# Objective
#6547 accidentally broke change detection for SparseSet components by using `Ticks::from_tick_cells` with the wrong argument order.
## Solution
Use the right argument order. Add a regression test.
# Objective
Prevent future unsoundness that was seen in #6623.
## Solution
Newtype both indexes in `Archetype` and `Table` as `ArchetypeRow` and `TableRow`. This avoids weird numerical manipulation on the indices, and can be stored and treated opaquely. Also enforces the source and destination of where these indices at a type level.
---
## Changelog
Changed: `Archetype` indices and `Table` rows have been newtyped as `ArchetypeRow` and `TableRow`.
# Objective
Fixes#4884. `ComponentTicks` stores both added and changed ticks contiguously in the same 8 bytes. This is convenient when passing around both together, but causes half the bytes fetched from memory for the purposes of change detection to effectively go unused. This is inefficient when most queries (no filter, mutating *something*) only write out to the changed ticks.
## Solution
Split the storage for change detection ticks into two separate `Vec`s inside `Column`. Fetch only what is needed during iteration.
This also potentially also removes one blocker from autovectorization of dense queries.
EDIT: This is confirmed to enable autovectorization of dense queries in `for_each` and `par_for_each` where possible. Unfortunately `iter` has other blockers that prevent it.
### TODO
- [x] Microbenchmark
- [x] Check if this allows query iteration to autovectorize simple loops.
- [x] Clean up all of the spurious tuples now littered throughout the API
### Open Questions
- ~~Is `Mut::is_added` absolutely necessary? Can we not just use `Added` or `ChangeTrackers`?~~ It's optimized out if unused.
- ~~Does the fetch of the added ticks get optimized out if not used?~~ Yes it is.
---
## Changelog
Added: `Tick`, a wrapper around a single change detection tick.
Added: `Column::get_added_ticks`
Added: `Column::get_column_ticks`
Added: `SparseSet::get_added_ticks`
Added: `SparseSet::get_column_ticks`
Changed: `Column` now stores added and changed ticks separately internally.
Changed: Most APIs returning `&UnsafeCell<ComponentTicks>` now returns `TickCells` instead, which contains two separate `&UnsafeCell<Tick>` for either component ticks.
Changed: `Query::for_each(_mut)`, `Query::par_for_each(_mut)` will now leverage autovectorization to speed up query iteration where possible.
## Migration Guide
TODO
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
# Objective
Add documentation `#[world_query(ignore)]`. Fixes#6283.
---
I've only described it's behavior so far (which appears to be the same as with `system_param`). Is there another use-case for this besides with `PhantomData`? I could only find a single usage of this construct on GitHub, which is [here](ffcb816927/bevy/examples/ecs/custom_query_param.rs (L102)).
I was also wondering if it would make sense to add a usage example to the `custom_query_example`? 🤔 That's why it's currently still in there.
Co-authored-by: Lucas Jenß <243719+x3ro@users.noreply.github.com>
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
- Do not implement `Copy` or `Clone` for `Fetch` types as this is kind of sus soundness wise (it feels like cloning an `IterMut` in safe code to me). Cloning a fetch seems important to think about soundness wise when doing it so I prefer this over adding a `Clone` bound to the assoc type definition (i.e. `type Fetch: Clone`) even though that would also solve the other listed things here.
- Remove a bunch of `QueryFetch<'w, Q>: Clone` bounds from our API as now all fetches can be "cloned" for use in `iter_combinations`. This should also help avoid the type inference regression ptrification introduced where `for<'a> QueryFetch<'a, Q>: Trait` bounds misbehave since we no longer need any of those kind of higher ranked bounds (although in practice we had none anyway).
- Stop being able to "forget" to implement clone for fetches, we've had a lot of issues where either `derive(Clone)` was used instead of a manual impl (so we ended up with too tight bounds on the impl) or flat out forgot to implement Clone at all. With this change all fetches are able to be cloned for `iter_combinations` so this will no longer be possible to mess up.
On an unrelated note, while making this PR I realised we probably want safety invariants on `archetype/table_fetch` that nothing aliases the table_row/archetype_index according to the access we set.
---
## Changelog
`Clone` and `Copy` were removed from all `Fetch` types.
## Migration Guide
- Call `WorldQuery::clone_fetch` instead of `fetch.clone()`. Make sure to add safety comments :)
Make API users aware that the type aliases `QueryItem` and `QueryFetch` can be used instead of the more bloated alternative with `WorldQueryGats`.
Fixes#5842
# Objective
Simplify the worldquery trait hierarchy as much as possible by putting it all in one trait. If/when gats are stabilised this can be trivially migrated over to use them, although that's not why I made this PR, those reasons are:
- Moves all of the conceptually related unsafe code for a worldquery next to eachother
- Removes now unnecessary traits simplifying the "type system magic" in bevy_ecs
---
## Changelog
All methods/functions/types/consts on `FetchState` and `Fetch` traits have been moved to the `WorldQuery` trait and the other traits removed. `WorldQueryGats` now only contains an `Item` and `Fetch` assoc type.
## Migration Guide
Implementors should move items in impls to the `WorldQuery/Gats` traits and remove any `Fetch`/`FetchState` impls
Any use sites of items in the `Fetch`/`FetchState` traits should be updated to use the `WorldQuery` trait items instead
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`ReadOnlyWorldQuery` should have required `Self::ReadOnly = Self` so that calling `.iter()` on a readonly query is equivelent to calling `iter_mut()`.
## Solution
add `ReadOnly = Self` to the definition of `ReadOnlyWorldQuery`
---
## Changelog
ReadOnlyWorldQuery's `ReadOnly` assoc type is now always equal to `Self`
## Migration Guide
Make `Self::ReadOnly = Self` hold
# Objective
remove `QF` generics from a bunch of types and methods on query related items. this has a few benefits:
- simplifies type signatures `fn iter(&self) -> QueryIter<'_, 's, Q::ReadOnly, F::ReadOnly>` is (imo) conceptually simpler than `fn iter(&self) -> QueryIter<'_, 's, Q, ROQueryFetch<'_, Q>, F>`
- `Fetch` is mostly an implementation detail but previously we had to expose it on every `iter` `get` etc method
- Allows us to potentially in the future simplify the `WorldQuery` trait hierarchy by removing the `Fetch` trait
## Solution
remove the `QF` generic and add a way to (unsafely) turn `&QueryState<Q1, F1>` into `&QueryState<Q2, F2>`
---
## Changelog/Migration Guide
The `QF` generic was removed from various `Query` iterator types and some methods, you should update your code to use the type of the corresponding worldquery of the fetch type that was being used, or call `as_readonly`/`as_nop` to convert a querystate to the appropriate type. For example:
`.get_single_unchecked_manual::<ROQueryFetch<Q>>(..)` -> `.as_readonly().get_single_unchecked_manual(..)`
`my_field: QueryIter<'w, 's, Q, ROQueryFetch<'w, Q>, F>` -> `my_field: QueryIter<'w, 's, Q::ReadOnly, F::ReadOnly>`
# Objective
- `.iter_combinations_*()` cannot be used on custom derived `WorldQuery`, so this fixes that
- Fixes#5284
## Solution
- `#[derive(Clone)]` on the `Fetch` of the proc macro derive.
- `#[derive(Clone)]` for `AnyOf` to satisfy tests.
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
# Objective
the code in these fns are always identical so stop having two functions
## Solution
make them the same function
---
## Changelog
change `matches_archetype` and `matches_table` to `fn matches_component_set(&self, &SparseArray<ComponentId, usize>) -> bool` then do extremely boring updating of all `FetchState` impls
## Migration Guide
- move logic of `matches_archetype` and `matches_table` into `matches_component_set` in any manual `FetchState` impls
# Objective
Fixes#4657
Example code that wasnt panic'ing before this PR (and so was unsound):
```rust
#[test]
#[should_panic = "error[B0001]"]
fn option_has_no_filter_with() {
fn sys(_1: Query<(Option<&A>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn any_of_has_no_filter_with() {
fn sys(_1: Query<(AnyOf<(&A, ())>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn or_has_no_filter_with() {
fn sys(_1: Query<&mut B, Or<(With<A>, With<B>)>>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
```
## Solution
- Only add the intersection of `with`/`without` accesses of all the elements in `Or/AnyOf` to the world query's `FilteredAccess<ComponentId>` instead of the union.
- `Option`'s fix can be thought of the same way since its basically `AnyOf<T, ()>` but its impl is just simpler as `()` has no `with`/`without` accesses
---
## Changelog
- `Or`/`AnyOf`/`Option` will now report more query conflicts in order to fix unsoundness
## Migration Guide
- If you are now getting query conflicts from `Or`/`AnyOf`/`Option` rip to you and ur welcome for it now being caught
# Objective
The pointer types introduced in #3001 are useful not just in `bevy_ecs`, but also in crates like `bevy_reflect` (#4475) or even outside of bevy.
## Solution
Extract `Ptr<'a>`, `PtrMut<'a>`, `OwnedPtr<'a>`, `ThinSlicePtr<'a, T>` and `UnsafeCellDeref` from `bevy_ecs::ptr` into `bevy_ptr`.
**Note:** `bevy_ecs` still reexports the `bevy_ptr` as `bevy_ecs::ptr` so that crates like `bevy_transform` can use the `Bundle` derive without needing to depend on `bevy_ptr` themselves.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
## Objective
This fixes#1686.
`size_hint` can be useful even if a little niche. For example,
`collect::<Vec<_>>()` uses the `size_hint` of Iterator it collects from
to pre-allocate a memory slice large enough to not require re-allocating
when pushing all the elements of the iterator.
## Solution
To this effect I made the following changes:
* Add a `IS_ARCHETYPAL` associated constant to the `Fetch` trait,
this constant tells us when it is safe to assume that the `Fetch`
relies exclusively on archetypes to filter queried entities
* Add `IS_ARCHETYPAL` to all the implementations of `Fetch`
* Use that constant in `QueryIter::size_hint` to provide a more useful
## Migration guide
The new associated constant is an API breaking change. For the user,
if they implemented a custom `Fetch`, it means they have to add this
associated constant to their implementation. Either `true` if it doesn't limit
the number of entities returned in a query beyond that of archetypes, or
`false` for when it does.
# Objective
- Closes#786
- Closes#2252
- Closes#2588
This PR implements a derive macro that allows users to define their queries as structs with named fields.
## Example
```rust
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct NumQuery<'w, T: Component, P: Component> {
entity: Entity,
u: UNumQuery<'w>,
generic: GenericQuery<'w, T, P>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct UNumQuery<'w> {
u_16: &'w u16,
u_32_opt: Option<&'w u32>,
}
#[derive(WorldQuery)]
#[world_query(derive(Debug))]
struct GenericQuery<'w, T: Component, P: Component> {
generic: (&'w T, &'w P),
}
#[derive(WorldQuery)]
#[world_query(filter)]
struct NumQueryFilter<T: Component, P: Component> {
_u_16: With<u16>,
_u_32: With<u32>,
_or: Or<(With<i16>, Changed<u16>, Added<u32>)>,
_generic_tuple: (With<T>, With<P>),
_without: Without<Option<u16>>,
_tp: PhantomData<(T, P)>,
}
fn print_nums_readonly(query: Query<NumQuery<u64, i64>, NumQueryFilter<u64, i64>>) {
for num in query.iter() {
println!("{:#?}", num);
}
}
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct MutNumQuery<'w, T: Component, P: Component> {
i_16: &'w mut i16,
i_32_opt: Option<&'w mut i32>,
}
fn print_nums(mut query: Query<MutNumQuery, NumQueryFilter<u64, i64>>) {
for num in query.iter_mut() {
println!("{:#?}", num);
}
}
```
## TODOs:
- [x] Add support for `&T` and `&mut T`
- [x] Test
- [x] Add support for optional types
- [x] Test
- [x] Add support for `Entity`
- [x] Test
- [x] Add support for nested `WorldQuery`
- [x] Test
- [x] Add support for tuples
- [x] Test
- [x] Add support for generics
- [x] Test
- [x] Add support for query filters
- [x] Test
- [x] Add support for `PhantomData`
- [x] Test
- [x] Refactor `read_world_query_field_type_info`
- [x] Properly document `readonly` attribute for nested queries and the static assertions that guarantee safety
- [x] Test that we never implement `ReadOnlyFetch` for types that need mutable access
- [x] Test that we insert static assertions for nested `WorldQuery` that a user marked as readonly
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
Implements a new Queryable called AnyOf, which will return an item as long as at least one of it's requested Queryables returns something. For example, a `Query<AnyOf<(&A, &B, &C)>>` will return items with type `(Option<&A>, Option<&B>, Option<&C>)`, and will guarantee that for every element at least one of the option s is Some. This is a shorthand for queries like `Query<(Option<&A>, Option<&B>, Option<&C>), Or<(With<A>, With<B>, With&C>)>>`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
# Objective
- New clippy lints with rust 1.57 are failing
## Solution
- Fixed clippy lints following suggestions
- I ignored clippy in old renderer because there was many and it will be removed soon
A sample implementation of how to have `iter()` work on mutable queries without breaking aliasing rules.
# Objective
- Fixes#753
## Solution
- Added a ReadOnlyFetch to WorldQuery that is the `&T` version of `&mut T` that is used to specify the return type for read only operations like `iter()`.
- ~~As the comment suggests specifying the bound doesn't work due to restrictions on defining recursive implementations (like `Or`). However bounds on the functions are fine~~ Never mind I misread how `Or` was constructed, bounds now exist.
- Note that the only mutable one has a new `Fetch` for readonly as the `State` has to be the same for any of this to work
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
This:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_system(test)
.run();
}
fn test(entities: Query<Entity>) {
let mut combinations = entities.iter_combinations_mut();
while let Some([e1, e2]) = combinations.fetch_next() {
dbg!(e1);
}
}
```
fails with the message "the trait bound `bevy::ecs::query::EntityFetch: std::clone::Clone` is not satisfied".
## Solution
It works after adding the naive clone implementation to EntityFetch. I'm not super familiar with ECS internals, so I'd appreciate input on this.
Continuing the work on reducing the safety footguns in the code, I've removed one extra `UnsafeCell` in favour of safe `Cell` usage inisde `ComponentTicks`. That change led to discovery of misbehaving component insert logic, where data wasn't properly dropped when overwritten. Apart from that being fixed, some method names were changed to better convey the "initialize new allocation" and "replace existing allocation" semantic.
Depends on #2221, I will rebase this PR after the dependency is merged. For now, review just the last commit.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
`ResMut`, `Mut` and `ReflectMut` all share very similar code for change detection.
This PR is a first pass at refactoring these implementation and removing a lot of the duplicated code.
Note, this introduces a new trait `ChangeDetectable`.
Please feel free to comment away and let me know what you think!
Related to [discussion on discord](https://discord.com/channels/691052431525675048/742569353878437978/824731187724681289)
With const generics, it is now possible to write generic iterator over multiple entities at once.
This enables patterns of query iterations like
```rust
for [e1, e2, e3] in query.iter_combinations() {
// do something with relation of all three entities
}
```
The compiler is able to infer the correct iterator for given size of array, so either of those work
```rust
for [e1, e2] in query.iter_combinations() { ... }
for [e1, e2, e3] in query.iter_combinations() { ... }
```
This feature can be very useful for systems like collision detection.
When you ask for permutations of size K of N entities:
- if K == N, you get one result of all entities
- if K < N, you get all possible subsets of N with size K, without repetition
- if K > N, the result set is empty (no permutation of size K exist)
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Problem Definition
The current change tracking (via flags for both components and resources) fails to detect changes made by systems that are scheduled to run earlier in the frame than they are.
This issue is discussed at length in [#68](https://github.com/bevyengine/bevy/issues/68) and [#54](https://github.com/bevyengine/bevy/issues/54).
This is very much a draft PR, and contributions are welcome and needed.
# Criteria
1. Each change is detected at least once, no matter the ordering.
2. Each change is detected at most once, no matter the ordering.
3. Changes should be detected the same frame that they are made.
4. Competitive ergonomics. Ideally does not require opting-in.
5. Low CPU overhead of computation.
6. Memory efficient. This must not increase over time, except where the number of entities / resources does.
7. Changes should not be lost for systems that don't run.
8. A frame needs to act as a pure function. Given the same set of entities / components it needs to produce the same end state without side-effects.
**Exact** change-tracking proposals satisfy criteria 1 and 2.
**Conservative** change-tracking proposals satisfy criteria 1 but not 2.
**Flaky** change tracking proposals satisfy criteria 2 but not 1.
# Code Base Navigation
There are three types of flags:
- `Added`: A piece of data was added to an entity / `Resources`.
- `Mutated`: A piece of data was able to be modified, because its `DerefMut` was accessed
- `Changed`: The bitwise OR of `Added` and `Changed`
The special behavior of `ChangedRes`, with respect to the scheduler is being removed in [#1313](https://github.com/bevyengine/bevy/pull/1313) and does not need to be reproduced.
`ChangedRes` and friends can be found in "bevy_ecs/core/resources/resource_query.rs".
The `Flags` trait for Components can be found in "bevy_ecs/core/query.rs".
`ComponentFlags` are stored in "bevy_ecs/core/archetypes.rs", defined on line 446.
# Proposals
**Proposal 5 was selected for implementation.**
## Proposal 0: No Change Detection
The baseline, where computations are performed on everything regardless of whether it changed.
**Type:** Conservative
**Pros:**
- already implemented
- will never miss events
- no overhead
**Cons:**
- tons of repeated work
- doesn't allow users to avoid repeating work (or monitoring for other changes)
## Proposal 1: Earlier-This-Tick Change Detection
The current approach as of Bevy 0.4. Flags are set, and then flushed at the end of each frame.
**Type:** Flaky
**Pros:**
- already implemented
- simple to understand
- low memory overhead (2 bits per component)
- low time overhead (clear every flag once per frame)
**Cons:**
- misses systems based on ordering
- systems that don't run every frame miss changes
- duplicates detection when looping
- can lead to unresolvable circular dependencies
## Proposal 2: Two-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in either the current frame's list of changes or the previous frame's.
**Type:** Conservative
**Pros:**
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- can result in a great deal of duplicated work
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 3: Last-Tick Change Detection
Flags persist for two frames, using a double-buffer system identical to that used in events.
A change is observed if it is found in the previous frame's list of changes.
**Type:** Exact
**Pros:**
- exact
- easy to understand
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- change detection is always delayed, possibly causing painful chained delays
- systems that don't run every frame miss changes
- duplicates detection when looping
## Proposal 4: Flag-Doubling Change Detection
Combine Proposal 2 and Proposal 3. Differentiate between `JustChanged` (current behavior) and `Changed` (Proposal 3).
Pack this data into the flags according to [this implementation proposal](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804).
**Type:** Flaky + Exact
**Pros:**
- allows users to acc
- easy to implement
- low memory overhead (4 bits per component)
- low time overhead (bit mask and shift every flag once per frame)
**Cons:**
- users must specify the type of change detection required
- still quite fragile to system ordering effects when using the flaky `JustChanged` form
- cannot get immediate + exact results
- systems that don't run every frame miss changes
- duplicates detection when looping
## [SELECTED] Proposal 5: Generation-Counter Change Detection
A global counter is increased after each system is run. Each component saves the time of last mutation, and each system saves the time of last execution. Mutation is detected when the component's counter is greater than the system's counter. Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-769174804). How to handle addition detection is unsolved; the current proposal is to use the highest bit of the counter as in proposal 1.
**Type:** Exact (for mutations), flaky (for additions)
**Pros:**
- low time overhead (set component counter on access, set system counter after execution)
- robust to systems that don't run every frame
- robust to systems that loop
**Cons:**
- moderately complex implementation
- must be modified as systems are inserted dynamically
- medium memory overhead (4 bytes per component + system)
- unsolved addition detection
## Proposal 6: System-Data Change Detection
For each system, track which system's changes it has seen. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- conceptually simple
**Cons:**
- requires storing data on each system
- implementation is complex
- must be modified as systems are inserted dynamically
## Proposal 7: Total-Order Change Detection
Discussed [here](https://github.com/bevyengine/bevy/issues/68#issuecomment-754326523). This proposal is somewhat complicated by the new scheduler, but I believe it should still be conceptually feasible. This approach is only worth fully designing and implementing if Proposal 5 fails in some way.
**Type:** Exact
**Pros:**
- exact
- efficient data storage relative to other exact proposals
**Cons:**
- requires access to the scheduler
- complex implementation and difficulty grokking
- must be modified as systems are inserted dynamically
# Tests
- We will need to verify properties 1, 2, 3, 7 and 8. Priority: 1 > 2 = 3 > 8 > 7
- Ideally we can use identical user-facing syntax for all proposals, allowing us to re-use the same syntax for each.
- When writing tests, we need to carefully specify order using explicit dependencies.
- These tests will need to be duplicated for both components and resources.
- We need to be sure to handle cases where ambiguous system orders exist.
`changing_system` is always the system that makes the changes, and `detecting_system` always detects the changes.
The component / resource changed will be simple boolean wrapper structs.
## Basic Added / Mutated / Changed
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 2
## At Least Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs after `detecting_system`
- verify at the end of tick 2
## At Most Once
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs once before `detecting_system`
- increment a counter based on the number of changes detected
- verify at the end of tick 2
## Fast Detection
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs before `detecting_system`
- verify at the end of tick 1
## Ambiguous System Ordering Robustness
2 x 3 x 2 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs [before/after] `detecting_system` in tick 1
- `changing_system` runs [after/before] `detecting_system` in tick 2
## System Pausing
2 x 3 design:
- Resources vs. Components
- Added vs. Changed vs. Mutated
- `changing_system` runs in tick 1, then is disabled by run criteria
- `detecting_system` is disabled by run criteria until it is run once during tick 3
- verify at the end of tick 3
## Addition Causes Mutation
2 design:
- Resources vs. Components
- `adding_system_1` adds a component / resource
- `adding system_2` adds the same component / resource
- verify the `Mutated` flag at the end of the tick
- verify the `Added` flag at the end of the tick
First check tests for: https://github.com/bevyengine/bevy/issues/333
Second check tests for: https://github.com/bevyengine/bevy/issues/1443
## Changes Made By Commands
- `adding_system` runs in Update in tick 1, and sends a command to add a component
- `detecting_system` runs in Update in tick 1 and 2, after `adding_system`
- We can't detect the changes in tick 1, since they haven't been processed yet
- If we were to track these changes as being emitted by `adding_system`, we can't detect the changes in tick 2 either, since `detecting_system` has already run once after `adding_system` :(
# Benchmarks
See: [general advice](https://github.com/bevyengine/bevy/blob/master/docs/profiling.md), [Criterion crate](https://github.com/bheisler/criterion.rs)
There are several critical parameters to vary:
1. entity count (1 to 10^9)
2. fraction of entities that are changed (0% to 100%)
3. cost to perform work on changed entities, i.e. workload (1 ns to 1s)
1 and 2 should be varied between benchmark runs. 3 can be added on computationally.
We want to measure:
- memory cost
- run time
We should collect these measurements across several frames (100?) to reduce bootup effects and accurately measure the mean, variance and drift.
Entity-component change detection is much more important to benchmark than resource change detection, due to the orders of magnitude higher number of pieces of data.
No change detection at all should be included in benchmarks as a second control for cases where missing changes is unacceptable.
## Graphs
1. y: performance, x: log_10(entity count), color: proposal, facet: performance metric. Set cost to perform work to 0.
2. y: run time, x: cost to perform work, color: proposal, facet: fraction changed. Set number of entities to 10^6
3. y: memory, x: frames, color: proposal
# Conclusions
1. Is the theoretical categorization of the proposals correct according to our tests?
2. How does the performance of the proposals compare without any load?
3. How does the performance of the proposals compare with realistic loads?
4. At what workload does more exact change tracking become worth the (presumably) higher overhead?
5. When does adding change-detection to save on work become worthwhile?
6. Is there enough divergence in performance between the best solutions in each class to ship more than one change-tracking solution?
# Implementation Plan
1. Write a test suite.
2. Verify that tests fail for existing approach.
3. Write a benchmark suite.
4. Get performance numbers for existing approach.
5. Implement, test and benchmark various solutions using a Git branch per proposal.
6. Create a draft PR with all solutions and present results to team.
7. Select a solution and replace existing change detection.
Co-authored-by: Brice DAVIER <bricedavier@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
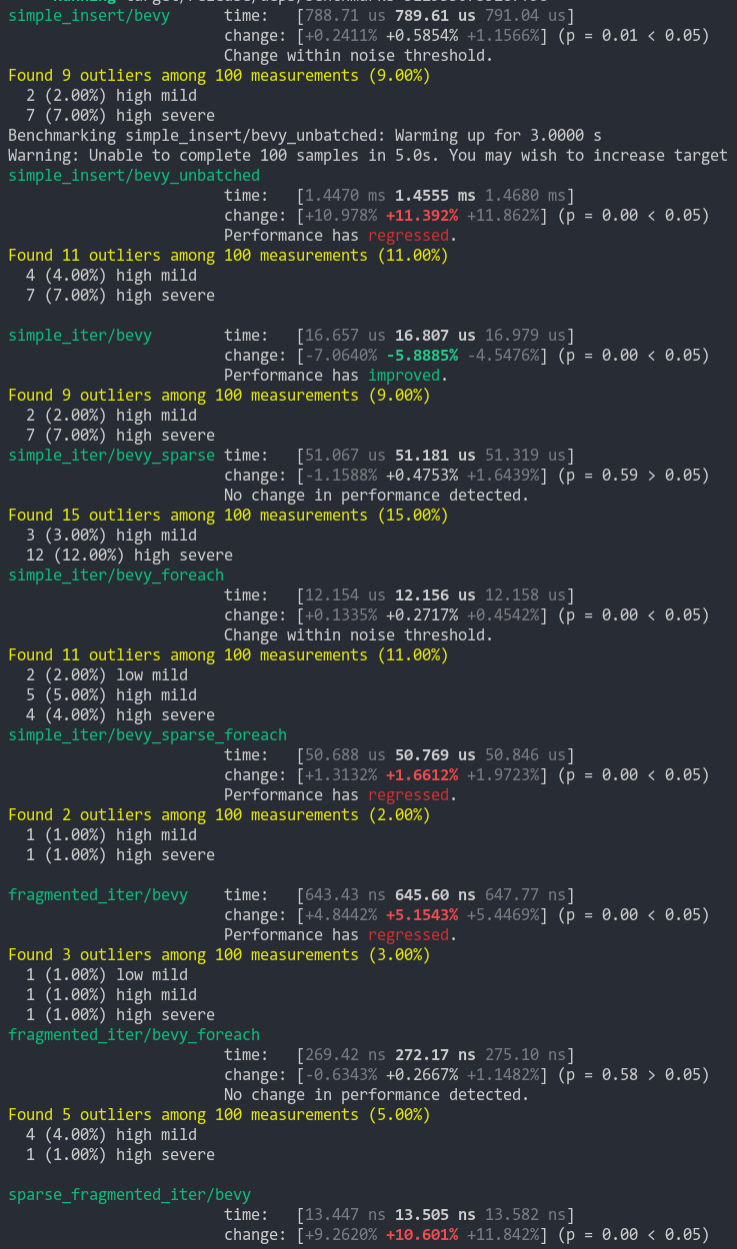
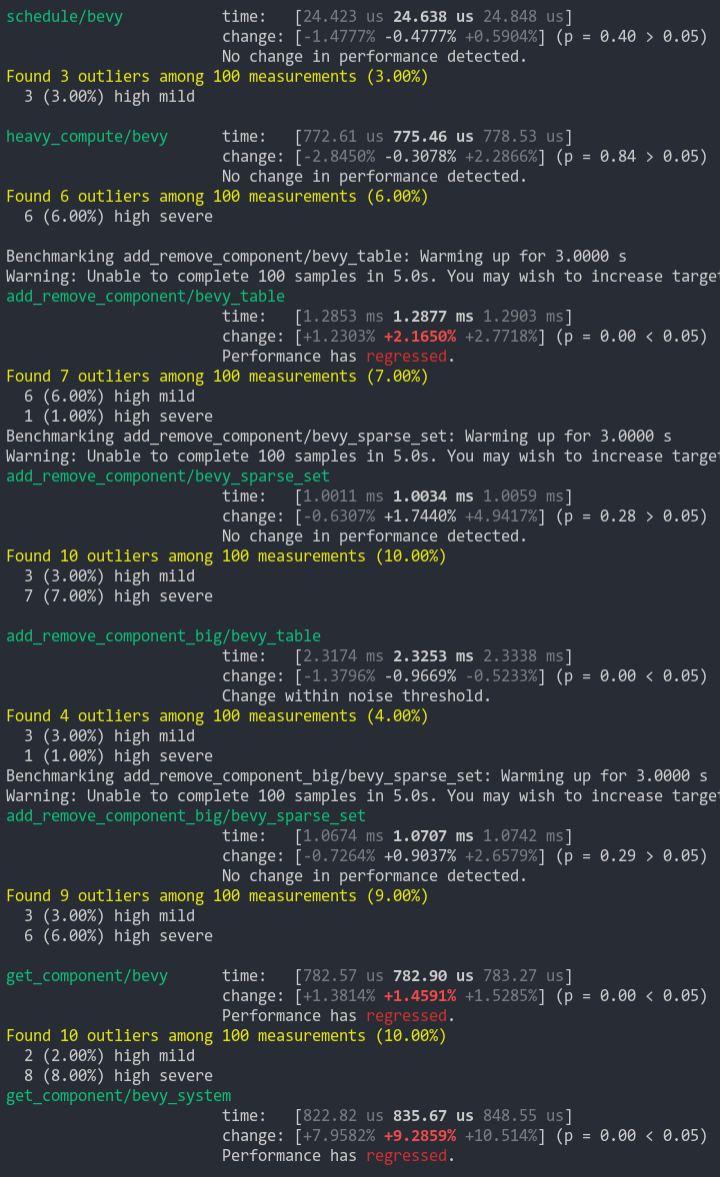
Removes `get_unchecked` and `get_unchecked_mut` from `Tables` and `Archetypes` collections in favor of safe Index implementations. This fixes a safety error in `Archetypes::get_id_or_insert()` (which previously relied on TableId being valid to be safe ... the alternative was to make that method unsafe too). It also cuts down on a lot of unsafe and makes the code easier to look at. I'm not sure what changed since the last benchmark, but these numbers are more favorable than my last tests of similar changes. I didn't include the Components collection as those severely killed perf last time I tried. But this does inspire me to try again (just in a separate pr)!
Note that the `simple_insert/bevy_unbatched` benchmark fluctuates a lot on both branches (this was also true for prior versions of bevy). It seems like the allocator has more variance for many small allocations. And `sparse_frag_iter/bevy` operates on such a small scale that 10% fluctuations are common.
Some benches do take a small hit here, but I personally think its worth it.
This also fixes a safety error in Query::for_each_mut, which needed to mutably borrow Query (aaahh!).
{kind=link}
{kind=link}