3918: Add support for feature attributes in struct literal r=matklad a=bnjjj
As promised here is the next PR to solve 2 different scenarios with feature flag on struct literal.
close#3870
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
3901: Add more heuristics for hiding obvious param hints r=matklad a=IceSentry
This will now hide `value`, `pat`, `rhs` and `other`. These words were selected from the std because they are used in commonly used functions with only a single param and are obvious by their use.
It will also hide the hint if the passed param **starts** or end with the param_name. Maybe we could also split on '_' and check if one of the string is the param_name.
I think it would be good to also hide `bytes` if the type is `[u8; n]` but I'm not sure how to get the param type signature.
Closes#3900
Co-authored-by: IceSentry <c.giguere42@gmail.com>
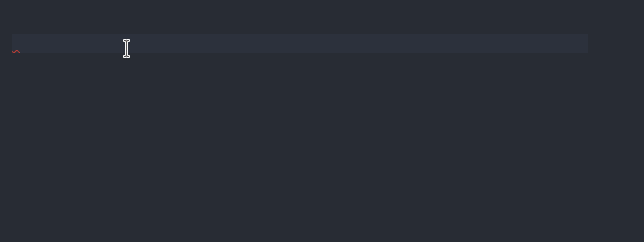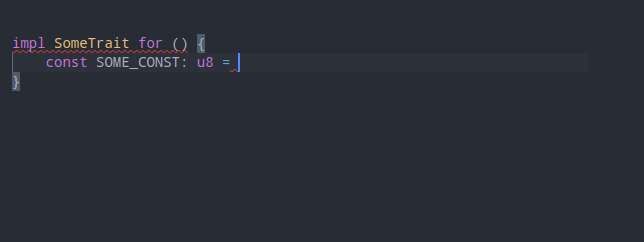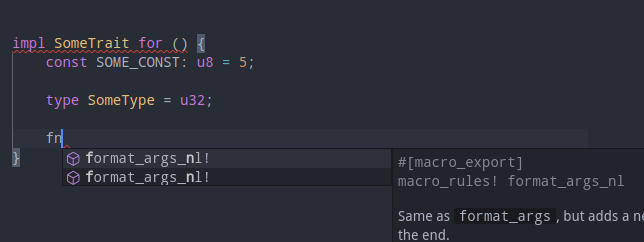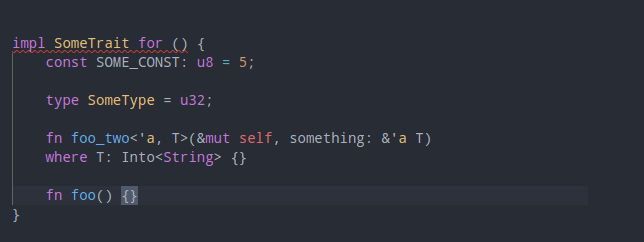
3880: Add support for attributes for struct fields r=matklad a=bnjjj
Hello I try to solve this example:
```rust
struct MyStruct {
my_val: usize,
#[cfg(feature = "foo")]
bar: bool,
}
impl MyStruct {
#[cfg(feature = "foo")]
pub(crate) fn new(my_val: usize, bar: bool) -> Self {
Self { my_val, bar }
}
#[cfg(not(feature = "foo"))]
pub(crate) fn new(my_val: usize, _bar: bool) -> Self {
Self { my_val }
}
}
```
Here is a draft PR to try to solve this issue. In fact for now when i have this kind of example, rust-analyzer tells me that my second Self {} miss the bar field. Which is a bug.
I have some difficulties to add this features. Here in my draft I share my work about adding attributes support on struct field data. But I'm stuck when I have to fetch attributes from parent expressions. I don't really know how to do that. For the first iteration I just want to solve my issue without solving on all different expressions. And then after I will try to implement that on different kind of expression. I think I have to fetch my FunctionId and then I will be able to find attributes with myFunction.attrs() But I don't know if it's the right way.
@matklad (or anyone else) if you can help me it would be great :D
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
This will now hide "value", "pat", "rhs" and "other"
These words were selected from the std because they are used in common functions with only a single param and are obvious by their use.
I think it would be good to also hide "bytes" if the type is `[u8; n]` but I'm not sure how to get the param type signature
It will also hide the hint if the passed param starts or end with the param_name
- Adds a new AstElement trait that is implemented by all generated
node, token and enum structs
- Overhauls the code generators to code-generate all tokens, and
also enhances enums to support including tokens, node, and nested
enums
3826: Flatten nested highlight ranges during DFS traversal r=matklad a=ltentrup
Implements the flattening of nested highlights from #3447.
There is a caveat: I needed to add `Clone` to `HighlightedRange` to split highlight ranges ~and the nesting does not appear in the syntax highlighting test (it does appear in the accidental-quadratic test but there it is not checked against a ground-truth)~.
I have added a test case for the example mentioned in #3447.
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
3892: Add L_DOLLAR for TYPE_RECOVERY_SET r=matklad a=edwin0cheng
This PR is a hot fix for issue #3861 that just prevent it make the parser being stuck.
The actual problem described in https://github.com/rust-analyzer/rust-analyzer/pull/3873#issuecomment-610208693 is a very deep rabbit hole I don't want to dig right now :(
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
The sytax tree output files now use .rast extension
(rust-analyzer syntax tree or rust abstract syntax tree
(whatever)).
This format has a editors/code/ra_syntax_tree.tmGrammar.json declaration
that supplies nice syntax highlighting for .rast files.
3843: Remove rustc_lexer dependency in favour of rustc-ap-rustc_lexer r=est31 a=est31
The latter is auto-published on a regular schedule (Right now weekly).
See also https://github.com/alexcrichton/rustc-auto-publish
Co-authored-by: est31 <MTest31@outlook.com>
3829: Adds to SSR match for semantically equivalent call and method call r=matklad a=mikhail-m1
#3186
maybe I've missed some corner cases, but it works in general
Co-authored-by: Mikhail Modin <mikhailm1@gmail.com>
In textmate, keyword.control is used for all kinds of things; in fact,
the default scope mapping for keyword is keyword.control!
So let's add a less ambiguous controlFlow modifier
See Microsoft/vscode#94367
The big change here is counting binders, not
variables (https://github.com/rust-lang/chalk/pull/360). We have to adapt to the
same scheme for our `Ty::Bound`. It's mostly fine though, even makes some things
more clear.
We treat macro calls as expressions (there's appropriate Into impl),
which causes problem if there's expresison and non-expression macro in
the same node (like in the match arm).
We fix this problem by nesting macor patterns into another node (the
same way we nest path into PathExpr or PathPat). Ideally, we probably
should add a similar nesting for macro expressions, but that needs
some careful thinking about macros in blocks: `{ am_i_expression!() }`.
3746: Add create_function assist r=flodiebold a=TimoFreiberg
The function part of #3639, creating methods will come later
- [X] Function arguments
- [X] Function call arguments
- [x] Method call arguments
- [x] Literal arguments
- [x] Variable reference arguments
- [X] Migrate to `ast::make` API
Done, but there are some ugly spots.
Issues to handle in another PR:
- function reference arguments: Their type isn't printed properly right now.
The "insert explicit type" assist has the same issue and this is probably a relatively rare usecase.
- generating proper names for all kinds of argument expressions (if, loop, ...?)
Without this, it's totally possible for the assist to generate invalid argument names.
I think the assist it's already helpful enough to be shipped as it is, at least for me the main usecase involves passing in named references.
Besides, the Rust tooling ecosystem is immature enough that some janky behaviour in a new assist probably won't scare anyone off.
- select the generated placeholder body so it's a bit easier to overwrite it
- create method (`self.foo<|>(..)` or `some_foo.foo<|>(..)`) instead of create_function.
The main difference would be finding (or creating) the impl block and inserting the `self` argument correctly
- more specific default arg names for literals.
So far, every generated argument whose name can't be taken from the call site is called `arg` (with a number suffix if necessary).
- creating functions in another module of the same crate.
E.g. when typing `some_mod::foo<|>(...)` when in `lib.rs`, I'd want to have `foo` generated in `some_mod.rs` and jump there.
Issues: the mod could exist in `some_mod.rs`, in `lib.rs` as `mod some_mod`, or inside another mod but be imported via `use other_mod::some_mod`.
- refer to arguments of the generated function with a qualified path if the types aren't imported yet
(alternative: run autoimport. i think starting with a qualified path is cleaner and there's already an assist to replace a qualified path with an import and an unqualified path)
- add type arguments of the arguments to the generated function
- Autocomplete functions with information from unresolved calls (see https://github.com/rust-analyzer/rust-analyzer/pull/3746#issuecomment-605281323)
Issues: see https://github.com/rust-analyzer/rust-analyzer/pull/3746#issuecomment-605282542. The unresolved call could be anywhere. But just offering this autocompletion for unresolved calls in the same module would already be cool.
Co-authored-by: Timo Freiberg <timo.freiberg@gmail.com>
3814: Add impl From for enum variant assist r=flodiebold a=mattyhall
Basically adds a From impl for tuple enum variants with one field. It was recommended to me on the zulip to maybe try using the trait solver, but I had trouble with that as, although it could resolve the trait impl, it couldn't resolve the variable unambiguously in real use. I'm also unsure of how it would work if there were already multiple From impls to resolve - I can't see a way we could get more than one solution to my query.
Fixes#3766
Co-authored-by: Matthew Hall <matthew@quickbeam.me.uk>
This commit is a fixup of a bug I introduced by using a PackageId to refer to a crate when its name conflicts with a dependency.
It turns out the package id currently is `name version path` while cargo expects `name:version` as argument.
Basically adds a From impl for tuple enum variants with one field. Added
to cover the fairly common case of implementing your own Error that can
be created from another one, although other use cases exist.
3806: lower bool literal value r=flodiebold a=JoshMcguigan
Following up on #3805, this PR adds the literal value to `ast::LiteralKind` so when we lower we can use the actual value from the source code rather than the default value for the type. Ultimately I plan to use this for exhaustiveness checking in #3706.
I didn't include this in the previous PR because I wasn't sure if it made sense to add this information to `ast::LiteralKind` or provide some other mechanism to get this from `ast::Literal`.
For now I've only implemented this for boolean literals, but I think it could be easily extended to other types. A possible exception to this are string literals, since we may not want to clone around an owned string to hold onto in `ast::LiteralKind`, and it'd be nice to avoid adding a generic lifetime as well. Perhaps we won't ever care about the actual value of a string literal?
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3797: Don't show chaining hints for record literals and unit structs r=matklad a=lnicola
Fixes#3796
r? @Veetaha
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
3805: lower literal patterns r=JoshMcguigan a=JoshMcguigan
While working on #3706 I discovered literal patterns weren't being lowered. This PR implements that lowering.
Questions for reviewers:
1. This re-uses the existing conversion from `ast::LiteralKind` to `Literal`, but `ast::LiteralKind` doesn't include information about the actual value of the literal, which causes `Literal` to be created with the default value for the type (rather than the actual value in the source code). Am I correct in thinking that we'd eventually want to change things in such a way that we could initialize the `Literal` with the actual literal value? Is there an existing issue for this, or else perhaps I should create one to discuss how it should be implemented? My main question would be whether `ast::LiteralKind` should be extended to hold the actual value, or if we should provide some other way to get that information from `ast::Literal`?
2. I couldn't find tests which directly cover this, but it does seem to work in #3706. Do we have unit tests for this lowering code?
3. I'm not sure why `lit.literal()` returns an `Option`. Is returning a `Pat::Missing` in the `None` case the right thing to do?
4. I was basically practicing type-system driven development to figure out the transformation from `ast::Pat::LiteralPat` to `Pat::Lit`. I don't have an immediate question here, but I just wanted to ensure this section is looked at closely during review.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3780: Simplify r=matklad a=Veetaha
I absolutely love tha fact that removing `.clone()` simplifies the code comparing to other languages where it's actually the contrary (ahem ~~`std::move()`~~)
3787: vscode: add syntax tree inspection hovers and highlights r=matklad a=Veetaha
I implemented the reverse mapping (when you hover in the rust editor), but it seems overcomplicated, so I removed it
Related #3682
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
3778: Use more functional programming in ArenaMap::insert r=matklad a=kjeremy
I find this more readable and it flattens out the body a little. Others may disagree.
Co-authored-by: kjeremy <kjeremy@gmail.com>
3781: Add crate versions when running cargo -p commands. r=matklad a=o0Ignition0o
If someone (unfortunately) creates a project that happens to have the same name as one of its (future) dependencies, there is [a way for them to change the dependency's alias in the Cargo.toml file](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html#renaming-dependencies-in-cargotoml), to mitigate the name conflict. Unfortunately cargo -p commands don't seem to pick it up, which seems to put rust-analyzer run commands in a tough situation:
```
> Executing task: cargo test --package config --example default -- tests --nocapture <
error: There are multiple `config` packages in your project, and the specification `config` is ambiguous.
Please re-run this command with `-p <spec>` where `<spec>` is one of the following:
config:0.1.0
config:0.9.3
The terminal process terminated with exit code: 101
```
cargo suggests us to be more specific and refer to a package by its name and version, which this PR achieves.
I passed the version as a String because I don't really understand how the ra_db types work, but I would love to switch it to [a fully fledged Version type](https://steveklabnik.github.io/semver/semver/index.html) if you guide me towards that :)
Co-authored-by: o0Ignition0o <jeremy.lempereur@gmail.com>
Until now cargo commands with the -p flag would pass the package name only.
It doesn't play super well with the toml Renaming dependencies feature.
This commit specifies the package name and version when a cargo command is run with the -p flag,
to avoid ambiguities.
This commit changes the parser to attach doc-comments to the corresponding declaration in case there are newlines in between the doc-comment and the declaration.
3761: Append new match arms rather than replacing all of them r=matklad a=mattyhall
This means we now retain comments when filling in match arms. This fixes#3687. This is my first contribution so apologies if it needs a rethink! I think in particular the way I find the position to append to and remove_if_only_whitespace are a little hairy.
Co-authored-by: Matthew Hall <matthew@quickbeam.me.uk>
3727: Introduce ra_proc_macro r=matklad a=edwin0cheng
This PR implemented:
1. Reading dylib path of proc-macro crate from cargo check , similar to how `OUTDIR` is obtained.
2. Added a new crate `ra_proc_macro` and implement the foot-work for reading result from external proc-macro expander.
3. Added a struct `ProcMacroClient` , which will be responsible to the client side communication to the External process.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3722: Fix parsing lambdas with return type r=matklad a=matklad
We should eat only a single block, and not whatever larger expression
may start with a block.
closes#3721
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3707: Add ItemScope::visibility_of r=matklad a=edwin0cheng
~This PR implements `HasVisibility` for various constructs and change `Definition::search_scope` to use `Visibility` directly instead of depends on ad-hoc string parsing.~
This PR added `visibility_of` in `ItemScope` and `Module` and use it directly directly instead of depends on ad-hoc string parsing.
And also add a FIXME to indicate that there is a bug which do not search child-submodules in other files recursively in `Definition::search_scope`.
I will submit another PR to fix that bug after this is merged.
cc @flodiebold
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3664: Introduce TokenConverter Trait r=matklad a=edwin0cheng
This PR add a `TokenConverter` Trait to share the conversion logic between raw `lexer` token and Syntax Node Token.
Related #2158.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3700: fill match arms with empty block rather than unit tuple r=matklad a=JoshMcguigan
As requested by @Veetaha in #3689 and #3687, this modifies the fill match arms assist to create match arms as an empty block `{}` rather than a unit tuple `()`.
In one test I left one of the pre-existing match arms as a unit tuple, and added a body to another match arm, to demonstrate that the contents of existing match arms persist.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3696: vscode: more type safety r=matklad a=Veetaha
3698: Consider references when applying postfix completions r=matklad a=SomeoneToIgnore
Sometimes my RA debugging workflow breaks because `.dbg` is applied to the variable that is used later in the code.
It's safer to consider the refences to avoid this for completions that may trigger the move.
3703: Don't try to enable proposed API's on stable r=matklad a=matklad
bors r+
🤖
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3689: implement fill match arm assist for tuple of enums r=matklad a=JoshMcguigan
This updates the fill match arm assist to work in cases where the user is matching on a tuple of enums.
Note, for now this does not apply when some match arms exist (other than the trivial `_`), but I think this could be added in the future.
I think this also lays the groundwork for filling match arms when matching on tuples of non-enum values, for example a tuple of an enum and a boolean.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3632: ra_cargo_watch: log errors r=matklad a=Veetaha
Until this moment we totally ignored all the errors from cargo process. Though this is still true, but we
now try to log ones that are critical (i.e. misconfiguration errors and ignore compile errors).
This fixes#3631, and gives us a better error message to more gracefully handle the #3265

Though I think that outputting this only to `Output` channel is not enough. We should somehow warn the user that he passed wrong arguments to `cargo-watch.args`. I didn't bother looking for how to do this now, but this PR at least gives us something.
*cc* @kiljacken @matklad
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
As stated by matklad, reading the stderr
should be done alngside with
stdout via select() (or I guess poll()),
there is no such implementation in stdlib,
since it is quite low level and platform-dependent and it
also requires quite a bit of unrelated code we don't use it for now.
As referenced by bjorn3, there is an implementation of the needed read2() function
in rustc compiletest. The better solution will be to extract this function
to a separate crate in future:
https://github.com/rust-analyzer/rust-analyzer/pull/3632#discussion_r395605298
3671: Add identity expansion checking in ill-form expansion r=flodiebold a=edwin0cheng
This PR try to add more checking code in error case in macro expansion. The bug in #3642 is introduced by #3580 , which allow ill-form macro expansion in *all* kind of macro expansions.
In general we should separate hypothetical macro expansion and the actual macro expansion call. However, currently the `Semantic` workflow we are using only support single macro expansion type, we might want to review it and make it works in both ways. (Maybe add a field in `MacroCallLoc` for differentiation)
Fix#3642
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3623: 'Fill match arms' should work with existing match arms r=matklad a=slyngbaek
Addresses #3039
This essentially adds missing match arms. The algorithm for this
can get complicated rather quickly so bail in certain conditions
and rely on a PlaceholderPat.
The algorighm works as such:
- Iterate through the Enum Def Variants
- Attempt to see if the variant already exists as a match arm
- If yes, skip the enum variant. If no, include it.
- If it becomes complicated, rather than exhaustively deal with every
branch, mark it as a "partial match" and simply include the
placeholder.
Conditions for "complication":
- The match arm contains a match guard
- Any kind of nested destrucuring
Order the resulting merged match branches as such:
1. Provided match arms
2. Missing enum variant branch arms
3. End with Placeholder if required
- Add extra tests
Co-authored-by: Steffen Lyngbaek <steffenlyngbaek@gmail.com>
Iterate through TupleStructPat's until a MatchArm if
one exists. Store in a new is_pat_bind_and_path bool
and allow the `complete_scope` to find matches.
Added some tests to ensure it works in simple and nested cases.
Addresses #3039
This essentially adds missing match arms. The algorithm for this
can get complicated rather quickly so bail in certain conditions
and rely on a PlaceholderPat.
The algorighm works as such:
- Iterate through the Enum Def Variants
- Attempt to see if the variant already exists as a match arm
- If yes, skip the enum variant. If no, include it.
- If it becomes complicated, rather than exhaustively deal with every
branch, mark it as a "partial match" and simply include the
placeholder.
Conditions for "complication":
- The match arm contains a match guard
- Any kind of nested destrucuring
Order the resulting merged match branches as such:
1. Provided match arms
2. Missing enum variant branch arms
3. End with Placeholder if required
- Add extra tests
It improves compile time in `--release` mode quite a bit, it doesn't
really slow things down and, conceptually, it seems closer to what we
want the physical architecture to look like (we don't want to
monomorphise EVERYTHING in a single leaf crate).
3573: Check all crates of the workspace r=matklad a=matklad
Previously, if the root of the was was a real crate, only this crate
was checked.
Ideally, we might want some kind of config here (which might be just
overriding the whole command), but `--workspace` is def a nicer
default.
r? @kiljacken
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3587: Use WorkDoneProgress LSP API for initial load r=matklad a=slyngbaek
Addresses #3283
Rather than using custom UI for showing the loaded state. Rely
on the WorkDoneProgress API in 3.15.0
https://microsoft.github.io/language-server-protocol/specification#workDoneProgress.
No client-side work was necessary. The UI is not exactly what is
described in the issue but afaict that's how VS Code implements the LSP
API.
- The WorkDoneProgressEnd does not appear to display its message
contents (controlled by vscode)
Co-authored-by: Steffen Lyngbaek <steffenlyngbaek@gmail.com>
3591: Support local macro_rules r=matklad a=edwin0cheng
This PR implement local `macro_rules` in function body, by adding following things:
1. While lowering, add a `MacroDefId` in body's `ItemScope` as a textual legacy macro.
2. Make `Expander::enter_expand` search with given `ItemScope`.
3. Make `Resolver::resolve_path_as_macro` search with `LocalItemScope`.
Fix#2181
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
Addresses #3283
Rather than using custom UI for showing the loaded state. Rely
on the WorkDoneProgress API in 3.15.0
https://microsoft.github.io/language-server-protocol/specification#workDoneProgress.
No client-side work was necessary. The UI is not exactly what is
described in the issue but afaict that's how VS Code implements the LSP
API.
- The WorkDoneProgressEnd does not appear to display its message
contents (controlled by vscode)
3561: feat: add debug code lens r=matklad a=hdevalke
Refs #3539
3577: Protect against infinite macro expansion in def collector r=edwin0cheng a=flodiebold
Something I noticed while trying to make macro expansion more resilient against errors.
There was a test for this, but it wasn't actually working because the first recursive expansion failed. (The comma...)
Even with this limit, that test (when fixed) still takes some time to pass because of the exponential growth of the expansions, so I disabled it and added a different one without growth.
CC @edwin0cheng
Co-authored-by: Hannes De Valkeneer <hannes@de-valkeneer.be>
Co-authored-by: hdevalke <2261239+hdevalke@users.noreply.github.com>
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
There was a test for this, but it wasn't actually working because the first
recursive expansion failed. (The comma...)
Even with this limit, that test (when fixed) still takes some time to pass
because of the exponential growth of the expansions, so I disabled it and added
a different one without growth.
The `ty` function in code_model returned the type with placeholders for type
parameters. That's nice for printing, but not good for completion, because
placeholders won't unify with anything else: So the type we got for `HashMap`
was `HashMap<K, V, T>`, which doesn't unify with `HashMap<?, ?, RandomState>`,
so the `new` method wasn't shown.
Now we instead return `HashMap<{unknown}, {unknown}, {unknown}>`, which does
unify with the impl type. Maybe we should just expose this properly as variables
though, i.e. we'd return something like `exists<type, type, type> HashMap<?0,
?1, ?2>` (in Chalk notation). It'll make the API more complicated, but harder to
misuse. (And it would handle cases like `type TypeAlias<T> = HashMap<T, T>` more
correctly.)
Previously, if the root of the was was a real crate, only this crate
was checked.
Ideally, we might want some kind of config here (which might be just
overriding the whole command), but `--workspace` is def a nicer
default.
3553: Completions do not show for function with same name as mod r=matklad a=JoshMcguigan
fixes#3444
I've added a test case in `crates/ra_ide/src/completion/complete_path.rs` which verifies the described behavior in #3444. Digging in, I found that [the module scope iterator](ba62d8bd1c/crates/ra_ide/src/completion/complete_path.rs (L22)) only provides the module `z`, and does not provide the function `z` (although if I name the function something else then it does show up here).
I thought perhaps the name wasn't being properly resolved, but I added a test in `crates/ra_hir_def/src/nameres/tests.rs` which seems to suggest that it is? I've tried to figure out how to bridge the gap between these two tests (one passing, one failing) to see where the function `z` is being dropped, but to this point I haven't been able to track it down.
Any pointers on where I might look for this?
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3543: Parameter inlay hint separate from variable type inlay? #2876 r=matklad a=slyngbaek
Add setting to allow enabling either type inlay hints or parameter
inlay hints or both. Group the the max inlay hint length option
into the object.
- Add a new type for the inlayHint options.
- Add tests to ensure the inlays don't happen on the server side
Co-authored-by: Steffen Lyngbaek <steffenlyngbaek@gmail.com>
3559: Implement builtin assert! macro r=matklad a=edwin0cheng
This PR add a dummy implementation for `assert!` macro, which mainly make `hover` and `goto-def` works on arguments inside it.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3564: Better handling of a few kinds of cargo/clippy diagnostics r=matklad a=kiljacken
This was initially supposed to just be a fix for #3433, but I caught a few things that ended up being useful as well.
This PR primarily makes us handle multi-edit fix suggestions properly. Instead of just applying the first fix we apply all the parts of the fix in a single action.
Second up, this PR handles diagnostics with multiple primary spans, f.x. the unused import diagnostic from rustc:

The LSP doesn't handle this too well, as it only support a single complete range for each diagnostic, so we get duplicate messages in the problem panel of VSCode:
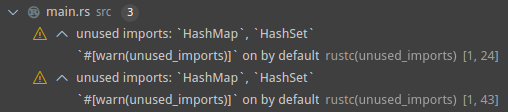
However, I feel like the improved visual aspect in-editor outweighs the duplication in the problem panel. I'm open to not including the second commit if anybody really doesn't like the idea of duplicate diagnostics in the problem pane.
Fixes#3433Fixes#3257
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
- Instead of a single object type, use several individual nested types
to allow toggling from the settings GUI
- Remove unused struct definitions
- Install and test that the toggles work
3549: Implement env! macro r=matklad a=edwin0cheng
This PR implements `env!` macro by adding following things:
1. Added `additional_outdirs` settings in vscode. (naming to be bikeshed)
2. Added `ExternSourceId` which is a wrapping for SourceRootId but only used in extern sources. It is because `OUT_DIR` is not belonged to any crate and we have to access it behind an `AstDatabase`.
3. This PR does not implement the `OUT_DIR` parsing from `cargo check`. I don't have general design about this, @kiljacken could we reuse some cargo watch code for that ?
~~Block on [#3536]~~
PS: After this PR , we (kind of) completed the `include!(concat!(env!('OUT_DIR'), "foo.rs")` macro call combo. [Exodia Obliterate!](https://www.youtube.com/watch?v=RfqNH3FoGi0)
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3542: Renames work on struct field shorthands r=matklad a=m-n
When renaming either a local or a struct field, struct field shorthands are now renamed correctly.
Happy to refactor this if it doesn't fit the design of the code. Thanks for adding the suggestion of where to start on the issue.
I wasn't sure if I should also look at the behavior of renaming when placing the cursor at the field shorthand; the following describes the behavior with this patch:
```rust
#[test]
fn test_rename_field_shorthand_for_unspecified() {
// when renaming a shorthand, should we have a way to specify
// between renaming the field and the local?
//
// If not is this the correct default?
test_rename(
r#"
struct Foo {
i: i32,
}
impl Foo {
fn new(i: i32) -> Self {
Self { i<|> }
}
}
"#,
"j",
r#"
struct Foo {
i: i32,
}
impl Foo {
fn new(j: i32) -> Self {
Self { i: j }
}
}
"#,
);
}
```
Resolves#3431
Co-authored-by: Matt Niemeir <matt.niemeir@gmail.com>
- Updated naming of config
- Define struct in ra_ide and use remote derive in rust-analyzer/config
- Make inlayConfig type more flexible to support more future types
- Remove constructor only used in tests
Add setting to allow enabling either type inlay hints or parameter
inlay hints or both. Group the the max inlay hint length option
into the object.
- Add a new type for the inlayHint options.
- Add tests to ensure the inlays don't happen on the server side
To test whether the receiver type matches for the impl, we unify the given self
type (in this case `HashSet<{unknown}>`) with the self type of the
impl (`HashSet<?0>`), but if the given self type contains Unknowns, they won't
be unified with the variables in those places. So we got a receiver type that
was different from the expected one, and concluded the impl doesn't match.
The fix is slightly hacky; if after the unification, our variables are still
there, we make them fall back to Unknown. This does make some sense though,
since we don't want to 'leak' the variables.
Fixes#3547.
3536: Add get and set for `Env` r=matklad a=edwin0cheng
This PR add three things :
1. Add `get` and `set` in `Env`.
2. Implement fixture meta for `with_single_file`.
3. Add `env` meta in fixture.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3526: Silence "file out of workspace" errors r=matklad a=matklad
We really should fix this limitation of the VFS, but it's some way off
at the moment, so let's just silence the user-visible error for now.
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3513: Completion in macros r=matklad a=flodiebold
I experimented a bit with completion in macros. It's kind of working, but there are a lot of rough edges.
- I'm trying to expand the macro call with the inserted fake token. This requires some hacky additions on the HIR level to be able to do "hypothetical" expansions. There should probably be a nicer API for this, if we want to do it this way. I'm not sure whether it's worth it, because we still can't do a lot if the original macro call didn't expand in nearly the same way. E.g. if we have something like `println!("", x<|>)` the expansions will look the same and everything is fine; but in that case we could maybe have achieved the same result in a simpler way. If we have something like `m!(<|>)` where `m!()` doesn't even expand or expands to something very different, we don't really know what to do anyway.
- Relatedly, there are a lot of cases where this doesn't work because either the original call or the hypothetical call doesn't expand. E.g. if we have `m!(x.<|>)` the original token tree doesn't parse as an expression; if we have `m!(match x { <|> })` the hypothetical token tree doesn't parse. It would be nice if we could have better error recovery in these cases.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3516: Handle visibility in more cases in completion r=matklad a=flodiebold
This means we don't show private items when completing paths or method calls.
We might want to show private items if we can edit their definition and provide a "make public" assist, but I feel like we'd need better sorting of completion items for that, so they can be not shown or sorted to the bottom by default. Until then, they're usually more of a distraction to me.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3518: Add parse_to_token_tree r=matklad a=edwin0cheng
This PR introduce a function for parsing `&str` to `tt::TokenTree`:
```rust
// Convert a string to a `TokenTree`
pub fn parse_to_token_tree(text: &str) -> Option<(tt::Subtree, TokenMap)> {
````
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
Allow trait autocompletions for unimplemented associated fn's, types,
and consts without using explicit keywords before hand (fn, type,
const).
The sequel to #3108.
3499: Resolve `Self::AssocTy` in impls r=matklad a=flodiebold
To do this we need to carry around the original resolution a bit, because `Self`
gets resolved to the actual type immediately, but you're not allowed to write
the equivalent type in a projection. (I tried just comparing the projection base
type with the impl self type, but that seemed too dirty.) This is basically how
rustc does it as well.
Fixes#3249.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
To do this we need to carry around the original resolution a bit, because `Self`
gets resolved to the actual type immediately, but you're not allowed to write
the equivalent type in a projection. (I tried just comparing the projection base
type with the impl self type, but that seemed too dirty.) This is basically how
rustc does it as well.
Fixes#3249.
3494: Implement include macro r=matklad a=edwin0cheng
This PR implement builtin `include` macro.
* It does not support include as expression yet.
* It doesn't consider `env!("OUT_DIR")` yet.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3483: Unfold groups with single assists into plain assists r=matklad a=SomeoneToIgnore
A follow-up of https://github.com/rust-analyzer/rust-analyzer/pull/3120/files#r378788698 , made to show more detailed label when the assist group contains a single element
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
3482: Fix regression from #3451 r=matklad a=edwin0cheng
There is a regression from #3451 such that the following code has failed to parse in raw item collecting phase:
```rust
macro_rules! with_std {
($($i:item)*) => ($(#[cfg(feature = "std")]$i)*)
}
with_std! {
mod macros;
mod others;
}
```
### Rationale
We always assume the last token of an statement will not end with a whitespace, which is true. It is because in parsing phase, we always emit `SyntaxNode` before any whitespace. Such that in various parts of RA code, we solely check the semi-colon by using `SyntaxNode::last_child_token() == ";"` .
However, in #3451, we insert some whitespaces between puncts such that we broke above assumption. This PR fixed this bug by make sure we don't add any whitespace if it is a semicolon.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
Note that `detail` was replced with `function_signature` to avoid
calling `from` on FunctionSignature twice.
I didn't add new tests because the current ones seem enough.
3429: Fix panic on eager expansion r=matklad a=edwin0cheng
When lazy expanding inside an eager macro, its *parent* file of that lazy macro call must be already exists such that a panic is occurred because that parent file is the eager macro we are processing.
This PR fix this bug by store the argument syntax node as another eager macro id for that purpose.
Personally I don't know if it is a good answer for this bug.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3428: Move reference classification to ra_ide_db r=matklad a=matklad
Lost some marks along the way :-(
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3392: Implement concat eager macro r=matklad a=edwin0cheng
This PR implements the following things:
1. Add basic eager macro infrastructure by introducing `EagerCallId` such that the new `MacroCallId` is defined as :
```
#[derive(Debug, Clone, Copy, PartialEq, Eq, Hash)]
pub enum MacroCallId {
LazyMacro(LazyMacroId),
EagerMacro(EagerMacroId),
}
```
2. Add `concat!` builtin macro.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3425: Fix a bug for single dollar sign macro r=matklad a=edwin0cheng
This PR fixed a bug to allow the following valid `macro_rules!` :
```rust
macro_rules! m {
($) => ($)
}
```
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3405: More principled approach for gotodef for field shorhand r=matklad a=matklad
Callers can now decide for themselves if they should prefer field or
local definition. By default, it's the local.
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
3385: Fix#3373 r=matklad a=flodiebold
Basically, we need to allow variables in the caller self type to unify with the
impl's declared self type. That requires some more contortions in the variable
handling. I'm looking forward to (hopefully) handling this in a cleaner way when
we switch to Chalk's types and unification code.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3387: Type inference for slice patterns r=flodiebold a=JoshMcguigan
Fixes#3043
Notes to reviewer:
1. This only works if `expected` is `Ty::Apply`. I'm not sure of the implications of this.
1. This only works if the slice pattern only has a prefix. I think this means it doesn't work for subslice patterns, which are currently only available behind a feature flag.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
3384: fix#2377 super::super::* r=flodiebold a=JoshMcguigan
Thanks @matklad for the detailed explanation on #2377. I believe this fixes it.
One thing I'm not sure about is you said the fix would involve changing `crates/ra_hir_def/src/path/lower/lower.rs`, but I only changed `crates/ra_hir_def/src/path/lower/lower_use.rs`. I'm not sure what kind of test code I'd have to write to expose the issue in `lower.rs`, but I'd be happy to add it if you are able to provide additional guidance.
closes#2377
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Basically, we need to allow variables in the caller self type to unify with the
impl's declared self type. That requires some more contortions in the variable
handling. I'm looking forward to (hopefully) handling this in a cleaner way when
we switch to Chalk's types and unification code.
3309: Find cargo toml up the fs r=matklad a=not-much-io
Currently rust-analyzer will look for Cargo.toml in the root of the project and if failing that then go down the filesystem until root.
This unfortunately wouldn't work automatically with (what I imagine is) a fairly common project structure. As an example with multiple languages like:
```
js/
..
rust/
Cargo.toml
...
```
Added this small change so rust-analyzer would glance one level up if not found in root or down the filesystem.
## Why not go deeper?
Could be problematic with large project vendored dependencies etc.
## Why not add a Cargo.toml manual setting option?
Loosely related and a good idea, however the convenience of having this automated also is hard to pass up.
## Testing?
Build a binary with various logs and checked it in a project with such a structure:
```
[ERROR ra_project_model] find_cargo_toml()
[ERROR ra_project_model] find_cargo_toml_up_the_fs()
[ERROR ra_project_model] entities: ReadDir("/workspaces/my-project")
[ERROR ra_project_model] candidate: "/workspaces/my-project/rust/Cargo.toml", exists: true
```
## Edge Cases?
If you have multiple Cargo.toml files one level deeper AND not in the root, will get whatever comes first (order undefined), example:
```
crate1/
Cargo.toml
crate2/
Cargo.toml
... (no root Cargo.toml)
```
However this is quite unusual and wouldn't have worked before either. This is only resolvable via manually choosing.
Co-authored-by: nmio <kristo.koert@gmail.com>
E.g. for `&{ some_string() }` in a context where a `&str` is expected, we
reported a mismatch inside the block. The problem is that we're passing an
expectation of `str` down, but the expectation is more of a hint in this case.
There's a long comment in rustc about this, which I just copied.
Also, fix reported location for type mismatches in macros.
3366: Simpilfy original_range logic r=matklad a=edwin0cheng
This PR fixed another [bug](https://github.com/rust-analyzer/rust-analyzer/issues/3000#issuecomment-592474844) which incorrectly map the wrong range of `punct` in macro_call and simplify the logic a little bit by introducing an `ascend_call_token` function.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3359: Remove AnalysisHost::type_of r=matklad a=edwin0cheng
This PR remove ` AnalysisHost::type_of` (It is subsume by hover now) and use `Semantics::type_of_x` to infer the type inside `hover` directly.
And this also solved a bug : Right now hovering on a string literal inside a macro will show up a `&str` popup correctly. (Except if that involved builtin macro, e.g. `println`)
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3285: Handle trivia in Structural Search and Replace r=matklad a=adamrk
Addresses the second point of https://github.com/rust-analyzer/rust-analyzer/issues/3186.
Structural search and replace will now match code that has varies from the pattern in whitespace or comments.
One issue is that it's not clear where comments in the matched code should go in the replacement. With this change they're just tacked on at the end, which can cause some unexpected moving of comments (see the last test example).
Co-authored-by: adamrk <ark.email@gmail.com>
This introduces the new type -- Semantics.
Semantics maps SyntaxNodes to various semantic info, such as type,
name resolution or macro expansions.
To do so, Semantics maintains a HashMap which maps every node it saw
to the file from which the node originated. This is enough to get all
the necessary hir bits just from syntax.
3263: Implement unsizing coercions using Chalk r=matklad a=flodiebold
These are coercions like `&[T; n] -> &[T]`, which are handled by the `Unsize` and `CoerceUnsized` traits. The impls for `Unsize` are all built in to the compiler and require special handling, so we need to provide them to Chalk.
This adds the following `Unsize` impls:
- `Unsize<[T]> for [T; _]`
- `Unsize<dyn Trait> for T where T: Trait`
- `Unsize<dyn SuperTrait> for dyn SubTrait`
Hence we are still missing the 'unsizing the last field of a generic struct' case.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3260: Refactor how builtins are resolved r=matklad a=flodiebold
This fixes autocompletion suggesting e.g. `self::usize`. (I thought we had a bug for that, but I didn't find it.)
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
3262: Fix handling of const patterns r=matklad a=flodiebold
E.g. in `match x { None => ... }`, `None` is a path pattern (resolving to the
option variant), not a binding. To determine this, we need to try to resolve the
name during lowering. This isn't too hard since we already need to resolve names
for macro expansion anyway (though maybe a bit hacky).
Fixes#1618.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
E.g. in `match x { None => ... }`, `None` is a path pattern (resolving to the
option variant), not a binding. To determine this, we need to try to resolve the
name during lowering. This isn't too hard since we already need to resolve names
for macro expansion anyway (though maybe a bit hacky).
Fixes#1618.
3228: Use proper range for hover on macro arguments r=matklad a=edwin0cheng
This PR use `original_range` to remap the range of found syntax node in `hover` and thus it should return the proper text range now.
fixed#3000fixed#3135
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3026: ra_syntax: reshape SyntaxError for the sake of removing redundancy r=matklad a=Veetaha
Followup of #2911, also puts some crosses to the todo list of #223.
**AHTUNG!** A big part of the diff of this PR are test data files changes.
Simplified `SyntaxError` that was `SyntaxError { kind: { /* big enum */ }, location: Location }` to `SyntaxError(String, TextRange)`. I am not sure whether the tuple struct here is best fit, I am inclined to add names to the fields, because I already provide getters `SyntaxError::message()`, `SyntaxError::range()`.
I also removed `Location` altogether ...
This is currently WIP, because the following is not done:
- [ ] ~~Add tests to `test_data` dir for unescape errors *// I don't know where to put these errors in particular, because they are out of the scope of the lexer and parser. However, I have an idea in mind that we move all validators we have right now to parsing stage, but this is up to discussion...*~~ **[UPD]** I came to a conclusion that tree validation logic, which unescape errors are a part of, should be rethought of, we currently have no tests and no place to put tests for tree validations. So I'd like to extract potential redesign (maybe move of tree validation to ra_parser) and adding tests for this into a separate task.
Co-authored-by: Veetaha <gerzoh1@gmail.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
3099: Init implementation of structural search replace r=matklad a=mikhail-m1
next steps:
* ignore space and other minor difference
* add support to ra_cli
* call rust parser to check pattern
* documentation
original issue #2267
Co-authored-by: Mikhail Modin <mikhailm1@gmail.com>
3108: Magic Completion for `impl Trait for` Associated Items r=matklad a=kdelorey
# Summary
This PR adds a set of magic completions to auto complete associated trait items (functions/consts/types).
## Notes
Since the assist and completion share the same logic when figuring out the associated items that are missing, a shared utility was created in the `ra_assists::utils` module.
Resolves#1046
As this is my first PR to the rust-analyzer project, I'm new to the codebase, feedback welcomed!
Co-authored-by: Kevin DeLorey <2295721+kdelorey@users.noreply.github.com>
3153: When a single test is run, do not run others with overlapping names r=matklad a=SomeoneToIgnore
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
3179: Introduce AsMacroCall trait r=matklad a=edwin0cheng
This PR introduce `AsMacroCall` trait to help convert `ast::MacroCall` to `MacroCallId`. The main goal here is to centralize various conversions to single place and make implementing eager macro calls without further ado.
```rust
pub trait AsMacroCall {
fn as_call_id(
&self,
db: &(impl db::DefDatabase + AstDatabase),
resolver: impl Fn(path::ModPath) -> Option<MacroDefId>,
) -> Option<MacroCallId>;
}
```
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
3157: Extend analysis-stats a bit r=matklad a=flodiebold
This adds some tools helpful when debugging nondeterminism in analysis-stats:
- a `--randomize` option that analyses everything in random order
- a `-vv` option that prints even more detail
Also add a debug log if Chalk fuel is exhausted (which would be a source of
nondeterminism, but didn't happen in my tests).
I found one source of nondeterminism (rust-lang/chalk#331), but there are still
other cases remaining.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
This adds some tools helpful when debugging nondeterminism in analysis-stats:
- a `--randomize` option that analyses everything in random order
- a `-vv` option that prints even more detail
Also add a debug log if Chalk fuel is exhausted (which would be a source of
nondeterminism, but didn't happen in my tests).
I found one source of nondeterminism (rust-lang/chalk#331), but there are still
other cases remaining.
3147: Check that impl self type matches up with expected self type in path mode r=matklad a=flodiebold
Fixes#3144.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3062: Implement slice pattern AST > HIR lowering r=jplatte a=jplatte
WIP. The necessary changes for parsing are implemented, but actual inference is not yet. Just wanted to upload what I've got so far so it doesn't get duplicated :)
Will fix#3043
Co-authored-by: Jonas Platte <jplatte+git@posteo.de>
3050: Refactor type parameters, implement argument position impl trait r=matklad a=flodiebold
I wanted to implement APIT by lowering to type parameters because we need to do that anyway for correctness and don't need Chalk support for it; this grew into some more wide-ranging refactoring of how type parameters are handled 😅
- use Ty::Bound instead of Ty::Param to represent polymorphism, and explicitly
count binders. This gets us closer to Chalk's way of doing things, and means
that we now only use Param as a placeholder for an unknown type, e.g. within
a generic function. I.e. we're never using Param in a situation where we want
to substitute it, and the method to do that is gone; `subst` now always works
on bound variables. (This changes how the types of generic functions print;
previously, you'd get something like `fn identity<i32>(T) -> T`, but now we
display the substituted signature `fn identity<i32>(i32) -> i32`, which I think
makes more sense.)
- once we do this, it's more natural to represent `Param` by a globally unique
ID; the use of indices was mostly to make substituting easier. This also
means we fix the bug where `Param` loses its name when going through Chalk.
- I would actually like to rename `Param` to `Placeholder` to better reflect its use and
get closer to Chalk, but I'll leave that to a follow-up.
- introduce a context for type lowering, to allow lowering `impl Trait` to
different things depending on where we are. And since we have that, we can
also lower type parameters directly to variables instead of placeholders.
Also, we'll be able to use this later to collect diagnostics.
- implement argument position impl trait by lowering it to type parameters.
I've realized that this is necessary to correctly implement it; e.g. consider
`fn foo(impl Display) -> impl Something`. It's observable that the return
type of e.g. `foo(1u32)` unifies with itself, but doesn't unify with e.g.
`foo(1i32)`; so the return type needs to be parameterized by the argument
type.
This fixes a few bugs as well:
- type parameters 'losing' their name when they go through Chalk, as mentioned
above (i.e. getting `[missing name]` somewhere)
- impl trait not being considered as implementing the super traits (very
noticeable for the `db` in RA)
- the fact that argument impl trait was only turned into variables when the
function got called caused type mismatches when the function was used as a
value (fixes a few type mismatches in RA)
The one thing I'm not so happy with here is how we're lowering `impl Trait` types to variables; since `TypeRef`s don't have an identity currently, we just count how many of them we have seen while going through the function signature. That's quite fragile though, since we have to do it while desugaring generics and while lowering the type signature, and in the exact same order in both cases. We could consider either giving only `TypeRef::ImplTrait` a local id, or maybe just giving all `TypeRef`s an identity after all (we talked about this before)...
Follow-up tasks:
- handle return position impl trait; we basically need to create a variable and some trait obligations for that variable
- rename `Param` to `Placeholder`
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
3047: Update async unsafe fn ordering in parser r=matklad a=kiljacken
As of rust-lang/rust#61319 the correct order for functions that are both unsafe and async is: `async unsafe fn` and not `unsafe async fn`.
This commit updates the parser tests to reflect this, and corrects parsing behavior to accept the correct ordering.
Fixes#3025
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
3040: Rework value parameter parsing r=matklad a=tobz1000
Fixes#2847.
- `Fn__(...)` parameters with idents/patterns no longer parse
- Trait function parameters with arbitrary patterns parse
- Trait function parameters without idents/patterns no longer parse
- `fn(...)` parameters no longer parse with patterns other than a single ident
__Question__: The pre-existing test `param_list_opt_patterns` has been kept as-is, although the name no longer makes sense (it's testing `Fn__(...)` params, which aren't allowed patterns any more). What would be best to do about this?
Co-authored-by: Toby Dimmick <tobydimmick@pm.me>
As of rust-lang/rust#61319 the correct order for functions that are both
unsafe and async is: `async unsafe fn` and not `unsafe async fn`.
This commit updates the parser tests to reflect this, and corrects
parsing behavior to accept the correct ordering.
Fixes#3025
- `Fn__(...)` parameters with idents/patterns no longer parse
- Trait function parameters with arbitrary patterns parse
- Trait function parameters without idents/patterns no longer parse
- `fn(...)` parameters no longer parse with patterns other than a single ident
This intention is pretty slow for `impl Interator`, because it has a
ton of default methods which need to be substituted.
The proper fix here is to not compute the actual edit until the user
triggers the action, but that's awkward to do in the LSP right now, so
let's just put a profiling code for now.
2962: Differentiate underscore alias from named aliases r=matklad a=zombiefungus
pre for Fixing Issue 2736
edited to avoid autoclosing the issue
Co-authored-by: zombiefungus <divmermarlav@gmail.com>
2959: Rework how we send diagnostics to client r=matklad a=kiljacken
The previous way of sending from the thread pool suffered from stale diagnostics due to being canceled before we could clear the old ones.
The key change is moving to sending diagnostics from the main loop thread, but doing all the hard work in the thread pool. This should provide the best of both worlds, with little to no of the downsides.
This should hopefully fix a lot of issues, but we'll need testing in each individual issue to be sure.
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
The previous way of sending from the thread pool suffered from stale
diagnostics due to being canceled before we could clear the old ones.
The key change is moving to sending diagnostics from the main loop
thread, but doing all the hard work in the thread pool. This should
provide the best of both worlds, with little to no of the downsides.
This should hopefully fix a lot of issues, but we'll need testing in
each individual issue to be sure.
The extra allocation for message should not matter here at all, but
using a static string is just as ergonomic, if not more, and there's
no reason to write deliberately slow code
By default, `spawn` inherits stderr/stdout/stderr of the parent
process, and so, if child, for example does fcntl(O_NONBLOCK), weird
stuff happens to us.
Closes https://github.com/rust-analyzer/lsp-server/pull/10
2920: Better handle illformed node id from metadata r=matklad a=edwin0cheng
In some rare cases, deps node-id from cargo-metadata do not match its version-id, which cause a panic in `cargo-workspace.rs`. This PR try to ignore these ill-formed node id from `cargo-metadata`. An alternative is return `Err` in these cases but I think make it resilience is a better choice here.
Related #2767
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2895: Rewrite ra_prof's profile printing r=michalt a=michalt
This changes the way we print things to first construct a mapping from
events to the children and uses that mapping to actually print things.
It should not change the actual output that we produce.
The new approach two benefits:
* It avoids a potential quadratic behavior of the previous approach.
For instance, for a vector of N elements:
```
[Message{level: (N - 1)}, ..., Message{level: 1}, Message{level: 0}]
```
we would first do a linear scan to find entry with level 0, then
another scan to find one with level 1, etc.
* It makes it much easier to improve the output in the future, because
we now pre-compute the children for each entry and can easily take
that into account when printing.
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
Co-authored-by: Michal Terepeta <michal.terepeta@gmail.com>
We previously used serde's stream deserializer to read json blobs from
the cargo output. It has an issue though: If the deserializer encounters
invalid input, it gets stuck reporting the same error again and again
because it is unable to foward over the input until it reaches a new
valid object.
Reading a line at a time and manually deserializing fixes this issue,
because cargo makes sure to only outpu one json blob per line, so should
we encounter invalid input, we can just skip a line and continue.
The main reason this would happen is stray printf-debugging in
procedural macros, so we still report that an error occured, but we
handle it gracefully now.
Fixes#2935
2931: Added documentation to test_utils r=matklad a=Veetaha
Added some doc comments to test_utils functions while studying this crate. They should be all stable enough to document them.
Also some minor code relocation in `parse_fixture()` closer to its usage according to the advice of @matklad.
Co-authored-by: Veetaha <gerzoh1@gmail.com>
2924: Modify ordering of drops in check watcher to only ever have one cargo r=matklad a=kiljacken
Due to the way drops are ordered when assigning to a mutable variable we
were launching a new cargo sub-process before letting the old one quite.
By explicitly replacing the original watcher with a dummy first, we
ensure it is dropped and the process is completed, before we start the
new process.
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
Due to the way drops are ordered when assigning to a mutable variable we
were launching a new cargo sub-process before letting the old one quite.
By explicitly replacing the original watcher with a dummy first, we
ensure it is dropped and the process is completed, before we start the
new process.
2810: Improves reference search by StructLiteral r=mikhail-m1 a=mikhail-m1
Hey, I've made some changes to improve search for struct literals, now it works for `struct Foo<|> {`, `struct Foo <|>{`, `struct Foo<|>(`. Unfortunately tuple creation is represented as a call expression, so for tuples it works only is search is started in a tuple declaration. It leads to incorrect classification of function calls during search phase, but from user perspective it's not visible and works as expected. May be it worth to add a comment or rename it to remove this misleading classification. Issue #2549.
Co-authored-by: Mikhail Modin <mikhailm1@gmail.com>
2887: Initial auto import action implementation r=matklad a=SomeoneToIgnore
Closes https://github.com/rust-analyzer/rust-analyzer/issues/2180
Adds an auto import action implementation.
This implementation is not ideal and has a few limitations:
* The import search functionality should be moved into a separate crate accessible from ra_assists.
This requires a lot of changes and a preliminary design.
Currently the functionality is provided as a trait impl, more on that here: https://github.com/rust-analyzer/rust-analyzer/issues/2180#issuecomment-575690942
* Due to the design desicion from the previous item, no doctests are run for the new aciton (look for a new FIXME in the PR)
* For the same reason, I have to create the mock trait implementaion to test the assist
* Ideally, I think we should have this feature as a diagnostics (that detects an absense of an import) that has a corresponding quickfix action that gets evaluated on demand.
Curretly we perform the import search every time we resolve the import which looks suboptimal.
This requires `classify_name_ref` to be moved from ra_ide, so not done currently.
A few improvements to the imports mechanism to be considered later:
* Constants like `ra_syntax::SyntaxKind::NAME` are not imported, because they are not present in the database
* Method usages are not imported, they are found in the database, but `find_use_path` does not return any import paths for them
* Some import paths returned by the `find_use_path` method end up in `core::` or `alloc::` instead of `std:`, for example: `core::fmt::Debug` instead of `std::fmt::Debug`.
This is not an error techically, but still looks weird.
* No detection of cases where a trait should be imported in order to be able to call a method
* Improve `auto_import_text_edit` functionality: refactor it and move away from the place it is now, add better logic for merging the new import with already existing imports
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
2899: Provide more runners for potential tests r=matklad a=SomeoneToIgnore
Based on the https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Fwg-rls-2.2E0/topic/Runners.20for.20custom.20test.20annotations discussion.
Adds a test runner for every method that has an annotation that contains `test` word in it, allowing to run tests annotated with custom testing annotations such as `#[tokio::test]`, `#[test_case(...)]` and others at costs of potentially emitting some false-positives.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
@matklad mentioned this might be a good idea.
So the general idea is that we don't really need the lock, as we can
just clone the check watcher state when creating a snapshot. We can then
use `Arc::get_mut` to get mutable access to the state from `WorldState`
when needed.
Running with this it seems to improve responsiveness a bit while cargo
is running, but I have no hard numbers to prove it. In any case, a
serialization point less is always better when we're trying to be
responsive.
This changes the way we print things to first construct a mapping from
events to the children and uses that mapping to actually print things.
It should not change the actual output that we produce.
The new approach two benefits:
* It avoids a potential quadratic behavior of the previous approach.
For instance, for a vector of N elements:
```
[Message{level: (N - 1)}, ..., Message{level: 1}, Message{level: 0}]
```
we would first do a linear scan to find entry with level 0, then
another scan to find one with level 1, etc.
* It makes it much easier to improve the output in the future, because
we now pre-compute the children for each entry and can easily take
that into account when printing.
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
2877: "Insert explicit type " assist fix#2869, fix typo r=matklad a=TomasKralCZ
So this was quite straightforward. I basically looked at how the other assists work and tried doing something simillar. I also fixed a typo in the other assist.
Co-authored-by: TomasKralCZ <tomas@kral.hk>
Previously `ra_prof` wouldn't actually print the unaccounted time in
some cases.
We would print, for instance, this:
```
5ms - foo
2ms - bar
```
instead of:
```
5ms - foo
2ms - bar
3ms - ???
```
The fix is to properly handle the case when an entry has 0 children
instead of using the `last` variable.
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
2865: fix(mixed): fixed a couple of typos and added a todo r=kjeremy a=Veetaha
Fixed a couple of typos and added a todo while studying the codebase.
Co-authored-by: Veetaha <gerzoh1@gmail.com>
2827: Fix array element attribute position r=matklad a=edwin0cheng
This PR fixed a bug which an ATTR node insert in the wrong place in array element. ~~And introduce `precede_next` for allow outer attributes to insert into a parsed `expr`.~~
related #2783
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2837: Accidentally quadratic r=matklad a=matklad
Our syntax highlighting is accdentally quadratic. Current state of the PR fixes it in a pretty crude way, looks like for the proper fix we need to redo how source-analyzer works.
**NB:** don't be scared by diff stats, that's mostly a test-data file
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
2844: Use dummy value for line! and column! macro r=matklad a=edwin0cheng
Use dummy value `0` for line! and column! macro.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2834: refactor(ra_syntax.validation): removed code duplication from validate_literal() r=kiljacken a=Veetaha
Hi! This is my first ever contribution to this project.
I've taken some dirty job from issue #223
This is a simple atomic PR to remove code duplication according to FIXME comment in the function that is the main focus of the further development.
I just didn't want to mix refactoring with the implementation of new features...
I am not sure whether you prefer such atomic PRs here or you'd rather have a single PR that contains all atomic commits inside of it?
So if you want me to add all that validation in one PR I'll mark this one as WIP and update it when the work is finished, otherwise, I'll go with the option of creating separate PRs per each feature of validation of strings, numbers, and comments respectively.
### Comments about refactoring
Yeah, reducing the duplication is quite hard here, extracting into stateless functions could be another option but the number of their arguments would be very big and repeated across char and string implementations so that just writing their types and names would become cumbersome.
I tried the option of having everything captured implicitly in the closure but failed since rust doesn't have templated (or generic) closures as C++ does, this is needed because `unescape_byte*()` and `unescape_char|str()` have different return types...
Maybe I am missing something here? I may be wrong because I am not enough experienced in Rust...
Well, I am awaiting any kind of feedback!
Co-authored-by: Veetaha <gerzoh1@gmail.com>
2807: Use attr location for builtin derive in goto-implementation r=matklad a=edwin0cheng
This PR is use attribute location for builtin derive in `ImplBlock`'s NavigationTarget such that the goto-implementation will goto to a correct position.
Related to #2531
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2803: Fix various names, e.g. Iterator not resolving in core prelude r=matklad a=flodiebold
Basically, `Iterator` is re-exported via several steps, which happened to not be
resolved yet when we got to the prelude import, but since the name resolved to
the reexport from `core::iter` (just to no actual items), we gave up trying to
resolve it further.
Maybe part of the problem is that we can have
`PartialResolvedImport::Unresolved` or `PartialResolvedImport::Indeterminate`
with `None` in all namespaces, and handle them differently.
Fixes#2683.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
Basically, `Iterator` is re-exported via several steps, which happened to not be
resolved yet when we got to the prelude import, but since the name resolved to
the reexport from `core::iter` (just to no actual items), we gave up trying to
resolve it further.
Maybe part of the problem is that we can have
`PartialResolvedImport::Unresolved` or `PartialResolvedImport::Indeterminate`
with `None` in all namespaces, and handle them differently.
Fixes#2683.
2791: Slightly more robust cargo watcher root search r=kiljacken a=kiljacken
Fixes#2780 (hopefully).
Use the already painstakingly found `workspaces` instead of naively using `folder_roots` from editor.
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
2795: Use dummy value for macro file in bulitin macros r=matklad a=edwin0cheng
This PR skip the actual line and column computation for `MacroFile` and return a dummy value instead.
Related to #2794
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2790: Add test for macro expansion in various expressions r=edwin0cheng a=flodiebold
cc @edwin0cheng
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
2786: Proper handling local in hover r=flodiebold a=edwin0cheng
This PR implement back the `Local` hover information generation, which is fall back to a general case catch previously :
9a44f627be/crates/ra_ide/src/hover.rs (L173-L182)
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2772: Actually test references r=kjeremy a=kjeremy
This will be a little more work when `ReferenceSearchResults` change but I think it's easier to maintain in the end. It also follows a similar pattern to navigation targets and call hierarchy.
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
2771: Remove the Default impl for SourceRoot r=matklad a=michalt
Let's be always explicit whether we create a library (i.e., an immutable
dependency) or a local `SourceRoot`, since it can have a large impact on
the validation performance in salsa. (we found it the hard way recently,
where the `Default` instance made it quite tricky to spot a bug)
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
Co-authored-by: Michal Terepeta <michal.terepeta@gmail.com>
Let's be always explicit whether we create a library (i.e., an immutable
dependency) or a local `SourceRoot`, since it can have a large impact on
the validation performance in salsa. (we found it the hard way recently,
where the `Default` instance made it quite tricky to spot a bug)
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
When processing a change with added libraries, we used
`Default::default` for `SourceRoot` which sets `is_library` to false.
Since we use `is_library` to decide whether to use low or high
durability, I believe that this caused us to mark many library
dependencies as having low durability and thus increased the size of the
graph that salsa needed to verify on every change.
Based on my initial tests this speeds up the `CrateDefMapQuery` on
rust-analyzer from about ~64ms to ~14ms and reduces the number of
validations for the query from over 60k to about 7k.
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
2726: Improve profiling output when duration filter is specified r=matklad a=michalt
In particular:
- Use strict inequality for comparisons, since that's what the filter
syntax supports.
- Convert to millis for comparisons, since that's the unit used both
for the filter and when printing.
Now something like `RA_PROFILE='*>0'` will only print things that took
at least 1ms (when rounded to millis).
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
Co-authored-by: Michal Terepeta <michal.terepeta@gmail.com>
The `-` turned into a `+` during a refactoring.
The original issue was caused by `Read` resolving wrongly to a trait without
type parameters instead of a struct with one parameter; this only fixes the
crash, not the wrong resolution.
This change:
- introduces `compute_crate_def_map` query and renames
`CrateDefMap::crate_def_map_query` for consistency,
- annotates `crate_def_map` as `salsa::transparent` and adds a
top-level `crate_def_map` wrapper function around that starts the
profiler and immediately calls into `compute_crate_def_map` query.
This allows us to better understand where we spent the time, in
particular, how much is spent in the recomputaiton and how much in
salsa.
Example output (where we don't actually re-compute anything, but the
query still takes a non-trivial amount of time):
```
211ms - handle_inlay_hints
150ms - get_inlay_hints
150ms - SourceAnalyzer::new
65ms - def_with_body_from_child_node
65ms - analyze_container
65ms - analyze_container
65ms - Module::from_definition
65ms - Module::from_file
65ms - crate_def_map
1ms - parse_macro_query (6 calls)
0ms - raw_items_query (1 calls)
64ms - ???
```
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
In particular:
- Use strict inequality for comparisons, since that's what the filter
syntax supports.
- Convert to millis for comparisons, since that's the unit used both
for the filter and when printing.
Now something like `RA_PROFILE='*>0'` will only print things that took
at least 1ms (when rounded to millis).
Signed-off-by: Michal Terepeta <michal.terepeta@gmail.com>
2681: cargo-watcher: Resolve macro call site in more cases r=matklad a=kiljacken
This resolves the actual macro call site in a few more cases, f.x. when a macro invokes `compile_error!` (I'm looking at you `ra_hir_def::path::__path`).
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
2668: In-server cargo check watching r=matklad a=kiljacken
Opening a draft now so people can follow the progress, and comment if they spot something stupid.
Things that need doing:
- [x] Running cargo check on save
- [x] Pipe through configuration options from client
- [x] Tests for parsing behavior
- [x] Remove existing cargo watch support from VSCode extension
- [x] Progress notification in VSCode extension using LSP 3.15 `$/progress` notification
- [ ] ~~Rework ra-ide diagnostics to support secondary messages~~
- [ ] ~~Make cargo-check watcher use ra-ide diagnostics~~
~~I'd love some input on whether to try to keep the status bar progress thingy for VSCode? It will require some plumbing, and maintaining yet another rust-analyzer specific LSP notification, which I'm not sure we want to.~~
Fixes#1894
Co-authored-by: Emil Lauridsen <mine809@gmail.com>
2667: Visibility r=matklad a=flodiebold
This adds the infrastructure for handling visibility (for fields and methods, not in name resolution) in the HIR and code model, and as a first application hides struct fields from completions if they're not visible from the current module. (We might want to relax this again later, but I think it's ok for now?)
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
2657: Omit closure parameters in closure type display strings r=flodiebold a=SomeoneToIgnore
Part of https://github.com/rust-analyzer/rust-analyzer/issues/1946
I wonder, should we display the the closure trait (Fn/FnMut/FnOnce) in inlay hints instead of `|...|` at all?
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
2658: Only add features flags if non-empty r=matklad a=edwin0cheng
This prevent error when disabled `all-features` in a cargo workspace, because of `--features is not allowed in the root of a virtual workspace` when running `cargo metadata`.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2661: Implement infer await from async function r=flodiebold a=edwin0cheng
This PR is my attempt for trying to add support for infer `.await` expression from an `async` function, by desugaring its return type to `Impl Future<Output=RetType>`.
Note that I don't know it is supposed to desugaring it in that phase, if it is not suitable in current design, just feel free to reject it :)
r=@flodiebold
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
2636: Chalk update and refactoring r=flodiebold a=flodiebold
This updates the Chalk integration to https://github.com/rust-lang/chalk/pull/311, which will presumably get merged soon, and refactors it some more, most notably introducing our own `TypeFamily` instead of reusing `ChalkIr`. It's still mostly the same as `ChalkIr` though, except for using Salsa `InternId`s directly.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
It's not very different, except we can directly use Salsa IDs instead of casting
them. This means we need to refactor the handling of errors to get rid of
UNKNOWN_TRAIT though.
2641: Parse const generics r=matklad a=roblabla
Adds very primitive support for parsing const generics (`const IDENT: TY`) so that rust-analyzer stops complaining about the syntax being invalid.
Fixes#1574Fixes#2281
Co-authored-by: roblabla <unfiltered@roblab.la>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}