# Objective
Implement Debug trait for SpriteBundle and SpriteSheetBundle
It's helpful and other basic bundles like TransformBundle and
VisibilityBundle already implement this trait
Make the renamings/changes regarding texture atlases a bit less
confusing by calling `TextureAtlasLayout` a layout, not a texture atlas.
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Reduce the size of `bevy_utils`
(https://github.com/bevyengine/bevy/issues/11478)
## Solution
Move `EntityHash` related types into `bevy_ecs`. This also allows us
access to `Entity`, which means we no longer need `EntityHashMap`'s
first generic argument.
---
## Changelog
- Moved `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` into `bevy::ecs::entity::hash` .
- Removed `EntityHashMap`'s first generic argument. It is now hardcoded
to always be `Entity`.
## Migration Guide
- Uses of `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` now have to be imported from `bevy::ecs::entity::hash`.
- Uses of `EntityHashMap` no longer have to specify the first generic
parameter. It is now hardcoded to always be `Entity`.
This fixes a `FIXME` in `extract_meshes` and results in a performance
improvement.
As a result of this change, meshes in the render world might not be
attached to entities anymore. Therefore, the `entity` parameter to
`RenderCommand::render()` is now wrapped in an `Option`. Most
applications that use the render app's ECS can simply unwrap the
`Option`.
Note that for now sprites, gizmos, and UI elements still use the render
world as usual.
## Migration guide
* For efficiency reasons, some meshes in the render world may not have
corresponding `Entity` IDs anymore. As a result, the `entity` parameter
to `RenderCommand::render()` is now wrapped in an `Option`. Custom
rendering code may need to be updated to handle the case in which no
`Entity` exists for an object that is to be rendered.
> Follow up to #11600 and #10588
@mockersf expressed some [valid
concerns](https://github.com/bevyengine/bevy/pull/11600#issuecomment-1932796498)
about the current system this PR attempts to fix:
The `ComputedTextureSlices` reacts to asset change in both `bevy_sprite`
and `bevy_ui`, meaning that if the `ImageScaleMode` is inserted by
default in the bundles, we will iterate through most 2d items every time
an asset is updated.
# Solution
- `ImageScaleMode` only has two variants: `Sliced` and `Tiled`. I
removed the `Stretched` default
- `ImageScaleMode` is no longer part of any bundle, but the relevant
bundles explain that this additional component can be inserted
This way, the *absence* of `ImageScaleMode` means the image will be
stretched, and its *presence* will include the entity to the various
slicing systems
Optional components in bundles would make this more straigthfoward
# Additional work
Should I add new bundles with the `ImageScaleMode` component ?
> Follow up to #10588
> Closes#11749 (Supersedes #11756)
Enable Texture slicing for the following UI nodes:
- `ImageBundle`
- `ButtonBundle`
<img width="739" alt="Screenshot 2024-01-29 at 13 57 43"
src="https://github.com/bevyengine/bevy/assets/26703856/37675681-74eb-4689-ab42-024310cf3134">
I also added a collection of `fantazy-ui-borders` from
[Kenney's](www.kenney.nl) assets, with the appropriate license (CC).
If it's a problem I can use the same textures as the `sprite_slice`
example
# Work done
Added the `ImageScaleMode` component to the targetted bundles, most of
the logic is directly reused from `bevy_sprite`.
The only additional internal component is the UI specific
`ComputedSlices`, which does the same thing as its spritee equivalent
but adapted to UI code.
Again the slicing is not compatible with `TextureAtlas`, it's something
I need to tackle more deeply in the future
# Fixes
* [x] I noticed that `TextureSlicer::compute_slices` could infinitely
loop if the border was larger that the image half extents, now an error
is triggered and the texture will fallback to being stretched
* [x] I noticed that when using small textures with very small *tiling*
options we could generate hundred of thousands of slices. Now I set a
minimum size of 1 pixel per slice, which is already ridiculously small,
and a warning will be sent at runtime when slice count goes above 1000
* [x] Sprite slicing with `flip_x` or `flip_y` would give incorrect
results, correct flipping is now supported to both sprites and ui image
nodes thanks to @odecay observation
# GPU Alternative
I create a separate branch attempting to implementing 9 slicing and
tiling directly through the `ui.wgsl` fragment shader. It works but
requires sending more data to the GPU:
- slice border
- tiling factors
And more importantly, the actual quad *scale* which is hard to put in
the shader with the current code, so that would be for a later iteration
# Objective
Currently the `missing_docs` lint is allowed-by-default and enabled at
crate level when their documentations is complete (see #3492).
This PR proposes to inverse this logic by making `missing_docs`
warn-by-default and mark crates with imcomplete docs allowed.
## Solution
Makes `missing_docs` warn at workspace level and allowed at crate level
when the docs is imcomplete.
# Objective
Right now, all assets in the main world get extracted and prepared in
the render world (if the asset's using the RenderAssetPlugin). This is
unfortunate for two cases:
1. **TextureAtlas** / **FontAtlas**: This one's huge. The individual
`Image` assets that make up the atlas are cloned and prepared
individually when there's no reason for them to be. The atlas textures
are built on the CPU in the main world. *There can be hundreds of images
that get prepared for rendering only not to be used.*
2. If one loads an Image and needs to transform it in a system before
rendering it, kind of like the [decompression
example](https://github.com/bevyengine/bevy/blob/main/examples/asset/asset_decompression.rs#L120),
there's a price paid for extracting & preparing the asset that's not
intended to be rendered yet.
------
* References #10520
* References #1782
## Solution
This changes the `RenderAssetPersistencePolicy` enum to bitflags. I felt
that the objective with the parameter is so similar in nature to wgpu's
[`TextureUsages`](https://docs.rs/wgpu/latest/wgpu/struct.TextureUsages.html)
and
[`BufferUsages`](https://docs.rs/wgpu/latest/wgpu/struct.BufferUsages.html),
that it may as well be just like that.
```rust
// This asset only needs to be in the main world. Don't extract and prepare it.
RenderAssetUsages::MAIN_WORLD
// Keep this asset in the main world and
RenderAssetUsages::MAIN_WORLD | RenderAssetUsages::RENDER_WORLD
// This asset is only needed in the render world. Remove it from the asset server once extracted.
RenderAssetUsages::RENDER_WORLD
```
### Alternate Solution
I considered introducing a third field to `RenderAssetPersistencePolicy`
enum:
```rust
enum RenderAssetPersistencePolicy {
/// Keep the asset in the main world after extracting to the render world.
Keep,
/// Remove the asset from the main world after extracting to the render world.
Unload,
/// This doesn't need to be in the render world at all.
NoExtract, // <-----
}
```
Functional, but this seemed like shoehorning. Another option is renaming
the enum to something like:
```rust
enum RenderAssetExtractionPolicy {
/// Extract the asset and keep it in the main world.
Extract,
/// Remove the asset from the main world after extracting to the render world.
ExtractAndUnload,
/// This doesn't need to be in the render world at all.
NoExtract,
}
```
I think this last one could be a good option if the bitflags are too
clunky.
## Migration Guide
* `RenderAssetPersistencePolicy::Keep` → `RenderAssetUsage::MAIN_WORLD |
RenderAssetUsage::RENDER_WORLD` (or `RenderAssetUsage::default()`)
* `RenderAssetPersistencePolicy::Unload` →
`RenderAssetUsage::RENDER_WORLD`
* For types implementing the `RenderAsset` trait, change `fn
persistence_policy(&self) -> RenderAssetPersistencePolicy` to `fn
asset_usage(&self) -> RenderAssetUsages`.
* Change any references to `cpu_persistent_access`
(`RenderAssetPersistencePolicy`) to `asset_usage` (`RenderAssetUsage`).
This applies to `Image`, `Mesh`, and a few other types.
# Objective
Fixes#11479
## Solution
- Remove `collide_aabb.rs`
- Re-implement the example-specific collision code in the example,
taking advantage of the new `IntersectsVolume` trait.
## Changelog
- Removed `sprite::collide_aabb::collide` and
`sprite::collide_aabb::Collision`.
## Migration Guide
`sprite::collide_aabb::collide` and `sprite::collide_aabb::Collision`
were removed.
```rust
// Before
let collision = bevy::sprite::collide_aabb::collide(a_pos, a_size, b_pos, b_size);
if collision.is_some() {
// ...
}
// After
let collision = Aabb2d::new(a_pos.truncate(), a_size / 2.)
.intersects(&Aabb2d::new(b_pos.truncate(), b_size / 2.));
if collision {
// ...
}
```
If you were making use `collide_aabb::Collision`, see the new
`collide_with_side` function in the [`breakout`
example](https://bevyengine.org/examples/Games/breakout/).
## Discussion
As discussed in the linked issue, maybe we want to wait on `bevy_sprite`
generally making use of `Aabb2b` so users don't need to construct it
manually. But since they **do** need to construct the bounding circle
for the ball manually, this doesn't seem like a big deal to me.
---------
Co-authored-by: IQuick 143 <IQuick143cz@gmail.com>
# Objective
Allow TextureAtlasBuilder in AssetLoader.
Fixes#2987
## Solution
- TextureAtlasBuilder no longer hold just AssetIds that are used to
retrieve the actual image data in `finish`, but &Image instead.
- TextureAtlasBuilder now required AssetId only optionally (and it is
only used to retrieve the index from the AssetId in TextureAtlasLayout),
## Issues
- The issue mentioned here
https://github.com/bevyengine/bevy/pull/11474#issuecomment-1904676937
now also extends to the actual atlas texture. In short: Calling
add_texture multiple times for the same texture will lead to duplicate
image data in the atlas texture and additional indices.
If you provide an AssetId we can probably do something to de-duplicate
the entries while keeping insertion order (suggestions welcome on how
exactly). But if you don't then we are out of luck (unless we can and
want to hash the image, which I do not think we want).
---
## Changelog
### Changed
- TextureAtlasBuilder `add_texture` can be called without providing an
AssetId
- TextureAtlasBuilder `finish` no longer takes Assets<Image> and no
longer returns a Handle<Image>
## Migration Guide
- For `add_texture` you need to wrap your AssetId in Some
- `finish` now returns the atlas texture image directly instead of a
handle. Provide the atlas texture to `add` on Assets<Texture> to get a
Handle<Image>
# Objective
https://github.com/bevyengine/bevy/pull/5103 caused a bug where
`Sprite::rect` was ignored by the engine. (Did nothing)
## Solution
My solution changes the way how Bevy calculates the rect, based on this
table:
| `atlas_rect` | `Sprite::rect` | Result |
|--------------|----------------|------------------------------------------------------|
| `None` | `None` | `None` |
| `None` | `Some` | `Sprite::rect` |
| `Some` | `None` | `atlas_rect` |
| `Some` | `Some` | `Sprite::rect` is used, relative to `atlas_rect.min`
|
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
TextureAtlases are commonly used to drive animations described as a
consecutive range of indices. The current TextureAtlasBuilder uses the
AssetId of the image to determine the index of the texture in the
TextureAtlas. The AssetId of an Image Asset can change between runs.
The TextureAtlas exposes
[`get_texture_index`](https://docs.rs/bevy/latest/bevy/sprite/struct.TextureAtlas.html#method.get_texture_index)
to get the index from a given AssetId, but this needlessly complicates
the process of creating a simple TextureAtlas animation.
Fixes#2459
## Solution
- Use the (ordered) image_ids of the 'texture to place' vector to
retrieve the packed locations and compose the textures of the
TextureAtlas.
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
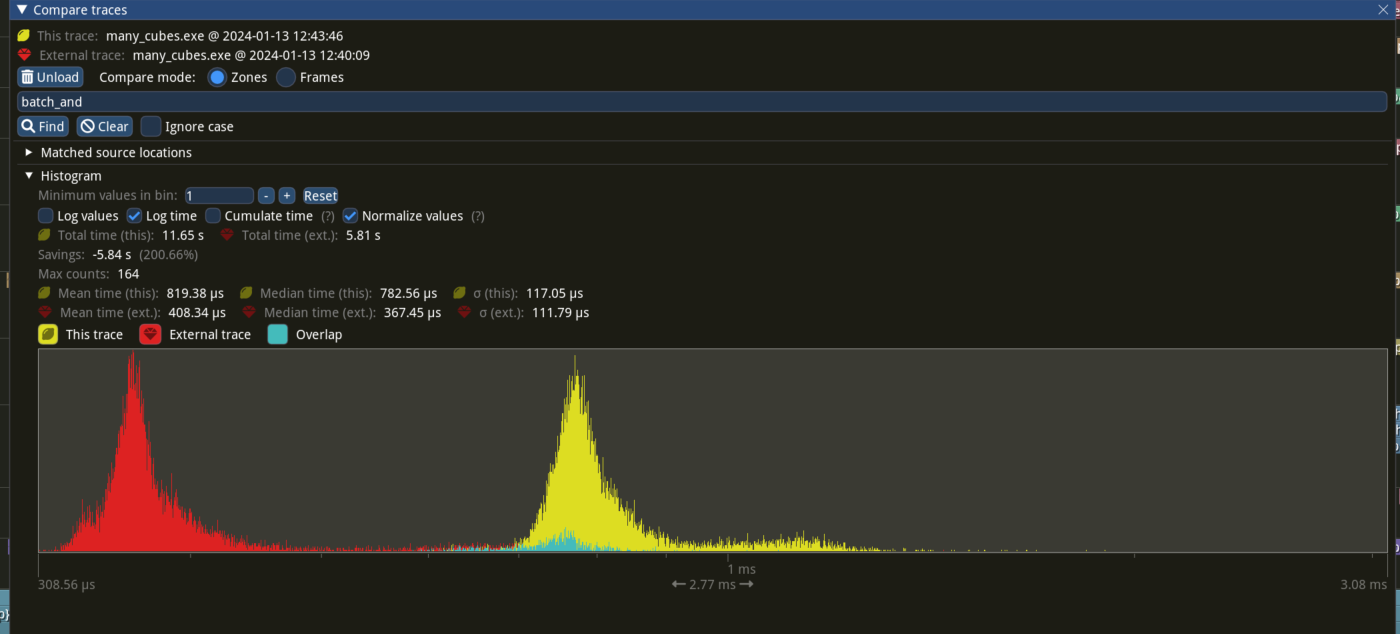
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
# Objective
> Old MR: #5072
> ~~Associated UI MR: #5070~~
> Adresses #1618
Unify sprite management
## Solution
- Remove the `Handle<Image>` field in `TextureAtlas` which is the main
cause for all the boilerplate
- Remove the redundant `TextureAtlasSprite` component
- Renamed `TextureAtlas` asset to `TextureAtlasLayout`
([suggestion](https://github.com/bevyengine/bevy/pull/5103#discussion_r917281844))
- Add a `TextureAtlas` component, containing the atlas layout handle and
the section index
The difference between this solution and #5072 is that instead of the
`enum` approach is that we can more easily manipulate texture sheets
without any breaking changes for classic `SpriteBundle`s (@mockersf
[comment](https://github.com/bevyengine/bevy/pull/5072#issuecomment-1165836139))
Also, this approach is more *data oriented* extracting the
`Handle<Image>` and avoiding complex texture atlas manipulations to
retrieve the texture in both applicative and engine code.
With this method, the only difference between a `SpriteBundle` and a
`SpriteSheetBundle` is an **additional** component storing the atlas
handle and the index.
~~This solution can be applied to `bevy_ui` as well (see #5070).~~
EDIT: I also applied this solution to Bevy UI
## Changelog
- (**BREAKING**) Removed `TextureAtlasSprite`
- (**BREAKING**) Renamed `TextureAtlas` to `TextureAtlasLayout`
- (**BREAKING**) `SpriteSheetBundle`:
- Uses a `Sprite` instead of a `TextureAtlasSprite` component
- Has a `texture` field containing a `Handle<Image>` like the
`SpriteBundle`
- Has a new `TextureAtlas` component instead of a
`Handle<TextureAtlasLayout>`
- (**BREAKING**) `DynamicTextureAtlasBuilder::add_texture` takes an
additional `&Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasLayout::from_grid` no longer takes a
`Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasBuilder::finish` now returns a
`Result<(TextureAtlasLayout, Handle<Image>), _>`
- `bevy_text`:
- `GlyphAtlasInfo` stores the texture `Handle<Image>`
- `FontAtlas` stores the texture `Handle<Image>`
- `bevy_ui`:
- (**BREAKING**) Removed `UiAtlasImage` , the atlas bundle is now
identical to the `ImageBundle` with an additional `TextureAtlas`
## Migration Guide
* Sprites
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(SpriteSheetBundle {
- sprite: TextureAtlasSprite::new(0),
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ texture: texture_handle,
..Default::default()
});
}
```
* UI
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(AtlasImageBundle {
- texture_atlas_image: UiTextureAtlasImage {
- index: 0,
- flip_x: false,
- flip_y: false,
- },
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ image: UiImage {
+ texture: texture_handle,
+ flip_x: false,
+ flip_y: false,
+ },
..Default::default()
});
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
> Replaces #5213
# Objective
Implement sprite tiling and [9 slice
scaling](https://en.wikipedia.org/wiki/9-slice_scaling) for
`bevy_sprite`.
Allowing slice scaling and texture tiling.
Basic scaling vs 9 slice scaling:

Slicing example:
<img width="481" alt="Screenshot 2022-07-05 at 15 05 49"
src="https://user-images.githubusercontent.com/26703856/177336112-9e961af0-c0af-4197-aec9-430c1170a79d.png">
Tiling example:
<img width="1329" alt="Screenshot 2023-11-16 at 13 53 32"
src="https://github.com/bevyengine/bevy/assets/26703856/14db39b7-d9e0-4bc3-ba0e-b1f2db39ae8f">
# Solution
- `SpriteBundlue` now has a `scale_mode` component storing a
`SpriteScaleMode` enum with three variants:
- `Stretched` (default)
- `Tiled` to have sprites tile horizontally and/or vertically
- `Sliced` allowing 9 slicing the texture and optionally tile some
sections with a `Textureslicer`.
- `bevy_sprite` has two extra systems to compute a
`ComputedTextureSlices` if necessary,:
- One system react to changes on `Sprite`, `Handle<Image>` or
`SpriteScaleMode`
- The other listens to `AssetEvent<Image>` to compute slices on sprites
when the texture is ready or changed
- I updated the `bevy_sprite` extraction stage to extract potentially
multiple textures instead of one, depending on the presence of
`ComputedTextureSlices`
- I added two examples showcasing the slicing and tiling feature.
The addition of `ComputedTextureSlices` as a cache is to avoid querying
the image data, to retrieve its dimensions, every frame in a extract or
prepare stage. Also it reacts to changes so we can have stuff like this
(tiling example):
https://github.com/bevyengine/bevy/assets/26703856/a349a9f3-33c3-471f-8ef4-a0e5dfce3b01
# Related
- [ ] Once #5103 or #10099 is merged I can enable tiling and slicing for
texture sheets as ui
# To discuss
There is an other option, to consider slice/tiling as part of the asset,
using the new asset preprocessing but I have no clue on how to do it.
Also, instead of retrieving the Image dimensions, we could use the same
system as the sprite sheet and have the user give the image dimensions
directly (grid). But I think it's less user friendly
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
- Since #10520, assets are unloaded from RAM by default. This breaks a
number of scenario:
- using `load_folder`
- loading a gltf, then going through its mesh to transform them /
compute a collider / ...
- any assets/subassets scenario should be `Keep` as you can't know what
the user will do with the assets
- android suspension, where GPU memory is unloaded
- Alternative to #11202
## Solution
- Keep assets on CPU memory by default
# Objective
- No point in keeping Meshes/Images in RAM once they're going to be sent
to the GPU, and kept in VRAM. This saves a _significant_ amount of
memory (several GBs) on scenes like bistro.
- References
- https://github.com/bevyengine/bevy/pull/1782
- https://github.com/bevyengine/bevy/pull/8624
## Solution
- Augment RenderAsset with the capability to unload the underlying asset
after extracting to the render world.
- Mesh/Image now have a cpu_persistent_access field. If this field is
RenderAssetPersistencePolicy::Unload, the asset will be unloaded from
Assets<T>.
- A new AssetEvent is sent upon dropping the last strong handle for the
asset, which signals to the RenderAsset to remove the GPU version of the
asset.
---
## Changelog
- Added `AssetEvent::NoLongerUsed` and
`AssetEvent::is_no_longer_used()`. This event is sent when the last
strong handle of an asset is dropped.
- Rewrote the API for `RenderAsset` to allow for unloading the asset
data from the CPU.
- Added `RenderAssetPersistencePolicy`.
- Added `Mesh::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `Image::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `ImageLoaderSettings::cpu_persistent_access`.
- Added `ExrTextureLoaderSettings`.
- Added `HdrTextureLoaderSettings`.
## Migration Guide
- Asset loaders (GLTF, etc) now load meshes and textures without
`cpu_persistent_access`. These assets will be removed from
`Assets<Mesh>` and `Assets<Image>` once `RenderAssets<Mesh>` and
`RenderAssets<Image>` contain the GPU versions of these assets, in order
to reduce memory usage. If you require access to the asset data from the
CPU in future frames after the GLTF asset has been loaded, modify all
dependent `Mesh` and `Image` assets and set `cpu_persistent_access` to
`RenderAssetPersistencePolicy::Keep`.
- `Mesh` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `Image` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `MorphTargetImage::new()` now requires a new `cpu_persistent_access`
parameter. Set it to `RenderAssetPersistencePolicy::Keep` to mimic the
previous behavior.
- `DynamicTextureAtlasBuilder::add_texture()` now requires that the
`TextureAtlas` you pass has an `Image` with `cpu_persistent_access:
RenderAssetPersistencePolicy::Keep`. Ensure you construct the image
properly for the texture atlas.
- The `RenderAsset` trait has significantly changed, and requires
adapting your existing implementations.
- The trait now requires `Clone`.
- The `ExtractedAsset` associated type has been removed (the type itself
is now extracted).
- The signature of `prepare_asset()` is slightly different
- A new `persistence_policy()` method is now required (return
RenderAssetPersistencePolicy::Unload to match the previous behavior).
- Match on the new `NoLongerUsed` variant for exhaustive matches of
`AssetEvent`.
This expands upon https://github.com/bevyengine/bevy/pull/11134.
I found myself needing `tonemapping_pipeline_key` for some custom 2d
draw functions. #11134 exported the 3d version of
`tonemapping_pipeline_key` and this PR exports the 2d version. I also
made `alpha_mode_pipeline_key` public for good measure.
# Objective
- Refactor collide code and add tests.
## Solution
- Rebase the changes made in #4485.
Co-authored-by: Eduardo Canellas de Oliveira <eduardo.canellas@bemobi.com>
# Objective
- Fixes#10587, where the `Aabb` component of entities with `Sprite` and
`Handle<Image>` components was not automatically updated when
`Sprite::custom_size` changed.
## Solution
- In the query for entities with `Sprite` components in
`calculate_bounds_2d`, use the `Changed` filter to detect for `Sprites`
that changed as well as sprites that do not have `Aabb` components. As
noted in the issue, this will cause the `Aabb` to be recalculated when
other fields of the `Sprite` component change, but calculating the
`Aabb` for sprites is trivial.
---
## Changelog
- Modified query for entities with `Sprite` components in
`calculate_bounds_2d`, so that entities with `Sprite` components that
changed will also have their AABB recalculated.
# Objective
- bevy_sprite crate is missing docs for important types. `Sprite` being
undocumented was especially confusing for me even though it is one of
the first types I need to learn.
## Solution
- Improves the situation a little by adding some documentations.
I'm unsure about my understanding of functionality and writing. I'm
happy to be pointed out any mistakes.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
# Objective
A workaround for a webgl issue was introduced in #9383 but one function
for mesh2d was missed.
## Solution
Applied the migration guide from #9383 in
`mesh2d_normal_local_to_world()
Note: I'm not using normals so I have not tested the bug & fix
# Objective
avoid panics from `calculate_bounds` systems if entities are despawned
in PostUpdate.
there's a running general discussion (#10166) about command panicking.
in the meantime we may as well fix up some cases where it's clear a
failure to insert is safe.
## Solution
change `.insert(aabb)` to `.try_insert(aabb)`
# Objective
- Materials should be a more frequent rebind then meshes (due to being
able to use a single vertex buffer, such as in #10164) and therefore
should be in a higher bind group.
---
## Changelog
- For 2d and 3d mesh/material setups (but not UI materials, or other
rendering setups such as gizmos, sprites, or text), mesh data is now in
bind group 1, and material data is now in bind group 2, which is swapped
from how they were before.
## Migration Guide
- Custom 2d and 3d mesh/material shaders should now use bind group 2
`@group(2) @binding(x)` for their bound resources, instead of bind group
1.
- Many internal pieces of rendering code have changed so that mesh data
is now in bind group 1, and material data is now in bind group 2.
Semi-custom rendering setups (that don't use the Material or Material2d
APIs) should adapt to these changes.
# Objective
- Follow up to #9694
## Solution
- Same api as #9694 but adapted for `BindGroupLayoutEntry`
- Use the same `ShaderStages` visibilty for all entries by default
- Add `BindingType` helper function that mirror the wgsl equivalent and
that make writing layouts much simpler.
Before:
```rust
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2,
multisampled: false,
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: bevy::render::render_resource::BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(PostProcessSettings::min_size()),
},
count: None,
},
],
});
```
After:
```rust
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout"),
&BindGroupLayoutEntries::sequential(
ShaderStages::FRAGMENT,
(
texture_2d_f32(),
sampler(SamplerBindingType::Filtering),
uniform_buffer(false, Some(PostProcessSettings::min_size())),
),
),
);
```
Here's a more extreme example in bevy_solari:
86dab7f5da
---
## Changelog
- Added `BindGroupLayoutEntries` and all `BindingType` helper functions.
## Migration Guide
`RenderDevice::create_bind_group_layout()` doesn't take a
`BindGroupLayoutDescriptor` anymore. You need to provide the parameters
separately
```rust
// 0.12
let layout = render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
label: Some("post_process_bind_group_layout"),
entries: &[
BindGroupLayoutEntry {
// ...
},
],
});
// 0.13
let layout = render_device.create_bind_group_layout(
"post_process_bind_group_layout",
&[
BindGroupLayoutEntry {
// ...
},
],
);
```
## TODO
- [x] implement a `Dynamic` variant
- [x] update the `RenderDevice::create_bind_group_layout()` api to match
the one from `RenderDevice::creat_bind_group()`
- [x] docs
# Objective
`wgpu` has a helper method `texture.as_image_copy()` for a common
pattern when making a default-like `ImageCopyTexture` from a texture.
This is used in various places in Bevy for texture copy operations, but
it was not used where `write_texture` is called.
## Solution
- Replace struct `ImageCopyTexture` initialization with
`texture.as_image_copy()` where appropriate
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
It is currently impossible to control the relative ordering of two 2D
materials at the same depth. This is required to implement wireframes
for 2D meshes correctly
(https://github.com/bevyengine/bevy/issues/5881).
## Solution
Add a `Material2d::depth_bias` function that mirrors the existing 3D
`Material::depth_bias` function.
(this is pulled out of https://github.com/bevyengine/bevy/pull/10489)
---
## Changelog
### Added
- Added `Material2d::depth_bias`
## Migration Guide
`PreparedMaterial2d` has a new `depth_bias` field. A value of 0.0 can be
used to get the previous behavior.
# Objective
- Fix adding `#![allow(clippy::type_complexity)]` everywhere. like #9796
## Solution
- Use the new [lints] table that will land in 1.74
(https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#lints)
- inherit lint to the workspace, crates and examples.
```
[lints]
workspace = true
```
## Changelog
- Bump rust version to 1.74
- Enable lints table for the workspace
```toml
[workspace.lints.clippy]
type_complexity = "allow"
```
- Allow type complexity for all crates and examples
```toml
[lints]
workspace = true
```
---------
Co-authored-by: Martín Maita <47983254+mnmaita@users.noreply.github.com>
# Objective
- Build on the changes in https://github.com/bevyengine/bevy/pull/9982
- Use `ImageSamplerDescriptor` as the "public image sampler descriptor"
interface in all places (for consistency)
- Make it possible to configure textures to use the "default" sampler
(as configured in the `DefaultImageSampler` resource)
- Fix a bug introduced in #9982 that prevents configured samplers from
being used in Basis, KTX2, and DDS textures
---
## Migration Guide
- When using the `Image` API, use `ImageSamplerDescriptor` instead of
`wgpu::SamplerDescriptor`
- If writing custom wgpu renderer features that work with `Image`, call
`&image_sampler.as_wgpu()` to convert to a wgpu descriptor.
# Objective
A follow-up PR for https://github.com/bevyengine/bevy/pull/10221
## Changelog
Replaced usages of texture_descriptor.size with the helper methods of
`Image` through the entire engine codebase
# Objective
To get the width or height of an image you do:
```rust
self.texture_descriptor.size.{width, height}
```
that is quite verbose.
This PR adds some convenient methods for Image to reduce verbosity.
## Changelog
* Add a `width()` method for getting the width of an image.
* Add a `height()` method for getting the height of an image.
* Rename the `size()` method to `size_f32()`.
* Add a `size()` method for getting the size of an image as u32.
* Renamed the `aspect_2d()` method to `aspect_ratio()`.
## Migration Guide
Replace calls to the `Image::size()` method with `size_f32()`.
Replace calls to the `Image::aspect_2d()` method with `aspect_ratio()`.
# Objective
Simplify bind group creation code. alternative to (and based on) #9476
## Solution
- Add a `BindGroupEntries` struct that can transparently be used where
`&[BindGroupEntry<'b>]` is required in BindGroupDescriptors.
Allows constructing the descriptor's entries as:
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::with_indexes((
(2, &my_sampler),
(3, my_uniform),
)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 2,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 3,
resource: my_uniform,
},
],
);
```
or
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::sequential((&my_sampler, my_uniform)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 0,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 1,
resource: my_uniform,
},
],
);
```
the structs has no user facing macros, is tuple-type-based so stack
allocated, and has no noticeable impact on compile time.
- Also adds a `DynamicBindGroupEntries` struct with a similar api that
uses a `Vec` under the hood and allows extending the entries.
- Modifies `RenderDevice::create_bind_group` to take separate arguments
`label`, `layout` and `entries` instead of a `BindGroupDescriptor`
struct. The struct can't be stored due to the internal references, and
with only 3 members arguably does not add enough context to justify
itself.
- Modify the codebase to use the new api and the `BindGroupEntries` /
`DynamicBindGroupEntries` structs where appropriate (whenever the
entries slice contains more than 1 member).
## Migration Guide
- Calls to `RenderDevice::create_bind_group({BindGroupDescriptor {
label, layout, entries })` must be amended to
`RenderDevice::create_bind_group(label, layout, entries)`.
- If `label`s have been specified as `"bind_group_name".into()`, they
need to change to just `"bind_group_name"`. `Some("bind_group_name")`
and `None` will still work, but `Some("bind_group_name")` can optionally
be simplified to just `"bind_group_name"`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- bump naga_oil to 0.10
- update shader imports to use rusty syntax
## Migration Guide
naga_oil 0.10 reworks the import mechanism to support more syntax to
make it more rusty, and test for item use before importing to determine
which imports are modules and which are items, which allows:
- use rust-style imports
```
#import bevy_pbr::{
pbr_functions::{alpha_discard as discard, apply_pbr_lighting},
mesh_bindings,
}
```
- import partial paths:
```
#import part::of::path
...
path::remainder::function();
```
which will call to `part::of::path::remainder::function`
- use fully qualified paths without importing:
```
// #import bevy_pbr::pbr_functions
bevy_pbr::pbr_functions::pbr()
```
- use imported items without qualifying
```
#import bevy_pbr::pbr_functions::pbr
// for backwards compatibility the old style is still supported:
// #import bevy_pbr::pbr_functions pbr
...
pbr()
```
- allows most imported items to end with `_` and numbers (naga_oil#30).
still doesn't allow struct members to end with `_` or numbers but it's
progress.
- the vast majority of existing shader code will work without changes,
but will emit "deprecated" warnings for old-style imports. these can be
suppressed with the `allow-deprecated` feature.
- partly breaks overrides (as far as i'm aware nobody uses these yet) -
now overrides will only be applied if the overriding module is added as
an additional import in the arguments to `Composer::make_naga_module` or
`Composer::add_composable_module`. this is necessary to support
determining whether imports are modules or items.
# Objective
allow extending `Material`s (including the built in `StandardMaterial`)
with custom vertex/fragment shaders and additional data, to easily get
pbr lighting with custom modifications, or otherwise extend a base
material.
# Solution
- added `ExtendedMaterial<B: Material, E: MaterialExtension>` which
contains a base material and a user-defined extension.
- added example `extended_material` showing how to use it
- modified AsBindGroup to have "unprepared" functions that return raw
resources / layout entries so that the extended material can combine
them
note: doesn't currently work with array resources, as i can't figure out
how to make the OwnedBindingResource::get_binding() work, as wgpu
requires a `&'a[&'a TextureView]` and i have a `Vec<TextureView>`.
# Migration Guide
manual implementations of `AsBindGroup` will need to be adjusted, the
changes are pretty straightforward and can be seen in the diff for e.g.
the `texture_binding_array` example.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Fixes#9676
Possible alternative to #9708
`Text2dBundles` are not currently drawn because the render-world-only
entities for glyphs that are created in `extract_text2d_sprite` are not
tracked by the per-view `VisibleEntities`.
## Solution
Add an `Option<Entity>` to `ExtractedSprite` that keeps track of the
original entity that caused a "glyph entity" to be created.
Use that in `queue_sprites` if it exists when checking view visibility.
## Benchmarks
Quick benchmarks. Average FPS over 1500 frames.
| bench | before fps | after fps | diff |
|-|-|-|-|
|many_sprites|884.93|879.00|🟡 -0.7%|
|bevymark -- --benchmark --waves 100 --per-wave 1000 --mode
sprite|75.99|75.93|🟡 -0.1%|
|bevymark -- --benchmark --waves 50 --per-wave 1000 --mode
mesh2d|32.85|32.58|🟡 -0.8%|
# Objective
cleanup some pbr shader code. improve shader stage io consistency and
make pbr.wgsl (probably many people's first foray into bevy shader code)
a little more human-readable. also fix a couple of small issues with
deferred rendering.
## Solution
mesh_vertex_output:
- rename to forward_io (to align with prepass_io)
- rename `MeshVertexOutput` to `VertexOutput` (to align with prepass_io)
- move `Vertex` from mesh.wgsl into here (to align with prepass_io)
prepass_io:
- remove `FragmentInput`, use `VertexOutput` directly (to align with
forward_io)
- rename `VertexOutput::clip_position` to `position` (to align with
forward_io)
pbr.wgsl:
- restructure so we don't need `#ifdefs` on the actual entrypoint, use
VertexOutput and FragmentOutput in all cases and use #ifdefs to import
the right struct definitions.
- rearrange to make the flow clearer
- move alpha_discard up from `pbr_functions::pbr` to avoid needing to
call it on some branches and not others
- add a bunch of comments
deferred_lighting:
- move ssao into the `!unlit` block to reflect forward behaviour
correctly
- fix compile error with deferred + premultiply_alpha
## Migration Guide
in custom material shaders:
- `pbr_functions::pbr` no longer calls to
`pbr_functions::alpha_discard`. if you were using the `pbr` function in
a custom shader with alpha mask mode you now also need to call
alpha_discard manually
- rename imports of `bevy_pbr::mesh_vertex_output` to
`bevy_pbr::forward_io`
- rename instances of `MeshVertexOutput` to `VertexOutput`
in custom material prepass shaders:
- rename instances of `VertexOutput::clip_position` to
`VertexOutput::position`
# Objective
- After https://github.com/bevyengine/bevy/pull/9903, example
`mesh2d_manual` doesn't render anything
## Solution
- Fix the example using the new `RenderMesh2dInstances`
# Objective
- Fix TextureAtlasBuilder padding issue
TextureAtlasBuilder padding is reserved during add_texture() but can
still be changed afterwards. This means that changing padding after the
textures will be wrongly applied, either distorting the textures or
panicking if new padding is higher than texture+old padding.
## Solution
- Delay applying padding until finish()
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
- Implement the foundations of automatic batching/instancing of draw
commands as the next step from #89
- NOTE: More performance improvements will come when more data is
managed and bound in ways that do not require rebinding such as mesh,
material, and texture data.
## Solution
- The core idea for batching of draw commands is to check whether any of
the information that has to be passed when encoding a draw command
changes between two things that are being drawn according to the sorted
render phase order. These should be things like the pipeline, bind
groups and their dynamic offsets, index/vertex buffers, and so on.
- The following assumptions have been made:
- Only entities with prepared assets (pipelines, materials, meshes) are
queued to phases
- View bindings are constant across a phase for a given draw function as
phases are per-view
- `batch_and_prepare_render_phase` is the only system that performs this
batching and has sole responsibility for preparing the per-object data.
As such the mesh binding and dynamic offsets are assumed to only vary as
a result of the `batch_and_prepare_render_phase` system, e.g. due to
having to split data across separate uniform bindings within the same
buffer due to the maximum uniform buffer binding size.
- Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform
in arrays in GPU buffers rather than each one being at a dynamic offset
in a uniform buffer. This is the same optimisation that was made for 3D
not long ago.
- Change batch size for a range in `PhaseItem`, adding API for getting
or mutating the range. This is more flexible than a size as the length
of the range can be used in place of the size, but the start and end can
be otherwise whatever is needed.
- Add an optional mesh bind group dynamic offset to `PhaseItem`. This
avoids having to do a massive table move just to insert
`GpuArrayBufferIndex` components.
## Benchmarks
All tests have been run on an M1 Max on AC power. `bevymark` and
`many_cubes` were modified to use 1920x1080 with a scale factor of 1. I
run a script that runs a separate Tracy capture process, and then runs
the bevy example with `--features bevy_ci_testing,trace_tracy` and
`CI_TESTING_CONFIG=../benchmark.ron` with the contents of
`../benchmark.ron`:
```rust
(
exit_after: Some(1500)
)
```
...in order to run each test for 1500 frames.
The recent changes to `many_cubes` and `bevymark` added reproducible
random number generation so that with the same settings, the same rng
will occur. They also added benchmark modes that use a fixed delta time
for animations. Combined this means that the same frames should be
rendered both on main and on the branch.
The graphs compare main (yellow) to this PR (red).
### 3D Mesh `many_cubes --benchmark`
<img width="1411" alt="Screenshot 2023-09-03 at 23 42 10"
src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4">
The mesh and material are the same for all instances. This is basically
the best case for the initial batching implementation as it results in 1
draw for the ~11.7k visible meshes. It gives a ~30% reduction in median
frame time.
The 1000th frame is identical using the flip tool:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4615 seconds
```
### 3D Mesh `many_cubes --benchmark --material-texture-count 10`
<img width="1404" alt="Screenshot 2023-09-03 at 23 45 18"
src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf">
This run uses 10 different materials by varying their textures. The
materials are randomly selected, and there is no sorting by material
bind group for opaque 3D so any batching is 'random'. The PR produces a
~5% reduction in median frame time. If we were to sort the opaque phase
by the material bind group, then this should be a lot faster. This
produces about 10.5k draws for the 11.7k visible entities. This makes
sense as randomly selecting from 10 materials gives a chance that two
adjacent entities randomly select the same material and can be batched.
The 1000th frame is identical in flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4537 seconds
```
### 3D Mesh `many_cubes --benchmark --vary-per-instance`
<img width="1394" alt="Screenshot 2023-09-03 at 23 48 44"
src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f">
This run varies the material data per instance by randomly-generating
its colour. This is the worst case for batching and that it performs
about the same as `main` is a good thing as it demonstrates that the
batching has minimal overhead when dealing with ~11k visible mesh
entities.
The 1000th frame is identical according to flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4568 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d`
<img width="1412" alt="Screenshot 2023-09-03 at 23 59 56"
src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4">
This spawns 160 waves of 1000 quad meshes that are shaded with
ColorMaterial. Each wave has a different material so 160 waves currently
should result in 160 batches. This results in a 50% reduction in median
frame time.
Capturing a screenshot of the 1000th frame main vs PR gives:

```
Mean: 0.001222
Weighted median: 0.750432
1st weighted quartile: 0.453494
3rd weighted quartile: 0.969758
Min: 0.000000
Max: 0.990296
Evaluation time: 0.4255 seconds
```
So they seem to produce the same results. I also double-checked the
number of draws. `main` does 160000 draws, and the PR does 160, as
expected.
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --material-texture-count 10`
<img width="1392" alt="Screenshot 2023-09-04 at 00 09 22"
src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c">
This generates 10 textures and generates materials for each of those and
then selects one material per wave. The median frame time is reduced by
50%. Similar to the plain run above, this produces 160 draws on the PR
and 160000 on `main` and the 1000th frame is identical (ignoring the fps
counter text overlay).

```
Mean: 0.002877
Weighted median: 0.964980
1st weighted quartile: 0.668871
3rd weighted quartile: 0.982749
Min: 0.000000
Max: 0.992377
Evaluation time: 0.4301 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --vary-per-instance`
<img width="1396" alt="Screenshot 2023-09-04 at 00 13 53"
src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb">
This creates unique materials per instance by randomly-generating the
material's colour. This is the worst case for 2D batching. Somehow, this
PR manages a 7% reduction in median frame time. Both main and this PR
issue 160000 draws.
The 1000th frame is the same:

```
Mean: 0.001214
Weighted median: 0.937499
1st weighted quartile: 0.635467
3rd weighted quartile: 0.979085
Min: 0.000000
Max: 0.988971
Evaluation time: 0.4462 seconds
```
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite`
<img width="1396" alt="Screenshot 2023-09-04 at 12 21 12"
src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43">
This just spawns 160 waves of 1000 sprites. There should be and is no
notable difference between main and the PR.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --material-texture-count 10`
<img width="1389" alt="Screenshot 2023-09-04 at 12 36 08"
src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413">
This spawns the sprites selecting a texture at random per instance from
the 10 generated textures. This has no significant change vs main and
shouldn't.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --vary-per-instance`
<img width="1401" alt="Screenshot 2023-09-04 at 12 29 52"
src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6">
This sets the sprite colour as being unique per instance. This can still
all be drawn using one batch. There should be no difference but the PR
produces median frame times that are 4% higher. Investigation showed no
clear sources of cost, rather a mix of give and take that should not
happen. It seems like noise in the results.
### Summary
| Benchmark | % change in median frame time |
| ------------- | ------------- |
| many_cubes | 🟩 -30% |
| many_cubes 10 materials | 🟩 -5% |
| many_cubes unique materials | 🟩 ~0% |
| bevymark mesh2d | 🟩 -50% |
| bevymark mesh2d 10 materials | 🟩 -50% |
| bevymark mesh2d unique materials | 🟩 -7% |
| bevymark sprite | 🟥 2% |
| bevymark sprite 10 materials | 🟥 0.6% |
| bevymark sprite unique materials | 🟥 4.1% |
---
## Changelog
- Added: 2D and 3D mesh entities that share the same mesh and material
(same textures, same data) are now batched into the same draw command
for better performance.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective
Some rendering system did heavy use of `if let`, and could be improved
by using `let else`.
## Solution
- Reduce rightward drift by using let-else over if-let
- Extract value-to-key mappings to their own functions so that the
system is less bloated, easier to understand
- Use a `let` binding instead of untupling in closure argument to reduce
indentation
## Note to reviewers
Enable the "no white space diff" for easier viewing.
In the "Files changed" view, click on the little cog right of the "Jump
to" text, on the row where the "Review changes" button is. then enable
the "Hide whitespace" checkbox and click reload.
# Objective
- When adding/removing bindings in large binding lists, git would
generate very difficult-to-read diffs
## Solution
- Move the `@group(X) @binding(Y)` into the same line as the binding
type declaration
# Objective
Replace instances of
```rust
for x in collection.iter{_mut}() {
```
with
```rust
for x in &{mut} collection {
```
This also changes CI to no longer suppress this lint. Note that since
this lint only shows up when using clippy in pedantic mode, it was
probably unnecessary to suppress this lint in the first place.
# Objective
`TextureAtlas` supports pregenerated texture atlases with padding, but
`TextureAtlasBuilder` can't add padding when it creates a new atlas.
fixes#8150
## Solution
Add a method `padding` to `TextureAtlasBuilder` that sets the amount of
padding to add around each texture.
When queueing the textures to be copied, add the padding value to the
size of each source texture. Then when copying the source textures to
the output atlas texture subtract the same padding value from the sizes
of the target rects.
unpadded:
<img width="961" alt="texture_atlas_example"
src="https://github.com/bevyengine/bevy/assets/27962798/8cf02442-dc3e-4429-90f1-543bc9270d8b">
padded:
<img width="961" alt="texture_atlas_example_with_padding"
src="https://github.com/bevyengine/bevy/assets/27962798/da347bcc-b083-4650-ba0c-86883853764f">
---
## Changelog
`TextureAtlasBuilder`
* Added support for building texture atlases with padding.
* Adds a `padding` method to `TextureAtlasBuilder` that can be used to
set an amount of padding to add between the sprites of the generated
texture atlas.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
{kind=link}
{kind=link}