Note that `for` type is rust-analyzer's own invention.
Both the reference and syn allow `for` only for fnptr types, and we
allow them everywhere. This needs to be checked with respect to type
bounds grammar...
The TypeRef name comes from IntelliJ days, where you often have both
type *syntax* as well as *semantical* representation of types in
scope. And naming both Type is confusing.
In rust-analyzer however, we use ast types as `ast::Type`, and have
many more semantic counterparts to ast types, so avoiding name clash
here is just confusing.
5596: Add checkOnSave.noDefaultFeatures and correct, how we handle some cargo flags. r=clemenswasser a=clemenswasser
This PR adds the `rust-analyzer.checkOnSave.noDefaultFeatures` option
and fixes the handling of `cargo.allFeatures`, `cargo.noDefaultFeatures` and `cargo.features`.
Fixes: #5550
Co-authored-by: Clemens Wasser <clemens.wasser@gmail.com>
This commit fixes the handling of user-defined configuration
of some cargo options. Previously you could either specify
`--all-features`, `--no-default-features` or `--features`.
Now you can specify either `--all-features` or `--no-default-features`
and `--features`. This commit also corrects the `--features`
command-line argument creation inside of `load_extern_resources`.
5567: SSR: Wrap placeholder expansions in parenthesis when necessary r=matklad a=davidlattimore
e.g. `foo($a) ==> $a.to_string()` should produce `(1 + 2).to_string()` not `1 + 2.to_string()`
We don't yet try to determine if the whole replacement needs to be wrapped in parenthesis. That's harder and I think perhaps less often an issue.
Co-authored-by: David Lattimore <dml@google.com>
e.g. `foo($a) ==> $a.to_string()` should produce `(1 + 2).to_string()`
not `1 + 2.to_string()`
We don't yet try to determine if the whole replacement needs to be
wrapped in parenthesis. That's harder and I think perhaps less often an
issue.
5554: Fix remove_dbg r=matklad a=petr-tik
Closes#5129
Addresses two issues:
- keep the parens from dbg!() in case the call is chained or there is
semantic difference if parens are excluded
- Exclude the semicolon after the dbg!(); by checking if it was
accidentally included in the macro_call
investigated, but decided against:
fix ast::MacroCall extraction to never include semicolons at the end -
this logic lives in rowan.
Defensively shorten the macro_range if there is a semicolon token.
Deleted unneccessary temp variable macro_args
Renamed macro_content to "paste_instead_of_dbg", because it isn't a
simple extraction of text inside dbg!() anymore
Co-authored-by: petr-tik <petr-tik@users.noreply.github.com>
5563: Check all targets for package-level tasks r=matklad a=SomeoneToIgnore
When invoking "Select Runnable" with the caret on a runnable with a specific target (test, bench, binary), append the corresponding argument for the `cargo check -p` module runnable.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
replaced match with let-if variable assignment
removed the unnecessary semicolon_on_end variable
converted all code and expected test variables to raw strings
and inlined them in asserts
The primary advantage of ungrammar is that it (eventually) allows one
to describe concrete syntax tree structure -- with alternatives and
specific sequence of tokens & nodes.
That should be re-usable for:
* generate `make` calls
* Rust reference
* Hypothetical parser's evented API
We loose doc comments for the time being unfortunately. I don't think
we should add support for doc comments to ungrammar -- they'll make
grammar file hard to read. We might supply docs as out-of band info,
or maybe just via a reference, but we'll think about that once things
are no longer in flux
5564: SSR: Restrict to current selection if any r=davidlattimore a=davidlattimore
The selection is also used to avoid unnecessary work, but only to the file level. Further restricting unnecessary work is left for later.
Co-authored-by: David Lattimore <dml@google.com>
5565: SSR: Don't mix non-path-based rules with path-based r=matklad a=davidlattimore
If any rules contain paths, then we reject any rules that don't contain paths. Allowing a mix leads to strange semantics, since the path-based rules only match things where the path refers to semantically the same thing, whereas the non-path-based rules could match anything. Specifically, if we have a rule like `foo ==>> bar` we only want to match the `foo` that is in the current scope, not any `foo`. However "foo" can be parsed as a pattern (BIND_PAT -> NAME -> IDENT). Allowing such a rule through would result in renaming everything called `foo` to `bar`. It'd also be slow, since without a path, we'd have to use the slow-scan search mechanism.
Co-authored-by: David Lattimore <dml@google.com>
If any rules contain paths, then we reject any rules that don't contain paths. Allowing a mix leads to strange semantics, since the path-based rules only match things where the path refers to semantically the same thing, whereas the non-path-based rules could match anything. Specifically, if we have a rule like `foo ==>> bar` we only want to match the `foo` that is in the current scope, not any `foo`. However "foo" can be parsed as a pattern (BIND_PAT -> NAME -> IDENT). Allowing such a rule through would result in renaming everything called `foo` to `bar`. It'd also be slow, since without a path, we'd have to use the slow-scan search mechanism.
Addresses two issues:
- keep the parens from dbg!() in case the call is chained or there is
semantic difference if parens are excluded
- Exclude the semicolon after the dbg!(); by checking if it was
accidentally included in the macro_call
investigated, but decided against:
fix ast::MacroCall extraction to never include semicolons at the end -
this logic lives in rowan.
Defensively shorten the macro_range if there is a semicolon token.
Deleted unneccessary temp variable macro_args
Renamed macro_content to "paste_instead_of_dbg", because it isn't a
simple extraction of text inside dbg!() anymore
It seems that Semantics::scope, if given a statement node, won't resolve
locals that were defined in the current scope, only in parent scopes.
Not sure if this is intended / expected behavior, but we work around it
for now by finding another nearby node to use as the scope (e.g. the
expression inside the EXPR_STMT).
5520: Add DocumentData to represent in-memory document with LSP info r=matklad a=kjeremy
At the moment this only holds document version information but in the near-future it will hold other things like semantic token delta info.
Co-authored-by: kjeremy <kjeremy@gmail.com>
5522: Increace tracing-tree version from 0.1.3 to 0.1.4 r=kjeremy a=vandenheuvel
Co-authored-by: Bram van den Heuvel <b.vandenheuvel@student.tudelft.nl>
5516: Better LSP conformance r=matklad a=vsrs
At the moment rust-analyzer does not fully conform to the LSP. This PR fixes two LSP related issues:
1) rust-analyzer sends predefined server capabilities and does not take supplied client capabilities in mind.
2) rust-analyzer uses dynamic `textDocument/didSave` registration even if the client does not support it.
Co-authored-by: vsrs <vit@conrlab.com>
5518: Use resolved paths in SSR rules r=matklad a=davidlattimore
The main user-visible changes are:
* SSR now matches paths based on whether they resolve to the same thing instead of whether they're written the same.
* So `foo()` won't match `foo()` if it's a different function `foo()`, but will match `bar::foo()` if it's the same `foo`.
* Paths in the replacement will now be rendered with appropriate qualification for their context.
* For example `foo::Bar` will render as just `Bar` inside the module `foo`, but might render as `baz::foo::Bar` from elsewhere.
* This means that all paths in the search pattern and replacement template must be able to be resolved.
* It now also matters where you invoke SSR from, since paths are resolved relative to wherever that is.
* Search now uses find-uses on paths to locate places to try matching. This means that when a path is present in the pattern, search will generally be pretty fast.
* Function calls can now match method calls again, but this time only if they resolve to the same function.
Co-authored-by: David Lattimore <dml@google.com>
This differs from how this used to work before I removed it in that:
a) It's only one direction. Function calls in the pattern can match
method calls in the code, but not the other way around.
b) We now check that the function call in the pattern resolves to the
same function as the method call in the code.
The lack of (b) was the reason I felt the need to remove the feature
before.
Previously, submatches were handled simply by searching in placeholders
for more matches. That only works if we search all nodes in the tree
recursively. In a subsequent commit, I intend to make search not always
be recursive recursive. This commit prepares for that by finding all
matches, even if they overlap, then nesting them and removing
overlapping matches.
In a later commit, paths in templates will be resolved. This allows us
to render the path with appropriate qualifiers for its context. Here we
prepare for that change by updating existing tests where I'd previously
not bothered to define the items that the template referred to.
The methods `edits_for_file` and `find_matches_in_file` are replaced with just `edits` and `matches`. This simplifies the API a bit, but more importantly it makes it possible in a subsequent commit for SSR to decide to not search all files.
Also renamed find_matches to slow_scan_node to reflect that it's a slow
way to do things. Actually the name came from a later commit and
probably makes more sense once there's an alternative.
This is in preparation for a subsequent commit where we add special
handling for paths in the template, allowing them to be qualified
differently in different contexts.
Previously we had:
- Multiple rules
- Each rule had its pattern parsed as an expression, path etc
This meant that there were two levels at which there could be multiple
rules.
Now we just have multiple rules. If a pattern can parse as more than one
kind of thing, then they get stored as multiple separate rules.
We also now don't have separate fields for the different kinds of things
that a pattern can parse as. This makes adding new kinds of things
simpler.
Previously, add_search_pattern would construct a rule with a dummy
replacement. Now the replacement is an Option. This is slightly cleaner
and also opens the way for parsing the replacement template as the same
kind of thing as the search pattern.
5498: assists: change_return_type_to_result: clarify assist description r=matklad a=matthiaskrgr
I had a -> Option<PathBuf> fn, which I wanted to change to Result<PathBuf, _>, but despite advertising to do so, the assist did not change the result type to Result<PathBuf, _> but instead just wrapped it in a Result: <Result<Option<PathBuf>, _>.
I changed the assist description to "Wrap return type in Result" to clarify that the assist only wraps the preexisting type and does not do any actual Option-to-Result refactoring.
Co-authored-by: Matthias Krüger <matthias.krueger@famsik.de>
5497: Store macro invocation parameters as text instead of tt r=jonas-schievink a=lnicola
We don't want to expand macros on every source change because it can be arbitrarily slow, but the token trees can be rather large. So instead we can cache the invocation parameters (as text).
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
I had a -> Option<PathBuf> fn, which I wanted to change to Result<PathBuf, _>, but despite advertising to do so, the assist did not
change the result type to Result<PathBuf, _> but instead just wrapped it in a Result: <Result<Option<PathBuf>, _>.
I changed the assist description to "Wrap return type in Result" to clarify that the assist only wraps the preexisting type and does
not do any deep Option-to-Result refactoring.
5481: Track document versions in the server r=kjeremy a=kjeremy
This also pushes diagnostics for the correct file version on close so that when it is reopened stale diagnostics are not shown.
Closes#5452
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
5478: Replace existing visibility modifier in fix_visibility r=matklad a=TimoFreiberg
Fixes#4636
I would have liked to do something about the `// FIXME: this really should be a fix for diagnostic, rather than an assist.`, but that would take a while and there's no reason not to fix this immediately.
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
5451: Highlight more cases of SyntaxKind when it is a punctuation r=matklad a=GrayJack
This maybe closes#5406
Closes #5453
Separate what one expect to be a punctuation semantic token (like `,`, `;`, `(`, etc), and what is not (`&`, `::`, `+`, etc)
5463: Bump lexer r=matklad a=kjeremy
Since we're now on rust 1.45
5465: Bump chalk r=matklad a=kjeremy
5466: Do not show default types in function and closure return values r=matklad a=SomeoneToIgnore
Avoid things like
<img width="522" alt="image" src="https://user-images.githubusercontent.com/2690773/87985936-1bbe4f80-cae5-11ea-9b8a-5383d896c296.png">
Co-authored-by: GrayJack <gr41.j4ck@gmail.com>
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
5467: Allow null or empty values for configuration r=matklad a=kjeremy
Allow the client to respond to `workspace/configuration` with `null` values. This is allowed per the spec if the client doesn't know about the configuration we've requested.
This also protects against `null` or `{}` during initialize. I'm not sure if we want to interpret `{}` as "don't change anything" but I think that's a reasonable approach to take.
This should help with LSP clients working out of the box.
Fixes#5464
Co-authored-by: kjeremy <kjeremy@gmail.com>
It is currently unused, but, in the future, it will be used to:
* drive certain UX (symbols search by default will look only in the
members)
* improve performance (rust-analyzer will assume that non-members
change rarely)
If not specified, is_workspace member is inferred from the path
5423: Correctly resolve assoc. types in path bindings r=matklad a=jonas-schievink
Previously invoking goto def on `impl Iterator<Item<|> = ()>` would go to `Iterator`, not `Item`. This fixes that.
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
5327: Mark fixes from check as preferred r=matklad a=kjeremy
This allows us to run the auto fix command from vscode to automatically fix diagnostics in the file.
They are also distinguished in the UI.
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
4676: proc_macro: fix current nightly/future stable ABI incompatibility r=matklad a=robojumper
With rust-lang/rust#72233, the proc_macro ABI has changed, leading to the `test_derive_serialize_proc_macro` test believing that `serde` wants to pass the struct name as a byte string literal instead of a string literal.
Fixes#4866.
Co-authored-by: robojumper <robojumper@gmail.com>
5401: Implement Chalk closure support r=matklad a=flodiebold
This makes use of Chalk's closure support, which means we can get rid of our last built-in impls and a bunch of other surrounding stuff.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
5350: Filter assists r=matklad a=kjeremy
Uses the `CodeActionContext::only` field to compute only those assists the client cares about.
It works but I don't really like the implementation.
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
5345: Semantic Highlighting: Emit mutable modifier for 'self' when applicable r=matklad a=Veykril
This PR implements emitting the mutable modifier for the self keyword when applicable for semantic highlighting as mentioned in #5041. The rendered highlighting test html file:

As you can see it does not emit the modifier when `self` is not used in a mutable context even if it is declared mutably in the enclosing function. I'm not sure if this is actually something wanted or not.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
5377: Fix classify_name_ref on multi-path macro calls r=matklad a=jonas-schievink
Previously, "go to definition" on `log<|>::info!(...)` would go to the `info!` macro, not to the `log` crate. This fixes that.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5375: Use more explicit type for save registration r=matklad a=kjeremy
This was introduced in the latest lsp-types
Co-authored-by: kjeremy <kjeremy@gmail.com>
5367: missing impl members: remove assoc. type bounds r=matklad a=jonas-schievink
Previously "Add missing impl members" would paste bounds on associated types into the impl, which is not allowed. This removes them before pasting the item.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5355: Add a license field to all the crates r=matklad a=JohnTitor
Some are unnecessary but it's okay to have it, I think.
cc https://github.com/rust-lang/rust/issues/74269
Co-authored-by: Yuki Okushi <huyuumi.dev@gmail.com>
We dont' need this for perf. `Relaxed` ordering is enough here, as we
only have one location. I prefer to use minimal ordering, because that
makes it easier to reason about the code.
5331: Fix#4966 r=flodiebold a=flodiebold
We add a level of binders when converting our function pointer to Chalk's; we need to remove it again on the way back.
Fixes#4966.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
5326: infer: Add type inference support for Union types r=flodiebold a=otavio
This adds the type inference to Union types and add a small test case
for it, ensuring it keeps working in future.
Fixes: #5277
Signed-off-by: Otavio Salvador <otavio@ossystems.com.br>
----
#
Co-authored-by: Otavio Salvador <otavio@ossystems.com.br>
This adds the type inference to Union types and add a small test case
for it, ensuring it keeps working in future.
Fixes: #5277
Signed-off-by: Otavio Salvador <otavio@ossystems.com.br>
cc #4944
cc #5317
This doesn't fully close#4944 -- looks like we hit SO in syntax
highlighting, when we use `Semantics::expand_macro`.
Seems like we need to place expansion limit on the macro itself (store
it as a part of MacroCallId?)!
4996: Correctly generate new struct field in file containing struct def r=matklad a=TimoFreiberg
WIP because the test doesn't pass.
Testing the fix by hand looked good, although quickfixes seem to not support setting the editor cursor yet, which i think we want for "generate missing defs from usage" fixes.
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
5286: Only take first 500 syntax errors r=jonas-schievink a=yihuang
Too many syntax errors make some editor/ide slow, fix#3434.
Co-authored-by: yihuang <yi.codeplayer@gmail.com>
5270: Add argument count mismatch diagnostic r=matklad a=jonas-schievink
Closes https://github.com/rust-analyzer/rust-analyzer/issues/4025.
This currently has one false positive on this line, where `max` is resolved to `Iterator::max` instead of `Ord::max`:
8aa10c00a4/crates/expect/src/lib.rs (L263)
(I have no idea why it thinks that `usize` is an `Iterator`)
TODO:
* [x] Tests
* [x] Improve diagnostic text for method calls
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Previous solution for binning paths into disjoint directories was
simple and fast -- just a single binary search.
Unfortunatelly, it wasn't coorrect: if the ditr are
/d
/d/a
/d/c
then partitioning the file /d/b/lib.rs won't pick /d as a correct
directory.
The correct solution here is a trie, but it requires exposing path
components.
So, we use a poor man's substitution -- a *vector* of sorted paths,
such that each bucket is prefix-free
closes#5246
5244: Add a command to compute memory usage statistics r=matklad a=jonas-schievink
This allows inspecting memory usage on a live rust-analyzer instance after it has been used interactively.
This will only work with `--features jemalloc`, so maybe it should print something more useful when that's not available? Right now it will just print 0 Bytes for every query.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5245: Refactor AssistBuilder to manage a SourceChange r=matklad a=theduke
`AssistBuilder` now managaes a full `SourceChange` instead of a
`Vec<SourceFileEdit>`.
This prepares AssistBuilder to handle creation of new files.
Co-authored-by: Christoph Herzog <chris@theduke.at>
5197: SSR internal refactorings r=davidlattimore a=davidlattimore
- Extract error code out to a separate module
- Improve error reporting when a test fails
- Refactor matching code
- Update tests so that all paths in search patterns can be resolved
Co-authored-by: David Lattimore <dml@google.com>
5211: Fix inference of indexing argument (partly) r=flodiebold a=flodiebold
We need to add the `T: Index<Arg>` obligation to be resolved later as well, otherwise we can't make inferences about `Arg` later based on the `Index` impls.
This still doesn't fix indexing with integer variables though; there's a further problem with Chalk floundering because of the variable, I think.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
We need to add the `T: Index<Arg>` obligation to be resolved later as well,
otherwise we can't make inferences about `Arg` later based on the `Index` impls.
This still doesn't fix indexing with integer variables though; there's a further
problem with Chalk floundering because of the variable, I think.
5209: Fixes to memory usage stats r=matklad a=jonas-schievink
This brings the unaccounted memory down from 287mb to 250mb, and displays memory used by VFS and "other" allocations.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5116: Categorize assists r=matklad a=kjeremy
Categorize assists so that editors can use them. Follows the LSP spec pretty close (and some things may need adjustments) but this populates the Refactor menu in vscode and pushes quickfixes through again.
This is a prerequisite to filtering out assists that the client doesn't care about.
Fixes#4147
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
Co-authored-by: kjeremy <kjeremy@gmail.com>
5192: Implement rust-analyzer feature configuration to tests. r=matklad a=daxpedda
Fixes#3198.
I'm unsure if it is desired this way, maybe we want to make a seperate configuration?
Co-authored-by: daxpedda <daxpedda@gmail.com>
5089: Disable auto-complete on comments r=matklad a=BGluth
Resolves#4907 by disabling any auto-completion on comments.
As flodiebold [pointed out](https://github.com/rust-analyzer/rust-analyzer/issues/4907#issuecomment-648439979), in the future we may want to support some form of auto-completion within doc comments, but for now it was suggested to just disable auto-completion on them entirely.
The implementation involves adding a new field `is_comment` to `CompletionContext` and checking if the immediate token we auto-completed on is a comment. I couldn't see a case where we need to check any of the ancestors, but let me know if this is not sufficient. I also wasn't sure if it was necessary to add a new field to this struct, but I decided it's probably the best option if we want to potentially do auto-completion on doc comments in the future.
Finally, the three tests I added should I think ideally not filter results by `CompletionKind::Keyword`, but if I want to get unfiltered results, I need access to a non-public function [get_all_completion_items](9a4d02faf9/crates/ra_ide/src/completion/test_utils.rs (L32-L39)) which I don't know if I should make public just for this.
5161: SSR: Add initial support for placeholder constraints r=matklad a=davidlattimore
5184: Always install required nightly extension if current one is not nightly r=matklad a=Veetaha
This is weird, but having switched back to stable by uninstalling the extension appears that vscode doesn't destroy the `PersistentState` and thus changing to `nightly` channel doesn't work because the last check for nightly extension was less than 1 hour ago. The simple solution is to skip this check if we know that the current extension version is not nightly.
5185: Force showing extension activation error pop-up notification r=matklad a=Veetaha
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/5091
5186: fix: correct pd/ppd/tfn/tmod completion doc r=matklad a=fannheyward
a33eefa3b2/crates/ra_ide/src/completion/complete_snippet.rs (L23-L24)
Co-authored-by: BGluth <gluthb@gmail.com>
Co-authored-by: David Lattimore <dml@google.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
Co-authored-by: Heyward Fann <fannheyward@gmail.com>
5149: Implement Chalk variable kinds r=flodiebold a=flodiebold
This means we need to keep track of the kinds (general/int/float) of variables in `Canonical`, which requires some more ceremony. (It also exposes some places where we're not really dealing with canonicalization correctly -- another thing to be cleaned up when we switch to using Chalk's types directly.)
Should fix the last remaining issue of #2534.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
This means we need to keep track of the kinds (general/int/float) of variables
in `Canonical`, which requires some more ceremony. (It also exposes some places
where we're not really dealing with canonicalization correctly -- another thing
to be cleaned up when we switch to using Chalk's types directly.)
Should fix the last remaining issue of #2534.
5175: More memory-efficient impl collection r=matklad a=jonas-schievink
This saves roughly 90 MB in `ImplsFromDepsQuery`, which used to copy the list of all impls from libcore into *every* crate in the graph. It also stops collecting inherent impls from dependencies entirely, as those can only be located within the crate defining the self type.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
This makes the intention of inherent vs. trait impls somewhat more
clear and also fixes (?) an issue where trait impls with an unresolved
trait were added as inherent impls instead (hence the test changes).
5154: Structured search debugging r=matklad a=davidlattimore
Adds a "search" mode to the rust-analyzer binary that does structured search (SSR without the replace part). This is intended primarily for debugging why a bit of code isn't matching a pattern.
5157: Use dynamic dispatch in AstDiagnostic r=matklad a=lnicola
Co-authored-by: David Lattimore <dml@google.com>
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5142: analysis-stats: allow parallel type inference r=matklad a=jonas-schievink
This is mostly just for testing/fun, but it looks like type inference can be sped up massively with little to no effort (since it runs after the serial phases are already done).
Without `--parallel`:
```
Item Collection: 16.43597698s, 683mb allocated 720mb resident
Inference: 25.429774879s, 1720mb allocated 1781mb resident
Total: 41.865866352s, 1720mb allocated 1781mb resident
```
With `--parallel`:
```
Item Collection: 16.380369815s, 683mb allocated 735mb resident
Parallel Inference: 7.449166445s, 1721mb allocated 1812mb resident
Inference: 143.437157ms, 1721mb allocated 1812mb resident
Total: 23.973303611s, 1721mb allocated 1812mb resident
```
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5136: Split namespace maps in `ItemScope` r=jonas-schievink a=jonas-schievink
Reduces memory usage of the CrateDefMap query by ~130 MB (50%) on r-a.
I was also looking into handling glob imports more efficiently (storing scope chains instead of always duplicating everything into the glob-importing module's scope), but it seems that this already gives the most significant wins.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5101: Add expect -- a light-weight alternative to insta r=matklad a=matklad
This PR implements a small snapshot-testing library. Snapshot updating is done by setting an env var, or by using editor feature (which runs a test with env-var set).
Here's workflow for updating a failing test:
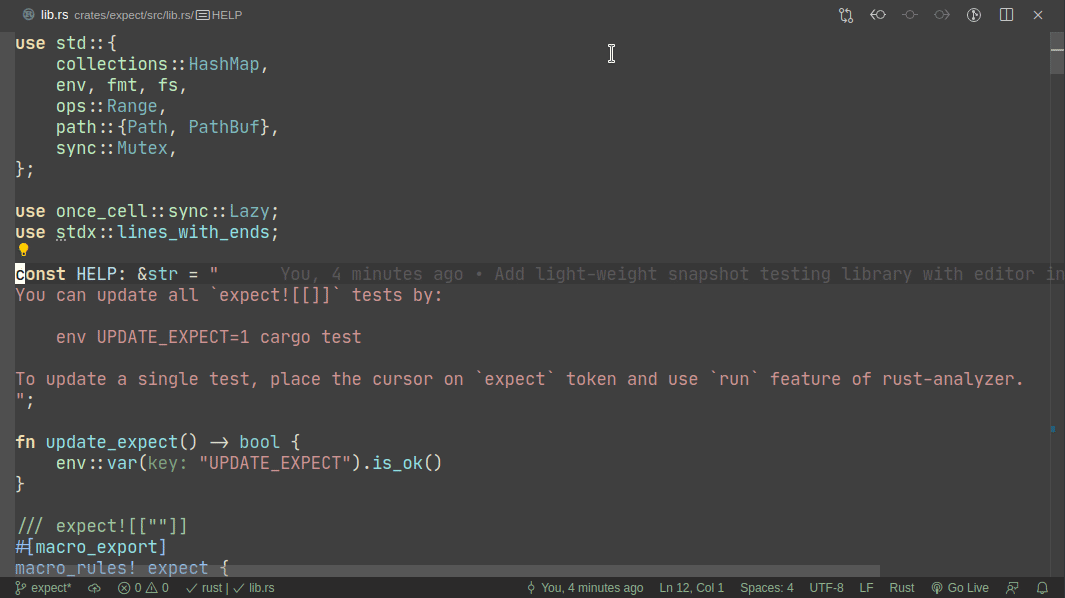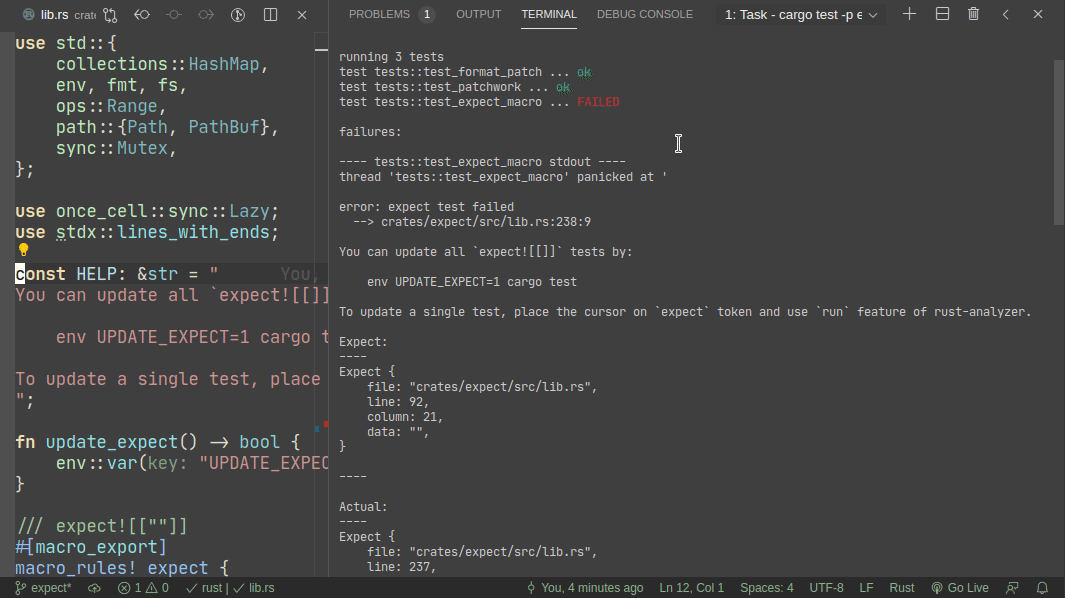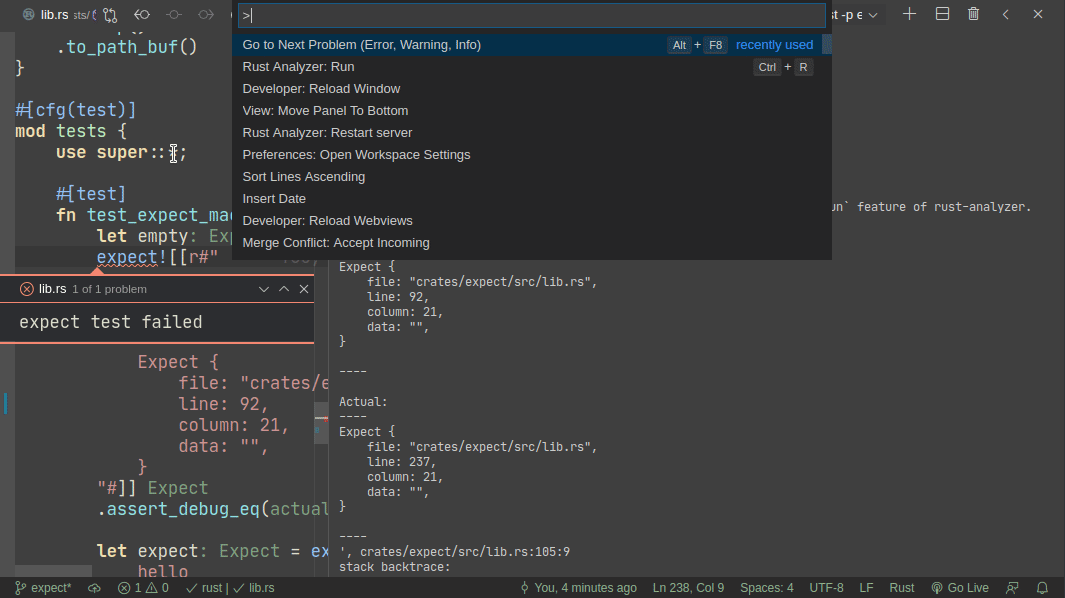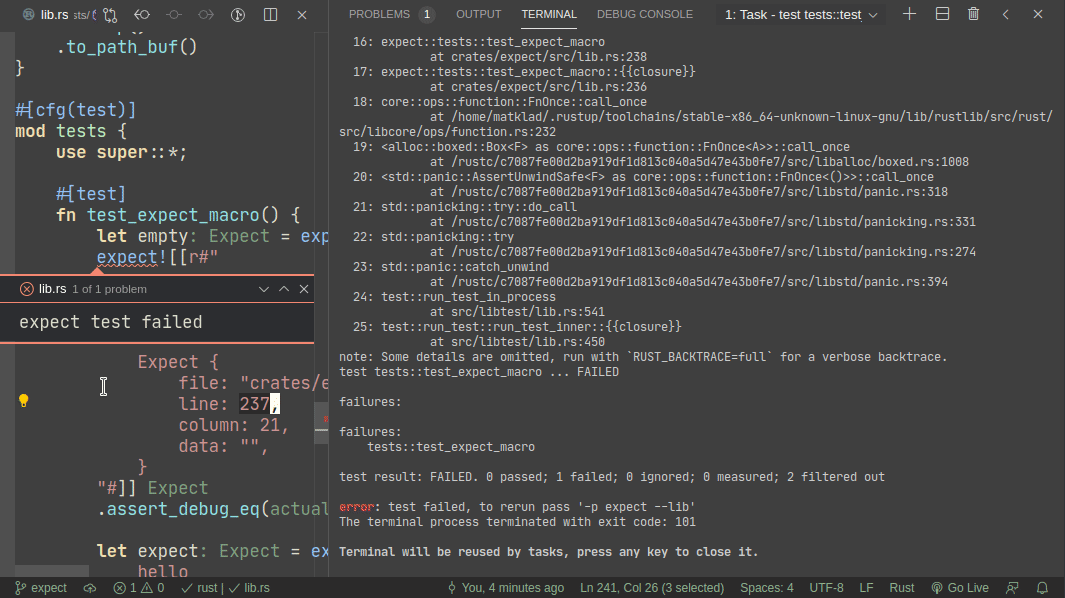
Here's workflow for adding a new test:
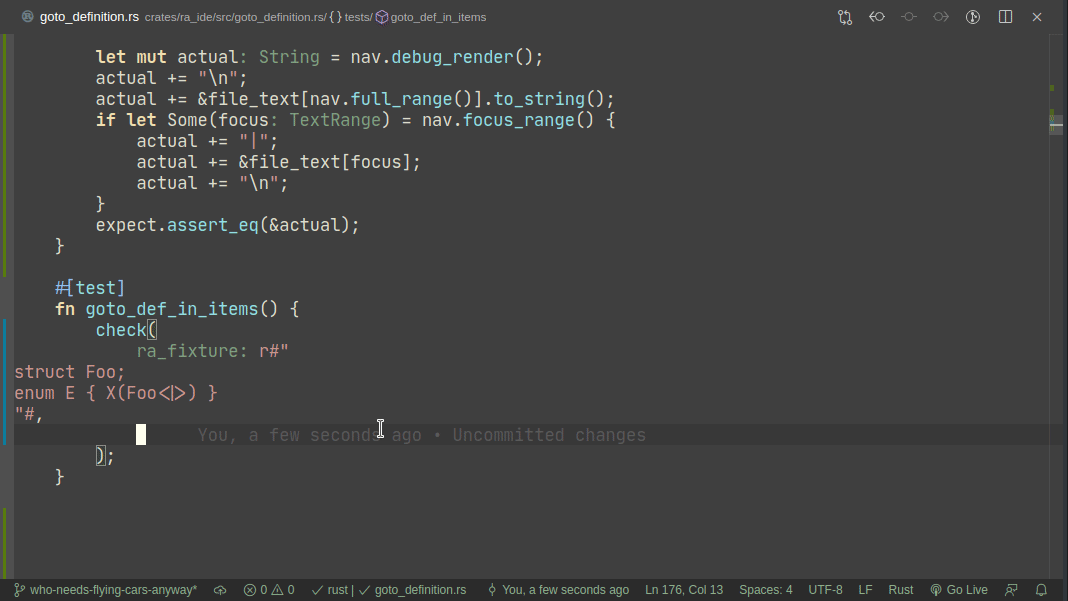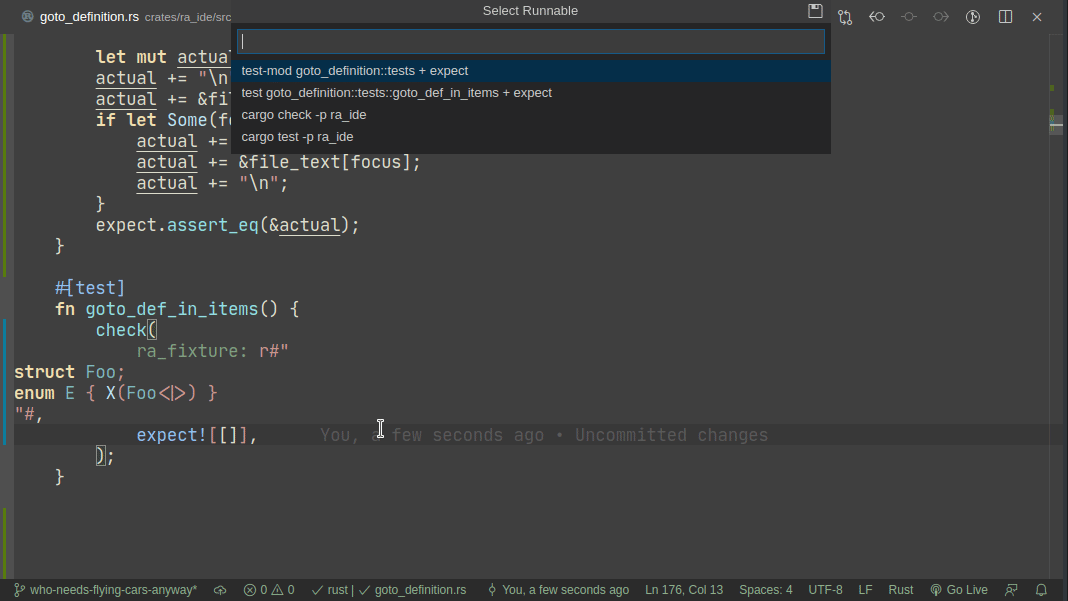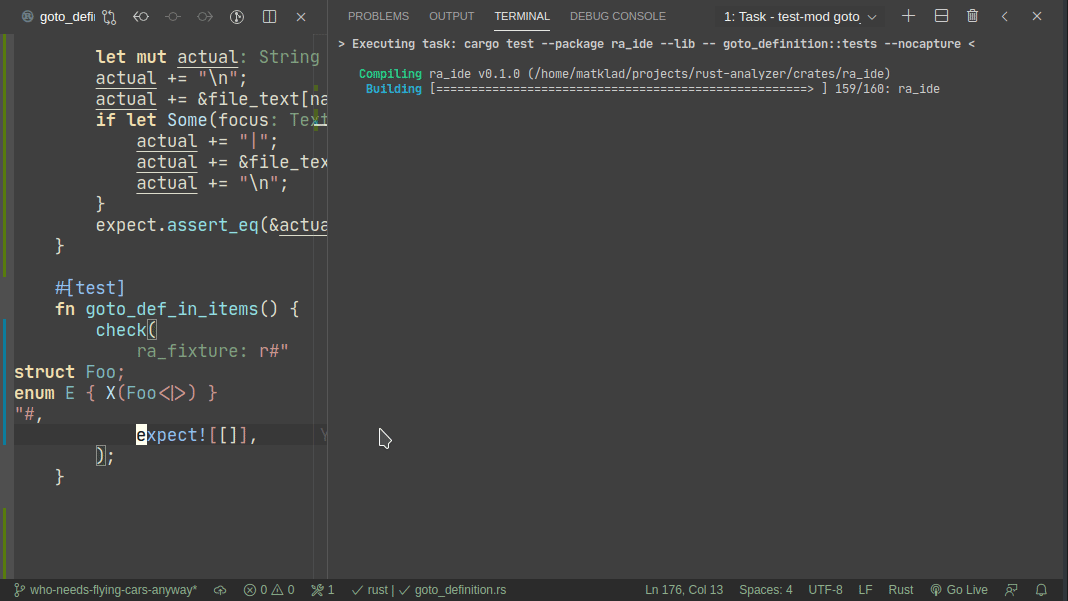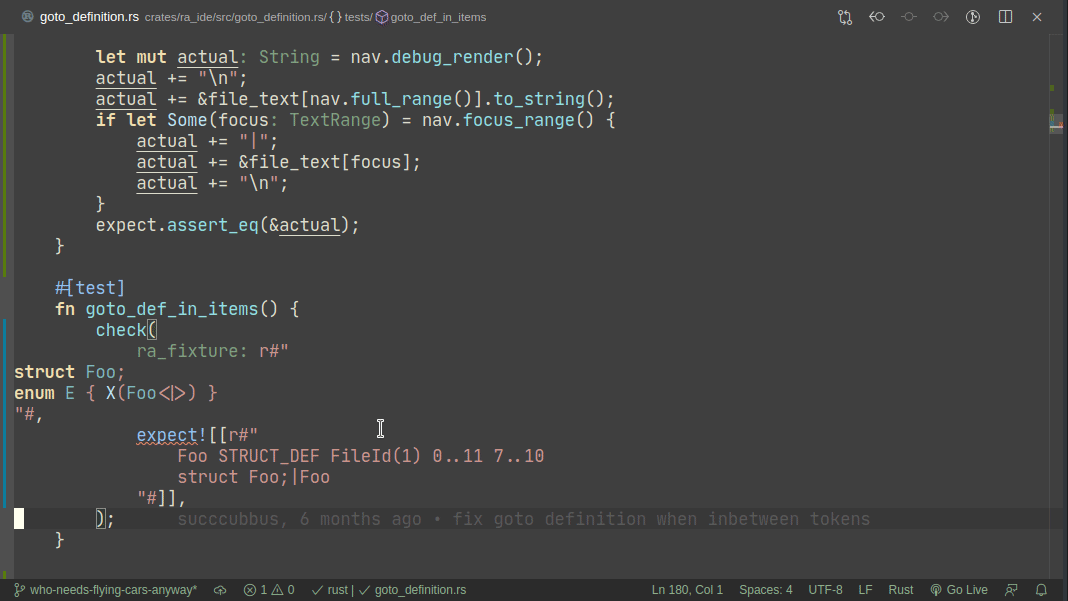
Note that colorized diffs are not implemented in this PR, but should be easy to add (we already use them in test_utils).
Main differences from insta (which is essential for rust-analyzer development, thanks @mitsuhiko!):
* self-updating tests, no need for a separate tool
* fewer features (only inline snapshots, no redactions)
* fewer deps (no yaml, no persistence)
* tighter integration with editor
* first-class snapshot object, which can be used to write test functions (as opposed to testing macros)
* trivial to tweak for rust-analyzer needs, by virtue of being a workspace member.
I think eventually we should converge to a single snapshot testing library, but I am not sure that `expect` is exactly right, so I suggest rolling with both insta and expect for some time (if folks agree that expect might be better in the first place!).
# Editor Integration Implementation
The thing I am most excited about is the ability to update a specific snapshot from the editor. I want this to be available to other snapshot-testing libraries (cc @mitsuhiko, @aaronabramov), so I want to document how this works.
The ideal UI here would be a code action (💡). Unfortunately, it seems like it is impossible to implement without some kind of persistence (if you save test failures into some kind of a database, like insta does, than you can read the database from the editor plugin). Note that it is possible to highlight error by outputing error message in rustc's format. Unfortunately, one can't use the same trick to implement a quick fix.
For this reason, expect makes use of another rust-analyzer feature -- ability to run a single test at the cursor position. This does need some expect-specific code in rust-analyzer unfortunately. Specifically, if rust-analyzer notices that the cursor is on `expect!` macro, it adds a special flag to runnable's JSON. However, given #5017 it is possible to approximate this well-enough without rust-analyzer integration. Specifically, an extension can register a special runner which checks (using regexes) if rust-anlyzer runnable covers text with specific macro invocation and do special magic in that case.
closes#3835
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
5120: Add a simple SSR subcommand to the rust-analyzer command line binary r=davidlattimore a=davidlattimore
Is adding the dependency on ra_ide_db OK? It's needed for the call to `db.local_roots()`
Co-authored-by: David Lattimore <dml@google.com>
5096: Fix handling of whitespace when applying SSR within macro expansions. r=matklad a=davidlattimore
I originally did replacement by passing in the full file text. Then as some point I thought I could do without it. Turns out calling .text() on a node coming from a macro expansion isn't a great idea, especially when you then try and use ranges from the original source to cut that text. The test I added here actually panics without the rest of this change (sorry I didn't notice sooner).
5097: Fix SSR prompt following #4919 r=matklad a=davidlattimore
Co-authored-by: David Lattimore <dml@google.com>
5126: Use more of FxHash* r=matklad a=lnicola
```
-rwxr-xr-x 1 me me 37917528 Jun 29 17:26 /home/me/.cargo/bin/rust-analyzer
-rwxr-xr-x 1 me me 37904056 Jun 29 18:14 /home/me/.cargo/bin/rust-analyzer
```
Saved 13.5 KB there :-).
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5124: (Partially) fix handling of type params depending on type params r=matklad a=flodiebold
If the first type parameter gets inferred, that's still not handled correctly; it'll require some more refactoring: E.g. if we have `Thing<T, F=fn() -> T>` and then instantiate `Thing<_>`, that gets turned into `Thing<_, fn() -> _>` before the `_` is instantiated into a type variable -- so afterwards, we have two type variables without any connection to each other.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
If the first type parameter gets inferred, that's still not handled correctly;
it'll require some more refactoring: E.g. if we have `Thing<T, F=fn() -> T>` and
then instantiate `Thing<_>`, that gets turned into `Thing<_, fn() -> _>` before
the `_` is instantiated into a type variable -- so afterwards, we have two type
variables without any connection to each other.
This test needs to be updated after every change (it contains line
number), which is annoying.
It also fails on windows due to \, so it's easier to remove it.
Move unsafe_expressions to unsafe_validation.rs, replace vec tracking of
child exprs with inline macro, add debug assert to ensure tracked
children match walked children exactly
I originally did replacement by passing in the full file text. Then as some point I thought I could do without it. Turns out calling .text() on a node coming from a macro expansion isn't a great idea, especially when you then try and use ranges from the original source to cut that text. The test I added here actually panics without the rest of this change (sorry I didn't notice sooner).
5033: Order of glob imports should not affect import shadowing r=Nashenas88 a=Nashenas88
Fixes#5032
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
5083: Micro-optimize lookahead in composite tokens r=matklad a=lnicola
I'm not sure that this is measurable, but can't hurt, I guess.
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
4945: do not suggest assist for return type to result in bad case r=matklad a=bnjjj
close#4826
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
5066: Infer type for slice wildcard patterns r=flodiebold a=adamrk
Resolves https://github.com/rust-analyzer/rust-analyzer/issues/4830
The issue is just that we were never inferring the type for the wildcard `..` in slice patterns.
Co-authored-by: adamrk <ark.email@gmail.com>
5063: Store field/variant attrs in ItemTree and use it for adt.rs queries r=jonas-schievink a=jonas-schievink
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
There are two reasons why we don't want a generic ra_progress crate
just yet:
*First*, it introduces a common interface between separate components,
and that is usually undesirable (b/c components start to fit the
interface, rather than doing what makes most sense for each particular
component).
*Second*, it introduces a separate async channel for progress, which
makes it harder to correlate progress reports with the work done. Ie,
when we see 100% progress, it's not blindly obvious that the work has
actually finished, we might have some pending messages still.
5015: Account for updated module ids when determining whether a resolution is changed r=matklad a=Nashenas88
Fixes#4943
5027: Make Debug less verbose for VfsPath and use Display in analysis-stats r=matklad a=lnicola
5028: Remove namedExports config r=matklad a=lnicola
Fixes a warning:
```
(!) Plugin commonjs: The namedExports option from "@rollup/plugin-commonjs" is deprecated. Named exports are now handled automatically.
```
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5024: Simplify r=matklad a=matklad
bors r+
🤖
5026: Disable file watching when running slow tests r=matklad a=matklad
This should rid us of the intermittent test failure
https://github.com/rust-analyzer/rust-analyzer/pull/5017#issuecomment-648717983
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4940: Add support for marking doctest items as distinct from normal code r=ltentrup a=Nashenas88
This adds `HighlightTag::Generic | HighlightModifier::Injected` as the default highlight for all elements within a doctest. Please feel free to suggest that a new tag be created or a different one used.

Fixes#4929Fixes#4939
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
Co-authored-by: Paul Daniel Faria <nashenas88@users.noreply.github.com>
5004: Fix panic in split/merge import assists r=matklad a=lnicola
Fixes#4368#4905
Not sure if this is the best solution here. Maybe the `make` functions should be fallible? We generally seem to be playing whack-a-mole with panics in assists, although most of them are `unwrap`s in the assist code.
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5002: Fix underflow panic when doctests are at top of file r=Nashenas88 a=Nashenas88
While debugging a comment at the top of a test string, I discovered that the offset calculations could underflow and panic. This only seemed to occur in tests, I assume because it's running a debug mode. The wrapping is quickly fixed later on in release mode, which is why this seems to have gone unnoticed. The new checks ensure the value is always positive or zero.
Co-authored-by: Paul Daniel Faria <nashenas88@users.noreply.github.com>
4999: SSR: Allow matching of whole macro calls r=matklad a=davidlattimore
Matching within macro calls is to come later and matching of macro calls within macro calls later still.
Co-authored-by: David Lattimore <dml@google.com>
5000: Remove RelativePathBuf from fixture r=matklad a=matklad
The paths in fixture are not really relative (the default one is
`/main.rs`), so it doesn't make sense to use `RelativePathBuf` here.
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4900: Self variant enum res fix r=BGluth a=BGluth
Fixes#4789.
This is my first PR for this project, so it's probably worth giving it an extra close look.
A few things that I wasn't sure about:
- Is `resolve_path` really the best place to perform this check? It seemed like a natural place, but perhaps there's a better place?
- When handling the new variant `PathResolution::VariantDef`, I couldn't see an obvious variant of `TypeNs` to return in `in_type_ns` for Unions and Structs.
Co-authored-by: BGluth <gluthb@gmail.com>
4921: Allow SSR to match type references, items, paths and patterns r=davidlattimore a=davidlattimore
Part of #3186
Co-authored-by: David Lattimore <dml@google.com>
4947: Replace `impls_in_trait` query with smarter use of `CrateImplDefs` r=matklad a=jonas-schievink
`impls_in_trait` was allocating a whopping ~400 MB of RAM when running analysis-stats on r-a itself.
Remove it, instead adding a query that computes a summary `CrateImplDefs` map for all transitive dependencies. This can probably still be made more efficient, but this already reduces the peak memory usage by 25% without much performance impact on analysis-stats.
**Before**:
```
Total: 34.962107188s, 2083mb allocated 2141mb resident
422mb ImplsForTraitQuery (deps)
250mb CrateDefMapQueryQuery
147mb MacroArgQuery
140mb TraitSolveQuery (deps)
68mb InferQueryQuery (deps)
62mb ImplDatumQuery (deps)
```
**After**:
```
Total: 35.261100358s, 1520mb allocated 1569mb resident
250mb CrateDefMapQueryQuery
147mb MacroArgQuery
144mb TraitSolveQuery (deps)
68mb InferQueryQuery (deps)
61mb ImplDatumQuery (deps)
45mb BodyQuery
45mb ImplDatumQuery
```
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
4958: Infer FnSig via Fn traits r=flodiebold a=adamrk
Addresses https://github.com/rust-analyzer/rust-analyzer/issues/4481.
When inferring types check if the callee implements one of the builtin `Fn` traits. Also autoderef the callee before trying to figure out it's `FnSig`.
Co-authored-by: adamrk <ark.email@gmail.com>
When referring to an associated type of a super trait, we used the substs of the
subtrait. That led to the #4931 crash if the subtrait had less parameters, but
it could also lead to other incorrectness if just the order was different.
Fixes#4931.
4851: Add quickfix to add a struct field r=TimoFreiberg a=TimoFreiberg
Related to #4563
I created a quickfix for record literals first because the NoSuchField diagnostic was already there.
To offer that quickfix for FieldExprs with unknown fields I'd need to add a new diagnostic (or create a `NoSuchField` diagnostic for those cases)
I think it'd make sense to make this a snippet completion (to select the generated type), but this would require changing the `Analysis` API and I'd like some feedback before I touch that.
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
4937: Allow overriding rust-analyzer display version r=matklad a=oxalica
The build script invokes `git` for version information which is displayed when rust-analyzer is called with `--version`. But in build environment without `git` or when the source code is not a git repo, there's no way to manually specify the version information.
This patch respects environment variable ~`REV`~ `RUST_ANALYZER_REV` in compile time for overriding.
Related: https://github.com/NixOS/nixpkgs/pull/90976
Co-authored-by: oxalica <oxalicc@pm.me>
The task of `partition` function is to bin the flat list of paths into
disjoint filesets. Ideally, it should be incremental -- each new file
should be added to a specific fileset.
However, preliminary measurnments show that it is actually fast enough
if we just optimize this to use a binary search instead of a linear
scan.
4930: Avoid all unchecked indexing in match checking r=flodiebold a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/4416, but replaces it with a false positive.
r? @flodiebold
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
4903: Add highlighting support for doc comments r=matklad a=Nashenas88
The language server protocol includes a semantic modifier for documentation. This change exports that modifier for doc comments so users can choose to highlight them differently compared to regular comments.
Example:
<img width="375" alt="Screen Shot 2020-06-16 at 10 34 14 AM" src="https://user-images.githubusercontent.com/1673130/84788271-f6599580-afbc-11ea-96e5-7a0215da620b.png">
CC @woody77
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
4934: Remove special casing for library symbols r=matklad a=matklad
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
4927: Better encapsulate reverse-mapping of files to cargo targets r=matklad a=matklad
We need to find a better way to do it...
CrateGraph by itself is fine, CargoWorkspace as well, but the mapping
between the two seems arbitrary...
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4913: Remove debugging code for incremental sync r=matklad a=lnicola
4915: Inspect markdown code fences to determine whether to apply syntax highlighting r=matklad a=ltentrup
Fixes#4904
4916: Warnings as hint or info r=matklad a=GabbeV
Fixes#4229
This PR is my second attempt at providing a solution to the above issue. My last PR(#4721) had to be rolled back(#4862) due to it overriding behavior many users expected. This PR solves a broader problem while trying to minimize surprises for the users.
### Problem description
The underlying problem this PR tries to solve is the mismatch between [Rustc lint levels](https://doc.rust-lang.org/rustc/lints/levels.html) and [LSP diagnostic severity](https://microsoft.github.io/language-server-protocol/specification#diagnostic). Rustc currently doesn't have a lint level less severe than warning forcing the user to disable warnings if they think they get to noisy. LSP however provides two severitys below warning, information and hint. This allows editors like VSCode to provide more fine grained control over how prominently to show different diagnostics.
Info severity shows a blue squiggly underline in code and can be filtered separately from errors and warnings in the problems panel.


Hint severity doesn't show up in the problems panel at all and only show three dots under the affected code or just faded text if the diagnostic also has the unnecessary tag.
### Solution
The solution provided by this PR allows the user to configure lists of of warnings to report as info severity and hint severity respectively. I purposefully only convert warnings and not errors as i believe it's a good idea to have the editor show the same severity as the compiler as much as possible.

### Open questions
#### Discoverability
How do we teach this to new and existing users? Should a section be added to the user manual? If so where and what should it say?
#### Defaults
Other languages such as TypeScript report unused code as hint by default. Should rust-analyzer similarly report some problems as hint/info by default?
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
Co-authored-by: Gabriel Valfridsson <gabriel.valfridsson@gmail.com>
Anchoring to the SourceRoot wont' work if the path is absolute:
#[path = "/tmp/foo.rs"]
mod foo;
Anchoring to a file will.
However, we *should* anchor, instead of just producing an abs path.
I can imagine a situation where, for example, rust-analyzer processes
crates from different machines (or, for example, from in-memory git
branch), where the same absolute path in different crates might refer
to different files in the end!
4876: Syntactic highlighting of NAME_REF for injections r=matklad a=ltentrup
This commit adds a function that tries to determine the syntax highlighting class of NAME_REFs based on the usage.
It is used for highlighting injections (such as highlighting of doctests) as the semantic logic will most of the time result in unresolved references.
It also adds a color to unresolved references in HTML encoding.
Follow up of #4683.
Fixes#4809.
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
This commit adds a function that tries to determine the syntax highlighting class of NAME_REFs based on the usage.
It is used for highlighting injections (such as highlighting of doctests) as the semantic logic will most of the time result in unresolved references.
It also adds a color to unresolved references in HTML encoding.
4860: Accept relative paths in rust-project.json r=matklad a=tweksteen
If a relative path is found as part of Crate.root_module or Root.path, interpret it as relative to the location of the rust-project.json file.
Fixes: #4816
Co-authored-by: Thiébaud Weksteen <tweek@google.com>
4882: _match.rs: improve comment formatting r=matklad a=jonas-schievink
This results in much nicer rustdoc output
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
It's a good idea to distinguish between absolute and relative paths at
the type level, to avoid accidental dependency on the cwd, which
really shouldn't matter for rust-analyzer service
4700: Add top level keywords completion r=matklad a=mcrakhman
This fixes the following issue: https://github.com/rust-analyzer/rust-analyzer/issues/4566.
Also added simple logic which filters the keywords which can be used with unsafe on the top level.
Co-authored-by: Mikhail Rakhmanov <rakhmanov.m@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4857: Fix invalid shorthand initialization diagnostic for tuple structs r=jonas-schievink a=OptimalStrategy
Initializing tuple structs explicitly, like in the example below, produces a "Shorthand struct initialization" diagnostic that leads to a compilation error when applied:
```rust
struct S(usize);
fn main() {
let s = S { 0: 0 }; // OK, but triggers the diagnostic
// let s = S { 0 }; // Compilation error
}
```
This PR adds a check that the field name is not a literal.
Co-authored-by: OptimalStrategy <george@usan-podgornov.com>
Co-authored-by: OptimalStrategy <17456182+OptimalStrategy@users.noreply.github.com>
4833: Separating parsing of `for` in predicates and types r=matklad a=matthewjasper
We now correctly accept `for<'a> (&'a F): Fn(&'a str)` in a where clause and correctly reject `for<'a> &'a u32` as a type.
Co-authored-by: Matthew Jasper <mjjasper1@gmail.com>
4849: Make known paths use `core` instead of `std` r=matklad a=jonas-schievink
I'm not sure if this causes problems today, but it seems like it easily could, if rust-analyzer processes the libstd sources for the right `--target` and that target is a `#![no_std]`-only target.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}