mirror of
https://github.com/bevyengine/bevy
synced 2025-01-13 05:38:54 +00:00
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
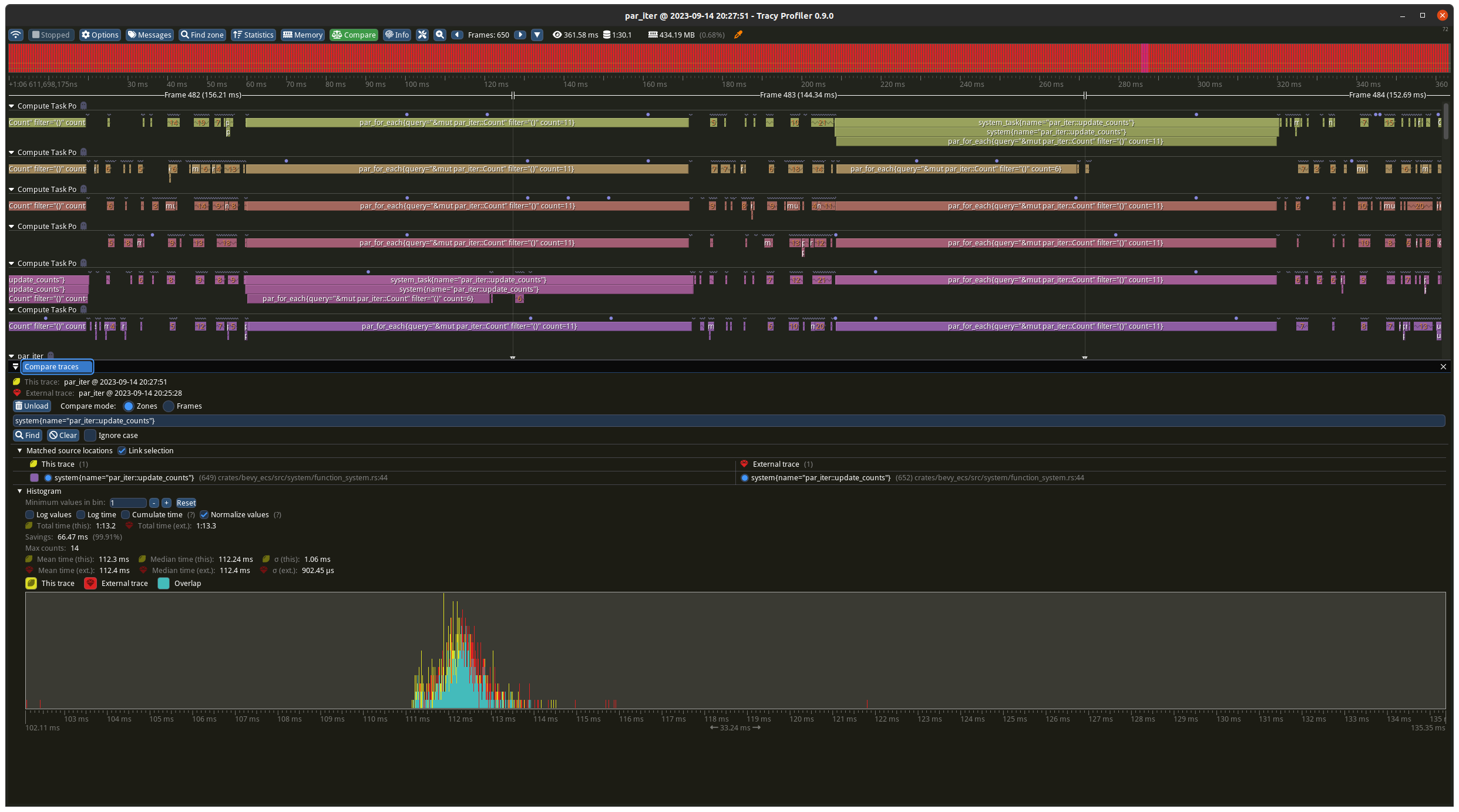
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
|
||
|---|---|---|
| .. | ||
| bevy_a11y | ||
| bevy_animation | ||
| bevy_app | ||
| bevy_asset | ||
| bevy_audio | ||
| bevy_core | ||
| bevy_core_pipeline | ||
| bevy_derive | ||
| bevy_diagnostic | ||
| bevy_dylib | ||
| bevy_dynamic_plugin | ||
| bevy_ecs | ||
| bevy_ecs_compile_fail_tests | ||
| bevy_encase_derive | ||
| bevy_gilrs | ||
| bevy_gizmos | ||
| bevy_gltf | ||
| bevy_hierarchy | ||
| bevy_input | ||
| bevy_internal | ||
| bevy_log | ||
| bevy_macro_utils | ||
| bevy_macros_compile_fail_tests | ||
| bevy_math | ||
| bevy_mikktspace | ||
| bevy_pbr | ||
| bevy_ptr | ||
| bevy_reflect | ||
| bevy_reflect_compile_fail_tests | ||
| bevy_render | ||
| bevy_scene | ||
| bevy_sprite | ||
| bevy_tasks | ||
| bevy_text | ||
| bevy_time | ||
| bevy_transform | ||
| bevy_ui | ||
| bevy_utils | ||
| bevy_window | ||
| bevy_winit | ||