This PR closes#11978
# Objective
Fix rendering on iOS Simulators.
iOS Simulator doesn't support the capability CUBE_ARRAY_TEXTURES, since
0.13 this started to make iOS Simulator not render anything with the
following message being outputted:
```
2024-02-19T14:59:34.896266Z ERROR bevy_render::render_resource::pipeline_cache: failed to create shader module: Validation Error
Caused by:
In Device::create_shader_module
Shader validation error:
Type [40] '' is invalid
Capability Capabilities(CUBE_ARRAY_TEXTURES) is required
```
## Solution
- Split up NO_ARRAY_TEXTURES_SUPPORT into both NO_ARRAY_TEXTURES_SUPPORT
and NO_CUBE_ARRAY_TEXTURES_SUPPORT and correctly apply
NO_ARRAY_TEXTURES_SUPPORT for iOS Simulator using the cfg flag
introduced in #10178.
---
## Changelog
### Fixed
- Rendering on iOS Simulator due to missing CUBE_ARRAY_TEXTURES support.
---------
Co-authored-by: Sam Pettersson <sam.pettersson@geoguessr.com>
# Objective
- Globals are supposed to be available in vertex shader but that was
mistakenly removed in 0.13
## Solution
- Configure the visibility of the globals correctly
Fixes https://github.com/bevyengine/bevy/issues/12015
Fixes#12016.
Bump version after release
This PR has been auto-generated
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Closes#11985
## Solution
- alpha.rs has been moved from bevy_pbr into bevy_render; bevy_pbr and
bevy_gltf now access `AlphaMode` through bevy_render.
---
## Migration Guide
In the present implementation, external consumers of `AlphaMode` will
have to access it through bevy_render rather than through bevy_pbr,
changing their import from `bevy_pbr::AlphaMode` to
`bevy_render::alpha::AlphaMode` (or the corresponding glob import from
`bevy_pbr::prelude::*` to `bevy_render::prelude::*`).
## Uncertainties
Some remaining things from this that I am uncertain about:
- Here, the `app.register_type<AlphaMode>()` call has been moved from
`PbrPlugin` to `RenderPlugin`; I'm not sure if this is quite right, and
I was unable to find any direct relationship between `PbrPlugin` and
`RenderPlugin`.
- `AlphaMode` was placed in the prelude of bevy_render. I'm not certain
that this is actually appropriate.
- bevy_pbr does not re-export `AlphaMode`, which makes this a breaking
change for external consumers.
Any of these things could be easily changed; I'm just not confident that
I necessarily adopted the right approach in these (known) ways since
this codebase and ecosystem is quite new to me.
Adopted #8266, so copy-pasting the description from there:
# Objective
Support the KHR_texture_transform extension for the glTF loader.
- Fixes#6335
- Fixes#11869
- Implements part of #11350
- Implements the GLTF part of #399
## Solution
As is, this only supports a single transform. Looking at Godot's source,
they support one transform with an optional second one for detail, AO,
and emission. glTF specifies one per texture. The public domain
materials I looked at seem to share the same transform. So maybe having
just one is acceptable for now. I tried to include a warning if multiple
different transforms exist for the same material.
Note the gltf crate doesn't expose the texture transform for the normal
and occlusion textures, which it should, so I just ignored those for
now. (note by @janhohenheim: this is still the case)
Via `cargo run --release --example scene_viewer
~/src/clone/glTF-Sample-Models/2.0/TextureTransformTest/glTF/TextureTransformTest.gltf`:

## Changelog
Support for the
[KHR_texture_transform](https://github.com/KhronosGroup/glTF/tree/main/extensions/2.0/Khronos/KHR_texture_transform)
extension added. Texture UVs that were scaled, rotated, or offset in a
GLTF are now properly handled.
---------
Co-authored-by: Al McElrath <hello@yrns.org>
Co-authored-by: Kanabenki <lucien.menassol@gmail.com>
# Objective
- Save 16 bytes per MeshUniform in uniform/storage buffers.
## Solution
- Reorder members of MeshUniform to capitalise on alignment and size
rules for tighter data packing. Before the size of a MeshUniform was 160
bytes, and after it is 144 bytes, saving 16 bytes of unused padding for
alignment.
---
## Changelog
- Reduced the size of MeshUniform by 16 bytes.
# Objective
Fixes#11908
## Solution
- Remove the `naga_oil` dependency from `bevy_pbr`.
- We were doing a little dance to disable `glsl` support on not-wasm, so
incorporate that dance into `bevy_render`'s `Cargo.toml`.
They cause the number of texture bindings to overflow on those
platforms. Ultimately, we shouldn't unconditionally disable them, but
this fixes a crash blocking 0.13.
Closes#11885.
I did this during the prepass, but I neglected to do it during the
shadow map pass, causing a panic when directional lights with shadows
were enabled with lightmapped meshes present. This patch fixes the
issue.
Closes#11898.
# Objective
#10644 introduced nice "statically typed" labels that replace the old
strings. I would like to propose some changes to the names introduced:
* `SubGraph2d` -> `Core2d` and `SubGraph3d` -> `Core3d`. The names of
these graphs have been / should continue to be the "core 2d" graph not
the "sub graph 2d" graph. The crate is called `bevy_core_pipeline`, the
modules are still `core_2d` and `core_3d`, etc.
* `Labels2d` and `Labels3d`, at the very least, should not be plural to
follow naming conventions. A Label enum is not a "collection of labels",
it is a _specific_ Label. However I think `Label2d` and `Label3d` is
significantly less clear than `Node2d` and `Node3d`, so I propose those
changes here. I've done the same for `LabelsPbr` -> `NodePbr` and
`LabelsUi` -> `NodeUi`
Additionally, #10644 accidentally made one of the Camera2dBundle
constructors use the 3D graph instead of the 2D graph. I've fixed that
here.
---
## Changelog
* Renamed `SubGraph2d` -> `Core2d`, `SubGraph3d` -> `Core3d`, `Labels2d`
-> `Node2d`, `Labels3d` -> `Node3d`, `LabelsUi` -> `NodeUi`, `LabelsPbr`
-> `NodePbr`
# Objective
Provide a public replacement for `Into<MeshUniform>` trait impl which
was removed by #10231.
I made use of this in the `bevy_mod_outline` crate and will have to
duplicate this function if it's not accessible.
## Solution
Change the MeshUniform::new() method to be public.
# Objective
After adding configurable exposure, we set the default ev100 value to
`7` (indoor). This brought us out of sync with Blender's configuration
and defaults. This PR changes the default to `9.7` (bright indoor or
very overcast outdoors), as I calibrated in #11577. This feels like a
very reasonable default.
The other changes generally center around tweaking Bevy's lighting
defaults and examples to play nicely with this number, alongside a few
other tweaks and improvements.
Note that for artistic reasons I have reverted some examples, which
changed to directional lights in #11581, back to point lights.
Fixes#11577
---
## Changelog
- Changed `Exposure::ev100` from `7` to `9.7` to better match Blender
- Renamed `ExposureSettings` to `Exposure`
- `Camera3dBundle` now includes `Exposure` for discoverability
- Bumped `FULL_DAYLIGHT ` and `DIRECT_SUNLIGHT` to represent the
middle-to-top of those ranges instead of near the bottom
- Added new `AMBIENT_DAYLIGHT` constant and set that as the new
`DirectionalLight` default illuminance.
- `PointLight` and `SpotLight` now have a default `intensity` of
1,000,000 lumens. This makes them actually useful in the context of the
new "semi-outdoor" exposure and puts them in the "cinema lighting"
category instead of the "common household light" category. They are also
reasonably close to the Blender default.
- `AmbientLight` default has been bumped from `20` to `80`.
## Migration Guide
- The increased `Exposure::ev100` means that all existing 3D lighting
will need to be adjusted to match (DirectionalLights, PointLights,
SpotLights, EnvironmentMapLights, etc). Or alternatively, you can adjust
the `Exposure::ev100` on your cameras to work nicely with your current
lighting values. If you are currently relying on default intensity
values, you might need to change the intensity to achieve the same
effect. Note that in Bevy 0.12, point/spot lights had a different hard
coded ev100 value than directional lights. In Bevy 0.13, they use the
same ev100, so if you have both in your scene, the _scale_ between these
light types has changed and you will likely need to adjust one or both
of them.
# Objective
Fix https://github.com/bevyengine/bevy/issues/11577.
## Solution
Fix the examples, add a few constants to make setting light values
easier, and change the default lighting settings to be more realistic.
(Now designed for an overcast day instead of an indoor environment)
---
I did not include any example-related changes in here.
## Changelogs (not including breaking changes)
### bevy_pbr
- Added `light_consts` module (included in prelude), which contains
common lux and lumen values for lights.
- Added `AmbientLight::NONE` constant, which is an ambient light with a
brightness of 0.
- Added non-EV100 variants for `ExposureSettings`'s EV100 constants,
which allow easier construction of an `ExposureSettings` from a EV100
constant.
## Breaking changes
### bevy_pbr
The several default lighting values were changed:
- `PointLight`'s default `intensity` is now `2000.0`
- `SpotLight`'s default `intensity` is now `2000.0`
- `DirectionalLight`'s default `illuminance` is now
`light_consts::lux::OVERCAST_DAY` (`1000.`)
- `AmbientLight`'s default `brightness` is now `20.0`
# Objective
`RenderMeshInstance::material_bind_group_id` is only set from
`queue_material_meshes::<M>`. this field is used (only) for determining
batch groups, so some items may be batched incorrectly if they have
never been in the camera's view or if they don't use the Material
abstraction.
in particular, shadow views render more meshes than the main camera, and
currently batch some meshes where the object has never entered the
camera view together. this is quite hard to trigger, but should occur in
a scene with out-of-view alpha-mask materials (so that the material
instance actually affects the shadow) in the path of a light.
this is also a footgun for custom pipelines: failing to set the
material_bind_group_id will result in all meshes being batched together
and all using the closest/furthest material to the camera (depending on
sort order).
## Solution
- queue_shadows now sets the material_bind_group_id correctly
- `MeshPipeline` doesn't attempt to batch meshes if the
material_bind_group_id has not been set. custom pipelines still need to
set this field to take advantage of batching, but will at least render
correctly if it is not set
# Objective
- Fixes#11782.
## Solution
- Remove the run condition for `apply_global_wireframe_material`, since
it prevent detecting when meshes are added or the `NoWireframe` marker
component is removed from an entity. Alternatively this could be done by
using a run condition like "added `Handle<Mesh>` or removed
`NoWireframe` or `WireframeConfig` changed" but this seems less clear to
me than directly letting the queries on
`apply_global_wireframe_material` do the filtering.
# Objective
Reduce the size of `bevy_utils`
(https://github.com/bevyengine/bevy/issues/11478)
## Solution
Move `EntityHash` related types into `bevy_ecs`. This also allows us
access to `Entity`, which means we no longer need `EntityHashMap`'s
first generic argument.
---
## Changelog
- Moved `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` into `bevy::ecs::entity::hash` .
- Removed `EntityHashMap`'s first generic argument. It is now hardcoded
to always be `Entity`.
## Migration Guide
- Uses of `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` now have to be imported from `bevy::ecs::entity::hash`.
- Uses of `EntityHashMap` no longer have to specify the first generic
parameter. It is now hardcoded to always be `Entity`.
This fixes a `FIXME` in `extract_meshes` and results in a performance
improvement.
As a result of this change, meshes in the render world might not be
attached to entities anymore. Therefore, the `entity` parameter to
`RenderCommand::render()` is now wrapped in an `Option`. Most
applications that use the render app's ECS can simply unwrap the
`Option`.
Note that for now sprites, gizmos, and UI elements still use the render
world as usual.
## Migration guide
* For efficiency reasons, some meshes in the render world may not have
corresponding `Entity` IDs anymore. As a result, the `entity` parameter
to `RenderCommand::render()` is now wrapped in an `Option`. Custom
rendering code may need to be updated to handle the case in which no
`Entity` exists for an object that is to be rendered.
# Objective
- Encoding many GPU commands (such as in a renderpass with many draws,
such as the main opaque pass) onto a `wgpu::CommandEncoder` is very
expensive, and takes a long time.
- To improve performance, we want to perform the command encoding for
these heavy passes in parallel.
## Solution
- `RenderContext` can now queue up "command buffer generation tasks"
which are closures that will generate a command buffer when called.
- When finalizing the render context to produce the final list of
command buffers, these tasks are run in parallel on the
`ComputeTaskPool` to produce their corresponding command buffers.
- The general idea is that the node graph will run in serial, but in a
node, instead of doing rendering work, you can add tasks to do render
work in parallel with other node's tasks that get ran at the end of the
graph execution.
## Nodes Parallelized
- `MainOpaquePass3dNode`
- `PrepassNode`
- `DeferredGBufferPrepassNode`
- `ShadowPassNode` (One task per view)
## Future Work
- For large number of draws calls, might be worth further subdividing
passes into 2+ tasks.
- Extend this to UI, 2d, transparent, and transmissive nodes?
- Needs testing - small command buffers are inefficient - it may be
worth reverting to the serial command encoder usage for render phases
with few items.
- All "serial" (traditional) rendering work must finish before parallel
rendering tasks (the new stuff) can start to run.
- There is still only one submission to the graphics queue at the end of
the graph execution. There is still no ability to submit work earlier.
## Performance Improvement
Thanks to @Elabajaba for testing on Bistro.

TLDR: Without shadow mapping, this PR has no impact. _With_ shadow
mapping, this PR gives **~40 more fps** than main.
---
## Changelog
- `MainOpaquePass3dNode`, `PrepassNode`, `DeferredGBufferPrepassNode`,
and each shadow map within `ShadowPassNode` are now encoded in parallel,
giving _greatly_ increased CPU performance, mainly when shadow mapping
is enabled.
- Does not work on WASM or AMD+Windows+Vulkan.
- Added `RenderContext::add_command_buffer_generation_task()`.
- `RenderContext::new()` now takes adapter info
- Some render graph and Node related types and methods now have
additional lifetime constraints.
## Migration Guide
`RenderContext::new()` now takes adapter info
- Some render graph and Node related types and methods now have
additional lifetime constraints.
---------
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
Don't try to create a uniform buffer for light probes if there are no
views.
Fixes the panic on examples that have no views, such as
`touch_input_events`.
# Objective
Bevy could benefit from *irradiance volumes*, also known as *voxel
global illumination* or simply as light probes (though this term is not
preferred, as multiple techniques can be called light probes).
Irradiance volumes are a form of baked global illumination; they work by
sampling the light at the centers of each voxel within a cuboid. At
runtime, the voxels surrounding the fragment center are sampled and
interpolated to produce indirect diffuse illumination.
## Solution
This is divided into two sections. The first is copied and pasted from
the irradiance volume module documentation and describes the technique.
The second part consists of notes on the implementation.
### Overview
An *irradiance volume* is a cuboid voxel region consisting of
regularly-spaced precomputed samples of diffuse indirect light. They're
ideal if you have a dynamic object such as a character that can move
about
static non-moving geometry such as a level in a game, and you want that
dynamic object to be affected by the light bouncing off that static
geometry.
To use irradiance volumes, you need to precompute, or *bake*, the
indirect
light in your scene. Bevy doesn't currently come with a way to do this.
Fortunately, [Blender] provides a [baking tool] as part of the Eevee
renderer, and its irradiance volumes are compatible with those used by
Bevy.
The [`bevy-baked-gi`] project provides a tool, `export-blender-gi`, that
can
extract the baked irradiance volumes from the Blender `.blend` file and
package them up into a `.ktx2` texture for use by the engine. See the
documentation in the `bevy-baked-gi` project for more details as to this
workflow.
Like all light probes in Bevy, irradiance volumes are 1×1×1 cubes that
can
be arbitrarily scaled, rotated, and positioned in a scene with the
[`bevy_transform::components::Transform`] component. The 3D voxel grid
will
be stretched to fill the interior of the cube, and the illumination from
the
irradiance volume will apply to all fragments within that bounding
region.
Bevy's irradiance volumes are based on Valve's [*ambient cubes*] as used
in
*Half-Life 2* ([Mitchell 2006], slide 27). These encode a single color
of
light from the six 3D cardinal directions and blend the sides together
according to the surface normal.
The primary reason for choosing ambient cubes is to match Blender, so
that
its Eevee renderer can be used for baking. However, they also have some
advantages over the common second-order spherical harmonics approach:
ambient cubes don't suffer from ringing artifacts, they are smaller (6
colors for ambient cubes as opposed to 9 for spherical harmonics), and
evaluation is faster. A smaller basis allows for a denser grid of voxels
with the same storage requirements.
If you wish to use a tool other than `export-blender-gi` to produce the
irradiance volumes, you'll need to pack the irradiance volumes in the
following format. The irradiance volume of resolution *(Rx, Ry, Rz)* is
expected to be a 3D texture of dimensions *(Rx, 2Ry, 3Rz)*. The
unnormalized
texture coordinate *(s, t, p)* of the voxel at coordinate *(x, y, z)*
with
side *S* ∈ *{-X, +X, -Y, +Y, -Z, +Z}* is as follows:
```text
s = x
t = y + ⎰ 0 if S ∈ {-X, -Y, -Z}
⎱ Ry if S ∈ {+X, +Y, +Z}
⎧ 0 if S ∈ {-X, +X}
p = z + ⎨ Rz if S ∈ {-Y, +Y}
⎩ 2Rz if S ∈ {-Z, +Z}
```
Visually, in a left-handed coordinate system with Y up, viewed from the
right, the 3D texture looks like a stacked series of voxel grids, one
for
each cube side, in this order:
| **+X** | **+Y** | **+Z** |
| ------ | ------ | ------ |
| **-X** | **-Y** | **-Z** |
A terminology note: Other engines may refer to irradiance volumes as
*voxel
global illumination*, *VXGI*, or simply as *light probes*. Sometimes
*light
probe* refers to what Bevy calls a reflection probe. In Bevy, *light
probe*
is a generic term that encompasses all cuboid bounding regions that
capture
indirect illumination, whether based on voxels or not.
Note that, if binding arrays aren't supported (e.g. on WebGPU or WebGL
2),
then only the closest irradiance volume to the view will be taken into
account during rendering.
[*ambient cubes*]:
https://advances.realtimerendering.com/s2006/Mitchell-ShadingInValvesSourceEngine.pdf
[Mitchell 2006]:
https://advances.realtimerendering.com/s2006/Mitchell-ShadingInValvesSourceEngine.pdf
[Blender]: http://blender.org/
[baking tool]:
https://docs.blender.org/manual/en/latest/render/eevee/render_settings/indirect_lighting.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
### Implementation notes
This patch generalizes light probes so as to reuse as much code as
possible between irradiance volumes and the existing reflection probes.
This approach was chosen because both techniques share numerous
similarities:
1. Both irradiance volumes and reflection probes are cuboid bounding
regions.
2. Both are responsible for providing baked indirect light.
3. Both techniques involve presenting a variable number of textures to
the shader from which indirect light is sampled. (In the current
implementation, this uses binding arrays.)
4. Both irradiance volumes and reflection probes require gathering and
sorting probes by distance on CPU.
5. Both techniques require the GPU to search through a list of bounding
regions.
6. Both will eventually want to have falloff so that we can smoothly
blend as objects enter and exit the probes' influence ranges. (This is
not implemented yet to keep this patch relatively small and reviewable.)
To do this, we generalize most of the methods in the reflection probes
patch #11366 to be generic over a trait, `LightProbeComponent`. This
trait is implemented by both `EnvironmentMapLight` (for reflection
probes) and `IrradianceVolume` (for irradiance volumes). Using a trait
will allow us to add more types of light probes in the future. In
particular, I highly suspect we will want real-time reflection planes
for mirrors in the future, which can be easily slotted into this
framework.
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
### Added
* A new `IrradianceVolume` asset type is available for baked voxelized
light probes. You can bake the global illumination using Blender or
another tool of your choice and use it in Bevy to apply indirect
illumination to dynamic objects.
# Objective
During my exploratory work on the remote editor, I found a couple of
types that were either not registered, or that were missing
`ReflectDefault`.
## Solution
- Added registration and `ReflectDefault` where applicable
- (Drive by fix) Moved `Option<f32>` registration to `bevy_core` instead
of `bevy_ui`, along with similar types.
---
## Changelog
- Fixed: Registered `FogSettings`, `FogFalloff`,
`ParallaxMappingMethod`, `OpaqueRendererMethod` structs for reflection
- Fixed: Registered `ReflectDefault` trait for `ColorGrading` and
`CascadeShadowConfig` structs
# Objective
Bevy does ridiculous amount of drawcalls, and our batching isn't very
effective because we sort by distance and only batch if we get multiple
of the same object in a row. This can give us slightly better GPU
performance when not using the depth prepass (due to less overdraw), but
ends up being massively CPU bottlenecked due to doing thousands of
unnecessary drawcalls.
## Solution
Change the sort functions to sort by pipeline key then by mesh id for
large performance gains in more realistic scenes than our stress tests.
Pipelines changed:
- Opaque3d
- Opaque3dDeferred
- Opaque3dPrepass

---
## Changelog
- Opaque3d drawing order is now sorted by pipeline and mesh, rather than
by distance. This trades off a bit of GPU time in exchange for massively
better batching in scenes that aren't only drawing huge amounts of a
single object.
# Objective
- Some places manually use a `bool` /`AtomicBool` to warn once.
## Solution
- Use the `warn_once` macro which internally creates an `AtomicBool`.
Downside: in some case the warning state would have been reset after
recreating the struct carrying the warn state, whereas now it will
always warn only once per program run (For example, if all
`MeshPipeline`s are dropped or the `World` is recreated for
`Local<bool>`/ a `bool` resource, which shouldn't happen over the course
of a standard `App` run).
---
## Changelog
### Removed
- `FontAtlasWarning` has been removed, but the corresponding warning is
still emitted.
# Objective
- Pipeline compilation is slow and blocks the frame
- Closes https://github.com/bevyengine/bevy/issues/8224
## Solution
- Compile pipelines in a Task on the AsyncComputeTaskPool
---
## Changelog
- Render/compute pipeline compilation is now done asynchronously over
multiple frames when the multi-threaded feature is enabled and on
non-wasm and non-macOS platforms
- Added `CachedPipelineState::Creating`
- Added `PipelineCache::block_on_render_pipeline()`
- Added `bevy_utils::futures::check_ready`
- Added `bevy_render/multi-threaded` cargo feature
## Migration Guide
- Match on the new `Creating` variant for exhaustive matches of
`CachedPipelineState`
# Objective
Currently the `missing_docs` lint is allowed-by-default and enabled at
crate level when their documentations is complete (see #3492).
This PR proposes to inverse this logic by making `missing_docs`
warn-by-default and mark crates with imcomplete docs allowed.
## Solution
Makes `missing_docs` warn at workspace level and allowed at crate level
when the docs is imcomplete.
# Objective
- Address #10338
## Solution
- When implementing specular and diffuse transmission, I inadvertently
introduced a performance regression. On high-end hardware it is barely
noticeable, but **for lower-end hardware it can be pretty brutal**. If I
understand it correctly, this is likely due to use of masking by the GPU
to implement control flow, which means that you still pay the price for
the branches you don't take;
- To avoid that, this PR introduces new shader defs (controlled via
`StandardMaterialKey`) that conditionally include the transmission
logic, that way the shader code for both types of transmission isn't
even sent to the GPU if you're not using them;
- This PR also renames ~~`STANDARDMATERIAL_NORMAL_MAP`~~ to
`STANDARD_MATERIAL_NORMAL_MAP` for consistency with the naming
convention used elsewhere in the codebase. (Drive-by fix)
---
## Changelog
- Added new shader defs, set when using transmission in the
`StandardMaterial`:
- `STANDARD_MATERIAL_SPECULAR_TRANSMISSION`;
- `STANDARD_MATERIAL_DIFFUSE_TRANSMISSION`;
- `STANDARD_MATERIAL_SPECULAR_OR_DIFFUSE_TRANSMISSION`.
- Fixed performance regression caused by the introduction of
transmission, by gating transmission shader logic behind the newly
introduced shader defs;
- Renamed ~~`STANDARDMATERIAL_NORMAL_MAP`~~ to
`STANDARD_MATERIAL_NORMAL_MAP` for consistency;
## Migration Guide
- If you were using `#ifdef STANDARDMATERIAL_NORMAL_MAP` on your shader
code, make sure to update the name to `STANDARD_MATERIAL_NORMAL_MAP`;
(with an underscore between `STANDARD` and `MATERIAL`)
# Objective
The whole `Cow<'static, str>` naming for nodes and subgraphs in
`RenderGraph` is a mess.
## Solution
Replaces hardcoded and potentially overlapping strings for nodes and
subgraphs inside `RenderGraph` with bevy's labelsystem.
---
## Changelog
* Two new labels: `RenderLabel` and `RenderSubGraph`.
* Replaced all uses for hardcoded strings with those labels
* Moved `Taa` label from its own mod to all the other `Labels3d`
* `add_render_graph_edges` now needs a tuple of labels
* Moved `ScreenSpaceAmbientOcclusion` label from its own mod with the
`ShadowPass` label to `LabelsPbr`
* Removed `NodeId`
* Renamed `Edges.id()` to `Edges.label()`
* Removed `NodeLabel`
* Changed examples according to the new label system
* Introduced new `RenderLabel`s: `Labels2d`, `Labels3d`, `LabelsPbr`,
`LabelsUi`
* Introduced new `RenderSubGraph`s: `SubGraph2d`, `SubGraph3d`,
`SubGraphUi`
* Removed `Reflect` and `Default` derive from `CameraRenderGraph`
component struct
* Improved some error messages
## Migration Guide
For Nodes and SubGraphs, instead of using hardcoded strings, you now
pass labels, which can be derived with structs and enums.
```rs
// old
#[derive(Default)]
struct MyRenderNode;
impl MyRenderNode {
pub const NAME: &'static str = "my_render_node"
}
render_app
.add_render_graph_node::<ViewNodeRunner<MyRenderNode>>(
core_3d::graph::NAME,
MyRenderNode::NAME,
)
.add_render_graph_edges(
core_3d::graph::NAME,
&[
core_3d::graph::node::TONEMAPPING,
MyRenderNode::NAME,
core_3d::graph::node::END_MAIN_PASS_POST_PROCESSING,
],
);
// new
use bevy::core_pipeline::core_3d::graph::{Labels3d, SubGraph3d};
#[derive(Debug, Hash, PartialEq, Eq, Clone, RenderLabel)]
pub struct MyRenderLabel;
#[derive(Default)]
struct MyRenderNode;
render_app
.add_render_graph_node::<ViewNodeRunner<MyRenderNode>>(
SubGraph3d,
MyRenderLabel,
)
.add_render_graph_edges(
SubGraph3d,
(
Labels3d::Tonemapping,
MyRenderLabel,
Labels3d::EndMainPassPostProcessing,
),
);
```
### SubGraphs
#### in `bevy_core_pipeline::core_2d::graph`
| old string-based path | new label |
|-----------------------|-----------|
| `NAME` | `SubGraph2d` |
#### in `bevy_core_pipeline::core_3d::graph`
| old string-based path | new label |
|-----------------------|-----------|
| `NAME` | `SubGraph3d` |
#### in `bevy_ui::render`
| old string-based path | new label |
|-----------------------|-----------|
| `draw_ui_graph::NAME` | `graph::SubGraphUi` |
### Nodes
#### in `bevy_core_pipeline::core_2d::graph`
| old string-based path | new label |
|-----------------------|-----------|
| `node::MSAA_WRITEBACK` | `Labels2d::MsaaWriteback` |
| `node::MAIN_PASS` | `Labels2d::MainPass` |
| `node::BLOOM` | `Labels2d::Bloom` |
| `node::TONEMAPPING` | `Labels2d::Tonemapping` |
| `node::FXAA` | `Labels2d::Fxaa` |
| `node::UPSCALING` | `Labels2d::Upscaling` |
| `node::CONTRAST_ADAPTIVE_SHARPENING` |
`Labels2d::ConstrastAdaptiveSharpening` |
| `node::END_MAIN_PASS_POST_PROCESSING` |
`Labels2d::EndMainPassPostProcessing` |
#### in `bevy_core_pipeline::core_3d::graph`
| old string-based path | new label |
|-----------------------|-----------|
| `node::MSAA_WRITEBACK` | `Labels3d::MsaaWriteback` |
| `node::PREPASS` | `Labels3d::Prepass` |
| `node::DEFERRED_PREPASS` | `Labels3d::DeferredPrepass` |
| `node::COPY_DEFERRED_LIGHTING_ID` | `Labels3d::CopyDeferredLightingId`
|
| `node::END_PREPASSES` | `Labels3d::EndPrepasses` |
| `node::START_MAIN_PASS` | `Labels3d::StartMainPass` |
| `node::MAIN_OPAQUE_PASS` | `Labels3d::MainOpaquePass` |
| `node::MAIN_TRANSMISSIVE_PASS` | `Labels3d::MainTransmissivePass` |
| `node::MAIN_TRANSPARENT_PASS` | `Labels3d::MainTransparentPass` |
| `node::END_MAIN_PASS` | `Labels3d::EndMainPass` |
| `node::BLOOM` | `Labels3d::Bloom` |
| `node::TONEMAPPING` | `Labels3d::Tonemapping` |
| `node::FXAA` | `Labels3d::Fxaa` |
| `node::UPSCALING` | `Labels3d::Upscaling` |
| `node::CONTRAST_ADAPTIVE_SHARPENING` |
`Labels3d::ContrastAdaptiveSharpening` |
| `node::END_MAIN_PASS_POST_PROCESSING` |
`Labels3d::EndMainPassPostProcessing` |
#### in `bevy_core_pipeline`
| old string-based path | new label |
|-----------------------|-----------|
| `taa::draw_3d_graph::node::TAA` | `Labels3d::Taa` |
#### in `bevy_pbr`
| old string-based path | new label |
|-----------------------|-----------|
| `draw_3d_graph::node::SHADOW_PASS` | `LabelsPbr::ShadowPass` |
| `ssao::draw_3d_graph::node::SCREEN_SPACE_AMBIENT_OCCLUSION` |
`LabelsPbr::ScreenSpaceAmbientOcclusion` |
| `deferred::DEFFERED_LIGHTING_PASS` | `LabelsPbr::DeferredLightingPass`
|
#### in `bevy_render`
| old string-based path | new label |
|-----------------------|-----------|
| `main_graph::node::CAMERA_DRIVER` | `graph::CameraDriverLabel` |
#### in `bevy_ui::render`
| old string-based path | new label |
|-----------------------|-----------|
| `draw_ui_graph::node::UI_PASS` | `graph::LabelsUi::UiPass` |
---
## Future work
* Make `NodeSlot`s also use types. Ideally, we have an enum with unit
variants where every variant resembles one slot. Then to make sure you
are using the right slot enum and make rust-analyzer play nicely with
it, we should make an associated type in the `Node` trait. With today's
system, we can introduce 3rd party slots to a node, and i wasnt sure if
this was used, so I didn't do this in this PR.
## Unresolved Questions
When looking at the `post_processing` example, we have a struct for the
label and a struct for the node, this seems like boilerplate and on
discord, @IceSentry (sowy for the ping)
[asked](https://discord.com/channels/691052431525675048/743663924229963868/1175197016947699742)
if a node could automatically introduce a label (or i completely
misunderstood that). The problem with that is, that nodes like
`EmptyNode` exist multiple times *inside the same* (sub)graph, so there
we need extern labels to distinguish between those. Hopefully we can
find a way to reduce boilerplate and still have everything unique. For
EmptyNode, we could maybe make a macro which implements an "empty node"
for a type, but for nodes which contain code and need to be present
multiple times, this could get nasty...
# Objective
When developing my game I realized `extract_clusters` and
`prepare_clusters` systems are taking a lot of time despite me creating
very little lights. Reducing number of clusters from the default 4096 to
2048 or less greatly improved performance and stabilized FPS (~300 ->
1000+). I debugged it and found out that the main reason for this is
cloning `VisiblePointLights` in `extract_clusters` system. It contains
light entities grouped by clusters that they affect. The problem is that
we clone 4096 (assuming the default clusters configuration) vectors
every frame. If many of them happen to be non-empty it starts to be a
bottleneck because there is a lot of heap allocation. It wouldn't be a
problem if we reused those vectors in following frames but we don't.
## Solution
Avoid cloning multiple vectors and instead build a single vector
containing data for all clusters.
I've recorded a trace in `3d_scene` example with disabled v-sync before
and after the change.
Mean FPS went from 424 to 990. Mean time for `extract_clusters` system
was reduced from 210 us to 24 us and `prepare_clusters` from 189 us to
87 us.

---
## Changelog
- Improved performance of `extract_clusters` and `prepare_clusters`
systems for scenes where lights affect a big part of it.
# Objective
DXC+DX12 debug builds with an environment map have been broken since
https://github.com/bevyengine/bevy/pull/11366 merged due to an internal
compiler error in DXC. I tracked it down to a single `break` statement
and reported it upstream
(https://github.com/microsoft/DirectXShaderCompiler/issues/6183)
## Solution
Workaround the ICE by setting the for loop index variable to the max
value of the loop to avoid the `break` that's causing the ICE.
This works because it's the last thing in the for loop.
The `reflection_probes` and `pbr` examples both appear to still work
correctly.
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
TypeUuid is deprecated, remove it.
## Migration Guide
Convert any uses of `#[derive(TypeUuid)]` with `#[derive(TypePath]` for
more complex uses see the relevant
[documentation](https://docs.rs/bevy/latest/bevy/prelude/trait.TypePath.html)
for more information.
---------
Co-authored-by: ebola <dev@axiomatic>
# Objective
- Prep for https://github.com/bevyengine/bevy/pull/10164
- Make deferred_lighting_pass_id a ColorAttachment
- Correctly extract shadow view frusta so that the view uniforms get
populated
- Make some needed things public
- Misc formatting
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
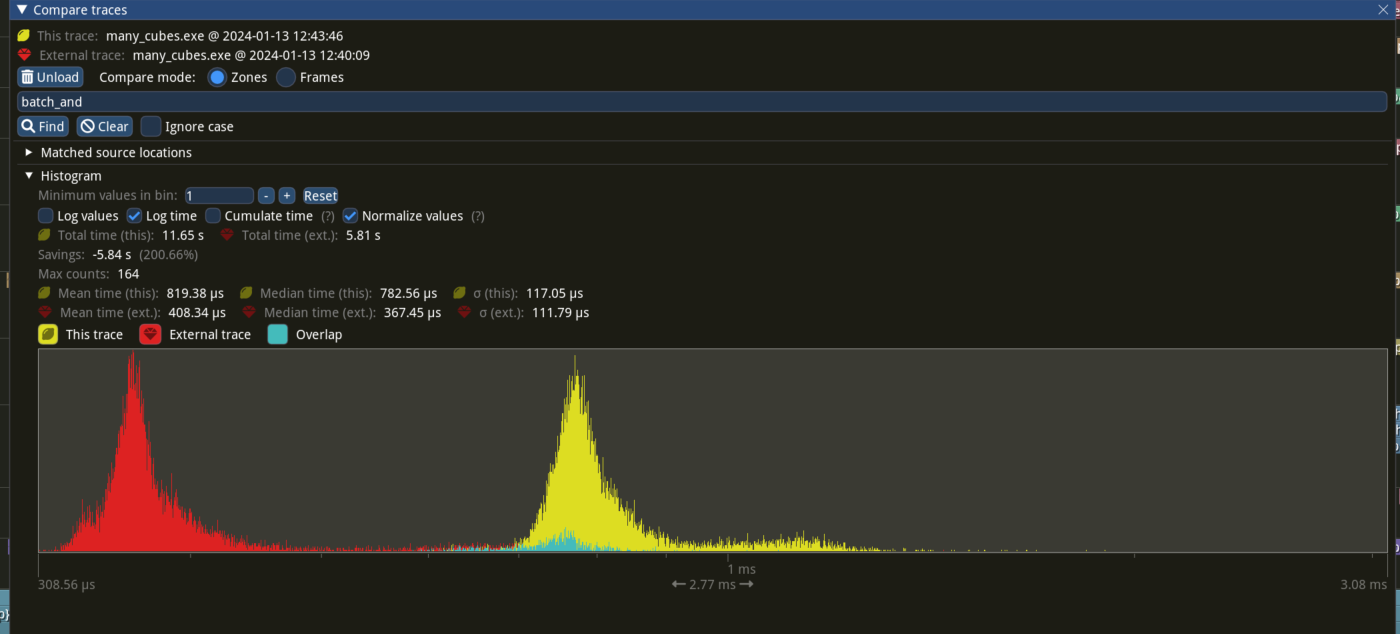
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
This pull request re-submits #10057, which was backed out for breaking
macOS, iOS, and Android. I've tested this version on macOS and Android
and on the iOS simulator.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
Rebased and finished version of
https://github.com/bevyengine/bevy/pull/8407. Huge thanks to @GitGhillie
for adjusting all the examples, and the many other people who helped
write this PR (@superdump , @coreh , among others) :)
Fixes https://github.com/bevyengine/bevy/issues/8369
---
## Changelog
- Added a `brightness` control to `Skybox`.
- Added an `intensity` control to `EnvironmentMapLight`.
- Added `ExposureSettings` and `PhysicalCameraParameters` for
controlling exposure of 3D cameras.
- Removed the baked-in `DirectionalLight` exposure Bevy previously
hardcoded internally.
## Migration Guide
- If using a `Skybox` or `EnvironmentMapLight`, use the new `brightness`
and `intensity` controls to adjust their strength.
- All 3D scene will now have different apparent brightnesses due to Bevy
implementing proper exposure controls. You will have to adjust the
intensity of your lights and/or your camera exposure via the new
`ExposureSettings` component to compensate.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
Co-authored-by: Marco Buono <thecoreh@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/11222
## Solution
SSAO's sample_mip_level was always giving negative values because it was
in UV space (0..1) when it needed to be in pixel units (0..resolution).
Fixing it so it properly samples lower mip levels when appropriate is a
pretty large speedup (~3.2ms -> ~1ms at 4k, ~507us-> 256us at 1080p on a
6800xt), and I didn't notice any obvious visual quality differences.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
{kind=link}