8.8 KiB
Architecture
This document describes the high-level architecture of rust-analyzer. If you want to familiarize yourself with the code base, you are just in the right place!
See also the guide, which walks through a particular snapshot of rust-analyzer code base.
Yet another resource is this playlist with videos about various parts of the analyzer:
https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE
Note that the guide and videos are pretty dated, this document should be in generally fresher.
The Big Picture
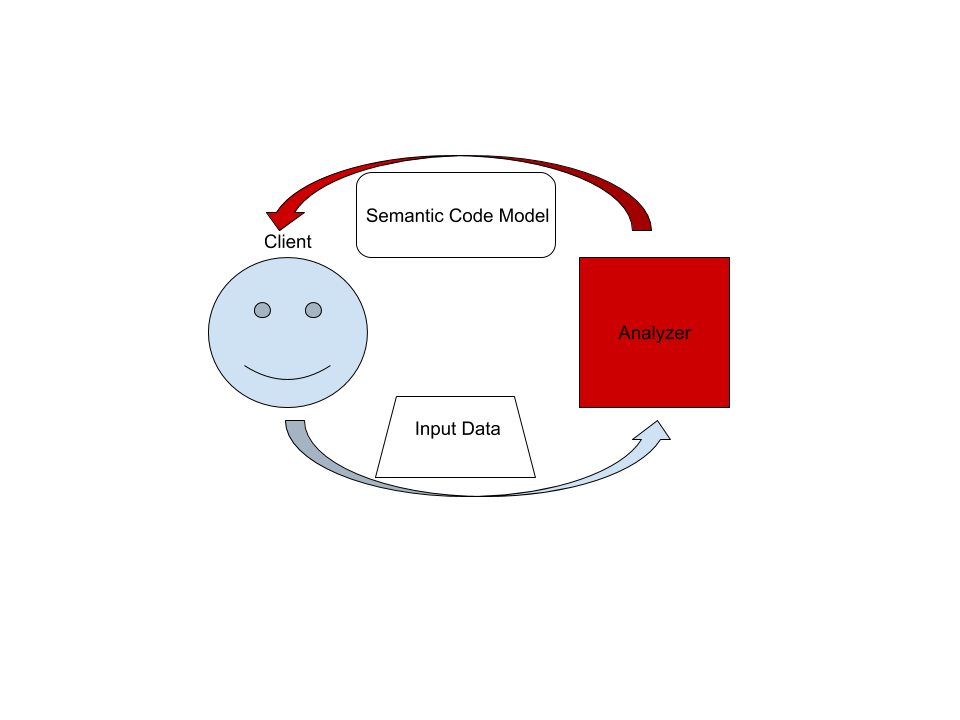
On the highest level, rust-analyzer is a thing which accepts input source code from the client and produces a structured semantic model of the code.
More specifically, input data consists of a set of test files ((PathBuf, String) pairs) and information about project structure, captured in the so
called CrateGraph. The crate graph specifies which files are crate roots,
which cfg flags are specified for each crate and what dependencies exist between
the crates. The analyzer keeps all this input data in memory and never does any
IO. Because the input data are source code, which typically measures in tens of
megabytes at most, keeping everything in memory is OK.
A "structured semantic model" is basically an object-oriented representation of modules, functions and types which appear in the source code. This representation is fully "resolved": all expressions have types, all references are bound to declarations, etc.
The client can submit a small delta of input data (typically, a change to a single file) and get a fresh code model which accounts for changes.
The underlying engine makes sure that model is computed lazily (on-demand) and can be quickly updated for small modifications.
Code generation
Some of the components of this repository are generated through automatic
processes. cargo xtask codegen runs all generation tasks. Generated code is
committed to the git repository.
In particular, cargo xtask codegen generates:
-
syntax_kind/generated-- the set of terminals and non-terminals of rust grammar. -
ast/generated-- AST data structure. -
doc_tests/generated,test_data/parser/inline-- tests for assists and the parser.
The source for 1 and 2 is in ast_src.rs.
Code Walk-Through
crates/ra_syntax, crates/ra_parser
Rust syntax tree structure and parser. See RFC and ./syntax.md for some design notes.
- rowan library is used for constructing syntax trees.
grammarmodule is the actual parser. It is a hand-written recursive descent parser, which produces a sequence of events like "start node X", "finish node Y". It works similarly to kotlin's parser, which is a good source of inspiration for dealing with syntax errors and incomplete input. Original libsyntax parser is what we use for the definition of the Rust language.TreeSinkandTokenSourcetraits bridge the tree-agnostic parser fromgrammarwithrowantrees.astprovides a type safe API on top of the rawrowantree.ast_srcdescription of the grammar, which is used to generatesyntax_kindsandastmodules, usingcargo xtask codegencommand.
Tests for ra_syntax are mostly data-driven: test_data/parser contains subdirectories with a bunch of .rs
(test vectors) and .txt files with corresponding syntax trees. During testing, we check
.rs against .txt. If the .txt file is missing, it is created (this is how you update
tests). Additionally, running cargo xtask codegen will walk the grammar module and collect
all // test test_name comments into files inside test_data/parser/inline directory.
Note
api_walkthrough
in particular: it shows off various methods of working with syntax tree.
See #93 for an example PR which fixes a bug in the grammar.
crates/ra_db
We use the salsa crate for incremental and
on-demand computation. Roughly, you can think of salsa as a key-value store, but
it also can compute derived values using specified functions. The ra_db crate
provides basic infrastructure for interacting with salsa. Crucially, it
defines most of the "input" queries: facts supplied by the client of the
analyzer. Reading the docs of the ra_db::input module should be useful:
everything else is strictly derived from those inputs.
crates/ra_hir* crates
HIR provides high-level "object oriented" access to Rust code.
The principal difference between HIR and syntax trees is that HIR is bound to a
particular crate instance. That is, it has cfg flags and features applied. So,
the relation between syntax and HIR is many-to-one. The source_binder module
is responsible for guessing a HIR for a particular source position.
Underneath, HIR works on top of salsa, using a HirDatabase trait.
ra_hir_xxx crates have a strong ECS flavor, in that they work with raw ids and
directly query the database.
The top-level ra_hir façade crate wraps ids into a more OO-flavored API.
crates/ra_ide
A stateful library for analyzing many Rust files as they change. AnalysisHost
is a mutable entity (clojure's atom) which holds the current state, incorporates
changes and hands out Analysis --- an immutable and consistent snapshot of
the world state at a point in time, which actually powers analysis.
One interesting aspect of analysis is its support for cancellation. When a
change is applied to AnalysisHost, first all currently active snapshots are
canceled. Only after all snapshots are dropped the change actually affects the
database.
APIs in this crate are IDE centric: they take text offsets as input and produce
offsets and strings as output. This works on top of rich code model powered by
hir.
crates/rust-analyzer
An LSP implementation which wraps ra_ide into a language server protocol.
ra_vfs
Although hir and ra_ide don't do any IO, we need to be able to read
files from disk at the end of the day. This is what ra_vfs does. It also
manages overlays: "dirty" files in the editor, whose "true" contents is
different from data on disk. This is more or less the single really
platform-dependent component, so it lives in a separate repository and has an
extensive cross-platform CI testing.
Testing Infrastructure
Rust Analyzer has three interesting systems boundaries to concentrate tests on.
The outermost boundary is the rust-analyzer crate, which defines an LSP
interface in terms of stdio. We do integration testing of this component, by
feeding it with a stream of LSP requests and checking responses. These tests are
known as "heavy", because they interact with Cargo and read real files from
disk. For this reason, we try to avoid writing too many tests on this boundary:
in a statically typed language, it's hard to make an error in the protocol
itself if messages are themselves typed.
The middle, and most important, boundary is ra_ide. Unlike
rust-analyzer, which exposes API, ide uses Rust API and is intended to
use by various tools. Typical test creates an AnalysisHost, calls some
Analysis functions and compares the results against expectation.
The innermost and most elaborate boundary is hir. It has a much richer
vocabulary of types than ide, but the basic testing setup is the same: we
create a database, run some queries, assert result.
For comparisons, we use the expect crate for snapshot testing.
To test various analysis corner cases and avoid forgetting about old tests, we
use so-called marks. See the marks module in the test_utils crate for more.