# Objective
- Use the `Material` abstraction for the Wireframes
- Right now this doesn't have many benefits other than simplifying some
of the rendering code
- We can reuse the default vertex shader and avoid rendering
inconsistencies
- The goal is to have a material with a color on each mesh so this
approach will make it easier to implement
- Originally done in https://github.com/bevyengine/bevy/pull/5303 but I
decided to split the Material part to it's own PR and then adding
per-entity colors and globally configurable colors will be a much
simpler diff.
## Solution
- Use the new `Material` abstraction for the Wireframes
## Notes
It's possible this isn't ideal since this adds a
`Handle<WireframeMaterial>` to all the meshes compared to the original
approach that didn't need anything. I didn't notice any performance
impact on my machine.
This might be a surprising usage of `Material` at first, because
intuitively you only have one material per mesh, but the way it's
implemented you can have as many different types of materials as you
want on a mesh.
## Migration Guide
`WireframePipeline` was removed. If you were using it directly, please
create an issue explaining your use case.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Add serde Deserialize and Serialize for structs that doesn't implement
it, even if they could benefit from it
## Solution
- Derive these traits for the structs Style, BackgroundColor,
BorderColor and Outline.
---
Adopted from #8954, co-authored by @pyrotechnick
# Objective
The Bevy ecosystem currently reflects `Quat` via "value" rather than the
more appropriate "struct" strategy. This behaviour is inconsistent to
that of similar types, i.e. `Vec3`. Additionally, employing the "value"
strategy causes instances of `Quat` to be serialised as a sequence `[x,
y, z, w]` rather than structures of shape `{ x, y, z, w }`.
The [comments surrounding the applicable
code](bec299fa6e/crates/bevy_reflect/src/impls/glam.rs (L254))
give context and historical reasons for this discrepancy:
```
// Quat fields are read-only (as of now), and reflection is currently missing
// mechanisms for read-only fields. I doubt those mechanisms would be added,
// so for now quaternions will remain as values. They are represented identically
// to Vec4 and DVec4, so you may use those instead and convert between.
```
This limitation has [since been lifted by the upstream
crate](374625163e),
glam.
## Solution
Migrating the reflect strategy of Quat from "value" to "struct" via
replacing `impl_reflect_value` with `impl_reflect_struct` resolves the
issue.
## Changelog
Migrated `Quat` reflection strategy to "struct" from "value"
Migration Guide
Changed Quat serialization/deserialization from sequences `[x, y, z, w]`
to structures `{ x, y, z, w }`.
---------
Co-authored-by: pyrotechnick <13998+pyrotechnick@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
~~Currently blocked on an upstream bug that causes crashes when
minimizing/resizing on dx12 https://github.com/gfx-rs/wgpu/issues/3967~~
wgpu 0.17.1 is out which fixes it
# Objective
Keep wgpu up to date.
## Solution
Update wgpu and naga_oil.
Currently this depends on an unreleased (and unmerged) branch of
naga_oil, and hasn't been properly tested yet.
The wgpu side of this seems to have been an extremely trivial upgrade
(all the upgrade work seems to be in naga_oil). This also lets us remove
the workarounds for pack/unpack4x8unorm in the SSAO shaders.
Lets us close the dx12 part of
https://github.com/bevyengine/bevy/issues/8888
related: https://github.com/bevyengine/bevy/issues/9304
---
## Changelog
Update to wgpu 0.17 and naga_oil 0.9
# Objective
- This PR aims to make creating meshes a little bit more ergonomic,
specifically by removing the need for intermediate mutable variables.
## Solution
- We add methods that consume the `Mesh` and return a mesh with the
specified changes, so that meshes can be entirely constructed via
builder-style calls, without intermediate variables;
- Methods are flagged with `#[must_use]` to ensure proper use;
- Examples are updated to use the new methods where applicable. Some
examples are kept with the mutating methods so that users can still
easily discover them, and also where the new methods wouldn't really be
an improvement.
## Examples
Before:
```rust
let mut mesh = Mesh::new(PrimitiveTopology::TriangleList);
mesh.insert_attribute(Mesh::ATTRIBUTE_POSITION, vs);
mesh.insert_attribute(Mesh::ATTRIBUTE_NORMAL, vns);
mesh.insert_attribute(Mesh::ATTRIBUTE_UV_0, vts);
mesh.set_indices(Some(Indices::U32(tris)));
mesh
```
After:
```rust
Mesh::new(PrimitiveTopology::TriangleList)
.with_inserted_attribute(Mesh::ATTRIBUTE_POSITION, vs)
.with_inserted_attribute(Mesh::ATTRIBUTE_NORMAL, vns)
.with_inserted_attribute(Mesh::ATTRIBUTE_UV_0, vts)
.with_indices(Some(Indices::U32(tris)))
```
Before:
```rust
let mut cube = Mesh::from(shape::Cube { size: 1.0 });
cube.generate_tangents().unwrap();
PbrBundle {
mesh: meshes.add(cube),
..default()
}
```
After:
```rust
PbrBundle {
mesh: meshes.add(
Mesh::from(shape::Cube { size: 1.0 })
.with_generated_tangents()
.unwrap(),
),
..default()
}
```
---
## Changelog
- Added consuming builder methods for more ergonomic `Mesh` creation:
`with_inserted_attribute()`, `with_removed_attribute()`,
`with_indices()`, `with_duplicated_vertices()`,
`with_computed_flat_normals()`, `with_generated_tangents()`,
`with_morph_targets()`, `with_morph_target_names()`.
# Objective
Closes#9955.
Use the same interface for all "pure" builder types: taking and
returning `Self` (and not `&mut Self`).
## Solution
Changed `DynamicSceneBuilder`, `SceneFilter` and `TableBuilder` to take
and return `Self`.
## Changelog
### Changed
- `DynamicSceneBuilder` and `SceneBuilder` methods in `bevy_ecs` now
take and return `Self`.
## Migration guide
When using `bevy_ecs::DynamicSceneBuilder` and `bevy_ecs::SceneBuilder`,
instead of binding the builder to a variable, directly use it. Methods
on those types now consume `Self`, so you will need to re-bind the
builder if you don't `build` it immediately.
Before:
```rust
let mut scene_builder = DynamicSceneBuilder::from_world(&world);
let scene = scene_builder.extract_entity(a).extract_entity(b).build();
```
After:
```rust
let scene = DynamicSceneBuilder::from_world(&world)
.extract_entity(a)
.extract_entity(b)
.build();
```
# Objective
Spatial audio was heroically thrown together at the last minute for Bevy
0.10, but right now it's a bit of a pain to use -- users need to
manually update audio sinks with the position of the listener / emitter.
Hopefully the migration guide entry speaks for itself.
## Solution
Add a new `SpatialListener` component and automatically update sinks
with the position of the listener and and emitter.
## Changelog
`SpatialAudioSink`s are now automatically updated with positions of
emitters and listeners.
## Migration Guide
Spatial audio now automatically uses the transform of the `AudioBundle`
and of an entity with a `SpatialListener` component.
If you were manually scaling emitter/listener positions, you can use the
`spatial_scale` field of `AudioPlugin` instead.
```rust
// Old
commands.spawn(
SpatialAudioBundle {
source: asset_server.load("sounds/Windless Slopes.ogg"),
settings: PlaybackSettings::LOOP,
spatial: SpatialSettings::new(listener_position, gap, emitter_position),
},
);
fn update(
emitter_query: Query<(&Transform, &SpatialAudioSink)>,
listener_query: Query<&Transform, With<Listener>>,
) {
let listener = listener_query.single();
for (transform, sink) in &emitter_query {
sink.set_emitter_position(transform.translation);
sink.set_listener_position(*listener, gap);
}
}
// New
commands.spawn((
SpatialBundle::from_transform(Transform::from_translation(emitter_position)),
AudioBundle {
source: asset_server.load("sounds/Windless Slopes.ogg"),
settings: PlaybackSettings::LOOP.with_spatial(true),
},
));
commands.spawn((
SpatialBundle::from_transform(Transform::from_translation(listener_position)),
SpatialListener::new(gap),
));
```
## Discussion
I removed `SpatialAudioBundle` because the `SpatialSettings` component
was made mostly redundant, and without that it was identical to
`AudioBundle`.
`SpatialListener` is a bare component and not a bundle which is feeling
like a maybe a strange choice. That happened from a natural aversion
both to nested bundles and to duplicating `Transform` etc in bundles and
from figuring that it is likely to just be tacked on to some other
bundle (player, head, camera) most of the time.
Let me know what you think about these things / everything else.
---------
Co-authored-by: Mike <mike.hsu@gmail.com>
# Objective
- Followup to #7184.
- ~Deprecate `TypeUuid` and remove its internal references.~ No longer
part of this PR.
- Use `TypePath` for the type registry, and (de)serialisation instead of
`std::any::type_name`.
- Allow accessing type path information behind proxies.
## Solution
- Introduce methods on `TypeInfo` and friends for dynamically querying
type path. These methods supersede the old `type_name` methods.
- Remove `Reflect::type_name` in favor of `DynamicTypePath::type_path`
and `TypeInfo::type_path_table`.
- Switch all uses of `std::any::type_name` in reflection, non-debugging
contexts to use `TypePath`.
---
## Changelog
- Added `TypePathTable` for dynamically accessing methods on `TypePath`
through `TypeInfo` and the type registry.
- Removed `type_name` from all `TypeInfo`-like structs.
- Added `type_path` and `type_path_table` methods to all `TypeInfo`-like
structs.
- Removed `Reflect::type_name` in favor of
`DynamicTypePath::reflect_type_path` and `TypeInfo::type_path`.
- Changed the signature of all `DynamicTypePath` methods to return
strings with a static lifetime.
## Migration Guide
- Rely on `TypePath` instead of `std::any::type_name` for all stability
guarantees and for use in all reflection contexts, this is used through
with one of the following APIs:
- `TypePath::type_path` if you have a concrete type and not a value.
- `DynamicTypePath::reflect_type_path` if you have an `dyn Reflect`
value without a concrete type.
- `TypeInfo::type_path` for use through the registry or if you want to
work with the represented type of a `DynamicFoo`.
- Remove `type_name` from manual `Reflect` implementations.
- Use `type_path` and `type_path_table` in place of `type_name` on
`TypeInfo`-like structs.
- Use `get_with_type_path(_mut)` over `get_with_type_name(_mut)`.
## Note to reviewers
I think if anything we were a little overzealous in merging #7184 and we
should take that extra care here.
In my mind, this is the "point of no return" for `TypePath` and while I
think we all agree on the design, we should carefully consider if the
finer details and current implementations are actually how we want them
moving forward.
For example [this incorrect `TypePath` implementation for
`String`](3fea3c6c0b/crates/bevy_reflect/src/impls/std.rs (L90))
(note that `String` is in the default Rust prelude) snuck in completely
under the radar.
Updates the requirements on [toml_edit](https://github.com/toml-rs/toml)
to permit the latest version.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="ed597ebad1"><code>ed597eb</code></a>
chore: Release</li>
<li><a
href="257a0fdc59"><code>257a0fd</code></a>
docs: Update changelog</li>
<li><a
href="4b44f53a31"><code>4b44f53</code></a>
Merge pull request <a
href="https://redirect.github.com/toml-rs/toml/issues/617">#617</a> from
epage/update</li>
<li><a
href="7eaf286110"><code>7eaf286</code></a>
fix(parser): Failed on mixed inline tables</li>
<li><a
href="e1f20378a2"><code>e1f2037</code></a>
test: Verify with latest data</li>
<li><a
href="2f9253c9eb"><code>2f9253c</code></a>
chore: Update toml-test</li>
<li><a
href="c9b481cab5"><code>c9b481c</code></a>
test(toml): Ensure tables are used for validation</li>
<li><a
href="43d7f29cfd"><code>43d7f29</code></a>
Merge pull request <a
href="https://redirect.github.com/toml-rs/toml/issues/615">#615</a> from
toml-rs/renovate/actions-checkout-4.x</li>
<li><a
href="ef9b8372c8"><code>ef9b837</code></a>
chore(deps): update actions/checkout action to v4</li>
<li><a
href="d308188db7"><code>d308188</code></a>
chore: Release</li>
<li>Additional commits viewable in <a
href="https://github.com/toml-rs/toml/compare/v0.19.0...v0.20.2">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
fix#9605
spotlight culling uses an incorrect cluster aabb for orthographic
projections: it does not take into account the near and far cluster
bounds at all.
## Solution
use z_near and z_far to determine cluster aabb in orthographic mode.
i'm not 100% sure this is the only change that's needed, but i am sure
this change is needed, and the example seems to work well now
(CLUSTERED_FORWARD_DEBUG_CLUSTER_LIGHT_COMPLEXITY shows good bounds
around the cone for a variety of orthographic setups).
# Objective
Webgl2 broke when pcf was merged.
Fixes#10048
## Solution
Change the `textureSampleCompareLevel` in shadow_sampling.wgsl to
`textureSampleCompare` to make it work again.
# Objective
Currently, the only way for custom components that participate in
rendering to opt into the higher-performance extraction method in #9903
is to implement the `RenderInstances` data structure and the extraction
logic manually. This is inconvenient compared to the `ExtractComponent`
API.
## Solution
This commit creates a new `RenderInstance` trait that mirrors the
existing `ExtractComponent` method but uses the higher-performance
approach that #9903 uses. Additionally, `RenderInstance` is more
flexible than `ExtractComponent`, because it can extract multiple
components at once. This makes high-performance rendering components
essentially as easy to write as the existing ones based on component
extraction.
---
## Changelog
### Added
A new `RenderInstance` trait is available mirroring `ExtractComponent`,
but using a higher-performance method to extract one or more components
to the render world. If you have custom components that rendering takes
into account, you may consider migration from `ExtractComponent` to
`RenderInstance` for higher performance.
# Objective
- Improve antialiasing for non-point light shadow edges.
- Very partially addresses
https://github.com/bevyengine/bevy/issues/3628.
## Solution
- Implements "The Witness"'s shadow map sampling technique.
- Ported from @superdump's old branch, all credit to them :)
- Implements "Call of Duty: Advanced Warfare"'s stochastic shadow map
sampling technique when the velocity prepass is enabled, for use with
TAA.
- Uses interleaved gradient noise to generate a random angle, and then
averages 8 samples in a spiral pattern, rotated by the random angle.
- I also tried spatiotemporal blue noise, but it was far too noisy to be
filtered by TAA alone. In the future, we should try spatiotemporal blue
noise + a specialized shadow denoiser such as
https://gpuopen.com/fidelityfx-denoiser/#shadow. This approach would
also be useful for hybrid rasterized applications with raytraced
shadows.
- The COD presentation has an interesting temporal dithering of the
noise for use with temporal supersampling that we should revisit when we
get DLSS/FSR/other TSR.
---
## Changelog
* Added `ShadowFilteringMethod`. Improved directional light and
spotlight shadow edges to be less aliased.
## Migration Guide
* Shadows cast by directional lights or spotlights now have smoother
edges. To revert to the old behavior, add
`ShadowFilteringMethod::Hardware2x2` to your cameras.
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- After https://github.com/bevyengine/bevy/pull/9903, example
`mesh2d_manual` doesn't render anything
## Solution
- Fix the example using the new `RenderMesh2dInstances`
# Objective
- Fix TextureAtlasBuilder padding issue
TextureAtlasBuilder padding is reserved during add_texture() but can
still be changed afterwards. This means that changing padding after the
textures will be wrongly applied, either distorting the textures or
panicking if new padding is higher than texture+old padding.
## Solution
- Delay applying padding until finish()
# Objective
Allow Bevy apps to run without requiring to start from the main thread.
This allows other projects and applications to do things like spawning a
normal or scoped
thread and run Bevy applications there.
The current behaviour if you try this is a panic.
## Solution
Allow this by default on platforms winit supports this behaviour on
(x11, Wayland, Windows).
---
## Changelog
### Added
- Added the ability to start Bevy apps outside of the main thread on
x11, Wayland, Windows
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@nordicsemi.no>
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#8140
## Solution
- Added Explicit Error Typing for `AssetLoader` and `AssetSaver`, which
were the last instances of `anyhow` in use across Bevy.
---
## Changelog
- Added an associated type `Error` to `AssetLoader` and `AssetSaver` for
use with the `load` and `save` methods respectively.
- Changed `ErasedAssetLoader` and `ErasedAssetSaver` `load` and `save`
methods to use `Box<dyn Error + Send + Sync + 'static>` to allow for
arbitrary `Error` types from the non-erased trait variants. Note the
strict requirements match the pre-existing requirements around
`anyhow::Error`.
## Migration Guide
- `anyhow` is no longer exported by `bevy_asset`; Add it to your own
project (if required).
- `AssetLoader` and `AssetSaver` have an associated type `Error`; Define
an appropriate error type (e.g., using `thiserror`), or use a pre-made
error type (e.g., `anyhow::Error`). Note that using `anyhow::Error` is a
drop-in replacement.
- `AssetLoaderError` has been removed; Define a new error type, or use
an alternative (e.g., `anyhow::Error`)
- All the first-party `AssetLoader`'s and `AssetSaver`'s now return
relevant (and narrow) error types instead of a single ambiguous type;
Match over the specific error type, or encapsulate (`Box<dyn>`,
`thiserror`, `anyhow`, etc.)
## Notes
A simpler PR to resolve this issue would simply define a Bevy `Error`
type defined as `Box<dyn std::error::Error + Send + Sync + 'static>`,
but I think this type of error handling should be discouraged when
possible. Since only 2 traits required the use of `anyhow`, it isn't a
substantive body of work to solidify these error types, and remove
`anyhow` entirely. End users are still encouraged to use `anyhow` if
that is their preferred error handling style. Arguably, adding the
`Error` associated type gives more freedom to end-users to decide
whether they want more or less explicit error handling (`anyhow` vs
`thiserror`).
As an aside, I didn't perform any testing on Android or WASM. CI passed
locally, but there may be mistakes for those platforms I missed.
# Objective
assets v2 broke custom shader imports. fix them
## Solution
store handles of any file dependencies in the `Shader` to avoid them
being immediately dropped.
also added a use into the `shader_material` example so that it'll be
harder to break support in future.
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
https://github.com/bevyengine/bevy/pull/7328 introduced an API to
override the global wireframe config. I believe it is flawed for a few
reasons.
This PR uses a non-breaking API. Instead of making the `Wireframe` an
enum I introduced the `NeverRenderWireframe` component. Here's the
reason why I think this is better:
- Easier to migrate since it doesn't change the old behaviour.
Essentially nothing to migrate. Right now this PR is a breaking change
but I don't think it has to be.
- It's similar to other "per mesh" rendering features like
NotShadowCaster/NotShadowReceiver
- It doesn't force new users to also think about global vs not global if
all they want is to render a wireframe
- This would also let you filter at the query definition level instead
of filtering when running the query
## Solution
- Introduce a `NeverRenderWireframe` component that ignores the global
config
---
## Changelog
- Added a `NeverRenderWireframe` component that ignores the global
`WireframeConfig`
# Objective
Add support for drawing outlines outside the borders of UI nodes.
## Solution
Add a new `Outline` component with `width`, `offset` and `color` fields.
Added `outline_width` and `outline_offset` fields to `Node`. This is set
after layout recomputation by the `resolve_outlines_system`.
Properties of outlines:
* Unlike borders, outlines have to be the same width on each edge.
* Outlines do not occupy any space in the layout.
* The `Outline` component won't be added to any of the UI node bundles,
it needs to be inserted separately.
* Outlines are drawn outside the node's border, so they are clipped
using the clipping rect of their entity's parent UI node (if it exists).
* `Val::Percent` outline widths are resolved based on the width of the
outlined UI node.
* The offset of the `Outline` adds space between an outline and the edge
of its node.
I was leaning towards adding an `outline` field to `Style` but a
separate component seems more efficient for queries and change
detection. The `Outline` component isn't added to bundles for the same
reason.
---
## Examples
* This image is from the `borders` example from the Bevy UI examples but
modified to include outlines. The UI nodes are the dark red rectangles,
the bright red rectangles are borders and the white lines offset from
each node are the outlines. The yellow rectangles are separate nodes
contained with the dark red nodes:
<img width="406" alt="outlines"
src="https://github.com/bevyengine/bevy/assets/27962798/4e6f315a-019f-42a4-94ee-cca8e684d64a">
* This is from the same example but using a branch that implements
border-radius. Here the the outlines are in orange and there is no
offset applied. I broke the borders implementation somehow during the
merge, which is why some of the borders from the first screenshot are
missing 😅. The outlines work nicely though (as long as you
can forgive the lack of anti-aliasing):

---
## Notes
As I explained above, I don't think the `Outline` component should be
added to UI node bundles. We can have helper functions though, perhaps
something as simple as:
```rust
impl NodeBundle {
pub fn with_outline(self, outline: Outline) -> (Self, Outline) {
(self, outline)
}
}
```
I didn't include anything like this as I wanted to keep the PR's scope
as narrow as possible. Maybe `with_outline` should be in a trait that we
implement for each UI node bundle.
---
## Changelog
Added support for outlines to Bevy UI.
* The `Outline` component adds an outline to a UI node.
* The `outline_width` field added to `Node` holds the resolved width of
the outline, which is set by the `resolve_outlines_system` after layout
recomputation.
* Outlines are drawn by the system `extract_uinode_outlines`.
# Objective
- When I've tested alternative async executors with bevy a common
problem is that they deadlock when we try to run nested scopes. i.e.
running a multithreaded schedule from inside another multithreaded
schedule. This adds a test to bevy_tasks for that so the issue can be
spotted earlier while developing.
## Changelog
- add a test for nested scopes.
# Objective
Fix warnings:
- #[warn(clippy::needless_pass_by_ref_mut)]
- #[warn(elided_lifetimes_in_associated_constant)]
## Solution
- Remove mut
- add &'static
## Errors
```rust
warning: this argument is a mutable reference, but not used mutably
--> crates/bevy_hierarchy/src/child_builder.rs:672:31
|
672 | fn assert_children(world: &mut World, parent: Entity, children: Option<&[Entity]>) {
| ^^^^^^^^^^ help: consider changing to: `&World`
|
= note: this is cfg-gated and may require further changes
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#needless_pass_by_ref_mut
= note: `#[warn(clippy::needless_pass_by_ref_mut)]` on by default
```
```rust
warning: `&` without an explicit lifetime name cannot be used here
--> examples/shader/post_processing.rs:120:21
|
120 | pub const NAME: &str = "post_process";
| ^
|
= warning: this was previously accepted by the compiler but is being phased out; it will become a hard error in a future release!
= note: for more information, see issue #115010 <https://github.com/rust-lang/rust/issues/115010>
= note: `#[warn(elided_lifetimes_in_associated_constant)]` on by default
help: use the `'static` lifetime
|
120 | pub const NAME: &'static str = "post_process";
| +++++++
```
# Objective
Allow the user to choose between "Add wireframes to these specific
entities" or "Add wireframes to everything _except_ these specific
entities".
Fixes#7309
# Solution
Make the `Wireframe` component act like an override to the global
configuration.
Having `global` set to `false`, and adding a `Wireframe` with `enable:
true` acts exactly as before.
But now the opposite is also possible: Set `global` to `true` and add a
`Wireframe` with `enable: false` will draw wireframes for everything
_except_ that entity.
Updated the example to show how overriding the global config works.
# Objective
- Fixes#9884
- Add API for ignoring ambiguities on certain resource or components.
## Solution
- Add a `IgnoreSchedulingAmbiguitiy` resource to the world which holds
the `ComponentIds` to be ignored
- Filter out ambiguities with those component id's.
## Changelog
- add `allow_ambiguous_component` and `allow_ambiguous_resource` apis
for ignoring ambiguities
---------
Co-authored-by: Ryan Johnson <ryanj00a@gmail.com>
# Objective
- Finish documenting `bevy_gltf`.
## Solution
- Document the remaining items, add links to the glTF spec where
relevant. Add the `warn(missing_doc)` attribute.
# Objective
- See fewer warnings when running `cargo clippy` locally.
## Solution
- allow `clippy::type_complexity` in more places, which also signals to
users they should do the same.
# Objective
`bevy_a11y` was impossible to integrate into some third-party projects
in part because it insisted on managing the accessibility tree on its
own.
## Solution
The changes in this PR were necessary to get `bevy_egui` working with
Bevy's AccessKit integration. They were tested on a fork of 0.11,
developed against `bevy_egui`, then ported to main and tested against
the `ui` example.
## Changelog
### Changed
* Add `bevy_a11y::ManageAccessibilityUpdates` to indicate whether the
ECS should manage accessibility tree updates.
* Add getter/setter to `bevy_a11y::AccessibilityRequested`.
* Add `bevy_a11y::AccessibilitySystem` `SystemSet` for ordering relative
to accessibility tree updates.
* Upgrade `accesskit` to v0.12.0.
### Fixed
* Correctly set initial accessibility focus to new windows on creation.
## Migration Guide
### Change direct accesses of `AccessibilityRequested` to use
`AccessibilityRequested.::get()`/`AccessibilityRequested::set()`
#### Before
```
use std::sync::atomic::Ordering;
// To access
accessibility_requested.load(Ordering::SeqCst)
// To update
accessibility_requested.store(true, Ordering::SeqCst);
```
#### After
```
// To access
accessibility_requested.get()
// To update
accessibility_requested.set(true);
```
---------
Co-authored-by: StaffEngineer <111751109+StaffEngineer@users.noreply.github.com>
Conventionally, the second UV map (`TEXCOORD1`, `UV1`) is used for
lightmap UVs. This commit allows Bevy to import them, so that a custom
shader that applies lightmaps can use those UVs if desired.
Note that this doesn't actually apply lightmaps to Bevy meshes; that
will be a followup. It does, however, open the door to future Bevy
plugins that implement baked global illumination.
## Changelog
### Added
The Bevy glTF loader now imports a second UV channel (`TEXCOORD1`,
`UV1`) from meshes if present. This can be used by custom shaders to
implement lightmapping.
# Objective
- Handle suspend / resume events on Android without exiting
## Solution
- On suspend: despawn the window, and set the control flow to wait for
events from the OS
- On resume: spawn a new window, and set the control flow to poll
In this video, you can see the Android example being suspended, stopping
receiving events, and working again after being resumed
https://github.com/bevyengine/bevy/assets/8672791/aaaf4b09-ee6a-4a0d-87ad-41f05def7945
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
- Fixes#4610
## Solution
- Replaced all instances of `parking_lot` locks with equivalents from
`std::sync`. Acquiring locks within `std::sync` can fail, so
`.expect("Lock Poisoned")` statements were added where required.
## Comments
In [this
comment](https://github.com/bevyengine/bevy/issues/4610#issuecomment-1592407881),
the lack of deadlock detection was mentioned as a potential reason to
not make this change. From what I can gather, Bevy doesn't appear to be
using this functionality within the engine. Unless it was expected that
a Bevy consumer was expected to enable and use this functionality, it
appears to be a feature lost without consequence.
Unfortunately, `cpal` and `wgpu` both still rely on `parking_lot`,
leaving it in the dependency graph even after this change.
From my basic experimentation, this change doesn't appear to have any
performance impacts, positive or negative. I tested this using
`bevymark` with 50,000 entities and observed 20ms of frame-time before
and after the change. More extensive testing with larger/real projects
should probably be done.
# Objective
`Has<T>` was added to bevy_ecs, but we're still using the
`Option<With<T>>` pattern in multiple locations.
## Solution
Replace them with `Has<T>`.
# Objective
Add a new method so you can do `set_if_neq` with dereferencing
components: `as_deref_mut()`!
## Solution
Added an as_deref_mut method so that we can use `set_if_neq()` without
having to wrap up types for derefencable components
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Fixes#9363
## Solution
Moved `fq_std` from `bevy_reflect_derive` to `bevy_macro_utils`. This
does make the `FQ*` types public where they were previously private,
which is a change to the public-facing API, but I don't believe a
breaking one. Additionally, I've done a basic QA pass over the
`bevy_macro_utils` crate, adding `deny(unsafe)`, `warn(missing_docs)`,
and documentation where required.
# Objective
Avert a panic when removing resources from Scenes.
### Reproduction Steps
```rust
let mut scene = Scene::new(World::default());
scene.world.init_resource::<Time>();
scene.world.remove_resource::<Time>();
scene.clone_with(&app.resource::<AppTypeRegistry>());
```
### Panic Message
```
thread 'Compute Task Pool (10)' panicked at 'Requested resource bevy_time::time::Time does not exist in the `World`.
Did you forget to add it using `app.insert_resource` / `app.init_resource`?
Resources are also implicitly added via `app.add_event`,
and can be added by plugins.', .../bevy/crates/bevy_ecs/src/reflect/resource.rs:203:52
```
## Solution
Check that the resource actually still exists before copying.
---
## Changelog
- resolved a panic caused by removing resources from scenes
# Objective
Finish documenting `bevy_scene`.
## Solution
Document the remaining items and add a crate-level `warn(missing_doc)`
attribute as for the other crates with completed documentation.
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
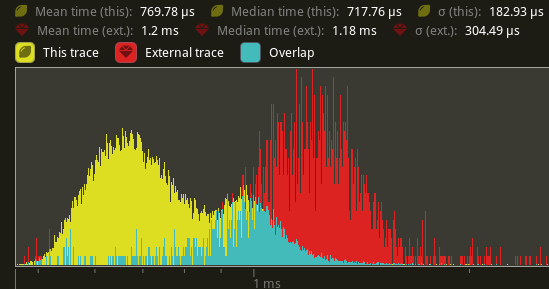
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
# Objective
- sometimes when bevy shuts down on certain machines the render thread
tries to send the time after the main world has been dropped.
- fixes an error mentioned in a reply in
https://github.com/bevyengine/bevy/issues/9543
---
## Changelog
- ignore disconnected errors from the time channel.
# Objective
The `States::variants` method was once used to construct `OnExit` and
`OnEnter` schedules for every possible value of a given `States` type.
[Since the switch to lazily initialized
schedules](https://github.com/bevyengine/bevy/pull/8028/files#diff-b2fba3a0c86e496085ce7f0e3f1de5960cb754c7d215ed0f087aa556e529f97f),
we no longer need to track every possible value.
This also opens the door to `States` types that aren't enums.
## Solution
- Remove the unused `States::variants` method and its associated type.
- Remove the enum-only restriction on derived States types.
---
## Changelog
- Removed `States::variants` and its associated type.
- Derived `States` can now be datatypes other than enums.
## Migration Guide
- `States::variants` no longer exists. If you relied on this function,
consider using a library that provides enum iterators.