# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
- When Miri is failing, it can be very slow to do so
<img width="1397" alt="Screenshot 2022-05-14 at 03 05 40" src="https://user-images.githubusercontent.com/8672791/168405111-c5e27d63-7a5a-4a5e-b679-abbeeb3201d2.png">
## Solution
- Set the timeout for Miri to 60 minutes (it's 6 hours by default). It runs in around 10 minutes when successful
- Fix cache key as it was set to the same as another task that doesn't build with the same parameters
# Objective
`bevy_ecs` assumes that `u32 as usize` is a lossless operation and in a few cases relies on this for soundness and correctness. The only platforms that Rust compiles to where this invariant is broken are 16-bit systems.
A very clear example of this behavior is in the SparseSetIndex impl for Entity, where it converts a u32 into a usize to act as an index. If usize is 16-bit, the conversion will overflow and provide the caller with the wrong index. This can easily result in previously unforseen aliased mutable borrows (i.e. Query::get_many_mut).
## Solution
Explicitly fail compilation on 16-bit platforms instead of introducing UB.
Properly supporting 16-bit systems will likely need a workable use case first.
---
## Changelog
Removed: Ability to compile `bevy_ecs` on 16-bit platforms.
## Migration Guide
`bevy_ecs` will now explicitly fail to compile on 16-bit platforms. If this is required, there is currently no alternative. Please file an issue (https://github.com/bevyengine/bevy/issues) to help detail your use case.
# Objective
> ℹ️ **Note**: This is a rebased version of #2383. A large portion of it has not been touched (only a few minor changes) so that any additional discussion may happen here. All credit should go to @NathanSWard for their work on the original PR.
- Currently reflection is not supported for arrays.
- Fixes#1213
## Solution
* Implement reflection for arrays via the `Array` trait.
* Note, `Array` is different from `List` in the way that you cannot push elements onto an array as they are statically sized.
* Now `List` is defined as a sub-trait of `Array`.
---
## Changelog
* Added the `Array` reflection trait
* Allows arrays up to length 32 to be reflected via the `Array` trait
## Migration Guide
* The `List` trait now has the `Array` supertrait. This means that `clone_dynamic` will need to specify which version to use:
```rust
// Before
let cloned = my_list.clone_dynamic();
// After
let cloned = List::clone_dynamic(&my_list);
```
* All implementers of `List` will now need to implement `Array` (this mostly involves moving the existing methods to the `Array` impl)
Co-authored-by: NathanW <nathansward@comcast.net>
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- It's pretty common to want to check if an EventReader has received one or multiple events while also needing to consume the iterator to "clear" the EventReader.
- The current approach is to do something like `events.iter().count() > 0` or `events.iter().last().is_some()`. It's not immediately obvious that the purpose of that is to consume the events and check if there were any events. My solution doesn't really solve that part, but it encapsulates the pattern.
## Solution
- Add a `.clear()` method that consumes the iterator.
- It takes the EventReader by value to make sure it isn't used again after it has been called.
---
## Migration Guide
Not a breaking change, but if you ever found yourself in a situation where you needed to consume the EventReader and check if there was any events you can now use
```rust
fn system(events: EventReader<MyEvent>) {
if !events.is_empty {
events.clear();
// Process the fact that one or more event was received
}
}
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
`Query::par_for_each` and it's variants do not show up when profiling using `tracy` or other profilers. Failing to show the impact of changing batch size, the overhead of scheduling tasks, overall thread utilization, etc. other than the effect on the surrounding system.
## Solution
Add a child span that is entered on every spawned task.
Example view of the results in `tracy` using a modified `parallel_query`:
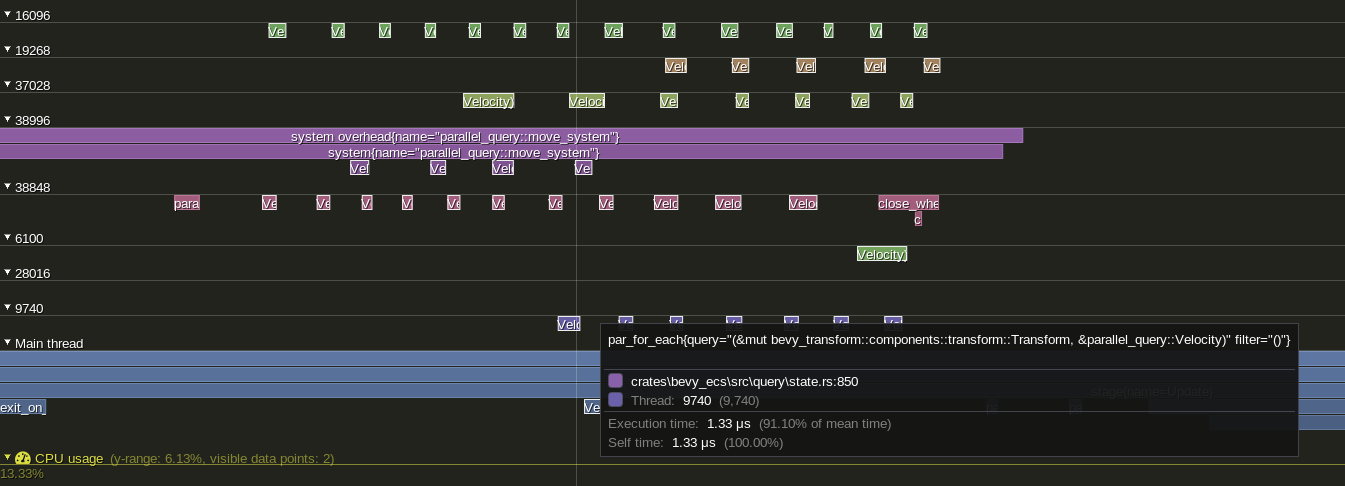
---
## Changelog
Added: `tracing` spans for `Query::par_for_each` and its variants. Spans should now be visible for all
# Objective
The `bevy_reflect_derive` crate is not the cleanest or easiest to follow/maintain. The `lib.rs` file is especially difficult with over 1000 lines of code written in a confusing order. This is just a result of growth within the crate and it would be nice to clean it up for future work.
## Solution
Split `bevy_reflect_derive` into many more submodules. The submodules include:
* `container_attributes` - Code relating to container attributes
* `derive_data` - Code relating to reflection-based derive metadata
* `field_attributes` - Code relating to field attributes
* `impls` - Code containing actual reflection implementations
* `reflect_value` - Code relating to reflection-based value metadata
* `registration` - Code relating to type registration
* `utility` - General-purpose utility functions
This leaves the `lib.rs` file to contain only the public macros, making it much easier to digest (and fewer than 200 lines).
By breaking up the code into smaller modules, we make it easier for future contributors to find the code they're looking for or identify which module best fits their own additions.
### Metadata Structs
This cleanup also adds two big metadata structs: `ReflectFieldAttr` and `ReflectDeriveData`. The former is used to store all attributes for a struct field (if any). The latter is used to store all metadata for struct-based derive inputs.
Both significantly reduce code duplication and make editing these macros much simpler. The tradeoff is that we may collect more metadata than needed. However, this is usually a small thing (such as checking for attributes when they're not really needed or creating a `ReflectFieldAttr` for every field regardless of whether they actually have an attribute).
We could try to remove these tradeoffs and squeeze some more performance out, but doing so might come at the cost of developer experience. Personally, I think it's much nicer to create a `ReflectFieldAttr` for every field since it means I don't have to do two `Option` checks. Others may disagree, though, and so we can discuss changing this either in this PR or in a future one.
### Out of Scope
_Some_ documentation has been added or improved, but ultimately good docs are probably best saved for a dedicated PR.
## 🔍 Focus Points (for reviewers)
I know it's a lot to sift through, so here is a list of **key points for reviewers**:
- The following files contain code that was mostly just relocated:
- `reflect_value.rs`
- `registration.rs`
- `container_attributes.rs` was also mostly moved but features some general cleanup (reducing nesting, removing hardcoded strings, etc.) and lots of doc comments
- Most impl logic was moved from `lib.rs` to `impls.rs`, but they have been significantly modified to use the new `ReflectDeriveData` metadata struct in order to reduce duplication.
- `derive_data.rs` and `field_attributes.rs` contain almost entirely new code and should probably be given the most attention.
- Likewise, `from_reflect.rs` saw major changes using `ReflectDeriveData` so it should also be given focus.
- There was no change to the `lib.rs` exports so the end-user API should be the same.
## Prior Work
This task was initially tackled by @NathanSWard in #2377 (which was closed in favor of this PR), so hats off to them for beating me to the punch by nearly a year!
---
## Changelog
* **[INTERNAL]** Split `bevy_reflect_derive` into smaller submodules
* **[INTERNAL]** Add `ReflectFieldAttr`
* **[INTERNAL]** Add `ReflectDeriveData`
* Add `BevyManifest::get_path_direct()` method (`bevy_macro_utils`)
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
The frame marker event was emitted in the loop of presenting all the windows. This would mark the frame as finished multiple times if more than one window is used.
## Solution
Move the frame marker to after the `for`-loop, so that it gets executed only once.
# Objective
- The code in `events.rs` was a bit messy. There was lots of duplication between `EventReader` and `ManualEventReader`, and the state management code is not needed.
## Solution
- Clean it up.
## Future work
Should we remove the type parameter from `ManualEventReader`?
It doesn't have any meaning outside of its source `Events`. But there's no real reason why it needs to have a type parameter - it's just plain data. I didn't remove it yet to keep the type safety in some of the users of it (primarily related to `&mut World` usage)
# Objective
Relevant issue: #4474
Currently glam types implement Reflect as a value, which is problematic for reflection, making scripting/editor work much more difficult. This PR re-implements them as structs.
## Solution
Added a new proc macro, `impl_reflect_struct`, which replaces `impl_reflect_value` and `impl_from_reflect_value` for glam types. This macro could also be used for other types, but I don't know of any that would require it. It's specifically useful for foreign types that cannot derive Reflect normally.
---
## Changelog
### Added
- `impl_reflect_struct` proc macro
### Changed
- Glam reflect impls have been replaced with `impl_reflect_struct`
- from_reflect's `impl_struct` altered to take an optional custom constructor, allowing non-default non-constructible foreign types to use it
- Calls to `impl_struct` altered to conform to new signature
- Altered glam types (All vec/mat combinations) have a different serialization structure, as they are reflected differently now.
## Migration Guide
This will break altered glam types serialized to RON scenes, as they will expect to be serialized/deserialized as structs rather than values now. A future PR to add custom serialization for non-value types is likely on the way to restore previous behavior. Additionally, calls to `impl_struct` must add a `None` parameter to the end of the call to restore previous behavior.
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
Required for https://github.com/bevyengine/bevy/pull/4402.
# Objective
- derived `SystemParam` implementations were never `ReadOnlySystemParamFetch`
- We want them to be, e.g. for `EventReader`
## Solution
- If possible, 'forward' the impl of `ReadOnlySystemParamFetch`.
# Objective
- (Eventually) reduce noise in reporting access conflicts between unordered systems.
- `SystemStage` only looks at unfiltered `ComponentId` access, any conflicts reported are potentially `false`.
- the systems could still be accessing disjoint archetypes
- Comparing systems' filtered access sets can maybe avoid that (for statically known component types).
- #4204
## Solution
- Modify `SparseSetIndex` trait to require `PartialEq`, `Eq`, and `Hash` (all internal types except `BundleId` already did).
- Add `is_compatible` and `get_conflicts` methods to `FilteredAccessSet<T>`
- (existing method renamed to `get_conflicts_single`)
- Add docs for those and all the other methods while I'm at it.
## Objective
- ~~Make absurdly long-lived changes stay detectable for even longer (without leveling up to `u64`).~~
- Give all changes a consistent maximum lifespan.
- Improve code clarity.
## Solution
- ~~Increase the frequency of `check_tick` scans to increase the oldest reliably-detectable change.~~
(Deferred until we can benchmark the cost of a scan.)
- Ignore changes older than the maximum reliably-detectable age.
- General refactoring—name the constants, use them everywhere, and update the docs.
- Update test cases to check for the specified behavior.
## Related
This PR addresses (at least partially) the concerns raised in:
- #3071
- #3082 (and associated PR #3084)
## Background
- #1471
Given the minimum interval between `check_ticks` scans, `N`, the oldest reliably-detectable change is `u32::MAX - (2 * N - 1)` (or `MAX_CHANGE_AGE`). Reducing `N` from ~530 million (current value) to something like ~2 million would extend the lifetime of changes by a billion.
| minimum `check_ticks` interval | oldest reliably-detectable change | usable % of `u32::MAX` |
| --- | --- | --- |
| `u32::MAX / 8` (536,870,911) | `(u32::MAX / 4) * 3` | 75.0% |
| `2_000_000` | `u32::MAX - 3_999_999` | 99.9% |
Similarly, changes are still allowed to be between `MAX_CHANGE_AGE`-old and `u32::MAX`-old in the interim between `check_tick` scans. While we prevent their age from overflowing, the test to detect changes still compares raw values. This makes failure ultimately unreliable, since when ancient changes stop being detected varies depending on when the next scan occurs.
## Open Question
Currently, systems and system states are incorrectly initialized with their `last_change_tick` set to `0`, which doesn't handle wraparound correctly.
For consistent behavior, they should either be initialized to the world's `last_change_tick` (and detect no changes) or to `MAX_CHANGE_AGE` behind the world's current `change_tick` (and detect everything as a change). I've currently gone with the latter since that was closer to the existing behavior.
## Follow-up Work
(Edited: entire section)
We haven't actually profiled how long a `check_ticks` scan takes on a "large" `World` , so we don't know if it's safe to increase their frequency. However, we are currently relying on play sessions not lasting long enough to trigger a scan and apps not having enough entities/archetypes for it to be "expensive" (our assumption). That isn't a real solution. (Either scanning never costs enough to impact frame times or we provide an option to use `u64` change ticks. Nobody will accept random hiccups.)
To further extend the lifetime of changes, we actually only need to increment the world tick if a system has `Fetch: !ReadOnlySystemParamFetch`. The behavior will be identical because all writes are sequenced, but I'm not sure how to implement that in a way that the compiler can optimize the branch out.
Also, since having no false positives depends on a `check_ticks` scan running at least every `2 * N - 1` ticks, a `last_check_tick` should also be stored in the `World` so that any lull in system execution (like a command flush) could trigger a scan if needed. To be completely robust, all the systems initialized on the world should be scanned, not just those in the current stage.
# Objective
- Add two missing ogg vorbis audio extensions.
## Solution
- Add the two missing extensions to the list
- The file format is the same, there are simply two other possible extensions files can use.
- This can be easily (manually) tested by renaming the extension of `assets/sounds/Windless Slopes.ogg` to end in either `.oga` or `.spx` (in both the filesystem and in `examples/audio/audio.rs`) and then running `cargo run --example audio` and observing that the music still plays.
## More info
From the [wikipedia article for Ogg](https://en.wikipedia.org/wiki/Ogg):
> Ogg audio media is registered as [IANA](https://en.wikipedia.org/wiki/Internet_Assigned_Numbers_Authority) [media type](https://en.wikipedia.org/wiki/Media_type) audio/ogg with file extensions .oga, .ogg, and [.spx](https://en.wikipedia.org/wiki/Speex).
The current workaround is to rename any files ending in `.oga` or `.spx` to end in `.ogg` instead, which complicates tracking assets procured from other organizations.
See also [a corresponding change to bevy_kira_audio](https://github.com/NiklasEi/bevy_kira_audio/pull/8)
---
## Changelog
### Added
- Vorbis audio files may now use the `.oga` and `.spx` filename extensions in addition to the more common `.ogg` filename extension.
# Objective
It is possible to get a mutable reference to a `TypeRegistration` using
`TypeRegistry::get_mut`. However, none of its other methods
(`get_mut_with_name`, `get_type_data`, `iter`, etc.) have mutable
versions.
Besides improving consistency, this change would facilitate use cases
which involve storing mutable state data in the `TypeRegistry`.
## Solution
Provides a trivial wrapper around the mutable accessors that the
`TypeRegistration` already provides. Exactly mirrors the existing
immutable versions.
# Objective
Make it easy to get position and index data from Meshes.
## Solution
It was previously possible to get the mesh data by manually matching on `Mesh::VertexAttributeValues` and `Mesh::Indices`as in the bodies of these two methods (`VertexAttributeValues::as_float3(&self)` and `Indices::iter(&self)`), but that's needless duplication that making these methods `pub` fixes.
# Objective
- Remove `Resource` binding on events, introduce a new `Event` trait
- Ensure event iterators are `ExactSizeIterator`
## Solution
- Builds on #2382 and #2969
## Changelog
- Events<T>, EventWriter<T>, EventReader<T> and so on now require that the underlying type is Event, rather than Resource. Both of these are trivial supertraits of Send + Sync + 'static with universal blanket implementations: this change is currently purely cosmetic.
- Event reader iterators now implement ExactSizeIterator
In a `PluginGroupBuilder`, when adding a plugin that was already in the group (potentially disabled), it was then added twice to the app builder when calling `finish`. As the plugin is kept in an `HashMap`, it is not possible to have the same plugins twice with different configuration.
This PR updates the order of the plugin group so that each plugin is present only once.
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
- New PRs are labeled with Needs-Triage, but this is unhelpful and creates busy work: it's just as easy to check for unlabelled PRs, especially now that we no longer have an unlabelled backlog.
Note: this is not true for issues. Issues start with at least one label based on which template they use, and so there's no good way to filter for issues that need attention from the triage team.
## Solution
- Remove responsible CI tasks.
# Objective
- noticed a few Vec3 and Vec2 that could be const
## Solution
- Declared them as const
- It seems to make a tiny improvement in example `many_light`, but given that the change is not complex at all it could still be worth it
# Objective
We have some macros that are public but only used internally for now. They fail on user's code due to the use of crate names like `bevy_utils`, while the user only has `bevy::utils`. There are two affected macros.
- `bevy_utils::define_label`: it may be useful in user's code for defining custom kinds of label traits (this is why I made this PR).
- `bevy_asset::load_internal_asset`: not useful currently due to limitations of the debug asset server, but this may change in the future.
## Solution
We can make them work by using `$crate` instead of names of their own crates, which can refer to the macro's defining crate regardless of the user's setup. Even though our objective is rather low-priority here, the solution adds no maintenance cost so it is still worthwhile.
# Objective
- Have an easy way to compare spans between executions
## Solution
- Add a tool to compare spans from chrome traces
```bash
> cargo run --release -p spancmp -- --help
Compiling spancmp v0.1.0
Finished release [optimized] target(s) in 1.10s
Running `target/release/spancmp --help`
spancmp
USAGE:
spancmp [OPTIONS] <TRACE> [SECOND_TRACE]
ARGS:
<TRACE>
<SECOND_TRACE>
OPTIONS:
-h, --help Print help information
-p, --pattern <PATTERN> Filter spans by name matching the pattern
-t, --threshold <THRESHOLD> Filter spans that have an average shorther than the threshold
[default: 0]
```
for each span, it will display the count, minimum duration, average duration and max duration. It can be filtered by a pattern on the span name or by a minimum average duration.
just displaying a trace

comparing two traces

Co-authored-by: Robert Swain <robert.swain@gmail.com>
1. change `PtrMut::as_ptr(self)` and `OwnedPtr::as_ptr(self)` to take `&self`, otherwise printing the pointer will prevent doing anything else afterwards
2. make all `as_ptr` methods safe. There's nothing unsafe about obtaining a pointer, these kinds of methods are safe in std as well [str::as_ptr](https://doc.rust-lang.org/stable/std/primitive.str.html#method.as_ptr), [Rc::as_ptr](https://doc.rust-lang.org/stable/std/rc/struct.Rc.html#method.as_ptr)
3. rename `offset`/`add` to `byte_offset`/`byte_add`. The unprefixed methods in std add in increments of `std::mem::size_of::<T>`, not in bytes. There's a PR for rust to add these byte_ methods https://github.com/rust-lang/rust/pull/95643 and at the call site it makes it much more clear that you need to do `.byte_add(i * layout_size)` instead of `.add(i)`
# Objective
Fixes#3180, builds from https://github.com/bevyengine/bevy/pull/2898
## Solution
Support requesting a window to be closed and closing a window in `bevy_window`, and handle this in `bevy_winit`.
This is a stopgap until we move to windows as entites, which I'm sure I'll get around to eventually.
## Changelog
### Added
- `Window::close` to allow closing windows.
- `WindowClosed` to allow reacting to windows being closed.
### Changed
Replaced `bevy::system::exit_on_esc_system` with `bevy:🪟:close_on_esc`.
## Fixed
The app no longer exits when any window is closed. This difference is only observable when there are multiple windows.
## Migration Guide
`bevy::input::system::exit_on_esc_system` has been removed. Use `bevy:🪟:close_on_esc` instead.
`CloseWindow` has been removed. Use `Window::close` instead.
The `Close` variant has been added to `WindowCommand`. Handle this by closing the relevant window.
# Objective
Fixes#4556
## Solution
StorageBuffer must use the Size of the std430 representation to calculate the buffer size, as the std430 representation is the data that will be written to it.
# Objective
Add support for vertex colors
## Solution
This change is modeled after how vertex tangents are handled, so the shader is conditionally compiled with vertex color support if the mesh has the corresponding attribute set.
Vertex colors are multiplied by the base color. I'm not sure if this is the best for all cases, but may be useful for modifying vertex colors without creating a new mesh.
I chose `VertexFormat::Float32x4`, but I'd prefer 16-bit floats if/when support is added.
## Changelog
### Added
- Vertex colors can be specified using the `Mesh::ATTRIBUTE_COLOR` mesh attribute.
# Objective
Bevy users often want to create circles and other simple shapes.
All the machinery is in place to accomplish this, and there are external crates that help. But when writing code for e.g. a new bevy example, it's not really possible to draw a circle without bringing in a new asset, writing a bunch of scary looking mesh code, or adding a dependency.
In particular, this PR was inspired by this interaction in another PR: https://github.com/bevyengine/bevy/pull/3721#issuecomment-1016774535
## Solution
This PR adds `shape::RegularPolygon` and `shape::Circle` (which is just a `RegularPolygon` that defaults to a large number of sides)
## Discussion
There's a lot of ongoing discussion about shapes in <https://github.com/bevyengine/rfcs/pull/12> and at least one other lingering shape PR (although it seems incomplete).
That RFC currently includes `RegularPolygon` and `Circle` shapes, so I don't think that having working mesh generation code in the engine for those shapes would add much burden to an author of an implementation.
But if we'd prefer not to add additional shapes until after that's sorted out, I'm happy to close this for now.
## Alternatives for users
For any users stumbling on this issue, here are some plugins that will help if you need more shapes.
https://github.com/Nilirad/bevy_prototype_lyonhttps://github.com/johanhelsing/bevy_smudhttps://github.com/Weasy666/bevy_svghttps://github.com/redpandamonium/bevy_more_shapeshttps://github.com/ForesightMiningSoftwareCorporation/bevy_polyline
# Objective
- When spawning a sprite the alpha is used for transparency, but when using the `Color::into()` implementation to spawn a `StandardMaterial`, the alpha is ignored.
- Pretty much everytime I want to make something transparent I started with a `Color::rgb().into()` and I'm always surprised that it doesn't work when changing it to `Color::rgba().into()`
- It's possible there's an issue with this approach I am not thinking of, but I'm not sure what's the point of setting an alpha value without the goal of making a color transparent.
## Solution
- Set the alpha_mode to AlphaMode::Blend when the alpha is not the default value.
---
## Migration Guide
This is not a breaking change, but it can easily be migrated to reduce boilerplate
```rust
commands.spawn_bundle(PbrBundle {
mesh: meshes.add(shape::Cube::default().into()),
material: materials.add(StandardMaterial {
base_color: Color::rgba(1.0, 0.0, 0.0, 0.75),
alpha_mode: AlphaMode::Blend,
..default()
}),
..default()
});
// becomes
commands.spawn_bundle(PbrBundle {
mesh: meshes.add(shape::Cube::default().into()),
material: materials.add(Color::rgba(1.0, 0.0, 0.0, 0.75).into()),
..default()
});
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
The pointer types introduced in #3001 are useful not just in `bevy_ecs`, but also in crates like `bevy_reflect` (#4475) or even outside of bevy.
## Solution
Extract `Ptr<'a>`, `PtrMut<'a>`, `OwnedPtr<'a>`, `ThinSlicePtr<'a, T>` and `UnsafeCellDeref` from `bevy_ecs::ptr` into `bevy_ptr`.
**Note:** `bevy_ecs` still reexports the `bevy_ptr` as `bevy_ecs::ptr` so that crates like `bevy_transform` can use the `Bundle` derive without needing to depend on `bevy_ptr` themselves.
# Objective
- `RunOnce` was a manual `System` implementation.
- Adding run criteria to stages was yet to be systemyoten
## Solution
- Make it a normal function
- yeet
## Changelog
- Replaced `RunOnce` with `ShouldRun::once`
## Migration guide
The run criterion `RunOnce`, which would make the controlled systems run only once, has been replaced with a new run criterion function `ShouldRun::once`. Replace all instances of `RunOnce` with `ShouldRun::once`.
# Objective
The `Ptr` types gives free access to the underlying `NonNull<u8>`, which adds more publicly visible pointer wrangling than there needs to be. There are also a few edge cases where Ptr types could be more readily utilized for properly validating the soundness of ECS operations.
## Solution
- Replace `*Ptr(Mut)::inner` with `cast` which requires a concrete type to give the pointer. This function could also have a `debug_assert` with an alignment check to ensure that the pointer is aligned properly, but is currently not included.
- Use `OwningPtr::read` in ECS macros over casting the inner pointer around.
# Objective
- After #3412, `Camera::world_to_screen` got a little bit uglier to use by needing to provide both `Windows` and `Assets<Image>`, even though only one would be needed b697e73c3d/crates/bevy_render/src/camera/camera.rs (L117-L123)
- Some time, exact coordinates are not needed but normalized device coordinates is enough
## Solution
- Add a function to just get NDC
### Problem
It currently isn't possible to construct the default value of a reflected type. Because of that, it isn't possible to use `add_component` of `ReflectComponent` to add a new component to an entity because you can't know what the initial value should be.
### Solution
1. add `ReflectDefault` type
```rust
#[derive(Clone)]
pub struct ReflectDefault {
default: fn() -> Box<dyn Reflect>,
}
impl ReflectDefault {
pub fn default(&self) -> Box<dyn Reflect> {
(self.default)()
}
}
impl<T: Reflect + Default> FromType<T> for ReflectDefault {
fn from_type() -> Self {
ReflectDefault {
default: || Box::new(T::default()),
}
}
}
```
2. add `#[reflect(Default)]` to all component types that implement `Default` and are user facing (so not `ComputedSize`, `CubemapVisibleEntities` etc.)
This makes it possible to add the default value of a component to an entity without any compile-time information:
```rust
fn main() {
let mut app = App::new();
app.register_type::<Camera>();
let type_registry = app.world.get_resource::<TypeRegistry>().unwrap();
let type_registry = type_registry.read();
let camera_registration = type_registry.get(std::any::TypeId::of::<Camera>()).unwrap();
let reflect_default = camera_registration.data::<ReflectDefault>().unwrap();
let reflect_component = camera_registration
.data::<ReflectComponent>()
.unwrap()
.clone();
let default = reflect_default.default();
drop(type_registry);
let entity = app.world.spawn().id();
reflect_component.add_component(&mut app.world, entity, &*default);
let camera = app.world.entity(entity).get::<Camera>().unwrap();
dbg!(&camera);
}
```
### Open questions
- should we have `ReflectDefault` or `ReflectFromWorld` or both?
# Objective
- While optimising many_cubes, I noticed that all material handles are extracted regardless of whether the entity to which the handle belongs is visible or not. As such >100k handles are extracted when only <20k are visible.
## Solution
- Only extract material handles of visible entities.
- This improves `many_cubes -- sphere` from ~42fps to ~48fps. It reduces not only the extraction time but also system commands time. `Handle<StandardMaterial>` extraction and its system commands went from 0.522ms + 3.710ms respectively, to 0.267ms + 0.227ms an 88% reduction for this system for this case. It's very view dependent but...
# Objective
- Creating and executing render passes has GPU overhead. If there are no phase items in the render phase to draw, then this overhead should not be incurred as it has no benefit.
## Solution
- Check if there are no phase items to draw, and if not, do not construct not execute the render pass
---
## Changelog
- Changed: Do not create nor execute empty render passes
# Objective
- Original objective was to add doc build warning check to the ci local execution
- I somewhat deviated and changed other things...
## Solution
`cargo run -p ci` can now take more parameters:
* `format` - cargo fmt
* `clippy` - clippy
* `compile-fail` - bevy_ecs_compile_fail_tests tests
* `test` - tests but not doc tests and do not build examples
* `doc-test` - doc tests
* `doc-check` - doc build and warnings
* `bench-check` - check that benches build
* `example-check` - check that examples build
* `lints` - group - run lints and format and clippy
* `doc` - group - run doc-test and doc-check
* `compile` - group - run compile-fail and bench-check and example-check
* not providing a parameter will run everything
Ci is using those when possible:
* `build` jobs now don't run doc tests and don't build examples. it makes this job faster, but doc tests and examples are not built for each architecture target
* `ci` job doesn't run the `compile-fail` part but only format and clippy, taking less time
* `check-benches` becomes `check-compiles` and runs the `compile` tasks. It takes longer. I also fixed how it was using cache
* `check-doc` job is now independent and also run the doc tests, so it takes longer. I commented out the deadlinks check as it takes 2.5 minutes (to install) and doesn't work
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}