12 KiB
0. Concetti di base sugli LLM
Pretraining
Il pretraining è la fase fondamentale nello sviluppo di un modello di linguaggio di grandi dimensioni (LLM) in cui il modello è esposto a enormi e diversificati volumi di dati testuali. Durante questa fase, l'LLM apprende le strutture fondamentali, i modelli e le sfumature del linguaggio, inclusi grammatica, vocabolario, sintassi e relazioni contestuali. Elaborando questi dati estesi, il modello acquisisce una comprensione ampia del linguaggio e della conoscenza generale del mondo. Questa base completa consente all'LLM di generare testi coerenti e contestualmente rilevanti. Successivamente, questo modello pre-addestrato può subire un fine-tuning, in cui viene ulteriormente addestrato su dataset specializzati per adattare le sue capacità a compiti o domini specifici, migliorando le sue prestazioni e rilevanza nelle applicazioni mirate.
Componenti principali degli LLM
Di solito, un LLM è caratterizzato dalla configurazione utilizzata per addestrarlo. Questi sono i componenti comuni quando si addestra un LLM:
- Parametri: I parametri sono i pesi e i bias apprendibili nella rete neurale. Questi sono i numeri che il processo di addestramento regola per minimizzare la funzione di perdita e migliorare le prestazioni del modello sul compito. Gli LLM di solito utilizzano milioni di parametri.
- Lunghezza del contesto: Questa è la lunghezza massima di ciascuna frase utilizzata per il pre-addestramento dell'LLM.
- Dimensione dell'embedding: La dimensione del vettore utilizzato per rappresentare ciascun token o parola. Gli LLM di solito utilizzano miliardi di dimensioni.
- Dimensione nascosta: La dimensione degli strati nascosti nella rete neurale.
- Numero di strati (Profondità): Quanti strati ha il modello. Gli LLM di solito utilizzano decine di strati.
- Numero di teste di attenzione: Nei modelli transformer, questo è il numero di meccanismi di attenzione separati utilizzati in ciascun strato. Gli LLM di solito utilizzano decine di teste.
- Dropout: Il dropout è qualcosa come la percentuale di dati che viene rimossa (le probabilità diventano 0) durante l'addestramento utilizzato per prevenire l'overfitting. Gli LLM di solito utilizzano tra 0-20%.
Configurazione del modello GPT-2:
GPT_CONFIG_124M = {
"vocab_size": 50257, // Vocabulary size of the BPE tokenizer
"context_length": 1024, // Context length
"emb_dim": 768, // Embedding dimension
"n_heads": 12, // Number of attention heads
"n_layers": 12, // Number of layers
"drop_rate": 0.1, // Dropout rate: 10%
"qkv_bias": False // Query-Key-Value bias
}
Tensors in PyTorch
In PyTorch, un tensor è una struttura dati fondamentale che funge da array multidimensionale, generalizzando concetti come scalari, vettori e matrici a dimensioni potenzialmente superiori. I tensori sono il modo principale in cui i dati vengono rappresentati e manipolati in PyTorch, specialmente nel contesto del deep learning e delle reti neurali.
Concetto Matematico di Tensors
- Scalari: Tensors di rango 0, che rappresentano un singolo numero (zero-dimensionale). Come: 5
- Vettori: Tensors di rango 1, che rappresentano un array unidimensionale di numeri. Come: [5,1]
- Matrici: Tensors di rango 2, che rappresentano array bidimensionali con righe e colonne. Come: 1,3], [5,2
- Tensors di Rango Superiore: Tensors di rango 3 o superiore, che rappresentano dati in dimensioni superiori (ad es., tensori 3D per immagini a colori).
Tensors come Contenitori di Dati
Da una prospettiva computazionale, i tensori agiscono come contenitori per dati multidimensionali, dove ogni dimensione può rappresentare diverse caratteristiche o aspetti dei dati. Questo rende i tensori altamente adatti per gestire set di dati complessi in compiti di machine learning.
Tensors di PyTorch vs. Array NumPy
Sebbene i tensori di PyTorch siano simili agli array NumPy nella loro capacità di memorizzare e manipolare dati numerici, offrono funzionalità aggiuntive cruciali per il deep learning:
- Differenziazione Automatica: I tensori di PyTorch supportano il calcolo automatico dei gradienti (autograd), il che semplifica il processo di calcolo delle derivate necessarie per l'addestramento delle reti neurali.
- Accelerazione GPU: I tensori in PyTorch possono essere spostati e calcolati su GPU, accelerando significativamente i calcoli su larga scala.
Creazione di Tensors in PyTorch
Puoi creare tensori utilizzando la funzione torch.tensor:
pythonCopy codeimport torch
# Scalar (0D tensor)
tensor0d = torch.tensor(1)
# Vector (1D tensor)
tensor1d = torch.tensor([1, 2, 3])
# Matrix (2D tensor)
tensor2d = torch.tensor([[1, 2],
[3, 4]])
# 3D Tensor
tensor3d = torch.tensor([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
Tipi di Dati dei Tensor
I tensori PyTorch possono memorizzare dati di vari tipi, come interi e numeri in virgola mobile.
Puoi controllare il tipo di dato di un tensore utilizzando l'attributo .dtype:
tensor1d = torch.tensor([1, 2, 3])
print(tensor1d.dtype) # Output: torch.int64
- I tensori creati da interi Python sono di tipo
torch.int64. - I tensori creati da float Python sono di tipo
torch.float32.
Per cambiare il tipo di dato di un tensore, usa il metodo .to():
float_tensor = tensor1d.to(torch.float32)
print(float_tensor.dtype) # Output: torch.float32
Operazioni Tensoriali Comuni
PyTorch fornisce una varietà di operazioni per manipolare i tensori:
- Accesso alla Forma: Usa
.shapeper ottenere le dimensioni di un tensore.
print(tensor2d.shape) # Output: torch.Size([2, 2])
- Ristrutturazione dei Tensori: Usa
.reshape()o.view()per cambiare la forma.
reshaped = tensor2d.reshape(4, 1)
- Trasposizione dei Tensori: Usa
.Tper trasporre un tensore 2D.
transposed = tensor2d.T
- Moltiplicazione Matriciale: Usa
.matmul()o l'operatore@.
result = tensor2d @ tensor2d.T
Importanza nel Deep Learning
I tensori sono essenziali in PyTorch per costruire e addestrare reti neurali:
- Memorizzano i dati di input, i pesi e i bias.
- Facilitano le operazioni necessarie per i passaggi in avanti e indietro negli algoritmi di addestramento.
- Con autograd, i tensori abilitano il calcolo automatico dei gradienti, semplificando il processo di ottimizzazione.
Differenziazione Automatica
La differenziazione automatica (AD) è una tecnica computazionale utilizzata per valutare le derivate (gradienti) delle funzioni in modo efficiente e accurato. Nel contesto delle reti neurali, l'AD consente il calcolo dei gradienti necessari per algoritmi di ottimizzazione come il gradiente discendente. PyTorch fornisce un motore di differenziazione automatica chiamato autograd che semplifica questo processo.
Spiegazione Matematica della Differenziazione Automatica
1. La Regola della Catena
Al centro della differenziazione automatica c'è la regola della catena del calcolo. La regola della catena afferma che se hai una composizione di funzioni, la derivata della funzione composita è il prodotto delle derivate delle funzioni composte.
Matematicamente, se y=f(u) e u=g(x), allora la derivata di y rispetto a x è:
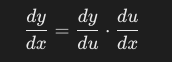
2. Grafo Computazionale
Nell'AD, i calcoli sono rappresentati come nodi in un grafo computazionale, dove ogni nodo corrisponde a un'operazione o a una variabile. Attraversando questo grafo, possiamo calcolare le derivate in modo efficiente.
- Esempio
Consideriamo una funzione semplice:

Dove:
σ(z)è la funzione sigmoide.y=1.0è l'etichetta target.Lè la perdita.
Vogliamo calcolare il gradiente della perdita L rispetto al peso w e al bias b.
4. Calcolo Manuale dei Gradienti

5. Calcolo Numerico

Implementazione della Differenziazione Automatica in PyTorch
Ora, vediamo come PyTorch automatizza questo processo.
pythonCopy codeimport torch
import torch.nn.functional as F
# Define input and target
x = torch.tensor([1.1])
y = torch.tensor([1.0])
# Initialize weights with requires_grad=True to track computations
w = torch.tensor([2.2], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
# Forward pass
z = x * w + b
a = torch.sigmoid(z)
loss = F.binary_cross_entropy(a, y)
# Backward pass
loss.backward()
# Gradients
print("Gradient w.r.t w:", w.grad)
print("Gradient w.r.t b:", b.grad)
Output:
cssCopy codeGradient w.r.t w: tensor([-0.0898])
Gradient w.r.t b: tensor([-0.0817])
Backpropagation in Bigger Neural Networks
1.Extending to Multilayer Networks
In reti neurali più grandi con più strati, il processo di calcolo dei gradienti diventa più complesso a causa dell'aumento del numero di parametri e operazioni. Tuttavia, i principi fondamentali rimangono gli stessi:
- Forward Pass: Calcola l'output della rete passando gli input attraverso ciascun strato.
- Compute Loss: Valuta la funzione di perdita utilizzando l'output della rete e le etichette target.
- Backward Pass (Backpropagation): Calcola i gradienti della perdita rispetto a ciascun parametro nella rete applicando la regola della catena in modo ricorsivo dallo strato di output fino allo strato di input.
2. Backpropagation Algorithm
- Step 1: Inizializza i parametri della rete (pesi e bias).
- Step 2: Per ogni esempio di addestramento, esegui un forward pass per calcolare gli output.
- Step 3: Calcola la perdita.
- Step 4: Calcola i gradienti della perdita rispetto a ciascun parametro utilizzando la regola della catena.
- Step 5: Aggiorna i parametri utilizzando un algoritmo di ottimizzazione (ad es., discesa del gradiente).
3. Mathematical Representation
Considera una semplice rete neurale con un livello nascosto:

4. PyTorch Implementation
PyTorch semplifica questo processo con il suo motore autograd.
import torch
import torch.nn as nn
import torch.optim as optim
# Define a simple neural network
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 5) # Input layer to hidden layer
self.relu = nn.ReLU()
self.fc2 = nn.Linear(5, 1) # Hidden layer to output layer
self.sigmoid = nn.Sigmoid()
def forward(self, x):
h = self.relu(self.fc1(x))
y_hat = self.sigmoid(self.fc2(h))
return y_hat
# Instantiate the network
net = SimpleNet()
# Define loss function and optimizer
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
# Sample data
inputs = torch.randn(1, 10)
labels = torch.tensor([1.0])
# Training loop
optimizer.zero_grad() # Clear gradients
outputs = net(inputs) # Forward pass
loss = criterion(outputs, labels) # Compute loss
loss.backward() # Backward pass (compute gradients)
optimizer.step() # Update parameters
# Accessing gradients
for name, param in net.named_parameters():
if param.requires_grad:
print(f"Gradient of {name}: {param.grad}")
In questo codice:
- Forward Pass: Calcola le uscite della rete.
- Backward Pass:
loss.backward()calcola i gradienti della perdita rispetto a tutti i parametri. - Parameter Update:
optimizer.step()aggiorna i parametri in base ai gradienti calcolati.
5. Comprendere il Backward Pass
Durante il backward pass:
- PyTorch attraversa il grafo computazionale in ordine inverso.
- Per ogni operazione, applica la regola della catena per calcolare i gradienti.
- I gradienti vengono accumulati nell'attributo
.graddi ciascun tensore parametro.
6. Vantaggi della Differenziazione Automatica
- Efficienza: Evita calcoli ridondanti riutilizzando risultati intermedi.
- Precisione: Fornisce derivate esatte fino alla precisione della macchina.
- Facilità d'uso: Elimina il calcolo manuale delle derivate.