# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
Alternative to #7490. I wrote all of the code in this PR, but I have added @robtfm as co-author on commits that build on ideas from #7490. I would not have been able to solve these problems on my own without much more time investment and I'm largely just rephrasing the ideas from that PR.
Fixes#7435Fixes#7361Fixes#5721
## Solution
This implements the solution I [outlined here](https://github.com/bevyengine/bevy/pull/7490#issuecomment-1426580633).
* Adds "msaa writeback" as an explicit "msaa camera feature" and default to msaa_writeback: true for each camera. If this is true, a camera has MSAA enabled, and it isn't the first camera for the target, add a writeback before the main pass for that camera.
* Adds a CameraOutputMode, which can be used to configure if (and how) the results of a camera's rendering will be written to the final RenderTarget output texture (via the upscaling node). The `blend_state` and `color_attachment_load_op` are now configurable, giving much more control over how a camera will write to the output texture.
* Made cameras with the same target share the same main_texture tracker by using `Arc<AtomicUsize>`, which ensures continuity across cameras. This was previously broken / could produce weird results in some cases. `ViewTarget::main_texture()` is now correct in every context.
* Added a new generic / specializable BlitPipeline, which the new MsaaWritebackNode uses internally. The UpscalingPipelineNode now uses BlitPipeline instead of its own pipeline. We might ultimately need to fork this back out if we choose to add more configurability to the upscaling, but for now this will save on binary size by not embedding the same shader twice.
* Moved the "camera sorting" logic from the camera driver node to its own system. The results are now stored in the `SortedCameras` resource, which can be used anywhere in the renderer. MSAA writeback makes use of this.
---
## Changelog
- Added `Camera::msaa_writeback` which can enable and disable msaa writeback.
- Added specializable `BlitPipeline` and ported the upscaling node to use this.
- Added SortedCameras, exposing information that was previously internal to the camera driver node.
- Made cameras with the same target share the same main_texture tracker, which ensures continuity across cameras.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
While working on #7784, I noticed that a `#define VAR` in a `.wgsl` file is always effective, even if it its scope is not accepting lines.
Example:
```c
#define A
#ifndef A
#define B
#endif
```
Currently, `B` will be defined although it shouldn't. This PR fixes that.
## Solution
Move the branch responsible for `#define` lines into the last else branch, which is only evaluated if the current scope is accepting lines.
# Objective
There was PR that introduced support for storage buffer is `AsBindGroup` macro [#6129](https://github.com/bevyengine/bevy/pull/6129), but it does not give more granular control over storage buffer, it will always copy all the data no matter which part of it was updated. There is also currently another open PR #6669 that tries to achieve exactly that, it is just not up to date and seems abandoned (Sorry if that is not right). In this PR I'm proposing a solution for both of these approaches to co-exist using `#[storage(n, buffer)]` and `#[storage(n)]` to distinguish between the cases.
We could also discuss in this PR if there is a need to extend this support to DynamicBuffers as well.
# Objective
- Nothing render
```
ERROR bevy_render::render_resource::pipeline_cache: failed to process shader: Invalid shader def definition for '_import_path': bevy_pbr
```
## Solution
- Fix define regex so that it must have one whitespace after `define`
# Objective
- Fixes#7494
- It is now possible to define a ShaderDef from inside a shader. This can be useful to centralise a value, or making sure an import is only interpreted once
## Solution
- Support `#define <SHADERDEF_NAME> <optional value>`
# Objective
- ambiguities bad
## Solution
- solve ambiguities
- by either ignoring (e.g. on `queue_mesh_view_bind_groups` since `LightMeta` access is different)
- by introducing a dependency (`prepare_windows -> prepare_*` because the latter use the fallback Msaa)
- make `prepare_assets` public so that we can do a proper `.after`
# Objective
- Fix the environment map shader not working under webgl due to textureNumLevels() not being supported
- Fixes https://github.com/bevyengine/bevy/issues/7722
## Solution
- Instead of using textureNumLevels(), put an extra field in the GpuLights uniform to store the mip count
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Closes#7573
- Make `StartupSet` a base set
## Solution
- Add `#[system_set(base)]` to the enum declaration
- Replace `.in_set(StartupSet::...)` with `.in_base_set(StartupSet::...)`
**Note**: I don't really know what I'm doing and what exactly the difference between base and non-base sets are. I mostly opened this PR based on discussion in Discord. I also don't really know how to test that I didn't break everything. Your reviews are appreciated!
---
## Changelog
- `StartupSet` is now a base set
## Migration Guide
`StartupSet` is now a base set. This means that you have to use `.in_base_set` instead of `.in_set`:
### Before
```rs
app.add_system(foo.in_set(StartupSet::PreStartup))
```
### After
```rs
app.add_system(foo.in_base_set(StartupSet::PreStartup))
```
# Objective
Allow for creating pipelines that use push constants. To be able to use push constants. Fixes#4825
As of right now, trying to call `RenderPass::set_push_constants` will trigger the following error:
```
thread 'main' panicked at 'wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 59, Vulkan)>`
In a set_push_constant command
provided push constant is for stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT, however the pipeline layout has no push constant range for the stage(s) VERTEX | FRAGMENT | VERTEX_FRAGMENT
```
## Solution
Add a field push_constant_ranges to` RenderPipelineDescriptor` and `ComputePipelineDescriptor`.
This PR supersedes #4908 which now contains merge conflicts due to significant changes to `bevy_render`.
Meanwhile, this PR also made the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor` non-optional. If the user do not need to specify the bind group layouts, they can simply supply an empty vector here. No need for it to be optional.
---
## Changelog
- Add a field push_constant_ranges to RenderPipelineDescriptor and ComputePipelineDescriptor
- Made the `layout` field of RenderPipelineDescriptor and ComputePipelineDescriptor non-optional.
## Migration Guide
- Add push_constant_ranges: Vec::new() to every `RenderPipelineDescriptor` and `ComputePipelineDescriptor`
- Unwrap the optional values on the `layout` field of `RenderPipelineDescriptor` and `ComputePipelineDescriptor`. If the descriptor has no layout, supply an empty vector.
Co-authored-by: Zhixing Zhang <me@neoto.xin>
# Objective
Fixes#7295
Should we maybe default to 4x if 2x/8x is selected but not supported?
---
## Changelog
- Added 2x and 8x sample counts for MSAA.
# Objective
- Environment maps use these formats, and in the future rendering LUTs will need textures loaded by default in the engine
## Solution
- Make ktx2 and zstd part of the default feature
- Let examples assume these features are enabled
---
## Changelog
- `ktx2` and `zstd` are now party of bevy's default enabled features
## Migration Guide
- If you used the `ktx2` or `zstd` features, you no longer need to explicitly enable them, as they are now part of bevy's default enabled features
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
- Fixes: #7187
Since avoiding the `SRes::into_inner` call does not seem to be possible, this PR tries to at least document its usage.
I am not sure if I explained the lifetime issue correctly, please let me know if something is incorrect.
## Solution
- Add information about the `SRes::into_inner` usage on both `RenderCommand` and `Res`
Profiles show that in extremely hot loops, like the draw loops in the renderer, invoking the trace! macro has noticeable overhead, even if the trace log level is not enabled.
Solve this by introduce a 'wrapper' detailed_trace macro around trace, that wraps the trace! log statement in a trivially false if statement unless a cargo feature is enabled
# Objective
- Eliminate significant overhead observed with trace-level logging in render hot loops, even when trace log level is not enabled.
- This is an alternative solution to the one proposed in #7223
## Solution
- Introduce a wrapper around the `trace!` macro called `detailed_trace!`. This macro wraps the `trace!` macro with an if statement that is conditional on a new cargo feature, `detailed_trace`. When the feature is not enabled (the default), then the if statement is trivially false and should be optimized away at compile time.
- Convert the observed hot occurrences of trace logging in `TrackedRenderPass` with this new macro.
Testing the results of
```
cargo run --profile stress-test --features bevy/trace_tracy --example many_cubes -- spheres
```

shows significant improvement of the `main_opaque_pass_3d` of the renderer, a median time decrease from 6.0ms to 3.5ms.
---
## Changelog
- For performance reasons, some detailed renderer trace logs now require the use of cargo feature `detailed_trace` in addition to setting the log level to `TRACE` in order to be shown.
## Migration Guide
- Some detailed bevy trace events now require the use of the cargo feature `detailed_trace` in addition to enabling `TRACE` level logging to view. Should you wish to see these logs, please compile your code with the bevy feature `detailed_trace`. Currently, the only logs that are affected are the renderer logs pertaining to `TrackedRenderPass` functions
# Objective
There was issue #191 requesting subdivisions on the shape::Plane.
I also could have used this recently. I then write the solution.
Fixes #191
## Solution
I changed the shape::Plane to include subdivisions field and the code to create the subdivisions. I don't know how people are counting subdivisions so as I put in the doc comments 0 subdivisions results in the original geometry of the Plane.
Greater then 0 results in the number of lines dividing the plane.
I didn't know if it would be better to create a new struct that implemented this feature, say SubdivisionPlane or change Plane. I decided on changing Plane as that was what the original issue was.
It would be trivial to alter this to use another struct instead of altering Plane.
The issues of migration, although small, would be eliminated if a new struct was implemented.
## Changelog
### Added
Added subdivisions field to shape::Plane
## Migration Guide
All the examples needed to be updated to initalize the subdivisions field.
Also there were two tests in tests/window that need to be updated.
A user would have to update all their uses of shape::Plane to initalize the subdivisions field.
fixes#6799
# Objective
We should be able to reuse the `Globals` or `View` shader struct definitions from anywhere (including third party plugins) without needing to worry about defining unrelated shader defs.
Also we'd like to refactor these structs to not be repeatedly defined.
## Solution
Refactor both `Globals` and `View` into separate importable shaders.
Use the imports throughout.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- This makes code a little more readable now.
## Solution
- Use `position` provided by `Iter` instead of `enumerating` indices and `map`ping to the index.
This was missed in #7205.
Should be fixed now. 😄
## Migration Guide
- `SpecializedComputePipelines::specialize` now takes a `&PipelineCache` instead of a `&mut PipelineCache`
(Before)

(After)

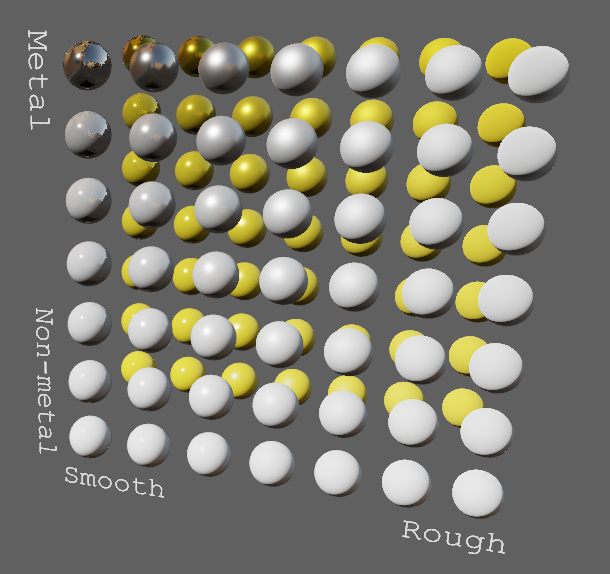
# Objective
- Improve lighting; especially reflections.
- Closes https://github.com/bevyengine/bevy/issues/4581.
## Solution
- Implement environment maps, providing better ambient light.
- Add microfacet multibounce approximation for specular highlights from Filament.
- Occlusion is no longer incorrectly applied to direct lighting. It now only applies to diffuse indirect light. Unsure if it's also supposed to apply to specular indirect light - the glTF specification just says "indirect light". In the case of ambient occlusion, for instance, that's usually only calculated as diffuse though. For now, I'm choosing to apply this just to indirect diffuse light, and not specular.
- Modified the PBR example to use an environment map, and have labels.
- Added `FallbackImageCubemap`.
## Implementation
- IBL technique references can be found in environment_map.wgsl.
- It's more accurate to use a LUT for the scale/bias. Filament has a good reference on generating this LUT. For now, I just used an analytic approximation.
- For now, environment maps must first be prefiltered outside of bevy using a 3rd party tool. See the `EnvironmentMap` documentation.
- Eventually, we should have our own prefiltering code, so that we can have dynamically changing environment maps, as well as let users drop in an HDR image and use asset preprocessing to create the needed textures using only bevy.
---
## Changelog
- Added an `EnvironmentMapLight` camera component that adds additional ambient light to a scene.
- StandardMaterials will now appear brighter and more saturated at high roughness, due to internal material changes. This is more physically correct.
- Fixed StandardMaterial occlusion being incorrectly applied to direct lighting.
- Added `FallbackImageCubemap`.
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
- Terminology used in field names and docs aren't accurate
- `window_origin` doesn't have any effect when `scaling_mode` is `ScalingMode::None`
- `left`, `right`, `bottom`, and `top` are set automatically unless `scaling_mode` is `None`. Fields that only sometimes give feedback are confusing.
- `ScalingMode::WindowSize` has no arguments, which is inconsistent with other `ScalingMode`s. 1 pixel = 1 world unit is also typically way too wide.
- `OrthographicProjection` feels generally less streamlined than its `PerspectiveProjection` counterpart
- Fixes#5818
- Fixes#6190
## Solution
- Improve consistency in `OrthographicProjection`'s public fields (they should either always give feedback or never give feedback).
- Improve consistency in `ScalingMode`'s arguments
- General usability improvements
- Improve accuracy of terminology:
- "Window" should refer to the physical window on the desktop
- "Viewport" should refer to the component in the window that images are drawn on (typically all of it)
- "View frustum" should refer to the volume captured by the projection
---
## Changelog
### Added
- Added argument to `ScalingMode::WindowSize` that specifies the number of pixels that equals one world unit.
- Added documentation for fields and enums
### Changed
- Renamed `window_origin` to `viewport_origin`, which now:
- Affects all `ScalingMode`s
- Takes a fraction of the viewport's width and height instead of an enum
- Removed `WindowOrigin` enum as it's obsolete
- Renamed `ScalingMode::None` to `ScalingMode::Fixed`, which now:
- Takes arguments to specify the projection size
- Replaced `left`, `right`, `bottom`, and `top` fields with a single `area: Rect`
- `scale` is now applied before updating `area`. Reading from it will take `scale` into account.
- Documentation changes to make terminology more accurate and consistent
## Migration Guide
- Change `window_origin` to `viewport_origin`; replace `WindowOrigin::Center` with `Vec2::new(0.5, 0.5)` and `WindowOrigin::BottomLeft` with `Vec2::new(0.0, 0.0)`
- For shadow projections and such, replace `left`, `right`, `bottom`, and `top` with `area: Rect::new(left, bottom, right, top)`
- For camera projections, remove l/r/b/t values from `OrthographicProjection` instantiations, as they no longer have any effect in any `ScalingMode`
- Change `ScalingMode::None` to `ScalingMode::Fixed`
- Replace manual changes of l/r/b/t with:
- Arguments in `ScalingMode::Fixed` to specify size
- `viewport_origin` to specify offset
- Change `ScalingMode::WindowSize` to `ScalingMode::WindowSize(1.0)`
# Objective
Fix#7377Fix#7513
## Solution
Record the changes made to the Bevy `Window` from `winit` as 'canon' to avoid Bevy sending those changes back to `winit` again, causing a feedback loop.
## Changelog
* Removed `ModifiesWindows` system label.
Neither `despawn_window` nor `changed_window` actually modify the `Window` component so all the `.after(ModifiesWindows)` shouldn't be necessary.
* Moved `changed_window` and `despawn_window` systems to `CoreStage::Last` to avoid systems making changes to the `Window` between `changed_window` and the end of the frame as they would be ignored.
## Migration Guide
The `ModifiesWindows` system label was removed.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Some render systems that have system set used as a label so that they can be referenced from somewhere else.
The 1:1 translation from `add_system_to_stage(Prepare, prepare_lights.label(PrepareLights))` is `add_system(prepare_lights.in_set(Prepare).in_set(PrepareLights)`, but configuring the `PrepareLights` set to be in `Prepare` would match the intention better (there are no systems in `PrepareLights` outside of `Prepare`) and it is easier for visualization tools to deal with.
# Solution
- replace
```rust
prepare_lights in PrepareLights
prepare_lights in Prepare
```
with
```rs
prepare_lights in PrepareLights
PrepareLights in Prepare
```
**Before**

**After**

# Objective
Buffers in bevy do not allow for setting buffer usage flags which can be useful for setting COPY_SRC, MAP_READ, MAP_WRITE, which allows for buffers to be copied from gpu to cpu for inspection.
## Solution
Add buffer_usage field to buffers and a set_usage function to set them
# Objective
- Fixes#766
## Solution
- Add a new `Lcha` member to `bevy_render::color::Color` enum
---
## Changelog
- Add a new `Lcha` member to `bevy_render::color::Color` enum
- Add `bevy_render::color::LchRepresentation` struct
# Objective
[as noted](https://github.com/bevyengine/bevy/pull/5950#discussion_r1080762807) by james, transmuting arcs may be UB.
we now store a `*const ()` pointer internally, and only rely on `ptr.cast::<()>().cast::<T>() == ptr`.
as a happy side effect this removes the need for boxing the value, so todo: potentially use this for release mode as well
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
Avoid ‘Unable to find a GPU! Make sure you have installed required drivers!’ .
Because many devices only support OpenGL without Vulkan.
Fixes#3191
## Solution
Use all backends supported by wgpu.
# Objective
Currently, shaders may only have syntax such as
```wgsl
#ifdef FOO
// foo code
#else
#ifdef BAR
// bar code
#else
#ifdef BAZ
// baz code
#else
// fallback code
#endif
#endif
#endif
```
This is hard to read and follow.
Add a way to allow writing `#else ifdef DEFINE` to reduce the number of scopes introduced and to increase readability.
## Solution
Refactor the current preprocessing a bit and add logic to allow `#else ifdef DEFINE`.
This includes per-scope tracking of whether a branch has been accepted.
Add a few tests for this feature.
With these changes we may now write:
```wgsl
#ifdef FOO
// foo code
#else ifdef BAR
// bar code
#else ifdef BAZ
// baz code
#else
// fallback code
#endif
```
instead.
---
## Changelog
- Add `#else ifdef` to shader preprocessing.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
In simple cases we might want to derive the `ExtractComponent` trait.
This adds symmetry to the existing `ExtractResource` derive.
## Solution
Add an implementation of `#[derive(ExtractComponent)]`.
The implementation is adapted from the existing `ExtractResource` derive macro.
Additionally, there is an attribute called `extract_component_filter`. This allows specifying a query filter type used when extracting.
If not specified, no filter (equal to `()`) is used.
So:
```rust
#[derive(Component, Clone, ExtractComponent)]
#[extract_component_filter(With<Fuel>)]
pub struct Car {
pub wheels: usize,
}
```
would expand to (a bit cleaned up here):
```rust
impl ExtractComponent for Car
{
type Query = &'static Self;
type Filter = With<Fuel>;
type Out = Self;
fn extract_component(item: QueryItem<'_, Self::Query>) -> Option<Self::Out> {
Some(item.clone())
}
}
```
---
## Changelog
- Added the ability to `#[derive(ExtractComponent)]` with an optional filter.
# Objective
- Fixes#4592
## Solution
- Implement `SrgbColorSpace` for `u8` via `f32`
- Convert KTX2 R8 and R8G8 non-linear sRGB to wgpu `R8Unorm` and `Rg8Unorm` as non-linear sRGB are not supported by wgpu for these formats
- Convert KTX2 R8G8B8 formats to `Rgba8Unorm` and `Rgba8UnormSrgb` by adding an alpha channel as the Rgb variants don't exist in wgpu
---
## Changelog
- Added: Support for KTX2 `R8_SRGB`, `R8_UNORM`, `R8G8_SRGB`, `R8G8_UNORM`, `R8G8B8_SRGB`, `R8G8B8_UNORM` formats by converting to supported wgpu formats as appropriate
# Objective
Add a `FromReflect` derive to the `Aabb` type, like all other math types, so we can reflect `Vec<Aabb>`.
## Solution
Just add it :)
---
## Changelog
### Added
- Implemented `FromReflect` for `Aabb`.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}