior desirable? There is largely one alternative: do not
yield an asset from the processor to the app until all of its
dependencies have been checked for changes. In some common cases (load
dependency has not changed since last run) this will increase startup
time. The main question is "by how much" and is that slower startup time
worth it in the interest of only yielding assets that are true to the
current state of the filesystem. Should this be configurable? I'm
starting to think we should only yield an asset after its (historical)
dependencies have been checked for changes + processed as necessary, but
I'm curious what you all think.
### Paths Are Currently The Only Canonical ID / Do We Want Asset UUIDs?
In this implementation AssetPaths are the only canonical asset
identifier (just like the previous Bevy Asset system and Godot). Moving
assets will result in re-scans (and currently reprocessing, although
reprocessing can easily be avoided with some changes). Asset
renames/moves will break code and assets that rely on specific paths,
unless those paths are fixed up.
Do we want / need "stable asset uuids"? Introducing them is very
possible:
1. Generate a UUID and include it in .meta files
2. Support UUID in AssetPath
3. Generate "asset indices" which are loaded on startup and map UUIDs to
paths.
4 (maybe). Consider only supporting UUIDs for processed assets so we can
generate quick-to-load indices instead of scanning meta files.
The main "pro" is that assets referencing UUIDs don't need to be
migrated when a path changes. The main "con" is that UUIDs cannot be
"lazily resolved" like paths. They need a full view of all assets to
answer the question "does this UUID exist". Which means UUIDs require
the AssetProcessor to fully finish startup scans before saying an asset
doesnt exist. And they essentially require asset pre-processing to use
in apps, because scanning all asset metadata files at runtime to resolve
a UUID is not viable for medium-to-large apps. It really requires a
pre-generated UUID index, which must be loaded before querying for
assets.
I personally think this should be investigated in a separate PR. Paths
aren't going anywhere ... _everyone_ uses filesystems (and
filesystem-like apis) to manage their asset source files. I consider
them permanent canonical asset information. Additionally, they behave
well for both processed and unprocessed asset modes. Given that Bevy is
supporting both, this feels like the right canonical ID to start with.
UUIDS (and maybe even other indexed-identifier types) can be added later
as necessary.
### Folder / File Naming Conventions
All asset processing config currently lives in the `.imported_assets`
folder. The processor transaction log is in `.imported_assets/log`.
Processed assets are added to `.imported_assets/Default`, which will
make migrating to processed asset profiles (ex: a
`.imported_assets/Mobile` profile) a non-breaking change. It also allows
us to create top-level files like `.imported_assets/log` without it
being interpreted as an asset. Meta files currently have a `.meta`
suffix. Do we like these names and conventions?
### Should the `AssetPlugin::processed_dev` configuration enable
`watch_for_changes` automatically?
Currently it does (which I think makes sense), but it does make it the
only configuration that enables watch_for_changes by default.
### Discuss on_loaded High Level Interface:
This PR includes a very rough "proof of concept" `on_loaded` system
adapter that uses the `LoadedWithDependencies` event in combination with
`asset_server.load_asset` dependency tracking to support this pattern
```rust
fn main() {
App::new()
.init_asset::<MyAssets>()
.add_systems(Update, on_loaded(create_array_texture))
.run();
}
#[derive(Asset, Clone)]
struct MyAssets {
#[dependency]
picture_of_my_cat: Handle<Image>,
#[dependency]
picture_of_my_other_cat: Handle<Image>,
}
impl FromWorld for ArrayTexture {
fn from_world(world: &mut World) -> Self {
picture_of_my_cat: server.load("meow.png"),
picture_of_my_other_cat: server.load("meeeeeeeow.png"),
}
}
fn spawn_cat(In(my_assets): In<MyAssets>, mut commands: Commands) {
commands.spawn(SpriteBundle {
texture: my_assets.picture_of_my_cat.clone(),
..default()
});
commands.spawn(SpriteBundle {
texture: my_assets.picture_of_my_other_cat.clone(),
..default()
});
}
```
The implementation is _very_ rough. And it is currently unsafe because
`bevy_ecs` doesn't expose some internals to do this safely from inside
`bevy_asset`. There are plenty of unanswered questions like:
* "do we add a Loadable" derive? (effectively automate the FromWorld
implementation above)
* Should `MyAssets` even be an Asset? (largely implemented this way
because it elegantly builds on `server.load_asset(MyAsset { .. })`
dependency tracking).
We should think hard about what our ideal API looks like (and if this is
a pattern we want to support). Not necessarily something we need to
solve in this PR. The current `on_loaded` impl should probably be
removed from this PR before merging.
## Clarifying Questions
### What about Assets as Entities?
This Bevy Asset V2 proposal implementation initially stored Assets as
ECS Entities. Instead of `AssetId<T>` + the `Assets<T>` resource it used
`Entity` as the asset id and Asset values were just ECS components.
There are plenty of compelling reasons to do this:
1. Easier to inline assets in Bevy Scenes (as they are "just" normal
entities + components)
2. More flexible queries: use the power of the ECS to filter assets (ex:
`Query<Mesh, With<Tree>>`).
3. Extensible. Users can add arbitrary component data to assets.
4. Things like "component visualization tools" work out of the box to
visualize asset data.
However Assets as Entities has a ton of caveats right now:
* We need to be able to allocate entity ids without a direct World
reference (aka rework id allocator in Entities ... i worked around this
in my prototypes by just pre allocating big chunks of entities)
* We want asset change events in addition to ECS change tracking ... how
do we populate them when mutations can come from anywhere? Do we use
Changed queries? This would require iterating over the change data for
all assets every frame. Is this acceptable or should we implement a new
"event based" component change detection option?
* Reconciling manually created assets with asset-system managed assets
has some nuance (ex: are they "loaded" / do they also have that
component metadata?)
* "how do we handle "static" / default entity handles" (ties in to the
Entity Indices discussion:
https://github.com/bevyengine/bevy/discussions/8319). This is necessary
for things like "built in" assets and default handles in things like
SpriteBundle.
* Storing asset information as a component makes it easy to "invalidate"
asset state by removing the component (or forcing modifications).
Ideally we have ways to lock this down (some combination of Rust type
privacy and ECS validation)
In practice, how we store and identify assets is a reasonably
superficial change (porting off of Assets as Entities and implementing
dedicated storage + ids took less than a day). So once we sort out the
remaining challenges the flip should be straightforward. Additionally, I
do still have "Assets as Entities" in my commit history, so we can reuse
that work. I personally think "assets as entities" is a good endgame,
but it also doesn't provide _significant_ value at the moment and it
certainly isn't ready yet with the current state of things.
### Why not Distill?
[Distill](https://github.com/amethyst/distill) is a high quality fully
featured asset system built in Rust. It is very natural to ask "why not
just use Distill?".
It is also worth calling out that for awhile, [we planned on adopting
Distill / I signed off on
it](https://github.com/bevyengine/bevy/issues/708).
However I think Bevy has a number of constraints that make Distill
adoption suboptimal:
* **Architectural Simplicity:**
* Distill's processor requires an in-memory database (lmdb) and RPC
networked API (using Cap'n Proto). Each of these introduces API
complexity that increases maintenance burden and "code grokability".
Ignoring tests, documentation, and examples, Distill has 24,237 lines of
Rust code (including generated code for RPC + database interactions). If
you ignore generated code, it has 11,499 lines.
* Bevy builds the AssetProcessor and AssetServer using pluggable
AssetReader/AssetWriter Rust traits with simple io interfaces. They do
not necessitate databases or RPC interfaces (although Readers/Writers
could use them if that is desired). Bevy Asset V2 (at the time of
writing this PR) is 5,384 lines of Rust code (ignoring tests,
documentation, and examples). Grain of salt: Distill does have more
features currently (ex: Asset Packing, GUIDS, remote-out-of-process
asset processor). I do plan to implement these features in Bevy Asset V2
and I personally highly doubt they will meaningfully close the 6115
lines-of-code gap.
* This complexity gap (which while illustrated by lines of code, is much
bigger than just that) is noteworthy to me. Bevy should be hackable and
there are pillars of Distill that are very hard to understand and
extend. This is a matter of opinion (and Bevy Asset V2 also has
complicated areas), but I think Bevy Asset V2 is much more approachable
for the average developer.
* Necessary disclaimer: counting lines of code is an extremely rough
complexity metric. Read the code and form your own opinions.
* **Optional Asset Processing:** Not all Bevy Apps (or Bevy App
developers) need / want asset preprocessing. Processing increases the
complexity of the development environment by introducing things like
meta files, imported asset storage, running processors in the
background, waiting for processing to finish, etc. Distill _requires_
preprocessing to work. With Bevy Asset V2 processing is fully opt-in.
The AssetServer isn't directly aware of asset processors at all.
AssetLoaders only care about converting bytes to runtime Assets ... they
don't know or care if the bytes were pre-processed or not. Processing is
"elegantly" (forgive my self-congratulatory phrasing) layered on top and
builds on the existing Asset system primitives.
* **Direct Filesystem Access to Processed Asset State:** Distill stores
processed assets in a database. This makes debugging / inspecting the
processed outputs harder (either requires special tooling to query the
database or they need to be "deployed" to be inspected). Bevy Asset V2,
on the other hand, stores processed assets in the filesystem (by default
... this is configurable). This makes interacting with the processed
state more natural. Note that both Godot and Unity's new asset system
store processed assets in the filesystem.
* **Portability**: Because Distill's processor uses lmdb and RPC
networking, it cannot be run on certain platforms (ex: lmdb is a
non-rust dependency that cannot run on the web, some platforms don't
support running network servers). Bevy should be able to process assets
everywhere (ex: run the Bevy Editor on the web, compile + process
shaders on mobile, etc). Distill does partially mitigate this problem by
supporting "streaming" assets via the RPC protocol, but this is not a
full solve from my perspective. And Bevy Asset V2 can (in theory) also
stream assets (without requiring RPC, although this isn't implemented
yet)
Note that I _do_ still think Distill would be a solid asset system for
Bevy. But I think the approach in this PR is a better solve for Bevy's
specific "asset system requirements".
### Doesn't async-fs just shim requests to "sync" `std::fs`? What is the
point?
"True async file io" has limited / spotty platform support. async-fs
(and the rust async ecosystem generally ... ex Tokio) currently use
async wrappers over std::fs that offload blocking requests to separate
threads. This may feel unsatisfying, but it _does_ still provide value
because it prevents our task pools from blocking on file system
operations (which would prevent progress when there are many tasks to
do, but all threads in a pool are currently blocking on file system
ops).
Additionally, using async APIs for our AssetReaders and AssetWriters
also provides value because we can later add support for "true async
file io" for platforms that support it. _And_ we can implement other
"true async io" asset backends (such as networked asset io).
## Draft TODO
- [x] Fill in missing filesystem event APIs: file removed event (which
is expressed as dangling RenameFrom events in some cases), file/folder
renamed event
- [x] Assets without loaders are not moved to the processed folder. This
breaks things like referenced `.bin` files for GLTFs. This should be
configurable per-non-asset-type.
- [x] Initial implementation of Reflect and FromReflect for Handle. The
"deserialization" parity bar is low here as this only worked with static
UUIDs in the old impl ... this is a non-trivial problem. Either we add a
Handle::AssetPath variant that gets "upgraded" to a strong handle on
scene load or we use a separate AssetRef type for Bevy scenes (which is
converted to a runtime Handle on load). This deserves its own discussion
in a different pr.
- [x] Populate read_asset_bytes hash when run by the processor (a bit of
a special case .. when run by the processor the processed meta will
contain the hash so we don't need to compute it on the spot, but we
don't want/need to read the meta when run by the main AssetServer)
- [x] Delay hot reloading: currently filesystem events are handled
immediately, which creates timing issues in some cases. For example hot
reloading images can sometimes break because the image isn't finished
writing. We should add a delay, likely similar to the [implementation in
this PR](https://github.com/bevyengine/bevy/pull/8503).
- [x] Port old platform-specific AssetIo implementations to the new
AssetReader interface (currently missing Android and web)
- [x] Resolve on_loaded unsafety (either by removing the API entirely or
removing the unsafe)
- [x] Runtime loader setting overrides
- [x] Remove remaining unwraps that should be error-handled. There are
number of TODOs here
- [x] Pretty AssetPath Display impl
- [x] Document more APIs
- [x] Resolve spurious "reloading because it has changed" events (to
repro run load_gltf with `processed_dev()`)
- [x] load_dependency hot reloading currently only works for processed
assets. If processing is disabled, load_dependency changes are not hot
reloaded.
- [x] Replace AssetInfo dependency load/fail counters with
`loading_dependencies: HashSet<UntypedAssetId>` to prevent reloads from
(potentially) breaking counters. Storing this will also enable
"dependency reloaded" events (see [Next Steps](#next-steps))
- [x] Re-add filesystem watcher cargo feature gate (currently it is not
optional)
- [ ] Migration Guide
- [ ] Changelog
## Followup TODO
- [ ] Replace "eager unchanged processed asset loading" behavior with
"don't returned unchanged processed asset until dependencies have been
checked".
- [ ] Add true `Ignore` AssetAction that does not copy the asset to the
imported_assets folder.
- [ ] Finish "live asset unloading" (ex: free up CPU asset memory after
uploading an image to the GPU), rethink RenderAssets, and port renderer
features. The `Assets` collection uses `Option<T>` for asset storage to
support its removal. (1) the Option might not actually be necessary ...
might be able to just remove from the collection entirely (2) need to
finalize removal apis
- [ ] Try replacing the "channel based" asset id recycling with
something a bit more efficient (ex: we might be able to use raw atomic
ints with some cleverness)
- [ ] Consider adding UUIDs to processed assets (scoped just to helping
identify moved assets ... not exposed to load queries ... see [Next
Steps](#next-steps))
- [ ] Store "last modified" source asset and meta timestamps in
processed meta files to enable skipping expensive hashing when the file
wasn't changed
- [ ] Fix "slow loop" handle drop fix
- [ ] Migrate to TypeName
- [x] Handle "loader preregistration". See #9429
## Next Steps
* **Configurable per-type defaults for AssetMeta**: It should be
possible to add configuration like "all png image meta should default to
using nearest sampling" (currently this hard-coded per-loader/processor
Settings::default() impls). Also see the "Folder Meta" bullet point.
* **Avoid Reprocessing on Asset Renames / Moves**: See the "canonical
asset ids" discussion in [Open Questions](#open-questions) and the
relevant bullet point in [Draft TODO](#draft-todo). Even without
canonical ids, folder renames could avoid reprocessing in some cases.
* **Multiple Asset Sources**: Expand AssetPath to support "asset source
names" and support multiple AssetReaders in the asset server (ex:
`webserver://some_path/image.png` backed by an Http webserver
AssetReader). The "default" asset reader would use normal
`some_path/image.png` paths. Ideally this works in combination with
multiple AssetWatchers for hot-reloading
* **Stable Type Names**: this pr removes the TypeUuid requirement from
assets in favor of `std::any::type_name`. This makes defining assets
easier (no need to generate a new uuid / use weird proc macro syntax).
It also makes reading meta files easier (because things have "friendly
names"). We also use type names for components in scene files. If they
are good enough for components, they are good enough for assets. And
consistency across Bevy pillars is desirable. However,
`std::any::type_name` is not guaranteed to be stable (although in
practice it is). We've developed a [stable type
path](https://github.com/bevyengine/bevy/pull/7184) to resolve this,
which should be adopted when it is ready.
* **Command Line Interface**: It should be possible to run the asset
processor in a separate process from the command line. This will also
require building a network-server-backed AssetReader to communicate
between the app and the processor. We've been planning to build a "bevy
cli" for awhile. This seems like a good excuse to build it.
* **Asset Packing**: This is largely an additive feature, so it made
sense to me to punt this until we've laid the foundations in this PR.
* **Per-Platform Processed Assets**: It should be possible to generate
assets for multiple platforms by supporting multiple "processor
profiles" per asset (ex: compress with format X on PC and Y on iOS). I
think there should probably be arbitrary "profiles" (which can be
separate from actual platforms), which are then assigned to a given
platform when generating the final asset distribution for that platform.
Ex: maybe devs want a "Mobile" profile that is shared between iOS and
Android. Or a "LowEnd" profile shared between web and mobile.
* **Versioning and Migrations**: Assets, Loaders, Savers, and Processors
need to have versions to determine if their schema is valid. If an asset
/ loader version is incompatible with the current version expected at
runtime, the processor should be able to migrate them. I think we should
try using Bevy Reflect for this, as it would allow us to load the old
version as a dynamic Reflect type without actually having the old Rust
type. It would also allow us to define "patches" to migrate between
versions (Bevy Reflect devs are currently working on patching). The
`.meta` file already has its own format version. Migrating that to new
versions should also be possible.
* **Real Copy-on-write AssetPaths**: Rust's actual Cow (clone-on-write
type) currently used by AssetPath can still result in String clones that
aren't actually necessary (cloning an Owned Cow clones the contents).
Bevy's asset system requires cloning AssetPaths in a number of places,
which result in actual clones of the internal Strings. This is not
efficient. AssetPath internals should be reworked to exhibit truer
cow-like-behavior that reduces String clones to the absolute minimum.
* **Consider processor-less processing**: In theory the AssetServer
could run processors "inline" even if the background AssetProcessor is
disabled. If we decide this is actually desirable, we could add this.
But I don't think its a priority in the short or medium term.
* **Pre-emptive dependency loading**: We could encode dependencies in
processed meta files, which could then be used by the Asset Server to
kick of dependency loads as early as possible (prior to starting the
actual asset load). Is this desirable? How much time would this save in
practice?
* **Optimize Processor With UntypedAssetIds**: The processor exclusively
uses AssetPath to identify assets currently. It might be possible to
swap these out for UntypedAssetIds in some places, which are smaller /
cheaper to hash and compare.
* **One to Many Asset Processing**: An asset source file that produces
many assets currently must be processed into a single "processed" asset
source. If labeled assets can be written separately they can each have
their own configured savers _and_ they could be loaded more granularly.
Definitely worth exploring!
* **Automatically Track "Runtime-only" Asset Dependencies**: Right now,
tracking "created at runtime" asset dependencies requires adding them
via `asset_server.load_asset(StandardMaterial::default())`. I think with
some cleverness we could also do this for
`materials.add(StandardMaterial::default())`, making tracking work
"everywhere". There are challenges here relating to change detection /
ensuring the server is made aware of dependency changes. This could be
expensive in some cases.
* **"Dependency Changed" events**: Some assets have runtime artifacts
that need to be re-generated when one of their dependencies change (ex:
regenerate a material's bind group when a Texture needs to change). We
are generating the dependency graph so we can definitely produce these
events. Buuuuut generating these events will have a cost / they could be
high frequency for some assets, so we might want this to be opt-in for
specific cases.
* **Investigate Storing More Information In Handles**: Handles can now
store arbitrary information, which makes it cheaper and easier to
access. How much should we move into them? Canonical asset load states
(via atomics)? (`handle.is_loaded()` would be very cool). Should we
store the entire asset and remove the `Assets<T>` collection?
(`Arc<RwLock<Option<Image>>>`?)
* **Support processing and loading files without extensions**: This is a
pretty arbitrary restriction and could be supported with very minimal
changes.
* **Folder Meta**: It would be nice if we could define per folder
processor configuration defaults (likely in a `.meta` or `.folder_meta`
file). Things like "default to linear filtering for all Images in this
folder".
* **Replace async_broadcast with event-listener?** This might be
approximately drop-in for some uses and it feels more light weight
* **Support Running the AssetProcessor on the Web**: Most of the hard
work is done here, but there are some easy straggling TODOs (make the
transaction log an interface instead of a direct file writer so we can
write a web storage backend, implement an AssetReader/AssetWriter that
reads/writes to something like LocalStorage).
* **Consider identifying and preventing circular dependencies**: This is
especially important for "processor dependencies", as processing will
silently never finish in these cases.
* **Built-in/Inlined Asset Hot Reloading**: This PR regresses
"built-in/inlined" asset hot reloading (previously provided by the
DebugAssetServer). I'm intentionally punting this because I think it can
be cleanly implemented with "multiple asset sources" by registering a
"debug asset source" (ex: `debug://bevy_pbr/src/render/pbr.wgsl` asset
paths) in combination with an AssetWatcher for that asset source and
support for "manually loading pats with asset bytes instead of
AssetReaders". The old DebugAssetServer was quite nasty and I'd love to
avoid that hackery going forward.
* **Investigate ways to remove double-parsing meta files**: Parsing meta
files currently involves parsing once with "minimal" versions of the
meta file to extract the type name of the loader/processor config, then
parsing again to parse the "full" meta. This is suboptimal. We should be
able to define custom deserializers that (1) assume the loader/processor
type name comes first (2) dynamically looks up the loader/processor
registrations to deserialize settings in-line (similar to components in
the bevy scene format). Another alternative: deserialize as dynamic
Reflect objects and then convert.
* **More runtime loading configuration**: Support using the Handle type
as a hint to select an asset loader (instead of relying on AssetPath
extensions)
* **More high level Processor trait implementations**: For example, it
might be worth adding support for arbitrary chains of "asset transforms"
that modify an in-memory asset representation between loading and
saving. (ex: load a Mesh, run a `subdivide_mesh` transform, followed by
a `flip_normals` transform, then save the mesh to an efficient
compressed format).
* **Bevy Scene Handle Deserialization**: (see the relevant [Draft TODO
item](#draft-todo) for context)
* **Explore High Level Load Interfaces**: See [this
discussion](#discuss-on_loaded-high-level-interface) for one prototype.
* **Asset Streaming**: It would be great if we could stream Assets (ex:
stream a long video file piece by piece)
* **ID Exchanging**: In this PR Asset Handles/AssetIds are bigger than
they need to be because they have a Uuid enum variant. If we implement
an "id exchanging" system that trades Uuids for "efficient runtime ids",
we can cut down on the size of AssetIds, making them more efficient.
This has some open design questions, such as how to spawn entities with
"default" handle values (as these wouldn't have access to the exchange
api in the current system).
* **Asset Path Fixup Tooling**: Assets that inline asset paths inside
them will break when an asset moves. The asset system provides the
functionality to detect when paths break. We should build a framework
that enables formats to define "path migrations". This is especially
important for scene files. For editor-generated files, we should also
consider using UUIDs (see other bullet point) to avoid the need to
migrate in these cases.
---------
Co-authored-by: BeastLe9enD <beastle9end@outlook.de>
Co-authored-by: Mike <mike.hsu@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Fix#8267.
Fixes half of #7840.
The `ComputedVisibility` component contains two flags: hierarchy
visibility, and view visibility (whether its visible to any cameras).
Due to the modular and open-ended way that view visibility is computed,
it triggers change detection every single frame, even when the value
does not change. Since hierarchy visibility is stored in the same
component as view visibility, this means that change detection for
inherited visibility is completely broken.
At the company I work for, this has become a real issue. We are using
change detection to only re-render scenes when necessary. The broken
state of change detection for computed visibility means that we have to
to rely on the non-inherited `Visibility` component for now. This is
workable in the early stages of our project, but since we will
inevitably want to use the hierarchy, we will have to either:
1. Roll our own solution for computed visibility.
2. Fix the issue for everyone.
## Solution
Split the `ComputedVisibility` component into two: `InheritedVisibilty`
and `ViewVisibility`.
This allows change detection to behave properly for
`InheritedVisibility`.
View visiblity is still erratic, although it is less useful to be able
to detect changes
for this flavor of visibility.
Overall, this actually simplifies the API. Since the visibility system
consists of
self-explaining components, it is much easier to document the behavior
and usage.
This approach is more modular and "ECS-like" -- one could
strip out the `ViewVisibility` component entirely if it's not needed,
and rely only on inherited visibility.
---
## Changelog
- `ComputedVisibility` has been removed in favor of:
`InheritedVisibility` and `ViewVisiblity`.
## Migration Guide
The `ComputedVisibilty` component has been split into
`InheritedVisiblity` and
`ViewVisibility`. Replace any usages of
`ComputedVisibility::is_visible_in_hierarchy`
with `InheritedVisibility::get`, and replace
`ComputedVisibility::is_visible_in_view`
with `ViewVisibility::get`.
```rust
// Before:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
computed_visibility: ComputedVisibility::default(),
});
// After:
commands.spawn(VisibilityBundle {
visibility: Visibility::Inherited,
inherited_visibility: InheritedVisibility::default(),
view_visibility: ViewVisibility::default(),
});
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_hierarchy() {
// After:
fn my_system(q: Query<&InheritedVisibility>) {
for inherited_visibility in &q {
if inherited_visibility.get() {
```
```rust
// Before:
fn my_system(q: Query<&ComputedVisibilty>) {
for vis in &q {
if vis.is_visible_in_view() {
// After:
fn my_system(q: Query<&ViewVisibility>) {
for view_visibility in &q {
if view_visibility.get() {
```
```rust
// Before:
fn my_system(mut q: Query<&mut ComputedVisibilty>) {
for vis in &mut q {
vis.set_visible_in_view();
// After:
fn my_system(mut q: Query<&mut ViewVisibility>) {
for view_visibility in &mut q {
view_visibility.set();
```
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
- The current `EventReader::iter` has been determined to cause confusion
among new Bevy users. It was suggested by @JoJoJet to rename the method
to better clarify its usage.
- Solves #9624
## Solution
- Rename `EventReader::iter` to `EventReader::read`.
- Rename `EventReader::iter_with_id` to `EventReader::read_with_id`.
- Rename `ManualEventReader::iter` to `ManualEventReader::read`.
- Rename `ManualEventReader::iter_with_id` to
`ManualEventReader::read_with_id`.
---
## Changelog
- `EventReader::iter` has been renamed to `EventReader::read`.
- `EventReader::iter_with_id` has been renamed to
`EventReader::read_with_id`.
- `ManualEventReader::iter` has been renamed to
`ManualEventReader::read`.
- `ManualEventReader::iter_with_id` has been renamed to
`ManualEventReader::read_with_id`.
- Deprecated `EventReader::iter`
- Deprecated `EventReader::iter_with_id`
- Deprecated `ManualEventReader::iter`
- Deprecated `ManualEventReader::iter_with_id`
## Migration Guide
- Existing usages of `EventReader::iter` and `EventReader::iter_with_id`
will have to be changed to `EventReader::read` and
`EventReader::read_with_id` respectively.
- Existing usages of `ManualEventReader::iter` and
`ManualEventReader::iter_with_id` will have to be changed to
`ManualEventReader::read` and `ManualEventReader::read_with_id`
respectively.
# Objective
- Fixes#9321
## Solution
- `EntityMap` has been replaced by a simple `HashMap<Entity, Entity>`.
---
## Changelog
- `EntityMap::world_scope` has been replaced with `World::world_scope`
to avoid creating a new trait. This is a public facing change to the
call semantics, but has no effect on results or behaviour.
- `EntityMap`, as a `HashMap`, now operates on `&Entity` rather than
`Entity`. This changes many standard access functions (e.g, `.get`) in a
public-facing way.
## Migration Guide
- Calls to `EntityMap::world_scope` can be directly replaced with the
following:
`map.world_scope(&mut world)` -> `world.world_scope(&mut map)`
- Calls to legacy `EntityMap` methods such as `EntityMap::get` must
explicitly include de/reference symbols:
`let entity = map.get(parent);` -> `let &entity = map.get(&parent);`
# Objective
Closes#9115, replaces #9117.
## Solution
Emit event when scene is ready.
---
## Changelog
### Added
- `SceneInstanceReady` event when scene becomes ready.
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/9250
## Changelog
- Move scene spawner systems to a new SpawnScene schedule which is after
Update and before PostUpdate (schedule order:
[PreUpdate][Update][SpawnScene][PostUpdate])
## Migration Guide
- Move scene spawner systems to a new SpawnScene schedule which is after
Update and before PostUpdate (schedule order:
[PreUpdate][Update][SpawnScene][PostUpdate]), you might remove system
ordering code related to scene spawning as the execution order has been
guaranteed by bevy engine.
---------
Co-authored-by: Hennadii Chernyshchyk <genaloner@gmail.com>
# Objective
Currently, `DynamicScene`s extract all components listed in the given
(or the world's) type registry. This acts as a quasi-filter of sorts.
However, it can be troublesome to use effectively and lacks decent
control.
For example, say you need to serialize only the following component over
the network:
```rust
#[derive(Reflect, Component, Default)]
#[reflect(Component)]
struct NPC {
name: Option<String>
}
```
To do this, you'd need to:
1. Create a new `AppTypeRegistry`
2. Register `NPC`
3. Register `Option<String>`
If we skip Step 3, then the entire scene might fail to serialize as
`Option<String>` requires registration.
Not only is this annoying and easy to forget, but it can leave users
with an impossible task: serializing a third-party type that contains
private types.
Generally, the third-party crate will register their private types
within a plugin so the user doesn't need to do it themselves. However,
this means we are now unable to serialize _just_ that type— we're forced
to allow everything!
## Solution
Add the `SceneFilter` enum for filtering components to extract.
This filter can be used to optionally allow or deny entire sets of
components/resources. With the `DynamicSceneBuilder`, users have more
control over how their `DynamicScene`s are built.
To only serialize a subset of components, use the `allow` method:
```rust
let scene = builder
.allow::<ComponentA>()
.allow::<ComponentB>()
.extract_entity(entity)
.build();
```
To serialize everything _but_ a subset of components, use the `deny`
method:
```rust
let scene = builder
.deny::<ComponentA>()
.deny::<ComponentB>()
.extract_entity(entity)
.build();
```
Or create a custom filter:
```rust
let components = HashSet::from([type_id]);
let filter = SceneFilter::Allowlist(components);
// let filter = SceneFilter::Denylist(components);
let scene = builder
.with_filter(Some(filter))
.extract_entity(entity)
.build();
```
Similar operations exist for resources:
<details>
<summary>View Resource Methods</summary>
To only serialize a subset of resources, use the `allow_resource`
method:
```rust
let scene = builder
.allow_resource::<ResourceA>()
.extract_resources()
.build();
```
To serialize everything _but_ a subset of resources, use the
`deny_resource` method:
```rust
let scene = builder
.deny_resource::<ResourceA>()
.extract_resources()
.build();
```
Or create a custom filter:
```rust
let resources = HashSet::from([type_id]);
let filter = SceneFilter::Allowlist(resources);
// let filter = SceneFilter::Denylist(resources);
let scene = builder
.with_resource_filter(Some(filter))
.extract_resources()
.build();
```
</details>
### Open Questions
- [x] ~~`allow` and `deny` are mutually exclusive. Currently, they
overwrite each other. Should this instead be a panic?~~ Took @soqb's
suggestion and made it so that the opposing method simply removes that
type from the list.
- [x] ~~`DynamicSceneBuilder` extracts entity data as soon as
`extract_entity`/`extract_entities` is called. Should this behavior
instead be moved to the `build` method to prevent ordering mixups (e.g.
`.allow::<Foo>().extract_entity(entity)` vs
`.extract_entity(entity).allow::<Foo>()`)? The tradeoff would be
iterating over the given entities twice: once at extraction and again at
build.~~ Based on the feedback from @Testare it sounds like it might be
better to just keep the current functionality (if anything we can open a
separate PR that adds deferred methods for extraction, so the
choice/performance hit is up to the user).
- [ ] An alternative might be to remove the filter from
`DynamicSceneBuilder` and have it as a separate parameter to the
extraction methods (either in the existing ones or as added
`extract_entity_with_filter`-type methods). Is this preferable?
- [x] ~~Should we include constructors that include common types to
allow/deny? For example, a `SceneFilter::standard_allowlist` that
includes things like `Parent` and `Children`?~~ Consensus suggests we
should. I may split this out into a followup PR, though.
- [x] ~~Should we add the ability to remove types from the filter
regardless of whether an allowlist or denylist (e.g.
`filter.remove::<Foo>()`)?~~ See the first list item
- [x] ~~Should `SceneFilter` be an enum? Would it make more sense as a
struct that contains an `is_denylist` boolean?~~ With the added
`SceneFilter::None` state (replacing the need to wrap in an `Option` or
rely on an empty `Denylist`), it seems an enum is better suited now
- [x] ~~Bikeshed: Do we like the naming convention? Should we instead
use `include`/`exclude` terminology?~~ Sounds like we're sticking with
`allow`/`deny`!
- [x] ~~Does this feature need a new example? Do we simply include it in
the existing one (maybe even as a comment?)? Should this be done in a
followup PR instead?~~ Example will be added in a followup PR
### Followup Tasks
- [ ] Add a dedicated `SceneFilter` example
- [ ] Possibly add default types to the filter (e.g. deny things like
`ComputedVisibility`, allow `Parent`, etc)
---
## Changelog
- Added the `SceneFilter` enum for filtering components and resources
when building a `DynamicScene`
- Added methods:
- `DynamicSceneBuilder::with_filter`
- `DynamicSceneBuilder::allow`
- `DynamicSceneBuilder::deny`
- `DynamicSceneBuilder::allow_all`
- `DynamicSceneBuilder::deny_all`
- `DynamicSceneBuilder::with_resource_filter`
- `DynamicSceneBuilder::allow_resource`
- `DynamicSceneBuilder::deny_resource`
- `DynamicSceneBuilder::allow_all_resources`
- `DynamicSceneBuilder::deny_all_resources`
- Removed methods:
- `DynamicSceneBuilder::from_world_with_type_registry`
- `DynamicScene::from_scene` and `DynamicScene::from_world` no longer
require an `AppTypeRegistry` reference
## Migration Guide
- `DynamicScene::from_scene` and `DynamicScene::from_world` no longer
require an `AppTypeRegistry` reference:
```rust
// OLD
let registry = world.resource::<AppTypeRegistry>();
let dynamic_scene = DynamicScene::from_world(&world, registry);
// let dynamic_scene = DynamicScene::from_scene(&scene, registry);
// NEW
let dynamic_scene = DynamicScene::from_world(&world);
// let dynamic_scene = DynamicScene::from_scene(&scene);
```
- Removed `DynamicSceneBuilder::from_world_with_type_registry`. Now the
registry is automatically taken from the given world:
```rust
// OLD
let registry = world.resource::<AppTypeRegistry>();
let builder = DynamicSceneBuilder::from_world_with_type_registry(&world,
registry);
// NEW
let builder = DynamicSceneBuilder::from_world(&world);
```
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Use `AppTypeRegistry` on API defined in `bevy_ecs`
(https://github.com/bevyengine/bevy/pull/8895#discussion_r1234748418)
A lot of the API on `Reflect` depends on a registry. When it comes to
the ECS. We should use `AppTypeRegistry` in the general case.
This is however impossible in `bevy_ecs`, since `AppTypeRegistry` is
defined in `bevy_app`.
## Solution
- Move `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
- Still add the resource in the `App` plugin, since bevy_ecs itself
doesn't know of plugins
Note that `bevy_ecs` is a dependency of `bevy_app`, so nothing
revolutionary happens.
## Alternative
- Define the API as a trait in `bevy_app` over `bevy_ecs`. (though this
prevents us from using bevy_ecs internals)
- Do not rely on `AppTypeRegistry` for the API in question, requring
users to extract themselves the resource and pass it to the API methods.
---
## Changelog
- Moved `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
## Migration Guide
- If you were **not** using a `prelude::*` to import `AppTypeRegistry`,
you should update your imports:
```diff
- use bevy::app::AppTypeRegistry;
+ use bevy::ecs::reflect::AppTypeRegistry
```
# Objective
- Fixes#8811 .
## Solution
- Rename "write" method to "apply" in Command trait definition.
- Rename other implementations of command trait throughout bevy's code
base.
---
## Changelog
- Changed: `Command::write` has been changed to `Command::apply`
- Changed: `EntityCommand::write` has been changed to
`EntityCommand::apply`
## Migration Guide
- `Command::write` implementations need to be changed to implement
`Command::apply` instead. This is a mere name change, with no further
actions needed.
- `EntityCommand::write` implementations need to be changed to implement
`EntityCommand::apply` instead. This is a mere name change, with no
further actions needed.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
After fixing dynamic scene to only map specific entities, we want
map_entities to default to the less error prone behavior and have the
previous behavior renamed to "map_all_entities." As this is a breaking
change, it could not be pushed out with the bug fix.
## Solution
Simple rename and refactor.
## Changelog
### Changed
- `map_entities` now accepts a list of entities to apply to, with
`map_all_entities` retaining previous behavior of applying to all
entities in the map.
## Migration Guide
- In `bevy_ecs`, `ReflectMapEntities::map_entites` now requires an
additional `entities` parameter to specify which entities it applies to.
To keep the old behavior, use the new
`ReflectMapEntities::map_all_entities`, but consider if passing the
entities in specifically might be better for your use case to avoid
bugs.
# Objective
- Handle dangling entity references inside scenes
- Handle references to entities with generation > 0 inside scenes
- Fix a latent bug in `Parent`'s `MapEntities` implementation, which
would, if the parent was outside the scene, cause the scene to be loaded
into the new world with a parent reference potentially pointing to some
random entity in that new world.
- Fixes#4793 and addresses #7235
## Solution
- DynamicScenes now identify entities with a `Entity` instead of a u32,
therefore including generation
- `World` exposes a new `reserve_generations` function that despawns an
entity and advances its generation by some extra amount.
- `MapEntities` implementations have a new `get_or_reserve` function
available that will always return an `Entity`, establishing a new
mapping to a dead entity when the entity they are called with is not in
the `EntityMap`. Subsequent calls with that same `Entity` will return
the same newly created dead entity reference, preserving equality
semantics.
- As a result, after loading a scene containing references to dead
entities (or entities otherwise outside the scene), those references
will all point to different generations on a single entity id in the new
world.
---
## Changelog
### Changed
- In serialized scenes, entities are now identified by a u64 instead of
a u32.
- In serialized scenes, components with entity references now have those
references serialize as u64s instead of structs.
### Fixed
- Scenes containing components with entity references will now
deserialize and add to a world reliably.
## Migration Guide
- `MapEntities` implementations must change from a `&EntityMap`
parameter to a `&mut EntityMapper` parameter and can no longer return a
`Result`. Finally, they should switch from calling `EntityMap::get` to
calling `EntityMapper::get_or_reserve`.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
after calling `SceneSpawner::spawn_as_child`, the scene spawner system
will always try to attach the scene instance to the parent once it is
loaded, even if the parent has been deleted, causing a panic.
## Solution
check if the parent is still alive, and don't spawn the scene instance
if not.
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
bevy-scene does not have a reason to depend on bevy-render except to
include the `Visibility` and `ComputedVisibility` components. Including
that in the dependency chain is unnecessary for people not using
`bevy_render`.
Also fixed a problem where compilation fails when the `serialize`
feature was not enabled.
## Solution
This was added in #5335 to address some of the problems caused by #5310.
Imo the user just always have to remember to include `VisibilityBundle`
when they spawn `SceneBundle` or `DynamicSceneBundle`, but that will be
a breaking change. This PR makes `bevy_render` an optional dependency of
`bevy_scene` instead to respect the existing behavior.
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Co-Authored-By: davier
[bricedavier@gmail.com](mailto:bricedavier@gmail.com)
Fixes#3576.
Adds a `resources` field in scene serialization data to allow
de/serializing resources that have reflection enabled.
## Solution
Most of this code is taken from a previous closed PR:
https://github.com/bevyengine/bevy/pull/3580. Most of the credit goes to
@Davier , what I did was mostly getting it to work on the latest main
branch of Bevy, along with adding a few asserts in the currently
existing tests to be sure everything is working properly.
This PR changes the scene format to include resources in this way:
```
(
resources: {
// List of resources here, keyed by resource type name.
},
entities: [
// Previous scene format here
],
)
```
An example taken from the tests:
```
(
resources: {
"bevy_scene::serde::tests::MyResource": (
foo: 123,
),
},
entities: {
// Previous scene format here
},
)
```
For this, a `resources` fields has been added on the `DynamicScene` and
the `DynamicSceneBuilder` structs. The latter now also has a method
named `extract_resources` to properly extract the existing resources
registered in the local type registry, in a similar way to
`extract_entities`.
---
## Changelog
Added: Reflect resources registered in the type registry used by dynamic
scenes will now be properly de/serialized in scene data.
## Migration Guide
Since the scene format has been changed, the user may not be able to use
scenes saved prior to this PR due to the `resources` scene field being
missing. ~~To preserve backwards compatibility, I will try to make the
`resources` fully optional so that old scenes can be loaded without
issue.~~
## TODOs
- [x] I may have to update a few doc blocks still referring to dynamic
scenes as mere container of entities, since they now include resources
as well.
- [x] ~~I want to make the `resources` key optional, as specified in the
Migration Guide, so that old scenes will be compatible with this
change.~~ Since this would only be trivial for ron format, I think it
might be better to consider it in a separate PR/discussion to figure out
if it could be done for binary serialization too.
- [x] I suppose it might be a good idea to add a resources in the scene
example so that users will quickly notice they can serialize resources
just like entities.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6760
- adds line and position on line info to scene errors
```text
Before:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)`
After:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)` at scenes/test/scene.scn.ron:10:4
```
## Solution
- use span_error to get position info. This is what the ron crate does
internally to get the position info.
562963f887/src/options.rs (L158)
## Changelog
- added line numbers to scene errors
---------
Co-authored-by: Paul Hansen <mail@paul.rs>
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
Ability to use `ReflectComponent` methods in dynamic type contexts with no access to `&World`.
This problem occurred to me when wanting to apply reflected types to an entity where the `&World` reference was already consumed by query iterator leaving only `EntityMut`.
## Solution
- Remove redundant `EntityMut` or `EntityRef` lookup from `World` and `Entity` in favor of taking `EntityMut` directly in `ReflectComponentFns`.
- Added `RefectComponent::contains` to determine without panic whether `apply` can be used.
## Changelog
- Changed function signatures of `ReflectComponent` methods, `apply`, `remove`, `contains`, and `reflect`.
## Migration Guide
- Call `World::entity` before calling into the changed `ReflectComponent` methods, most likely user already has a `EntityRef` or `EntityMut` which was being queried redundantly.
# Objective
This a follow-up to #6894, see https://github.com/bevyengine/bevy/pull/6894#discussion_r1045203113
The goal is to avoid cloning any string when getting a `&TypeRegistration` corresponding to a string which is being deserialized. As a bonus code duplication is also reduced.
## Solution
The manual deserialization of a string and lookup into the type registry has been moved into a separate `TypeRegistrationDeserializer` type, which implements `DeserializeSeed` with a `Visitor` that accepts any string with `visit_str`, even ones that may not live longer than that function call.
`BorrowedStr` has been removed since it's no longer used.
---
## Changelog
- The type `TypeRegistrationDeserializer` has been added, which simplifies getting a `&TypeRegistration` while deserializing a string.
# Objective
Fixes#6891
## Solution
Replaces deserializing map keys as `&str` with deserializing them as `String`.
This bug seems to occur when using something like `File` or `BufReader` rather than bytes or a string directly (I only tested `File` and `BufReader` for `rmp-serde` and `serde_json`). This might be an issue with other `Read` impls as well (except `&[u8]` it seems).
We already had passing tests for Message Pack but none that use a `File` or `BufReader`. This PR also adds or modifies tests to check for this in the future.
This change was also based on [feedback](https://github.com/bevyengine/bevy/pull/4561#discussion_r957385136) I received in a previous PR.
---
## Changelog
- Fix bug where scene deserialization using certain readers could fail (e.g. `BufReader`, `File`, etc.)
# Objective
- Dynamic scene builder can build scenes without components, if they didn't have any matching the type registry
- Those entities are not really useful in the final `DynamicScene`
## Solution
- Add a method `remove_empty_entities` that will remove empty entities. It's not called by default when calling `build`, I'm not sure if that's a good idea or not.
# Objective
Partially addresses #5504. Allow users to get an `Iterator<Item = EntityRef<'a>>` over all entities in the `World`.
## Solution
Change `World::iter_entities` to return an iterator of `EntityRef` instead of `Entity`.
Not sure how to tackle making an `Iterator<Item = EntityMut<'_>>` without being horribly unsound. Might need to wait for `LendingIterator` to stabilize so we can ensure only one of them is valid at a given time.
---
## Changelog
Changed: `World::iter_entities` now returns an iterator of `EntityRef` instead of `Entity`.
# Objective
Fixes#6661
## Solution
Make `SceneSpawner::spawn_dynamic` return `InstanceId` like other functions there.
---
## Changelog
Make `SceneSpawner::spawn_dynamic` return `InstanceId` instead of `()`.
# Objective
Fixes#6030, making ``serde`` optional.
## Solution
This was solved by making a ``serialize`` feature that can activate ``serde``, which is now optional.
When ``serialize`` is deactivated, the ``Plugin`` implementation for ``ScenePlugin`` does nothing.
Co-authored-by: Linus Käll <linus.kall.business@gmail.com>
# Objective
Closes#5934
Currently it is not possible to de/serialize data to non-self-describing formats using reflection.
## Solution
Add support for non-self-describing de/serialization using reflection.
This allows us to use binary formatters, like [`postcard`](https://crates.io/crates/postcard):
```rust
#[derive(Reflect, FromReflect, Debug, PartialEq)]
struct Foo {
data: String
}
let mut registry = TypeRegistry::new();
registry.register::<Foo>();
let input = Foo {
data: "Hello world!".to_string()
};
// === Serialize! === //
let serializer = ReflectSerializer::new(&input, ®istry);
let bytes: Vec<u8> = postcard::to_allocvec(&serializer).unwrap();
println!("{:?}", bytes); // Output: [129, 217, 61, 98, ...]
// === Deserialize! === //
let deserializer = UntypedReflectDeserializer::new(®istry);
let dynamic_output = deserializer
.deserialize(&mut postcard::Deserializer::from_bytes(&bytes))
.unwrap();
let output = <Foo as FromReflect>::from_reflect(dynamic_output.as_ref()).unwrap();
assert_eq!(expected, output); // OK!
```
#### Crates Tested
- ~~[`rmp-serde`](https://crates.io/crates/rmp-serde)~~ Apparently, this _is_ self-describing
- ~~[`bincode` v2.0.0-rc.1](https://crates.io/crates/bincode/2.0.0-rc.1) (using [this PR](https://github.com/bincode-org/bincode/pull/586))~~ This actually works for the latest release (v1.3.3) of [`bincode`](https://crates.io/crates/bincode) as well. You just need to be sure to use fixed-int encoding.
- [`postcard`](https://crates.io/crates/postcard)
## Future Work
Ideally, we would refactor the `serde` module, but I don't think I'll do that in this PR so as to keep the diff relatively small (and to avoid any painful rebases). This should probably be done once this is merged, though.
Some areas we could improve with a refactor:
* Split deserialization logic across multiple files
* Consolidate helper functions/structs
* Make the logic more DRY
---
## Changelog
- Add support for non-self-describing de/serialization using reflection.
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
Fixes#6059, changing all incorrect occurrences of ``id`` in the ``entity`` module to ``index``:
* struct level documentation,
* ``id`` struct field,
* ``id`` method and its documentation.
## Solution
Renaming and verifying using CI.
Co-authored-by: Edvin Kjell <43633999+Edwox@users.noreply.github.com>
# Objective
Entities are unique, however, this is not reflected in the scene format. Currently, entities are stored in a list where a user could inadvertently create a duplicate of the same entity.
## Solution
Switch from the list representation to a map representation for entities.
---
## Changelog
* The `entities` field in the scene format is now a map of entity ID to entity data
## Migration Guide
The scene format now stores its collection of entities in a map rather than a list:
```rust
// OLD
(
entities: [
(
entity: 12,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
),
],
)
// NEW
(
entities: {
12: (
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
),
},
)
```
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
Currently, `DynamicSceneBuilder` keeps track of entities via a `HashMap`. This has an unintended side-effect in that, when building the full `DynamicScene`, we aren't guaranteed any particular order.
In other words, inserting Entity A then Entity B can result in either `[A, B]` or `[B, A]`. This can be rather annoying when running tests on scenes generated via the builder as it will work sometimes but not other times. There's also the potential that this might unnecessarily clutter up VCS diffs for scene files (assuming they had an intentional order).
## Solution
Store `DynamicSceneBuilder`'s entities in a `Vec` rather than a `HashMap`.
---
## Changelog
* Stablized entity order in `DynamicSceneBuilder` (0.9.0-dev)
# Objective
Currently scenes define components using a list:
```rust
[
(
entity: 0,
components: [
{
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
{
"my_crate::Foo": (
text: "Hello World",
),
},
{
"my_crate::Bar": (
baz: 123,
),
},
],
),
]
```
However, this representation has some drawbacks (as pointed out by @Metadorius in [this](https://github.com/bevyengine/bevy/pull/4561#issuecomment-1202215565) comment):
1. Increased nesting and more characters (minor effect on overall size)
2. More importantly, by definition, entities cannot have more than one instance of any given component. Therefore, such data is best stored as a map— where all values are meant to have unique keys.
## Solution
Change `components` to store a map of components rather than a list:
```rust
[
(
entity: 0,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
"my_crate::Foo": (
text: "Hello World",
),
"my_crate::Bar": (
baz: 123
),
},
),
]
```
#### Code Representation
This change only affects the scene format itself. `DynamicEntity` still stores its components as a list. The reason for this is that storing such data as a map is not really needed since:
1. The "key" of each value is easily found by just calling `Reflect::type_name` on it
2. We should be generating such structs using the `World` itself which upholds the one-component-per-entity rule
One could in theory create manually create a `DynamicEntity` with duplicate components, but this isn't something I think we should focus on in this PR. `DynamicEntity` can be broken in other ways (i.e. storing a non-component in the components list), and resolving its issues can be done in a separate PR.
---
## Changelog
* The scene format now uses a map to represent the collection of components rather than a list
## Migration Guide
The scene format now uses a map to represent the collection of components. Scene files will need to update from the old list format.
<details>
<summary>Example Code</summary>
```rust
// OLD
[
(
entity: 0,
components: [
{
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
},
{
"my_crate::Foo": (
text: "Hello World",
),
},
{
"my_crate::Bar": (
baz: 123,
),
},
],
),
]
// NEW
[
(
entity: 0,
components: {
"bevy_transform::components::transform::Transform": (
translation: (
x: 0.0,
y: 0.0,
z: 0.0
),
rotation: (0.0, 0.0, 0.0, 1.0),
scale: (
x: 1.0,
y: 1.0,
z: 1.0
),
),
"my_crate::Foo": (
text: "Hello World",
),
"my_crate::Bar": (
baz: 123
),
},
),
]
```
</details>
# Objective
- Proactive changing of code to comply with warnings generated by beta of rustlang version of cargo clippy.
## Solution
- Code changed as recommended by `rustup update`, `rustup default beta`, `cargo run -p ci -- clippy`.
- Tested using `beta` and `stable`. No clippy warnings in either after changes made.
---
## Changelog
- Warnings fixed were: `clippy::explicit-auto-deref` (present in 11 files), `clippy::needless-borrow` (present in 2 files), and `clippy::only-used-in-recursion` (only 1 file).
# Objective
Scenes are currently represented as a list of entities. This is all we need currently, but we may want to add more data to this format in the future (metadata, asset lists, etc.).
It would be nice to update the format in preparation of possible future changes. Doing so now (i.e., before 0.9) could mean reduced[^1] breakage for things added in 0.10.
[^1]: Obviously, adding features runs the risk of breaking things regardless. But if all features added are for whatever reason optional or well-contained, then users should at least have an easier time updating.
## Solution
Made the scene root a struct rather than a list.
```rust
(
entities: [
// Entity data here...
]
)
```
---
## Changelog
* The scene format now puts the entity list in a newly added `entities` field, rather than having it be the root object
## Migration Guide
The scene file format now uses a struct as the root object rather than a list of entities. The list of entities is now found in the `entities` field of this struct.
```rust
// OLD
[
(
entity: 0,
components: [
// Components...
]
),
]
// NEW
(
entities: [
(
entity: 0,
components: [
// Components...
]
),
]
)
```
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Add a way to iterate over all entities from &World
## Solution
- Added a function `iter_entities` on World which returns an iterator of `Entity` derived from the entities in the `World`'s `archetypes`
---
## Changelog
- Added a function `iter_entities` on World, allowing iterating over all entities in contexts where you only have read-only access to the World.
# Objective
- make it easier to build dynamic scenes
## Solution
- add a builder to create a dynamic scene from a world. it can extract an entity or an iterator of entities
- alternative to #6013, leaving the "hierarchy iteration" part to #6185 which does it better
- alternative to #6004
- using a builder makes it easier to chain several extractions
# Objective
- Taking the API improvement out of #5431
- `iter_instance_entities` used to return an option of iterator, now it just returns an iterator
---
## Changelog
- If you use `SceneSpawner::iter_instance_entities`, it no longer returns an `Option`. The iterator will be empty if the return value used to be `None`
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
> Note: This is rebased off #4561 and can be viewed as a competitor to that PR. See `Comparison with #4561` section for details.
# Objective
The current serialization format used by `bevy_reflect` is both verbose and error-prone. Taking the following structs[^1] for example:
```rust
// -- src/inventory.rs
#[derive(Reflect)]
struct Inventory {
id: String,
max_storage: usize,
items: Vec<Item>
}
#[derive(Reflect)]
struct Item {
name: String
}
```
Given an inventory of a single item, this would serialize to something like:
```rust
// -- assets/inventory.ron
{
"type": "my_game::inventory::Inventory",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "inv001",
},
"max_storage": {
"type": "usize",
"value": 10
},
"items": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "my_game::inventory::Item",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Pickaxe"
},
},
},
],
},
},
}
```
Aside from being really long and difficult to read, it also has a few "gotchas" that users need to be aware of if they want to edit the file manually. A major one is the requirement that you use the proper keys for a given type. For structs, you need `"struct"`. For lists, `"list"`. For tuple structs, `"tuple_struct"`. And so on.
It also ***requires*** that the `"type"` entry come before the actual data. Despite being a map— which in programming is almost always orderless by default— the entries need to be in a particular order. Failure to follow the ordering convention results in a failure to deserialize the data.
This makes it very prone to errors and annoyances.
## Solution
Using #4042, we can remove a lot of the boilerplate and metadata needed by this older system. Since we now have static access to type information, we can simplify our serialized data to look like:
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
name: "Pickaxe"
),
],
),
}
```
This is much more digestible and a lot less error-prone (no more key requirements and no more extra type names).
Additionally, it is a lot more familiar to users as it follows conventional serde mechanics. For example, the struct is represented with `(...)` when serialized to RON.
#### Custom Serialization
Additionally, this PR adds the opt-in ability to specify a custom serde implementation to be used rather than the one created via reflection. For example[^1]:
```rust
// -- src/inventory.rs
#[derive(Reflect, Serialize)]
#[reflect(Serialize)]
struct Item {
#[serde(alias = "id")]
name: String
}
```
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
id: "Pickaxe"
),
],
),
},
```
By allowing users to define their own serialization methods, we do two things:
1. We give more control over how data is serialized/deserialized to the end user
2. We avoid having to re-define serde's attributes and forcing users to apply both (e.g. we don't need a `#[reflect(alias)]` attribute).
### Improved Formats
One of the improvements this PR provides is the ability to represent data in ways that are more conventional and/or familiar to users. Many users are familiar with RON so here are some of the ways we can now represent data in RON:
###### Structs
```js
{
"my_crate::Foo": (
bar: 123
)
}
// OR
{
"my_crate::Foo": Foo(
bar: 123
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Foo",
"struct": {
"bar": {
"type": "usize",
"value": 123
}
}
}
```
</details>
###### Tuples
```js
{
"(f32, f32)": (1.0, 2.0)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "(f32, f32)",
"tuple": [
{
"type": "f32",
"value": 1.0
},
{
"type": "f32",
"value": 2.0
}
]
}
```
</details>
###### Tuple Structs
```js
{
"my_crate::Bar": ("Hello World!")
}
// OR
{
"my_crate::Bar": Bar("Hello World!")
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Bar",
"tuple_struct": [
{
"type": "alloc::string::String",
"value": "Hello World!"
}
]
}
```
</details>
###### Arrays
It may be a bit surprising to some, but arrays now also use the tuple format. This is because they essentially _are_ tuples (a sequence of values with a fixed size), but only allow for homogenous types. Additionally, this is how RON handles them and is probably a result of the 32-capacity limit imposed on them (both by [serde](https://docs.rs/serde/latest/serde/trait.Serialize.html#impl-Serialize-for-%5BT%3B%2032%5D) and by [bevy_reflect](https://docs.rs/bevy/latest/bevy/reflect/trait.GetTypeRegistration.html#impl-GetTypeRegistration-for-%5BT%3B%2032%5D)).
```js
{
"[i32; 3]": (1, 2, 3)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "[i32; 3]",
"array": [
{
"type": "i32",
"value": 1
},
{
"type": "i32",
"value": 2
},
{
"type": "i32",
"value": 3
}
]
}
```
</details>
###### Enums
To make things simple, I'll just put a struct variant here, but the style applies to all variant types:
```js
{
"my_crate::ItemType": Consumable(
name: "Healing potion"
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::ItemType",
"enum": {
"variant": "Consumable",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Healing potion"
}
}
}
}
```
</details>
### Comparison with #4561
This PR is a rebased version of #4561. The reason for the split between the two is because this PR creates a _very_ different scene format. You may notice that the PR descriptions for either PR are pretty similar. This was done to better convey the changes depending on which (if any) gets merged first. If #4561 makes it in first, I will update this PR description accordingly.
---
## Changelog
* Re-worked serialization/deserialization for reflected types
* Added `TypedReflectDeserializer` for deserializing data with known `TypeInfo`
* Renamed `ReflectDeserializer` to `UntypedReflectDeserializer`
* ~~Replaced usages of `deserialize_any` with `deserialize_map` for non-self-describing formats~~ Reverted this change since there are still some issues that need to be sorted out (in a separate PR). By reverting this, crates like `bincode` can throw an error when attempting to deserialize non-self-describing formats (`bincode` results in `DeserializeAnyNotSupported`)
* Structs, tuples, tuple structs, arrays, and enums are now all de/serialized using conventional serde methods
## Migration Guide
* This PR reduces the verbosity of the scene format. Scenes will need to be updated accordingly:
```js
// Old format
{
"type": "my_game::item::Item",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "bevycraft:stone",
},
"tags": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "alloc::string::String",
"value": "material"
},
],
},
}
// New format
{
"my_game::item::Item": (
id: "bevycraft:stone",
tags: ["material"]
)
}
```
[^1]: Some derives omitted for brevity.
# Objective
- Update ron to 0.8.0
- Fix breaking changes
- Closes#5862
## Solution
- Removed now non-existing method call (behavior is now the same without it)
# Objective
- Easier to work with model assets
- Models are often one mesh, many textures. This can be hard to use in Bevy as it's not possible to clone the scene to have one scene for each material. It's still possible to instantiate the texture-less scene, then modify the texture material once spawned but that means happening during play and is quite more painful
## Solution
- Expose the code to clone a scene. This code already existed but was only possible to use to spawn the scene
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`ReflectResource` and `ReflectComponent` will panic on `apply` method if there is no such component. It's not very ergonomic. And not very good for performance since I need to check if such component exists first.
## Solution
* Add `ReflectComponent::apply_or_insert` and `ReflectResource::apply_or_insert` functions.
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
---
## Changelog
### Added
* `ReflectResource::apply_or_insert` and `ReflectComponent::apply_on_insert`.
### Changed
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
* Use `ReflectComponent::apply_on_insert` in `DynamicScene` instead of manual checking.
## Migration Guide
* Rename `ReflectComponent::add` into `ReflectComponent::insert`.
# Objective
Remove suffixes from reflect component and resource methods to closer match bevy norms.
## Solution
removed suffixes and also fixed a spelling error
---
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Hierarchy tools are not just used for `Transform`: they are also used for scenes.
- In the future there's interest in using them for other features, such as visiibility inheritance.
- The fact that these tools are found in `bevy_transform` causes a great deal of user and developer confusion
- Fixes#2758.
## Solution
- Split `bevy_transform` into two!
- Make everything work again.
Note that this is a very tightly scoped PR: I *know* there are code quality and docs issues that existed in bevy_transform that I've just moved around. We should fix those in a seperate PR and try to merge this ASAP to reduce the bitrot involved in splitting an entire crate.
## Frustrations
The API around `GlobalTransform` is a mess: we have massive code and docs duplication, no link between the two types and no clear way to extend this to other forms of inheritance.
In the medium-term, I feel pretty strongly that `GlobalTransform` should be replaced by something like `Inherited<Transform>`, which lives in `bevy_hierarchy`:
- avoids code duplication
- makes the inheritance pattern extensible
- links the types at the type-level
- allows us to remove all references to inheritance from `bevy_transform`, making it more useful as a standalone crate and cleaning up its docs
## Additional context
- double-blessed by @cart in https://github.com/bevyengine/bevy/issues/4141#issuecomment-1063592414 and https://github.com/bevyengine/bevy/issues/2758#issuecomment-913810963
- preparation for more advanced / cleaner hierarchy tools: go read https://github.com/bevyengine/rfcs/pull/53 !
- originally attempted by @finegeometer in #2789. It was a great idea, just needed more discussion!
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
Currently, simply calling `iter` on an event reader will mark all of it's events as read, even if the returned iterator is never used
## Solution
With this, the cursor will simply move to the last unread, but available event when iter is called, and incremented by one per `next` call.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fix#2406
Scene parenting was not done completely, leaving the hierarchy maintenance to the standard system. As scene spawning happens in stage `PreUpdate` and hierarchy maintenance in stage `PostUpdate`, this left the scene in an invalid state parent wise for part of a frame
## Solution
Also add/update the `Children` component when spawning the scene.
I kept the `Children` component as a `SmallVec`, it could be moved to an `HashSet` to guarantee uniqueness
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- there are a few new versions for `ron`, `winit`, `ndk`, `raw-window-handle`
- `cargo-deny` is failing due to new security issues / duplicated dependencies
## Solution
- Update our dependencies
- Note all new security issues, with which of Bevy direct dependency it comes from
- Update duplicate crate list, with which of Bevy direct dependency it comes from
`notify` is not updated here as it's in #2993
# Objective
Enable using exact World lifetimes during read-only access . This is motivated by the new renderer's need to allow read-only world-only queries to outlive the query itself (but still be constrained by the world lifetime).
For example:
115b170d1f/pipelined/bevy_pbr2/src/render/mod.rs (L774)
## Solution
Split out SystemParam state and world lifetimes and pipe those lifetimes up to read-only Query ops (and add into_inner for Res). According to every safety test I've run so far (except one), this is safe (see the temporary safety test commit). Note that changing the mutable variants to the new lifetimes would allow aliased mutable pointers (try doing that to see how it affects the temporary safety tests).
The new state lifetime on SystemParam does make `#[derive(SystemParam)]` more cumbersome (the current impl requires PhantomData if you don't use both lifetimes). We can make this better by detecting whether or not a lifetime is used in the derive and adjusting accordingly, but that should probably be done in its own pr.
## Why is this a draft?
The new lifetimes break QuerySet safety in one very specific case (see the query_set system in system_safety_test). We need to solve this before we can use the lifetimes given.
This is due to the fact that QuerySet is just a wrapper over Query, which now relies on world lifetimes instead of `&self` lifetimes to prevent aliasing (but in systems, each Query has its own implied lifetime, not a centralized world lifetime). I believe the fix is to rewrite QuerySet to have its own World lifetime (and own the internal reference). This will complicate the impl a bit, but I think it is doable. I'm curious if anyone else has better ideas.
Personally, I think these new lifetimes need to happen. We've gotta have a way to directly tie read-only World queries to the World lifetime. The new renderer is the first place this has come up, but I doubt it will be the last. Worst case scenario we can come up with a second `WorldLifetimeQuery<Q, F = ()>` parameter to enable these read-only scenarios, but I'd rather not add another type to the type zoo.
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet.
You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away.
Co-Authored-By: Carter Anderson <mcanders1@gmail.com>
# Objective
- Currently `Commands` are quite slow due to the need to allocate for each command and wrap it in a `Box<dyn Command>`.
- For example:
```rust
fn my_system(mut cmds: Commands) {
cmds.spawn().insert(42).insert(3.14);
}
```
will have 3 separate `Box<dyn Command>` that need to be allocated and ran.
## Solution
- Utilize a specialized data structure keyed `CommandQueueInner`.
- The purpose of `CommandQueueInner` is to hold a collection of commands in contiguous memory.
- This allows us to store each `Command` type contiguously in memory and quickly iterate through them and apply the `Command::write` trait function to each element.
I think [collection, thing_removed_from_collection] is a more natural order than [thing_removed_from_collection, collection]. Just a small tweak that I think we should include in 0.5.
Resolves#1253#1562
This makes the Commands apis consistent with World apis. This moves to a "type state" pattern (like World) where the "current entity" is stored in an `EntityCommands` builder.
In general this tends to cuts down on indentation and line count. It comes at the cost of needing to type `commands` more and adding more semicolons to terminate expressions.
I also added `spawn_bundle` to Commands because this is a common enough operation that I think its worth providing a shorthand.
* Adds labels and orderings to systems that need them (uses the new many-to-many labels for InputSystem)
* Removes the Event, PreEvent, Scene, and Ui stages in favor of First, PreUpdate, and PostUpdate (there is more collapsing potential, such as the Asset stages and _maybe_ removing First, but those have more nuance so they should be handled separately)
* Ambiguity detection now prints component conflicts
* Removed broken change filters from flex calculation (which implicitly relied on the z-update system always modifying translation.z). This will require more work to make it behave as expected so i just removed it (and it was already doing this work every frame).
This adds a `EventWriter<T>` `SystemParam` that is just a thin wrapper around `ResMut<Events<T>>`. This is primarily to have API symmetry between the reader and writer, and has the added benefit of easily improving the API later with no breaking changes.
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes#1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
### Simple Insert (from ecs_bench_suite)
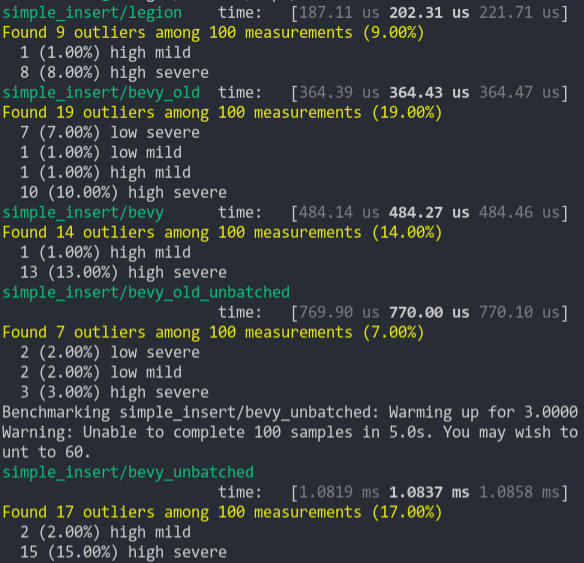
### Simpler Iter (from ecs_bench_suite)
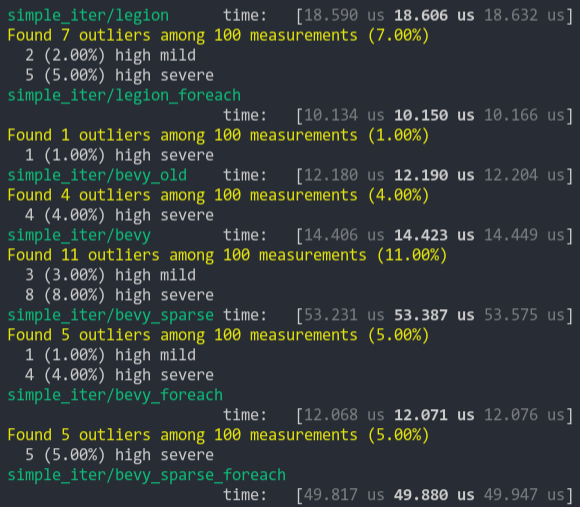
### Fragment Iter (from ecs_bench_suite)
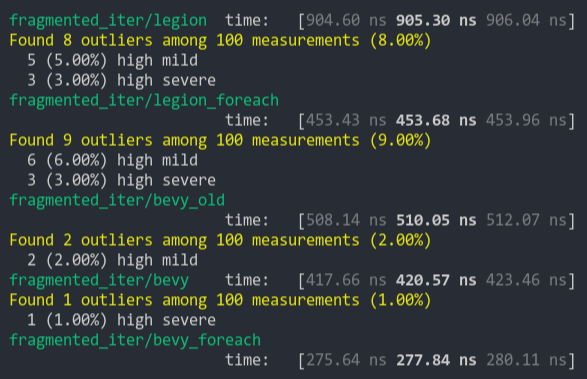
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
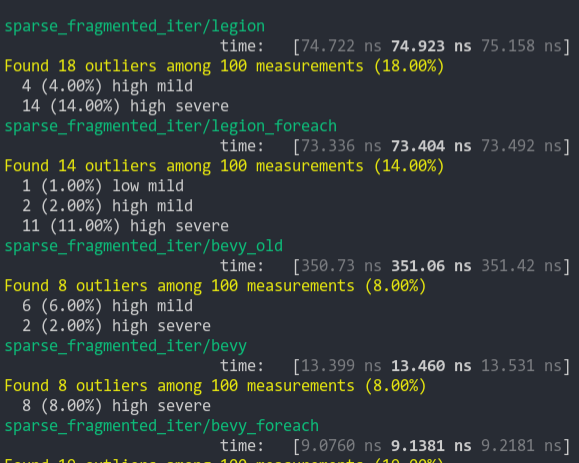
### Schedule (from ecs_bench_suite)
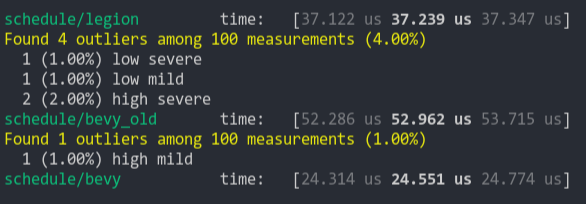
### Add Remove Component (from ecs_bench_suite)
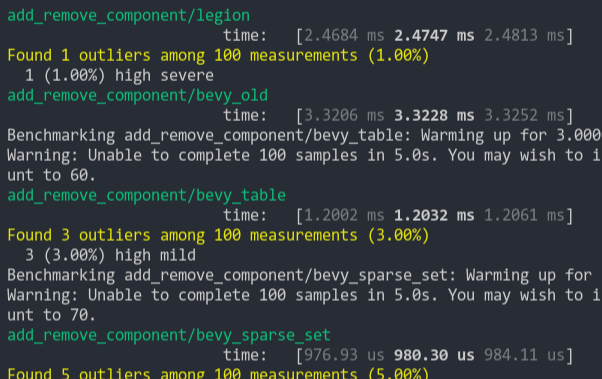
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
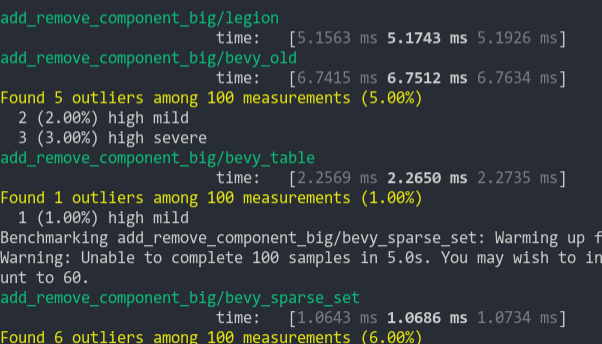
### Get Component
Looks up a single component value a large number of times
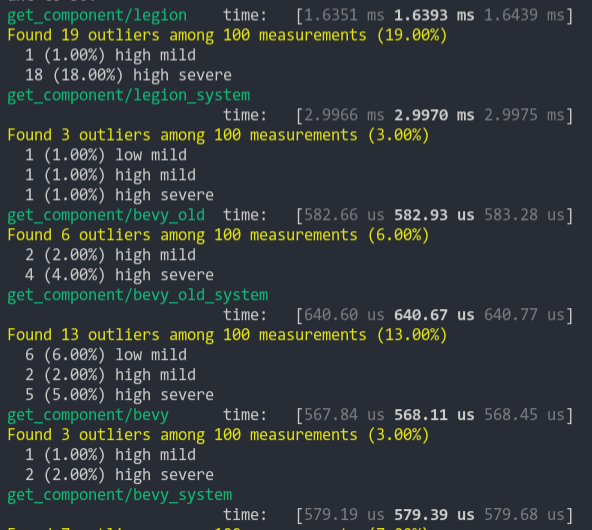
* Remove cfg!(feature = "metal-auto-capture")
This cfg! has existed since the initial commit, but the corresponding
feature has never been part of Cargo.toml
* Remove unnecessary handle_create_window_events call
* Remove EventLoopProxyPtr wrapper
* Remove unnecessary statics
* Fix unrelated deprecation warning to fix CI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}