# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Add texture sampling to the GLSL shader example, as naga does not support the commonly used sampler2d type.
Fixes#5059
## Solution
- Align the shader_material_glsl example behaviour with the shader_material example, as the later includes texture sampling.
- Update the GLSL shader to do texture sampling the way naga supports it, and document the way naga does not support it.
## Changelog
- The shader_material_glsl example has been updated to demonstrate texture sampling using the GLSL shading language.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
Intended to close#5073
## Solution
Adds a stress test that use TextureAtlas based on the existing many_sprites test using the animated sprite implementation from the sprite_sheet example.
In order to satisfy the goals described in #5073 the animations are all slightly offset.
Of note is that the original stress test was designed to test fullstrum culling. I kept this test similar as to facilitate easy comparisons between the use of TextureAtlas and without.
# Objective
Currently stress tests are vsynced. This is undesirable for a stress test, as you want to run them with uncapped framerates.
## Solution
Ensure all stress tests are using PresentMode::Immediate if they render anything.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make Bevy work on android
## Solution
- Update android metadata and add a few more
- Set the target sdk to 31 as it will soon (in august) be the minimum sdk level for play store
- Remove the custom code to create an activity and use ndk-glue macro instead
- Delay window creation event on android
- Set the example with compatibility settings for wgpu. Those are needed for Bevy to work on my 2019 android tablet
- Add a few details on how to debug in case of failures
- Fix running the example on emulator. This was failing because of the name of the example
Bevy still doesn't work on android with this, audio features need to be disabled because of an ndk-glue version mismatch: rodio depends on 0.6.2, winit on 0.5.2. You can test with:
```
cargo apk run --release --example android_example --no-default-features --features "bevy_winit,render"
```
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Small bug in the example game given in examples/ecs/ecs_guide
Currently, if there are 2 players in this example game, the function exclusive_player_system can add a player with the name "Player 2". However, the name should be "Player 3". This PR fixes this. I also add a message to inform that a new player has arrived in the mock game.
Co-authored-by: Dilyan Kostov <dilyanks@amazon.com>
# Objective
- Have information about examples only in one place that can be used for the repo and for the website (and remove the need to keep a list of example to build for wasm in the website 75acb73040/generate-wasm-examples/generate_wasm_examples.sh (L92-L99))
## Solution
- Add metadata about examples in `Cargo.toml`
- Build the `examples/README.md` from a template using those metadata. I used tera as the template engine to use the same tech as the website.
- Make CI fail if an example is missing metadata, or if the readme file needs to be updated (the command to update it is displayed in the failed step in CI)
## Remaining To Do
- After the next release with this merged in, the website will be able to be updated to use those metadata too
- I would like to build the examples in wasm and make them available at http://dev-docs.bevyengine.org/ but that will require more design
- https://github.com/bevyengine/bevy-website/issues/299 for other ToDos
Co-authored-by: Readme <github-actions@github.com>
# Objective
`bevy_ui` doesn't support correctly touch inputs because of two problems in the focus system:
- It attempts to retrieve touch input with a specific `0` id
- It doesn't retrieve touch positions and bases its focus solely on mouse position, absent from mobile devices
## Solution
I added a few methods to the `Touches` resource, allowing to check if **any** touch input was pressed, released or cancelled and to retrieve the *position* of the first pressed touch input and adapted the focus system.
I added a test button to the *iOS* example and it works correclty on emulator. I did not test on a real touch device as:
- Android is not working (https://github.com/bevyengine/bevy/issues/3249)
- I don't have an iOS device
- changed `EntityCountDiagnosticsPlugin` to not use an exclusive system to get its entity count
- removed mention of `WgpuResourceDiagnosticsPlugin` in example `log_diagnostics` as it doesn't exist anymore
- added ability to enable, disable ~~or toggle~~ a diagnostic (fix#3767)
- made diagnostic values lazy, so they are only computed if the diagnostic is enabled
- do not log an average for diagnostics with only one value
- removed `sum` function from diagnostic as it isn't really useful
- ~~do not keep an average of the FPS diagnostic. it is already an average on the last 20 frames, so the average FPS was an average of the last 20 frames over the last 20 frames~~
- do not compute the FPS value as an average over the last 20 frames but give the actual "instant FPS"
- updated log format to use variable capture
- added some doc
- the frame counter diagnostic value can be reseted to 0
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
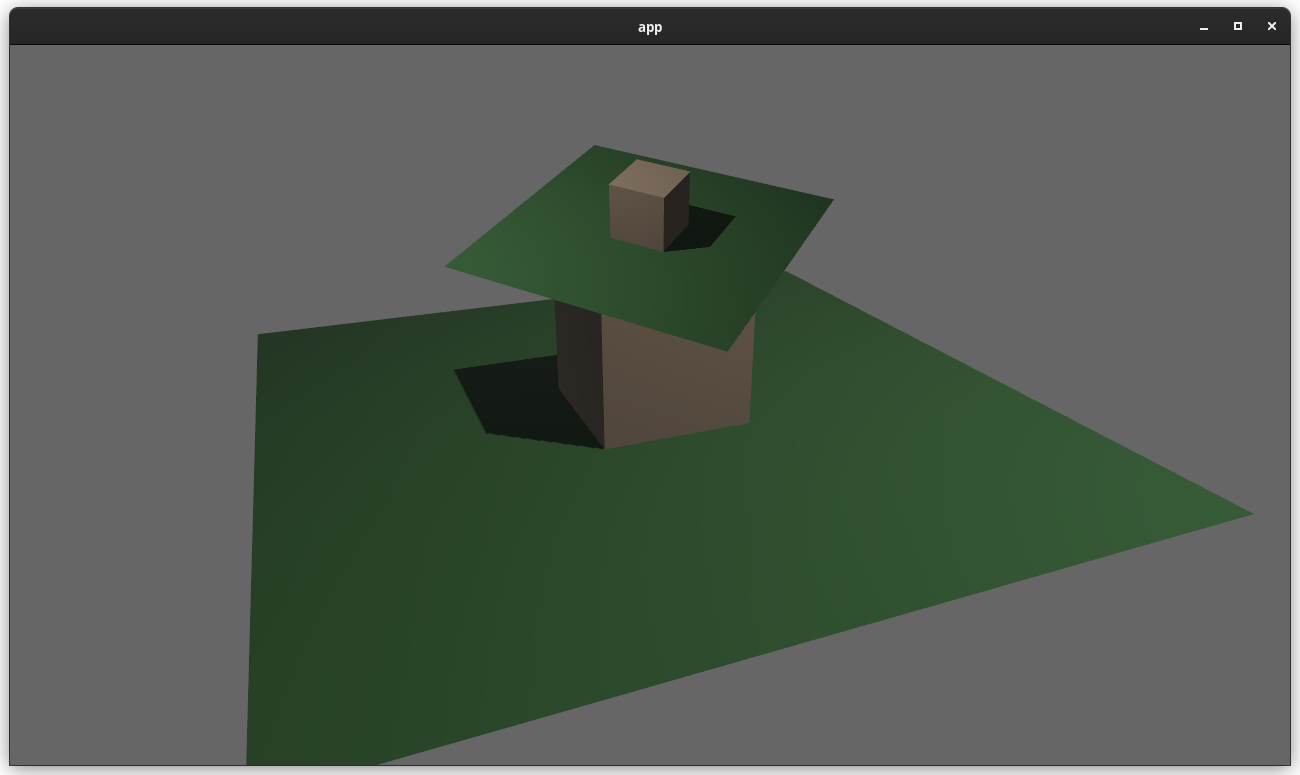
### two_passes example with the "second pass" camera configured to "load" the depth
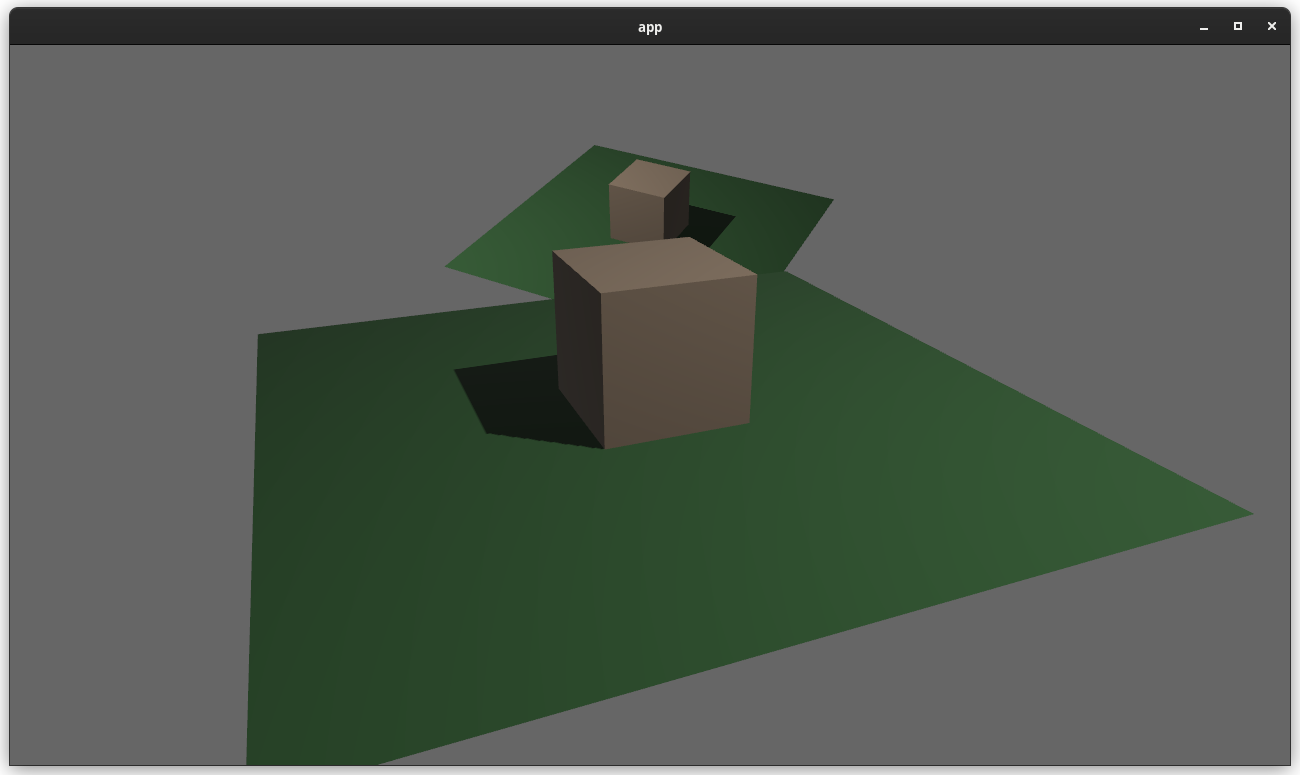
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
# Objective
In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access.
## Solution
Remove the `With<Handle<Mesh>>` filter
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
# Objective
- To fix the broken commented code in `examples/shader/compute_shader_game_of_life.rs` for disabling frame throttling
## Solution
- Change the commented code from using the old `WindowDescriptor::vsync` to the new `WindowDescriptor::present_mode`
### Note
I chose to use the fully qualified scope `bevy:🪟:PresentWindow::Immediate` rather than explicitly including `PresentWindow` to avoid an unused import when the code is commented.
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- Split PBR and 2D mesh shaders into types and bindings to prepare the shaders to be more reusable.
- See #3969 for details. I'm doing this in multiple steps to make review easier.
---
## Changelog
- Changed: 2D and PBR mesh shaders are now split into types and bindings, the following shader imports are available: `bevy_pbr::mesh_view_types`, `bevy_pbr::mesh_view_bindings`, `bevy_pbr::mesh_types`, `bevy_pbr::mesh_bindings`, `bevy_sprite::mesh2d_view_types`, `bevy_sprite::mesh2d_view_bindings`, `bevy_sprite::mesh2d_types`, `bevy_sprite::mesh2d_bindings`
## Migration Guide
- In shaders for 3D meshes:
- `#import bevy_pbr::mesh_view_bind_group` -> `#import bevy_pbr::mesh_view_bindings`
- `#import bevy_pbr::mesh_struct` -> `#import bevy_pbr::mesh_types`
- NOTE: If you are using the mesh bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_pbr::mesh_bindings` which itself imports the mesh types needed for the bindings.
- In shaders for 2D meshes:
- `#import bevy_sprite::mesh2d_view_bind_group` -> `#import bevy_sprite::mesh2d_view_bindings`
- `#import bevy_sprite::mesh2d_struct` -> `#import bevy_sprite::mesh2d_types`
- NOTE: If you are using the mesh2d bind group at bind group index 2, you can remove those binding statements in your shader and just use `#import bevy_sprite::mesh2d_bindings` which itself imports the mesh2d types needed for the bindings.
# Objective
- The `scene_viewer` example assumes the `animation` feature is enabled, which it is by default. However, animations may have a performance cost that is undesirable when testing performance, for example. Then it is useful to be able to disable the `animation` feature and one would still like the `scene_viewer` example to work.
## Solution
- Gate animation code in `scene_viewer` on the `animation` feature being enabled.
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
# Objective
- Add Vertex Color support to 2D meshes and ColorMaterial. This extends the work from #4528 (which in turn builds on the excellent tangent handling).
## Solution
- Added `#ifdef` wrapped support for vertex colors in the 2D mesh shader and `ColorMaterial` shader.
- Added an example, `mesh2d_vertex_color_texture` to demonstrate it in action.

---
## Changelog
- Added optional (ifdef wrapped) vertex color support to the 2dmesh and color material systems.
# Objective
- Sometimes, people might load an asset as one type, then use it with an `Asset`s for a different type.
- See e.g. #4784.
- This is especially likely with the Gltf types, since users may not have a clear conceptual model of what types the assets will be.
- We had an instance of this ourselves, in the `scene_viewer` example
## Solution
- Make `Assets::get` require a type safe handle.
---
## Changelog
### Changed
- `Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles.
### Added
- `HandleUntyped::typed_weak`, a helper function for creating a weak typed version of an exisitng `HandleUntyped`.
## Migration Guide
`Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles. If you were previously passing in:
- a `HandleId`, use `&Handle::weak(id)` instead, to create a weak handle. You may have been able to store a type safe `Handle` instead.
- a `HandleUntyped`, use `&handle_untyped.typed_weak()` to create a weak handle of the specified type. This is most likely to be the useful when using [load_folder](https://docs.rs/bevy_asset/latest/bevy_asset/struct.AssetServer.html#method.load_folder)
- a `Handle<U>` of of a different type, consider whether this is the correct handle type to store. If it is (i.e. the same handle id is used for multiple different Asset types) use `Handle::weak(handle.id)` to cast to a different type.
# Objective
Fixes#3183. Requiring a `&TaskPool` parameter is sort of meaningless if the only correct one is to use the one provided by `Res<ComputeTaskPool>` all the time.
## Solution
Have `QueryState` save a clone of the `ComputeTaskPool` which is used for all `par_for_each` functions.
~~Adds a small overhead of the internal `Arc` clone as a part of the startup, but the ergonomics win should be well worth this hardly-noticable overhead.~~
Updated the docs to note that it will panic the task pool is not present as a resource.
# Future Work
If https://github.com/bevyengine/rfcs/pull/54 is approved, we can replace these resource lookups with a static function call instead to get the `ComputeTaskPool`.
---
## Changelog
Removed: The `task_pool` parameter of `Query(State)::par_for_each(_mut)`. These calls will use the `World`'s `ComputeTaskPool` resource instead.
## Migration Guide
The `task_pool` parameter for `Query(State)::par_for_each(_mut)` has been removed. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(
task_pool: Res<ComputeTaskPool>,
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
If using `Query(State)` outside of a system run by the scheduler, you may need to manually configure and initialize a `ComputeTaskPool` as a resource in the `World`.
# Objective
- Coming from 7a596f1910 (r876310734)
- Simplify the examples regarding addition of `Msaa` Resource with default value.
## Solution
- Remove addition of `Msaa` Resource with default value from examples,
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by minimally splitting off time functionality into bevy_time. Functionality like that provided by #3002 would increase the complexity of bevy_time, so this is a good candidate for pulling into its own unit.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Pull the time module of bevy_core into a new crate, bevy_time.
# Migration guide
- Time related types (e.g. `Time`, `Timer`, `Stopwatch`, `FixedTimestep`, etc.) should be imported from `bevy::time::*` rather than `bevy::core::*`.
- If you were adding `CorePlugin` manually, you'll also want to add `TimePlugin` from `bevy::time`.
- The `bevy::core::CorePlugin::Time` system label is replaced with `bevy::time::TimeSystem`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
> ℹ️ **Note**: This is a rebased version of #2383. A large portion of it has not been touched (only a few minor changes) so that any additional discussion may happen here. All credit should go to @NathanSWard for their work on the original PR.
- Currently reflection is not supported for arrays.
- Fixes#1213
## Solution
* Implement reflection for arrays via the `Array` trait.
* Note, `Array` is different from `List` in the way that you cannot push elements onto an array as they are statically sized.
* Now `List` is defined as a sub-trait of `Array`.
---
## Changelog
* Added the `Array` reflection trait
* Allows arrays up to length 32 to be reflected via the `Array` trait
## Migration Guide
* The `List` trait now has the `Array` supertrait. This means that `clone_dynamic` will need to specify which version to use:
```rust
// Before
let cloned = my_list.clone_dynamic();
// After
let cloned = List::clone_dynamic(&my_list);
```
* All implementers of `List` will now need to implement `Array` (this mostly involves moving the existing methods to the `Array` impl)
Co-authored-by: NathanW <nathansward@comcast.net>
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- It's pretty common to want to check if an EventReader has received one or multiple events while also needing to consume the iterator to "clear" the EventReader.
- The current approach is to do something like `events.iter().count() > 0` or `events.iter().last().is_some()`. It's not immediately obvious that the purpose of that is to consume the events and check if there were any events. My solution doesn't really solve that part, but it encapsulates the pattern.
## Solution
- Add a `.clear()` method that consumes the iterator.
- It takes the EventReader by value to make sure it isn't used again after it has been called.
---
## Migration Guide
Not a breaking change, but if you ever found yourself in a situation where you needed to consume the EventReader and check if there was any events you can now use
```rust
fn system(events: EventReader<MyEvent>) {
if !events.is_empty {
events.clear();
// Process the fact that one or more event was received
}
}
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}