The `check_visibility` system currently follows this algorithm:
1. Store all meshes that were visible last frame in the
`PreviousVisibleMeshes` set.
2. Determine which meshes are visible. For each such visible mesh,
remove it from `PreviousVisibleMeshes`.
3. Mark all meshes that remain in `PreviousVisibleMeshes` as invisible.
This algorithm would be correct if the `check_visibility` were the only
system that marked meshes visible. However, it's not: the shadow-related
systems `check_dir_light_mesh_visibility` and
`check_point_light_mesh_visibility` can as well. This results in the
following sequence of events for meshes that are in a shadow map but
*not* visible from a camera:
A. `check_visibility` runs, finds that no camera contains these meshes,
and marks them hidden, which sets the changed flag.
B. `check_dir_light_mesh_visibility` and/or
`check_point_light_mesh_visibility` run, discover that these meshes
are visible in the shadow map, and marks them as visible, again
setting the `ViewVisibility` changed flag.
C. During the extraction phase, the mesh extraction system sees that
`ViewVisibility` is changed and re-extracts the mesh.
This is inefficient and results in needless work during rendering.
This patch fixes the issue in two ways:
* The `check_dir_light_mesh_visibility` and
`check_point_light_mesh_visibility` systems now remove meshes that they
discover from `PreviousVisibleMeshes`.
* Step (3) above has been moved from `check_visibility` to a separate
system, `mark_newly_hidden_entities_invisible`. This system runs after
all visibility-determining systems, ensuring that
`PreviousVisibleMeshes` contains only those meshes that truly became
invisible on this frame.
This fix dramatically improves the performance of [the Caldera
benchmark], when combined with several other patches I've submitted.
[the Caldera benchmark]:
https://github.com/DGriffin91/bevy_caldera_scene
PR #17688 broke motion vector computation, and therefore motion blur,
because it enabled retention of `MeshInputUniform`s, and
`MeshInputUniform`s contain the indices of the previous frame's
transform and the previous frame's skinned mesh joint matrices. On frame
N, if a `MeshInputUniform` is retained on GPU from the previous frame,
the `previous_input_index` and `previous_skin_index` would refer to the
indices for frame N - 2, not the index for frame N - 1.
This patch fixes the problems. It solves these issues in two different
ways, one for transforms and one for skins:
1. To fix transforms, this patch supplies the *frame index* to the
shader as part of the view uniforms, and specifies which frame index
each mesh's previous transform refers to. So, in the situation described
above, the frame index would be N, the previous frame index would be N -
1, and the `previous_input_frame_number` would be N - 2. The shader can
now detect this situation and infer that the mesh has been retained, and
can therefore conclude that the mesh's transform hasn't changed.
2. To fix skins, this patch replaces the explicit `previous_skin_index`
with an invariant that the index of the joints for the current frame and
the index of the joints for the previous frame are the same. This means
that the `MeshInputUniform` never has to be updated even if the skin is
animated. The downside is that we have to copy joint matrices from the
previous frame's buffer to the current frame's buffer in
`extract_skins`.
The rationale behind (2) is that we currently have no mechanism to
detect when joints that affect a skin have been updated, short of
comparing all the transforms and setting a flag for
`extract_meshes_for_gpu_building` to consume, which would regress
performance as we want `extract_skins` and
`extract_meshes_for_gpu_building` to be able to run in parallel.
To test this change, use `cargo run --example motion_blur`.
Currently, the specialized pipeline cache maps a (view entity, mesh
entity) tuple to the retained pipeline for that entity. This causes two
problems:
1. Using the view entity is incorrect, because the view entity isn't
stable from frame to frame.
2. Switching the view entity to a `RetainedViewEntity`, which is
necessary for correctness, significantly regresses performance of
`specialize_material_meshes` and `specialize_shadows` because of the
loss of the fast `EntityHash`.
This patch fixes both problems by switching to a *two-level* hash table.
The outer level of the table maps each `RetainedViewEntity` to an inner
table, which maps each `MainEntity` to its pipeline ID and change tick.
Because we loop over views first and, within that loop, loop over
entities visible from that view, we hoist the slow lookup of the view
entity out of the inner entity loop.
Additionally, this patch fixes a bug whereby pipeline IDs were leaked
when removing the view. We still have a problem with leaking pipeline
IDs for deleted entities, but that won't be fixed until the specialized
pipeline cache is retained.
This patch improves performance of the [Caldera benchmark] from 7.8×
faster than 0.14 to 9.0× faster than 0.14, when applied on top of the
global binding arrays PR, #17898.
[Caldera benchmark]: https://github.com/DGriffin91/bevy_caldera_scene
Currently, Bevy rebuilds the buffer containing all the transforms for
joints every frame, during the extraction phase. This is inefficient in
cases in which many skins are present in the scene and their joints
don't move, such as the Caldera test scene.
To address this problem, this commit switches skin extraction to use a
set of retained GPU buffers with allocations managed by the offset
allocator. I use fine-grained change detection in order to determine
which skins need updating. Note that the granularity is on the level of
an entire skin, not individual joints. Using the change detection at
that level would yield poor performance in common cases in which an
entire skin is animated at once. Also, this patch yields additional
performance from the fact that changing joint transforms no longer
requires the skinned mesh to be re-extracted.
Note that this optimization can be a double-edged sword. In
`many_foxes`, fine-grained change detection regressed the performance of
`extract_skins` by 3.4x. This is because every joint is updated every
frame in that example, so change detection is pointless and is pure
overhead. Because the `many_foxes` workload is actually representative
of animated scenes, this patch includes a heuristic that disables
fine-grained change detection if the number of transformed entities in
the frame exceeds a certain fraction of the total number of joints.
Currently, this threshold is set to 25%. Note that this is a crude
heuristic, because it doesn't distinguish between the number of
transformed *joints* and the number of transformed *entities*; however,
it should be good enough to yield the optimum code path most of the
time.
Finally, this patch fixes a bug whereby skinned meshes are actually
being incorrectly retained if the buffer offsets of the joints of those
skinned meshes changes from frame to frame. To fix this without
retaining skins, we would have to re-extract every skinned mesh every
frame. Doing this was a significant regression on Caldera. With this PR,
by contrast, mesh joints stay at the same buffer offset, so we don't
have to update the `MeshInputUniform` containing the buffer offset every
frame. This also makes PR #17717 easier to implement, because that PR
uses the buffer offset from the previous frame, and the logic for
calculating that is simplified if the previous frame's buffer offset is
guaranteed to be identical to that of the current frame.
On Caldera, this patch reduces the time spent in `extract_skins` from
1.79 ms to near zero. On `many_foxes`, this patch regresses the
performance of `extract_skins` by approximately 10%-25%, depending on
the number of foxes. This has only a small impact on frame rate.
The GPU can fill out many of the fields in `IndirectParametersMetadata`
using information it already has:
* `early_instance_count` and `late_instance_count` are always
initialized to zero.
* `mesh_index` is already present in the work item buffer as the
`input_index` of the first work item in each batch.
This patch moves these fields to a separate buffer, the *GPU indirect
parameters metadata* buffer. That way, it avoids having to write them on
CPU during `batch_and_prepare_binned_render_phase`. This effectively
reduces the number of bits that that function must write per mesh from
160 to 64 (in addition to the 64 bits per mesh *instance*).
Additionally, this PR refactors `UntypedPhaseIndirectParametersBuffers`
to add another layer, `MeshClassIndirectParametersBuffers`, which allows
abstracting over the buffers corresponding indexed and non-indexed
meshes. This patch doesn't make much use of this abstraction, but
forthcoming patches will, and it's overall a cleaner approach.
This didn't seem to have much of an effect by itself on
`batch_and_prepare_binned_render_phase` time, but subsequent PRs
dependent on this PR yield roughly a 2× speedup.
Appending to these vectors is performance-critical in
`batch_and_prepare_binned_render_phase`, so `RawBufferVec`, which
doesn't have the overhead of `encase`, is more appropriate.
The `output_index` field is only used in direct mode, and the
`indirect_parameters_index` field is only used in indirect mode.
Consequently, we can combine them into a single field, reducing the size
of `PreprocessWorkItem`, which
`batch_and_prepare_{binned,sorted}_render_phase` must construct every
frame for every mesh instance, from 96 bits to 64 bits.
# Objective
Update typos, fix new typos.
1.29.6 was just released to fix an
[issue](https://github.com/crate-ci/typos/issues/1228) where January's
corrections were not included in the binaries for the last release.
Reminder: typos can be tossed in the monthly [non-critical corrections
issue](https://github.com/crate-ci/typos/issues/1221).
## Solution
I chose to allow `implementors`, because a good argument seems to be
being made [here](https://github.com/crate-ci/typos/issues/1226) and
there is now a PR to address that.
## Discussion
Should I exclude `bevy_mikktspace`?
At one point I think we had an informal policy of "don't mess with
mikktspace until https://github.com/bevyengine/bevy/pull/9050 is merged"
but it doesn't seem like that is likely to be merged any time soon.
I think these particular corrections in mikktspace are fine because
- The same typo mistake seems to have been fixed in that PR
- The entire file containing these corrections was deleted in that PR
## Typo of the Month
correspindong -> corresponding
Currently, invocations of `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` can't run in parallel because
they write to scene-global GPU buffers. After PR #17698,
`batch_and_prepare_binned_render_phase` started accounting for the
lion's share of the CPU time, causing us to be strongly CPU bound on
scenes like Caldera when occlusion culling was on (because of the
overhead of batching for the Z-prepass). Although I eventually plan to
optimize `batch_and_prepare_binned_render_phase`, we can obtain
significant wins now by parallelizing that system across phases.
This commit splits all GPU buffers that
`batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` touches into separate buffers
for each phase so that the scheduler will run those phases in parallel.
At the end of batch preparation, we gather the render phases up into a
single resource with a new *collection* phase. Because we already run
mesh preprocessing separately for each phase in order to make occlusion
culling work, this is actually a cleaner separation. For example, mesh
output indices (the unique ID that identifies each mesh instance on GPU)
are now guaranteed to be sequential starting from 0, which will simplify
the forthcoming work to remove them in favor of the compute dispatch ID.
On Caldera, this brings the frame time down to approximately 9.1 ms with
occlusion culling on.

* Use texture atomics rather than buffer atomics for the visbuffer
(haven't tested perf on a raster-heavy scene yet)
* Unfortunately to clear the visbuffer we now need a compute pass to
clear it. Using wgpu's clear_texture function internally uses a buffer
-> image copy that's insanely expensive. Ideally it should be using
vkCmdClearColorImage, which I've opened an issue for
https://github.com/gfx-rs/wgpu/issues/7090. For now we'll have to stick
with a custom compute pass and all the extra code that brings.
* Faster resolve depth pass by discarding 0 depth pixels instead of
redundantly writing zero (2x faster for big depth textures like shadow
views)
## Objective
Get rid of a redundant Cargo feature flag.
## Solution
Use the built-in `target_abi = "sim"` instead of a custom Cargo feature
flag, which is set for the iOS (and visionOS and tvOS) simulator. This
has been stable since Rust 1.78.
In the future, some of this may become redundant if Wgpu implements
proper supper for the iOS Simulator:
https://github.com/gfx-rs/wgpu/issues/7057
CC @mockersf who implemented [the original
fix](https://github.com/bevyengine/bevy/pull/10178).
## Testing
- Open mobile example in Xcode.
- Launch the simulator.
- See that no errors are emitted.
- Remove the code cfg-guarded behind `target_abi = "sim"`.
- See that an error now happens.
(I haven't actually performed these steps on the latest `main`, because
I'm hitting an unrelated error (EDIT: It was
https://github.com/bevyengine/bevy/pull/17637). But tested it on
0.15.0).
---
## Migration Guide
> If you're using a project that builds upon the mobile example, remove
the `ios_simulator` feature from your `Cargo.toml` (Bevy now handles
this internally).
Currently, we look up each `MeshInputUniform` index in a hash table that
maps the main entity ID to the index every frame. This is inefficient,
cache unfriendly, and unnecessary, as the `MeshInputUniform` index for
an entity remains the same from frame to frame (even if the input
uniform changes). This commit changes the `IndexSet` in the `RenderBin`
to an `IndexMap` that maps the `MainEntity` to `MeshInputUniformIndex`
(a new type that this patch adds for more type safety).
On Caldera with parallel `batch_and_prepare_binned_render_phase`, this
patch improves that function from 3.18 ms to 2.42 ms, a 31% speedup.
# Objective
- Fixes#17797
## Solution
- `mesh` in `bevy_pbr::mesh_bindings` is behind a `ifndef
MESHLET_MESH_MATERIAL_PASS`. also gate `get_tag` which uses this `mesh`
## Testing
- Run the meshlet example
# Objective
Since previously we only had the alpha channel available, we stored the
mean of the transmittance in the aerial view lut, resulting in a grayer
fog than should be expected.
## Solution
- Calculate transmittance to scene in `render_sky` with two samples from
the transmittance lut
- use dual-source blending to effectively have per-component alpha
blending
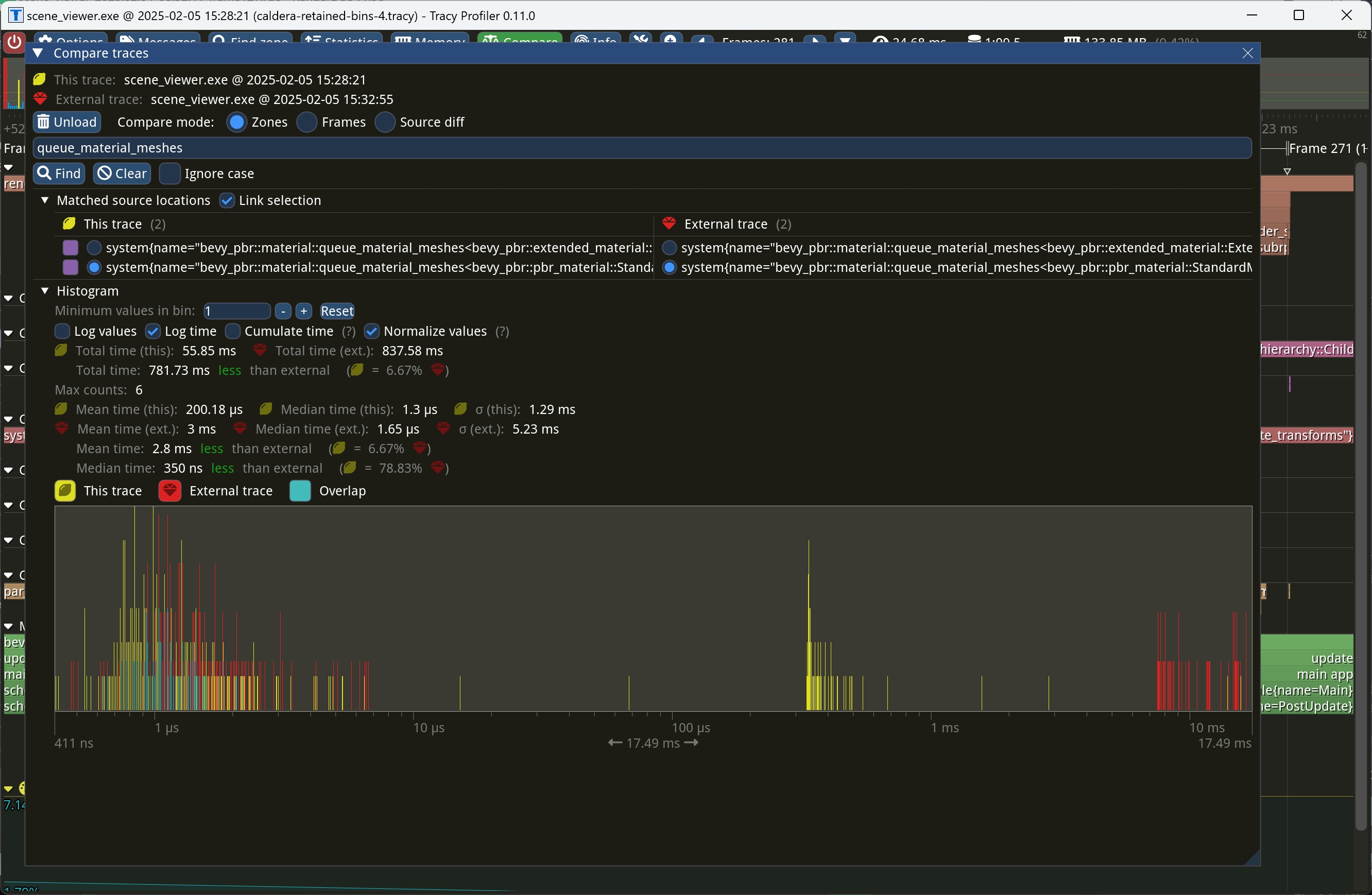
Currently, we *sweep*, or remove entities from bins when those entities
became invisible or changed phases, during `queue_material_meshes` and
similar phases. This, however, is wrong, because `queue_material_meshes`
executes once per material type, not once per phase. This could result
in sweeping bins multiple times per phase, which can corrupt the bins.
This commit fixes the issue by moving sweeping to a separate system that
runs after queuing.
This manifested itself as entities appearing and disappearing seemingly
at random.
Closes#17759.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Because of mesh preprocessing, users cannot rely on
`@builtin(instance_index)` in order to reference external data, as the
instance index is not stable, either from frame to frame or relative to
the total spawn order of mesh instances.
## Solution
Add a user supplied mesh index that can be used for referencing external
data when drawing instanced meshes.
Closes#13373
## Testing
Benchmarked `many_cubes` showing no difference in total frame time.
## Showcase
https://github.com/user-attachments/assets/80620147-aafc-4d9d-a8ee-e2149f7c8f3b
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/issues/17746
## Solution
- Change `Image.data` from being a `Vec<u8>` to a `Option<Vec<u8>>`
- Added functions to help with creating images
## Testing
- Did you test these changes? If so, how?
All current tests pass
Tested a variety of existing examples to make sure they don't crash
(they don't)
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
Linux x86 64-bit NixOS
---
## Migration Guide
Code that directly access `Image` data will now need to use unwrap or
handle the case where no data is provided.
Behaviour of new_fill slightly changed, but not in a way that is likely
to affect anything. It no longer panics and will fill the whole texture
instead of leaving black pixels if the data provided is not a nice
factor of the size of the image.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/pull/16966 tried to fix a bug where
`slot` wasn't passed to `parallaxed_uv` when not running under bindless,
but failed to account for meshlets. This surfaces on macOS where
bindless is disabled.
## Solution
Lift the slot variable out of the bindless condition so it's always
available.
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
- publish script copy the license files to all subcrates, meaning that
all publish are dirty. this breaks git verification of crates
- the order and list of crates to publish is manually maintained,
leading to error. cargo 1.84 is more strict and the list is currently
wrong
## Solution
- duplicate all the licenses to all crates and remove the
`--allow-dirty` flag
- instead of a manual list of crates, get it from `cargo package
--workspace`
- remove the `--no-verify` flag to... verify more things?
# Objective
Things were breaking post-cs.
## Solution
`specialize_mesh_materials` must run after
`collect_meshes_for_gpu_building`. Therefore, its placement in the
`PrepareAssets` set didn't make sense (also more generally). To fix, we
put this class of system in ~`PrepareResources`~ `QueueMeshes`, although
it potentially could use a more descriptive location. We may want to
review the placement of `check_views_need_specialization` which is also
currently in `PrepareAssets`.
Right now, we key the cached light change ticks off the `LightEntity`.
This uses the render world entity, which isn't stable between frames.
Thus in practice few shadows are retained from frame to frame. This PR
fixes the issue by keying off the `RetainedViewEntity` instead, which is
designed to be stable from frame to frame.
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
Right now, meshes aren't grouped together based on the bindless texture
slab when drawing shadows. This manifests itself as flickering in
Bistro. I believe that there are two causes of this:
1. Alpha masked shadows may try to sample from the wrong texture,
causing the alpha mask to appear and disappear.
2. Objects may try to sample from the blank textures that we pad out the
bindless slabs with, causing them to vanish intermittently.
This commit fixes the issue by including the material bind group ID as
part of the shadow batch set key, just as we do for the prepass and main
pass.
# Objective
- Make use of the new `weak_handle!` macro added in
https://github.com/bevyengine/bevy/pull/17384
## Solution
- Migrate bevy from `Handle::weak_from_u128` to the new `weak_handle!`
macro that takes a random UUID
- Deprecate `Handle::weak_from_u128`, since there are no remaining use
cases that can't also be addressed by constructing the type manually
## Testing
- `cargo run -p ci -- test`
---
## Migration Guide
Replace `Handle::weak_from_u128` with `weak_handle!` and a random UUID.
# Cold Specialization
## Objective
An ongoing part of our quest to retain everything in the render world,
cold-specialization aims to cache pipeline specialization so that
pipeline IDs can be recomputed only when necessary, rather than every
frame. This approach reduces redundant work in stable scenes, while
still accommodating scenarios in which materials, views, or visibility
might change, as well as unlocking future optimization work like
retaining render bins.
## Solution
Queue systems are split into a specialization system and queue system,
the former of which only runs when necessary to compute a new pipeline
id. Pipelines are invalidated using a combination of change detection
and ECS ticks.
### The difficulty with change detection
Detecting “what changed” can be tricky because pipeline specialization
depends not only on the entity’s components (e.g., mesh, material, etc.)
but also on which view (camera) it is rendering in. In other words, the
cache key for a given pipeline id is a view entity/render entity pair.
As such, it's not sufficient simply to react to change detection in
order to specialize -- an entity could currently be out of view or could
be rendered in the future in camera that is currently disabled or hasn't
spawned yet.
### Why ticks?
Ticks allow us to ensure correctness by allowing us to compare the last
time a view or entity was updated compared to the cached pipeline id.
This ensures that even if an entity was out of view or has never been
seen in a given camera before we can still correctly determine whether
it needs to be re-specialized or not.
## Testing
TODO: Tested a bunch of different examples, need to test more.
## Migration Guide
TODO
- `AssetEvents` has been moved into the `PostUpdate` schedule.
---------
Co-authored-by: Patrick Walton <pcwalton@mimiga.net>
We were calling `clear()` on the work item buffer table, which caused us
to deallocate all the CPU side buffers. This patch changes the logic to
instead just clear the buffers individually, but leave their backing
stores. This has two consequences:
1. To effectively retain work item buffers from frame to frame, we need
to key them off `RetainedViewEntity` values and not the render world
`Entity`, which is transient. This PR changes those buffers accordingly.
2. We need to clean up work item buffers that belong to views that went
away. Amusingly enough, we actually have a system,
`delete_old_work_item_buffers`, that tries to do this already, but it
wasn't doing anything because the `clear_batched_gpu_instance_buffers`
system already handled that. This patch actually makes the
`delete_old_work_item_buffers` system useful, by removing the clearing
behavior from `clear_batched_gpu_instance_buffers` and instead making
`delete_old_work_item_buffers` delete buffers corresponding to
nonexistent views.
On Bistro, this PR improves the performance of
`batch_and_prepare_binned_render_phase` from 61.2 us to 47.8 us, a 28%
speedup.

This patch fixes a bug whereby we're re-extracting every mesh every
frame. It's a regression from PR #17413. The code in question has
actually been in the tree with this bug for quite a while; it's that
just the code didn't actually run unless the renderer considered the
previous view transforms necessary. Occlusion culling expanded the set
of circumstances under which Bevy computes the previous view transforms,
causing this bug to appear more often.
This patch fixes the issue by checking to see if the previous transform
of a mesh actually differs from the current transform before copying the
current transform to the previous transform.
# Objective
- Fix the atmosphere LUT parameterization in the aerial -view and
sky-view LUTs
- Correct the light accumulation according to a ray-marched reference
- Avoid negative values of the sun disk illuminance when the sun disk is
below the horizon
## Solution
- Adding a Newton's method iteration to `fast_sqrt` function
- Switched to using `fast_acos_4` for better precision of the sun angle
towards the horizon (view mu angle = 0)
- Simplified the function for mapping to and from the Sky View UV
coordinates by removing an if statement and correctly apply the method
proposed by the [Hillarie
paper](https://sebh.github.io/publications/egsr2020.pdf) detailed in
section 5.3 and 5.4.
- Replaced the `ray_dir_ws.y` term with a shadow factor in the
`sample_sun_illuminance` function that correctly approximates the sun
disk occluded by the earth from any view point
## Testing
- Ran the atmosphere and SSAO examples to make sure the shaders still
compile and run as expected.
---
## Showcase
<img width="1151" alt="showcase-img"
src="https://github.com/user-attachments/assets/de875533-42bd-41f9-9fd0-d7cc57d6e51c"
/>
---------
Co-authored-by: Emerson Coskey <emerson@coskey.dev>
Unfortunately, Apple platforms don't have enough texture bindings to
properly support clustered decals. This should be fixed once `wgpu` has
first-class bindless texture support. In the meantime, we disable them.
Closes#17553.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
*Occlusion culling* allows the GPU to skip the vertex and fragment
shading overhead for objects that can be quickly proved to be invisible
because they're behind other geometry. A depth prepass already
eliminates most fragment shading overhead for occluded objects, but the
vertex shading overhead, as well as the cost of testing and rejecting
fragments against the Z-buffer, is presently unavoidable for standard
meshes. We currently perform occlusion culling only for meshlets. But
other meshes, such as skinned meshes, can benefit from occlusion culling
too in order to avoid the transform and skinning overhead for unseen
meshes.
This commit adapts the same [*two-phase occlusion culling*] technique
that meshlets use to Bevy's standard 3D mesh pipeline when the new
`OcclusionCulling` component, as well as the `DepthPrepass` component,
are present on the camera. It has these steps:
1. *Early depth prepass*: We use the hierarchical Z-buffer from the
previous frame to cull meshes for the initial depth prepass, effectively
rendering only the meshes that were visible in the last frame.
2. *Early depth downsample*: We downsample the depth buffer to create
another hierarchical Z-buffer, this time with the current view
transform.
3. *Late depth prepass*: We use the new hierarchical Z-buffer to test
all meshes that weren't rendered in the early depth prepass. Any meshes
that pass this check are rendered.
4. *Late depth downsample*: Again, we downsample the depth buffer to
create a hierarchical Z-buffer in preparation for the early depth
prepass of the next frame. This step is done after all the rendering, in
order to account for custom phase items that might write to the depth
buffer.
Note that this patch has no effect on the per-mesh CPU overhead for
occluded objects, which remains high for a GPU-driven renderer due to
the lack of `cold-specialization` and retained bins. If
`cold-specialization` and retained bins weren't on the horizon, then a
more traditional approach like potentially visible sets (PVS) or low-res
CPU rendering would probably be more efficient than the GPU-driven
approach that this patch implements for most scenes. However, at this
point the amount of effort required to implement a PVS baking tool or a
low-res CPU renderer would probably be greater than landing
`cold-specialization` and retained bins, and the GPU driven approach is
the more modern one anyway. It does mean that the performance
improvements from occlusion culling as implemented in this patch *today*
are likely to be limited, because of the high CPU overhead for occluded
meshes.
Note also that this patch currently doesn't implement occlusion culling
for 2D objects or shadow maps. Those can be addressed in a follow-up.
Additionally, note that the techniques in this patch require compute
shaders, which excludes support for WebGL 2.
This PR is marked experimental because of known precision issues with
the downsampling approach when applied to non-power-of-two framebuffer
sizes (i.e. most of them). These precision issues can, in rare cases,
cause objects to be judged occluded that in fact are not. (I've never
seen this in practice, but I know it's possible; it tends to be likelier
to happen with small meshes.) As a follow-up to this patch, we desire to
switch to the [SPD-based hi-Z buffer shader from the Granite engine],
which doesn't suffer from these problems, at which point we should be
able to graduate this feature from experimental status. I opted not to
include that rewrite in this patch for two reasons: (1) @JMS55 is
planning on doing the rewrite to coincide with the new availability of
image atomic operations in Naga; (2) to reduce the scope of this patch.
A new example, `occlusion_culling`, has been added. It demonstrates
objects becoming quickly occluded and disoccluded by dynamic geometry
and shows the number of objects that are actually being rendered. Also,
a new `--occlusion-culling` switch has been added to `scene_viewer`, in
order to make it easy to test this patch with large scenes like Bistro.
[*two-phase occlusion culling*]:
https://medium.com/@mil_kru/two-pass-occlusion-culling-4100edcad501
[Aaltonen SIGGRAPH 2015]:
https://www.advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf
[Some literature]:
https://gist.github.com/reduz/c5769d0e705d8ab7ac187d63be0099b5?permalink_comment_id=5040452#gistcomment-5040452
[SPD-based hi-Z buffer shader from the Granite engine]:
https://github.com/Themaister/Granite/blob/master/assets/shaders/post/hiz.comp
## Migration guide
* When enqueuing a custom mesh pipeline, work item buffers are now
created with
`bevy::render::batching::gpu_preprocessing::get_or_create_work_item_buffer`,
not `PreprocessWorkItemBuffers::new`. See the
`specialized_mesh_pipeline` example.
## Showcase
Occlusion culling example:

Bistro zoomed out, before occlusion culling:

Bistro zoomed out, after occlusion culling:

In this scene, occlusion culling reduces the number of meshes Bevy has
to render from 1591 to 585.
Currently, our default maximum shadow cascade distance is 1000 m, which
is quite distant compared to that of Unity (150 m), Unreal Engine 5 (200
m), and Godot (100 m). I also adjusted the default first cascade far
bound to be 10 m, which matches that of Unity (10.05 m) and Godot (10
m). Together, these changes should improve the default sharpness of
shadows of directional lights for typical scenes.
## Migration Guide
* The default shadow cascade far distance has been changed from 1000 to
150, and the default first cascade far bound has been changed from 5 to
10, in order to be similar to the defaults of other engines.
This commit allows specular highlights to be tinted with a color and for
the reflectance and color tint values to vary across a model via a pair
of maps. The implementation follows the [`KHR_materials_specular`] glTF
extension. In order to reduce the number of samplers and textures in the
default `StandardMaterial` configuration, the maps are gated behind the
`pbr_specular_textures` Cargo feature.
Specular tinting is currently unsupported in the deferred renderer,
because I didn't want to bloat the deferred G-buffers. A possible fix
for this in the future would be to make the G-buffer layout more
configurable, so that specular tints could be supported on an opt-in
basis. As an alternative, Bevy could force meshes with specular tints to
render in forward mode. Both of these solutions require some more
design, so I consider them out of scope for now.
Note that the map is a *specular* map, not a *reflectance* map. In Bevy
and Filament terms, the reflectance values in the specular map range
from [0.0, 0.5], rather than [0.0, 1.0]. This is an unfortunate
[`KHR_materials_specular`] specification requirement that stems from the
fact that glTF is specified in terms of a specular strength model, not
the reflectance model that Filament and Bevy use. A workaround, which is
noted in the `StandardMaterial` documentation, is to set the
`reflectance` value to 2.0, which spreads the specular map range from
[0.0, 1.0] as normal.
The glTF loader has been updated to parse the [`KHR_materials_specular`]
extension. Note that, unless the non-default `pbr_specular_textures` is
supplied, the maps are ignored. The `specularFactor` value is applied as
usual. Note that, as with the specular map, the glTF `specularFactor` is
twice Bevy's `reflectance` value.
This PR adds a new example, `specular_tint`, which demonstrates the
specular tint and map features. Note that this example requires the
[`KHR_materials_specular`] Cargo feature.
[`KHR_materials_specular`]:
https://github.com/KhronosGroup/glTF/tree/main/extensions/2.0/Khronos/KHR_materials_specular
## Changelog
### Added
* Specular highlights can now be tinted with the `specular_tint` field
in `StandardMaterial`.
* Specular maps are now available in `StandardMaterial`, gated behind
the `pbr_specular_textures` Cargo feature.
* The `KHR_materials_specular` glTF extension is now supported, allowing
for customization of specular reflectance and specular maps. Note that
the latter are gated behind the `pbr_specular_textures` Cargo feature.
This commit adds support for *decal projectors* to Bevy, allowing for
textures to be projected on top of geometry. Decal projectors are
clusterable objects, just as punctual lights and light probes are. This
means that decals are only evaluated for objects within the conservative
bounds of the projector, and they don't require a second pass.
These clustered decals require support for bindless textures and as such
currently don't work on WebGL 2, WebGPU, macOS, or iOS. For an
alternative that doesn't require bindless, see PR #16600. I believe that
both contact projective decals in #16600 and clustered decals are
desirable to have in Bevy. Contact projective decals offer broader
hardware and driver support, while clustered decals don't require the
creation of bounding geometry.
A new example, `decal_projectors`, has been added, which demonstrates
multiple decals on a rotating object. The decal projectors can be scaled
and rotated with the mouse.
There are several limitations of this initial patch that can be
addressed in follow-ups:
1. There's no way to specify the Z-index of decals. That is, the order
in which multiple decals are blended on top of one another is arbitrary.
A follow-up could introduce some sort of Z-index field so that artists
can specify that some decals should be blended on top of others.
2. Decals don't take the normal of the surface they're projected onto
into account. Most decal implementations in other engines have a feature
whereby the angle between the decal projector and the normal of the
surface must be within some threshold for the decal to appear. Often,
artists can specify a fade-off range for a smooth transition between
oblique surfaces and aligned surfaces.
3. There's no distance-based fadeoff toward the end of the projector
range. Many decal implementations have this.
This addresses #2401.
## Showcase

Implement procedural atmospheric scattering from [Sebastien Hillaire's
2020 paper](https://sebh.github.io/publications/egsr2020.pdf). This
approach should scale well even down to mobile hardware, and is
physically accurate.
## Co-author: @mate-h
He helped massively with getting this over the finish line, ensuring
everything was physically correct, correcting several places where I had
misunderstood or misapplied the paper, and improving the performance in
several places as well. Thanks!
## Credits
@aevyrie: helped find numerous bugs and improve the example to best show
off this feature :)
Built off of @mtsr's original branch, which handled the transmittance
lut (arguably the most important part)
## Showcase:


## For followup
- Integrate with pcwalton's volumetrics code
- refactor/reorganize for better integration with other effects
- have atmosphere transmittance affect directional lights
- add support for generating skybox/environment map
---------
Co-authored-by: Emerson Coskey <56370779+EmersonCoskey@users.noreply.github.com>
Co-authored-by: atlv <email@atlasdostal.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Emerson Coskey <coskey@emerlabs.net>
Co-authored-by: Máté Homolya <mate.homolya@gmail.com>
# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
Right now, we always include distance fog in the shader, which is
unfortunate as it's complex code and is rare. This commit changes it to
be a `#define` instead. I haven't confirmed that removing distance fog
meaningfully reduces VGPR usage, but it can't hurt.
This commit makes Bevy use change detection to only update
`RenderMaterialInstances` and `RenderMeshMaterialIds` when meshes have
been added, changed, or removed. `extract_mesh_materials`, the system
that extracts these, now follows the pattern that
`extract_meshes_for_gpu_building` established.
This improves frame time of `many_cubes` from 3.9ms to approximately
3.1ms, which slightly surpasses the performance of Bevy 0.14.
(Resubmitted from #16878 to clean up history.)

---------
Co-authored-by: Charlotte McElwain <charlotte.c.mcelwain@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
`bevy_ecs`'s `system` module is something of a grab bag, and *very*
large. This is particularly true for the `system_param` module, which is
more than 2k lines long!
While it could be defensible to put `Res` and `ResMut` there (lol no
they're in change_detection.rs, obviously), it doesn't make any sense to
put the `Resource` trait there. This is confusing to navigate (and
painful to work on and review).
## Solution
- Create a root level `bevy_ecs/resource.rs` module to mirror
`bevy_ecs/component.rs`
- move the `Resource` trait to that module
- move the `Resource` derive macro to that module as well (Rust really
likes when you pun on the names of the derive macro and trait and put
them in the same path)
- fix all of the imports
## Notes to reviewers
- We could probably move more stuff into here, but I wanted to keep this
PR as small as possible given the absurd level of import changes.
- This PR is ground work for my upcoming attempts to store resource data
on components (resources-as-entities). Splitting this code out will make
the work and review a bit easier, and is the sort of overdue refactor
that's good to do as part of more meaningful work.
## Testing
cargo build works!
## Migration Guide
`bevy_ecs::system::Resource` has been moved to
`bevy_ecs::resource::Resource`.
# Objective
The existing `RelationshipSourceCollection` uses `Vec` as the only
possible backing for our relationships. While a reasonable choice,
benchmarking use cases might reveal that a different data type is better
or faster.
For example:
- Not all relationships require a stable ordering between the
relationship sources (i.e. children). In cases where we a) have many
such relations and b) don't care about the ordering between them, a hash
set is likely a better datastructure than a `Vec`.
- The number of children-like entities may be small on average, and a
`smallvec` may be faster
## Solution
- Implement `RelationshipSourceCollection` for `EntityHashSet`, our
custom entity-optimized `HashSet`.
-~~Implement `DoubleEndedIterator` for `EntityHashSet` to make things
compile.~~
- This implementation was cursed and very surprising.
- Instead, by moving the iterator type on `RelationshipSourceCollection`
from an erased RPTIT to an explicit associated type we can add a trait
bound on the offending methods!
- Implement `RelationshipSourceCollection` for `SmallVec`
## Testing
I've added a pair of new tests to make sure this pattern compiles
successfully in practice!
## Migration Guide
`EntityHashSet` and `EntityHashMap` are no longer re-exported in
`bevy_ecs::entity` directly. If you were not using `bevy_ecs` / `bevy`'s
`prelude`, you can access them through their now-public modules,
`hash_set` and `hash_map` instead.
## Notes to reviewers
The `EntityHashSet::Iter` type needs to be public for this impl to be
allowed. I initially renamed it to something that wasn't ambiguous and
re-exported it, but as @Victoronz pointed out, that was somewhat
unidiomatic.
In
1a8564898f,
I instead made the `entity_hash_set` public (and its `entity_hash_set`)
sister public, and removed the re-export. I prefer this design (give me
module docs please), but it leads to a lot of churn in this PR.
Let me know which you'd prefer, and if you'd like me to split that
change out into its own micro PR.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/17111
## Solution
Move `#![warn(clippy::allow_attributes,
clippy::allow_attributes_without_reason)]` to the workspace `Cargo.toml`
## Testing
Lots of CI testing, and local testing too.
---------
Co-authored-by: Benjamin Brienen <benjamin.brienen@outlook.com>
This commit allows Bevy to use `multi_draw_indirect_count` for drawing
meshes. The `multi_draw_indirect_count` feature works just like
`multi_draw_indirect`, but it takes the number of indirect parameters
from a GPU buffer rather than specifying it on the CPU.
Currently, the CPU constructs the list of indirect draw parameters with
the instance count for each batch set to zero, uploads the resulting
buffer to the GPU, and dispatches a compute shader that bumps the
instance count for each mesh that survives culling. Unfortunately, this
is inefficient when we support `multi_draw_indirect_count`. Draw
commands corresponding to meshes for which all instances were culled
will remain present in the list when calling
`multi_draw_indirect_count`, causing overhead. Proper use of
`multi_draw_indirect_count` requires eliminating these empty draw
commands.
To address this inefficiency, this PR makes Bevy fully construct the
indirect draw commands on the GPU instead of on the CPU. Instead of
writing instance counts to the draw command buffer, the mesh
preprocessing shader now writes them to a separate *indirect metadata
buffer*. A second compute dispatch known as the *build indirect
parameters* shader runs after mesh preprocessing and converts the
indirect draw metadata into actual indirect draw commands for the GPU.
The build indirect parameters shader operates on a batch at a time,
rather than an instance at a time, and as such each thread writes only 0
or 1 indirect draw parameters, simplifying the current logic in
`mesh_preprocessing`, which currently has to have special cases for the
first mesh in each batch. The build indirect parameters shader emits
draw commands in a tightly packed manner, enabling maximally efficient
use of `multi_draw_indirect_count`.
Along the way, this patch switches mesh preprocessing to dispatch one
compute invocation per render phase per view, instead of dispatching one
compute invocation per view. This is preparation for two-phase occlusion
culling, in which we will have two mesh preprocessing stages. In that
scenario, the first mesh preprocessing stage must only process opaque
and alpha tested objects, so the work items must be separated into those
that are opaque or alpha tested and those that aren't. Thus this PR
splits out the work items into a separate buffer for each phase. As this
patch rewrites so much of the mesh preprocessing infrastructure, it was
simpler to just fold the change into this patch instead of deferring it
to the forthcoming occlusion culling PR.
Finally, this patch changes mesh preprocessing so that it runs
separately for indexed and non-indexed meshes. This is because draw
commands for indexed and non-indexed meshes have different sizes and
layouts. *The existing code is actually broken for non-indexed meshes*,
as it attempts to overlay the indirect parameters for non-indexed meshes
on top of those for indexed meshes. Consequently, right now the
parameters will be read incorrectly when multiple non-indexed meshes are
multi-drawn together. *This is a bug fix* and, as with the change to
dispatch phases separately noted above, was easiest to include in this
patch as opposed to separately.
## Migration Guide
* Systems that add custom phase items now need to populate the indirect
drawing-related buffers. See the `specialized_mesh_pipeline` example for
an example of how this is done.
# Objective
allow setting ambient light via component on cameras.
arguably fixes#7193
note i chose to use a component rather than an entity since it was not
clear to me how to manage multiple ambient sources for a single
renderlayer, and it makes for a very small changeset.
## Solution
- make ambient light a component as well as a resource
- extract it
- use the component if present on a camera, fallback to the resource
## Testing
i added
```rs
if index == 1 {
commands.entity(camera).insert(AmbientLight{
color: Color::linear_rgba(1.0, 0.0, 0.0, 1.0),
brightness: 1000.0,
..Default::default()
});
}
```
at line 84 of the split_screen example
---------
Co-authored-by: François Mockers <mockersf@gmail.com>
We won't be able to retain render phases from frame to frame if the keys
are unstable. It's not as simple as simply keying off the main world
entity, however, because some main world entities extract to multiple
render world entities. For example, directional lights extract to
multiple shadow cascades, and point lights extract to one view per
cubemap face. Therefore, we key off a new type, `RetainedViewEntity`,
which contains the main entity plus a *subview ID*.
This is part of the preparation for retained bins.
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
- Closes https://github.com/bevyengine/bevy/issues/14322.
## Solution
- Implement fast 4-sample bicubic filtering based on this shader toy
https://www.shadertoy.com/view/4df3Dn, with a small speedup from a ghost
of tushima presentation.
## Testing
- Did you test these changes? If so, how?
- Ran on lightmapped example. Practically no difference in that scene.
- Are there any parts that need more testing?
- Lightmapping a better scene.
## Changelog
- Lightmaps now have a higher quality bicubic sampling method (off by
default).
---------
Co-authored-by: Patrick Walton <pcwalton@mimiga.net>
# Objective
I realized that setting these to `deny` may have been a little
aggressive - especially since we upgrade warnings to denies in CI.
## Solution
Downgrades these lints to `warn`, so that compiles can work locally. CI
will still treat these as denies.