Build macOS distribution artifacts with XCode 13
After all of the `rust-lang/rust` Apple runners started using macOS 12, the builds created by CI began to use XCode 14.0.1. Due to this (as far as we can tell), XCode's build tools started to ignore the `MACOSX_DEPLOYMENT_TARGET` being defined by us for the distributed builds that let both `rustc` and `libstd` work on older versions. The current idea is that since XCode 14's macOS SDK doesn't support deployment targets before 10.13, it uses some default of its own. You can see the difference between stable's and the most recent nighty's supported versions [here](https://github.com/rust-lang/rust/issues/104570#issuecomment-1321225907).
I wasn't able to confirm my SDK versioning hypothesis locally since I think there's something jammed with my XCode installation, but hopefully this should still fix it for releases.
Closes https://github.com/rust-lang/rust/issues/104570
r? `@Mark-Simulacrum`
privacy: Fix more (potential) issues with effective visibilities
Continuation of https://github.com/rust-lang/rust/pull/103965.
See individual commits for more detailed description of the changes.
The shortcuts removed in 4eb63f618e and c7c7d16727 could actually be correct (or correct after some tweaks), but they used global reasoning like "we can skip this update because if the code compiles then some other update should do the same thing eventually".
I have some expertise in this area, but I still have doubt whether such global reasoning was correct or not, especially in presence of all possible exotic cases with imports.
After this PR all table changes should be "locally correct" after every update, even if it may be overcautious.
If similar optimizations are introduced again they will need detailed comments explaining why it's legal to do what they do and providing proofs.
Fixes https://github.com/rust-lang/rust/issues/104249.
Fixes https://github.com/rust-lang/rust/issues/104539.
Avoid `GenFuture` shim when compiling async constructs
Previously, async constructs would be lowered to "normal" generators, with an additional `from_generator` / `GenFuture` shim in between to convert from `Generator` to `Future`.
The compiler will now special-case these generators internally so that async constructs will *directly* implement `Future` without the need to go through the `from_generator` / `GenFuture` shim.
The primary motivation for this change was hiding this implementation detail in stack traces and debuginfo, but it can in theory also help the optimizer as there is less abstractions to see through.
---
Given this demo code:
```rust
pub async fn a(arg: u32) -> Backtrace {
let bt = b().await;
let _arg = arg;
bt
}
pub async fn b() -> Backtrace {
Backtrace::force_capture()
}
```
I would get the following with the latest stable compiler (on Windows):
```
4: async_codegen:🅱️:async_fn$0
at .\src\lib.rs:10
5: core::future::from_generator::impl$1::poll<enum2$<async_codegen:🅱️:async_fn_env$0> >
at /rustc/897e37553bba8b42751c67658967889d11ecd120\library\core\src\future\mod.rs:91
6: async_codegen:🅰️:async_fn$0
at .\src\lib.rs:4
7: core::future::from_generator::impl$1::poll<enum2$<async_codegen:🅰️:async_fn_env$0> >
at /rustc/897e37553bba8b42751c67658967889d11ecd120\library\core\src\future\mod.rs:91
```
whereas now I get a much cleaner stack trace:
```
3: async_codegen:🅱️:async_fn$0
at .\src\lib.rs:10
4: async_codegen:🅰️:async_fn$0
at .\src\lib.rs:4
```
Pass 128-bit C-style enum enumerator values to LLVM
Pass the full 128 bits of C-style enum enumerators through to LLVM. This means that debuginfo for C-style repr128 enums is now emitted correctly for DWARF platforms (as compared to not being correctly emitted on any platform).
Tracking issue: #56071
Check fat pointer metadata compatibility modulo regions
Regions don't really mean anything anyways during hir typeck.
If this `erase_regions` makes anyone nervous, it's probably equally valid to just equate the types using a type relation, but regardless we should _not_ be using strict type equality while region variables are present.
Fixes#103384
Support multiple targets for checkOnSave (in conjunction with cargo 1.64.0+)
This PR adds support for the ability to pass multiple `--target` flags when using
`cargo` 1.64.0+.
## Questions
I needed to change the type of two configurations options, but I did not plurialize the names to
avoid too much churn, should I ?
## Zulip thread
https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Frust-analyzer/topic/Issue.2013282.20.28supporting.20multiple.20targets.20with.201.2E64.2B.29
## Example
To see it working, on a macOS machine:
```sh
$ cd /tmp
$ cargo new cargo-multiple-targets-support-ra-test
$ cd !$
$ mkdir .cargo
$ echo '
[build]
target = [
"aarch64-apple-darwin",
"x86_64-apple-darwin",
]
' > .cargo/config.toml
$ echo '
fn main() {
#[cfg(all(target_arch = "aarch64", target_os = "macos"))]
{
let a = std::fs::read_to_string("/tmp/test-read");
}
#[cfg(all(target_arch = "x86_64", target_os = "macos"))]
{
let a = std::fs::read_to_string("/tmp/test-read");
}
#[cfg(all(target_arch = "x86_64", target_os = "windows"))]
{
let a = std::fs::read_to_string("/tmp/test-read");
}
}
' > src/main.rs
# launch your favorite editor with the version of RA from this PR
#
# You should see warnings under the first two `let a = ...` but not the third
```
## Screen
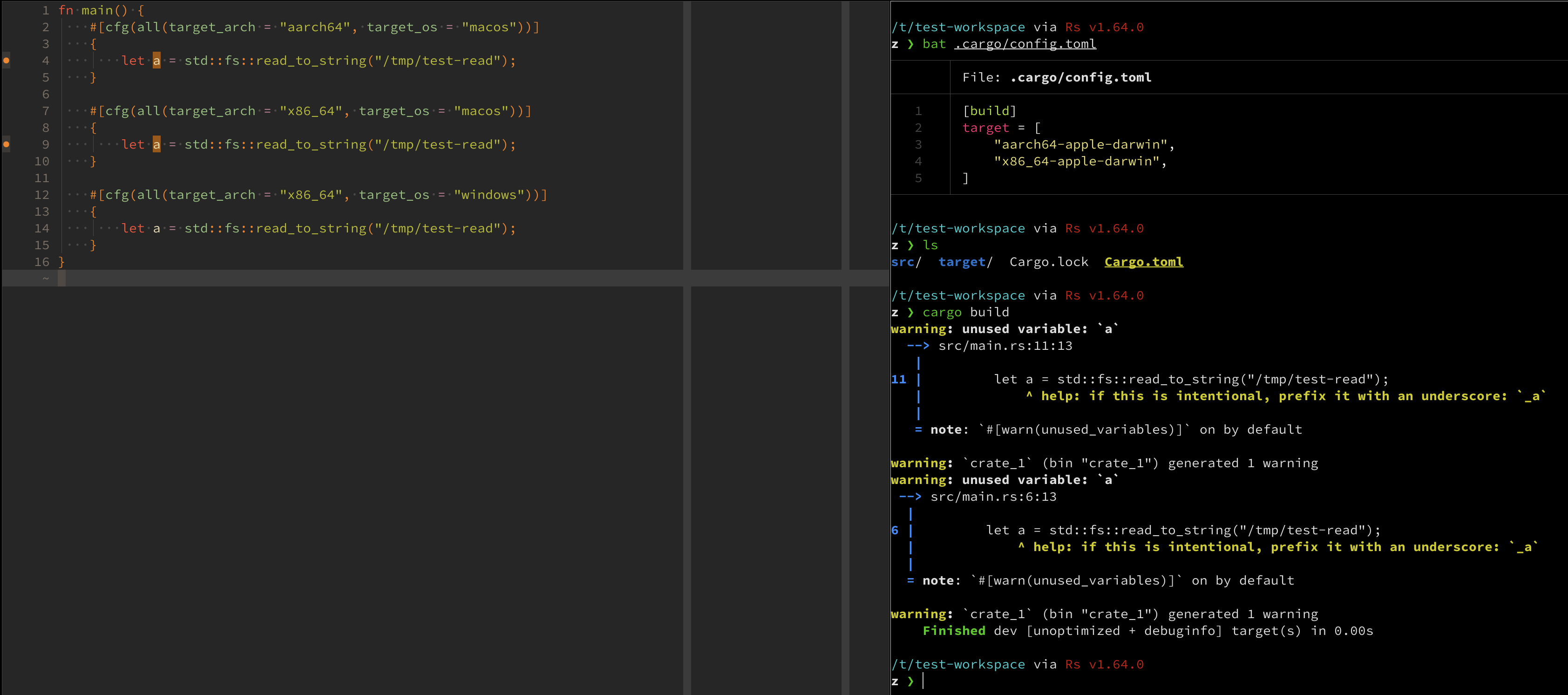
Helps with #13282
fix: format expression parsing edge-cases
- Handle positional arguments with formatting options (i.e. `{:b}`). Previously copied `:b` as an argument, producing broken code.
- Handle indexed positional arguments (`{0}`) ([reference](https://doc.rust-lang.org/std/fmt/#positional-parameters)). Previously copied over `0` as an argument.
Note: the assist also breaks when named arguments are used (`"{name}$0", name = 2 + 2` is converted to `"{}"$0, name`. I'm working on fix for that as well.
Support `#[track_caller]` on async fns
Adds `#[track_caller]` to the generator that is created when we desugar the async fn.
Fixes#78840
Open questions:
- What is the performance impact of adding `#[track_caller]` to every `GenFuture`'s `poll(...)` function, even if it's unused (i.e., the parent span does not set `#[track_caller]`)? We might need to set it only conditionally, if the indirection causes overhead we don't want.
internal: Update proc-macro-srv tests
Should have been included in #13548, but I didn't notice as those tests aren't run in our CI.
cc rust-lang/rust#104454
Fix inconsistent rounding of 0.5 when formatted to 0 decimal places
As described in #70336, when displaying values to zero decimal places the value of 0.5 is rounded to 1, which is inconsistent with the display of other half-integer values which round to even.
From testing the flt2dec implementation, it looks like this comes down to the condition in the fixed-width Dragon implementation where an empty buffer is treated as a case to apply rounding up. I believe the change below fixes it and updates only the relevant tests.
Nevertheless I am aware this is very much a core piece of functionality, so please take a very careful look to make sure I haven't missed anything. I hope this change does not break anything in the wider ecosystem as having a consistent rounding behaviour in floating point formatting is in my opinion a useful feature to have.
Resolves#70336
interpret: support for per-byte provenance
Also factors the provenance map into its own module.
The third commit does the same for the init mask. I can move it in a separate PR if you prefer.
Fixes https://github.com/rust-lang/miri/issues/2181
r? `@oli-obk`
Update several crates to bring support for the new Tier 3 Windows tar…
`cargo t` has passed on Windows 11 with both `x86_64-pc-windows-gnu` and `x86_64-pc-windows-gnullvm` targets.
fix: Strip comments and attributes off of all trait item completions
Previously, this was done in several places redundantly, but not for all items. It was also untested. This PR fixes that.
Add new MIR constant propagation based on dataflow analysis
The current constant propagation in `rustc_mir_transform/src/const_prop.rs` fails to handle many cases that would be expected from a constant propagation optimization. For example:
```rust
let x = if true { 0 } else { 0 };
```
This pull request adds a new constant propagation MIR optimization pass based on the existing dataflow analysis framework. Since most of the analysis is not unique to constant propagation, a generic framework has been extracted. It works on top of the existing framework and could be reused for other optimzations.
Closes#80038. Closes#81605.
## Todo
### Essential
- [x] [Writes to inactive enum variants](https://github.com/rust-lang/rust/pull/101168#pullrequestreview-1089493974). Resolved by rejecting the registration of places with downcast projections for now. Could be improved by flooding other variants if mutable access to a variant is observed.
- [X] Handle [`StatementKind::CopyNonOverlapping`](https://github.com/rust-lang/rust/pull/101168#discussion_r957774914). Resolved by flooding the destination.
- [x] Handle `UnsafeCell` / `!Freeze` correctly.
- [X] Overflow propagation of `CheckedBinaryOp`: Decided to not propagate if overflow flag is `true` (`false` will still be propagated)
- [x] More documentation in general.
- [x] Arguments for correctness, documentation of necessary assumptions.
- [x] Better performance, or alternatively, require `-Zmir-opt-level=3` for now.
### Extra
- [x] Add explicit unreachability, i.e. upgrading the lattice from $\mathbb{P} \to \mathbb{V}$ to $\set{\bot} \cup (\mathbb{P} \to \mathbb{V})$.
- [x] Use storage statements to improve precision.
- [ ] Consider opening issue for duplicate diagnostics: https://github.com/rust-lang/rust/pull/101168#issuecomment-1276609950
- [ ] Flood moved-from places with $\bot$ (requires some changes for places with tracked projections).
- [ ] Add downcast projections back in.
- [ ] [Algebraic simplifications](https://github.com/rust-lang/rust/pull/101168#discussion_r957967878) (possibly with a shared API; done by old const prop).
- [ ] Propagation through slices / arrays.
- [ ] Find other optimizations that are done by old `const_prop.rs`, but not by this one.
Wrap bundled static libraries into object files
Fixes#103044 (not sure, couldn't test locally)
Bundled static libraries should be wrapped into object files as it's done for metadata file.
r? `@petrochenkov`
Change the way libunwind is linked for *-windows-gnullvm targets
I have no idea why previous way works for `x86_64-fortanix-unknown-sgx` (assuming it actually works...) but not for `gnullvm`. It fails when linking libtest during Rust build (unless somebody adds `RUSTFLAGS='-Clinkarg=-lunwind'`).
Also fixes exception handling on AArch64.
Merge crossbeam-channel into `std::sync::mpsc`
This PR imports the [`crossbeam-channel`](https://github.com/crossbeam-rs/crossbeam/tree/master/crossbeam-channel#crossbeam-channel) crate into the standard library as a private module, `sync::mpmc`. `sync::mpsc` is now implemented as a thin wrapper around `sync::mpmc`. The primary purpose of this PR is to resolve https://github.com/rust-lang/rust/issues/39364. The public API intentionally remains the same.
The reason https://github.com/rust-lang/rust/issues/39364 has not been fixed in over 5 years is that the current channel is *incredibly* complex. It was written many years ago and has sat mostly untouched since. `crossbeam-channel` has become the most popular alternative on crates.io, amassing over 30 million downloads. While crossbeam's channel is also complex, like all fast concurrent data structures, it avoids some of the major issues with the current implementation around dynamic flavor upgrades. The new implementation decides on the datastructure to be used when the channel is created, and the channel retains that structure until it is dropped.
Replacing `sync::mpsc` with a simpler, less performant implementation has been discussed as an alternative. However, Rust touts itself as enabling *fearless concurrency*, and having the standard library feature a subpar implementation of a core concurrency primitive doesn't feel right. The argument is that slower is better than broken, but this PR shows that we can do better.
As mentioned before, the primary purpose of this PR is to fix https://github.com/rust-lang/rust/issues/39364, and so the public API intentionally remains the same. *After* that problem is fixed, the fact that `sync::mpmc` now exists makes it easier to fix the primary limitation of `mpsc`, the fact that it only supports a single consumer. spmc and mpmc are two other common concurrency patterns, and this change enables a path to deprecating `mpsc` and exposing a general `sync::channel` module that supports multiple consumers. It also implements other useful methods such as `send_timeout`. That said, exposing MPMC and other new functionality is mostly out of scope for this PR, and it would be helpful if discussion stays on topic :)
For what it's worth, the new implementation has also been shown to be more performant in [some basic benchmarks](https://github.com/crossbeam-rs/crossbeam/tree/master/crossbeam-channel/benchmarks#results).
cc `@taiki-e`
r? rust-lang/libs
Improve performance of `rem_euclid()` for signed integers
such code is copy from
https://github.com/rust-lang/rust/blob/master/library/std/src/f32.rs and
https://github.com/rust-lang/rust/blob/master/library/std/src/f64.rs
using `r+rhs.abs()` is faster than calc it with an if clause. Bench result:
```
$ cargo bench
Compiling div-euclid v0.1.0 (/me/div-euclid)
Finished bench [optimized] target(s) in 1.01s
Running unittests src/lib.rs (target/release/deps/div_euclid-7a4530ca7817d1ef)
running 7 tests
test tests::it_works ... ignored
test tests::bench_aaabs ... bench: 10,498,793 ns/iter (+/- 104,360)
test tests::bench_aadefault ... bench: 11,061,862 ns/iter (+/- 94,107)
test tests::bench_abs ... bench: 10,477,193 ns/iter (+/- 81,942)
test tests::bench_default ... bench: 10,622,983 ns/iter (+/- 25,119)
test tests::bench_zzabs ... bench: 10,481,971 ns/iter (+/- 43,787)
test tests::bench_zzdefault ... bench: 11,074,976 ns/iter (+/- 29,633)
test result: ok. 0 passed; 0 failed; 1 ignored; 6 measured; 0 filtered out; finished in 19.35s
```
It seems that, default `rem_euclid` triggered a branch prediction, thus `bench_default` is faster than `bench_aadefault` and `bench_aadefault`, which shuffles the order of calculations. but all of them slower than what it was in `f64`'s and `f32`'s `rem_euclid`, thus I submit this PR.
bench code:
```rust
#![feature(test)]
extern crate test;
fn rem_euclid(a:i32,rhs:i32)->i32{
let r = a % rhs;
if r < 0 { r + rhs.abs() } else { r }
}
#[cfg(test)]
mod tests {
use super::*;
use test::Bencher;
use rand::prelude::*;
use rand::rngs::SmallRng;
const N:i32=1000;
#[test]
fn it_works() {
let a: i32 = 7; // or any other integer type
let b = 4;
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
for i in &d {
for j in &n {
assert_eq!(i.rem_euclid(*j),rem_euclid(*i,*j));
}
}
assert_eq!(rem_euclid(a,b), 3);
assert_eq!(rem_euclid(-a,b), 1);
assert_eq!(rem_euclid(a,-b), 3);
assert_eq!(rem_euclid(-a,-b), 1);
}
#[bench]
fn bench_aaabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_aadefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_abs(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_default(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_zzabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_zzdefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
}
```
Resolve lifetimes independently for each item-like.
Now that the heavy-lifting is done on the AST and during lowering, we do not need to perform HIR lifetime resolution on a full item at once. Instead, we can treat each item-like independently, and look at `generics_of` the parent exceptionally for associated items.
{kind=link}
{kind=link}
{kind=link}