# Objective
- Fix disabling features in bevy_ecs (broken by #5630)
- Add tests in CI for bevy_ecs, bevy_reflect and bevy as those crates could be use standalone
Add the following message:
```
Items are returned in the order of the list of entities.
Entities that don't match the query are skipped.
```
Additionally, the docs in `iter.rs` and `state.rs` were updated to match those in `query.rs`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
At least partially addresses #6282.
Resources are currently stored as a dedicated Resource archetype (ID 1). This allows for easy code reusability, but unnecessarily adds 72 bytes (on 64-bit systems) to the struct that is only used for that one archetype. It also requires several fields to be `pub(crate)` which isn't ideal.
This should also remove one sparse-set lookup from fetching, inserting, and removing resources from a `World`.
## Solution
- Add `Resources` parallel to `Tables` and `SparseSets` and extract the functionality used by `Archetype` in it.
- Remove `unique_components` from `Archetype`
- Remove the `pub(crate)` on `Archetype::components`.
- Remove `ArchetypeId::RESOURCE`
- Remove `Archetypes::resource` and `Archetypes::resource_mut`
---
## Changelog
Added: `Resources` type to store resources.
Added: `Storages::resource`
Removed: `ArchetypeId::RESOURCE`
Removed: `Archetypes::resource` and `Archetypes::resources`
Removed: `Archetype::unique_components` and `Archetypes::unique_components_mut`
## Migration Guide
Resources have been moved to `Resources` under `Storages` in `World`. All code dependent on `Archetype::unique_components(_mut)` should access it via `world.storages().resources()` instead.
All APIs accessing the raw data of individual resources (mutable *and* read-only) have been removed as these APIs allowed for unsound unsafe code. All usages of these APIs should be changed to use `World::{get, insert, remove}_resource`.
# Objective
Speed up queries that are fragmented over many empty archetypes and tables.
## Solution
Add a early-out to check if the table or archetype is empty before iterating over it. This adds an extra branch for every archetype matched, but skips setting the archetype/table to the underlying state and any iteration over it.
This may not be worth it for the default `Query::iter` and maybe even the `Query::for_each` implementations, but this definitely avoids scheduling unnecessary tasks in the `Query::par_for_each` case.
Ideally, `matched_archetypes` should only contain archetypes where there's actually work to do, but this would add a `O(n)` flat cost to every call to `update_archetypes` that scales with the number of matched archetypes.
TODO: Benchmark
# Objective
- Fixes#6206
## Solution
- Create a constructor for creating `ReflectComponent` and `ReflectResource`
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
### Added
- Created constructors for `ReflectComponent` and `ReflectResource`, allowing for advanced scripting use-cases.
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
# Objective
- Add a way to iterate over all entities from &World
## Solution
- Added a function `iter_entities` on World which returns an iterator of `Entity` derived from the entities in the `World`'s `archetypes`
---
## Changelog
- Added a function `iter_entities` on World, allowing iterating over all entities in contexts where you only have read-only access to the World.
# Objective
> System chaining is a confusing name: it implies the ability to construct non-linear graphs, and suggests a sense of system ordering that is only incidentally true. Instead, it actually works by passing data from one system to the next, much like the pipe operator.
> In the accepted [stageless RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/45-stageless.md), this concept is renamed to piping, and "system chaining" is used to construct groups of systems with ordering dependencies between them.
Fixes#6225.
## Changelog
System chaining has been renamed to system piping to improve clarity (and free up the name for new ordering APIs).
## Migration Guide
The `.chain(handler_system)` method on systems is now `.pipe(handler_system)`.
The `IntoChainSystem` trait is now `IntoPipeSystem`, and the `ChainSystem` struct is now `PipeSystem`.
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
When designing an API, you may wish to provide access only to a specific field of a component or resource. The current options for doing this in safe code are
* `*Mut::into_inner`, which flags a change no matter what.
* `*Mut::bypass_change_detection`, which misses all changes.
## Solution
Add the method `map_unchanged`.
### Example
```rust
// When run, zeroes the translation of every entity.
fn reset_all(mut transforms: Query<&mut Transform>) {
for transform in &mut transforms {
// We pinky promise not to modify `t` within the closure.
let translation = transform.map_unchanged(|t| &mut t.translation);
// Only reset the translation if it isn't already zero.
translation.set_if_not_equal(Vec2::ZERO);
}
}
```
---
## Changelog
+ Added the method `map_unchanged` to types `Mut<T>`, `ResMut<T>`, and `NonSendMut<T>`.
# Background
Incremental implementation of #4299. The code is heavily borrowed from that PR.
# Objective
The execution order ambiguity checker often emits false positives, since bevy is not aware of invariants upheld by the user.
## Solution
Title
---
## Changelog
+ Added methods `SystemDescriptor::ignore_all_ambiguities` and `::ambiguous_with`. These allow you to silence warnings for specific system-order ambiguities.
## Migration Guide
***Note for maintainers**: This should replace the migration guide for #5916*
Ambiguity sets have been replaced with a simpler API.
```rust
// These systems technically conflict, but we don't care which order they run in.
fn jump_on_click(mouse: Res<Input<MouseButton>>, mut transforms: Query<&mut Transform>) { ... }
fn jump_on_spacebar(keys: Res<Input<KeyCode>>, mut transforms: Query<&mut Transform>) { ... }
//
// Before
#[derive(AmbiguitySetLabel)]
struct JumpSystems;
app
.add_system(jump_on_click.in_ambiguity_set(JumpSystems))
.add_system(jump_on_spacebar.in_ambiguity_set(JumpSystems));
//
// After
app
.add_system(jump_on_click.ambiguous_with(jump_on_spacebar))
.add_system(jump_on_spacebar);
```
# Objective
Relaxes the trait bound for `World::resource_scope` to allow non-send resources. Fixes#6037.
## Solution
No big changes in code had to be made. Added a check so that the non-send resources won't be accessed from a different thread.
---
## Changelog
- `World::resource_scope` accepts non-send resources now
- `World::resource_scope` verifies non-send access if the resource is non-send
- Two new tests are added, one for valid use of `World::resource_scope` with a non-send resource, and one for invalid use (calling it from a different thread, resulting in panic)
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
As explained by #5960, `Commands::get_or_spawn` may return a dangling `EntityCommands` that references a non-existing entities. As explained in [this comment], it may be undesirable to make the method return an `Option`.
- Addresses #5960
- Alternative to #5961
## Solution
This PR adds a doc comment to the method to inform the user that the returned `EntityCommands` is not guaranteed to be valid. It also adds panic doc comments on appropriate `EntityCommands` methods.
[this comment]: https://github.com/bevyengine/bevy/pull/5961#issuecomment-1259870849
# Objective
- Add ability to create nested spawns. This is needed for stageless. The current executor spawns tasks for each system early and runs the system by communicating through a channel. In stageless we want to spawn the task late, so that archetypes can be updated right before the task is run. The executor is run on a separate task, so this enables the scope to be passed to the spawned executor.
- Fixes#4301
## Solution
- Instantiate a single threaded executor on the scope and use that instead of the LocalExecutor. This allows the scope to be Send, but still able to spawn tasks onto the main thread the scope is run on. This works because while systems can access nonsend data. The systems themselves are Send. Because of this change we lose the ability to spawn nonsend tasks on the scope, but I don't think this is being used anywhere. Users would still be able to use spawn_local on TaskPools.
- Steals the lifetime tricks the `std:🧵:scope` uses to allow nested spawns, but disallow scope to be passed to tasks or threads not associated with the scope.
- Change the storage for the tasks to a `ConcurrentQueue`. This is to allow a &Scope to be passed for spawning instead of a &mut Scope. `ConcurrentQueue` was chosen because it was already in our dependency tree because `async_executor` depends on it.
- removed the optimizations for 0 and 1 spawned tasks. It did improve those cases, but made the cases of more than 1 task slower.
---
## Changelog
Add ability to nest spawns
```rust
fn main() {
let pool = TaskPool::new();
pool.scope(|scope| {
scope.spawn(async move {
// calling scope.spawn from an spawn task was not possible before
scope.spawn(async move {
// do something
});
});
})
}
```
## Migration Guide
If you were using explicit lifetimes and Passing Scope you'll need to specify two lifetimes now.
```rust
fn scoped_function<'scope>(scope: &mut Scope<'scope, ()>) {}
// should become
fn scoped_function<'scope>(scope: &Scope<'_, 'scope, ()>) {}
```
`scope.spawn_local` changed to `scope.spawn_on_scope` this should cover cases where you needed to run tasks on the local thread, but does not cover spawning Nonsend Futures.
## TODO
* [x] think real hard about all the lifetimes
* [x] add doc about what 'env and 'scope mean.
* [x] manually check that the single threaded task pool still works
* [x] Get updated perf numbers
* [x] check and make sure all the transmutes are necessary
* [x] move commented out test into a compile fail test
* [x] look through the tests for scope on std and see if I should add any more tests
Co-authored-by: Michael Hsu <myhsu@benjaminelectric.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Make `Res` cloneable
## Solution
Add an associated fn `clone(self: &Self) -. Self` instead of `Copy + Clone` trait impls to avoid `res.clone()` failing to clone out the underlying `T`
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
- Add unit tests for ambiguity detection reporting.
- Incremental implementation of #4299.
## Solution
- Refactor ambiguity detection internals to make it testable. As a bonus, this should make it easier to extend in the future.
## Notes
* This code was copy-pasted from #4299 and modified. Credit goes to @alice-i-cecile and @afonsolage, though I'm not sure who wrote what at this point.
## Objective
Fixes https://github.com/bevyengine/bevy/issues/6063
## Solution
- Use `then_some(x)` instead of `then( || x)`.
- Updated error logs from `bevy_ecs_compile_fail_tests`.
## Migration Guide
From Rust 1.63 to 1.64, a new Clippy error was added; now one should use `then_some(x)` instead of `then( || x)`.
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
The doc comments for `Command` methods are a bit inconsistent on the format, they sometimes go out of scope, and most importantly they are wrong, in the sense that they claim to perform the action described by the command, while in reality, they just push a command to perform the action.
- Follow-up of #5938.
- Related to #5913.
## Solution
- Where applicable, only stated that a `Command` is pushed.
- Added a “See also” section for similar methods.
- Added a missing “Panics” section for `Commands::entity`.
- Removed a wrong comment about `Commands::get_or_spawn` returning `None` (It does not return an option).
- Removed polluting descriptions of other items.
- Misc formatting changes.
## Future possibilities
Since the `Command` implementors (`Spawn`, `InsertBundle`, `InitResource`, ...) are public, I thought that it might be appropriate to describe the action of the command there instead of the method, and to add a `method → command struct` link to fill the gap.
If that seems too far-fetched, we may opt to make them private, if possible, or `#[doc(hidden)]`.
@BoxyUwU this is your fault.
Also cart didn't arrive in time to tell us not to do this.
# Objective
- Fix#2974
## Solution
- The first commit just does the actual change
- Follow up commits do steps to prove that this method works to unify as required, but this does not remove `insert_bundle`.
## Changelog
### Changed
Nested bundles now collapse automatically, and every `Component` now implements `Bundle`.
This means that you can combine bundles and components arbitrarily, for example:
```rust
// before:
.insert(A).insert_bundle(MyBBundle{..})
// after:
.insert_bundle((A, MyBBundle {..}))
```
Note that there will be a follow up PR that removes the current `insert` impl and renames `insert_bundle` to `insert`.
### Removed
The `bundle` attribute in `derive(Bundle)`.
## Migration guide
In `derive(Bundle)`, the `bundle` attribute has been removed. Nested bundles are not collapsed automatically. You should remove `#[bundle]` attributes.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes Issue #6005.
## Solution
Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound.
## Migration Guide
Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead.
# Objective
While using the ParallelExecutor, systems do not actually start until `prepare_systems` completes. In stages where there are large numbers of "empty" systems with very little work to do, this delay adds significant overhead, which can add up over many stages.
## Solution
Immediately and synchronously signal the start of systems that can run without dependencies inside `prepare_systems` instead of waiting for the first executor iteration after `prepare_systems` completes. Any system that is dependent on them still cannot run until after `prepare_systems` completes, but there are a large number of unconstrained systems in the base engine where this is a general benefit in almost every case.
## Performance
This change was tested against `many_foxes` in the default configuration. As this change is sensitive to the overhead around scheduling systems, the spans for measuring system timing, system overhead, and system commands were all commented out for these measurements.
The median stage timings between `main` and this PR are as follows:
|stage|main|this PR|
|:--|:--|:--|
|First|75.54 us|61.61 us|
|LoadAssets|51.05 us|42.32 us|
|PreUpdate|54.6 us|55.56 us|
|Update|61.89 us|51.5 us|
|PostUpdate|7.27 ms|6.71 ms|
|AssetEvents|47.82 us|35.95 us|
|Last|39.19 us|37.71 us|
|reserve_and_flush|57.83 us|48.2 us|
|Extract|1.41 ms|1.28 ms|
|Prepare|554.49 us|502.53 us|
|Queue|216.29 us|207.51 us|
|Sort|67.03 us|60.99 us|
|Render|1.73 ms|1.58 ms|
|Cleanup|33.55 us|30.76 us|
|Clear Entities|18.56 us|17.05 us|
|**full frame**|**11.9 ms**|**10.91 ms**|
For the first few stages, the benefit is small but cumulative over each. For PostUpdate in particular, this allows `parent_update` to run while prepare_systems is running, which is required for the animation and transform propagation systems, which dominate the time spent in the stage, but also frontloads the contention as the other "empty" systems are also running while `parent_update` is running. For Render, where there is just a single large exclusive system, the benefit comes from not waiting on a spuriously scheduled task on the task pool to kick off the system: it's immediately scheduled to run.
# Objective
EntityMut::world takes &mut self instead of &self I don't see any reason for this.
EntityRef is overly restrictive with fn world and could return &'w World
---
## Changelog
- EntityRef now implements Copy and Clone
- EntityRef::world is now fn(&self) -> &'w World instead of fn(&mut self) -> &World
- EntityMut::world is now fn(&self) -> &World instead of fn(&mut self) -> &World
# Objective
Currently, `Local` has a `Sync` bound. Theoretically this is unnecessary as a local can only ever be accessed from its own system, ensuring exclusive access on one thread. This PR removes this restriction.
## Solution
- By removing the `Resource` bound from `Local` and adding the new `SyncCell` threading primative, `Local` can have the `Sync` bound removed.
## Changelog
### Added
- Added `SyncCell` to `bevy_utils`
### Changed
- Removed `Resource` bound from `Local`
- `Local` is now wrapped in a `SyncCell`
## Migration Guide
- Any code relying on `Local<T>` having `T: Resource` may have to be changed, but this is unlikely.
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
# Objective
- Make people stop believing that commands are applied immediately (hopefully).
- Close#5913.
- Alternative to #5930.
## Solution
I added the clause “to perform impactful changes to the `World`” to the first line to subliminally help the reader accept the fact that some operations cannot be performed immediately without messing up everything.
Then I explicitely said that applying a command requires exclusive `World` access, and finally I proceeded to show when these commands are automatically applied.
I also added a brief paragraph about how commands can be applied manually, if they want.
---
### Further possibilities
If you agree, we can also change the text of the method documentation (in a separate PR) to stress about enqueueing an action instead of just performing it. For example, in `Commands::spawn`:
> Creates a new `Entity`
would be changed to something like:
> Issues a `Command` to spawn a new `Entity`
This may even have a greater effect, since when typing in an IDE, the docs of the method pop up and the programmer can read them on the fly.
# Objective
I wanted to run the code
```rust
let reflect_resource: ReflectResource = ...;
let value: Mut<dyn Reflect> = reflect_resource.reflect(world);
value.deref();
// ^ ERROR: deref method doesn't exist because `dyn Reflect` doesnt satisfy `: Sized`.
```
## Solution
Relax `Sized` bounds in all the methods and trait implementations for `Mut` and friends.
# Objective
This code is very disjoint, and the `stage.rs` file that it's in is already very long.
All I've done is move the code and clean up the compiler errors that result.
Followup to #5916, split out from #4299.
# Objective
Ambiguity sets are used to ignore system order ambiguities between groups of systems. However, they are not very useful: they are clunky, poorly integrated, and generally hampered by the difficulty using (or discovering) the ambiguity detector.
As a first step to the work in #4299, we're removing them.
## Migration Guide
Ambiguity sets have been removed.
# Objective
- Our existing change detection API is not flexible enough for advanced users: particularly those attempting to do rollback networking.
- This is an important use case, and with adequate warnings we can make mucking about with change ticks scary enough that users generally won't do it.
- Fixes#5633.
- Closes#2363.
## Changelog
- added `ChangeDetection::set_last_changed` to manually mutate the `last_change_ticks` field"
- the `ChangeDetection` trait now requires an `Inner` associated type, which contains the value being wrapped.
- added `ChangeDetection::bypass_change_detection`, which hands out a raw `&mut Inner`
## Migration Guide
Add the `Inner` associated type and new methods to any type that you've implemented `DetectChanges` for.
Make API users aware that the type aliases `QueryItem` and `QueryFetch` can be used instead of the more bloated alternative with `WorldQueryGats`.
Fixes#5842
# Objective
Clean up taffy nodes when the associated UI node gets removed. The current UI code will keep the taffy nodes around forever.
## Solution
Use `RemovedComponents<Node>` to iterate over nodes that are no longer valid UI nodes or that have been despawned, and remove them from taffy and the internal hash map.
## Implementation Notes
Do note that using `despawn()` instead of `despawn_recursive()` on a UI node that has children will result in a [warnings spam](https://github.com/bevyengine/bevy/blob/main/crates/bevy_ui/src/flex/mod.rs#L120) since the children will not be part of a proper UI hierarchy anymore.
---
## Changelog
- Fixed memory leak when nodes are removed in bevy_ui
# Objective
- Increase consistency across documentation of `Query` methods.
- Fixes#5506
## Solution
- See #4989. This PR is derived from it. It just includes changes to the `Query` methods' docs.
# Objective
- Update `Query` docs with better terminology
- add some performance remarks (Fixes#4742)
## Solution
- See #4989. This PR is derived from it. It just includes changes to the `Query` struct docs.
# Objective
- Fixes#5850
## Solution
- As described in the issue, added a `get_entity` method on `Commands` that returns an `Option<EntityCommands>`
## Changelog
- Added the new method with a simple doc test
- I have re-used `get_entity` in `entity`, similarly to how `get_single` is used in `single` while additionally preserving the error message
- Add `#[inline]` to both functions
Entities that have commands queued to despawn system will still return commands when `get_entity` is called but that is representative of the fact that the entity is still around until those commands are flushed.
A potential `contains_entity` could also be added in this PR if desired, that would effectively be replacing Entities.contains but may be more discoverable if this is a common use case.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
I'm build a UI system for bevy. In this UI system there is a concept of a system per UI entity. I had an issue where change detection wasn't working how I would expect and it's because when a function system is ran the `last_change_tick` is updated with the latest tick(from world). In my particular case I want to "wait" to update the `last_change_tick` until after my system runs for each entity.
## Solution
Initially I thought bypassing the change detection all together would be a good fix, but on talking to some users in discord a simpler fix is to just expose `last_change_tick` to the end users. This is achieved by adding the following to the `System` trait:
```rust
/// Allows users to get the system's last change tick.
fn get_last_change_tick(&self) -> u32;
/// Allows users to set the system's last change tick.
fn set_last_change_tick(&mut self, last_change_tick: u32);
```
This causes a bit of weirdness with two implementors of `System`. `FixedTimestep` and `ChainSystem` both implement system and thus it's required that some sort of implementation be given for the new functions. I solved this by outputting a warning and not doing anything for these systems.
I think it's important to understand why I can't add the new functions only to the function system and not to the `System` trait. In my code I store the systems generically as `Box<dyn System<...>>`. I do this because I have differing parameters that are being passed in depending on the UI widget's system. As far as I can tell there isn't a way to take a system trait and cast it into a specific type without knowing what those parameters are.
In my own code this ends up looking something like:
```rust
// Runs per entity.
let old_tick = widget_system.get_last_change_tick();
should_update_children = widget_system.run((widget_tree.clone(), entity.0), world);
widget_system.set_last_change_tick(old_tick);
// later on after all the entities have been processed:
for system in context.systems.values_mut() {
system.set_last_change_tick(world.read_change_tick());
}
```
## Changelog
- Added `get_last_change_tick` and `set_last_change_tick` to `System`'s.
# Objective
- `for_each` methods inconsistently used an actual generic param or `impl Trait` change it to use `impl Trait` always, change them to be consistent
- some methods returned `'w 's` or `'_ '_`, change them to return `'_ 's`
## Solution
- Do what i just said
---
## Changelog
- `iter_unsafe` and `get_unchecked` no longer return borrows tied to `'w`
## Migration Guide
transmute the returned borrow from `iter_unsafe` and `get_unchecked` if this broke you (although preferably find a way to write your code that doesnt need to do this...)
# Objective
remove `insert_resource_with_id` because `insert_resource_by_id` exists and does almost exactly the same thing
blocked on #5587 because otherwise we will leak a resource when it's inserted
## Solution
remove the function and also add a safety invariant of to `insert_resource_by_id` that the id be valid for the world.
I didn't see any discussion in #4447 about this safety invariant being left off in favor of a panic so I'm curious if there was one or if it just seemed nicer to have less safety invariants for callers to uphold 😅
---
## Changelog
- safety invariant added to `insert_resource_by_id` requiring the id to be valid for world
## Migration Guide
- audit any calls to `insert_resource_by_id` making sure that the id is valid for the world
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#5687
## Solution
Update the methods on the `Entity` struct to be `const`, so we can
define compile-time constants and more generally use them in a const
context.
---
## Changelog
### Added
- Most `Entity` methods are now `const fn`.
# Objective
- Reduce debugging burden when using events by telling user when they missed an event.
## Solution
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes#5817.
- Removes std::vec::Vec ambiguities in derive_bundle macro
## Solution
Prepend :: to standard library full Vec qualified type name (::std::vec::Vec)
# Objective
- Document `QueryCombinationIter`
## Solution
- Describe the item, add usage and examples
- Copy notes about the number of query items generated from the corresponding query methods (they will be removed in #5742 ([motivation]))
## Additional notes
- Derived from #4989
[motivation]: https://github.com/bevyengine/bevy/pull/4989#issuecomment-1208421496
# Objective
Right now, users have to implement basic system adapters such as `Option` <-> `Result` conversions by themselves. This is slightly annoying and discourages the use of system chaining.
## Solution
Add the module `system_adapter` to the prelude, which contains a collection of common adapters. This is very ergonomic in practice.
## Examples
Convenient early returning.
```rust
use bevy::prelude::*;
App::new()
// If the system fails, just try again next frame.
.add_system(pet_dog.chain(system_adapter::ignore))
.run();
#[derive(Component)]
struct Dog;
fn pet_dog(dogs: Query<(&Name, Option<&Parent>), With<Dog>>) -> Option<()> {
let (dog, dad) = dogs.iter().next()?;
println!("You pet {dog}. He/she/they are a good boy/girl/pupper.");
let (dad, _) = dogs.get(dad?.get()).ok()?;
println!("Their dad's name is {dad}");
Some(())
}
```
Converting the output of a system
```rust
use bevy::prelude::*;
App::new()
.add_system(
find_name
.chain(system_adapter::new(String::from))
.chain(spawn_with_name),
)
.run();
fn find_name() -> &'static str { /* ... */ }
fn spawn_with_name(In(name): In<String>, mut commands: Commands) {
commands.spawn().insert(Name::new(name));
}
```
---
## Changelog
* Added the module `bevy_ecs::prelude::system_adapter`, which contains a collection of common system chaining adapters.
* `new` - Converts a regular fn to a system adapter.
* `unwrap` - Similar to `Result::unwrap`
* `ignore` - Discards the output of the previous system.
# Objective
- Fixes#4451
## Solution
- Conditionally compile entity ID cursor as `AtomicI32` when compiling on a platform that does not support 64-bit atomics.
- This effectively raises the MSRV to 1.60 as it uses a `#[cfg]` that was only just stabilized there. (should this be noted in changelog?)
---
## Changelog
- Added `bevy_ecs` support for platforms without 64-bit atomic ints
## Migration Guide
N/A
# Objective
- Fixes#5365
- The `assert!()` when the resource from `World::resource_scope` is inserted into the world is not descriptive.
## Solution
- Add more context to the assert inside of `World::resource_scope` when the `FnOnce` param inserts the resource.
# Objective
- Similar to `SystemChangeTick`, probably somewhat useful for debugging messages.
---
## Changelog
- Added `SystemName` which copies the `SystemMeta::name` field so it can be accessed within a system.
# Objective
Rust 1.63 resolved [an issue](https://github.com/rust-lang/rust/issues/83701) that prevents you from combining explicit generic arguments with `impl Trait` arguments.
Now, we no longer need to use dynamic dispatch to work around this.
## Migration Guide
The methods `Schedule::get_stage` and `get_stage_mut` now accept `impl StageLabel` instead of `&dyn StageLabel`.
### Before
```rust
let stage = schedule.get_stage_mut::<SystemStage>(&MyLabel)?;
```
### After
```rust
let stage = schedule.get_stage_mut::<SystemStage>(MyLabel)?;
```
# Objective
Make CI pass on bevy main.
Update to rust-1.63, updated clippy to 1.63 which introduced the following enhancements:
- [undocumented_unsafe_blocks](https://rust-lang.github.io/rust-clippy/master/index.html#undocumented_unsafe_blocks): Now also lints on unsafe trait implementations
This caught two incorrectly written ( but existing) safety comments for unsafe traits.
## Solution
Fix the comment to use `SAFETY:`
# Objective
While trying out the lint `unsafe_op_in_unsafe_fn` I noticed that `insert_resource_by_id` didn't drop the old value if it already existed, and reimplemented `Column::replace` manually for no apparent reason.
## Solution
- use `Column::replace` and add a test expecting the correct drop count
---
## Changelog
- `World::insert_resource_by_id` will now correctly drop the old resource value, if one already existed
# Objective
- `ReflectMut` served no purpose that wasn't met by `Mut<dyn Reflect>` which is easier to understand since you have to deal with fewer types
- there is another `ReflectMut` type that could be confused with this one
## Solution/Changelog
- relax `T: ?Sized` bound in `Mut<T>`
- replace all instances of `ReflectMut` with `Mut<dyn Reflect>`
# Objective
Provide a safe API to access an `EntityMut`'s `World`.
## Solution
* Add `EntityMut::into_world_mut` for safe access to the entity's world.
---
## Changelog
* Add `EntityMut::into_world_mut` for safe access to the entity's world.
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Simplify the worldquery trait hierarchy as much as possible by putting it all in one trait. If/when gats are stabilised this can be trivially migrated over to use them, although that's not why I made this PR, those reasons are:
- Moves all of the conceptually related unsafe code for a worldquery next to eachother
- Removes now unnecessary traits simplifying the "type system magic" in bevy_ecs
---
## Changelog
All methods/functions/types/consts on `FetchState` and `Fetch` traits have been moved to the `WorldQuery` trait and the other traits removed. `WorldQueryGats` now only contains an `Item` and `Fetch` assoc type.
## Migration Guide
Implementors should move items in impls to the `WorldQuery/Gats` traits and remove any `Fetch`/`FetchState` impls
Any use sites of items in the `Fetch`/`FetchState` traits should be updated to use the `WorldQuery` trait items instead
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Currently, actually using a `Local` on a system requires that it be `T: FromWorld`, but that requirement is only expressed on the `SystemParam` machinery, which leads to the confusing error message for when the user attempts to add an invalid system. By adding these bounds to `Local` directly, it improves clarity on usage and semantics.
## Solution
- Add `T: FromWorld` bound to `Local`'s definition
## Migration Guide
- It might be possible for references to `Local`s without `T: FromWorld` to exist, but these should be exceedingly rare and probably dead code. In the event that one of these is encountered, the easiest solutions are to delete the code or wrap the inner `T` in an `Option` to allow it to be default constructed to `None`.
# Objective
Replace `many_for_each_mut` with `iter_many_mut` using the same tricks to avoid aliased mutability that `iter_combinations_mut` uses.
<sub>I tried rebasing the draft PR I made for this before and it died. F</sub>
## Why
`many_for_each_mut` is worse for a few reasons:
1. The closure prevents the use of `continue`, `break`, and `return` behaves like a limited `continue`.
2. rustfmt will crumple it and double the indentation when the line gets too long.
```rust
query.many_for_each_mut(
&entity_list,
|(mut transform, velocity, mut component_c)| {
// Double trouble.
},
);
```
3. It is more surprising to have `many_for_each_mut` as a mutable counterpart to `iter_many` than `iter_many_mut`.
4. It required a separate unsafe fn; more unsafe code to maintain.
5. The `iter_many_mut` API matches the existing `iter_combinations_mut` API.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`ReadOnlyWorldQuery` should have required `Self::ReadOnly = Self` so that calling `.iter()` on a readonly query is equivelent to calling `iter_mut()`.
## Solution
add `ReadOnly = Self` to the definition of `ReadOnlyWorldQuery`
---
## Changelog
ReadOnlyWorldQuery's `ReadOnly` assoc type is now always equal to `Self`
## Migration Guide
Make `Self::ReadOnly = Self` hold
# Objective
Enable treating components and resources equally, which can
simplify the implementation of some systems where only the change
detection feature is relevant and not the kind of object (resource or
component).
## Solution
Implement `From<ResMut<T>>` and `From<NonSendMut<T>>` for
`Mut`. Since the 3 structs are similar, and only differ by their system
param role, the conversion is trivial.
---
## Changelog
Added - `From<ResMut>` and `From<NonSendMut>` for `Mut<T>`.
# Objective
I noticed while working on #5366 that the documentation for label types wasn't working correctly. Having experimented with this for a few weeks, I believe that generating docs in macros is more effort than it's worth.
## Solution
Add more boilerplate, copy-paste and edit the docs across types. This also lets us add custom doctests for specific types. Also, we don't need `concat_idents` as a dependency anymore.
# Objective
- Allows conversion of mutable queries to immutable queries.
- Fixes#4606
## Solution
- Add `to_readonly` method on `Query`, which uses `QueryState::as_readonly`
- `AsRef` is not feasible because creation of new queries is needed.
---
## Changelog
### Added
- Allows conversion of mutable queries to immutable queries using `Query::to_readonly`.
after #5355, three methods were added on world:
* `send_event`
* `send_event_batch`
* `send_default_event`
rename `send_default_event` to `send_event_default` for better discoverability
# Objective
- With access to `World`, it's not obvious how to send an event.
- This is especially useful if you are writing a `Command` that needs to send an `Event`.
- `Events` are a first-class construct in bevy, even though they are just `Resources` under the hood. Their methods should be discoverable.
## Solution
- Provide a simple helpers to send events through `Res<Events<T>>`.
---
## Changelog
> `send_event`, `send_default_event`, and `send_event_batch` methods added to `World`.
# Objective
Fixes#5362
## Solution
Add the attribute `#[label(ignore_fields)]` for `*Label` types.
```rust
#[derive(SystemLabel)]
pub enum MyLabel {
One,
// Previously this was not allowed since labels cannot contain data.
#[system_label(ignore_fields)]
Two(PhantomData<usize>),
}
```
## Notes
This label makes it possible for equality to behave differently depending on whether or not you are treating the type as a label. For example:
```rust
#[derive(SystemLabel, PartialEq, Eq)]
#[system_label(ignore_fields)]
pub struct Foo(usize);
```
If you compare it as a label, it will ignore the wrapped fields as the user requested. But if you compare it as a `Foo`, the derive will incorrectly compare the inner fields. I see a few solutions
1. Do nothing. This is technically intended behavior, but I think we should do our best to prevent footguns.
2. Generate impls of `PartialEq` and `Eq` along with the `#[derive(Label)]` macros. This is a breaking change as it requires all users to remove these derives from their types.
3. Only allow `PhantomData` to be used with `ignore_fields` -- seems needlessly prescriptive.
---
## Changelog
* Added the `ignore_fields` attribute to the derive macros for `*Label` types.
* Added an example showing off different forms of the derive macro.
<!--
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- If this PR is a breaking change (relative to the last release of Bevy), describe how a user might need to migrate their code to support these changes
- Simply adding new functionality is not a breaking change.
- Fixing behavior that was definitely a bug, rather than a questionable design choice is not a breaking change.
-->
# Objective
remove `QF` generics from a bunch of types and methods on query related items. this has a few benefits:
- simplifies type signatures `fn iter(&self) -> QueryIter<'_, 's, Q::ReadOnly, F::ReadOnly>` is (imo) conceptually simpler than `fn iter(&self) -> QueryIter<'_, 's, Q, ROQueryFetch<'_, Q>, F>`
- `Fetch` is mostly an implementation detail but previously we had to expose it on every `iter` `get` etc method
- Allows us to potentially in the future simplify the `WorldQuery` trait hierarchy by removing the `Fetch` trait
## Solution
remove the `QF` generic and add a way to (unsafely) turn `&QueryState<Q1, F1>` into `&QueryState<Q2, F2>`
---
## Changelog/Migration Guide
The `QF` generic was removed from various `Query` iterator types and some methods, you should update your code to use the type of the corresponding worldquery of the fetch type that was being used, or call `as_readonly`/`as_nop` to convert a querystate to the appropriate type. For example:
`.get_single_unchecked_manual::<ROQueryFetch<Q>>(..)` -> `.as_readonly().get_single_unchecked_manual(..)`
`my_field: QueryIter<'w, 's, Q, ROQueryFetch<'w, Q>, F>` -> `my_field: QueryIter<'w, 's, Q::ReadOnly, F::ReadOnly>`
# Objective
- Closes#4954
- Reduce the complexity of the `{System, App, *}Label` APIs.
## Solution
For the sake of brevity I will only refer to `SystemLabel`, but everything applies to all of the other label types as well.
- Add `SystemLabelId`, a lightweight, `copy` struct.
- Convert custom types into `SystemLabelId` using the trait `SystemLabel`.
## Changelog
- String literals implement `SystemLabel` for now, but this should be changed with #4409 .
## Migration Guide
- Any previous use of `Box<dyn SystemLabel>` should be replaced with `SystemLabelId`.
- `AsSystemLabel` trait has been modified.
- No more output generics.
- Method `as_system_label` now returns `SystemLabelId`, removing an unnecessary level of indirection.
- If you *need* a label that is determined at runtime, you can use `Box::leak`. Not recommended.
## Questions for later
* Should we generate a `Debug` impl along with `#[derive(*Label)]`?
* Should we rename `as_str()`?
* Should we remove the extra derives (such as `Hash`) from builtin `*Label` types?
* Should we automatically derive types like `Clone, Copy, PartialEq, Eq`?
* More-ergonomic comparisons between `Label` and `LabelId`.
* Move `Dyn{Eq, Hash,Clone}` somewhere else.
* Some API to make interning dynamic labels easier.
* Optimize string representation
* Empty string for unit structs -- no debug info but faster comparisons
* Don't show enum types -- same tradeoffs as asbove.
Add compile time check for if a system is an exclusive system. Resolves#4788
Co-authored-by: Daniel Liu <mr.picklepinosaur@gmail.com>
Co-authored-by: Daniel Liu <danieliu3120@gmail.com>
Following https://github.com/bevyengine/bevy/pull/5124 I decided to add the `ExactSizeIterator` impl for `QueryCombinationIter`.
Also:
- Clean up the tests for `size_hint` and `len` for both the normal `QueryIter` and `QueryCombinationIter`.
- Add tests to `QueryCombinationIter` when it shouldn't be `ExactSizeIterator`
---
## Changelog
- Added `ExactSizeIterator` implementation for `QueryCombinatonIter`
# Objective
- `.iter_combinations_*()` cannot be used on custom derived `WorldQuery`, so this fixes that
- Fixes#5284
## Solution
- `#[derive(Clone)]` on the `Fetch` of the proc macro derive.
- `#[derive(Clone)]` for `AnyOf` to satisfy tests.
# Objective
Improve documentation, information users of the limitations in bevy's idiomatic patterns, and suggesting alternatives for when those limitations are encountered.
## Solution
* Add documentation to `Commands` informing the user of the option of writing one-shot commands with closures.
* Add documentation to `EventWriter` regarding the limitations of event types, and suggesting alternatives using commands.
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`ReflectResource` and `ReflectComponent` will panic on `apply` method if there is no such component. It's not very ergonomic. And not very good for performance since I need to check if such component exists first.
## Solution
* Add `ReflectComponent::apply_or_insert` and `ReflectResource::apply_or_insert` functions.
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
---
## Changelog
### Added
* `ReflectResource::apply_or_insert` and `ReflectComponent::apply_on_insert`.
### Changed
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
* Use `ReflectComponent::apply_on_insert` in `DynamicScene` instead of manual checking.
## Migration Guide
* Rename `ReflectComponent::add` into `ReflectComponent::insert`.
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`EntityMap` lacks documentation, don't have `len()` / `is_empty` and `insert` doesn't work as in the regular HashMap`.
## Solution
* Add `len()` method.
* Return previously mapped entity from `insert()` as in the regular `HashMap`.
* Add documentation.
---
## Changelog
* Add `EntityMap::len()`.
* Return previously mapped entity from `EntityMap::insert()` as in the regular `HashMap`.
* Add documentation for `EntityMap` methods.
# Objective
Remove suffixes from reflect component and resource methods to closer match bevy norms.
## Solution
removed suffixes and also fixed a spelling error
---
# Objective
- Help users fix issue when their app panic when executing a command on a despawned entity
## Solution
- Add an error code and a page describing how to debug the issue
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
This is a common and useful type. I frequently use this when working with `Events` resource directly, typically when caching the data or manipulating the `World` directly.
This is also useful when manually configuring the cleanup strategy for events.
The first leak:
```rust
#[test]
fn blob_vec_drop_empty_capacity() {
let item_layout = Layout:🆕:<Foo>();
let drop = drop_ptr::<Foo>;
let _ = unsafe { BlobVec::new(item_layout, Some(drop), 0) };
}
```
this is because we allocate the swap scratch in blobvec regardless of what the capacity is, but we only deallocate if capacity is > 0
The second leak:
```rust
#[test]
fn panic_while_overwriting_component() {
let helper = DropTestHelper::new();
let res = panic::catch_unwind(|| {
let mut world = World::new();
world
.spawn()
.insert(helper.make_component(true, 0))
.insert(helper.make_component(false, 1));
println!("Done inserting! Dropping world...");
});
let drop_log = helper.finish(res);
assert_eq!(
&*drop_log,
[
DropLogItem::Create(0),
DropLogItem::Create(1),
DropLogItem::Drop(0),
]
);
}
```
this is caused by us not running the drop impl on the to-be-inserted component if the drop impl of the overwritten component panics
---
managed to figure out where the leaks were by using this 10/10 command
```
cargo --quiet test --lib -- --list | sed 's/: test$//' | MIRIFLAGS="-Zmiri-disable-isolation" xargs -n1 cargo miri test --lib -- --exact
```
which runs every test one by one rather than all at once which let miri actually tell me which test had the leak 🙃
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
CI is now failing with some changes that landed in 1.62.
## Solution
* Fix an unused lifetime by using it (we double-used the `w` lifetime).
* Update compile_fail error messages
* temporarily disable check-unused-dependencies
# Objective
- Provide a way to see the components of an entity.
- Fixes#1467
## Solution
- Add `World::inspect_entity`. It accepts an `Entity` and returns a vector of `&ComponentInfo` that the entity has.
- Add `EntityCommands::log_components`. It logs the component names of the entity. (info level)
---
## Changelog
### Added
- Ability to inspect components of an entity through `World::inspect_entity` or `EntityCommands::log_components`
There are some outdated error messages for when a resource is not found. It references `add_resource` and `add_non_send_resource` which were renamed to `insert_resource` and `insert_non_send_resource`.
# Objective
- Fixes#3142
## Solution
- Done according to #3142
- Created new marker trait `ArchetypeFilter`
- Implement said trait to:
- `With<T>`
- `Without<T>`
- tuples containing only types that implement `ArchetypeFilter`, from 0 to 15 elements
- `Or<T>` where T is a tuple as described previously
- Changed `ExactSizeIterator` impl to include a new generic that must implement `WorldQuery` and `ArchetypeFilter`
- Added new tests
---
## Changelog
### Added
- `Query`s with archetypal filters can now use `.iter().len()` to get the exact size of the iterator.
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
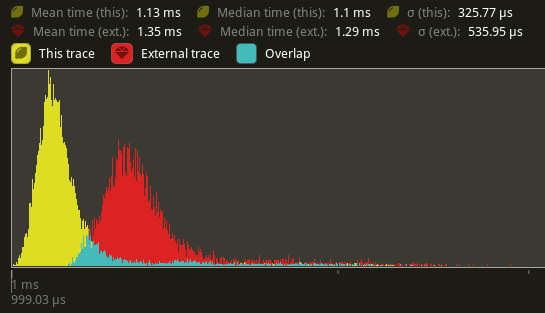
The command heavy `Extract` stage also saw a smaller overall improvement:
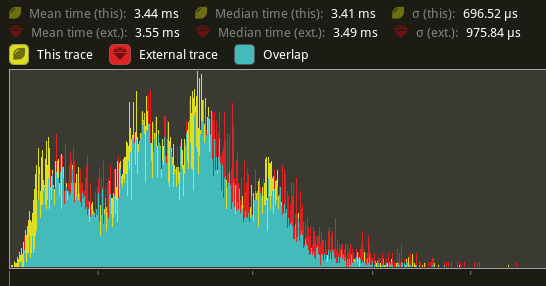
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
- Simplify the process of obtaining a `ComponentId` instance corresponding to a `Component`.
- Resolves#5060.
## Solution
- Add a `component_id::<T: Component>(&self)` function to both `World` and `Components` to retrieve the `ComponentId` associated with `T` from a immutable reference.
---
## Changelog
- Added `World::component_id::<C>()` and `Components::component_id::<C>()` to retrieve a `Component`'s corresponding `ComponentId` if it exists.
# Objective
Closes#1557. Partially addresses #3362.
Cleanup the public facing API for storage types. Most of these APIs are difficult to use safely when directly interfacing with these types, and is also currently impossible to interact with in normal ECS use as there is no `World::storages_mut`. The majority of these types should be easy enough to read, and perhaps mutate the contents, but never structurally altered without the same checks in the rest of bevy_ecs code. This both cleans up the public facing types and helps use unused code detection to remove a few of the APIs we're not using internally.
## Solution
- Mark all APIs that take `&mut T` under `bevy_ecs::storage` as `pub(crate)` or `pub(super)`
- Cleanup after it all.
Entire type visibility changes:
- `BlobVec` is `pub(super)`, only storage code should be directly interacting with it.
- `SparseArray` is now `pub(crate)` for the entire type. It's an implementation detail for `Table` and `(Component)SparseSet`.
- `TableMoveResult` is now `pub(crate)
---
## Changelog
TODO
## Migration Guide
Dear God, I hope not.
# Objective
The descriptions included in the API docs of `entity` module, `Entity` struct, and `Component` trait have some issues:
1. the concept of entity is not clearly defined,
2. descriptions are a little bit out of place,
3. in a case the description leak too many details about the implementation,
4. some descriptions are not exhaustive,
5. there are not enough examples,
6. the content can be formatted in a much better way.
## Solution
1. ~~Stress the fact that entity is an abstract and elementary concept. Abstract because the concept of entity is not hardcoded into the library but emerges from the interaction of `Entity` with every other part of `bevy_ecs`, like components and world methods. Elementary because it is a fundamental concept that cannot be defined with other terms (like point in euclidean geometry, or time in classical physics).~~ We decided to omit the definition of entity in the API docs ([see why]). It is only described in its relationship with components.
2. Information has been moved to relevant places and links are used instead in the other places.
3. Implementation details about `Entity` have been reduced.
4. Descriptions have been made more exhaustive by stating how to obtain and use items. Entity operations are enriched with `World` methods.
5. Examples have been added or enriched.
6. Sections have been added to organize content. Entity operations are now laid out in a table.
### Todo list
- [x] Break lines at sentence-level.
## For reviewers
- ~~I added a TODO over `Component` docs, make sure to check it out and discuss it if necessary.~~ ([Resolved])
- You can easily check the rendered documentation by doing `cargo doc -p bevy_ecs --no-deps --open`.
[see why]: https://github.com/bevyengine/bevy/pull/4767#discussion_r875106329
[Resolved]: https://github.com/bevyengine/bevy/pull/4767#discussion_r874127825
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
# Objective
- Fixes#4271
## Solution
- Check for a pending transition in addition to a scheduled operation.
- I don't see a valid reason for updating the state unless both `scheduled` and `transition` are empty.
# Objective
Following #4855, `Column` is just a parallel `BlobVec`/`Vec<UnsafeCell<ComponentTicks>>` pair, which is identical to the dense and ticks vecs in `ComponentSparseSet`, which has some code duplication with `Column`.
## Solution
Replace dense and ticks in `ComponentSparseSet` with a `Column`.
# Objective
Most of our `Iterator` impls satisfy the requirements of `std::iter::FusedIterator`, which has internal specialization that optimizes `Interator::fuse`. The std lib iterator combinators do have a few that rely on `fuse`, so this could optimize those use cases. I don't think we're using any of them in the engine itself, but beyond a light increase in compile time, it doesn't hurt to implement the trait.
## Solution
Implement the trait for all eligible iterators in first party crates. Also add a missing `ExactSizeIterator` on an iterator that could use it.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864Fixes#1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
(follow-up to #4423)
# Objective
Currently, it isn't possible to easily fire commands from within par_for_each blocks. This PR allows for issuing commands from within parallel scopes.
# Objective
This PR aims to improve the soundness of `CommandQueue`. In particular it aims to:
- make it sound to store commands that contain padding or uninitialized bytes;
- avoid uses of commands after moving them in the queue's buffer (`std::mem::forget` is technically a use of its argument);
- remove useless checks: `self.bytes.as_mut_ptr().is_null()` is always `false` because even `Vec`s that haven't allocated use a dangling pointer. Moreover the same pointer was used to write the command, so it ought to be valid for reads if it was for writes.
## Solution
- To soundly store padding or uninitialized bytes `CommandQueue` was changed to contain a `Vec<MaybeUninit<u8>>` instead of `Vec<u8>`;
- To avoid uses of the command through `std::mem::forget`, `ManuallyDrop` was used.
## Other observations
While writing this PR I noticed that `CommandQueue` doesn't seem to drop the commands that weren't applied. While this is a pretty niche case (you would have to be manually using `CommandQueue`/`std::mem::swap`ping one), I wonder if it should be documented anyway.
# Objective
Don't allocate memory for Component types known at compile-time. Save a bit of memory.
## Solution
Change `ComponentDescriptor::name` from `String` to `Cow<'static, str>` to use the `&'static str` returned by `std::any::type_name`.
# Objective
`debug_assert!` macros must still compile properly in release mode due to how they're implemented. This is causing release builds to fail.
## Solution
Change them to `assert!` macros inside `#[cfg(debug_assertions)]` blocks.
# Objective
- Higher order system could not be created by users.
- However, a simple change to `SystemParamFunction` allows this.
- Higher order systems in this case mean functions which return systems created using other systems, such as `chain` (which is basically equivalent to map)
## Solution
- Change `SystemParamFunction` to be a safe abstraction over `FnMut([In<In>,] ...params)->Out`.
- Note that I believe `SystemParamFunction` should not have been counted as part of our public api before this PR.
- This is because its only use was an unsafe function without an actionable safety comment.
- The safety comment was basically 'call this within bevy code'.
- I also believe that there are no external users in its current form.
- A quick search on Google and in the discord confirmed this.
## See also
- https://github.com/bevyengine/bevy/pull/4666, which uses this and subsumes the example here
---
## Changelog
### Added
- `SystemParamFunction`, which can be used to create higher order systems.
# Objective
Use less memory to store SparseSet components.
## Solution
Change `ComponentSparseSet` to only use `Entity::id` in it's key internally, and change the usize value in it's SparseArray to use u32 instead, as it cannot have more than u32::MAX live entities stored at once.
This should reduce the overhead of storing components in sparse set storage by 50%.
# Objective
Fixes#3183. Requiring a `&TaskPool` parameter is sort of meaningless if the only correct one is to use the one provided by `Res<ComputeTaskPool>` all the time.
## Solution
Have `QueryState` save a clone of the `ComputeTaskPool` which is used for all `par_for_each` functions.
~~Adds a small overhead of the internal `Arc` clone as a part of the startup, but the ergonomics win should be well worth this hardly-noticable overhead.~~
Updated the docs to note that it will panic the task pool is not present as a resource.
# Future Work
If https://github.com/bevyengine/rfcs/pull/54 is approved, we can replace these resource lookups with a static function call instead to get the `ComputeTaskPool`.
---
## Changelog
Removed: The `task_pool` parameter of `Query(State)::par_for_each(_mut)`. These calls will use the `World`'s `ComputeTaskPool` resource instead.
## Migration Guide
The `task_pool` parameter for `Query(State)::par_for_each(_mut)` has been removed. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(
task_pool: Res<ComputeTaskPool>,
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
If using `Query(State)` outside of a system run by the scheduler, you may need to manually configure and initialize a `ComputeTaskPool` as a resource in the `World`.
# Objective
The `ComponentId` in `Column` is redundant as it's stored in parallel in the surrounding `SparseSet` all the time.
## Solution
Remove it. Add `SparseSet::iter(_mut)` to parallel `HashMap::iter(_mut)` to allow iterating pairs of columns and their IDs.
---
## Changelog
Added: `SparseSet::iter` and `SparseSet::iter_mut`.
# Objective
- Rebase of #3159.
- Fixes https://github.com/bevyengine/bevy/issues/3156
- add #[inline] to single related functions so that they matches with other function defs
## Solution
* added functions to QueryState
* get_single_unchecked_manual
* get_single_unchecked
* get_single
* get_single_mut
* single
* single_mut
* make Query::get_single use QueryState::get_single_unchecked_manual
* added #[inline]
---
## Changelog
### Added
Functions `QueryState::single`, `QueryState::get_single`, `QueryState::single_mut`, `QueryState::get_single_mut`, `QueryState::get_single_unchecked`, `QueryState::get_single_unchecked_manual`.
### Changed
`QuerySingleError` is now in the `state` module.
## Migration Guide
Change `query::QuerySingleError` to `state::QuerySingleError`
Co-authored-by: 2ne1ugly <chattermin@gmail.com>
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
the code in these fns are always identical so stop having two functions
## Solution
make them the same function
---
## Changelog
change `matches_archetype` and `matches_table` to `fn matches_component_set(&self, &SparseArray<ComponentId, usize>) -> bool` then do extremely boring updating of all `FetchState` impls
## Migration Guide
- move logic of `matches_archetype` and `matches_table` into `matches_component_set` in any manual `FetchState` impls
# Objective
Even if bevy itself does not provide any builtin scripting or modding APIs, it should have the foundations for building them yourself.
For that it should be enough to have APIs that are not tied to the actual rust types with generics, but rather accept `ComponentId`s and `bevy_ptr` ptrs.
## Solution
Add the following APIs to bevy
```rust
fn EntityRef::get_by_id(ComponentId) -> Option<Ptr<'w>>;
fn EntityMut::get_by_id(ComponentId) -> Option<Ptr<'_>>;
fn EntityMut::get_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
fn World::get_resource_by_id(ComponentId) -> Option<Ptr<'_>>;
fn World::get_resource_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
// Safety: `value` must point to a valid value of the component
unsafe fn World::insert_resource_by_id(ComponentId, value: OwningPtr);
fn ComponentDescriptor::new_with_layout(..) -> Self;
fn World::init_component_with_descriptor(ComponentDescriptor) -> ComponentId;
```
~~This PR would definitely benefit from #3001 (lifetime'd pointers) to make sure that the lifetimes of the pointers are valid and the my-move pointer in `insert_resource_by_id` could be an `OwningPtr`, but that can be adapter later if/when #3001 is merged.~~
### Not in this PR
- inserting components on entities (this is very tied to types with bundles and the `BundleInserter`)
- an untyped version of a query (needs good API design, has a large implementation complexity, can be done in a third-party crate)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Fixes#4657
Example code that wasnt panic'ing before this PR (and so was unsound):
```rust
#[test]
#[should_panic = "error[B0001]"]
fn option_has_no_filter_with() {
fn sys(_1: Query<(Option<&A>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn any_of_has_no_filter_with() {
fn sys(_1: Query<(AnyOf<(&A, ())>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn or_has_no_filter_with() {
fn sys(_1: Query<&mut B, Or<(With<A>, With<B>)>>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
```
## Solution
- Only add the intersection of `with`/`without` accesses of all the elements in `Or/AnyOf` to the world query's `FilteredAccess<ComponentId>` instead of the union.
- `Option`'s fix can be thought of the same way since its basically `AnyOf<T, ()>` but its impl is just simpler as `()` has no `with`/`without` accesses
---
## Changelog
- `Or`/`AnyOf`/`Option` will now report more query conflicts in order to fix unsoundness
## Migration Guide
- If you are now getting query conflicts from `Or`/`AnyOf`/`Option` rip to you and ur welcome for it now being caught
# Objective
We have duplicated code between `QueryIter` and `QueryIterationCursor`. Reuse that code.
## Solution
- Reuse `QueryIterationCursor` inside `QueryIter`.
- Slim down `QueryIter` by removing the `&'w World`. It was only being used by the `size_hint` and `ExactSizeIterator` impls, which can use the QueryState and &Archetypes in the type already.
- Benchmark to make sure there is no significant regression.
Relevant benchmark results seem to show that there is no tangible difference between the two. Everything seems to be either identical or within a workable margin of error here.
```
group embed-cursor main
----- ------------ ----
fragmented_iter/base 1.00 387.4±19.70ns ? ?/sec 1.07 413.1±27.95ns ? ?/sec
many_maps_iter 1.00 27.3±0.22ms ? ?/sec 1.00 27.4±0.10ms ? ?/sec
simple_iter/base 1.00 13.8±0.07µs ? ?/sec 1.00 13.7±0.17µs ? ?/sec
simple_iter/sparse 1.00 61.9±0.37µs ? ?/sec 1.00 62.2±0.64µs ? ?/sec
simple_iter/system 1.00 13.7±0.34µs ? ?/sec 1.00 13.7±0.10µs ? ?/sec
sparse_fragmented_iter/base 1.00 11.0±0.54ns ? ?/sec 1.03 11.3±0.48ns ? ?/sec
world_query_iter/50000_entities_sparse 1.08 105.0±2.68µs ? ?/sec 1.00 97.5±2.18µs ? ?/sec
world_query_iter/50000_entities_table 1.00 27.3±0.13µs ? ?/sec 1.00 27.3±0.37µs ? ?/sec
```
# Objective
- We do a lot of function pointer calls in a hot loop (clearing entities in render). This is slow, since calling function pointers cannot be optimised out. We can avoid that in the cases where the function call is a no-op.
- Alternative to https://github.com/bevyengine/bevy/pull/2897
- On my machine, in `many_cubes`, this reduces dropping time from ~150μs to ~80μs.
## Solution
- Make `drop` in `BlobVec` an `Option`, recording whether the given drop impl is required or not.
- Note that this does add branching in some cases - we could consider splitting this into two fields, i.e. unconditionally call the `drop` fn pointer.
- My intuition of how often types stored in `World` should have non-trivial drops makes me think that would be slower, however.
N.B. Even once this lands, we should still test having a 'drop_multiple' variant - for types with a real `Drop` impl, the current implementation is definitely optimal.
# Objective
`bevy_ecs` assumes that `u32 as usize` is a lossless operation and in a few cases relies on this for soundness and correctness. The only platforms that Rust compiles to where this invariant is broken are 16-bit systems.
A very clear example of this behavior is in the SparseSetIndex impl for Entity, where it converts a u32 into a usize to act as an index. If usize is 16-bit, the conversion will overflow and provide the caller with the wrong index. This can easily result in previously unforseen aliased mutable borrows (i.e. Query::get_many_mut).
## Solution
Explicitly fail compilation on 16-bit platforms instead of introducing UB.
Properly supporting 16-bit systems will likely need a workable use case first.
---
## Changelog
Removed: Ability to compile `bevy_ecs` on 16-bit platforms.
## Migration Guide
`bevy_ecs` will now explicitly fail to compile on 16-bit platforms. If this is required, there is currently no alternative. Please file an issue (https://github.com/bevyengine/bevy/issues) to help detail your use case.
# Objective
- It's pretty common to want to check if an EventReader has received one or multiple events while also needing to consume the iterator to "clear" the EventReader.
- The current approach is to do something like `events.iter().count() > 0` or `events.iter().last().is_some()`. It's not immediately obvious that the purpose of that is to consume the events and check if there were any events. My solution doesn't really solve that part, but it encapsulates the pattern.
## Solution
- Add a `.clear()` method that consumes the iterator.
- It takes the EventReader by value to make sure it isn't used again after it has been called.
---
## Migration Guide
Not a breaking change, but if you ever found yourself in a situation where you needed to consume the EventReader and check if there was any events you can now use
```rust
fn system(events: EventReader<MyEvent>) {
if !events.is_empty {
events.clear();
// Process the fact that one or more event was received
}
}
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
`Query::par_for_each` and it's variants do not show up when profiling using `tracy` or other profilers. Failing to show the impact of changing batch size, the overhead of scheduling tasks, overall thread utilization, etc. other than the effect on the surrounding system.
## Solution
Add a child span that is entered on every spawned task.
Example view of the results in `tracy` using a modified `parallel_query`:
---
## Changelog
Added: `tracing` spans for `Query::par_for_each` and its variants. Spans should now be visible for all
# Objective
- The code in `events.rs` was a bit messy. There was lots of duplication between `EventReader` and `ManualEventReader`, and the state management code is not needed.
## Solution
- Clean it up.
## Future work
Should we remove the type parameter from `ManualEventReader`?
It doesn't have any meaning outside of its source `Events`. But there's no real reason why it needs to have a type parameter - it's just plain data. I didn't remove it yet to keep the type safety in some of the users of it (primarily related to `&mut World` usage)
Required for https://github.com/bevyengine/bevy/pull/4402.
# Objective
- derived `SystemParam` implementations were never `ReadOnlySystemParamFetch`
- We want them to be, e.g. for `EventReader`
## Solution
- If possible, 'forward' the impl of `ReadOnlySystemParamFetch`.
# Objective
- (Eventually) reduce noise in reporting access conflicts between unordered systems.
- `SystemStage` only looks at unfiltered `ComponentId` access, any conflicts reported are potentially `false`.
- the systems could still be accessing disjoint archetypes
- Comparing systems' filtered access sets can maybe avoid that (for statically known component types).
- #4204
## Solution
- Modify `SparseSetIndex` trait to require `PartialEq`, `Eq`, and `Hash` (all internal types except `BundleId` already did).
- Add `is_compatible` and `get_conflicts` methods to `FilteredAccessSet<T>`
- (existing method renamed to `get_conflicts_single`)
- Add docs for those and all the other methods while I'm at it.
## Objective
- ~~Make absurdly long-lived changes stay detectable for even longer (without leveling up to `u64`).~~
- Give all changes a consistent maximum lifespan.
- Improve code clarity.
## Solution
- ~~Increase the frequency of `check_tick` scans to increase the oldest reliably-detectable change.~~
(Deferred until we can benchmark the cost of a scan.)
- Ignore changes older than the maximum reliably-detectable age.
- General refactoring—name the constants, use them everywhere, and update the docs.
- Update test cases to check for the specified behavior.
## Related
This PR addresses (at least partially) the concerns raised in:
- #3071
- #3082 (and associated PR #3084)
## Background
- #1471
Given the minimum interval between `check_ticks` scans, `N`, the oldest reliably-detectable change is `u32::MAX - (2 * N - 1)` (or `MAX_CHANGE_AGE`). Reducing `N` from ~530 million (current value) to something like ~2 million would extend the lifetime of changes by a billion.
| minimum `check_ticks` interval | oldest reliably-detectable change | usable % of `u32::MAX` |
| --- | --- | --- |
| `u32::MAX / 8` (536,870,911) | `(u32::MAX / 4) * 3` | 75.0% |
| `2_000_000` | `u32::MAX - 3_999_999` | 99.9% |
Similarly, changes are still allowed to be between `MAX_CHANGE_AGE`-old and `u32::MAX`-old in the interim between `check_tick` scans. While we prevent their age from overflowing, the test to detect changes still compares raw values. This makes failure ultimately unreliable, since when ancient changes stop being detected varies depending on when the next scan occurs.
## Open Question
Currently, systems and system states are incorrectly initialized with their `last_change_tick` set to `0`, which doesn't handle wraparound correctly.
For consistent behavior, they should either be initialized to the world's `last_change_tick` (and detect no changes) or to `MAX_CHANGE_AGE` behind the world's current `change_tick` (and detect everything as a change). I've currently gone with the latter since that was closer to the existing behavior.
## Follow-up Work
(Edited: entire section)
We haven't actually profiled how long a `check_ticks` scan takes on a "large" `World` , so we don't know if it's safe to increase their frequency. However, we are currently relying on play sessions not lasting long enough to trigger a scan and apps not having enough entities/archetypes for it to be "expensive" (our assumption). That isn't a real solution. (Either scanning never costs enough to impact frame times or we provide an option to use `u64` change ticks. Nobody will accept random hiccups.)
To further extend the lifetime of changes, we actually only need to increment the world tick if a system has `Fetch: !ReadOnlySystemParamFetch`. The behavior will be identical because all writes are sequenced, but I'm not sure how to implement that in a way that the compiler can optimize the branch out.
Also, since having no false positives depends on a `check_ticks` scan running at least every `2 * N - 1` ticks, a `last_check_tick` should also be stored in the `World` so that any lull in system execution (like a command flush) could trigger a scan if needed. To be completely robust, all the systems initialized on the world should be scanned, not just those in the current stage.
# Objective
- Remove `Resource` binding on events, introduce a new `Event` trait
- Ensure event iterators are `ExactSizeIterator`
## Solution
- Builds on #2382 and #2969
## Changelog
- Events<T>, EventWriter<T>, EventReader<T> and so on now require that the underlying type is Event, rather than Resource. Both of these are trivial supertraits of Send + Sync + 'static with universal blanket implementations: this change is currently purely cosmetic.
- Event reader iterators now implement ExactSizeIterator
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}