We discussed with @alice-i-cecile privately on iterators and agreed that making a custom ordered iterator over query makes no sense since materialization is required anyway and it's better to reuse existing components or code. Therefore, just adding an example to the documentation as requested.
Fixes#1470.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Introduced in #1778, not fixed by #1931
The size of `Lights` buffer currently is :
```rust
16 // (color, `[f32; 4]`)
+ 16 // (number of lights, `f32` encoded as a `[f32; 4]`)
+ 10 // (maximum number of lights)
* ( 16 // (light position, `[f32; 4]`
+ 16 // (color, `[16; 4]`)
+ 4 // (inverse_range_squared, `f32`)
)
-> 392
```
This makes the pbr shader crash when running with Xcode debugger or with the WebGL2 backend. They both expect a buffer sized 512. This can also be seen on desktop by adding a second light to a scene with a color, it's position and color will be wrong.
adding a second light to example `load_gltf`:
```rust
commands
.spawn_bundle(PointLightBundle {
transform: Transform::from_xyz(-3.0, 5.0, -3.0),
point_light: PointLight {
color: Color::BLUE,
..Default::default()
},
..Default::default()
})
.insert(Rotates);
```
before fix:
<img width="1392" alt="Screenshot 2021-04-16 at 19 14 59" src="https://user-images.githubusercontent.com/8672791/115060744-866fb080-9ee8-11eb-8915-f87cc872ad48.png">
after fix:
<img width="1392" alt="Screenshot 2021-04-16 at 19 16 44" src="https://user-images.githubusercontent.com/8672791/115060759-8cfe2800-9ee8-11eb-92c2-d79f39c7b36b.png">
This PR changes `inverse_range_squared` to be a `[f32; 4]` instead of a `f32` to have the expected alignement
Fixes#1921
Buffer was growing with the actual number of lights instead of being limited to the max number of lights.
As it's a query that can be exactly sized, I also switched `count()` to `len()`
This includes a lot of single line comments where either saying more wasn't helpful or due to me not knowing enough about things yet to be able to go more indepth. Proofreading is very much welcome.
Allows render resources to move data to the heap by boxing them. I did this as a workaround to #1892, but it seems like it'd be useful regardless. If not, feel free to close this PR.
I've had problems with compiling and running the pbr example:
```
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Compilation("glslang_shader_preprocess:\nInfo log:\nERROR: 0:40: \'#version\' : must occur first in shader \nERROR: 0:40: \'#version\' : bad profile name; use es, core, or compatibility \nERROR: 0:40: \'#version\' : bad tokens following profile -- expected newline \nERROR: 3 compilation errors. No code generated.\n\n\nDebug log:\n\n")', crates/bevy_render/src/pipeline/pipeline_compiler.rs:161:22
```
I've checked each shader, and only one shader hasn't had `#version` in the first line.
This change fixed my issue.
Fixes#1846
Got scared of the other "Requested resource does not exist" error at line 395 in `system_param.rs`, under `impl<'a, T: Component> SystemParamFetch<'a> for ResMutState<T> {`. Someone with better knowledge of the code might be able to go in and improve that one.
Implements `Byteable` and `RenderResource` for any array containing `Byteable` elements. This allows `RenderResources` to be implemented on structs with arbitrarily-sized arrays, among other things:
```rust
#[derive(RenderResources, TypeUuid)]
#[uuid = "2733ff34-8f95-459f-bf04-3274e686ac5f"]
struct Foo {
buffer: [i32; 256],
}
```
From suggestion from Godot workflows: https://github.com/bevyengine/bevy/issues/1730#issuecomment-810321110
* Add a feature `bevy_debug` that will make Bevy read a debug config file to setup some debug systems
* Currently, only one that will exit after x frames
* Could add option to dump screen to image file once that's possible
* Add a job in CI workflow that will run a few examples using [`swiftshader`](https://github.com/google/swiftshader)
* This job takes around 13 minutes, so doesn't add to global CI duration
|example|number of frames|duration|
|-|-|-|
|`alien_cake_addict`|300|1:50|
|`breakout`|1800|0:44|
|`contributors`|1800|0:43|
|`load_gltf`|300|2:37|
|`scene`|1800|0:44|
Fixes#1809. It makes it also possible to use `derive` for `SystemParam` inside ECS and avoid manual implementation. An alternative solution to macro changes is to use `use crate as bevy_ecs;` in `event.rs`.
The `VertexBufferLayout` returned by `crates\bevy_render\src\mesh\mesh.rs:308` was unstable, because `HashMap.iter()` has a random order. This caused the pipeline_compiler to wrongly consider a specialization to be different (`crates\bevy_render\src\pipeline\pipeline_compiler.rs:123`), causing each mesh changed event to potentially result in a different `PipelineSpecialization`. This in turn caused `Draw` to emit a `set_pipeline` much more often than needed.
This fix shaves off a `BindPipeline` and two `BindDescriptorSets` (for the Camera and for global renderresources) for every mesh after the first that can now use the same specialization, where it didn't before (which was random).
`StableHashMap` was not a good replacement, because it isn't `Clone`, so instead I replaced it with a `BTreeMap` which is OK in this instance, because there shouldn't be many insertions on `Mesh.attributes` after the mesh is created.
related to #1700
This PR:
* documents all methods on `Input<T>`
* adds documentation on the struct about how to use it, and how to implement it for a new input type
* renames method `update` to a easier to understand `clear`
* adds two methods to check for state and clear it after, allowing easier use in the case of #1700
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
- prints glsl compile error message in multiple lines instead of `thread 'main' panicked at 'called Result::unwrap() on an Err value: Compilation("glslang_shader_parse:\nInfo log:\nERROR: 0:335: \'assign\' : l-value required \"anon@7\" (can\'t modify a uniform)\nERROR: 0:335: \'\' : compilation terminated \nERROR: 2 compilation errors. No code generated.\n\n\nDebug log:\n\n")', crates/bevy_render/src/pipeline/pipeline_compiler.rs:161:22`
- makes gltf error messages have more context
New error:
```rust
thread 'Compute Task Pool (5)' panicked at 'Shader compilation error:
glslang_shader_parse:
Info log:
ERROR: 0:12: 'assign' : l-value required "anon@1" (can't modify a uniform)
ERROR: 0:12: '' : compilation terminated
ERROR: 2 compilation errors. No code generated.
', crates/bevy_render/src/pipeline/pipeline_compiler.rs:364:5
```
These changes are a bit unrelated. I can open separate PRs if someone wants that.
After an inquiry on Reddit about support for Directional Lights and the unused properties on Light, I wanted to clean it up, to hopefully make it ever so slightly more clear for anyone wanting to add additional light types.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
After #1697 I looked at all other Iterators from Bevy and added overrides for `size_hint` where it wasn't done.
Also implemented `ExactSizeIterator` where applicable.
This reduces the size of executables when using bevy as dylib by
ensuring that they get codegened in bevy_assets instead of the game
itself. This by extension avoids pulling in parts of bevy_tasks and
async_task.
Before this change the breakout example was 923k big after this change
it is only 775k big for cg_clif. For cg_llvm in release mode breakout
shrinks from 356k to 316k. For cg_llvm in debug mode breakout shrinks
from 3814k to 3057k.
In shaders, `vec3` should be avoided for `std140` layout, as they take the size of a `vec4` and won't support manual padding by adding an additional `float`.
This change is needed for 3D to work in WebGL2. With it, I get PBR to render
<img width="1407" alt="Screenshot 2021-04-02 at 02 57 14" src="https://user-images.githubusercontent.com/8672791/113368551-5a3c2780-935f-11eb-8c8d-e9ba65b5ee98.png">
Without it, nothing renders... @cart Could this be considered for 0.5 release?
Also, I learned shaders 2 days ago, so don't hesitate to correct any issue or misunderstanding I may have
bevy_webgl2 PR in progress for Bevy 0.5 is here if you want to test: https://github.com/rparrett/bevy_webgl2/pull/1
fixes#1772
1st commit: the limit was at 11 as the macro was not using a range including the upper end. I changed that as it feels the purpose of the macro is clearer that way.
2nd commit: as suggested in the `// TODO`, I added a `Config` trait to go to 16 elements tuples. This means that if someone has a custom system parameter with a config that is not a tuple or an `Option`, they will have to implement `Config` for it instead of the standard `Default`.
I think [collection, thing_removed_from_collection] is a more natural order than [thing_removed_from_collection, collection]. Just a small tweak that I think we should include in 0.5.
This PR adds normal maps on top of PBR #1554. Once that PR lands, the changes should look simpler.
Edit: Turned out to be so little extra work, I added metallic/roughness texture too. And occlusion and emissive.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
The only API to add a parent/child relationship between existing entities is through commands, there is no easy way to do it from `World`. Manually inserting the components is not completely possible since `PreviousParent` has no public constructor.
This PR adds two methods to set entities as children of an `EntityMut`: `insert_children` and `push_children`. ~~The API is similar to the one on `Commands`, except that the parent is the `EntityMut`.~~ The API is the same as in #1703.
However, the `Parent` and `Children` components are defined in `bevy_transform` which depends on `bevy_ecs`, while `EntityMut` is defined in `bevy_ecs`, so the methods are added to the `BuildWorldChildren` trait instead.
If #1545 is merged this should be fixed too.
I'm aware cart was experimenting with entity hierarchies, but unless it's a coming soon this PR would be useful to have meanwhile.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Load textures from gltf as linear when needed.
This is for #1632, but can be done independently and won't have any visible impact before.
* during iteration over materials, register textures that need to be loaded as linear
* during iteration over textures
* directly load bytes from external files instead of adding them as dependencies in the load context
* configure the texture the same way for buffered and external textures
* if the texture is linear rgb, set as linear rgb
Fixes#1753.
The problem was introduced while reworking the logic around stages' own criteria. Before #1675 they used to be stored and processed inline with the systems' criteria, and systems without criteria used that of their stage. After, criteria-less systems think they should run, always. This PR more or less restores previous behavior; a less cludge solution can wait until after 0.5 - ideally, until stageless.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Frustum culling has some pretty major gaps right now (such as not supporting sprite transform scaling and not taking into account projections). It should be disabled by default until it provides a solid experience across all bevy use cases.
This is intended to help protect users against #1671. It doesn't resolve the issue, but I think its a good stop-gap solution for 0.5. A "full" fix would be very involved (and maybe not worth the added complexity).
Removing the checks on this line https://github.com/bevyengine/bevy/blob/main/crates/bevy_sprite/src/frustum_culling.rs#L64 and running the "many_sprites" example revealed two corner case bugs in bevy_ecs. The first, a simple and honest missed line introduced in #1471. The other, an insidious monster that has been there since the ECS v2 rewrite, just waiting for the time to strike:
1. #1471 accidentally removed the "insert" line for sparse set components with the "mutated" bundle state. Re-adding it fixes the problem. I did a slight refactor here to make the implementation simpler and remove a branch.
2. The other issue is nastier. ECS v2 added an "archetype graph". When determining what components were added/mutated during an archetype change, we read the FromBundle edge (which encodes this state) on the "new" archetype. The problem is that unlike "add edges" which are guaranteed to be unique for a given ("graph node", "bundle id") pair, FromBundle edges are not necessarily unique:
```rust
// OLD_ARCHETYPE -> NEW_ARCHETYPE
// [] -> [usize]
e.insert(2usize);
// [usize] -> [usize, i32]
e.insert(1i32);
// [usize, i32] -> [usize, i32]
e.insert(1i32);
// [usize, i32] -> [usize]
e.remove::<i32>();
// [usize] -> [usize, i32]
e.insert(1i32);
```
Note that the second `e.insert(1i32)` command has a different "archetype graph edge" than the first, but they both lead to the same "new archetype".
The fix here is simple: just remove FromBundle edges because they are broken and store the information in the "add edges", which are guaranteed to be unique.
FromBundle edges were added to cut down on the number of archetype accesses / make the archetype access patterns nicer. But benching this change resulted in no significant perf changes and the addition of get_2_mut() for archetypes resolves the access pattern issue.
In the current impl, next clears out the entire stack and replaces it with a new state. This PR moves this functionality into a replace method, and changes the behavior of next to only change the top state.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR adds two systems to the sprite module that culls Sprites and AtlasSprites that are not within the camera's view.
This is achieved by removing / adding a new `Viewable` Component dynamically.
Some of the render queries now use a `With<Viewable>` filter to only process the sprites that are actually on screen, which improves performance drastically for scene swith a large amount of sprites off-screen.
https://streamable.com/vvzh2u
This scene shows a map with a 320x320 tiles, with a grid size of 64p.
This is exactly 102400 Sprites in the entire scene.
Without this PR, this scene runs with 1 to 4 FPS.
With this PR..
.. at 720p, there are around 600 visible sprites and runs at ~215 FPS
.. at 1440p there are around 2000 visible sprites and runs at ~135 FPS
The Systems this PR adds take around 1.2ms (with 100K+ sprites in the scene)
Note:
This is only implemented for Sprites and AtlasTextureSprites.
There is no culling for 3D in this PR.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I'm opening this prematurely; consider this an RFC that predates RFCs and therefore not super-RFC-like.
This PR does two "big" things: decouple run criteria from system sets, reimagine system sets as weapons of mass system description.
### What it lets us do:
* Reuse run criteria within a stage.
* Pipe output of one run criteria as input to another.
* Assign labels, dependencies, run criteria, and ambiguity sets to many systems at the same time.
### Things already done:
* Decoupled run criteria from system sets.
* Mass system description superpowers to `SystemSet`.
* Implemented `RunCriteriaDescriptor`.
* Removed `VirtualSystemSet`.
* Centralized all run criteria of `SystemStage`.
* Extended system descriptors with per-system run criteria.
* `.before()` and `.after()` for run criteria.
* Explicit order between state driver and related run criteria. Fixes#1672.
* Opt-in run criteria deduplication; default behavior is to panic.
* Labels (not exposed) for state run criteria; state run criteria are deduplicated.
### API issues that need discussion:
* [`FixedTimestep::step(1.0).label("my label")`](eaccf857cd/crates/bevy_ecs/src/schedule/run_criteria.rs (L120-L122)) and [`FixedTimestep::step(1.0).with_label("my label")`](eaccf857cd/crates/bevy_core/src/time/fixed_timestep.rs (L86-L89)) are both valid but do very different things.
---
I will try to maintain this post up-to-date as things change. Do check the diffs in "edited" thingy from time to time.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Resolves#1253#1562
This makes the Commands apis consistent with World apis. This moves to a "type state" pattern (like World) where the "current entity" is stored in an `EntityCommands` builder.
In general this tends to cuts down on indentation and line count. It comes at the cost of needing to type `commands` more and adding more semicolons to terminate expressions.
I also added `spawn_bundle` to Commands because this is a common enough operation that I think its worth providing a shorthand.
Updates the requirements on [fixedbitset](https://github.com/bluss/fixedbitset) to permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/bluss/fixedbitset/commits">compare view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
This is a rebase of StarArawns PBR work from #261 with IngmarBitters work from #1160 cherry-picked on top.
I had to make a few minor changes to make some intermediate commits compile and the end result is not yet 100% what I expected, so there's a bit more work to do.
Co-authored-by: John Mitchell <toasterthegamer@gmail.com>
Co-authored-by: Ingmar Bitter <ingmar.bitter@gmail.com>
Fixes#1692
Alternative to #1696
This ensures that the capacity actually grows in increments of grow_amount, and also ensures that Table capacity is always <= column and entity vec capacity.
Debug logs that describe the new logic (running the example in #1692)
[out.txt](https://github.com/bevyengine/bevy/files/6173808/out.txt)
Alternative to #1203 and #1611
Camera bindings have historically been "hacked in". They were _required_ in all shaders and only supported a single Mat4. PBR (#1554) requires the CameraView matrix, but adding this using the "hacked" method forced users to either include all possible camera data in a single binding (#1203) or include all possible bindings (#1611).
This approach instead assigns each "active camera" its own RenderResourceBindings, which are populated by CameraNode. The PassNode then retrieves (and initializes) the relevant bind groups for all render pipelines used by visible entities.
* Enables any number of camera bindings , including zero (with any set or binding number ... set 0 should still be used to avoid rebinds).
* Renames Camera binding to CameraViewProj
* Adds CameraView binding
# Problem Definition
The current change tracking (via flags for both components and resources) fails to detect changes made by systems that are scheduled to run earlier in the frame than they are.
This issue is discussed at length in [#68](https://github.com/bevyengine/bevy/issues/68) and [#54](https://github.com/bevyengine/bevy/issues/54).
This is very much a draft PR, and contributions are welcome and needed.
# Criteria
1. Each change is detected at least once, no matter the ordering.
2. Each change is detected at most once, no matter the ordering.
3. Changes should be detected the same frame that they are made.
4. Competitive ergonomics. Ideally does not require opting-in.
5. Low CPU overhead of computation.
6. Memory efficient. This must not increase over time, except where the number of entities / resources does.
7. Changes should not be lost for systems that don't run.
8. A frame needs to act as a pure function. Given the same set of entities / components it needs to produce the same end state without side-effects.
**Exact** change-tracking proposals satisfy criteria 1 and 2.
**Conservative** change-tracking proposals satisfy criteria 1 but not 2.
**Flaky** change tracking proposals satisfy criteria 2 but not 1.
# Code Base Navigation
There are three types of flags:
- `Added`: A piece of data was added to an entity / `Resources`.
- `Mutated`: A piece of data was able to be modified, because its `DerefMut` was accessed
- `Changed`: The bitwise OR of `Added` and `Changed`
The special behavior of `ChangedRes`, with respect to the scheduler is being removed in [#1313](https://github.com/bevyengine/bevy/pull/1313) and does not need to be reproduced.
`ChangedRes` and friends can be found in "bevy_ecs/core/resources/resource_query.rs".
The `Flags` trait for Components can be found in "bevy_ecs/core/query.rs".
`ComponentFlags` are stored in "bevy_ecs/core/archetypes.rs", defined on line 446.
# Proposals
**Proposal 5 was selected for implementation.**
## Proposal 0: No Change Detection
The baseline, where computations are performed on everything regardless of whether it changed.
**Type:** Conservative
**Pros:**
- already implemented
- will never miss events
- no overhead
**Cons:**
- tons of repeated work
- doesn't allow users to avoid repeating work (or monitoring for other changes)
## Proposal 1: Earlier-This-Tick Change Detection
The current approach as of Bevy 0.4. Flags are set, and then flushed at the end of each frame.
**Type:** Flaky
**Pros:**
- already implemented
- simple to understand
- low memory overhead (2 bits per component)
- low time overhead (clear every flag once per frame)
**Cons:**
- misses systems based on ordering
- systems that don't run every frame miss changes
- duplicates detection when looping
- can lead to unresolvable circular dependencies
## Proposal 2: Two-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in either the current frame's list of changes or the previous frame's.
**Type:** Conservative
**Pros:**
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- can result in a great deal of duplicated work
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 3: Last-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in the previous frame's list of changes.
**Type:** Exact
**Pros:**
- exact
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- change detection is always delayed, possibly causing painful chained delays
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 4: Flag-Doubling Change Detection
Combine Proposal 2 and Proposal 3. Differentiate between `JustChanged` (current behavior) and `Changed` (Proposal 3).
Pack this data into the flags according to [this implementation proposal](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804).
**Type:** Flaky + Exact
**Pros:**
- allows users to acc
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- users must specify the type of change detection required
- still quite fragile to system ordering effects when using the flaky `JustChanged` form
- cannot get immediate + exact results
- systems that don't run every frame miss changes
- duplicates detection when looping
## [SELECTED] Proposal 5: Generation-Counter Change Detection
A global counter is increased after each system is run. Each component saves the time of last mutation, and each system saves the time of last execution. Mutation is detected when the component's counter is greater than the system's counter. Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804). How to handle addition detection is unsolved; the current proposal is to use the highest bit of the counter as in proposal 1.
**Type:** Exact (for mutations), flaky (for additions)
**Pros:**
- low time overhead (set component counter on access, set system counter after execution)
- robust to systems that don't run every frame
- robust to systems that loop
**Cons:**
- moderately complex implementation
- must be modified as systems are inserted dynamically
- medium memory overhead (4 bytes per component + system)
- unsolved addition detection
## Proposal 6: System-Data Change Detection
For each system, track which system's changes it has seen. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- conceptually simple
**Cons:**
- requires storing data on each system
- implementation is complex
- must be modified as systems are inserted dynamically
## Proposal 7: Total-Order Change Detection
Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-754326523). This proposal is somewhat complicated by the new scheduler, but I believe it should still be conceptually feasible. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- efficient data storage relative to other exact proposals
**Cons:**
- requires access to the scheduler
- complex implementation and difficulty grokking
- must be modified as systems are inserted dynamically
# Tests
- We will need to verify properties 1, 2, 3, 7 and 8. Priority: 1 > 2 = 3 > 8 > 7
- Ideally we can use identical user-facing syntax for all proposals, allowing us to re-use the same syntax for each.
- When writing tests, we need to carefully specify order using explicit dependencies.
- These tests will need to be duplicated for both components and resources.
- We need to be sure to handle cases where ambiguous system orders exist.
`changing_system` is always the system that makes the changes, and `detecting_system` always detects the changes.
The component / resource changed will be simple boolean wrapper structs.
## Basic Added / Mutated / Changed
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 2
## At Least Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs after `detecting_system`
- verify at the end of tick 2
## At Most Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs once before `detecting_system`
- increment a counter based on the number of changes detected
- verify at the end of tick 2
## Fast Detection
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 1
## Ambiguous System Ordering Robustness
2 x 3 x 2 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs [before/after] `detecting_system` in tick 1
- `changing_system` runs [after/before] `detecting_system` in tick 2
## System Pausing
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs in tick 1, then is disabled by run criteria
- `detecting_system` is disabled by run criteria until it is run once during tick 3
- verify at the end of tick 3
## Addition Causes Mutation
2 design:
- Resources vs. Components
- `adding_system_1` adds a component / resource
- `adding system_2` adds the same component / resource
- verify the `Mutated` flag at the end of the tick
- verify the `Added` flag at the end of the tick
First check tests for: https://github.com/bevyengine/bevy/issues/333
Second check tests for: https://github.com/bevyengine/bevy/issues/1443
## Changes Made By Commands
- `adding_system` runs in Update in tick 1, and sends a command to add a component
- `detecting_system` runs in Update in tick 1 and 2, after `adding_system`
- We can't detect the changes in tick 1, since they haven't been processed yet
- If we were to track these changes as being emitted by `adding_system`, we can't detect the changes in tick 2 either, since `detecting_system` has already run once after `adding_system` :(
# Benchmarks
See: [general advice](https://github.com/bevyengine/bevy/blob/master/docs/profiling.md), [Criterion crate](https://github.com/bheisler/criterion.rs)
There are several critical parameters to vary:
1. entity count (1 to 10^9)
2. fraction of entities that are changed (0% to 100%)
3. cost to perform work on changed entities, i.e. workload (1 ns to 1s)
1 and 2 should be varied between benchmark runs. 3 can be added on computationally.
We want to measure:
- memory cost
- run time
We should collect these measurements across several frames (100?) to reduce bootup effects and accurately measure the mean, variance and drift.
Entity-component change detection is much more important to benchmark than resource change detection, due to the orders of magnitude higher number of pieces of data.
No change detection at all should be included in benchmarks as a second control for cases where missing changes is unacceptable.
## Graphs
1. y: performance, x: log_10(entity count), color: proposal, facet: performance metric. Set cost to perform work to 0.
2. y: run time, x: cost to perform work, color: proposal, facet: fraction changed. Set number of entities to 10^6
3. y: memory, x: frames, color: proposal
# Conclusions
1. Is the theoretical categorization of the proposals correct according to our tests?
2. How does the performance of the proposals compare without any load?
3. How does the performance of the proposals compare with realistic loads?
4. At what workload does more exact change tracking become worth the (presumably) higher overhead?
5. When does adding change-detection to save on work become worthwhile?
6. Is there enough divergence in performance between the best solutions in each class to ship more than one change-tracking solution?
# Implementation Plan
1. Write a test suite.
2. Verify that tests fail for existing approach.
3. Write a benchmark suite.
4. Get performance numbers for existing approach.
5. Implement, test and benchmark various solutions using a Git branch per proposal.
6. Create a draft PR with all solutions and present results to team.
7. Select a solution and replace existing change detection.
Co-authored-by: Brice DAVIER <bricedavier@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
fixes#1599
* Added doc on `Transform` and `GlobalTransform` to describe usage and how `GlobalTransform` is updated
* Documented all methods on `Transform`
* `#[doc(hidden)]` most constructors and methods mutating `GlobalTransform`, documented the other
* Mentioned z-ordering for `Transform` in 2d
Many a game will provide some sort of video settings where a window mode option is a common inclusion. I ran into problems, however, with [egui's](https://github.com/emilk/egui) `combo_box` that imposes a `PartialEq` necessity. Deriving the trait would fix this problem, and as this does not break any existing API it should be a non-controversial change.
`Color` can now be from different color spaces or representation:
- sRGB
- linear RGB
- HSL
This fixes#1193 by allowing the creation of const colors of all types, and writing it to the linear RGB color space for rendering.
I went with an enum after trying with two different types (`Color` and `LinearColor`) to be able to use the different variants in all place where a `Color` is expected.
I also added the HLS representation because:
- I like it
- it's useful for some case, see example `contributors`: I can just change the saturation and lightness while keeping the hue of the color
- I think adding another variant not using `red`, `green`, `blue` makes it clearer there are differences
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Fixes#1100
Implementors must make sure that `Reflect::any` and `Reflect::any_mut` both return the `self` reference passed in (both for logical correctness and downcast safety).
fixes#1161, fixes#1243
this adds two systems:
- first is keeping an hashmap of textures and their containing color materials, then listening to events on textures to select color materials that should be updated
- second is chained to send a modified event for all color materials that need updating
An alternative to StateStages that uses SystemSets. Also includes pop and push operations since this was originally developed for my personal project which needed them.
Error message noticed in #1475
When an asset type hasn't been added to the app but a load was attempted, the error message wasn't helpful:
```
thread 'IO Task Pool (0)' panicked at 'Failed to find AssetLifecycle for label Some("Mesh0/Primitive0"), which has an asset type 8ecbac0f-f545-4473-ad43-e1f4243af51e. Are you sure that is a registered asset type?', /.cargo/git/checkouts/bevy-f7ffde730c324c74/89a41bc/crates/bevy_asset/src/asset_server.rs:435:17
```
means that
```rust
.add_asset::<bevy::render::prelude::Mesh>()
```
needs to be added.
* type name was not given, only UUID, which may make it hard to identify type across bevy/plugins
* instruction were not helpful as the `register_asset_type` method is not public
new error message:
```
thread 'IO Task Pool (1)' panicked at 'Failed to find AssetLifecycle for label 'Some("Mesh0/Primitive0")', which has an asset type "bevy_render::mesh::mesh::Mesh" (UUID 8ecbac0f-f545-4473-ad43-e1f4243af51e). Are you sure this asset type has been added to your app builder?', /bevy/crates/bevy_asset/src/asset_server.rs:435:17
```
As mentioned in #1609.
I'm not sure if this is desirable, but on top of factoring the `set` and `set_untracked` methods I added a warning when the return value of `set` isn't used to mitigate similar issues.
I silenced it for the only occurence where it's currently done 68606934e3/crates/bevy_asset/src/asset_server.rs (L468)
This removes the `GltfError::UnsupportedMinFilter` error.
I don't think this error should have existed in the first place, because it prevents users from using assets that bevy could totally render (without mipmap support as of yet).
It's much better to load the asset properly and then render it (even if it looks a little ugly), than to refuse to load the asset at all, giving users a confusing error.
it's a followup of #1550
I think calling explicit methods/values instead of default makes the code easier to read: "what is `Quat::default()`" vs "Oh, it's `Quat::IDENTITY`"
`Transform::identity()` and `GlobalTransform::identity()` can also be consts and I replaced the calls to their `default()` impl with `identity()`
Fixes all warnings from `cargo doc --all`.
Those related to code blocks were introduced in #1612, but re-formatting using the experimental features in `rustfmt.toml` doesn't seem to reintroduce them.
These are largely targeted at beginners, as `Entity`, `Component` and `System` are the most obvious terms to search when first getting introduced to Bevy.
Idea being this would be easier to grasp for end-users. Problem with the logical defaults is this breaks current setups, because light will become 20 times less bright. But most folks won't have customized this resource or will not have used `..Default::default()` due to lack of other fields.
That override was added to support pre 1.45 Versions of Rust, but Bevy requires currently the latest stable rust release.
This means that the reason for the override doesn't apply anymore.
Removes `get_unchecked` and `get_unchecked_mut` from `Tables` and `Archetypes` collections in favor of safe Index implementations. This fixes a safety error in `Archetypes::get_id_or_insert()` (which previously relied on TableId being valid to be safe ... the alternative was to make that method unsafe too). It also cuts down on a lot of unsafe and makes the code easier to look at. I'm not sure what changed since the last benchmark, but these numbers are more favorable than my last tests of similar changes. I didn't include the Components collection as those severely killed perf last time I tried. But this does inspire me to try again (just in a separate pr)!
Note that the `simple_insert/bevy_unbatched` benchmark fluctuates a lot on both branches (this was also true for prior versions of bevy). It seems like the allocator has more variance for many small allocations. And `sparse_frag_iter/bevy` operates on such a small scale that 10% fluctuations are common.
Some benches do take a small hit here, but I personally think its worth it.
This also fixes a safety error in Query::for_each_mut, which needed to mutably borrow Query (aaahh!).
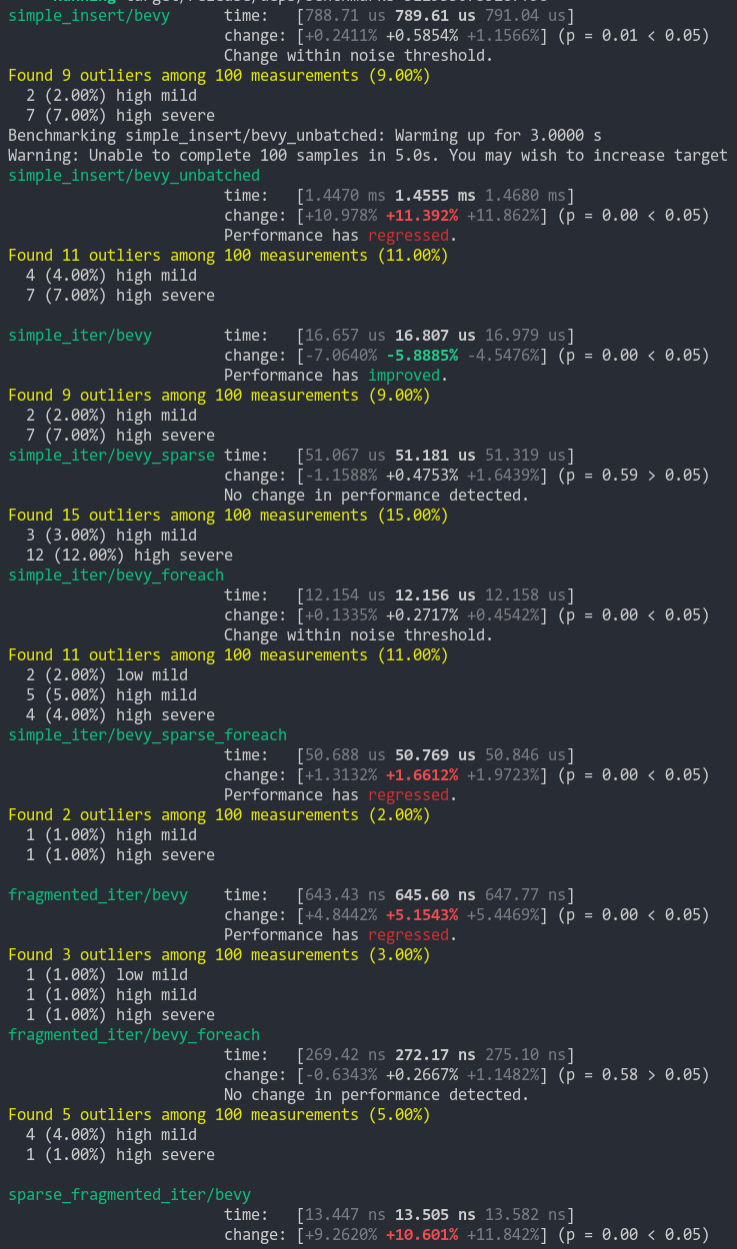
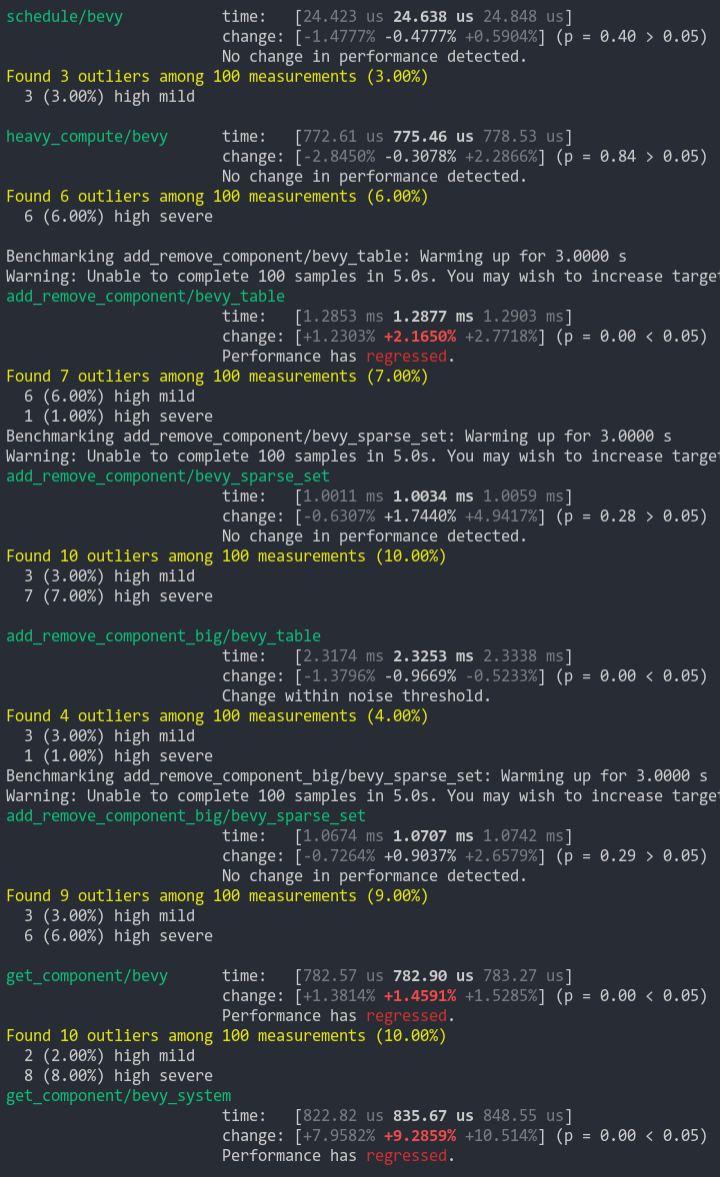
* Adds labels and orderings to systems that need them (uses the new many-to-many labels for InputSystem)
* Removes the Event, PreEvent, Scene, and Ui stages in favor of First, PreUpdate, and PostUpdate (there is more collapsing potential, such as the Asset stages and _maybe_ removing First, but those have more nuance so they should be handled separately)
* Ambiguity detection now prints component conflicts
* Removed broken change filters from flex calculation (which implicitly relied on the z-update system always modifying translation.z). This will require more work to make it behave as expected so i just removed it (and it was already doing this work every frame).
Should fix https://github.com/bevyengine/bevy/issues/1516.
I don't have any devices available to test this tbh but I feel like this was the only spot that could be causing a panic.
@ptircylinder since you posted this issue, could you please try to run the example on this branch and check if you get the same behavior while using your device? Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}