85 KiB
Support HackTricks and get benefits!
Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
Discover The PEASS Family, our collection of exclusive NFTs
Get the official PEASS & HackTricks swag
Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
Share your hacking tricks submitting PRs to the hacktricks github repo.
Types of services
Container services
Services that fall under container services have the following characteristics:
- The service itself runs on separate infrastructure instances, such as EC2.
- AWS is responsible for managing the operating system and the platform.
- A managed service is provided by AWS, which is typically the service itself for the actual application which are seen as containers.
- As a user of these container services, you have a number of management and security responsibilities, including managing network access security, such as network access control list rules and any firewalls.
- Also, platform-level identity and access management where it exists.
- Examples of AWS container services include Relational Database Service, Elastic Mapreduce, and Elastic Beanstalk.
Abstract Services
- These services are removed, abstracted, from the platform or management layer which cloud applications are built on.
- The services are accessed via endpoints using AWS application programming interfaces, APIs.
- The underlying infrastructure, operating system, and platform is managed by AWS.
- The abstracted services provide a multi-tenancy platform on which the underlying infrastructure is shared.
- Data is isolated via security mechanisms.
- Abstract services have a strong integration with IAM, and examples of abstract services include S3, DynamoDB, Amazon Glacier, and SQS.
IAM - Identity and Access Management
IAM is the service that will allow you to manage Authentication, Authorization and Access Control inside your AWS account.
- Authentication - Process of defining an identity and the verification of that identity. This process can be subdivided in: Identification and verification.
- Authorization - Determines what an identity can access within a system once it's been authenticated to it.
- Access Control - The method and process of how access is granted to a secure resource
IAM can be defined by its ability to manage, control and govern authentication, authorization and access control mechanisms of identities to your resources within your AWS account.
Users
This could be a real person within your organization who requires access to operate and maintain your AWS environment. Or it could be an account to be used by an application that may require permissions to access your AWS resources programmatically. Note that usernames must be unique.
CLI
- Access Key ID: 20 random uppercase alphanumeric characters like AKHDNAPO86BSHKDIRYT
- Secret access key ID: 40 random upper and lowercase characters: S836fh/J73yHSb64Ag3Rkdi/jaD6sPl6/antFtU (It's not possible to retrieve lost secret access key IDs).
Whenever you need to change the Access Key this is the process you should follow:
Create a new access key -> Apply the new key to system/application -> mark original one as inactive -> Test and verify new access key is working -> Delete old access key
MFA is supported when using the AWS CLI.
Groups
These are objects that contain multiple users. Permissions can be assigned to a user or inherit form a group. Giving permission to groups and not to users the secure way to grant permissions.
Roles
Roles are used to grant identities a set of permissions. Roles don't have any access keys or credentials associated with them. Roles are usually used with resources (like EC2 machines) but they can also be useful to grant temporary privileges to a user. Note that when for example an EC2 has an IAM role assigned, instead of saving some keys inside the machine, dynamic temporary access keys will be supplied by the IAM role to handle authentication and determine if access is authorized.
An IAM role consists of two types of policies: A trust policy, which cannot be empty, defining who can assume the role, and a permissions policy, which cannot be empty, defining what they can access.
AWS Security Token Service (STS)
This is a web service that enables you to request temporary, limited-privilege credentials for AWS Identity and Access Management (IAM) users or for users that you authenticate (federated users).
Policies
Policy Permissions
Are used to assign permissions. There are 2 types:
- AWS managed policies (preconfigured by AWS)
- Customer Managed Policies: Configured by you. You can create policies based on AWS managed policies (modifying one of them and creating your own), using the policy generator (a GUI view that helps you granting and denying permissions) or writing your own..
By default access is denied, access will be granted if an explicit role has been specified.
If single "Deny" exist, it will override the "Allow", except for requests that use the AWS account's root security credentials (which are allowed by default).
{
"Version": "2012-10-17", //Version of the policy
"Statement": [ //Main element, there can be more than 1 entry in this array
{
"Sid": "Stmt32894y234276923" //Unique identifier (optional)
"Effect": "Allow", //Allow or deny
"Action": [ //Actions that will be allowed or denied
"ec2:AttachVolume",
"ec2:DetachVolume"
],
"Resource": [ //Resource the action and effect will be applied to
"arn:aws:ec2:*:*:volume/*",
"arn:aws:ec2:*:*:instance/*"
],
"Condition": { //Optional element that allow to control when the permission will be effective
"ArnEquals": {"ec2:SourceInstanceARN": "arn:aws:ec2:*:*:instance/instance-id"}
}
}
]
}
Inline Policies
This kind of policies are directly assigned to a user, group or role. Then, they not appear in the Policies list as any other one can use them.
Inline policies are useful if you want to maintain a strict one-to-one relationship between a policy and the identity that it's applied to. For example, you want to be sure that the permissions in a policy are not inadvertently assigned to an identity other than the one they're intended for. When you use an inline policy, the permissions in the policy cannot be inadvertently attached to the wrong identity. In addition, when you use the AWS Management Console to delete that identity, the policies embedded in the identity are deleted as well. That's because they are part of the principal entity.
S3 Bucket Policies
Can only be applied to S3 Buckets. They contains an attribute called 'principal' that can be: IAM users, Federated users, another AWS account, an AWS service. Principals define who/what should be allowed or denied access to various S3 resources.
Multi-Factor Authentication
It's used to create an additional factor for authentication in addition to your existing methods, such as password, therefore, creating a multi-factor level of authentication.
You can use a free virtual application or a physical device. You can use apps like google authentication for free to activate a MFA in AWS.
Identity Federation
Identity federation allows users from identity providers which are external to AWS to access AWS resources securely without having to supply AWS user credentials from a valid IAM user account.
An example of an identity provider can be your own corporate Microsoft Active Directory(via SAML) or OpenID services (like Google). Federated access will then allow the users within it to access AWS.
AWS Identity Federation connects via IAM roles.
Cross Account Trusts and Roles
A user (trusting) can create a Cross Account Role with some policies and then, allow another user (trusted) to access his account but only having the access indicated in the new role policies. To create this, just create a new Role and select Cross Account Role. Roles for Cross-Account Access offers two options. Providing access between AWS accounts that you own, and providing access between an account that you own and a third party AWS account.
It's recommended to specify the user who is trusted and not put some generic thing because if not, other authenticated users like federated users will be able to also abuse this trust.
AWS Simple AD
Not supported:
- Trust Relations
- AD Admin Center
- Full PS API support
- AD Recycle Bin
- Group Managed Service Accounts
- Schema Extensions
- No Direct access to OS or Instances
Web Federation or OpenID Authentication
The app uses the AssumeRoleWithWebIdentity to create temporary credentials. However this doesn't grant access to the AWS console, just access to resources within AWS.
Other IAM options
- You can set a password policy setting options like minimum length and password requirements.
- You can download "Credential Report" with information about current credentials (like user creation time, is password enabled...). You can generate a credential report as often as once every four hours.
KMS - Key Management Service
AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to create and control customer master keys (CMKs), the encryption keys used to encrypt your data. AWS KMS CMKs are protected by hardware security modules (HSMs)
KMS uses symmetric cryptography. This is used to encrypt information as rest (for example, inside a S3). If you need to encrypt information in transit you need to use something like TLS.
KMS is a region specific service.
Administrators at Amazon do not have access to your keys. They cannot recover your keys and they do not help you with encryption of your keys. AWS simply administers the operating system and the underlying application it's up to us to administer our encryption keys and administer how those keys are used.
Customer Master Keys (CMK): Can encrypt data up to 4KB in size. They are typically used to create, encrypt, and decrypt the DEKs (Data Encryption Keys). Then the DEKs are used to encrypt the data.
A customer master key (CMK) is a logical representation of a master key in AWS KMS. In addition to the master key's identifiers and other metadata, including its creation date, description, and key state, a CMK contains the key material which used to encrypt and decrypt data. When you create a CMK, by default, AWS KMS generates the key material for that CMK. However, you can choose to create a CMK without key material and then import your own key material into that CMK.
There are 2 types of master keys:
- AWS managed CMKs: Used by other services to encrypt data. It's used by the service that created it in a region. They are created the first time you implement the encryption in that service. Rotates every 3 years and it's not possible to change it.
- Customer manager CMKs: Flexibility, rotation, configurable access and key policy. Enable and disable keys.
Envelope Encryption in the context of Key Management Service (KMS): Two-tier hierarchy system to encrypt data with data key and then encrypt data key with master key.
Key Policies
These defines who can use and access a key in KMS. By default root user has full access over KMS, if you delete this one, you need to contact AWS for support.
Properties of a policy:
- JSON based document
- Resource --> Affected resources (can be "*")
- Action --> kms:Encrypt, kms:Decrypt, kms:CreateGrant ... (permissions)
- Effect --> Allow/Deny
- Principal --> arn affected
- Conditions (optional) --> Condition to give the permissions
Grants:
- Allow to delegate your permissions to another AWS principal within your AWS account. You need to create them using the AWS KMS APIs. It can be indicated the CMK identifier, the grantee principal and the required level of opoeration (Decrypt, Encrypt, GenerateDataKey...)
- After the grant is created a GrantToken and a GratID are issued
Access:
- Via key policy -- If this exist, this takes precedent over the IAM policy, s the IAM olicy is not used
- Via IAM policy
- Via grants
Key Administrators
Key administrator by default:
- Have access to manage KMS but not to encrypt or decrypt data
- Only IAM users and roles can be added to Key Administrators list (not groups)
- If external CMK is used, Key Administrators have the permission to import key material
Rotation of CMKs
- The longer the same key is left in place, the more data is encrypted with that key, and if that key is breached, then the wider the blast area of data is at risk. In addition to this, the longer the key is active, the probability of it being breached increases.
- KMS rotate customer keys every 365 days (or you can perform the process manually whenever you want) and keys managed by AWS every 3 years and this time it cannot be changed.
- Older keys are retained to decrypt data that was encrypted prior to the rotation
- In a break, rotating the key won't remove the threat as it will be possible to decrypt all the data encrypted with the compromised key. However, the new data will be encrypted with the new key.
- If CMK is in state of disabled or pending deletion, KMS will not perform a key rotation until the CMK is re-enabled or deletion is cancelled.
Manual rotation
- A new CMK needs to be created, then, a new CMK-ID is created, so you will need to update any application to reference the new CMK-ID.
- To do this process easier you can use aliases to refer to a key-id and then just update the key the alias is referring to.
- You need to keep old keys to decrypt old files encrypted with it.
You can import keys from your on-premises key infrastructure .
Other information
KMS is priced per number of encryption/decryption requests received from all services per month.
KMS has full audit and compliance integration with CloudTrail; this is where you can audit all changes performed on KMS.
With KMS policy you can do the following:
- Limit who can create data keys and which services have access to use these keys
- Limit systems access to encrypt only, decrypt only or both
- Define to enable systems to access keys across regions (although it is not recommended as a failure in the region hosting KMS will affect availability of systems in other regions).
You cannot synchronize or move/copy keys across regions; you can only define rules to allow access across region.
S3
Amazon S3 is a service that allows you store important amounts of data.
Amazon S3 provides multiple options to achieve the protection of data at REST. The options include Permission (Policy), Encryption (Client and Server Side), Bucket Versioning and MFA based delete. The user can enable any of these options to achieve data protection. Data replication is an internal facility by AWS where S3 automatically replicates each object across all the Availability Zones and the organization need not enable it in this case.
With resource-based permissions, you can define permissions for sub-directories of your bucket separately.
S3 Access logs
It's possible to enable S3 access login (which by default is disabled) to some bucket and save the logs in a different bucket to know who is accessing the bucket. The source bucket and the target bucket (the one is saving the logs needs to be in the same region.
S3 Encryption Mechanisms
DEK means Data Encryption Key and is the key that is always generated and used to encrypt data.
Server-side encryption with S3 managed keys, SSE-S3: This option requires minimal configuration and all management of encryption keys used are managed by AWS. All you need to do is to upload your data and S3 will handle all other aspects. Each bucket in a S3 account is assigned a bucket key.
- Encryption:
- Object Data + created plaintext DEK --> Encrypted data (stored inside S3)
- Created plaintext DEK + S3 Master Key --> Encrypted DEK (stored inside S3) and plain text is deleted from memory
- Decryption:
- Encrypted DEK + S3 Master Key --> Plaintext DEK
- Plaintext DEK + Encrypted data --> Object Data
Please, note that in this case the key is managed by AWS (rotation only every 3 years). If you use your own key you willbe able to rotate, disable and apply access control.
Server-side encryption with KMS managed keys, SSE-KMS: This method allows S3 to use the key management service to generate your data encryption keys. KMS gives you a far greater flexibility of how your keys are managed. For example, you are able to disable, rotate, and apply access controls to the CMK, and order to against their usage using AWS Cloud Trail.
- Encryption:
- S3 request data keys from KMS CMK
- KMS uses a CMK to generate the pair DEK plaintext and DEK encrypted and send them to S£
- S3 uses the paintext key to encrypt the data, store the encrypted data and the encrypted key and deletes from memory the plain text key
- Decryption:
- S3 ask to KMS to decrypt the encrypted data key of the object
- KMS decrypt the data key with the CMK and send it back to S3
- S3 decrypts the object data
Server-side encryption with customer provided keys, SSE-C: This option gives you the opportunity to provide your own master key that you may already be using outside of AWS. Your customer-provided key would then be sent with your data to S3, where S3 would then perform the encryption for you.
- Encryption:
- The user sends the object data + Customer key to S3
- The customer key is used to encrypt the data and the encrypted data is stored
- a salted HMAC value of the customer key is stored also for future key validation
- the customer key is deleted from memory
- Decryption:
- The user send the customer key
- The key is validated against the HMAC value stored
- The customer provided key is then used to decrypt the data
Client-side encryption with KMS, CSE-KMS: Similarly to SSE-KMS, this also uses the key management service to generate your data encryption keys. However, this time KMS is called upon via the client not S3. The encryption then takes place client-side and the encrypted data is then sent to S3 to be stored.
- Encryption:
- Client request for a data key to KMS
- KMS returns the plaintext DEK and the encrypted DEK with the CMK
- Both keys are sent back
- The client then encrypts the data with the plaintext DEK and send to S3 the encrypted data + the encrypted DEK (which is saved as metadata of the encrypted data inside S3)
- Decryption:
- The encrypted data with the encrypted DEK is sent to the client
- The client asks KMS to decrypt the encrypted key using the CMK and KMS sends back the plaintext DEK
- The client can now decrypt the encrypted data
Client-side encryption with customer provided keys, CSE-C: Using this mechanism, you are able to utilize your own provided keys and use an AWS-SDK client to encrypt your data before sending it to S3 for storage.
- Encryption:
- The client generates a DEK and encrypts the plaintext data
- Then, using it's own custom CMK it encrypts the DEK
- submit the encrypted data + encrypted DEK to S3 where it's stored
- Decryption:
- S3 sends the encrypted data and DEK
- As the client already has the CMK used to encrypt the DEK, it decrypts the DEK and then uses the plaintext DEK to decrypt the data
HSM - Hardware Security Module
Cloud HSM is a FIPS 140 level two validated hardware device for secure cryptographic key storage (note that CloudHSM is a hardware appliance, it is not a virtualized service). It is a SafeNetLuna 7000 appliance with 5.3.13 preloaded. There are two firmware versions and which one you pick is really based on your exact needs. One is for FIPS 140-2 compliance and there was a newer version that can be used.
The unusual feature of CloudHSM is that it is a physical device, and thus it is not shared with other customers, or as it is commonly termed, multi-tenant. It is dedicated single tenant appliance exclusively made available to your workloads
Typically, a device is available within 15 minutes assuming there is capacity, but if the AZ is out of capacity it can take two weeks or more to acquire additional capacity.
Both KMS and CloudHSM are available to you at AWS and both are integrated with your apps at AWS. Since this is a physical device dedicated to you, the keys are stored on the device. Keys need to either be replicated to another device, backed up to offline storage, or exported to a standby appliance. This device is not backed by S3 or any other service at AWS like KMS.
In CloudHSM, you have to scale the service yourself. You have to provision enough CloudHSM devices to handle whatever your encryption needs are based on the encryption algorithms you have chosen to implement for your solution.
Key Management Service scaling is performed by AWS and automatically scales on demand, so as your use grows, so might the number of CloudHSM appliances that are required. Keep this in mind as you scale your solution and if your solution has auto-scaling, make sure your maximum scale is accounted for with enough CloudHSM appliances to service the solution.
Just like scaling, performance is up to you with CloudHSM. Performance varies based on which encryption algorithm is used and on how often you need to access or retrieve the keys to encrypt the data. Key management service performance is handled by Amazon and automatically scales as demand requires it. CloudHSM's performance is achieved by adding more appliances and if you need more performance you either add devices or alter the encryption method to the algorithm that is faster.
If your solution is multi-region, you should add several CloudHSM appliances in the second region and work out the cross-region connectivity with a private VPN connection or some method to ensure the traffic is always protected between the appliance at every layer of the connection. If you have a multi-region solution you need to think about how to replicate keys and set up additional CloudHSM devices in the regions where you operate. You can very quickly get into a scenario where you have six or eight devices spread across multiple regions, enabling full redundancy of your encryption keys.
CloudHSM is an enterprise class service for secured key storage and can be used as a root of trust for an enterprise. It can store private keys in PKI and certificate authority keys in X509 implementations. In addition to symmetric keys used in symmetric algorithms such as AES, KMS stores and physically protects symmetric keys only (cannot act as a certificate authority), so if you need to store PKI and CA keys a CloudHSM or two or three could be your solution.
CloudHSM is considerably more expensive than Key Management Service. CloudHSM is a hardware appliance so you have fix costs to provision the CloudHSM device, then an hourly cost to run the appliance. The cost is multiplied by as many CloudHSM appliances that are required to achieve your specific requirements.
Additionally, cross consideration must be made in the purchase of third party software such as SafeNet ProtectV software suites and integration time and effort. Key Management Service is a usage based and depends on the number of keys you have and the input and output operations. As key management provides seamless integration with many AWS services, integration costs should be significantly lower. Costs should be considered secondary factor in encryption solutions. Encryption is typically used for security and compliance.
With CloudHSM only you have access to the keys and without going into too much detail, with CloudHSM you manage your own keys. With KMS, you and Amazon co-manage your keys. AWS does have many policy safeguards against abuse and still cannot access your keys in either solution. The main distinction is compliance as it pertains to key ownership and management, and with CloudHSM, this is a hardware appliance that you manage and maintain with exclusive access to you and only you.
CloudHSM Suggestions
- Always deploy CloudHSM in an HA setup with at least two appliances in separate availability zones, and if possible, deploy a third either on premise or in another region at AWS.
- Be careful when initializing a CloudHSM. This action will destroy the keys, so either have another copy of the keys or be absolutely sure you do not and never, ever will need these keys to decrypt any data.
- CloudHSM only supports certain versions of firmware and software. Before performing any update, make sure the firmware and or software is supported by AWS. You can always contact AWS support to verify if the upgrade guide is unclear.
- The network configuration should never be changed. Remember, it's in a AWS data center and AWS is monitoring base hardware for you. This means that if the hardware fails, they will replace it for you, but only if they know it failed.
- The SysLog forward should not be removed or changed. You can always add a SysLog forwarder to direct the logs to your own collection tool.
- The SNMP configuration has the same basic restrictions as the network and SysLog folder. This should not be changed or removed. An additional SNMP configuration is fine, just make sure you do not change the one that is already on the appliance.
- Another interesting best practice from AWS is not to change the NTP configuration. It is not clear what would happen if you did, so keep in mind that if you don't use the same NTP configuration for the rest of your solution then you could have two time sources. Just be aware of this and know that the CloudHSM has to stay with the existing NTP source.
The initial launch charge for CloudHSM is $5,000 to allocate the hardware appliance dedicated for your use, then there is an hourly charge associated with running CloudHSM that is currently at $1.88 per hour of operation, or approximately $1,373 per month.
The most common reason to use CloudHSM is compliance standards that you must meet for regulatory reasons. KMS does not offer data support for asymmetric keys. CloudHSM does let you store asymmetric keys securely.
The public key is installed on the HSM appliance during provisioning so you can access the CloudHSM instance via SSH.
Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL.
You need to prepare a relational DB table with the format of the content that is going to appear in the monitored S3 buckets. And then, Amazon Athena will be able to populate the DB from th logs, so you can query it.
Amazon Athena supports the hability to query S3 data that is already encrypted and if configured to do so, Athena can also encrypt the results of the query which can then be stored in S3.
This encryption of results is independent of the underlying queried S3 data, meaning that even if the S3 data is not encrypted, the queried results can be encrypted. A couple of points to be aware of is that Amazon Athena only supports data that has been encrypted with the following S3 encryption methods, SSE-S3, SSE-KMS, and CSE-KMS.
SSE-C and CSE-E are not supported. In addition to this, it's important to understand that Amazon Athena will only run queries against encrypted objects that are in the same region as the query itself. If you need to query S3 data that's been encrypted using KMS, then specific permissions are required by the Athena user to enable them to perform the query.
AWS CloudTrail
This service tracks and monitors AWS API calls made within the environment. Each call to an API (event) is logged. Each logged event contains:
- The name of the called API:
eventName - The called service:
eventSource - The time:
eventTime - The IP address:
SourceIPAddress - The agent method:
userAgent. Examples:- Signing.amazonaws.com - From AWS Management Console
- console.amazonaws.com - Root user of the account
- lambda.amazonaws.com - AWS Lambda
- The request parameters:
requestParameters - The response elements:
responseElements
Event's are written to a new log file approximately each 5 minutes in a JSON file, they are held by CloudTrail and finally, log files are delivered to S3 approximately 15mins after.
CloudTrail allows to use log file integrity in order to be able to verify that your log files have remained unchanged since CloudTrail delivered them to you. It creates a SHA-256 hash of the logs inside a digest file. A sha-256 hash of the new logs is created every hour.
When creating a Trail the event selectors will allow you to indicate the trail to log: Management, data or insights events.
Logs are saved in an S3 bucket. By default Server Side Encryption is used (SSE-S3) so AWS will decrypt the content for the people that has access to it, but for additional security you can use SSE with KMS and your own keys.
Log File Naing Convention

S3 folder structure

Note that the folders "AWSLogs" and "CloudTrail" are fixed folder names,
Digest files have a similar folders path:

Aggregate Logs from Multiple Accounts
- Create a Trial in the AWS account where you want the log files to be delivered to
- Apply permissions to the destination S3 bucket allowing cross-account access for CloudTrail and allow each AWS account that needs access
- Create a new Trail in the other AWS accounts and select to use the created bucket in step 1
However, even if you can save al the logs in the same S3 bucket, you cannot aggregate CloudTrail logs from multiple accounts into a CloudWatch Logs belonging to a single AWS account
Log Files Checking
You can check that the logs haven't been altered by running
aws cloudtrail validate-logs --trail-arn <trailARN> --start-time <start-time> [--end-time <end-time>] [--s3-bucket <bucket-name>] [--s3-prefix <prefix>] [--verbose]
Logs to CloudWatch
CloudTrail can automatically send logs to CloudWatch so you can set alerts that warns you when suspicious activities are performed.
Note that in order to allow CloudTrail to send the logs to CloudWatch a role needs to be created that allows that action. If possible, it's recommended to use AWS default role to perform these actions. This role will allow CloudTrail to:
- CreateLogStream: This allows to create a CloudWatch Logs log streams
- PutLogEvents: Deliver CloudTrail logs to CloudWatch Logs log stream
Event History
CloudTrail Event History allows you to inspect in a table the logs that have been recorded:
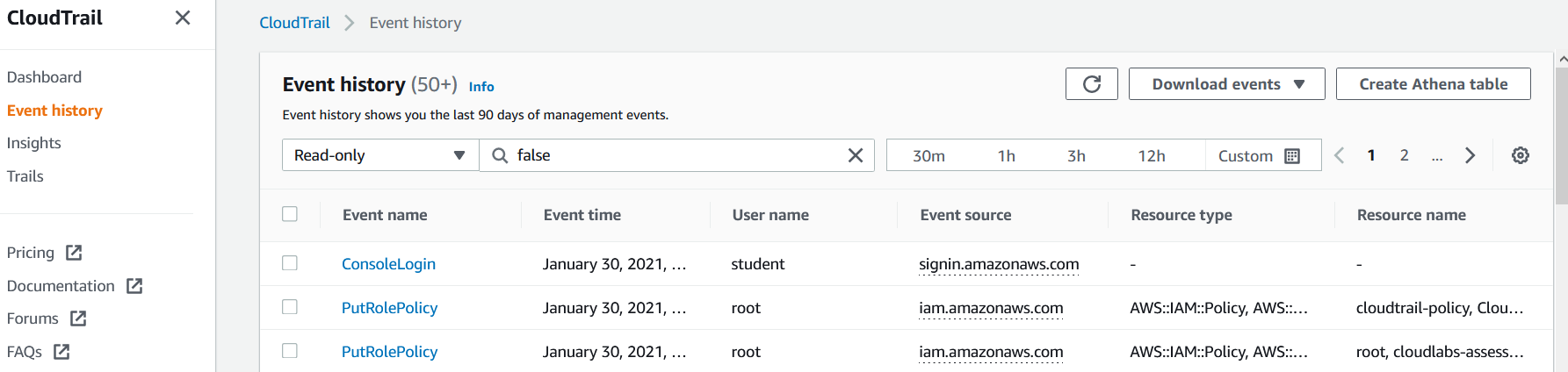
Insights
CloudTrail Insights automatically analyzes write management events from CloudTrail trails and alerts you to unusual activity. For example, if there is an increase in TerminateInstance events that differs from established baselines, you’ll see it as an Insight event. These events make finding and responding to unusual API activity easier than ever.
CloudWatch
Amazon CloudWatch allows to collect all of your logs in a single repository where you can create metrics and alarms based on the logs.
CloudWatch Log Event have a size limitation of 256KB of each log line.
You can monitor for example logs from CloudTrail.
Events that are monitored:
- Changes to Security Groups and NACLs
- Starting, Stopping, rebooting and terminating EC2instances
- Changes to Security Policies within IAM and S3
- Failed login attempts to the AWS Management Console
- API calls that resulted in failed authorization
- Filters to search in cloudwatch: https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/FilterAndPatternSyntax.html
Agent Installation
You can install agents insie your machines/containers to automatically send the logs back to CloudWatch.
- Create a role and attach it to the instance with permissions allowing CloudWatch to collect data from the instances in addition to interacting with AWS systems manager SSM (CloudWatchAgentAdminPolicy & AmazonEC2RoleforSSM)
- Download and install the agent onto the EC2 instance (https://s3.amazonaws.com/amazoncloudwatch-agent/linux/amd64/latest/AmazonCloudWatchAgent.zip). You can download it from inside the EC2 or install it automatically using AWS System Manager selecting the package AWS-ConfigureAWSPackage
- Configure and start the CloudWatch Agent
A log group has many streams. A stream has many events. And inside of each stream, the events are guaranteed to be in order.
Cost Explorer and Anomaly detection
This allows you to check how are you expending money in AWS services and help you detecting anomalies.
Moreover, you can configure an anomaly detection so AWS will warn you when some anomaly in costs is found.
Budgets
Budgets help to manage costs and usage. You can get alerted when a threshold is reached.
Also, they can be used for non cost related monitoring like the usage of a service (how many GB are used in a particular S3 bucket?).
AWS Config
AWS Config capture resource changes, so any change to a resource supported by Config can be recorded, which will record what changed along with other useful metadata, all held within a file known as a configuration item, a CI.
This service is region specific.
A configuration item or CI as it's known, is a key component of AWS Config. It is comprised of a JSON file that holds the configuration information, relationship information and other metadata as a point-in-time snapshot view of a supported resource. All the information that AWS Config can record for a resource is captured within the CI. A CI is created every time a supported resource has a change made to its configuration in any way. In addition to recording the details of the affected resource, AWS Config will also record CIs for any directly related resources to ensure the change did not affect those resources too.
- Metadata: Contains details about the configuration item itself. A version ID and a configuration ID, which uniquely identifies the CI. Ither information can include a MD5Hash that allows you to compare other CIs already recorded against the same resource.
- Attributes: This holds common attribute information against the actual resource. Within this section, we also have a unique resource ID, and any key value tags that are associated to the resource. The resource type is also listed. For example, if this was a CI for an EC2 instance, the resource types listed could be the network interface, or the elastic IP address for that EC2 instance
- Relationships: This holds information for any connected relationship that the resource may have. So within this section, it would show a clear description of any relationship to other resources that this resource had. For example, if the CI was for an EC2 instance, the relationship section may show the connection to a VPC along with the subnet that the EC2 instance resides in.
- Current configuration: This will display the same information that would be generated if you were to perform a describe or list API call made by the AWS CLI. AWS Config uses the same API calls to get the same information.
- Related events: This relates to AWS CloudTrail. This will display the AWS CloudTrail event ID that is related to the change that triggered the creation of this CI. There is a new CI made for every change made against a resource. As a result, different CloudTrail event IDs will be created.
Configuration History: It's possible to obtain the configuration history of resources thanks to the configurations items. A configuration history is delivered every 6 hours and contains all CI's for a particular resource type.
Configuration Streams: Configuration items are sent to an SNS Topic to enable analysis of the data.
Configuration Snapshots: Configuration items are used to create a point in time snapshot of all supported resources.
S3 is used to store the Configuration History files and any Configuration snapshots of your data within a single bucket, which is defined within the Configuration recorder. If you have multiple AWS accounts you may want to aggregate your configuration history files into the same S3 bucket for your primary account. However, you'll need to grant write access for this service principle, config.amazonaws.com, and your secondary accounts with write access to the S3 bucket in your primary account.
Config Rules
Config rules are a great way to help you enforce specific compliance checks and controls across your resources, and allows you to adopt an ideal deployment specification for each of your resource types. Each rule is essentially a lambda function that when called upon evaluates the resource and carries out some simple logic to determine the compliance result with the rule. Each time a change is made to one of your supported resources, AWS Config will check the compliance against any config rules that you have in place.
AWS have a number of predefined rules that fall under the security umbrella that are ready to use. For example, Rds-storage-encrypted. This checks whether storage encryption is activated by your RDS database instances. Encrypted-volumes. This checks to see if any EBS volumes that have an attached state are encrypted.
- AWS Managed rules: Set of predefined rules that cover a lot of best practices, so it's always worth browsing these rules first before setting up your own as there is a chance that the rule may already exist.
- Custom rules: You can create your own rules to check specific customconfigurations.
Limit of 50 config rules per region before you need to contact AWS for an increase.
Non compliant results are NOT deleted.
SNS Topic
SNS topic is used as a configuration stream for notifications from different AWS services like Config or CloudWatch alarms.
You can have various endpoints associated to the SNS stream.
You can use SNS topic to send notifications to you via email or to SQS to treate programatically the notification.
Inspector
The Amazon Inspector service is agent based, meaning it requires software agents to be installed on any EC2 instances you want to assess. This makes it an easy service to be configured and added at any point to existing resources already running within your AWS infrastructure. This helps Amazon Inspector to become a seamless integration with any of your existing security processes and procedures as another level of security.
These are the tests that AWS Inspector allow you to perform:
- CVEs
- CIS Benchmarks
- Security Best practices
- Network Reachability
You can make any of those run on the EC2 machines you decide.
Element of AWS Inspector
Role: Create or select a role to allow Amazon Inspector to have read only access to the EC2 instances (DescribeInstances)
Assessment Targets: Group of EC2 instances that you want to run an assessment against
AWS agents: Software agents that must be install on EC2 instances to monitor. Data is sent to Amazon Inspector using a TLS channel. A regular heartbeat is sent from the agent to the inspector asking for instructions. It can autoupdate itself
Assessment Templates: Define specific configurations as to how an assessment is run on your EC2 instances. An assessment template cannot be modified after creation.
- Rules packages to be used
- Duration of the assessment run 15min/1hour/8hours
- SNS topics, select when notify: Starts, finished, change state, reports a finding
- Attributes to b assigned to findings
Rule package: Contains a number of individual rules that are check against an EC2 when an assessment is run. Each one also have a severity (high, medium, low, informational). The possibilities are:
- Common Vulnerabilities and Exposures (CVEs)
- Center for Internet Security (CIS) Benchmark
- Security Best practices
Once you have configured the Amazon Inspector Role, the AWS Agents are Installed, the target is configured and the template is configured, you will be able to run it. An assessment run can be stopped, resumed, or deleted.
Amazon Inspector has a pre-defined set of rules, grouped into packages. Each Assessment Template defines which rules packages to be included in the test. Instances are being evaluated against rules packages included in the assessment template.
{% hint style="info" %} Note that nowadays AWS already allow you to autocreate all the necesary configurations and even automatically install the agents inside the EC2 instances. {% endhint %}
Reporting
Telemetry: data that is collected from an instance, detailing its configuration, behavior and processes during an assessment run. Once collected, the data is then sent back to Amazon Inspector in near-real-time over TLS where it is then stored and encrypted on S3 via an ephemeral KMS key. Amazon Inspector then accesses the S3 Bucket, decrypts the data in memory, and analyzes it against any rules packages used for that assessment to generate the findings.
Assessment Report: Provide details on what was assessed and the results of the assessment.
- The findings report contain the summary of the assessment, info about the EC2 and rules and the findings that occurred.
- The full report is the finding report + a list of rules that were passed.
Trusted Advisor
The main function of Trusted Advisor is to recommend improvements across your AWS account to help optimize and hone your environment based on AWS best practices. These recommendations cover four distinct categories. It's a is a cross-region service.
- Cost optimization: which helps to identify ways in which you could optimize your resources to save money.
- Performance: This scans your resources to highlight any potential performance issues across multiple services.
- Security: This category analyzes your environment for any potential security weaknesses or vulnerabilities.
- Fault tolerance: Which suggests best practices to maintain service operations by increasing resiliency should a fault or incident occur across your resources.
The full power and potential of AWS Trusted Advisor is only really available if you have a business or enterprise support plan with AWS. Without either of these plans, then you will only have access to six core checks that are freely available to everyone. These free core checks are split between the performance and security categories, with the majority of them being related to security. These are the 6 checks: service limits, Security Groups Specific Ports Unrestricted, Amazon EBS Public Snapshots, Amazon RDS Public Snapshots, IAM Use, and MFA on root account.
Trusted advisor can send notifications and you can exclude items from it.
Trusted advisor data is automatically refreshed every 24 hours, but you can perform a manual one 5 mins after the previous one.
Amazon GuardDuty
Amazon GuardDuty is a regional-based intelligent threat detection service, the first of its kind offered by AWS, which allows users to monitor their AWS account for unusual and unexpected behavior by analyzing VPC Flow Logs, AWS CloudTrail management event logs, Cloudtrail S3 data event logs, and DNS logs. It uses threat intelligence feeds, such as lists of malicious IP addresses and domains, and machine learning to identify unexpected and potentially unauthorized and malicious activity within your AWS environment. This can include issues like escalations of privileges, uses of exposed credentials, or communication with malicious IP addresses, or domains.
For example, GuardDuty can detect compromised EC2 instances serving malware or mining bitcoin. It also monitors AWS account access behavior for signs of compromise, such as unauthorized infrastructure deployments, like instances deployed in a Region that has never been used, or unusual API calls, like a password policy change to reduce password strength.
You can upload list of whitelisted and blacklisted IP addresses so GuardDuty takes that info into account.
Finding summary:
- Finding type
- Severity: 7-8.9High, 4-6.9Medium, 01-3.9Low
- Region
- Account ID
- Resource ID
- Time of detection
- Which threat list was used
The body has this information:
- Resource affected
- Action
- Actor: Ip address, port and domain
- Additional Information
You can invite other accounts to a different AWS GuardDuty account so every account is monitored from the same GuardDuty. The master account must invite the member accounts and then the representative of the member account must accept the invitation.
There are different IAM Role permissions to allow GuardDuty to get the information and to allow a user to upload IPs whitelisted and blacklisted.
GuarDuty uses a service-linked role called "AWSServiceRoleForAmazonGuardDuty" that allows it to retrieve metadata from affected endpoints.
You pay for the processing of your log files, per 1 million events per months from CloudTrail and per GB of analysed logs from VPC Flow
When a user disable GuardDuty, it will stop monitoring your AWS environment and it won't generate any new findings at all, and the existing findings will be lost.
If you just stop it, the existing findings will remain.
Amazon Macie
The main function of the service is to provide an automatic method of detecting, identifying, and also classifying data that you are storing within your AWS account.
The service is backed by machine learning, allowing your data to be actively reviewed as different actions are taken within your AWS account. Machine learning can spot access patterns and user behavior by analyzing cloud trail event data to alert against any unusual or irregular activity. Any findings made by Amazon Macie are presented within a dashboard which can trigger alerts, allowing you to quickly resolve any potential threat of exposure or compromise of your data.
Amazon Macie will automatically and continuously monitor and detect new data that is stored in Amazon S3. Using the abilities of machine learning and artificial intelligence, this service has the ability to familiarize over time, access patterns to data.
Amazon Macie also uses natural language processing methods to classify and interpret different data types and content. NLP uses principles from computer science and computational linguistics to look at the interactions between computers and the human language. In particular, how to program computers to understand and decipher language data. The service can automatically assign business values to data that is assessed in the form of a risk score. This enables Amazon Macie to order findings on a priority basis, enabling you to focus on the most critical alerts first. In addition to this, Amazon Macie also has the added benefit of being able to monitor and discover security changes governing your data. As well as identify specific security-centric data such as access keys held within an S3 bucket.
This protective and proactive security monitoring enables Amazon Macie to identify critical, sensitive, and security focused data such as API keys, secret keys, in addition to PII (personally identifiable information) and PHI data.
This is useful to avoid data leaks as Macie will detect if you are exposing people information to the Internet.
It's a regional service.
It requires the existence of IAM Role 'AWSMacieServiceCustomerSetupRole' and it needs AWS CloudTrail to be enabled.
Pre-defined alerts categories:
- Anonymized access
- Config compliance
- Credential Loss
- Data compliance
- Files hosting
- Identity enumeration
- Information loss
- Location anomaly
- Open permissions
- Privilege escalation
- Ransomware
- Service disruption
- Suspicious access
The alert summary provides detailed information to allow you to respond appropriately. It has a description that provides a deeper level of understanding of why it was generated. It also has a breakdown of the results.
The user has the possibility to create new custom alerts.
Dashboard categorization:
- S3 Objects for selected time range
- S3 Objects
- S3 Objects by PII - Personally Identifiable Information
- S3 Objects by ACL
- High-risk CloudTrail events and associated users
- High-risk CloudTrail errors and associated users
- Activity Location
- CloudTrail Events
- Activity ISPs
- CloudTrail user identity types
User Categories: Macie categorises the users in the following categories:
- Platinum: Users or roles considered to be making high risk API calls. Often they have admins privileges. You should monitor the pretty god in case they are compromised
- Gold: Users or roles with history of calling APIs related to infrastructure changes. You should also monitor them
- Silver: Users or roles performing medium level risk API calls
- Bronze: Users or roles using lowest level of risk based on API calls
Identity types:
- Root: Request made by root user
- IAM user: Request made by IAM user
- Assumed Role: Request made by temporary assumed credentials (AssumeRole API for STS)
- Federated User: Request made using temporary credentials (GetFederationToken API fro STS)
- AWS Account: Request made by a different AWS account
- AWS Service: Request made by an AWS service
Data classification: 4 file classifications exists:
- Content-Type: list files based on content-type detected. The given risk is determined by the type of content detected.
- File Extension: Same as content-type but based on the extension
- Theme: Categorises based on a series of keywords detected within the files
- Regex: Categories based on specific regexps
The final risk of a file will be the highest risk found between those 4 categories
The research function allows to create you own queries again all Amazon Macie data and perform a deep dive analysis of the data. You can filter results based on: CloudTrail Data, S3 Bucket properties and S3 Objects
It possible to invite other accounts to Amazon Macie so several accounts share Amazon Macie.
Route 53
You can very easily create health checks for web pages via Route53. For example you can create HTTP checks on port 80 to a page to check that the web server is working.
Route 53 service is mainly used for checking the health of the instances. To check the health of the instances we can ping a certain DNS point and we should get response from the instance if the instances are healthy.
CloufFront
Amazon CloudFront is AWS's content delivery network that speeds up distribution of your static and dynamic content through its worldwide network of edge locations. When you use a request content that you're hosting through Amazon CloudFront, the request is routed to the closest edge location which provides it the lowest latency to deliver the best performance. When CloudFront access logs are enabled you can record the request from each user requesting access to your website and distribution. As with S3 access logs, these logs are also stored on Amazon S3 for durable and persistent storage. There are no charges for enabling logging itself, however, as the logs are stored in S3 you will be stored for the storage used by S3.
The log files capture data over a period of time and depending on the amount of requests that are received by Amazon CloudFront for that distribution will depend on the amount of log fils that are generated. It's important to know that these log files are not created or written to on S3. S3 is simply where they are delivered to once the log file is full. Amazon CloudFront retains these logs until they are ready to be delivered to S3. Again, depending on the size of these log files this delivery can take between one and 24 hours.
By default cookie logging is disabled but you can enable it.
VPC
VPC Flow Logs
Within your VPC, you could potentially have hundreds or even thousands of resources all communicating between different subnets both public and private and also between different VPCs through VPC peering connections. VPC Flow Logs allows you to capture IP traffic information that flows between your network interfaces of your resources within your VPC.
Unlike S3 access logs and CloudFront access logs, the log data generated by VPC Flow Logs is not stored in S3. Instead, the log data captured is sent to CloudWatch logs.
Limitations:
- If you are running a VPC peered connection, then you'll only be able to see flow logs of peered VPCs that are within the same account.
- If you are still running resources within the EC2-Classic environment, then unfortunately you are not able to retrieve information from their interfaces
- Once a VPC Flow Log has been created, it cannot be changed. To alter the VPC Flow Log configuration, you need to delete it and then recreate a new one.
- The following traffic is not monitored and captured by the logs. DHCP traffic within the VPC, traffic from instances destined for the Amazon DNS Server.
- Any traffic destined to the IP address for the VPC default router and traffic to and from the following addresses, 169.254.169.254 which is used for gathering instance metadata, and 169.254.169.123 which is used for the Amazon Time Sync Service.
- Traffic relating to an Amazon Windows activation license from a Windows instance
- Traffic between a network load balancer interface and an endpoint network interface
For every network interface that publishes data to the CloudWatch log group, it will use a different log stream. And within each of these streams, there will be the flow log event data that shows the content of the log entries. Each of these logs captures data during a window of approximately 10 to 15 minutes.


Subnets
Subnets helps to enforce a greater level of security. Logical grouping of similar resources also helps you to maintain an ease of management across your infrastructure.
Valid CIDR are from a /16 netmask to a /28 netmask.
A subnet cannot be in different availability zones at the same time.
By having multiple Subnets with similar resources grouped together, it allows for greater security management. By implementing network level virtual firewalls, called network access control lists, or NACLs, it's possible to filter traffic on specific ports from both an ingress and egress point at the Subnet level.
When you create a subnet the network and broadcast address of the subnet can't be used for host addresses and AWS reserves the first three host IP addresses of each subnet for internal AWS usage: he first host address used is for the VPC router. The second address is reserved for AWS DNS and the third address is reserved for future use.
It's called public subnets to those that have direct access to the Internet, whereas private subnets do not.
In order to make a subnet public you need to create and attach an Internet gateway to your VPC. This Internet gateway is a managed service, controlled, configured, and maintained by AWS. It scales horizontally automatically, and is classified as a highly valuable component of your VPC infrastructure. Once your Internet gateway is attached to your VPC, you have a gateway to the Internet. However, at this point, your instances have no idea how to get out to the Internet. As a result, you need to add a default route to the route table associated with your subnet. The route could have a destination value of 0.0. 0. 0/0, and the target value will be set as your Internet gateway ID.
By default, all subnets have the automatic assigned of public IP addresses turned off but it can be turned on.
A local route within a route table enables communication between VPC subnets.
If you are connection a subnet with a different subnet you cannot access the subnets connected with the other subnet, you need to create connection with them directly. This also applies to internet gateways. You cannot go through a subnet connection to access internet, you need to assign the internet gateway to your subnet.
VPC Peering
VPC peering allows you to connect two or more VPCs together, using IPV4 or IPV6, as if they were a part of the same network.
Once the peer connectivity is established, resources in one VPC can access resources in the other. The connectivity between the VPCs is implemented through the existing AWS network infrastructure, and so it is highly available with no bandwidth bottleneck. As peered connections operate as if they were part of the same network, there are restrictions when it comes to your CIDR block ranges that can be used.
If you have overlapping or duplicate CIDR ranges for your VPC, then you'll not be able to peer the VPCs together.
Each AWS VPC will only communicate with its peer. As an example, if you have a peering connection between VPC 1 and VPC 2, and another connection between VPC 2 and VPC 3 as shown, then VPC 1 and 2 could communicate with each other directly, as can VPC 2 and VPC 3, however, VPC 1 and VPC 3 could not. You can't route through one VPC to get to another.
AWS Secrets Manager
AWS Secrets Manager is a great service to enhance your security posture by allowing you to remove any hard-coded secrets within your application and replacing them with a simple API call to the aid of your secrets manager which then services the request with the relevant secret. As a result, AWS Secrets Manager acts as a single source of truth for all your secrets across all of your applications.
AWS Secrets Manager enables the ease of rotating secrets and therefore enhancing the security of that secret. An example of this could be your database credentials. Other secret types can also have automatic rotation enabled through the use of lambda functions, for example, API keys.
Access to your secrets within AWS Secret Manager is governed by fine-grained IAM identity-based policies in addition to resource-based policies.
To allow a user form a different account to access your secret you need to authorize him to access the secret and also authorize him to decrypt the secret in KMS. The Key policy also needs to allows the external user to use it.
AWS Secrets Manager integrates with AWS KMS to encrypt your secrets within AWS Secrets Manager.
EMR
EMR is a managed service by AWS and is comprised of a cluster of EC2 instances that's highly scalable to process and run big data frameworks such Apache Hadoop and Spark.
From EMR version 4.8.0 and onwards, we have the ability to create a security configuration specifying different settings on how to manage encryption for your data within your clusters. You can either encrypt your data at rest, data in transit, or if required, both together. The great thing about these security configurations is they're not actually a part of your EC2 clusters.
One key point of EMR is that by default, the instances within a cluster do not encrypt data at rest. Once enabled, the following features are available.
- Linux Unified Key Setup: EBS cluster volumes can be encrypted using this method whereby you can specify AWS KMS to be used as your key management provider, or use a custom key provider.
- Open-Source HDFS encryption: This provides two Hadoop encryption options. Secure Hadoop RPC which would be set to privacy which uses simple authentication security layer, and data encryption of HDFS Block transfer which would be set to true to use the AES-256 algorithm.
From an encryption in transit perspective, you could enable open source transport layer security encryption features and select a certificate provider type which can be either PEM where you will need to manually create PEM certificates, bundle them up with a zip file and then reference the zip file in S3 or custom where you would add a custom certificate provider as a Java class that provides encryption artefacts.
Once the TLS certificate provider has been configured in the security configuration file, the following encryption applications specific encryption features can be enabled which will vary depending on your EMR version.
- Hadoop might reduce encrypted shuffle which uses TLS. Both secure Hadoop RPC which uses Simple Authentication Security Layer, and data encryption of HDFS Block Transfer which uses AES-256, are both activated when at rest encryption is enabled in the security configuration.
- Presto: When using EMR version 5.6.0 and later, any internal communication between Presto nodes will use SSL and TLS.
- Tez Shuffle Handler uses TLS.
- Spark: The Akka protocol uses TLS. Block Transfer Service uses Simple Authentication Security Layer and 3DES. External shuffle service uses the Simple Authentication Security Layer.
RDS - Relational Database Service
RDS allows you to set up a relational database using a number of different engines such as MySQL, Oracle, SQL Server, etc. During the creation of your RDS database instance, you have the opportunity to Enable Encryption at the Configure Advanced Settings screen under Database Options and Enable Encryption.
By enabling your encryption here, you are enabling encryption at rest for your storage, snapshots, read replicas and your back-ups. Keys to manage this encryption can be issued by using KMS. It's not possible to add this level of encryption after your database has been created. It has to be done during its creation.
However, there is a workaround allowing you to encrypt an unencrypted database as follows. You can create a snapshot of your unencrypted database, create an encrypted copy of that snapshot, use that encrypted snapshot to create a new database, and then, finally, your database would then be encrypted.
Amazon RDS sends data to CloudWatch every minute by default.
In addition to encryption offered by RDS itself at the application level, there are additional platform level encryption mechanisms that could be used for protecting data at rest including Oracle and SQL Server Transparent Data Encryption, known as TDE, and this could be used in conjunction with the method order discussed but it would impact the performance of the database MySQL cryptographic functions and Microsoft Transact-SQL cryptographic functions.
If you want to use the TDE method, then you must first ensure that the database is associated to an option group. Option groups provide default settings for your database and help with management which includes some security features. However, option groups only exist for the following database engines and versions.
Once the database is associated with an option group, you must ensure that the Oracle Transparent Data Encryption option is added to that group. Once this TDE option has been added to the option group, it cannot be removed. TDE can use two different encryption modes, firstly, TDE tablespace encryption which encrypts entire tables and, secondly, TDE column encryption which just encrypts individual elements of the database.
Amazon Kinesis Firehouse
Amazon Firehose is used to deliver real-time streaming data to different services and destinations within AWS, many of which can be used for big data such as S3 Redshift and Amazon Elasticsearch.
The service is fully managed by AWS, taking a lot of the administration of maintenance out of your hands. Firehose is used to receive data from your data producers where it then automatically delivers the data to your chosen destination.
Amazon Streams essentially collects and processes huge amounts of data in real time and makes it available for consumption.
This data can come from a variety of different sources. For example, log data from the infrastructure, social media, web clicks during feeds, market data, etc. So now we have a high-level overview of each of these. We need to understand how they implement encryption of any data process in stored should it be required.
When clients are sending data to Kinesis in transit, the data can be sent over HTTPS, which is HTTP with SSL encryption. However, once it enters the Kinesis service, it is then unencrypted by default. Using both Kinesis Streams and Firehose encryption, you can assure your streams remain encrypted up until the data is sent to its final destination. As Amazon Streams now has the ability to implement SSE encryption using KMS to encrypt data as it enters the stream directly from the producers.
If Amazon S3 is used as a destination, Firehose can implement encryption using SSE-KMS on S3.
As a part of this process, it's important to ensure that both producer and consumer applications have permissions to use the KMS key. Otherwise encryption and decryption will not be possible, and you will receive an unauthorized KMS master key permission error.
Kinesis SSE encryption will typically call upon KMS to generate a new data key every five minutes. So, if you had your stream running for a month or more, thousands of data keys would be generated within this time frame.
Amazon Redshift
Redshift is a fully managed service that can scale up to over a petabyte in size, which is used as a data warehouse for big data solutions. Using Redshift clusters, you are able to run analytics against your datasets using fast, SQL-based query tools and business intelligence applications to gather greater understanding of vision for your business.
Redshift offers encryption at rest using a four-tired hierarchy of encryption keys using either KMS or CloudHSM to manage the top tier of keys. When encryption is enabled for your cluster, it can't be disable and vice versa. When you have an unencrypted cluster, it can't be encrypted.
Encryption for your cluster can only happen during its creation, and once encrypted, the data, metadata, and any snapshots are also encrypted. The tiering level of encryption keys are as follows, tier one is the master key, tier two is the cluster encryption key, the CEK, tier three, the database encryption key, the DEK, and finally tier four, the data encryption keys themselves.
KMS
During the creation of your cluster, you can either select the default KMS key for Redshift or select your own CMK, which gives you more flexibility over the control of the key, specifically from an auditable perspective.
The default KMS key for Redshift is automatically created by Redshift the first time the key option is selected and used, and it is fully managed by AWS. The CMK is known as the master key, tier one, and once selected, Redshift can enforce the encryption process as follows. So Redshift will send a request to KMS for a new KMS key.
So Redshift will send a request to KMS for a new KMS key.
This KMS key is then encrypted with the CMK master key, tier one. This encrypted KMS data key is then used as the cluster encryption key, the CEK, tier two. This CEK is then sent by KMS to Redshift where it is stored separately from the cluster. Redshift then sends this encrypted CEK to the cluster over a secure channel where it is stored in memory.
Redshift then requests KMS to decrypt the CEK, tier two. This decrypted CEK is then also stored in memory. Redshift then creates a random database encryption key, the DEK, tier three, and loads that into the memory of the cluster. The decrypted CEK in memory then encrypts the DEK, which is also stored in memory.
This encrypted DEK is then sent over a secure channel and stored in Redshift separately from the cluster. Both the CEK and the DEK are now stored in memory of the cluster both in an encrypted and decrypted form. The decrypted DEK is then used to encrypt data keys, tier four, that are randomly generated by Redshift for each data block in the database.
You can use AWS Trusted Advisor to monitor the configuration of your Amazon S3 buckets and ensure that bucket logging is enabled, which can be useful for performing security audits and tracking usage patterns in S3.
CloudHSM
When working with CloudHSM to perform your encryption, firstly you must set up a trusted connection between your HSM client and Redshift while using client and server certificates.
This connection is required to provide secure communications, allowing encryption keys to be sent between your HSM client and your Redshift clusters. Using a randomly generated private and public key pair, Redshift creates a public client certificate, which is encrypted and stored by Redshift. This must be downloaded and registered to your HSM client, and assigned to the correct HSM partition.
You must then configure Redshift with the following details of your HSM client: the HSM IP address, the HSM partition name, the HSM partition password, and the public HSM server certificate, which is encrypted by CloudHSM using an internal master key. Once this information has been provided, Redshift will confirm and verify that it can connect and access development partition.
If your internal security policies or governance controls dictate that you must apply key rotation, then this is possible with Redshift enabling you to rotate encryption keys for encrypted clusters, however, you do need to be aware that during the key rotation process, it will make a cluster unavailable for a very short period of time, and so it's best to only rotate keys as and when you need to, or if you feel they may have been compromised.
During the rotation, Redshift will rotate the CEK for your cluster and for any backups of that cluster. It will rotate a DEK for the cluster but it's not possible to rotate a DEK for the snapshots stored in S3 that have been encrypted using the DEK. It will put the cluster into a state of 'rotating keys' until the process is completed when the status will return to 'available'.
WAF
AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits that may affect availability, compromise security, or consume excessive resources. AWS WAF gives you control over how traffic reaches your applications by enabling you to create security rules that block common attack patterns, such as SQL injection or cross-site scripting, and rules that filter out specific traffic patterns you define.
So there are a number of essential components relating to WAF, these being: Conditions, Rules and Web access control lists, also known as Web ACLs
Conditions
Conditions allow you to specify what elements of the incoming HTTP or HTTPS request you want WAF to be monitoring (XSS, GEO - filtering by location-, IP address, Size constraints, SQL Injection attacks, strings and regex matching). Note that if you are restricting a country from cloudfront, this request won't arrive to the waf.
You can have 100 conditions of each type, such as Geo Match or size constraints, however Regex is the exception to this rule where only 10 Regex conditions are allowed but this limit is possible to increase. You are able to have 100 rules and 50 Web ACLs per AWS account. You are limited to 5 rate-based-rules per account. Finally you can have 10,000 requests per second when using WAF within your application load balancer.
Rules
Using these conditions you can create rules: For example, block request if 2 conditions are met.
When creating your rule you will be asked to select a Rule Type: Regular Rule or Rate-Based Rule.
The only difference between a rate-based rule and a regular rule is that rate-based rules count the number of requests that are being received from a particular IP address over a time period of five minutes.
When you select a rate-based rule option, you are asked to enter the maximum number of requests from a single IP within a five minute time frame. When the count limit is reached, all other requests from that same IP address is then blocked. If the request rate falls back below the rate limit specified the traffic is then allowed to pass through and is no longer blocked. When setting your rate limit it must be set to a value above 2000. Any request under this limit is considered a Regular Rule.
Actions
An action is applied to each rule, these actions can either be Allow, Block or Count.
- When a request is allowed, it is forwarded onto the relevant CloudFront distribution or Application Load Balancer.
- When a request is blocked, the request is terminated there and no further processing of that request is taken.
- A Count action will count the number of requests that meet the conditions within that rule. This is a really good option to select when testing the rules to ensure that the rule is picking up the requests as expected before setting it to either Allow or Block.
If an incoming request does not meet any rule within the Web ACL then the request takes the action associated to a default action specified which can either be Allow or Block. An important point to make about these rules is that they are executed in the order that they are listed within a Web ACL. So be careful to architect this order correctly for your rule base, typically these are ordered as shown:
- WhiteListed Ips as Allow.
- BlackListed IPs Block
- Any Bad Signatures also as Block.
CloudWatch
WAF CloudWatch metrics are reported in one minute intervals by default and are kept for a two week period. The metrics monitored are AllowedRequests, BlockedRequests, CountedRequests, and PassedRequests.
AWS Firewall Manager
AWS Firewall Manager simplifies your administration and maintenance tasks across multiple accounts and resources for AWS WAF, AWS Shield Advanced, Amazon VPC security groups, and AWS Network Firewall. With Firewall Manager, you set up your AWS WAF firewall rules, Shield Advanced protections, Amazon VPC security groups, and Network Firewall firewalls just once. The service automatically applies the rules and protections across your accounts and resources, even as you add new resources.
It can group and protect specific resources together, for example, all resources with a particular tag or all of your CloudFront distributions. One key benefit of Firewall Manager is that it automatically protects certain resources that are added to your account as they become active.
Requisites: Created a Firewall Manager Master Account, setup an AWS organization and have added our member accounts and enable AWS Config.
A rule group (a set of WAF rules together) can be added to an AWS Firewall Manager Policy which is then associated to AWS resources, such as your cloudfront distributions or application load balances.
Firewall Manager policies only allow "Block" or "Count" options for a rule group (no "Allow" option).
AWS Shield
AWS Shield has been designed to help protect your infrastructure against distributed denial of service attacks, commonly known as DDoS.
AWS Shield Standard is free to everyone, and it offers DDoS protection against some of the more common layer three, the network layer, and layer four, transport layer, DDoS attacks. This protection is integrated with both CloudFront and Route 53.
AWS Shield advanced offers a greater level of protection for DDoS attacks across a wider scope of AWS services for an additional cost. This advanced level offers protection against your web applications running on EC2, CloudFront, ELB and also Route 53. In addition to these additional resource types being protected, there are enhanced levels of DDoS protection offered compared to that of Standard. And you will also have access to a 24-by-seven specialized DDoS response team at AWS, known as DRT.
Whereas the Standard version of Shield offered protection against layer three and layer four, Advanced also offers protection against layer seven, application, attacks.
VPN
Site-to-Site VPN
Connect your on premisses network with your VPC.
Concepts
-
VPN connection: A secure connection between your on-premises equipment and your VPCs.
-
VPN tunnel: An encrypted link where data can pass from the customer network to or from AWS.
Each VPN connection includes two VPN tunnels which you can simultaneously use for high availability.
-
Customer gateway: An AWS resource which provides information to AWS about your customer gateway device.
-
Customer gateway device: A physical device or software application on your side of the Site-to-Site VPN connection.
-
Virtual private gateway: The VPN concentrator on the Amazon side of the Site-to-Site VPN connection. You use a virtual private gateway or a transit gateway as the gateway for the Amazon side of the Site-to-Site VPN connection.
-
Transit gateway: A transit hub that can be used to interconnect your VPCs and on-premises networks. You use a transit gateway or virtual private gateway as the gateway for the Amazon side of the Site-to-Site VPN connection.
Limitations
- IPv6 traffic is not supported for VPN connections on a virtual private gateway.
- An AWS VPN connection does not support Path MTU Discovery.
In addition, take the following into consideration when you use Site-to-Site VPN.
- When connecting your VPCs to a common on-premises network, we recommend that you use non-overlapping CIDR blocks for your networks.
Components of Client VPN
Connect from your machine to your VPC
Concepts
- Client VPN endpoint: The resource that you create and configure to enable and manage client VPN sessions. It is the resource where all client VPN sessions are terminated.
- Target network: A target network is the network that you associate with a Client VPN endpoint. A subnet from a VPC is a target network. Associating a subnet with a Client VPN endpoint enables you to establish VPN sessions. You can associate multiple subnets with a Client VPN endpoint for high availability. All subnets must be from the same VPC. Each subnet must belong to a different Availability Zone.
- Route: Each Client VPN endpoint has a route table that describes the available destination network routes. Each route in the route table specifies the path for traffic to specific resources or networks.
- Authorization rules: An authorization rule restricts the users who can access a network. For a specified network, you configure the Active Directory or identity provider (IdP) group that is allowed access. Only users belonging to this group can access the specified network. By default, there are no authorization rules and you must configure authorization rules to enable users to access resources and networks.
- Client: The end user connecting to the Client VPN endpoint to establish a VPN session. End users need to download an OpenVPN client and use the Client VPN configuration file that you created to establish a VPN session.
- Client CIDR range: An IP address range from which to assign client IP addresses. Each connection to the Client VPN endpoint is assigned a unique IP address from the client CIDR range. You choose the client CIDR range, for example,
10.2.0.0/16. - Client VPN ports: AWS Client VPN supports ports 443 and 1194 for both TCP and UDP. The default is port 443.
- Client VPN network interfaces: When you associate a subnet with your Client VPN endpoint, we create Client VPN network interfaces in that subnet. Traffic that's sent to the VPC from the Client VPN endpoint is sent through a Client VPN network interface. Source network address translation (SNAT) is then applied, where the source IP address from the client CIDR range is translated to the Client VPN network interface IP address.
- Connection logging: You can enable connection logging for your Client VPN endpoint to log connection events. You can use this information to run forensics, analyze how your Client VPN endpoint is being used, or debug connection issues.
- Self-service portal: You can enable a self-service portal for your Client VPN endpoint. Clients can log into the web-based portal using their credentials and download the latest version of the Client VPN endpoint configuration file, or the latest version of the AWS provided client.
Limitations
-
Client CIDR ranges cannot overlap with the local CIDR of the VPC in which the associated subnet is located, or any routes manually added to the Client VPN endpoint's route table.
-
Client CIDR ranges must have a block size of at least /22 and must not be greater than /12.
-
A portion of the addresses in the client CIDR range are used to support the availability model of the Client VPN endpoint, and cannot be assigned to clients. Therefore, we recommend that you assign a CIDR block that contains twice the number of IP addresses that are required to enable the maximum number of concurrent connections that you plan to support on the Client VPN endpoint.
-
The client CIDR range cannot be changed after you create the Client VPN endpoint.
-
The subnets associated with a Client VPN endpoint must be in the same VPC.
-
You cannot associate multiple subnets from the same Availability Zone with a Client VPN endpoint.
-
A Client VPN endpoint does not support subnet associations in a dedicated tenancy VPC.
-
Client VPN supports IPv4 traffic only.
-
Client VPN is not Federal Information Processing Standards (FIPS) compliant.
-
If multi-factor authentication (MFA) is disabled for your Active Directory, a user password cannot be in the following format.
SCRV1:<base64_encoded_string>:<base64_encoded_string> -
The self-service portal is not available for clients that authenticate using mutual authentication.
Amazon Cognito
Amazon Cognito provides authentication, authorization, and user management for your web and mobile apps. Your users can sign in directly with a user name and password, or through a third party such as Facebook, Amazon, Google or Apple.
The two main components of Amazon Cognito are user pools and identity pools. User pools are user directories that provide sign-up and sign-in options for your app users. Identity pools enable you to grant your users access to other AWS services. You can use identity pools and user pools separately or together.
User pools
A user pool is a user directory in Amazon Cognito. With a user pool, your users can sign in to your web or mobile app through Amazon Cognito, or federate through a third-party identity provider (IdP). Whether your users sign in directly or through a third party, all members of the user pool have a directory profile that you can access through an SDK.
User pools provide:
- Sign-up and sign-in services.
- A built-in, customizable web UI to sign in users.
- Social sign-in with Facebook, Google, Login with Amazon, and Sign in with Apple, and through SAML and OIDC identity providers from your user pool.
- User directory management and user profiles.
- Security features such as multi-factor authentication (MFA), checks for compromised credentials, account takeover protection, and phone and email verification.
- Customized workflows and user migration through AWS Lambda triggers.
Identity pools
With an identity pool, your users can obtain temporary AWS credentials to access AWS services, such as Amazon S3 and DynamoDB. Identity pools support anonymous guest users, as well as the following identity providers that you can use to authenticate users for identity pools:
- Amazon Cognito user pools
- Social sign-in with Facebook, Google, Login with Amazon, and Sign in with Apple
- OpenID Connect (OIDC) providers
- SAML identity providers
- Developer authenticated identities
To save user profile information, your identity pool needs to be integrated with a user pool.
Support HackTricks and get benefits!
Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
Discover The PEASS Family, our collection of exclusive NFTs
Get the official PEASS & HackTricks swag
Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
Share your hacking tricks submitting PRs to the hacktricks github repo.