# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
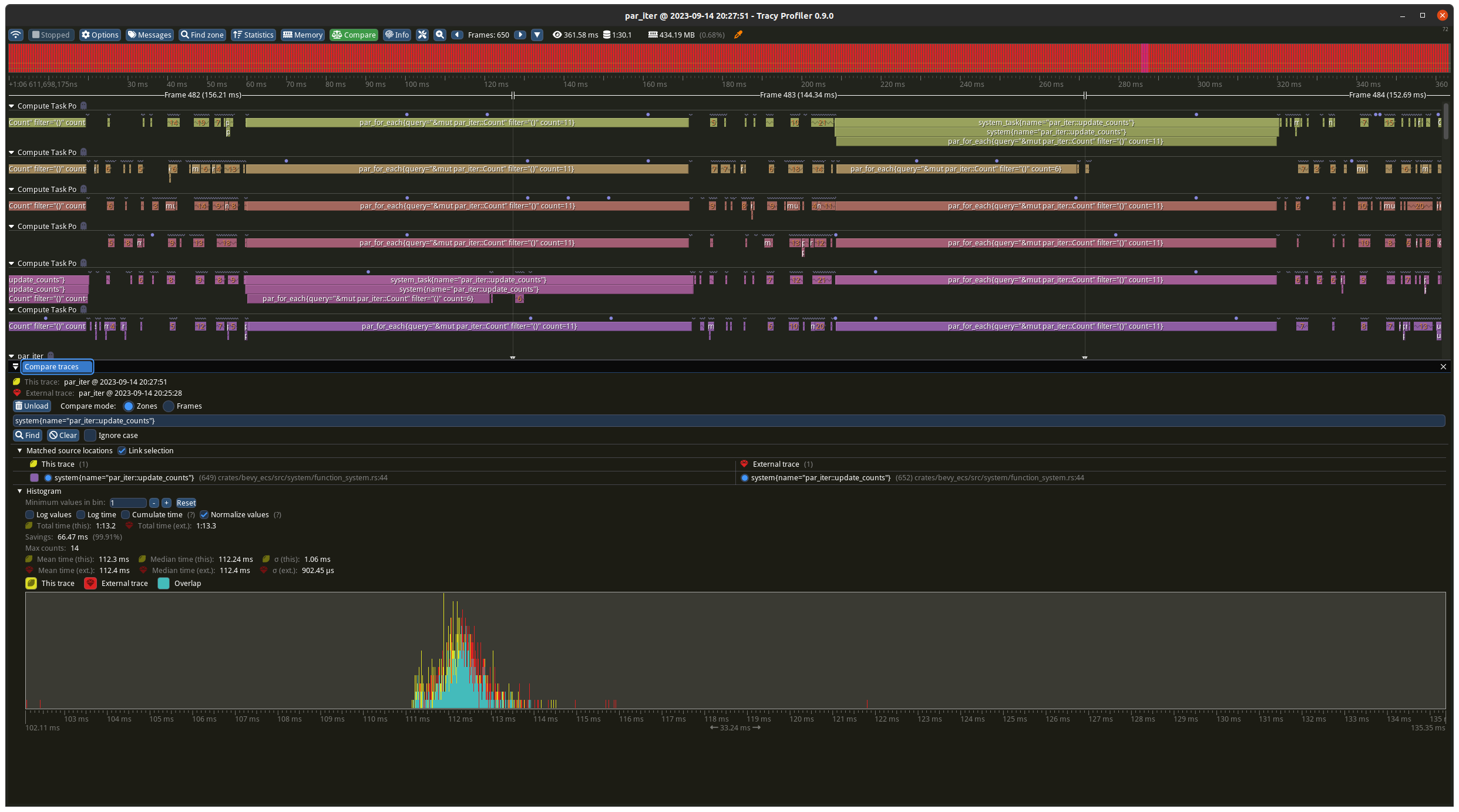
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
# Objective
The reasoning is similar to #8687.
I'm building a dynamic query. Currently, I store the ReflectFromPtr in
my dynamic `Fetch` type.
[See relevant
code](97ba68ae1e/src/fetches.rs (L14-L17))
However, `ReflectFromPtr` is:
- 16 bytes for TypeId
- 8 bytes for the non-mutable function pointer
- 8 bytes for the mutable function pointer
It's a lot, it adds 32 bytes to my base `Fetch` which is only
`ComponendId` (8 bytes) for a total of 40 bytes.
I only need one function per fetch, reducing the total dynamic fetch
size to 16 bytes.
Since I'm querying the components by the ComponendId associated with the
function pointer I'm using, I don't need the TypeId, it's a redundant
check.
In fact, I've difficulties coming up with situations where checking the
TypeId beforehand is relevant. So to me, if ReflectFromPtr makes sense
as a public API, exposing the function pointers also makes sense.
## Solution
- Make the fields public through methods.
---
## Changelog
- Add `from_ptr` and `from_ptr_mut` methods to `ReflectFromPtr` to
access the underlying function pointers
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
## Migration guide
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
# Objective
Rename RemovedComponents::iter/iter_with_id to read/read_with_id to make
it clear that it consume the data
Fixes#9755.
(It's my first pull request, if i've made any mistake, please let me
know)
## Solution
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
## Changelog
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
Deprecate RemovedComponents::iter/iter_with_id
Remove IntoIterator implementation
Update removal_detection example accordingly
---
## Migration Guide
Rename calls of RemovedComponents::iter/iter_with_id to
read/read_with_id
Replace IntoIterator iteration (&mut <RemovedComponents>) with .read()
---------
Co-authored-by: denshi_ika <mojang2824@gmail.com>
# Objective
When using `set_if_neq`, sometimes you'd like to know if the new value
was different from the old value so that you can perform some additional
branching.
## Solution
Return a bool from this function, which indicates whether or not the
value was overwritten.
---
## Changelog
* `DetectChangesMut::set_if_neq` now returns a boolean indicating
whether or not the value was changed.
## Migration Guide
The trait method `DetectChangesMut::set_if_neq` now returns a boolean
value indicating whether or not the value was changed. If you were
implementing this function manually, you must now return `true` if the
value was overwritten and `false` if the value was not.
# Objective
- The tick access methods mention "ticks" (as in: plural). Yet, most of
them only access a single tick.
## Solution
- Rename those methods and fix docs to reflect the singular aspect of
the return values
---
## Migration Guide
The following method names were renamed, from `foo_ticks_bar` to
`foo_tick_bar` (`ticks` is now singular, `tick`):
- `ComponentSparseSet::get_added_ticks` → `get_added_tick`
- `ComponentSparseSet::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks` → `get_added_tick`
- `Column::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks_unchecked` → `get_added_tick_unchecked`
- `Column::get_changed_ticks_unchecked` → `get_changed_tick_unchecked`
# Objective
- Make it possible to snapshot/save states
- Useful for re-using parts of the state system for rollback safe states
- Or to save states with scenes/savegames
## Solution
- Conditionally add the derive if the `bevy_reflect` is enabled
---
## Changelog
- `NextState<S>` and `State<S>` now implement `Reflect` as long as `S`
does.
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
- Fixes#9244.
## Solution
- Changed the `(Into)SystemSetConfigs` traits and structs be more like
the `(Into)SystemConfigs` traits and structs.
- Replaced uses of `IntoSystemSetConfig` with `IntoSystemSetConfigs`
- Added generic `ItemConfig` and `ItemConfigs` types.
- Changed `SystemConfig(s)` and `SystemSetConfig(s)` to be type aliases
to `ItemConfig(s)`.
- Added generic `process_configs` to `ScheduleGraph`.
- Changed `configure_sets_inner` and `add_systems_inner` to reuse
`process_configs`.
---
## Changelog
- Added `run_if` to `IntoSystemSetConfigs`
- Deprecated `Schedule::configure_set` and `App::configure_set`
- Removed `IntoSystemSetConfig`
## Migration Guide
- Use `App::configure_sets` instead of `App::configure_set`
- Use `Schedule::configure_sets` instead of `Schedule::configure_set`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently we don't have panicking alternative for getting components
from `Query` like for resources. Partially addresses #9443.
## Solution
- Add these functions.
---
## Changelog
### Added
- `Query::component` and `Query::component_mut` to get specific
component from query and panic on error.
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.
# Objective
- Fixes#9641
- Anonymous sets are named by their system members. When
`ScheduleBuildSettings::report_sets` is on, systems are named by their
sets. So when getting the anonymous set name this would cause an
infinite recursion.
## Solution
- When getting the anonymous system set name, don't get their system's
names with the sets the systems belong to.
## Other Possible solutions
- An alternate solution might be to skip anonymous sets when getting the
system's name for an anonymous set's name.
# Objective
- I broke ambiguity reporting in one of my refactors.
`conflicts_to_string` should have been using the passed in parameter
rather than the one stored on self.
# Objective
- The current `EventReader::iter` has been determined to cause confusion
among new Bevy users. It was suggested by @JoJoJet to rename the method
to better clarify its usage.
- Solves #9624
## Solution
- Rename `EventReader::iter` to `EventReader::read`.
- Rename `EventReader::iter_with_id` to `EventReader::read_with_id`.
- Rename `ManualEventReader::iter` to `ManualEventReader::read`.
- Rename `ManualEventReader::iter_with_id` to
`ManualEventReader::read_with_id`.
---
## Changelog
- `EventReader::iter` has been renamed to `EventReader::read`.
- `EventReader::iter_with_id` has been renamed to
`EventReader::read_with_id`.
- `ManualEventReader::iter` has been renamed to
`ManualEventReader::read`.
- `ManualEventReader::iter_with_id` has been renamed to
`ManualEventReader::read_with_id`.
- Deprecated `EventReader::iter`
- Deprecated `EventReader::iter_with_id`
- Deprecated `ManualEventReader::iter`
- Deprecated `ManualEventReader::iter_with_id`
## Migration Guide
- Existing usages of `EventReader::iter` and `EventReader::iter_with_id`
will have to be changed to `EventReader::read` and
`EventReader::read_with_id` respectively.
- Existing usages of `ManualEventReader::iter` and
`ManualEventReader::iter_with_id` will have to be changed to
`ManualEventReader::read` and `ManualEventReader::read_with_id`
respectively.
# Objective
The latest `clippy` release has a much more aggressive application of
the
[`explicit_iter_loop`](https://rust-lang.github.io/rust-clippy/master/index.html#/explicit_into_iter_loop?groups=pedantic)
pedantic lint.
As a result, clippy now suggests the following:
```diff
-for event in events.iter() {
+for event in &mut events {
```
I'm generally in favor of this lint. Using `for mut item in &mut query`
is also recommended over `for mut item in query.iter_mut()` for good
reasons IMO.
But, it is my personal belief that `&mut events` is much less clear than
`events.iter()`.
Why? The reason is that the events from `EventReader` **are not
mutable**, they are immutable references to each event in the event
reader. `&mut events` suggests we are getting mutable access to events —
similarly to `&mut query` — which is not the case. Using `&mut events`
is therefore misleading.
`IntoIterator` requires a mutable `EventReader` because it updates the
internal `last_event_count`, not because it let you mutate it.
So clippy's suggested improvement is a downgrade.
## Solution
Do not implement `IntoIterator` for `&mut events`.
Without the impl, clippy won't suggest its "fix". This also prevents
generally people from using `&mut events` for iterating `EventReader`s,
which makes the ecosystem every-so-slightly better.
---
## Changelog
- Removed `IntoIterator` impl for `&mut EventReader`
## Migration Guide
- `&mut EventReader` does not implement `IntoIterator` anymore. replace
`for foo in &mut events` by `for foo in events.iter()`
# Objective
- Some of the old ambiguity tests didn't get ported over during schedule
v3.
## Solution
- Port over tests from
15ee98db8d/crates/bevy_ecs/src/schedule/ambiguity_detection.rs (L279-L612)
with minimal changes
- Make a method to convert the ambiguity conflicts to a string for
easier verification of correct results.
# Objective
Fix#4278Fix#5504Fix#9422
Provide safe ways to borrow an entire entity, while allowing disjoint
mutable access. `EntityRef` and `EntityMut` are not suitable for this,
since they provide access to the entire world -- they are just helper
types for working with `&World`/`&mut World`.
This has potential uses for reflection and serialization
## Solution
Remove `EntityRef::world`, which allows it to soundly be used within
queries.
`EntityMut` no longer supports structural world mutations, which allows
multiple instances of it to exist for different entities at once.
Structural world mutations are performed using the new type
`EntityWorldMut`.
```rust
fn disjoint_system(
q2: Query<&mut A>,
q1: Query<EntityMut, Without<A>>,
) { ... }
let [entity1, entity2] = world.many_entities_mut([id1, id2]);
*entity1.get_mut::<T>().unwrap() = *entity2.get().unwrap();
for entity in world.iter_entities_mut() {
...
}
```
---
## Changelog
- Removed `EntityRef::world`, to fix a soundness issue with queries.
+ Removed the ability to structurally mutate the world using
`EntityMut`, which allows it to be used in queries.
+ Added `EntityWorldMut`, which is used to perform structural mutations
that are no longer allowed using `EntityMut`.
## Migration Guide
**Note for maintainers: ensure that the guide for #9604 is updated
accordingly.**
Removed the method `EntityRef::world`, to fix a soundness issue with
queries. If you need access to `&World` while using an `EntityRef`,
consider passing the world as a separate parameter.
`EntityMut` can no longer perform 'structural' world mutations, such as
adding or removing components, or despawning the entity. Additionally,
`EntityMut::world`, `EntityMut::world_mut` , and
`EntityMut::world_scope` have been removed.
Instead, use the newly-added type `EntityWorldMut`, which is a helper
type for working with `&mut World`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Move schedule name into `Schedule` to allow the schedule name to be
used for errors and tracing in Schedule methods
- Fixes#9510
## Solution
- Move label onto `Schedule` and adjust api's on `World` and `Schedule`
to not pass explicit label where it makes sense to.
- add name to errors and tracing.
- `Schedule::new` now takes a label so either add the label or use
`Schedule::default` which uses a default label. `default` is mostly used
in doc examples and tests.
---
## Changelog
- move label onto `Schedule` to improve error message and logging for
schedules.
## Migration Guide
`Schedule::new` and `App::add_schedule`
```rust
// old
let schedule = Schedule::new();
app.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
app.add_schedule(schedule);
```
if you aren't using a label and are using the schedule struct directly
you can use the default constructor.
```rust
// old
let schedule = Schedule::new();
schedule.run(world);
// new
let schedule = Schedule::default();
schedule.run(world);
```
`Schedules:insert`
```rust
// old
let schedule = Schedule::new();
schedules.insert(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
schedules.insert(schedule);
```
`World::add_schedule`
```rust
// old
let schedule = Schedule::new();
world.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
world.add_schedule(schedule);
```
# Objective
Every frame, `Events::update` gets called, which clears out any old
events from the buffer. There should be a way of taking ownership of
these old events instead of throwing them away. My use-case is dumping
old events into a debug menu so they can be inspected later.
One potential workaround is to just have a system that clones any
incoming events and stores them in a list -- however, this requires the
events to implement `Clone`.
## Solution
Add `Events::update_drain`, which returns an iterator of the events that
were removed from the buffer.
# Objective
- Fixes: #9508
- Fixes: #9526
## Solution
- Adds
```rust
fn configure_schedules(&mut self, schedule_build_settings: ScheduleBuildSettings)
```
to `Schedules`, and `App` to simplify applying `ScheduleBuildSettings`
to all schedules.
---
## Migration Guide
- No breaking changes.
- Adds `Schedule::get_build_settings()` getter for the schedule's
`ScheduleBuildSettings`.
- Can replaced manual configuration of all schedules:
```rust
// Old
for (_, schedule) in app.world.resource_mut::<Schedules>().iter_mut() {
schedule.set_build_settings(build_settings);
}
// New
app.configure_schedules(build_settings);
```
# Objective
To enable non exclusive system usage of reflected components and make
reflection more ergonomic to use by making it more in line with standard
entity commands.
## Solution
- Implements a new `EntityCommands` extension trait for reflection
related functions in the reflect module of bevy_ecs.
- Implements 4 new commands, `insert_reflect`,
`insert_reflect_with_registry`, `remove_reflect`, and
`remove_reflect_with_registry`. Both insert commands take a `Box<dyn
Reflect>` component while the remove commands take the component type
name.
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module. (Might be worth making these just public to enable user end
custom entity commands in a different pr)
- Added basic tests to ensure the commands are actually working.
- Documentation of functions.
---
## Changelog
Added:
- Implements 4 new commands on the new entity commands extension.
- `insert_reflect`
- `remove_reflect`
- `insert_reflect_with_registry`
- `remove_reflect_with_registry`
The commands operate the same except the with_registry commands take a
generic parameter for a resource that implements `AsRef<TypeRegistry>`.
Otherwise the default commands use the `AppTypeRegistry` for reflection
data.
Changed:
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module.
> Hopefully this time it works. Please don't make me rebase again ☹
# Objective
- Fixes#4917
- Replaces #9602
## Solution
- Replaced `EntityCommand` implementation for `FnOnce` to apply to
`FnOnce(EntityMut)` instead of `FnOnce(Entity, &mut World)`
---
## Changelog
- `FnOnce(Entity, &mut World)` no longer implements `EntityCommand`.
This is a breaking change.
## Migration Guide
### 1. New-Type `FnOnce`
Create an `EntityCommand` type which implements the method you
previously wrote:
```rust
pub struct ClassicEntityCommand<F>(pub F);
impl<F> EntityCommand for ClassicEntityCommand<F>
where
F: FnOnce(Entity, &mut World) + Send + 'static,
{
fn apply(self, id: Entity, world: &mut World) {
(self.0)(id, world);
}
}
commands.add(ClassicEntityCommand(|id: Entity, world: &mut World| {
/* ... */
}));
```
### 2. Extract `(Entity, &mut World)` from `EntityMut`
The method `into_world_mut` can be used to gain access to the `World`
from an `EntityMut`.
```rust
let old = |id: Entity, world: &mut World| {
/* ... */
};
let new = |mut entity: EntityMut| {
let id = entity.id();
let world = entity.into_world_mut();
/* ... */
};
```
# Objective
The name `ManualEventIterator` is long and unnecessary, as this is the
iterator type used for both `EventReader` and `ManualEventReader`.
## Solution
Rename `ManualEventIterator` to `EventIterator`. To ease migration, add
a deprecated type alias with the old name.
---
## Changelog
- The types `ManualEventIterator{WithId}` have been renamed to
`EventIterator{WithId}`.
## Migration Guide
The type `ManualEventIterator` has been renamed to `EventIterator`.
Additonally, `ManualEventIteratorWithId` has been renamed to
`EventIteratorWithId`.
# Objective
#5483 allows for the creation of non-`Sync` locals. However, it's not
actually possible to use these types as there is a `Sync` bound on the
`Deref` impls.
## Solution
Remove the unnecessary bounds.
# Objective
- have errors in configure_set and configure_sets show the line number
of the user calling location rather than pointing to schedule.rs
- use display formatting for the errors
## Example Error Text
```text
// dependency loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: DependencyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:39
// after
thread 'main' panicked at 'System set `A` depends on itself.', examples/stress_tests/bevymark.rs:16:9
// hierarchy loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: HierarchyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:3
// after
thread 'main' panicked at 'System set `A` contains itself.', examples/stress_tests/bevymark.rs:16:9
// configuring a system type set
// before
thread 'main' panicked at 'configuring system type sets is not allowed', crates\bevy_ecs\src\schedule\config.rs:394:9
//after
thread 'main' panicked at 'configuring system type sets is not allowed', examples/stress_tests/bevymark.rs:16:9
```
Code to produce errors:
```rust
use bevy::prelude::*;
#[derive(SystemSet, Clone, Debug, PartialEq, Eq, Hash)]
enum TestSet {
A,
}
fn main() {
fn foo() {}
let mut app = App::empty();
// Hierarchy Loop
app.configure_set(Main, TestSet::A.in_set(TestSet::A));
// Dependency Loop
app.configure_set(Main, TestSet::A.after(TestSet::A));
// Configure System Type Set
app.configure_set(Main, foo.into_system_set());
}
```
# Objective
- Fixes#9321
## Solution
- `EntityMap` has been replaced by a simple `HashMap<Entity, Entity>`.
---
## Changelog
- `EntityMap::world_scope` has been replaced with `World::world_scope`
to avoid creating a new trait. This is a public facing change to the
call semantics, but has no effect on results or behaviour.
- `EntityMap`, as a `HashMap`, now operates on `&Entity` rather than
`Entity`. This changes many standard access functions (e.g, `.get`) in a
public-facing way.
## Migration Guide
- Calls to `EntityMap::world_scope` can be directly replaced with the
following:
`map.world_scope(&mut world)` -> `world.world_scope(&mut map)`
- Calls to legacy `EntityMap` methods such as `EntityMap::get` must
explicitly include de/reference symbols:
`let entity = map.get(parent);` -> `let &entity = map.get(&parent);`
# Objective
Make code relating to event more readable.
Currently the `impl` block of `Events` is split in two, and the big part
of its implementations are put at the end of the file, far from the
definition of the `struct`.
## Solution
- Move and merge the `impl` blocks of `Events` next to its definition.
- Move the `EventSequence` definition and implementations before the
`Events`, because they're pretty trivial and help understand how
`Events` work, rather than being buried bellow `Events`.
I separated those two steps in two commits to not be too confusing. I
didn't modify any code of documentation. I want to do a second PR with
such modifications after this one is merged.
# Objective
Similar to #6344, but contains only `ReflectBundle` changes. Useful for
scripting. The implementation has also been updated to look exactly like
`ReflectComponent`.
---
## Changelog
### Added
- Reflection for bundles.
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
Any time we wish to transform the output of a system, we currently use
system piping to do so:
```rust
my_system.pipe(|In(x)| do_something(x))
```
Unfortunately, system piping is not a zero cost abstraction. Each call
to `.pipe` requires allocating two extra access sets: one for the second
system and one for the combined accesses of both systems. This also adds
extra work to each call to `update_archetype_component_access`, which
stacks as one adds multiple layers of system piping.
## Solution
Add the `AdapterSystem` abstraction: similar to `CombinatorSystem`, this
allows you to implement a trait to generically control how a system is
run and how its inputs and outputs are processed. Unlike
`CombinatorSystem`, this does not have any overhead when computing world
accesses which makes it ideal for simple operations such as inverting or
ignoring the output of a system.
Add the extension method `.map(...)`: this is similar to `.pipe(...)`,
only it accepts a closure as an argument instead of an `In<T>` system.
```rust
my_system.map(do_something)
```
This has the added benefit of making system names less messy: a system
that ignores its output will just be called `my_system`, instead of
`Pipe(my_system, ignore)`
---
## Changelog
TODO
## Migration Guide
The `system_adapter` functions have been deprecated: use `.map` instead,
which is a lightweight alternative to `.pipe`.
```rust
// Before:
my_system.pipe(system_adapter::ignore)
my_system.pipe(system_adapter::unwrap)
my_system.pipe(system_adapter::new(T::from))
// After:
my_system.map(std::mem::drop)
my_system.map(Result::unwrap)
my_system.map(T::from)
// Before:
my_system.pipe(system_adapter::info)
my_system.pipe(system_adapter::dbg)
my_system.pipe(system_adapter::warn)
my_system.pipe(system_adapter::error)
// After:
my_system.map(bevy_utils::info)
my_system.map(bevy_utils::dbg)
my_system.map(bevy_utils::warn)
my_system.map(bevy_utils::error)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- break up large build_schedule system to make it easier to read
- Clean up related error messages.
- I have a follow up PR that adds the schedule name to the error
messages, but wanted to break this up from that.
## Changelog
- refactor `build_schedule` to be easier to read
## Sample Error Messages
Dependency Cycle
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
Hierarchy Cycle
```text
thread 'main' panicked at 'System set hierarchy contains cycle(s).
schedule has 1 in_set cycle(s):
cycle 1: set 'A' contains itself
set 'A'
... which contains set 'B'
... which contains set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
System Type Set
```text
thread 'main' panicked at 'Tried to order against `SystemTypeSet(fn foo())` in a schedule that has more than one `SystemTypeSet(fn foo())` instance. `SystemTypeSet(fn foo())` is a `SystemTypeSet` and cannot be used for ordering if ambiguous. Use a different set without this restriction.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Hierarchy Redundancy
```text
thread 'main' panicked at 'System set hierarchy contains redundant edges.
hierarchy contains redundant edge(s) -- system set 'X' cannot be child of set 'A', longer path exists
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Systems have ordering but interset
```text
thread 'main' panicked at '`A` and `C` have a `before`-`after` relationship (which may be transitive) but share systems.', crates\bevy_ecs\src\schedule\schedule.rs:227:51
```
Cross Dependency
```text
thread 'main' panicked at '`A` and `B` have both `in_set` and `before`-`after` relationships (these might be transitive). This combination is unsolvable as a system cannot run before or after a set it belongs to.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Ambiguity
```text
thread 'main' panicked at 'Systems with conflicting access have indeterminate run order.
1 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- res_mut and res_ref
conflict on: ["bevymark::ambiguity::X"]
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
# Objective
Sometimes you want to create a plugin with a custom run condition. In a
function, you take the `Condition` trait and then make a
`BoxedCondition` from it to store it. And then you want to add that
condition to a system, but you can't, because there is only the `run_if`
function available which takes `impl Condition<M>` instead of
`BoxedCondition`. So you have to create a wrapper type for the
`BoxedCondition` and implement the `System` and `ReadOnlySystem` traits
for the wrapper (Like it's done in the picture below). It's very
inconvenient and boilerplate. But there is an easy solution for that:
make the `run_if_inner` system that takes a `BoxedCondition` public.
Also, it makes sense to make `in_set_inner` function public as well with
the same motivation.

A chunk of the source code of the `bevy-inspector-egui` crate.
## Solution
Make `run_if_inner` function public.
Rename `run_if_inner` to `run_if_dyn`.
Make `in_set_inner` function public.
Rename `in_set_inner` to `in_set_dyn`.
## Changelog
Changed visibility of `run_if_inner` from `pub(crate)` to `pub`.
Renamed `run_if_inner` to `run_if_dyn`.
Changed visibility of `in_set_inner` from `pub(crate)` to `pub`.
Renamed `in_set_inner` to `in_set_dyn`.
## Migration Guide
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
* `Local` and `SystemName` implement `Debug` manually, but they could
derive it.
* `QueryState` and `dyn System` have unconventional debug formatting.
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
While being nobody other's issue as far I can tell, I want to create a
trait I plan to implement on `App` where more than one schedule is
modified.
My workaround so far was working with a closure that returns an
`ExecutorKind` from a match of the method variable.
It makes it easier for me to being able to clone `ExecutorKind` and I
don't see this being controversial for others working with Bevy.
I did nothing more than adding `Clone` to the derived traits, no
migration guide needed.
(If this worked out then the GitHub editor is not too shabby.)
# Objective
Just like
[`set_if_neq`](https://docs.rs/bevy_ecs/latest/bevy_ecs/change_detection/trait.DetectChangesMut.html#method.set_if_neq),
being able to express the "I don't want to unnecessarily trigger the
change detection" but with the ability to handle the previous value if
change occurs.
## Solution
Add `replace_if_neq` to `DetectChangesMut`.
---
## Changelog
- Added `DetectChangesMut::replace_if_neq`: like `set_if_neq` change the
value only if the new value if different from the current one, but
return the previous value if the change occurs.
Add a `RunSystem` extension trait to allow for immediate execution of
systems on a `World` for debugging and/or testing purposes.
# Objective
Fixes#6184
Initially, I made this CL as `ApplyCommands`. After a discussion with
@cart , we decided a more generic implementation would be better to
support all systems. This is the new revised CL. Sorry for the long
delay! 😅
This CL allows users to do this:
```rust
use bevy::prelude::*;
use bevy::ecs::system::RunSystem;
struct T(usize);
impl Resource for T {}
fn system(In(n): In<usize>, mut commands: Commands) -> usize {
commands.insert_resource(T(n));
n + 1
}
let mut world = World::default();
let n = world.run_system_with(1, system);
assert_eq!(n, 2);
assert_eq!(world.resource::<T>().0, 1);
```
## Solution
This is implemented as a trait extension and not included in any
preludes to ensure it's being used consciously.
Internally, it just initializes and runs a systems, and applies any
deferred parameters all "in place".
The trait has 2 functions (one of which calls the other by default):
- `run_system_with` is the general implementation, which allows user to
pass system input parameters
- `run_system` is the ergonomic wrapper for systems with no input
parameter (to avoid having the user pass `()` as input).
~~Additionally, this trait is also implemented for `&mut App`. I added
this mainly for ergonomics (`app.run_system` vs.
`app.world.run_system`).~~ (Removed based on feedback)
---------
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
- Fixes#9114
## Solution
Inside `ScheduleGraph::build_schedule()` the variable `node_count =
self.systems.len() + self.system_sets.len()` is used to calculate the
indices for the `reachable` bitset derived from `self.hierarchy.graph`.
However, the number of nodes inside `self.hierarchy.graph` does not
always correspond to `self.systems.len() + self.system_sets.len()` when
`ambiguous_with` is used, because an ambiguous set is added to
`system_sets` (because we need an `NodeId` for the ambiguity graph)
without adding a node to `self.hierarchy`.
In this PR, we rename `node_count` to the more descriptive name
`hg_node_count` and set it to `self.hierarchy.graph.node_count()`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fixes#9113
## Solution
disable `multi-threaded` default feature
## Migration Guide
The `multi-threaded` feature in `bevy_ecs` and `bevy_tasks` is no longer
enabled by default. However, this remains a default feature for the
umbrella `bevy` crate. If you depend on `bevy_ecs` or `bevy_tasks`
directly, you should consider enabling this to allow systems to run in
parallel.
# Objective
The `lifetimeless` module has been a source of confusion for bevy users
for a while now.
## Solution
Add a couple paragraph explaining that, yes, you can use one of the type
alias safely, without ever leaking any memory.