# Objective
Fixes#3180, builds from https://github.com/bevyengine/bevy/pull/2898
## Solution
Support requesting a window to be closed and closing a window in `bevy_window`, and handle this in `bevy_winit`.
This is a stopgap until we move to windows as entites, which I'm sure I'll get around to eventually.
## Changelog
### Added
- `Window::close` to allow closing windows.
- `WindowClosed` to allow reacting to windows being closed.
### Changed
Replaced `bevy::system::exit_on_esc_system` with `bevy:🪟:close_on_esc`.
## Fixed
The app no longer exits when any window is closed. This difference is only observable when there are multiple windows.
## Migration Guide
`bevy::input::system::exit_on_esc_system` has been removed. Use `bevy:🪟:close_on_esc` instead.
`CloseWindow` has been removed. Use `Window::close` instead.
The `Close` variant has been added to `WindowCommand`. Handle this by closing the relevant window.
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
Bevy users often want to create circles and other simple shapes.
All the machinery is in place to accomplish this, and there are external crates that help. But when writing code for e.g. a new bevy example, it's not really possible to draw a circle without bringing in a new asset, writing a bunch of scary looking mesh code, or adding a dependency.
In particular, this PR was inspired by this interaction in another PR: https://github.com/bevyengine/bevy/pull/3721#issuecomment-1016774535
## Solution
This PR adds `shape::RegularPolygon` and `shape::Circle` (which is just a `RegularPolygon` that defaults to a large number of sides)
## Discussion
There's a lot of ongoing discussion about shapes in <https://github.com/bevyengine/rfcs/pull/12> and at least one other lingering shape PR (although it seems incomplete).
That RFC currently includes `RegularPolygon` and `Circle` shapes, so I don't think that having working mesh generation code in the engine for those shapes would add much burden to an author of an implementation.
But if we'd prefer not to add additional shapes until after that's sorted out, I'm happy to close this for now.
## Alternatives for users
For any users stumbling on this issue, here are some plugins that will help if you need more shapes.
https://github.com/Nilirad/bevy_prototype_lyonhttps://github.com/johanhelsing/bevy_smudhttps://github.com/Weasy666/bevy_svghttps://github.com/redpandamonium/bevy_more_shapeshttps://github.com/ForesightMiningSoftwareCorporation/bevy_polyline
This is a replacement for #2106
This adds a `Metadata` struct which contains metadata information about a file, at the moment only the file type.
It also adds a `get_metadata` to `AssetIo` trait and an `asset_io` accessor method to `AssetServer` and `LoadContext`
I am not sure about the changes in `AndroidAssetIo ` and `WasmAssetIo`.
# Objective
- As requested here: https://github.com/bevyengine/bevy/pull/4520#issuecomment-1109302039
- Make it easier to spot issues with built-in shapes
## Solution
https://user-images.githubusercontent.com/200550/165624709-c40dfe7e-0e1e-4bd3-ae52-8ae66888c171.mp4
- Add an example showcasing the built-in 3d shapes with lighting/shadows
- Rotate objects in such a way that all faces are seen by the camera
- Add a UV debug texture
## Discussion
I'm not sure if this is what @alice-i-cecile had in mind, but I adapted the little "torus playground" from the issue linked above to include all built-in shapes.
This exact arrangement might not be particularly scalable if many more shapes are added. Maybe a slow camera pan, or cycling with the keyboard or on a timer, or a sidebar with buttons would work better. If one of the latter options is used, options for showing wireframes or computed flat normals might add some additional utility.
Ideally, I think we'd have a better way of visualizing normals.
Happy to rework this or close it if there's not a consensus around it being useful.
# Objective
- Part of the splitting process of #3692.
## Solution
- Remove / change the tuple structs inside of `gamepad.rs` of `bevy_input` to normal structs.
## Reasons
- It made the `gamepad_connection_system` cleaner.
- It made the `gamepad_input_events.rs` example cleaner (which is probably the most notable change for the user facing API).
- Tuple structs are not descriptive (`.0`, `.1`).
- Using tuple structs for more than 1 field is a bad idea (This means that the `Gamepad` type might be fine as a tuple struct, but I still prefer normal structs over tuple structs).
Feel free to discuss this change as this is more or less just a matter of taste.
## Changelog
### Changed
- The `Gamepad`, `GamepadButton`, `GamepadAxis`, `GamepadEvent` and `GamepadEventRaw` types are now normal structs instead of tuple structs and have a `new()` function.
## Migration Guide
- The `Gamepad`, `GamepadButton`, `GamepadAxis`, `GamepadEvent` and `GamepadEventRaw` types are now normal structs instead of tuple structs and have a `new()` function. To migrate change every instantiation to use the `new()` function instead and use the appropriate field names instead of `.0` and `.1`.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by moving FloatOrd to bevy_utils.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Move FloatOrd into bevy_utils. Fix the compile errors.
As a result, bevy_core_pipeline, bevy_pbr, bevy_sprite, bevy_text, and bevy_ui no longer depend on bevy_core (they were only using it for `FloatOrd` previously).
# Objective
- Closes#335.
- Related #4285.
- Part of the splitting process of #3503.
## Solution
- Move `Rect` to `bevy_ui` and rename it to `UiRect`.
## Reasons
- `Rect` is only used in `bevy_ui` and therefore calling it `UiRect` makes the intent clearer.
- We have two types that are called `Rect` currently and it's missleading (see `bevy_sprite::Rect` and #335).
- Discussion in #3503.
## Changelog
### Changed
- The `Rect` type got moved from `bevy_math` to `bevy_ui` and renamed to `UiRect`.
## Migration Guide
- The `Rect` type got renamed to `UiRect`. To migrate you just have to change every occurrence of `Rect` to `UiRect`.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Related #4276.
- Part of the splitting process of #3503.
## Solution
- Move `Size` to `bevy_ui`.
## Reasons
- `Size` is only needed in `bevy_ui` (because it needs to use `Val` instead of `f32`), but it's also used as a worse `Vec2` replacement in other areas.
- `Vec2` is more powerful than `Size` so it should be used whenever possible.
- Discussion in #3503.
## Changelog
### Changed
- The `Size` type got moved from `bevy_math` to `bevy_ui`.
## Migration Guide
- The `Size` type got moved from `bevy::math` to `bevy::ui`. To migrate you just have to import `bevy::ui::Size` instead of `bevy::math::Math` or use the `bevy::prelude` instead.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
- Fixes#4234
- Fixes#4473
- Built on top of #3989
- Improve performance of `assign_lights_to_clusters`
## Solution
- Remove the OBB-based cluster light assignment algorithm and calculation of view space AABBs
- Implement the 'iterative sphere refinement' algorithm used in Just Cause 3 by Emil Persson as documented in the Siggraph 2015 Practical Clustered Shading talk by Persson, on pages 42-44 http://newq.net/dl/pub/s2015_practical.pdf
- Adapt to also support orthographic projections
- Add `many_lights -- orthographic` for testing many lights using an orthographic projection
## Results
- `assign_lights_to_clusters` in `many_lights` before this PR on an M1 Max over 1500 frames had a median execution time of 1.71ms. With this PR it is 1.51ms, a reduction of 0.2ms or 11.7% for this system.
---
## Changelog
- Changed: Improved cluster light assignment performance
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Continue the effort to clean up this example
## Solution
- Store contributor name as component to avoid awkward vec of tuples
- Name the variable storing the Random Number Generator "rng"
- Use init_resource for resource implementing default
- Fix a few spots where an Entity was unnecessarily referenced and immediately dereferenced
- Fix up an awkward comment
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3499
## Solution
Uses a `HashMap` from `RenderTarget` to sampled textures when preparing `ViewTarget`s to ensure that two passes with the same render target get sampled to the same texture.
This builds on and depends on https://github.com/bevyengine/bevy/pull/3412, so this will be a draft PR until #3412 is merged. All changes for this PR are in the last commit.
# Objective
glTF files can contain cameras. Currently the scene viewer example uses _a_ camera defined in the file if possible, otherwise it spawns a new one. It would be nice if instead it could load all the cameras and cycle through them, while also having a separate user-controller camera.
## Solution
- instead of just a camera that is already defined, always spawn a new separate user-controller camera
- maintain a list of loaded cameras and cycle through them (wrapping to the user-controller camera) when pressing `C`
This matches the behavious that https://github.khronos.org/glTF-Sample-Viewer-Release/ has.
## Implementation notes
- The gltf scene asset loader just spawns the cameras into the world, but does not return a mapping of camera index to bevy entity. So instead the scene_viewer example just collects all spawned cameras with a good old `query.iter().collect()`, so the order is unspecified and may change between runs.
## Demo
https://user-images.githubusercontent.com/22177966/161826637-40161482-5b3b-4df5-aae8-1d5e9b918393.mp4
using the virtual city glTF sample file: https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/VC
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Several examples are useful for qualitative tests of Bevy's performance
- By contrast, these are less useful for learning material: they are often relatively complex and have large amounts of setup and are performance optimized.
## Solution
- Move bevymark, many_sprites and many_cubes into the new stress_tests example folder
- Move contributors into the games folder: unlike the remaining examples in the 2d folder, it is not focused on demonstrating a clear feature.
Remove the 'chaining' api, as it's peculiar
~~Implement the label traits for `Box<dyn ThatTrait>` (n.b. I'm not confident about this change, but it was the quickest path to not regressing)~~
Remove the need for '`.system`' when using run criteria piping
# Objective
- Make use of storage buffers, where they are available, for clustered forward bindings to support far more point lights in a scene
- Fixes#3605
- Based on top of #4079
This branch on an M1 Max can keep 60fps with about 2150 point lights of radius 1m in the Sponza scene where I've been testing. The bottleneck is mostly assigning lights to clusters which grows faster than linearly (I think 1000 lights was about 1.5ms and 5000 was 7.5ms). I have seen papers and presentations leveraging compute shaders that can get this up to over 1 million. That said, I think any further optimisations should probably be done in a separate PR.
## Solution
- Add `RenderDevice` to the `Material` and `SpecializedMaterial` trait `::key()` functions to allow setting flags on the keys depending on feature/limit availability
- Make `GpuPointLights` and `ViewClusterBuffers` into enums containing `UniformVec` and `StorageBuffer` variants. Implement the necessary API on them to make usage the same for both cases, and the only difference is at initialisation time.
- Appropriate shader defs in the shader code to handle the two cases
## Context on some decisions / open questions
- I'm using `max_storage_buffers_per_shader_stage >= 3` as a check to see if storage buffers are supported. I was thinking about diving into 'binding resource management' but it feels like we don't have enough use cases to understand the problem yet, and it is mostly a separate concern to this PR, so I think it should be handled separately.
- Should `ViewClusterBuffers` and `ViewClusterBindings` be merged, duplicating the count variables into the enum variants?
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Changing animation mid animation can leave the model not in its original position
- ~~The movement speed is fixed, no matter the size of the model~~
## Solution
- when changing animation, set it to its initial state and wait for one frame before changing the animation
- ~~when settings the camera controller, use the camera transform to know how far it is from the origin and use the distance for the speed~~
The scene viewer example doesn't run on wasm because it sets the asset folder to `std::env::var("CARGO_MANIFEST_DIR").unwrap()`, which isn't supported on the web.
Solution: set the asset folder to `"."` instead.
# Objective
- `Local`s can no longer be accessed outside of their creating system, but these docs say they can be.
- There's also little reason to have a pure wrapper type for `Local`s; they can just use the real type. The parameter name should be sufficiently documenting.
# Objective
- Only move the camera when explicitly wanted, otherwise the camera goes crazy if the cursor isn't already in the middle of the window when it opens.
## Solution
- Check if the Left mouse button is pressed before updating the mouse delta
- Input is configurable
The example was broken in #3635 when the `ActiveCamera` logic was introduced, after which there could only be one active `Camera3d` globally.
Ideally there could be one `Camera3d` per render target, not globally, but that isn't the case yet.
To fix the example, we need to
- don't use `Camera3d` twice, add a new `SecondWindowCamera3d` marker
- add the `CameraTypePlugin::<SecondWindowCamera3d>`
- extract the correct `RenderPhase`s
- add a 3d pass driver node for the secondary camera
Fixes#4378
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Since #4224, using labels which only refer to one system doesn't make sense.
## Solution
- Remove some of those.
## Future work
- We should remove the ability to use strings as system labels entirely. I haven't in this PR because there are tests which use this, and that's a lot of code to change.
- The only use cases for labels are either intra-crate, which use #4224, or inter-crate, which should either use #4224 or explicit types. Neither of those should use strings.
# Objective
Add a system parameter `ParamSet` to be used as container for conflicting parameters.
## Solution
Added two methods to the SystemParamState trait, which gives the access used by the parameter. Did the implementation. Added some convenience methods to FilteredAccessSet. Changed `get_conflicts` to return every conflicting component instead of breaking on the first conflicting `FilteredAccess`.
Co-authored-by: bilsen <40690317+bilsen@users.noreply.github.com>
# Objective
Fixes#4344.
## Solution
Add a new component `Text2dBounds` to `Text2dBundle` that specifies the maximum width and height of text. Text will wrap according to this size.
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
1. Spawning walls in the Breakout example was hard to follow and error-prone.
2. The strategy used in `paddle_movement_system` was somewhat convoluted.
3. Correctly modifying the size of the arena was hard, due to implicit coupling between the bounds and the bounds that the paddle can move in.
## Solution
1. Refactor this to use a WallBundle struct with a builder; neatly demonstrating some essential patterns along the way.
2. Use clamp and avoid using weird &mut strategies.
3. Refactor logic to allow users to tweak the brick size, and automatically adjust the number of rows and columns to match.
4. Make the brick layout more like classic breakout!
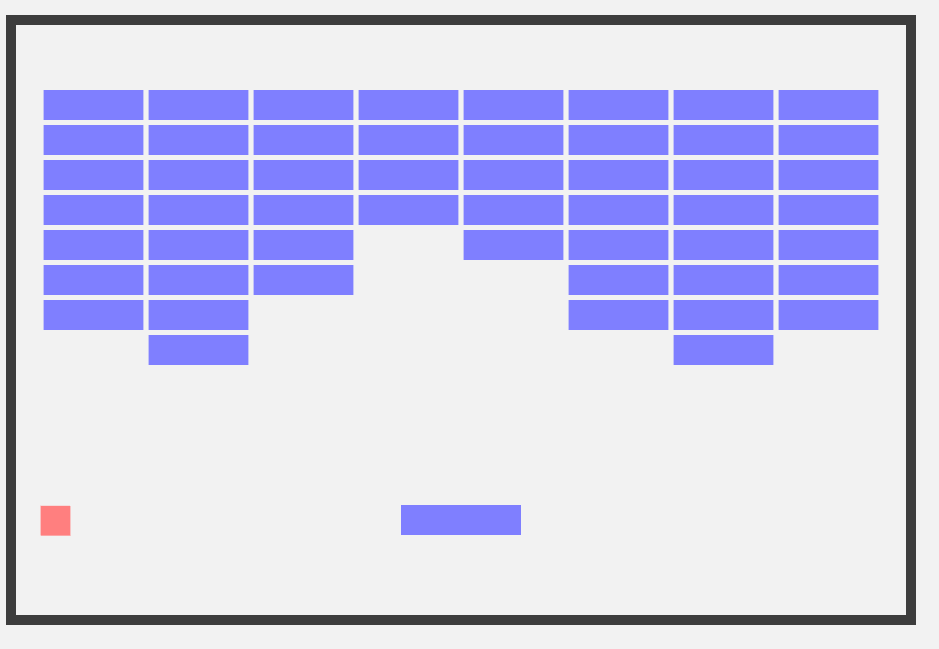
# Objective
- The Breakout example uses system names like `paddle_movement_system`
- _system syntax is redundant
- the [community has spoken](https://github.com/bevyengine/bevy/discussions/2804), and prefers to avoid `_system` system names by a more than 2:1 ratio
- existing system names were not terribly descriptive
## Solution
- rename the systems to take the form of `verb`, rather than `noun_system` to better capture the behavior they are implenting
- yeet `_system`
This adds the concept of "default labels" for systems (currently scoped to "parallel systems", but this could just as easily be implemented for "exclusive systems"). Function systems now include their function's `SystemTypeIdLabel` by default.
This enables the following patterns:
```rust
// ordering two systems without manually defining labels
app
.add_system(update_velocity)
.add_system(movement.after(update_velocity))
// ordering sets of systems without manually defining labels
app
.add_system(foo)
.add_system_set(
SystemSet::new()
.after(foo)
.with_system(bar)
.with_system(baz)
)
```
Fixes: #4219
Related to: #4220
Credit to @aevyrie @alice-i-cecile @DJMcNab (and probably others) for proposing (and supporting) this idea about a year ago. I was a big dummy that both shut down this (very good) idea and then forgot I did that. Sorry. You all were right!
# Objective
- The components in the Breakout game are defined in a strange fashion.
- Components should decouple behavior wherever possible.
- Systems should be as general as possible, to make extending behavior easier.
- Marker components are idiomatic and useful, but marker components and query filters were not used.
- The existing design makes it challenging for beginners to extend the example into a high-quality game.
## Solution
- Refactor component definitions in the Breakout example to reflect principles above.
## Context
A small portion of the changes made in #2094. Interacts with changes in #4255; merge conflicts will have to be resolved.
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Objective
There recently was a discussion on Discord about a possible test case for stress-testing transform hierarchies.
## Solution
Create a test case for stress testing transform propagation.
*Edit:* I have scrapped my previous example and built something more functional and less focused on visuals.
There are three test setups:
- `TestCase::Tree` recursively creates a tree with a specified depth and branch width
- `TestCase::NonUniformTree` is the same as `Tree` but omits nodes in a way that makes the tree "lean" towards one side, like this:
<details>
<summary></summary>
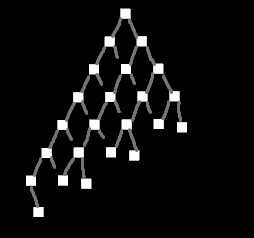
</details>
- `TestCase::Humanoids` creates one or more separate hierarchies based on the structure of common humanoid rigs
- this can both insert `active` and `inactive` instances of the human rig
It's possible to parameterize which parts of the hierarchy get updated (transform change) and which remain unchanged. This is based on @james7132 suggestion:
There's a probability to decide which entities should remain static. On top of that these changes can be limited to a certain range in the hierarchy (min_depth..max_depth).
# Objective
- The Breakout example has a lot of configurable constant values for setup, but these are buried in the source code.
- Magic numbers scattered in the source code are hard to follow.
- Providing constants up front makes tweaking examples very approachable.
## Solution
- Move magic numbers into constants
## Context
Part of the changes made in #2094; split out for easier review.
# Objective
- Allow quick and easy testing of scenes
## Solution
- Add a `scene-viewer` tool based on `load_gltf`.
- Run it with e.g. `cargo run --release --example scene_viewer --features jpeg -- ../some/path/assets/models/Sponza/glTF/Sponza.gltf#Scene0`
- Configure the asset path as pointing to the repo root for convenience (paths specified relative to current working directory)
- Copy over the camera controller from the `shadow_biases` example
- Support toggling the light animation
- Support toggling shadows
- Support adjusting the directional light shadow projection (cascaded shadow maps will remove the need for this later)
I don't want to do too much on it up-front. Rather we can add features over time as we need them.
# Objective
- Make the example a little easier to follow by removing unnecessary steps.
## Solution
- `Assets<Image>` will give us a handle for our render texture if we call `add()` instead of `set()`. No need to set it manually; one less thing to think about while reading the example.
{kind=link}
{kind=link}