fix: generate async delegate methods
Fixes a bug where the generated async method doesn't await the result before returning it.
This is an example of what the output looked like:
```rust
struct Age<T>(T);
impl<T> Age<T> {
pub(crate) async fn age<J, 'a>(&'a mut self, ty: T, arg: J) -> T {
self.0
}
}
struct Person<T> {
age: Age<T>,
}
impl<T> Person<T> {
pub(crate) async fn age<J, 'a>(&'a mut self, ty: T, arg: J) -> T {
self.age.age(ty, arg) // .await is missing
}
}
```
The `.await` is missing, so the return type is `impl Future<Output = T>` instead of `T`
feat: add the ability to limit the number of threads launched by `main_loop`
## Motivation
`main_loop` defaults to launch as many threads as cpus in one machine. When developing on multi-core remote servers on multiple projects, this will lead to thousands of idle threads being created. This is very annoying when one wants check whether his program under developing is running correctly via `htop`.
<img width="756" alt="image" src="https://user-images.githubusercontent.com/41831480/206656419-fa3f0dd2-e554-4f36-be1b-29d54739930c.png">
## Contribution
This patch introduce the configuration option `rust-analyzer.numThreads` to set the desired thread number used by the main thread pool.
This should have no effects on the performance as not all threads are actually used.
<img width="1325" alt="image" src="https://user-images.githubusercontent.com/41831480/206656834-fe625c4c-b993-4771-8a82-7427c297fd41.png">
## Demonstration
The following is a snippet of `lunarvim` configuration using my own build.
```lua
vim.list_extend(lvim.lsp.automatic_configuration.skipped_servers, { "rust_analyzer" })
require("lvim.lsp.manager").setup("rust_analyzer", {
cmd = { "env", "RA_LOG=debug", "RA_LOG_FILE=/tmp/ra-test.log",
"/home/jlhu/Projects/rust-analyzer/target/debug/rust-analyzer",
},
init_options = {
numThreads = 4,
},
settings = {
cachePriming = {
numThreads = 8,
},
},
})
```
## Limitations
The `numThreads` can only be modified via `initializationOptions` in early initialisation because everything has to wait until the thread pool starts including the dynamic settings modification support.
The `numThreads` also does not reflect the end results of how many threads is actually created, because I have not yet tracked down everything that spawns threads.
add wrapping/checked/saturating assist
This addresses #13452
I'm not sure about the structure of the code. I'm not sure if it needs to be 3 separate assists, and if that means it needs to be in 3 separate files as well.
Most of the logic is in `util.rs`, which feels funny to me, but there seems to be a pattern of 1 assist per file, and this seems better than duplicating the logic.
Let me know if anything needs changes 😁
fix a bunch of clippy lints
fixes a bunch of clippy lints for fun and profit
i'm aware of this repo's position on clippy. The changes are split into separate commits so they can be reviewed separately
feat: Package Windows release artifacts as ZIP and add symbols file
Closes#13872Closes#7747
CC #10371
This allows us to ship a format that's easier to handle on Windows. As a bonus, we can also include the PDB, to get useful stack traces. Unfortunately, it adds a couple of dependencies to `xtask`, increasing the debug build times from 1.28 to 1.58 s (release from 1.60s to 2.20s) on my system.
Apply fallback before final obligation resolution
Fixes#13249Fixes#13518
We've been applying fallback to type variables independently even when there are some unresolved obligations that associate them. This PR applies fallback to unresolved scalar type variables before the final attempt of resolving obligations, which enables us to infer more.
Unlike rustc, which has separate storages for each kind of type variables, we currently don't have a way to retrieve only integer/float type variables without folding/visiting every single type we've inferred. I've repurposed `TypeVariableData` as bitflags that also hold the kind of the type variable it's referring to so that we can "reconstruct" scalar type variables from their indices.
This PR increases the number of ??ty for rust-analyzer repo not because we regress and fail to infer the existing code but because we fail to infer the new code. It seems we have problems inferring some functions bitflags produces.
Support multi-character punct tokens in MBE
Fixes#11497
In the context of MBE, consecutive puncts are parsed as multi-character punct tokens whenever possible. For example, `:::` is parsed as ``[Punct(`::`), Punct(`:`)]`` and shouldn't get matched to patterns like `: : :` or `: ::`.
We have implemented this behavior only for when we match puncts against `tt` fragments, but not when we match puncts literally. This PR extracts the multi-character punct handling procedure into a separate method and extends its support for literal matching.
For good measure, this PR adds support for `<-` token, which is still [considered as one token in rustc](e396186407/compiler/rustc_ast/src/token.rs (L249)) despite the placement syntax having been removed.
fix: merge multiple intersecting ranges
Fixes#13791
In `check_intersection_and_push()`, there may exist two ranges we should merge with the new one. We've been assuming there should be only one range that intersects, which lead to [this assertion](da15d92a32/crates/text-edit/src/lib.rs (L192)) to fail under specific circumstances.
Use `rustc_safe_intrinsic` attribute to check for intrinsic safety
Instead of maintaining a list that is poorly kept in sync we can just use the attribute.
This will make new RA versions unusable with old toolchains that don't have the attribute yet. Should we keep maintaining the list as a fallback or just don't care?
derive 'Hash'
clippy doesn't like that `PartialEq` is derived, and `Hash` is manually implemented. This PR resolves that by deriving the `Hash` implementation.
Moar linting: needless_borrow, let_unit_value, ...
* There are a few needless borrows that don't seem to be needed. I even did a quick assembly comparison and posted a q to stackoveflow on it. See [here](https://stackoverflow.com/questions/74910196/advantages-of-pass-by-ref-val-with-impl-intoiteratoritem-impl-asrefstr)
* removed several `let _ = ...` when they don't look necessary (even a few ones that were not suggested by clippy (?))
* some unneeded assignment+return - keep the code a bit leaner
* a few `writeln!` instead of `write!`, or even consolidate write!
* a nice optimization to use `ch.is_ascii_digit` instead of `ch.is_digit(10)`
fix: handle lifetime variables in `CallableSig` query
Fixes#13838
The problem is similar to #13223: we've been skipping non-empty binders, letting lifetime bound variables escape.
I ended up refactoring `hir_ty::callable_sig_from_fnonce()`. Like #13223, I chose to make use of `InferenceTable` which is capable of handling variables (I feel we should always use it when we solve trait-related stuff instead of manually building obligations/queries).
I couldn't make up a test that crashes without this patch (since the function I'm fixing is only used *outside* `hir-ty`, simple `hir-ty` test wouldn't cause crash), but at least I tested with my local build and made sure it doesn't crash with the code in the original issue. I'd appreciate any help to find a regression test.
* There are a few needless borrows that don't seem to be needed. I even did a quick assembly comparison and posted a q to stackoveflow on it. See [here](https://stackoverflow.com/questions/74910196/advantages-of-pass-by-ref-val-with-impl-intoiteratoritem-impl-asrefstr)
* removed several `let _ = ...` when they don't look necessary (even a few ones that were not suggested by clippy (?))
* there were a few `then(|| ctor{})` that clippy suggested to replace with `then_some(ctor{})` -- seems reasonable?
* some unneeded assignment+return - keep the code a bit leaner
* a few `writeln!` instead of `write!`, or even consolidate write!
* a nice optimization to use `ch.is_ascii_digit` instead of `ch.is_digit(10)`
This makes code more readale and concise,
moving all format arguments like `format!("{}", foo)`
into the more compact `format!("{foo}")` form.
The change was automatically created with, so there are far less change
of an accidental typo.
```
cargo clippy --fix -- -A clippy::all -W clippy::uninlined_format_args
```
Seems like these can be safely fixed. With one, I was particularly
surprised -- `Some(pats) => &**pats,` in body.rs?
```
cargo clippy --fix -- -A clippy::all -D clippy::explicit_auto_deref
```
I am not certain if this will improve performance,
but it seems having a .clone() without any need should be removed.
This was done with clippy, and manually reviewed:
```
cargo clippy --fix -- -A clippy::all -D clippy::redundant_clone
```
feat: Add an option to hide adjustment hints outside of `unsafe` blocks and functions
As the title suggests: this PR adds an option (namely `rust-analyzer.inlayHints.expressionAdjustmentHints.hideOutsideUnsafe`) that allows to hide adjustment hints outside of `unsafe` blocks and functions:
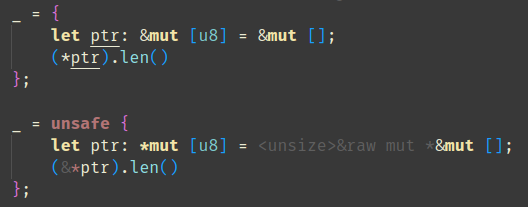
Requested by `@BoxyUwU` <3
fix: Correctly check for parentheses redundancy in `remove_parentheses` assist
This is quite a bunch of code and some hacks, but I _think_ this time it's correct.
I've added a lot of tests, most of which fail with the assist impl from #13733 :')
Complete enum variants without parens when snippets are disabled
This handles the portion of #13767 that bothered me, but I can try to work on the other parts we discussed if needed.
fix: resolve all inference vars in `InferenceResult::assoc_resolutions`
I think this fixes '#13773, ~but still haven't found repro. I'll try finding one so we can have a regression test~.
We should resolve every inference variable in `InferenceResult` after inference is done. We started recording `Substitution`s for each resolved associated items in #13725, but failed to do so which causes crash when analyzing source in IDE layer.
fix: make make_body respect comments in extract_function
Possible fix for #13621
### Points to help in review:
- Earlier we were only considering statements in a block expr and hence comments were being ignored, now we handle tokens hence making it aware of comments and then preserving them using `hacky_block_expr_with_comments`
Seems like I am not able to attach output video, github is glitching for it :(
fix: breaking snippets on typed incomplete suggestions
Possible fix for #7929
Fix the case where if a user types `&&42.o`, snippet completion was still applying &&Ok(42). Note this was fixed previously on `&&42.` but this still remained a problem for this case
Previous relevant PR: #13517
### Points to help in review:
- The main problem why everything broke on adding an extra `o` was, earlier `dot_receiver` was `42.` which was a `LITERAL` but now `42.o` becomes a `FIELD_EXPR`
- Till now `include_references` was just checking for parent of `LITERAL` and if it was a `REF_EXPR`, but now we consider `FIELD_EXPR` and traverse all of them, finally to reach `REF_EXPR`. If `REF_EXPR` is not found we just return the original `initial_element`
- We are constructing a new node during `include_references` because if we rely on `dot_receiver` solely we would get `&&42.o` to be replaced with, but we want `&&42` to be replaced with
### Output Video:
https://user-images.githubusercontent.com/49019259/205420166-efbdef78-5b3a-4aef-ab4b-d892dac056a0.mov
Hope everything I wrote makes sense 😅
Also interestingly previous PR's number was `13517` and this PR's number is `13715`, nicee
feat: allow unwrap block in let initializers
Possible fix for #13679
### Points to help in review:
- I just added a parent case for let statements and it seems everything else was in place already, so turned out to be a small fix
fix: add fallback case in generated `PartialEq` impl
Partially fixes#13727.
When generating `PartialEq` implementations for enums, the original code can already generate the following fallback case:
```rs
_ => std::mem::discriminant(self) == std::mem::discriminant(other),
```
However, it has been suppressed in the following example for no good reason:
```rs
enum Either<T, U> {
Left(T),
Right(U),
}
impl<T, U> PartialEq for Either<T, U> {
fn eq(&self, other: &Self) -> bool {
match (self, other) {
(Self::Left(l0), Self::Left(r0)) => l0 == r0,
(Self::Right(l0), Self::Right(r0)) => l0 == r0,
// _ => std::mem::discriminant(self) == std::mem::discriminant(other),
// ^ this completes the match arms!
}
}
}
```
This PR has removed that suppression logic.
~~Of course, the PR could have suppressed the fallback case generation for single-variant enums instead, but I believe that this case is quite rare and should be caught by `#[warn(unreachable_patterns)]` anyway.~~
After this fix, when the enum has >1 variants, the following fallback arm will be generated :
* `_ => false,` if we've already gone through every case where the variants of `self` and `other` match;
* The original one (as stated above) in other cases.
---
Note: The code example is still wrong after the fix due to incorrect trait bounds.
fix: normalize projection after discarding free `BoundVar`s in RPIT
Fixes#13307
When we lower the return type of a function, it may contain free `BoundVar`s in `OpaqueType`'s substitution, which would cause panic during canonicalization as part of projection normalization. Those `BoundVar`s are irrelevant in this context and will be discarded, and we should defer projection normalization until then.
fix: only shift `BoundVar`s that come from outside lowering context
Fixes#13734
There are some free functions `TyLoweringContext` methods call, which do not know anything about current binders in scope. We need to shift in the `BoundVar`s in substitutions that we get from them (#4952), but not those we get from `TyLoweringContext` methods.
Compute data layout of types
cc #4091
Things that aren't working:
* Closures
* Generators (so no support for `Future` I think)
* Opaque types
* Type alias and associated types which may need normalization
Things that show wrong result:
* ~Enums with explicit discriminant~
* SIMD types
* ~`NonZero*` and similar standard library items which control layout with special attributes~
At the user level, I didn't put much work, since I wasn't confident about what is the best way to present this information. Currently it shows size and align for ADTs, and size, align, offset for struct fields, in the hover, similar to clangd. I used it some days and I feel I liked it, but we may consider it too noisy and move it to an assist or command.
The old value was for the old chalk-engine solver, nowadays the newer chalk-recursive solver is used.
The new solver currently uses fuel a bit more quickly, so a higher value is needed.
Running analysis-stats showed that a value of 100 increases the amount of unknown types,
while for a value of 1000 it's staying mostly the same.
Add `move_const_to_impl` assist
Closes#13277
For the initial implementation, this assist:
- only applies to inherent impl. Much as we can *technically* provide this assist for default impl in trait definitions, it'd be complicated to get it right.
- may break code when the const's name collides with an item of a trait the self type implements.
Comments in the code explain those caveats in a bit more detail.
Fix the case where if a user types `&&42.o`, snippet completion
was still applying &&Ok(42). Note this was fixed previously
on `&&42.` but this still remained a problem for this case
Don't show runnable code lenses in libraries outside of the workspace
Addresses #13664. For now I'm just disabling runnable code lenses since the ones that display the number of references and implementations do work correctly with external code.
Also made a tiny TypeScript change to use the typed `sendNotification` overload.
fix: check tail expressions more precisely in `extract_function`
Fixes#13620
When extracting expressions with control flows into a function, we can avoid wrapping tail expressions in `Option` or `Result` when they are also tail expressions of the container we're extracting from (see #7840, #9773). This is controlled by `ContainerInfo::is_in_tail`, but we've been computing it by checking if the tail expression of the range to extract is contained in the container's syntactically last expression, which may be a block that contains both tail and non-tail expressions (e.g. in #13620, the range to be extracted is not a tail expression but we set the flag to true).
This PR tries to compute the flag as precise as possible by utilizing `for_each_tail_expr()` (and also moves the flag to `Function` struct as it's more of a property of the function to be extracted than of the container).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}