CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Remove need to call `.get()` on two ticks to compare them for
equality.
## Solution
- Derive `Eq` and `PartialEq`.
---
## Changelog
> `Tick` now implements `Eq` and `PartialEq`
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title. This is necessary in order to update
[`bevy-trait-query`](https://crates.io/crates/bevy-trait-query) to Bevy
0.11.
---
## Changelog
Added the unsafe function `UnsafeWorldCell::storages`, which provides
unchecked access to the internal data stores of a `World`.
# Objective
`World::entity`, `World::entity_mut` and `Commands::entity` should be
marked with `track_caller` to display where (in user code) the call with
the invalid `Entity` was made. `Commands::entity` already has the
attibute, but it does nothing due to the call to `unwrap_or_else`.
## Solution
- Apply the `track_caller` attribute to the `World::entity_mut` and
`World::entity`.
- Remove the call to `unwrap_or_else` which makes the `track_caller`
attribute useless (because `unwrap_or_else` is not `track_caller`
itself). The avoid eager evaluation of the panicking branch it is never
inlined.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
Partially address #5504. Fix#4278. Provide "whole entity" access in
queries. This can be useful when you don't know at compile time what
you're accessing (i.e. reflection via `ReflectComponent`).
## Solution
Implement `WorldQuery` for `EntityRef`.
- This provides read-only access to the entire entity, and supports
anything that `EntityRef` can normally do.
- It matches all archetypes and tables and will densely iterate when
possible.
- It marks all of the ArchetypeComponentIds of a matched archetype as
read.
- Adding it to a query will cause it to panic if used in conjunction
with any other mutable access.
- Expanded the docs on Query to advertise this feature.
- Added tests to ensure the panics were working as intended.
- Added `EntityRef` to the ECS prelude.
To make this safe, `EntityRef::world` was removed as it gave potential
`UnsafeCell`-like access to other parts of the `World` including aliased
mutable access to the components it would otherwise read safely.
## Performance
Not great beyond the additional parallelization opportunity over
exclusive systems. The `EntityRef` is fetched from `Entities` like any
other call to `World::entity`, which can be very random access heavy.
This could be simplified if `ArchetypeRow` is available in
`WorldQuery::fetch`'s arguments, but that's likely not something we
should optimize for.
## Future work
An equivalent API where it gives mutable access to all components on a
entity can be done with a scoped version of `EntityMut` where it does
not provide `&mut World` access nor allow for structural changes to the
entity is feasible as well. This could be done as a safe alternative to
exclusive system when structural mutation isn't required or the target
set of entities is scoped.
---
## Changelog
Added: `Access::has_any_write`
Added: `EntityRef` now implements `WorldQuery`. Allows read-only access
to the entire entity, incompatible with any other mutable access, can be
mixed with `With`/`Without` filters for more targeted use.
Added: `EntityRef` to `bevy::ecs::prelude`.
Removed: `EntityRef::world`
## Migration Guide
TODO
---------
Co-authored-by: Carter Weinberg <weinbergcarter@gmail.com>
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Use `AppTypeRegistry` on API defined in `bevy_ecs`
(https://github.com/bevyengine/bevy/pull/8895#discussion_r1234748418)
A lot of the API on `Reflect` depends on a registry. When it comes to
the ECS. We should use `AppTypeRegistry` in the general case.
This is however impossible in `bevy_ecs`, since `AppTypeRegistry` is
defined in `bevy_app`.
## Solution
- Move `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
- Still add the resource in the `App` plugin, since bevy_ecs itself
doesn't know of plugins
Note that `bevy_ecs` is a dependency of `bevy_app`, so nothing
revolutionary happens.
## Alternative
- Define the API as a trait in `bevy_app` over `bevy_ecs`. (though this
prevents us from using bevy_ecs internals)
- Do not rely on `AppTypeRegistry` for the API in question, requring
users to extract themselves the resource and pass it to the API methods.
---
## Changelog
- Moved `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
## Migration Guide
- If you were **not** using a `prelude::*` to import `AppTypeRegistry`,
you should update your imports:
```diff
- use bevy::app::AppTypeRegistry;
+ use bevy::ecs::reflect::AppTypeRegistry
```
# Objective
`WorldQuery::Fetch` is a type used to optimize the implementation of
queries. These types are hidden and not intended to be outside of the
engine, so there is no need to provide type aliases to make it easier to
refer to them. If a user absolutely needs to refer to one of these
types, they can always just refer to the associated type directly.
## Solution
Deprecate these type aliases.
---
## Changelog
- Deprecated the type aliases `QueryFetch` and `ROQueryFetch`.
## Migration Guide
The type aliases `bevy_ecs::query::QueryFetch` and `ROQueryFetch` have
been deprecated. If you need to refer to a `WorldQuery` struct's fetch
type, refer to the associated type defined on `WorldQuery` directly:
```rust
// Before:
type MyFetch<'w> = QueryFetch<'w, MyQuery>;
type MyFetchReadOnly<'w> = ROQueryFetch<'w, MyQuery>;
// After:
type MyFetch<'w> = <MyQuery as WorldQuery>::Fetch;
type MyFetchReadOnly<'w> = <<MyQuery as WorldQuery>::ReadOnly as WorldQuery>::Fetch;
```
Repetitively fetching ReflectResource and ReflectComponent from the
TypeRegistry is costly.
We want to access the underlying `fn`s. to do so, we expose the
`ReflectResourceFns` and `ReflectComponentFns` stored in ReflectResource
and ReflectComponent.
---
## Changelog
- Add the `fn_pointers` methods to `ReflectResource` and
`ReflectComponent` returning the underlying `ReflectResourceFns` and
`ReflectComponentFns`
# Objective
- Fixes#7811
## Solution
- I added `Has<T>` (and `HasFetch<T>` ) and implemented `WorldQuery`,
`ReadonlyWorldQuery`, and `ArchetypeFilter` it
- I also added documentation with an example and a unit test
I believe I've done everything right but this is my first contribution
and I'm not an ECS expert so someone who is should probably check my
implementation. I based it on what `Or<With<T>,>`, would do. The only
difference is that `Has` does not update component access - adding `Has`
to a query should never affect whether or not it is disjoint with
another query *I think*.
---
## Changelog
## Added
- Added `Has<T>` WorldQuery to find out whether or not an entity has a
particular component.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Cleanup the `reflect.rs` file in `bevy_ecs`, it's very large and can
get difficult to navigate
## Solution
- Split the file into 3 modules, re-export the types in the
`reflect/mod.rs` to keep a perfectly identical API.
- Add **internal** architecture doc explaining how `ReflectComponent`
works. Note that this doc is internal only, since `component.rs` is not
exposed publicly.
### Tips to reviewers
To review this change properly, you need to compare it to the previous
version of `reflect.rs`. The diff from this PR does not help at all!
What you will need to do is compare `reflect.rs` individually with each
newly created file.
Here is how I did it:
- Adding my fork as remote `git remote add nicopap
https://github.com/nicopap/bevy.git`
- Checkout out the branch `git checkout nicopap/split_ecs_reflect`
- Checkout the old `reflect.rs` by running `git checkout HEAD~1 --
crates/bevy_ecs/src/reflect.rs`
- Compare the old with the new with `git diff --no-index
crates/bevy_ecs/src/reflect.rs crates/bevy_ecs/src/reflect/component.rs`
You could also concatenate everything into a single file and compare
against it:
- `cat
crates/bevy_ecs/src/reflect/{component,resource,map_entities,mod}.rs >
new_reflect.rs`
- `git diff --no-index crates/bevy_ecs/src/reflect.rs new_reflect.rs`
# Objective
Resolves#7558.
Systems that are known to never modify the world implement the trait
`ReadOnlySystem`. This is a perfect place to add a safe API for running
a system with a shared reference to a World.
---
## Changelog
- Added the trait method `ReadOnlySystem::run_readonly`, which allows a
system to be run using `&World`.
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
`ComponentIdFor` is a type that gives you access to a component's
`ComponentId` in a system. It is currently awkward to use, since it must
be wrapped in a `Local<>` to be used.
## Solution
Make `ComponentIdFor` a proper SystemParam.
---
## Changelog
- Refactored the type `ComponentIdFor` in order to simplify how it is
used.
## Migration Guide
The type `ComponentIdFor<T>` now implements `SystemParam` instead of
`FromWorld` -- this means it should be used as the parameter for a
system directly instead of being used in a `Local`.
```rust
// Before:
fn my_system(
component_id: Local<ComponentIdFor<MyComponent>>,
) {
let component_id = **component_id;
}
// After:
fn my_system(
component_id: ComponentIdFor<MyComponent>,
) {
let component_id = component_id.get();
}
```
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
The method `UnsafeWorldCell::read_change_tick` was renamed in #8588, but
I forgot to update a usage of this method in a doctest.
## Solution
Update the method call.
# Objective
To mirror the `Ref` added as `WorldQuery`, and the `Mut` in
`EntityMut::get_mut`, we add `EntityRef::get_ref`, which retrieves `T`
with tick information, but *immutably*.
## Solution
- Add the method in question, also add it to`UnsafeEntityCell` since
this seems to be the best way of getting that information.
Also update/add safety comments to neighboring code.
---
## Changelog
- Add `EntityRef::get_ref` to get an `Option<Ref<T>>` from `EntityRef`
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The method `QueryState::par_iter` does not currently force the query to
be read-only. This means you can unsoundly mutate a world through an
immutable reference in safe code.
```rust
fn bad_system(world: &World, mut query: Local<QueryState<&mut T>>) {
query.par_iter(world).for_each_mut(|mut x| *x = unsoundness);
}
```
## Solution
Use read-only versions of the `WorldQuery` types.
---
## Migration Guide
The function `QueryState::par_iter` now forces any world accesses to be
read-only, similar to how `QueryState::iter` works. Any code that
previously mutated the world using this method was *unsound*. If you
need to mutate the world, use `par_iter_mut` instead.
# Objective
Make a combined system cloneable if both systems are cloneable on their
own. This is necessary for using chained conditions (e.g
`cond1.and_then(cond2)`) with `distributive_run_if()`.
## Solution
Implement `Clone` for `CombinatorSystem<Func, A, B>` where `A, B:
Clone`.
# Objective
EntityRef::get_change_ticks mentions that ComponentTicks is useful to
create change detection for your own runtime.
However, ComponentTicks doesn't even expose enough data to create
something that implements DetectChanges. Specifically, we need to be
able to extract the last change tick.
## Solution
We add a method to get the last change tick. We also add a method to get
the added tick.
## Changelog
- Add `last_changed_tick` and `added_tick` to `ComponentTicks`
# Objective
- Fixes#8811 .
## Solution
- Rename "write" method to "apply" in Command trait definition.
- Rename other implementations of command trait throughout bevy's code
base.
---
## Changelog
- Changed: `Command::write` has been changed to `Command::apply`
- Changed: `EntityCommand::write` has been changed to
`EntityCommand::apply`
## Migration Guide
- `Command::write` implementations need to be changed to implement
`Command::apply` instead. This is a mere name change, with no further
actions needed.
- `EntityCommand::write` implementations need to be changed to implement
`EntityCommand::apply` instead. This is a mere name change, with no
further actions needed.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- I can't map unsized type using `Ref::map` (for example `dyn Reflect`)
## Solution
- Allow unsized types (this is possible because `Ref` stores a reference
to `T`)
# Objective
`QueryState` exposes a `get_manual` and `iter_manual` method. However,
there is now `iter_many_manual`.
`iter_many_manual` is useful when you have a `&World` (eg: the `world`
in a `Scene`) and want to run a query several times on it (eg:
iteratively navigate a hierarchy by calling `iter_many` on `Children`
component).
`iter_many`'s need for a `&mut World` makes the API much less flexible.
The exclusive access pattern requires doing some very funky dance and
excludes a category of algorithms for hierarchy traversal.
## Solution
- Add a `iter_many_manual` method to `QueryState`
### Alternative
My current workaround is to use `get_manual`. However, this doesn't
benefit from the optimizations on `QueryManyIter`.
---
## Changelog
- Add a `iter_many_manual` method to `QueryState`
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
`Ref` is a useful way of accessing change detection data.
However, unlike `Mut`, it doesn't expose a constructor or even a way to
go from `Ref<A>` to `Ref<B>`.
Such methods could be useful, for example, to 3rd party crates that want
to expose change detection information in a clean way.
My use case is to map a `Ref<T>` into a `Ref<dyn Reflect>`, and keep
change detection info to avoid running expansive routines.
## Solution
We add the `new` and `map` methods. Since similar methods exist on `Mut`
where they are much more footgunny to use, I judged that it was
acceptable to create such methods.
## Workaround
Currently, it's not possible to create/project `Ref`s. One can define
their own `Ref` and implement `ChangeDetection` on it. One would then
use `ChangeTrackers` to populate the custom `Ref` with tick data.
---
## Changelog
- Added the `Ref::map` and `Ref::new` methods for more ergonomic `Ref`s
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
Be consistent with `Resource`s and `Components` and have `Event` types
be more self-documenting.
Although not susceptible to accidentally using a function instead of a
value due to `Event`s only being initialized by their type, much of the
same reasoning for removing the blanket impl on `Resource` also applies
here.
* Not immediately obvious if a type is intended to be an event
* Prevent invisible conflicts if the same third-party or primitive types
are used as events
* Allows for further extensions (e.g. opt-in warning for missed events)
## Solution
Remove the blanket impl for the `Event` trait. Add a derive macro for
it.
---
## Changelog
- `Event` is no longer implemented for all applicable types. Add the
`#[derive(Event)]` macro for events.
## Migration Guide
* Add the `#[derive(Event)]` macro for events. Third-party types used as
events should be wrapped in a newtype.
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
- `apply_system_buffers` is an unhelpful name: it introduces a new
internal-only concept
- this is particularly rough for beginners as reasoning about how
commands work is a critical stumbling block
## Solution
- rename `apply_system_buffers` to the more descriptive `apply_deferred`
- rename related fields, arguments and methods in the internals fo
bevy_ecs for consistency
- update the docs
## Changelog
`apply_system_buffers` has been renamed to `apply_deferred`, to more
clearly communicate its intent and relation to `Deferred` system
parameters like `Commands`.
## Migration Guide
- `apply_system_buffers` has been renamed to `apply_deferred`
- the `apply_system_buffers` method on the `System` trait has been
renamed to `apply_deferred`
- the `is_apply_system_buffers` function has been replaced by
`is_apply_deferred`
- `Executor::set_apply_final_buffers` is now
`Executor::set_apply_final_deferred`
- `Schedule::apply_system_buffers` is now `Schedule::apply_deferred`
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
- Supress false positive `redundant_clone` lints.
- Supress inactionable `result_large_err` lint.
Most of the size(50 out of 68 bytes) is coming from
`naga::WithSpan<naga::valid::ValidationError>`
# Objective
The `Condition` trait is only implemented for systems and system
functions that take no input. This can make it awkward to write
conditions that are intended to be used with system piping.
## Solution
Add an `In` generic to the trait. It defaults to `()`.
---
## Changelog
- Made the `Condition` trait generic over system inputs.
# Objective
Several of our built-in `Command` types are too public:
- `GetOrSpawn` is public, even though it only makes sense to call it
from within `Commands::get_or_spawn`.
- `Remove` and `RemoveResource` contain public `PhantomData` marker
fields.
## Solution
Remove `GetOrSpawn` and use an anonymous command. Make the marker fields
private.
---
## Migration Guide
The `Command` types `Remove` and `RemoveResource` may no longer be
constructed manually.
```rust
// Before:
commands.add(Remove::<T> {
entity: id,
phantom: PhantomData,
});
// After:
commands.add(Remove::<T>::new(id));
// Before:
commands.add(RemoveResource::<T> { phantom: PhantomData });
// After:
commands.add(RemoveResource::<T>::new());
```
The command type `GetOrSpawn` has been removed. It was not possible to
use this type outside of `bevy_ecs`.
# Objective
Add documentation to `Query` and `QueryState` errors in bevy_ecs
(`QuerySingleError`, `QueryEntityError`, `QueryComponentError`)
## Solution
- Change display message for `QueryEntityError::QueryDoesNotMatch`: this
error can also happen when the entity has a component which is filtered
out (with `Without<C>`)
- Fix wrong reference in the documentation of `Query::get_component` and
`Query::get_component_mut` from `QueryEntityError` to
`QueryComponentError`
- Complete the documentation of the three error enum variants.
- Add examples for `QueryComponentError::MissingReadAccess` and
`QueryComponentError::MissingWriteAccess`
- Add reference to `QueryState` in `QueryEntityError`'s documentation.
---
## Migration Guide
Expect `QueryEntityError::QueryDoesNotMatch`'s display message to
change? Not sure that counts.
---------
Co-authored-by: harudagondi <giogdeasis@gmail.com>
# Objective
Fix#7833.
Safety comments in the multi-threaded executor don't really talk about
system world accesses, which makes it unclear if the code is actually
valid.
## Solution
Update the `System` trait to use `UnsafeWorldCell`. This type's API is
written in a way that makes it much easier to cleanly maintain safety
invariants. Use this type throughout the multi-threaded executor, with a
liberal use of safety comments.
---
## Migration Guide
The `System` trait now uses `UnsafeWorldCell` instead of `&World`. This
type provides a robust API for interior mutable world access.
- The method `run_unsafe` uses this type to manage world mutations
across multiple threads.
- The method `update_archetype_component_access` uses this type to
ensure that only world metadata can be used.
```rust
let mut system = IntoSystem::into_system(my_system);
system.initialize(&mut world);
// Before:
system.update_archetype_component_access(&world);
unsafe { system.run_unsafe(&world) }
// After:
system.update_archetype_component_access(world.as_unsafe_world_cell_readonly());
unsafe { system.run_unsafe(world.as_unsafe_world_cell()) }
```
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow for directly call methods on states without first calling
`state.get().my_method()`
## Solution
- Implement `Deref` for `State<S>` with `Target = S`
---
*I did not implement `DerefMut` because states hold no data and should
only be changed via `NextState::set()`*
# Objective
This method has no documentation and it's extremely unclear what it
does, or what the returned tick represents.
## Solution
Write documentation.
# Objective
The unit test `chang_tick_wraparound` is meant to ensure that change
ticks correctly deal with wrapping by setting the world's
`last_change_tick` to `u32::MAX`. However, since systems don't use* the
value of `World::last_change_tick`, this test doesn't actually involve
any wrapping behavior.
*exclusive systems do use `World::last_change_tick`; however it gets
overwritten by the system's own last tick in `System::run`.
## Solution
Use `QueryState` instead of systems in the unit test. This approach
actually uses `World::last_change_tick`, so it properly tests that
change ticks deal with wrapping correctly.
# Objective
`ScheduleGraph` currently stores run conditions in a
`Option<Vec<BoxedCondition>>`. The `Option` is unnecessary, since we can
just use an empty vector instead of `None`.
# Objective
The method `UnsafeWorldCell::world_mut` is a special case, since its
safety contract is more difficult to satisfy than the other methods on
`UnsafeWorldCell`. Rewrite its documentation to be specific about when
it can and cannot be used. Provide examples and emphasize that it is
unsound to call in most cases.
# Objective
The method `UnsafeWorldCell::read_change_tick` is longer than it needs
to be. `World` only has a method called this because it has two methods
for getting a change tick: one that takes `&self` and one that takes
`&mut self`. Since this distinction is not applicable to
`UnsafeWorldCell`, we should just call this method `change_tick`.
## Solution
Deprecate the current method and add a new one called `change_tick`.
---
## Changelog
- Renamed `UnsafeWorldCell::read_change_tick` to `change_tick`.
## Migration Guide
The `UnsafeWorldCell` method `read_change_tick` has been renamed to
`change_tick`.
# Objective
Fixes#8528
## Solution
Manually implement `PartialEq`, `Eq`, `PartialOrd`, `Ord`, and `Hash`
for `bevy_ecs::event::EventId`. These new implementations do not rely on
the `Event` implementing the same traits allowing `EventId` to be used
in more cases.
# Objective
After fixing dynamic scene to only map specific entities, we want
map_entities to default to the less error prone behavior and have the
previous behavior renamed to "map_all_entities." As this is a breaking
change, it could not be pushed out with the bug fix.
## Solution
Simple rename and refactor.
## Changelog
### Changed
- `map_entities` now accepts a list of entities to apply to, with
`map_all_entities` retaining previous behavior of applying to all
entities in the map.
## Migration Guide
- In `bevy_ecs`, `ReflectMapEntities::map_entites` now requires an
additional `entities` parameter to specify which entities it applies to.
To keep the old behavior, use the new
`ReflectMapEntities::map_all_entities`, but consider if passing the
entities in specifically might be better for your use case to avoid
bugs.
# Objective
- Handle dangling entity references inside scenes
- Handle references to entities with generation > 0 inside scenes
- Fix a latent bug in `Parent`'s `MapEntities` implementation, which
would, if the parent was outside the scene, cause the scene to be loaded
into the new world with a parent reference potentially pointing to some
random entity in that new world.
- Fixes#4793 and addresses #7235
## Solution
- DynamicScenes now identify entities with a `Entity` instead of a u32,
therefore including generation
- `World` exposes a new `reserve_generations` function that despawns an
entity and advances its generation by some extra amount.
- `MapEntities` implementations have a new `get_or_reserve` function
available that will always return an `Entity`, establishing a new
mapping to a dead entity when the entity they are called with is not in
the `EntityMap`. Subsequent calls with that same `Entity` will return
the same newly created dead entity reference, preserving equality
semantics.
- As a result, after loading a scene containing references to dead
entities (or entities otherwise outside the scene), those references
will all point to different generations on a single entity id in the new
world.
---
## Changelog
### Changed
- In serialized scenes, entities are now identified by a u64 instead of
a u32.
- In serialized scenes, components with entity references now have those
references serialize as u64s instead of structs.
### Fixed
- Scenes containing components with entity references will now
deserialize and add to a world reliably.
## Migration Guide
- `MapEntities` implementations must change from a `&EntityMap`
parameter to a `&mut EntityMapper` parameter and can no longer return a
`Result`. Finally, they should switch from calling `EntityMap::get` to
calling `EntityMapper::get_or_reserve`.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Methods for interacting with world schedules currently have two
variants: one that takes `impl ScheduleLabel` and one that takes `&dyn
ScheduleLabel`. Operations such as `run_schedule` or `schedule_scope`
only use the label by reference, so there is little reason to have an
owned variant of these functions.
## Solution
Decrease maintenance burden by merging the `ref` variants of these
functions with the owned variants.
---
## Changelog
- Deprecated `World::run_schedule_ref`. It is now redundant, since
`World::run_schedule` can take values by reference.
## Migration Guide
The method `World::run_schedule_ref` has been deprecated, and will be
removed in the next version of Bevy. Use `run_schedule` instead.
# Objective
Label traits such as `ScheduleLabel` currently have a major footgun: the
trait is implemented for `Box<dyn ScheduleLabel>`, but the
implementation does not function as one would expect since `Box<T>` is
considered to be a distinct type from `T`. This is because the behavior
of the `ScheduleLabel` trait is specified mainly through blanket
implementations, which prevents `Box<dyn ScheduleLabel>` from being
properly special-cased.
## Solution
Replace the blanket-implemented behavior with a series of methods
defined on `ScheduleLabel`. This allows us to fully special-case
`Box<dyn ScheduleLabel>` .
---
## Changelog
Fixed a bug where boxed label types (such as `Box<dyn ScheduleLabel>`)
behaved incorrectly when compared with concretely-typed labels.
## Migration Guide
The `ScheduleLabel` trait has been refactored to no longer depend on the
traits `std::any::Any`, `bevy_utils::DynEq`, and `bevy_utils::DynHash`.
Any manual implementations will need to implement new trait methods in
their stead.
```rust
impl ScheduleLabel for MyType {
// Before:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
// After:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
fn as_dyn_eq(&self) -> &dyn DynEq {
self
}
// No, `mut state: &mut` is not a typo.
fn dyn_hash(&self, mut state: &mut dyn Hasher) {
self.hash(&mut state);
// Hashing the TypeId isn't strictly necessary, but it prevents collisions.
TypeId::of::<Self>().hash(&mut state);
}
}
```
Added helper extracted from #7711. that PR contains some controversy
conditions, but this one should be good to go.
---
## Changelog
### Added
- `any_component_removed` condition.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Follow-up to #8377.
As the system module has been refactored, there are many types that no
longer make sense to live in the files that they do:
- The `IntoSystem` trait is in `function_system.rs`, even though this
trait is relevant to all kinds of systems. Same for the `In<T>` type.
- `PipeSystem` is now just an implementation of `CombinatorSystem`, so
`system_piping.rs` no longer needs its own file.
## Solution
- Move `IntoSystem`, `In<T>`, and system piping combinators & tests into
the top-level `mod.rs` file for `bevy_ecs::system`.
- Move `PipeSystem` into `combinator.rs`.
# Objective
- Currently, it is not possible to call `.pipe` on a system that takes
any input other than `()`.
- The `IntoPipeSystem` trait is currently very difficult to parse due to
its use of generics.
## Solution
Remove the `IntoPipeSystem` trait, and move the `pipe` method to
`IntoSystem`.
---
## Changelog
- System piping has been made more flexible: it is now possible to call
`.pipe` on a system that takes an input.
## Migration Guide
The `IntoPipeSystem` trait has been removed, and the `pipe` method has
been moved to the `IntoSystem` trait.
```rust
// Before:
use bevy_ecs::system::IntoPipeSystem;
schedule.add_systems(first.pipe(second));
// After:
use bevy_ecs::system::IntoSystem;
schedule.add_systems(first.pipe(second));
```
# Objective
- Fixes unclear warning when `insert_non_send_resource` is called on a
Send resource
## Solution
- Add a message to the asssert statement that checks this
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The implementation of `System::run_unsafe` for `FunctionSystem` requires
that the world is the same one used to initialize the system. However,
the `System` trait has no requirements that the world actually matches,
which makes this implementation unsound.
This was previously mentioned in
https://github.com/bevyengine/bevy/pull/7605#issuecomment-1426491871
Fixes part of #7833.
## Solution
Add the safety invariant that
`System::update_archetype_component_access` must be called prior to
`System::run_unsafe`. Since
`FunctionSystem::update_archetype_component_access` properly validates
the world, this ensures that `run_unsafe` is not called with a
mismatched world.
Most exclusive systems are not required to be run on the same world that
they are initialized with, so this is not a concern for them. Systems
formed by combining an exclusive system with a regular system *do*
require the world to match, however the validation is done inside of
`System::run` when needed.
# Objective
This PR attempts to improve query compatibility checks in scenarios
involving `Or` filters.
Currently, for the following two disjoint queries, Bevy will throw a
panic:
```
fn sys(_: Query<&mut C, Or<(With<A>, With<B>)>>, _: Query<&mut C, (Without<A>, Without<B>)>) {}
```
This PR addresses this particular scenario.
## Solution
`FilteredAccess::with` now stores a vector of `AccessFilters`
(representing a pair of `with` and `without` bitsets), where each member
represents an `Or` "variant".
Filters like `(With<A>, Or<(With<B>, Without<C>)>` are expected to be
expanded into `A * B + A * !C`.
When calculating whether queries are compatible, every `AccessFilters`
of a query is tested for incompatibility with every `AccessFilters` of
another query.
---
## Changelog
- Improved system and query data access compatibility checks in
scenarios involving `Or` filters
---------
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
If you want to execute a schedule on the world using arbitrarily complex
behavior, you currently need to use "hokey-pokey strats": remove the
schedule from the world, do your thing, and add it back to the world.
Not only is this cumbersome, it's potentially error-prone as one might
forget to re-insert the schedule.
## Solution
Add the `World::{try}schedule_scope{ref}` family of functions, which is
a convenient abstraction over hokey pokey strats. This method
essentially works the same way as `World::resource_scope`.
### Example
```rust
// Run the schedule five times.
world.schedule_scope(MySchedule, |world, schedule| {
for _ in 0..5 {
schedule.run(world);
}
});
```
---
## Changelog
Added the `World::schedule_scope` family of methods, which provide a way
to get mutable access to a world and one of its schedules at the same
time.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The behavior of change detection within `PipeSystem` is very tricky and
subtle, and is not currently covered by any of our tests as far as I'm
aware.
# Objective
Upon closer inspection, there are a few functions in the ECS that are
not being inlined, even with the highest optimizations and LTO enabled:
- Almost all
[WorldQuery::init_fetch](9fd5f20e25/results/query_get.s (L57))
calls. Affects `Query::get` calls in hot loops. In particular, the
`WorldQuery` implementation for `()` is used *everywhere* as the default
filter and is effectively a no-op.
-
[Entities::get](9fd5f20e25/results/query_get.s (L39)).
Affects `Query::get`, `World::get`, and any component insertion or
removal.
-
[Entities::set](9fd5f20e25/results/entity_remove.s (L2487)).
Affects any component insertion or removal.
-
[Tick::new](9fd5f20e25/results/entity_insert.s (L1368)).
I've only seen this in component insertion and spawning.
- ArchetypeRow::new
- BlobVec::set_len
Almost all of these have trivial or even empty implementations or have
significant opportunity to be optimized into surrounding code when
inlined with LTO enabled.
## Solution
Inline them
# Objective
The method `World::try_run_schedule` currently panics if the `Schedules`
resource does not exist, but it should just return an `Err`. Similarly,
`World::add_schedule` panics unnecessarily if the resource does not
exist.
Also, the documentation for `World::add_schedule` is completely wrong.
## Solution
When the `Schedules` resource does not exist, we now treat it the same
as if it did exist but was empty. When calling `add_schedule`, we
initialize it if it does not exist.
# Objective
Fixes#8215 and #8152. When systems panic, it causes the main thread to
panic as well, which clutters the output.
## Solution
Resolves the panic in the multi-threaded scheduler. Also adds an extra
message that tells the user the system that panicked.
Using the example from the issue, here is what the messages now look
like:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Update, panicking_system)
.run();
}
fn panicking_system() {
panic!("oooh scary");
}
```
### Before
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2m 58s
Running `target\debug\bevy_test.exe`
2023-03-30T22:19:09.234932Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'Compute Task Pool (5)' panicked at 'A system has panicked so the executor cannot continue.: RecvError', E:\Projects\Rust\bevy\crates\bevy_ecs\src\schedule\executor\multi_threaded.rs:194:60
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', E:\Projects\Rust\bevy\crates\bevy_tasks\src\task_pool.rs:376:49
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
### After
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2.39s
Running `target\debug\bevy_test.exe`
2023-03-30T22:11:24.748513Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Encountered a panic in system `bevy_test::panicking_system`!
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix#8191.
Currently, a state transition will be triggered whenever the `NextState`
resource has a value, even if that "transition" is to the same state as
the previous one. This caused surprising/meaningless behavior, such as
the existence of an `OnTransition { from: A, to: A }` schedule.
## Solution
State transition schedules now only run if the new state is not equal to
the old state. Change detection works the same way, only being triggered
when the states compare not equal.
---
## Changelog
- State transition schedules are no longer run when transitioning to and
from the same state.
## Migration Guide
State transitions are now only triggered when the exited and entered
state differ. This means that if the world is currently in state `A`,
the `OnEnter(A)` schedule (or `OnExit`) will no longer be run if you
queue up a state transition to the same state `A`.
# Objective
Noticed while writing #7728 that we are using `trace!` logs in our event
functions. This has shown to have significant overhead, even trace level
logs are disabled globally, as seen in #7639.
## Solution
Use the `detailed_trace!` macro introduced in #7639. Also removed the
`event_trace` function that was only used in one location.
---
## Changelog
Changed: Event trace logs are now feature gated behind the
`detailed-trace` feature.
Fixes#8333
# Objective
Fixes issue which causes failure to compile if using
`#![deny(missing_docs)]`.
## Solution
Added some very basic commenting to the generated read-only fields.
honestly I feel this to be up for debate since the comments are very
basic and give very little useful information but the purpose of this PR
is to fix the issue at hand.
---
## Changelog
Added comments to the derive macro and the projects now successfully
compile.
---------
Co-authored-by: lupan <kallll5@hotmail.com>
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
State requires a kind of awkward `state.0` to get the current state and
exposes the field directly to manipulation.
## Solution
Make it accessible through a getter method as well as privatize the
field to make sure false assumptions about setting the state aren't
made.
## Migration Guide
- Use `State::get` instead of accessing the tuple field directly.
# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
While migrating the engine to use the `Tick` type in #7905, I forgot to
update `UnsafeWorldCell::increment_change_tick`.
## Solution
Update the function.
---
## Changelog
- The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
## Migration Guide
The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
Our regression tests for `SystemParam` currently consist of a bunch of
loosely dispersed struct definitions. This is messy, and doesn't fully
test their functionality.
## Solution
Group the struct definitions into functions annotated with `#[test]`.
This not only makes the module more organized, but it allows us to call
`assert_is_system`, which has the potential to catch some bugs that
would have been missed with the old approach. Also, this approach is
consistent with how `WorldQuery` regression tests are organized.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
I ran into a case where I need to create a `CommandQueue` and push
standard `Command` actions like `Insert` or `Remove` to it manually. I
saw that `Remove` looked as follows:
```rust
struct Remove<T> {
entity: Entity,
phantom: PhantomData<T>
}
```
so naturally, I tried to use `Remove::<Foo>::from(entity)` but it didn't
exist. We need to specify the `PhantomData` explicitly when creating
this command action. The same goes for `RemoveResource` and
`InitResource`
## Solution
This PR implements the following:
- `From<Entity>` for `Remove<T>`
- `Default` for `RemoveResource` and `InitResource`
- use these traits in the implementation of methods of `Commands`
- rename `phantom` field on the structs above to `_phantom` to have a
more uniform field naming scheme for the command actions
---
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
- Added: implemented `From<Entity>` for `Remove<T>` and `Default` for
`RemoveResource` and `InitResource` for ergonomics
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
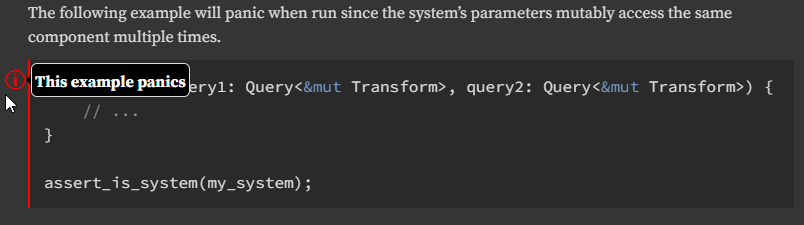
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This MR is a rebased and alternative proposal to
https://github.com/bevyengine/bevy/pull/5602
# Objective
- https://github.com/bevyengine/bevy/pull/4447 implemented untyped
(using component ids instead of generics and TypeId) APIs for
inserting/accessing resources and accessing components, but left
inserting components for another PR (this one)
## Solution
- add `EntityMut::insert_by_id`
- split `Bundle` into `DynamicBundle` with `get_components` and `Bundle:
DynamicBundle`. This allows the `BundleInserter` machinery to be reused
for bundles that can only be written, not read, and have no statically
available `ComponentIds`
- Compared to the original MR this approach exposes unsafe endpoints and
requires the user to manage instantiated `BundleIds`. This is quite easy
for the end user to do and does not incur the performance penalty of
checking whether component input is correctly provided for the
`BundleId`.
- This MR does ensure that constructing `BundleId` itself is safe
---
## Changelog
- add methods for inserting bundles and components to:
`world.entity_mut(entity).insert_by_id`
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
`EntityMut::move_entity_from_remove` had two soundness bugs:
- When removing the entity from the archetype, the swapped entity had its table row updated to the same as the removed entity's
- When removing the entity from the table, the swapped entity did not have its table row updated
`BundleInsert::insert` had two/three soundness bugs
- When moving an entity to a new archetype from an `insert`, the swapped entity had its table row set to a different entities
- When moving an entity to a new table from an `insert`, the swapped entity did not have its table row updated
See added tests for examples that trigger those bugs
`EntityMut::despawn` had two soundness bugs
- When despawning an entity, the swapped entity had its table row set to a different entities even if the table didnt change
- When despawning an entity, the swapped entity did not have its table row updated
# Objective
- A more intuitive distinction between the two. `remove_intersection` is verbose and unclear.
- `EntityMut::remove` and `Commands::remove` should match.
## Solution
- What the title says.
---
## Migration Guide
Before
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).remove::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove_intersection::<Parent>();
}
}
}
```
After
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).take::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove::<Parent>();
}
}
}
```
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
While we use `#[doc(hidden)]` to try and hide marker generics from the user, these types reveal themselves in compiler errors, adding visual noise and confusion.
## Solution
Replace the `AlreadyWasSystem` marker generic with `()`, to reduce visual noise in error messages. This also makes it possible to return `impl Condition<()>` from combinators.
For function systems, use their function signature as the marker type. This should drastically improve the legibility of some error messages.
The `InputMarker` type has been removed, since it is unnecessary.
# Objective
Several places in the ECS use marker generics to avoid overlapping trait implementations, but different places alternately refer to it as `Params` and `Marker`. This is potentially confusing, since it might not be clear that the same pattern is being used. Additionally, users might be misled into thinking that the `Params` type corresponds to the `SystemParam`s of a system.
## Solution
Rename `Params` to `Marker`.
# Objective
Fixes#3980
## Solution
Added examples to show how to run a `Schedule`, one with a unique system, and another with several systems
---
## Changelog
- Added: examples in docs to show how to run a `Schedule`
Co-authored-by: remiCzn <77072160+remiCzn@users.noreply.github.com>
# Objective
The `BoxedCondition` type alias does not require the underlying system to be read-only.
## Solution
Define the type alias using `ReadOnlySystem` instead of `System`.
Graph theory make head hurty. Closes#7367.
Basically, when we topologically sort the dependency graph, we already find its strongly-connected components (a really [neat algorithm][1]). This PR adds an algorithm that can dissect those into simple cycles, giving us more useful error reports.
test: `system_build_errors::dependency_cycle`
```
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
```
```
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
```
test: `system_build_errors::hierarchy_cycle`
```
schedule has 1 in_set cycle(s):
cycle 1: system set 'A' contains itself
system set 'A'
... which contains system set 'B'
... which contains system set 'A'
```
[1]: https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
{kind=link}
{kind=link}