# Objective
Fixes#15940
## Solution
Remove the `pub use` and fix the compile errors.
Make `bevy_image` available as `bevy::image`.
## Testing
Feature Frenzy would be good here! Maybe I'll learn how to use it if I
have some time this weekend, or maybe a reviewer can use it.
## Migration Guide
Use `bevy_image` instead of `bevy_render::texture` items.
---------
Co-authored-by: chompaa <antony.m.3012@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Choose LOD based on normal simplification error in addition to
position error
- Update meshoptimizer to 0.22, which has a bunch of simplifier
improvements
## Testing
- Did you test these changes? If so, how?
- Visualize normals, and compare LOD changes before and after. Normals
no longer visibly change as the LOD cut changes.
- Are there any parts that need more testing?
- No
- How can other people (reviewers) test your changes? Is there anything
specific they need to know?
- Run the meshlet example in this PR and on main and move around to
change the LOD cut. Before running each example, in
meshlet_mesh_material.wgsl, replace `let color = vec3(rand_f(&rng),
rand_f(&rng), rand_f(&rng));` with `let color =
(vertex_output.world_normal + 1.0) / 2.0;`. Make sure to download the
appropriate bunny asset for each branch!
The two additional linear texture samplers that PCSS added caused us to
blow past the limit on Apple Silicon macOS and WebGL. To fix the issue,
this commit adds a `--feature pbr_pcss` feature gate that disables PCSS
if not present.
Closes#15345.
Closes#15525.
Closes#15821.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Prepare for streaming by storing vertex data per-meshlet, rather than
per-mesh (this means duplicating vertices per-meshlet)
- Compress vertex data to reduce the cost of this
## Solution
The important parts are in from_mesh.rs, the changes to the Meshlet type
in asset.rs, and the changes in meshlet_bindings.wgsl. Everything else
is pretty secondary/boilerplate/straightforward changes.
- Positions are quantized in centimeters with a user-provided power of 2
factor (ideally auto-determined, but that's a TODO for the future),
encoded as an offset relative to the minimum value within the meshlet,
and then stored as a packed list of bits using the minimum number of
bits needed for each vertex position channel for that meshlet
- E.g. quantize positions (lossly, throws away precision that's not
needed leading to using less bits in the bitstream encoding)
- Get the min/max quantized value of each X/Y/Z channel of the quantized
positions within a meshlet
- Encode values relative to the min value of the meshlet. E.g. convert
from [min, max] to [0, max - min]
- The new max value in the meshlet is (max - min), which only takes N
bits, so we only need N bits to store each channel within the meshlet
(lossless)
- We can store the min value and that it takes N bits per channel in the
meshlet metadata, and reconstruct the position from the bitstream
- Normals are octahedral encoded and than snorm2x16 packed and stored as
a single u32.
- Would be better to implement the precise variant of octhedral encoding
for extra precision (no extra decode cost), but decided to keep it
simple for now and leave that as a followup
- Tried doing a quantizing and bitstream encoding scheme like I did for
positions, but struggled to get it smaller. Decided to go with this for
simplicity for now
- UVs are uncompressed and take a full 64bits per vertex which is
expensive
- In the future this should be improved
- Tangents, as of the previous PR, are not explicitly stored and are
instead derived from screen space gradients
- While I'm here, split up MeshletMeshSaverLoader into two separate
types
Other future changes include implementing a smaller encoding of triangle
data (3 u8 indices = 24 bits per triangle currently), and more
disk-oriented compression schemes.
References:
* "A Deep Dive into UE5's Nanite Virtualized Geometry"
https://advances.realtimerendering.com/s2021/Karis_Nanite_SIGGRAPH_Advances_2021_final.pdf#page=128
(also available on youtube)
* "Towards Practical Meshlet Compression"
https://arxiv.org/pdf/2404.06359
* "Vertex quantization in Omniforce Game Engine"
https://daniilvinn.github.io/2024/05/04/omniforce-vertex-quantization.html
## Testing
- Did you test these changes? If so, how?
- Converted the stanford bunny, and rendered it with a debug material
showing normals, and confirmed that it's identical to what's on main.
EDIT: See additional testing in the comments below.
- Are there any parts that need more testing?
- Could use some more size comparisons on various meshes, and testing
different quantization factors. Not sure if 4 is a good default. EDIT:
See additional testing in the comments below.
- Also did not test runtime performance of the shaders. EDIT: See
additional testing in the comments below.
- How can other people (reviewers) test your changes? Is there anything
specific they need to know?
- Use my unholy script, replacing the meshlet example
https://paste.rs/7xQHk.rs (must make MeshletMesh fields pub instead of
pub crate, must add lz4_flex as a dev-dependency) (must compile with
meshlet and meshlet_processor features, mesh must have only positions,
normals, and UVs, no vertex colors or tangents)
---
## Migration Guide
- TBD by JMS55 at the end of the release
# Objective
- Fix issue #2611
## Solution
- Add `--generate-link-to-definition` to all the `rustdoc-args` arrays
in the `Cargo.toml`s (for docs.rs)
- Add `--generate-link-to-definition` to the `RUSTDOCFLAGS` environment
variable in the docs workflow (for dev-docs.bevyengine.org)
- Document all the workspace crates in the docs workflow (needed because
otherwise only the source code of the `bevy` package will be included,
making the argument useless)
- I think this also fixes#3662, since it fixes the bug on
dev-docs.bevyengine.org, while on docs.rs it has been fixed for a while
on their side.
---
## Changelog
- The source code viewer on docs.rs now includes links to the
definitions.
# Objective
- Using bincode to deserialize binary into a MeshletMesh is expensive
(~77ms for a 5mb file).
## Solution
- Write a custom deserializer using bytemuck's Pod types and slice
casting.
- Total asset load time has gone from ~102ms to ~12ms.
- Change some types I never meant to be public to private and other misc
cleanup.
## Testing
- Ran the meshlet example and added timing spans to the asset loader.
---
## Changelog
- Improved `MeshletMesh` loading speed
- The `MeshletMesh` disk format has changed, and
`MESHLET_MESH_ASSET_VERSION` has been bumped
- `MeshletMesh` fields are now private
- Renamed `MeshletMeshSaverLoad` to `MeshletMeshSaverLoader`
- The `Meshlet`, `MeshletBoundingSpheres`, and `MeshletBoundingSphere`
types are now private
- Removed `MeshletMeshSaveOrLoadError::SerializationOrDeserialization`
- Added `MeshletMeshSaveOrLoadError::WrongFileType`
## Migration Guide
- Regenerate your `MeshletMesh` assets, as the disk format has changed,
and `MESHLET_MESH_ASSET_VERSION` has been bumped
- `MeshletMesh` fields are now private
- `MeshletMeshSaverLoad` is now named `MeshletMeshSaverLoader`
- The `Meshlet`, `MeshletBoundingSpheres`, and `MeshletBoundingSphere`
types are now private
- `MeshletMeshSaveOrLoadError::SerializationOrDeserialization` has been
removed
- Added `MeshletMeshSaveOrLoadError::WrongFileType`, match on this
variant if you match on `MeshletMeshSaveOrLoadError`
Bump version after release
This PR has been auto-generated
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
# Objective
- Standard Material is starting to run out of samplers (currently uses
13 with no additional features off, I think in 0.13 it was 12).
- This change adds a new feature switch, modelled on the other ones
which add features to Standard Material, to turn off the new anisotropy
feature by default.
## Solution
- feature + texture define
## Testing
- Anisotropy example still works fine
- Other samples work fine
- Standard Material now takes 12 samplers by default on my Mac instead
of 13
## Migration Guide
- Add feature pbr_anisotropy_texture if you are using that texture in
any standard materials.
---------
Co-authored-by: John Payne <20407779+johngpayne@users.noreply.github.com>
This change updates meshopt-rs to 0.3 to take advantage of the newly
added sparse simplification mode: by default, simplifier assumes that
the entire mesh is simplified and runs a set of calculations that are
O(vertex count), but in our case we simplify many small mesh subsets
which is inefficient.
Sparse mode instead assumes that the simplified subset is only using a
portion of the vertex buffer, and optimizes accordingly. This changes
the meaning of the error (as it becomes relative to the subset, in our
case a meshlet group); to ensure consistent error selection, we also use
the ErrorAbsolute mode which allows us to operate in mesh coordinate
space.
Additionally, meshopt 0.3 runs optimizeMeshlet automatically as part of
`build_meshlets` so we no longer need to call it ourselves.
This reduces the time to build meshlet representation for Stanford Bunny
mesh from ~1.65s to ~0.45s (3.7x) in optimized builds.
# Objective
- The current version of the `meshopt` dependency is incorrect, as
`bevy_pbr` uses features introduced in `meshopt` `0.2.1`
- This causes errors like this when only `meshopt` `0.2` is present in
`Cargo.lock`:
```
error[E0432]: unresolved imports
`meshopt::ffi::meshopt_optimizeMeshlet`, `meshopt::simplify_scale`
--> crates\bevy_pbr\src\meshlet\from_mesh.rs:10:27
|
10 | ffi::{meshopt_Bounds, meshopt_optimizeMeshlet},
| ^^^^^^^^^^^^^^^^^^^^^^^
| no `meshopt_optimizeMeshlet` in `ffi`
| help: a similar name exists in the module: `meshopt_optimizeOverdraw`
11 | simplify, simplify_scale, Meshlets, SimplifyOptions,
VertexDataAdapter,
| ^^^^^^^^^^^^^^ no `simplify_scale` in the root
```
## Solution
- Specify the actual minimum version of `meshopt` that `bevy_pbr`
requires
Clearcoat is a separate material layer that represents a thin
translucent layer of a material. Examples include (from the [Filament
spec]) car paint, soda cans, and lacquered wood. This commit implements
support for clearcoat following the Filament and Khronos specifications,
marking the beginnings of support for multiple PBR layers in Bevy.
The [`KHR_materials_clearcoat`] specification describes the clearcoat
support in glTF. In Blender, applying a clearcoat to the Principled BSDF
node causes the clearcoat settings to be exported via this extension. As
of this commit, Bevy parses and reads the extension data when present in
glTF. Note that the `gltf` crate has no support for
`KHR_materials_clearcoat`; this patch therefore implements the JSON
semantics manually.
Clearcoat is integrated with `StandardMaterial`, but the code is behind
a series of `#ifdef`s that only activate when clearcoat is present.
Additionally, the `pbr_feature_layer_material_textures` Cargo feature
must be active in order to enable support for clearcoat factor maps,
clearcoat roughness maps, and clearcoat normal maps. This approach
mirrors the same pattern used by the existing transmission feature and
exists to avoid running out of texture bindings on platforms like WebGL
and WebGPU. Note that constant clearcoat factors and roughness values
*are* supported in the browser; only the relatively-less-common maps are
disabled on those platforms.
This patch refactors the lighting code in `StandardMaterial`
significantly in order to better support multiple layers in a natural
way. That code was due for a refactor in any case, so this is a nice
improvement.
A new demo, `clearcoat`, has been added. It's based on [the
corresponding three.js demo], but all the assets (aside from the skybox
and environment map) are my original work.
[Filament spec]:
https://google.github.io/filament/Filament.html#materialsystem/clearcoatmodel
[`KHR_materials_clearcoat`]:
https://github.com/KhronosGroup/glTF/blob/main/extensions/2.0/Khronos/KHR_materials_clearcoat/README.md
[the corresponding three.js demo]:
https://threejs.org/examples/webgl_materials_physical_clearcoat.html


## Changelog
### Added
* `StandardMaterial` now supports a clearcoat layer, which represents a
thin translucent layer over an underlying material.
* The glTF loader now supports the `KHR_materials_clearcoat` extension,
representing materials with clearcoat layers.
## Migration Guide
* The lighting functions in the `pbr_lighting` WGSL module now have
clearcoat parameters, if `STANDARD_MATERIAL_CLEARCOAT` is defined.
* The `R` reflection vector parameter has been removed from some
lighting functions, as it was unused.
# Objective
Minimize the number of dependencies low in the tree.
## Solution
* Remove the dependency on rustc-hash in bevy_ecs (not used) and
bevy_macro_utils (only used in one spot).
* Deduplicate the dependency on `sha1_smol` with the existing blake3
dependency already being used for bevy_asset.
* Remove the unused `ron` dependency on `bevy_app`
* Make the `serde` dependency for `bevy_ecs` optional. It's only used
for serializing Entity.
* Change the `wgpu` dependency to `wgpu-types`, and make it optional for
`bevy_color`.
* Remove the unused `thread-local` dependency on `bevy_render`.
* Make multiple dependencies for `bevy_tasks` optional and enabled only
when running with the `multi-threaded` feature. Preferably they'd be
disabled all the time on wasm, but I couldn't find a clean way to do
this.
---
## Changelog
TODO
## Migration Guide
TODO
# Objective
Since BufferVec was first introduced, `bytemuck` has added additional
traits with fewer restrictions than `Pod`. Within BufferVec, we only
rely on the constraints of `bytemuck::cast_slice` to a `u8` slice, which
now only requires `T: NoUninit` which is a strict superset of `Pod`
types.
## Solution
Change out the `Pod` generic type constraint with `NoUninit`. Also
taking the opportunity to substitute `cast_slice` with
`must_cast_slice`, which avoids a runtime panic in place of a compile
time failure if `T` cannot be used.
---
## Changelog
Changed: `BufferVec` now supports working with types containing
`NoUninit` but not `Pod` members.
Changed: `BufferVec` will now fail to compile if used with a type that
cannot be safely read from. Most notably, this includes ZSTs, which
would previously always panic at runtime.
This commit makes the following optimizations:
## `MeshPipelineKey`/`BaseMeshPipelineKey` split
`MeshPipelineKey` has been split into `BaseMeshPipelineKey`, which lives
in `bevy_render` and `MeshPipelineKey`, which lives in `bevy_pbr`.
Conceptually, `BaseMeshPipelineKey` is a superclass of
`MeshPipelineKey`. For `BaseMeshPipelineKey`, the bits start at the
highest (most significant) bit and grow downward toward the lowest bit;
for `MeshPipelineKey`, the bits start at the lowest bit and grow upward
toward the highest bit. This prevents them from colliding.
The goal of this is to avoid having to reassemble bits of the pipeline
key for every mesh every frame. Instead, we can just use a bitwise or
operation to combine the pieces that make up a `MeshPipelineKey`.
## `specialize_slow`
Previously, all of `specialize()` was marked as `#[inline]`. This
bloated `queue_material_meshes` unnecessarily, as a large chunk of it
ended up being a slow path that was rarely hit. This commit refactors
the function to move the slow path to `specialize_slow()`.
Together, these two changes shave about 5% off `queue_material_meshes`:

## Migration Guide
- The `primitive_topology` field on `GpuMesh` is now an accessor method:
`GpuMesh::primitive_topology()`.
- For performance reasons, `MeshPipelineKey` has been split into
`BaseMeshPipelineKey`, which lives in `bevy_render`, and
`MeshPipelineKey`, which lives in `bevy_pbr`. These two should be
combined with bitwise-or to produce the final `MeshPipelineKey`.
# Objective
Improve code quality involving fixedbitset.
## Solution
Update to fixedbitset 0.5. Use the new `grow_and_insert` function
instead of `grow` and `insert` functions separately.
This should also speed up most of the set operations involving
fixedbitset. They should be ~2x faster, but testing this against the
stress tests seems to show little to no difference. The multithreaded
executor doesn't seem to be all that much faster in many_cubes and
many_foxes. These use cases are likely dominated by other operations or
the bitsets aren't big enough to make them the bottleneck.
This introduces a duplicate dependency due to petgraph and wgpu, but the
former may take some time to update.
## Changelog
Removed: `Access::grow`
## Migration Guide
`Access::grow` has been removed. It's no longer needed. Remove all
references to it.
# Objective
Fix missing `TextBundle` (and many others) which are present in the main
crate as default features but optional in the sub-crate. See:
- https://docs.rs/bevy/0.13.0/bevy/ui/node_bundles/index.html
- https://docs.rs/bevy_ui/0.13.0/bevy_ui/node_bundles/index.html
~~There are probably other instances in other crates that I could track
down, but maybe "all-features = true" should be used by default in all
sub-crates? Not sure.~~ (There were many.) I only noticed this because
rust-analyzer's "open docs" features takes me to the sub-crate, not the
main one.
## Solution
Add "all-features = true" to docs.rs metadata for crates that use
features.
## Changelog
### Changed
- Unified features documented on docs.rs between main crate and
sub-crates
# Objective
Make bevy_utils less of a compilation bottleneck. Tackle #11478.
## Solution
* Move all of the directly reexported dependencies and move them to
where they're actually used.
* Remove the UUID utilities that have gone unused since `TypePath` took
over for `TypeUuid`.
* There was also a extraneous bytemuck dependency on `bevy_core` that
has not been used for a long time (since `encase` became the primary way
to prepare GPU buffers).
* Remove the `all_tuples` macro reexport from bevy_ecs since it's
accessible from `bevy_utils`.
---
## Changelog
Removed: Many of the reexports from bevy_utils (petgraph, uuid, nonmax,
smallvec, and thiserror).
Removed: bevy_core's reexports of bytemuck.
## Migration Guide
bevy_utils' reexports of petgraph, uuid, nonmax, smallvec, and thiserror
have been removed.
bevy_core' reexports of bytemuck's types has been removed.
Add them as dependencies in your own crate instead.
# Objective
- As part of the migration process we need to a) see the end effect of
the migration on user ergonomics b) check for serious perf regressions
c) actually migrate the code
- To accomplish this, I'm going to attempt to migrate all of the
remaining user-facing usages of `LegacyColor` in one PR, being careful
to keep a clean commit history.
- Fixes#12056.
## Solution
I've chosen to use the polymorphic `Color` type as our standard
user-facing API.
- [x] Migrate `bevy_gizmos`.
- [x] Take `impl Into<Color>` in all `bevy_gizmos` APIs
- [x] Migrate sprites
- [x] Migrate UI
- [x] Migrate `ColorMaterial`
- [x] Migrate `MaterialMesh2D`
- [x] Migrate fog
- [x] Migrate lights
- [x] Migrate StandardMaterial
- [x] Migrate wireframes
- [x] Migrate clear color
- [x] Migrate text
- [x] Migrate gltf loader
- [x] Register color types for reflection
- [x] Remove `LegacyColor`
- [x] Make sure CI passes
Incidental improvements to ease migration:
- added `Color::srgba_u8`, `Color::srgba_from_array` and friends
- added `set_alpha`, `is_fully_transparent` and `is_fully_opaque` to the
`Alpha` trait
- add and immediately deprecate (lol) `Color::rgb` and friends in favor
of more explicit and consistent `Color::srgb`
- standardized on white and black for most example text colors
- added vector field traits to `LinearRgba`: ~~`Add`, `Sub`,
`AddAssign`, `SubAssign`,~~ `Mul<f32>` and `Div<f32>`. Multiplications
and divisions do not scale alpha. `Add` and `Sub` have been cut from
this PR.
- added `LinearRgba` and `Srgba` `RED/GREEN/BLUE`
- added `LinearRgba_to_f32_array` and `LinearRgba::to_u32`
## Migration Guide
Bevy's color types have changed! Wherever you used a
`bevy::render::Color`, a `bevy::color::Color` is used instead.
These are quite similar! Both are enums storing a color in a specific
color space (or to be more precise, using a specific color model).
However, each of the different color models now has its own type.
TODO...
- `Color::rgba`, `Color::rgb`, `Color::rbga_u8`, `Color::rgb_u8`,
`Color::rgb_from_array` are now `Color::srgba`, `Color::srgb`,
`Color::srgba_u8`, `Color::srgb_u8` and `Color::srgb_from_array`.
- `Color::set_a` and `Color::a` is now `Color::set_alpha` and
`Color::alpha`. These are part of the `Alpha` trait in `bevy_color`.
- `Color::is_fully_transparent` is now part of the `Alpha` trait in
`bevy_color`
- `Color::r`, `Color::set_r`, `Color::with_r` and the equivalents for
`g`, `b` `h`, `s` and `l` have been removed due to causing silent
relatively expensive conversions. Convert your `Color` into the desired
color space, perform your operations there, and then convert it back
into a polymorphic `Color` enum.
- `Color::hex` is now `Srgba::hex`. Call `.into` or construct a
`Color::Srgba` variant manually to convert it.
- `WireframeMaterial`, `ExtractedUiNode`, `ExtractedDirectionalLight`,
`ExtractedPointLight`, `ExtractedSpotLight` and `ExtractedSprite` now
store a `LinearRgba`, rather than a polymorphic `Color`
- `Color::rgb_linear` and `Color::rgba_linear` are now
`Color::linear_rgb` and `Color::linear_rgba`
- The various CSS color constants are no longer stored directly on
`Color`. Instead, they're defined in the `Srgba` color space, and
accessed via `bevy::color::palettes::css`. Call `.into()` on them to
convert them into a `Color` for quick debugging use, and consider using
the much prettier `tailwind` palette for prototyping.
- The `LIME_GREEN` color has been renamed to `LIMEGREEN` to comply with
the standard naming.
- Vector field arithmetic operations on `Color` (add, subtract, multiply
and divide by a f32) have been removed. Instead, convert your colors
into `LinearRgba` space, and perform your operations explicitly there.
This is particularly relevant when working with emissive or HDR colors,
whose color channel values are routinely outside of the ordinary 0 to 1
range.
- `Color::as_linear_rgba_f32` has been removed. Call
`LinearRgba::to_f32_array` instead, converting if needed.
- `Color::as_linear_rgba_u32` has been removed. Call
`LinearRgba::to_u32` instead, converting if needed.
- Several other color conversion methods to transform LCH or HSL colors
into float arrays or `Vec` types have been removed. Please reimplement
these externally or open a PR to re-add them if you found them
particularly useful.
- Various methods on `Color` such as `rgb` or `hsl` to convert the color
into a specific color space have been removed. Convert into
`LinearRgba`, then to the color space of your choice.
- Various implicitly-converting color value methods on `Color` such as
`r`, `g`, `b` or `h` have been removed. Please convert it into the color
space of your choice, then check these properties.
- `Color` no longer implements `AsBindGroup`. Store a `LinearRgba`
internally instead to avoid conversion costs.
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
Co-authored-by: Afonso Lage <lage.afonso@gmail.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
#7348 added `bevy_utils::Parallel` and replaced the usage of the
`ThreadLocal<Cell<Vec<...>>>` in `check_visibility`, but we were also
using it in `extract_meshes`.
## Solution
Refactor the system to use `Parallel` instead.
# Objective
- Add the new `-Zcheck-cfg` checks to catch more warnings
- Fixes#12091
## Solution
- Create a new `cfg-check` to the CI that runs `cargo check -Zcheck-cfg
--workspace` using cargo nightly (and fails if there are warnings)
- Fix all warnings generated by the new check
---
## Changelog
- Remove all redundant imports
- Fix cfg wasm32 targets
- Add 3 dead code exceptions (should StandardColor be unused?)
- Convert ios_simulator to a feature (I'm not sure if this is the right
way to do it, but the check complained before)
## Migration Guide
No breaking changes
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Fixes#12016.
Bump version after release
This PR has been auto-generated
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fixes#11908
## Solution
- Remove the `naga_oil` dependency from `bevy_pbr`.
- We were doing a little dance to disable `glsl` support on not-wasm, so
incorporate that dance into `bevy_render`'s `Cargo.toml`.
# Objective
- Pipeline compilation is slow and blocks the frame
- Closes https://github.com/bevyengine/bevy/issues/8224
## Solution
- Compile pipelines in a Task on the AsyncComputeTaskPool
---
## Changelog
- Render/compute pipeline compilation is now done asynchronously over
multiple frames when the multi-threaded feature is enabled and on
non-wasm and non-macOS platforms
- Added `CachedPipelineState::Creating`
- Added `PipelineCache::block_on_render_pipeline()`
- Added `bevy_utils::futures::check_ready`
- Added `bevy_render/multi-threaded` cargo feature
## Migration Guide
- Match on the new `Creating` variant for exhaustive matches of
`CachedPipelineState`
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
This pull request re-submits #10057, which was backed out for breaking
macOS, iOS, and Android. I've tested this version on macOS and Android
and on the iOS simulator.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
Matches versioning & features from other Cargo.toml files in the
project.
# Objective
Resolves#10932
## Solution
Added smallvec to the bevy_utils cargo.toml and added a line to
re-export the crate. Target version and features set to match what's
used in the other bevy crates.
# Objective
Keep up to date with wgpu.
## Solution
Update the wgpu version.
Currently blocked on naga_oil updating to naga 0.14 and releasing a new
version.
3d scenes (or maybe any scene with lighting?) currently don't render
anything due to
```
error: naga_oil bug, please file a report: composer failed to build a valid header: Type [2] '' is invalid
= Capability Capabilities(CUBE_ARRAY_TEXTURES) is required
```
I'm not sure what should be passed in for `wgpu::InstanceFlags`, or if we want to make the gles3minorversion configurable (might be useful for debugging?)
Currently blocked on https://github.com/bevyengine/naga_oil/pull/63, and https://github.com/gfx-rs/wgpu/issues/4569 to be fixed upstream in wgpu first.
## Known issues
Amd+windows+vulkan has issues with texture_binding_arrays (see the image [here](https://github.com/bevyengine/bevy/pull/10266#issuecomment-1819946278)), but that'll be fixed in the next wgpu/naga version, and you can just use dx12 as a workaround for now (Amd+linux mesa+vulkan texture_binding_arrays are fixed though).
---
## Changelog
Updated wgpu to 0.18, naga to 0.14.2, and naga_oil to 0.11.
- Windows desktop GL should now be less painful as it no longer requires Angle.
- You can now toggle shader validation and debug information for debug and release builds using `WgpuSettings.instance_flags` and [InstanceFlags](https://docs.rs/wgpu/0.18.0/wgpu/struct.InstanceFlags.html)
## Migration Guide
- `RenderPassDescriptor` `color_attachments` (as well as `RenderPassColorAttachment`, and `RenderPassDepthStencilAttachment`) now use `StoreOp::Store` or `StoreOp::Discard` instead of a `boolean` to declare whether or not they should be stored.
- `RenderPassDescriptor` now have `timestamp_writes` and `occlusion_query_set` fields. These can safely be set to `None`.
- `ComputePassDescriptor` now have a `timestamp_writes` field. This can be set to `None` for now.
- See the [wgpu changelog](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v0180-2023-10-25) for additional details
# Objective
- Standardize fmt for toml files
## Solution
- Add [taplo](https://taplo.tamasfe.dev/) to CI (check for fmt and diff
for toml files), for context taplo is used by the most popular extension
in VScode [Even Better
TOML](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml
- Add contribution section to explain toml fmt with taplo.
Now to pass CI you need to run `taplo fmt --option indent_string=" "` or
if you use vscode have the `Even Better TOML` extension with 4 spaces
for indent
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fix adding `#![allow(clippy::type_complexity)]` everywhere. like #9796
## Solution
- Use the new [lints] table that will land in 1.74
(https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#lints)
- inherit lint to the workspace, crates and examples.
```
[lints]
workspace = true
```
## Changelog
- Bump rust version to 1.74
- Enable lints table for the workspace
```toml
[workspace.lints.clippy]
type_complexity = "allow"
```
- Allow type complexity for all crates and examples
```toml
[lints]
workspace = true
```
---------
Co-authored-by: Martín Maita <47983254+mnmaita@users.noreply.github.com>
Preparing next release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
<img width="1920" alt="Screenshot 2023-04-26 at 01 07 34"
src="https://user-images.githubusercontent.com/418473/234467578-0f34187b-5863-4ea1-88e9-7a6bb8ce8da3.png">
This PR adds both diffuse and specular light transmission capabilities
to the `StandardMaterial`, with support for screen space refractions.
This enables realistically representing a wide range of real-world
materials, such as:
- Glass; (Including frosted glass)
- Transparent and translucent plastics;
- Various liquids and gels;
- Gemstones;
- Marble;
- Wax;
- Paper;
- Leaves;
- Porcelain.
Unlike existing support for transparency, light transmission does not
rely on fixed function alpha blending, and therefore works with both
`AlphaMode::Opaque` and `AlphaMode::Mask` materials.
## Solution
- Introduces a number of transmission related fields in the
`StandardMaterial`;
- For specular transmission:
- Adds logic to take a view main texture snapshot after the opaque
phase; (in order to perform screen space refractions)
- Introduces a new `Transmissive3d` phase to the renderer, to which all
meshes with `transmission > 0.0` materials are sent.
- Calculates a light exit point (of the approximate mesh volume) using
`ior` and `thickness` properties
- Samples the snapshot texture with an adaptive number of taps across a
`roughness`-controlled radius enabling “blurry” refractions
- For diffuse transmission:
- Approximates transmitted diffuse light by using a second, flipped +
displaced, diffuse-only Lambertian lobe for each light source.
## To Do
- [x] Figure out where `fresnel_mix()` is taking place, if at all, and
where `dielectric_specular` is being calculated, if at all, and update
them to use the `ior` value (Not a blocker, just a nice-to-have for more
correct BSDF)
- To the _best of my knowledge, this is now taking place, after
964340cdd. The fresnel mix is actually "split" into two parts in our
implementation, one `(1 - fresnel(...))` in the transmission, and
`fresnel()` in the light implementations. A surface with more
reflectance now will produce slightly dimmer transmission towards the
grazing angle, as more of the light gets reflected.
- [x] Add `transmission_texture`
- [x] Add `diffuse_transmission_texture`
- [x] Add `thickness_texture`
- [x] Add `attenuation_distance` and `attenuation_color`
- [x] Connect values to glTF loader
- [x] `transmission` and `transmission_texture`
- [x] `thickness` and `thickness_texture`
- [x] `ior`
- [ ] `diffuse_transmission` and `diffuse_transmission_texture` (needs
upstream support in `gltf` crate, not a blocker)
- [x] Add support for multiple screen space refraction “steps”
- [x] Conditionally create no transmission snapshot texture at all if
`steps == 0`
- [x] Conditionally enable/disable screen space refraction transmission
snapshots
- [x] Read from depth pre-pass to prevent refracting pixels in front of
the light exit point
- [x] Use `interleaved_gradient_noise()` function for sampling blur in a
way that benefits from TAA
- [x] Drill down a TAA `#define`, tweak some aspects of the effect
conditionally based on it
- [x] Remove const array that's crashing under HLSL (unless a new `naga`
release with https://github.com/gfx-rs/naga/pull/2496 comes out before
we merge this)
- [ ] Look into alternatives to the `switch` hack for dynamically
indexing the const array (might not be needed, compilers seem to be
decent at expanding it)
- [ ] Add pipeline keys for gating transmission (do we really want/need
this?)
- [x] Tweak some material field/function names?
## A Note on Texture Packing
_This was originally added as a comment to the
`specular_transmission_texture`, `thickness_texture` and
`diffuse_transmission_texture` documentation, I removed it since it was
more confusing than helpful, and will likely be made redundant/will need
to be updated once we have a better infrastructure for preprocessing
assets_
Due to how channels are mapped, you can more efficiently use a single
shared texture image
for configuring the following:
- R - `specular_transmission_texture`
- G - `thickness_texture`
- B - _unused_
- A - `diffuse_transmission_texture`
The `KHR_materials_diffuse_transmission` glTF extension also defines a
`diffuseTransmissionColorTexture`,
that _we don't currently support_. One might choose to pack the
intensity and color textures together,
using RGB for the color and A for the intensity, in which case this
packing advice doesn't really apply.
---
## Changelog
- Added a new `Transmissive3d` render phase for rendering specular
transmissive materials with screen space refractions
- Added rendering support for transmitted environment map light on the
`StandardMaterial` as a fallback for screen space refractions
- Added `diffuse_transmission`, `specular_transmission`, `thickness`,
`ior`, `attenuation_distance` and `attenuation_color` to the
`StandardMaterial`
- Added `diffuse_transmission_texture`, `specular_transmission_texture`,
`thickness_texture` to the `StandardMaterial`, gated behind a new
`pbr_transmission_textures` cargo feature (off by default, for maximum
hardware compatibility)
- Added `Camera3d::screen_space_specular_transmission_steps` for
controlling the number of “layers of transparency” rendered for
transmissive objects
- Added a `TransmittedShadowReceiver` component for enabling shadows in
(diffusely) transmitted light. (disabled by default, as it requires
carefully setting up the `thickness` to avoid self-shadow artifacts)
- Added support for the `KHR_materials_transmission`,
`KHR_materials_ior` and `KHR_materials_volume` glTF extensions
- Renamed items related to temporal jitter for greater consistency
## Migration Guide
- `SsaoPipelineKey::temporal_noise` has been renamed to
`SsaoPipelineKey::temporal_jitter`
- The `TAA` shader def (controlled by the presence of the
`TemporalAntiAliasSettings` component in the camera) has been replaced
with the `TEMPORAL_JITTER` shader def (controlled by the presence of the
`TemporalJitter` component in the camera)
- `MeshPipelineKey::TAA` has been replaced by
`MeshPipelineKey::TEMPORAL_JITTER`
- The `TEMPORAL_NOISE` shader def has been consolidated with
`TEMPORAL_JITTER`
# Objective
- bump naga_oil to 0.10
- update shader imports to use rusty syntax
## Migration Guide
naga_oil 0.10 reworks the import mechanism to support more syntax to
make it more rusty, and test for item use before importing to determine
which imports are modules and which are items, which allows:
- use rust-style imports
```
#import bevy_pbr::{
pbr_functions::{alpha_discard as discard, apply_pbr_lighting},
mesh_bindings,
}
```
- import partial paths:
```
#import part::of::path
...
path::remainder::function();
```
which will call to `part::of::path::remainder::function`
- use fully qualified paths without importing:
```
// #import bevy_pbr::pbr_functions
bevy_pbr::pbr_functions::pbr()
```
- use imported items without qualifying
```
#import bevy_pbr::pbr_functions::pbr
// for backwards compatibility the old style is still supported:
// #import bevy_pbr::pbr_functions pbr
...
pbr()
```
- allows most imported items to end with `_` and numbers (naga_oil#30).
still doesn't allow struct members to end with `_` or numbers but it's
progress.
- the vast majority of existing shader code will work without changes,
but will emit "deprecated" warnings for old-style imports. these can be
suppressed with the `allow-deprecated` feature.
- partly breaks overrides (as far as i'm aware nobody uses these yet) -
now overrides will only be applied if the overriding module is added as
an additional import in the arguments to `Composer::make_naga_module` or
`Composer::add_composable_module`. this is necessary to support
determining whether imports are modules or items.
~~Currently blocked on an upstream bug that causes crashes when
minimizing/resizing on dx12 https://github.com/gfx-rs/wgpu/issues/3967~~
wgpu 0.17.1 is out which fixes it
# Objective
Keep wgpu up to date.
## Solution
Update wgpu and naga_oil.
Currently this depends on an unreleased (and unmerged) branch of
naga_oil, and hasn't been properly tested yet.
The wgpu side of this seems to have been an extremely trivial upgrade
(all the upgrade work seems to be in naga_oil). This also lets us remove
the workarounds for pack/unpack4x8unorm in the SSAO shaders.
Lets us close the dx12 part of
https://github.com/bevyengine/bevy/issues/8888
related: https://github.com/bevyengine/bevy/issues/9304
---
## Changelog
Update to wgpu 0.17 and naga_oil 0.9
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
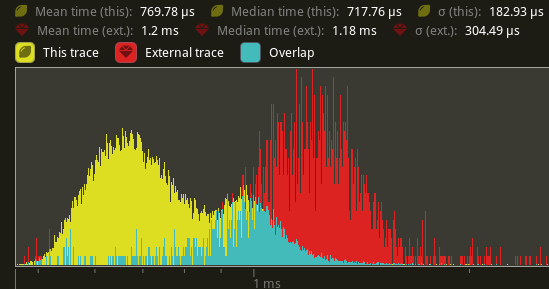
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
This is a continuation of this PR: #8062
# Objective
- Reorder render schedule sets to allow data preparation when phase item
order is known to support improved batching
- Part of the batching/instancing etc plan from here:
https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074
- The original idea came from @inodentry and proved to be a good one.
Thanks!
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new
ordering
## Solution
- Move `Prepare` and `PrepareFlush` after `PhaseSortFlush`
- Add a `PrepareAssets` set that runs in parallel with other systems and
sets in the render schedule.
- Put prepare_assets systems in the `PrepareAssets` set
- If explicit dependencies are needed on Mesh or Material RenderAssets
then depend on the appropriate system.
- Add `ManageViews` and `ManageViewsFlush` sets between
`ExtractCommands` and Queue
- Move `queue_mesh*_bind_group` to the Prepare stage
- Rename them to `prepare_`
- Put systems that prepare resources (buffers, textures, etc.) into a
`PrepareResources` set inside `Prepare`
- Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set
after `PrepareResources`
- Move `prepare_lights` to the `ManageViews` set
- `prepare_lights` creates views and this must happen before `Queue`
- This system needs refactoring to stop handling all responsibilities
- Gather lights, sort, and create shadow map views. Store sorted light
entities in a resource
- Remove `BatchedPhaseItem`
- Replace `batch_range` with `batch_size` representing how many items to
skip after rendering the item or to skip the item entirely if
`batch_size` is 0.
- `queue_sprites` has been split into `queue_sprites` for queueing phase
items and `prepare_sprites` for batching after the `PhaseSort`
- `PhaseItem`s are still inserted in `queue_sprites`
- After sorting adjacent compatible sprite phase items are accumulated
into `SpriteBatch` components on the first entity of each batch,
containing a range of vertex indices. The associated `PhaseItem`'s
`batch_size` is updated appropriately.
- `SpriteBatch` items are then drawn skipping over the other items in
the batch based on the value in `batch_size`
- A very similar refactor was performed on `bevy_ui`
---
## Changelog
Changed:
- Reordered and reworked render app schedule sets. The main change is
that data is extracted, queued, sorted, and then prepared when the order
of data is known.
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the
reordering.
## Migration Guide
- Assets such as materials and meshes should now be created in
`PrepareAssets` e.g. `prepare_assets<Mesh>`
- Queueing entities to `RenderPhase`s continues to be done in `Queue`
e.g. `queue_sprites`
- Preparing resources (textures, buffers, etc.) should now be done in
`PrepareResources`, e.g. `prepare_prepass_textures`,
`prepare_mesh_uniforms`
- Prepare bind groups should now be done in `PrepareBindGroups` e.g.
`prepare_mesh_bind_group`
- Any batching or instancing can now be done in `Prepare` where the
order of the phase items is known e.g. `prepare_sprites`
## Next Steps
- Introduce some generic mechanism to ensure items that can be batched
are grouped in the phase item order, currently you could easily have
`[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching.
- Investigate improved orderings for building the MeshUniform buffer
- Implementing batching across the rest of bevy
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
- Reduce the number of rebindings to enable batching of draw commands
## Solution
- Use the new `GpuArrayBuffer` for `MeshUniform` data to store all
`MeshUniform` data in arrays within fewer bindings
- Sort opaque/alpha mask prepass, opaque/alpha mask main, and shadow
phases also by the batch per-object data binding dynamic offset to
improve performance on WebGL2.
---
## Changelog
- Changed: Per-object `MeshUniform` data is now managed by
`GpuArrayBuffer` as arrays in buffers that need to be indexed into.
## Migration Guide
Accessing the `model` member of an individual mesh object's shader
`Mesh` struct the old way where each `MeshUniform` was stored at its own
dynamic offset:
```rust
struct Vertex {
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh.model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
The new way where one needs to index into the array of `Mesh`es for the
batch:
```rust
struct Vertex {
@builtin(instance_index) instance_index: u32,
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh[vertex.instance_index].model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
Note that using the instance_index is the default way to pass the
per-object index into the shader, but if you wish to do custom rendering
approaches you can pass it in however you like.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
{kind=link}