5192: Implement rust-analyzer feature configuration to tests. r=matklad a=daxpedda
Fixes#3198.
I'm unsure if it is desired this way, maybe we want to make a seperate configuration?
Co-authored-by: daxpedda <daxpedda@gmail.com>
5089: Disable auto-complete on comments r=matklad a=BGluth
Resolves#4907 by disabling any auto-completion on comments.
As flodiebold [pointed out](https://github.com/rust-analyzer/rust-analyzer/issues/4907#issuecomment-648439979), in the future we may want to support some form of auto-completion within doc comments, but for now it was suggested to just disable auto-completion on them entirely.
The implementation involves adding a new field `is_comment` to `CompletionContext` and checking if the immediate token we auto-completed on is a comment. I couldn't see a case where we need to check any of the ancestors, but let me know if this is not sufficient. I also wasn't sure if it was necessary to add a new field to this struct, but I decided it's probably the best option if we want to potentially do auto-completion on doc comments in the future.
Finally, the three tests I added should I think ideally not filter results by `CompletionKind::Keyword`, but if I want to get unfiltered results, I need access to a non-public function [get_all_completion_items](9a4d02faf9/crates/ra_ide/src/completion/test_utils.rs (L32-L39)) which I don't know if I should make public just for this.
5161: SSR: Add initial support for placeholder constraints r=matklad a=davidlattimore
5184: Always install required nightly extension if current one is not nightly r=matklad a=Veetaha
This is weird, but having switched back to stable by uninstalling the extension appears that vscode doesn't destroy the `PersistentState` and thus changing to `nightly` channel doesn't work because the last check for nightly extension was less than 1 hour ago. The simple solution is to skip this check if we know that the current extension version is not nightly.
5185: Force showing extension activation error pop-up notification r=matklad a=Veetaha
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/5091
5186: fix: correct pd/ppd/tfn/tmod completion doc r=matklad a=fannheyward
a33eefa3b2/crates/ra_ide/src/completion/complete_snippet.rs (L23-L24)
Co-authored-by: BGluth <gluthb@gmail.com>
Co-authored-by: David Lattimore <dml@google.com>
Co-authored-by: Veetaha <veetaha2@gmail.com>
Co-authored-by: Heyward Fann <fannheyward@gmail.com>
5149: Implement Chalk variable kinds r=flodiebold a=flodiebold
This means we need to keep track of the kinds (general/int/float) of variables in `Canonical`, which requires some more ceremony. (It also exposes some places where we're not really dealing with canonicalization correctly -- another thing to be cleaned up when we switch to using Chalk's types directly.)
Should fix the last remaining issue of #2534.
Co-authored-by: Florian Diebold <florian.diebold@freiheit.com>
This means we need to keep track of the kinds (general/int/float) of variables
in `Canonical`, which requires some more ceremony. (It also exposes some places
where we're not really dealing with canonicalization correctly -- another thing
to be cleaned up when we switch to using Chalk's types directly.)
Should fix the last remaining issue of #2534.
5175: More memory-efficient impl collection r=matklad a=jonas-schievink
This saves roughly 90 MB in `ImplsFromDepsQuery`, which used to copy the list of all impls from libcore into *every* crate in the graph. It also stops collecting inherent impls from dependencies entirely, as those can only be located within the crate defining the self type.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
This makes the intention of inherent vs. trait impls somewhat more
clear and also fixes (?) an issue where trait impls with an unresolved
trait were added as inherent impls instead (hence the test changes).
5154: Structured search debugging r=matklad a=davidlattimore
Adds a "search" mode to the rust-analyzer binary that does structured search (SSR without the replace part). This is intended primarily for debugging why a bit of code isn't matching a pattern.
5157: Use dynamic dispatch in AstDiagnostic r=matklad a=lnicola
Co-authored-by: David Lattimore <dml@google.com>
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5142: analysis-stats: allow parallel type inference r=matklad a=jonas-schievink
This is mostly just for testing/fun, but it looks like type inference can be sped up massively with little to no effort (since it runs after the serial phases are already done).
Without `--parallel`:
```
Item Collection: 16.43597698s, 683mb allocated 720mb resident
Inference: 25.429774879s, 1720mb allocated 1781mb resident
Total: 41.865866352s, 1720mb allocated 1781mb resident
```
With `--parallel`:
```
Item Collection: 16.380369815s, 683mb allocated 735mb resident
Parallel Inference: 7.449166445s, 1721mb allocated 1812mb resident
Inference: 143.437157ms, 1721mb allocated 1812mb resident
Total: 23.973303611s, 1721mb allocated 1812mb resident
```
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5136: Split namespace maps in `ItemScope` r=jonas-schievink a=jonas-schievink
Reduces memory usage of the CrateDefMap query by ~130 MB (50%) on r-a.
I was also looking into handling glob imports more efficiently (storing scope chains instead of always duplicating everything into the glob-importing module's scope), but it seems that this already gives the most significant wins.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5101: Add expect -- a light-weight alternative to insta r=matklad a=matklad
This PR implements a small snapshot-testing library. Snapshot updating is done by setting an env var, or by using editor feature (which runs a test with env-var set).
Here's workflow for updating a failing test:
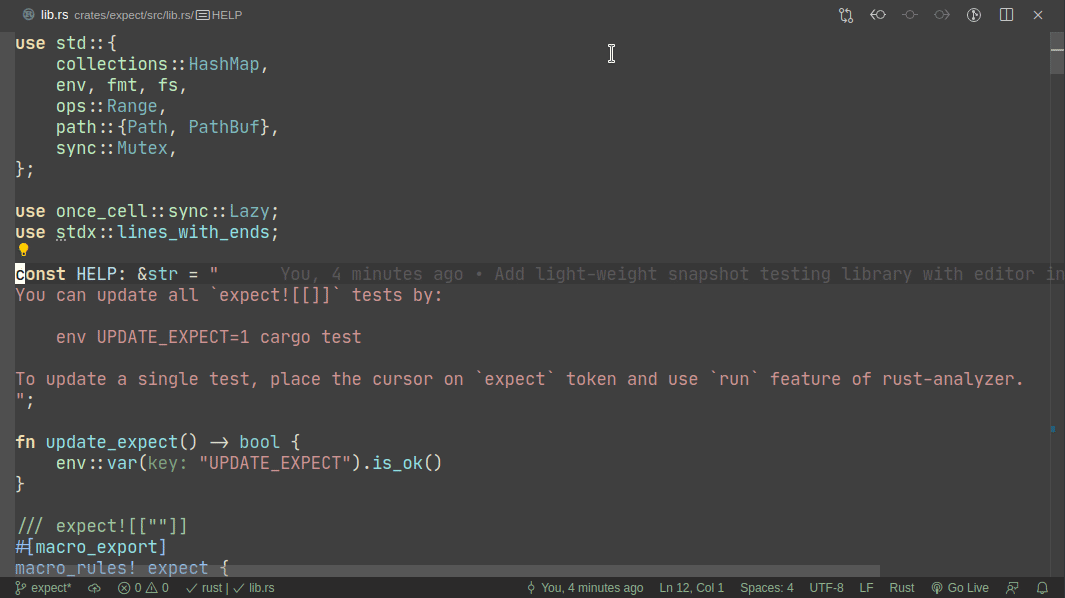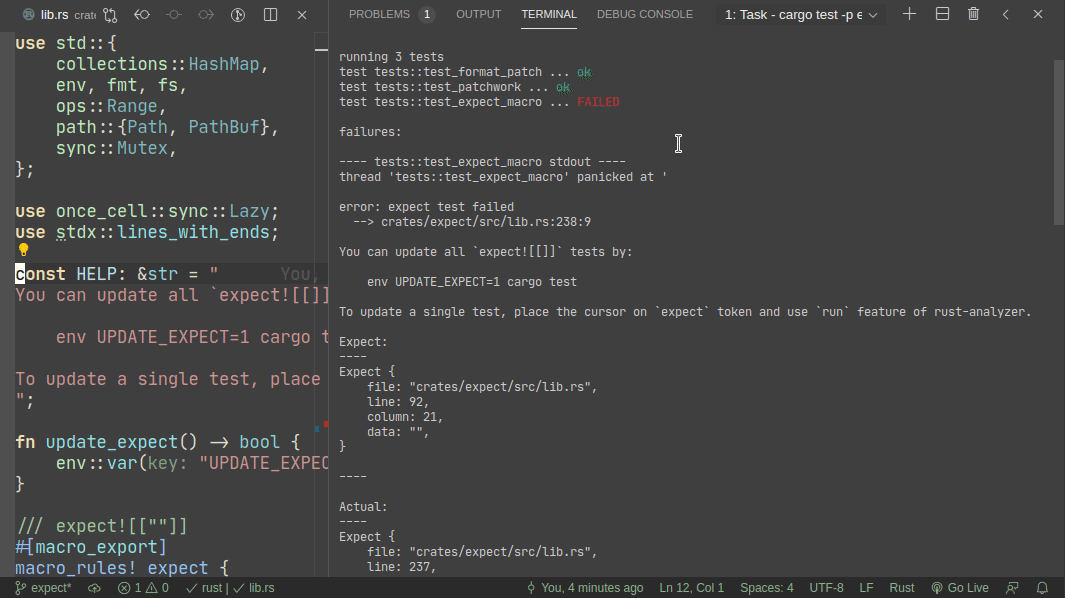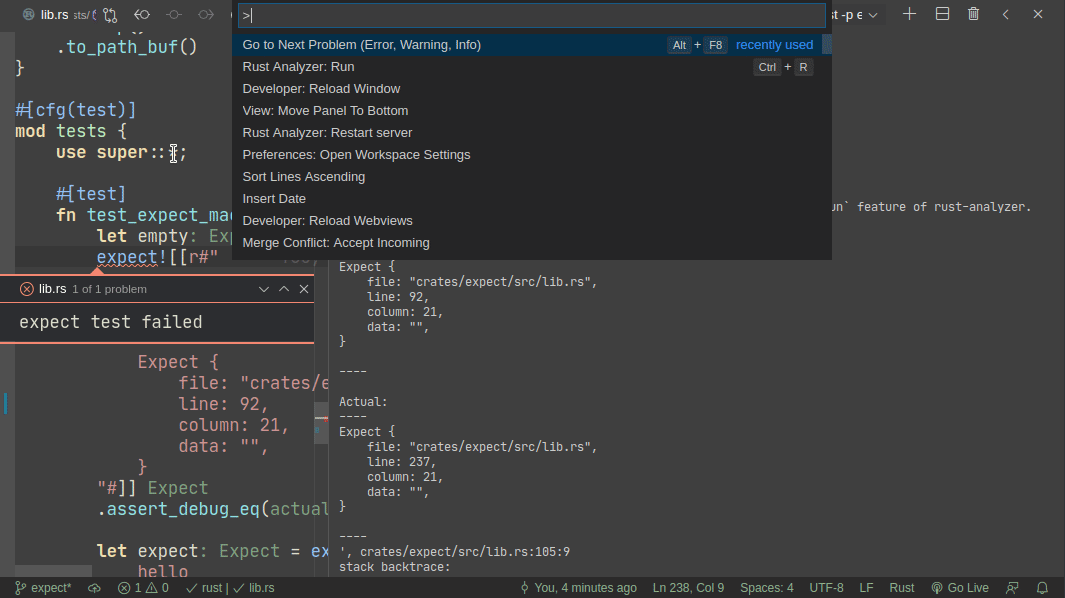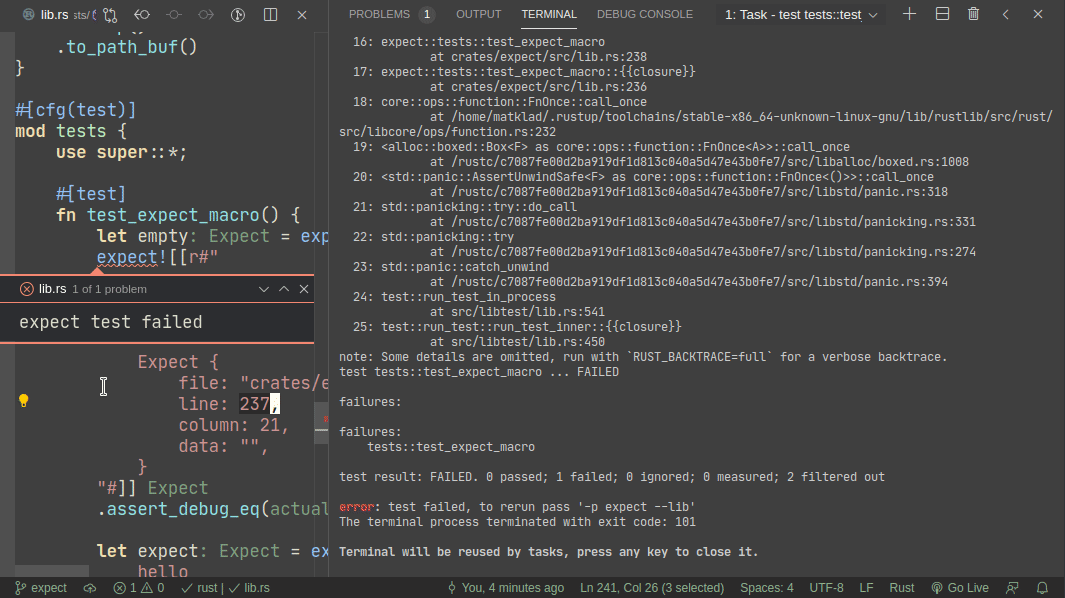
Here's workflow for adding a new test:
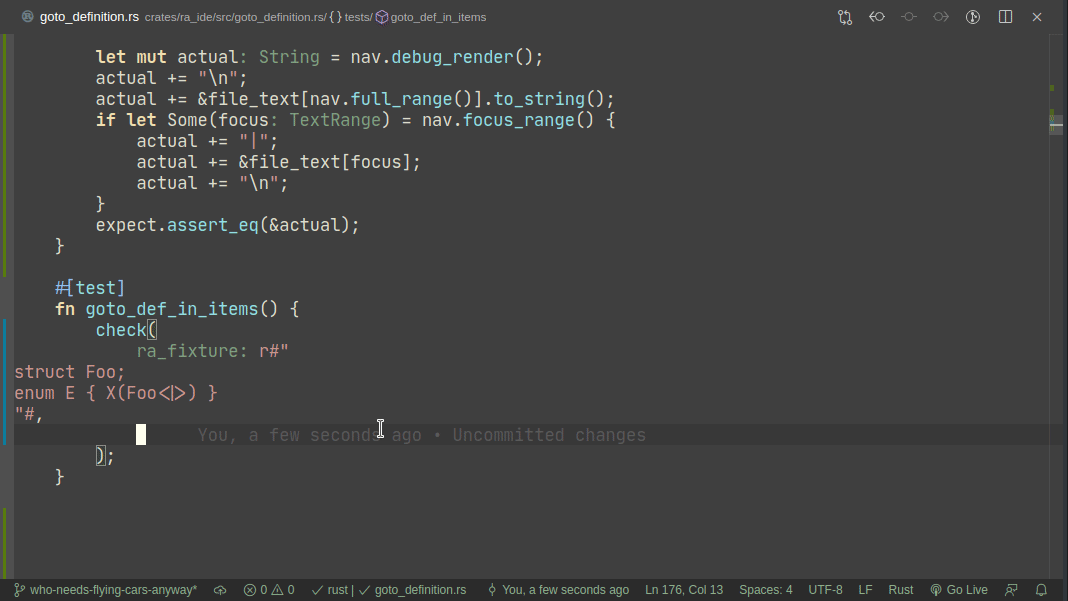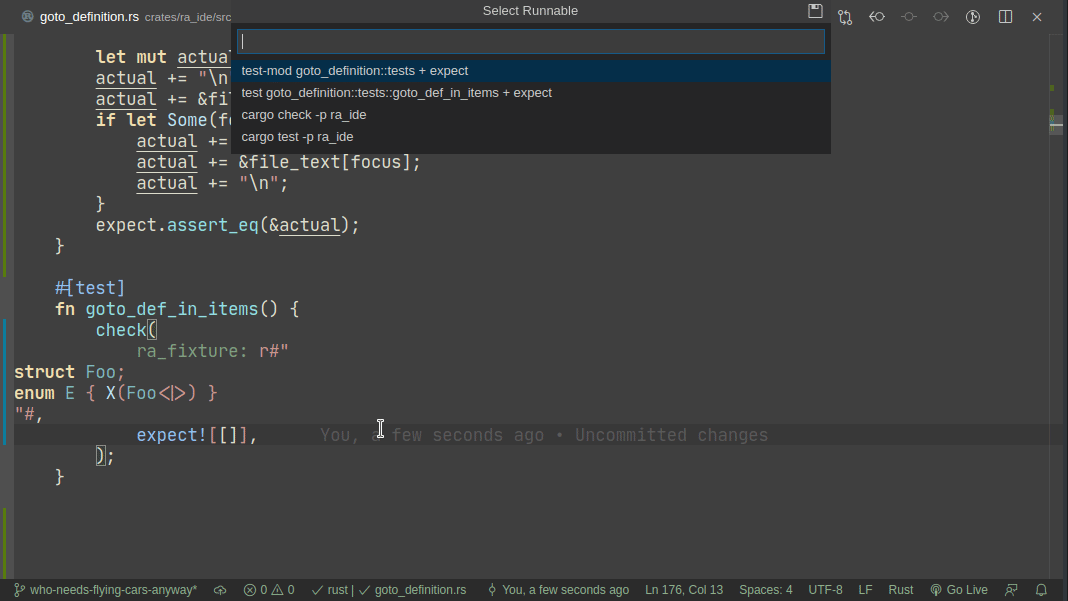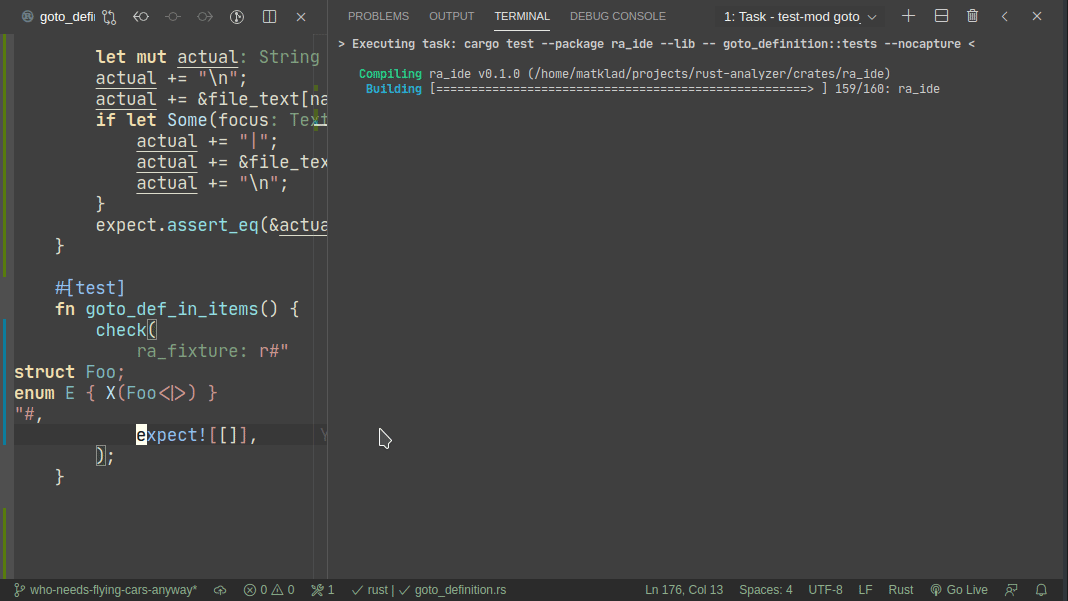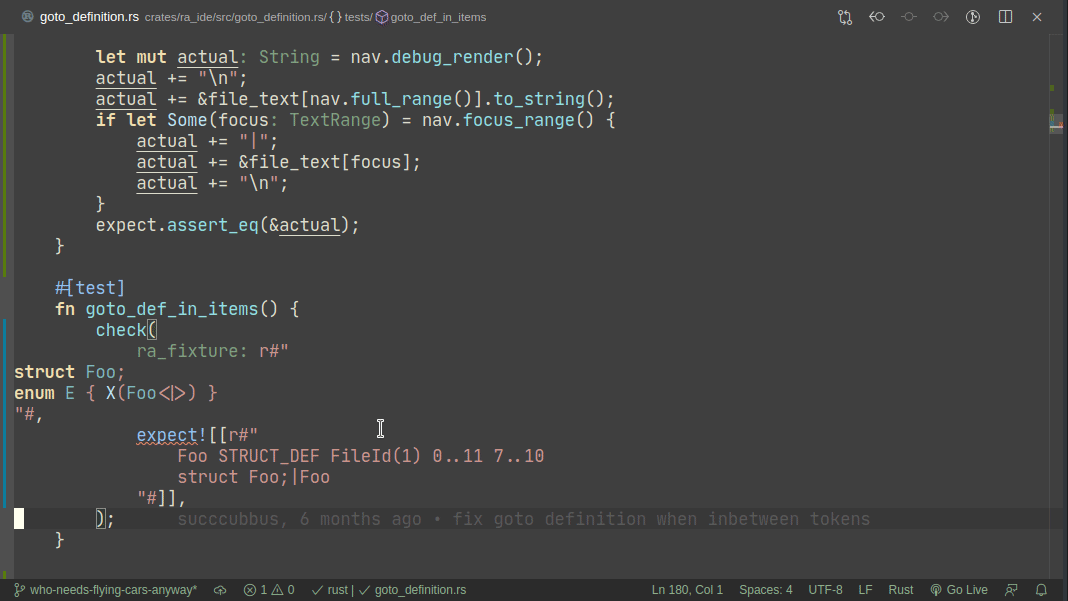
Note that colorized diffs are not implemented in this PR, but should be easy to add (we already use them in test_utils).
Main differences from insta (which is essential for rust-analyzer development, thanks @mitsuhiko!):
* self-updating tests, no need for a separate tool
* fewer features (only inline snapshots, no redactions)
* fewer deps (no yaml, no persistence)
* tighter integration with editor
* first-class snapshot object, which can be used to write test functions (as opposed to testing macros)
* trivial to tweak for rust-analyzer needs, by virtue of being a workspace member.
I think eventually we should converge to a single snapshot testing library, but I am not sure that `expect` is exactly right, so I suggest rolling with both insta and expect for some time (if folks agree that expect might be better in the first place!).
# Editor Integration Implementation
The thing I am most excited about is the ability to update a specific snapshot from the editor. I want this to be available to other snapshot-testing libraries (cc @mitsuhiko, @aaronabramov), so I want to document how this works.
The ideal UI here would be a code action (💡). Unfortunately, it seems like it is impossible to implement without some kind of persistence (if you save test failures into some kind of a database, like insta does, than you can read the database from the editor plugin). Note that it is possible to highlight error by outputing error message in rustc's format. Unfortunately, one can't use the same trick to implement a quick fix.
For this reason, expect makes use of another rust-analyzer feature -- ability to run a single test at the cursor position. This does need some expect-specific code in rust-analyzer unfortunately. Specifically, if rust-analyzer notices that the cursor is on `expect!` macro, it adds a special flag to runnable's JSON. However, given #5017 it is possible to approximate this well-enough without rust-analyzer integration. Specifically, an extension can register a special runner which checks (using regexes) if rust-anlyzer runnable covers text with specific macro invocation and do special magic in that case.
closes#3835
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
5120: Add a simple SSR subcommand to the rust-analyzer command line binary r=davidlattimore a=davidlattimore
Is adding the dependency on ra_ide_db OK? It's needed for the call to `db.local_roots()`
Co-authored-by: David Lattimore <dml@google.com>
5096: Fix handling of whitespace when applying SSR within macro expansions. r=matklad a=davidlattimore
I originally did replacement by passing in the full file text. Then as some point I thought I could do without it. Turns out calling .text() on a node coming from a macro expansion isn't a great idea, especially when you then try and use ranges from the original source to cut that text. The test I added here actually panics without the rest of this change (sorry I didn't notice sooner).
5097: Fix SSR prompt following #4919 r=matklad a=davidlattimore
Co-authored-by: David Lattimore <dml@google.com>
5126: Use more of FxHash* r=matklad a=lnicola
```
-rwxr-xr-x 1 me me 37917528 Jun 29 17:26 /home/me/.cargo/bin/rust-analyzer
-rwxr-xr-x 1 me me 37904056 Jun 29 18:14 /home/me/.cargo/bin/rust-analyzer
```
Saved 13.5 KB there :-).
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
5124: (Partially) fix handling of type params depending on type params r=matklad a=flodiebold
If the first type parameter gets inferred, that's still not handled correctly; it'll require some more refactoring: E.g. if we have `Thing<T, F=fn() -> T>` and then instantiate `Thing<_>`, that gets turned into `Thing<_, fn() -> _>` before the `_` is instantiated into a type variable -- so afterwards, we have two type variables without any connection to each other.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
If the first type parameter gets inferred, that's still not handled correctly;
it'll require some more refactoring: E.g. if we have `Thing<T, F=fn() -> T>` and
then instantiate `Thing<_>`, that gets turned into `Thing<_, fn() -> _>` before
the `_` is instantiated into a type variable -- so afterwards, we have two type
variables without any connection to each other.
This test needs to be updated after every change (it contains line
number), which is annoying.
It also fails on windows due to \, so it's easier to remove it.
Move unsafe_expressions to unsafe_validation.rs, replace vec tracking of
child exprs with inline macro, add debug assert to ensure tracked
children match walked children exactly
I originally did replacement by passing in the full file text. Then as some point I thought I could do without it. Turns out calling .text() on a node coming from a macro expansion isn't a great idea, especially when you then try and use ranges from the original source to cut that text. The test I added here actually panics without the rest of this change (sorry I didn't notice sooner).
5033: Order of glob imports should not affect import shadowing r=Nashenas88 a=Nashenas88
Fixes#5032
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
5083: Micro-optimize lookahead in composite tokens r=matklad a=lnicola
I'm not sure that this is measurable, but can't hurt, I guess.
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
4945: do not suggest assist for return type to result in bad case r=matklad a=bnjjj
close#4826
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
5066: Infer type for slice wildcard patterns r=flodiebold a=adamrk
Resolves https://github.com/rust-analyzer/rust-analyzer/issues/4830
The issue is just that we were never inferring the type for the wildcard `..` in slice patterns.
Co-authored-by: adamrk <ark.email@gmail.com>
5063: Store field/variant attrs in ItemTree and use it for adt.rs queries r=jonas-schievink a=jonas-schievink
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
There are two reasons why we don't want a generic ra_progress crate
just yet:
*First*, it introduces a common interface between separate components,
and that is usually undesirable (b/c components start to fit the
interface, rather than doing what makes most sense for each particular
component).
*Second*, it introduces a separate async channel for progress, which
makes it harder to correlate progress reports with the work done. Ie,
when we see 100% progress, it's not blindly obvious that the work has
actually finished, we might have some pending messages still.
{kind=link}
{kind=link}
{kind=link}