Currently, `MeshUniform`s are rather large: 160 bytes. They're also
somewhat expensive to compute, because they involve taking the inverse
of a 3x4 matrix. Finally, if a mesh is present in multiple views, that
mesh will have a separate `MeshUniform` for each and every view, which
is wasteful.
This commit fixes these issues by introducing the concept of a *mesh
input uniform* and adding a *mesh uniform building* compute shader pass.
The `MeshInputUniform` is simply the minimum amount of data needed for
the GPU to compute the full `MeshUniform`. Most of this data is just the
transform and is therefore only 64 bytes. `MeshInputUniform`s are
computed during the *extraction* phase, much like skins are today, in
order to avoid needlessly copying transforms around on CPU. (In fact,
the render app has been changed to only store the translation of each
mesh; it no longer cares about any other part of the transform, which is
stored only on the GPU and the main world.) Before rendering, the
`build_mesh_uniforms` pass runs to expand the `MeshInputUniform`s to the
full `MeshUniform`.
The mesh uniform building pass does the following, all on GPU:
1. Copy the appropriate fields of the `MeshInputUniform` to the
`MeshUniform` slot. If a single mesh is present in multiple views, this
effectively duplicates it into each view.
2. Compute the inverse transpose of the model transform, used for
transforming normals.
3. If applicable, copy the mesh's transform from the previous frame for
TAA. To support this, we double-buffer the `MeshInputUniform`s over two
frames and swap the buffers each frame. The `MeshInputUniform`s for the
current frame contain the index of that mesh's `MeshInputUniform` for
the previous frame.
This commit produces wins in virtually every CPU part of the pipeline:
`extract_meshes`, `queue_material_meshes`,
`batch_and_prepare_render_phase`, and especially
`write_batched_instance_buffer` are all faster. Shrinking the amount of
CPU data that has to be shuffled around speeds up the entire rendering
process.
| Benchmark | This branch | `main` | Speedup |
|------------------------|-------------|---------|---------|
| `many_cubes -nfc` | 17.259 | 24.529 | 42.12% |
| `many_cubes -nfc -vpi` | 302.116 | 312.123 | 3.31% |
| `many_foxes` | 3.227 | 3.515 | 8.92% |
Because mesh uniform building requires compute shader, and WebGL 2 has
no compute shader, the existing CPU mesh uniform building code has been
left as-is. Many types now have both CPU mesh uniform building and GPU
mesh uniform building modes. Developers can opt into the old CPU mesh
uniform building by setting the `use_gpu_uniform_builder` option on
`PbrPlugin` to `false`.
Below are graphs of the CPU portions of `many-cubes
--no-frustum-culling`. Yellow is this branch, red is `main`.
`extract_meshes`:

It's notable that we get a small win even though we're now writing to a
GPU buffer.
`queue_material_meshes`:

There's a bit of a regression here; not sure what's causing it. In any
case it's very outweighed by the other gains.
`batch_and_prepare_render_phase`:

There's a huge win here, enough to make batching basically drop off the
profile.
`write_batched_instance_buffer`:

There's a massive improvement here, as expected. Note that a lot of it
simply comes from the fact that `MeshInputUniform` is `Pod`. (This isn't
a maintainability problem in my view because `MeshInputUniform` is so
simple: just 16 tightly-packed words.)
## Changelog
### Added
* Per-mesh instance data is now generated on GPU with a compute shader
instead of CPU, resulting in rendering performance improvements on
platforms where compute shaders are supported.
## Migration guide
* Custom render phases now need multiple systems beyond just
`batch_and_prepare_render_phase`. Code that was previously creating
custom render phases should now add a `BinnedRenderPhasePlugin` or
`SortedRenderPhasePlugin` as appropriate instead of directly adding
`batch_and_prepare_render_phase`.
# Objective
- Replace `RenderMaterials` / `RenderMaterials2d` / `RenderUiMaterials`
with `RenderAssets` to enable implementing changes to one thing,
`RenderAssets`, that applies to all use cases rather than duplicating
changes everywhere for multiple things that should be one thing.
- Adopts #8149
## Solution
- Make RenderAsset generic over the destination type rather than the
source type as in #8149
- Use `RenderAssets<PreparedMaterial<M>>` etc for render materials
---
## Changelog
- Changed:
- The `RenderAsset` trait is now implemented on the destination type.
Its `SourceAsset` associated type refers to the type of the source
asset.
- `RenderMaterials`, `RenderMaterials2d`, and `RenderUiMaterials` have
been replaced by `RenderAssets<PreparedMaterial<M>>` and similar.
## Migration Guide
- `RenderAsset` is now implemented for the destination type rather that
the source asset type. The source asset type is now the `RenderAsset`
trait's `SourceAsset` associated type.
This commit makes the following optimizations:
## `MeshPipelineKey`/`BaseMeshPipelineKey` split
`MeshPipelineKey` has been split into `BaseMeshPipelineKey`, which lives
in `bevy_render` and `MeshPipelineKey`, which lives in `bevy_pbr`.
Conceptually, `BaseMeshPipelineKey` is a superclass of
`MeshPipelineKey`. For `BaseMeshPipelineKey`, the bits start at the
highest (most significant) bit and grow downward toward the lowest bit;
for `MeshPipelineKey`, the bits start at the lowest bit and grow upward
toward the highest bit. This prevents them from colliding.
The goal of this is to avoid having to reassemble bits of the pipeline
key for every mesh every frame. Instead, we can just use a bitwise or
operation to combine the pieces that make up a `MeshPipelineKey`.
## `specialize_slow`
Previously, all of `specialize()` was marked as `#[inline]`. This
bloated `queue_material_meshes` unnecessarily, as a large chunk of it
ended up being a slow path that was rarely hit. This commit refactors
the function to move the slow path to `specialize_slow()`.
Together, these two changes shave about 5% off `queue_material_meshes`:

## Migration Guide
- The `primitive_topology` field on `GpuMesh` is now an accessor method:
`GpuMesh::primitive_topology()`.
- For performance reasons, `MeshPipelineKey` has been split into
`BaseMeshPipelineKey`, which lives in `bevy_render`, and
`MeshPipelineKey`, which lives in `bevy_pbr`. These two should be
combined with bitwise-or to produce the final `MeshPipelineKey`.
# Objective
This is a necessary precursor to #9122 (this was split from that PR to
reduce the amount of code to review all at once).
Moving `!Send` resource ownership to `App` will make it unambiguously
`!Send`. `SubApp` must be `Send`, so it can't wrap `App`.
## Solution
Refactor `App` and `SubApp` to not have a recursive relationship. Since
`SubApp` no longer wraps `App`, once `!Send` resources are moved out of
`World` and into `App`, `SubApp` will become unambiguously `Send`.
There could be less code duplication between `App` and `SubApp`, but
that would break `App` method chaining.
## Changelog
- `SubApp` no longer wraps `App`.
- `App` fields are no longer publicly accessible.
- `App` can no longer be converted into a `SubApp`.
- Various methods now return references to a `SubApp` instead of an
`App`.
## Migration Guide
- To construct a sub-app, use `SubApp::new()`. `App` can no longer
convert into `SubApp`.
- If you implemented a trait for `App`, you may want to implement it for
`SubApp` as well.
- If you're accessing `app.world` directly, you now have to use
`app.world()` and `app.world_mut()`.
- `App::sub_app` now returns `&SubApp`.
- `App::sub_app_mut` now returns `&mut SubApp`.
- `App::get_sub_app` now returns `Option<&SubApp>.`
- `App::get_sub_app_mut` now returns `Option<&mut SubApp>.`
Today, we sort all entities added to all phases, even the phases that
don't strictly need sorting, such as the opaque and shadow phases. This
results in a performance loss because our `PhaseItem`s are rather large
in memory, so sorting is slow. Additionally, determining the boundaries
of batches is an O(n) process.
This commit makes Bevy instead applicable place phase items into *bins*
keyed by *bin keys*, which have the invariant that everything in the
same bin is potentially batchable. This makes determining batch
boundaries O(1), because everything in the same bin can be batched.
Instead of sorting each entity, we now sort only the bin keys. This
drops the sorting time to near-zero on workloads with few bins like
`many_cubes --no-frustum-culling`. Memory usage is improved too, with
batch boundaries and dynamic indices now implicit instead of explicit.
The improved memory usage results in a significant win even on
unbatchable workloads like `many_cubes --no-frustum-culling
--vary-material-data-per-instance`, presumably due to cache effects.
Not all phases can be binned; some, such as transparent and transmissive
phases, must still be sorted. To handle this, this commit splits
`PhaseItem` into `BinnedPhaseItem` and `SortedPhaseItem`. Most of the
logic that today deals with `PhaseItem`s has been moved to
`SortedPhaseItem`. `BinnedPhaseItem` has the new logic.
Frame time results (in ms/frame) are as follows:
| Benchmark | `binning` | `main` | Speedup |
| ------------------------ | --------- | ------- | ------- |
| `many_cubes -nfc -vpi` | 232.179 | 312.123 | 34.43% |
| `many_cubes -nfc` | 25.874 | 30.117 | 16.40% |
| `many_foxes` | 3.276 | 3.515 | 7.30% |
(`-nfc` is short for `--no-frustum-culling`; `-vpi` is short for
`--vary-per-instance`.)
---
## Changelog
### Changed
* Render phases have been split into binned and sorted phases. Binned
phases, such as the common opaque phase, achieve improved CPU
performance by avoiding the sorting step.
## Migration Guide
- `PhaseItem` has been split into `BinnedPhaseItem` and
`SortedPhaseItem`. If your code has custom `PhaseItem`s, you will need
to migrate them to one of these two types. `SortedPhaseItem` requires
the fewest code changes, but you may want to pick `BinnedPhaseItem` if
your phase doesn't require sorting, as that enables higher performance.
## Tracy graphs
`many-cubes --no-frustum-culling`, `main` branch:
<img width="1064" alt="Screenshot 2024-03-12 180037"
src="https://github.com/bevyengine/bevy/assets/157897/e1180ce8-8e89-46d2-85e3-f59f72109a55">
`many-cubes --no-frustum-culling`, this branch:
<img width="1064" alt="Screenshot 2024-03-12 180011"
src="https://github.com/bevyengine/bevy/assets/157897/0899f036-6075-44c5-a972-44d95895f46c">
You can see that `batch_and_prepare_binned_render_phase` is a much
smaller fraction of the time. Zooming in on that function, with yellow
being this branch and red being `main`, we see:
<img width="1064" alt="Screenshot 2024-03-12 175832"
src="https://github.com/bevyengine/bevy/assets/157897/0dfc8d3f-49f4-496e-8825-a66e64d356d0">
The binning happens in `queue_material_meshes`. Again with yellow being
this branch and red being `main`:
<img width="1064" alt="Screenshot 2024-03-12 175755"
src="https://github.com/bevyengine/bevy/assets/157897/b9b20dc1-11c8-400c-a6cc-1c2e09c1bb96">
We can see that there is a small regression in `queue_material_meshes`
performance, but it's not nearly enough to outweigh the large gains in
`batch_and_prepare_binned_render_phase`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Wireframes are currently supported for 3D meshes using the
`WireframePlugin` in `bevy_pbr`. This PR adds the same functionality for
2D meshes.
Closes#5881.
## Solution
Since there's no easy way to share material implementations between 2D,
3D, and UI, this is mostly a straight copy and rename from the original
plugin into `bevy_sprite`.
<img width="1392" alt="image"
src="https://github.com/bevyengine/bevy/assets/3961616/7aca156f-448a-4c7e-89b8-0a72c5919769">
---
## Changelog
- Added `Wireframe2dPlugin` and related types to support 2D wireframes.
- Added an example to demonstrate how to use 2D wireframes
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Fixes#12712
## Solution
- Move the `float_ord.rs` file to `bevy_math`
- Change any `bevy_utils::FloatOrd` statements to `bevy_math::FloatOrd`
---
## Changelog
- Moved `FloatOrd` from `bevy_utils` to `bevy_math`
## Migration Guide
- References to `bevy_utils::FloatOrd` should be changed to
`bevy_math::FloatOrd`
# Objective
Resolves#3824. `unsafe` code should be the exception, not the norm in
Rust. It's obviously needed for various use cases as it's interfacing
with platforms and essentially running the borrow checker at runtime in
the ECS, but the touted benefits of Bevy is that we are able to heavily
leverage Rust's safety, and we should be holding ourselves accountable
to that by minimizing our unsafe footprint.
## Solution
Deny `unsafe_code` workspace wide. Add explicit exceptions for the
following crates, and forbid it in almost all of the others.
* bevy_ecs - Obvious given how much unsafe is needed to achieve
performant results
* bevy_ptr - Works with raw pointers, even more low level than bevy_ecs.
* bevy_render - due to needing to integrate with wgpu
* bevy_window - due to needing to integrate with raw_window_handle
* bevy_utils - Several unsafe utilities used by bevy_ecs. Ideally moved
into bevy_ecs instead of made publicly usable.
* bevy_reflect - Required for the unsafe type casting it's doing.
* bevy_transform - for the parallel transform propagation
* bevy_gizmos - For the SystemParam impls it has.
* bevy_assets - To support reflection. Might not be required, not 100%
sure yet.
* bevy_mikktspace - due to being a conversion from a C library. Pending
safe rewrite.
* bevy_dynamic_plugin - Inherently unsafe due to the dynamic loading
nature.
Several uses of unsafe were rewritten, as they did not need to be using
them:
* bevy_text - a case of `Option::unchecked` could be rewritten as a
normal for loop and match instead of an iterator.
* bevy_color - the Pod/Zeroable implementations were replaceable with
bytemuck's derive macros.
# Objective
Currently the built docs only shows the logo and favicon for the top
level `bevy` crate. This makes views like
https://docs.rs/bevy_ecs/latest/bevy_ecs/ look potentially unrelated to
the project at first glance.
## Solution
Reproduce the docs attributes for every crate that Bevy publishes.
Ideally this would be done with some workspace level Cargo.toml control,
but AFAICT, such support does not exist.
# Objective
Remove color specialization from `SpritePipeline` after it became
useless in #9597
## Solution
Removed the `COLORED` flag from the pipeline key and removed the
specializing the pipeline over it.
---
## Changelog
### Removed
- `SpritePipelineKey` no longer contains the `COLORED` flag. The flag
has had no effect on how the pipeline operates for a while.
## Migration Guide
- The raw values for the `HDR`, `TONEMAP_IN_SHADER` and `DEBAND_DITHER`
flags have changed, so if you were constructing the pipeline key from
raw `u32`s you'll have to account for that.
Fixes#12600
## Solution
Removed Into<AssetId<T>> for Handle<T> as proposed in Issue
conversation, fixed dependent code
## Migration guide
If you use passing Handle by value as AssetId, you should pass reference
or call .id() method on it
Before (0.13):
`assets.insert(handle, value);`
After (0.14):
`assets.insert(&handle, value);`
or
`assets.insert(handle.id(), value);`
# Objective
Improve code quality involving fixedbitset.
## Solution
Update to fixedbitset 0.5. Use the new `grow_and_insert` function
instead of `grow` and `insert` functions separately.
This should also speed up most of the set operations involving
fixedbitset. They should be ~2x faster, but testing this against the
stress tests seems to show little to no difference. The multithreaded
executor doesn't seem to be all that much faster in many_cubes and
many_foxes. These use cases are likely dominated by other operations or
the bitsets aren't big enough to make them the bottleneck.
This introduces a duplicate dependency due to petgraph and wgpu, but the
former may take some time to update.
## Changelog
Removed: `Access::grow`
## Migration Guide
`Access::grow` has been removed. It's no longer needed. Remove all
references to it.
# Objective
assets that don't load before they get removed are retried forever,
causing buffer churn and slowdown.
## Solution
stop trying to prepare dead assets.
# Objective
Follow up to #11600 and #10588https://github.com/bevyengine/bevy/issues/11944 made clear that some
people want to use slicing with texture atlases
## Changelog
* Added support for `TextureAtlas` slicing and tiling.
`SpriteSheetBundle` and `AtlasImageBundle` can now use `ImageScaleMode`
* Added new `ui_texture_atlas_slice` example using a texture sheet
<img width="798" alt="Screenshot 2024-02-23 at 11 58 35"
src="https://github.com/bevyengine/bevy/assets/26703856/47a8b764-127c-4a06-893f-181703777501">
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Pablo Reinhardt <126117294+pablo-lua@users.noreply.github.com>
# Objective
After the `TextureAtlas` changes that landed in 0.13,
`SpriteSheetBundle` is equivalent to `TextureAtlas` + `SpriteBundle` and
`AtlasImageBundle` is equivalent to `TextureAtlas` + `ImageBundle`. As
such, the atlas bundles aren't particularly useful / necessary additions
to the API anymore.
In addition, atlas bundles are inconsistent with `ImageScaleMode` (also
introduced in 0.13) which doesn't have its own version of each image
bundle.
## Solution
Deprecate `SpriteSheetBundle` and `AtlasImageBundle` in favor of
including `TextureAtlas` as a separate component alongside
`SpriteBundle` and `ImageBundle`, respectively.
---
## Changelog
- Deprecated `SpriteSheetBundle` and `AtlasImageBundle`.
## Migration Guide
- `SpriteSheetBundle` has been deprecated. Use `TextureAtlas` alongside
a `SpriteBundle` instead.
- `AtlasImageBundle` has been deprecated. Use `TextureAtlas` alongside
an `ImageBundle` instead.
# Objective
Fixes#11298. Make the use of bevy_log vs bevy_utils::tracing more
consistent.
## Solution
Replace all uses of bevy_log's logging macros with the reexport from
bevy_utils. Remove bevy_log as a dependency where it's no longer needed
anymore.
Ideally we should just be using tracing directly, but given that all of
these crates are already using bevy_utils, this likely isn't that great
of a loss right now.
Although we cached hashes of `MeshVertexBufferLayout`, we were paying
the cost of `PartialEq` on `InnerMeshVertexBufferLayout` for every
entity, every frame. This patch changes that logic to place
`MeshVertexBufferLayout`s in `Arc`s so that they can be compared and
hashed by pointer. This results in a 28% speedup in the
`queue_material_meshes` phase of `many_cubes`, with frustum culling
disabled.
Additionally, this patch contains two minor changes:
1. This commit flattens the specialized mesh pipeline cache to one level
of hash tables instead of two. This saves a hash lookup.
2. The example `many_cubes` has been given a `--no-frustum-culling`
flag, to aid in benchmarking.
See the Tracy profile:
<img width="1064" alt="Screenshot 2024-02-29 144406"
src="https://github.com/bevyengine/bevy/assets/157897/18632f1d-1fdd-4ac7-90ed-2d10306b2a1e">
## Migration guide
* Duplicate `MeshVertexBufferLayout`s are now combined into a single
object, `MeshVertexBufferLayoutRef`, which contains an
atomically-reference-counted pointer to the layout. Code that was using
`MeshVertexBufferLayout` may need to be updated to use
`MeshVertexBufferLayoutRef` instead.
# Objective
- As part of the migration process we need to a) see the end effect of
the migration on user ergonomics b) check for serious perf regressions
c) actually migrate the code
- To accomplish this, I'm going to attempt to migrate all of the
remaining user-facing usages of `LegacyColor` in one PR, being careful
to keep a clean commit history.
- Fixes#12056.
## Solution
I've chosen to use the polymorphic `Color` type as our standard
user-facing API.
- [x] Migrate `bevy_gizmos`.
- [x] Take `impl Into<Color>` in all `bevy_gizmos` APIs
- [x] Migrate sprites
- [x] Migrate UI
- [x] Migrate `ColorMaterial`
- [x] Migrate `MaterialMesh2D`
- [x] Migrate fog
- [x] Migrate lights
- [x] Migrate StandardMaterial
- [x] Migrate wireframes
- [x] Migrate clear color
- [x] Migrate text
- [x] Migrate gltf loader
- [x] Register color types for reflection
- [x] Remove `LegacyColor`
- [x] Make sure CI passes
Incidental improvements to ease migration:
- added `Color::srgba_u8`, `Color::srgba_from_array` and friends
- added `set_alpha`, `is_fully_transparent` and `is_fully_opaque` to the
`Alpha` trait
- add and immediately deprecate (lol) `Color::rgb` and friends in favor
of more explicit and consistent `Color::srgb`
- standardized on white and black for most example text colors
- added vector field traits to `LinearRgba`: ~~`Add`, `Sub`,
`AddAssign`, `SubAssign`,~~ `Mul<f32>` and `Div<f32>`. Multiplications
and divisions do not scale alpha. `Add` and `Sub` have been cut from
this PR.
- added `LinearRgba` and `Srgba` `RED/GREEN/BLUE`
- added `LinearRgba_to_f32_array` and `LinearRgba::to_u32`
## Migration Guide
Bevy's color types have changed! Wherever you used a
`bevy::render::Color`, a `bevy::color::Color` is used instead.
These are quite similar! Both are enums storing a color in a specific
color space (or to be more precise, using a specific color model).
However, each of the different color models now has its own type.
TODO...
- `Color::rgba`, `Color::rgb`, `Color::rbga_u8`, `Color::rgb_u8`,
`Color::rgb_from_array` are now `Color::srgba`, `Color::srgb`,
`Color::srgba_u8`, `Color::srgb_u8` and `Color::srgb_from_array`.
- `Color::set_a` and `Color::a` is now `Color::set_alpha` and
`Color::alpha`. These are part of the `Alpha` trait in `bevy_color`.
- `Color::is_fully_transparent` is now part of the `Alpha` trait in
`bevy_color`
- `Color::r`, `Color::set_r`, `Color::with_r` and the equivalents for
`g`, `b` `h`, `s` and `l` have been removed due to causing silent
relatively expensive conversions. Convert your `Color` into the desired
color space, perform your operations there, and then convert it back
into a polymorphic `Color` enum.
- `Color::hex` is now `Srgba::hex`. Call `.into` or construct a
`Color::Srgba` variant manually to convert it.
- `WireframeMaterial`, `ExtractedUiNode`, `ExtractedDirectionalLight`,
`ExtractedPointLight`, `ExtractedSpotLight` and `ExtractedSprite` now
store a `LinearRgba`, rather than a polymorphic `Color`
- `Color::rgb_linear` and `Color::rgba_linear` are now
`Color::linear_rgb` and `Color::linear_rgba`
- The various CSS color constants are no longer stored directly on
`Color`. Instead, they're defined in the `Srgba` color space, and
accessed via `bevy::color::palettes::css`. Call `.into()` on them to
convert them into a `Color` for quick debugging use, and consider using
the much prettier `tailwind` palette for prototyping.
- The `LIME_GREEN` color has been renamed to `LIMEGREEN` to comply with
the standard naming.
- Vector field arithmetic operations on `Color` (add, subtract, multiply
and divide by a f32) have been removed. Instead, convert your colors
into `LinearRgba` space, and perform your operations explicitly there.
This is particularly relevant when working with emissive or HDR colors,
whose color channel values are routinely outside of the ordinary 0 to 1
range.
- `Color::as_linear_rgba_f32` has been removed. Call
`LinearRgba::to_f32_array` instead, converting if needed.
- `Color::as_linear_rgba_u32` has been removed. Call
`LinearRgba::to_u32` instead, converting if needed.
- Several other color conversion methods to transform LCH or HSL colors
into float arrays or `Vec` types have been removed. Please reimplement
these externally or open a PR to re-add them if you found them
particularly useful.
- Various methods on `Color` such as `rgb` or `hsl` to convert the color
into a specific color space have been removed. Convert into
`LinearRgba`, then to the color space of your choice.
- Various implicitly-converting color value methods on `Color` such as
`r`, `g`, `b` or `h` have been removed. Please convert it into the color
space of your choice, then check these properties.
- `Color` no longer implements `AsBindGroup`. Store a `LinearRgba`
internally instead to avoid conversion costs.
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
Co-authored-by: Afonso Lage <lage.afonso@gmail.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
The physical width and height (pixels) of an image is always integers,
but for `GpuImage` bevy currently stores them as `Vec2` (`f32`).
Switching to `UVec2` makes this more consistent with the [underlying
texture data](https://docs.rs/wgpu/latest/wgpu/struct.Extent3d.html).
I'm not sure if this is worth the change in the surface level API. If
not, feel free to close this PR.
## Solution
- Replace uses of `Vec2` with `UVec2` when referring to texture
dimensions.
- Use integer types for the texture atlas dimensions and sections.
[`Sprite::rect`](a81a2d1da3/crates/bevy_sprite/src/sprite.rs (L29))
remains unchanged, so manually specifying a sub-pixel region of an image
is still possible.
---
## Changelog
- `GpuImage` now stores its size as `UVec2` instead of `Vec2`.
- Texture atlases store their size and sections as `UVec2` and `URect`
respectively.
- `UiImageSize` stores its size as `UVec2`.
## Migration Guide
- Change floating point types (`Vec2`, `Rect`) to their respective
unsigned integer versions (`UVec2`, `URect`) when using `GpuImage`,
`TextureAtlasLayout`, `TextureAtlasBuilder`,
`DynamicAtlasTextureBuilder` or `FontAtlas`.
# Objective
- Add the new `-Zcheck-cfg` checks to catch more warnings
- Fixes#12091
## Solution
- Create a new `cfg-check` to the CI that runs `cargo check -Zcheck-cfg
--workspace` using cargo nightly (and fails if there are warnings)
- Fix all warnings generated by the new check
---
## Changelog
- Remove all redundant imports
- Fix cfg wasm32 targets
- Add 3 dead code exceptions (should StandardColor be unused?)
- Convert ios_simulator to a feature (I'm not sure if this is the right
way to do it, but the check complained before)
## Migration Guide
No breaking changes
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The migration process for `bevy_color` (#12013) will be fairly involved:
there will be hundreds of affected files, and a large number of APIs.
## Solution
To allow us to proceed granularly, we're going to keep both
`bevy_color::Color` (new) and `bevy_render::Color` (old) around until
the migration is complete.
However, simply doing this directly is confusing! They're both called
`Color`, making it very hard to tell when a portion of the code has been
ported.
As discussed in #12056, by renaming the old `Color` type, we can make it
easier to gradually migrate over, one API at a time.
## Migration Guide
THIS MIGRATION GUIDE INTENTIONALLY LEFT BLANK.
This change should not be shipped to end users: delete this section in
the final migration guide!
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
Fixes#12016.
Bump version after release
This PR has been auto-generated
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
Adopted #8266, so copy-pasting the description from there:
# Objective
Support the KHR_texture_transform extension for the glTF loader.
- Fixes#6335
- Fixes#11869
- Implements part of #11350
- Implements the GLTF part of #399
## Solution
As is, this only supports a single transform. Looking at Godot's source,
they support one transform with an optional second one for detail, AO,
and emission. glTF specifies one per texture. The public domain
materials I looked at seem to share the same transform. So maybe having
just one is acceptable for now. I tried to include a warning if multiple
different transforms exist for the same material.
Note the gltf crate doesn't expose the texture transform for the normal
and occlusion textures, which it should, so I just ignored those for
now. (note by @janhohenheim: this is still the case)
Via `cargo run --release --example scene_viewer
~/src/clone/glTF-Sample-Models/2.0/TextureTransformTest/glTF/TextureTransformTest.gltf`:

## Changelog
Support for the
[KHR_texture_transform](https://github.com/KhronosGroup/glTF/tree/main/extensions/2.0/Khronos/KHR_texture_transform)
extension added. Texture UVs that were scaled, rotated, or offset in a
GLTF are now properly handled.
---------
Co-authored-by: Al McElrath <hello@yrns.org>
Co-authored-by: Kanabenki <lucien.menassol@gmail.com>
# Objective
Implement Debug trait for SpriteBundle and SpriteSheetBundle
It's helpful and other basic bundles like TransformBundle and
VisibilityBundle already implement this trait
Make the renamings/changes regarding texture atlases a bit less
confusing by calling `TextureAtlasLayout` a layout, not a texture atlas.
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Reduce the size of `bevy_utils`
(https://github.com/bevyengine/bevy/issues/11478)
## Solution
Move `EntityHash` related types into `bevy_ecs`. This also allows us
access to `Entity`, which means we no longer need `EntityHashMap`'s
first generic argument.
---
## Changelog
- Moved `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` into `bevy::ecs::entity::hash` .
- Removed `EntityHashMap`'s first generic argument. It is now hardcoded
to always be `Entity`.
## Migration Guide
- Uses of `bevy::utils::{EntityHash, EntityHasher, EntityHashMap,
EntityHashSet}` now have to be imported from `bevy::ecs::entity::hash`.
- Uses of `EntityHashMap` no longer have to specify the first generic
parameter. It is now hardcoded to always be `Entity`.
This fixes a `FIXME` in `extract_meshes` and results in a performance
improvement.
As a result of this change, meshes in the render world might not be
attached to entities anymore. Therefore, the `entity` parameter to
`RenderCommand::render()` is now wrapped in an `Option`. Most
applications that use the render app's ECS can simply unwrap the
`Option`.
Note that for now sprites, gizmos, and UI elements still use the render
world as usual.
## Migration guide
* For efficiency reasons, some meshes in the render world may not have
corresponding `Entity` IDs anymore. As a result, the `entity` parameter
to `RenderCommand::render()` is now wrapped in an `Option`. Custom
rendering code may need to be updated to handle the case in which no
`Entity` exists for an object that is to be rendered.
> Follow up to #11600 and #10588
@mockersf expressed some [valid
concerns](https://github.com/bevyengine/bevy/pull/11600#issuecomment-1932796498)
about the current system this PR attempts to fix:
The `ComputedTextureSlices` reacts to asset change in both `bevy_sprite`
and `bevy_ui`, meaning that if the `ImageScaleMode` is inserted by
default in the bundles, we will iterate through most 2d items every time
an asset is updated.
# Solution
- `ImageScaleMode` only has two variants: `Sliced` and `Tiled`. I
removed the `Stretched` default
- `ImageScaleMode` is no longer part of any bundle, but the relevant
bundles explain that this additional component can be inserted
This way, the *absence* of `ImageScaleMode` means the image will be
stretched, and its *presence* will include the entity to the various
slicing systems
Optional components in bundles would make this more straigthfoward
# Additional work
Should I add new bundles with the `ImageScaleMode` component ?
> Follow up to #10588
> Closes#11749 (Supersedes #11756)
Enable Texture slicing for the following UI nodes:
- `ImageBundle`
- `ButtonBundle`
<img width="739" alt="Screenshot 2024-01-29 at 13 57 43"
src="https://github.com/bevyengine/bevy/assets/26703856/37675681-74eb-4689-ab42-024310cf3134">
I also added a collection of `fantazy-ui-borders` from
[Kenney's](www.kenney.nl) assets, with the appropriate license (CC).
If it's a problem I can use the same textures as the `sprite_slice`
example
# Work done
Added the `ImageScaleMode` component to the targetted bundles, most of
the logic is directly reused from `bevy_sprite`.
The only additional internal component is the UI specific
`ComputedSlices`, which does the same thing as its spritee equivalent
but adapted to UI code.
Again the slicing is not compatible with `TextureAtlas`, it's something
I need to tackle more deeply in the future
# Fixes
* [x] I noticed that `TextureSlicer::compute_slices` could infinitely
loop if the border was larger that the image half extents, now an error
is triggered and the texture will fallback to being stretched
* [x] I noticed that when using small textures with very small *tiling*
options we could generate hundred of thousands of slices. Now I set a
minimum size of 1 pixel per slice, which is already ridiculously small,
and a warning will be sent at runtime when slice count goes above 1000
* [x] Sprite slicing with `flip_x` or `flip_y` would give incorrect
results, correct flipping is now supported to both sprites and ui image
nodes thanks to @odecay observation
# GPU Alternative
I create a separate branch attempting to implementing 9 slicing and
tiling directly through the `ui.wgsl` fragment shader. It works but
requires sending more data to the GPU:
- slice border
- tiling factors
And more importantly, the actual quad *scale* which is hard to put in
the shader with the current code, so that would be for a later iteration
# Objective
Currently the `missing_docs` lint is allowed-by-default and enabled at
crate level when their documentations is complete (see #3492).
This PR proposes to inverse this logic by making `missing_docs`
warn-by-default and mark crates with imcomplete docs allowed.
## Solution
Makes `missing_docs` warn at workspace level and allowed at crate level
when the docs is imcomplete.
# Objective
Right now, all assets in the main world get extracted and prepared in
the render world (if the asset's using the RenderAssetPlugin). This is
unfortunate for two cases:
1. **TextureAtlas** / **FontAtlas**: This one's huge. The individual
`Image` assets that make up the atlas are cloned and prepared
individually when there's no reason for them to be. The atlas textures
are built on the CPU in the main world. *There can be hundreds of images
that get prepared for rendering only not to be used.*
2. If one loads an Image and needs to transform it in a system before
rendering it, kind of like the [decompression
example](https://github.com/bevyengine/bevy/blob/main/examples/asset/asset_decompression.rs#L120),
there's a price paid for extracting & preparing the asset that's not
intended to be rendered yet.
------
* References #10520
* References #1782
## Solution
This changes the `RenderAssetPersistencePolicy` enum to bitflags. I felt
that the objective with the parameter is so similar in nature to wgpu's
[`TextureUsages`](https://docs.rs/wgpu/latest/wgpu/struct.TextureUsages.html)
and
[`BufferUsages`](https://docs.rs/wgpu/latest/wgpu/struct.BufferUsages.html),
that it may as well be just like that.
```rust
// This asset only needs to be in the main world. Don't extract and prepare it.
RenderAssetUsages::MAIN_WORLD
// Keep this asset in the main world and
RenderAssetUsages::MAIN_WORLD | RenderAssetUsages::RENDER_WORLD
// This asset is only needed in the render world. Remove it from the asset server once extracted.
RenderAssetUsages::RENDER_WORLD
```
### Alternate Solution
I considered introducing a third field to `RenderAssetPersistencePolicy`
enum:
```rust
enum RenderAssetPersistencePolicy {
/// Keep the asset in the main world after extracting to the render world.
Keep,
/// Remove the asset from the main world after extracting to the render world.
Unload,
/// This doesn't need to be in the render world at all.
NoExtract, // <-----
}
```
Functional, but this seemed like shoehorning. Another option is renaming
the enum to something like:
```rust
enum RenderAssetExtractionPolicy {
/// Extract the asset and keep it in the main world.
Extract,
/// Remove the asset from the main world after extracting to the render world.
ExtractAndUnload,
/// This doesn't need to be in the render world at all.
NoExtract,
}
```
I think this last one could be a good option if the bitflags are too
clunky.
## Migration Guide
* `RenderAssetPersistencePolicy::Keep` → `RenderAssetUsage::MAIN_WORLD |
RenderAssetUsage::RENDER_WORLD` (or `RenderAssetUsage::default()`)
* `RenderAssetPersistencePolicy::Unload` →
`RenderAssetUsage::RENDER_WORLD`
* For types implementing the `RenderAsset` trait, change `fn
persistence_policy(&self) -> RenderAssetPersistencePolicy` to `fn
asset_usage(&self) -> RenderAssetUsages`.
* Change any references to `cpu_persistent_access`
(`RenderAssetPersistencePolicy`) to `asset_usage` (`RenderAssetUsage`).
This applies to `Image`, `Mesh`, and a few other types.
# Objective
Fixes#11479
## Solution
- Remove `collide_aabb.rs`
- Re-implement the example-specific collision code in the example,
taking advantage of the new `IntersectsVolume` trait.
## Changelog
- Removed `sprite::collide_aabb::collide` and
`sprite::collide_aabb::Collision`.
## Migration Guide
`sprite::collide_aabb::collide` and `sprite::collide_aabb::Collision`
were removed.
```rust
// Before
let collision = bevy::sprite::collide_aabb::collide(a_pos, a_size, b_pos, b_size);
if collision.is_some() {
// ...
}
// After
let collision = Aabb2d::new(a_pos.truncate(), a_size / 2.)
.intersects(&Aabb2d::new(b_pos.truncate(), b_size / 2.));
if collision {
// ...
}
```
If you were making use `collide_aabb::Collision`, see the new
`collide_with_side` function in the [`breakout`
example](https://bevyengine.org/examples/Games/breakout/).
## Discussion
As discussed in the linked issue, maybe we want to wait on `bevy_sprite`
generally making use of `Aabb2b` so users don't need to construct it
manually. But since they **do** need to construct the bounding circle
for the ball manually, this doesn't seem like a big deal to me.
---------
Co-authored-by: IQuick 143 <IQuick143cz@gmail.com>
# Objective
Allow TextureAtlasBuilder in AssetLoader.
Fixes#2987
## Solution
- TextureAtlasBuilder no longer hold just AssetIds that are used to
retrieve the actual image data in `finish`, but &Image instead.
- TextureAtlasBuilder now required AssetId only optionally (and it is
only used to retrieve the index from the AssetId in TextureAtlasLayout),
## Issues
- The issue mentioned here
https://github.com/bevyengine/bevy/pull/11474#issuecomment-1904676937
now also extends to the actual atlas texture. In short: Calling
add_texture multiple times for the same texture will lead to duplicate
image data in the atlas texture and additional indices.
If you provide an AssetId we can probably do something to de-duplicate
the entries while keeping insertion order (suggestions welcome on how
exactly). But if you don't then we are out of luck (unless we can and
want to hash the image, which I do not think we want).
---
## Changelog
### Changed
- TextureAtlasBuilder `add_texture` can be called without providing an
AssetId
- TextureAtlasBuilder `finish` no longer takes Assets<Image> and no
longer returns a Handle<Image>
## Migration Guide
- For `add_texture` you need to wrap your AssetId in Some
- `finish` now returns the atlas texture image directly instead of a
handle. Provide the atlas texture to `add` on Assets<Texture> to get a
Handle<Image>
# Objective
https://github.com/bevyengine/bevy/pull/5103 caused a bug where
`Sprite::rect` was ignored by the engine. (Did nothing)
## Solution
My solution changes the way how Bevy calculates the rect, based on this
table:
| `atlas_rect` | `Sprite::rect` | Result |
|--------------|----------------|------------------------------------------------------|
| `None` | `None` | `None` |
| `None` | `Some` | `Sprite::rect` |
| `Some` | `None` | `atlas_rect` |
| `Some` | `Some` | `Sprite::rect` is used, relative to `atlas_rect.min`
|
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
TextureAtlases are commonly used to drive animations described as a
consecutive range of indices. The current TextureAtlasBuilder uses the
AssetId of the image to determine the index of the texture in the
TextureAtlas. The AssetId of an Image Asset can change between runs.
The TextureAtlas exposes
[`get_texture_index`](https://docs.rs/bevy/latest/bevy/sprite/struct.TextureAtlas.html#method.get_texture_index)
to get the index from a given AssetId, but this needlessly complicates
the process of creating a simple TextureAtlas animation.
Fixes#2459
## Solution
- Use the (ordered) image_ids of the 'texture to place' vector to
retrieve the packed locations and compose the textures of the
TextureAtlas.
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
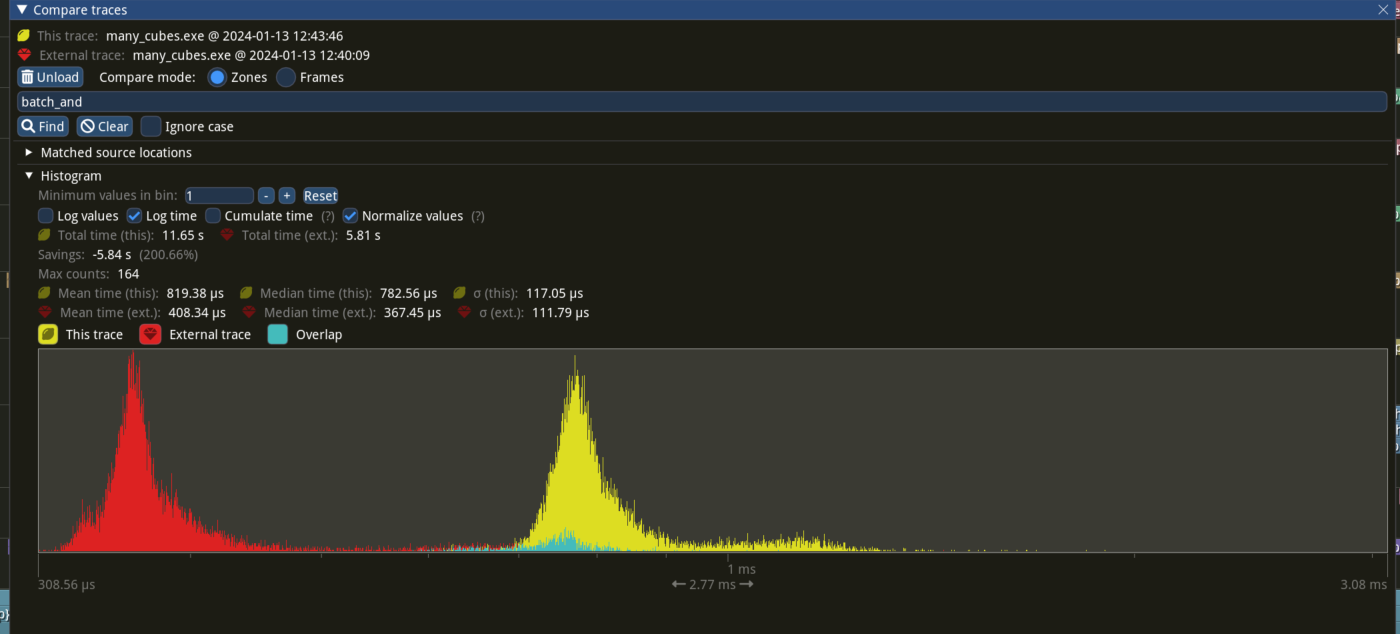
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
# Objective
> Old MR: #5072
> ~~Associated UI MR: #5070~~
> Adresses #1618
Unify sprite management
## Solution
- Remove the `Handle<Image>` field in `TextureAtlas` which is the main
cause for all the boilerplate
- Remove the redundant `TextureAtlasSprite` component
- Renamed `TextureAtlas` asset to `TextureAtlasLayout`
([suggestion](https://github.com/bevyengine/bevy/pull/5103#discussion_r917281844))
- Add a `TextureAtlas` component, containing the atlas layout handle and
the section index
The difference between this solution and #5072 is that instead of the
`enum` approach is that we can more easily manipulate texture sheets
without any breaking changes for classic `SpriteBundle`s (@mockersf
[comment](https://github.com/bevyengine/bevy/pull/5072#issuecomment-1165836139))
Also, this approach is more *data oriented* extracting the
`Handle<Image>` and avoiding complex texture atlas manipulations to
retrieve the texture in both applicative and engine code.
With this method, the only difference between a `SpriteBundle` and a
`SpriteSheetBundle` is an **additional** component storing the atlas
handle and the index.
~~This solution can be applied to `bevy_ui` as well (see #5070).~~
EDIT: I also applied this solution to Bevy UI
## Changelog
- (**BREAKING**) Removed `TextureAtlasSprite`
- (**BREAKING**) Renamed `TextureAtlas` to `TextureAtlasLayout`
- (**BREAKING**) `SpriteSheetBundle`:
- Uses a `Sprite` instead of a `TextureAtlasSprite` component
- Has a `texture` field containing a `Handle<Image>` like the
`SpriteBundle`
- Has a new `TextureAtlas` component instead of a
`Handle<TextureAtlasLayout>`
- (**BREAKING**) `DynamicTextureAtlasBuilder::add_texture` takes an
additional `&Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasLayout::from_grid` no longer takes a
`Handle<Image>` parameter
- (**BREAKING**) `TextureAtlasBuilder::finish` now returns a
`Result<(TextureAtlasLayout, Handle<Image>), _>`
- `bevy_text`:
- `GlyphAtlasInfo` stores the texture `Handle<Image>`
- `FontAtlas` stores the texture `Handle<Image>`
- `bevy_ui`:
- (**BREAKING**) Removed `UiAtlasImage` , the atlas bundle is now
identical to the `ImageBundle` with an additional `TextureAtlas`
## Migration Guide
* Sprites
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(SpriteSheetBundle {
- sprite: TextureAtlasSprite::new(0),
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ texture: texture_handle,
..Default::default()
});
}
```
* UI
```diff
fn my_system(
mut images: ResMut<Assets<Image>>,
- mut atlases: ResMut<Assets<TextureAtlas>>,
+ mut atlases: ResMut<Assets<TextureAtlasLayout>>,
asset_server: Res<AssetServer>
) {
let texture_handle: asset_server.load("my_texture.png");
- let layout = TextureAtlas::from_grid(texture_handle, Vec2::new(25.0, 25.0), 5, 5, None, None);
+ let layout = TextureAtlasLayout::from_grid(Vec2::new(25.0, 25.0), 5, 5, None, None);
let layout_handle = atlases.add(layout);
commands.spawn(AtlasImageBundle {
- texture_atlas_image: UiTextureAtlasImage {
- index: 0,
- flip_x: false,
- flip_y: false,
- },
- texture_atlas: atlas_handle,
+ atlas: TextureAtlas {
+ layout: layout_handle,
+ index: 0
+ },
+ image: UiImage {
+ texture: texture_handle,
+ flip_x: false,
+ flip_y: false,
+ },
..Default::default()
});
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
> Replaces #5213
# Objective
Implement sprite tiling and [9 slice
scaling](https://en.wikipedia.org/wiki/9-slice_scaling) for
`bevy_sprite`.
Allowing slice scaling and texture tiling.
Basic scaling vs 9 slice scaling:

Slicing example:
<img width="481" alt="Screenshot 2022-07-05 at 15 05 49"
src="https://user-images.githubusercontent.com/26703856/177336112-9e961af0-c0af-4197-aec9-430c1170a79d.png">
Tiling example:
<img width="1329" alt="Screenshot 2023-11-16 at 13 53 32"
src="https://github.com/bevyengine/bevy/assets/26703856/14db39b7-d9e0-4bc3-ba0e-b1f2db39ae8f">
# Solution
- `SpriteBundlue` now has a `scale_mode` component storing a
`SpriteScaleMode` enum with three variants:
- `Stretched` (default)
- `Tiled` to have sprites tile horizontally and/or vertically
- `Sliced` allowing 9 slicing the texture and optionally tile some
sections with a `Textureslicer`.
- `bevy_sprite` has two extra systems to compute a
`ComputedTextureSlices` if necessary,:
- One system react to changes on `Sprite`, `Handle<Image>` or
`SpriteScaleMode`
- The other listens to `AssetEvent<Image>` to compute slices on sprites
when the texture is ready or changed
- I updated the `bevy_sprite` extraction stage to extract potentially
multiple textures instead of one, depending on the presence of
`ComputedTextureSlices`
- I added two examples showcasing the slicing and tiling feature.
The addition of `ComputedTextureSlices` as a cache is to avoid querying
the image data, to retrieve its dimensions, every frame in a extract or
prepare stage. Also it reacts to changes so we can have stuff like this
(tiling example):
https://github.com/bevyengine/bevy/assets/26703856/a349a9f3-33c3-471f-8ef4-a0e5dfce3b01
# Related
- [ ] Once #5103 or #10099 is merged I can enable tiling and slicing for
texture sheets as ui
# To discuss
There is an other option, to consider slice/tiling as part of the asset,
using the new asset preprocessing but I have no clue on how to do it.
Also, instead of retrieving the Image dimensions, we could use the same
system as the sprite sheet and have the user give the image dimensions
directly (grid). But I think it's less user friendly
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
- Since #10520, assets are unloaded from RAM by default. This breaks a
number of scenario:
- using `load_folder`
- loading a gltf, then going through its mesh to transform them /
compute a collider / ...
- any assets/subassets scenario should be `Keep` as you can't know what
the user will do with the assets
- android suspension, where GPU memory is unloaded
- Alternative to #11202
## Solution
- Keep assets on CPU memory by default
# Objective
- No point in keeping Meshes/Images in RAM once they're going to be sent
to the GPU, and kept in VRAM. This saves a _significant_ amount of
memory (several GBs) on scenes like bistro.
- References
- https://github.com/bevyengine/bevy/pull/1782
- https://github.com/bevyengine/bevy/pull/8624
## Solution
- Augment RenderAsset with the capability to unload the underlying asset
after extracting to the render world.
- Mesh/Image now have a cpu_persistent_access field. If this field is
RenderAssetPersistencePolicy::Unload, the asset will be unloaded from
Assets<T>.
- A new AssetEvent is sent upon dropping the last strong handle for the
asset, which signals to the RenderAsset to remove the GPU version of the
asset.
---
## Changelog
- Added `AssetEvent::NoLongerUsed` and
`AssetEvent::is_no_longer_used()`. This event is sent when the last
strong handle of an asset is dropped.
- Rewrote the API for `RenderAsset` to allow for unloading the asset
data from the CPU.
- Added `RenderAssetPersistencePolicy`.
- Added `Mesh::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `Image::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `ImageLoaderSettings::cpu_persistent_access`.
- Added `ExrTextureLoaderSettings`.
- Added `HdrTextureLoaderSettings`.
## Migration Guide
- Asset loaders (GLTF, etc) now load meshes and textures without
`cpu_persistent_access`. These assets will be removed from
`Assets<Mesh>` and `Assets<Image>` once `RenderAssets<Mesh>` and
`RenderAssets<Image>` contain the GPU versions of these assets, in order
to reduce memory usage. If you require access to the asset data from the
CPU in future frames after the GLTF asset has been loaded, modify all
dependent `Mesh` and `Image` assets and set `cpu_persistent_access` to
`RenderAssetPersistencePolicy::Keep`.
- `Mesh` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `Image` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `MorphTargetImage::new()` now requires a new `cpu_persistent_access`
parameter. Set it to `RenderAssetPersistencePolicy::Keep` to mimic the
previous behavior.
- `DynamicTextureAtlasBuilder::add_texture()` now requires that the
`TextureAtlas` you pass has an `Image` with `cpu_persistent_access:
RenderAssetPersistencePolicy::Keep`. Ensure you construct the image
properly for the texture atlas.
- The `RenderAsset` trait has significantly changed, and requires
adapting your existing implementations.
- The trait now requires `Clone`.
- The `ExtractedAsset` associated type has been removed (the type itself
is now extracted).
- The signature of `prepare_asset()` is slightly different
- A new `persistence_policy()` method is now required (return
RenderAssetPersistencePolicy::Unload to match the previous behavior).
- Match on the new `NoLongerUsed` variant for exhaustive matches of
`AssetEvent`.
This expands upon https://github.com/bevyengine/bevy/pull/11134.
I found myself needing `tonemapping_pipeline_key` for some custom 2d
draw functions. #11134 exported the 3d version of
`tonemapping_pipeline_key` and this PR exports the 2d version. I also
made `alpha_mode_pipeline_key` public for good measure.
# Objective
- Refactor collide code and add tests.
## Solution
- Rebase the changes made in #4485.
Co-authored-by: Eduardo Canellas de Oliveira <eduardo.canellas@bemobi.com>
{kind=link}
{kind=link}
{kind=link}