[Context on
Discord](https://discord.com/channels/601130461678272522/855947301380947968/1219425984990806207)
# Description
- Rename `CustomValue::value_string()` to `type_name()` to reflect its
usage better.
- Change print behavior to always call `to_base_value()` first, to give
the custom value better control over the output.
- Change `describe --detailed` to show the type name as the subtype,
rather than trying to describe the base value.
- Change custom `Type` to use `type_name()` rather than `typetag_name()`
to make things like `PluginCustomValue` more transparent
One question: should `describe --detailed` still include a description
of the base value somewhere? I'm torn on it, it seems possibly useful
for some things (maybe sqlite databases?), but having `describe -d` not
include the custom type name anywhere felt weird. Another option would
be to add another method to `CustomValue` for info to be displayed in
`describe`, so that it can be more type-specific?
# User-Facing Changes
Everything above has implications for printing and `describe` on custom
values
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
Adds support for the following operations on plugin custom values, in
addition to `to_base_value` which was already present:
- `follow_path_int()`
- `follow_path_string()`
- `partial_cmp()`
- `operation()`
- `Drop` (notification, if opted into with
`CustomValue::notify_plugin_on_drop`)
There are additionally customizable methods within the `Plugin` and
`StreamingPlugin` traits for implementing these functions in a way that
requires access to the plugin state, as a registered handle model such
as might be used in a dataframes plugin would.
`Value::append` was also changed to handle custom values correctly.
# User-Facing Changes
- Signature of `CustomValue::follow_path_string` and
`CustomValue::follow_path_int` changed to give access to the span of the
custom value itself, useful for some errors.
- Plugins using custom values have to be recompiled because the engine
will try to do custom value operations that aren't supported
- Plugins can do more things 🎉
# Tests + Formatting
Tests were added for all of the new custom values functionality.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Document protocol reference `CustomValueOp` variants:
- [ ] `FollowPathInt`
- [ ] `FollowPathString`
- [ ] `PartialCmp`
- [ ] `Operation`
- [ ] `Dropped`
- [ ] Document `notify_on_drop` optional field in `PluginCustomValue`
# Description
Clippy fixes for
[items_after_test_module](https://rust-lang.github.io/rust-clippy/master/index.html#/items_after_test_module)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Fixes https://github.com/nushell/nushell/issues/11716
The problem is in our [record creation
API](0d518bf813/crates/nu-protocol/src/value/record.rs (L33))
which panics if the numbers of columns and values are different. I added
a safe variant that returns a `Result` and used it in the `rotate`
command.
## TODO in another PR:
Go through all `from_raw_cols_vals_unchecked()` (this includes the
`record!` macro which uses the unchecked version) and make sure that
either
a) it is guaranteed the number of cols and vals is the same, or
b) convert the call to `from_raw_cols_vals()`
Reason: Nushell should never panic.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Constructing the internals of `Record` without checking the lengths is
bad. (also incompatible with changes to how we store records)
- Use `Record::from_raw_cols_vals` in dataframe code
- Use `record!` macro in dataframe test
- Use `record!` in `nu-color-config` tests
- Stop direct record construction in `nu-command`
- Refactor table construction in `from nuon`
# User-Facing Changes
None
# Tests + Formatting
No new tests, updated tests in equal fashion
# Description
Replace `.to_string()` used in `GenericError` with `.into()` as
`.into()` seems more popular
Replace `Vec::new()` used in `GenericError` with `vec![]` as `vec![]`
seems more popular
(There are so, so many)
# Description
Use `record!` macro instead of defining two separate `vec!` for `cols`
and `vals` when appropriate.
This visually aligns the key with the value.
Further more you don't have to deal with the construction of `Record {
cols, vals }` so we can hide the implementation details in the future.
## State
Not covering all possible commands yet, also some tests/examples are
better expressed by creating cols and vals separately.
# User/Developer-Facing Changes
The examples and tests should read more natural. No relevant functional
change
# Bycatch
Where I noticed it I replaced usage of `Value` constructors with
`Span::test_data()` or `Span::unknown()` to the `Value::test_...`
constructors. This should make things more readable and also simplify
changes to the `Span` system in the future.
# Description
As part of the refactor to split spans off of Value, this moves to using
helper functions to create values, and using `.span()` instead of
matching span out of Value directly.
Hoping to get a few more helping hands to finish this, as there are a
lot of commands to update :)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <windsoilder@outlook.com>
# Description
This doesn't really do much that the user could see, but it helps get us
ready to do the steps of the refactor to split the span off of Value, so
that values can be spanless. This allows us to have top-level values
that can hold both a Value and a Span, without requiring that all values
have them.
We expect to see significant memory reduction by removing so many
unnecessary spans from values. For example, a table of 100,000 rows and
5 columns would have a savings of ~8megs in just spans that are almost
always duplicated.
# User-Facing Changes
Nothing yet
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR creates a new `Record` type to reduce duplicate code and
possibly bugs as well. (This is an edited version of #9648.)
- `Record` implements `FromIterator` and `IntoIterator` and so can be
iterated over or collected into. For example, this helps with
conversions to and from (hash)maps. (Also, no more
`cols.iter().zip(vals)`!)
- `Record` has a `push(col, val)` function to help insure that the
number of columns is equal to the number of values. I caught a few
potential bugs thanks to this (e.g. in the `ls` command).
- Finally, this PR also adds a `record!` macro that helps simplify
record creation. It is used like so:
```rust
record! {
"key1" => some_value,
"key2" => Value::string("text", span),
"key3" => Value::int(optional_int.unwrap_or(0), span),
"key4" => Value::bool(config.setting, span),
}
```
Since macros hinder formatting, etc., the right hand side values should
be relatively short and sweet like the examples above.
Where possible, prefer `record!` or `.collect()` on an iterator instead
of multiple `Record::push`s, since the first two automatically set the
record capacity and do less work overall.
# User-Facing Changes
Besides the changes in `nu-protocol` the only other breaking changes are
to `nu-table::{ExpandedTable::build_map, JustTable::kv_table}`.
# Description
This PR helps the sqlite handling better by surrounding table names with
brackets. This makes it easier to have table names with spaces like
`Basin / profile`.
Closes#9751
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Our `ShellError` at the moment has a `std::mem::size_of<ShellError>` of
136 bytes (on AMD64). As a result `Value` directly storing the struct
also required 136 bytes (thanks to alignment requirements).
This change stores the `Value::Error` `ShellError` on the heap.
Pro:
- Value now needs just 80 bytes
- Should be 1 cacheline less (still at least 2 cachelines)
Con:
- More small heap allocations when dealing with `Value::Error`
- More heap fragmentation
- Potential for additional required memcopies
# Further code changes
Includes a small refactor of `try` due to a type mismatch in its large
match.
# User-Facing Changes
None for regular users.
Plugin authors may have to update their matches on `Value` if they use
`nu-protocol`
Needs benchmarking to see if there is a benefit in real world workloads.
**Update** small improvements in runtime for workloads with high volume
of values. Significant reduction in maximum resident set size, when many
values are held in memory.
# Tests + Formatting
Continuation of #8229 and #8326
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
# Call to action
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Commits (so far)
- Remove `ShellError::FeatureNotEnabled`
- Name fields on `SE::ExternalNotSupported`
- Name field on `SE::InvalidProbability`
- Name fields on `SE::NushellFailed` variants
- Remove unused `SE::NushellFailedSpannedHelp`
- Name field on `SE::VariableNotFoundAtRuntime`
- Name fields on `SE::EnvVarNotFoundAtRuntime`
- Name fields on `SE::ModuleNotFoundAtRuntime`
- Remove usused `ModuleOrOverlayNotFoundAtRuntime`
- Name fields on `SE::OverlayNotFoundAtRuntime`
- Name field on `SE::NotFound`
# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
I've been working on streaming and pipeline interruption lately. It was
bothering me that checking ctrl+c (something we want to do often) always
requires a bunch of boilerplate like:
```rust
use std::sync::atomic::Ordering;
if let Some(ctrlc) = &engine_state.ctrlc {
if ctrlc.load(Ordering::SeqCst) {
...
```
I added a helper method to cut that down to:
```rust
if nu_utils::ctrl_c::was_pressed(&engine_state.ctrlc) {
...
```
This change makes SQLite queries (`open foo.db`, `open foo.db | query db
"select ..."`) cancellable using `ctrl+c`. Previously they were not
cancellable, which made it unpleasant to accidentally open a very large
database or run an unexpectedly slow query!
UX-wise there's not too much to show:
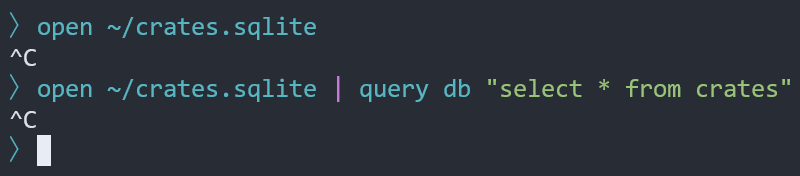
## Notes
I was hoping to make SQLite queries streamable as part of this work, but
I ran into 2 problems:
1. `rusqlite` lifetimes are nightmarishly complex and they make it hard
to create a `ListStream` iterator
2. The functions on Nu's `CustomValue` trait return `Value` not
`PipelineData` and so `CustomValue` implementations can't stream data
AFAICT.
This PR changes the `schema` command for viewing the schema of a SQLite
database file. It removes 1 level of nesting (intended to handle
multiple databases in the same connection) that I believe is
unnecessary.
### Before
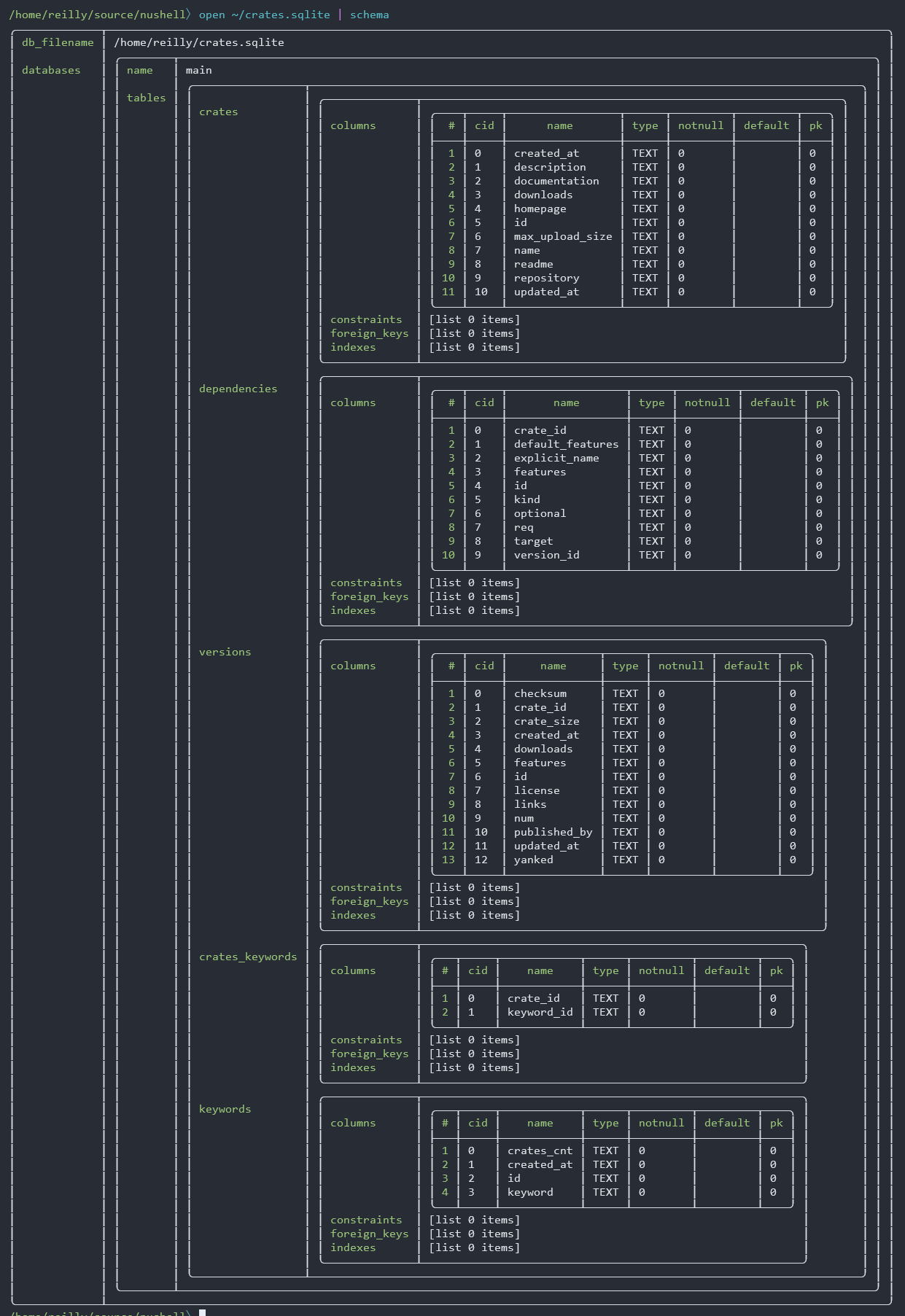
### After

## Rationale
A SQLite database connection can technically be associated with multiple
non-temporary databases using [the ATTACH DATABASE
command](https://www.sqlite.org/lang_attach.html). But it's not possible
to do that _in the context of Nushell_, and so I believe that there is
no benefit to displaying the schema as if there could be multiple
databases.
I initially raised this concern back in April, but we decided to keep
the database nesting because at the time we were still looking into more
generalized database functionality (i.e. not just SQLite). I believe
that rationale no longer applies.
Also, the existing code would not have worked correctly even if a
connection had multiple databases; for every database, it was looking up
tables without filtering them by database:
6295b20545/crates/nu-command/src/database/values/sqlite.rs (L104-L118)
## Future Work
I'd like to add information on views+triggers to the `schema` output.
I'm also working on making it possible to `ctrl+c` reading from a
database (which is turning into a massive yak shave).
* database commands
* db commands
* filesystem opens sqlite file
* clippy error
* corrected error in ci file
* removes matrix flag from ci
* flax matrix for clippy
* add conditional compile for tests
* add conditional compile for tests
* correct order of command
* correct error msg
* correct typo
2022-04-24 10:29:21 +01:00
Renamed from crates/nu-command/src/database/sqlite.rs (Browse further)
{kind=link}
{kind=link}
{kind=link}