Matches versioning & features from other Cargo.toml files in the
project.
# Objective
Resolves#10932
## Solution
Added smallvec to the bevy_utils cargo.toml and added a line to
re-export the crate. Target version and features set to match what's
used in the other bevy crates.
# Objective
Keep up to date with wgpu.
## Solution
Update the wgpu version.
Currently blocked on naga_oil updating to naga 0.14 and releasing a new
version.
3d scenes (or maybe any scene with lighting?) currently don't render
anything due to
```
error: naga_oil bug, please file a report: composer failed to build a valid header: Type [2] '' is invalid
= Capability Capabilities(CUBE_ARRAY_TEXTURES) is required
```
I'm not sure what should be passed in for `wgpu::InstanceFlags`, or if we want to make the gles3minorversion configurable (might be useful for debugging?)
Currently blocked on https://github.com/bevyengine/naga_oil/pull/63, and https://github.com/gfx-rs/wgpu/issues/4569 to be fixed upstream in wgpu first.
## Known issues
Amd+windows+vulkan has issues with texture_binding_arrays (see the image [here](https://github.com/bevyengine/bevy/pull/10266#issuecomment-1819946278)), but that'll be fixed in the next wgpu/naga version, and you can just use dx12 as a workaround for now (Amd+linux mesa+vulkan texture_binding_arrays are fixed though).
---
## Changelog
Updated wgpu to 0.18, naga to 0.14.2, and naga_oil to 0.11.
- Windows desktop GL should now be less painful as it no longer requires Angle.
- You can now toggle shader validation and debug information for debug and release builds using `WgpuSettings.instance_flags` and [InstanceFlags](https://docs.rs/wgpu/0.18.0/wgpu/struct.InstanceFlags.html)
## Migration Guide
- `RenderPassDescriptor` `color_attachments` (as well as `RenderPassColorAttachment`, and `RenderPassDepthStencilAttachment`) now use `StoreOp::Store` or `StoreOp::Discard` instead of a `boolean` to declare whether or not they should be stored.
- `RenderPassDescriptor` now have `timestamp_writes` and `occlusion_query_set` fields. These can safely be set to `None`.
- `ComputePassDescriptor` now have a `timestamp_writes` field. This can be set to `None` for now.
- See the [wgpu changelog](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v0180-2023-10-25) for additional details
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
- Follow up to #9694
## Solution
- Same api as #9694 but adapted for `BindGroupLayoutEntry`
- Use the same `ShaderStages` visibilty for all entries by default
- Add `BindingType` helper function that mirror the wgsl equivalent and
that make writing layouts much simpler.
Before:
```rust
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2,
multisampled: false,
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: bevy::render::render_resource::BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(PostProcessSettings::min_size()),
},
count: None,
},
],
});
```
After:
```rust
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout"),
&BindGroupLayoutEntries::sequential(
ShaderStages::FRAGMENT,
(
texture_2d_f32(),
sampler(SamplerBindingType::Filtering),
uniform_buffer(false, Some(PostProcessSettings::min_size())),
),
),
);
```
Here's a more extreme example in bevy_solari:
86dab7f5da
---
## Changelog
- Added `BindGroupLayoutEntries` and all `BindingType` helper functions.
## Migration Guide
`RenderDevice::create_bind_group_layout()` doesn't take a
`BindGroupLayoutDescriptor` anymore. You need to provide the parameters
separately
```rust
// 0.12
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
// ...
},
],
});
// 0.13
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout",
&[
BindGroupLayoutEntry {
// ...
},
],
);
```
## TODO
- [x] implement a `Dynamic` variant
- [x] update the `RenderDevice::create_bind_group_layout()` api to match
the one from `RenderDevice::creat_bind_group()`
- [x] docs
# Objective
Simplify bind group creation code. alternative to (and based on) #9476
## Solution
- Add a `BindGroupEntries` struct that can transparently be used where
`&[BindGroupEntry<'b>]` is required in BindGroupDescriptors.
Allows constructing the descriptor's entries as:
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::with_indexes((
(2, &my_sampler),
(3, my_uniform),
)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 2,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 3,
resource: my_uniform,
},
],
);
```
or
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::sequential((&my_sampler, my_uniform)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 0,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 1,
resource: my_uniform,
},
],
);
```
the structs has no user facing macros, is tuple-type-based so stack
allocated, and has no noticeable impact on compile time.
- Also adds a `DynamicBindGroupEntries` struct with a similar api that
uses a `Vec` under the hood and allows extending the entries.
- Modifies `RenderDevice::create_bind_group` to take separate arguments
`label`, `layout` and `entries` instead of a `BindGroupDescriptor`
struct. The struct can't be stored due to the internal references, and
with only 3 members arguably does not add enough context to justify
itself.
- Modify the codebase to use the new api and the `BindGroupEntries` /
`DynamicBindGroupEntries` structs where appropriate (whenever the
entries slice contains more than 1 member).
## Migration Guide
- Calls to `RenderDevice::create_bind_group({BindGroupDescriptor {
label, layout, entries })` must be amended to
`RenderDevice::create_bind_group(label, layout, entries)`.
- If `label`s have been specified as `"bind_group_name".into()`, they
need to change to just `"bind_group_name"`. `Some("bind_group_name")`
and `None` will still work, but `Some("bind_group_name")` can optionally
be simplified to just `"bind_group_name"`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- sometimes when bevy shuts down on certain machines the render thread
tries to send the time after the main world has been dropped.
- fixes an error mentioned in a reply in
https://github.com/bevyengine/bevy/issues/9543
---
## Changelog
- ignore disconnected errors from the time channel.
This is a duplicate of #9632, it was created since I forgot to make a
new branch when I first made this PR, so I was having trouble resolving
merge conflicts, meaning I had to rebuild my PR.
# Objective
- Allow other plugins to create the renderer resources. An example of
where this would be required is my [OpenXR
plugin](https://github.com/awtterpip/bevy_openxr)
## Solution
- Changed the bevy RenderPlugin to optionally take precreated render
resources instead of a configuration.
## Migration Guide
The `RenderPlugin` now takes a `RenderCreation` enum instead of
`WgpuSettings`. `RenderSettings::default()` returns
`RenderSettings::Automatic(WgpuSettings::default())`. `RenderSettings`
also implements `From<WgpuSettings>`.
```rust
// before
RenderPlugin {
wgpu_settings: WgpuSettings {
...
},
}
// now
RenderPlugin {
render_creation: RenderCreation::Automatic(WgpuSettings {
...
}),
}
// or
RenderPlugin {
render_creation: WgpuSettings {
...
}.into(),
}
```
---------
Co-authored-by: Malek <pocmalek@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Fixes https://github.com/bevyengine/bevy/issues/1207
# Objective
Right now, it's impossible to capture a screenshot of the entire window
without forking bevy. This is because
- The swapchain texture never has the COPY_SRC usage
- It can't be accessed without taking ownership of it
- Taking ownership of it breaks *a lot* of stuff
## Solution
- Introduce a dedicated api for taking a screenshot of a given bevy
window, and guarantee this screenshot will always match up with what
gets put on the screen.
---
## Changelog
- Added the `ScreenshotManager` resource with two functions,
`take_screenshot` and `save_screenshot_to_disk`
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
`TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` was already included in `adapter.features()` on non-wasm target, and since it is the default value for `WgpuSettings.features`, the subsequent code will also combine into this feature:
b6066c30b6/crates/bevy_render/src/renderer/mod.rs (L155-L156)
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Currently, Bevy only supports rendering to the current "surface texture format". This means that "render to texture" scenarios must use the exact format the primary window's surface uses, or Bevy will crash. This is even harder than it used to be now that we detect preferred surface formats at runtime instead of using hard coded BevyDefault values.
## Solution
1. Look up and store each window surface's texture format alongside other extracted window information
2. Specialize the upscaling pass on the current `RenderTarget`'s texture format, now that we can cheaply correlate render targets to their current texture format
3. Remove the old `SurfaceTextureFormat` and `AvailableTextureFormats`: these are now redundant with the information stored on each extracted window, and probably should not have been globals in the first place (as in theory each surface could have a different format).
This means you can now use any texture format you want when rendering to a texture! For example, changing the `render_to_texture` example to use `R16Float` now doesn't crash / properly only stores the red component:
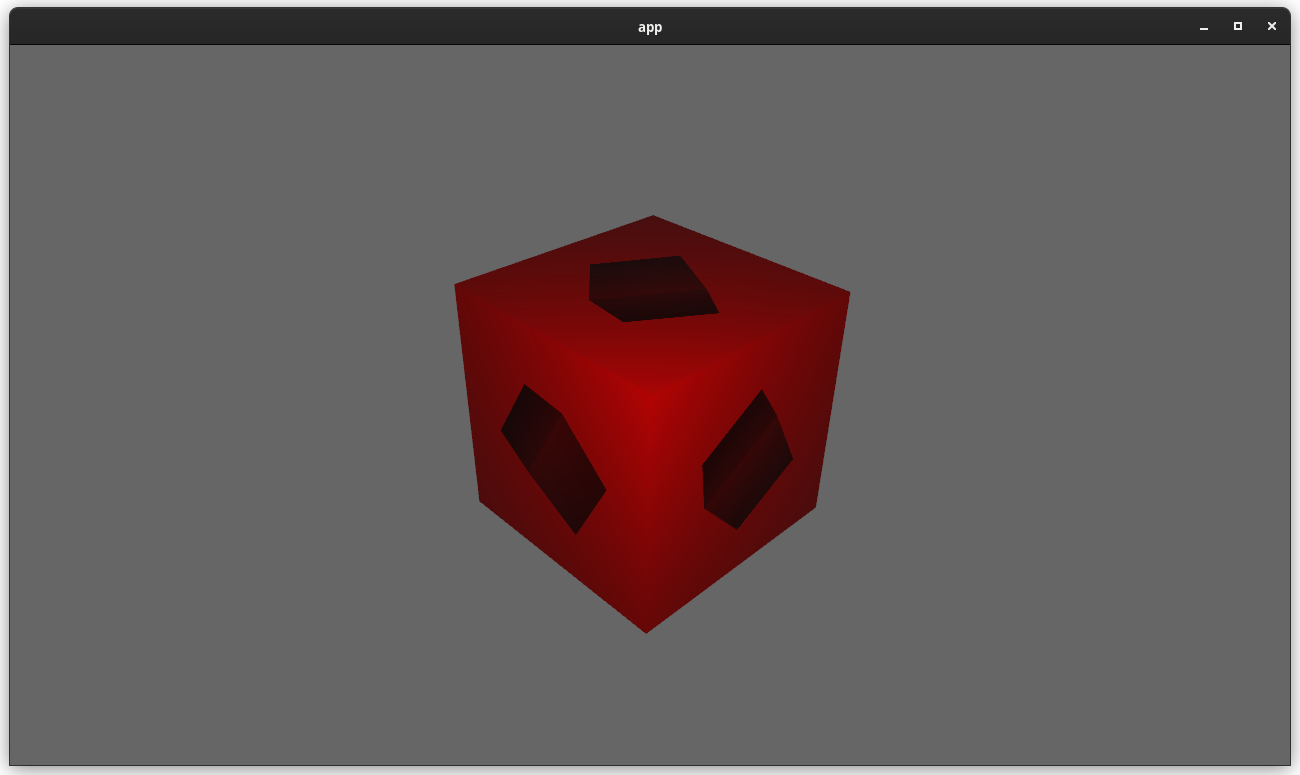
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
As suggested in #6104, it would be nice to link directly to `linux_dependencies.md` file in the panic message when running on Linux. And when not compiling for Linux, we fall back to the old message.
Signed-off-by: Lena Milizé <me@lvmn.org>
# Objective
Resolves#6104.
## Solution
Add link to `linux_dependencies.md` when compiling for Linux, and fall back to the old one when not.
# Objective
There is no Srgb support on some GPU and display protocols with `winit` (for example, Nvidia's GPUs with Wayland). Thus `TextureFormat::bevy_default()` which returns `Rgba8UnormSrgb` or `Bgra8UnormSrgb` will cause panics on such platforms. This patch will resolve this problem. Fix https://github.com/bevyengine/bevy/issues/3897.
## Solution
Make `initialize_renderer` expose `wgpu::Adapter` and `first_available_texture_format`, use the `first_available_texture_format` by default.
## Changelog
* Fixed https://github.com/bevyengine/bevy/issues/3897.
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- The time update is currently done in the wrong part of the schedule. For a single frame the current order of things is update input, update time (First stage), other stages, render stage (frame presentation). So when we update the time it includes the input processing of the current frame and the frame presentation of the previous frame. This is a problem when vsync is on. When input processing takes a longer amount of time for a frame, the vsync wait time gets shorter. So when these are not paired correctly we can potentially have a long input processing time added to the normal vsync wait time in the previous frame. This leads to inaccurate frame time reporting and more variance of the time than actually exists. For more details of why this is an issue see the linked issue below.
- Helps with https://github.com/bevyengine/bevy/issues/4669
- Supercedes https://github.com/bevyengine/bevy/pull/4728 and https://github.com/bevyengine/bevy/pull/4735. This PR should be less controversial than those because it doesn't add to the API surface.
## Solution
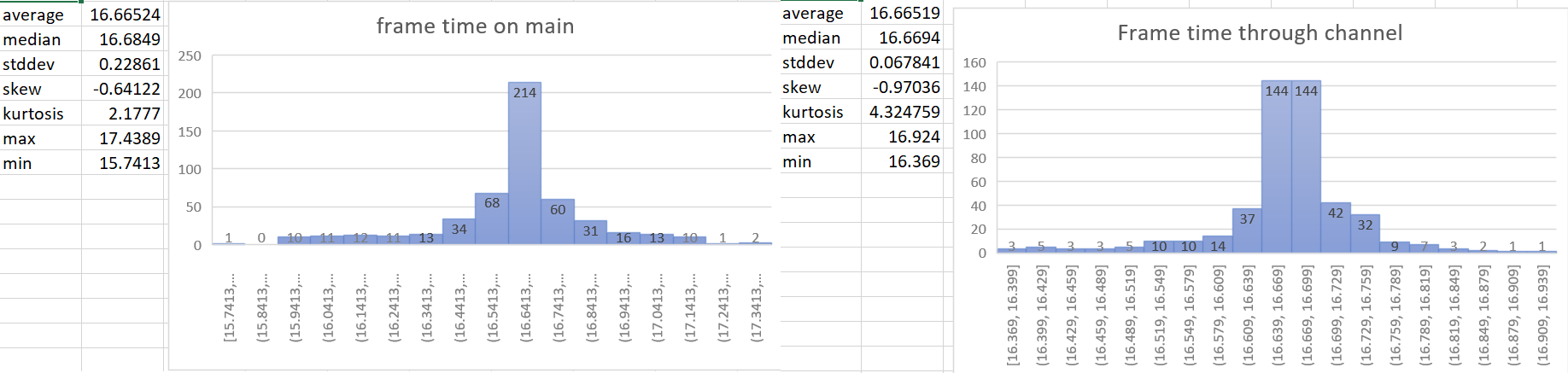
- The most accurate frame time would come from hardware. We currently don't have access to that for multiple reasons, so the next best thing we can do is measure the frame time as close to frame presentation as possible. This PR gets the Instant::now() for the time immediately after frame presentation in the render system and then sends that time to the app world through a channel.
- implements suggestion from @aevyrie from here https://github.com/bevyengine/bevy/pull/4728#discussion_r872010606
## Statistics
---
## Changelog
- Make frame time reporting more accurate.
## Migration Guide
`time.delta()` now reports zero for 2 frames on startup instead of 1 frame.
# Objective
Currently, providing the wrong number of inputs to a render graph node triggers this assertion:
```
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `2`', /[redacted]/bevy/crates/bevy_render/src/renderer/graph_runner.rs:164:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
This does not provide the user any context.
## Solution
Add a new `RenderGraphRunnerError` variant to handle this case. The new message looks like this:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > node (name: 'Some("outline_pass")') has 2 input slots, but was provided 1 values
```
---
## Changelog
### Changed
`RenderGraphRunnerError` now has a new variant, `MismatchedInputCount`.
## Migration Guide
Exhaustive matches on `RenderGraphRunnerError` will need to add a branch to handle the new `MismatchedInputCount` variant.
# Objective
The frame marker event was emitted in the loop of presenting all the windows. This would mark the frame as finished multiple times if more than one window is used.
## Solution
Move the frame marker to after the `for`-loop, so that it gets executed only once.
Currently `tracy` interprets the entire trace as one frame because the marker for frames isn't being recorded.
~~When an event with `tracy.trace_marker=true` is recorded, `tracing-tracy` will mark the frame as finished:
<aa0b96b2ae/tracing-tracy/src/lib.rs (L240)>~~
~~Unfortunately this leads to~~
```rs
INFO bevy_app:frame: bevy_app::app: finished frame tracy.frame_mark=true
```
~~being printed every frame (we can't use DEBUG because bevy_log sets `max_release_level_info`.~~
Instead of emitting an event that gets logged every frame, we can depend on tracy-client itself and call `finish_continuous_frame!();`
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
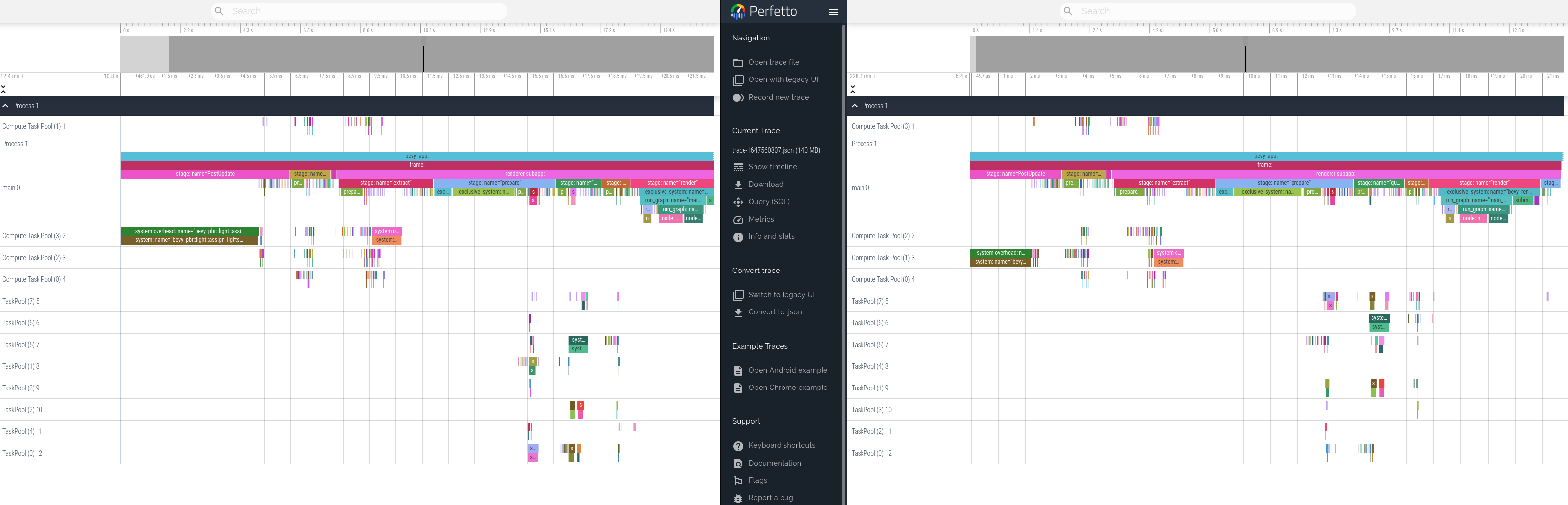
Tracing added support for "inline span entering", which cuts down on a lot of complexity:
```rust
let span = info_span!("my_span").entered();
```
This adapts our code to use this pattern where possible, and updates our docs to recommend it.
This produces equivalent tracing behavior. Here is a side by side profile of "before" and "after" these changes.
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
Currently, errors in the render graph runner are exposed via a `Result::unwrap()` panic message, which dumps the debug representation of the error.
## Solution
This PR updates `render_system` to log the chain of errors, followed by an explicit panic:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > encountered an error when running a sub-graph
ERROR bevy_render::renderer: > tried to pass inputs to sub-graph "outline_graph", which has no input slots
thread 'main' panicked at 'Error running render graph: encountered an error when running a sub-graph', /[redacted]/bevy/crates/bevy_render/src/renderer/mod.rs:44:9
```
Some errors' `Display` impls (via `thiserror`) have also been updated to provide more detail about the cause of the error.
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
- `WgpuOptions` is mutated to be updated with the actual device limits and features, but this information is readily available to both the main and render worlds through the `RenderDevice` which has .limits() and .features() methods
- Information about the adapter in terms of its name, the backend in use, etc were not being exposed but have clear use cases for being used to take decisions about what rendering code to use. For example, if something works well on AMD GPUs but poorly on Intel GPUs. Or perhaps something works well in Vulkan but poorly in DX12.
## Solution
- Stop mutating `WgpuOptions `and don't insert the updated values into the main and render worlds
- Return `AdapterInfo` from `initialize_renderer` and insert it into the main and render worlds
- Use `RenderDevice` limits in the lighting code that was using `WgpuOptions.limits`.
- Renamed `WgpuOptions` to `WgpuSettings`
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Support overriding wgpu features and limits that were calculated from default values or queried from the adapter/backend.
- Fixes#3686
## Solution
- Add `disabled_features: Option<wgpu::Features>` to `WgpuOptions`
- Add `constrained_limits: Option<wgpu::Limits>` to `WgpuOptions`
- After maybe obtaining updated features and limits from the adapter/backend in the case of `WgpuOptionsPriority::Functionality`, enable the `WgpuOptions` `features`, disable the `disabled_features`, and constrain the `limits` by `constrained_limits`.
- Note that constraining the limits means for `wgpu::Limits` members named `max_.*` we take the minimum of that which was configured/queried for the backend/adapter and the specified constrained limit value. This means the configured/queried value is used if the constrained limit is larger as that is as much as the device/API supports, or the constrained limit value is used if it is smaller as we are imposing an artificial constraint. For members named `min_.*` we take the maximum instead. For example, a minimum stride might be 256 but we set constrained limit value of 1024, then 1024 is the more conservative value. If the constrained limit value were 16, then 256 would be the more conservative.
# Objective
- While it is not safe to enable mappable primary buffers for all GPUs, it should be preferred for integrated GPUs where an integrated GPU is one that is sharing system memory.
## Solution
- Auto-disable mappable primary buffers only for discrete GPUs. If the GPU is integrated and mappable primary buffers are supported, use them.
# Objective
- When using `WgpuOptionsPriority::Functionality`, which is the default, wgpu::Features::MAPPABLE_PRIMARY_BUFFERS would be automatically enabled. This feature can and does have a significant negative impact on performance for discrete GPUs where resizable bar is not supported, which is a common case. As such, this feature should not be automatically enabled.
- Fixes the performance regression part of https://github.com/bevyengine/bevy/issues/3686 and at least some, if not all cases of https://github.com/bevyengine/bevy/issues/3687
## Solution
- When using `WgpuOptionsPriority::Functionality`, use the adapter-supported features, enable `TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` and disable `MAPPABLE_PRIMARY_BUFFERS`
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_render` crate.
# Objective
- Allow the user to specify the priority when configuring wgpu features/limits and by default use the maximum capabilities of the chosen adapter.
## Solution
- Add a `WgpuOptionsPriority` enum with `Compatibility`, `Functionality` and `WebGL2` options.
- Add a `priority: WgpuOptionsPriority` member to `WgpuOptions`.
- When initialising the renderer, if `WgpuOptions::priority == WgpuOptionsPriority::Functionality`, query the adapter for the available features and limits, use them when creating a device, and update `WgpuOptions` with those values. If `Compatibility` use the behaviour as before this PR. If `WebGL2` then use the WebGL2 downlevel limits as used when when building for wasm, for convenience of testing WebGL2 limits without having to build for wasm.
- Add an environment variable `WGPU_OPTIONS_PRIO` that takes `compatibility`, `functionality`, `webgl2`.
- Default to `WgpuOptionsPriority::Functionality`.
- Insert updated `WgpuOptions` into render app world as well. This is useful for applying the limits when rendering, such as limiting the directional light shadow map texture to 2048x2048 when using WebGL2 downlevel limits but not on wasm.
- Reduced `draw_state` logs from `debug` to `trace` and added `debug` level logs for the wgpu features and limits. Use `RUST_LOG=bevy_render=debug` to see the output.
# Objective
- 3d examples fail to run in webgl2 because of unsupported texture formats or texture too large
## Solution
- switch to supported formats if a feature is enabled. I choose a feature instead of a build target to not conflict with a potential webgpu support
Very inspired by 6813b2edc5, and need #3290 to work.
I named the feature `webgl2`, but it's only needed if one want to use PBR in webgl2. Examples using only 2D already work.
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- There are a few warnings when building Bevy docs for dead links
- CI seems to not catch those warnings when it should
## Solution
- Enable doc CI on all Bevy workspace
- Fix warnings
- Also noticed plugin GilrsPlugin was not added anymore when feature was enabled
First commit to check that CI would actually fail with it: https://github.com/bevyengine/bevy/runs/4532652688?check_suite_focus=true
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
Upgrades both the old and new renderer to wgpu 0.11 (and naga 0.7). This builds on @zicklag's work here #2556.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}