# Objective
Fixes `StandardMaterial` texture update (see sample code below).
Most probably fixes#3674 (did not test)
## Solution
Material updates, such as PBR update, reference the underlying `GpuImage`. Like here: 9a7852db0f/crates/bevy_pbr/src/pbr_material.rs (L177)
However, currently the `GpuImage` update may actually happen *after* the material update fetches the gpu image. Resulting in the material actually not being updated for the correct gpu image.
In this pull req, I introduce new systemlabels for the renderassetplugin. Also assigned the RenderAssetPlugin::<Image> to the `PreAssetExtract` stage, so that it is executed before any material updates.
Code to test.
Expected behavior:
* should update to red texture
Unexpected behavior (before this merge):
* texture stays randomly as green one (depending on the execution order of systems)
```rust
use bevy::{
prelude::*,
render::render_resource::{Extent3d, TextureDimension, TextureFormat},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_startup_system(setup)
.add_system(changes)
.run();
}
struct Iteration(usize);
#[derive(Component)]
struct MyComponent;
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
mut images: ResMut<Assets<Image>>,
) {
commands.spawn_bundle(PointLightBundle {
point_light: PointLight {
..Default::default()
},
transform: Transform::from_xyz(4.0, 8.0, 4.0),
..Default::default()
});
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(-2.0, 0.0, 5.0)
.looking_at(Vec3::new(0.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
commands.insert_resource(Iteration(0));
commands
.spawn_bundle(PbrBundle {
mesh: meshes.add(Mesh::from(shape::Quad::new(Vec2::new(3., 2.)))),
material: materials.add(StandardMaterial {
base_color_texture: Some(images.add(Image::new(
Extent3d {
width: 600,
height: 400,
depth_or_array_layers: 1,
},
TextureDimension::D2,
[0, 255, 0, 128].repeat(600 * 400), // GREEN
TextureFormat::Rgba8Unorm,
))),
..Default::default()
}),
..Default::default()
})
.insert(MyComponent);
}
fn changes(
mut materials: ResMut<Assets<StandardMaterial>>,
mut images: ResMut<Assets<Image>>,
mut iteration: ResMut<Iteration>,
webview_query: Query<&Handle<StandardMaterial>, With<MyComponent>>,
) {
if iteration.0 == 2 {
let material = materials.get_mut(webview_query.single()).unwrap();
let image = images
.get_mut(material.base_color_texture.as_ref().unwrap())
.unwrap();
image
.data
.copy_from_slice(&[255, 0, 0, 255].repeat(600 * 400));
}
iteration.0 += 1;
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add a helper for storage buffers similar to `UniformVec`
## Solution
- Add a `StorageBuffer<T, U>` where `T` is the main body of the shader struct without any final variable-sized array member, and `U` is the type of the items in a variable-sized array.
- Use `()` as the type for unwanted parts, e.g. `StorageBuffer<(), Vec4>::default()` would construct a binding that would work with `struct MyType { data: array<vec4<f32>>; }` in WGSL and `StorageBuffer<MyType, ()>::default()` would work with `struct MyType { ... }` in WGSL as long as there are no variable-sized arrays.
- Std430 requires that there is at most one variable-sized array in a storage buffer, that if there is one it is the last member of the binding, and that it has at least one item. `StorageBuffer` handles all of these constraints.
Add support for removing nodes, edges, and subgraphs. This enables live re-wiring of the render graph.
This was something I did to support the MSAA implementation, but it turned out to be unnecessary there. However, it is still useful so here it is in its own PR.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
When loading a gltf scene with a camera, bevy will panic at ``thread 'main' panicked at 'scene contains the unregistered type `bevy_render:📷:bundle::Camera3d`. consider registering the type using `app.register_type::<T>()`', /home/jakob/dev/rust/contrib/bevy/bevy/crates/bevy_scene/src/scene_spawner.rs:332:35``.
## Solution
Register the camera types to fix the panic.
# Objective
- Reduce time spent in the `check_visibility` system
## Solution
- Use `Vec3A` for all bounding volume types to leverage SIMD optimisations and to avoid repeated runtime conversions from `Vec3` to `Vec3A`
- Inline all bounding volume intersection methods
- Add on-the-fly calculated `Aabb` -> `Sphere` and do `Sphere`-`Frustum` intersection tests before `Aabb`-`Frustum` tests. This is faster for `many_cubes` but could be slower in other cases where the sphere test gives a false-positive that the `Aabb` test discards. Also, I tested precalculating the `Sphere`s and inserting them alongside the `Aabb` but this was slower.
- Do not test meshes against the far plane. Apparently games don't do this anymore with infinite projections, and it's one fewer plane to test against. I made it optional and still do the test for culling lights but that is up for discussion.
- These collectively reduce `check_visibility` execution time in `many_cubes -- sphere` from 2.76ms to 1.48ms and increase frame rate from ~42fps to ~44fps
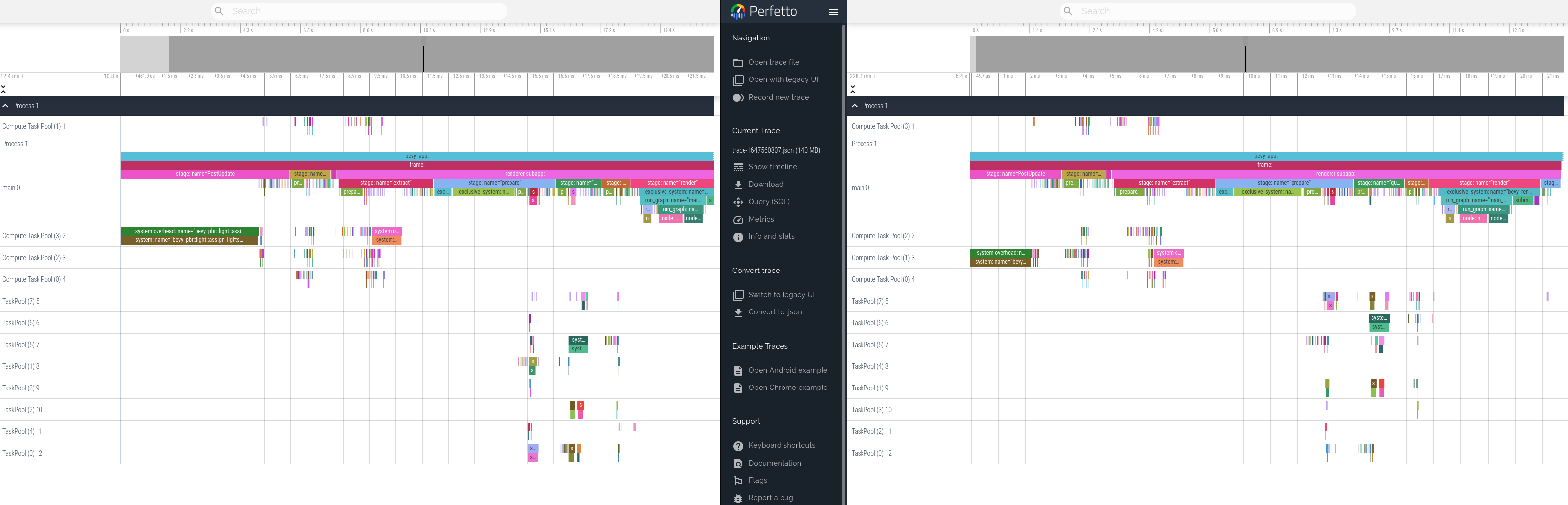
Tracing added support for "inline span entering", which cuts down on a lot of complexity:
```rust
let span = info_span!("my_span").entered();
```
This adapts our code to use this pattern where possible, and updates our docs to recommend it.
This produces equivalent tracing behavior. Here is a side by side profile of "before" and "after" these changes.
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
- Fixes#3300
- `RunSystem` is messy
## Solution
- Adds the trick theorised in https://github.com/bevyengine/bevy/issues/3300#issuecomment-991791234
P.S. I also want this for an experimental refactoring of `Assets`, to remove the duplication of `Events<AssetEvent<T>>`
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Hierarchy tools are not just used for `Transform`: they are also used for scenes.
- In the future there's interest in using them for other features, such as visiibility inheritance.
- The fact that these tools are found in `bevy_transform` causes a great deal of user and developer confusion
- Fixes#2758.
## Solution
- Split `bevy_transform` into two!
- Make everything work again.
Note that this is a very tightly scoped PR: I *know* there are code quality and docs issues that existed in bevy_transform that I've just moved around. We should fix those in a seperate PR and try to merge this ASAP to reduce the bitrot involved in splitting an entire crate.
## Frustrations
The API around `GlobalTransform` is a mess: we have massive code and docs duplication, no link between the two types and no clear way to extend this to other forms of inheritance.
In the medium-term, I feel pretty strongly that `GlobalTransform` should be replaced by something like `Inherited<Transform>`, which lives in `bevy_hierarchy`:
- avoids code duplication
- makes the inheritance pattern extensible
- links the types at the type-level
- allows us to remove all references to inheritance from `bevy_transform`, making it more useful as a standalone crate and cleaning up its docs
## Additional context
- double-blessed by @cart in https://github.com/bevyengine/bevy/issues/4141#issuecomment-1063592414 and https://github.com/bevyengine/bevy/issues/2758#issuecomment-913810963
- preparation for more advanced / cleaner hierarchy tools: go read https://github.com/bevyengine/rfcs/pull/53 !
- originally attempted by @finegeometer in #2789. It was a great idea, just needed more discussion!
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
**Problem**
- whenever you want more than one of the builtin cameras (for example multiple windows, split screen, portals), you need to add a render graph node that executes the correct sub graph, extract the camera into the render world and add the correct `RenderPhase<T>` components
- querying for the 3d camera is annoying because you need to compare the camera's name to e.g. `CameraPlugin::CAMERA_3d`
**Solution**
- Introduce the marker types `Camera3d`, `Camera2d` and `CameraUi`
-> `Query<&mut Transform, With<Camera3d>>` works
- `PerspectiveCameraBundle::new_3d()` and `PerspectiveCameraBundle::<Camera3d>::default()` contain the `Camera3d` marker
- `OrthographicCameraBundle::new_3d()` has `Camera3d`, `OrthographicCameraBundle::new_2d()` has `Camera2d`
- remove `ActiveCameras`, `ExtractedCameraNames`
- run 2d, 3d and ui passes for every camera of their respective marker
-> no custom setup for multiple windows example needed
**Open questions**
- do we need a replacement for `ActiveCameras`? What about a component `ActiveCamera { is_active: bool }` similar to `Visibility`?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make insertion of uniform components faster
## Solution
- Use batch insertion in the prepare_uniform_components system
- Improves `many_cubes -- sphere` from ~42fps to ~43fps
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#3744
## Solution
The old code used the formula `normal . center + d + radius <= 0` to determine if the sphere with center `center` and radius `radius` is outside the plane with normal `normal` and distance from origin `d`. This only works if `normal` is normalized, which is not necessarily the case. Instead, `normal` and `d` are both multiplied by some factor that `radius` isn't multiplied by. So the additional code multiplied `radius` by that factor.
# Objective
Currently, errors in the render graph runner are exposed via a `Result::unwrap()` panic message, which dumps the debug representation of the error.
## Solution
This PR updates `render_system` to log the chain of errors, followed by an explicit panic:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > encountered an error when running a sub-graph
ERROR bevy_render::renderer: > tried to pass inputs to sub-graph "outline_graph", which has no input slots
thread 'main' panicked at 'Error running render graph: encountered an error when running a sub-graph', /[redacted]/bevy/crates/bevy_render/src/renderer/mod.rs:44:9
```
Some errors' `Display` impls (via `thiserror`) have also been updated to provide more detail about the cause of the error.
# Objective
- Currently there is now way of making an indirect draw call from a tracked render pass.
- This is a very useful feature for GPU based rendering.
## Solution
- Expose the `draw_indirect` and `draw_indexed_indirect` methods from the wgpu `RenderPass` in the `TrackedRenderPass`.
## Alternative
- #3595: Expose the underlying `RenderPass` directly
# Objective
- In the large majority of cases, users were calling `.unwrap()` immediately after `.get_resource`.
- Attempting to add more helpful error messages here resulted in endless manual boilerplate (see #3899 and the linked PRs).
## Solution
- Add an infallible variant named `.resource` and so on.
- Use these infallible variants over `.get_resource().unwrap()` across the code base.
## Notes
I did not provide equivalent methods on `WorldCell`, in favor of removing it entirely in #3939.
## Migration Guide
Infallible variants of `.get_resource` have been added that implicitly panic, rather than needing to be unwrapped.
Replace `world.get_resource::<Foo>().unwrap()` with `world.resource::<Foo>()`.
## Impact
- `.unwrap` search results before: 1084
- `.unwrap` search results after: 942
- internal `unwrap_or_else` calls added: 4
- trivial unwrap calls removed from tests and code: 146
- uses of the new `try_get_resource` API: 11
- percentage of the time the unwrapping API was used internally: 93%
# Objective
Will fix#3377 and #3254
## Solution
Use an enum to represent either a `WindowId` or `Handle<Image>` in place of `Camera::window`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds "hot reloading" of internal assets, which is normally not possible because they are loaded using `include_str` / direct Asset collection access.
This is accomplished via the following:
* Add a new `debug_asset_server` feature flag
* When that feature flag is enabled, create a second App with a second AssetServer that points to a configured location (by default the `crates` folder). Plugins that want to add hot reloading support for their assets can call the new `app.add_debug_asset::<T>()` and `app.init_debug_asset_loader::<T>()` functions.
* Load "internal" assets using the new `load_internal_asset` macro. By default this is identical to the current "include_str + register in asset collection" approach. But if the `debug_asset_server` feature flag is enabled, it will also load the asset dynamically in the debug asset server using the file path. It will then set up a correlation between the "debug asset" and the "actual asset" by listening for asset change events.
This is an alternative to #3673. The goal was to keep the boilerplate and features flags to a minimum for bevy plugin authors, and allow them to home their shaders near relevant code.
This is a draft because I haven't done _any_ quality control on this yet. I'll probably rename things and remove a bunch of unwraps. I just got it working and wanted to use it to start a conversation.
Fixes#3660
This enables shaders to (optionally) define their import path inside their source. This has a number of benefits:
1. enables users to define their own custom paths directly in their assets
2. moves the import path "close" to the asset instead of centralized in the plugin definition, which seems "better" to me.
3. makes "internal hot shader reloading" way more reasonable (see #3966)
4. logically opens the door to importing "parts" of a shader by defining "import_path blocks".
```rust
#define_import_path bevy_pbr::mesh_struct
struct Mesh {
model: mat4x4<f32>;
inverse_transpose_model: mat4x4<f32>;
// 'flags' is a bit field indicating various options. u32 is 32 bits so we have up to 32 options.
flags: u32;
};
let MESH_FLAGS_SHADOW_RECEIVER_BIT: u32 = 1u;
```
For some keys, it is too expensive to hash them on every lookup. Historically in Bevy, we have regrettably done the "wrong" thing in these cases (pre-computing hashes, then re-hashing them) because Rust's built in hashed collections don't give us the tools we need to do otherwise. Doing this is "wrong" because two different values can result in the same hash. Hashed collections generally get around this by falling back to equality checks on hash collisions. You can't do that if the key _is_ the hash. Additionally, re-hashing a hash increase the odds of collision!
#3959 needs pre-hashing to be viable, so I decided to finally properly solve the problem. The solution involves two different changes:
1. A new generalized "pre-hashing" solution in bevy_utils: `Hashed<T>` types, which store a value alongside a pre-computed hash. And `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . `PreHashMap` is just an alias for a normal HashMap that uses `Hashed<T>` as the key and a new `PassHash` implementation as the Hasher.
2. Replacing the `std::collections` re-exports in `bevy_utils` with equivalent `hashbrown` impls. Avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. The latest version of `hashbrown` adds support for the `entity_ref` api, so we can move to that in preparation for an std migration, if thats the direction they seem to be going in. Note that adding hashbrown doesn't increase our dependency count because it was already in our tree.
In addition to providing these core tools, I also ported the "table identity hashing" in `bevy_ecs` to `raw_entry_mut`, which was a particularly egregious case.
The biggest outstanding case is `AssetPathId`, which stores a pre-hash. We need AssetPathId to be cheaply clone-able (and ideally Copy), but `Hashed<AssetPath>` requires ownership of the AssetPath, which makes cloning ids way more expensive. We could consider doing `Hashed<Arc<AssetPath>>`, but cloning an arc is still a non-trivial expensive that needs to be considered. I would like to handle this in a separate PR. And given that we will be re-evaluating the Bevy Assets implementation in the very near future, I'd prefer to hold off until after that conversation is concluded.
# Objective
- `WgpuOptions` is mutated to be updated with the actual device limits and features, but this information is readily available to both the main and render worlds through the `RenderDevice` which has .limits() and .features() methods
- Information about the adapter in terms of its name, the backend in use, etc were not being exposed but have clear use cases for being used to take decisions about what rendering code to use. For example, if something works well on AMD GPUs but poorly on Intel GPUs. Or perhaps something works well in Vulkan but poorly in DX12.
## Solution
- Stop mutating `WgpuOptions `and don't insert the updated values into the main and render worlds
- Return `AdapterInfo` from `initialize_renderer` and insert it into the main and render worlds
- Use `RenderDevice` limits in the lighting code that was using `WgpuOptions.limits`.
- Renamed `WgpuOptions` to `WgpuSettings`
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Support overriding wgpu features and limits that were calculated from default values or queried from the adapter/backend.
- Fixes#3686
## Solution
- Add `disabled_features: Option<wgpu::Features>` to `WgpuOptions`
- Add `constrained_limits: Option<wgpu::Limits>` to `WgpuOptions`
- After maybe obtaining updated features and limits from the adapter/backend in the case of `WgpuOptionsPriority::Functionality`, enable the `WgpuOptions` `features`, disable the `disabled_features`, and constrain the `limits` by `constrained_limits`.
- Note that constraining the limits means for `wgpu::Limits` members named `max_.*` we take the minimum of that which was configured/queried for the backend/adapter and the specified constrained limit value. This means the configured/queried value is used if the constrained limit is larger as that is as much as the device/API supports, or the constrained limit value is used if it is smaller as we are imposing an artificial constraint. For members named `min_.*` we take the maximum instead. For example, a minimum stride might be 256 but we set constrained limit value of 1024, then 1024 is the more conservative value. If the constrained limit value were 16, then 256 would be the more conservative.
# Objective
If a user attempts to `.add_render_command::<P, C>()` on a world that does not contain `DrawFunctions<P>`, the engine panics with a generic `Option::unwrap` message:
```
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:318:76
```
## Solution
This PR adds a panic message describing the problem:
```
thread 'main' panicked at 'DrawFunctions<outline::MeshStencil> must be added to the world as a resource before adding render commands to it', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:322:17
```
# Objective
The documentation was unclear but it seemed like it was intended to _only_ flip the texture coordinates of the quad. However, it was also swapping the vertex positions, which resulted in inverted winding order so the front became a back face, and the normal was pointing into the face instead of out of it.
## Solution
- This change makes the only difference the UVs being horizontally flipped.
(cherry picked from commit de943381bd2a8b242c94db99e6c7bbd70006d7c3)
# Objective
The view uniform lacks view transform information. The inverse transform is currently provided but this is not sufficient if you do not have access to an `inverse` function (such as in WGSL).
## Solution
Grab the view transform, put it in the view uniform, use the same matrix to compute the inverse as well.
# Objective
The docs for `{VertexState, FragmentState}::entry_point` stipulate that the entry point function in the shader must return void. This seems to be specific to GLSL; WGSL has no `void` type and its entry point functions return values that describe their output.
## Solution
Remove the mention of the `void` return type.
# Objective
Enable the user to specify any presentation modes (including `Mailbox`).
Fixes#3807
## Solution
I've added a new `PresentMode` enum in `bevy_window` that mirrors the `wgpu` enum 1:1. Alternatively, I could add a new dependency on `wgpu-types` if that would be preferred.
## Objective
When print shader validation error messages, we didn't print the sources and error message text, which led to some confusing error messages.
```cs
error:
┌─ wgsl:15:11
│
15 │ return material.color + 1u;
│ ^^^^^^^^^^^^^^^^^^^^ naga::Expression [11]
```
## Solution
New error message:
```cs
error: Entry point fragment at Vertex is invalid
┌─ wgsl:15:11
│
15 │ return material.color + 1u;
│ ^^^^^^^^^^^^^^^^^^^^ naga::Expression [11]
│
= Expression [11] is invalid
= Operation Add can't work with [8] and [10]
```
# Objective
Add a simple way for user to get the size of a loaded texture in an Image object.
Aims to solve #3689
## Solution
Add a `size() -> Vec2` method
Add two simple tests for this method.
Updates:
. method named changed from `size_2d` to `size`
# Objective
- While it is not safe to enable mappable primary buffers for all GPUs, it should be preferred for integrated GPUs where an integrated GPU is one that is sharing system memory.
## Solution
- Auto-disable mappable primary buffers only for discrete GPUs. If the GPU is integrated and mappable primary buffers are supported, use them.
# Objective
In order to create a glsl shader, we must provide the `naga::ShaderStage` type which is not exported by bevy, meaning a user would have to manually include naga just to access this type.
`pub fn from_glsl(source: impl Into<Cow<'static, str>>, stage: naga::ShaderStage) -> Shader {`
## Solution
Re-rexport naga::ShaderStage from `render_resources`
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
# Objective
- When using `WgpuOptionsPriority::Functionality`, which is the default, wgpu::Features::MAPPABLE_PRIMARY_BUFFERS would be automatically enabled. This feature can and does have a significant negative impact on performance for discrete GPUs where resizable bar is not supported, which is a common case. As such, this feature should not be automatically enabled.
- Fixes the performance regression part of https://github.com/bevyengine/bevy/issues/3686 and at least some, if not all cases of https://github.com/bevyengine/bevy/issues/3687
## Solution
- When using `WgpuOptionsPriority::Functionality`, use the adapter-supported features, enable `TEXTURE_ADAPTER_SPECIFIC_FORMAT_FEATURES` and disable `MAPPABLE_PRIMARY_BUFFERS`
Fixed doc comment where render Node input/output methods refered to using `RenderContext` for interaction instead of `RenderGraphContext`
# Objective
The doc comments for `Node` refer to `RenderContext` for slots instead of `RenderGraphContext`, which is only confusing because `Node::run` is passed both `RenderContext` and `RenderGraphContext`
## Solution
Fixed the typo
Super tiny thing. Found this while reviewing #3479.
# Objective
- Simplify code
- Fix the link in the doc comment
## Solution
- Import a single item :)
Co-authored-by: Pascal Hertleif <pascal@technocreatives.com>
# Objective
CI should check for missing backticks in doc comments.
Fixes#3435
## Solution
`clippy` has a lint for this: `doc_markdown`. This enables that lint in the CI script.
Of course, enabling this lint in CI causes a bunch of lint errors, so I've gone through and fixed all of them. This was a huge edit that touched a ton of files, so I split the PR up by crate.
When all of the following are merged, the CI should pass and this can be merged.
+ [x] #3467
+ [x] #3468
+ [x] #3470
+ [x] #3469
+ [x] #3471
+ [x] #3472
+ [x] #3473
+ [x] #3474
+ [x] #3475
+ [x] #3476
+ [x] #3477
+ [x] #3478
+ [x] #3479
+ [x] #3480
+ [x] #3481
+ [x] #3482
+ [x] #3483
+ [x] #3484
+ [x] #3485
+ [x] #3486
{kind=link}
{kind=link}