Test metadata collection in Bors CI workflow
This PR adds a new check to bors CI workflows, which ensures that the metadata collection success, when it's run as part of the `deploy` script. I've only added it to bors workflows, as the runtime will be high while it'll also succeed most of the time. This is a preparation for rust-lang/rust-clippy#8947.
---
changelog: none
r? `@ghost`
Fix some `#[expect]` lint interaction
Fixing the first few lints that aren't caught by `#[expect]`. The root cause of these examples was, that the lint was emitted at the wrong location.
---
changelog: none
r? `@Jarcho`
cc: rust-lang/rust#97660
Improve lint doc consistency
changelog: none
This is a continuation of #8908.
Notable changes:
- Removed empty `Known Problems` sections
- Removed "Good"/"Bad" language (replaced with "Use instead")
- Removed (and added some 😄) duplication
- Ignored the [`create_dir`] example so it doesn't create `clippy_lints/foo` 😄
fix(lint): check const context
close: https://github.com/rust-lang/rust-clippy/issues/8898
This PR fixes a bug in checked_conversions.
Thank you in advance.
changelog: check const context in checked_conversions.
This commit makes type folding more like the way chalk does it.
Currently, `TypeFoldable` has `fold_with` and `super_fold_with` methods.
- `fold_with` is the standard entry point, and defaults to calling
`super_fold_with`.
- `super_fold_with` does the actual work of traversing a type.
- For a few types of interest (`Ty`, `Region`, etc.) `fold_with` instead
calls into a `TypeFolder`, which can then call back into
`super_fold_with`.
With the new approach, `TypeFoldable` has `fold_with` and
`TypeSuperFoldable` has `super_fold_with`.
- `fold_with` is still the standard entry point, *and* it does the
actual work of traversing a type, for all types except types of
interest.
- `super_fold_with` is only implemented for the types of interest.
Benefits of the new model.
- I find it easier to understand. The distinction between types of
interest and other types is clearer, and `super_fold_with` doesn't
exist for most types.
- With the current model is easy to get confused and implement a
`super_fold_with` method that should be left defaulted. (Some of the
precursor commits fixed such cases.)
- With the current model it's easy to call `super_fold_with` within
`TypeFolder` impls where `fold_with` should be called. The new
approach makes this mistake impossible, and this commit fixes a number
of such cases.
- It's potentially faster, because it avoids the `fold_with` ->
`super_fold_with` call in all cases except types of interest. A lot of
the time the compile would inline those away, but not necessarily
always.
Remove migrate borrowck mode
Closes#58781Closes#43234
# Stabilization proposal
This PR proposes the stabilization of `#![feature(nll)]` and the removal of `-Z borrowck`. Current borrow checking behavior of item bodies is currently done by first infering regions *lexically* and reporting any errors during HIR type checking. If there *are* any errors, then MIR borrowck (NLL) never occurs. If there *aren't* any errors, then MIR borrowck happens and any errors there would be reported. This PR removes the lexical region check of item bodies entirely and only uses MIR borrowck. Because MIR borrowck could never *not* be run for a compiled program, this should not break any programs. It does, however, change diagnostics significantly and allows a slightly larger set of programs to compile.
Tracking issue: #43234
RFC: https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md
Version: 1.63 (2022-06-30 => beta, 2022-08-11 => stable).
## Motivation
Over time, the Rust borrow checker has become "smarter" and thus allowed more programs to compile. There have been three different implementations: AST borrowck, MIR borrowck, and polonius (well, in progress). Additionally, there is the "lexical region resolver", which (roughly) solves the constraints generated through HIR typeck. It is not a full borrow checker, but does emit some errors.
The AST borrowck was the original implementation of the borrow checker and was part of the initially stabilized Rust 1.0. In mid 2017, work began to implement the current MIR borrow checker and that effort ompleted by the end of 2017, for the most part. During 2018, efforts were made to migrate away from the AST borrow checker to the MIR borrow checker - eventually culminating into "migrate" mode - where HIR typeck with lexical region resolving following by MIR borrow checking - being active by default in the 2018 edition.
In early 2019, migrate mode was turned on by default in the 2015 edition as well, but with MIR borrowck errors emitted as warnings. By late 2019, these warnings were upgraded to full errors. This was followed by the complete removal of the AST borrow checker.
In the period since, various errors emitted by the MIR borrow checker have been improved to the point that they are mostly the same or better than those emitted by the lexical region resolver.
While there do remain some degradations in errors (tracked under the [NLL-diagnostics tag](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-diagnostics), those are sufficiently small and rare enough that increased flexibility of MIR borrow check-only is now a worthwhile tradeoff.
## What is stabilized
As said previously, this does not fundamentally change the landscape of accepted programs. However, there are a [few](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-fixed-by-NLL) cases where programs can compile under `feature(nll)`, but not otherwise.
There are two notable patterns that are "fixed" by this stabilization. First, the `scoped_threads` feature, which is a continutation of a pre-1.0 API, can sometimes emit a [weird lifetime error](https://github.com/rust-lang/rust/issues/95527) without NLL. Second, actually seen in the standard library. In the `Extend` impl for `HashMap`, there is an implied bound of `K: 'a` that is available with NLL on but not without - this is utilized in the impl.
As mentioned before, there are a large number of diagnostic differences. Most of them are better, but some are worse. None are serious or happen often enough to need to block this PR. The biggest change is the loss of error code for a number of lifetime errors in favor of more general "lifetime may not live long enough" error. While this may *seem* bad, the former error codes were just attempts to somewhat-arbitrarily bin together lifetime errors of the same type; however, on paper, they end up being roughly the same with roughly the same kinds of solutions.
## What isn't stabilized
This PR does not completely remove the lexical region resolver. In the future, it may be possible to remove that (while still keeping HIR typeck) or to remove it together with HIR typeck.
## Tests
Many test outputs get updated by this PR. However, there are number of tests specifically geared towards NLL under `src/test/ui/nll`
## History
* On 2017-07-14, [tracking issue opened](https://github.com/rust-lang/rust/issues/43234)
* On 2017-07-20, [initial empty MIR pass added](https://github.com/rust-lang/rust/pull/43271)
* On 2017-08-29, [RFC opened](https://github.com/rust-lang/rfcs/pull/2094)
* On 2017-11-16, [Integrate MIR type-checker with NLL](https://github.com/rust-lang/rust/pull/45825)
* On 2017-12-20, [NLL feature complete](https://github.com/rust-lang/rust/pull/46862)
* On 2018-07-07, [Don't run AST borrowck on mir mode](https://github.com/rust-lang/rust/pull/52083)
* On 2018-07-27, [Add migrate mode](https://github.com/rust-lang/rust/pull/52681)
* On 2019-04-22, [Enable migrate mode on 2015 edition](https://github.com/rust-lang/rust/pull/59114)
* On 2019-08-26, [Don't downgrade errors on 2015 edition](https://github.com/rust-lang/rust/pull/64221)
* On 2019-08-27, [Remove AST borrowck](https://github.com/rust-lang/rust/pull/64790)
* Don't lint on `.cloned().flatten()` when `T::Item` doesn't implement `IntoIterator`
* Reduce verbosity of lint message
* Narrow down the scope of the replacement range
Clippy book
A work in progress Clippy Book using mdbook. See #6011.
This is currently just a moving around of things:
1. The current README.md split up a bit and put into sections.
1. A rough outline of Clippy lint categories (currently no content, potentially add a basic introduction for each and some example, see questions below.
1. The `docs` content repurposed into a top level `Development` section.
1. The current Roadmap.
Some big questions:
1. is `guide/` the right place? I'm modeling after mdbook itself.
1. What is the relationship between ALL the Clippy Lints and this guide? It seems like they can coexist. Does that mean the guide should just point to the current side with regard to actual lints, and maybe just include some examples to keep it interesting? Keeping both up to date seems like a maintenance nightmare unless its automated somehow. Or should the current ALL the Clippy lints somehow be incorporated into the book?
1. Related to the above, where should this guide be published since the `gh-pages` branch is already in use?
1. This PR doesn't currently change any existing content. Obviously that would make sense assuming the general structure and relocation is an acceptable approach.
---
Open Tasks for follow up PR:
- Set up CI/CD
- Split up Installation and Usage
- Add more content to Usage (and Installation) chapters
- Enhance CI chapter with more examples for different CIs
---
changelog: The first version of the *Clippy Book*
staring, *The Clippy Team*, *Bors* and *rustc*
List configuration values can now be extended instead of replaced
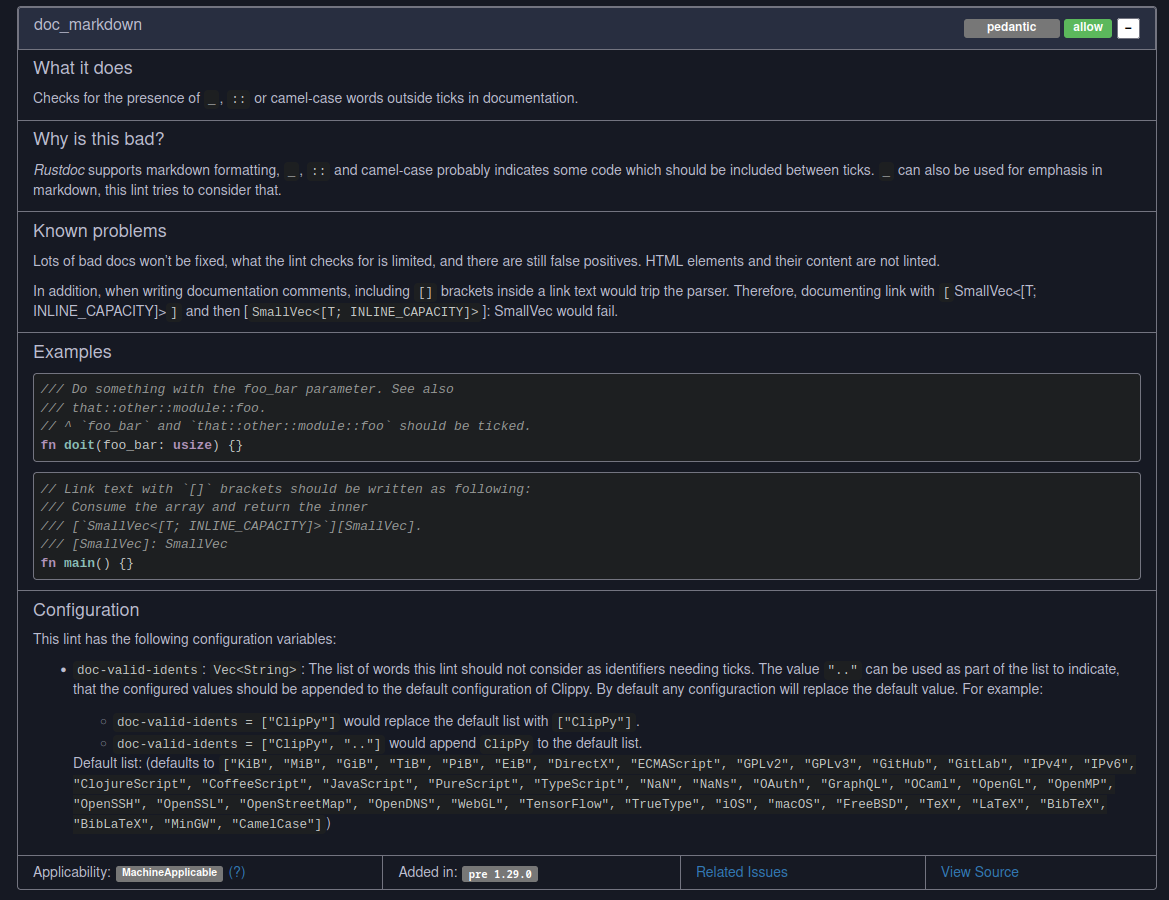
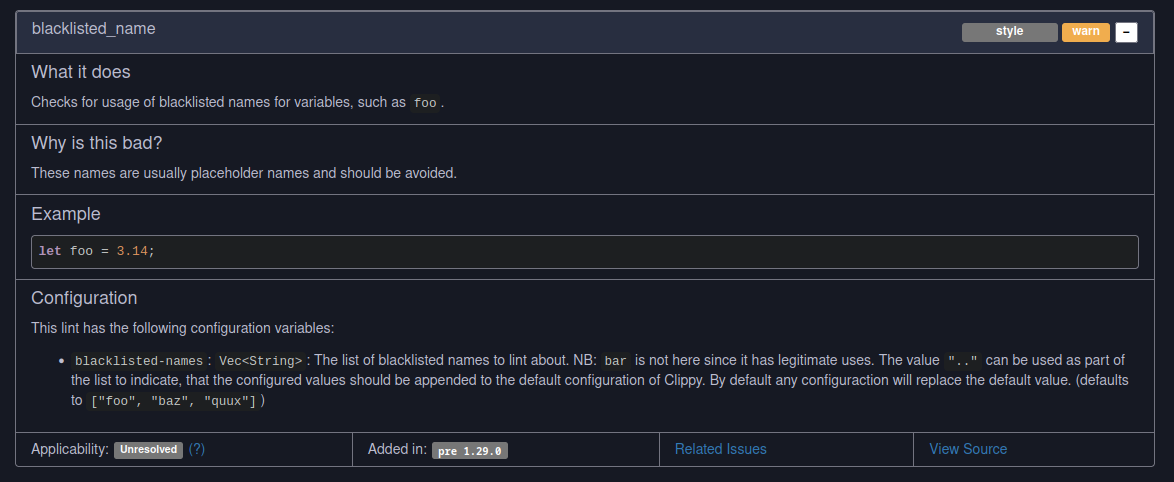
I've seen some `clippy.toml` files, that have a few additions to the default list of a configuration and then a copy of our default. The list will therefore not be updated, when we add new names. This change should make it simple for new users to append values instead of replacing them.
I'm uncertain if the documentation of the `".."` is apparent. Any suggestions are welcome. I've also check that the lint list displays the examples correctly.
<details>
<summary>Lint list screenshots</summary>
</details>
---
changelog: enhancement: [`doc_markdown`]: Users can now indicate, that the `doc-valid-idents` should extend the default and not replace it
changelog: enhancement: [`blacklisted-name`]: Users can now indicate, that the `blacklisted-names` should extend the default and not replace it
Closes: #8877
That's it. Have a fantastic weekend to everyone reading this. Here is a cookie 🍪
- Move doc about defining remotes to the front and use the defined
remotes in the further documentation
- Don't recommend pushing to the remote repo directly
- Add some clarifying comments
This removes the empty separate files for the different groups and adds
a single file giving short explanations for each group and what to
expect from those groups.
The UI tests now use the latest edition by default. Testing on older
editions should almost never be necessary, so I don't see a need to
document this.
This reformats all the internal docs, so that the md files use at most
80 characters per line. This is the usual formatting of md files. We
allow 120 chars per line in CI though.
{kind=link}
{kind=link}